java面试:有了解过kafka架构吗,可以详细讲一讲吗
kafka是一个消息队列的常见架构,负责对消息的传递和管理,进而来保证服务的上下游具有一个相对较好的性能,因此在java的面试当中,kafka常常会最为一个考察要点来判断面试者对mq消息队列的熟悉程度,因此今天我们就对kafka消息队列进行分享和讲解,希望大家能从中学习到知识,能够有所收获。
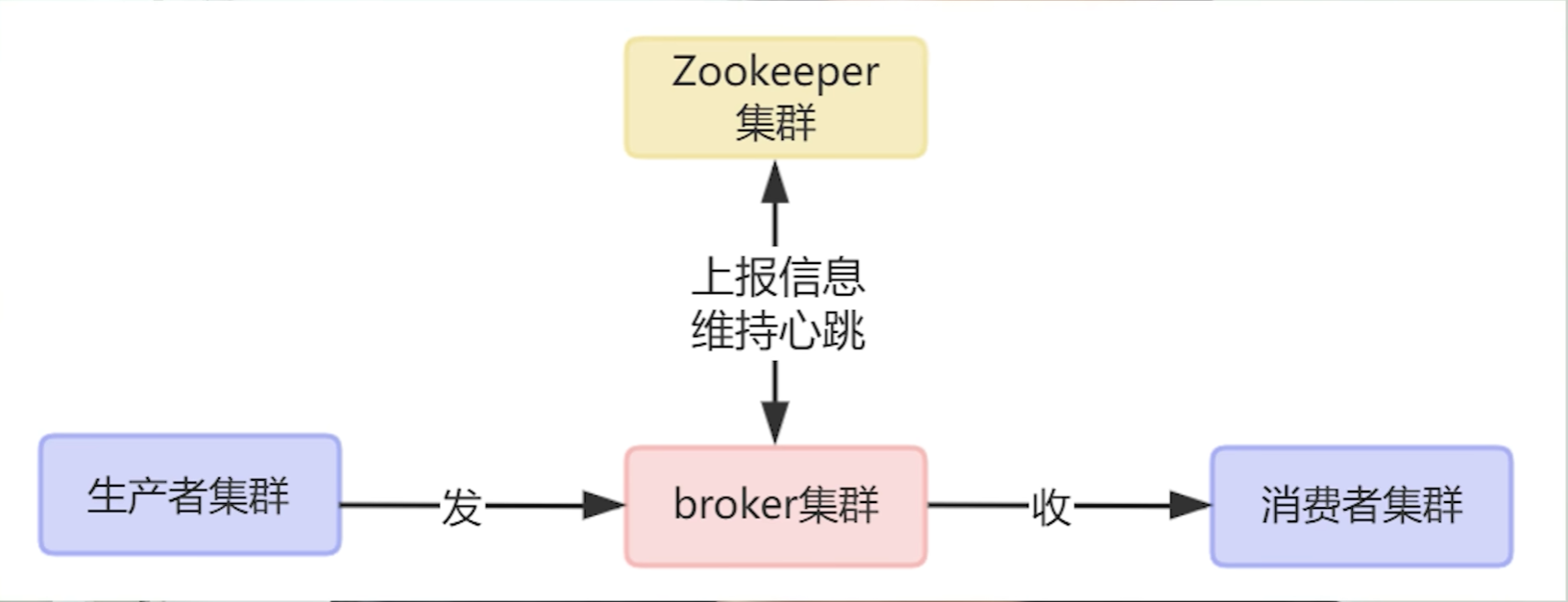
1.kafka的整体架构
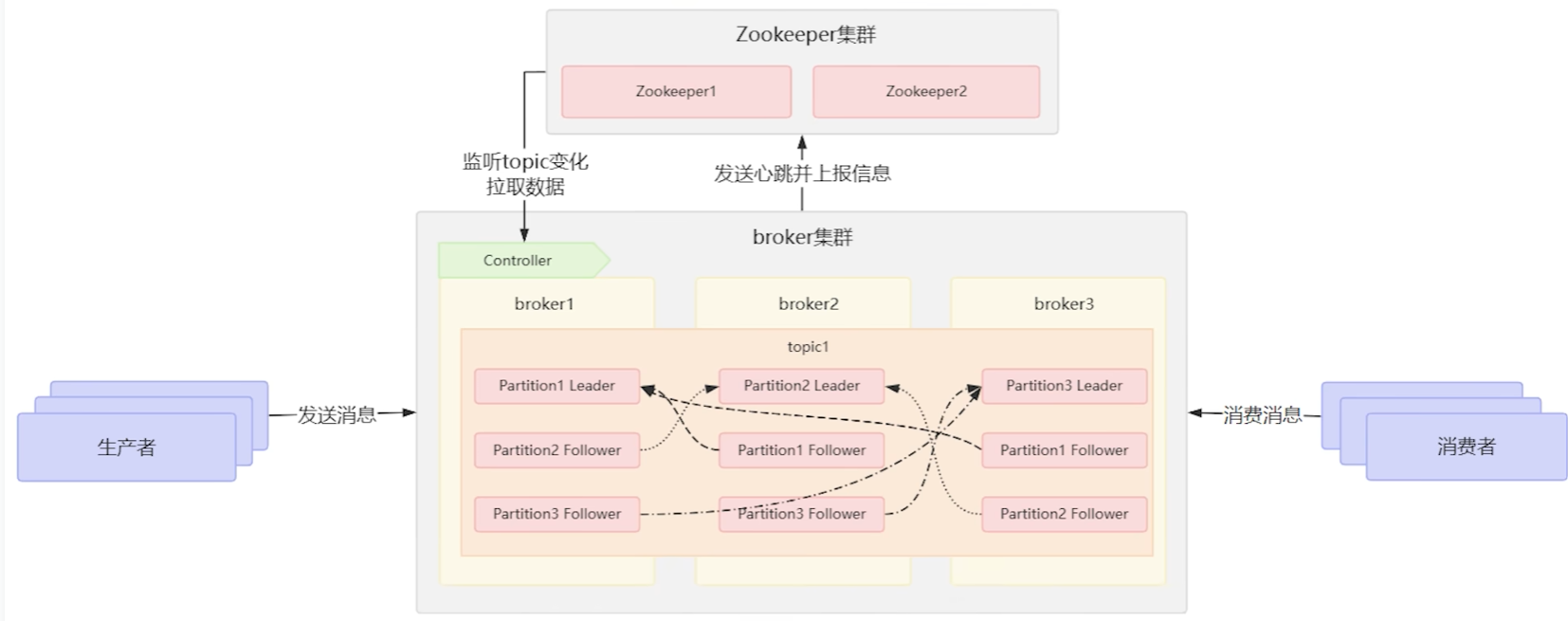
与上一期讲解的mq设计的逻辑核心类似,kafak消息队列的构成的过程当中是包含发送信息数据的生产者,用于处理生产者信息和接受处理消费者拉取请求的borker,管理broker的ZK注册中心,以及获得数据的消费者,具体结构如下图所示:
2.kafka当中的topic
