【内存管理】深入理解内存映射(Memory Mapping)与mmap:实现高效零拷贝的DMA缓冲区共享
获取更多相关的笔试面试题,可收藏系列博文,持续更新中:
C语言|BSP开发|嵌入式软件|Linux驱动|笔试面试题汇总帖
一、什么是内存映射?
内存映射(Memory Mapping) 是操作系统提供的一种机制,它允许将文件或设备直接映射到进程的虚拟地址空间。通过内存映射,进程可以像访问普通内存一样访问文件内容或硬件设备的内存区域,而无需使用传统的read/write系统调用。
1.1 内存映射的基本概念
// mmap系统调用原型 void *mmap(void *addr, size_t length, int prot, int flags, int fd, off_t offset);
内存映射的核心思想是:建立一段虚拟内存区域与某个后备存储(文件、设备内存等)之间的直接关联。当进程访问这段虚拟内存时,操作系统会自动处理数据的加载和存储。
二、mmap系统调用的工作机制
2.1 mmap参数详解
void *mmap(void *addr, // 期望的映射起始地址(通常为NULL,由系统选择)size_t length, // 映射区域的长度int prot, // 保护权限:PROT_READ, PROT_WRITE, PROT_EXECint flags, // 映射标志:MAP_SHARED, MAP_PRIVATE, MAP_ANONYMOUS等int fd, // 文件描述符(设备文件或普通文件)off_t offset); // 文件中的偏移量
2.2 mmap的两种主要用途
-
文件映射:将磁盘文件映射到内存,实现文件I/O
-
匿名映射:创建不与任何文件关联的内存区域,用于进程间共享内存
-
设备内存映射:将硬件设备的内存(如DMA缓冲区)映射到用户空间
三、将内核DMA缓冲区映射到用户空间的完整流程
让我们通过一个具体的驱动示例,详细说明如何将内核空间的DMA缓冲区映射到用户空间。
3.1 驱动端:分配和管理DMA缓冲区
#include <linux/mm.h>
#include <linux/dma-mapping.h>struct my_driver_data {void *dma_buffer; // DMA缓冲区的内核虚拟地址dma_addr_t dma_handle; // DMA缓冲区的物理地址(总线地址)size_t buffer_size;struct device *dev;
};// 1. 分配DMA缓冲区
static int allocate_dma_buffer(struct my_driver_data *data, size_t size)
{data->buffer_size = size;// 分配一致性DMA映射(缓存一致)data->dma_buffer = dma_alloc_coherent(data->dev, size, &data->dma_handle, GFP_KERNEL);if (!data->dma_buffer) {return -ENOMEM;}printk(KERN_INFO "Allocated DMA buffer: virt=%p, phys=%pad, size=%zu\n",data->dma_buffer, &data->dma_handle, size);return 0;
}
3.2 驱动端:实现mmap文件操作
// 2. 实现mmap操作
static int my_driver_mmap(struct file *filp, struct vm_area_struct *vma)
{struct my_driver_data *data = filp->private_data;unsigned long offset = vma->vm_pgoff << PAGE_SHIFT;unsigned long size = vma->vm_end - vma->vm_start;int ret;// 检查映射范围是否有效if (offset + size > data->buffer_size) {return -EINVAL;}// 设置VMA标志vma->vm_page_prot = pgprot_noncached(vma->vm_page_prot); // 非缓存映射vma->vm_ops = &my_driver_vm_ops; // 设置VMA操作// 将物理页映射到用户空间ret = remap_pfn_range(vma, vma->vm_start,data->dma_handle >> PAGE_SHIFT, // 物理页帧号size, vma->vm_page_prot);if (ret) {printk(KERN_ERR "Failed to remap DMA buffer: %d\n", ret);return ret;}printk(KERN_DEBUG "Mapped DMA buffer to user space: %lu bytes\n", size);return 0;
}// 3. 定义文件操作结构
