2025年8月AGI月评|AI开源项目全解析:从智能体到3D世界,技术边界再突破
〔更多精彩AI内容,尽在 「魔方AI空间」 ,引领AIGC科技时代〕
本文作者:猫先生
知识库主页:https://oizxc9sdhbc.feishu.cn/wiki/FGS5wST0Hiy6xJklyPTcTVOqnAd
引言
8月的AI开源领域,从智能体自主决策到多模态内容生成,从视频动画创作到3D世界构建,一系列前沿项目正以突破性技术重新定义创作边界与交互体验。
无论是通过混合专家架构实现低成本高质量视频生成的Wan2.2,还是利用扩散模型精准修复高分辨率图像的HYPIR;无论是支持多角色情感动画的FantasyPortrait,还是让开发者一键构建自主智能体的Youtu-agent……这些项目不仅展现了技术的前沿性,更在影视创作、虚拟交互、教育科研等实际场景中展现出强大的落地潜力。
本文将聚焦这些开源项目的核心技术亮点与行业应用方向,带您深度解析8月AI领域的创新图谱。
一、智能体与多模态理解:从自主决策到跨模态融合
1. Youtu-agent:灵活强大的开源自主智能体框架
技术亮点:作为开源智能体框架,支持多种智能体范式(如单智能体/多智能体协作)与丰富工具集(如API调用、环境交互),开发者可通过简单配置快速构建适用于复杂任务(如科研实验、自动化流程)的自主智能体,降低开发门槛。
