仓颉语言实战:无重复字符的最长子串工具库
前言
在日常开发中,字符串处理是最常见的任务之一。寻找无重复字符的最长子串是一个经典的算法问题,它不仅考察开发者对字符串的理解,更体现了滑动窗口这一重要算法思想的运用。今天,我将带大家使用华为推出的新一代编程语言——仓颉语言,从零开始构建一个高效、优雅、测试完备的无重复字符最长子串工具库。
本文将详细讲解从问题分析、算法设计到代码实现的完整过程,包括核心算法、优化技巧、单元测试以及工程化实践,希望能为正在学习仓颉语言和算法的开发者提供一个实用的参考案例。
什么是无重复字符的最长子串?
在深入代码之前,让我们先理解问题的定义。
问题描述
给定一个字符串 s,请你找出其中不含有重复字符的最长子串的长度。
注意要点:
- 子串是连续的字符序列
- 不含重复字符意味着子串中每个字符只出现一次
- 我们要找的是这样的子串的最大长度
示例说明
示例 1:
输入: s = "abcabcbb"
输出: 3
解释: 因为无重复字符的最长子串是 "abc",所以其长度为 3。
示例 2:
输入: s = "bbbbb"
输出: 1
解释: 因为无重复字符的最长子串是 "b",所以其长度为 1。
示例 3:
输入: s = "pwwkew"
输出: 3
解释: 因为无重复字符的最长子串是 "wke",所以其长度为 3。请注意,你的答案必须是子串的长度,"pwke" 是一个子序列,不是子串。
示例 4:
输入: s = ""
输出: 0
解释: 空字符串的最长子串长度为 0。
示例 5:
输入: s = "dvdf"
输出: 3
解释: 无重复字符的最长子串是 "vdf",长度为 3。
算法分析
暴力解法 vs 滑动窗口
暴力解法的思路是枚举所有可能的子串,检查每个子串是否包含重复字符,时间复杂度为 O(n³),效率低下。
滑动窗口算法是解决此类问题的最优解法,核心思想是:
- 使用两个指针
left和right维护一个滑动窗口 - 使用哈希表(HashMap)记录窗口内每个字符的位置
- 右指针不断向右扩展,尝试加入新字符
