RAG的17种方式实现方式研究
图片来源网络,侵权联系删

文章目录
- 一、文档分块策略:筑牢知识地基
- 1. 基础版RAG(Simple RAG):快速验证的入门级
- 2. 语义分块(Semantic Chunking):保障语义完整的进阶方案
- 3. 上下文增强(Context Enriched):提升长文档推理的连贯方案
- 4. 块头标签(Contextual Headers):适配结构化文档的精准方案”
- 5. 文档增强(Augmentation):扩大检索覆盖的多视图
- 二、检索与排序增强:精准命中知识的关键环节
- 6. 查询改写(Query Transformation):扩大检索覆盖的多问法
- 7. 重排序(Reranker):提升精准度的二次筛选
- 8. 相关片段提取(RSE,Relevant Span Extraction):定位关键信息的精准
- 9. 上下文压缩(Contextual Compression):降低Token成本的精简方案
- 10. 混合检索(Hybrid Retrieval):平衡精度与召回的综合方案
- 三、后处理与反馈优化:持续进化的动态系统
- 11. 反馈闭环(Feedback Loop):基于用户行为的优化
- 12. 自适应检索(Adaptive RAG):多场景适配
- 13. 自我决策RAG(Self RAG):提升效率的智能跳过
- 14. 知识图谱增强(Knowledge Graph):结构化知识的深度关联
- 15. 层次索引(Hierarchical Indices):节省计算开销
- 16. 假设性文档嵌入(HyDE,Hypothetical Document Embedding):应对模糊问题的逆向方案
- 17. 纠错式RAG(CRAG:Corrective RAG):容错性强的问题补全
- 四、RAG方式的选型指南
- 五、总结:RAG的核心是灵活组合与持续迭代
一、文档分块策略:筑牢知识地基
文档分块是将长文本切割为适合检索的“语义单元”,直接影响后续检索的召回率(找到相关信息)与相关性(信息精准度)。以下5种分块策略适配不同文档类型与业务需求:
1. 基础版RAG(Simple RAG):快速验证的入门级
- 技术原理:采用“问题向量化→向量库检索→内容拼接→LLM生成”的极简流程。文档分块仅按固定字符长度(如512token、1024token)切割,无需复杂语义处理。
- 核心优势:开发成本低(30分钟内可搭建)、流程简单,适合快速验证RAG可行性。
- 适用场景:文档结构简单(如单页产品说明、FAQ文档)、对检索精度要求不高的轻量场景。
- 工具适配:LangChain基础文档加载器(
SimpleDirectoryReader)+ FAISS向量库(快速实现向量检索)。 - 代码示例(简化版):
from langchain.document_loaders import SimpleDirectoryReader from langchain.vectorstores import FAISS from langchain.embeddings import HuggingFaceEmbeddings# 加载文档 loader = SimpleDirectoryReader(input_dir="./data") documents = loader.load()# 分块(固定长度) from langchain.text_splitter import CharacterTextSplitter text_splitter = CharacterTextSplitter(chunk_size=512, chunk_overlap=0) doc_splits = text_splitter.split_documents(documents)# 构建向量库 embed_model = HuggingFaceEmbeddings(model_name="all-MiniLM-L6-v2") vectorstore = FAISS.from_documents(doc_splits, embed_model)
2. 语义分块(Semantic Chunking):保障语义完整的进阶方案
- 技术原理:摒弃固定长度切割,改用语言模型(如BERT)或句法树分析文档语义逻辑,在句子、段落的语义断点处分割(例如按“章节标题→子标题→段落”的层级拆分),确保每个分块具备独立、完整的语义。
- 关键技术:Transformer Embedding(捕捉语义特征)+ 动态窗口(根据语义连贯性调整分块边界)。
