rocketMQ-基本使用和原理简介
简介
rocketMQ是阿里开发的消息队列,2016年捐献给apache,2017年成为apache的顶级项目,具有高性能、高可靠、高实时、分布式等特点。消息队列是分布式系统中的重要组件,主要解决应用耦合、异步消息、流量削峰等问题。
官网地址:https://rocketmq.apache.org/
安装
在官网下载二进制压缩包即可,它依赖Java的环境,是免安装的,并且是跨平台的,安装完成后配置环境变量即可
入门案例
搭建集群
一个单nameserver、单broker的rocketMQ集群
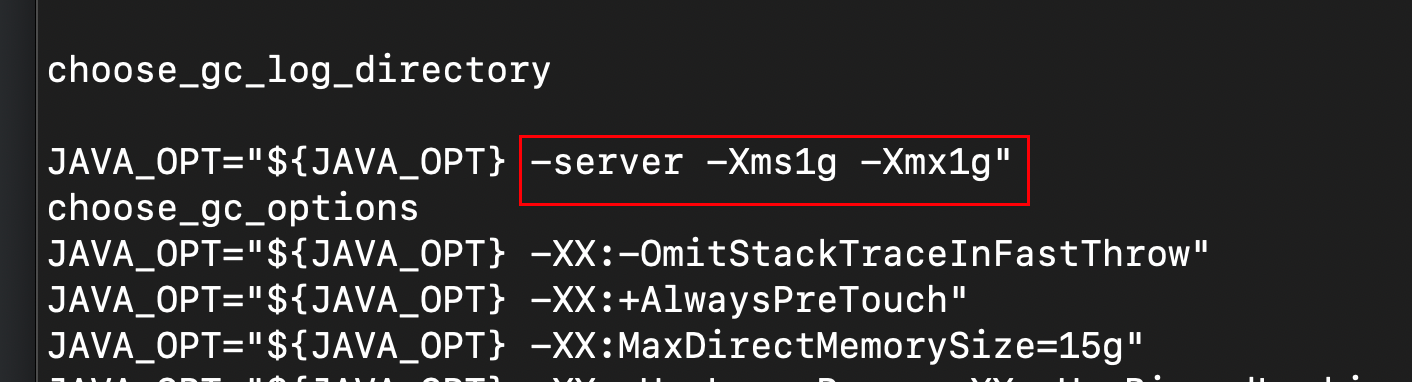
第一步:修改rocketMQ的配置,rocketMQ的默认内存比较大,打开bin/runbroker.sh和bin/runserver.sh,修改分配给JVM的内存。
第二步:在Linux系统上启动rocketMQ。rocketMQ是一个消息队列,是服务端相关的软件,通常是部署在Linux平台上的。rocketMQ分为nameserver和broker两部分,nameserver负责调度,broker负责存储数据,
- 启动nameserver:
sh ${ROCKETMQ_HOME}/bin/mqnamesrv &,后台启动
Java HotSpot(TM) 64-Bit Server VM warning: Using the DefNew young collector with the CMS collector is deprecated and will likely be removed in a future release
Java HotSpot(TM) 64-Bit Server VM warning: UseCMSCompactAtFullCollection is deprecated and will likely be removed in a future release.
The Name Server boot success. serializeType=JSON
- 启动broker:
sh ${ROCKETMQ_HOME}/bin/mqbroker -n 192.168.1.3:9876 &,后台启动,启动时指定nameserver的位置,它的默认端口是9876
The broker[Linux4-CentOS7, 192.168.0.3:10911] boot success. serializeType=JSON and name server is 192.168.0.3:9876
可以执行jps命令,验证启动结果
[root@Linux4-CentOS7 ~]# jps
2147 Jps
1974 NamesrvStartup
2044 BrokerStartup
在用户目录下可以找到rocketMQ的日志,可以通过日志来观察rocketMQ的运行情况。
编写生产者、消费者
第三步:编写Java代码,分为两个部分,一个部分负责生产数据,然后把数据发送到rocketMQ中,另一个部分负责消费数据
maven依赖:
<dependency><groupId>org.apache.rocketmq</groupId><artifactId>rocketmq-client</artifactId><version>4.2.0</version>
</dependency>
常量类:集中管理常量
public class Constants {/*** 单个rocketMQ节点*/public static final String nameServerAddress = "192.168.0.3:9876";/*** 生产者组1*/public static final String PRODUCT_GROUP1 = "producerGroup1";/*** 消费者组1*/public static final String CONSUMER_GROUP1 = "consumerGroup1";/*** topic test1*/public static final String TOPIC_TEST1 = "TopicTest1";/*** topic下的tag*/public static final String TAG1 = "tag1";
}
生产者:
import org.apache.rocketmq.client.producer.DefaultMQProducer;
import org.apache.rocketmq.client.producer.SendResult;
import org.apache.rocketmq.common.message.Message;
import org.example.utils.DateTimeUtil;
import org.wyj.constant.Constants;import java.nio.charset.StandardCharsets;// 生产者,同步发送消息
public class Demo1Producer {private static final int count = 3;public static void main(String[] args) throws Exception {// 设置生产者组名DefaultMQProducer producer = new DefaultMQProducer(Constants.DEMO1_PRODUCT_GROUP1);// 指定name server的地址producer.setNamesrvAddr(Constants.nameServerAddress);// 启动producer实例producer.start();// 发送消息for (int i = 1; i <= count; i++) {// 编辑消息String msg = "sync send msg " + DateTimeUtil.convertTsWithMillisPattern(System.currentTimeMillis());Message message = new Message(Constants.DEMO1_TOPIC, Constants.TAG1, msg.getBytes(StandardCharsets.UTF_8));// 发送同步消息SendResult sendResult = producer.send(message);System.out.println("msg = " + msg + "; msgId = " + sendResult.getMsgId());}producer.shutdown();}
}
消费者:
import org.apache.rocketmq.client.consumer.DefaultMQPushConsumer;
import org.apache.rocketmq.client.consumer.listener.ConsumeConcurrentlyStatus;
import org.apache.rocketmq.client.consumer.listener.MessageListenerConcurrently;
import org.apache.rocketmq.client.exception.MQClientException;
import org.apache.rocketmq.common.message.MessageExt;
import org.wyj.constant.Constants;// 消费者
public class Demo1Consumer {public static void main(String[] args) {// 设置消费者组名DefaultMQPushConsumer consumer = new DefaultMQPushConsumer(Constants.DEMO1_CONSUMER_GROUP1);// 设置name server的位置consumer.setNamesrvAddr(Constants.nameServerAddress);// 设置要订阅的主题和tagstry {consumer.subscribe(Constants.DEMO1_TOPIC, "*");} catch (MQClientException e) {throw new RuntimeException(e);}// 设置监听器,用于处理消息consumer.registerMessageListener((MessageListenerConcurrently) (msgList, context) -> {for (MessageExt messageExt : msgList) {System.out.printf("body = %s, tags = %s 消息体 = %s\n", new String(messageExt.getBody()), messageExt.getTags(), messageExt.getMsgId());}return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;});try {consumer.start();} catch (MQClientException e) {throw new RuntimeException(e);}System.out.println("Consumer Started.");}
}
这里展示部分运行结果:
1、生产者的返回值:
{"sendStatus": "SEND_OK","msgId": "AC1074017D6518B4AAC279D4C7B10000","messageQueue": {"topic": "TopicTest1","brokerName": "Linux1","queueId": 1},"queueOffset": 5,"offsetMsgId": "C0A8000300002A9F000000000000659B","regionId": "DefaultRegion","traceOn": true
}
2、消费者接收到的消息体:
{"topic": "TopicTest1","flag": 0,"properties": {"MIN_OFFSET": "0","MAX_OFFSET": "6","CONSUME_START_TIME": "1748072787906","UNIQ_KEY": "AC1074017D6518B4AAC279D4C7B10000","CLUSTER": "DefaultCluster","TAGS": "tag1"},"body": "aGVsbG8gcm9ja2V0TVEgMQ==","queueId": 1,"storeSize": 191,"queueOffset": 5,"sysFlag": 0,"bornTimestamp": 1748072787889,"bornHost": "192.168.0.1:56993","storeTimestamp": 1748072745571,"storeHost": "192.168.0.3:10911","msgId": "AC1074017D6518B4AAC279D4C7B10000","commitLogOffset": 26011,"bodyCRC": 199835508,"reconsumeTimes": 0,"preparedTransactionOffset": 0,"offsetMsgId": "C0A8000300002A9F000000000000659B","bornHostBytes": "wKgAAQAA3qE=","storeHostBytes": "wKgAAwAAKp8=","bornHostString": "192.168.0.1","bornHostNameString": "192.168.0.1","tags": "tag1","delayTimeLevel": 0,"waitStoreMsgOK": true
}
这些消息体中的数据,在随后都会学习到。
消息体中的字段内容讲解:
- sendStatus:发送状态
- msgId:生产者创建的消息id
- offsetMsgId:broker创建的消息id
- messageQueue:topic下存储消息的队列,这里相当于分区的概念
总结
在入门案例中,搭建了一个最简单的rocketMQ集群,包含单个nameserver、单个broker,并且创建了一个生产者、一个消费者,生产者指定自己的生产者组,指定nameserver的位置,然后向指定的topic同步发送消息,消费者同样指定自己的消费者组,指定nameserver的位置、指定自己要消费的topic,然后注册一个监听器,用于消费指定topic下的消息
概念和特性
基本架构
rocketMQ以集群的形式工作,集群中有两种类型的节点,nameserver和broker,此外,还有生产者和消费者
集群的基本架构:
- nameserver:rocketMQ集群的大脑,相当于一个路由控制中心,负责管理broker,它会接收broker的注册信息、提供心跳检测机制、保存topic路由信息。一个rocketMQ集群中可以有多个nameserver,它们之间没有主从的区别,每个nameserver都存储相同的信息,避免单点问题,同时又免除了主从切换的问题,所以broker需要向每个nameserver上报信息。nameserver负责负载均衡。
- broker:负责消息的存储和查询,可以有备用节点,分为主broker和备份broker。单个broker和所有的nameserver都保持长连接及心跳,并且会定时将topic信息注册到nameserver。
- 生产者:负责生产消息,支持集群方式部署。
- 消费者:负责消费消息,支持集群方式部署。
集群的大致工作机制:首先启动nameserver,然后启动broker,broker在启动的时候会去向nameserver注册并且发送心跳,broker会定时向nameserver注册topic信息,生产者在启动的时候会从nameserver上拉取topic相关的broker信息,然后向broker发送消息,消费者也一样。
消息的逻辑模型和物理模型
逻辑模型:topic和tag
- topic:主题,类似于数据表,是一类消息的集合,是发布消息、订阅消息的基本单位
- tag:标签,用于区分同一主题下不同类型的消息。topic是消息的一级分类,tag是消息的二级分类,rocketMQ提供了两级消息分类
物理模型:
- 队列:Message Queue,一个topic下可以包含多个MessageQueue,每个MessageQueue存储在不同的broker上,类似于kafka中的分区,队列的引入使得消息可以分布式、集群化,具备了水平扩展能力。队列是topic的物理分片,是并行消费的基本单位。
读写队列:queue分为读队列、写队列,生产者发送消息进入写队列,消费者从读队列读取数据。读写队列并不是两个独立的队列,而是一个物理队列的两种视图,写队列是生产者视角看到的,读队列是消费者视角看到的,这么设计是为了运维方便,生产环境下最好保证读写队列的个数相等。例如,如果读队列的数量比实际队列数量多,那么多出来的数量,会平均再分配到实际队列上,相当于多个读队列对应一个实际队列,也就是多个消费者消费同一个队列中的数据。
一个消费者组内,一个消费者可以消费多个队列,但是一个队列只能被一个消费者消费,这样做可以避免多个消费者之间的并发冲突,所以消费者组内的消费者的数量应该小于或等于topic下的分区数,如果超过分区数,则多出来的消费者将不能消费消息。
消息的组成部分:
- 主题:topic
- 主题下的标签:tag
- 业务键:keys,用于消息追踪
- 自定义属性:允许开发者在消息中附加额外的键值对信息,用于过滤、路由,或传递上下文数据,自定义属性是字符串类型的键值对
- 消息体:body,二进制内容
消息的顺序:一个topic下单个队列中消息的消费是有顺序的,多个queue之间的消费是并行的
消息的发送方式
消息的发送方式:同步发送、异步发送、单向发送。
- 同步发送:发送完消息后再返回,性能最低,但是最安全
