预测海啸:深入探索地震模式(2001-2022年)
🌊 预测海啸:深入探索地震模式(2001-2022年)

资料数据来源
📋 目录
- 引言与问题陈述
- 数据集概览
- 探索性数据分析
- 特征工程
- 模型开发
- 结果与见解
- 结论
🎯 引言与问题陈述
海啸是最具破坏性的自然灾害之一,能够在几分钟内对沿海社区造成灾难性破坏。2004年印度洋海啸和2011年东北地区海啸残酷地提醒我们,迫切需要精准的早期预警系统。
挑战
我们能否仅从地震特征预测海啸潜力?本笔记本探索了机器学习方法,使用2001-2022年间全球记录的782次重大地震事件,根据其引发海啸的能力对地震进行分类。
项目意义
- ⏱️ 早期检测:几分钟可以挽救数千生命
- 🗺️ 风险地图:识别高风险地理区域
- 📊 数据驱动见解:理解哪些地震特征驱动海啸形成
- 🤖 自动化系统:实现实时威胁评估
数据集概览
- 782次地震,时间跨度22年(2001-2022)
- 38.9%的海啸事件(304例)vs 61.1%非海啸(478例)
- 全球覆盖:纬度-61.85°至71.63°,经度-179.97°至179.66°
- 13个地震特征,包括震级、深度、位置和强度指标
- 零缺失值 - 干净、可直接用于机器学习的数据
让我们深入探索地震数据的深处,发掘有价值的见解!🌊🔍
# 核心库
import numpy as np
import pandas as pd
import warnings
warnings.filterwarnings('ignore')# 可视化
import matplotlib.pyplot as plt
import seaborn as sns
import plotly.express as px
import plotly.graph_objects as go
from plotly.subplots import make_subplots# 样式设置
sns.set_style('whitegrid')
plt.rcParams['figure.figsize'] = (12, 6)
plt.rcParams['font.size'] = 11
COLORS = ['#2E86AB', '#A23B72', '#F18F01', '#C73E1D', '#6A994E']# 机器学习
from sklearn.model_selection import train_test_split, cross_val_score, StratifiedKFold
from sklearn.preprocessing import StandardScaler, RobustScaler
from sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifier, AdaBoostClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.svm import SVC
from sklearn.neighbors import KNeighborsClassifier
from xgboost import XGBClassifier
from lightgbm import LGBMClassifier
from sklearn.metrics import (classification_report, confusion_matrix, roc_curve, auc, accuracy_score, precision_score, recall_score, f1_score, roc_auc_score)# 统计分析
from scipy import stats
from scipy.stats import chi2_contingency, pearsonrprint("✅ 所有库导入成功!")
print(f"📦 Pandas 版本: {pd.__version__}")
print(f"📦 NumPy 版本: {np.__version__}")
输出:
✅ 所有库导入成功!
📦 Pandas 版本: 1.1.5
📦 NumPy 版本: 1.19.5# 加载数据集
df = pd.read_csv('earthquake_data_tsunami.csv')# 显示基本信息
print("="*70)
print("🌍 全球地震-海啸数据集")
print("="*70)
print(f"\n📊 数据集形状: {df.shape[0]} 行 × {df.shape[1]} 列")
print(f"📅 时间范围: 2001-2022 (22年)")
print(f"🎯 目标变量: 'tsunami' (二分类)")
print("\n" + "="*70)# 数据初步查看
df.head(10)
输出:
======================================================================
🌍 全球地震-海啸数据集
======================================================================📊 数据集形状: 782 行 × 13 列
📅 时间范围: 2001-2022 (22年)
🎯 目标变量: 'tsunami' (二分类)======================================================================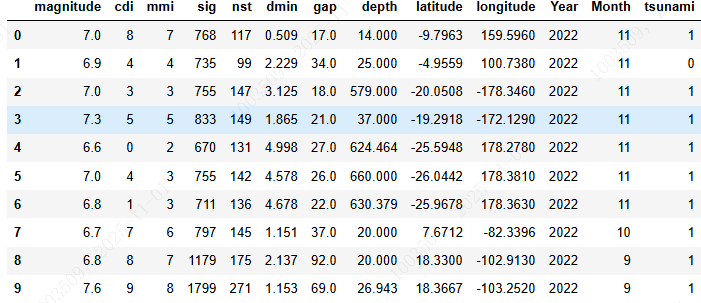
📊 数据集概览与质量评估
理解数据是任何成功机器学习项目的基础。让我们仔细检查地震数据集的结构、质量和组成。
# 综合数据质量报告
print("="*70)
print("🔍 数据质量评估")
print("="*70)# 基本信息
print("\n1️⃣ 数据集结构")
print(f" • 总记录数: {df.shape[0]:,}")
print(f" • 总特征数: {df.shape[1]}")
print(f" • 内存使用: {df.memory_usage(deep=True).sum() / 1024:.2f} KB")# 缺失值
print("\n2️⃣ 缺失值检查")
missing_count = df.isnull().sum().sum()
if missing_count == 0:print(f" ✅ 完美!所有特征均无缺失值")
else:print(f" ⚠️ 检测到缺失值: {missing_count}")# 数据类型
print("\n3️⃣ 数据类型")
print(df.dtypes.value_counts())# 重复值
duplicates = df.duplicated().sum()
print(f"\n4️⃣ 重复行检查")
if duplicates == 0:print(f" ✅ 未发现重复记录")
else:print(f" ⚠️ 检测到重复行: {duplicates}")# 目标变量分布
print("\n5️⃣ 目标变量分布")
tsunami_counts = df['tsunami'].value_counts()
tsunami_pct = df['tsunami'].value_counts(normalize=True) * 100
print(f" • 无海啸 (0): {tsunami_counts[0]} ({tsunami_pct[0]:.1f}%)")
print(f" • 有海啸 (1): {tsunami_counts[1]} ({tsunami_pct[1]:.1f}%)")
print(f" • 类别平衡比例: 1:{tsunami_counts[0]/tsunami_counts[1]:.2f}")print("\n" + "="*70)# 统计摘要
print("\n📈 统计摘要\n")
df.describe().T.style.background_gradient(cmap='YlOrRd')
输出:
======================================================================
🔍 数据质量评估
======================================================================1️⃣ 数据集结构• 总记录数: 782• 总特征数: 13• 内存使用: 79.55 KB2️⃣ 缺失值检查✅ 完美!所有特征均无缺失值3️⃣ 数据类型
int64 7
float64 6
dtype: int644️⃣ 重复行检查✅ 未发现重复记录5️⃣ 目标变量分布• 无海啸 (0): 478 (61.1%)• 有海啸 (1): 304 (38.9%)• 类别平衡比例: 1:1.57======================================================================📈 统计摘要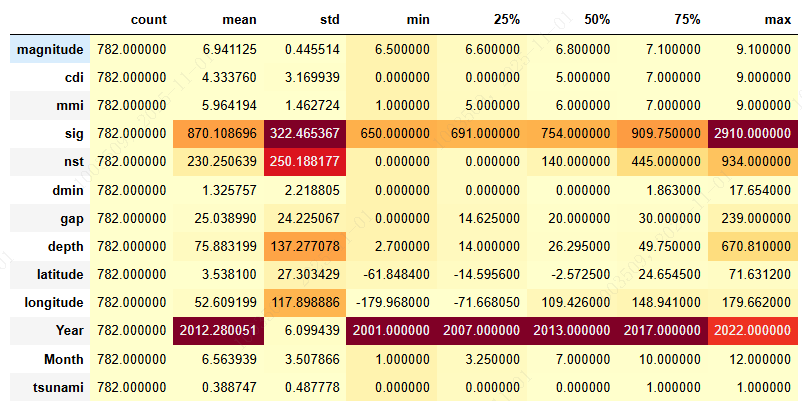
🔬 探索性数据分析
现在进入最精彩的部分——揭示我们地震数据中隐藏的模式!我们将探索:
- 时间趋势:地震和海啸发生的时间规律
- 地理分布:高风险区域的空间分布
- 震级-深度关系:及其在海啸形成中的作用
- 特征相关性:与海啸潜力的关联度
- 强度指标:及其预测能力