- 核心优势:避免机械分块导致的语义断裂,提升长文档推理的连贯性(如学术论文、技术手册的分块)。
- 适用场景:文档结构复杂(如长篇论文、产品手册)、需要保留语义逻辑的场景。
- 代码示例(使用LangChain的
RecursiveCharacterTextSplitter):from langchain.text_splitter import RecursiveCharacterTextSplitter# 语义分块(按段落、句子拆分,保留语义连贯性) text_splitter = RecursiveCharacterTextSplitter(chunk_size=512,chunk_overlap=128,separators=["\n\n", "\n", "。", "!", "?"], # 按语义分隔符拆分length_function=len ) doc_splits = text_splitter.split_documents(documents)
3. 上下文增强(Context Enriched):提升长文档推理的连贯方案
- 技术原理:为每个分块添加前后邻居段落(如“前一段落+当前块+后一段落”),组成“上下文块”。这样可保留块的上下文信息,避免孤立分块导致的“断章取义”。
- 核心优势:提升长文档推理的连贯性(如用户问“产品的售后服务政策”,可通过上下文块获取“购买流程→售后服务”的完整信息)。
- 适用场景:需要结合上下文理解的长文档场景(如历史文献、合同条款)。
- 实现细节:使用
SlidingWindowTextSplitter(滑动窗口分块),设置window_size(窗口大小)和step_size(滑动步长)。
4. 块头标签(Contextual Headers):适配结构化文档的精准方案”
- 技术原理:提取文档中的标题、章节名、段落主题等结构性元数据(如“1.1 产品功能”“2.3 法律责任”),将这些元数据与正文内容一起嵌入向量。
- 核心优势:增强分块的“分类与上下文提示能力”,让检索更精准(如用户问“产品的退款政策”,可直接定位到“3.2 退款流程”块)。
- 适用场景:结构明确的文档(如技术手册、法律文书、企业内部章程)。
- 实现细节:使用
Document对象的metadata属性存储元数据,例如:from langchain.schema import Document# 为文档添加元数据(标题、章节名) doc = Document(page_content="这是产品功能的具体描述...",metadata={"title": "产品功能", "section": "1.1"} )
5. 文档增强(Augmentation):扩大检索覆盖的多视图
- 技术原理:为每个文档构建多个“视图”(如摘要、正文、元数据、关键词),将这些视图统一存入向量数据库(如ChunkRAG的多向量索引)。
- 核心优势:从多个角度覆盖文档信息,提升检索的召回率(如用户问“产品的核心功能”,可通过“摘要”视图快速匹配;问“产品的详细参数”,可通过“正文”视图获取)。
- 适用场景:文档内容丰富的场景(如企业知识库、图书馆数据库)。
- 工具适配:ChunkRAG、DocView RAG(支持多视图自动生成)。

二、检索与排序增强:精准命中知识的关键环节
检索阶段的目标是“从海量知识库中快速找到与问题最相关的信息”,需平衡“召回率”(找到所有相关信息)与“精准度”(找到最相关信息)。以下4种方法可实现RAG的“持续进化”:
6. 查询改写(Query Transformation):扩大检索覆盖的多问法
- 技术原理:用LLM将用户输入的问题生成多个语义等价问法(如同义词替换、句式转换),再分别进行向量检索。例如,用户问“如何优化RAG的分块策略”,LLM生成“RAG分块策略的优化方法”“怎样改进RAG的文档分块”等多个问法。
- 核心优势:覆盖更多潜在的相关内容,解决用户提问“表述单一”的问题。
- 工具链:LangChain MultiQueryRetriever(自动生成多问法)。
- 代码示例:
from langchain.retrievers import MultiQueryRetriever# 初始化MultiQueryRetriever retriever = MultiQueryRetriever.from_llm(llm=ChatOpenAI(model="gpt-3.5-turbo"),base_retriever=vectorstore.as_retriever(),query_prompt="""请将以下问题改写为3个语义等价的问法:原始问题:{query}""" )# 检索(生成3个问法,分别检索) results = retriever.get_relevant_documents("如何优化RAG的分块策略")
