(论文速读)CUT3R:具有持续状态的连续三维感知模型
论文题目:Continuous 3D Perception Model with Persistent State(具有持续状态的连续三维感知模型)
会议:CVPR2025
摘要:我们提出了一个统一的框架,能够解决广泛的3d任务。我们的方法的特点是一个有状态的循环模型,随着每次新的观察不断更新其状态表示。给定一个图像流,这种不断发展的状态可以用于以在线方式为每个新输入生成度量尺度的点图(逐像素3D点)。这些点图位于一个共同的坐标系中,可以累积成一个连贯的、密集的场景重建,并在新图像到达时更新。我们的模型,称为CUT3R (3D重建的连续更新变压器),捕获了现实世界场景的丰富先验:它不仅可以从图像观测中预测准确的点图,还可以通过探测虚拟的、未观察到的视图来推断场景中未见过的区域。我们的方法简单但高度灵活,自然地接受不同长度的图像,可能是视频流或无序的照片集合,包含静态和动态内容。我们在各种3D/4D任务中评估我们的方法,并在每个任务中展示具有竞争力或最先进的性能。
项目页面:https://cut3r.github.io/。

CUT3R: 具有持久状态的连续3D感知模型
引言
想象一下,当你走进一个新的餐厅,仅需一瞥就能开始推断其布局和氛围。随着你继续观察,你的大脑会持续完善对这个3D环境的心理模型。这种将世界先验知识与连续观测流相结合的能力,正是人类视觉感知的核心优势。
来自加州大学伯克利分校和Google DeepMind的研究团队在CVPR 2025上发表的论文《Continuous 3D Perception Model with Persistent State》(CUT3R),正是受此启发,提出了一个革命性的3D感知框架。
传统方法面临的挑战
在深入CUT3R之前,让我们先了解现有3D重建方法的局限:
1. "白板式"重建的困境
传统的SfM(Structure from Motion)和SLAM系统采用"tabula rasa"(白板)方法——每次处理新场景都从零开始。这在以下场景中表现不佳:
- 稀疏观测:照片数量有限时难以重建
- 动态物体:运动的人或物体会干扰重建
- 退化运动:相机运动不够丰富时失败
2. 现有学习方法的局限
虽然DUSt3R等学习方法引入了数据驱动的先验,但仍存在问题:
- 仅支持图像对:DUSt3R只能处理两张图片
- 需要离线对齐:扩展到多视角需要耗时的全局对齐
- 无法在线更新:不能随着新观测的到来动态改进重建
- 缺乏场景推理:无法预测未观测到的区域
CUT3R的核心创新
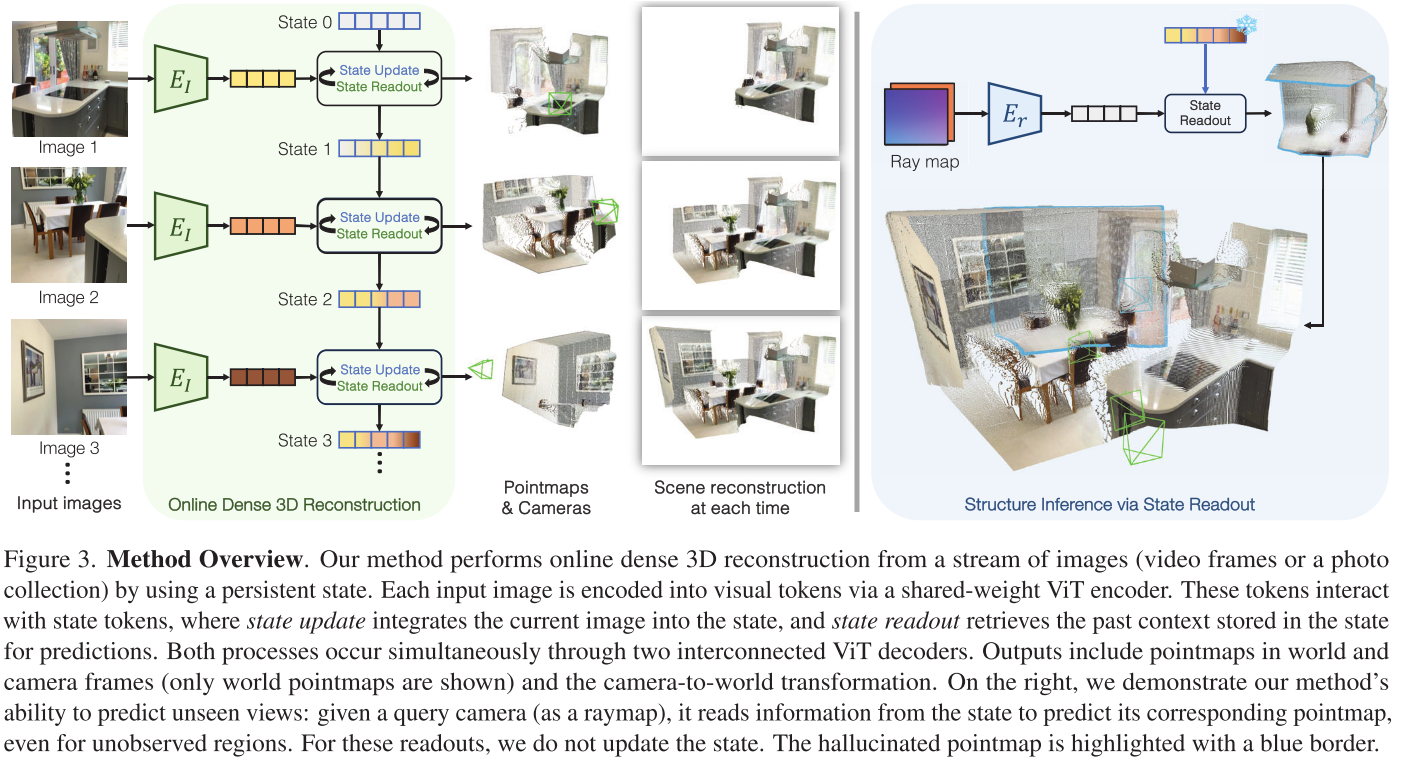
创新1:持久状态表示(Persistent State)
CUT3R的核心是一个持续更新的内部状态,它如同一个"3D场景记忆库":
状态 = 768个可学习的tokens(每个维度768)
这个状态会随着每一帧新图像的输入而更新,累积场景的3D知识。就像人类大脑不断完善对环境的理解一样。
创新2:双向交互机制
对于每一帧输入图像,CUT3R同时进行两个操作:
- 状态更新(State Update):将当前图像的信息融入状态
- 状态读取(State Readout):从状态中提取历史信息用于预测
这通过两个互联的Transformer解码器实现,确保信息的有效双向流动。
创新3:直接输出度量尺度的3D
与许多方法不同,CUT3R直接预测真实尺度(米为单位)的3D点云:
- 世界坐标系点云:所有帧共享的全局坐标
- 相机坐标系点云:每帧自身的局部坐标
- 6-DOF相机位姿:从当前帧到世界坐标系的变换
关键是:不需要任何相机内参或外参作为输入!
创新4:虚拟视角查询

这是CUT3R最酷的功能之一。你可以用一个"虚拟相机"查询状态:
输入:Raymap(射线图,6通道图像,编码每个像素的射线原点和方向)
输出:该虚拟视角下的3D点云和颜色
这意味着模型可以**"想象"**未被拍摄到的场景部分!例如:
- 输入一张室内照片,查询背后的墙
- 模型能推断出合理的3D结构
这类似于图像的Masked Autoencoder,但在3D场景级别操作。
创新5:统一训练框架
CUT3R在32个多样化数据集上训练:
- 静态场景(ScanNet++、7-Scenes)
- 动态场景(DynamicStereo、TUM-dynamics)
- 室外场景(KITTI、Waymo、MegaDepth)
- 合成数据(TartanAir、Synscapes)
训练采用课程学习策略:
- 阶段1:4视角序列,静态场景,224×224分辨率