项目主页:https://tencent.github.io/Youtu-agent/
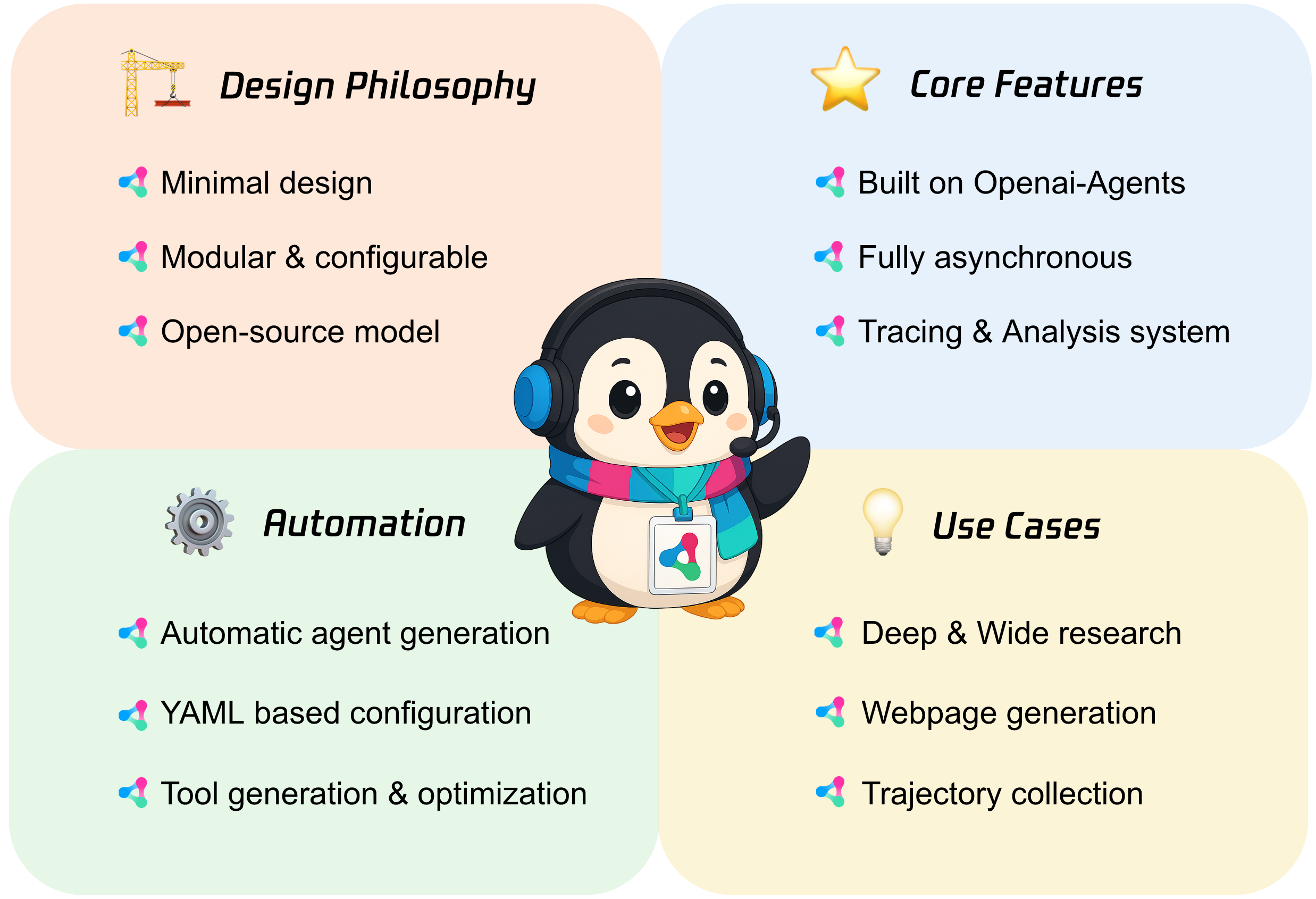
行业应用:科研模拟(如机器人集群控制)、企业自动化流程(如客服智能体)、教育场景(如学生编程实验辅助)。
技术点评:通过标准化工具链与灵活范式设计,解决了传统智能体开发中“框架适配难、工具调用复杂”的痛点,加速自主智能体的普及应用。
2. Ovis:结构化对齐的多模态大语言模型架构
技术亮点:通过结构化对齐视觉与文本嵌入(如将图像中的物体位置、动作信息与文本描述精准映射),解决传统多模态模型中“视觉-文本信息割裂”的问题,显著提升图像描述生成、视觉问答等任务的准确性。
项目主页:https://github.com/AIDC-AI/Ovis
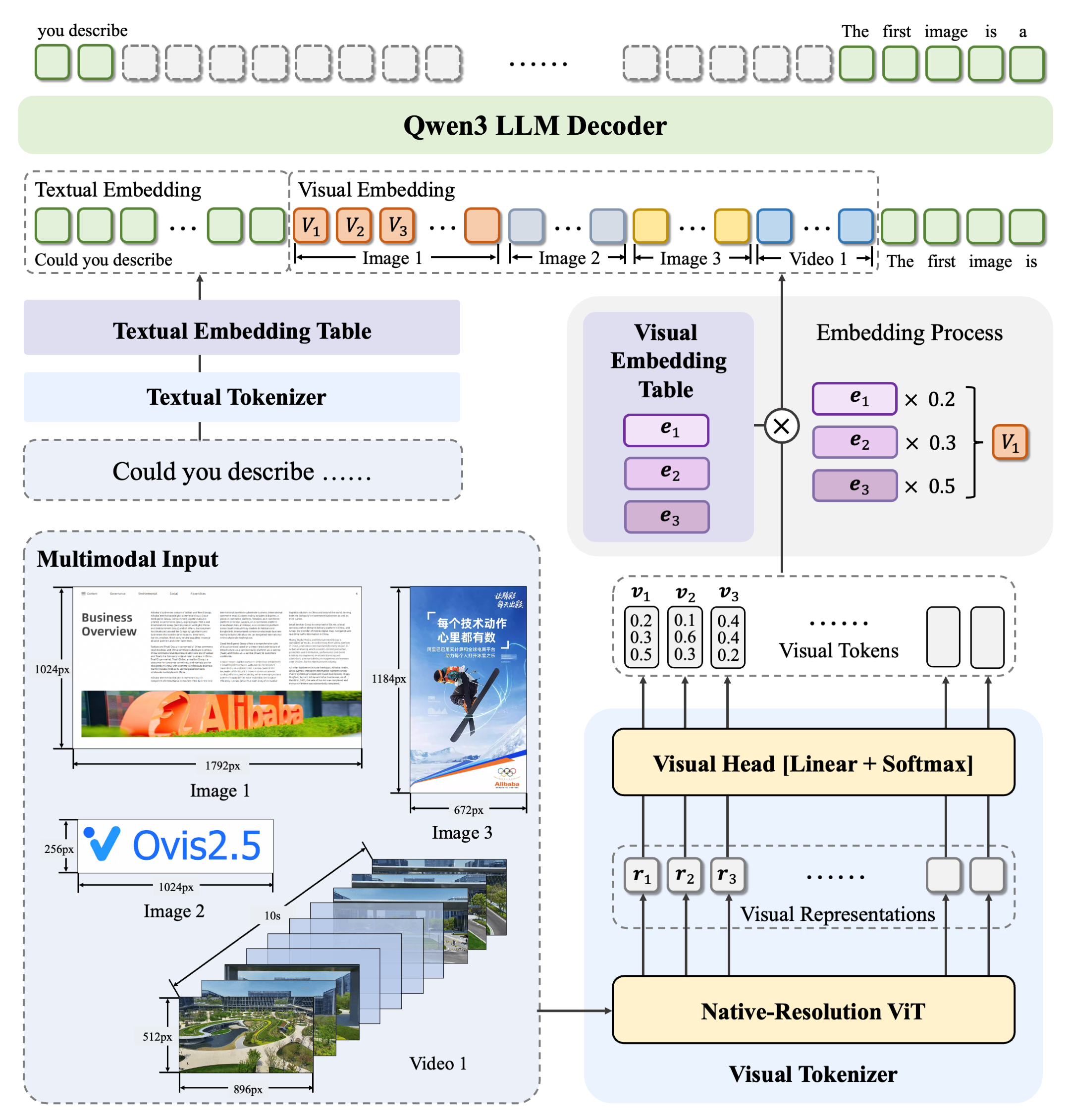
行业应用:智能安防(如监控视频内容理解)、电商(如商品图片与文本关联推荐)、医疗影像辅助诊断(如影像报告自动生成)。
技术点评:结构化对齐机制增强了模型对多模态信息的深度融合能力,为复杂场景下的跨模态任务提供了更可靠的解决方案。
3. WeKnora:基于LLM的文档理解与语义检索框架
技术亮点:采用检索增强生成(RAG)机制,支持多模态文档(如PDF+图表、扫描件+文字)处理,通过大语言模型实现智能问答与语义检索,同时具备灵活部署能力(适配云端/本地)。
