INT 303 Big Data Analysis 大数据分析 Pt.4 数据可视化
文章目录
- 1. 可视化的动机
- 2. 可视化的原则
- 2.1 最大化数据与墨水的比例
- 2.2 不要在尺度上撒谎
- 2.3 最小化图表垃圾
- 2.4 清晰、详细且全面的标签
- 3. 可视化的类型
- 3.1 分布(Distribution)
- 3.1.1 直方图(Histograms)
- 3.1.2 散点图(scatter plots)
- 3.2 关系(Relationship)
- 3.2.1 气泡图(bubble chart)
- 3.2.2 通过多个低维度图表发现关系
- 3.3 构成(Composition)
- 3.3.1 饼图(Pie Chart)
- 3.3.2 堆叠面积图(Stacked Area Graph)
- 3.4 比较(Comparison)
- 3.4.1 多重直方图(Multiple Histograms)
- 3.4.2 箱形图(Boxplots)
- 3.4.2.1 正偏态(Right-Skewed)和负偏态(Left-Skewed)
- 4. 可视化的例子
- 5. 可视化工具
1. 可视化的动机
下图展示了四个数据集的简单统计特征,它们的统计特征相同,但它们的图形表示和数据分布却大不相同。
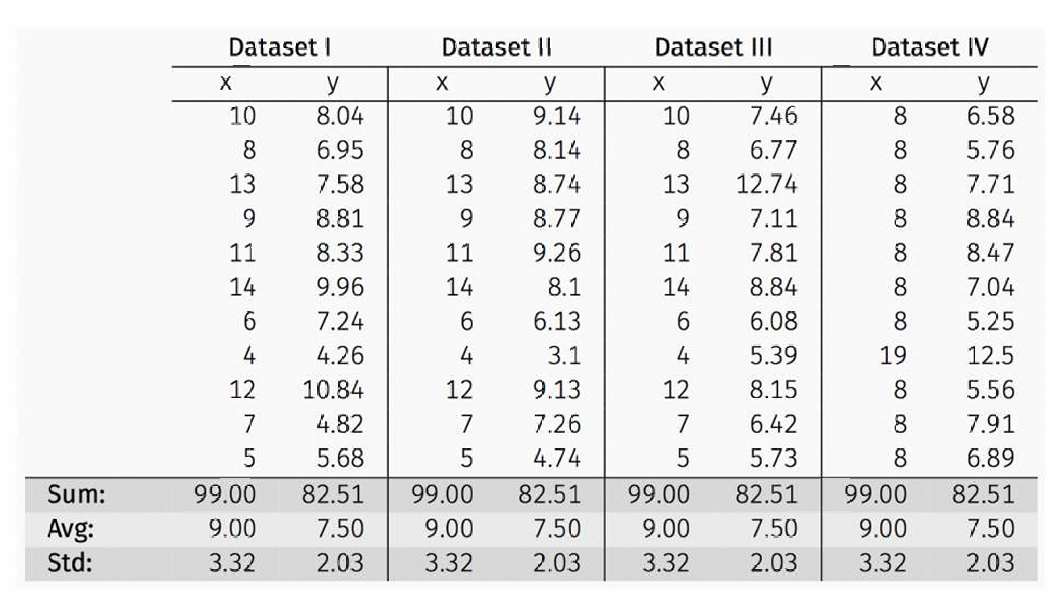
所以仅仅依赖于简单的统计特征是不够的,还需要考虑数据的分布和图形表示。
下图用散点图展示了它们的数据分布。
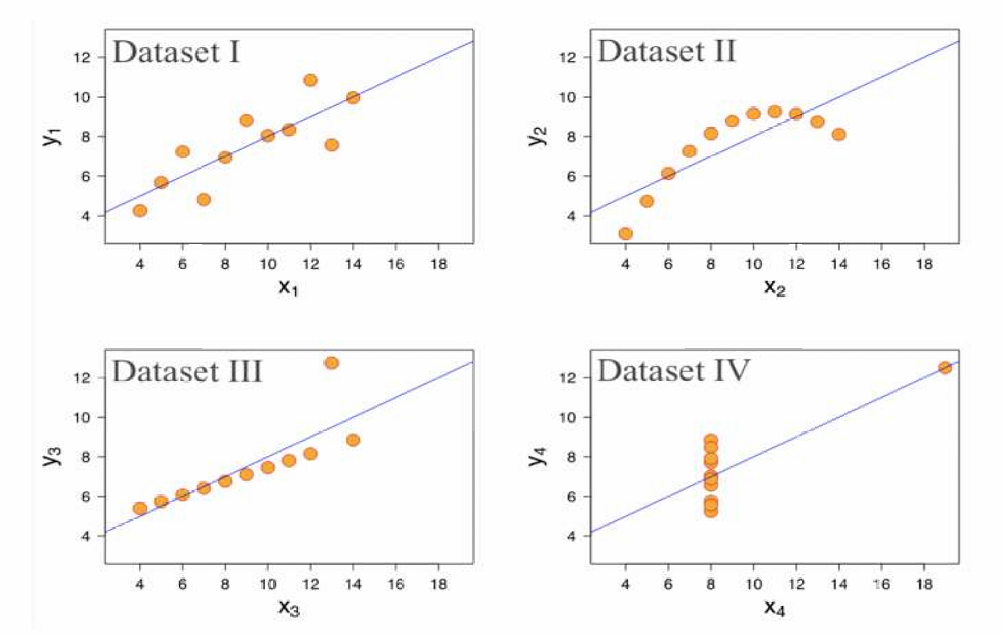
所以即使统计特征相同,数据的实际分布和关系可能大不相同。
再比如,某次作业的平均分是7.64分,看上去分数还可以,但是我们看一下分布图。
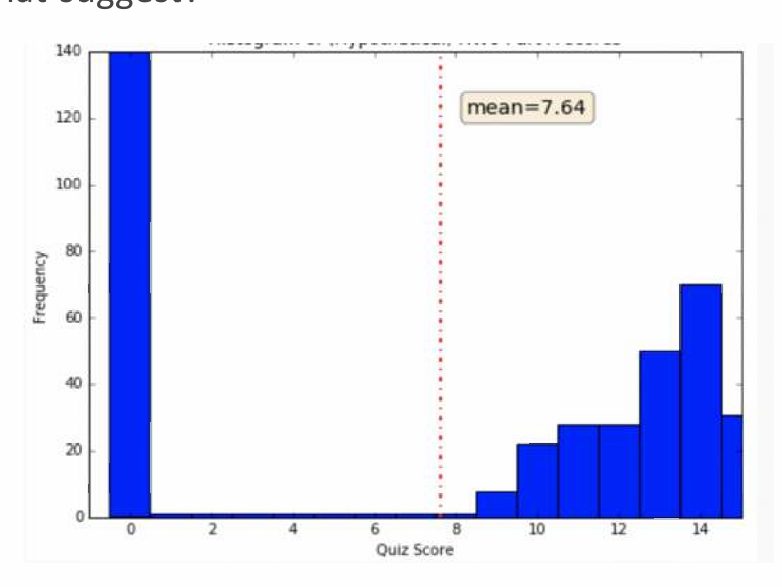
虽然平均分是7.64,但实际上大多数学生的成绩远低于这个平均值,只有少数学生的成绩较高,从而拉高了平均分。
因此数据可视化是一种工具,可以帮助我们更直观地理解和分析数据。
通过可视化,我们可以:
- 发现数据中可能不易察觉的模式和趋势。
- 帮助我们形成假设,即对数据可能展示的某种关系或模式的初步猜测。