- 阶段2:加入动态场景和部分标注数据
- 阶段3:提高分辨率至512像素,多种纵横比
- 阶段4:冻结编码器,训练4-64帧长序列
技术架构解析
整体流程
输入图像 → ViT编码器 → 图像tokens↓与状态tokens交互(双向Transformer解码器)↓输出:世界点云 + 相机点云 + 位姿
关键组件
- 图像编码器:ViT-Large,初始化自DUSt3R预训练权重
- 解码器:ViT-Base,768个状态tokens
- 输出头:
Head_self:预测相机坐标系点云(DPT架构)Head_world:预测世界坐标系点云(DPT架构)Head_pose:预测6-DOF位姿(MLP)Head_color:预测颜色(仅用于raymap查询)
损失函数
总损失 = L_conf + L_pose + L_rgb其中:
L_conf = 置信度加权的3D回归损失
L_pose = 位姿L2损失
L_rgb = 颜色MSE损失(仅raymap模式)
实验结果深度分析
1. 单目深度估计:SOTA性能
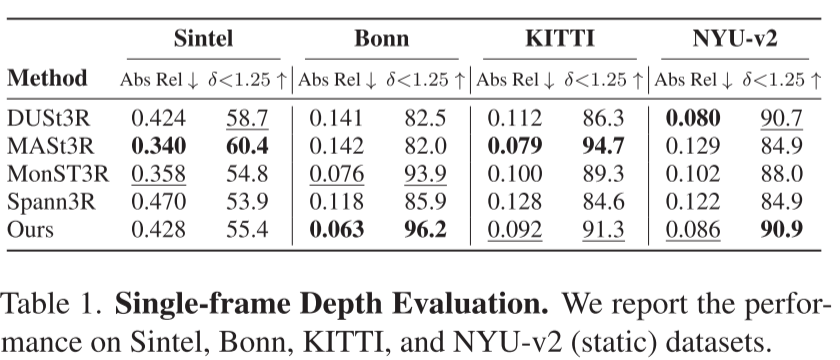
在零样本跨域测试中:
| 数据集 | Abs Rel↓ | δ<1.25↑ |
|---|---|---|
| Bonn | 0.063 | 96.2% |
| NYU-v2 | 0.086 | 90.9% |
| KITTI | 0.092 | 91.3% |
| Sintel | 0.428 | 55.4% |
分析:在室内场景(Bonn、NYU-v2)上表现最佳,证明了模型对不同场景的泛化能力。
2. 视频深度估计:速度与精度的完美平衡
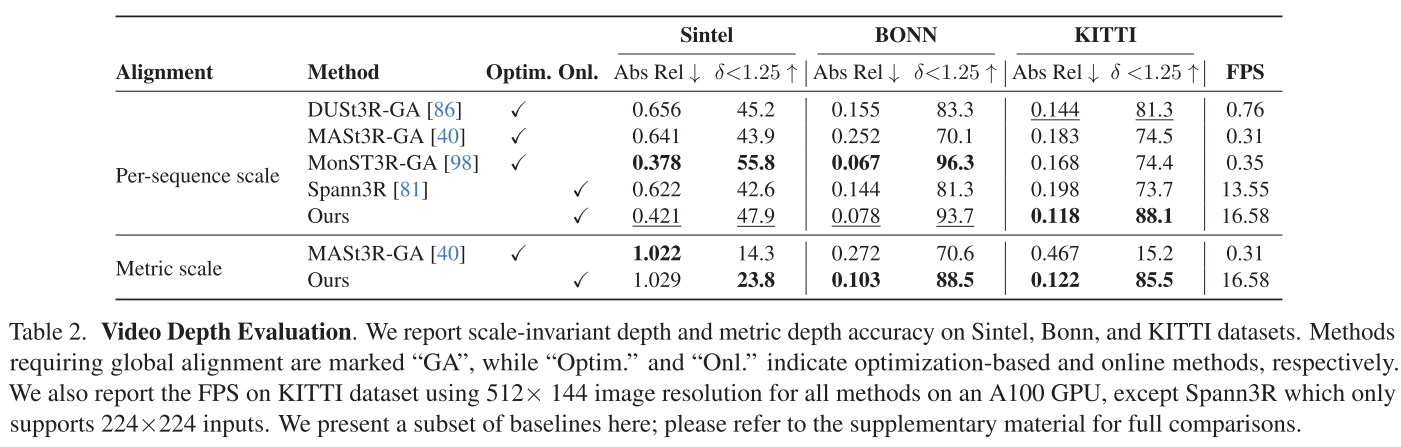
与需要全局对齐的方法比较:
| 方法 | KITTI Abs Rel↓ | FPS | 类型 |
|---|---|---|---|
| MonST3R-GA | 0.168 | 0.35 | 离线优化 |
| CUT3R | 0.118 | 16.58 | 在线 |
| Spann3R | 0.198 | 13.55 | 在线 |
关键发现:
- CUT3R在保持在线运行的同时,性能超越许多离线方法
- 速度比MonST3R快47倍!