- 异步发送:调用发送消息的方法后,立刻返回,同时提供回调函数处理发送结果,性能和安全性都居中
- 单向发送:调用发送消息的方法后,立刻返回,不关心消息的发送结果,性能最高,但安全性最低。
同步发送
案例1:同步发送,入门案例中就是一个同步发送的案例,直接调用send方法并且接收返回值,就是同步发送
异步发送
案例2:异步发送,这里只展示部分代码,因为只是在入门案例的基础上做了部分修改
for (int i = 1; i <= count; i++) {// 编辑消息String msg = "async send " + System.currentTimeMillis();Message message = new Message(Constants.TOPIC_TEST1, "tag1", msg.getBytes(StandardCharsets.UTF_8));producer.send(message, new SendCallback() {@Overridepublic void onSuccess(SendResult sendResult) {System.out.println("msg = " + msg + "; msgId = " + sendResult.getMsgId());}@Overridepublic void onException(Throwable e) {e.printStackTrace();System.err.println("发送失败");}});
}
和案例1不同的是,调用send,同时提供一个回调函数,发送完成后会调用回调函数,处理发送成功或发送失败的情况。观察案例1和案例2的运行情况,可以发现,同步发送,消息之间是有序的,异步发送,消息之间是无序的,因为发送消息时没有阻塞,所以异步发送效率更高。
单向发送
案例3:单向发送,同样是在案例1的基础上稍作修改。
for (int i = 1; i <= count; i++) {String msg = "one way send " + System.currentTimeMillis();Message message = new Message(Constants.TOPIC_TEST1, "tag1", msg.getBytes(StandardCharsets.UTF_8));producer.sendOneway(message);
}
总结:如果追求极致的性能,推荐单向发送,它不关心消息是否发送成功,如果追求安全,推荐同步发送,介于这两者之间,选择异步发送,但也要处理好发送失败的场景,例如,可以选择打印日志或者发送报警信息。
消息的类型
rocketMQ提供的多种消息类型,来满足不同的需求,包括普通消息、顺序消息、延迟消息、事务消息。
普通消息
之前的案例中都是普通消息,只是发送方式不同。
顺序消息
顺序消息:分为全局有序和部分有序
- 全局有序:生产者指定topic只创建一个分区,并且消费者也要配置按顺序消费,具体是使用 MessageListenerOrderly 类型的监听器,而不是之前案例中使用的 MessageListenerConcurrently
- 部分有序:只需要保证一个队列中的消息有序消费即可,消费者使用队列选择器,把同一类型的消息放到一个队列中,并且消费者也要配置按顺序消费。
案例1:顺序消息之全局有序
生产者:这里只展示部分代码
DefaultMQProducer producer = new DefaultMQProducer("send-mode-producer-group");
producer.setNamesrvAddr(Constants.clusterNameServerAddress);
// 设置topic下只允许一个分区
producer.setDefaultTopicQueueNums(1);
producer.start();
消费者:同样只展示部分代码,注意,监听器是 MessageListenerOrderly 类型的
consumer.registerMessageListener((MessageListenerOrderly) (msgList, context) -> {for (MessageExt messageExt : msgList) {System.out.printf("body = %s, tags = %s 消息体 = %s\n", new String(messageExt.getBody()), messageExt.getTags(), messageExt.getMsgId());}return ConsumeOrderlyStatus.SUCCESS;
});
案例2:局部有序。一个订单有三个消息,创建、支付、发货,这三个消息的顺序不可以乱,但是多个订单之间可以是无序的,这里模拟发送多个订单的创建、支付、发货消息,
public class Demo5Producer {private static final int count = 3;public static void main(String[] args) throws Exception {// 设置生产者组名DefaultMQProducer producer = new DefaultMQProducer(Constants.DEMO5_PRODUCER_GROUP1);// 指定name server的地址producer.setNamesrvAddr(Constants.nameServerAddress);// 指定超时时间producer.setSendMsgTimeout(1000);// 启动producer实例producer.start();// 发送消息for (int i = 1; i <= count; i++) {long orderId = i;// 1、创建订单Order order = createOrder(orderId, "订单" + orderId);byte[] bytes = JsonUtil.toJson(order).getBytes(StandardCharsets.UTF_8);Message message = new Message(Constants.ORDER_TOPIC, Constants.TAG1, bytes);message.setKeys("key-" + i);SendResult sendResult = producer.send(message, createMessageOrderSelector(), order.getId());System.out.println("msg = " + message + "; msgId = " + sendResult.getMsgId());// 2、支付changeOrderStatus(order, OrderStatusEnum.PAY.getId());bytes = JsonUtil.toJson(order).getBytes(StandardCharsets.UTF_8);message = new Message(Constants.ORDER_TOPIC, Constants.TAG1, bytes);message.setKeys("key-" + i);sendResult = producer.send(message, createMessageOrderSelector(), order.getId());System.out.println("msg = " + message + "; msgId = " + sendResult.getMsgId());// 3、发货changeOrderStatus(order, OrderStatusEnum.SEND_PRODUCT.getId());bytes = JsonUtil.toJson(order).getBytes(StandardCharsets.UTF_8);message = new Message(Constants.ORDER_TOPIC, Constants.TAG1, bytes);message.setKeys("key-" + i);sendResult = producer.send(message, createMessageOrderSelector(), order.getId());System.out.println("msg = " + message + "; msgId = " + sendResult.getMsgId());}producer.shutdown();}// messageQueue选择器,这里用于把同一个订单下的消息发送到同一个分区中 private static MessageQueueSelector createMessageOrderSelector() {return new MessageQueueSelector() {@Overridepublic MessageQueue select(List<MessageQueue> mqs, Message msg, Object arg) {return mqs.get(calIndex(mqs, arg));}};}private static int calIndex(List<MessageQueue> mqs, Object arg) {Long id = (Long) arg;return (int) (id % mqs.size());}// 用于构建数据的两个方法,让主流程代码更简洁private static void changeOrderStatus(Order order, Integer status) {if (order == null) {throw new RuntimeException("订单为null");}if (!OrderStatusEnum.match(status)) {throw new RuntimeException("状态不正确 status = " + status);}order.setStatus(status);}private static Order createOrder(Long orderId, String name) {if (orderId == null || orderId <= 0) {throw new RuntimeException("订单编码不正确");}if (name == null || name.isEmpty()) {throw new RuntimeException("订单名称不正确");}Order order = new Order();order.setId(orderId);order.setName(name);order.setStatus(OrderStatusEnum.CREATE.getId());return order;}
}发送消息时指定选择器,可以保证消息局部有序,在这里,同一个订单id下的消息被发送到同一个分区,同时再配置消费者按序消费,案例1中有介绍
延迟消息
延迟消息:把消息写入broker后需要延迟一定时间才能被消费
- 内部机制:rocketMQ会判断生产者发送的是否是一个延迟消息,如果是,会修改消息的topic,先发送到延迟topic,broker内部有一个计时器,到时间后,把延迟消息投递到正常队列。
- 使用场景:常用于超时业务,例如,订单支付超时关单,VIP会员超时提醒,通常是使用定时任务来解决这些问题,但是会造成大量的空扫浪费性能,所以可以考虑使用延迟消息来解决。
rocketMQ中有18个延迟等级,最低1秒,最高延迟2小时,可以通过修改配置文件来增加延迟级别。
案例:
public class Demo5DelaySendProducer {private static final int count = 10;public static void main(String[] args) throws Exception {// 设置生产者组名DefaultMQProducer producer = new DefaultMQProducer("send-mode-producer-group");// 指定name server的地址producer.setNamesrvAddr(Constants.clusterNameServerAddress);// 启动producer实例producer.start();// 发送消息for (int i = 1; i <= count; i++) {String msg = "delay send " + System.currentTimeMillis();Message message = new Message(Constants.TOPIC_TEST1, "tag1", msg.getBytes(StandardCharsets.UTF_8));// 延迟级别3,代表10s延迟message.setDelayTimeLevel(3);SendResult sendResult = producer.send(message);System.out.println("msg = " + msg + "; msgId = " + sendResult.getMsgId());}producer.shutdown();}
}
事务消息
事务消息,rocketMQ提供的一种分布式事务的解决方案,基于“两阶段提交”的思想,确保本地事务和消息发送要么全部成功,要么全部失败,避免本地事务和消息发送的状态不一致。
事务消息的核心流程:
- 生产者发送半事务消息到broker,确保消息能成功到达broker,避免网络故障等原因
- 生产者接收到broker返回的“半消息发送成功”的确认后,执行本地事务,执行完成后,向broker发送本地事务的执行状态,成功或失败
- broker收到本地事务的执行状态后,如果本地事务执行成功,broker将半消息标记为可消费,如果本地事务执行失败,broker删除半消息
- 如果上一步中broker没有收到本地事务的状态,broker会向生产者发送回查请求,直到broker收到明确的事务结果,或者超出次数限制,broker才会停止回查
事务消息的机制:通过 半消息 + 事务确认 + 回查机制,确保本地事务和消息发送的一致性
- 半消息:一种特殊的消息,发送给broker后,会被标记为暂不可消费,它需要等待生产者确认本地事务执行结果后,才会最终被提交,变为可消费,或者被删除
- 事务确认:生产者执行本地事务后,向broker返回状态,状态包括 执行成功、执行失败、未知
- 回查机制:当生产者由于某种原因,例如,网络延迟、生产者崩溃,没有发送事务确认到broker,broker会向生产者发送回查请求,确认本地事务的状态,确保消息的一致性。
特点:
- 不支持延时消息、批量消息,事务消息必须是单条消息
- 半消息在broker中默认保存72小时
- 性能损耗:相比普通消息,事务消息更加复杂,性能略低,适合核心链路并且是非高频的场景
- 事务消息通过半消息机制确保消息不会丢失,回查机制确保最终一致性,超时机制自动处理悬挂事务。
案例:模拟用户下单,并且给用户赠送积分的场景。在本地事务中创建订单信息,然后发送一个消息到mq,触发下游服务向指定用户赠送积分。
import org.apache.rocketmq.client.exception.MQClientException;
import org.apache.rocketmq.client.producer.*;
import org.apache.rocketmq.common.message.Message;
import org.apache.rocketmq.common.message.MessageExt;
import org.example.utils.CommonUtil;
import org.example.utils.JsonUtil;
import org.wyj.domain.beans.Order;
import org.wyj.domain.beans.OrderPointMsg;
import org.wyj.domain.constant.Constants;