- 传达分析结果的强大工具。帮助我们简洁地呈现信息和观点,提供证据和支持,以及影响和说服他人。
- 确定分析/建模的下一步。
2. 可视化的原则
2.1 最大化数据与墨水的比例
这个原则强调在图表中应该尽可能多地展示数据,而减少不必要的装饰和非数据元素。目的是让图表更加简洁,使观众能够更容易地看到和理解数据本身。
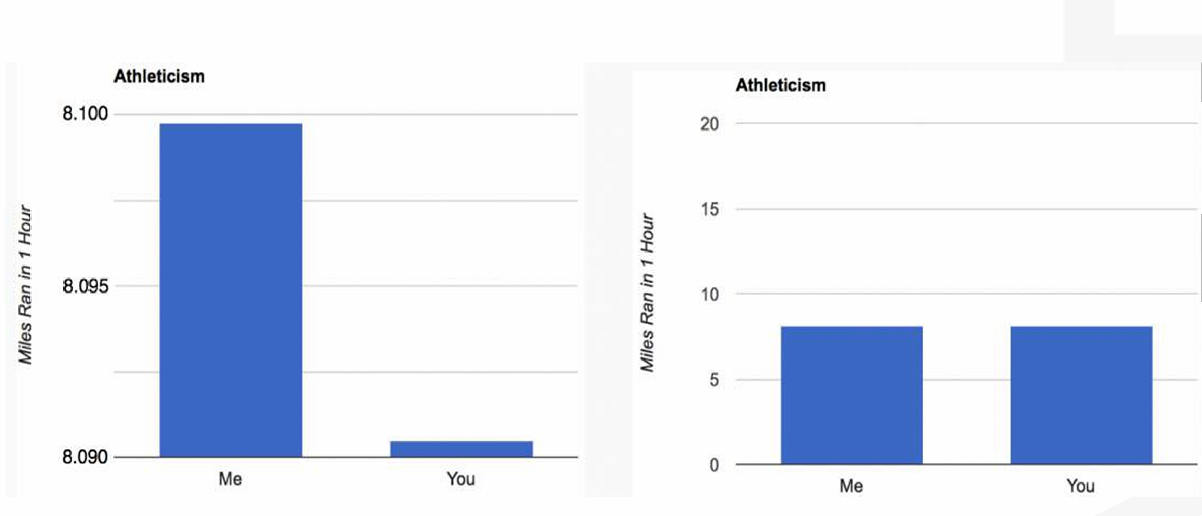
2.2 不要在尺度上撒谎
这个原则,也称为“谎言因子”(Lie Factor),指的是不应该通过调整图表的尺度(如轴的起点或间隔)来误导观众对数据的解读。图表的尺度应该公正地反映数据的真实情况。
如下图左边使用了非常小的尺度范围(从8.090到8.100),这使得两者之间的差异看起来非常大,尽管实际上差异非常小(只有0.01英里)。
下图右边是个正确的示例。
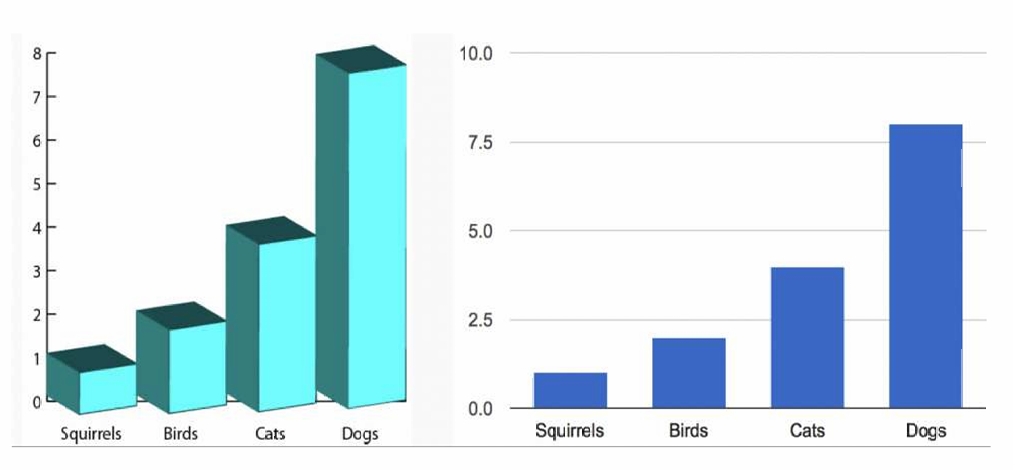
2.3 最小化图表垃圾
在图表中只展示数据的变化,而不是设计的变化。图表垃圾指的是图表中那些对数据理解无益的装饰性元素,它们可能会分散观众的注意力,甚至误导观众。这一点与第一点近似。
下图左边就是个错误的示例,右边是正确的示例。
2.4 清晰、详细且全面的标签
标签应该易于阅读,使用清晰、易读的字体和大小。
而且标签应该提供足够的信息,以便观众能够理解图表的内容和上下文。
需要确保图表中的所有元素都有适当的标签,包括轴标签、图例、标题和任何注释。
3. 可视化的类型
每种类型都针对数据的不同方面,有多种类型:
- 分布(Distribution):
这种类型的可视化用于展示一个或多个变量在可能值范围内的分布情况。常见的分布可视化包括直方图、箱型图和密度图。它们可以帮助我们了解数据的集中趋势、分散程度以及是否存在异常值。 - 关系(Relationship):
关系可视化用于展示数据集中多个变量之间的关联性。散点图、气泡图和热力图是展示变量之间关系的常用工具。通过这些图表,我们可以观察变量之间是否存在线性或非线性关系,以及它们之间的相关性强度。 - 构成(Composition):
