C++ 面向对象三大特性之一——继承
继承
继承的概念
继承机制是面向对象程序设计使代码可以复用最重要的手段。它允许程序员在保持原有类特性的基础上进行扩展,增加功能,产生新的类,这个新的类就叫做派生类。继承体现了面向对象程序设计的层次结构,体现了由简单到复杂的过程。以前我们接触的复用都是函数复用(函数调用,模板的使用)。现在的继承是类设计层次的复用
- 继承的思想是属性相同,例如有两个类分别为学生和老师,他们都是人,如果单独进行设计都要设计姓名,年龄,身高等,那么为了类设计层次的复用,把这些相同的属性抽象为一个类名为人,那么学生和老师就可以继承人的属性,例如姓名,年龄,身高等,从而进行类设计层次的复用
- 并且继承后,人的成员(成员变量和成员函数)都会变成学生和老师成员的一部分
class person
{
public:void Print(){cout << _age << endl;cout << _name << endl;}protected:int _age = 18;string _name = "xiaowang";
};class student :public person
{protected:int _stuid = 111111;
};class teacher :public person
{protected:int _teaid = 222222;
};int main()
{student s;teacher t;s.Print();t.Print();return 0;
}
基类 person :
- 包含保护成员变量 _age (默认值18)和 _name (默认值"xiaowang")。
- 公有成员函数 Print() ,用于输出 _age 和 _name 。
派生类 student 和 teacher :
- 均以 public 方式继承 person 类。
- 分别有保护成员变量 _studid (值111111)和 _teaid (值222222)。
main 函数:
- 定义 student 类对象 s 和 teacher 类对象 t 。
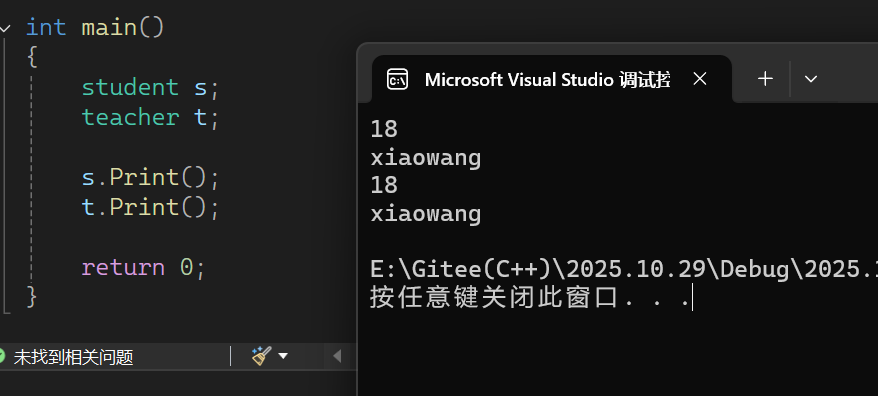
- 调用它们的 Print() 函数,最终会输出两次基类中的 _age (18)和 _name ("xiaowang")。
输出与调试结果:
从调试结果中可以看出:
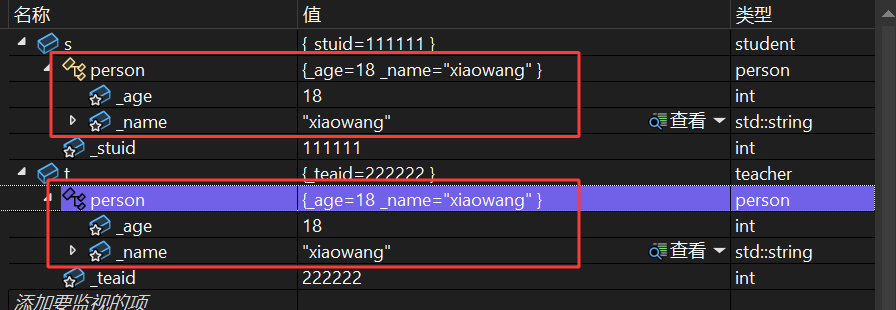
- 派生类 student (对象 s )和 teacher (对象 t )中,包含了基类 person 的所有成员( _age 和 _name ),同时还有自身的成员( _studid 和 _teaid )。这体现了继承的“代码复用”特性——派生类无需重复定义基类的成员,直接继承使用。
- 基类 person 的成员 _age 初始化为18, _name 初始化为“xiaowang”;派生类 student 的 _studid 初始化为111111, teacher 的 _teaid 初始化为222222。这说明类的成员变量在定义时的默认值会被正确初始化,继承关系中基类和派生类的初始化逻辑各自生效。
- 还有一点是虽然 student 和 teacher 都继承自 person ,但它们的对象( s 和 t )是相互独立的实例,各自拥有一份基类 person 的成员副本,不会相互干扰。
继承的定义
定义格式
person是父类,又称基类。student和teacher是子类,又称派生类
- 继承方式分为public继承,protected继承,private继承
- 继承使用方法:class 子类名 :继承方式 父类名
//派生类 :继承方式 基类
class student :public person
{protected:int _stuid = 111111;
};
继承方式和访问限定符

继承基类访问方式的变化
| 基类成员\继承方式 | public继承 | protected继承 | private继承 |
| 基类的public成员 | 派生类的public成员 | 派生类的protected成员 | 派生类的private成员 |
| 基类的protected成员 | 派生类的protected成员 | 派生类的protected成员 | 派生类的private成员 |
| 基类的private成员 | 在派生类中不可见 | 在派生类中不可见 | 派生类中不可见 |
总结:
- 基类的private成员在派生类中无论以什么方式继承都是不可见的。基类的 private 成员会被继承到派生类对象中,但语法上完全不可访问——无论在派生类内部还是外部,都不能直接操作。注意:这和派生类自身的 private 成员不同,派生类自己的 private 成员仅在类内部可访问,类外不可访问。
- 若希望“基类成员不在派生类外部直接访问,但在派生类内部可访问”,就把基类成员定义为 protected 。这说明 protected 是为继承场景专门设计的访问限定符。
- 基类成员在派生类中的访问权限,取“基类访问限定符”和“继承方式”中权限更小的那个。权限大小关系: public > protected > private 。
- 用 class 定义类时,默认继承方式是private继承;用 struct 定义类时,默认继承方式是public继承。实际开发中建议显式写出继承方式,避免歧义。
- 最常用的是 public继承 ;protected/private继承 使用场景极少,且不建议使用——因为它们继承的成员仅能在派生类内部使用,代码可维护性差。
派生类进行公有继承
class person
{
public:void Print(){cout << _age << endl;cout << _name << endl;}
protected:int _age = 18;
private:string _name = "xiaowang";
};class student :public person
{
public:void fun(){_age = 20;Print();}
protected:int _stuid = 111111;
};int main()
{student s;s.fun();s.Print();return 0;
}
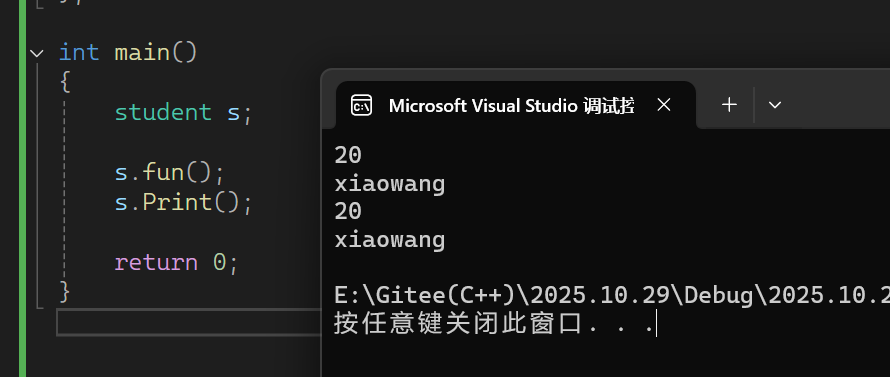
运行结果如下:
- 基类的public成员可以在派生类的里面和外面进行调用
- 基类的protected成员只能在派生类里面进行访问,在派生类外面不能进行访问
- 基类的private成员在派生类的里面和外面都不可以进行访问
派生类进行保护继承或私有继承
class person
{
public:void Print(){cout << _age << endl;cout << _name << endl;}
protected:int _age = 18;
private:string _name = "xiaowang";
};//class student :private person
class student :protected person
{
public:void fun(){_age = 21;Print();}
protected:int _stuid = 111111;
};int main()
{student s;s.fun();return 0;
}
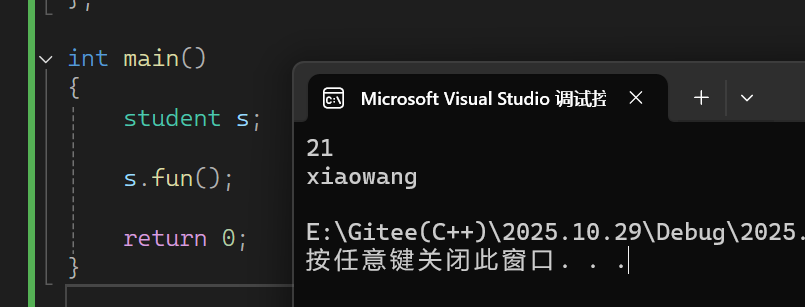
运行结果如下:
- 基类的public成员在派生类里面可以进行访问,在派生类外面不可以进行访问
- 基类的protected成员在派生类里面可以进行访问,在派生类外面不可以进行访问
- 基类的private成员在派生类的里面和外面都不可以进行访问
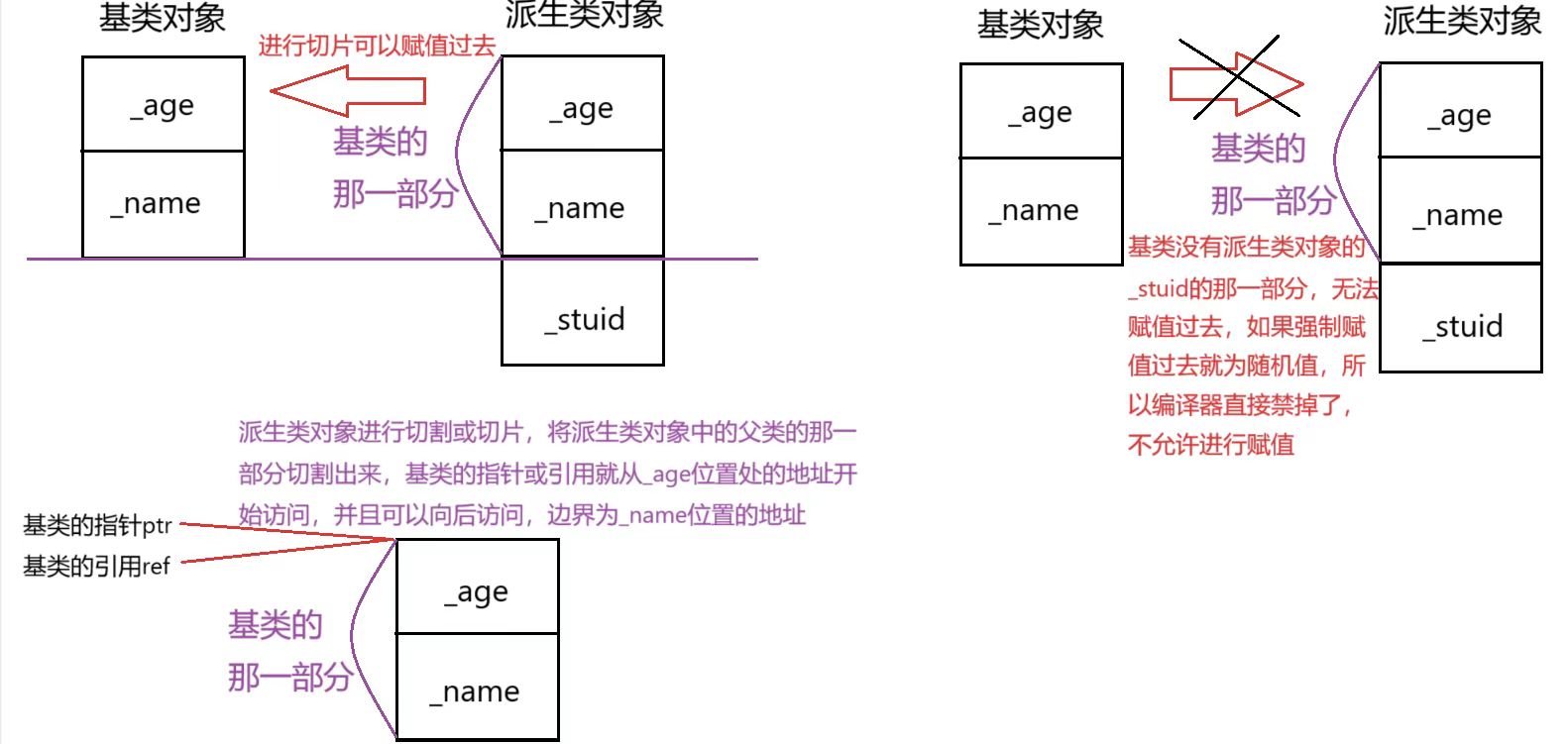
基类和派生类之间的转换
public继承的派生类对象可以赋值给基类的指针 / 基类的引用。这里实际上是赋值兼容,发生了切片,也叫做切割。可以把派生类对象理解为两部分,基类的那一部分和派生类自己的那一部分。切片或切割也就是将派生类对象中的基类的那一部分切割出来进行赋值
- 我们已知: 当类型不兼容的赋值方式可以进行强制类型转换或隐式类型转换,但是这里是一个特例: 由于发生了赋值兼容转换,所以切割或切片不产生消耗,即不会产生临时变量
说明:由于int和double的类型不兼容,在赋值的过程中int类型的 i 会先产生一个const double类型的临时变量,这个临时变量具有常性,权限为只读,普通引用的权限是可读可写,进行引用属于权限的放大,所以不能被普通引用,但是可以被权限为只读的const引用进行引用,这样就属于权限的平移,可以进行引用,这个赋值的过程中产生了一个具有常性的临时变量
我们知道,派生类对象可以赋值给基类引用,这个过程会发生“赋值兼容”(即“切片/切割”——派生类对象中属于基类的部分会被提取出来,赋值给基类引用)。这里用可读可写的普通基类引用 rp 去引用派生类对象 s ,编译器未报错。这说明:在派生类对象向基类引用赋值的“切片”过程中,没有产生只读的临时变量,因此普通基类引用(可读可写权限)可以直接引用派生类对象中属于基类的部分,权限匹配且无需额外的常性约束。