7. 重排序(Reranker):提升精准度的二次筛选
- 技术原理:对检索到的TopK候选文档(如前10个),用Cross-Encoder/BERT等模型重新打分并排序,保留相关性最高的文档。
- 核心优势:过滤掉“语义相关但内容不精准”的文档(如检索“2024年AI领域最新论文”时,排除“2023年AI论文”)。
- 模型选择:MonoT5、Cohere Reranker(精度可提升30%以上)。
- 实现细节:使用
CrossEncoder模型对文档与问题的相关性进行打分,例如:from langchain.retrievers import ContextualCompressionRetriever from langchain.retrievers.document_compressors import CrossEncoderReranker# 初始化重排序压缩器 compressor = CrossEncoderReranker(model_name="cross-encoder/ms-marco-MiniLM-L-6-v2")# 构建压缩检索器(先检索Top10,再重排序取Top3) compression_retriever = ContextualCompressionRetriever(base_compressor=compressor,base_retriever=vectorstore.as_retriever(search_kwargs={"k": 10}) )# 检索(返回Top3重排序后的文档) results = compression_retriever.get_relevant_documents("2024年AI领域最新论文")
8. 相关片段提取(RSE,Relevant Span Extraction):定位关键信息的精准
- 技术原理:在长文档中定位与问题最相关的“片段/句子”(而非整段),避免冗余信息干扰。例如,检索“产品的保修期限”,可直接定位到“本产品保修期为1年”这句话。
- 技术方案:交叉编码器(Cross-Encoder)+ Pointer Network(定位关键片段)。
- 核心优势:提升长文档推理的“针对性”,减少LLM处理冗余信息的成本。
- 适用场景:长文档场景(如法律条文、学术论文)。
9. 上下文压缩(Contextual Compression):降低Token成本的精简方案
- 技术原理:对检索结果执行“信息压缩”,剔除无关内容(如广告、重复信息),保留关键句子或段落。例如,检索到一篇1000字的文章,可压缩为200字的核心内容。
- 核心优势:降低LLM的Token输入成本(减少计算资源消耗),提升响应速度。
- 工具适配:LangChain Compression Retriever(支持自动压缩)。
- 代码示例:
from langchain.retrievers import ContextualCompressionRetriever from langchain.retrievers.document_compressors import DocumentCompressorPipeline from langchain.retrievers.document_compressors import LengthBasedCompressor# 初始化压缩器(剔除超过500token的文档) compressor = DocumentCompressorPipeline([LengthBasedCompressor(max_length=500) ])# 构建压缩检索器 compression_retriever = ContextualCompressionRetriever(base_compressor=compressor,base_retriever=vectorstore.as_retriever() )# 检索(返回压缩后的文档) results = compression_retriever.get_relevant_documents("产品的核心功能")

10. 混合检索(Hybrid Retrieval):平衡精度与召回的综合方案
