LLM之Agent(二十四)| AI Agents上下文工程(Context Engineering)指南

在快速发展的人工智能世界中, 上下文工程已成为构建智能、自适应和可靠的人工智能代理的关键技能。与依赖静态逻辑的传统软件系统不同,由大型语言模型 (LLM) 提供支持的人工智能代理在很大程度上依赖于提供给它们的上下文来有效地做出决策、推理和执行任务。
本文将深入探讨一下什么是上下文工程、为什么它对 AI Agent具有挑战性以及如何使用 LangGraph(一个用于构建有状态 AI 代理的强大框架)实现上下文工程。我们将使用实际示例、工作流程和图表,尽量让每个人都能够理解,从初学者到经验丰富的开发人员。
一、什么是上下文工程(Context Engineering)
将AI Agent视为一个功能强大的助手,他需要明确的指令和相关信息才能做好工作。 上下文工程是设计和管理围绕 AI Agent的信息生态系统(称为“上下文”)的过程。这是为了在正确的时间以正确的格式向代理提供正确的信息,以便它能够准确有效地执行任务。
与侧重于制定单一、措辞良好的指令的提示工程不同,上下文工程是更广泛的系统级方法,它涉及编排指令、对话历史记录、记忆和外部数据等多个组件来指导代理的行为。正如 Andrej Karpathy 所说,上下文工程是“用下一步的正确信息填充上下文窗口的微妙艺术和科学”。
二、为什么上下文很重要
LLM 是AI Agent背后的大脑,不像人类那样具有固有的记忆或上下文。LLM完全依赖于上下文窗口大小,一个有限的空间大小(例如 8k、32k 或 128k 标记),上下文窗口需要同时保存他们处理的所有信息。如果上下文不完整、不相关或结构不良,AI Agent的输出将不准确或无济于事。上下文工程可以确保AI Agent拥有成功所需的一切,就像为厨师提供正确的食材和食谱来烹饪完美的菜肴一样。
三、为什么上下文工程很重要
提高Agent性能:正确的上下文可以带来更准确、更相关和更人性化的响应;
减少错误:许多Agent的故障是由于上下文缺失或不相关造成的,而不仅仅是模型限制;
支持复杂任务:Agents只有在具有正确的上下文时才能处理多步骤工作流、长时间对话和专用领域。
Example:
想象一下,您正在计划邀请一些朋友进行晚宴。如果您只说“计划一顿晚餐”,厨师可能会因为不知道您的偏好、预算或宾客名单而苦苦挣扎。但是,如果您提供:
说明 :“计划 10 人的素食晚餐。”
偏好 : “我喜欢意大利菜,有两位客人对坚果过敏。”
历史 : “上次,我们吃了意大利面,每个人都喜欢。”
工具 :“使用我的食谱书并检查食品储藏室。
厨师现在可以计划一顿美味的晚餐了。上下文工程对人工智能代理也是如此,确保他们全面了解做出明智的决策。
四、为什么上下文工程对 AI Agent来说更难
AI Agent比简单的聊天机器人更复杂,因为它们旨在处理动态的多步骤任务,通常涉及工具、内存和外部数据。这种复杂性使上下文工程具有挑战性,原因如下:
有限的上下文窗口:LLM 的上下文窗口有限,因此您无法一次向它们提供所有内容。决定包含或排除哪些内容对于避免使模型不堪重负或丢失重要信息至关重要;
动态任务:AI Agent经常执行多步骤工作流程(例如,研究、总结和响应)。每个步骤都需要不同的上下文,因此很难提前预测相关内容;
记忆管理:与人类不同,AI Agent不会自然地记住过去的互动。跨会话管理短期和长期记忆是一项技术挑战;
工具过载:AI Agent通常可以访问多种工具(例如搜索 API、数据库)。选择正确的工具并将其输出集成到上下文中而不造成混淆是很棘手的;
意外检索:设计不当的上下文可能会导致检索不相关或不需要的信息,例如当 ChatGPT 在图像生成任务中意外使用用户的位置。
平衡相关性和简洁性:提供太多上下文可能会使模型不知所措,而太少可能会导致响应不完整。取得适当的平衡是一门艺术。
4.1 AI Agent的上下文类型
AI Agent的上下文来自各种来源,每个来源都有独特的用途。以下是上下文的主要类型:

4.2 Memory类型
记忆(Memory)是上下文工程的关键组成部分,使代理能够保留和回忆信息。借鉴人类认知科学,AI Agent使用三种主要类型的记忆,如 CoALA 论文中所述:

语义记忆(Semantic Memory):将其视为代理的“知识库”。它存储用户偏好或特定领域信息等事实(例如,“法国首都是巴黎”)。它通常使用矢量数据库或知识图谱来实现高效检索。
情景记忆(Episodic Memory):这就像代理的“日记”,记录特定的互动。例如,它可能会存储用户上周询问食谱并给出了积极的反馈。情景记忆通常作为少量示例来实现,以指导未来的行为。
程序记忆(Procedural Memory):这是代理的“剧本”,定义了它如何执行任务。它通常编码在系统提示或代理代码中,并且可以通过反馈或反思来发展。
4.3 常见的上下文工程策略
上下文工程涉及有效管理上下文的四种主要策略: 写入 、 选择 、 压缩和隔离 。