项目主页:https://github.com/Tencent/WeKnora
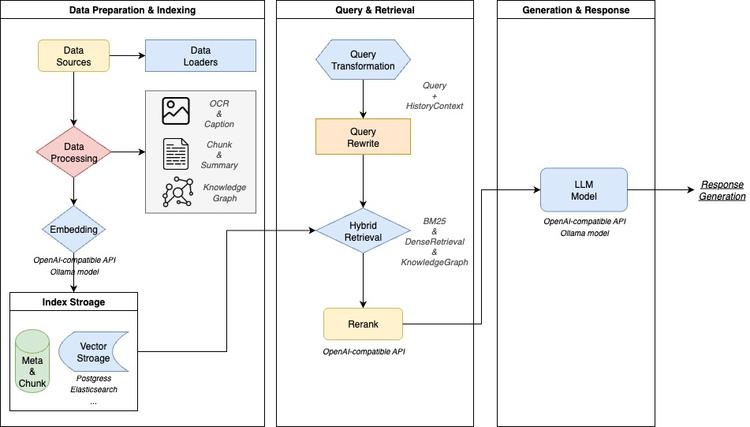
行业应用:企业知识管理(如内部文档智能搜索)、科研文献分析(如论文关键信息提取)、技术支持(如用户手册快速答疑)。
技术点评:RAG机制结合大语言模型的理解能力,解决了传统文档检索中“关键词匹配不准、上下文缺失”的问题,提升信息获取效率。
二、视频生成与虚拟试穿:质量、效率与真实性的突破
4. Wan2.2:升级版大规模视频生成模型
技术亮点:引入混合专家(MoE)架构(动态调用不同专家模块处理特定任务)、高压缩率视频自编码器(降低计算资源消耗)及精心策划的美学数据(提升生成内容的视觉质量),支持文本到视频、图像到视频、文本图像到视频、语音到视频等多样化生成任务。
项目主页:https://github.com/Wan-Video/Wan2.2
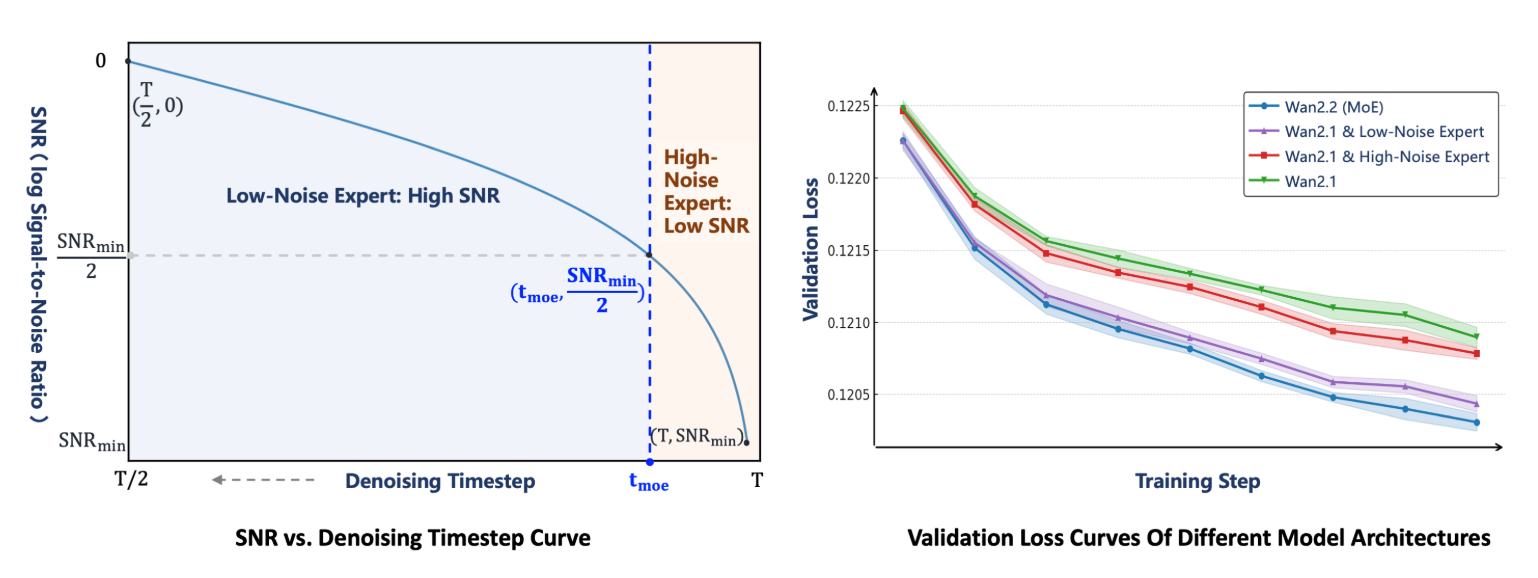
行业应用:影视预告片制作、广告创意视频生成、虚拟直播内容生产。
技术点评:MoE架构平衡了模型性能与计算成本,高压缩率自编码器解决了长视频生成的效率瓶颈,是视频生成领域“低成本高质量”的代表。
5. DreamVVT:两阶段视频虚拟试穿技术