- 这得益于状态的隐式对齐,避免了显式全局优化
3. 相机位姿估计:动态场景的挑战
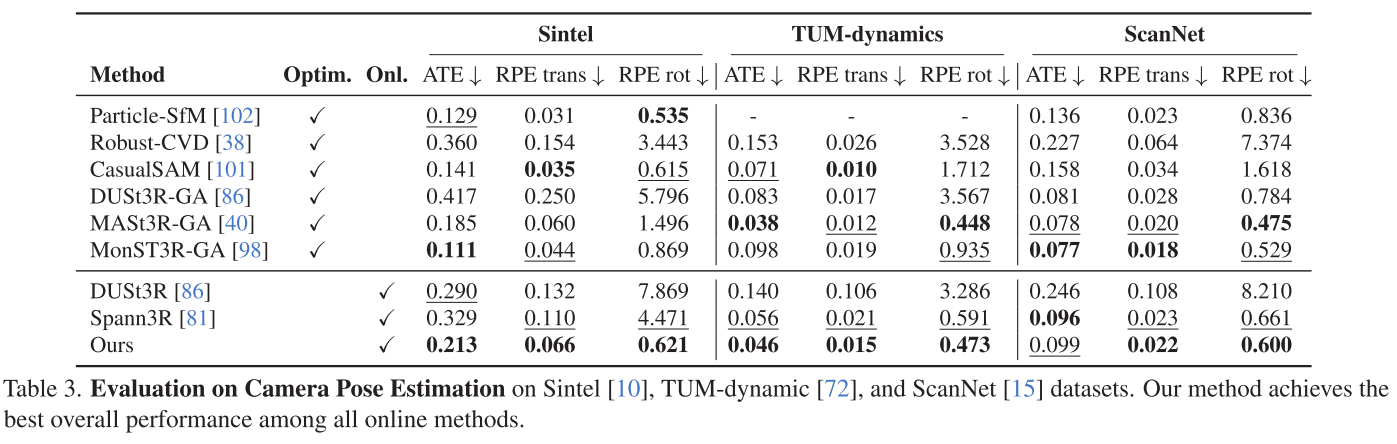
在包含大量运动物体的数据集上:
Sintel数据集(动态场景):
- CUT3R: ATE=0.213(在线方法最佳)
- CasualSAM: ATE=0.141(需优化)
- MonST3R-GA: ATE=0.111(需优化+光流)
TUM-dynamics数据集:
- CUT3R: ATE=0.046(在线方法最佳)
- Spann3R: ATE=0.056
分析:CUT3R在在线方法中表现最佳,与需要额外优化的方法差距正在缩小。
4. 3D重建:稀疏观测下的卓越表现
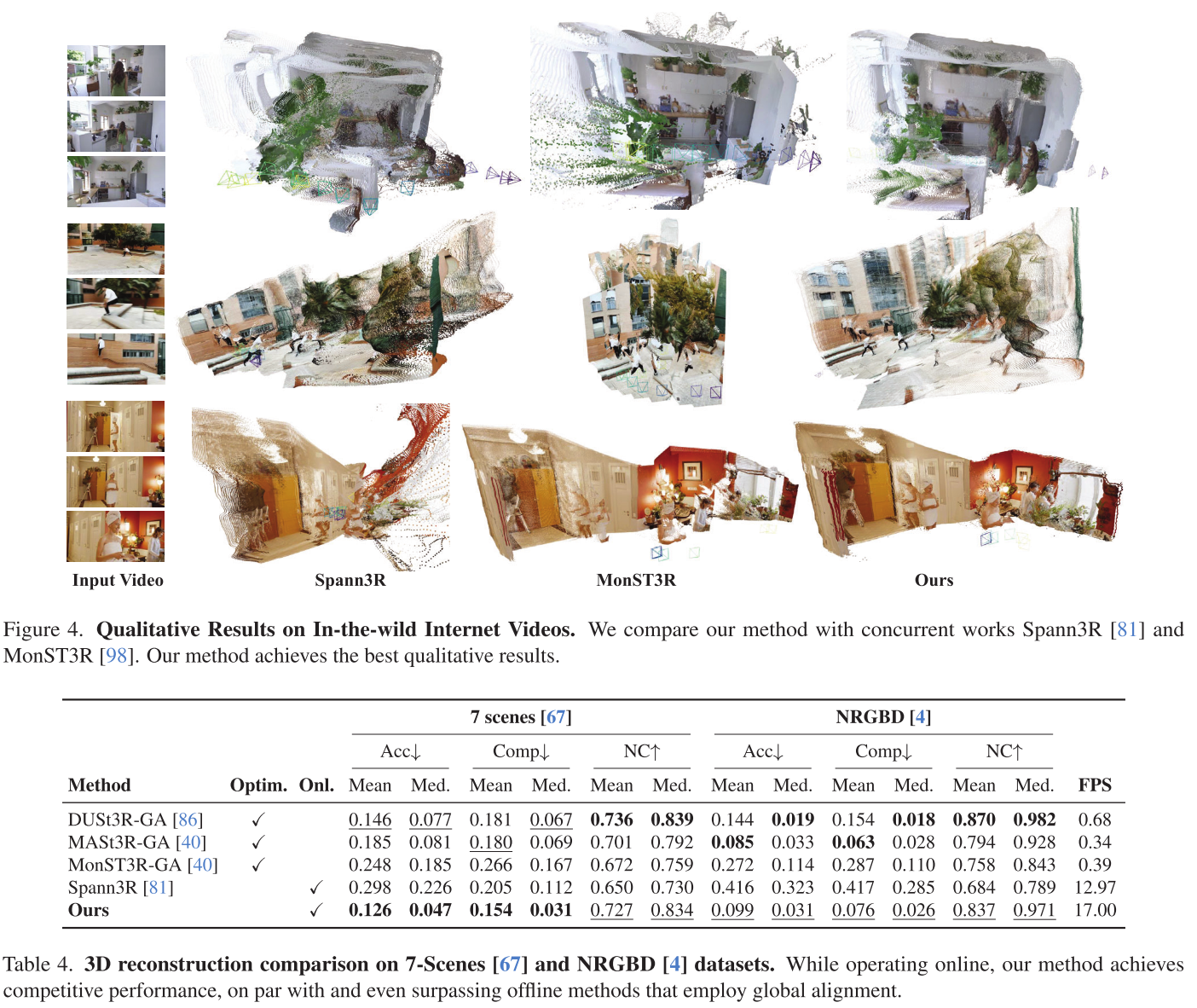
在极稀疏设置(每场景仅2-5帧)下:
7-Scenes数据集:
| 方法 | Accuracy↓ | Completion↓ | NC↑ | FPS |
|---|---|---|---|---|
| DUSt3R-GA | 0.146 | 0.181 | 0.736 | 0.68 |
| CUT3R | 0.126 | 0.154 | 0.727 | 17.00 |
关键优势:
- 精度更高(Accuracy降低14%)
- 完整性更好(Completion降低15%)
- 速度快25倍
5. 定性结果:视觉对比
在野外视频上的表现:
| 场景类型 | CUT3R | Spann3R | MonST3R |
|---|---|---|---|
| 动态人物 | ✅完整 | ❌失败 | ✅较好 |
| 静态室内 | ✅最佳 | ⚠️一般 | ⚠️过拟合 |
| 室外场景 | ✅清晰 | ⚠️模糊 | ✅较好 |
观察:
- Spann3R在动态场景失效(未训练动态数据)
- MonST3R在静态场景可能过拟合
- CUT3R在各种场景下保持稳定高质量
消融研究:状态更新的重要性
研究团队设计了"重访"实验:
- 在线模式:正常处理图像流
- 重访模式:先处理完所有图像得到最终状态,然后用这个状态重新处理
