JAVA高频面试题
HashMap的底层数据结构?
jdk8以前:数组+链表
Jdk8以后:数组加链表加红黑树
为什么要引入红黑树?
链表长度大于8之后,会从链表变成红黑树,这样做的目的时因为链表的查询复杂度为O(1)而红黑树在数据量大的时候,他的查询效率要比链表的高。
扩容机制是什么?为什么他的数组长度永远都是2的幂次?
1.是根据扩容因子来的默认是0.75,比如长度为16,那么到了16*0.75=12时,就进行扩容,扩容的长度为16*2=32。
2.因为底层的Hash算法,2的幂次的长度有利于他更均匀的分配数据
为什么在JDK7到JDK8要把头插改成尾插?为什么他解决冲突的方式是链表加红黑树?
1.在并发的时候不安全,两个线程同时进行扩容操作,会把链表变成环形链表,出现死循环的结果
2,链表加红黑树并没有“减少”冲突的发生次数,而是“优化”了冲突发生后的处理效率,极大地缓解了冲突带来的性能瓶颈。链表的时间复杂度为O(n),红黑树的时间复杂度O(logN),时间复杂度优化了,处理冲突和判断是否有冲突的处理效率高了。
ArrayList和LinkedList有什么区别?
前者是底层数据结构是数组,后者是链表,链表适合删除或者新增头节点和尾节点,前者适合查询
ConcurrentHashMap是怎么实现的?ConcurrentHashMap在JDK7到JDK8做了什么升级?
他是线程安全的HashMap,
JDK7
主要是靠那个分段锁实现并发安全,默认有16个segment数组,每个都有一把锁,一共16个小锁,各个线程操作不同的段,互不打扰。可以简单的认为每个segment存放的就是一个单独的HashMap。
JDK8
由于并发度是由他的数组大小决定的,那么数组一旦初始化,后期的扩容只能一段一段的扩,性能提升有限。JDK8直接摒弃了segment,用Node节点代替,每个桶上一把锁,锁的粒度更小了,而且插入时,优先用CAS无锁状态插入,冲突了再加Synchronizd。
而且和HashMap一样,1.7是数组加链表,1.8是数组加链表加红黑树。
什么是乐观锁和悲观锁,CAS是怎么实现的?
这是一种思想,乐观的认为不会发生并发冲突,所以他的核心观念就是不加锁,
悲观锁就是悲观的认为并发冲突一定会发生,所以他把读和写都加上了锁,安全是安全,不过性能太低了,干啥都加锁。
CAS就是基于乐观锁的思想实现的一种机制,比较并交换,先说比较,线程用自己的old value和共享资源的new value进行比较,比较通过了,那就交换这两个值,拿到共享资源,没有拿到共享资源的线程就一直自旋,等待共享资源的释放,顺便提一下,比较并交换是两步操作,他的原子性是通过硬件锁,锁住总线的方式来保证的
ABA问题:
这个问题就是线程1想要访问共享变量A,但是在这之前,线程2他把共享变量改成了B,这个时候线程2把他又改回了A,共享变量:A->B->A
这个时候虽然共享变量的值改回去了。但是这个变化可能意味着某些依赖条件已经改变(例如,在链表操作中,节点可能已经被移出链表后又重新加入),导致 线程1 的 CAS 成功可能是不正确或危险的。
解决办法:
就是给他加一个版本号,让他每次修改的时候。版本号就会变化(默认是递增),这样就能够保证他的一个正确性了。
Synchronized和ReenTrantLock有什么区别?
主要有以下三点区别:
1.ReentrantLock他是基于AQS实现的,AQS底层有tryAquire()方法,对应到ReentranLock这里就是TryLock,尝试获取锁,获取到了,我就执行,获取不到我就能干别的事去了。这是Syntranized没有的
2.公平锁和非公平锁机制:Synchronizd是非公平的锁,reentranLock锁是既可以公平又可以非公平,reentranlock里有两个子类,fireSync和NonfireSync,二者都重写了tryquire方法,前者是用的等待队列,先进先出,保证了公平性,后者实现了插队的功能,保证了非公平性。
3.Synchronizd有锁池和等待池,锁池存放的是获取锁失败的线程,等待池他存放的是通信时主动放弃锁的线程,reentrantLock:获取锁失败的线程放在等待队列中,获取锁成功但是还要等资源响应的线程放在Condtion类中。
原子类是如何实现的?
volatile + CAS + (自旋/适应性策略)
volatile:保证可见性
CAS:解决了原子性问题,他底层是加了硬件锁嘛。
自旋/适应性策略:解决了获取锁失败后的处理策略
Volatile的关键字有什么作用?
他的作用是保证线程之间的可见性,他的底层实现,其实是依靠cpu的缓存一致性协议来实现的
什么是JMM?什么是指令重排序?什么是happens before原则?
