*HQL语法简介
目录
Hive数据类型
DDL语言
建表语法树
语法讲解
DML语法
语法讲解
DQL语法
官网提供了详细的文档Apache Hive:语言手册用于学习,这里只作介绍。
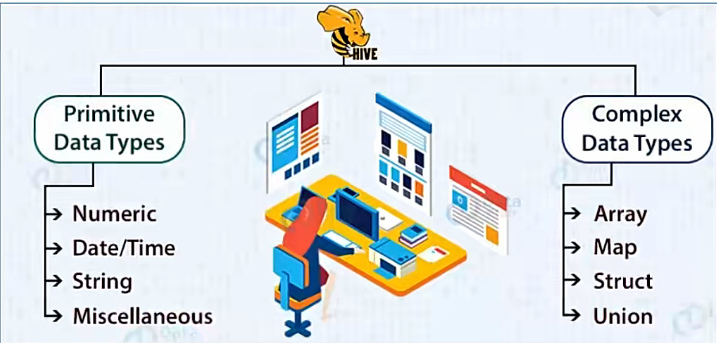
Hive数据类型
指Hive表中的列字段类型,分为原生数据类型(数值、时间、字符串、杂项)和复杂数据类型(数组、映射、结构体、联合体)。
DDL语言
Data Definition Language:数据定义语言,用于定义和管理数据库中的schema,包括对数据库和表的创建、修改、删除操作。
建表语法树

①建表声明
- CREATE TABLE:声明“创建表”;
- TEMOPORARY:可选,创建临时表,会话结束自动删除;
- EXTERNAL:可选,创建外部表,若省略则为内部表;
- IF NOT EXISTS:可选,避免表已存在而报错;
- [db_name.]table_name:指定数据库(可选,默认当前数据库)和表名。
②字段定义
- col_name:列名;
- data_type:数据类型;
- COMMENT col_comment:可选,为该列添加注释。
③表注释
- COMMENT table_comment:为整个表添加注释。
④分区
- PARTITONED BY:声明“创建分区表”,按列值拆分目录。
⑤分桶与排序
- CLUSTERED BY:声明“创建分桶表”,按列的哈希值拆分文件;
- SORTED BY:可选,指定桶内数据的排序规则;
- num_buckets:分桶数量,需合理选择。
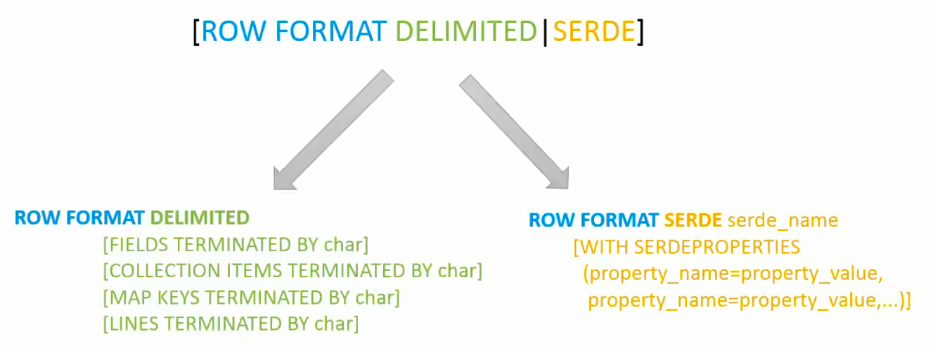
⑥行格式与序列化
- ROW FORMAT DELIMITED:用于普通文本文件的格式定义,需要配合FIELDS TERMINATED BY(列分隔符)等子句,简单说就是拆分数据;
- SERDE:用于自定义序列化/反序列化逻辑;
- SERDEPROPERTIES:为SerDe指定属性。
⑦存储格式
- STORED AS:指定表数据的文件存储格式,常见的有TEXTFILE(普通文本文件)、ORC(列式存储格式)、PARQUET(跨引擎兼容的列式存储格式)
⑧存储路径
- LOCATION:指定表数据在HDFS上的存储路径,由hive.metastore.warehouse.dir属性指定,默认是:/user/hive/warehouse
⑨表属性
- TBLPROPERTIES:为表添加自定义属性,常用于标记表的元信息或Hive的特殊配置。
语法讲解
EXTERNAL
①外部表:表的元数据(desc formatted table_name 查询表的元数据信息)由数据库维护,但实际数据文件存储在用户指定的路径下。
当删除外部表时,仅删除表的元数据(表结构),不会删除底层(HDFS)数据文件;直接操作HDFS文件时,Hive不会自动感知需要手动刷新。
②内部表:表的数据由数据库完全管理,实际数据文件默认存储在Hive仓库目录。
当删除内部表的时候,同时删除表的元数据和底层数据文件;需要将数据导入Hive仓库。
IF NOT EXISTS
①在自动化等场景下,用于保证脚本的稳定性。避免因为报错导致脚本后续无法执行,加上IF NOT EXISTS后,会跳过已存在的表,确保流程正常跑完;
②脚本需要重复执行,不报错比建表成功更重要,因为表可能早就建好了,但是需要确保它存在。
SERDE
全称Serializer/Deserializer,序列化/反序列化器。序列化是对象转化为字节码的过程,反序列化是字节码转化为对象的过程。
读取数据(反序列化):查询表时,Hive通过将HDFS上的原始文件解析为表的字段,确保字段与表结构对应;
写入数据(序列化):当向表中插入数据时,Hive通过SERDE将表的字段转换为符合存储格式的字节流,写入HDFS。