- 基类对象不可以赋值给派生类对象
- 基类的指针或引用可以通过强制类型转换赋值给派生类的指针或引用。因为基类的指针或引用是有可能指向派生类的父类的那一部分。所以这种方式必须是基类的指针或引用指向派生类对象的时候才最安全。
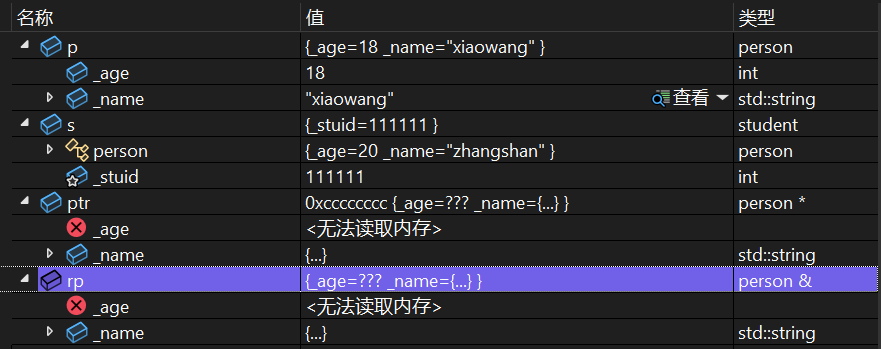
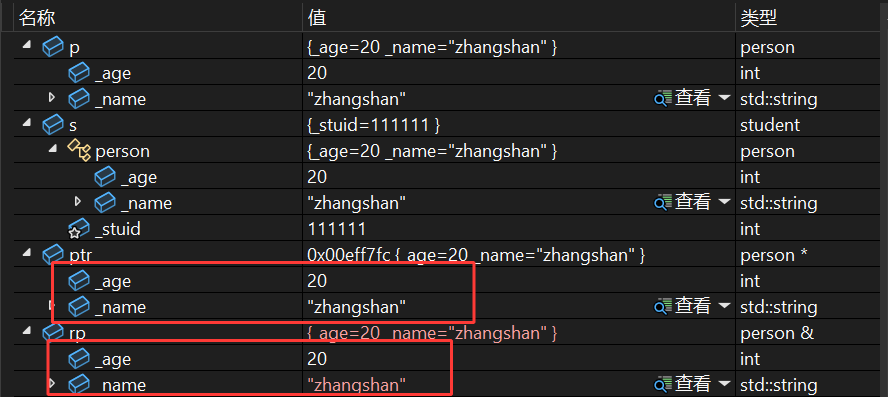
class person
{
public:int _age = 18;string _name = "xiaowang";
};class student :public person
{
protected:int _stuid = 111111;
};int main()
{person p;student s;s._age = 20;s._name = "zhangsan";p = s;person* ptr = &s;person& rp = s;return 0;
}
切片特性:
在 main 函数中,派生类对象 s 可以通过以下方式“切片”为基类对象/引用/指针:
- 对象赋值: p = s; —— 派生类对象 s 中属于基类 person 的部分( _age 和 _name )会被赋值给基类对象 p 。
- 指针赋值: person* ptr = &s; —— 基类指针 ptr 指向派生类对象 s 中属于基类的部分。
- 引用赋值: person& rp = s; —— 基类引用 rp 绑定到派生类对象 s 中属于基类的部分。
这三种操作的本质都是将派生类对象中基类的部分切割提取出来,以基类的视角进行访问或操作,属于C++继承体系中“赋值兼容规则”的体现。
由于是 public 继承,派生类对象 s 可以直接访问从基类继承的公有成员 _age 和 _name (如 s._age = 20; 、 s._name = "zhangshan"; ),这体现了 public 继承下基类公有成员的可访问性。
运行结果如下:
赋值前:
赋值后:
继承中的作用域
在继承体系中的基类和派生类都有其独立的作用域
隐藏
当派生类和基类中有同名成员(变量或函数)时,派生类中的同名成员将屏蔽基类中的同名成员,直接对当前派生类的同名成员进行访问,这种情况叫做隐藏,也叫做重定义(在派生类的成员函数中,可以使用 基类::同名成员 的形式直接访问基类的同名成员)
注意,如果是派生类和基类中的成员函数构成隐藏的话,只要函数名相同就构成隐藏,但是,在实际的继承体系中,最好不要定义同名成员
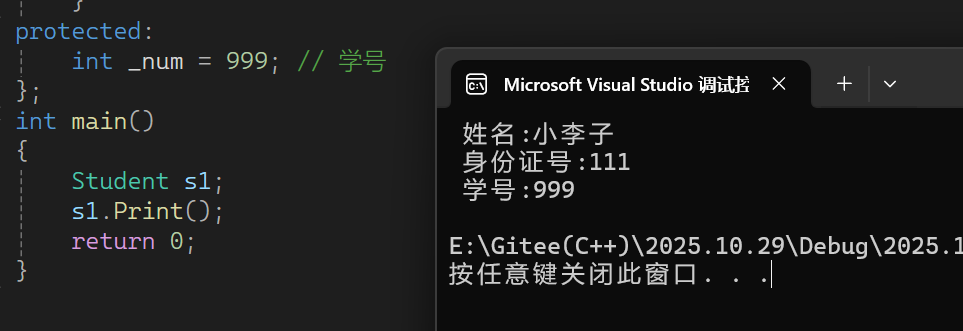
class Person
{
protected:string _name = "小李子"; // 姓名int _num = 111; // ⾝份证号
};
class Student : public Person
{
public:void Print(){cout << " 姓名:" << _name << endl;cout << " 身份证号:" << Person::_num << endl;cout << " 学号:" << _num << endl;}
protected:int _num = 999; // 学号
};
int main()
{Student s1;s1.Print();return 0;
}输出结果:
例题
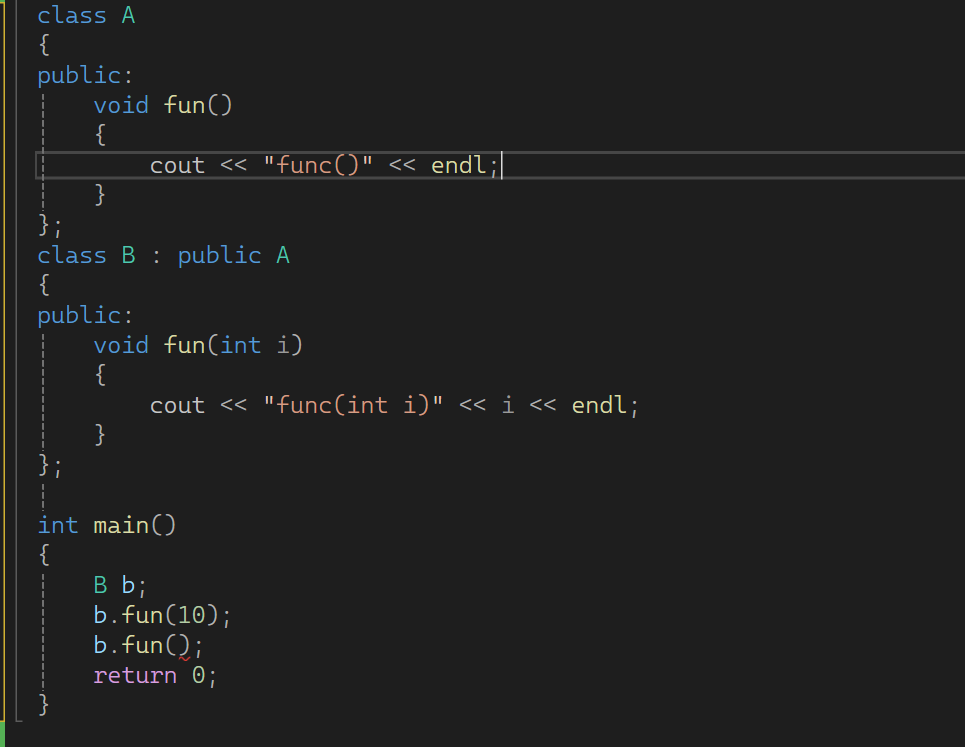

3.2.1 答案:B(隐藏)
- 在C++中,派生类 B 中的 fun(int i) 与基类 A 中的 fun() 函数名相同但参数不同,前面说过 :只要函数名相同就构成隐藏,所以这种情况属于隐藏(重定义)。
- 重载要求在同一作用域内函数名相同、参数列表不同;但是这里两个 fun 分别在基类和派生类作用域(作用域不同),因此不构成重载。
3.2.2 答案:A(编译报错)
- 派生类 B 中定义了 fun(int i) ,会隐藏基类 A 中的 fun() 。当执行 b.fun() 时,编译器会在派生类 B 中查找 fun 函数,但 B 中只有带 int 参数的 fun(int i) ,没有无参的 fun() ,因此编译阶段就会报错。
派生类的默认成员函数
基类和派生类归根结底还是类,那么它们各自肯定会有属于自己的6个默认成员函数,一般类而言,当我们不写的时候,编译器会默认帮我们生成这六个成员函数,那么在派生类中,这几个成员函数是如何生成的呢?