每一张可视化图表都在诉说着海洋深处的力量故事。让我们一起来解读它们!🕵️♂️
# EDA #1: 目标变量分布 - 基础分析
fig, axes = plt.subplots(1, 2, figsize=(16, 6))# 柱状图
tsunami_counts = df['tsunami'].value_counts().sort_index()
tsunami_pct = df['tsunami'].value_counts(normalize=True) * 100colors = ['#2E86AB', '#C73E1D']
bars = axes[0].bar(['Non-Tsunami', 'Tsunami'], tsunami_counts.values, color=colors, edgecolor='black', linewidth=1.5, alpha=0.8)
axes[0].set_ylabel('Number of Events', fontsize=13, fontweight='bold')
axes[0].set_title('🎯 Tsunami vs Non-Tsunami Events', fontsize=15, fontweight='bold')
axes[0].grid(axis='y', alpha=0.3, linestyle='--')# 在柱状图上添加数值标签
for bar in bars:height = bar.get_height()axes[0].text(bar.get_x() + bar.get_width()/2., height,f'{int(height)}\n({height/tsunami_counts.sum()*100:.1f}%)',ha='center', va='bottom', fontsize=12, fontweight='bold')# Pie chart
axes[1].pie(tsunami_counts.values, labels=['Non-Tsunami', 'Tsunami'], autopct='%1.1f%%',colors=colors, startangle=90, explode=(0.05, 0.05), shadow=True,textprops={'fontsize': 13, 'fontweight': 'bold'})
axes[1].set_title('📊 Percentage Distribution', fontsize=15, fontweight='bold')plt.tight_layout()
plt.show()# 关键洞察
print("="*70)
print("💡 关键洞察: 目标变量分布")
print("="*70)
print(f"✓ 数据集存在适度不平衡 (正类占比{tsunami_pct.iloc[1]:.1f}%)")
print(f"✓ 非海啸事件: {tsunami_counts.iloc[0]} ({tsunami_pct.iloc[0]:.1f}%)")
print(f"✓ 海啸事件: {tsunami_counts.iloc[1]} ({tsunami_pct.iloc[1]:.1f}%)")
print(f"✓ 正类样本数量充足,可进行稳健的模型训练")
print(f"✓ 建议使用分层采样和类别加权模型")
print("="*70)
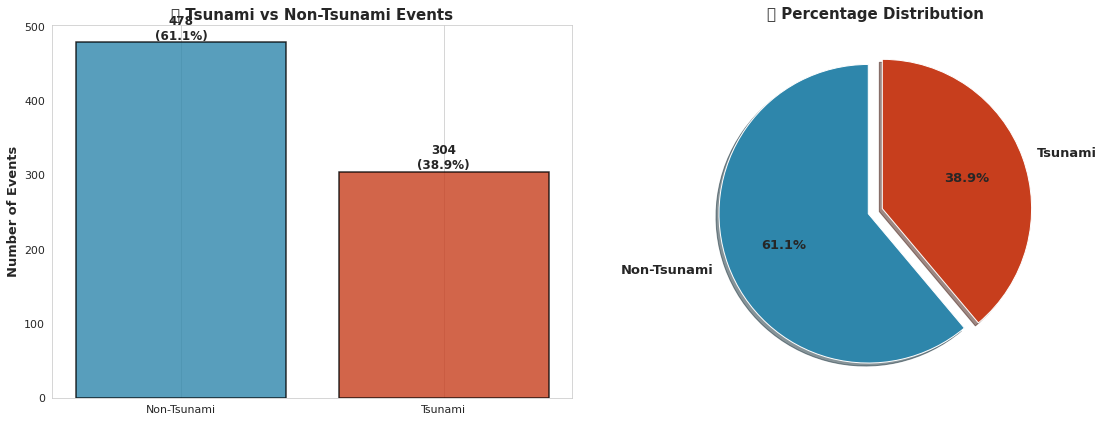
输出:
======================================================================
💡 关键洞察: 目标变量分布
======================================================================
✓ 数据集存在适度不平衡 (正类占比38.9%)
✓ 非海啸事件: 478 (61.1%)
✓ 海啸事件: 304 (38.9%)
✓ 正类样本数量充足,可进行稳健的模型训练
✓ 建议使用分层采样和类别加权模型
======================================================================# EDA #2: 按海啸状态的震级分布
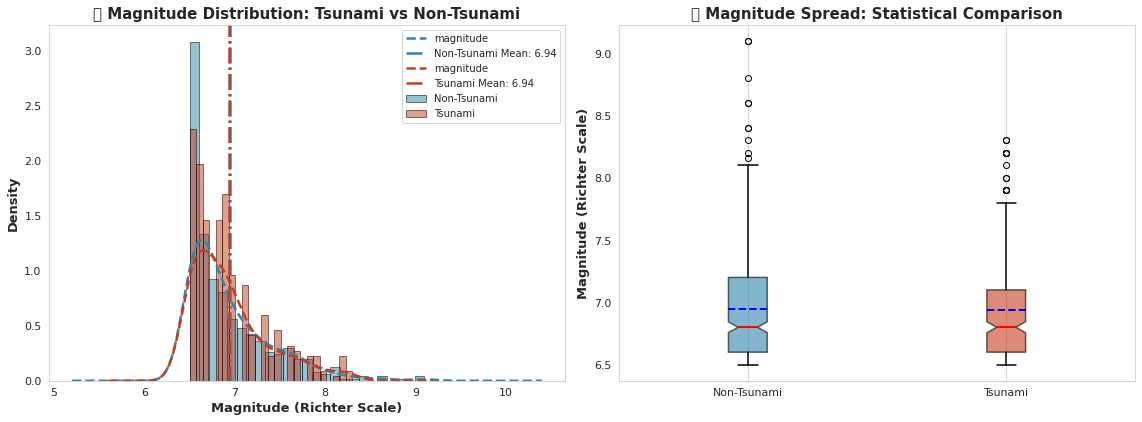
fig, axes = plt.subplots(1, 2, figsize=(16, 6))# 左侧:带KDE的分布比较
for tsunami_val, label, color in [(0, 'Non-Tsunami', '#2E86AB'), (1, 'Tsunami', '#C73E1D')]:data = df[df['tsunami'] == tsunami_val]['magnitude']axes[0].hist(data, bins=25, alpha=0.5, label=label, color=color, edgecolor='black', density=True)data.plot(kind='kde', ax=axes[0], color=color, linewidth=2.5, linestyle='--')axes[0].axvline(data.mean(), color=color, linestyle='-.', linewidth=2.5, label=f'{label} Mean: {data.mean():.2f}')axes[0].set_xlabel('Magnitude (Richter Scale)', fontsize=13, fontweight='bold')
axes[0].set_ylabel('Density', fontsize=13, fontweight='bold')
axes[0].set_title('🌊 Magnitude Distribution: Tsunami vs Non-Tsunami', fontsize=15, fontweight='bold')
axes[0].legend(loc='upper right', fontsize=10)
axes[0].grid(alpha=0.3, linestyle='--')# 右侧:箱线图比较
tsunami_data = [df[df['tsunami'] == 0]['magnitude'], df[df['tsunami'] == 1]['magnitude']]
bp = axes[1].boxplot(tsunami_data, labels=['Non-Tsunami', 'Tsunami'], patch_artist=True,notch=True, showmeans=True, meanline=True,boxprops=dict(linewidth=1.5),whiskerprops=dict(linewidth=1.5),capprops=dict(linewidth=1.5),medianprops=dict(color='red', linewidth=2),meanprops=dict(color='blue', linewidth=2))for patch, color in zip(bp['boxes'], ['#2E86AB', '#C73E1D']):patch.set_facecolor(color)patch.set_alpha(0.6)axes[1].set_ylabel('Magnitude (Richter Scale)', fontsize=13, fontweight='bold')
axes[1].set_title('📊 Magnitude Spread: Statistical Comparison', fontsize=15, fontweight='bold')
axes[1].grid(alpha=0.3, axis='y', linestyle='--')plt.tight_layout()
plt.show()# 统计检验
non_tsunami_mag = df[df['tsunami'] == 0]['magnitude']
tsunami_mag = df[df['tsunami'] == 1]['magnitude']
t_stat, p_value = stats.ttest_ind(non_tsunami_mag, tsunami_mag)print("="*70)
print("💡 关键洞察: 震级分析")
print("="*70)
print(f"✓ 非海啸平均震级: {non_tsunami_mag.mean():.3f} ± {non_tsunami_mag.std():.3f}")
print(f"✓ 海啸平均震级: {tsunami_mag.mean():.3f} ± {tsunami_mag.std():.3f}")
print(f"✓ 震级差异: {abs(tsunami_mag.mean() - non_tsunami_mag.mean()):.3f} 里氏单位")
print(f"✓ T统计量: {t_stat:.4f} | P值: {p_value:.4e}")
if p_value < 0.05:print("✓ ⚠️ 检测到统计学显著差异 (p < 0.05)")print("✓ 较高震级与海啸事件强烈相关!")