import org.wyj.domain.enums.OrderStatusEnum;import java.math.BigDecimal;
import java.nio.charset.StandardCharsets;
import java.util.Date;
import java.util.Random;public class Demo7TransactionSendProducer {public static void main(String[] args) {// 设置生产者组名TransactionMQProducer producer = new TransactionMQProducer(Constants.DEMO7_PRODUCER_GROUP1);// 指定name server的地址producer.setNamesrvAddr(Constants.nameServerAddress);// 第三步:事务回查监听器:当rocketMQ无法接受到本地事务的最终状态,例如因为网络超时、生产者崩溃等原因的影响,// 会定期调用当前监听器,回查本地事务的执行状态。回查机制可能会被多次执行,要注意幂等性。producer.setTransactionCheckListener(new TransactionCheckListener() {@Overridepublic LocalTransactionState checkLocalTransactionState(MessageExt msg) {CommonUtil.print("执行状态检查 " + JsonUtil.toJson(msg));try {Long orderId = Long.valueOf(msg.getKeys());Order order = selectOrderById(orderId);return LocalTransactionState.COMMIT_MESSAGE;} catch (Exception e) {// log.errore.printStackTrace();return LocalTransactionState.ROLLBACK_MESSAGE;}}});// 启动producer实例try {producer.start();} catch (MQClientException e) {throw new RuntimeException(e);}// 执行业务逻辑:创建订单,这里还没有执行本地事务Order order = createOrder();// 组装下游积分服务需要的数据OrderPointMsg orderPointMsg = createOrderPointMsg(order);// 发送消息Message message = new Message(Constants.DEMO7_TOPIC, Constants.TAG1,JsonUtil.toJson(orderPointMsg).getBytes(StandardCharsets.UTF_8));message.setKeys(String.valueOf(order.getOrderId()));// 第一步:发送半消息,然后接收broker的返回SendResult sendResult;try {sendResult = producer.sendMessageInTransaction(message, new LocalTransactionExecuter() {// 第二步:发送消息成功之后,broker会调用这里的回调方法,用户在这里执行本地事务,然后向// rocketMQ返回本地事务的执行结果@Overridepublic LocalTransactionState executeLocalTransactionBranch(Message msg, Object arg) {CommonUtil.print("事务消息的回调方法" +JsonUtil.toJson(msg) + " " + JsonUtil.toJson(arg));try {// 执行本地事务saveOrder(order);} catch (Exception e) {e.printStackTrace();return LocalTransactionState.ROLLBACK_MESSAGE;}// 返回本地事务的执行结果return LocalTransactionState.COMMIT_MESSAGE;}}, order.getOrderId());} catch (MQClientException e) {throw new RuntimeException(e);}CommonUtil.print("sendResult = " + sendResult);producer.shutdown();}/*** 根据id查询订单*/private static Order selectOrderById(Long id) {CommonUtil.print("根据id查询订单 " + id);return null;}/*** 保存订单*/private static int saveOrder(Order order) {CommonUtil.print("执行本地事务,保存订单 " + JsonUtil.toJson(order));return 1;}/*** 下游积分服务需要的数据*/public static OrderPointMsg createOrderPointMsg(Order order) {return OrderPointMsg.builder().orderId(order.getOrderId()).user(order.getUser()).money(order.getMoney()).build();}/*** 创建订单*/private static Order createOrder() {Random random = new Random();int id = random.nextInt(100);CommonUtil.print("执行业务逻辑,创建订单");return Order.builder().orderId((long) id).name("订单1").status(OrderStatusEnum.CREATE.getId()).createTime(new Date()).user("user1").money(BigDecimal.valueOf(100)).build();}
}
发送半消息后,到在回调方法中执行本地事务,它们之间的间隔很短。启动消费者,消费者可以成功消费到消息。
这里不通过代码来展示其它案例,仅做简单介绍,另外两种情况,
- 1、本地事务执行失败,消费者不会消费到消息,
- 2、本地事务执行超时,一直没有向broker返回本地事务状态,broker会发送回查请求,确认本地事务的状态,用户可以在本地事务执行完成后加一个休眠来模拟这种状态。本案例中,大概在1分钟后,如果broker收不到本地事务的确认消息,就会发送回查请求,而且会重复发送多次
本地事务和回查机制之间如何传递数据
试想一个问题,执行本地事务的代码和回查机制的代码,它们之间互相看不到彼此,在回查机制中,应该如何判断本地事务的执行结果,举一个例子,在LocalTransactionExecuter中执行本地事务,假设是要向数据库中保存一条数据,然后数据库返回自增id,在事务回查监听器中,要怎么获取到这个id,根据它作为参数,来判断本地事务是否执行成功。
解决方案:使用业务唯一键 + 外部存储,将本地事务的状态保存到一个外部存储中,在回查时通过一个唯一的业务键来查询。案例中的解决方案正是如此,没有使用数据库的自增id,而是使用了一个业务id,同时把它直接保存到了数据库中
回查机制的配置
例如,broker如果收不到本地事务的确认消息,多久之后开始回查,最多回查机制,要注意,这些是broker的特性,要配置在broker上。
配置案例:在 broker.conf 中添加
# 事务回查间隔(1分钟)
transactionCheckInterval=60000
# 事务超时时间(5分钟)
transactionTimeout=300000
# 最大回查次数(3次)
transactionCheckMax=3
不使用事务消息可以吗?
事务消息的另一种解决方案:使用spring提供的能力,本地事务和发送消息放到同一个被@Transactional注解的方法中,如果本地事务失败,消息不会发送,如果消息发送失败,本地事务回滚。
这样在极端场景下会有问题:
- 消息发送成功但ack丢失,那么本地事务会回滚,但是消息已经发送成功。
- 当本地事务提交后但应用崩溃,消息可能根本没发出。
所以如果系统追求强一致性,可以牺牲部分性能,在发送消息的场景使用事务消息。
事务消息的本质是实现了分布式系统中的两阶段提交协议:
- 阶段1,准备阶段,发送半消息
- 阶段2,提交或回滚,决定最终状态
配置消费者的特性
消费方式:推、拉
消费方式主要有两种:推模式 push、拉模式 pull
推模式:消费者注册一个监听器到rocketMQ客户端,客户端的内部会维护一个长轮询机制,不断地从broker拉取消息。推模式的底层是通过长轮询的拉模式实现的,这种方式的好处在于可以保证高实时性,同时,如果让broker主动推送消息到某个消费者的话,该消费者如果消费不及时,可能导致消息堆积在它那里,所以,由消费者主动拉取,让消费者掌控主动权,避免消息堆积在某个消费者。
拉模式:由消费者主动向broker发起拉取消息请求,消费者需要自己负责管理偏移量,拉取频率等。拉模式适合低实时性的业务场景,例如批处理、定时任务,并且它的复杂度比较高,但是好处是消费者可以控制消费频率和消费条数。
拉模式需要预先创建topic,推模式则不必。
在命令行手动创建topic:./mqadmin updateTopic -n nameserver地址 -t topic名称 -c 集群名称
案例1:推模式
public class Demo8Consumer {public static void main(String[] args) {DefaultMQPushConsumer consumer = new DefaultMQPushConsumer(Constants.DEMO8_CONSUMER_GROUP1);consumer.setNamesrvAddr(Constants.nameServerAddress);try {consumer.subscribe(Constants.DEMO8_TOPIC, "*");} catch (MQClientException e) {throw new RuntimeException(e);}// 消费者注册一个监听器到rocketMQ客户端consumer.registerMessageListener(new MessageListenerConcurrently() {@Overridepublic ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> msgs, ConsumeConcurrentlyContext context) {CommonUtil.print("context = " + JsonUtil.toJson(context));try {for (MessageExt messageExt : msgs) {String topic = messageExt.getTopic();String tags = messageExt.getTags();String body = new String(messageExt.getBody(), StandardCharsets.UTF_8);CommonUtil.print("消费消息:" + topic + " " + tags + " " + body);}} catch (Exception e) {e.printStackTrace();return ConsumeConcurrentlyStatus.RECONSUME_LATER;}return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;}});try {consumer.start();} catch (MQClientException e) {throw new RuntimeException(e);}CommonUtil.print("消费者启动....");}
}
案例2:拉模式
public class Demo9Consumer {// 用于存储每个队列的消费偏移量private static final Map<MessageQueue, Long> OFFSET_TABLE = new HashMap<>();private static final Integer MAX_NUM = 32;private static final String ALL_TAGS = "*";public static void main(String[] args) {DefaultMQPullConsumer consumer = new DefaultMQPullConsumer(Constants.DEMO9_CONSUMER_GROUP1);consumer.setNamesrvAddr(Constants.nameServerAddress);try {consumer.start();} catch (MQClientException e) {throw new RuntimeException(e);}// 获取topic下所有的消息队列Set<MessageQueue> messageQueues;try {messageQueues = consumer.fetchSubscribeMessageQueues(Constants.DEMO9_TOPIC);} catch (MQClientException e) {throw new RuntimeException(e);}while (true) {for (MessageQueue messageQueue : messageQueues) {CommonUtil.print("开始拉取队列:" + JsonUtil.toJson(messageQueue));long offset = getLongValue(OFFSET_TABLE.get(messageQueue));// 拉取消息PullResult pullResult;try {pullResult = consumer.pull(messageQueue, ALL_TAGS, offset, MAX_NUM);} catch (MQClientException | RemotingException | MQBrokerException | InterruptedException e) {throw new RuntimeException(e);}// 处理消息switch (pullResult.getPullStatus()) {case FOUND: // 发现消息List<MessageExt> msgFoundList = pullResult.getMsgFoundList();for (MessageExt messageExt : msgFoundList) {String topic = messageExt.getTopic();String tags = messageExt.getTags();String body = new String(messageExt.getBody(), StandardCharsets.UTF_8);CommonUtil.print("消费消息:" + topic + " " + tags + " " + body);// 更新偏移量OFFSET_TABLE.put(messageQueue, pullResult.getNextBeginOffset());}break;case NO_NEW_MSG:CommonUtil.print("没有新消息");break;case NO_MATCHED_MSG:CommonUtil.print("没有标签匹配的消息");break;case OFFSET_ILLEGAL:CommonUtil.print("偏移量非法");break;}}// 拉取完之后休眠5stry {Thread.sleep(5000L);} catch (InterruptedException e) {throw new RuntimeException(e);}}}public static long getLongValue(Long value) {if (value == null) {return 0L;}return value;}