从消息的角度来说,消息事实上是具有许多的类型的,为了方便消息的管理,所以broker通过topic来对消息进行分类,这样生产者就可以将不同类型的消息发送到对应的topic上,而消费者也可以通过订阅不同的topic来获取收集消息。
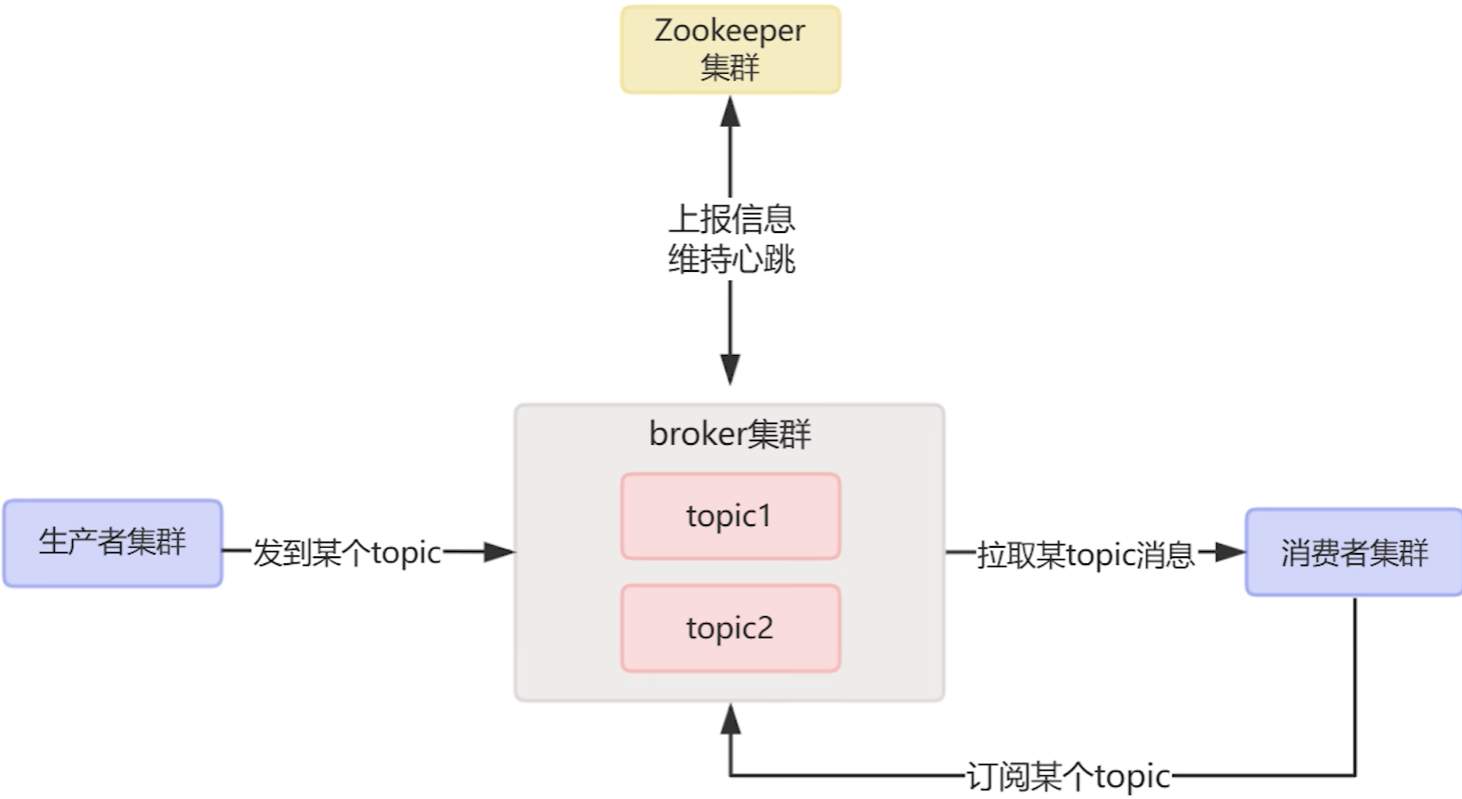
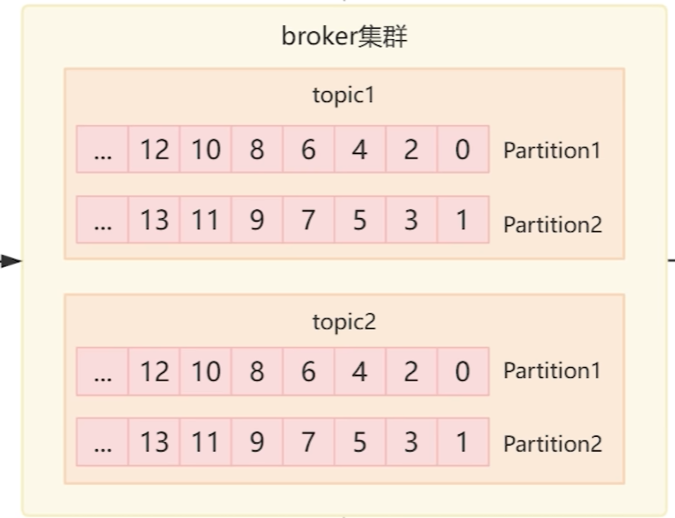
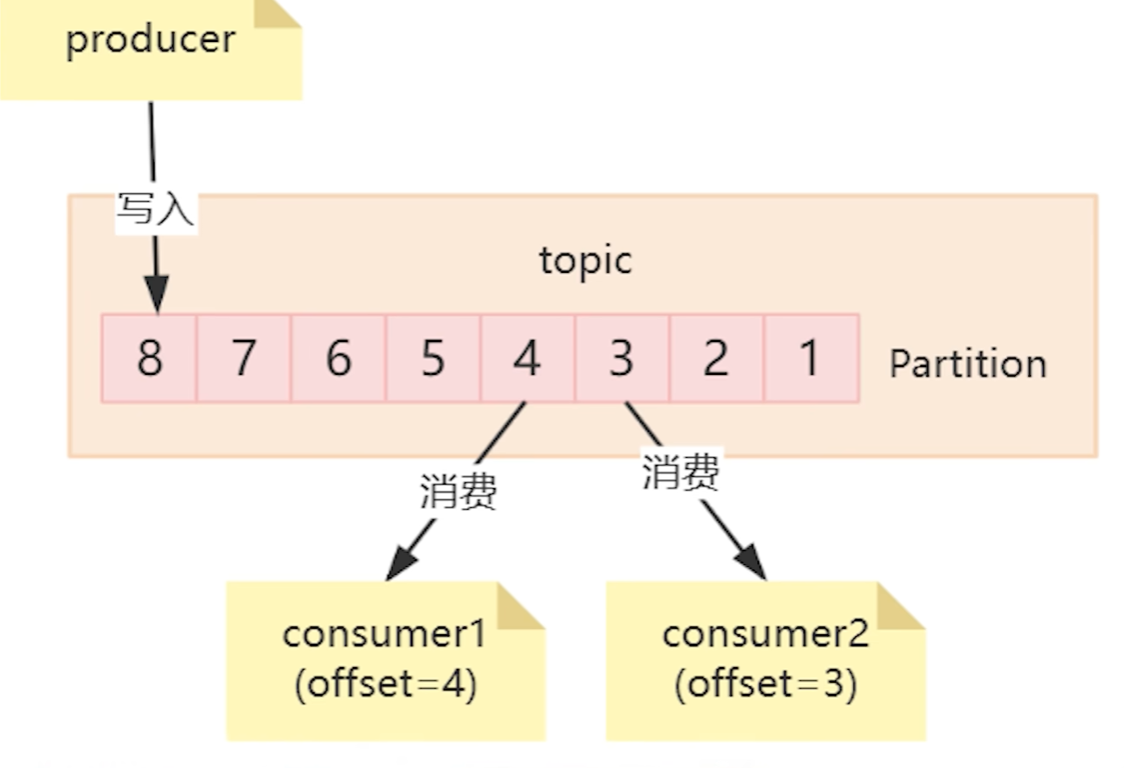
同时我们也知道同一条消息是可以被多个消费者消费的,但是这么多不同的消费者,我们是需要记录这些消费的的消费进度的,所以在toopic当中的每条消息实则还做了partition的分区,而每一条信息被称之为offset,消费者只要在读取使用数据的过程中记录保存对应的offset接可以了。
broker中topic的分区
分区写入消费的逻辑
3.kafka的高可用