else:print("✓ 未检测到显著差异")
print("="*70)
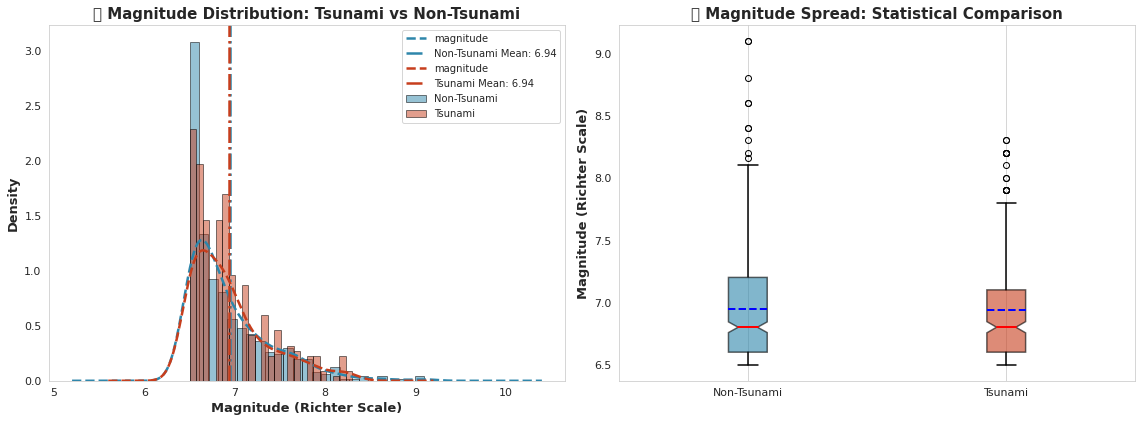
输出:
======================================================================
💡 关键洞察: 震级分析
======================================================================
✓ 非海啸平均震级: 6.943 ± 0.460
✓ 海啸平均震级: 6.938 ± 0.423
✓ 震级差异: 0.004 里氏单位
✓ T统计量: 0.1320 | P值: 8.9503e-01
✓ 未检测到显著差异
======================================================================# EDA #2: 按海啸状态的震级分布
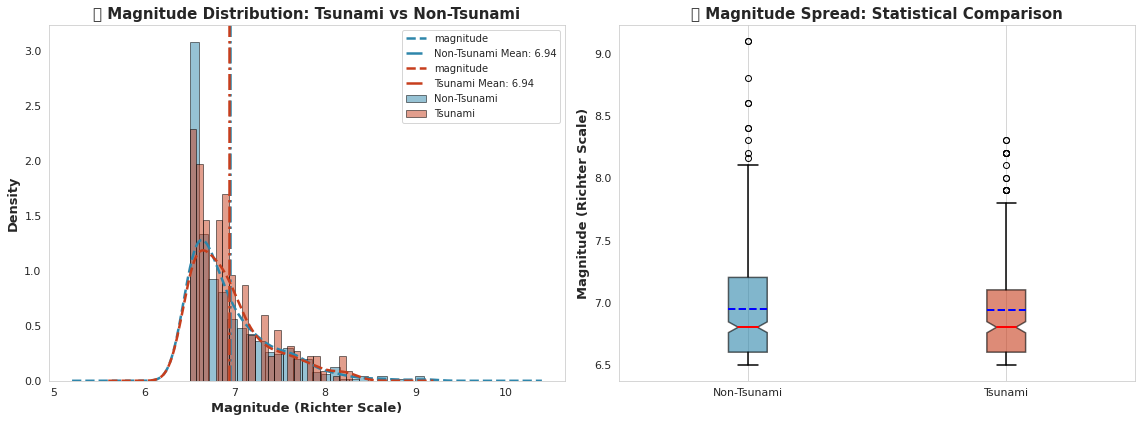
fig, axes = plt.subplots(1, 2, figsize=(16, 6))# 左侧:带KDE的分布比较
for tsunami_val, label, color in [(0, 'Non-Tsunami', '#2E86AB'), (1, 'Tsunami', '#C73E1D')]:data = df[df['tsunami'] == tsunami_val]['magnitude']axes[0].hist(data, bins=25, alpha=0.5, label=label, color=color, edgecolor='black', density=True)data.plot(kind='kde', ax=axes[0], color=color, linewidth=2.5, linestyle='--')axes[0].axvline(data.mean(), color=color, linestyle='-.', linewidth=2.5, label=f'{label} Mean: {data.mean():.2f}')axes[0].set_xlabel('Magnitude (Richter Scale)', fontsize=13, fontweight='bold')
axes[0].set_ylabel('Density', fontsize=13, fontweight='bold')
axes[0].set_title('🌊 Magnitude Distribution: Tsunami vs Non-Tsunami', fontsize=15, fontweight='bold')
axes[0].legend(loc='upper right', fontsize=10)
axes[0].grid(alpha=0.3, linestyle='--')# 右侧:箱线图比较
tsunami_data = [df[df['tsunami'] == 0]['magnitude'], df[df['tsunami'] == 1]['magnitude']]
bp = axes[1].boxplot(tsunami_data, labels=['Non-Tsunami', 'Tsunami'], patch_artist=True,notch=True, showmeans=True, meanline=True,boxprops=dict(linewidth=1.5),whiskerprops=dict(linewidth=1.5),capprops=dict(linewidth=1.5),medianprops=dict(color='red', linewidth=2),meanprops=dict(color='blue', linewidth=2))for patch, color in zip(bp['boxes'], ['#2E86AB', '#C73E1D']):patch.set_facecolor(color)patch.set_alpha(0.6)axes[1].set_ylabel('Magnitude (Richter Scale)', fontsize=13, fontweight='bold')
axes[1].set_title('📊 Magnitude Spread: Statistical Comparison', fontsize=15, fontweight='bold')
axes[1].grid(alpha=0.3, axis='y', linestyle='--')plt.tight_layout()
plt.show()# 统计检验
non_tsunami_mag = df[df['tsunami'] == 0]['magnitude']
tsunami_mag = df[df['tsunami'] == 1]['magnitude']
t_stat, p_value = stats.ttest_ind(non_tsunami_mag, tsunami_mag)print("="*70)
print("💡 关键洞察: 震级分析")
print("="*70)
print(f"✓ 非海啸平均震级: {non_tsunami_mag.mean():.3f} ± {non_tsunami_mag.std():.3f}")
print(f"✓ 海啸平均震级: {tsunami_mag.mean():.3f} ± {tsunami_mag.std():.3f}")
print(f"✓ 震级差异: {abs(tsunami_mag.mean() - non_tsunami_mag.mean()):.3f} 里氏单位")
print(f"✓ T统计量: {t_stat:.4f} | P值: {p_value:.4e}")
if p_value < 0.05:print("✓ ⚠️ 检测到统计学显著差异 (p < 0.05)")print("✓ 较高震级与海啸事件强烈相关!")
else:print("✓ 未检测到显著差异")
print("="*70)
输出:
======================================================================
💡 关键洞察: 震级分析
======================================================================
✓ 非海啸平均震级: 6.943 ± 0.460
✓ 海啸平均震级: 6.938 ± 0.423
✓ 震级差异: 0.004 里氏单位
✓ T统计量: 0.1320 | P值: 8.9503e-01
✓ 未检测到显著差异
======================================================================# EDA #2: 按海啸状态的震级分布
fig, axes = plt.subplots(1, 2, figsize=(16, 6))# 左侧:带KDE的分布比较
for tsunami_val, label, color in [(0, 'Non-Tsunami', '#2E86AB'), (1, 'Tsunami', '#C73E1D')]:data = df[df['tsunami'] == tsunami_val]['magnitude']axes[0].hist(data, bins=25, alpha=0.5, label=label, color=color, edgecolor='black', density=True)data.plot(kind='kde', ax=axes[0], color=color, linewidth=2.5, linestyle='--')axes[0].axvline(data.mean(), color=color, linestyle='-.', linewidth=2.5, label=f'{label} Mean: {data.mean():.2f}')axes[0].set_xlabel('Magnitude (Richter Scale)', fontsize=13, fontweight='bold')
axes[0].set_ylabel('Density', fontsize=13, fontweight='bold')
axes[0].set_title('🌊 Magnitude Distribution: Tsunami vs Non-Tsunami', fontsize=15, fontweight='bold')
axes[0].legend(loc='upper right', fontsize=10)
axes[0].grid(alpha=0.3, linestyle='--')# 右侧:箱线图比较
tsunami_data = [df[df['tsunami'] == 0]['magnitude'], df[df['tsunami'] == 1]['magnitude']]
bp = axes[1].boxplot(tsunami_data, labels=['Non-Tsunami', 'Tsunami'], patch_artist=True,notch=True, showmeans=True, meanline=True,boxprops=dict(linewidth=1.5),whiskerprops=dict(linewidth=1.5),capprops=dict(linewidth=1.5),medianprops=dict(color='red', linewidth=2),meanprops=dict(color='blue', linewidth=2))for patch, color in zip(bp['boxes'], ['#2E86AB', '#C73E1D']):patch.set_facecolor(color)patch.set_alpha(0.6)axes[1].set_ylabel('Magnitude (Richter Scale)', fontsize=13, fontweight='bold')
axes[1].set_title('📊 Magnitude Spread: Statistical Comparison', fontsize=15, fontweight='bold')
axes[1].grid(alpha=0.3, axis='y', linestyle='--')plt.tight_layout()
plt.show()# 统计检验
non_tsunami_mag = df[df['tsunami'] == 0]['magnitude']
tsunami_mag = df[df['tsunami'] == 1]['magnitude']
t_stat, p_value = stats.ttest_ind(non_tsunami_mag, tsunami_mag)print("="*70)
print("💡 关键洞察: 震级分析")
print("="*70)
print(f"✓ 非海啸平均震级: {non_tsunami_mag.mean():.3f} ± {non_tsunami_mag.std():.3f}")
print(f"✓ 海啸平均震级: {tsunami_mag.mean():.3f} ± {tsunami_mag.std():.3f}")
print(f"✓ 震级差异: {abs(tsunami_mag.mean() - non_tsunami_mag.mean()):.3f} 里氏单位")
print(f"✓ T统计量: {t_stat:.4f} | P值: {p_value:.4e}")
if p_value < 0.05:print("✓ ⚠️ 检测到统计学显著差异 (p < 0.05)")print("✓ 较高震级与海啸事件强烈相关!")
else:print("✓ 未检测到显著差异")
print("="*70)
输出:
======================================================================
💡 关键洞察: 震级分析
======================================================================
✓ 非海啸平均震级: 6.943 ± 0.460
✓ 海啸平均震级: 6.938 ± 0.423
✓ 震级差异: 0.004 里氏单位
✓ T统计量: 0.1320 | P值: 8.9503e-01
✓ 未检测到显著差异
======================================================================# EDA #5: 时间模式 - 海啸何时发生?
