神经网络组植物分类学习规划与本周进展综述13
一、YOLOv5模型训练
1.1 数据调整(一定整理成如下结构)
·images:存放图片
·train:训练集图片
·val:验证集图片。
·labels:存放标签
·train:训练集标签文件,要与训练集图片名称--对应
·val:验证集标签文件,要与验证集图片名称一-对应
1.2 关于labels文件夹的设计
将标注数据单独放在labels文件夹,且与images的文件一 一对应,是为了明确 “图像 - 标签” 的关联关系:
每张图片都有一个同名的标签文件(比如cat001.jpg对应cat001.txt),标签文件里存储了图片中目标的类别、位置等标注信息。
这种结构能让 YOLOv5 在训练时快速匹配 “图像内容” 和 “标注信息”,避免数据混乱。
1.3 验证集的图片也需要标注
因为验证集的作用是评估模型在未见过的标注数据上的表现,需要通过标注好的标签来计算模型预测的准确率、精确率等指标(比如模型预测了一个目标的位置和类别,需要和标注的真实位置、类别对比,才能知道模型预测得准不准)。如果验证集图片没有标注,就无法客观地衡量模型的性能了。
1.4 训练集(train)与验证集(val)的意义
把数据分为训练集和验证集,是机器学习中避免 “过拟合”、评估模型泛化能力的核心手段:
(1) 训练集(train)
作用:让模型学习知识。模型会在训练集上反复迭代,学习图像特征与目标标注之间的规律(比如 “什么样的像素组合属于猫,它的位置在哪里”)。
特点:数据量通常占比最大(比如 70%-80%)。
(2)验证集(val)
作用:检验模型的学习效果,且验证集的数据从未被模型 “见过”。通过验证集的表现,我们可以判断模型是否 “学懂了”(比如会不会把狗误判成猫),以及是否出现了 “过拟合”(比如只记住了训练集的细节,换张图就识别不准)。
特点:数据量相对较小(比如 20%-30%),与训练集完全无重叠。
二、操作:在原有图片标注成功之后,增加新的标注图片
2.1 合并标注数据
(1)整理新图片与标签
将新标注的图片放入images/train或images/val(根据用途划分),对应的标签文件放入labels/train或labels/val,确保图片与标签文件名称一一对应。