假设一个topic的partition是整体的被存储在某一个机器上的,那这个机器的io就成为了这个topic的性能瓶颈,这样的效率和可用性会不太高,为了解决这种问题,topic下的partition被分为了多段,而每一段的partition只存储部分信息,而broker是集群,因此一个topic下的多个partition就可以被分散到不同的broker节点当中,这样我们单机存储的性能问题就被解决了。

不过依旧会存在一定的问题,首先就是虽然说消息被分散了出去,但kafka就只能保证单个partition队列中的消息是有序的,而同一个topic下的partition切片的有序性就无法保证了。
而其次就是,假设broker故障宕机了就会导致其所存储的部分partition数据就丢失了,这样的结果就是消息的完整性就相对较差了
为了解决这个问题,kafka提供了一个多副本机制,每个parttition数据都会同步到其他的broker节点当中,而这些broker节点就相当与partition的副本,而这些节点回选取一个leader节点去和生产者和消费者进行交互,获取到请求后,kafka就会将数据同步给其他的所有副本,同时这个推选出来的leader节点,就会包含所有的读写操作,来方便管理用户的消费进度,而假设读取的是副节点的数据,offset就较为难管理了。
4.kafka的消费者组的概念
为了能够及时的将数据消费掉,因此kafak增加了消费者组的概念,多个消费者组成消费者组,而这些消费者组就能够并行的对消息进行消费。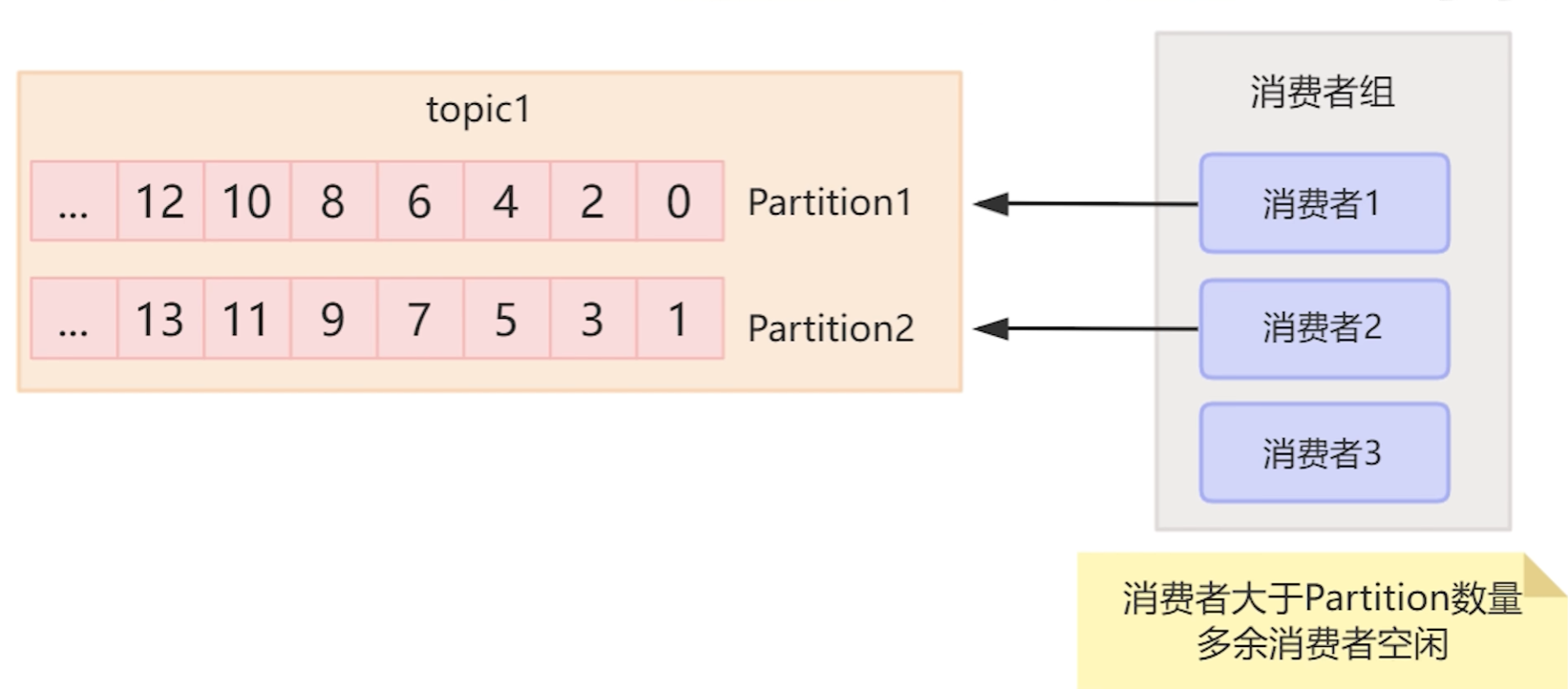
5.kafka的工作流程
为了保证工作流程顺利进行,kafka需要保证生产者要发送信息到哪个broker中,而消费者需要从那个broker中获取信息,因此kafak当中的broker集群会定时的向zk注册中心发送心跳包,这样zk就掌管了所有broker的topic和partition的信息,而broker会选举一个管理者叫controller,controller会持续监听zk当中的数据,当发现zk的topic数据发生变化时,controller就会拉取最新的消息,广播给每个broker,因此broker本省就有所有的集群信息和路由表。
生产者访问broker就能获取到路由信息,将消息发送给对应topic的partiton的leader的broker,而broker收到消息就会写到partiton的末尾,分配offset,然后同步数据构建partition副本。
消费者通过访问borker就可以获得订阅信息和路由信息,就知道去哪个broker中去拉取信息了,然后通过offset去读取对应节点的消息。
今天的分享就到这里了,希望这篇博客能给你一些帮助,让你对关于kafka架构的问题得到进一步的提升,在面试的时候能从容面对面试官。