}消费者获取topic下的所有队列,循环从每个队列中拉取数据。
消费模式:集群模式和广播模式
这两个是消费者的特性:
- 集群模式:CLUSTERING,一条消息只会被同一个消费者组下的某个消费者实例消费一次。同一个消费者组下,消息一旦被某个实例消费过,其它实例将不会消费该条消息。
- 广播模式:BROADCASTING,一条消息只会被同一个消费者组下的每个消费者实例都消费一次
集群模式是默认模式,广播模式需要手动配置。集群模式的offset由broker统一管理,广播模式的offset由消费者自己管理。
适用场景:集群模式适合大部分业务场景,广播模式适合配置更新、缓存同步等非业务场景。
案例:设置消费者为广播模式
// 设置消费者为广播模式
consumer.setMessageModel(MessageModel.BROADCASTING);
并发消费模式和顺序消费模式
这应该是rocketMQ特有的,消费者向rocketMQ客户端注册监听器时,选择不同类型的监听器,可以控制是并发消费,还是顺序消费
案例1:并发消费,监听器的类型是 MessageListenerConcurrently
consumer.registerMessageListener((MessageListenerConcurrently) (msgList, context) -> {for (MessageExt messageExt : msgList) {System.out.printf("body = %s, tags = %s 消息体 = %s\n", new String(messageExt.getBody()), messageExt.getTags(), messageExt.getMsgId());}return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
});
案例2:顺序消费,监听器的类型是 MessageListenerOrderly
consumer.registerMessageListener(new MessageListenerOrderly() {@Overridepublic ConsumeOrderlyStatus consumeMessage(List<MessageExt> msgs, ConsumeOrderlyContext context) {for (MessageExt msg : msgs) {System.out.printf("body = %s, tags = %s 消息体 = %s\n", new String(msg.getBody()), msg.getTags(), msg.getMsgId());}return ConsumeOrderlyStatus.SUCCESS;}
});
顺序消费可以保证同一messageQueue内的消息有序,在之前学习顺序消息的时候,消费者使用的就是 MessageListenerOrderly
消费者初次启动时的消费位置
共有三种选择:
- 从最后位置开始消费:这是默认的,CONSUME_FROM_LAST_OFFSET,忽略所有历史消息,只消费启动之后才产生的消息。
- 从最早位置开始消费:CONSUME_FROM_FIRST_OFFSET,不管消息是何时产生的,都从这个topic队列的第一条消息开始消费。
- 从指定时间戳开始消费:CONSUME_FROM_TIMESTAMP,通常用于数据修复等
这三个选项只作用于消费者第一次启动时,如果消费者已经消费过,broker会保存offset,消费者下次启动后,会从offset出继续消费。
案例:
// 初次启动时从头开始消费
consumer.setConsumeFromWhere(ConsumeFromWhere.CONSUME_FROM_FIRST_OFFSET);
只有当broker上没有找到这个消费者组的消费偏移量记录时,setConsumeFromWhere 的设置才会生效,作为初始化策略。
消息的重试机制
重试机制分为普通消息的重试机制和顺序消息的重试机制。
普通消息的重试机制:普通消息如果消费失败,会被投递到retry topic中,每个topic都有自己的retry topic,名称是“%RETRY%消费者组名”。重试的间隔时间:第一次重试间隔10s,第二次和重试和第一次重试之间间隔30s,第三次和第二次间隔1分钟,以后每次重试的间隔时间都会增加,共重试16次,16次依然失败,消息进入死信队列。进入死信队列的消息通常需要用户手动处理。
顺序消息的重试机制:首先要说明一下顺序消息的机制。顺序消息分为局部有序和全部有序。对于局部有序,在生产者端,使用选择器,把同一个业务逻辑下的消息发送到指定的队列中,例如,同一个订单号下的消息,或者同一个用户的消息,在消费者端,使用顺序消息的API来消费。对于全局有序,只需要把topic下的队列设置为1个,就是全局有序,通常不会使用这种方式,因为它会严重影响吞吐量,在消费者端同样使用顺序消费的API来消费。顺序消息的重试机制是,如果消费失败,这条消息不会被投递到重试队列中,而是立刻重试,直到成功,所以顺序消息如果消费失败,会阻塞整个队列,其它消息都无法正常消费。
rocketMQ中,消息都是批量处理的,如果一批消息中,某些消息处理成功,某些消息处理失败,该怎么办?两种常见的解决方案:
- 把消息记录到数据库中,通过定时任务重试
- 消息消费失败后,发送一条新的消息到重试主题中,由新的消费者重试
死信队列
死信队列,用于存储经过多次重试后依然失败的消息,rocketMQ中具体是16次,是一个特殊的队列。死信队列由rocketMQ自动创建,命名规则是 “%DLQ%消费者组名称”,每个消费者组有自己独立的死信队列,进入死信队列的消息不会自动被消费者处理,必须手动介入,死信消息不会被自动删除,需要手动清理。死信队列中出现消息证明程序出问题了,程序员应该及时排查问题
rocketMQ集群
搭建集群
在实际生产中,rocketmq通常是以集群的形式工作的,这里搭建一个rocketmq集群。
rocketmq集群支持多种模式:下面提到的master、slave指的是broker节点的master、slave。
- 单master:只有一个broker节点并且没有slave作为备份。存在单点问题,通常只有学习时使用
- 多master:有多个broker节点但是它们都没有slave作为备份,性能最高。缺点是一旦某台服务器宕机,这台服务器上的消息将不能被消费订阅,影响消息的实时性。
- 多master多slave-同步:每个broker节点都有一个master和多个slave,master和slave之间采用同步双写的方式,主备都写成功,才算成功。好处是不用担心消息丢失,坏处是性能略低
- 多master多slave-异步:每个broker节点都有一个master和多个slave,master和slave之间采用异步复制的方式来同步数据,主备之间消息有延迟。好处是性能较高,坏处是消息可能丢失
这里选择搭建一个多master多slave-异步复制的集群。搭建过程中需要做的事情,就是配置broker的特性,每个broker服务都需要单独编写一个配置文件,至于nameserver,直接启动即可,但是要把所有nameserver的地址存储到每个broker相关的配置文件中。
开始搭建:
1、环境介绍:这里搭建一个2主2从-异步复制的rocketMQ集群,共有两台虚拟机,两台上面都有namesever节点,每台上面都有一个主broker、一个备broker,同一个broker的主、备放在不同的机器上。
| 机器 | 节点 |
|---|---|
| 192.168.0.4 | nameserver:9876 |
| broker-a:10910 | |
| broker-b-s:10921 | |
| 192.168.0.5 | nameserver:9876 |
| broker-a-s:10920 | |
| broker-b:10911 |
2、编写broker的配置文件,在conf/2m-2s-async目录下编写,这是rocketmq自带的
broker-a主节点的配置:
# 集群名称
brokerClusterName=c1# broker的基本信息,主broker和备份broker的brokerName相同,brokerId=0表示当前broker是主节点,
brokerName=broker-a
brokerId=0
deleteWhen=04
fileReservedTime=48
brokerRole=ASYNC_MASTER
flushDiskType=ASYNC_FLUSH # 异步刷盘#Broker 对外服务的监听端口
listenPort=10910
#是否允许 Broker 自动创建Topic,建议线下开启,线上关闭
autoCreateTopicEnable=true
#是否允许 Broker 自动创建订阅组,建议线下开启,线上关闭
autoCreateSubscriptionGroup=true
#nameServer地址,分号分割
namesrvAddr=192.168.0.4:9876;192.168.0.5:9876
#存储路径
storePathRootDir=/opt/rocketmq-4.9.3/store/broker-a
#commitLog 存储路径
storePathCommitLog=/opt/rocketmq-4.9.3/store/broker-a/commitlog
#消费队列存储路径存储路径
storePathConsumeQueue=/opt/rocketmq-4.9.3/store/broker-a/consumequeue
#消息索引存储路径
storePathIndex=/opt/rocketmq-4.9.3/store/broker-a/index
#checkpoint 文件存储路径
storeCheckpoint=/opt/rocketmq-4.9.3/store/checkpoint
#abort 文件存储路径
abortFile=/opt/rocketmq-4.9.3/store/abort
broker-b主节点、broker-a备份节点、broker-b备份节点,都需要有自己的配置文件,和上面的一样,这里不再展示它们的配置详情,要注意,相同broker的主节点和备份节点,name相同,id=0是主节点,id=1以上是备份节点,每个节点的存储路径也需要修改。
需要为每个broker都编写一份配置文件,配置文件中的端口、brokerName、brokerId、存储路径,都必须是当前broker独有的。
依照这份配置文件,再编写另外3份配置文件,这里不详细展示了。
3、启动集群
启动nameserver:sh ${ROCKETMQ_HOME}/bin/mqnamesrv &,在两台机器上都执行这个命令
启动broker:注意启动顺序,先启动主节点,再启动备份节点,sh ${ROCKETMQ_HOME}/bin/mqbroker -c ${ROCKETMQ_HOME}/conf/2m-2s-async/broker-a.properties &,这里只展示启动一个节点的命令,启动时需要指定配置文件的路径,注意,配置文件决定了节点类型。
完成。
总结:搭建集群,就是为每个broker服务编写自己的配置文件,然后再依次启动,broker的配置文件中记录了nameserver的地址。nameserver直接启动即可,broker服务启动时需要指定配置文件,先启动主broker,然后再启动备份broker。
这个集群不具备自动恢复的功能,如果broker主节点宕机了,需要手动把slave节点切换为主节点,功能相对较弱,如果想要slave节点可以自动切换为master节点,可以再部署一个dledger集群,这里不做介绍了。
搭建控制台
控制台的下载地址:https://gitcode.com/gh_mirrors/ro/rocketmq-dashboard,搭建过程中有一个误区,就是rocketmq-console,这个最新版已经不用,现在是单独提取出了一个dashboard,来作为控制台服务。
下载好源码后,是一个前后端不分离的springboot项目,配置nameserver的地址,然后启动即可,参考项目中的README.md,可以直接在IDE中启动,也可以编译打包,部署到服务器上。
搭建结果:
在命令行查看集群信息
查看日志
- tail -f ~/logs/rocketmqlogs/namesrv.log ,nameserver的运行日志
- tail -f ~/logs/rocketmqlogs/broker.log,broker的运行日志
- tail -f ~/logs/rocketmqlogs/store.log,消息存储相关的日志
关闭集群
先关闭broker,再关闭nameserver
- 关闭broker:
sh ${ROCKETMQ_HOME}/bin/mqshutdown broker - 关闭nameserver:
sh ${ROCKETMQ_HOME}/bin/mqshutdown namesrv
mqadmin命令的使用
因为控制台的版本问题,有些信息在控制台无法查看,所以学习了几个命令行指令,记录在这里
集群相关
1、查看集群列表 clusterList
执行命令:${ROCKETMQ_HOME}/bin/mqadmin clusterList -n 192.168.1.4:9876
结果:结果中包括集群中的broker列表,包括每个broker的名称、id、ip地址、版本号,以及写入消息的TPS、读取消息的TPS,最后,PCWait是页面缓存等待时间,#Hour是消息堆积时间,@SPACE是磁盘使用率

从结果中分析当前集群,broker采用了两主两从的架构,写入和写出的TPS是0,证明当前集群空闲中,PCWait,页面缓存等待时间为0,表示磁盘性能良好,无等待时间,消息堆积时间很大,证明有非常旧的消息堆积中集群中,或者系统时间配置错误,#SPACE,磁盘利用率是11%,状态良好
2、查看broker的详细状态 brokerStatus
执行命令:${ROCKETMQ_HOME}/bin/mqadmin brokerStatus -n <nameserver的IP地址:端口号> -c <集群名称>
结果:这个命令展示出了集群中每个broker节点的详细指标。指标可以分为如下几个部分:
- broker的基本信息:启动时间、版本号、运行时间
- 磁盘相关的指标:磁盘使用率、现存消息的最小偏移量和最大偏移量等
- 消息生产指标:写入消息的总数、写入消息的TPS、消息的平均大小等
- 消息消费指标:拉取消息的TPS、消费了多少消息等
- 线程池指标:broker内部使用的线程池,用于处理生产者发送消息
# 最左侧一列是broker的ip地址和端口号,然后是指标和值# broker的启动时间
192.168.1.3:10911 bootTimestamp : 1759550191393
# broker的版本号,一个是内部的,一个是对用户使用的
192.168.1.3:10911 brokerVersion : 399
192.168.1.3:10911 brokerVersionDesc : V4_9_3
# 运行时间
192.168.1.3:10911 runtime : [ 1 days, 5 hours, 22 minutes, 7 seconds ]# 磁盘状态相关的指标# 磁盘容量,这里总容量是16.4G,还剩5.9G,状态健康,需监控
192.168.1.3:10911 commitLogDirCapacity : Total : 16.4 GiB, Free : 5.9 GiB.