①ROW FORMAT DELIMITED
用于普通文本文件的分隔符配置,本质上时对Hive内置的LazySimpleSerDe的简化封装。
例:
CREATE TABLE student (id INT,name STRING,scores ARRAY<INT>
)
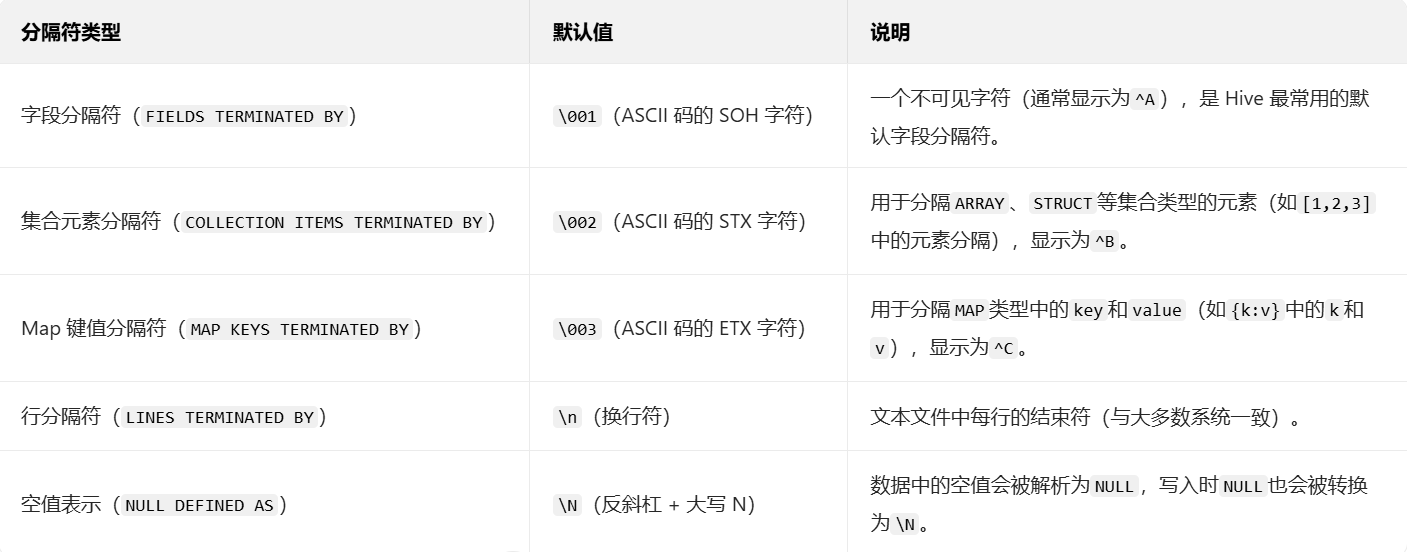
ROW FORMAT DELIMITEDFIELDS TERMINATED BY ',' -- 字段之间的分隔符(如逗号)COLLECTION ITEMS TERMINATED BY '|' -- 集合元素(如ARRAY)的分隔符(如竖线)MAP KEYS TERMINATED BY ':' -- MAP类型中key和value的分隔符(如冒号)LINES TERMINATED BY '\n' -- 行之间的分隔符(如换行符)NULL DEFINED AS ''; -- 空值的表示方式(如空字符串)
STORED AS TEXTFILE;-- 下面两种写法等价
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
WITH SERDEPROPERTIES ("field.delim" = ",")②ROW FORMAT SERDE
SERDE是更底层的分隔符配置方式,直接指定用于解析数据的Serializer/Deserializer类或自定义,支持任意数据格式()。通过官方文档来帮助使用:Apache Hive:SerDe
例:
-- 解析JSON格式(使用JsonSerDe)
CREATE TABLE user_log (user_id STRING,action STRING
)
ROW FORMAT SERDE 'org.apache.hive.hcatalog.data.JsonSerDe'
WITH SERDEPROPERTIES ("mapping.userid" = "user_id" -- JSON字段与表字段的映射(解决命名不一致)
)
STORED AS TEXTFILE;③不使用ROW FORMAT
Hive在建表的时候,如果没有ROW FORMAT语法,Hive 的默认分隔符就是LazySimpleSerDe的默认分隔符,与使用ROW FORMAT DELIMITED但未指定具体分隔符时完全一致。
tip:可以通过desc formatted tablename命令来查看表的相关SerDe信息,默认是:

PARTITIONED BY
在Hive中,分区表通过在表结构中添加分区列(不属于表的实际字段,用于分类的标记),数据会按分区列的值存储在不同的子目录中。目的是减少扫描数据量、优化查询效率,它类似文件系统,每个分区对应一个子目录。
①创建分区表
CREATE TABLE log_partitioned (user_id STRING,action STRING,time STRING
)
PARTITIONED BY (dt STRING COMMENT '日期,格式yyyy-MM-dd', country STRING COMMENT '国家代码')
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
STORED AS TEXTFILE;-- 表的实际字段是user_id、action、time,先按日期分区后再按国家分区②分区表的操作
- 向分区表插入数据,需指定分区列的值,数据会被写入对应分区目录:
-- 插入数据到dt=2023-10-01、country=CN分区
INSERT INTO log_partitioned PARTITION (dt='2023-10-01', country='CN')
VALUES ('u123', 'click', '10:00:00'), ('u456', 'view', '10:05:00');- 加载数据到分区,通过