构成可视化用于展示数据集中某一部分与整体的关系。饼图、条形图和堆叠条形图是展示构成的常用图表。它们可以帮助我们理解各个部分在整体中所占的比例,以及各部分之间的相对大小。 - 比较(Comparison):
比较可视化用于展示不同变量或数据集之间的差异和相似性。条形图、折线图和雷达图是进行比较的常用工具。通过这些图表,我们可以直观地比较不同类别、时间点或条件下的数据趋势和变化。
3.1 分布(Distribution)
当我们想要研究定量值(即可以用数字表示的值,如身高、体重、分数等)如何沿着某个轴(通常是图表的x轴或y轴)分布时,分布图表是一个很好的选择。
通过观察数据的形状(即数据在图表上的分布形态),用户可以识别数据的以下特征:
值的范围(Value range):数据集中最小值和最大值之间的差异,这可以帮助我们了解数据的总体分布范围。
集中趋势(Central tendency):数据集中趋势的度量,通常包括平均值(mean)、中位数(median)和众数(mode)。这些度量可以帮助我们了解数据的中心位置。
异常值(Outliers):数据集中远离其他数据点的值。这些值可能是由于错误、特殊情况或极端情况造成的,识别它们对于理解数据的整体分布和进行进一步分析非常重要。
3.1.1 直方图(Histograms)
直方图是一种可视化工具,用于展示一维数据在特定值范围内的分布情况。它通过将数据分成若干个区间(称为“bins”或“桶”),并计算每个区间内数据点的数量(频率),来展示数据的分布形态。
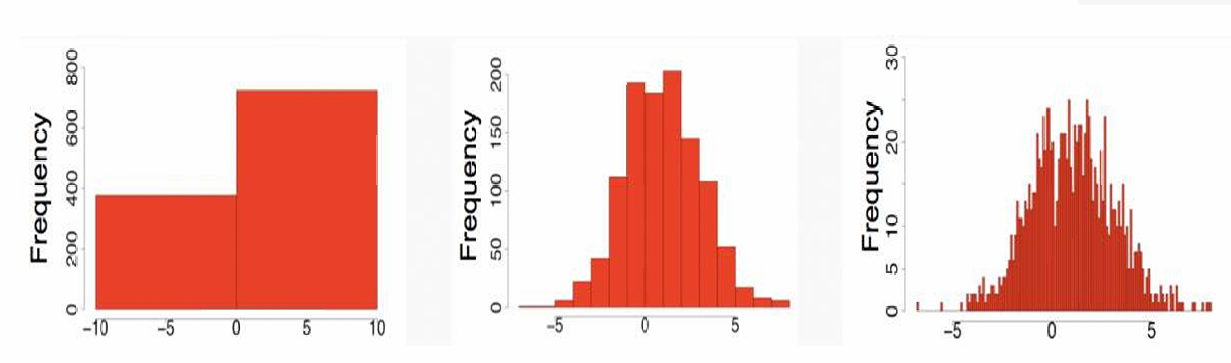
注意:直方图中的趋势对“bins”的数量非常敏感。
3.1.2 散点图(scatter plots)
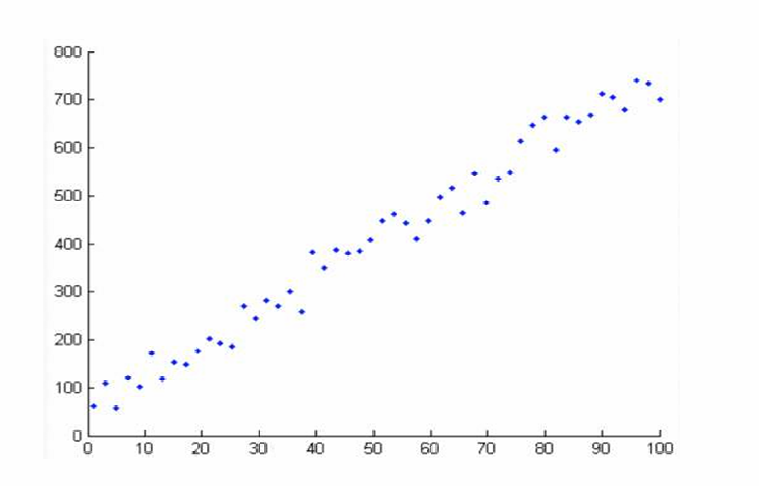
散点图是一种数据可视化工具,用于展示多维数据在特定值范围内的分布情况。它通过在二维平面上绘制点来表示数据点,每个点的位置由数据的两个属性决定。
散点图也可以用来展示多维数据在不同值上的分布情况。通过观察散点图中点的分布,我们可以了解数据的分布特征,如集中趋势、分散程度和异常值。
散点图更常用于展示多维数据中两个不同属性之间的关系。通过观察点的排列方式,我们可以识别变量之间的相关性、趋势和模式。
