python - day 12
输入和输出
输出格式美化
repr()和str()
如果你希望将输出的值转成字符串,可以使用 repr() 或 str() 函数来实现。
- str(): 函数返回一个用户易读的表达形式。
- repr(): 产生一个解释器易读的表达形式。
这两个函数我不太理解,str()显示的东西好像是给人看的,然后repr()显示的信息是给电脑看的。
eg:
text ="hello,world\n";
print("str()函数输出:",str(text));
print("repr()函数输出:",repr(text));运行结果:

左对齐,右对齐,居中对齐
ljust(),rjust()和 center()
左对齐,右对齐,居中对齐可以分别使用 ljust(),rjust()和 center()函数来实现。
语法格式;
字符串.ljust(宽度[, 填充字符])
字符串.rjust(宽度[, 填充字符])
字符串.center(宽度[, 填充字符])宽度:最终字符串的总长度
填充字符(可选):用来填充空位的字符,默认是空格
注意使用对象只能是字符串,非字符串使用str()函数进行转换。
eg:
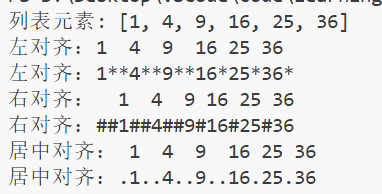
text =[x*x for x in range(1,7)];
print("列表元素:",text);print("左对齐:",end="");
for i in text:print(str(i).ljust(3),end="");#左对齐print("\n左对齐:",end="");
for i in text:print(str(i).ljust(3,"*"),end="");#左对齐,填充字符为*print("\n右对齐:",end="");#因为上面的for循环中最后是end=" ",所以这里用\n换行;
for i in text:print(str(i).rjust(3),end="");#右对齐print("\n右对齐:",end="");#因为上面的for循环中最后是end=" ",所以这里用\n换行;
for i in text:print(str(i).rjust(3,"#"),end="");#右对齐print("\n居中对齐:",end="");
for i in text:print(str(i).center(3),end="");print("\n居中对齐:",end="");
for i in text:print(str(i).center(3,"."),end="");运行结果:
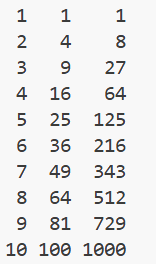
eg:
for i in range(1,11):print(str(i).rjust(2),str(i*i).rjust(3),end="");print(str(i*i*i).rjust(5));运行结果:
str.format()
基本使用:
括号及其里面的字符 (称作格式化字段) 将会被 format() 中的参数替换。
在括号中的数字用于指向传入对象在 format() 中的位置。
如果在 format() 中使用了关键字参数, 那么它们的值会指向使用该名字的参数。
位置和关键字参数是可以结合使用的
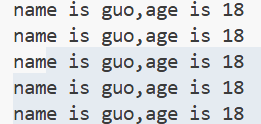
eg:
print("name is {},age is {}".format("guo",18));