默认构造函数
默认成员函数 - 规则高度相似
两份部分分开处理:
1、基类成员(看成一个整体,调用基类构造)
2、派生类成员(跟类和对象一样)
派生类的构造函数在走初始化列表前会优先自动调用基类的默认构造函数完成基类那一部分成员的初始化,如果基类没有默认成员函数,那么在派生类的构造函数中必须显示调用基类的构造函数
class Person
{
public:Person(const char* name = "peter"): _name(name){cout << "Person()" << endl;}
protected:string _name;
};class Student :public Person
{
public:Student(const char* name,int id):_id(id){cout << "Student()" << endl;}protected:int _id;
};int main()
{Student s("zhangshan", 111111);return 0;
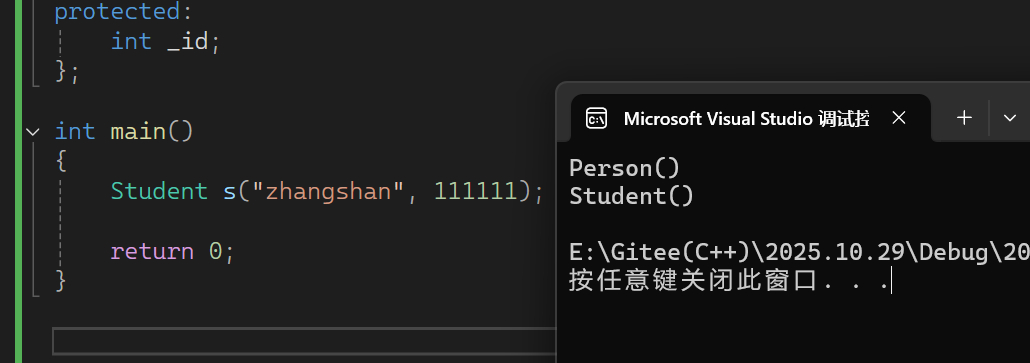
}运行结果如下:
基类有默认构造函数的情况下,定义派生类对象,调用派生类的构造函数时,编译器走派生类的初始化列表前会优先调用基类的默认构造函数完成基类那一部分成员的初始化,调用完基类的默认构造函数后再对自身的成员变量进行初始化

class Person
{
public:Person(const char* name): _name(name){cout << "Person()" << endl;}
protected:string _name;
};class Student :public Person
{
public:Student(const char* name,int id):Person(name),_id(id){cout << "Student()" << endl;}protected:int _id;
};int main()
{Student s("zhangshan", 111111);return 0;
}
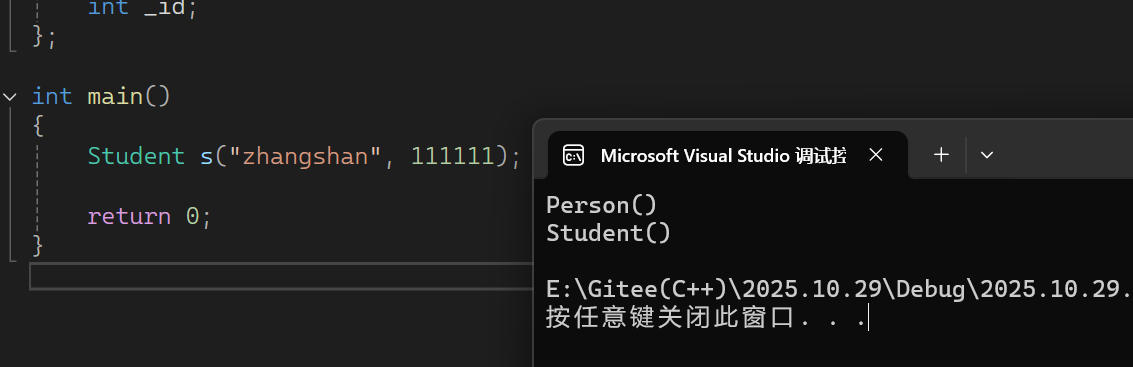
运行结果如下
当基类没有默认构造函数的时候,定义派生类对象,调用派生类的构造函数,编译器在走初始化列表时,编译器只能够去调用基类的默认构造函数,当基类没有默认构造函数的时候,这时候需要我们显示在初始化列表像定义匿名对象一样,传入参数进行显示调用基类的构造函数完成基类那部分成员的初始化,显示调用完基类的构造函数后再对自身的成员变量进行初始化
当前代码中,基类 Person 没有默认构造函数。
默认构造函数的定义是:无需传参就能调用的构造函数,满足以下任一条件就是默认构造:
- 1. 编译器自动生成的无参构造(当类中没有显式定义任何构造函数时);
- 2. 显式定义的、无参数的构造函数(如 Person(){} );
- 3. 显式定义的、所有参数都有默认值的构造函数(如之前代码中 Person(const char* name = "peter") )。
而当前基类的构造函数是 Person(const char* name) —— 它必须传一个 const char* 类型的参数才能调用,既不是无参构造,也没有给参数设默认值,所以完全不符合默认构造的条件,基类自然就没有默认构造函数。
这也是为什么派生类 Student 的构造函数必须显式写 : Person(name) ——本质就是把基类 Person 当成一个“整体”来初始化。因为基类没有默认构造,无法自动调用,只能手动传参调用它的带参构造。

拷贝构造函数
先拷贝基类部分,再拷贝派生类自身部分
派生类的拷贝构造函数必须显示调用基类的拷贝构造函数完成基类的拷贝初始化,因为拷贝构造函数也属于构造函数,如果没有显示调用,那么编译器就会去调用默认构造函数去完成对基类那部分的初始化,这时候基类中的数据不是我们原想要进行拷贝的数据,而是初始化的数据,所以我们必须要显示调用基类的拷贝构造函数
class Person
{
public:Person(const char* name = "peter"): _name(name){cout << "Person()" << endl;}Person(const Person& p): _name(p._name){cout << "Person(const Person& p)" << endl;}
protected:string _name;
};class Student :public Person
{
public:Student(const char* name,int id):Person(name) ,_id(id){cout << "Student()" << endl;}Student(const Student& s):Person(s) //显式调用基类的拷贝构造,_id(s._id){cout << "Student(const Student& s)" << endl;}protected:int _id;
};int main()