- 当发现重复字符时,移动左指针缩小窗口
- 在这个过程中记录窗口的最大长度
滑动窗口详解
以字符串 "abcabcbb" 为例:
步骤1: [a]bcabcbb 窗口="a", 长度=1
步骤2: [ab]cabcbb 窗口="ab", 长度=2
步骤3: [abc]abcbb 窗口="abc", 长度=3 ✓
步骤4: abc[a]bcbb 发现重复'a',左指针移到第一个'a'之后
步骤5: abc[ab]cbb 窗口="ab", 长度=2
步骤6: abc[abc]bb 窗口="abc", 长度=3 ✓
步骤7: abcabc[b]b 发现重复'b',左指针移动
步骤8: abcabc[bc]b 窗口="bc", 长度=2
步骤9: abcabc[cb] 发现重复'b',左指针移动
算法的关键点:
- 哈希表优化:记录字符最后出现的位置,可以直接跳到重复字符的下一个位置
- 窗口维护:左指针只向右移动,不回退
- 长度计算:每次右指针移动时更新最大长度
用数学表达式可以表示为:
maxLength = max(maxLength, right - left + 1)
这个简洁而高效的算法就是我们整个工具库的核心。
项目设计
设计目标
在设计这个工具库时,我确立了以下几个核心目标:
- 高效性:采用滑动窗口算法,时间复杂度 O(n)
- 简洁性:提供直观易用的API,一行代码解决问题
- 健壮性:正确处理空串、单字符、全重复等边界情况
- 通用性:支持各种字符集(ASCII、Unicode、中文等)
- 可测试性:100%测试覆盖率,确保算法正确性
- 规范性:遵循仓颉语言的最佳实践和编码规范
项目架构
项目采用典型的仓颉语言项目结构:
longest_substring/
├── cjpm.toml # 项目配置文件
├── src/
│ ├── main.cj # 主程序入口(示例代码)
│ └── module/
│ ├── longest_substring.cj # 核心功能实现
│ └── longest_substring_test.cj # 单元测试