在打开LabelImg的时候,选取之前标注好的文件夹train或val,之前标注过的数据在LabelImg中不会显示已经标记过了。为了避免这个情况,可以把新加的图片创建一个暂时的新的文件夹,images和label都创建一样名称的文件夹。标注完之后再把图片分批移动到对应的train或val中。
(2)无需额外操作
YOLOv5 在训练时会自动读取images和labels下的train、val文件夹,只要路径正确,新数据会和原有数据一起参与训练。
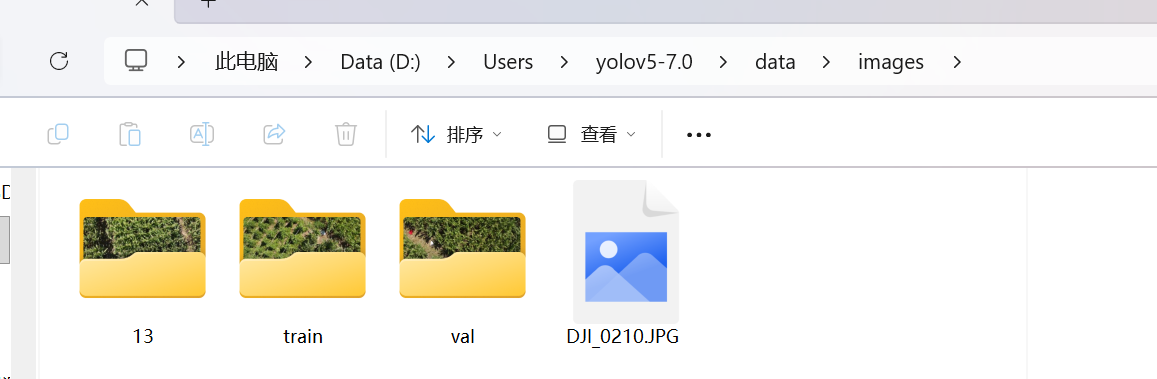
2.1 处理classes.txt文件
(1)classes.txt用于定义目标检测的类别,必须保持全局唯一且一致,否则会导致类别混乱。
若新标注引入了新类别:将新类别添加到classes.txt的末尾,确保所有类别在文件中按顺序唯一存在。
若类别无变化:直接使用原有classes.txt,避免创建多个classes.txt文件。
按照以上操作,就能确保新旧数据合并训练时类别统一、数据完整,模型可以学习到所有标注的目标特征。
(2)标注工具的类别管理逻辑是 “基于你配置的classes.txt来加载类别,不会自动生成新的类别文件”,具体分两种情况:
1)标注类别与原有classes.txt一致
如果新标注的类别名称和原有classes.txt里的完全相同(比如都是 “man”“bus” 等),标注工具会直接调用已有classes.txt中的类别,不会生成新的classes.txt,标注完成后只需将新标签和图片按之前的目录结构(labels/train、images/train等)存放即可,训练时能自动合并。
2) 标注时误生成新类别文件
如果标注工具意外生成了新的classes.txt,需要手动检查:
对比新旧classes.txt的内容,确保类别名称、顺序完全一致。
将新类别文件删除,统一使用原始的classes.txt,避免类别定义冲突。
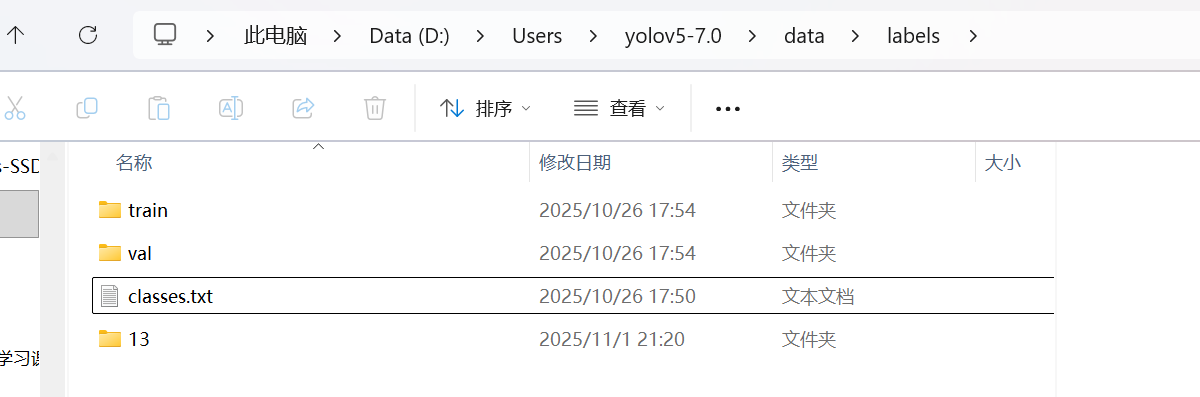
三、操作:标注新的图片,并分别放到对应的文件夹下面
3.1 images文件夹
3.2 labels文件夹
四、问题与反思
有时候激活YOLov5环境的时候,明明有环境,并且有时可以激活,有时不能激活,解决办法入下(可以输入具体的yolov5 地址 来激活)
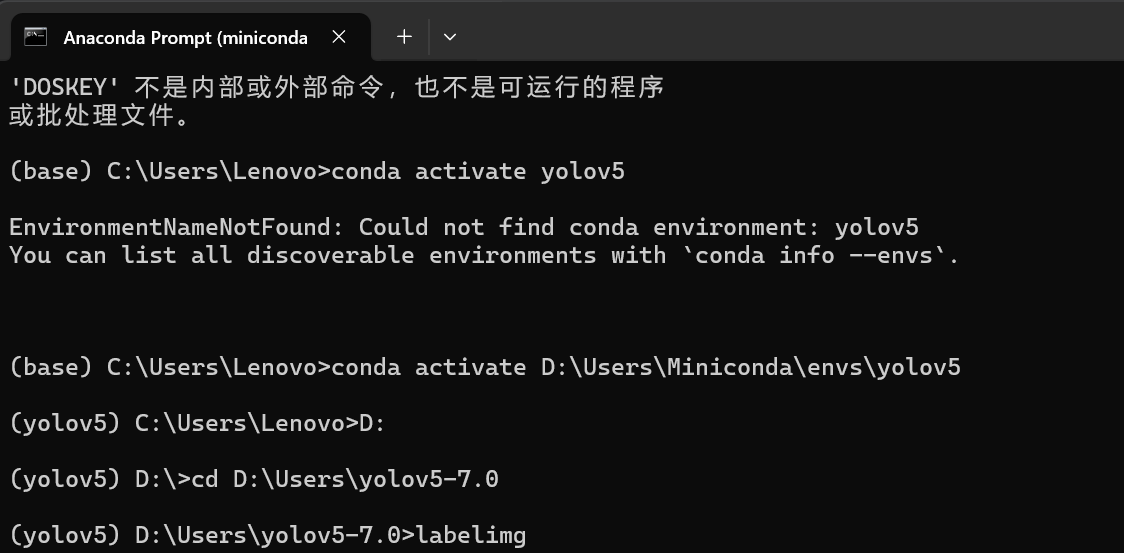
五、下周学习规划
修改现有模型,适配当前数据集,进行训练,分开corn和ground