中科大自适应推理具身导航框架!AdaNav:基于不确定性驱动自适应推理的视觉语言导航
作者: Xin Ding, Jianyu Wei, Yifan Yang, Shiqi Jiang, Qianxi Zhang, Hao Wu, Fucheng Jia, Liang Mi, Yuxuan Yan, Weijun Wang, Yunxin Liu, Zhibo Chen, Ting Cao
单位:中国科学技术大学,微软研究院,南京大学,中南大学,浙江大学,清华大学人工智能产业研究院
论文标题:AdaNav: Adaptive Reasoning with Uncertainty for Vision-Language Navigation
论文链接:https://arxiv.org/pdf/2509.24387v1
代码链接:https://github.com/xinding-sys/AdaNav
主要贡献
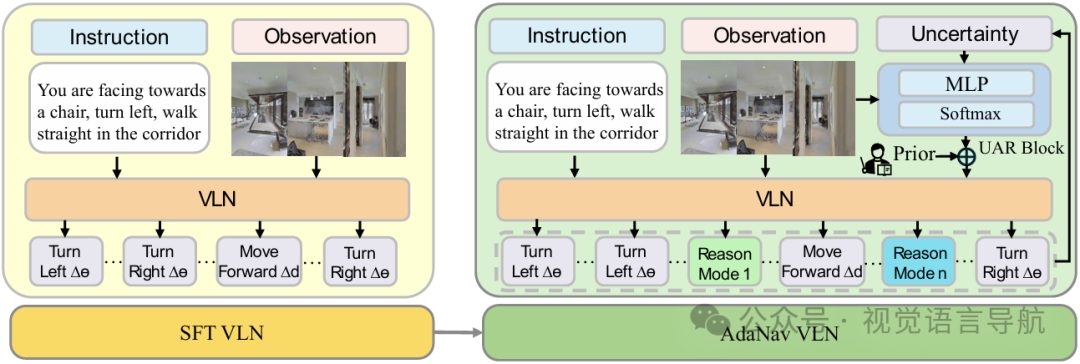
提出基于不确定性的自适应推理框架了AdaNav,通过引入不确定性自适应推理块(UAR Block)和启发式到强化学习(Heuristic-to-RL)的训练机制,使智能体能够在导航过程中根据需要动态地触发推理,解决了固定步长推理导致的性能次优和计算开销问题。
在仅使用6K训练样本的情况下,AdaNav在多个基准测试中取得了显著的性能提升,超过了使用百万级数据训练的闭源模型。例如,在R2R val-unseen上成功率提高了20%,在RxR-CE上提高了11.7%,在真实世界场景中提高了11.4%。
该框架使推理更加困难感知和模式自适应,随着训练的进行,推理步骤更加集中在困难的轨迹上,且推理模式的选择也更加合理,同时减少了平均推理步数,提高了效率。
研究背景
视觉语言导航(VLN)要求智能体能够理解自然语言指令,并将其与连续的视觉观察相结合,以执行长期的导航轨迹。现有的基于视觉语言模型(VLM)的方法存在两个主要挑战:一致的时间对齐和稳健的感知-动作映射。