#format会将{}内的变量替换成对应的值。
print("name is {0},age is {1}".format("guo",18));
#0,1,2,3...代表变量的位置。
print("name is {1},age is {0}".format(18,"guo"));
#和上面对比一下,可以发现{0}和{1}的位置互换了。
print("name is {name},age is {age}".format(name="guo",age=18));
#也可以用变量名来指定位置。
print("name is {},age is {}".format("guo",18,"male"));
#如果format的变量个数和format的位置个数不一致,则多余的变量会被忽略。运行结果:
在 : 后传入一个整数, 可以保证该域至少有这么多的宽度
通过>、<、^设置对齐方式,分别表示右对齐,左对齐和居中对齐。
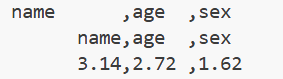
eg:
print("{:10},{:5},{:4}".format("name","age","sex"));#通过冒号设置对齐方式和宽度。
print("{:>10},{:<5},{:^4}".format("name","age","sex"));#通过>、<、^设置对齐方式。
print("{:>10.2f},{:<5.2f},{:^4.2f}".format(3.1415926,2.7182818,1.6180339));#通过.设置小数点后的精度。运行结果:
第三个是可选项 : 和格式标识符的结合,格式标识符,就是老实的那种百分号标识符,想%s,%f,%d,然后%5.2f就是浮点数右对齐五个单位,保留两位小数,然后%-5.f就是左对齐,那个负号说明左对齐,但百分号格式化中没有直接实现居中对齐的符号。
旧式字符串格式化
就是上面说的那种
eg:
print("%10s,%5s,%4s"%("name","age","sex"));
print("%10.2f,%-5.3f"%(3.1415926,2.7182818));运行结果:

f-string
先回顾一下f-string用法
eg:
name = "guo"
age = 18
sex = "male"
print(f"name is {name},age is {age},sex is {sex}");#f-string,可以直接在字符串中嵌入变量。运行结果:
![]()
用f-string实现左右中对齐,也是通过冒号(:)和 ><^实现的
eg:
name = "guo"
age = 18
sex = "male"
print(f"name is {name:10},age is {age:5}.sex is {sex:4}");#同样的还是使用冒号设置对齐方式和宽度。
print(f"name is {name:>10},age is {age:<5},sex is {sex:^4}");#通过>、<、^设置对齐方式。
print(f"height is{17.5:6.2f},weight is {71.8:5.2f}");#通过.设置小数点后的精度。运行结果:

zfill()
它会在数字的左边填充 0
eg:
print(str(123).zfill(5));#zfill()函数,在字符串前面填充0,使得字符串总长度为指定长度。运行结果:
![]()