4.3.1 写
编写上下文意味着将信息存储在上下文窗口之外以供以后使用。例如,代理可以使用暂存本记下计划或中间结果。例如,Anthropic 的多智能体研究人员将其计划保存到内存中,以避免在上下文窗口被截断时丢失它。
示例 :计划旅行的代理可能会将草稿行程保存到文件或内存存储中,以便在以后的步骤中参考。
4.3.2 选择
选择相关上下文至关重要,尤其是对于语义记忆和情景记忆。 检索增强生成 (RAG) 等技术使用嵌入或知识图谱来仅获取最相关的信息。例如,ChatGPT 使用嵌入来检索用户特定的记忆,但选择不当可能会导致错误,例如注入不相关的数据。
示例 :对于有关“意大利餐厅”的查询,代理仅从用户的内存中检索与餐厅相关的事实,而忽略不相关的首选项,例如最喜欢的颜色。
4.3.3 压缩
压缩涉及汇总或修剪上下文以适应 LLM 的上下文窗口。例如,LangGraph 允许汇总消息列表以减少令牌使用。
示例 :关于一个项目的长时间对话总结为:“用户讨论了项目 X,更喜欢敏捷方法,截止日期是下个月。
4.3.4 隔离
隔离上下文意味着对不相关的信息进行沙盒处理以防止混淆。例如,将工具描述限制为仅与当前任务相关的工具描述可以避免代理过载。
示例 :起草电子邮件时,代理只能看到与电子邮件相关的工具(send_email、check_calendar),而忽略不相关的工具,例如 search_web。
五、使用 LangGraph 进行上下文工程
LangGraph 是 LangChain 推出的一个功能强大的低级编排框架,使开发人员能够构建有状态、可控的 AI Agent。与抽象细节的高级框架不同,LangGraph 可以让您对上下文、记忆和工作流程进行细粒度控制,使其成为上下文工程的理想选择。
5.1 LangGraph 中的关键概念