# 磁盘使用率
192.168.1.3:10911 commitLogDiskRatio : 0.64
192.168.1.3:10911 commitLogDiskRatio_/root/store/commitlog: 0.64
192.168.1.3:10911 consumeQueueDiskRatio : 0.64
# CommitLog最大物理偏移量。表示自broker启动以来累计写入的数据量。
192.168.1.3:10911 commitLogMaxOffset : 654609820
# CommitLog最小物理偏移量。为0表示没有消息过期被清理,或者所有消息都未被消费。
192.168.1.3:10911 commitLogMinOffset : 0
# 最早一条消息的存储时间。如果这个时间太早,表明有很久之前的消息没有被消费,是很严重的问题
192.168.1.3:10911 earliestMessageTimeStamp : 1756610302691
# 剩余的没有被刷新到磁盘的数据量
192.168.1.3:10911 remainHowManyDataToFlush : 0 B
# 剩余的临时存储缓冲区数量。值很大,表示资源充足
192.168.1.3:10911 remainTransientStoreBufferNumbs : 2147483647# 消息生产指标# broker启动以来累计接收的消息总条数。
192.168.1.3:10911 putMessageTimesTotal : 2826
# 今天写入的消息总数
192.168.1.3:10911 msgPutTotalTodayNow : 2826
# 消息的总大小,这里单位是字节,大约是1M多
192.168.1.3:10911 putMessageSizeTotal : 1082697
# 消息的平均大小
192.168.1.3:10911 putMessageAverageSize : 383.119957537155
# 实时消息写入TPS。通常是3个值,分别代表最近1分钟、5分钟、15分钟的平均值。这里全为0,表示当前没有写入的消息
192.168.1.3:10911 putTps : 0.0 0.0 0.0
# 消息写入处理最大耗时,单位是毫秒。最慢的一次写入花了59ms
192.168.1.3:10911 putMessageEntireTimeMax : 59
# 消息写入失败的次数总和,这里为0,表示没有写入失败的消息
192.168.1.3:10911 putMessageFailedTimes : 0
# 消息写入耗时分段统计。所有区间都是0,因为当前没有正在发生的写入操作。
192.168.1.3:10911 putMessageDistributeTime : [<=0ms]:0 [0~10ms]:0 [10~50ms]:0 [50~100ms]:0 [100~200ms]:0 [200~500ms]:0 [500ms~1s]:0 [1~2s]:0 [2~3s]:0 [3~4s]:0 [4~5s]:0 [5~10s]:0 [10s~]:0 # 消息消费指标# 今天至今消费的消息总数
192.168.1.3:10911 msgGetTotalTodayNow : 1575
# 消息拉取请求的总TPS,下面FoundTps表示拉取到消息的请求的TPS,MissTps表示没有拉取到消息的请求的TPS,
# 这里很多请求都是没有拉取到消息的,证明空轮询非常高
192.168.1.3:10911 getTotalTps : 0.9997000899730081 0.5332089179191523 0.004766678173262571
192.168.1.3:10911 getFoundTps : 0.0 0.0 1.4576997471750981E-5
192.168.1.3:10911 getMissTps : 0.9997000899730081 0.5332089179191523 0.00475210117579082
# 拉取消息的最大耗时,单位是毫秒
192.168.1.3:10911 getMessageEntireTimeMax : 16
# 从其它Broker转移消息的TPS,主从架构中使用
192.168.1.3:10911 getTransferedTps : 0.0 0.0 1.4576997471750981E-5# 线程池相关的指标# QueueCapacity是线程池的等待队列、QueueHeadWaitTimeMills是队列头部任务的等待时间、QueueSize是队列中的任务数。
# sendThreadPool,处理生产者发送消息的请求,pullThreadPool,处理消费者拉取消息的请求,queryThreadPool,
# 处理各种查询请求,EndTransactionThreadPool,专门处理事务消息的第二阶段,提交或回滚
192.168.1.3:10911 pullThreadPoolQueueCapacity : 100000
192.168.1.3:10911 pullThreadPoolQueueHeadWaitTimeMills: 0
192.168.1.3:10911 pullThreadPoolQueueSize : 0192.168.1.3:10911 queryThreadPoolQueueCapacity : 20000
192.168.1.3:10911 queryThreadPoolQueueHeadWaitTimeMills: 0
192.168.1.3:10911 queryThreadPoolQueueSize : 0192.168.1.3:10911 sendThreadPoolQueueCapacity : 10000
192.168.1.3:10911 sendThreadPoolQueueHeadWaitTimeMills: 0
192.168.1.3:10911 sendThreadPoolQueueSize : 0192.168.1.3:10911 EndTransactionThreadPoolQueueCapacity: 100000
192.168.1.3:10911 EndTransactionQueueSize : 0# 页面缓存锁等待时间。为0表示无锁竞争。
192.168.1.3:10911 pageCacheLockTimeMills : 0# 定时消息队列的偏移量:例如 scheduleMessageOffset_10: 180,182 表示延迟级别10的队列,最小偏移量180,最大偏移量182,即有2条消息。
192.168.1.3:10911 scheduleMessageOffset_10 : 180,182
192.168.1.3:10911 scheduleMessageOffset_11 : 1,3
192.168.1.3:10911 scheduleMessageOffset_12 : 1,3
192.168.1.3:10911 scheduleMessageOffset_13 : 1,3
192.168.1.3:10911 scheduleMessageOffset_14 : 1,3
192.168.1.3:10911 scheduleMessageOffset_15 : 1,3
192.168.1.3:10911 scheduleMessageOffset_16 : 1,3
192.168.1.3:10911 scheduleMessageOffset_17 : 1,3
192.168.1.3:10911 scheduleMessageOffset_18 : 1,3
192.168.1.3:10911 scheduleMessageOffset_3 : 110,112
192.168.1.3:10911 scheduleMessageOffset_4 : 139,141
192.168.1.3:10911 scheduleMessageOffset_5 : 168,170
192.168.1.3:10911 scheduleMessageOffset_6 : 198,200
192.168.1.3:10911 scheduleMessageOffset_7 : 257,259
192.168.1.3:10911 scheduleMessageOffset_8 : 257,259
192.168.1.3:10911 scheduleMessageOffset_9 : 257,259# 其它
192.168.1.3:10911 startAcceptSendRequestTimeStamp : 0
192.168.1.3:10911 dispatchBehindBytes : 0
192.168.1.3:10911 dispatchMaxBuffer : 0
192.168.1.3:10911 msgPutTotalTodayMorning : 0
192.168.1.3:10911 msgPutTotalYesterdayMorning : 0
192.168.1.3:10911 msgGetTotalTodayMorning : 0
192.168.1.3:10911 msgGetTotalYesterdayMorning : 0
topic相关
1、查看topic列表 topicList
这个命令只是查看topic的名称列表
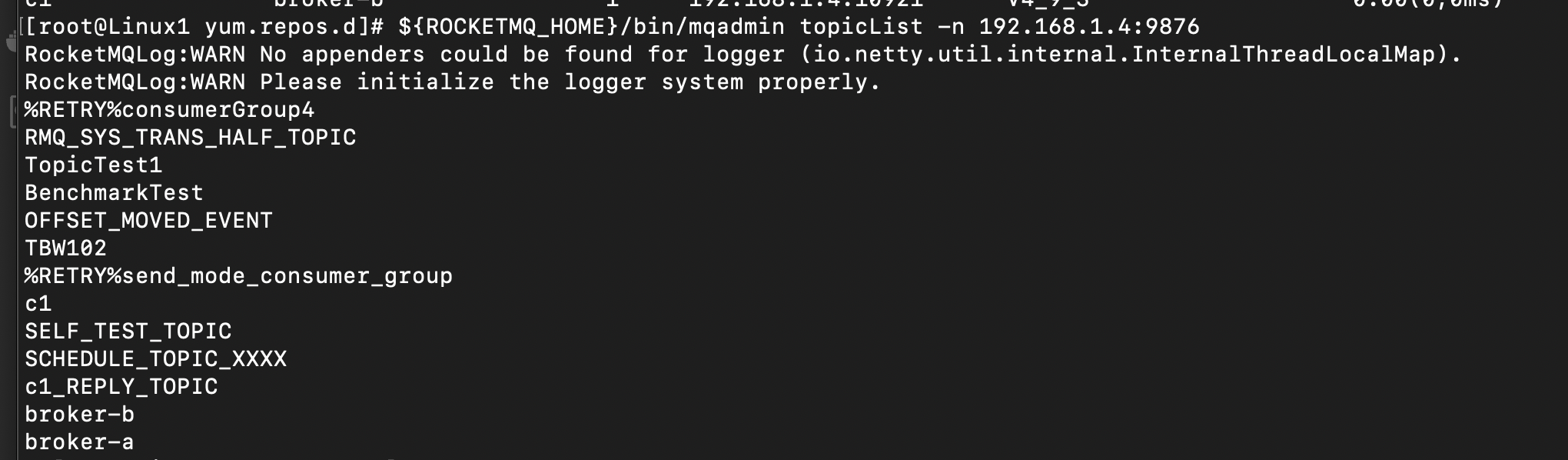
执行命令:${ROCKETMQ_HOME}/bin/mqadmin topicList -n <nameserver的IP地址:端口号>
结果:这里只是展示出每个topic的名称,包括集群自带的topic
2、查看topic的路由信息 topicRoute
执行命令:${ROCKETMQ_HOME}/bin/mqadmin topicRoute -n nameserverIP地址:端口号 -t topic名称
结果:结果中展示了topic存储于哪些broker、topic的中的队列和权限。在这里,topic存储于broker-b,并且broker-b是主从架构的,topic内部有四个读队列和四个写队列。读写队列是逻辑上的概念,实际上只有四个队列,之所以称为读写队列是为了方便运维。
{"brokerDatas":[{"brokerAddrs":{0:"192.168.1.5:10911",1:"192.168.1.4:10921"},"brokerName":"broker-b","cluster":"c1"}],"filterServerTable":{},"queueDatas":[{"brokerName":"broker-b","perm":6, /* 读写权限 二进制: 110 = 4(读) + 2(写) ,允许生产和消费*/"readQueueNums":4,"topicSysFlag":0,"writeQueueNums":4}]
}
3、查看topic的状态 topicStatus
执行命令:${ROCKETMQ_HOME}/bin/mqadmin topicStatus -n <IP地址:端口号> -t <topic名称>
结果:topic内每个队列的消费情况,minOffset是当前队列内的最小偏移量,当消息因为过期被清理,这个偏移量会增加,maxOffset是最大偏移量, maxOffset - minOffset,就是当前队列内的消息总量,Last Updated是最后更新时间,是broker向nameserver上报路由信息的时间。

4、查看topic中的消息 queryMsgByOffset
这里是根据消息偏移量来查看 。
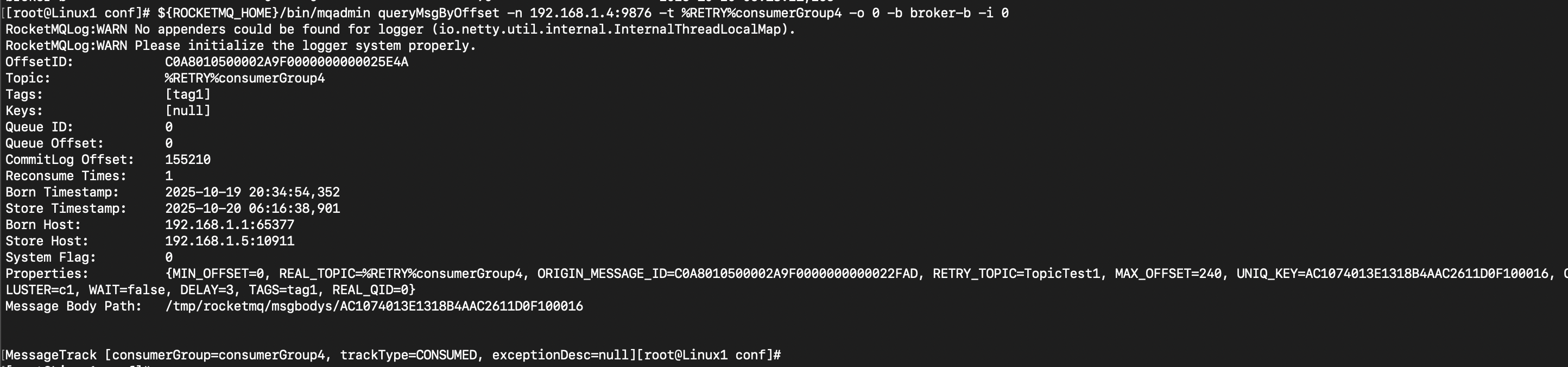
执行命令:${ROCKETMQ_HOME}/bin/mqadmin queryMsgByOffset -n 192.168.1.4:9876 -t %RETRY%consumerGroup4 -b broker-b -i 0 -o 0 ,这条命令中的参数, -b,消息在哪个broker,-i,队列id,-o,消息的偏移量,这里表示查询broker-b上队列0中的第0条消息
执行结果:结果中的Message Body Path,就是存放了消息体的临时文件,其它信息是消息的特性,只要查看这个文件中的内容就可以了。
5、在命令行手动创建topic updateTopic
执行命令:./mqadmin updateTopic -n nameserver地址 -t topic名称 -c 集群名称
消费者相关
1、查看一个topic有哪些消费者组
这个需要在控制台查看,没有找到相关命令
2、查看消费者组的状态 consumerSatus
执行命令:${ROCKETMQ_HOME}/bin/mqadmin consumerStatus -n <nameserver地址> -g <消费者组名>
结果:结果中展示了消费者的地址、版本号,以及是否负载均衡

3、查看消费者组的消费进度 consumerProgress
执行命令:${ROCKETMQ_HOME}/bin/mqadmin consumerProgress -n <nameserver地址> -g <消费者组名>
结果:结果中展示了消费者组对应的所有topic下的队列,主要有两个指标,broker offset是broker端的消息进度,consumer offset是消费者端消费到了哪里,这两个指标的差异,就是diff列的值,表示消费者的进度落后了多少

4、查看指定broker下消费者的状态 brokerConsumeStats
执行命令:${ROCKETMQ_HOME}/bin/mqadmin brokerConsumeStats -n <nameserver地址> -b <broker地址>
这里就不展示结果了,和上面的一样
5、查看消费失败的消息
基于rocketMQ的运行机制,如果某个消费者消费失败,该消息会被投递到特定的topic中,相当于重试队列,topic的名称是%RETRY%消费者组名,只要查看这个topic中的消息,就可以知道当前消费者有没有消费失败的消息,并且消息详情是什么。
A. 查看当前消费者对应的重试topic的状态:${ROCKETMQ_HOME}/bin/mqadmin topicStatus -n <nameserver地址> -t %RETRY%消费者组名称,如果可以查到数据,在之前有介绍,它会展示消息的偏移量,然后根据偏移量,查询消息详情。下面是执行结果,从结果中可以看出,重试队列中有90条消息。