例如,在图中展示的散点图中,x轴和y轴分别代表两个不同的变量。从图中可以看出,随着x轴值的增加,y轴值也呈现出增加的趋势,这表明这两个变量之间可能存在正相关关系。
3.2 关系(Relationship)
通过可视化,我们可以识别变量之间是否存在某种统计相关性。
可视化可以帮助我们快速识别这些异常值,它们可能是由于错误或特殊事件造成的。
通过可视化,我们可以观察到数据点是否倾向于聚集在一起,形成不同的群组。
人类的视觉能力有限,我们通常只能同时理解三个维度的数据。然而,通过将额外的变量映射到数据点的大小、颜色或形状上,我们可以在二维或三维空间中可视化更多的信息。
下面的图用颜色编码来有效地表示三维数据中的分类属性。
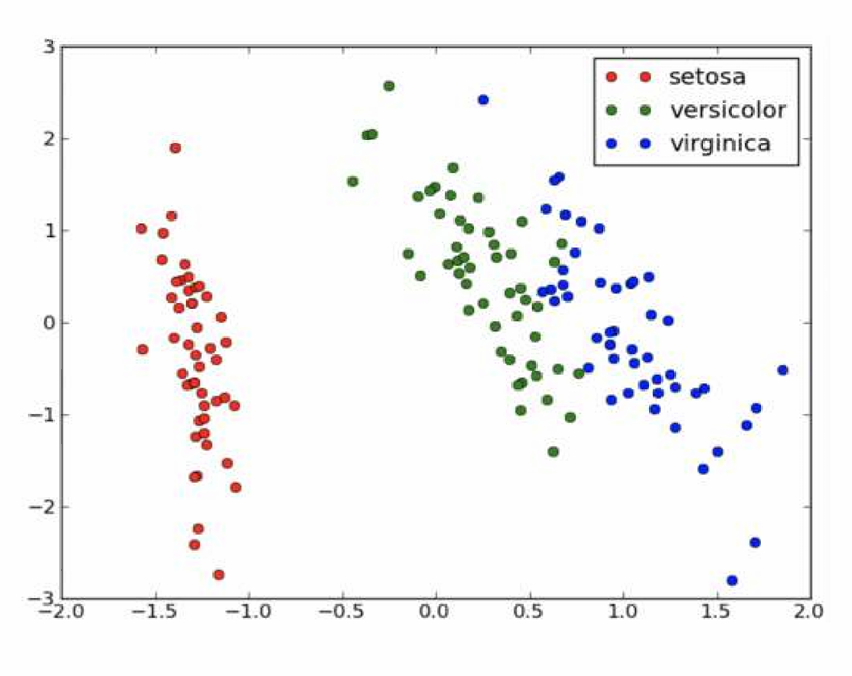
这里的散点图展示了一组鸢尾花(Iris)的测量数据,包括花瓣长度、萼片长度和鸢尾花的类型。这里使用了三种不同的颜色来表示三种不同类型的鸢尾花
所以更多维度并不总是更好,例如下面的图展示了一组高维数据。
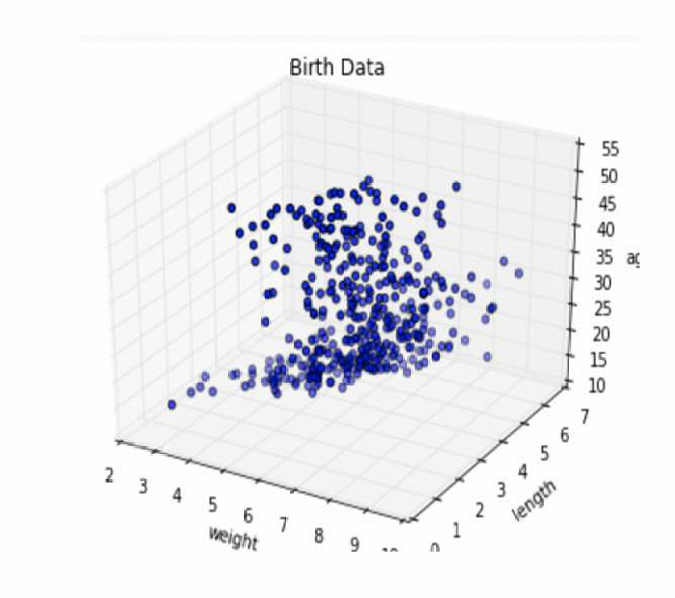
其中x轴表示体重,y轴表示身长,z轴表示年龄。所以说,过多的维度可能会使图表变得复杂,难以解读。
3.2.1 气泡图(bubble chart)
对于三维数据,可以通过气泡图中的大小来编码定量属性。
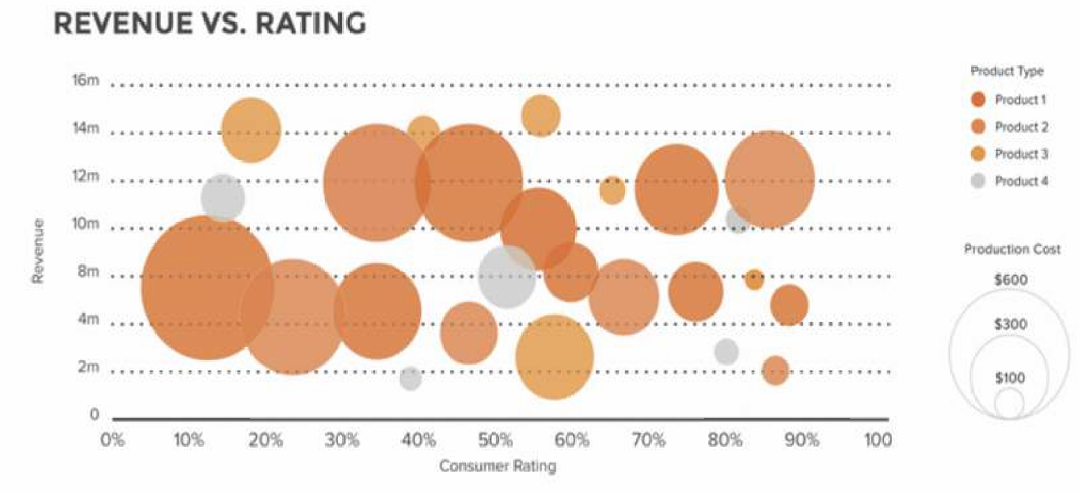
图中展示了一组消费者产品的数据,每个气泡代表一个产品。
x轴表示消费者评分(从0%到100%),y轴表示收入(以百万美元为单位,从0到16m),气泡的大小表示生产成本(从$100到$600)。
不同颜色的气泡代表不同类型的产品(Product 1到Product 4)。
3.2.2 通过多个低维度图表发现关系
通过观察多个二维图表,我们可以更容易地识别数据中的模式和关系。
如图所示。
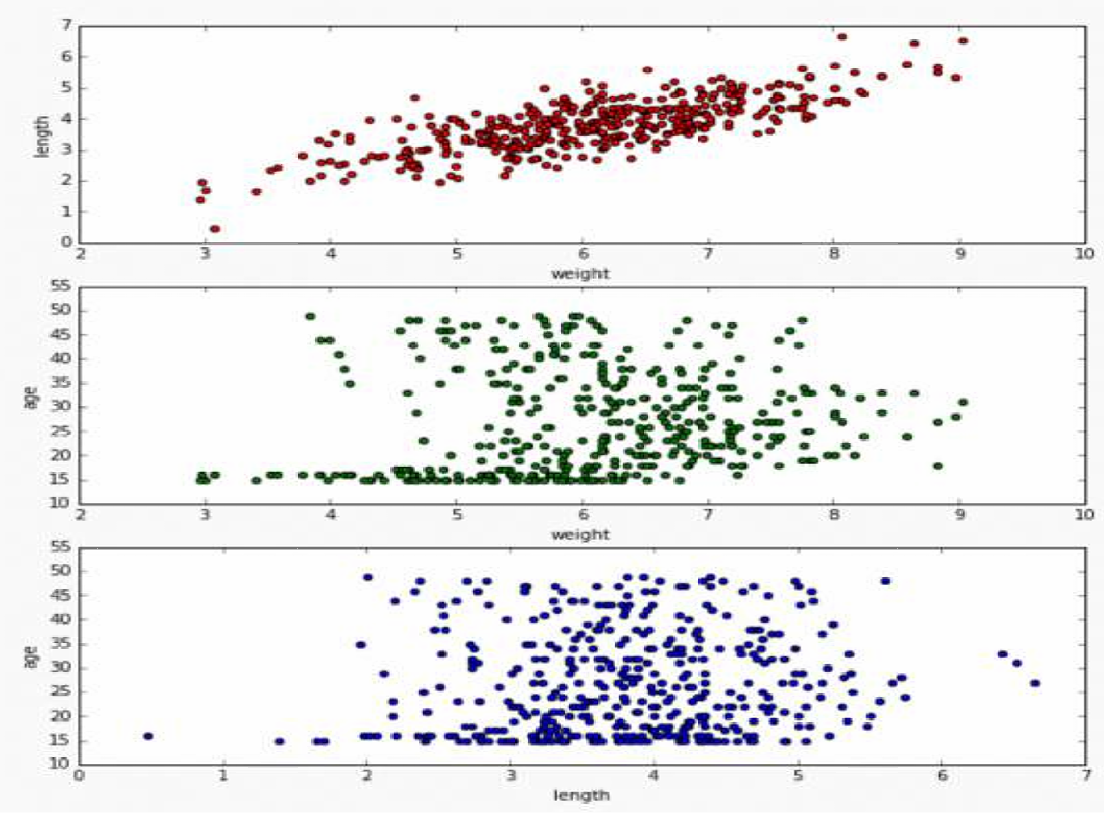
第一个散点图(红色):展示了变量“weight”(重量)与“length”(长度)之间的关系。图中的点呈现出一定的正相关趋势,即随着重量的增加,长度也倾向于增加。