LOAD DATA将外部文件加载到指定分区:
-- 将本地文件加载到dt=2023-10-02、country=US分区
LOAD DATA LOCAL INPATH '/local/path/us_log_2023-10-02.txt'
INTO TABLE log_partitioned
PARTITION (dt='2023-10-02', country='US');- 查询分区数据,通过
WHERE子句指定分区列,实现 “分区裁剪”(只扫描目标分区):
-- 只查询2023-10-01中国的日志,效率高
SELECT * FROM log_partitioned
WHERE dt='2023-10-01' AND country='CN';- 新增/删除分区,删除分区会删除分区目录和数据:
ALTER TABLE log_partitioned ADD IF NOT EXISTS
PARTITION (dt='2023-10-03', country='JP')
LOCATION '/user/data/logs/dt=2023-10-03/country=JP'; -- 可选:指定自定义路径ALTER TABLE log_partitioned DROP IF EXISTS
PARTITION (dt='2023-10-01', country='CN');- 查看分区信息
-- 查看表的所有分区
SHOW PARTITIONS log_partitioned;-- 查看分区的详细信息(路径、创建时间等)
DESCRIBE FORMATTED log_partitioned PARTITION (dt='2023-10-01', country='CN');③分区表的类型
- 静态分区:向分区表插入数据时,手动显式指定所有分区列的值,Hive会将数据写入对应分区目录。适用于分区数量少、分区值已知的场景;
-- 插入数据时,显式指定分区列的值(静态分区)
INSERT INTO log_partitioned
PARTITION (dt='2023-10-01', country='CN') -- 手动指定分区值
VALUES
('u123', 'click', '10:00:00'),
('u456', 'view', '10:05:00');- 动态分区:向分区表插入数据时,不手动指定分区列的值,而是由Hive根据查询结果中的字段自动推断分区值(一一对应的位置映射),并创建对应分区。适用于分区数量多、分区值不固定的场景。
-- 允许动态分区(默认false)
SET hive.exec.dynamic.partition = true;
-- 非严格模式(允许所有分区列都是动态的,默认strict会要求至少一个静态分区)
SET hive.exec.dynamic.partition.mode = nonstrict;-- 插入时不指定具体分区值,声明与查询后的最后几个非分区列一一对应,自动创建分区列
INSERT INTO log_partitioned
PARTITION (dt, country) -- 只声明分区列,不指定值
SELECT user_id, -- 对应表的user_id字段action, -- 对应表的action字段time, -- 对应表的time字段log_dt, -- 对应分区列dtlog_country -- 对应分区列country
FROM raw_logs;④分区表注意事项
- 分区列应该避免过多;
- 若直接在HDFS上手动创建分区目录,Hive元数据不会自动识别,需执行MSCK REPAIR TABLE table_name刷新分区。
CLUSTERED BY
分桶是一种将数据按指定列的哈希值拆分为固定数量文件(桶)的优化手段,目的是提升查询效率、数据均匀分布。