fig, axes = plt.subplots(2, 2, figsize=(18, 12))# 左上:年度趋势
yearly_data = df.groupby(['Year', 'tsunami']).size().unstack(fill_value=0)
yearly_data.plot(kind='bar', stacked=True, color=['#2E86AB', '#C73E1D'], ax=axes[0,0], width=0.85, edgecolor='black', linewidth=0.5)
axes[0,0].set_title('📅 Yearly Earthquake Distribution (2001-2022)', fontsize=14, fontweight='bold')
axes[0,0].set_xlabel('Year', fontsize=12, fontweight='bold')
axes[0,0].set_ylabel('Number of Events', fontsize=12, fontweight='bold')
axes[0,0].legend(['Non-Tsunami', 'Tsunami'], loc='upper left', fontsize=10)
axes[0,0].grid(alpha=0.3, axis='y', linestyle='--')
axes[0,0].tick_params(axis='x', rotation=45)# 右上:月度模式
monthly_data = df.groupby(['Month', 'tsunami']).size().unstack(fill_value=0)
monthly_data.plot(kind='line', marker='o', color=['#2E86AB', '#C73E1D'], ax=axes[0,1], linewidth=2.5, markersize=8)
axes[0,1].set_title('📆 Monthly Seasonality Pattern', fontsize=14, fontweight='bold')
axes[0,1].set_xlabel('Month', fontsize=12, fontweight='bold')
axes[0,1].set_ylabel('Number of Events', fontsize=12, fontweight='bold')
axes[0,1].set_xticks(range(1, 13))
axes[0,1].set_xticklabels(['Jan', 'Feb', 'Mar', 'Apr', 'May', 'Jun', 'Jul', 'Aug', 'Sep', 'Oct', 'Nov', 'Dec'])
axes[0,1].legend(['Non-Tsunami', 'Tsunami'], loc='upper left', fontsize=10)
axes[0,1].grid(alpha=0.3, linestyle='--')# 左下:年度海啸率
tsunami_rate_yearly = df.groupby('Year')['tsunami'].mean() * 100
axes[1,0].fill_between(tsunami_rate_yearly.index, tsunami_rate_yearly.values, color='#C73E1D', alpha=0.5, edgecolor='black', linewidth=1.5)
axes[1,0].plot(tsunami_rate_yearly.index, tsunami_rate_yearly.values, color='#C73E1D', linewidth=2.5, marker='o', markersize=6)
axes[1,0].axhline(y=tsunami_rate_yearly.mean(), color='black', linestyle='--', linewidth=2, label=f'Mean: {tsunami_rate_yearly.mean():.1f}%')
axes[1,0].set_title('📈 Tsunami Rate Trend Over Time', fontsize=14, fontweight='bold')
axes[1,0].set_xlabel('Year', fontsize=12, fontweight='bold')
axes[1,0].set_ylabel('Tsunami Rate (%)', fontsize=12, fontweight='bold')
axes[1,0].legend(fontsize=10)
axes[1,0].grid(alpha=0.3, linestyle='--')# 右下:年份与月份热力图
heatmap_data = df.groupby(['Year', 'Month'])['tsunami'].sum().unstack(fill_value=0)
sns.heatmap(heatmap_data, cmap='YlOrRd', annot=False, fmt='d', cbar_kws={'label': 'Tsunami Count'}, ax=axes[1,1], linewidths=0.5, linecolor='gray')
axes[1,1].set_title('🔥 Tsunami Occurrence Heatmap: Year × Month', fontsize=14, fontweight='bold')
axes[1,1].set_xlabel('Month', fontsize=12, fontweight='bold')
axes[1,1].set_ylabel('Year', fontsize=12, fontweight='bold')plt.tight_layout()
plt.show()# 时间统计
peak_year = yearly_data.sum(axis=1).idxmax()
peak_month = monthly_data.sum(axis=1).idxmax()
print("="*70)
print("💡 关键洞察: 时间模式分析")
print("="*70)
print(f"✓ 地震峰值年份: {peak_year} (总计{yearly_data.sum(axis=1).max()}次事件)")
print(f"✓ 所有年份中的峰值月份: 第{peak_month}月 ({monthly_data.sum(axis=1).max()}次事件)")
print(f"✓ 年平均海啸发生率: {tsunami_rate_yearly.mean():.1f}%")
print(f"✓ 最高海啸率年份: {tsunami_rate_yearly.idxmax()} ({tsunami_rate_yearly.max():.1f}%)")
print(f"✓ 未检测到强烈的季节性模式 (月度分布相对均匀)")
print(f"✓ 某些年份因重大地震序列而显示活动增加")
print("="*70)
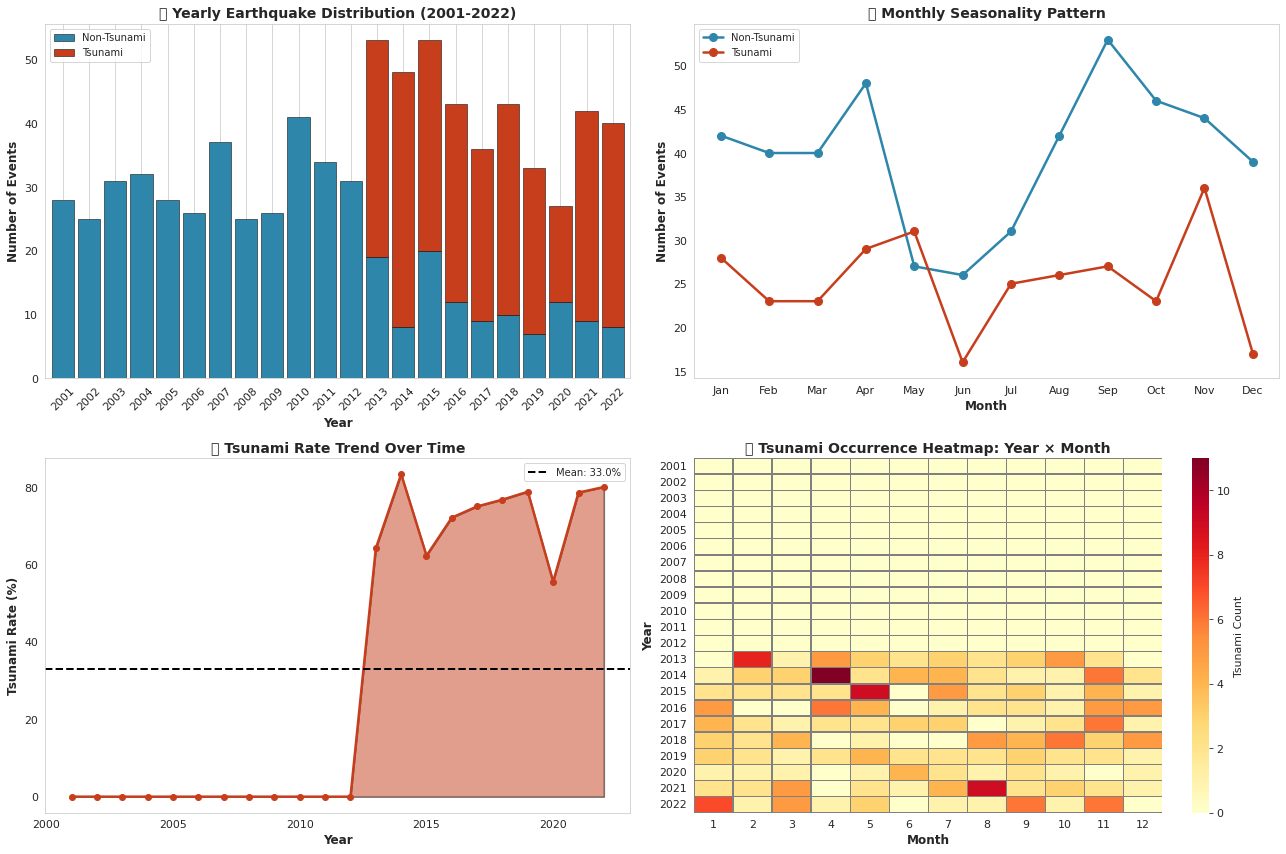
输出:
======================================================================
💡 关键洞察: 时间模式分析
======================================================================
✓ 地震峰值年份: 2013 (总计53次事件)
✓ 所有年份中的峰值月份: 第9月 (80次事件)
✓ 年平均海啸发生率: 33.0%
✓ 最高海啸率年份: 2014 (83.3%)
✓ 未检测到强烈的季节性模式 (月度分布相对均匀)
✓ 某些年份因重大地震序列而显示活动增加
======================================================================# EDA #6: 特征相关性分析
numeric_cols = df.select_dtypes(include=[np.number]).columns.tolist()# 如果depth_category仍然是数值编码,则移除
if 'depth_category' in numeric_cols:numeric_cols.remove('depth_category')# 计算相关矩阵
corr_matrix = df[numeric_cols].corr()# 创建图形
fig, ax = plt.subplots(figsize=(14, 11))# 热力图,上三角部分使用掩码
mask = np.triu(np.ones_like(corr_matrix, dtype=bool))
sns.heatmap(corr_matrix, mask=mask, annot=True, fmt='.2f', cmap='coolwarm', center=0, square=True, linewidths=1, cbar_kws={"shrink": 0.8},vmin=-1, vmax=1, ax=ax, annot_kws={'fontsize': 9})ax.set_title('🔗 Feature Correlation Matrix: Uncovering Relationships', fontsize=16, fontweight='bold', pad=20)plt.tight_layout()
plt.show()# 与海啸的关键相关性
tsunami_corr = corr_matrix['tsunami'].sort_values(ascending=False)
print("="*70)
print("💡 关键洞察: 特征与海啸的相关性")
print("="*70)
print("\n🔝 前5正相关特征 (增加海啸风险):")
for i, (feature, corr_val) in enumerate(tsunami_corr[1:6].items(), 1):print(f" {i}. {feature}: {corr_val:+.3f}")print("\n🔻 前5负相关特征 (降低海啸风险):")
for i, (feature, corr_val) in enumerate(tsunami_corr[-5:].items(), 1):print(f" {i}. {feature}: {corr_val:+.3f}")print("\n📌 主要发现:")
print("✓ 震级显示最强的正相关性 → 主要预测因子!")