第二个散点图(绿色):展示了变量“weight”(重量)与“age”(年龄)之间的关系。图中的点分布较为分散,显示出这两个变量之间的关系可能不太明显或存在较大的变异性。
第三个散点图(蓝色):展示了变量“length”(长度)与“age”(年龄)之间的关系。图中的点同样分布较为分散,表明这两个变量之间的关系可能也不明显。
这样我们观察这些二维散点图,我们就可以更清晰地看到每个变量对之间的关系,而不是试图在一个高维图表中同时理解多个变量。
3.3 构成(Composition)
构成图用于展示数据集中某一部分与整体的关系。这种类型的图表可以帮助我们理解各个部分在整体中所占的比例,以及各部分之间的相对大小。
构成图可以同时展示相对值(如百分比)和绝对值(如具体的数量或金额)。
构成图不仅可以用于展示静态数据(即某一时刻的数据分布),也可以用于展示时间序列数据(即随时间变化的数据分布)。这使得构成图成为一种非常灵活的可视化工具,可以应用于多种不同的数据分析场景。
3.3.1 饼图(Pie Chart)
饼图是一种可视化变量(或单个组)静态构成(也就是分布)的方法
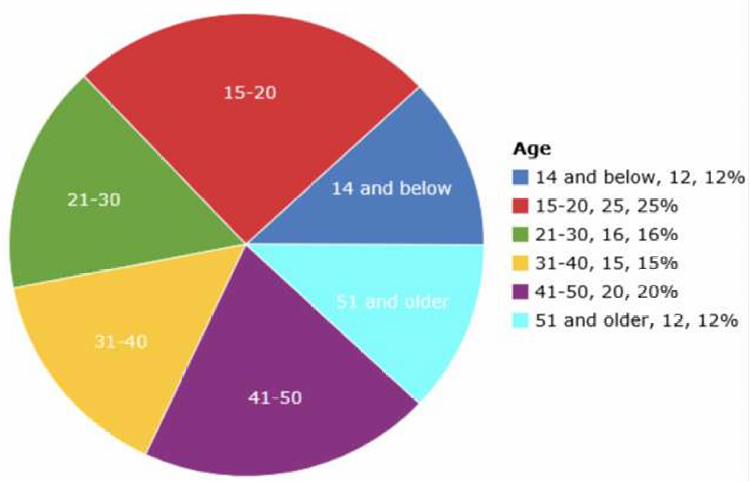
尽管饼图可以直观地展示各部分与整体的关系,但它们在比较不同分类的比例时可能不如条形图直观,尤其是当分类很多或者比例相近时。条形图通常更容易比较不同类别的大小,因此在实际应用中更受青睐。
3.3.2 堆叠面积图(Stacked Area Graph)
堆叠面积图是一种可视化组的构成随时间(或其他定量变量)变化的方法。这展示了一个分类变量(AgeGroup)与一个定量变量(年份)之间的关系。
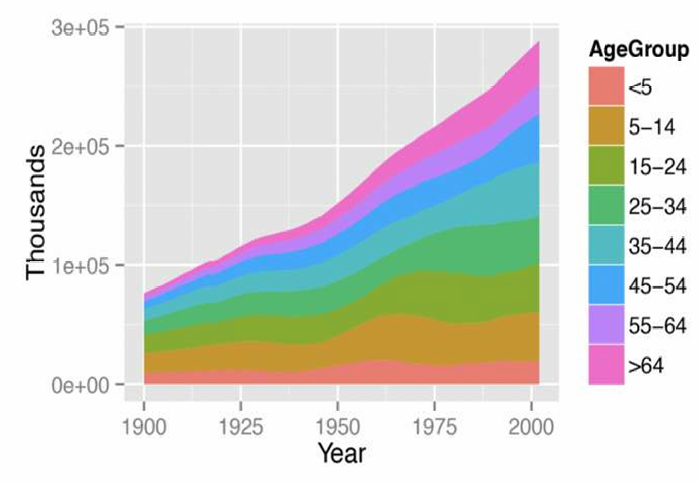
如图所示,不同颜色的区域代表不同的年龄组,图例说明了每种颜色对应的年龄组。
这个堆叠面积图表示了不同年龄组(AgeGroup)随时间变化的人口数量。
3.4 比较(Comparison)
比较图表用于比较数据集中不同值的大小,以及轻松识别数据中的最小值或最大值。
如果需要比较随时间变化的值,折线图(line charts)或条形图(bar charts)通常是最佳选择,因为它们能够展示数据随时间的趋势和变化。
条形图或柱状图(Bar or column charts)适用于比较不同项目或类别之间的值。
