基于深度学习YoloV8模型垃圾分类系统 深度学习pytorch 大数据 (数据集+源码+文档)✅
博主介绍:✌全网粉丝10W+,前互联网大厂软件研发、集结硕博英豪成立软件开发工作室,专注于计算机相关专业项目实战6年之久,累计开发项目作品上万套。凭借丰富的经验与专业实力,已帮助成千上万的学生顺利毕业,选择我们,就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅点击查看作者主页,了解更多项目!
🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、毕业设计:2026年计算机专业毕业设计选题汇总(建议收藏)✅
2、最全计算机专业毕业设计选题大全(建议收藏)✅
1、项目介绍
技术栈:
python语言、PyQt5图形界面、YoloV8模型、opencv、Torch
【技术栈】
1.目标检测:使用 YoloV8 进行模型训练。
2.图像处理:使用 torch 库进行模型的使用检测。
3.GUI开发:使用 PyQt5 库创建用户界面,实现图像显示、检测结果展示等功能。
1、项目功能
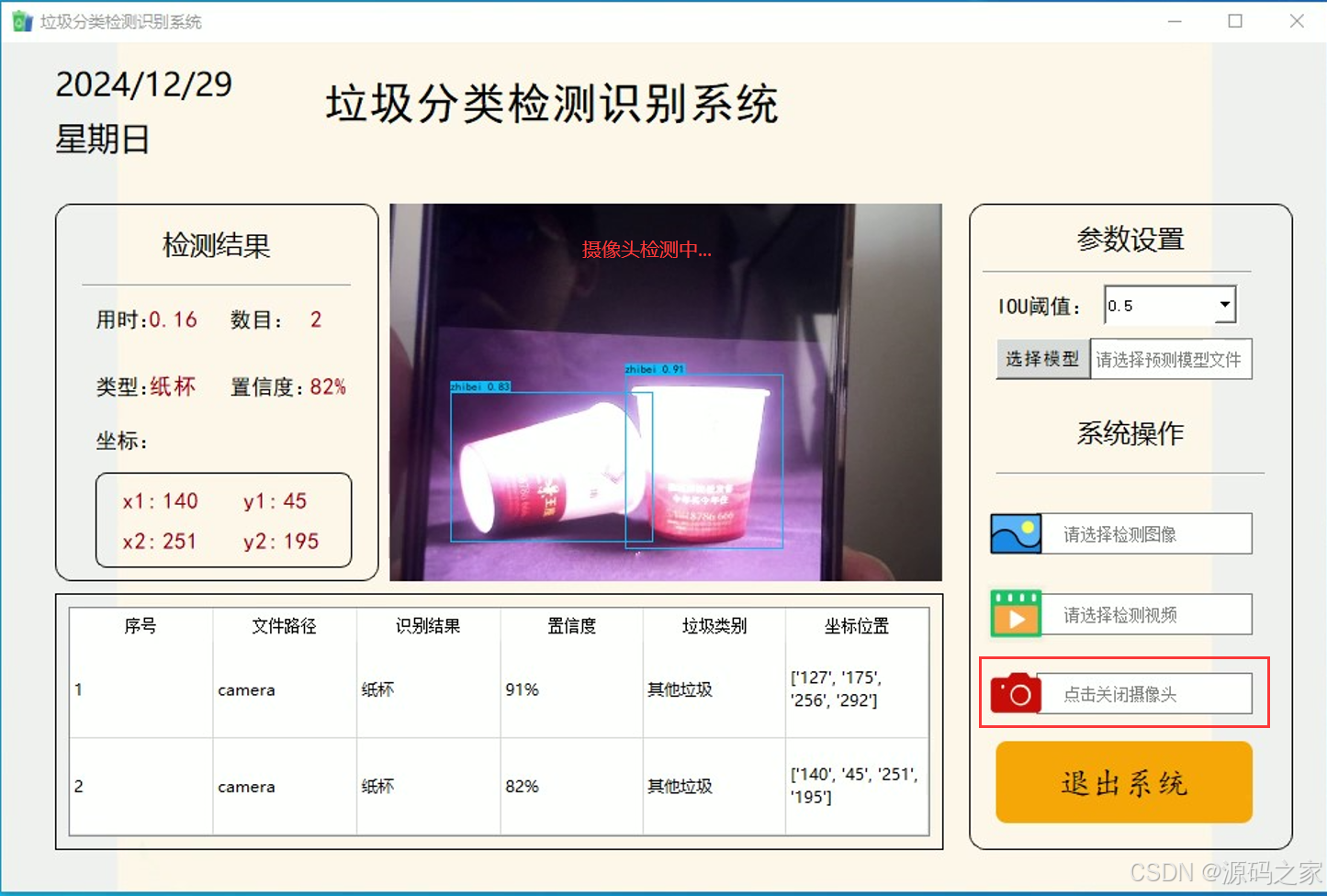
检测图像,判断图像中的垃圾物品及其坐标,将检测出的图像通过可视化界面展示出来。可通过图片、视频、摄像头三种方式获取图像信息。
2、数据集说明
有3400多张图片数据集,38种垃圾识别种类
2、项目界面
(1)首页