读取键盘输入
input()函数
str=input("请输入字符串:");#输入字符串,并将其赋值给变量str,括号内的提示信息是输入提示。
print("你输入的内容是:",str);运行结果:

读和写文件
open() 将会返回一个 file 对象,基本语法格式如下:
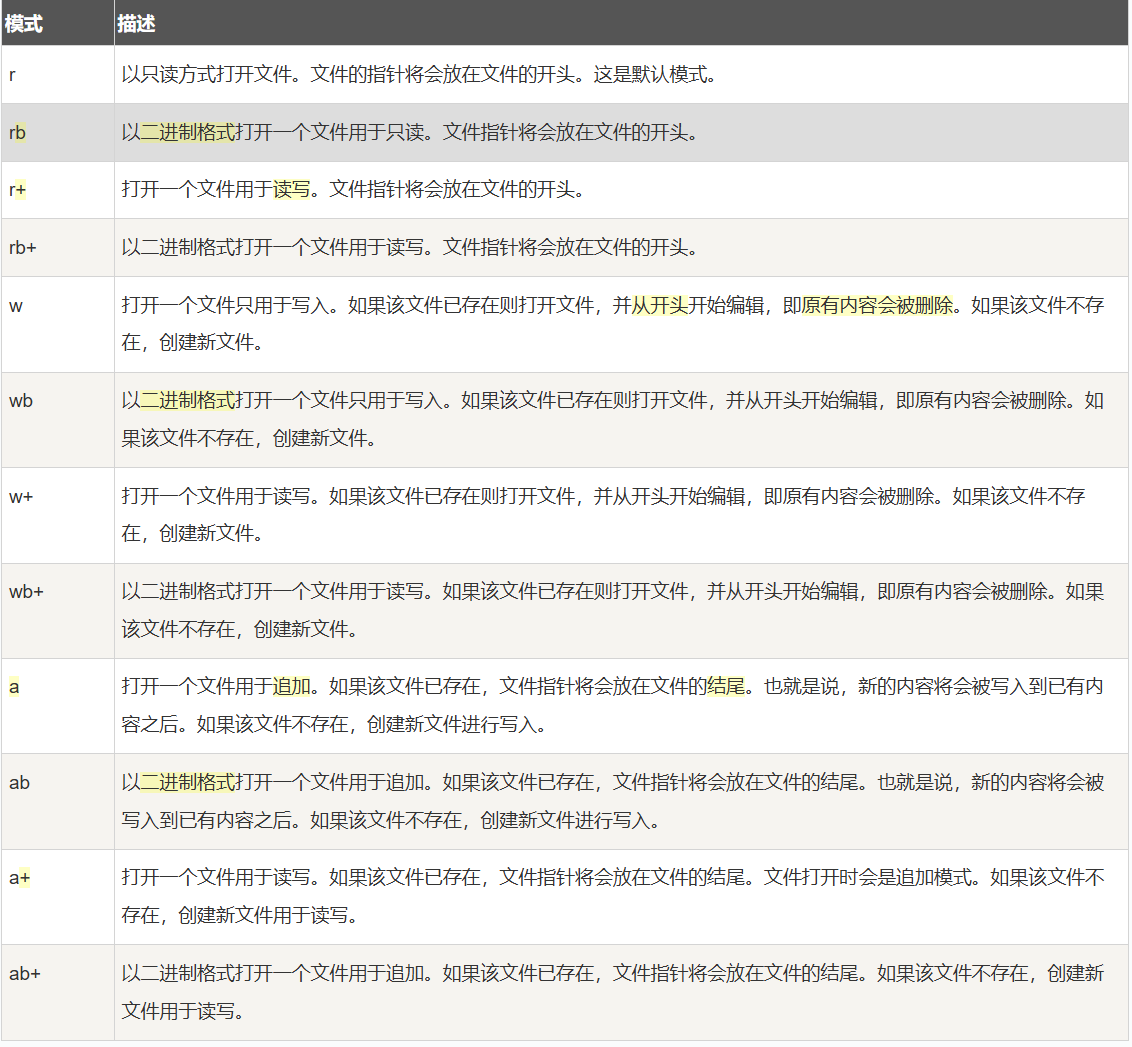
open(filename, mode)- filename:包含了你要访问的文件名称的字符串值,即文件在电脑中的存储地址。
- mode:决定了打开文件的模式:只读,写入,追加等。所有可取值见如下的完全列表。这个参数是非强制的,默认文件访问模式为只读(r)。
这个只有三种基本形式,只读r ,写入w,追加a,b说明是以二进制的格式展现,+说明同时允许读写。
之后就是前三者和后两者的组合,rb表示以二进制的格式打开一个文件,只读;r+说明可以读写;rb+,说明以二进制的形式打开一个文件,可以读写;写入w和追加a也是同样的;
这里区分一下r+,w+,a+,三者都可以读写,但r+是文件指针在文件开头,写入内容时不会删除原有内容,w+也是文件指针在文件开头,但写入内容时会删除原有内容,a+是文件指针在文件末尾,新的内容会直接写在原有内容后面。
文件对象的方法:
f.read(),f.readline(),f.readlins(),f.write(),f.tell(),f.seek(),f.close()。
分别是读,读一行,读所有行,写,告知当前文件指针所在位置(就是读到哪了),调整文件指针位置,关闭文件。
f.read()
为了读取一个文件的内容,调用 f.read(size), 这将读取一定数目的数据, 然后作为字符串或字节对象返回。
size 是一个可选的数字类型的参数。 当 size 被忽略了或者为负, 那么该文件的所有内容都将被读取并且返回。
f.readline()
f.readline() 会从文件中读取单独的一行。换行符为 '\n'。f.readline() 如果返回一个空字符串, 说明已经已经读取到最后一行。
f.readlines()
f.readlines() 将返回该文件中包含的所有行。
如果设置可选参数 sizehint, 则读取指定长度的字节, 并且将这些字节按行分割。
f.write()
f.write(string) 将 string 写入到文件中, 然后返回写入的字符数。
如果要写入一些不是字符串的东西, 那么将需要先进行转换。
f.tell()
f.tell() 用于返回文件当前的读/写位置(即文件指针的位置)。文件指针表示从文件开头开始的字节数偏移量。f.tell() 返回一个整数,表示文件指针的当前位置。
f.seek()
如果要改变文件指针当前的位置, 可以使用 f.seek(offset, from_what) 函数。
f.seek(offset, whence) 用于移动文件指针到指定位置。
offset 表示相对于 whence 参数的偏移量,from_what 的值, 如果是 0 表示开头, 如果是 1 表示当前位置, 2 表示文件的结尾,例如:
- seek(x,0) : 从起始位置即文件首行首字符开始移动 x 个字符
- seek(x,1) : 表示从当前位置往后移动x个字符
- seek(-x,2):表示从文件的结尾往前移动x个字符
from_what 值为默认为0,即文件开头。
当你处理完一个文件后, 调用 f.close() 来关闭文件并释放系统的资源,如果尝试再调用该文件,则会抛出异常。