1.以"一次编译,到处运行"为宗旨,为了屏蔽这个不同的操作系统的内存模型的影响,自己创建了一个内存模型:JMM
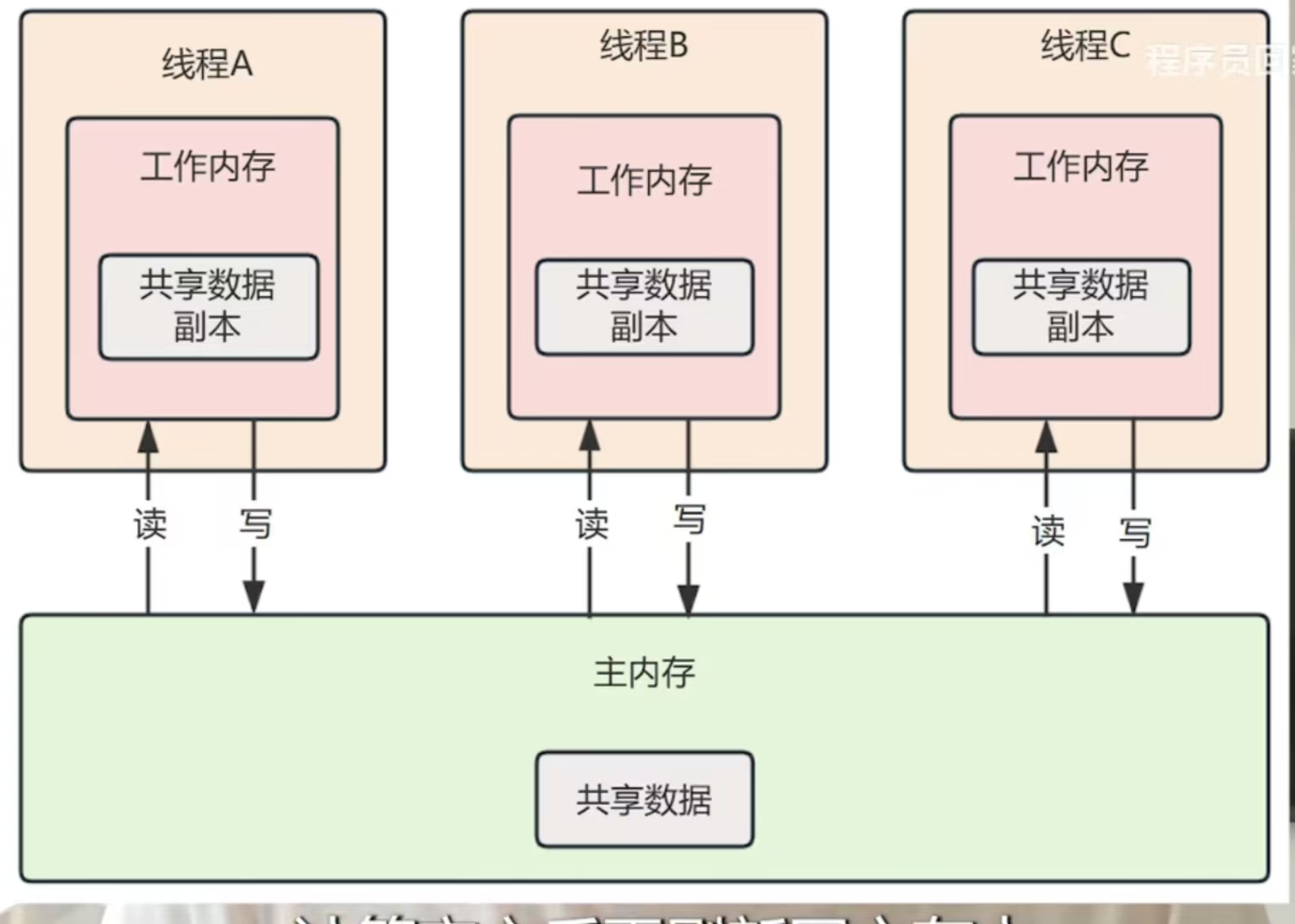
内存模型如图,线程要获取数据,首先要先把共享数据读到主内存在进行计算,计算完之后再把数据刷回到主内存
工作内存和共享内存之间的交互,JMM设计了八种原子操作
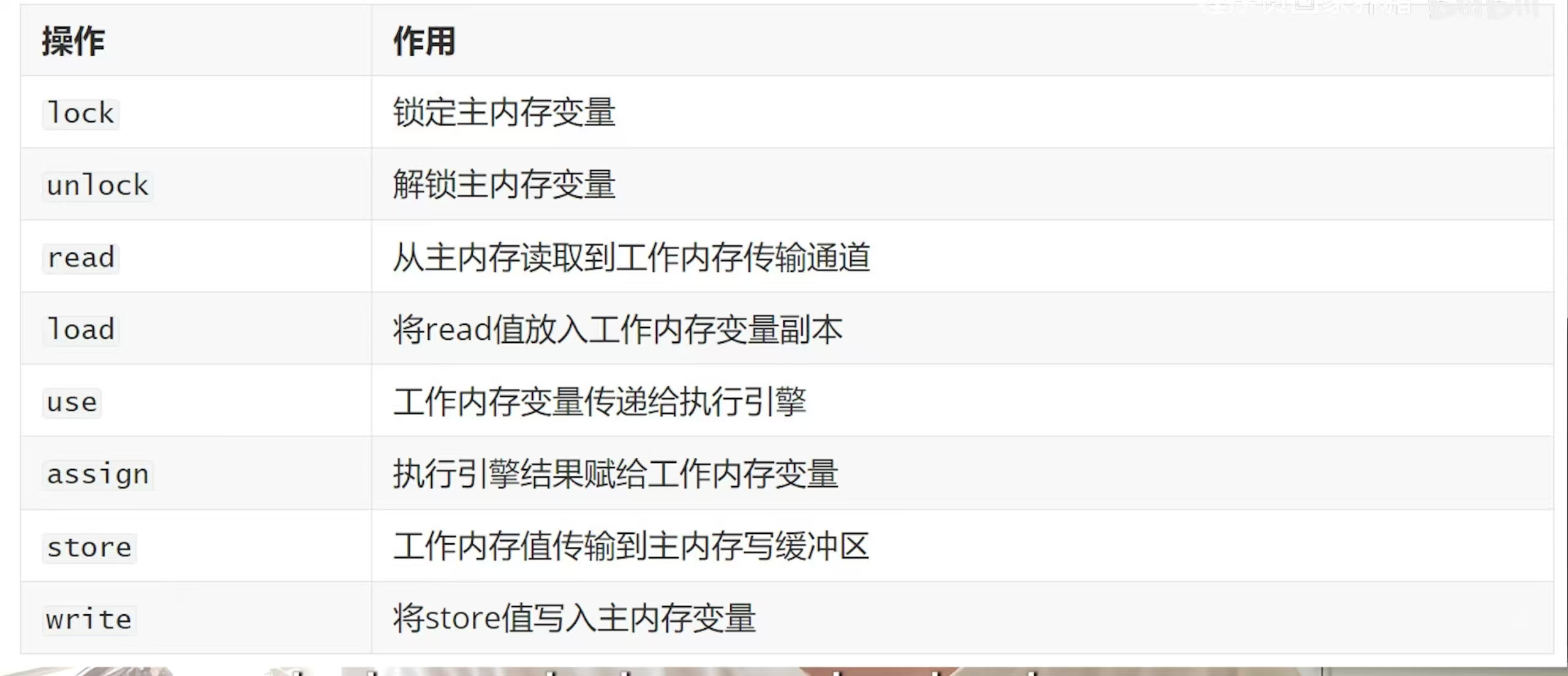
简单来说就是对主存加锁,拿到变量去工作内存,然后把变量更新之后放回到主存,然后解锁。
指令重排序:
JMM数据交互的操作执行的时机,具体怎么实现,就要靠内存屏障去保障内存操作的顺序性和可见性

happens before规则
传递性:a->b b->c a->c
a happens before b,也就是说单线程内,前面的操作对于后面的操作是可见的

Synchronized锁升级的流程?
为什么要锁升级?
不同的时间点锁竞争和并发量是不同的,高并发的时间点其实不多,每次线程获取锁失败,要被阻塞时,底层的操作系统都要从用户态转变为内核态,开销会很大。
无锁:这个时候,适用于深夜基本上没人买东西的时候,并发量非常小,没有加锁的必要
偏向锁:当有一个线程来抢锁,那此时就升级为偏向锁
轻量级锁:当第二个线程来抢锁我就升级为轻量级锁,没有拿到资源的线程就自旋,不用阻塞,这样就避免了性能开销。而且此时线程自旋的时间不会特别长,CPU的浪费不会特别多。
重量级锁:当线程多了,锁竞争激烈的时候,你就不能只让他自旋了,不然自旋时间特别久的话,他是非常浪费CPU资源的(拿着资源不干事)
锁监视器:
锁监视器是一个对象。里面有四个主要的字段:
持有锁的线程:记录当前获取锁的线程
等待池:调用wait()方法的线程,也就是主动放弃锁的线程
锁池:获取锁失败的线程
记录锁的重入次数:计数器,记录重入次数
都是阻塞的线程为什么要分别放在两个地方呢?
这是因为等待池里的线程是调用wait()方法主动放弃锁,是为了等待别的资源齐全了,再执行自己的方法。锁池是获取锁失败的线程,他想的是立马抢到锁然后执行。