B. 然后根据偏移量查看消息详情,具体命令上面有介绍
生产者相关
1、查看生产者是否在线 producerConnection
执行命令: ${ROCKETMQ_HOME}/bin/mqadmin producerConnection -n 192.168.1.4:9876 -g log_practice_producer_group -t log_practice_log_topic
结果:
0001 172.16.116.1@30618 192.168.1.1:55634 JAVA V4_5_2
导出配置信息
1、导出集群的元数据信息
会导出消费者、topic的配置信息到指定目录
执行命令:${ROCKETMQ_HOME}/bin/mqadmin exportMetadata -n 192.168.1.3:9876 -c DefaultCluster -f /tmp/rocketmq/export
结果:
{"exportTime":1759567513063,"topicConfigTable":{ /*topic配置*/"demo12_topic":{ /* 单个topic */"order":false, /*是否顺序消息,这是生产者配置的*/"perm":6, /*主题的权限:这是一个二进制位掩码。6 转换为二进制是 110,具体为:4(读) + 2(写) = 6。表示该主题允许生产者和消费者使用。*/"readQueueNums":4, /* 读队列数量:这是消费者从该主题消费消息时并行度的关键指标。有几个队列,意味着最多可以有几个消费者实例同时消费这个主题,在同一个消费者组内*/"topicFilterType":"SINGLE_TAG", /* 主题过滤类型:SINGLE_TAG 表示这个主题使用Tag过滤模式。这是最常用的过滤方式,消费者可以订阅特定的Tag来过滤消息。 */"topicName":"demo12_topic","topicSysFlag":0, /* 主题系统标志位:用于内部标识主题的特殊状态,如是否是单元化主题等。0 表示这是一个普通的、无特殊标志的主题。 */"writeQueueNums":4 /* 写队列数量:这是生产者向该主题发送消息时并行度的关键指标。消息会根据算法(如轮询)发送到不同的队列中。通常情况下,读队列和写队列的数量必须相等,否则会导致消息无法被正确路由和消费,读写队列是逻辑上的指标,它们实际上是相同的队列,只是为了方便运维进行区分 */}},"subscriptionGroupTable":{ /*消费者组配置*/"demo15ConsumerGroup1":{ /* 单个消费者组 */"brokerId":0, /* broker的id */"consumeBroadcastEnable":true, /*是否允许广播模式消费:true 表示该消费者组允许以广播模式消费消息。广播模式和集群模式是消费者的特性,广播模式下,一条消息会被一个消费者组内的所有消费者消费,集群模式下,一条消息会被一个消费者组内的单个消费者消费 */"consumeEnable":true, /* 是否允许消费:true 表示该消费者组可以正常消费消息。如果设置为 false,则该组下的所有消费者将暂停消费。 */"consumeFromMinEnable":true, /* 是否从最小偏移量开始消费:值为true,表示当一个新的消费者实例启动时,如果broker上没有找到其消费进度,Offset,则从队列的最旧的消息开始消费,值如果为false,表示从队列的最新的消息开始消费。 */"groupName":"demo15ConsumerGroup1","notifyConsumerIdsChangedEnable":true, /* 是否在消费者列表变化时通知:当有消费者上线或下线时,Broker 会通知整个消费者组进行重新平衡。必须为 true 以保证负载均衡正常工作。 */"retryMaxTimes":16, /* 最大重试次数:当消息消费失败后,会被发送到重试队列。这个配置决定了在将消息投递到死信队列之前,最多可以重试的次数。*/"retryQueueNums":1, /* 重试队列数量 */"whichBrokerWhenConsumeSlowly":1 /* 消费缓慢时建议从哪个broker消费。这是一个负载均衡的建议值,通常客户端会忽略。 */}}
}
导出的内容包括:所有topic和消费者组的配置信息
- topic的配置信息:topic名称、是否顺序消息、权限、读队列数量、写队列数量等
- 消费者组的配置:消费者组的名称、最大重试次数、重试队列数量、广播模式还是集群模式、是否从最小偏移量开始消费等。
2、导出集群的配置信息
执行命令:${ROCKETMQ_HOME}/bin/mqadmin exportConfigs -n 192.168.1.3:9876 -f /tmp/rocketmq/export -c DefaultCluster
结果:
{"clusterScale":{ /* 集群规模 */"namesrvSize":1, /* nameserver数量 */"slaveBrokerSize":0, /* 从broker数量,从节点作为主节点的热备份,提供数据冗余和读负载均衡 */"masterBrokerSize":1 /* 主broker数量,主节点负责处理所有的写请求和大部分读请求。生产环境通常有多个主节点来承载不同的topic */},"brokerConfigs":{ /* broker配置 */"localhost":{ /* 单个broker,这里broker的名称是localhost */"flushDiskType":"ASYNC_FLUSH", /* 刷盘方式:ASYNC_FLUSH,异步刷盘,表示消息先写入系统页面缓存就返回成功,然后由操作系统异步刷入磁盘。性能极高,但宕机可能丢失消息。另一种是 SYNC_FLUSH,同步刷盘,保证消息持久化后才返回,性能差但可靠性高。 */"brokerName":"localhost","autoCreateTopicEnable":"true", /* 是否允许自动创建topic,生产环境建议关闭 */"brokerClusterName":"DefaultCluster", /* broker所在的集群名称 */"traceTopicEnable":"false", /* 消息轨迹跟踪 */"traceOn":"true", /* 消息轨迹跟踪 */"brokerRole":"ASYNC_MASTER", /* broker的角色,ASYNC_MASTER,当前broker是一个异步刷盘的主broker */"messageDelayLevel":"1s 5s 10s 30s 1m 2m 3m 4m 5m 6m 7m 8m 9m 10m 20m 30m 1h 2h", /* 延迟消息的等级。生产者可以发送延迟消息,指定消息在某个延迟级别后才被投递给消费者。例如,级别1表示延迟1秒,级别2表示延迟5秒,以此类推。 */"fileReservedTime":"72", /* 文件保留时间。单位是小时。表示消息数据在磁盘上保留的时间 */"msgTraceTopicName":"RMQ_SYS_TRACE_TOPIC", /* 消息轨迹数据存储的Topic */"useTLS":"false", /* 是否使用TLS加密通信 */"filterServerNums":"0", /* 过滤服务器数量。用于更复杂的服务端消息过滤,如基于SQL92 */"brokerId":"0","slaveReadEnable":"false", /* 是否允许从从节点读取 */"autoCreateSubscriptionGroup":"true", /* 是否自动创建订阅组。当消费者以一个不存在的消费者组启动时,broker会自动创建它 */"maxMessageSize":"4194304" /* 单条消息的最大大小。单位是字节。4194304 bytes = 4 MB。超过此大小的消息将被拒绝。 */}}
}
集群的配置信息中包括:nameserver和broker的配置信息
- 集群规模:nameserver的数量、主broker数量、从broker数量
- 每个broker的配置信息:broker名称、broker角色(主还是从)、刷盘方式、单条消息的最大限制、文件保留时间等。
3、导出集群的指标信息
执行命令:${ROCKETMQ_HOME}/bin/mqadmin exportMetrics -n 192.168.1.3:9876 -f /tmp/rocketmq/export -c DefaultCluster
结果:
{"totalData":{ /* 集群汇总数据 */"totalOneDayNum":{ /* 24小时消息总量 */"transOneDayInNum":0, /* 过去24小时,事务消息的写入总量 */"scheduleOneDayInNum":1286, /* 过去24小时,定时/延迟消息的写入总量 */"normalOneDayOutNum":0, /* 过去24小时,普通消息的写入总量 */"normalOneDayInNum":0 /* 过去24小时,普通消息的消费总量 */},"totalTps":{ /* 集群实时吞吐量 */"totalScheduleInTps":0.0, /* 定时/延迟消息的实时写入速率(条/秒)。为0.0表示在生成此报告的瞬间,没有新的定时消息正在被写入。 */"totalNormalInTps":0.0,"totalTransInTps":0.0,"totalNormalOutTps":0.0}},"evaluateReport":{ /* broker节点的详细报告*/"localhost":{ /* 单个broker节点 */"runtimeVersion":{ /* 版本信息 */"rocketmqVersion":"V4_9_3", /* broker的版本 */"clientInfo":["JAVA%V4_2_0_SNAPSHOT"] /* 连接到该broker的客户端的版本,这里是一个列表 */},"runtimeQuota":{ /* 运行时配额 */"diskRatio":{ /* 磁盘使用率。包括 commitLogDiskRatio 和 consumeQueueDiskRatio。0.64 表示 64%。这是一个非常健康的水平,表明磁盘空间充足。如果超过85%则需要警惕,超过90%则非常危险。 */"commitLogDiskRatio":"0.64", "consumeQueueDiskRatio":"0.64"},"topicSize":21, /* 当前broker上topic个数 */"tps":{ /* broker的实时tps */"scheduleInTps":0.0,"normalInTps":0.0,"normalOutTps":0.0,"transInTps":0.0},"groupSize":19, /* 当前broker上消费者组个数 */"oneDayNum":{ /* broker上24小时的tps */"transOneDayInNum":0,"scheduleOneDayInNum":1286,"normalOneDayOutNum":0,"normalOneDayInNum":0},"messageAverageSize":"383.10660980810235" /* 消息的平均大小,单位是字节。约 383 Bytes。这是评估网络带宽和存储容量规划的重要依据。 */},"runtimeEnv":{ /* 运行时环境 */"cpuNum":"2" /* broker服务器的CPU核心数 */}}}
}
集群的指标信息中包括:
- 24小时消息数据汇总:过去24小时,写入的事务消息总量、延迟消息总量、普通消息总量、消费消息总量
- 集群实时吞吐量:写入消息的实时tps、读取消息的实时tps
- 每个broker节点的详细报告:broker的版本信息、磁盘使用率、topic个数、实时tps、当前broker上消费者组个数、消息平均大小、broker的运行时环境、broker过去24小时的tps
内部机制
消息的存储
消息在磁盘上的存储:消息存储在commitLog、consumeQueue、indexFile三个文件中
- commitLog:消息主文件,所有消息,无论属于哪个topic,都会存入到当前文件中,而且是顺序写入。单个文件大小默认1G,采用MapperFile机制,将磁盘文件直接映射到jvm内存,减少用户态与内核态的的io拷贝。
- consumeQueue:每个topic下的每个queue对应一个当前文件,作为消息的索引,记录消息在commitLog中的位置,供消费者消费。单个索引条目中的内容包括 offset (消息在commitLog中的偏移量)、message size(消息长度)。
- indexFile:可选的“键值索引”文件,用于通过消息的key快速查找消息,如果用户有设置的话。所有topic的key公用indexFile文件,
消息发送后,broker先把消息顺序写入到commitLog,随后再异步写入comsumeQueue文件,如果消息设置了key,在异步生成indexFile文件。
索引设计的核心特点:
- 分层索引,各司其职:ConsumeQueue 是 “顺序消费索引”,支持消费者按 Offset 顺序高效读取消息,保证消费性能。IndexFile 是 “随机查询索引”,支持按 Key 快速定位消息,满足业务查询需求。
- 异步构建,不阻塞写入:索引均由后台线程异步生成,避免阻塞commitLog的顺序写入,保证写入性能
默认情况下,rocketmq会在用户目录下,新建一个store文件夹,来存储消息数据,文件夹中的内容:
- config文件夹:存放运行时期的配置信息,包括topic信息、消费者组、消费者的消费情况等,配置信息存储在json文件中
- 消息体相关:
- commitlog文件夹:存放消息实体
- consumequeue文件夹:存储commitlog中消息的索引位置,以topic为单位进行存放
- index文件夹:存放索引文件,用来实现根据key进行消息的快速查询
- checkpoint:记录commitlog、consumequeue、index文件最后刷盘的时间戳
- abort:broker启动后自动创建,broker正常关闭的话abort也会被删除
负载均衡机制