为了应对这些挑战,以往的研究引入了显式推理,但固定步长的推理不仅计算开销大,还会导致过度思考,降低导航质量。理想的VLN智能体应该能够自适应地推理,即根据需要决定何时以及如何推理,但实现这种自适应性并缓解大语言模型(LLM)的过度自信问题通常需要大量的特定任务数据进行监督微调,而这些数据收集成本高昂。
方法
问题定义
视觉语言导航
环境与动作空间:考虑一个标准的VLN设置,智能体被放置在一个3D环境 中,具有状态空间 和动作空间 ,其中 和 分别表示角度和距离。
任务目标:给定自然语言指令 和连续的视觉观察 ,智能体需要执行一个轨迹 ,以达到由指令 隐式指定的目标状态 ,目标是最大化任务成功率:其中, 是指示函数,表示最终状态是否为目标状态。
自适应推理导航
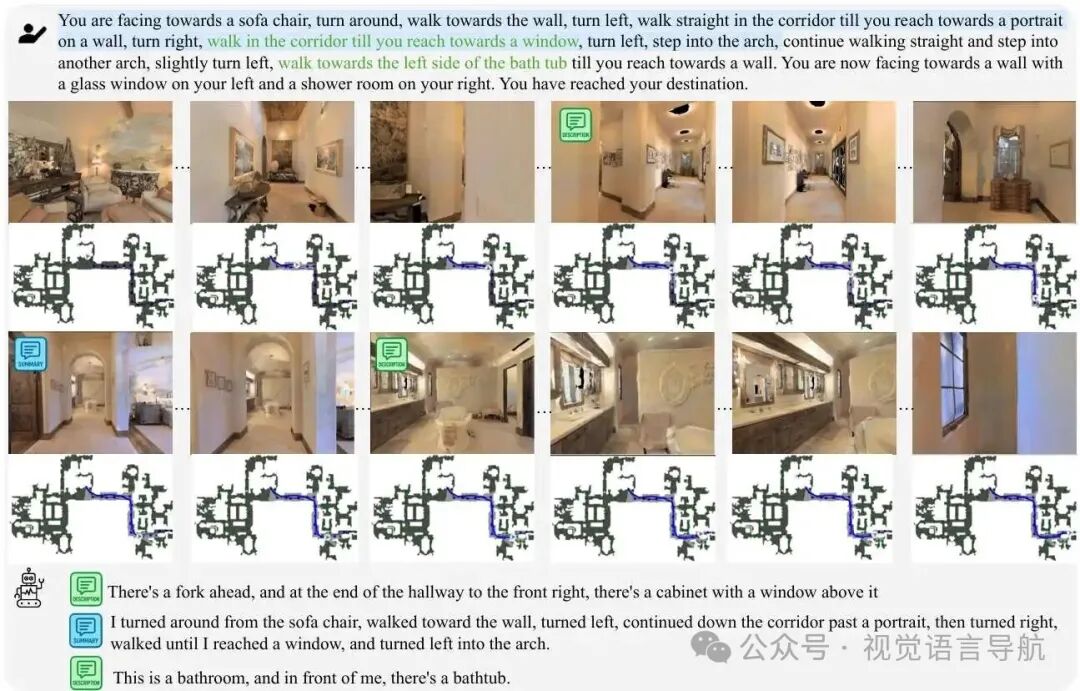
推理模式与内容:为了提高VLN在长期和复杂环境中的性能,允许智能体在每一步 进行显式推理,推理模式变量 ,其中 表示不进行推理, 是预定义的推理模式集合(如描述、总结、错误纠正)。推理内容为 。
联合策略:智能体的策略由两部分组成:
导航策略 :根据导航相关的历史信息 、指令 和之前的推理内容 决定动作 。
推理策略 :决定何时进行推理(通过 或 )以及使用哪种推理模式(通过 )。
整体策略:联合策略为:其中, 表示完整的导航和推理历史信息。
优化目标:通过联合优化导航和推理策略,目标是最大化任务性能,同时保持计算效率:其中, 同时考虑导航成功(如进度或成功指标)和推理调用引起的延迟惩罚。
AdaNav的设计与实现
动机
自适应推理需要智能体能够选择性地决定何时推理有益以及调用哪种模式。然而,现有的大语言模型(LLM)对任务难度不敏感,容易过度自信。
在LLM研究中,通过监督微调引入高质量的推理痕迹可以缓解这一问题。但对于具身智能体,收集这样的高质量交互痕迹成本过高。
因此,AdaNav提出了一种替代方法,利用可解释的不确定性信号动态触发推理,无需依赖大规模推理监督。
不确定性自适应推理块
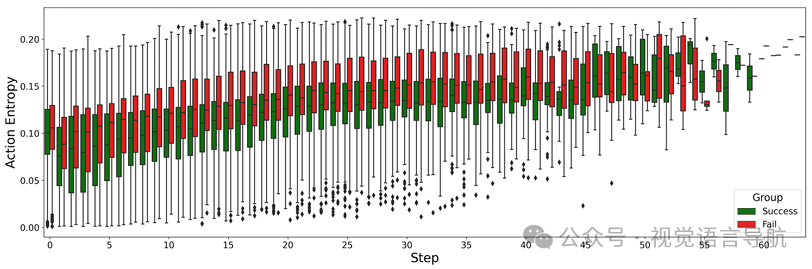