Synchronized是不是可重入锁,可重入锁是为了保证什么?
1.Synchronized是可重入锁
2.可重入锁为了保证防止自我死锁的场景,普通锁的场景:比如线程A拿到了一把锁(锁了很多方法,是个大代码块),但是线程A还想访问里面的方法,那就还需要获取同一把锁,但是只能获取一次锁,那这个时候是既不能调用里面的方法,又不能退出来(因为锁还没有释放),所以这个时候就死锁了。
所以要有可重入锁:
拿到锁进来大代码块里了,然后计数器+1,然后你又要拿大代码块里面的方法的锁,那这个时候,计数器+1,等到你把两个方法都执行完了,那就计数器-1再-1,此时计数器=0,所以锁释放。
AQS队列是怎么实现的,他是怎么实现一个公平锁的?
他是把一个个的线程看成一个个节点,然后把它们组成一个双向链表,基于双向链表的一个等待队列,双向链表是为了保证过期的线程能够更好的及时被移除,执行发现过期的节点,直接用prev方法定位到上一个节点,然后在直接next下一个有效节点就OK了。独享模式和共享模式,前者是一次唤醒一个线程,后者是需要多少个线程就唤醒多少个。
等待队列的特性就是先进先出嘛,那自然就能够保证线程的公平性
线程池的核心参数是什么?他提交任务的流程是什么,他的线程池的核心参数又要怎么计算?
线程的创建和销毁开销非常的大,那为什么大呢?
注意:java21创建了虚拟线程,那就不用转换操作系统状态就能完成线程的创建与销毁。
因为java他是一对一的线程模型,就是java创建一个线程,操作系统就要从用户态转换到内核态去进行操作,销毁线程也是一样。这种状态的改变时非常的消耗性能的。
那我们能不能不要频繁的去创建和销毁线程?
能,找个容器给他存起来线程池里面有线程(正式牛马),有任务过来了,我的线程就去处理任务。当任务越来越多的时候,如果忙不过来,那就用个任务队列(桌上没处理的文件)把他们存起来。(没完成的工作先放着),如果还忙不过来,就找了几个临时工:创建几个临时线程(实习生),那如果任务执行完了,大伙没活干了,临时线程就要被销毁,所以就要设置一个临时线程的最大空闲时间(实习期)
那如果要是任务队列满了,又有新的任务来了,线程和临时线程都在忙,根本有心无力这时候该怎么办呢?