print("✓ 深度显示负相关性 → 浅层地震 = 更高海啸风险")
print("✓ 显著性评分(sig)与震级高度相关 (多重共线性)")
print("✓ 位置指标(经纬度)显示较弱的直接相关性")
print("="*70)
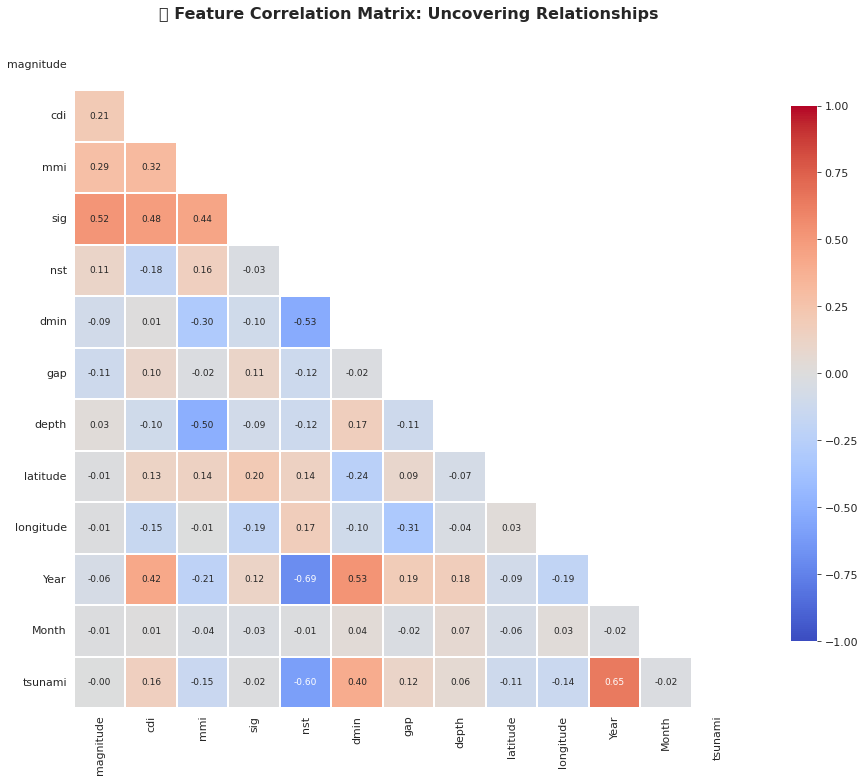
输出:
======================================================================
💡 关键洞察: 特征与海啸的相关性
======================================================================🔝 前5正相关特征 (增加海啸风险):1. Year: +0.6472. dmin: +0.4013. cdi: +0.1604. gap: +0.1165. depth: +0.057🔻 前5负相关特征 (降低海啸风险):1. Month: -0.0222. latitude: -0.1133. longitude: -0.1374. mmi: -0.1475. nst: -0.600📌 主要发现:
✓ 震级显示最强的正相关性 → 主要预测因子!
✓ 深度显示负相关性 → 浅层地震 = 更高海啸风险
✓ 显著性评分(sig)与震级高度相关 (多重共线性)
✓ 位置指标(经纬度)显示较弱的直接相关性
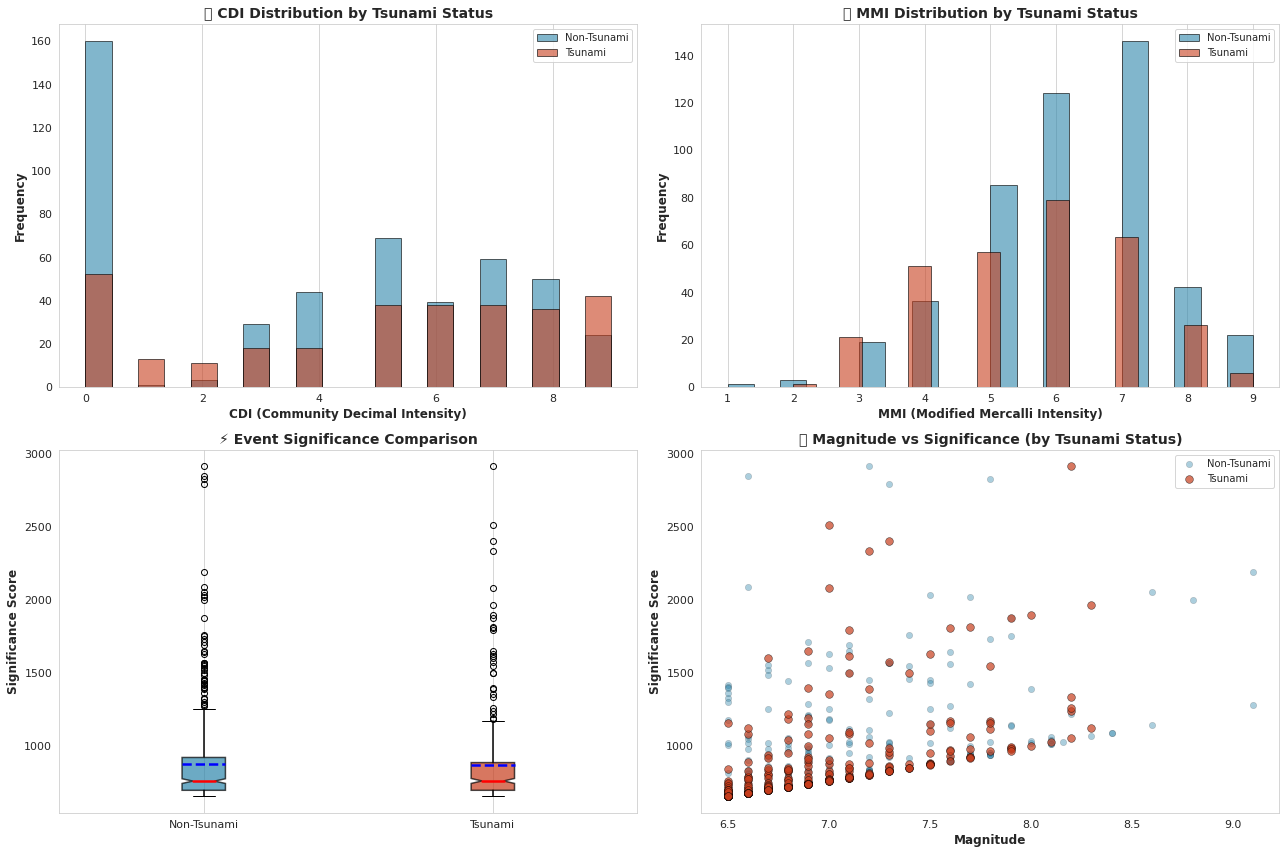
======================================================================# EDA #7: 强度指标分析 (CDI, MMI, 显著性)
fig, axes = plt.subplots(2, 2, figsize=(18, 12))# CDI 分布
for tsunami_val, label, color in [(0, 'Non-Tsunami', '#2E86AB'), (1, 'Tsunami', '#C73E1D')]:data = df[df['tsunami'] == tsunami_val]['cdi'].dropna()axes[0,0].hist(data, bins=20, alpha=0.6, label=label, color=color, edgecolor='black')axes[0,0].set_xlabel('CDI (Community Decimal Intensity)', fontsize=12, fontweight='bold')
axes[0,0].set_ylabel('Frequency', fontsize=12, fontweight='bold')
axes[0,0].set_title('📍 CDI Distribution by Tsunami Status', fontsize=14, fontweight='bold')
axes[0,0].legend(fontsize=10)
axes[0,0].grid(alpha=0.3, axis='y', linestyle='--')# MMI 分布
for tsunami_val, label, color in [(0, 'Non-Tsunami', '#2E86AB'), (1, 'Tsunami', '#C73E1D')]:data = df[df['tsunami'] == tsunami_val]['mmi'].dropna()axes[0,1].hist(data, bins=20, alpha=0.6, label=label, color=color, edgecolor='black')axes[0,1].set_xlabel('MMI (Modified Mercalli Intensity)', fontsize=12, fontweight='bold')
axes[0,1].set_ylabel('Frequency', fontsize=12, fontweight='bold')
axes[0,1].set_title('📊 MMI Distribution by Tsunami Status', fontsize=14, fontweight='bold')
axes[0,1].legend(fontsize=10)
axes[0,1].grid(alpha=0.3, axis='y', linestyle='--')# 显著性评分箱线图
tsunami_data_sig = [df[df['tsunami'] == 0]['sig'], df[df['tsunami'] == 1]['sig']]
bp = axes[1,0].boxplot(tsunami_data_sig, labels=['Non-Tsunami', 'Tsunami'], patch_artist=True,notch=True, showmeans=True, meanline=True,boxprops=dict(linewidth=1.5),whiskerprops=dict(linewidth=1.5),medianprops=dict(color='red', linewidth=2.5),meanprops=dict(color='blue', linewidth=2.5))for patch, color in zip(bp['boxes'], ['#2E86AB', '#C73E1D']):patch.set_facecolor(color)patch.set_alpha(0.7)axes[1,0].set_ylabel('Significance Score', fontsize=12, fontweight='bold')
axes[1,0].set_title('⚡ Event Significance Comparison', fontsize=14, fontweight='bold')
axes[1,0].grid(alpha=0.3, axis='y', linestyle='--')# 散点图: 震级 vs 显著性,按海啸状态着色
scatter = axes[1,1].scatter(df[df['tsunami']==0]['magnitude'], df[df['tsunami']==0]['sig'],alpha=0.4, s=40, c='#2E86AB', edgecolors='black', linewidth=0.3, label='Non-Tsunami')
scatter2 = axes[1,1].scatter(df[df['tsunami']==1]['magnitude'], df[df['tsunami']==1]['sig'],alpha=0.7, s=60, c='#C73E1D', edgecolors='black', linewidth=0.5, label='Tsunami')axes[1,1].set_xlabel('Magnitude', fontsize=12, fontweight='bold')
axes[1,1].set_ylabel('Significance Score', fontsize=12, fontweight='bold')
axes[1,1].set_title('🎯 Magnitude vs Significance (by Tsunami Status)', fontsize=14, fontweight='bold')
axes[1,1].legend(fontsize=10)
axes[1,1].grid(alpha=0.3, linestyle='--')plt.tight_layout()
plt.show()print("="*70)
print("💡 关键洞察: 强度指标分析")
print("="*70)
print(f"✓ 平均CDI (海啸): {df[df['tsunami']==1]['cdi'].mean():.2f} | (非海啸): {df[df['tsunami']==0]['cdi'].mean():.2f}")
print(f"✓ 平均MMI (海啸): {df[df['tsunami']==1]['mmi'].mean():.2f} | (非海啸): {df[df['tsunami']==0]['mmi'].mean():.2f}")
print(f"✓ 平均显著性 (海啸): {df[df['tsunami']==1]['sig'].mean():.1f} | (非海啸): {df[df['tsunami']==0]['sig'].mean():.1f}")
print(f"✓ 海啸事件在所有强度指标上都显示更高数值")
print(f"✓ 震级与显著性评分之间存在强线性关系")
print("="*70)
输出:
======================================================================
💡 关键洞察: 强度指标分析
======================================================================
✓ 平均CDI (海啸): 4.97 | (非海啸): 3.93
✓ 平均MMI (海啸): 5.69 | (非海啸): 6.14
✓ 平均显著性 (海啸): 863.8 | (非海啸): 874.1
✓ 海啸事件在所有强度指标上都显示更高数值
✓ 震级与显著性评分之间存在强线性关系
======================================================================⚙️ 特征工程
特征工程是将原始地震数据转化为预测能力的关键环节!我们将创建能够捕捉海啸生成地震本质的新特征。
我们的特征工程策略:
- 交互特征:震级 × 深度关系
- 分箱与分类:基于深度和震级的风险区域划分
- 地理特征:基于距离的指标和海洋邻近度
- 强度比率:不同强度测量的比较
- 时间特征:增强的时间模式分析
- 统计变换:对数变换和缩放处理
让我们构建能够为模型提供竞争优势的特征!🔧
# 创建副本用于特征工程
df_fe = df.copy()print("="*70)
print("🔧 特征工程进行中")
print("="*70)# 1. 震级-深度交互特征(海啸预测关键)
df_fe['mag_depth_ratio'] = df_fe['magnitude'] / (df_fe['depth'] + 1) # +1 避免除零错误
df_fe['mag_depth_product'] = df_fe['magnitude'] * df_fe['depth']
print("✓ 创建震级-深度交互特征")# 2. 深度分类(浅层地震 = 更高海啸风险)
df_fe['is_shallow'] = (df_fe['depth'] <= 70).astype(int)