折线图(Line charts)适用于展示数据随时间的连续变化,它们通过线条连接各个数据点,给人一种连续性的感觉,适合展示趋势和模式。
饼图(Pie charts)也可以用来比较数据,特别是当需要展示各部分占整体的比例时。每个扇区的大小表示该部分在整体中的相对重要性或比例。
3.4.1 多重直方图(Multiple Histograms)
在同一轴上绘制多个直方图(以及这里的分布核密度估计)是一种可视化不同变量如何比较(或同一变量在特定组别中如何变化)的方法。
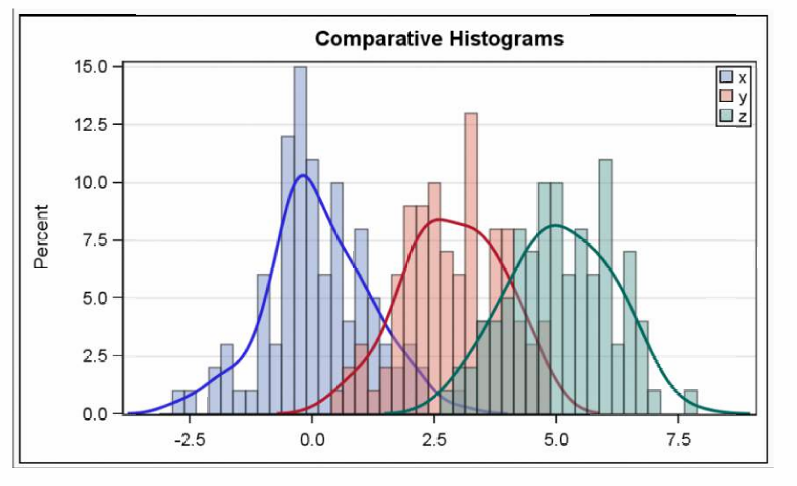
除了直方图,图中还包含了核密度估计(Kernel Density Estimates,KDE)曲线,这些曲线提供了分布的平滑估计,有助于更清晰地展示分布的形状。
3.4.2 箱形图(Boxplots)
箱形图是一种简化的可视化方法,用于比较不同组别的定量变量。它突出显示了数据集中的范围、四分位数、中位数和任何异常值。
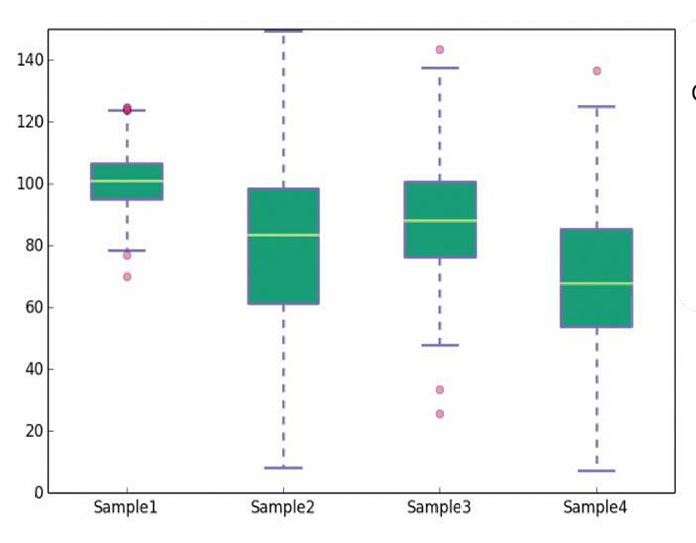
每个箱形图由一个矩形框(表示数据的四分位数范围)、一条中线(表示中位数)、以及上下的“须”(表示数据的范围,不包括异常值)组成。
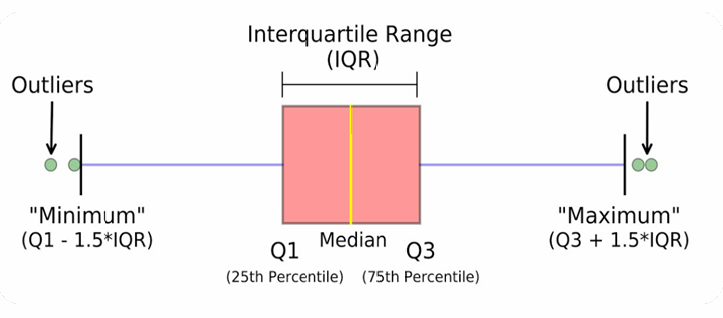
“Minimum”(最小值):Q1(第一四分位数)减去1.5倍的四分位距(IQR,即Q3-Q1)。
“Q1”(第一四分位数):数据中有25%的值小于或等于这个值。
“Median”(中位数):数据中有50%的值小于或等于这个值。
“Q3”(第三四分位数):数据中有75%的值小于或等于这个值。
“Maximum”(最大值):Q3加上1.5倍的四分位距。
“Interquartile Range (IQR)”(四分位距):Q3和Q1之间的范围,表示数据的中间50%的分布。
除此以外,还有异常值(Outliers),这些点位于“须”之外,表示与其他数据点有显著差异的值。
3.4.2.1 正偏态(Right-Skewed)和负偏态(Left-Skewed)
如果数据看起来不是对称的,每个样本是否显示出相同类型的不对称性呢?