技术亮点:基于扩散变换器(DiT)框架,通过两阶段生成(先生成基础视频再优化细节)与未配对人体中心数据训练,实现在复杂动作(如跑步、跳舞)、动态环境(如户外光照变化)和相机动态(如镜头移动)下,服装细节的高保真度与时间一致性(如衣摆摆动自然)。
项目主页:https://virtu-lab.github.io/
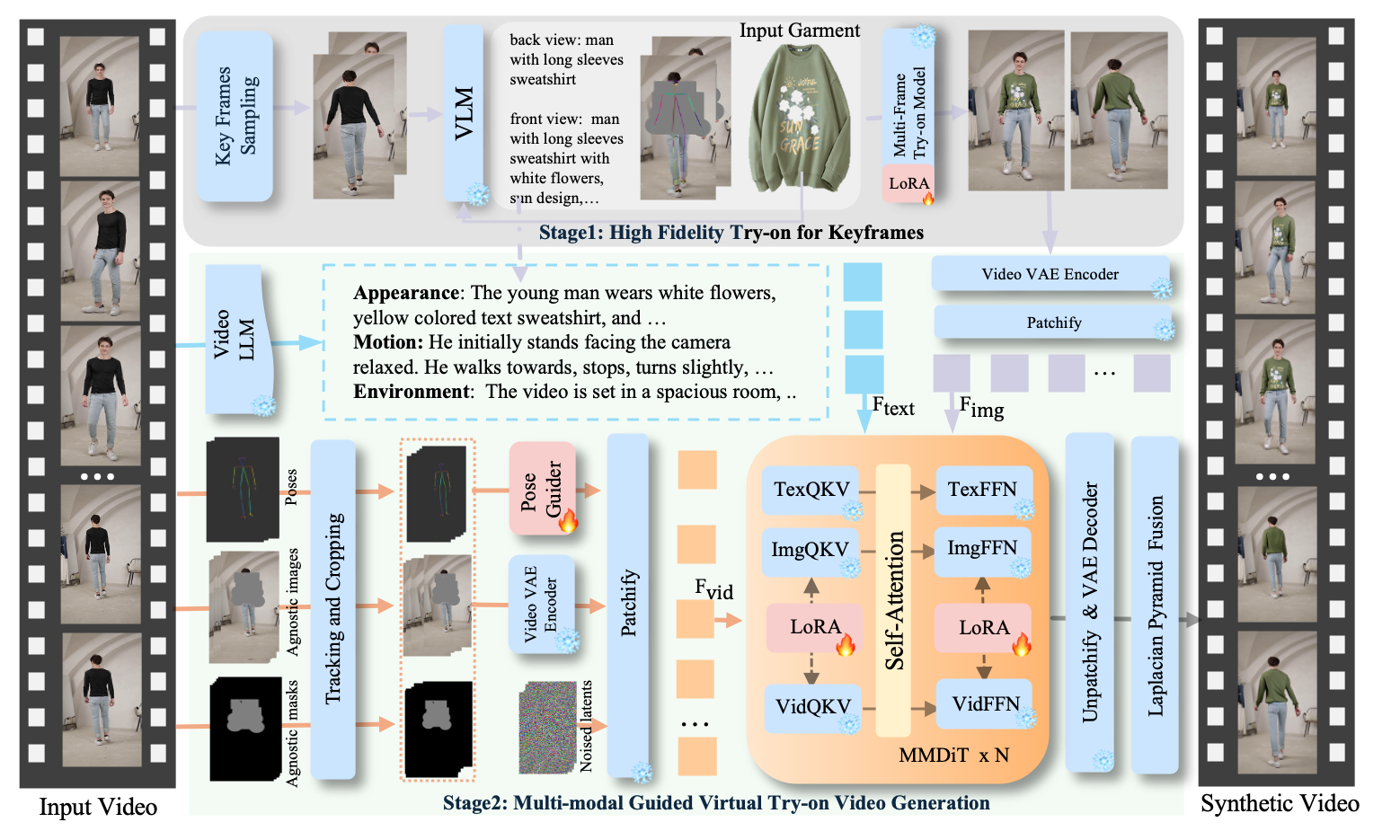
行业应用:在线购物虚拟试衣间(如服装、配饰试穿)、影视特效(如角色服装快速替换)、虚拟偶像服装设计。
技术点评:未配对数据训练增强了模型泛化性,两阶段生成策略解决了复杂场景下的细节失真问题,推动虚拟试穿技术走向实用化。
6. LongVie:可控超长视频生成框架
技术亮点:通过多模态引导(如文本+关键帧提示)与自回归生成策略(逐步生成并优化每一帧),结合动态全局-局部记忆机制(解决长视频中的时空不一致性),实现高质量超长视频(如5分钟以上连续剧情)生成。
项目主页:https://vchitect.github.io/LongVie-project/
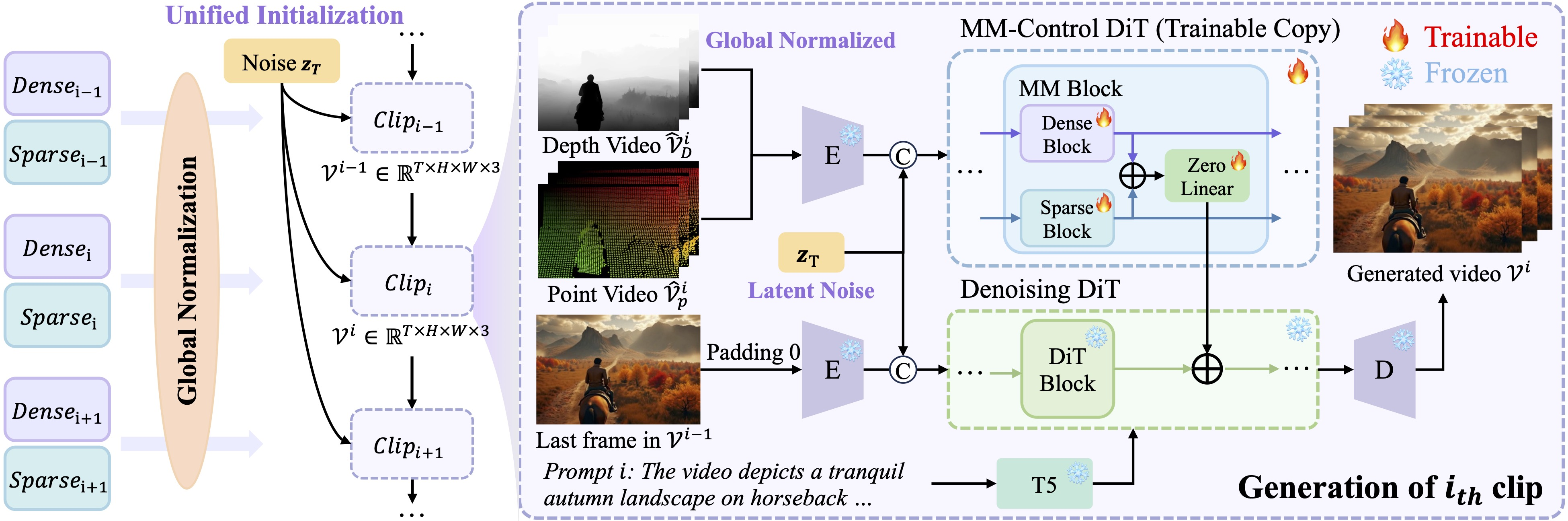
行业应用:动画剧集制作、广告长镜头叙事、沉浸式虚拟场景漫游。
技术点评:自回归生成与记忆机制的结合,突破了传统方法在长视频生成中的“视觉退化”瓶颈,为长内容创作提供技术支撑。
三、动画制作与3D世界生成:从流程自动化到沉浸式体验
7. ToonComposer:生成式AI动画制作技术