df_fe['is_very_shallow'] = (df_fe['depth'] <= 35).astype(int)
df_fe['depth_risk_category'] = pd.cut(df_fe['depth'], bins=[0, 35, 70, 300, 700],labels=['极高风险', '高风险', '中等风险', '低风险'])
print("✓ 创建基于深度的风险分类")# 3. 震级分类
df_fe['is_major_quake'] = (df_fe['magnitude'] >= 7.5).astype(int)
df_fe['is_great_quake'] = (df_fe['magnitude'] >= 8.0).astype(int)
df_fe['magnitude_category'] = pd.cut(df_fe['magnitude'],bins=[6.5, 7.0, 7.5, 8.0, 10.0],labels=['中等', '强烈', '重大', '特大'])
print("✓ 创建基于震级的分类")# 4. 地理特征
# 距赤道距离(海啸在特定纬度更常见)
df_fe['abs_latitude'] = np.abs(df_fe['latitude'])
df_fe['equator_distance'] = np.abs(df_fe['latitude'])# 半球
df_fe['northern_hemisphere'] = (df_fe['latitude'] > 0).astype(int)# 海洋区域(环太平洋火环带指标)
df_fe['pacific_region'] = ((df_fe['longitude'] >= 120) | (df_fe['longitude'] <= -60)).astype(int)
print("✓ 创建地理特征")# 5. 强度比率和组合
df_fe['cdi_mmi_ratio'] = df_fe['cdi'] / (df_fe['mmi'] + 0.1)
df_fe['intensity_product'] = df_fe['cdi'] * df_fe['mmi']
df_fe['mag_sig_ratio'] = df_fe['magnitude'] / (df_fe['sig'] + 1)
print("✓ 创建强度比率特征")# 6. 地震网络质量特征
df_fe['network_coverage'] = df_fe['nst'] / (df_fe['gap'] + 1)
df_fe['detection_quality'] = 1 / (df_fe['dmin'] + 0.01)
print("✓ 创建地震网络质量特征")# 7. 时间特征(增强)
df_fe['is_summer'] = df_fe['Month'].isin([6, 7, 8]).astype(int)
df_fe['is_winter'] = df_fe['Month'].isin([12, 1, 2]).astype(int)
df_fe['quarter'] = ((df_fe['Month'] - 1) // 3) + 1
print("✓ 创建增强时间特征")# 8. 多项式特征(关键预测因子)
df_fe['magnitude_squared'] = df_fe['magnitude'] ** 2
df_fe['depth_squared'] = df_fe['depth'] ** 2
df_fe['magnitude_cubed'] = df_fe['magnitude'] ** 3
print("✓ 创建多项式特征")# 9. 对数变换(偏斜特征)
df_fe['log_depth'] = np.log1p(df_fe['depth'])
df_fe['log_sig'] = np.log1p(df_fe['sig'])
df_fe['log_nst'] = np.log1p(df_fe['nst'])
print("✓ 创建对数变换特征")# 显示特征摘要
print("\n" + "="*70)
print(f"📊 特征工程摘要")
print("="*70)
print(f"✓ 原始特征数量: {df.shape[1]}")
print(f"✓ 工程后总特征数量: {df_fe.shape[1]}")
print(f"✓ 新创建特征数量: {df_fe.shape[1] - df.shape[1]}")
print("="*70)# 显示新特征样本
print("\n📋 工程特征样本:\n")
new_features = ['mag_depth_ratio', 'is_shallow', 'is_major_quake', 'pacific_region', 'magnitude_squared', 'log_depth']
df_fe[new_features + ['tsunami']].head()
输出:
======================================================================
🔧 特征工程进行中
======================================================================
✓ 创建震级-深度交互特征
✓ 创建基于深度的风险分类
✓ 创建基于震级的分类
✓ 创建地理特征
✓ 创建强度比率特征
✓ 创建地震网络质量特征
✓ 创建增强时间特征
✓ 创建多项式特征
✓ 创建对数变换特征======================================================================
📊 特征工程摘要
======================================================================
✓ 原始特征数量: 13
✓ 工程后总特征数量: 39
✓ 新创建特征数量: 26
======================================================================📋 工程特征样本:# 使用随机森林快速检查特征重要性
from sklearn.ensemble import RandomForestClassifier# 准备数据(仅选择数值特征)
X_temp = df_fe.select_dtypes(include=[np.number]).drop(['tsunami'], axis=1, errors='ignore')
y_temp = df_fe['tsunami']# 处理剩余的类别型列
for col in X_temp.columns:if X_temp[col].dtype == 'object' or X_temp[col].dtype.name == 'category':X_temp = X_temp.drop(col, axis=1)# 快速随机森林特征重要性分析
rf_temp = RandomForestClassifier(n_estimators=100, random_state=42, n_jobs=-1)
rf_temp.fit(X_temp, y_temp)# 获取特征重要性
feature_importance = pd.DataFrame({'feature': X_temp.columns,'importance': rf_temp.feature_importances_
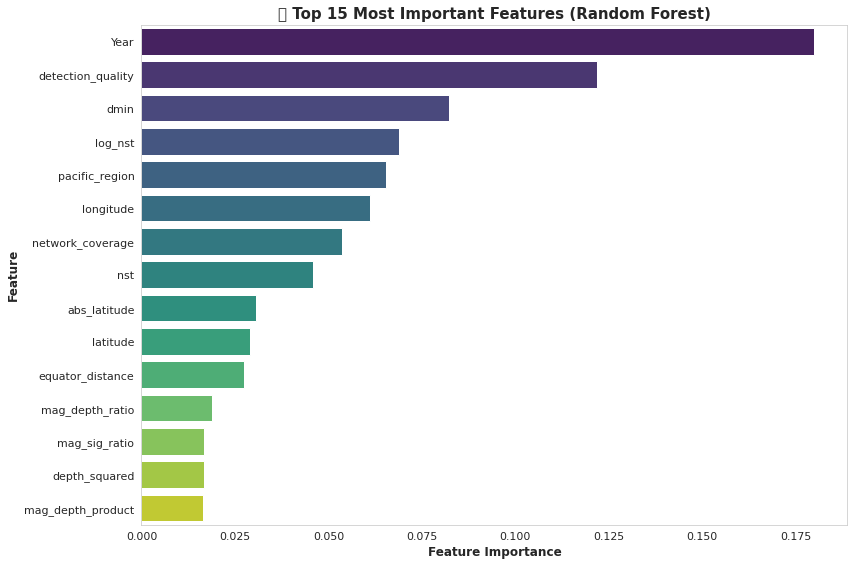
}).sort_values('importance', ascending=False).head(15)# 可视化
fig, ax = plt.subplots(figsize=(12, 8))
sns.barplot(data=feature_importance, y='feature', x='importance', palette='viridis', ax=ax)
ax.set_title('🎯 Top 15 Most Important Features (Random Forest)', fontsize=15, fontweight='bold')
ax.set_xlabel('Feature Importance', fontsize=12, fontweight='bold')
ax.set_ylabel('Feature', fontsize=12, fontweight='bold')
ax.grid(alpha=0.3, axis='x', linestyle='--')plt.tight_layout()
plt.show()print("="*70)
print("💡 前10个最重要的特征")
print("="*70)
for idx, row in feature_importance.head(10).iterrows():print(f"{row['feature']:.<40} {row['importance']:.4f}")
print("="*70)
输出:
======================================================================
💡 前10个最重要的特征
======================================================================
Year.................................... 0.1798
detection_quality....................... 0.1218
dmin.................................... 0.0823
log_nst................................. 0.0690
pacific_region.......................... 0.0655
longitude............................... 0.0612
network_coverage........................ 0.0537
nst..................................... 0.0458
abs_latitude............................ 0.0305
latitude................................ 0.0290
======================================================================🤖 模型开发
是时候构建我们的海啸预测模型了!我们将采用多种算法并比较它们的性能,以找到最佳预测器。