rocketMQ中的负载均衡,涉及到两部分,一是从生产者到broker,二是从broker到消费者,其中,从broker到消费者是最复杂的:
- 生产者到broker : 生产者会把消息轮流发送到topic下的每个分区,分区存储在不同的broker上,从而实现broker的负载均衡
- broker到消费者 : broker到消费者的负载均衡,由消费者来完成。 消费者获取topic下的队列列表、消费者组的成员列表,计算出自己应该消费哪些队列,然后去消费这些队列,每个消费者组都会根据相同的数据、使用相同的策略,进行相同的计算,所以得到的结果也是相同的,它们彼此之间不需要进行数据同步。broker有一个兜底措施,就是它会校验一个队列只能有一个消费者,避免极端情况。 消费者启动、消费者组内消费者变动、topic队列发生变化、消费者定时触发(默认20s检查一次),都会触发消费者组的负载均衡,负载均衡可能会导致消息轻微堆积,如果消息比较多的话。
消费者使用的分配策略:
- 平均分配:默认策略。将队列按顺序平均分给每个消费者,多出来的队列依次分配给前几个消费者。大多数通用场景,适合队列和消费者数量变化不频繁的情况。
- 环形分配:队列按顺序排成环形,消费者依次轮流领取队列
- 按机房分配:优先将消费者所在机房的 Broker 队列分配给它,跨机房队列按平均策略分配。
- 一致性哈希:基于消费者 ID 计算哈希值,队列根据哈希值分配给最近的消费者,节点变化时仅影响少量队列。消费者实例频繁上下线,希望减少队列迁移开销
offset管理
rocketMQ通过offset来维护消费者的消费进度,消费者消费结束后,会提交offset给broker。offset可以同步提交,也可以异步提交,
offset的同步提交和异步提交:
- 同步提交:消费者在消费完消息后,会向broker提交这些消息的offset,若broker没有响应,则重新提交,如果响应了,响应中包含下一批次消息的offset。
- 异步提交:消费者消费完消息后,会向broker提交这些消息的offset,broker会响应,但是消费者不会等待broker的响应,它会直接获取下一批次消息的offset。
offset信息的存储分为本地offset管理和远程offset管理,本地offset管理是消费者来存储offset,远程offset管理是broker来存储offset,
rocketMQ中的零拷贝技术
零拷贝技术主要应用于读场景,写场景的拷贝不可避免。
零拷贝,一种优化数据传输效率的技术,核心目标是减少数据在用户空间和内核空间之间的冗余拷贝,同时降低CPU参与数据搬运的频率,从而提升IO密集型场景的性能。
传统数据传输的问题:读取数据的场景下,存在多次数据拷贝和上下文切换,
- 第一步:磁盘通过DMA(直接内存访问),将数据拷贝到内核缓冲区(页缓存,page cache)
- 第二步:CPU将内核缓冲区的数据拷贝到用户缓冲区(用户进程的内存空间)
- 用户代码,对数据进行计算
- 第三步:CPU将用户缓冲区的数据拷贝到内核空间的socket缓冲区
- 第四步:socket缓冲区的数据通过DMA拷贝到网卡缓冲区,最终发送到网络
整个过程中,发生了四次拷贝,2次DMA拷贝和2次CPU拷贝。
两种不同的零拷贝技术:mmap、sendfile
内存映射技术:memory mapping,mmap,核心是建立用户进程虚拟地址空间和内核缓冲区之间的映射,减少把数据从内核拷贝到用户进程的开销。用户进程调用mmap函数,内核将文件数据通过DMA拷贝到内核缓冲区,并建立内核缓冲区与用户进程虚拟地址空间之间的联系,用户进程可以直接操作内核缓冲区的数据,无需把内核缓存区的数据复制到用户空间下。mmap减少了一次CPU拷贝。
sendfile:Linux系统提供的专门用于“文件到网络”直接传输的系统调用,全程在内核空间完成数据传输,完全避免用户空间参与,是更彻底的零拷贝优化。整体流程:
- DMA将文件数据从磁盘拷贝到内核缓冲区
- 内核通过地址映射,将内核缓冲区的数据关联到socket缓冲区,这里无需CPU拷贝,
- DMA将socket缓冲区的数据拷贝到网卡缓冲区
相比传统流程,sendfile仅需两次DMA拷贝,避免了CPU拷贝和用户空间的参与,属于“零CPU拷贝”,sendfile仅支持文件到网络的传输,无法反向传输,依赖内核实现。
rocketMQ和kafka都使用了零拷贝技术,但是,kafka使用的是sendfile,rocketMQ使用的是mmap。因为mmap技术可以感知到发送的内容,通过这些内容,rocketMQ可以实现一些原生的功能,所以rocketMQ功能相较于kafka更强,但是吞吐量比kafka低。
实战
springboot整合rocketMQ
第一步:maven依赖
<dependency><groupId>org.apache.rocketmq</groupId><artifactId>rocketmq-spring-boot-starter</artifactId><version>2.0.4</version>
</dependency>
第二步:配置rocketMQ,在springboot默认的配置文件中
rocketmq.name-server=192.168.1.4:9876;192.168.1.5:9876# 生产者指定group
rocketmq.producer.group=log_practice_producer_group
# 消息发送超时时长,默认3s
rocketmq.producer.send-message-timeout=3000
# 同步发送消息失败重试次数,默认2
rocketmq.producer.retry-times-when-send-failed=0
# 异步发送消息失败重试次数,默认2
rocketmq.producer.retry-times-when-send-async-failed=0# topic
log_topic=log_practice_log_topic
第三步:编写生产者
配置生产者:
@Configuration
public class SpringConfig {@Value("${rocketmq.name-server}")private String rocketMQNameServer;@Value("${rocketmq.producer.group}")private String rocketMQProducerGroup;@Value("${rocketmq.producer.send-message-timeout}")private Integer rocketMQProducerSendMsgTimeout;@Value("${rocketmq.producer.retry-times-when-send-failed}")private Integer rocketMQProducerRetryTimesWhenSendFailed;@Value("${rocketmq.producer.retry-times-when-send-async-failed}")private Integer rocketMQProducerRetryTimesWhenSendAsyncFailed;// rocketMQ@Bean("rocketMQProducer")public DefaultMQProducer rocketMQProducer() {DefaultMQProducer producer = new DefaultMQProducer();producer.setNamesrvAddr(rocketMQNameServer);producer.setProducerGroup(rocketMQProducerGroup);producer.setSendMsgTimeout(rocketMQProducerSendMsgTimeout);producer.setRetryTimesWhenSendFailed(rocketMQProducerRetryTimesWhenSendFailed);producer.setRetryTimesWhenSendAsyncFailed(rocketMQProducerRetryTimesWhenSendAsyncFailed);return producer;}
}
发送消息:
@Service
public class ProducerService {private static final Logger logger = LoggerFactory.getLogger(ProducerService.class);// @Autowired
// private RocketMQTemplate rocketMQTemplate;@Autowired@Qualifier("rocketMQProducer")private DefaultMQProducer rocketMQProducer;@Autowiredprivate ApplicationEventPublisher applicationEventPublisher;@Autowiredprivate MqMsgRetryMapper mqMsgRetryMapper;@Value("${log_topic}")private String logTopic;public void send(String topic, String msg) throws MQBrokerException, RemotingException,InterruptedException, MQClientException {logger.info("send 发送mq消息:topic={}, content={}", topic, msg);Message message = new Message();message.setTopic(topic);message.setBody(msg.getBytes(StandardCharsets.UTF_8));rocketMQProducer.send(message);}}
第四步:编写消息消费者
@Service
@RocketMQMessageListener(topic = "${log_topic}", consumerGroup = "log_practice_consumer_group")
public class LogTopicListener implements RocketMQListener<String> {private static final Logger logger = LoggerFactory.getLogger(LogTopicListener.class);@Autowiredprivate StringRedisTemplate redisTemplate;@Autowiredprivate LogMapper logMapper;private static final String LOCK_KEY = "LOG_CONSUMER_LOCK_KEY_";/*** 消费用户操作日志相关的消息*/@Overridepublic void onMessage(String message) {logger.info("LogTopicListener 监听到的消息 content={}", message);try {LogDO logDO = JSON.parseObject(message, LogDO.class);if (logDO.getBizType() == null || logDO.getOpType() == null) {logger.error("log数据不正确 {}", JSON.toJSONString(logDO));return;}String lockKey = LOCK_KEY + logDO.getRequestId();String lockValue = UUID.randomUUID().toString();// 原子性操作:判断一个key是否存在,如果不存在,创建key,然后返回true,否则返回falseBoolean b = redisTemplate.opsForValue().setIfAbsent(lockKey, lockValue, 1, TimeUnit.HOURS);if (Boolean.FALSE.equals(b)) {logger.error("该消息已被消费过 lockKey={}", lockKey);return;}logger.info("redis设置缓存成功 lockKey={},lockValue={}", lockKey, lockValue);// 业务逻辑logMapper.insert(logDO);} catch (Exception e) {logger.error("消费消息发生业务异常", e);throw new RuntimeException(e);}}
}
第五步:验证,编写一个控制器,调用消息发送者,然后从外部访问控制器
@RestController
@RequestMapping("/api/v1/mq")
public class MqController {private static final Logger LOG = LoggerFactory.getLogger(MqController.class);@Autowiredprivate ProducerService producer;@PostMapping("/send")public String send(@RequestBody String requestBody) {LOG.info("params:" + requestBody);producer.send(requestBody);return "success";}
}
完成。
如何避免消息丢失
会导致消息丢失的情况:
- 如果消息量特别大,或者一瞬间涌入大量请求,broker可能会由于来不及处理消息,而返回失败,这个时候客户端通常会重试,取决于用户配置的重试次数,即使这样还是有可能发生生产者端消息丢失的情况
- 如果rocketMQ集群配置的是主从异步复制,当主节点挂掉的时候,可能会丢失少量消息,如果不允许消息丢失,改成同步复制,可以解决这个问题,但是这样会降低吞吐量,取决于用户的需求。
以上是我所知的,可能发生消息丢失的情况,主要出现在生产者到broker、broker异步复制这两步,从broker到消费者通常不会丢消息,但是有可能重复消费。
从生产者到broker丢消息,该怎么解决?