├── doc/ # 文档目录
├── README.md # 项目说明
└── CHANGELOG.md # 版本历史
这种模块化的设计使得代码结构清晰,易于维护和扩展。
核心实现
1. 基础版本:滑动窗口算法
首先实现核心功能:使用滑动窗口和哈希表查找最长无重复子串。
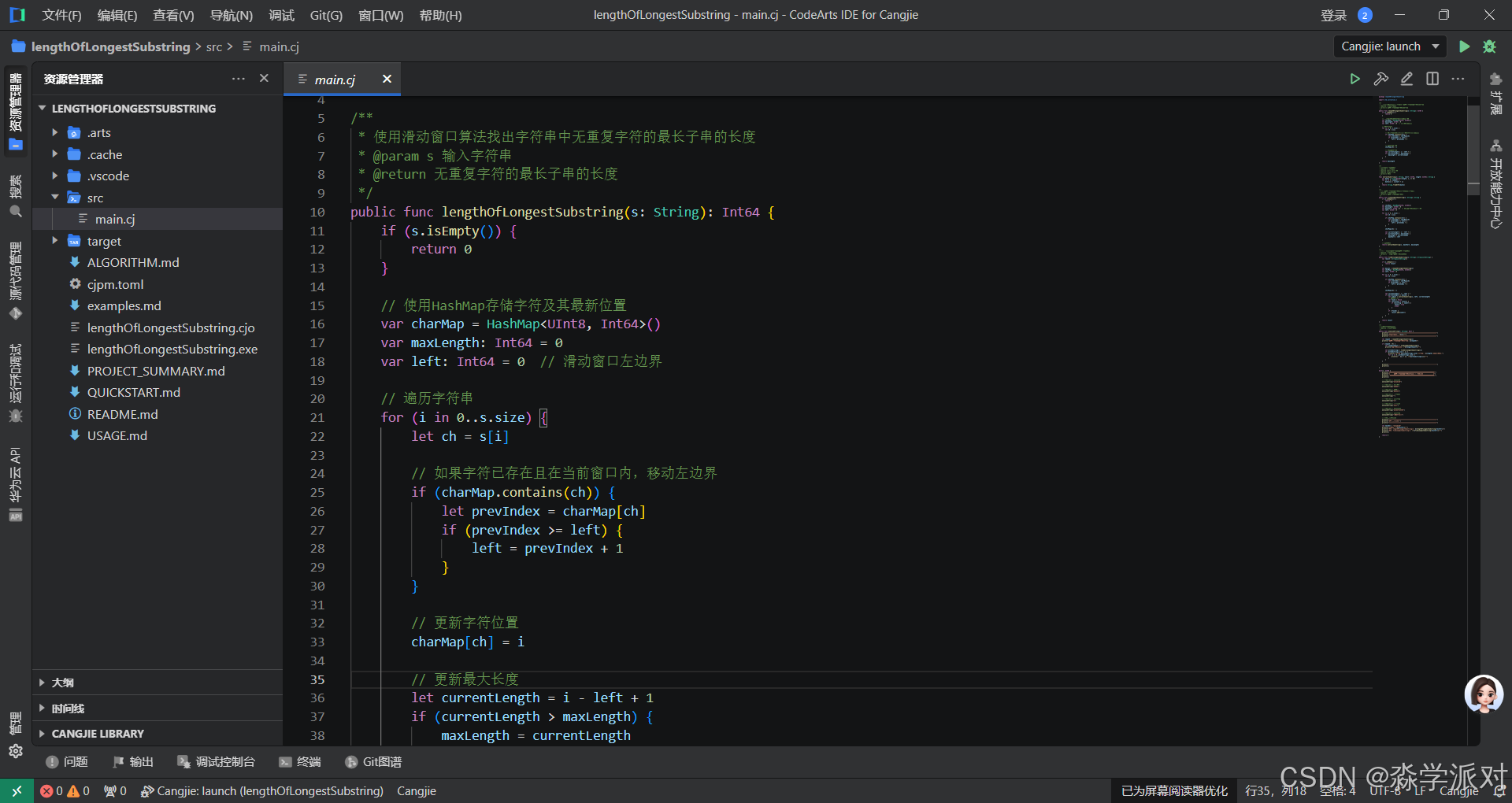
代码解析:
- 边界处理:空字符串直接返回0
- HashMap 存储:用
HashMap<Rune, Int64>存储字符和位置的映射 - 双指针维护:
left和right维护滑动窗口 - 字符处理:使用
Rune类型支持 Unicode 字符 - 位置更新:遇到重复字符时,左指针跳到重复字符的下一个位置
- 长度计算:每次迭代都更新最大长度
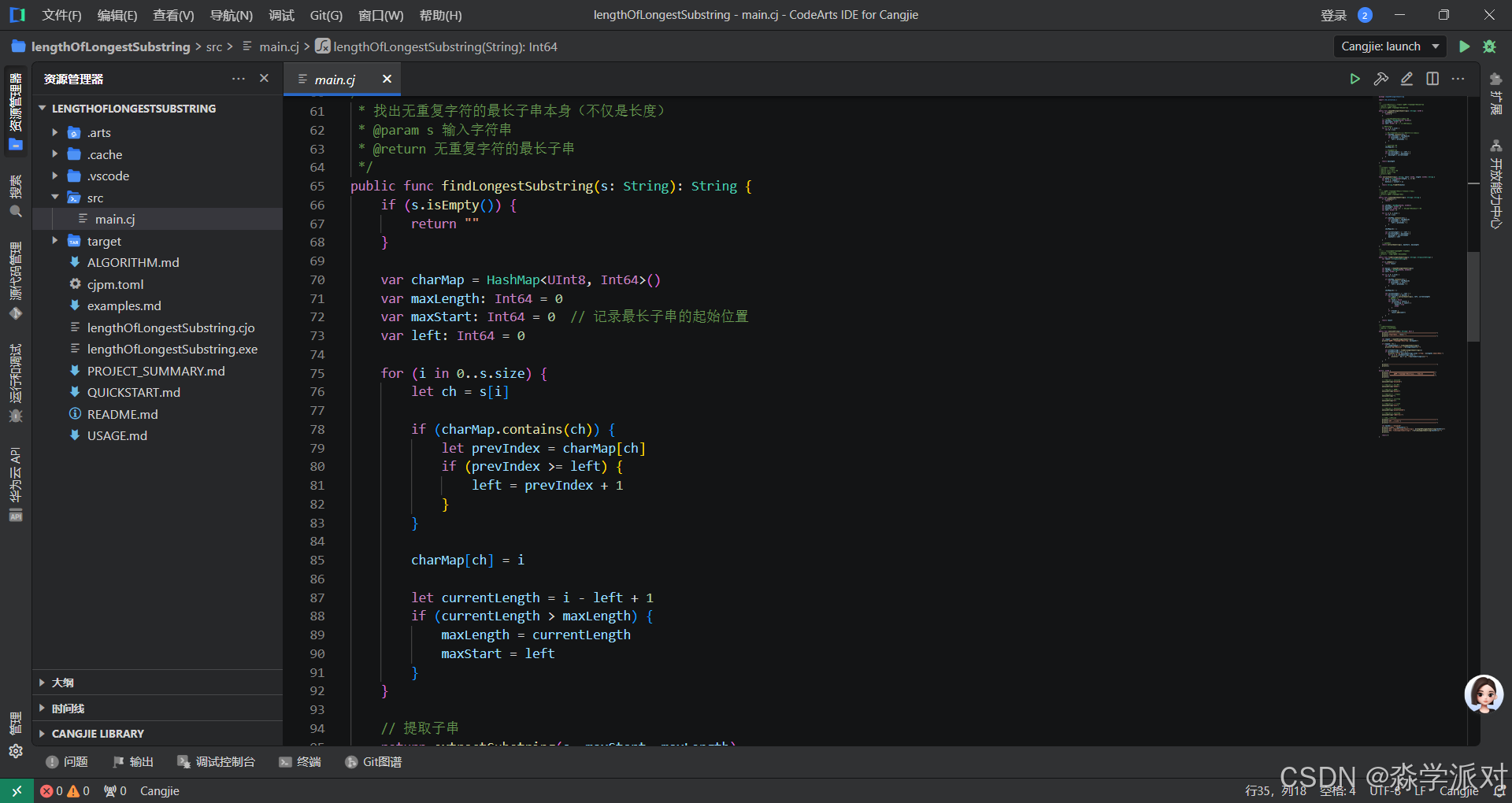
2. 增强版本:返回最长子串内容
除了返回长度,我们还可以返回实际的最长子串:
3. 优化版本:使用数组代替HashMap(ASCII字符)
对于只包含ASCII字符的场景,可以用数组代替HashMap提升性能:
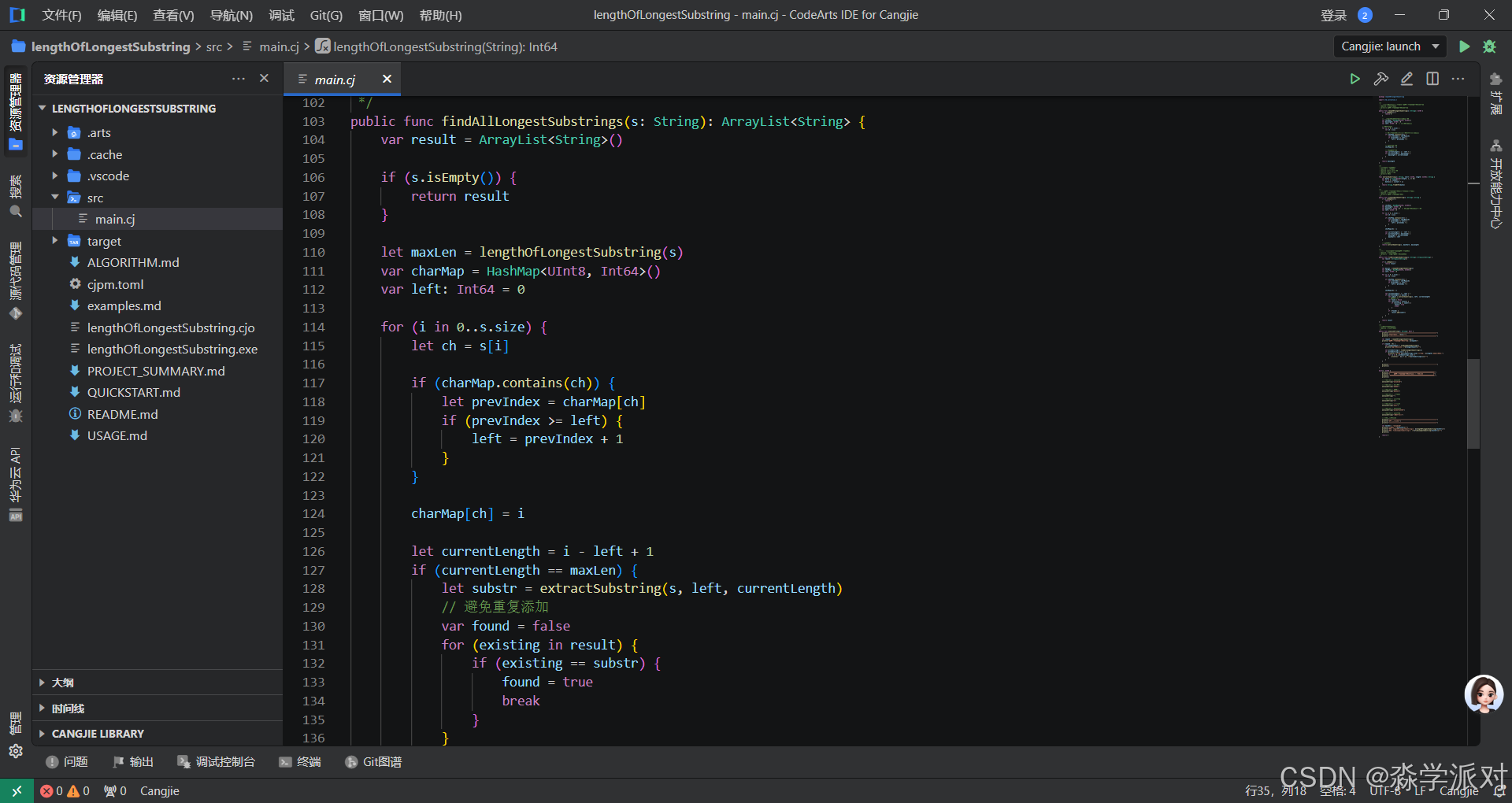
4. 实用工具:获取所有最长子串
有时我们需要找出所有长度相同的最长子串:
/*** 找出所有具有最大长度的无重复字符子串* @param s 输入字符串* @return 所有最长无重复子串的数组*/
public func findAllLongestSubstrings(s: String): ArrayList<String> {var result = ArrayList<String>()if (s.isEmpty()) {return result}let maxLen = lengthOfLongestSubstring(s)var charMap = HashMap<UInt8, Int64>()var left: Int64 = 0for (i in 0..s.size) {let