{Student s("zhangshan", 111111);Student s1(s);return 0;
}
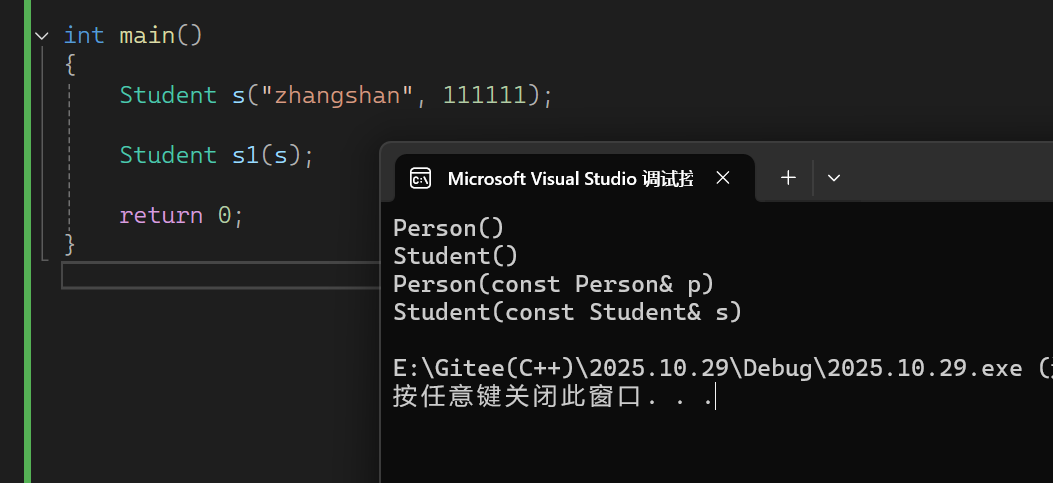
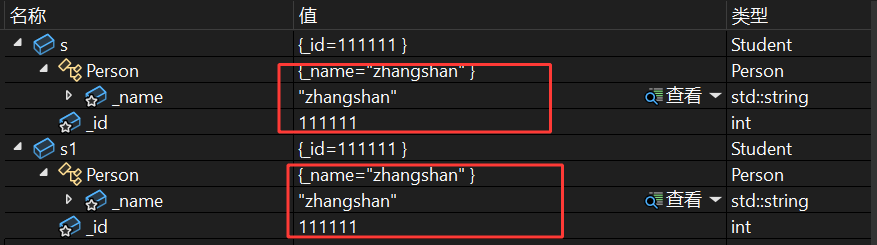
Student s1(s); : 当用已有的 Student 对象 s 初始化新对象 s1 时,执行顺序是:
先调用基类 Person 的拷贝构造 , 派生类 Student 的拷贝构造中, Person(s) 是显式调用基类的拷贝构造:
- s 是派生类对象,这里会发生“切片”—— 只取 s 中属于基类 Person 的部分(即 _name = "zhangshan" ),传递给基类拷贝构造的参数 p ;
- 基类拷贝构造用 p._name 初始化 s1 的基类部分( s1._name = "zhangshan" ),并输出 Person(const Person& p) 。
再调用派生类 Student 的拷贝构造 , 基类部分拷贝完成后,再初始化派生类自身的成员:
- 用 s._id 初始化 s1._id ( s1._id = 111111 ),并输出 Student(const Student& s) 。
输出结果:
赋值重载函数
派生类的operator=必须要显示调用基类的operator=完成对基类的赋值
class Person
{
public:Person(const char* name = "peter"): _name(name){cout << "Person()" << endl;}Person(const Person& p): _name(p._name){cout << "Person(const Person& p)" << endl;}Person& operator=(const Person& p){cout << "Person operator=(const Person& p)" << endl;if (this != &p)_name = p._name;return *this;}protected:string _name;
};class Student :public Person
{
public:Student(const char* name,int id):Person(name),_id(id){cout << "Student()" << endl;}Student(const Student& s):Person(s),_id(s._id){cout << "Student(const Student& s)" << endl;}Student& operator=(const Student& s){cout << "Student& operator=(const Student& s)" << endl;if (this != &s){Person::operator=(s);//这里必须使用 基类::operator=的方式进行调用_id = s._id; //如果直接调用operaotr=会产生一直去调用派生类的} //operator=引发无穷递归调用,导致栈溢出return *this;}protected:int _id;
};int main()
{Student s("zhangshan", 111111);Student s1(s);Student s2("lisi", 222222);s1 = s2;return 0;
}
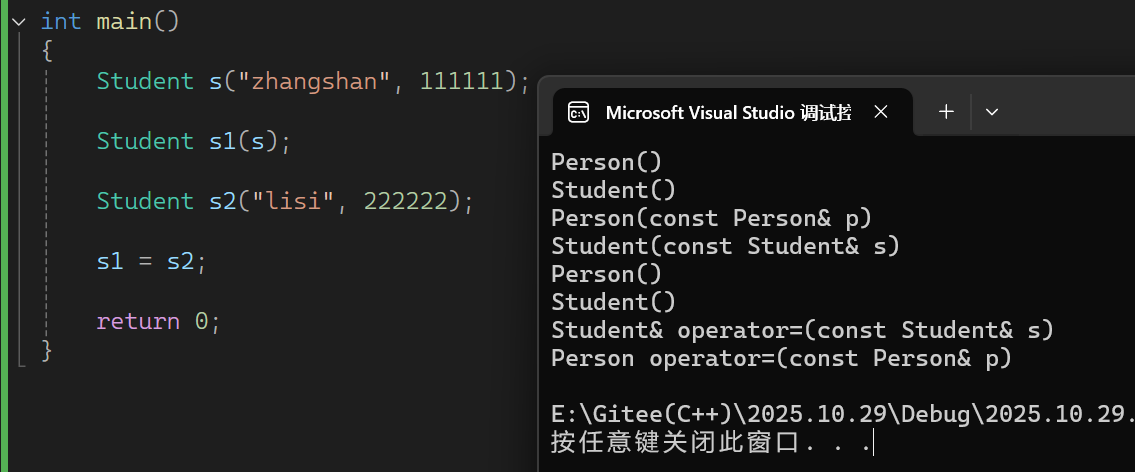
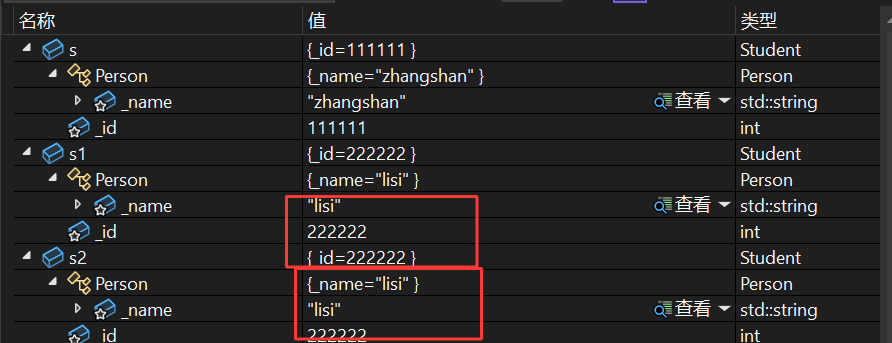
s1 和 s2 都是已初始化的 Student 对象,执行 s1 = s2 时,顺序是:
先调用基类 Person 的赋值重载 : 派生类 Student 的赋值重载中, Person::operator=(s) 是显式调用基类的赋值重载:
- s 是派生类对象,这里会“切片”—— 只取 s 中属于基类 Person 的部分( _name = "lisi" ),传递给基类赋值重载的参数 p ;
- 基类赋值重载判断 this != &p (避免自赋值),将 p._name 赋值给 s1 的基类部分( s1._name = "lisi" ),输出 Person operator=(const Person& p) 。
再赋值派生类 Student 自身的成员 : 基类部分赋值完成后,再赋值派生类自己的成员:
- 将 s2._id 赋值给 s1._id ( s1._id = 222222 ),输出 Student& operator=(const Student& s) 。
注意点 : 为什么写 Person::operator=(s) 而不写 operator=(s)?
若省略 Person:: ,编译器会认为调用的是派生类自己的 operator= (即 Student::operator= ),导致无限递归调用(自己调自己),最终栈溢出。必须加 Person:: 限定作用域:明确告诉编译器“调用基类的赋值重载”,才能正确赋值基类成员 _name 。