- 技术原理:结合向量检索(语义相似)与关键词检索(精确匹配),兼顾语义理解与精准关键词匹配。例如,用户问“2024年AI领域最新论文”,向量检索可找到“语义相关”的论文,关键词检索可找到“包含‘2024年’‘AI’”的论文。
- 技术组合:Pinecone(向量检索)+ Elasticsearch(关键词检索)。
- 核心优势:平衡“精确度”与“召回率”,适合复杂查询场景。

三、后处理与反馈优化:持续进化的动态系统
优秀的RAG系统不仅能“精准检索”,还能根据用户反馈、业务变化动态优化。以下8种方法可实现RAG的“持续进化”:
11. 反馈闭环(Feedback Loop):基于用户行为的优化
- 技术原理:收集用户对RAG输出的行为反馈(如“点击查看原文”“满意度评分”“手动修正答案”),将反馈数据标注为“正样本”(用户认可)或“负样本”(用户否定),用于更新排序模型或向量库的权重,形成“用户反馈→模型迭代→效果提升”的闭环。
- 核心优势:形成“用户反馈→模型迭代→效果提升”的闭环,长期优化检索效果。
- 适用场景:用户交互频繁的场景(如智能客服、企业内部知识库)。
- 落地技巧:用Redis存储实时反馈数据,每周进行一次模型微调(避免数据延迟影响效果)。
12. 自适应检索(Adaptive RAG):多场景适配
- 技术原理:先用小模型(如Llama 2-7B)或规则引擎识别用户问题类型(如“事实查询”“逻辑推理”“代码生成”),再根据问题类型动态选择检索策略。例如:
- “事实查询”(如“地球半径是多少”):用“基础检索+重排序”;
- “逻辑推理”(如“为什么RAG能解决幻觉问题”):用“查询改写+HyDE”;
- “代码生成”(如“如何用Python实现RAG”):用“上下文增强检索”。
- 核心优势:避免“一刀切”的检索策略,适配多业务场景的差异化需求。
- 技术组合:LangChain Router(问题分类)+ MultiVector Retriever(多策略检索)。
13. 自我决策RAG(Self RAG):提升效率的智能跳过
- 技术原理:在检索前增加“自我判断”环节——让LLM根据问题判断“是否需要外部知识支持”:
- 若问题属于大模型已掌握的常识(如“地球半径是多少”),则直接生成答案,跳过检索流程;
- 若问题需要外部知识(如“2024年AI领域最新论文”),则触发检索。
- 核心优势:减少不必要的检索操作,提升响应速度(平均耗时可降低30%~50%),节省计算资源。
- Prompt设计示例:“请判断:回答该问题是否需要调用外部知识库?若不需要,请直接回答;若需要,请列出所需知识的关键词。”
- 工具适配:Self-RAG(LangGraph实现,支持自反思机制)。

14. 知识图谱增强(Knowledge Graph):结构化知识的深度关联
- 技术原理:将非结构化文档转化为**“实体-关系-属性”的三维知识图谱(如“产品→属于→科技公司”“产品→具有→功能A”),在检索时不仅进行文本检索,还可基于知识图谱进行关联检索与路径推理**(如用户问“产品的开发商”,可通过“产品→属于→科技公司”关系直接定位)。
- 常用工具:Neo4j(图数据库存储)、KGLM(图谱嵌入模型)。
- 核心优势:支持语义联想(发现潜在知识关联)、清晰解释实体关系(让回答更具逻辑性)。
- 适用场景:需要深度关联知识的场景(如企业知识图谱、医疗诊断辅助)。
- 代码示例(使用Neo4j进行知识图谱检索):
// 查询产品的开发商(实体-关系-属性) MATCH (p:Product {name: "产品A"})-[:BELONGS_TO]->(c:Company) RETURN c.name
15. 层次索引(Hierarchical Indices):节省计算开销
- 技术原理:借鉴文档目录的层级结构,对文档构建目录级别的分层索引体系(如“一级目录→二级目录→三级目录→文档块”),检索时按从顶层到底层的顺序逐层检索,避免对整个文档库进行全量检索。
- 关键技术:Nested FAISS(嵌套向量索引)、TreeIndex(树状索引结构)。
- 核心优势:大幅节省检索的计算开销(如100万篇文档的检索,可从“全量检索”变为“目录定位+局部检索”)。
- 适用场景:文档数量庞大、内容复杂的场景(如企业知识库、图书馆数据库)。
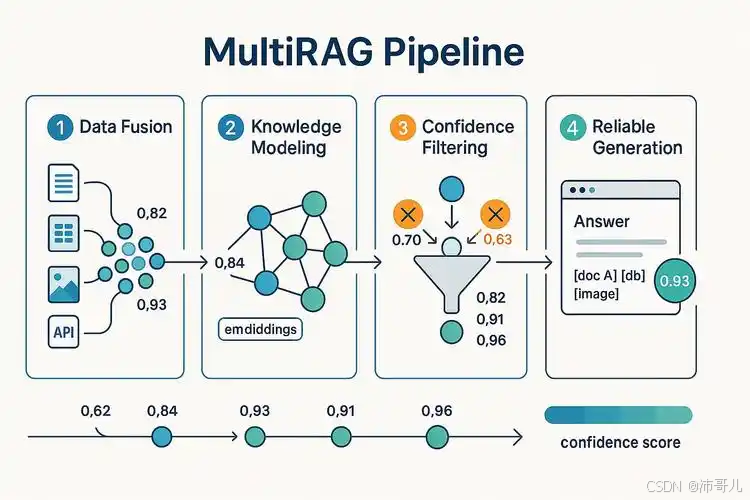
16. 假设性文档嵌入(HyDE,Hypothetical Document Embedding):应对模糊问题的逆向方案