一种常见的解决方案:把发送消息失败后的重试次数设为0,避免重试,加重broker的负担,然后,把发送失败的消息保存到数据库中,通过定时任务扫描的方式,来重新发送,定时任务内部,设置最大重试次数和退避策略(重试间隔逐渐增加的策略),避免无限重试,还可以把定时任务改为spring事件,精准触发重试,避免定时任务空扫。另一种方案,是使用事务消息,但是这会降低吞吐量,并且消息发送失败会影响主流程,适合主流程和消息发送必须保持一致的情况。再一种方案,就是接口限流,避免发送大量数据,打垮broker。
代码实践:
第一步:关闭生产者的重试机制
# 同步发送消息失败重试次数,默认2
rocketmq.producer.retry-times-when-send-failed=0
# 异步发送消息失败重试次数,默认2
rocketmq.producer.retry-times-when-send-async-failed=0
第二步:生产者发送消息时处理发送失败的情况
// 发送消息,包含处理发送失败的逻辑
public void sendMsgWithRetry(String topic, String msg) {logger.info("sendMsgWithRetry 发送mq消息:topic={}, content={}", topic, msg);try {rocketMQTemplate.syncSend(topic, msg);} catch (Exception e) {logger.error("消息发送失败", e);// 消息发送失败的处理逻辑// 1、把消息保存到数据库中MqMsgRetryDO mqMsgRetryDO = buildMqMsgRetryDO(topic, msg);mqMsgRetryMapper.insert(mqMsgRetryDO);// 2、触发spring事件,在事件处理器中重试MqMsgRetryEvent event = new MqMsgRetryEvent(mqMsgRetryDO.getId());applicationEventPublisher.publishEvent(event);}
}private MqMsgRetryDO buildMqMsgRetryDO(String topic, String msg) {MqMsgRetryDO mqMsgRetryDO = new MqMsgRetryDO();mqMsgRetryDO.setTopic(topic);mqMsgRetryDO.setContent(msg);mqMsgRetryDO.setRetryTime(0);mqMsgRetryDO.setStatus(MqMsgRetryStatusEnum.PENDING_RETRY.getId());mqMsgRetryDO.buildInsert("sys");return mqMsgRetryDO;
}
第三步:事件处理器,重试的逻辑
@Component
public class MqMsgRetryEventListener implements ApplicationListener<MqMsgRetryEvent> {private static final Logger log = LoggerFactory.getLogger(MqMsgRetryEventListener.class);@Autowiredprivate MqMsgRetryMapper mqMsgRetryMapper;@Autowiredprivate ProducerService producerService;@Autowiredprivate ScheduledExecutorService scheduledExecutorService;// 重试间隔单位private static final Integer DELAY_UNIT = 5;@Overridepublic void onApplicationEvent(MqMsgRetryEvent event) {log.info("MqMsgRetryEventListener 开始处理spring事件 event={}, event.source={}", JSON.toJSONString(event), event.getSource());Long id = (Long) event.getSource();if (id == null) {log.error("id解析失败,返回 id={}", event.getSource());return;}MqMsgRetryDO mqMsgRetryDO = mqMsgRetryMapper.selectById(id);if (mqMsgRetryDO == null) {log.error("重试msg不存在,无需同步 id={}", id);return;}if (Objects.equals(mqMsgRetryDO.getStatus(), MqMsgRetryStatusEnum.RETRY_SUCCESS.getId())) {log.error("已经同步成功,无需同步 msgDO={}", JSON.toJSONString(mqMsgRetryDO));return;}// 提交异步任务到定时任务线程池scheduledExecutorService.schedule(new RetryMsgTask(mqMsgRetryDO), DELAY_UNIT, TimeUnit.SECONDS);}private class RetryMsgTask implements Runnable {// 执行次数private int executeCount = 0;private final MqMsgRetryDO mqMsgRetryDO;public RetryMsgTask(MqMsgRetryDO mqMsgRetryDO) {this.mqMsgRetryDO = mqMsgRetryDO;}@Overridepublic void run() {log.info("定时任务开始执行 executeCount={}, task={}", executeCount, JSON.toJSONString(mqMsgRetryDO));executeCount++;try {producerService.send(mqMsgRetryDO.getTopic(), mqMsgRetryDO.getContent());} catch (Exception e) {log.error("MqMsgRetryEventListener 消息发送失败", e);// 重试int MAX_EXECUTE_COUNT = 3;if (executeCount >= MAX_EXECUTE_COUNT) {// TODO 告警的逻辑log.error("最终消息经过{}次发送后依然没有成功 {}", executeCount, JSON.toJSONString(mqMsgRetryDO));return;}int delay = (executeCount + 1) * DELAY_UNIT;scheduledExecutorService.schedule(this, delay, TimeUnit.SECONDS);return;}log.info("重试成功 msgDO={}", JSON.toJSONString(mqMsgRetryDO));mqMsgRetryDO.setRetryTime(mqMsgRetryDO.getRetryTime() + executeCount);mqMsgRetryDO.setStatus(MqMsgRetryStatusEnum.RETRY_SUCCESS.getId());mqMsgRetryMapper.updateById(mqMsgRetryDO);}}
}
事件处理器中向定时任务线程池提交任务,重试的逻辑放到定时任务线程池中
幂等性消费:如何避免消息重复消费
为什么会出现重复消费?主要是网络波动、服务重启等原因,导致通信中断,已经投递或消费的消息,没有返回ack确认消息,导致重复投递:
- 生产者重复发送,例如,网络波动,生产者发送消息后没有收到确认,然后重复发送
- broker重复投递,例如,broker在主从切换时,可能重复投递
- 消费者重复处理,例如,消费者重启,导致消费成功的消息没有上报offset,从而造成重复消费
面对可能出现的消息重复,消息中间件提供了三种消息语义,这是每个消息中间件都有的概念,不单是rocketMQ。
消息中间件的消息语义,共有三个:至少一次(at least once)、至多一次(at most once)、精确一次(exactly once)。
1、至少一次:消息不会丢失,但可能重复消费,这是默认的消息语义
- rocketMQ的实现方式:在生产者端,发送消息后,等待broker的确认,如果发送失败,会重试,消费者端先处理业务,成功后再确认,如果失败,会重试
- 使用场景:大多数业务场景
2、至多一次:消息可能丢失,但不会重试。
- rocketMQ的实现方式:在生产者端,发送消息后,不等待broker的确认,立刻返回,关闭重试机制,在消费者端,拉取消息后立即确认,再处理业务,如果失败,也不会重试。
- 使用场景:日志收集、实时收集(允许少量数据丢失)
3、精确一次:消息既不丢失,也不重复消费,它的性能开销最大,实现最复杂。
- rocketMQ不支持精确一次
- 使用场景:核心业务。
如何确保没有重复消费? rocketMQ本身无法保证不重复,需要消费者自己处理,常见的解决方案:
- 方案1:消费消息之前,先加分布式锁,避免并发冲突,再设计一个唯一标识,写入到redis中,表示消息已经消费过,幂等锁1个小时失效。这里必须要加分布式锁,因为可能存在多个消费者同时发现没有幂等锁,同时去消费的情况,造成重复消费。
- 方案2:基于redis的特性,使用lua脚本 ,把判断幂等key是否存在,如果不存在,就创建,这个操作优化为原子操作
消息堆积
消息堆积是由于消费者消费能力不足引起的,例如突然来了大量的流量,消费者端来不及处理,解决思路是提高消费者的消费能力,但要避免把下游打垮。
解决思路:topic增加分区数、增加消费者的实例数并且不超过队列数
参考
学习的过程中看到的一些优秀的博客:
https://blog.csdn.net/weixin_48133130/article/details/134126430?ops_request_misc=%257B%2522request%255Fid%2522%253A%25222379c1c505bed33601b0fd629c84c5c4%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=2379c1c505bed33601b0fd629c84c5c4&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~top_positive~default-1-134126430-null-null.142^v102^pc_search_result_base1&utm_term=rocketmq&spm=1018.2226.3001.4187- https://blog.csdn.net/zhiyikeji/article/details/138286088
- 集群搭建:https://segmentfault.com/a/1190000039367254
- 排查日志:https://blog.hwgzhu.com/article/rocketmq-consumer-log
- 面试题:https://blog.csdn.net/ctwctw/article/details/107463884