输出结果:
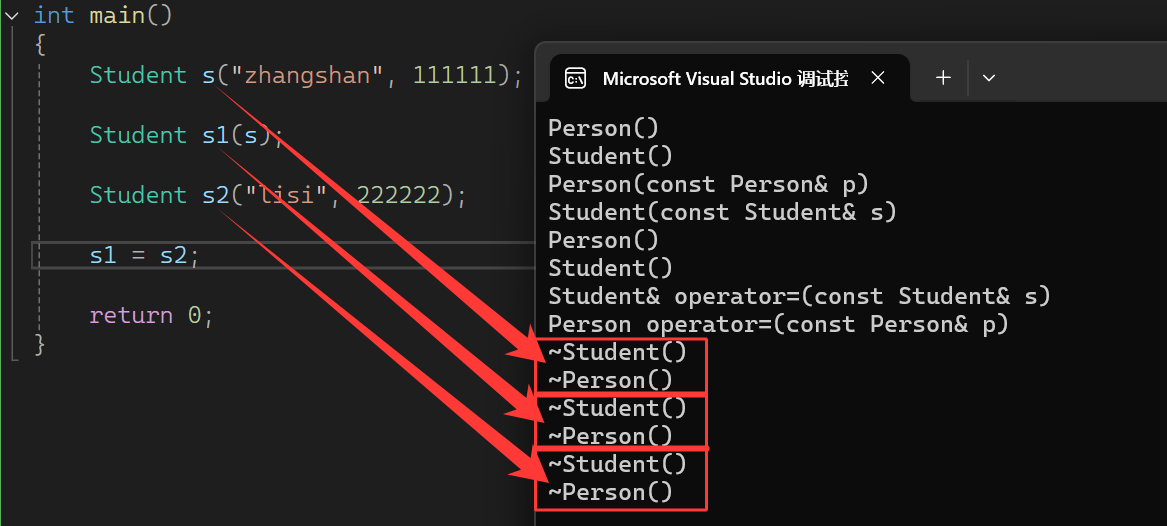
析构函数
1. 析构顺序与自动调用规则
派生类析构函数执行完毕后,编译器会自动调用基类析构函数。这样保证了“先清理派生类自身成员,再清理基类成员”的顺序(与构造顺序相反:构造先基类后派生类,析构先派生类后基类)。需要注意:不能在派生类析构中显式调用基类析构,否则会因成员访问逻辑出错导致问题。
2. 析构顺序的底层逻辑(与对象定义顺序一致)
派生类对象中,基类部分“先定义”,派生类自身部分“后定义”;
生命周期结束时,“后定义的派生类自身部分先析构”,“先定义的基类部分后析构”;
这一规则有效保证了“栈上对象先定义后析构、后定义先析构”的顺序,避免资源清理混乱。
3. 析构函数的“隐藏”与虚析构的必要性
析构函数名称会被编译器统一修饰(如 destructor() ),因此若基类析构不加 virtual ,子类析构与父类析构会构成“隐藏”关系(类似普通函数的重定义,不构成多态);
若需通过“基类指针指向派生类对象”的方式正确析构(避免内存泄漏),必须给基类析构加 virtual ,使其构成多态,确保派生类析构被调用。
class Person
{
public:Person(const char* name = "peter"): _name(name){cout << "Person()" << endl;}Person(const Person& p): _name(p._name){cout << "Person(const Person& p)" << endl;}Person& operator=(const Person& p){cout << "Person operator=(const Person& p)" << endl;if (this != &p)_name = p._name;return *this;}~Person(){cout << "~Person()" << endl;}protected:string _name;
};class Student :public Person
{
public:Student(const char* name, int id):Person(name), _id(id){cout << "Student()" << endl;}Student(const Student& s):Person(s), _id(s._id){cout << "Student(const Student& s)" << endl;}Student& operator=(const Student& s){cout << "Student& operator=(const Student& s)" << endl;if (this != &s){Person::operator=(s);_id = s._id;}return *this;}~Student(){cout << "~Student()" << endl;}protected:int _id;
};int main()
{Student s("zhangshan", 111111);Student s1(s);Student s2("lisi", 222222);s1 = s2;return 0;
}输出结果:

继承与友元
1. 友元关系不能继承,也就是说基类的友元函数不能访问的基类的派生类的保护和私有成员
2. 如果基类的友元函数想要访问基类的派生类的私有和保护成员,应该声明为派生类的友元函数
class Person
{friend void Print(const Person& p);
public:protected:int _age = 18;
private:string _name = "xiaowang";
};void Print(const Person& p)
{cout << p._age << endl;cout << p._name << endl;
}class Student :public Person
{friend void Print(const Person& p);
public:protected:int _stuid = 111111;
};int main()
{Student s;Person p;Print(p);Print(s);return 0;
}
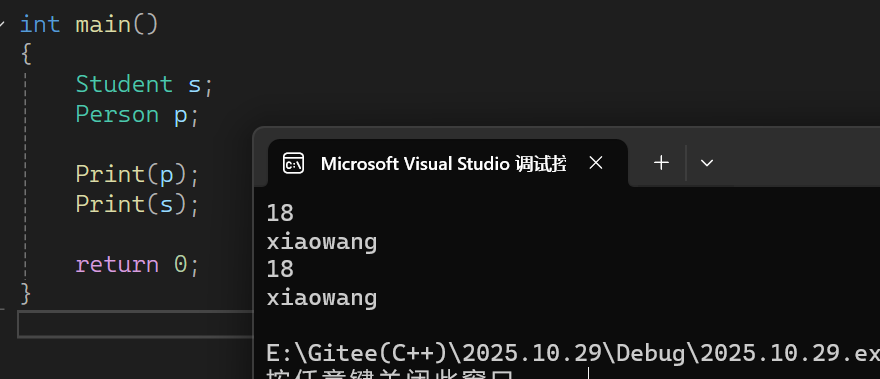
1. 友元关系不具有继承性
- 基类 Person 的友元函数 Print ,仅能访问基类自身的成员,以及派生类对象中从基类继承的部分;无法直接访问派生类 Student 自己新增的成员(如 _stuid )。
2. 继承中成员访问的实际表现
- 调用 Print(p) 时,正常输出 Person 的 _age (18)和 _name ("xiaowang");调用 Print(s) 时,只能访问 s 中属于 Person 的部分(同样输出 18 和 "xiaowang" ),无法访问 s 自身的 _stuid 。