(2)口罩—其他垃圾

(3)口香糖—其他垃圾

(4)纸杯—其他垃圾
3、项目说明
摘要
随着环境保护和资源回收利用的日益重要,垃圾分类成为全球关注的焦点。传统的垃圾分类方法存在效率低下和误分类的问题,而基于深度学习的目标检测技术在提高分类精度和效率方面展现了广阔的前景。本研究提出了一种基于YOLOv8(You Only Look Once version 8)目标检测算法的垃圾分类系统,能够对36类垃圾进行准确识别和分类。为提高模型的泛化能力和分类效果,本文通过网络爬虫获取3490张垃圾图像,构建了包含36类垃圾的自制数据集,并采用LabelImg工具进行数据标注。利用YOLOv8算法对数据集进行训练,采取冻结和解冻阶段的训练策略,模型训练总共进行了300个Epoch,初始学习率为1e-2,并通过余弦退火的学习率衰减策略逐步调整学习率。实验结果表明,该系统能够在不同类别的垃圾分类任务中实现较高的平均精度(mAP),展现出良好的分类性能和应用前景。通过该研究,进一步证明了YOLOv8算法在垃圾分类等多类别目标检测任务中的高效性和准确性。
关键词:垃圾分类,YOLOv8,目标检测,深度学习,分类系统
4、核心代码
if mode == "predict":'''1、如果想要进行检测完的图片的保存,利用r_image.save("test.jpg")即可保存,直接在predict.py里进行修改即可。 2、如果想要获得预测框的坐标,可以进入yolo.detect_image函数,在绘图部分读取top,left,bottom,right这四个值。3、如果想要利用预测框截取下目标,可以进入yolo.detect_image函数,在绘图部分利用获取到的top,left,bottom,right这四个值在原图上利用矩阵的方式进行截取。4、如果想要在预测图上写额外的字,比如检测到的特定目标的数量,可以进入yolo.detect_image函数,在绘图部分对predicted_class进行判断,比如判断if predicted_class == 'car': 即可判断当前目标是否为车,然后记录数量即可。利用draw.text即可写字。'''while True:img = input('Input image filename:')try:image = Image.open(img)except:print('Open Error! Try again!')continueelse:r_image = yolo.detect_image(image, crop=crop, count=count)r_image.show()elif mode == "video":capture = cv2.VideoCapture(video_path)if video_save_path != "":fourcc = cv2.VideoWriter_fourcc(*'XVID')size = (int(capture.get(cv2.CAP_PROP_FRAME_WIDTH)), int(capture.get(cv2.CAP_PROP_FRAME_HEIGHT)))out = cv2.VideoWriter(video_save_path, fourcc, video_fps, size)ref, frame = capture.read()if not ref:raise ValueError("未能正确读取摄像头(视频),请注意是否正确安装摄像头(是否正确填写视频路径)。")fps = 0.0while (True):t1 = time.time()# 读取某一帧ref, frame = capture.read()if not ref:break# 格式转变,BGRtoRGBframe = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)# 转变成Imageframe = Image.fromarray(np.uint8(frame))# 进行检测frame = np.array(yolo.detect_image(frame))# RGBtoBGR满足opencv显示格式frame = cv2.cvtColor(frame, cv2.COLOR_RGB2BGR)fps = (fps + (1. / (time.time() - t1))) / 2print("fps= %.2f" % (fps))frame = cv2.putText(frame, "fps= %.2f" % (fps), (0, 40), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 2)cv2.imshow("video", frame)c = cv2.waitKey(1) & 0xffif video_save_path != "":out.write(frame)if c == 27:capture.release()breakprint("Video Detection Done!")capture.release()if video_save_path != "":print("Save processed video to the path :" + video_save_path)out.release()cv2.destroyAllWindows()elif mode == "fps":img = Image.open(fps_image_path)tact_time = yolo.get_FPS(img, test_interval)print(str(tact_time) + ' seconds, ' + str(1 / tact_time) + 'FPS, @batch_size 1')elif mode == "dir_predict":import osfrom tqdm import tqdmimg_names = os.listdir(dir_origin_path)for img_name in tqdm(img_names):if img_name.lower().endswith(('.bmp', '.dib', '.png', '.jpg', '.jpeg', '.pbm', '.pgm', '.ppm', '.tif', '.tiff')):image_path = os.path.join(dir_origin_path, img_name)image = Image.open(image_path)r_image = yolo.detect_image(image)if not os.path.exists(dir_save_path):os.makedirs(dir_save_path)r_image.save(os.path.join(dir_save_path, img_name.replace(".jpg", ".png")), quality=95, subsampling=0)elif mode == "heatmap":while True:img = input('Input image filename:')try:image = Image.open(img)except:print('Open Error! Try again!')continueelse:yolo.detect_heatmap(image, heatmap_save_path)elif mode == "export_onnx":yolo.convert_to_onnx(simplify, onnx_save_path)else:raise AssertionError("Please specify the correct mode: 'predict', 'video', 'fps', 'heatmap', 'export_onnx', 'dir_predict'.")🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目编程以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
5、源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