下图展示了三种情况:
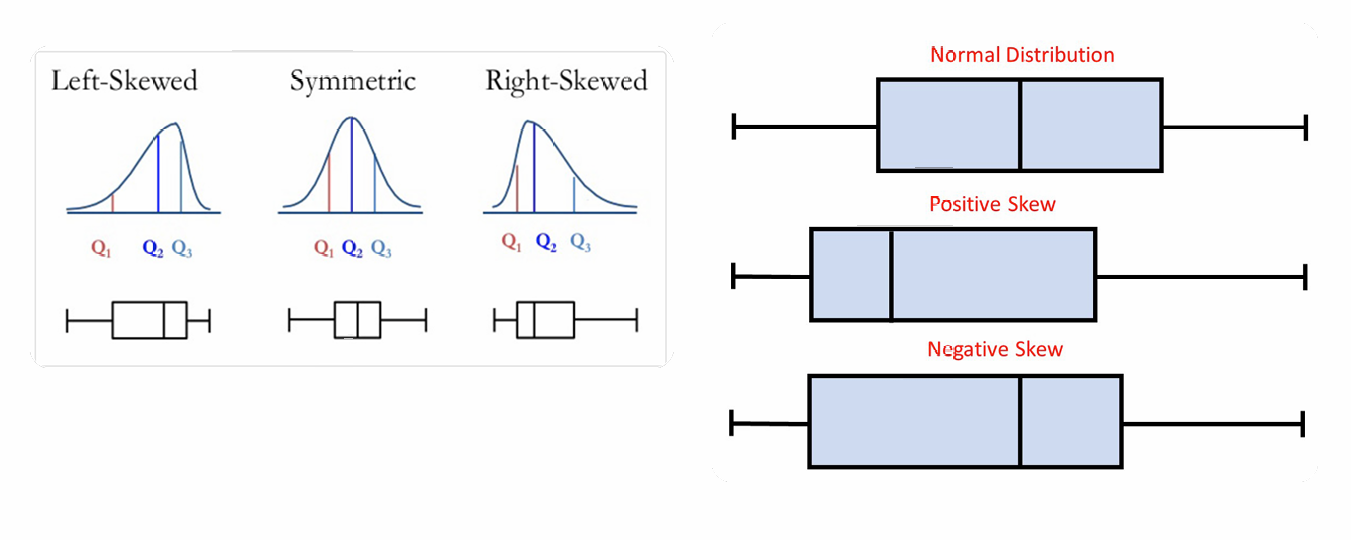
左偏态(Left-Skewed):分布的尾部在左侧,意味着较小的值比大的值更多,数据的中位数(Q2)位于均值(平均值)的右侧。
对称(Symmetric):分布是对称的,呈现出钟形曲线,中位数、均值和众数大致重合。
右偏态(Right-Skewed):分布的尾部在右侧,意味着较大的值比小的值更多,数据的中位数(Q2)位于均值的左侧。
其分别对应不同的箱线图:
负偏态(Negative Skew):箱形图显示左侧的“须”更长,表示数据分布的尾部在左侧。
正态分布(Normal Distribution):箱形图显示数据均匀分布,没有明显的偏态。
正偏态(Positive Skew):箱形图显示右侧的“须”(whisker)更长,表示数据分布的尾部在右侧。
4. 可视化的例子
我们现在尝试一个数据集。
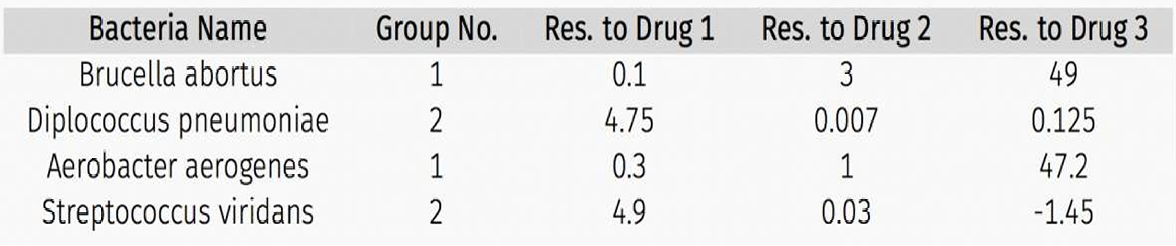
我们可以先试着用分组条形图展示每种细菌对每种药物的抗性比较。
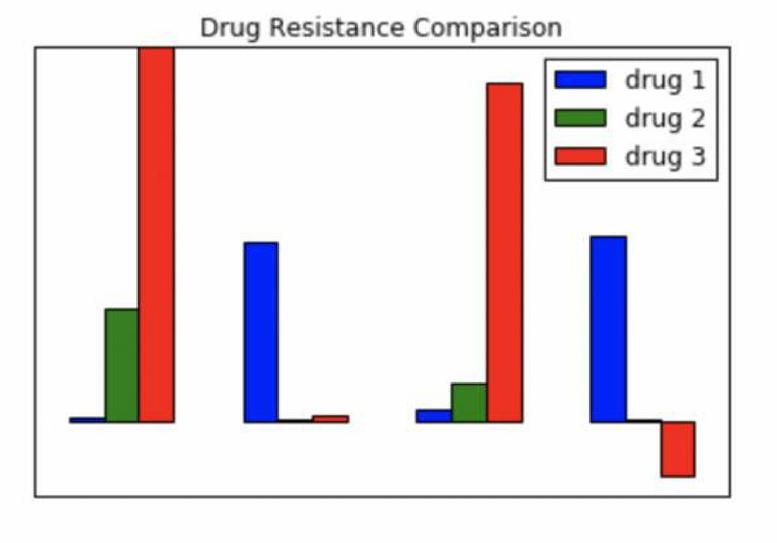
现在我们再尝试通过分组条形图来可视化每种细菌对每种药物的抗性比较,我们按照分组来排序。
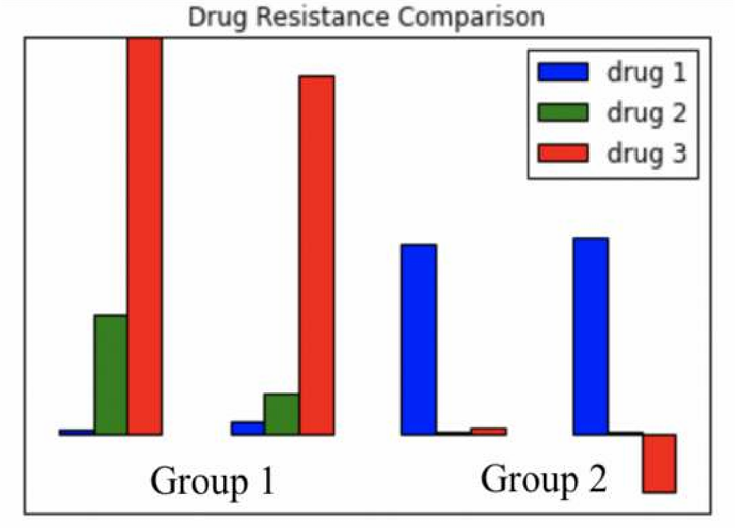
前一组结果不清晰,但是这一组很清晰。Group1对药物3的抗性都很高,而Group2对药物1的抗性较高。