简言之,友元是“类级别的特殊权限”,不会随继承自动传递给派生类的新增成员。
输出结果:
继承与静态成员
- 基类定义了static静态成员,那么在整个继承体系里就只有一个这样的成员。无论派生出多少个子类都只有一个static静态成员
- 那么我们可以根据这个特性以及派生类在进行构造的时候会去优先调用基类的默认构造函数完成派生类中基类那部分成员的初始化,在基类定义静态成员变量,那么同时在基类的默认构造函数使用static静态成员变量用于统计基类进行构造的总次数即统计出了基类及其派生类的总个数
class Person
{
public:Person(){_count++;}static int _count;
};int Person::_count = 0;class Student :public Person
{
public:Student(){}
};int main()
{Person p;Student s1;Student s2;Student s3;cout << Person::_count << endl;return 0;
}
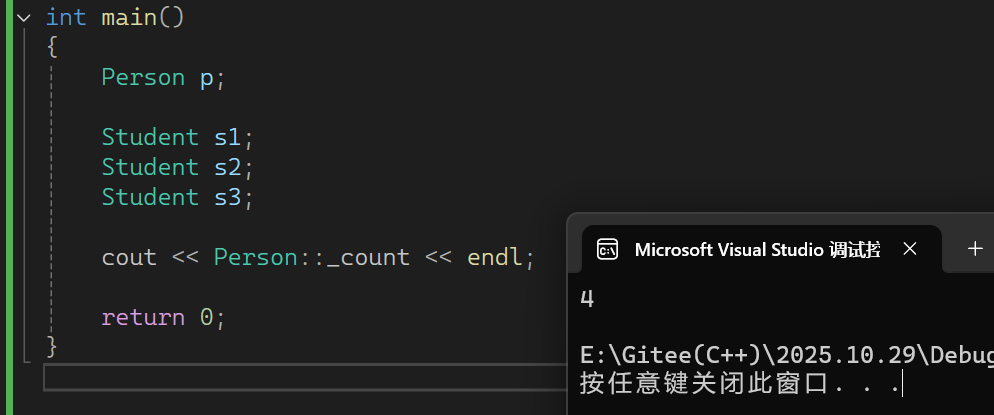
运行结果如下
- 定义了1个基类,3个派生类,基类及其对应的派生类共计4个,结果正确
菱形继承和菱形虚拟继承
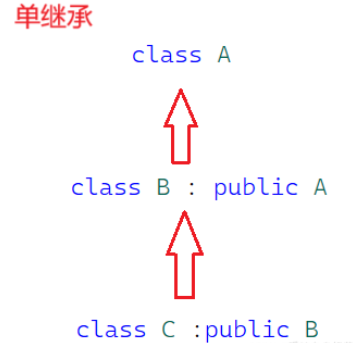
单继承
单继承:一个子类只有一个直接父类时,这个继承关系称为单继承
class A
{
public:int _a;
};class B : public A
{
public:int _b;
};class C :public B
{
public:int _c;
};int main()
{C c;c._a = 1;c._b = 2;c._c = 3;return 0;
}
调试结果:
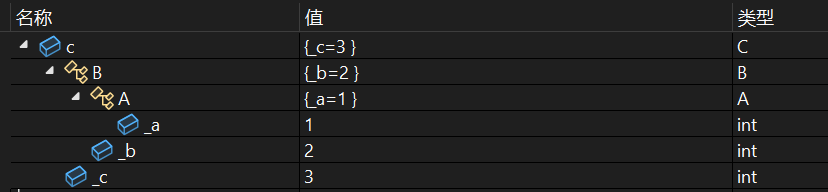
多继承
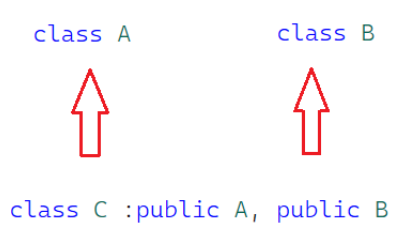
- 多继承:一个子类有两个或两个以上直接父类时,称这种继承关系为多继承
- 多继承的使用方法是在子类的位置对多个父类使用逗号,进行间隔,其余方式public形式不变,进行继承
- 以下图为例,根据class C :public A, public B语句中的继承对象A, B出现先后的顺序在内存中依次放置对象A,对象B,多继承中先继承对象A的放在对象C存储的内存空间的开头,对象A之后是放置的对象B
class A
{
public:int _a;
};class B
{
public:int _b;
};class C :public A, public B
{
public:int _c;
};int main()
{C c;c._a = 1;c._b = 2;c._c = 3;return 0;
}
调试结果:
可以看出A和B是c的基类
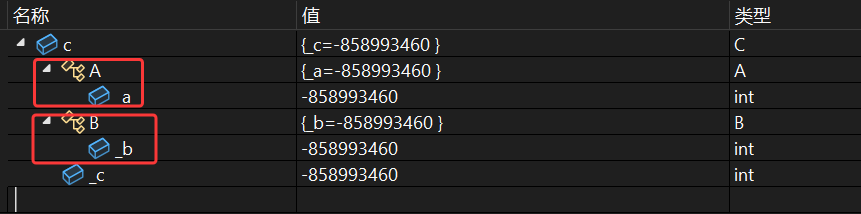
菱形继承
菱形继承是多继承的一种特殊情况,由于继承关系上类似菱形,所以就称这种特殊的多继承为菱形继承
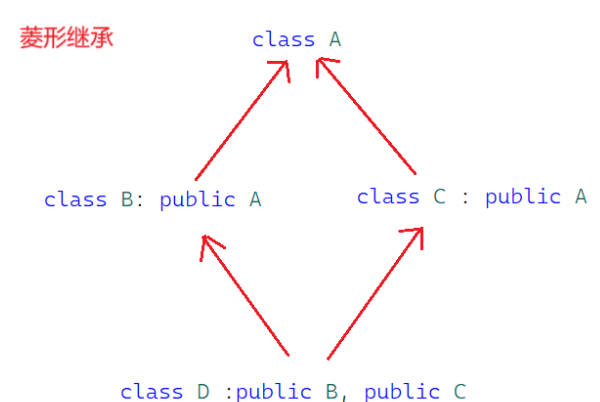
从这幅图中可以看出:
- 类A是顶层基类。
- 类B和类C都公有继承( public )自类A。
- 类D又公有继承自类B和类C。
- 这种继承结构形状如菱形,会导致类D中存在两份类A的成员(数据或方法),容易引发二义性和数据冗余两个问题,这两个问题同时也是相互关联的 , C++中可通过虚继承来解决这一问题。
class A
{
public:int _a;
};class B: public A
{
public:int _b;
};class C : public A
{
public:int _c;
};class D :public B, public C
{
public:int _d;
};int main()
{D d;return 0;
}
调试结果:
- 那么在对象d中就会有两个_a的成员变量这就存在了数据冗余问题,如果要进行调用_a,那么编译器就不知道要调用哪一个_a,这就存在了二义性问题
- 由于存在两个_a,存在二义性问题,进行调用_a编译器不知道会调用哪一个_a,那么编译进行语法检查的时候编译器会直接进行报错
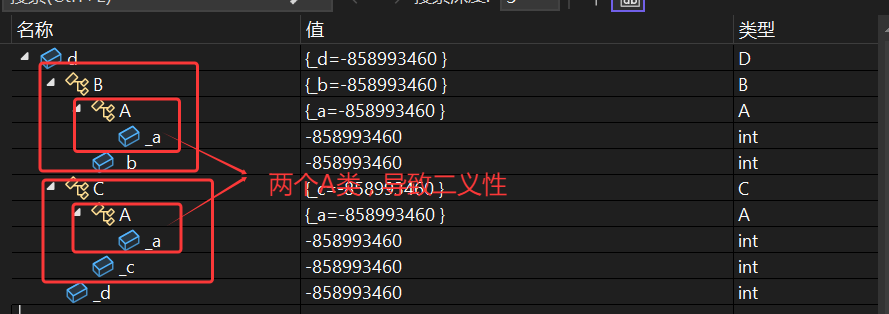
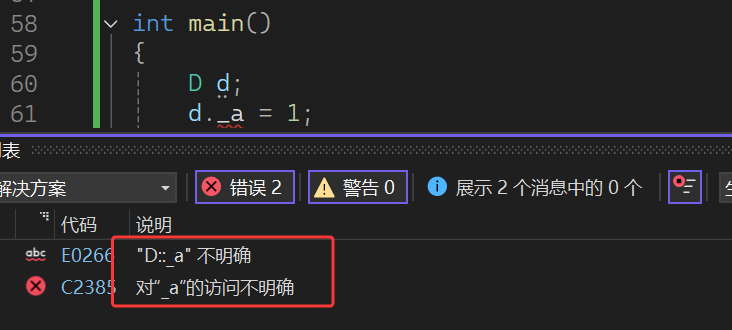
解决办法
解决办法1 : 采用显示指定访问哪个父类成员可以缓解二义性问题,但是针对数据冗余的问题无法解决
int main()
{D d;d.B::_a = 1;d.C::_a = 2;return 0;
}
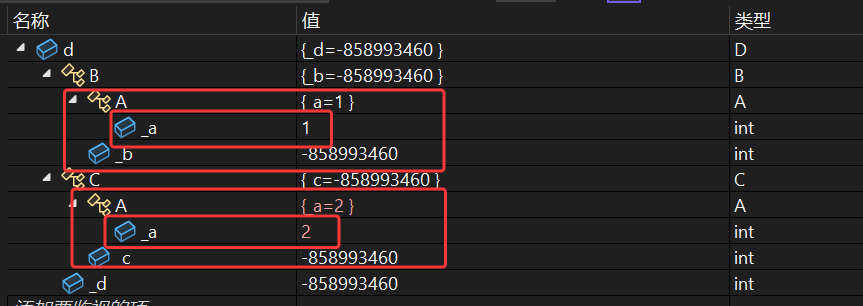
调试结果:
- 这样可以访问到两个_a,但是这种的显示指定父类的成员调用方式还需要写父类::这种形式,同时针对数据冗余还无法解决,对于d对象仅需要一个_a即可,不需要两个_a,同时我们想要直接使用d._a去访问_a,那么该如何去做呢?