结果(7-Scenes数据集):
| 模式 | Accuracy↓ | Completion↓ |
|---|---|---|
| 在线 | 0.126 | 0.154 |
| 重访 | 0.113 | 0.107 |
结论:状态确实会随着更多观测而改进!重访模式让状态"看到"全局上下文,进一步提升精度。
虚拟视角推断:看不见的地方
这是CUT3R最令人兴奋的功能。实验设置:
- 输入:单张图像
- 查询:未见过的视角(用ground truth相机参数)
- 输出:该视角的3D点云
成功案例:

- 输入灌木照片 → 查询侧面 → 预测出背面的灌木
- 输入室内照片 → 查询地面 → 推断出地板结构
- 输入厨房照片 → 查询角落 → 生成烤箱和凳子
局限性:
- 预测的高频细节较少(确定性方法的通病)
- 外推太远的视角会变模糊
- 未来可引入生成式方法改进
与竞争方法的对比
vs DUSt3R
- ✅ 支持任意数量图像(DUSt3R仅支持图像对)
- ✅ 在线运行(DUSt3R需离线全局对齐)
- ✅ 度量尺度(两者都支持)
- ✅ 动态场景(DUSt3R主要针对静态)
vs Spann3R
- ✅ 动态场景支持(Spann3R不支持)
- ✅ 更好的重建质量
- ✅ 场景推理能力(Spann3R的内存仅作缓存)
- ⚖️ 类似的在线处理能力
vs MonST3R
- ✅ 真正在线(MonST3R需全局对齐)
- ✅ 快50倍
- ✅ 静态场景更稳定(MonST3R可能过拟合动态数据)
- ⚖️ 动态场景性能相当
技术细节与实现
训练配置
- GPU: 8×A100 (80GB)
- 优化器: AdamW
- 学习率: 1e-4,线性warmup + cosine decay
- 批次大小: 根据序列长度调整
- 训练时间: 约数周(完整课程)
推理性能
- 输入分辨率: 最大边512像素
- FPS: 16-17 (A100 GPU, KITTI数据集)
- 内存: 状态仅768×768维,相对紧凑
支持的输入格式
- ✅ 连续视频流
- ✅ 无序照片集合