动作熵作为不确定性度量:受语言推理中高熵token对单步文本生成影响较大的启发,定义动作熵 作为不确定性度量:其中, 是生成的token数量, 是词汇表大小, 是时间步 时词汇表中第 个token的概率。
动作熵的有效性验证:通过诊断研究发现,失败的轨迹具有高且持续的动作熵,而成功的轨迹保持较低的动作熵。单独的即时动作熵不足以预测失败,但结合历史动作熵趋势和当前动作熵状态可以提供更可靠的信号 。
UAR Block设计:UAR Block结合历史动作熵 和当前观察 ,形成推理相关信息 ,并将其转化为紧凑的控制向量:直接参数化推理模式的logits。从这个向量中,模式选择策略为:
启发式到强化学习训练
基于不确定性的先验:在冷启动阶段,由于RL策略尚未学会有意义的模式选择,因此使用基于不确定性的先验初始化训练。直观上,较高的熵表示较高的不确定性,需要更强的推理。计算标量熵分数为过去熵的均值 ,并将其映射到包含“无推理”选项的推理模式上的软先验分布:其中, 是模式特定的熵阈值, 控制先验的平滑度。
启发式到RL的过渡:为了逐渐从启发式先验转移到学习到的RL策略,将先验分布与模型预测融合为:其中, 从1逐渐衰减到0,允许RL策略 逐渐接管启发式先验 。因此,模式选择策略可以表示为:
奖励设计:首先定义推理成本为基于相对推理长度的归一化惩罚:其中, 是当前步的推理长度, 是成功样本组中最短的生成长度, 是一个常数惩罚窗口。
导航目标奖励:采用基于距离减少的常见外在奖励,即时奖励定义为 ,其中 表示从当前状态 到目标位置 的测地线距离。
整体任务奖励:将外在奖励和推理成本结合起来,整体任务奖励定义为折扣累积回报:其中, 是折扣因子,控制未来奖励的权重。这种奖励设计鼓励智能体高效地向目标导航,同时避免不必要的推理开销。
实验
性能提升
实验设置
基础模型:选择两个开源的VLN模型NAVID和NAVILA作为基础模型,AdaNav被集成到这些模型中。
训练数据:从R2R和RxR的训练集中随机采样3000个episode进行训练。
硬件配置:使用4块NVIDIA RTX A100 GPU进行训练。