①创建分桶表
- 选择一个或多个分桶列;
- 计算每条数据的分桶列值的哈希值;
- 用哈希值对指定的桶数量取模(hash(col) % num_buckets),得到该数据所属的桶编号;
- 相同桶编号的数据被写入同一个文件,最终生成num_buckets个文件,每个文件对应一个桶。
CREATE TABLE user_behavior (user_id STRING,action STRING,time STRING
)
-- 按user_id分4个桶,每个桶内按time升序排序
CLUSTERED BY (user_id)
SORTED BY (time ASC)
INTO 4 BUCKETS
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
STORED AS ORC; -- 分桶表建议用列式存储(ORC/Parquet),效率更高-- 数据会按user_id的哈希值 %4 分配到 4 个桶(文件)中;
-- 每个桶内的记录会按time升序排列。②分桶表注意事项
- 插入数据到分桶表,必须通过INSERT ... SELECT,且需开启分桶强制检查参数:
-- 开启分桶强制检查(确保数据按分桶规则写入,默认false)
SET hive.enforce.bucketing = true;-- 从原始表插入数据到分桶表
INSERT INTO user_behavior
SELECT user_id, action, time FROM raw_behavior;- 根据数据量和集群规模合理设置桶数量,过多会产生大量小文件,过少无法发挥并行优势;
- 优先选查询中常用JOIN或GROUP BY的列;
- 与分区结合使用,可以多维度优化。
DML语法
Data Manipulation Language:数据操纵语言,用于对数据库中的数据进行查询、插入、更新、删除等操作。
语法讲解
SELECT
用于从表中提取数据,支持复杂的过滤、分组、排序和关联。
INSERT
将数据写入表或分区、桶,不建议单条插入。
语法树

①INSERT INTO:向表或分区追加数据:
-- 插入到非分区表
INSERT INTO table student
SELECT id, name FROM temp_student;-- 插入到分区表(静态分区)
INSERT INTO table log_partitioned PARTITION (dt='2023-10-03', country='CN')
SELECT user_id, action, time FROM raw_logs WHERE log_dt='2023-10-03' AND log_country='CN';-- 插入到分区表(动态分区,需开启参数)
SET hive.exec.dynamic.partition=true;
SET hive.exec.dynamic.partition.mode=nonstrict;
INSERT INTO table log_partitioned PARTITION (dt, country)
SELECT user_id, action, time, log_dt, log_country FROM raw_logs;②INSERT OVERWRITE:覆盖插入,删除表或分区原有数据,再插入新数据,慎用:
-- 覆盖整个表
INSERT OVERWRITE table student
SELECT id, name FROM temp_student;-- 覆盖指定分区
INSERT OVERWRITE table log_partitioned PARTITION (dt='2023-10-03')
SELECT user_id, action, time, country FROM new_logs WHERE dt='2023-10-03';③FROM...INSERT:多表插入,从一个源表一次性向多个目标表插入数据,可以减少扫描的次数:
FROM raw_logs
-- 插入到表1
INSERT INTO table log_cn PARTITION (country='CN')
SELECT user_id, action, time, dt WHERE log_country='CN'
-- 插入到表2
INSERT INTO table log_us PARTITION (country='US')
SELECT user_id, action, time, dt WHERE log_country='US';UPDATE
Hive在ACID事务支持的表中支持UPDATE操作,用于修改符合条件的行。前提:表必须是内部表且存储格式为ORC,需开启事务配置。
-- 事务配置
SET hive.support.concurrency = true;
SET hive.enforce.bucketing = true;
SET hive.exec.dynamic.partition.mode = nonstrict;语法树
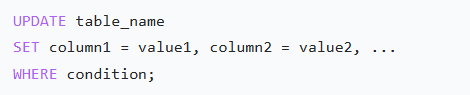
-- 更新用户u123的行为记录
UPDATE user_behavior
SET action = 'purchase'
WHERE user_id = 'u123' AND time = '10:00:00';DELETE
也需要表支持 ACID 事务,用于删除条件的行。
语法树

LOAD DATA
用于将外部文件(本地或HDFS)中的数据移动或复制到Hive表或分区中,本质是文件系统操作。
语法树

-- 从本地加载数据到分区表(追加)
LOAD DATA LOCAL INPATH '/local/path/log_2023-10-01.txt'
INTO TABLE log_partitioned
PARTITION (dt='2023-10-01', country='CN');-- 从HDFS加载数据并覆盖原有数据
LOAD DATA INPATH '/user/data/new_logs/'
OVERWRITE INTO TABLE student;INSERT OVERWRITE DIRECTORY
将查询结果导出到本地文件系统或HDFS路径。是覆盖操作,慎用。

-- 导出查询结果到本地目录(按逗号分隔)
INSERT OVERWRITE LOCAL DIRECTORY '/local/output/'
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
SELECT user_id, action FROM log_partitioned WHERE dt='2023-10-01';-- 导出到HDFS目录
INSERT OVERWRITE DIRECTORY '/user/output/'
SELECT * FROM student;DQL语法
语法树

- Distinct:去重
- WHERE:分组前过滤(不能使用聚合函数,因为聚合函数是对分组后的数据进行计算)
- GROUP BY:分组(SELECT中的字段必须为分组列或聚合函数,否则无法确定取哪一行的值)
- HAVING:分组后过滤
- ORDER BY:对全表数据排序
- CLUSTER BY:按列分发并排序
- DISTRIBUTE BY:按列将数据分发到不同Reduce任务,相同值进同一个Reduce
- SORT BY:在每个Reduce任务内排序,局部排序,效率高于ORDER BY
- LIMIT:限制返回结果行数
- 执行顺序:FROM--->WHERE--->GROUP BY--->HAVING--->ORDER BY--->SELECT
Pycharm连接HS2