- ✅ 宽基线图像
- ✅ 甚至非重叠图像
- ✅ 静态和动态混合场景
局限性与未来方向
当前局限
长序列漂移
- 问题:在非常长的序列(如数千帧)上可能累积误差
- 原因:缺乏显式全局对齐
- 方案:未来可加入隐式或显式全局对齐
确定性推理的模糊性
- 问题:外推远视角时结果模糊
- 原因:采用回归而非生成方法
- 方案:引入扩散模型等生成式方法
训练时间
- 问题:循环网络训练耗时
- 影响:实验迭代速度较慢
- 方案:探索更高效的训练策略
未来研究方向
全局一致性增强
- 结合bundle adjustment
- 引入循环闭合检测
生成式扩展
- 集成扩散模型生成更清晰的外推视角
- 保持度量尺度的生成式重建
实时应用
- 移动设备部署
- AR/VR实时重建
更长上下文
- 支持数千帧的稳定重建
- 大规模场景映射
实际应用场景
1. AR/VR
- 实时场景重建与理解
- 虚拟物体放置(需要3D理解)
- 空间计算
2. 机器人导航
- 在线SLAM
- 动态障碍物处理
- 场景补全(推断遮挡区域)
3. 自动驾驶
- 实时3D感知
- 处理行人、车辆等动态物体
- 稀疏传感器融合
4. 文化遗产数字化
- 从游客照片重建古迹
- 处理稀疏、无序的照片集合
- 补全缺失部分
5. 电影/游戏制作
- 场景快速建模
- 虚拟镜头预览
- 资产生成
总结
CUT3R代表了3D视觉感知的重要进步,它的核心贡献包括:
- 首个在线度量尺度3D重建系统,支持任意长度图像流
- 持久状态机制,实现了真正的连续学习和场景理解
- 统一框架,同时解决深度估计、位姿估计、3D重建等多个任务
- 场景推理能力,能预测未观测到的3D结构
- 卓越性能,在保持在线运行的同时达到或超越离线方法
更重要的是,CUT3R展示了一种新的范式:不是孤立地处理每个场景,而是像人类一样,持续积累经验,在线学习,边观察边完善理解。这为未来的3D视觉系统指明了方向。
随着代码的开源和社区的采用,我们可以期待CUT3R在各种实际应用中发挥重要作用,从AR/VR到机器人,从自动驾驶到文化遗产保护,真正让机器"看懂"三维世界。