基准测试:在R2R和RxR的val-unseen分割上评估导航性能,并在ScanQA验证集上评估空间场景理解能力。
实验结果
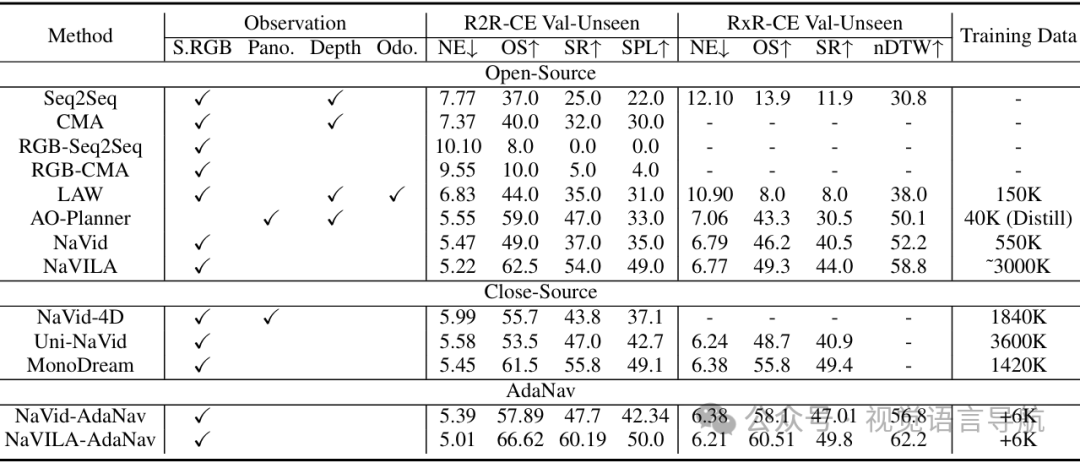
VLN-CE基准测试:与使用百万级数据训练的闭源模型相比,AdaNav在仅使用6K训练样本的情况下,成功率显著提升。具体来说,在R2R val-unseen上成功率提高了20%,在RxR-CE val-unseen上提高了14.6%。
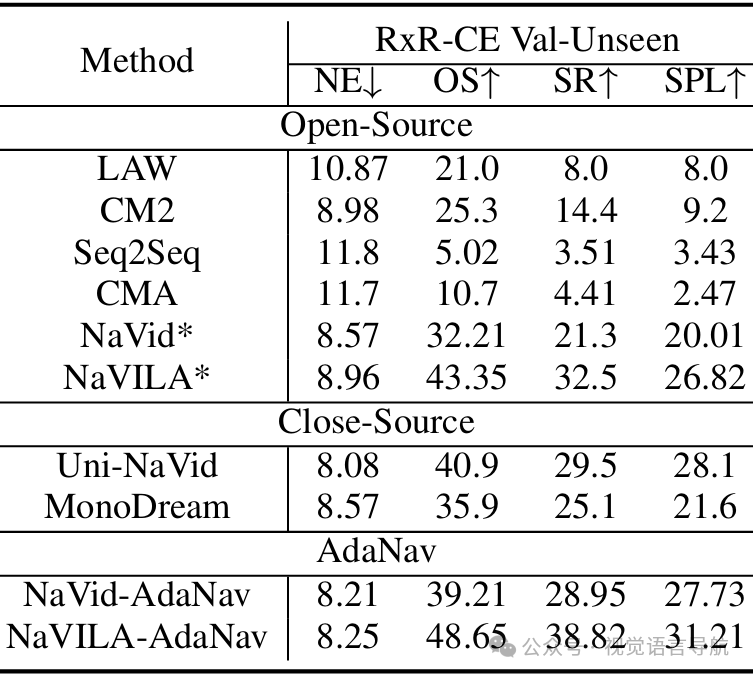
跨数据集评估:在仅使用R2R数据训练的情况下,AdaNav在RxR val-unseen上的零样本评估中表现优异,超过了所有闭源基线模型,展示了强大的泛化能力。
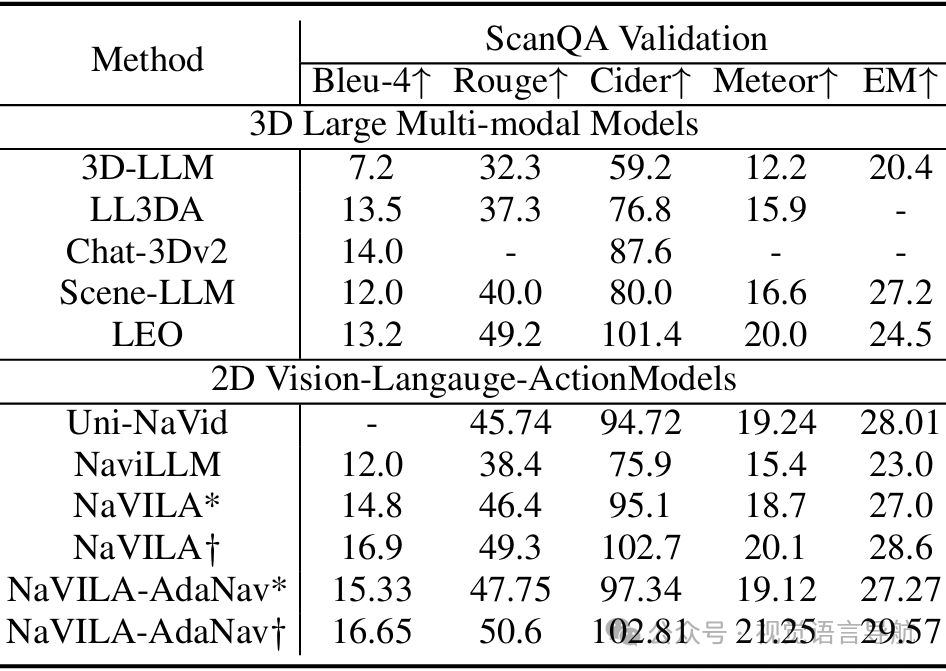
空间场景理解:在ScanQA验证集上,AdaNav不仅保持了基础模型的通用场景理解能力,还略有提升,表明其在推理训练后增强了鲁棒性和泛化能力。
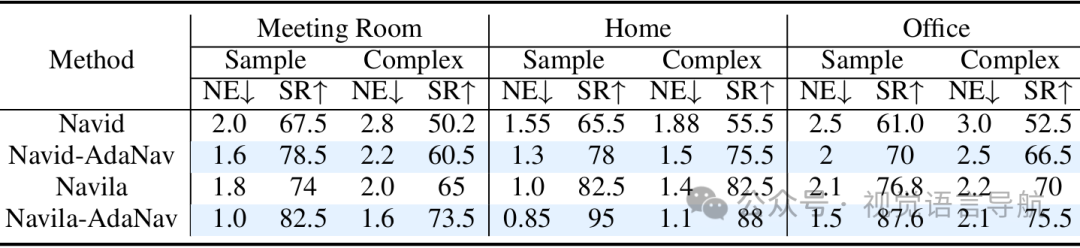
真实世界评估:在真实世界环境中,使用25个样本或复杂指令进行实验,AdaNav在会议室、家庭和办公室三种环境中的成功率显著提高,平均成功率提升了约11.4%。
UAR Block分析
实验方法
训练数据规模:分别使用2K、4K和6K训练数据进行训练,观察UAR Block的行为变化。
推理调用分析:统计推理调用的频率、分布以及不同推理模式(描述、总结、错误纠正)的使用情况。
任务难度分类:根据基础模型的成功与否将任务分为“容易”和“困难”两类,分析UAR Block在不同难度任务中的推理触发行为。
实验结果

推理频率:随着训练数据的增加,模型倾向于减少推理调用的频率,将推理集中在关键时刻,从而平衡效率和效果。
推理模式选择:在后期步骤中,模型更倾向于使用总结和错误纠正模式,显示出基于任务上下文的自适应模式选择能力。
任务难度响应:在基础模型失败的任务(即“困难”任务)中,推理调用的频率显著增加,表明UAR Block能够自适应地将推理能力分配给更具挑战性的场景。
