索引的知识总结
索引是什么?
索引可以通俗理解为书籍目录
MYSQL的索引是一种数据结构,他可以帮助数据库高效地查询、更新数据表中的数据,索引通过一定的规则排列数据表中的记录,使得对表的查询可以通过索引的搜索来加快速度
索引数据结构的选择
1.hash 时间复杂度O(1),但他不支持范围查找
2.二叉搜索树 时间复杂度:可能会退化为单边树O(N)
中序遍历是一个有序序列--》支持范围查找
磁盘的IO是制约数据库性能的主要因素
3.N叉树
每个节点可以有超过两个子节点,可以解决树高的问题,时间复杂度为O(logN)
上述这些数据结构都不能满足索引的要求,下面我们介绍B+树
4.B+树
B+树是一种经常用于数据库和文件系统等场合的平衡查找树,MYSQL索引采用这种数据结构
时间复杂度O(logN)
B+树与B树对比:1.叶子结点之间有相互连接的引用MYSQL使用的是双向链表
2.非叶子结点的值都包含在叶子结点中
3.对于B树而言,在相同树高情况下,查找的时间复杂度相同,性能均衡
(B树的详细知识会在数据结构部分介绍)
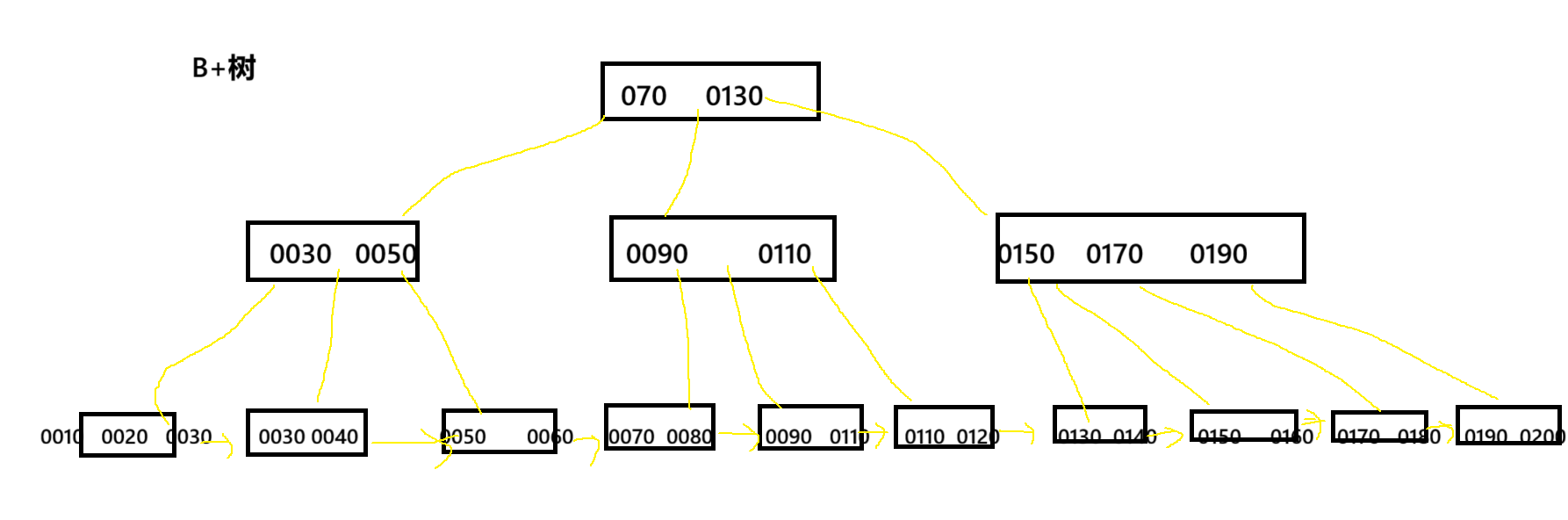
索引如何工作
索引如何工作要从MYSQL的存储结构了解
MYSQL中的页
基本知识
在.ibd文件中最重要的结构体是页Page --页是内存与磁盘交互的最小单元
页内部的地址是连续的,默认大小是16kb,即使页中无数据,也会有16kb,同时与B+树的结点对应
根据局部性原理,以页读取,减少磁盘的IO来提高性能
查看页的大小的操作
show variables like 'innode_page_size';
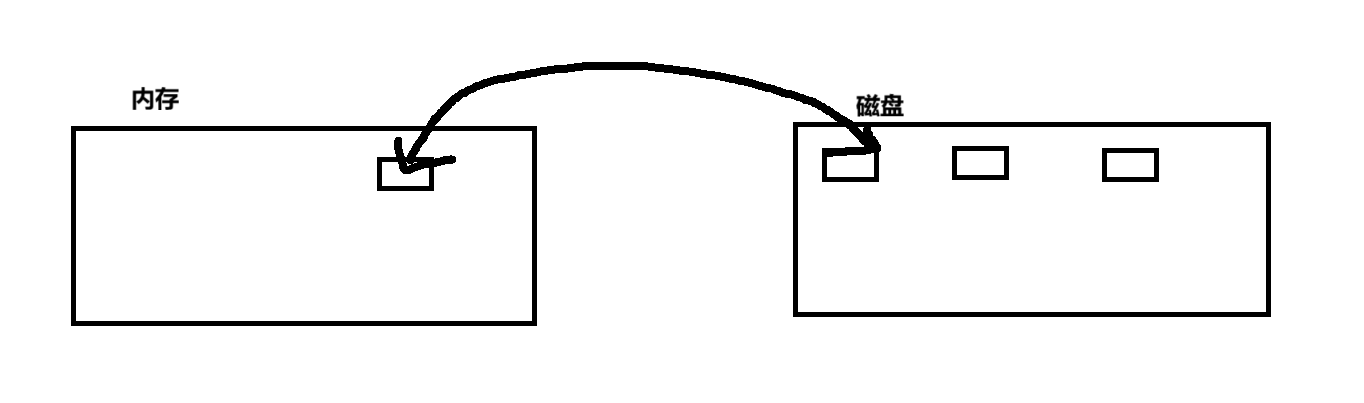
Linux操作系统中管理文件的最小单位是4KB,MYSQL作为一个数据库程序,以4KB大小管理数据太少了,所以定义16KB为默认页的大小
在数据落盘之前会记录各种日志,以保证重启之后可以找到没落盘的数据内容
每创建一张表生成一个保存数据的文件称为独立表空间文件,MYSQL有很多页类型,这里我们只讨论数据页/索引页
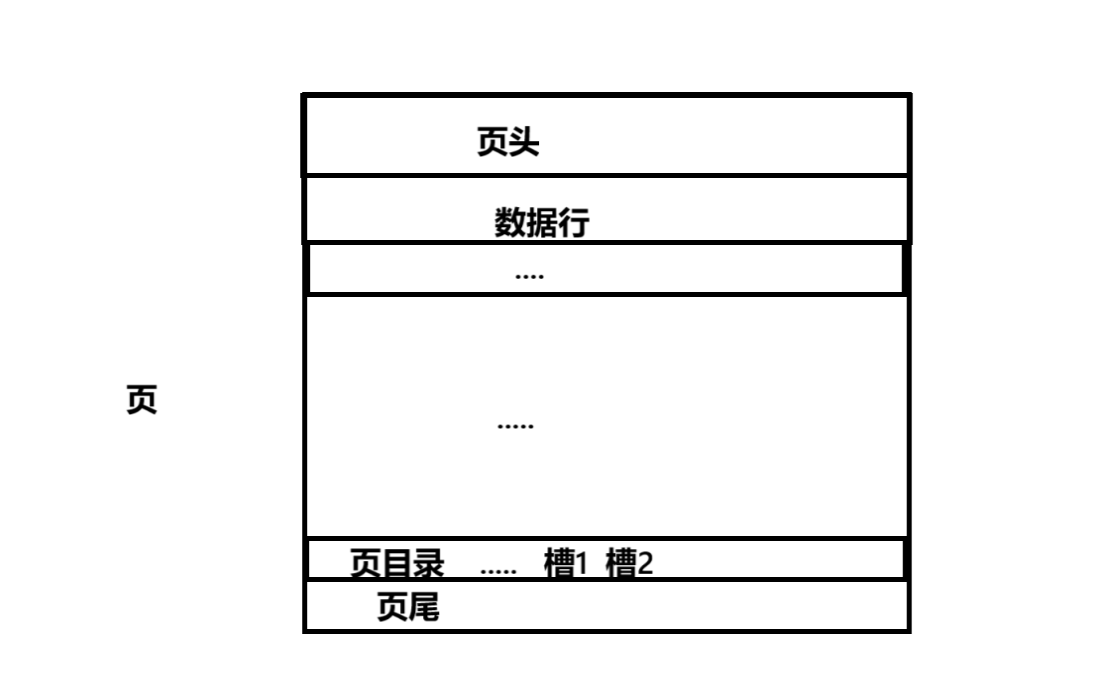
通过页号和页大小,可以计算出下一页和上一页在磁盘上的偏移量
页主体:保存真实数据的主要区域,每创建一个新页,都会自动分配两个行,页内最小行Infimun,页内最大行Suporemun 最小行和最大行不存真实信息
