深度学习(8)Adam 优化器、卷积神经网络与反向传播
一、Adam 优化算法(Adam Optimizer)
1. Adam 是什么?
Adam(Adaptive Moment Estimation,自适应矩估计)是一种在深度学习中常用的优化算法。它结合了两种经典优化方法的优点:
Momentum(动量法):加快收敛;
RMSProp:自适应调整学习率。
Adam 能在不同参数维度上自适应地调整学习率,同时保留动量的加速效果,因此非常适合处理噪声大、数据量大或稀疏梯度问题的场景。
2. Adam 的核心思想
Adam 在每次参数更新时,维护了两个“动量”:
一阶矩估计(Momentum):
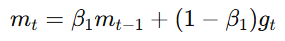
表示梯度的加权平均,用来“平滑”梯度变化。
二阶矩估计(RMSProp):
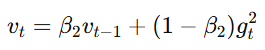
表示梯度平方的加权平均,用于调节不同参数的学习率。
然后进行偏差修正:
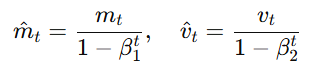
最后更新参数:
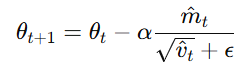
其中:
α:学习率(learning rate)
β1,β2:动量参数(通常取 0.9 和 0.999)
ϵ:防止除零的小常数(如
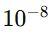 )
)
3. Adam 的优点
优点:
计算效率高;
对超参数不敏感;
自适应学习率;
收敛速度快;
能很好地处理稀疏梯度。
缺点:
在某些任务上容易停滞于局部最优;
不一定能带来更好的泛化性能(比 SGD 略差)。
4. TensorFlow 示例
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.001),loss='categorical_crossentropy',metrics=['accuracy'])
二、卷积层(Convolutional Layer)
1. 卷积层的介绍
卷积层(Convolutional Layer)是 卷积神经网络(CNN, Convolutional Neural Network) 的核心组成部分。它的主要功能是从输入数据中自动提取局部特征(如边缘、纹理、形状等)。在图像处理中,卷积层能让神经网络学会:
第一层识别边缘;
第二层识别形状;
第三层识别物体特征。
2. 卷积运算的原理
卷积操作通过一个称为卷积核(Filter 或 Kernel)的小矩阵,在输入图像上滑动(滑动窗口),计算加权和。
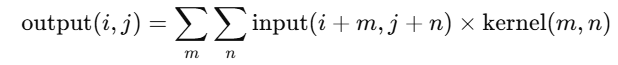
如下图所示(示意):
输入图像 (5x5) 1 2 3 0 1 0 1 2 3 1 3 1 2 2 0 0 2 3 1 1 1 0 2 2 3卷积核 (3x3) 1 0 1 0 1 0 1 0 1
通过卷积操作可得到输出特征图(Feature Map)。
3. 卷积层的样式
卷积层的主要超参数包括:
滤波器数量(filters):决定输出通道数;
卷积核大小(kernel_size):通常为 3×3;
步幅(stride):控制滑动步长;
填充(padding):保持尺寸一致(same)或缩小尺寸(valid)。
tf.keras.layers.Conv2D(filters=32, kernel_size=(3,3), strides=1, padding='same', activation='relu')
4. 卷积层的优点
优点总结:
参数少:共享卷积核,减少训练参数;
计算快:局部连接结构加快计算;
防止过拟合:参数减少后模型更稳健;
可视化强:每层可视化为特征提取效果。
5. 举例说明
例如在识别人脸时:
第一个卷积层学习“边缘”;
第二层学习“眼睛和鼻子”;
第三层学习“人脸结构”。
三、卷积神经网络(CNN)
卷积神经网络是将卷积层、池化层(Pooling)、全连接层(Fully Connected Layer)组合在一起的深度网络。典型结构如下:
输入层 → 卷积层 → 池化层 → 卷积层 → 池化层 → 全连接层 → 输出层
1. 池化层(Pooling Layer)
池化用于降维,常用方法:
最大池化(Max Pooling):取局部区域最大值;
平均池化(Average Pooling):取平均值。
tf.keras.layers.MaxPooling2D(pool_size=(2, 2))
2. 全连接层(Fully Connected Layer)
在卷积层提取特征后,最后通过全连接层将这些特征映射为具体类别(如猫/狗识别)。
四、反向传播(Backpropagation)
1. 什么是反向传播?
反向传播是神经网络学习的核心算法,用于计算每个参数的梯度(Gradient),并将其用于优化器更新参数。其本质是应用链式法则(Chain Rule)来高效求导。
2. 工作流程
- 前向传播(Forward Propagation):计算预测输出 y^。
- 计算损失(Loss):比较 y^ 和真实值 y。
- 反向传播(Backpropagation):计算损失函数对每个参数的偏导数。
- 参数更新(Optimization):使用优化器(如 Adam、SGD)更新参数值。
3. 数学形式(链式法则)
对于某一层 LLL:
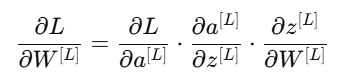
这样每一层的梯度都可以从后一层传递回来,形成高效的链式计算。
4. 为什么反向传播高效?
关键点:
通过共享中间变量(如激活值),避免重复求导;
每层梯度只需局部计算;
与矩阵运算结合后,可高效在 GPU 上并行。
五、总结
| 模块 | 主要功能 | 优点 |
|---|---|---|
| Adam 优化器 | 更新参数 | 自适应学习率、收敛快 |
| 卷积层 | 提取局部特征 | 减少参数、防止过拟合 |
| CNN 网络 | 多层特征学习 | 可处理图像、语音等结构化数据 |
| 反向传播 | 计算梯度并更新权重 | 高效、通用 |
Adam 是目前最常用的优化算法之一;
卷积层让模型具备自动特征提取能力;
CNN 结构是图像识别的核心框架;
反向传播是所有深度学习模型的“灵魂算法”。