当处理一个文件对象时, 使用 with 关键字是非常好的方式。
eg:
f = open("D:/Desktop/11.1.txt","r+",encoding="utf-8");#用open()函数打开文件,前面的路径是文件的路径,后面的是打开模式,r+表示可读可写。str1 = f.read();#用read()函数读取文件内容,并将其赋值给变量str。
f.seek(0,0);#用seek()函数将文件指针移动到文件开头。因为read()函数读取文件时,指针位置在读取完内容后停留在最后一个字符的后面,所以需要用seek()函数将指针移动到文件开头。
str2 = f.readline();#用readline()函数读取文件第一行内容,并将其赋值给变量str。
f.seek(0);
str3 = f.readlines();#用readlines()函数读取文件所有内容,并将其赋值给变量str。
print("文件内容是:\n",str1,"\n");
print("第一行内容是:\n",str2);
print("所有内容是:\n",str3);index=f.tell();
#我这里通过tell()函数获取当前文件指针位置,并将其赋值给变量index,以记录当前位置,这样一会就可以回溯到现在的位置,只打印后面写入的内容
f.write("\ni love");
f.seek(index);str4 = f.read();
print("\n写入后,剩余内容是:",str4);
index = f.tell();
print("\n当前文件指针位置是:",index);
f.seek(0);
print("\n最后文件内容是:",f.read());f.close();#用close()函数关闭文件。运行结果:

这里可以看出f.read()和f.readlines()的区别,虽然两者都会读取所有内容,但输出形式不同。
使用时遇到的各种错误:
1、文件打开错误,我改正的时使用了下面的方法一,'encoding='utf-8' 就可以了,因为我的不是gbk编码。
UnicodeDecodeError: 'gbk' codec can't decode byte 0xae in position 40: illegal multibyte sequence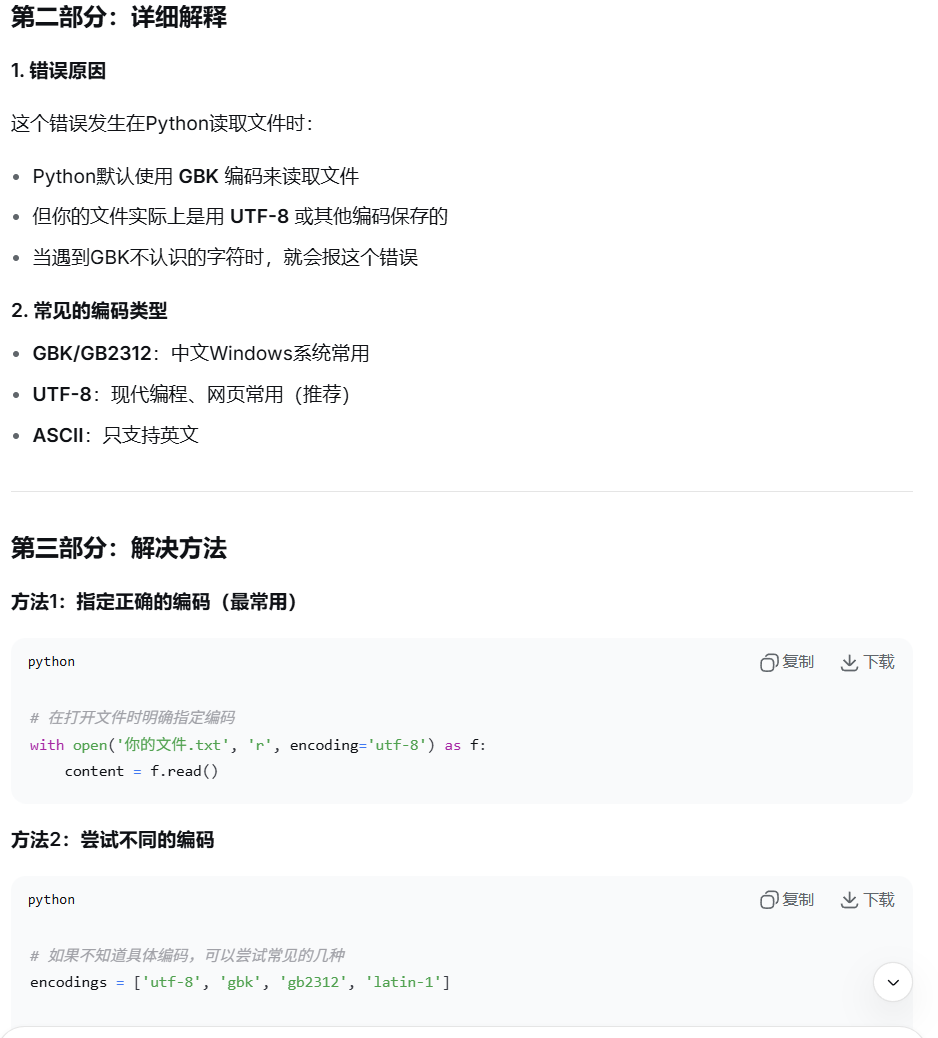
2、文件指针位置,在读了一个文件之后,文件指针会自动后移
文件指针在第一次 read() 后移到了末尾,后续操作都从末尾开始。
解决方法:在每次需要重新读取时使用 f.seek(0) 重置文件指针到开头。

3、f.seek()使用场景问题,这个错误是因为在使用文本模式下不支持相对定位的 seek() 操作
o.UnsupportedOperation: can't do nonzero end-relative seeks另外发现rb+和encoding ='utf-8',不兼容,前者是二进制模式,后者是文本模式,且使用rb+打开文件时,读写时都需要进行格式转换。
即下面的str1 = binary_content.decode('utf-8'),把二进制数据转换成人类可读的字符串。这里使用 UTF-8密码本 把密码翻译成我们能看懂的文字。
这里有这个问题,是因为我希望在后面只打印我写入的内容,然后要调整指针,我的方法就是先通过f.tell(),先记住当前位置,一会回溯。