- 技术原理:采用“逆向思维”,先让LLM根据用户问题尝试生成一个**“理想答案”(如用户问“如何优化RAG的分块策略”,LLM生成“优化RAG分块策略的方法包括语义分块、上下文增强等”),然后将这个理想答案进行向量转化,基于该向量在文档库中反向检索**可能支持该答案的相关材料(如“语义分块的技术原理”“上下文增强的实现方法”),最终以检索到的材料为依据生成实际回答。
- 适用场景:文档碎片化严重、内容分散(如多个文档提到“语义分块”但未集中说明),或用户提问为长问句、需求不够明确的场景。
- 代码示例(使用Qwen生成假设答案):
from dashscope import Generation# 定义HyDE生成函数 def generate_hyde_query(original_query: str) -> str:prompt = f"""请根据以下问题,生成一个假设性的、详细的答案。即使你不确定正确答案,也请模仿百科知识的风格和语气来写。问题:{original_query}假设性答案:"""response = Generation.call(model='qwen-max',prompt=prompt,seed=12345,top_p=0.8)hyde_text = response.output['text'].strip()return hyde_text# 生成假设答案 hyde_query = generate_hyde_query("牛顿第一定律是什么?") print(hyde_query)
17. 纠错式RAG(CRAG:Corrective RAG):容错性强的问题补全
- 技术原理:在检索前增加“问题纠错与补全”模块,修复用户提问中的错别字、语法错误、上下文缺失等问题,将优化后的提问作为最终的检索输入。例如:
- 错别字修复:“RAG分快策略”→“RAG分块策略”(用PySpellChecker);
- 上下文补全:“怎么优化这个策略”→“怎么优化RAG的文档分块策略”(用Claude 3 Haiku)。
- 适用场景:用户为非技术人员(如企业行政查询HR手册)、提问口语化或存在语法错误的场景。
- 工具链:PySpellChecker(拼写纠错)+ Claude 3 Haiku(轻量问题补全)+ Prompt Template(标准化问题格式)。
四、RAG方式的选型指南
实际落地时,无需全部采用17种方式,需根据业务目标选择核心方案。以下是不同需求场景的选型推荐(结合):
| 应用目标 | 推荐方法组合 | 核心优势 |
|---|---|---|
| 快速上线(1~2周落地) | Simple RAG + 基础向量库(FAISS) | 开发成本低,无需复杂定制 |
| 提升回答准确性 | 语义分块 + Reranker + RSE | 从分块、排序、提取三环节保障信息精准度 |
| 扩大检索覆盖范围 | Query Transformation + Fusion + 文档增强 | 多问法、多策略、多视图覆盖更多相关内容 |
| 降低成本与提升效率 | Self RAG + Contextual Compression + 多级索引 | 减少检索次数、压缩Token、加速大规模检索 |
| 支持结构化知识查询 | 块头标签分块 + Knowledge Graph | 适配层级文档,挖掘实体关联 |
| 基于用户反馈持续优化 | Feedback Loop + Adaptive RAG | 动态适配用户需求,长期提升系统效果 |
| 应对非专业用户提问 | CRAG + HyDE | 修复问题错误,补充上下文,提升容错性 |

五、总结:RAG的核心是灵活组合与持续迭代
RAG并非单一工具,而是“文档处理→检索增强→生成优化→反馈迭代”的全链路系统。其核心价值在于“让LLM用上准确、实时的外部知识”,解决传统LLM的“知识滞后”“幻觉生成”“输出不可控”等痛点。
在实际生产中,需避免两个误区:
- “追求大而全”:盲目叠加多种方法会导致系统复杂度过高,增加开发与维护成本;
- “固守单一方案”:忽略业务变化对RAG效果的影响(如用户需求升级、文档内容更新)。
建议的落地路径是:
- 第一步:用Simple RAG验证业务可行性(如搭建一个内部FAQ机器人);
- 第二步:根据用户反馈引入核心优化方案(如语义分块提升检索精度、Reranker提升回答准确性);
- 第三步:通过反馈闭环实现长期迭代(如用用户满意度评分优化排序模型)。
只有让RAG与业务场景深度绑定,才能真正发挥其“精准、可控、可进化”的核心价值,为企业带来实际的业务价值(如降低客服成本、提升员工效率、优化用户体验)。