5.2 为什么使用LangGraph
可控性:准确定义代理工作流程每个步骤的上下文;
记忆管理:支持短期和长期记忆,内置持久性;
动态工作流程:创建具有节点和边缘的复杂多步骤工作流程,例如流程图;
工具集成:无缝集成工具和 RAG 以进行动态上下文检索;
人机交互:允许人类反馈来完善上下文或记忆。
六、使用LangGraph
6.1 安装LangGraph
要开始使用 LangGraph,首先,需要 Python 和必要的软件包。安装方法如下:
pip install langgraph langchain langchain-community还需要 OpenAI、Anthropic 或 Groq 等 LLM 提供商。对于这个例子,我们将使用 Anthropic 的 Claude 模型,所以安装 Anthropic 集成:
pip install langchain-anthropic将 API 密钥设置为环境变量:
export ANTHROPIC_API_KEY="your-api-key"6.2 LangGraph工作流
LangGraph 将代理工作流组织为图表 ,其中:
Nodes表示任务(例如,调用 LLM、获取数据);
Edges定义任务之间的流;
State保存在执行过程中演变的动态上下文(例如messages、memory)。
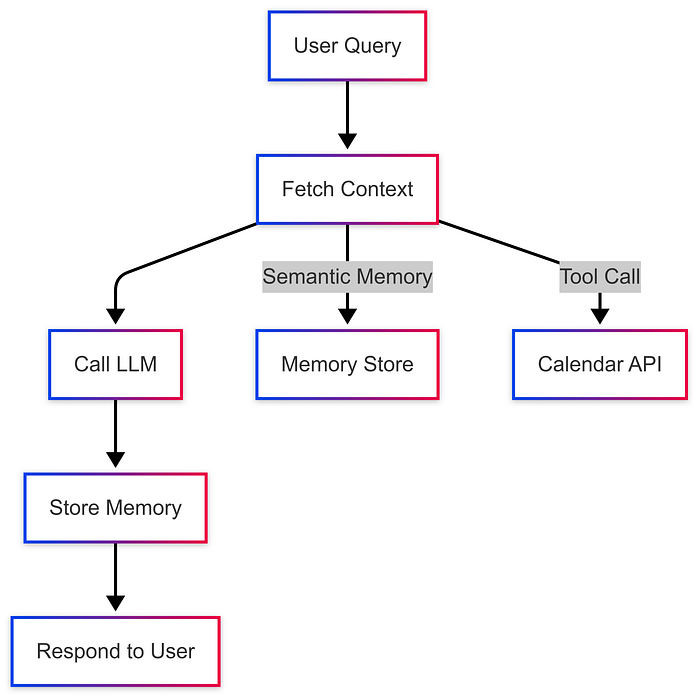
下面我们使用上下文工程完成一个简单的电子邮件代理工作流程:
接收用户查询:用户询问“起草一封关于明天会议的电子邮件给 Jim;
获取上下文:检索用户偏好(例如语气)和日历数据;
使用 LLM 处理:使用 LLM 根据上下文起草电子邮件;
存储内存:将交互保存为情景记忆以供将来参考;
回复:将草稿的电子邮件返回给用户。
LangGraph工作流程图如下所示:
第1步、定义State
State会保存各种上下文信息,包括消息、用户首选项和记忆。
from typing_extensions import TypedDict
from langchain_core.messages import AnyMessageclass AgentState(TypedDict):messages: list[AnyMessage] user_name: str preferences: dict memory_summary: str第2步、设置Tools
定义 check_calendar 等工具以动态获取上下文。
from langchain_core.tools import tool@tool
def check_calendar():"""Check the user's calendar for availability.""" return {"availability": "Free at 3 PM tomorrow"}第3步、创建工作流
定义用于获取上下文、调用 LLM 和存储内存的节点。
from langgraph.graph import StateGraph
from langchain_anthropic import ChatAnthropic
from langchain_core.messages import HumanMessage, SystemMessage# Initialize the LLM
llm = ChatAnthropic(model="claude-3-7-sonnet-latest")def fetch_context_node(state: AgentState):# Simulate fetching semantic memory (e.g., user preferences) state["preferences"] = {"tone": "formal", "signature": "Best regards, {user_name}"} # Call calendar tool calendar_data = check_calendar() state["memory_summary"] = f"Calendar: {calendar_data['availability']}" return statedef llm_node(state: AgentState):system_prompt = f""" You are a helpful assistant for {state['user_name']}. Preferences: {state['preferences']}. Context: {state['memory_summary']}. Draft an email based on the user's request. """ messages = [SystemMessage(content=system_prompt)] + state["messages"] response = llm.invoke(messages) state["messages"].append(response) return statedef store_memory_node(state: AgentState):# Simulate storing episodic memory state["memory_summary"] += f"\nDrafted email for {state['user_name']}." return state# Build the graph
builder = StateGraph(AgentState)
builder.add_node("fetch_context", fetch_context_node)
builder.add_node("llm", llm_node)
builder.add_node("store_memory", store_memory_node)
builder.add_edge("fetch_context", "llm")
builder.add_edge("llm", "store_memory")
builder.set_entry_point("fetch_context")
graph = builder.compile()第4步、运行Agent
使用用户查询调用代理。
initial_state = {"messages": [HumanMessage(content="Draft an email to Jim about tomorrow’s meeting.")], "user_name": "Alice", "preferences": {}, "memory_summary": ""
}result = graph.invoke(initial_state)
print(result["messages"][-1].content)输出示例:
Subject: Meeting Tomorrow at 3 PMDear Jim,
I hope this email finds you well. I am writing to confirm our meeting scheduled for tomorrow at 3 PM. Please let me know if this time works for you or if we need to reschedule.
Best regards,
Alice代码解释:
State:AgentState 保存动态上下文(消息、首选项、内存);
Nodes:
fetch_context_node:检索用户偏好(语义记忆)和日历数据(工具输出)。
llm_node:使用 LLM 起草电子邮件,结合来自州的上下文。
store_memory_node:将交互保存为情景记忆。
Edges:定义流:获取上下文→调用 LLM →存储内存;
Context Engineering:代理动态获取相关上下文(日历、首选项)并将其压缩为 LLM 的简洁提示。
6.3 使用 LangMem 添加长期记忆
LangGraph 与 LangMem 集成,LangMem 是一个用于长期记忆管理的库。以下是使用 LangMem 添加语义内存的方法:
from langmem import MemoryStore# Initializing memory store
memory_store = MemoryStore(namespace="user_alice")def fetch_context_node(state: AgentState):# Fetching semantic memory facts = memory_store.search(query=state["messages"][-1].content) state["preferences"] = facts.get("preferences", {"tone": "formal"}) calendar_data = check_calendar() state["memory_summary"] = f"Calendar: {calendar_data['availability']}" return statedef store_memory_node(state: AgentState):# Store semantic and episodic memory memory_store.store({"preferences": state["preferences"], "interaction": state["messages"][-1].content}) state["memory_summary"] += f"\nDrafted email for {state['user_name']}." return state此代码使用 LangMem 来存储和检索用户偏好(语义记忆)和交互详细信息(情景记忆),确保代理记住过去跨会话的交互。
七、上下文工程的实用技巧
使用 RAG 进行检索:集成 Pinecone 或 Weaviate 等向量数据库,以实现高效的语义记忆检索。
总结长期历史:压缩对话历史记录以避免token限制。LangGraph 的实用程序可以汇总消息列表。
命名空间记忆: 使用 LangMem 的命名空间按用户或应用程序组织记忆,防止跨用户数据泄露。
动态工具选择:使用语义搜索(例如 LangGraph 的 Bigtool 库)为每个任务选择相关工具。
反思和学习:实施反思(元提示)以根据用户反馈完善程序记忆。