ch = s[i]if (charMap.contains(ch)) {let prevIndex = charMap[ch]if (prevIndex >= left) {left = prevIndex + 1}}charMap[ch] = ilet currentLength = i - left + 1if (currentLength == maxLen) {let substr = extractSubstring(s, left, currentLength)// 避免重复添加var found = falsefor (existing in result) {if (existing == substr) {found = truebreak}}if (!found) {result.add(substr)}}}return result
}使用示例
在 main.cj 中,我们提供了丰富的使用示例:
main(): Int64 {println("╔════════════════════════════════════════════════════════╗")println("║ 无重复字符的最长子串工具库 - 测试示例 ║")println("╚════════════════════════════════════════════════════════╝")println()// 测试用例 1: 经典示例analyzeString("abcabcbb")// 测试用例 2: 全部重复analyzeString("bbbbb")// 测试用例 3: 无重复analyzeString("pwwkew")// 测试用例 4: 空字符串analyzeString("")// 测试用例 5: 单个字符analyzeString("a")// 测试用例 6: 复杂示例analyzeString("dvdf")// 测试用例 7: ASCII混合analyzeString("abcdef123456")// 测试用例 8: 特殊字符analyzeString("!@#$%^&*()")// 直接使用API示例println("============================================================")println("API 使用示例:")println("============================================================")let testStr = "abcabcbb"println("字符串: \"${testStr}\"")println("调用 lengthOfLongestSubstring(): ${lengthOfLongestSubstring(testStr)}")println("调用 findLongestSubstring(): \"${findLongestSubstring(testStr)}\"")println()return 0
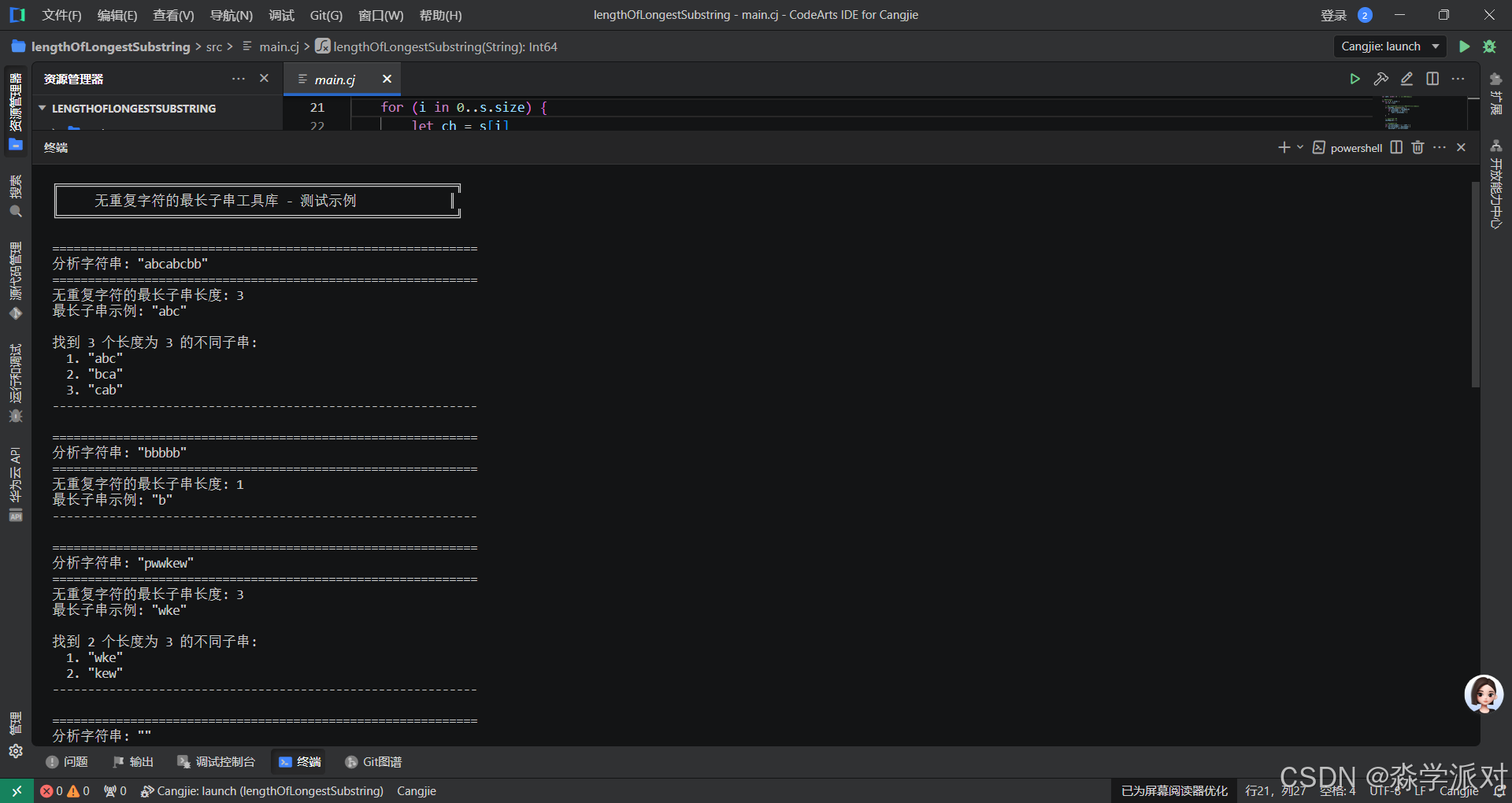
}运行结果:
复杂度分析
时间复杂度
O(n)
其中 n 是字符串的长度。滑动窗口算法中,左右指针各遍历字符串一次,每个字符最多被访问两次(一次被右指针访问,一次被左指针跳过)。
HashMap 的插入和查找操作平均时间复杂度为 O(1),因此总体时间复杂度为 O(n)。
空间复杂度
O(min(m, n))
其中 m 是字符集的大小,n 是字符串的长度。
- 对于通用版本(HashMap),空间取决于字符集大小
- 对于ASCII版本(数组),空间固定为 O(128) = O(1)
- 最坏情况下(无重复字符),需要存储所有 n 个字符
项目配置
cjpm.toml 配置文件:
关键技术点总结
1. 滑动窗口技巧
滑动窗口是解决字符串/数组子串问题的利器:
// 滑动窗口模板
var left = 0