技术亮点:将传统动画生产流程(如分镜绘制、关键帧制作、中间帧补全)自动化,通过生成式AI直接生成流畅的动画片段,显著降低人工成本并提升效率(如单日可生成原本需数周的动画内容)。
项目主页:https://lg-li.github.io/project/tooncomposer/
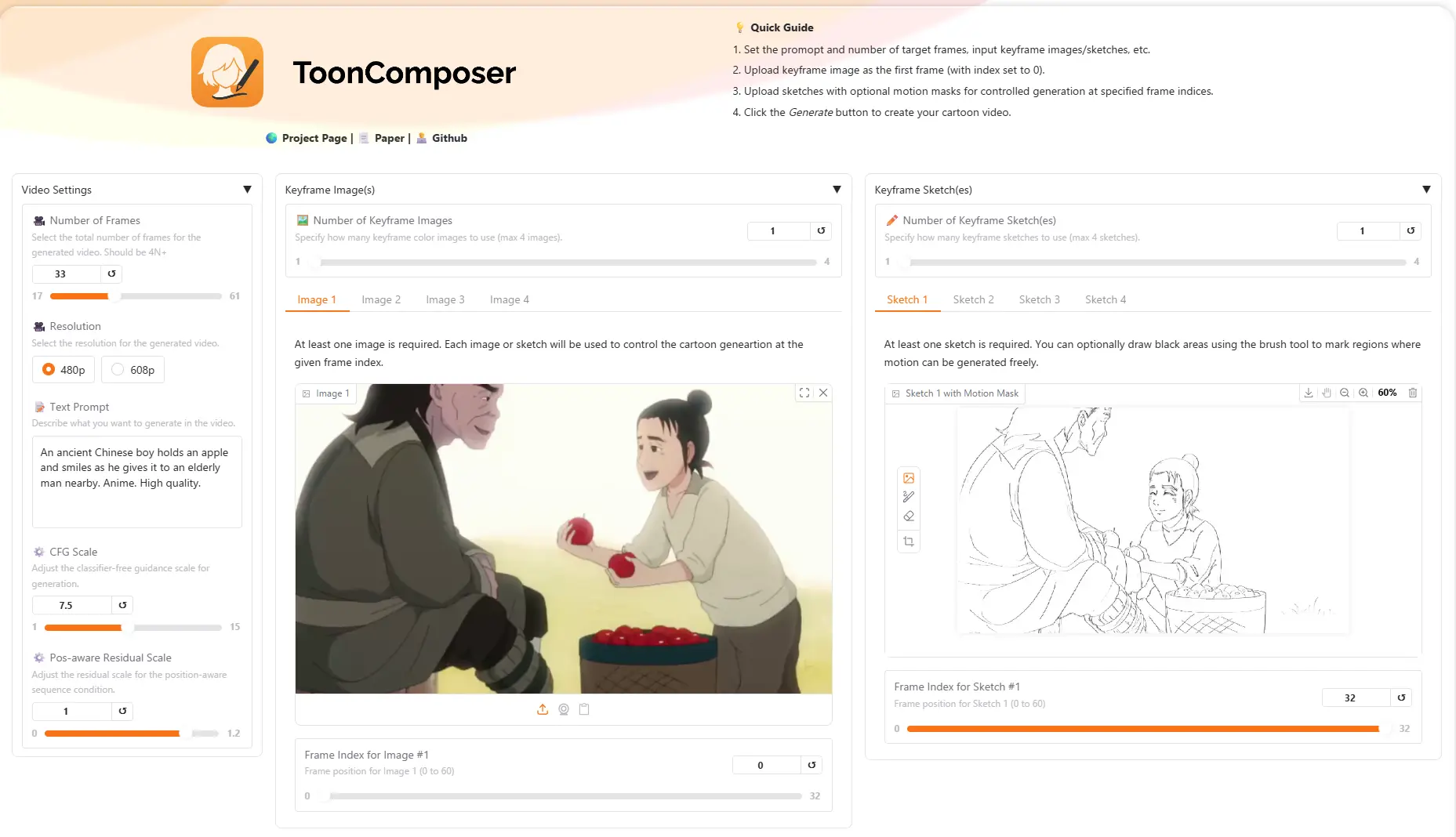
行业应用:动画工作室(如短片、番剧制作)、游戏开发(如过场动画生成)、在线教育(如互动课件动画)。
技术点评:流程自动化解放了动画师的重复劳动,使创意聚焦于故事设计,推动动画产业降本增效。
8. HunyuanWorld 1.0:文字/图像生成沉浸式3D世界
技术亮点:结合全景图代理(生成多角度场景视图)、语义分层(区分场景中的物体、建筑等层级)与层次化3D重建技术(从粗到细构建细节),支持从文字描述(如“中世纪城堡”)或图像输入生成可探索、交互的360°3D世界。
项目主页:https://3d-models.hunyuan.tencent.com/world/

行业应用:虚拟现实(VR)游戏场景构建、元宇宙空间设计、教育科普(如历史场景还原)。
技术点评:多技术融合实现了“从输入到可交互3D世界”的端到端生成,提升了3D内容创作的效率与沉浸感。
四、语音生成与图像修复:高表现力与精准修复
9. MOSS-TTSD:中英双语对话语音生成技术