static const struct file_operations my_driver_fops = {.owner = THIS_MODULE,.mmap = my_driver_mmap,.open = my_driver_open,.release = my_driver_release,// ... 其他操作
};
3.3 更现代的DMA映射方法
对于DMA缓冲区,Linux提供了专门的映射函数:
// 使用DMA专用的mmap方法
static int my_driver_dma_mmap(struct file *filp, struct vm_area_struct *vma)
{struct my_driver_data *data = filp->private_data;return dma_mmap_coherent(data->dev, // 关联的设备vma, // VMA区域data->dma_buffer, // 内核虚拟地址data->dma_handle, // DMA句柄data->buffer_size); // 缓冲区大小
}
3.4 用户空间:使用mmap映射DMA缓冲区
// 用户空间应用程序
#include <stdio.h>
#include <stdlib.h>
#include <fcntl.h>
#include <unistd.h>
#include <sys/mman.h>int main()
{int fd;void *mapped_buffer;size_t buffer_size = 1024 * 1024; // 1MB缓冲区// 1. 打开设备文件fd = open("/dev/my_device", O_RDWR);if (fd < 0) {perror("Failed to open device");return -1;}// 2. 使用mmap映射DMA缓冲区到用户空间mapped_buffer = mmap(NULL, // 由系统选择地址buffer_size, // 映射大小PROT_READ | PROT_WRITE, // 可读可写MAP_SHARED, // 共享映射fd, // 设备文件描述符0); // 偏移量if (mapped_buffer == MAP_FAILED) {perror("mmap failed");close(fd);return -1;}printf("Successfully mapped DMA buffer at %p\n", mapped_buffer);// 3. 现在可以直接访问DMA缓冲区!// 例如:从设备读取数据printf("First 4 bytes from DMA buffer: 0x%08x\n", *(unsigned int*)mapped_buffer);// 或者:向设备写入数据strcpy((char*)mapped_buffer, "Hello from userspace!");// 4. 清理munmap(mapped_buffer, buffer_size);close(fd);return 0;
}
四、mmap映射过程的底层机制
为了更好地理解mmap的工作原理,让我们看看内核如何建立用户空间到DMA缓冲区的映射:
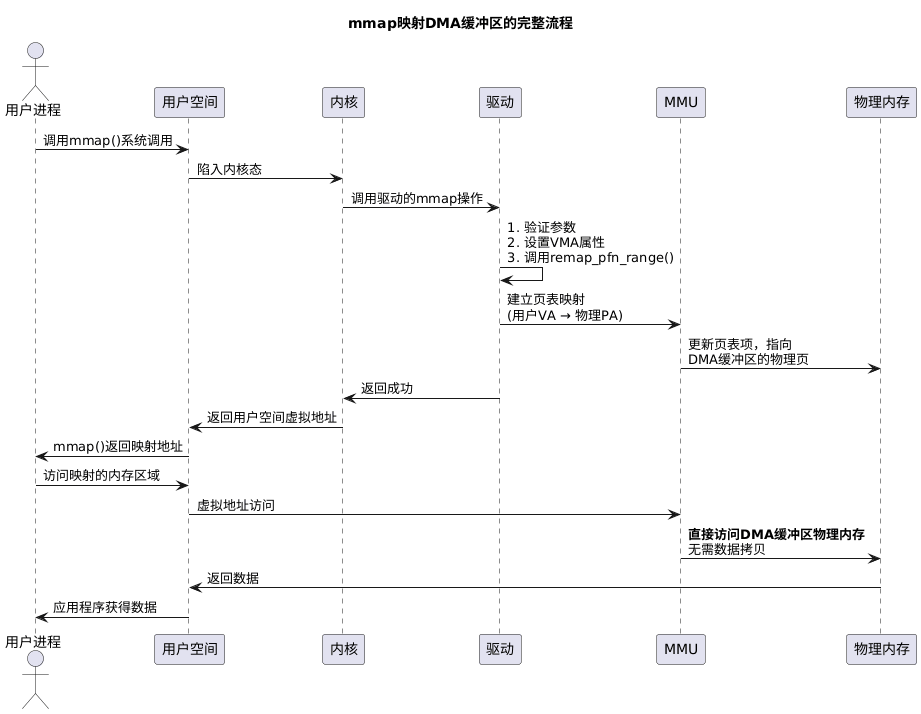
4.1 页表映射的关键步骤
当remap_pfn_range()被调用时,内核执行以下关键操作:
-
计算物理页帧号:
pfn = dma_handle >> PAGE_SHIFT -
建立页表项:为指定范围的用户虚拟地址创建页表项,指向DMA缓冲区的物理页
-
设置缓存属性:通过
pgprot_noncached()确保映射是非缓存的,这对于设备内存访问很重要
五、mmap的优势分析
5.1 零拷贝(Zero-copy)优势
与传统read/write相比,mmap实现了真正的零拷贝:
传统read/write的数据流:
设备内存 → 内核缓冲区 → 用户空间缓冲区(2次数据拷贝)
mmap的数据流:
设备内存 → 用户空间直接访问(0次数据拷贝)
5.2 性能对比测试
// 性能测试示例:传统IO vs mmap
void benchmark_io_vs_mmap(int fd, size_t data_size)
{struct timespec start, end;char *buffer = malloc(data_size);char *mapped_addr;// 1. 测试传统read/writeclock_gettime(CLOCK_MONOTONIC, &start);read(fd, buffer, data_size); // 数据拷贝到用户缓冲区process_data(buffer, data_size); // 处理数据write(fd, buffer, data_size); // 数据拷贝回内核clock_gettime(CLOCK_MONOTONIC, &end);printf("read/write time: %ld ns\n", (end.tv_sec - start.tv_sec) * 1000000000 + (end.tv_nsec - start.tv_nsec));// 2. 