那就涉及到拒绝策略了
那问题又来了,这个时候创建线程是创建普通线程还是守护线程呢?创建线程的时候又该怎么去给线程命名,所以就要搞一个线程工厂,让他去负责统一创建线程,根据业务对线程命名,这样就好排查问题:业务出了问题就能定位到具体的线程池和线程,线程出了问题也能定位到业务,所以不同的业务要用不同的线程池。
所以线程池的七大参数:
1.核心线程数(正式牛马)、最大线程数(正式+实习牛马),线程工厂(根据规则创建线程),拒绝策略,临时线程的空闲时间(实习期)、时间单位、阻塞队列(堆积任务)

接口和抽象类有什么区别?
接口中的方法,类里实现起来要重写他的所有方法
抽象类是一个类,他是为了开发规范发明的一个类
什么是单例模式?能给我写一个双重锁的检查吗?
单例模式就是确保一个类 只能创建一个对象 的设计模式
public class Singleton {// volatile 关键字确保多线程环境下的可见性和禁止指令重排序private static volatile Singleton instance;// 私有构造函数:禁止外部 new 创建对象private Singleton() {System.out.println("Singleton created");}// 全局访问点public static Singleton getInstance() {// 第一次检查:如果已存在实例直接返回(避免不必要的同步)if (instance == null) {// 同步代码块:保证只有一个线程进入创建synchronized (Singleton.class) {// 第二次检查:防止阻塞线程恢复后重复创建if (instance == null) {instance = new Singleton();}}}return instance;}
}Mysql的事务隔离级别?什么是ACID?
ACID:原子性,隔离性,持久性,一致性
读未提交(啥都解决不了),读已提交(解决脏读),不可重复读(解决可重复读),串行化(都可以解决)
在MVCC下可重复读是怎么实现的,他还有幻读的可能性吗?
快照读:事务开始时就拍了张照片,然后你的事务结束前都是参考这张所谓的照片去读取数据的。
当前读:这时候要修改某个数据,当然只能拿最新的数据,这就是当前读,读当前最新的数据
1.MVCC的可重复读就是他的快照读实现的,重复的读一张照片,怎么读都还是那些数据
2.不能完全解决幻读问题
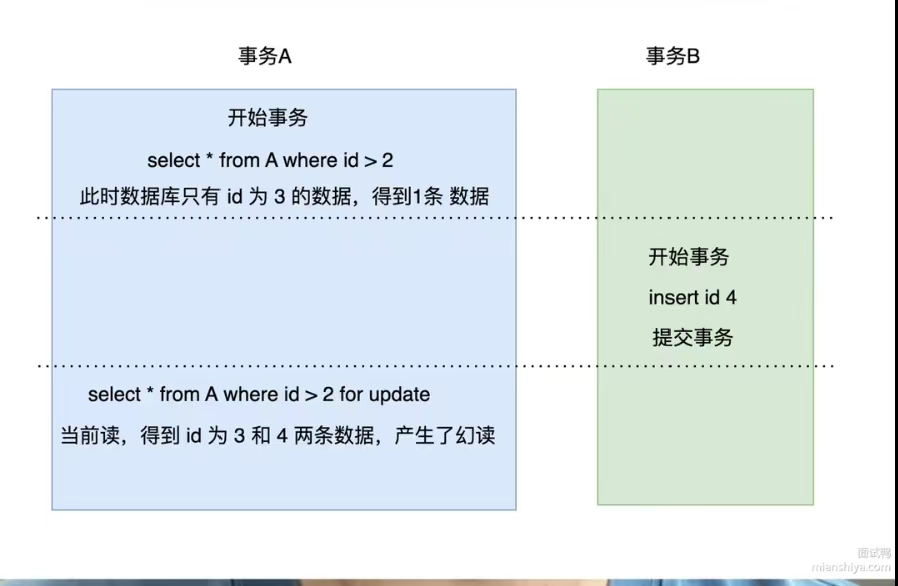
事务1是单纯的查询,是快照读,这时候比如读出来3条数据,事务2插入了一条数据,并且提交了事务,然后,事务1要修改事务了,那必须是切换为当前读,所以这个时候读到了最新的数据,总数记录变成了4条,所以此时幻读了。
什么是间隙锁?什么是临间锁?
间隙锁:防止插入的范围锁,在某个范围不能插入,锁的范围是(10,15)全开的区间,锁住的区间不能新增
临键锁:这个也是范围锁,但是是(10,15]左开右闭区间,锁住的区间不能新增删除修改
二者的区别就是;锁的范围不一样,然后能避免幻读。
什么是索引的回表查询,怎么避免这个问题?
你一开始访问的是二级索引,他的叶子节点上挂着Id,然后你拿着这个Id再去找对应Id的数据,
创建索引的时候少创建二级索引。避免索引失效,比如最左前缀法则等等,然后保证他能够走主键索引
mysql有哪些常见的索引?索引在哪些情况下会失效?
常见的索引:主键索引,二级索引
违反最左前缀法则,在索引上实现运算
有用过explain这个关键字嘛?
这个关键字用于查询sql语句的执行情况,放在sql语句的前面,然后他查出来的结果有一些参数:执行耗时,是否全表查询,走的什么索引等等
Inndb下Mysql的索引数据结构是什么?