新页插入一个数据时,将Infimun连接到第一个数据行时,最后一行真实数据指向Suporemun
页目录 最小行单独为一组,数组行的分组,每个分组最多可以容纳8条记录,超过8条时会分裂出一个新的组,最大行永远在最后一个分组中
创建分组时会在页目录中创建一个槽,槽的数量与分组的数据是一致的,槽会指定对应分组的最后一条记录,同时保存这条记录的主键值
数据页头:记录了当前页保存数据相关的信息
B+树与页
非叶子结点保存索引数据,叶子结点保存真实数据
非叶子结点 :索引页,保存的是主键的值和子节点的引用
叶子结点:保存具体数据
注意:所有关于页的操作和访问都是在内存中进行的
索引的分类
1.主键索引
当一个表上定义一个主键primary key时,自动创建索引,索引的值是主键列值,InnoDB使用他为聚集索引
2.普通索引
为了提升查询索引,工作时通常为查询频繁的列创建索引,可以包含多个列
3.唯一索引
定义Unique,自动创建唯一索引 不允许有重复值
4.全文索引
基于文本列上创建,加快对这些列中包含的数据查询和DML操作,用于全文搜索,仅有MyISAM和InnoDB支持
5.聚集索引
聚集索引 可以标识数据行的唯一性
与主键索引是同义词,如果未定义主键,InnoDB会使用第一个Unique和Not Null作为聚集索引,如果这也没有,InnoDB会新插入行并用6字节ROW.ID来记录
6.非聚集索引/二级索引
二级索引中的每条记录都包含该行的主键列,以及二级索引指定的列
InnoDB使用这个主键值来搜索聚集索引中的行的过程叫回表查询
7.索引覆盖
通过索引查询的列包含在索引中,不用回表查询了,这种现象叫索引覆盖
注意:创建索引之后都会生成一颗索引树(也会占用磁盘空间,所以我们创建索引时要考虑)
索引的使用
创建索引
1.自动创建----内部,这里我们建议为表添加一个主键值
2.手动创建
主键索引 PRI
1.创建表时创建主键 2.创建表时单独指定主键列
3.修改表中的列为主键索引
alter table 表名 [add/ modify/drop] 要修改的内容
-- 创建表时指定主键
create table t_pk1(id bigint PRIMARY KEY auto_increment,name varchar(20)
);
desc t_pk1;-- 创建表时单独指定主键列