技术亮点:支持多说话人对话文本生成高质量语音(如情感丰富、语调自然的对话),具备零样本音色克隆(无需大量样本即可模仿特定人声)与长语音生成能力(如连续1小时对话)。
项目主页:https://www.open-moss.com/cn/moss-ttsd/
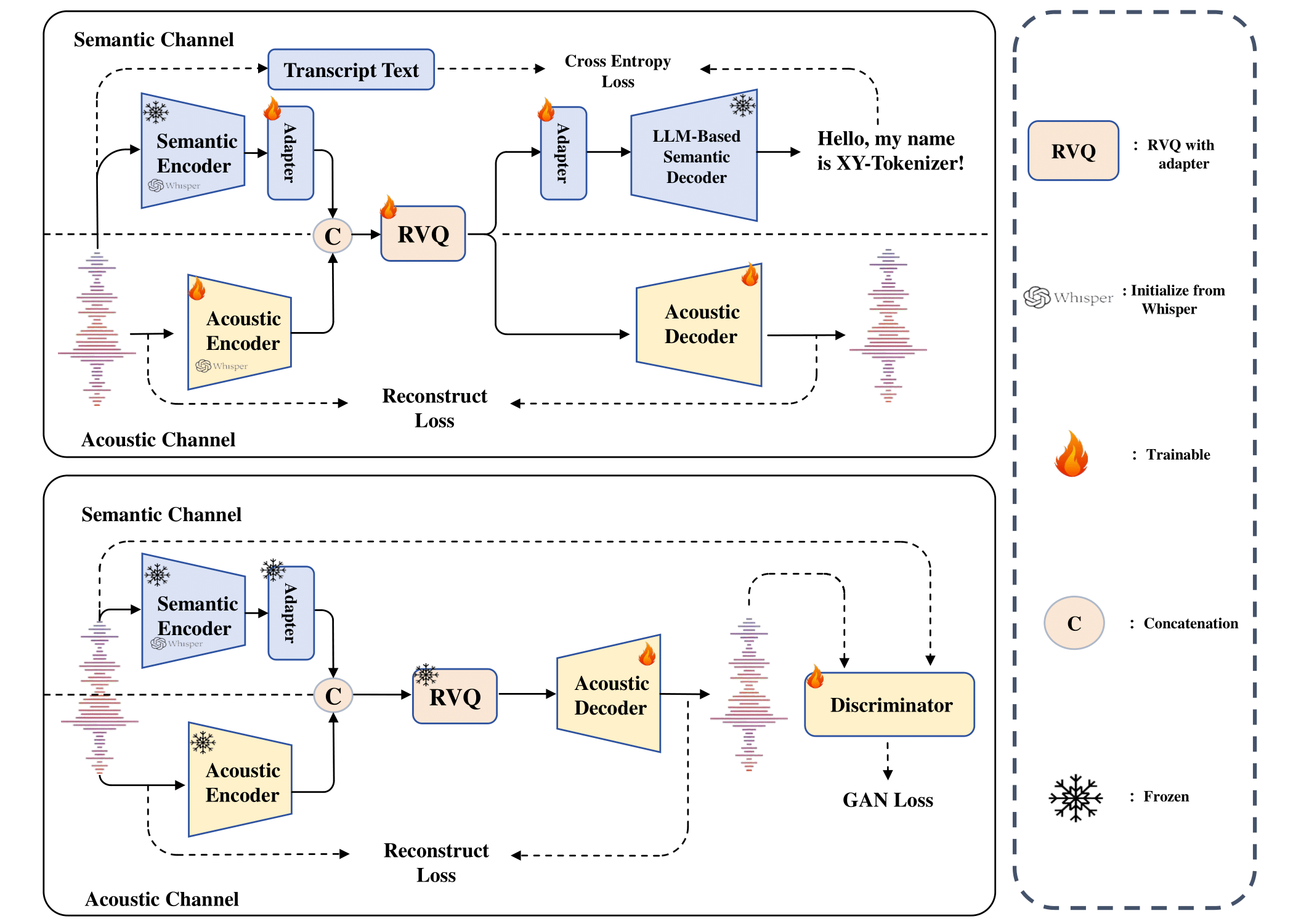
行业应用:播客制作(如多人访谈音频生成)、访谈节目后期(如虚拟主持人配音)、有声书录制(如多角色朗读)。
技术点评:零样本音色克隆降低了语音定制成本,长语音生成能力满足了专业内容生产需求。
10. HYPIR:基于扩散模型的图像修复技术
技术亮点:利用扩散模型生成的分数先验(捕捉图像的潜在结构信息),精准修复图像中的破损区域(如划痕、遮挡),尤其在高分辨率图像(如4K以上)修复中保持细节清晰度与自然过渡。
项目主页:https://github.com/XPixelGroup/HYPIR

行业应用:老照片修复(如家庭珍贵影像还原)、医疗影像处理(如CT片缺失区域补全)、数字文物修复(如古画裂缝填补)。
技术点评:分数先验的引入提升了修复的精准度,解决了传统方法在细节保留上的不足。
五、视频目标分割与肖像动画:复杂场景下的精准处理
11. SeC:渐进式概念构建的视频目标分割框架
技术亮点:通过逐步构建高级、以目标为中心的概念表示(如先识别“人”,再细化到“穿红衣服的人”),在复杂场景(如多人拥挤、背景杂乱)中精准分割目标,提升分割边界清晰度与稳定性。