他是优化后的B+树索引,底部之间的节点形成一个双向链表,用这个数据结构的好处是他的数据全都在叶子节点上,方便我们查询。
mysql的三大日志?
undoLog:
bingdoLog:
redolog:适用于事务的回滚
Redis的数据类型, 底层实现原理, 使用场景
String: 动态字符串 缓存
list 双向链表 消息队列,消息列表
set 集合 朋友圈点赞
zset 跳表+hash表 排行榜
Hash Mapmap(value也是键值对) 用户信息,商品信息
缓存击穿/穿透/雪崩
缓存穿透:
大量前端请求到一个不存在的key,缓存中没有这个key,全部去查数据库,导致数据库的压力巨大。
解决办法:
1.缓存空值,对value为空的key也存在缓存(对内存压力很大)
2.布隆过滤器
缓存击穿:热key在某个时间过期了,然后大量请求过来,压力打到数据库。
解决办法:1.互斥锁(线程1发现key过期了,加一把锁,然后重建数据库)
2.逻辑过期
雪崩:就是某个redis服务崩了,或者大量的key同时失效,导致这个大量的请求打到数据库,然后导致数据库压力巨大
解决办法:
1.redis的集群模式
2.给key的过期时间设置随机值
redis和数据库的一致性问题?
1.先删除缓存和先删除数据库都会有脏数据的产生。
2.使用延迟双删,修改完数据库之后隔一段时间再删一次缓存,不过具体延迟多久也不清楚,所以也会有脏数据。
3.使用MQ的消息监听,把二者联系起来,依靠MQ的可靠性
4.用cancel作为中间件,也是监听的功能
redis为什么快,redis的IO多路复用模型?
redis的IO多路复用模型?
//TODO
1.redis是内存,是硬件的特性导致的他快
2.用一个线程去管理这些个socket,这些socket可读可写时会第一时间通知这个线程,当socket准备就绪了的时候,他会在通知用户进程的同时,把socket推送给用户空间,避免了他们遍历socket判断是否就绪浪费很多时间
能用redis去实现一套登录的机制嘛
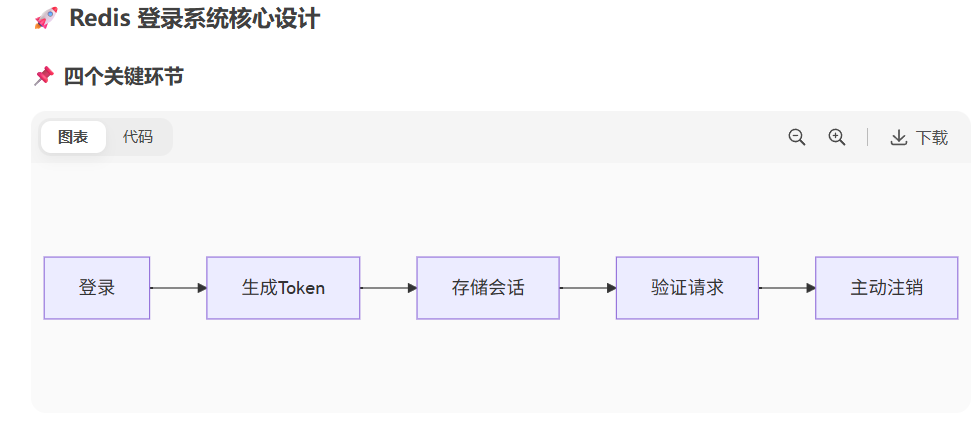
redis的登录,登录重要的是token的存储和验证,以及之后的用户注销(删除token记录)
存储token:
redis存储token,设置过期时间,用的是hash结构存储的这个token (key:User_Token,value:token)防止token泄漏还可以:用jwt签名算法加密
验证token:
找一下redis中是否含有token,并且有没有过期,过期了就自动续签,更新过期时间
删除用户:redis删token
在线用户数量的统计:统计key的数量
redis的主从同步,redis的持久化机制
redis的主从同步:
这是redis集群的问题,为了防止reids的压力太大导致宕机,从而导致缓存雪崩,设计了一套这个redis的主从模式,用一个keepalive的插件去时刻监听主节点,主节点跪了,立马从节点顶上,那这么多的从节点,我怎么知道该选哪个?这个时候就看三个方面,第一个是内存大的redis先顶上,因为内存大,能存更多的数据。第二个就是看复制偏移量,主从节点之间是有联系的,从节点会复制主节点的数据,复制的越多复制偏移量就越大,那数据最接近于主节点的从节点就是最适合当主节点的。第三个就是按照序号排了。
redis中的大Key和热Key你该怎么去优化?
大Key:
1.分片存储,把大key拆分成很多的小key
2.调整参数,让系统优先用一些小型的集合去装我们的key,如果key能压缩,比如文本,那就可以先压缩一下
3.定期删除:把redis里面的key定期删除一下,释放内存
热Key:
读多写少的场景:
1.把他多分到几个从节点里头,支持读操作
2.还可以放在本地缓存里头
3.设置VIP的key,让他单独的放在一个节点里,独享服务
4.第一个线程进来,拿到的结果,回去共用
5.设置永不过期,避免缓存击穿,
6.熔断降级: 如果发现Redis快扛不住了(访问量爆炸),直接返回一个默认值(比如“服务繁忙”或者一个缓存的老数据),保护Redis别被冲垮。
有没有JVM的调优,JVM的垃圾回收算法,JVM的内存空间?