create table t_pk2(id bigint auto_increment,name varchar(20),PRIMARY KEY(id)
);
show index from t_pk2;
create table t_pk3(id bigint,name varchar(20)
);
show index from t_pk3;-- 修改表中的id列为主键索引
ALTER TABLE t_pk3 ADD PRIMARY KEY(id);
ALTER TABLE t_pk3 modify id bigint auto_increment;唯一索引 UNI
1.创建表时创建唯一键 2.创建表示单独指定唯一键
3.修改
普通索引
1.创建表时指定索引列 2.修改表
3.单独创建索引并制定索引名 create index index_name on 表名(列名)index 为关键词
创建时期:1.创建初期就知道查询频繁 2.使用过程中知道查询频繁
-- 创建表时指定普通索引
create table t_index1(id bigint primary key auto_increment,name varchar(20),sno varchar(20),index(sno)
);
desc t_index1;
create table t_index2(id bigint primary key auto_increment,name varchar(20),sno varchar(20)
);
alter table t_index2 add index(sno);-- 单独创建索引并制定索引名
create table t_index3(id bigint PRIMARY KEY auto_increment,name varchar(20),sno varchar(20)
);
create index idx_t_index3_sno on t_index3(sno);
复合索引
语法与创建普通索引相同,只不过指定多个列,列与列之间用逗号隔开
查看索引
show keys from 表名;
desc 表名;
删除索引
主键索引 语法: alter table 表名 drop primary key;
其他索引 语法: alter table 表名 drop index 索引名;
补充 如何查看自己写的SQL有没有走索引 ?
可以查看执行计划 explain +正常SQL语句
KEY是我们真是用到的索引