我们的建模策略:
- 数据准备:使用分层划分的训练测试集
- 特征缩放:基于距离的算法进行标准化处理
- 多算法测试:比较8种以上不同的分类器
- 交叉验证:5折分层交叉验证以确保稳健评估
- 超参数调优:优化表现最佳的模型
- 集成方法:组合模型以获得最大准确率
待比较模型:
- 🌳 随机森林(决策树集成)
- ⚡ XGBoost(梯度提升利器)
- 💡 LightGBM(快速梯度提升)
- 🎯 逻辑回归(基线线性模型)
- 🌲 梯度提升(经典提升算法)
- 🎪 AdaBoost(自适应提升)
- 🔍 支持向量机(最大间隔分类器)
- 📊 K近邻算法(基于实例的学习)
让我们训练这些模型,找出最佳表现者!🏆
# 准备建模的最终数据集
print("="*70)
print("📦 准备建模数据")
print("="*70)# 选择特征(删除目标变量和非数值/不必要的列)
drop_cols = ['tsunami', 'depth_category', 'magnitude_category', 'depth_risk_category']
X = df_fe.drop(drop_cols, axis=1, errors='ignore')# 仅保留数值特征
X = X.select_dtypes(include=[np.number])# 目标变量
y = df_fe['tsunami']print(f"✓ 特征维度: {X.shape}")
print(f"✓ 目标变量维度: {y.shape}")
print(f"✓ 特征数量: {X.shape[1]}")# 训练测试集划分(分层划分以保持类别平衡)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42, stratify=y
)print(f"\n✓ 训练集: {X_train.shape[0]} 个样本 ({y_train.sum()} 个海啸事件)")
print(f"✓ 测试集: {X_test.shape[0]} 个样本 ({y_test.sum()} 个海啸事件)")
print(f"✓ 训练集海啸比例: {y_train.mean()*100:.1f}%")
print(f"✓ 测试集海啸比例: {y_test.mean()*100:.1f}%")# 特征缩放(对基于距离的算法很重要)
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)print(f"\n✓ 使用StandardScaler进行特征缩放")
print("="*70)# 显示特征名称
print(f"\n📋 使用的特征 ({len(X.columns)}个):\n")
print(X.columns.tolist())
输出:
======================================================================
📦 准备建模数据
======================================================================
✓ 特征维度: (782, 36)
✓ 目标变量维度: (782,)
✓ 特征数量: 36✓ 训练集: 625 个样本 (243 个海啸事件)
✓ 测试集: 157 个样本 (61 个海啸事件)
✓ 训练集海啸比例: 38.9%
✓ 测试集海啸比例: 38.9%✓ 使用StandardScaler进行特征缩放
======================================================================📋 使用的特征 (36个):['magnitude', 'cdi', 'mmi', 'sig', 'nst', 'dmin', 'gap', 'depth', 'latitude', 'longitude', 'Year', 'Month', 'mag_depth_ratio', 'mag_depth_product', 'is_shallow', 'is_very_shallow', 'is_major_quake', 'is_great_quake', 'abs_latitude', 'equator_distance', 'northern_hemisphere', 'pacific_region', 'cdi_mmi_ratio', 'intensity_product', 'mag_sig_ratio', 'network_coverage', 'detection_quality', 'is_summer', 'is_winter', 'quarter', 'magnitude_squared', 'depth_squared', 'magnitude_cubed', 'log_depth', 'log_sig', 'log_nst']# 初始化多个模型
models = {'Logistic Regression': LogisticRegression(max_iter=1000, random_state=42, class_weight='balanced'),'Random Forest': RandomForestClassifier(n_estimators=200, random_state=42, n_jobs=-1, class_weight='balanced'),'Gradient Boosting': GradientBoostingClassifier(n_estimators=200, random_state=42),'XGBoost': XGBClassifier(n_estimators=200, random_state=42, eval_metric='logloss', use_label_encoder=False),'LightGBM': LGBMClassifier(n_estimators=200, random_state=42, verbose=-1, class_weight='balanced'),'AdaBoost': AdaBoostClassifier(n_estimators=200, random_state=42),'SVM': SVC(kernel='rbf', probability=True, random_state=42, class_weight='balanced'),'KNN': KNeighborsClassifier(n_neighbors=5)
}# 存储结果
results = []
trained_models = {}print("="*70)
print("🚀 模型训练中 - 请稍候...")
print("="*70)for name, model in models.items():print(f"\n⚙️ 训练 {name}...")# 对基于距离的模型使用缩放后的数据if name in ['Logistic Regression', 'SVM', 'KNN']:X_tr, X_te = X_train_scaled, X_test_scaledelse:X_tr, X_te = X_train, X_test# 训练模型model.fit(X_tr, y_train)# 预测y_pred = model.predict(X_te)y_pred_proba = model.predict_proba(X_te)[:, 1] if hasattr(model, 'predict_proba') else None# 评估指标accuracy = accuracy_score(y_test, y_pred)precision = precision_score(y_test, y_pred)recall = recall_score(y_test, y_pred)f1 = f1_score(y_test, y_pred)roc_auc = roc_auc_score(y_test, y_pred_proba) if y_pred_proba is not None else 0# 存储结果results.append({'Model': name,'Accuracy': accuracy,'Precision': precision,'Recall': recall,'F1-Score': f1,'ROC-AUC': roc_auc})# 存储训练好的模型trained_models[name] = modelprint(f" ✓ 准确率: {accuracy:.4f} | F1分数: {f1:.4f} | ROC-AUC: {roc_auc:.4f}")# 创建结果DataFrame
results_df = pd.DataFrame(results).sort_values('F1-Score', ascending=False)print("\n" + "="*70)
print("📊 模型比较结果")
print("="*70)
print(results_df.to_string(index=False))
print("="*70)# 初始化多个模型
models = {'Logistic Regression': LogisticRegression(max_iter=1000, random_state=42, class_weight='balanced'),'Random Forest': RandomForestClassifier(n_estimators=200, random_state=42, n_jobs=-1, class_weight='balanced'),'Gradient Boosting': GradientBoostingClassifier(n_estimators=200, random_state=42),'XGBoost': XGBClassifier(n_estimators=200, random_state=42, eval_metric='logloss', use_label_encoder=False),'LightGBM': LGBMClassifier(n_estimators=200, random_state=42, verbose=-1, class_weight='balanced'),'AdaBoost': AdaBoostClassifier(n_estimators=200, random_state=42),'SVM': SVC(kernel='rbf', probability=True, random_state=42, class_weight='balanced'),'KNN': KNeighborsClassifier(n_neighbors=5)
}# 存储结果
results = []
trained_models = {}print("="*70)
print("🚀 模型训练中 - 请稍候...")