项目主页:https://rookiexiong7.github.io/projects/SeC/
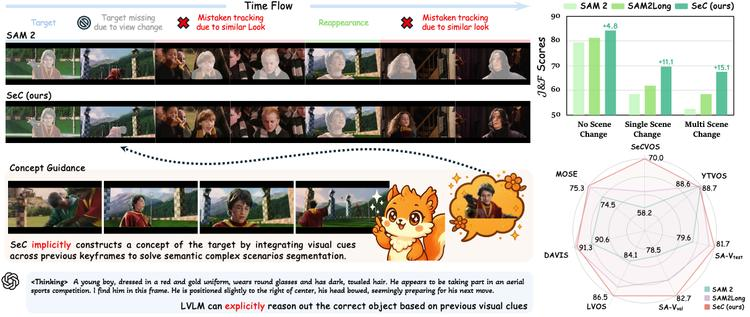
行业应用:自动驾驶(如行人/车辆精准识别)、视频监控(如特定目标追踪)、影视特效(如背景替换)。
技术点评:渐进式概念构建解决了传统方法在复杂场景下的“目标混淆”问题,增强了分割的鲁棒性。
12. FantasyPortrait:多角色肖像动画生成技术
技术亮点:基于扩散变换器,通过表情增强学习策略(捕捉面部微表情细节)与掩码交叉注意力机制(避免多角色间的特征干扰),从静态图像生成高保真、富有情感的多角色肖像动画(如多人对话场景),支持跨身份重演(如让历史人物“复活”说话)。
项目主页:https://fantasy-amap.github.io/fantasy-portrait/
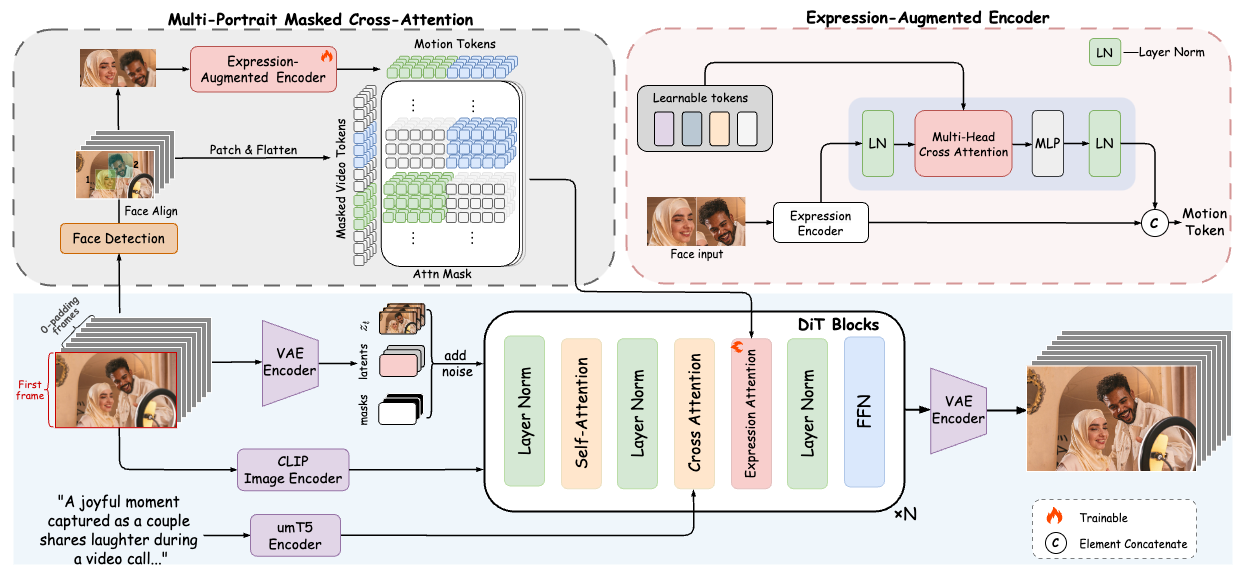
行业应用:虚拟主播(如多角色互动直播)、影视制作(如历史场景复原)、广告创意(如品牌代言人动画)。
技术点评:表情增强与掩码机制解决了多角色动画中的“特征串扰”难题,提升了情感表达的自然度。
总结与展望
8月的AIGC开源项目覆盖智能体、多模态理解、视频生成、动画制作、3D世界构建、语音合成及图像修复等多个领域,核心趋势包括:
多模态深度融合(如Ovis的结构化对齐、WeKnora的文档理解);
生成效率与质量双提升(如Wan2.2的MoE架构、LongVie的超长视频控制);
复杂场景精准处理(如SeC的目标分割、HYPIR的高分辨率修复);
创作流程自动化(如ToonComposer的动画生成、HunyuanWorld的3D世界构建)。
未来,随着这些技术的落地,内容创作将进一步民主化(低成本、低门槛),机器人交互更自然(如Youtu-agent的自主决策),虚拟与现实边界更模糊(如HunyuanWorld的沉浸式3D世界)。开发者可重点关注Wan2.2的视频生成能力、Ovis的多模态对齐技术及HunyuanWorld的3D重建方案,挖掘商业化潜力。
推荐阅读
► AGI新时代的探索之旅:2025 AIGCmagic社区全新启航
► 技术资讯: 魔方AI新视界
► 项目应用:开源视界
► 技术专栏: 多模态大模型最新技术解读专栏 | AI视频最新技术解读专栏 | 大模型基础入门系列专栏 | 视频内容理解技术专栏 | 从零走向AGI系列
► 技术综述: 一文掌握视频扩散模型 | YOLO系列的十年全面综述 | 人体视频生成技术:挑战、方法和见解 | 一文读懂多模态大模型(MLLM)|一文搞懂RAG技术范式演变及Agentic RAG|强化学习技术全面解读 SFT、RLHF、RLAIF、DPO|一文搞懂DeepSeek的技术演进之路