什么是垃圾
如果应该对象已经没有任何应该地方引用他,他就是垃圾
怎么确认是垃圾
引用计数法
给对象添加一个引用计数器,每当有一个地方引用它时,计数器加一。反之每当一个引用失效时,计数器减一。当计数器为0时,则表示对象不被引用。
可达分析
设立若干根对象(GC Root),每个对象都是一个子节点,当一个对象找不到根时,就认为该对象不可达。
触发条件
Minor GC触发机制
当年轻代满时就会触发Minor GC,这里的年轻代指的是Eden代满,Survivor满不会引发GC。
FULL GC触发机制
老年代空间不足方法区空间不足通过Minor GC后进入老年代的平均大小大于老年代的可用内存。由Eden区、From Survivor区向To Survivor区复制时,对象大小大于To Space可用内存,则把对象转存到老年代,且老年代的可用内存小于该对象大小System.gc()方法的调用,系统建议执行Full GC,但是不必然执行。
JVM的垃圾回收算法
标记清除法:标记到的对象就会被清除,然后再这样会产大量的内存碎片。
标记压缩法:在标记清除法上面做了优化,清除完的空间会被压缩。
逃逸分析?
new 一个对象,一般是会放在堆区,但这也不是绝对的,比如new 的一个对象只在他的方法里面运行,那就把它放到本地方法栈,这样做的好处就是:方法栈里面的对象用完就直接清理掉了,大大减轻了GC的压力
如何避免out of memory这个错误?(OOM)
1.避免直接读取大文件到内存,而是分批次,流式处理,分块读取
2.ThreadLocal变量使用完之后没有调用remove()方法去删除,线程池复用线程时,ThreadLocal数据残留,导致内存泄漏。久而久之就会内存溢出,解决办法就是及时的删除ThreadLocal,用finally{ remove() }
3.创建大量线程,超过了内存就会容易OOM,我们可以用线程池对线程进行管理
内存泄漏
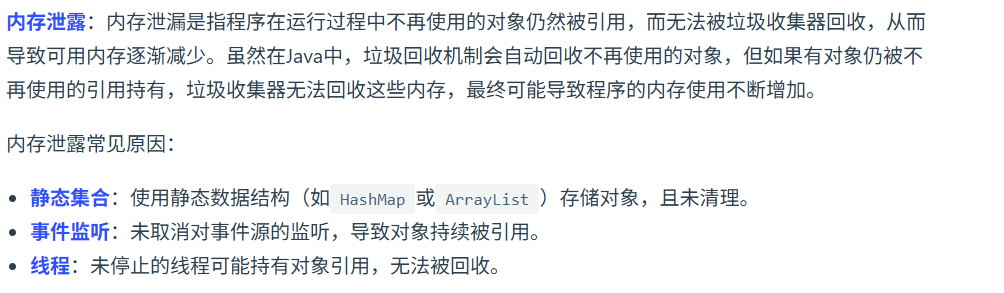
内存溢出:

你的项目中有没有内存泄漏的问题?
长生命周期对象持有短生命周期对象引用
比如在一个单例的工具类中,缓存了大量临时生成的业务对象(如用户请求数据),但没有及时清理。这些对象本应随请求结束被回收,却因被单例持有导致长期驻留内存,最终 OOM。
解决:改用弱引用(WeakReference)存储缓存,或定时清理过期数据,结合缓存淘汰策略(如 LRU)。资源未正确释放
例如使用 ThreadLocal 存储线程上下文信息后,在 Web 环境中未调用 remove (),导致 Tomcat 线程池的核心线程长期持有对象引用。此外,IO 流、数据库连接未在 finally 中关闭也可能引发类似问题。
解决:通过 AOP 或拦截器统一处理 ThreadLocal 的清理,使用 try-with-resources 确保资源自动释放,并结合 JVM 监控工具(如 VisualVM)定期排查。
Springboot涉及了哪些设计模式?
单例模式:每个类都有一个实例对象。在IOC容器中,对于单例作用域的Bean,容器只创建一个实例对象
单例模式的两个模式:饿汉模式,懒汉模式
饿汉模式:在IOC容器启动时就会创建Bean,Springboot的设计模式更倾向于饿汉模式,但只要我们在Bean类上加一个@Lazy注解,这个Bean就会在第一次访问时才会创建
懒汉模式:调用他的访问方法才会创建Bean。
单例Bean的好处:
建造者模式:
一般时Build为后缀,有build类对类的属性值修改就会方便很多
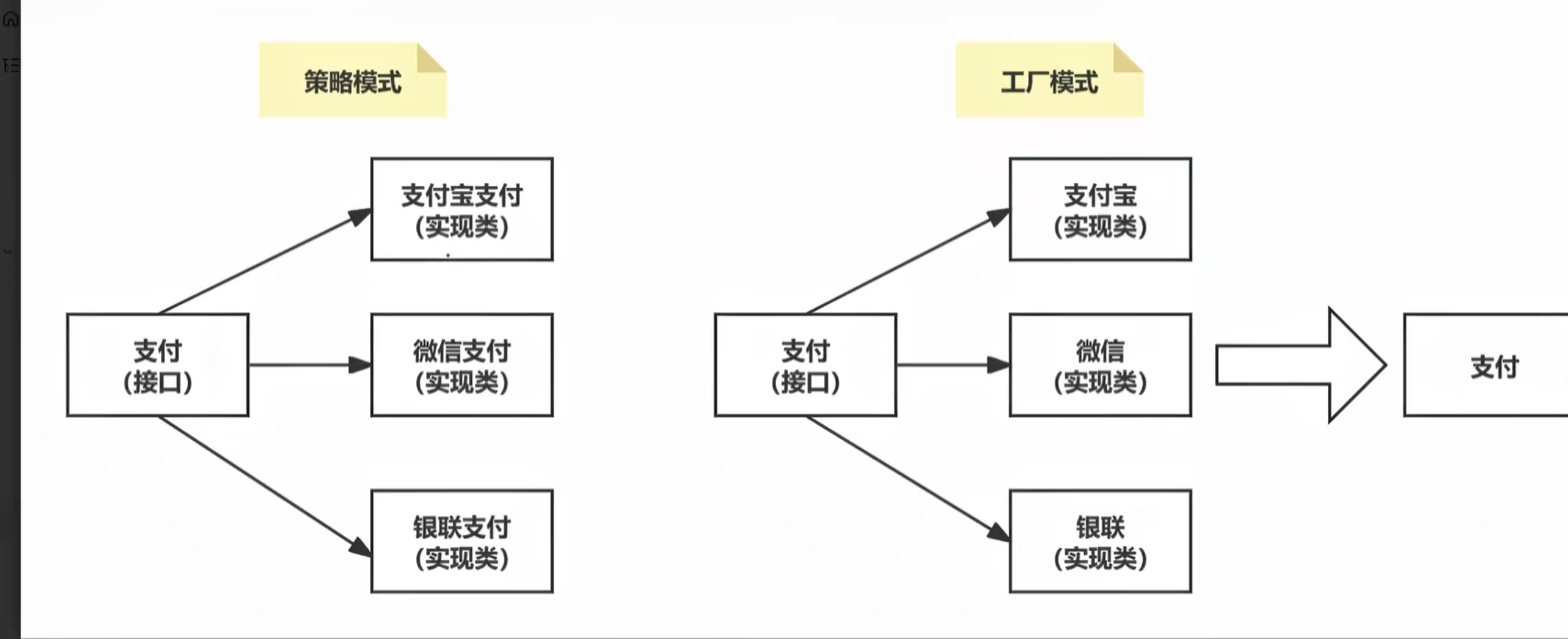
工厂模式:
工厂模式:就是你要完成一个支付的接口,你就创建三个支付类,支付类调用相应的支付接口,微信调用微信支付。
策略模式:是创建三个支付的方法,要支付的时候直接调用支付方法
Spring中a依赖b,b依赖a,spring是怎么解决的?