解决办法2 : 虚继承
- 虚拟继承可以解决菱形继承的数据冗余和二义性问题。以上述的对象模型为例,在B和C继承A的时候采用虚拟继承,即可解决问题。虚拟继承是特定的解决菱形继承的方式,在其它场景不要进行使用
- 这种虚拟继承的使用方式是在菱形继承中进行多继承的前父类的位置(一个子类有两个即以上的父类,这多个父类)使用virtual关键字修饰,在在B和C继承A的时使用virtual关键字修饰,具体操作方式如下图示例
class A
{
public:int _a;
};class B : virtual public A
{
public:int _b;
};class C : virtual public A
{
public:int _c;
};class D :public B, public C
{
public:int _d;
};int main()
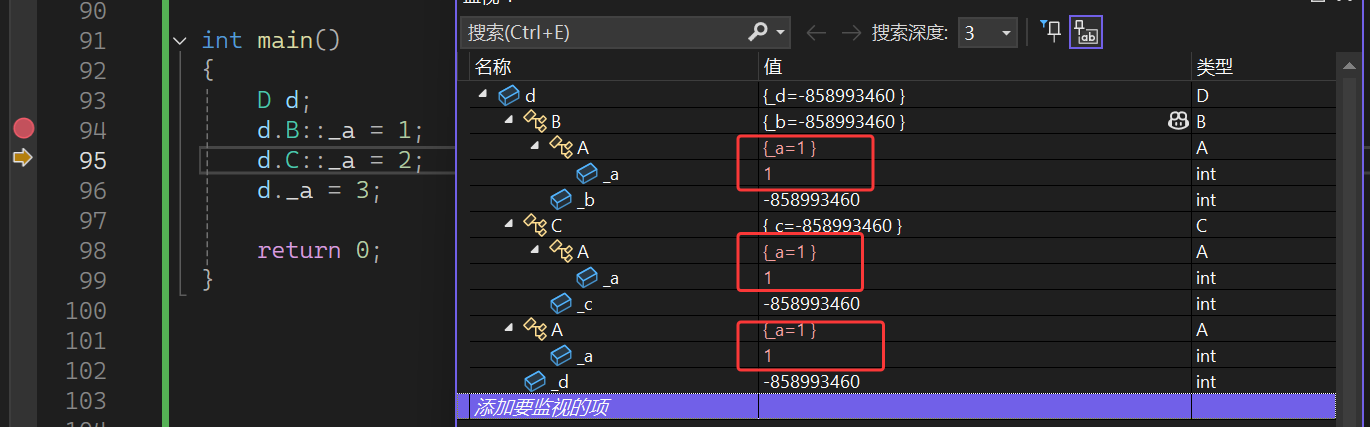
{D d;d.B::_a = 1;d.C::_a = 2;d._a = 3;return 0;
}
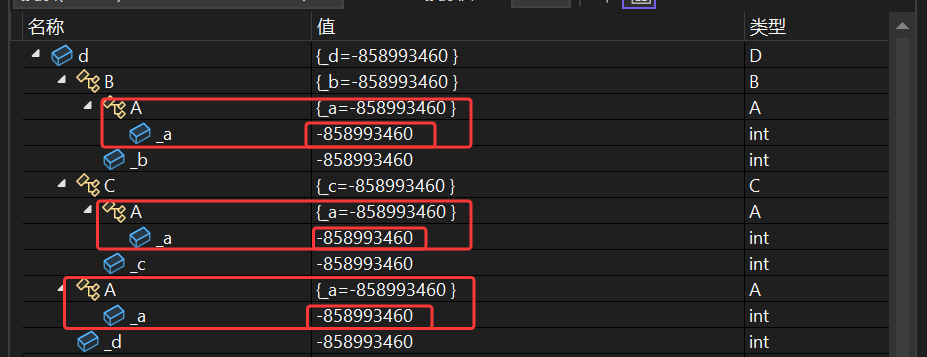
调试结果:
这样d对象中就只有一个_a,父类B和C中的_a以及d中的_a都是一个_a
对象 d 刚创建时,其包含的 B::A::_a 、 C::A::_a 以及直接访问的 _a 数值完全一致(都是随机值 -858993460 )。这是因为虚继承机制确保了这些看似多个的 _a 实际上指向同一份内存 , 即同一个_a。
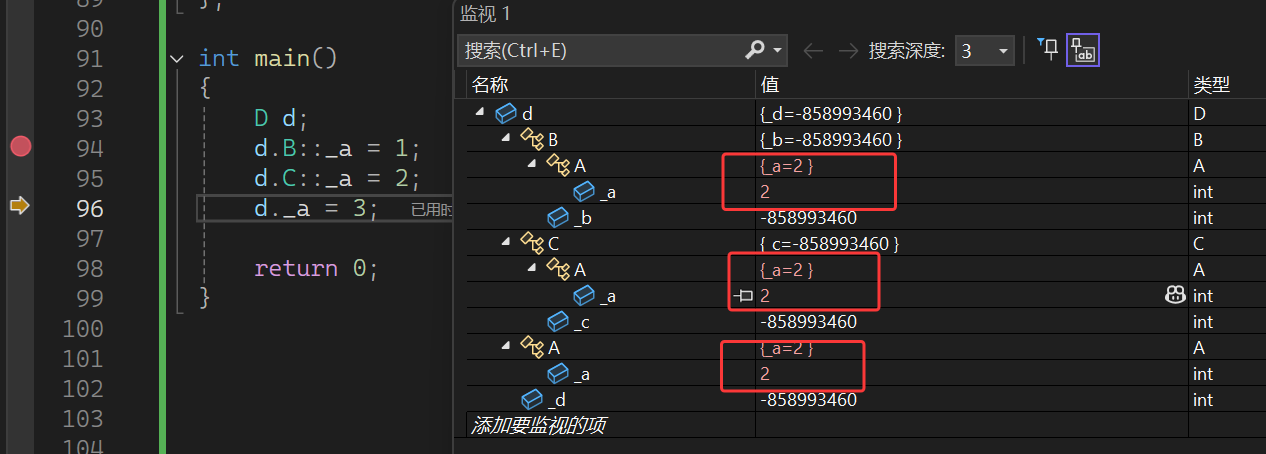
当给 B 路径下的 _a 赋值为 1 后,所有三个分支下的 _a 都变成了 1 。这直接证明了虚继承下 A 的成员在 D 中只有一份。
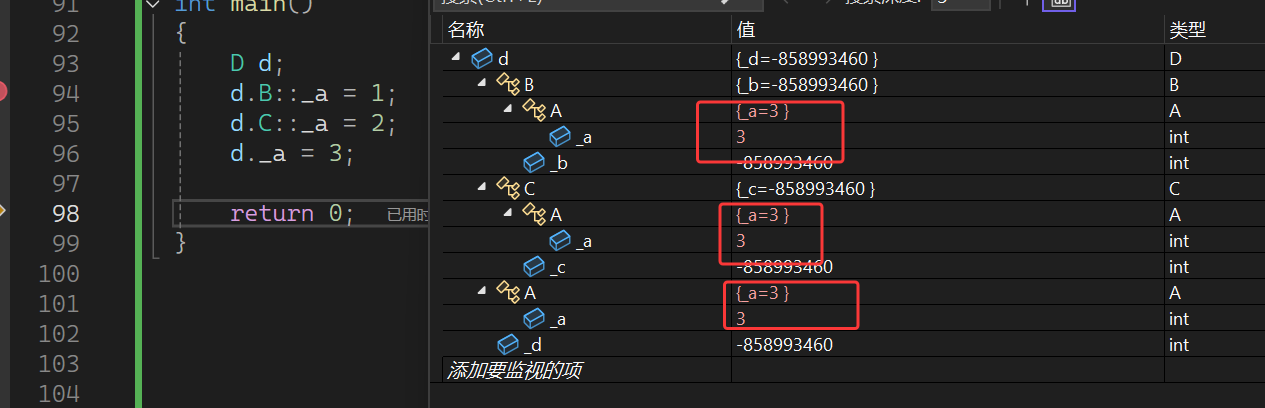
先给 C 路径下的 _a 赋值为 2 ,所有 _a 同步变为 2 ;再直接通过 d._a = 3 赋值,所有 _a 最终变为 3 。
这进一步说明:虚继承让 D 中 A 的成员被“合并”为一份,无论通过 B 、 C 还是直接访问 _a ,操作的都是同一块内存。从而解决了数据冗余和二义性的问题
继承和组合
- public继承是一种is-a的关系,也就是说每个派生类的对象都是一个基类对象
- 组合是一种has-a的关系,也就是说有两个对象A和B,B组合了A,也就是说每个B对象中都有一个A对象
class A
{};class B:public A//B和A是继承关系,B继承了A
{};class C//A和C是组合关系,C组合了A
{
private:A _a;
};
在实际应用中优先使用类和类之间的组合而不是类继承
- 继承允许你根据基类的实现去定义派生类的实现。通过这种复用基类方式生成派生类的方式通常称为白箱复用。在这种继承方式中,基类的内部实现细节对派生类可见。继承的方式一定程度上破坏了基类的封装性,在派生类中可以访问使用基类的公有和保护成员,那么基类的改变,对派生类的影响就很大。基类和派生类之间的依赖关系很高,耦合度高。
- 组合同样也是一种复用方式。组合要求被组合的对象具有良好定义的接口。这种复用方式被称为黑盒复用。假设B组合了A,那么B仅可以访问A类的公有成员,那么A类的改变,对B的影响不是很大,B对A的依赖性不是很强,所以耦合度低
所以根据上面的结论,继承的耦合度高,组合的耦合度低,由于在软件设计层次追求的是高内聚,即类内的关联很强,低耦合,即类外的关联性很弱
- 所以当这个类的实现可以使用继承去实现又可以使用组合去实现的时候,优先使用组合
- 当这个类比较适合使用继承的去实现时候就使用继承,当比较适合使用组合去实现的时候就使用组合
- 那么同时要实现多态的时候就必须使用继承。
总结:
本文系统介绍了C++继承机制,重点包括:
- 继承概念与作用:实现类层次复用,派生类可扩展基类功能。
- 继承方式与访问控制:详细说明public/protected/private继承对成员可见性的影响。
- 派生类构造/析构规则:强调基类成员初始化顺序与显示调用必要性。
- 菱形继承问题:通过虚继承解决数据冗余和二义性。
- 继承与组合对比:分析is-a与has-a关系的适用场景,建议优先使用组合降低耦合度。 继承是面向对象核心特性,正确使用能有效提高代码复用性和可维护性。
感谢大家的观看!