消融研究
组件消融
实验方法
去除UAR Block:推理以固定步长(例如每5步)或随机方式触发,不使用自适应控制。
去除启发式先验:仅依赖强化学习从头开始训练,不使用基于不确定性的启发式先验。
去除强化学习微调:仅使用启发式信号指导推理触发,不进行进一步的策略优化。
实验结果
去除UAR Block:性能显著下降,表明自适应推理控制对于提升导航性能至关重要。
去除启发式先验:训练初期性能较差,说明启发式先验为训练提供了有效的初始引导。
去除强化学习微调:性能不如完整AdaNav,表明强化学习微调能够进一步优化推理策略,提升性能。
超参数敏感性
实验方法
关键超参数:主要分析模式特定的熵阈值 和平滑因子 。
实验设置:分别测试不同的 (如80%、85%、90%)和 值,观察对性能的影响。
实验结果
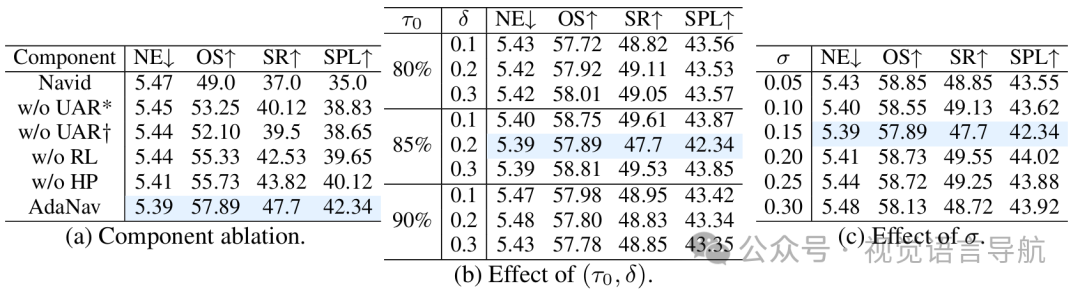
熵阈值:较低的 值(如80%)在训练初期提供了更宽松的推理触发条件,有助于模型更快地学习推理模式。随着 的增加,模型需要更高的不确定性才会触发推理,从而提高了推理的效率。
阈值增量:适当的 值能够平衡不同推理模式之间的触发条件,使模型能够根据任务难度灵活选择推理模式。
平滑因子:较大的 值使先验分布更加平滑,有助于模型在不同推理模式之间平滑过渡,但过大的 可能导致模型对不确定性信号不够敏感。
结论与未来工作
结论:
AdaNav通过结合可解释的启发式先验和最优的强化学习,提供了一种可扩展的、自适应的推理方法,无需依赖昂贵的标记推理数据,即可在具身任务中实现高效的、困难感知的和模式自适应的推理。
该方法在多个基准测试和真实世界部署中都表现出色,为具身智能体的推理能力提升提供了一个有前景的方向。
未来工作:
可以进一步探索如何在更复杂的环境和任务中应用和优化AdaNav,例如在多智能体交互场景中实现自适应推理,或者将该框架扩展到其他需要推理的具身任务中。
此外,还可以研究如何进一步提高推理的效率和准确性,以及如何更好地利用有限的数据来训练更强大的推理模型。