这是设计问题,合理的解决方案应该是:创建一个C,并且将a,b作为C类的成员变量,这样的话就是C依赖于a和b,这样能很好的避免循环依赖的问题。
更深入的讲:
容器去构建一个A时,会发现还需要一个B,构建B会发现还需要一个A,这样就会死循环。
具体方案:使用二级缓存:容器会去检测是否存在循环依赖,如果存在,首先构建A的过程,会先实例化A,并且放入二级缓存(A的状态:实例化未属性填充未初始化)填充A的属性的时候,会发现需要一个B属性,那么就去创建B,发现又需要一个A,此时我们从二级缓存中,去拿到一个半初始化状态的A(早期暴露的Bean),把他赋值给B对象,那么B创建好之后,将B的引用赋值给A,再将A从二级缓存中拉到一级缓存,那就完成了。
AOP是怎么实现的
切面编程,把一些共性的方法抽取出来,做成一个Aop的类,类里面就有共性的逻辑
然后有方法需要用这个共性的方法就在开头加一个注解
2.3 通知
通知定义了切面的具体行为,也就是在何时、何地、以何种方式对目标方法进行增强。根据增强发生的时机,通知分为:
前置通知(Before Advice):在方法调用前执行。
后置通知(After Advice):在方法调用后执行。
返回通知(After Returning Advice):在方法成功返回后执行。
异常通知(After Throwing Advice):在方法抛出异常后执行。
环绕通知(Around Advice):在方法执行的前后都执行,可以完全控制方法的执行过程。
除了JDK的动态代理,你还了解其他的代理模式吗?
静态代理:代理角色对被代理角色某个方法执行前或者后进行功能增强
也就是中介对房东的收租方法增强了,中介帮房东讲价了
Spring的AOP是运行时代理还是编译时代理?
AOP是运行时代理,他避免了编译阶段对目标类字节码的直接修改
事务注解什么时候会失效?
@Transactional注解失效的重点场景可以归纳为以下几类:
方法访问权限问题:注解仅对
public方法生效,非 public 方法(如 private)的事务会失效。自调用场景:同一类中方法互相调用时,被调用方法的事务会失效,因为未经过 Spring 代理对象。
异常处理不当:
- 捕获异常后未重新抛出
- 抛出的异常不在
rollbackFor指定范围内(默认只处理 RuntimeException 和 Error)
类未被 Spring 管理:未加
@Service等注解的类,事务注解不生效。配置问题:
- 传播行为配置错误(如 NOT_SUPPORTED)
- 数据库引擎不支持事务(如 MyISAM)
- readOnly=true 时执行写操作
这些场景的核心原因是违背了 Spring 事务基于 AOP 代理的实现机制,导致事务增强逻辑无法正常触发。
redis的各种场景下的作用
String结构:
计数器
Redis的String的原子性的自增操作,可以去做一个计数器,记录某个网页的访问量,Key:网页视频Id,value:访问次数。
计数器限流:
针对IP或者接口做一个限流,路径为Key,访问次数为value。到了一定的阈值时,比如每分钟超过120次时,我们就拒绝请求。存在隐患:第一分钟和第二分钟的一个交界处,他会允许两倍的流量,比如说极端情况60秒来了120个请求,61秒来了120个请求,两秒内(几乎同一时间来了240个请求)这种情况是redis限流器解决不了的
Hash结构
购物车:id为key,商品id为field,然后商品数据时Value
不可靠的配置中心
List结构:
双端队列(有序可重复)
先进先出,后进先出,都可以
实现一个简单的消息队列,生产者创建任务放到消息队列里,消费者去拿。要保证消息队列的幂等性,那就每个消息都设置一个唯一id,消费者去保存这些处理过的消息id,避免重复消费。
Set
点赞,set集合可以交集并集,所以共同好友,共同爱好都可以
Zset:
排行榜:主要是依赖他的底层是有序的特性
滑动窗口的限流:用户IP为key,时间戳为socre
MyBatis的一级二级缓存
一级缓存:基于PerpetualCache的HashMap本地缓存,其存储的作用域为Session,Session级别的缓存,当Session进行flush或者close之后,该Session中的所有Cache就将被清空,一级缓存默认是打开的。
二级缓存:基于namespace和mapper的作用域起作用的,默认也是PerpetualCache的HashMap本地缓存,需要单独开启。
二级缓存什么时候会被清理?