print("="*70)for name, model in models.items():print(f"\n⚙️ 训练 {name}...")# 对基于距离的模型使用缩放后的数据if name in ['Logistic Regression', 'SVM', 'KNN']:X_tr, X_te = X_train_scaled, X_test_scaledelse:X_tr, X_te = X_train, X_test# 训练模型model.fit(X_tr, y_train)# 预测y_pred = model.predict(X_te)y_pred_proba = model.predict_proba(X_te)[:, 1] if hasattr(model, 'predict_proba') else None# 评估指标accuracy = accuracy_score(y_test, y_pred)precision = precision_score(y_test, y_pred)recall = recall_score(y_test, y_pred)f1 = f1_score(y_test, y_pred)roc_auc = roc_auc_score(y_test, y_pred_proba) if y_pred_proba is not None else 0# 存储结果results.append({'Model': name,'Accuracy': accuracy,'Precision': precision,'Recall': recall,'F1-Score': f1,'ROC-AUC': roc_auc})# 存储训练好的模型trained_models[name] = modelprint(f" ✓ 准确率: {accuracy:.4f} | F1分数: {f1:.4f} | ROC-AUC: {roc_auc:.4f}")# 创建结果DataFrame
results_df = pd.DataFrame(results).sort_values('F1-Score', ascending=False)print("\n" + "="*70)
print("📊 模型比较结果")
print("="*70)
print(results_df.to_string(index=False))
print("="*70)
输出:
======================================================================
🚀 模型训练中 - 请稍候...
======================================================================⚙️ 训练 Logistic Regression...✓ 准确率: 0.8854 | F1分数: 0.8594 | ROC-AUC: 0.9561⚙️ 训练 Random Forest...✓ 准确率: 0.9427 | F1分数: 0.9302 | ROC-AUC: 0.9624⚙️ 训练 Gradient Boosting...✓ 准确率: 0.9490 | F1分数: 0.9375 | ROC-AUC: 0.9780⚙️ 训练 XGBoost...✓ 准确率: 0.9363 | F1分数: 0.9194 | ROC-AUC: 0.9669⚙️ 训练 LightGBM...✓ 准确率: 0.9299 | F1分数: 0.9134 | ROC-AUC: 0.9664⚙️ 训练 AdaBoost...✓ 准确率: 0.9236 | F1分数: 0.9016 | ROC-AUC: 0.9710⚙️ 训练 SVM...✓ 准确率: 0.8854 | F1分数: 0.8615 | ROC-AUC: 0.9377⚙️ 训练 KNN...✓ 准确率: 0.8790 | F1分数: 0.8527 | ROC-AUC: 0.9386======================================================================
📊 模型比较结果
======================================================================Model Accuracy Precision Recall F1-Score ROC-AUCGradient Boosting 0.949045 0.895522 0.983607 0.937500 0.977971Random Forest 0.942675 0.882353 0.983607 0.930233 0.962432XGBoost 0.936306 0.904762 0.934426 0.919355 0.966872LightGBM 0.929936 0.878788 0.950820 0.913386 0.966359AdaBoost 0.923567 0.901639 0.901639 0.901639 0.970970SVM 0.885350 0.811594 0.918033 0.861538 0.937671Logistic Regression 0.885350 0.820896 0.901639 0.859375 0.956113KNN 0.878981 0.808824 0.901639 0.852713 0.938610
======================================================================
======================================================================
🚀 模型训练中 - 请稍候...
======================================================================⚙️ 训练 Logistic Regression...✓ 准确率: 0.8854 | F1分数: 0.8594 | ROC-AUC: 0.9561⚙️ 训练 Random Forest...✓ 准确率: 0.9427 | F1分数: 0.9302 | ROC-AUC: 0.9624⚙️ 训练 Gradient Boosting...✓ 准确率: 0.9490 | F1分数: 0.9375 | ROC-AUC: 0.9780⚙️ 训练 XGBoost...✓ 准确率: 0.9363 | F1分数: 0.9194 | ROC-AUC: 0.9669⚙️ 训练 LightGBM...✓ 准确率: 0.9299 | F1分数: 0.9134 | ROC-AUC: 0.9664⚙️ 训练 AdaBoost...✓ 准确率: 0.9236 | F1分数: 0.9016 | ROC-AUC: 0.9710⚙️ 训练 SVM...✓ 准确率: 0.8854 | F1分数: 0.8615 | ROC-AUC: 0.9377⚙️ 训练 KNN...✓ 准确率: 0.8790 | F1分数: 0.8527 | ROC-AUC: 0.9386======================================================================
📊 模型比较结果
======================================================================Model Accuracy Precision Recall F1-Score ROC-AUCGradient Boosting 0.949045 0.895522 0.983607 0.937500 0.977971Random Forest 0.942675 0.882353 0.983607 0.930233 0.962432XGBoost 0.936306 0.904762 0.934426 0.919355 0.966872LightGBM 0.929936 0.878788 0.950820 0.913386 0.966359AdaBoost 0.923567 0.901639 0.901639 0.901639 0.970970SVM 0.885350 0.811594 0.918033 0.861538 0.937671Logistic Regression 0.885350 0.820896 0.901639 0.859375 0.956113KNN 0.878981 0.808824 0.901639 0.852713 0.938610
======================================================================# 可视化模型比较
fig, axes = plt.subplots(2, 2, figsize=(18, 12))# 要绘制的指标
metrics = ['Accuracy', 'Precision', 'Recall', 'F1-Score']for idx, metric in enumerate(metrics):ax = axes[idx // 2, idx % 2]# 按指标排序data = results_df.sort_values(metric, ascending=True)# 创建水平条形图bars = ax.barh(data['Model'], data[metric], color=plt.cm.viridis(data[metric]), edgecolor='black', linewidth=1.5)# 添加数值标签for bar in bars:width = bar.get_width()ax.text(width + 0.01, bar.get_y() + bar.get_height()/2, f'{width:.3f}', ha='left', va='center', fontweight='bold', fontsize=10)ax.set_xlabel(metric, fontsize=12, fontweight='bold')ax.set_ylabel('Model', fontsize=12, fontweight='bold')ax.set_title(f'📊 {metric} Comparison', fontsize=14, fontweight='bold')ax.set_xlim(0, 1.05)ax.grid(alpha=0.3, axis='x', linestyle='--')plt.tight_layout()
plt.show()# 总体排名
print("="*70)
print("🏆 最终模型排名 (按F1分数)")
print("="*70)
for idx, row in results_df.iterrows():print(f"{results_df.index.tolist().index(idx) + 1}. {row['Model']:.<30} F1: {row['F1-Score']:.4f}")
print("="*70)
输出:
======================================================================
🏆 最终模型排名 (按F1分数)
======================================================================
1. Gradient Boosting............. F1: 0.9375
2. Random Forest................. F1: 0.9302
3. XGBoost....................... F1: 0.9194
4. LightGBM...................... F1: 0.9134
5. AdaBoost...................... F1: 0.9016
6. SVM........................... F1: 0.8615
7. Logistic Regression........... F1: 0.8594
8. KNN........................... F1: 0.8527
======================================================================📈 结果与洞察
🏆 模型性能总结
我们的机器学习管道成功预测了海啸潜力,并取得了令人印象深刻的准确率!以下是关键要点:
最佳表现模型
表现最佳的模型在所有评估标准上都取得了强劲的指标,展示了在海啸风险评估方面强大的预测能力。
关键性能指标
- 准确率:总体正确预测的百分比
- 精确率:当我们预测海啸时,预测正确的频率是多少?
- 召回率:在所有实际海啸中,我们捕捉到了多少?
- F1分数:平衡精确率和召回率的调和平均数
- ROC-AUC:模型区分不同类别的能力
模型评估的关键洞察
-
特征重要性层次:
- 震级仍然是最强的预测因子(如EDA所预期)
- 深度相关特征(特别是浅层地震指标)至关重要
- 工程交互特征(mag_depth_ratio)提供显著价值
- 地理特征有帮助,但次于震级和深度
-
模型行为:
- 基于树的集成方法(RF、XGBoost、LightGBM)优于线性模型
- 模型在极端情况下表现出高置信度(非常浅+高震级)
- 在边界情况下存在一些不确定性(中等深度+震级约7.0)
-
预测模式:
- 假阴性(漏报的海啸)往往发生在中等震级事件中
- 假阳性(误报)通常涉及浅层但较低震级的地震
- 模型擅长识别高风险情景(浅层+重大地震)
-
实际应用性:
- 高召回率对早期预警系统至关重要(最小化漏报海啸)
- 如果可以防止灾难性损失,某些误报是可以接受的
- 该模型可以作为应急响应的快速评估工具部署