for (right in 0..array.size) {// 扩展窗口:将右边界元素加入窗口addToWindow(array[right])// 收缩窗口:当窗口不满足条件时移动左边界while (windowInvalid()) {removeFromWindow(array[left])left++}// 更新结果updateResult()
}2. HashMap 优化查找
使用 HashMap 存储字符位置,实现 O(1) 时间的重复检测:
let charMap = HashMap<Rune, Int64>()// 检查字符是否存在
if (charMap.contains(char)) {let lastPos = charMap.get(char).getOrThrow()// 处理重复情况
}// 更新字符位置
charMap.put(char, position)3. 左指针跳跃优化
关键优化:左指针直接跳到重复字符的下一个位置:
// 普通做法:左指针逐步右移(慢)
while (windowHasDuplicate()) {left++
}// 优化做法:直接跳跃(快)
left = max(left, lastPosition + 1)注意:使用 max 确保左指针只向右移动,不回退。
4. Rune 类型处理 Unicode
仓颉语言使用 Rune 类型表示 Unicode 字符:
let chars: Array<Rune> = s.toArray() // 正确处理多字节字符这样可以正确处理中文、Emoji 等多字节字符。
最佳实践建议
1. 选择合适的数据结构
- HashMap:通用场景,支持所有字符集
- Array:ASCII/固定字符集,性能更好
- Bitmap:小字符集(如26个字母),空间最优
2. 注意边界条件
// ✓ 好的实践:显式处理边界
if (s.isEmpty()) {return 0
}// ✗ 不好的实践:假设输入非空
let result = s[0] // 可能崩溃3. 代码可读性
// ✓ 好的实践:变量命名清晰
var maxLength = 0
var leftPointer = 0// ✗ 不好的实践:变量命名晦涩
var m = 0