当作用域下发生了增删改的时候,它里面的select会全部删除。
MyBatis的执行流程:
1.读取Mybatis的配置文件()
2.构建会话工厂()
3.会话工厂设置session对象(包含了所有的sql语句)
4.操作数据库接口,executor执行器,同时负责缓存的维护
5.输入参数映射
6.输出结果映射
MyBatis是否支持延迟加载?
开启全局延时加载:
延时加载和立即加载的区别:
比如Dish表里边有口味表,我要查菜品名字的时候
延时加载:我会只查询菜品表,口味表等需要查到的时候再查
立即加载:我会把两个表的数据都查出来
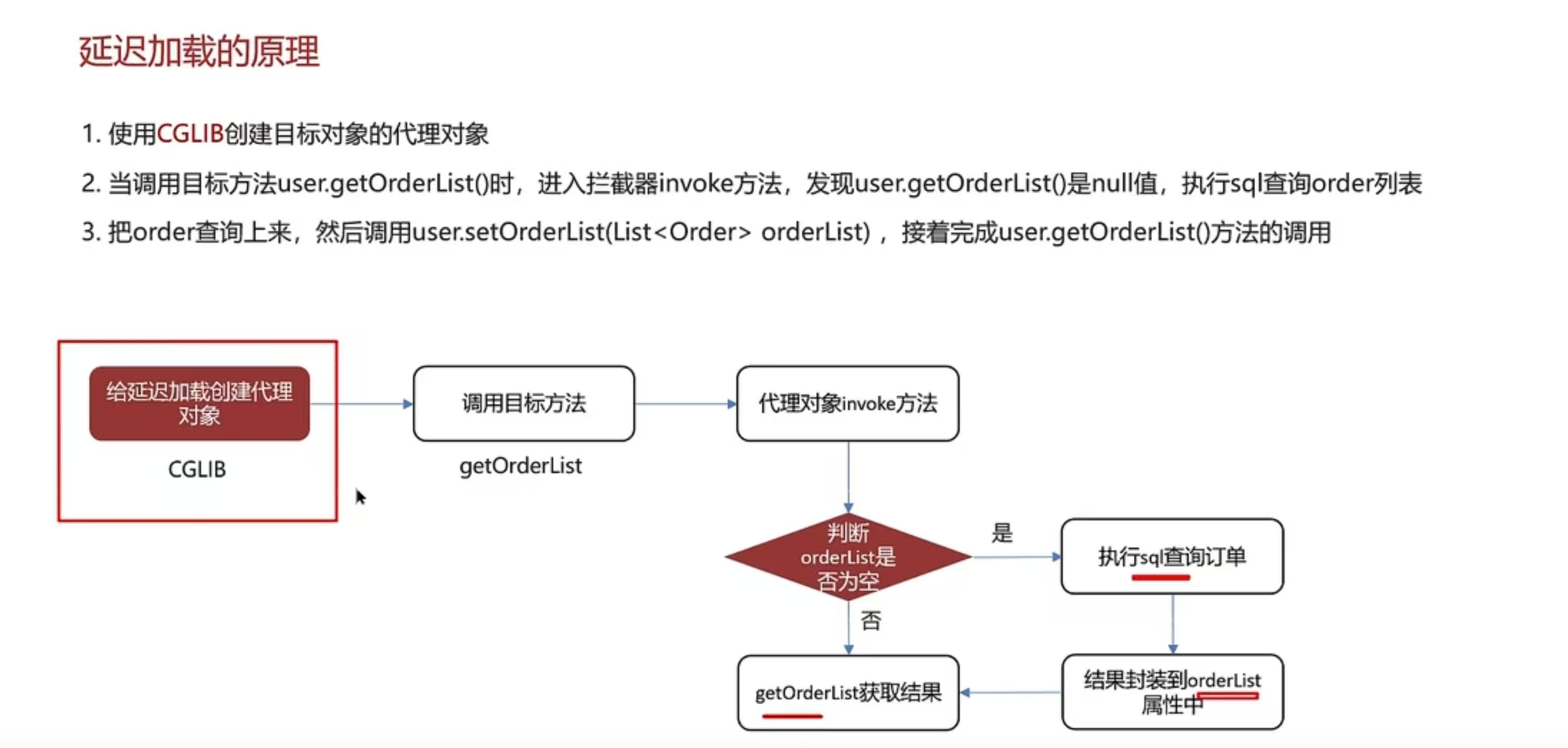
底层原理:
1.使用了CGLIB创建目标对象的代理对象
2.当调用目标方法时,进入拦截器的invoke方法
进程和线程和协程的区别?

线程基础

线程池的种类有哪些?
1.创建使用固定线程数的线程池
特点:核心线程数和最大线程数一样,没有救急线程
阻塞队列是LinkedBlockingQueue,最大容量为Integer.MAX_VALUE
适用场景:适合任务量已知的时候,相对耗时的任务
2.单线程化的线程池
特点:核心线程数和最大线程数都是1
阻塞队列是LinkedBlockingQueue,最大容量为Integer.MAX_VALUE
适用场景:按照顺序执行任务的线程
3.可缓存线程池
核心线程数是0
最大线程数:Integer.MAX_VALUE
阻塞队列为SynchronousQueue:不存储元素的阻塞队列,每个插入操作都必须等待一个移出操作。
适合任务数比较密集,但每个任务执行时间较短的情况