测试mmapmapped_addr = mmap(NULL, data_size, PROT_READ|PROT_WRITE, MAP_SHARED, fd, 0);clock_gettime(CLOCK_MONOTONIC, &start);process_data(mapped_addr, data_size); // 直接处理映射内存clock_gettime(CLOCK_MONOTONIC, &end);printf("mmap time: %ld ns\n", (end.tv_sec - start.tv_sec) * 1000000000 + (end.tv_nsec - start.tv_nsec));munmap(mapped_addr, data_size);free(buffer);
}
5.3 综合优势总结
| 优势类别 | 具体表现 | 适用场景 |
|---|---|---|
| 性能优势 | 零拷贝数据传输 | 高频数据交换、大文件处理 |
| 减少系统调用开销 | 实时系统、低延迟应用 | |
| 避免用户/内核态切换 | 高性能计算 | |
| 编程优势 | 简化代码逻辑 | 设备驱动、共享内存应用 |
| 自然的内存访问语义 | 图形处理、信号处理 | |
| 便于调试和监控 | 开发阶段 | |
| 系统优势 | 延迟分配物理内存 | 稀疏大文件处理 |
| 智能的页面调度 | 数据库系统 | |
| 内存共享能力 | 进程间通信 |
六、实际应用场景
6.1 图形显示框架
// 图形显示驱动中的典型mmap应用
struct fb_info *info = framebuffer_device;// 将显卡帧缓冲区映射到用户空间
static int fb_mmap(struct fb_info *info, struct vm_area_struct *vma)
{unsigned long start = vma->vm_start;unsigned long size = vma->vm_end - vma->vm_start;unsigned long offset = vma->vm_pgoff << PAGE_SHIFT;// 映射帧缓冲区物理内存return vm_iomap_memory(vma, info->fix.smem_start + offset, size);
}
6.2 网络数据包处理
在高性能网络应用中,mmap用于零拷贝网络数据包处理:
// DPDK等高性能网络框架使用mmap // 将网卡DMA环缓冲区映射到用户空间,实现零拷贝包处理 void *rx_rings = mmap(NULL, ring_size, PROT_READ|PROT_WRITE, MAP_SHARED, nic_fd, RX_RING_OFFSET);
七、注意事项和最佳实践
7.1 缓存一致性问题
对于DMA设备内存,通常需要使用非缓存映射:
// 正确的DMA内存映射方式 vma->vm_page_prot = pgprot_noncached(vma->vm_page_prot); ret = remap_pfn_range(vma, vma->vm_start, pfn, size, vma->vm_page_prot);
7.2 内存对齐要求
// 确保DMA缓冲区正确对齐 data->dma_buffer = dma_alloc_coherent(dev, size + PAGE_SIZE - 1, // 向上对齐&data->dma_handle, GFP_KERNEL); // 对齐到页边界 data->dma_buffer = PTR_ALIGN(data->dma_buffer, PAGE_SIZE); data->dma_handle = ALIGN(data->dma_handle, PAGE_SIZE);
7.3 错误处理
static int safe_dma_mmap(struct file *filp, struct vm_area_struct *vma)
{// 检查映射参数if (vma->vm_end - vma->vm_start > MAX_ALLOWED_MAPPING) {return -EINVAL;}// 检查权限if ((vma->vm_flags & VM_WRITE) && !(vma->vm_flags & VM_SHARED)) {return -EINVAL; // 私有写映射不支持}// 执行映射return my_driver_dma_mmap(filp, vma);
}
八、总结
内存映射(mmap)是现代操作系统中的一项核心技术,它通过建立用户虚拟地址到物理内存(包括DMA缓冲区)的直接映射,实现了:
-
零拷贝数据传输:消除用户空间和内核空间之间的数据拷贝开销
-
简化编程模型:提供自然的内存访问接口,替代复杂的read/write操作
-
高性能I/O:大幅减少系统调用和上下文切换开销
-
灵活的内存共享:支持进程间、内核与用户空间的高效数据共享
在驱动开发中,通过实现mmap操作将DMA缓冲区暴露给用户空间,是构建高性能设备访问框架的关键技术。这种机制被广泛应用于图形显示、网络处理、多媒体编解码、数据库系统等对性能要求极高的场景。