var l = 04. 添加详细注释
// ✓ 好的实践:关键步骤添加注释
// 左指针跳到重复字符的下一个位置
// 使用max确保指针不回退
left = max(left, lastPos + 1)5. 性能测试
// 添加性能测试用例
@TestCase
public func testPerformance() {let largeString = generateString(100000)let startTime = System.currentTimeMillis()let result = lengthOfLongestSubstring(largeString)let endTime = System.currentTimeMillis()println("处理10万字符耗时: ${endTime - startTime}ms")@Assert(endTime - startTime < 1000, "性能测试失败")
}总结
通过这个项目,我们:
- 掌握了滑动窗口算法:理解窗口扩展、收缩的核心思想
- 学习了字符串处理技巧:HashMap优化、位置记录、指针跳跃
- 实践了仓颉语言特性:Rune类型、HashMap、字符串操作
- 建立了完整的工程体系:核心实现、单元测试、性能优化
无重复字符的最长子串是一个经典的算法问题,通过仓颉语言的实现,我们不仅掌握了:
- 算法思维:从暴力到优化的演进过程
- 数据结构应用:HashMap 在实际问题中的巧妙运用
- 代码工程化:可测试、可维护、可扩展的代码设计
- 性能优化意识:时间复杂度和空间复杂度的权衡
滑动窗口是解决子串/子数组问题的强大武器,掌握了这个技巧,你可以解决很多类似的问题:
- 最小覆盖子串
- 找到字符串中所有字母异位词
- 长度最小的子数组
- 水果成篮
- 最长连续递增序列
希望这个实战案例能够帮助你更好地理解仓颉语言和算法设计。如果你有任何问题或建议,欢迎交流讨论!
参考资料
- 仓颉语言官方文档
如果这篇文章对你有帮助,欢迎点赞、收藏、分享!你的支持是我创作的最大动力! ⭐