5. 可视化工具
TREEVIS.NET是一个专注于可视化技术资源的在线平台,其提供了一个可视化技术目录,用户可以通过它来探索和了解不同的数据可视化方法和工具。
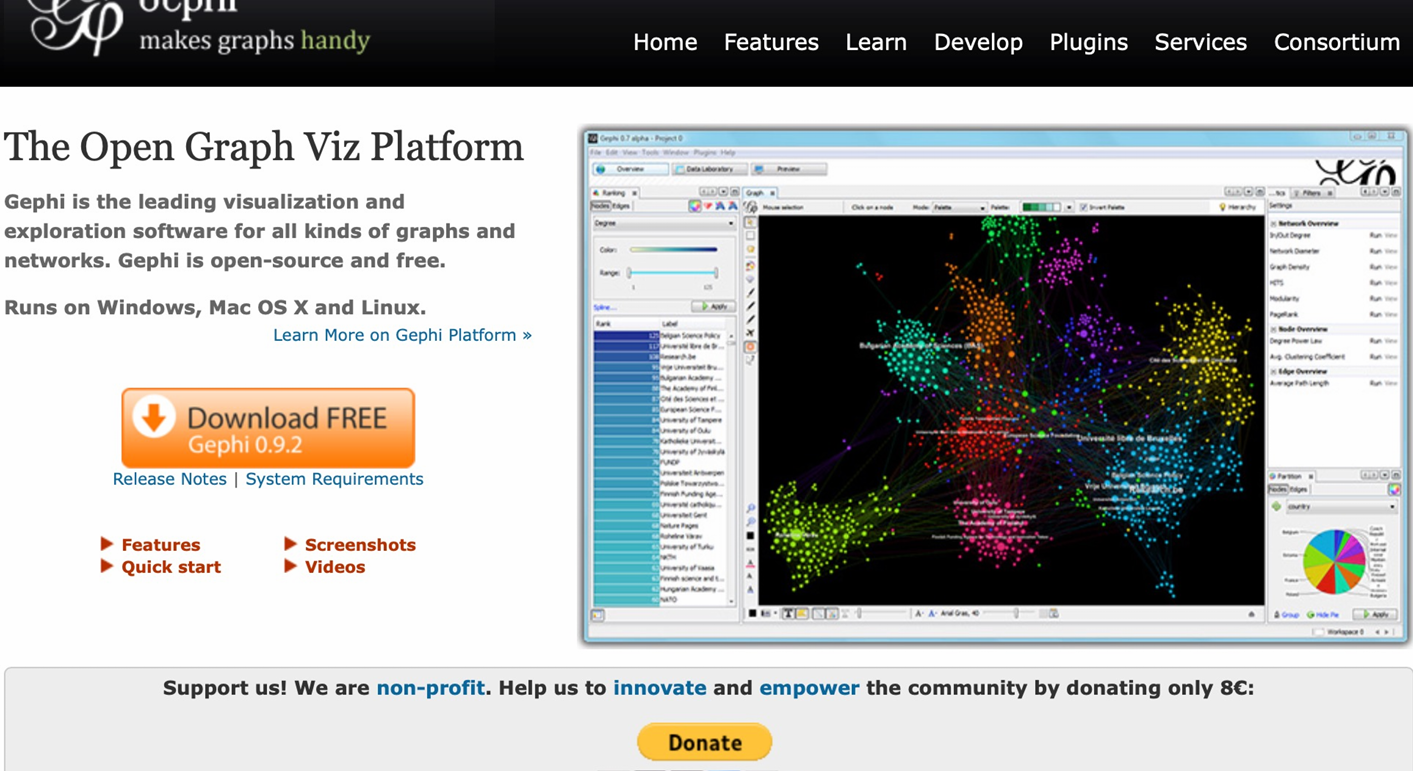
Gephi 是一个开源的图形可视化和探索软件平台,主要用于处理和分析各种类型的图形和网络数据。
R/shiny,Shiny 是 R 语言的一个包,它允许用户创建交互式网页应用程序。通过 Shiny,数据科学家和分析师可以轻松地将他们的分析转化为交互式的报告或仪表板。
plotly/dash,Plotly 是一个用于创建交互式图表的库,支持多种编程语言,包括 Python 和 R。Dash 是 Plotly 提供的一个框架,用于构建复杂的交互式数据应用程序。
Tableau 是一个流行的商业智能和数据可视化工具,它提供了一个拖放式的界面,用户可以轻松地创建交互式和可分享的仪表板。
D3.js(Data-Driven Documents)是一个基于 JavaScript 的库,它允许用户使用 HTML、SVG 和 CSS 来创建复杂的交互式图形和数据可视化。
Vega 和 Vega-Lite 是两个相关的可视化语法和工具,它们允许用户以声明式的方式创建交互式图形。其中Vega-Lite 是 Vega 的一个轻量级版本,它提供了一个更简单、更易于学习的语法,适合快速创建基本的图表和可视化。