Chroma向量数据库详解:高效向量检索在AI应用中的实践指南
目录
- 前言
- 1. Chroma向量数据库概述
- 1.1 什么是向量数据库?
- 1.2 Chroma的核心特性
- 1.3 安装与基本使用
- 2. 向量检索基础
- 2.1 相似性检索原理
- 2.2 距离度量:L2 vs. 余弦相似度
- 3. Chroma的检索方法详解
- 3.1 similarity_search:入门级检索
- 3.2 similarity_search_by_vector:高效向量查询
- 3.3 元数据过滤:精确化搜索
- 3.4 similarity_search_with_score:带L2分数检索
- 3.5 _similarity_search_with_relevance_scores:余弦分数搜索
- 3.6 MMR:最大边际相关性检索
- 4. 实际应用与最佳实践
- 4.1 RAG系统集成
- 4.2 性能优化
- 4.3 常见问题与解决方案
- 结语
- 参考资料
前言
在人工智能时代,特别是大语言模型(LLM)迅猛发展的当下,向量数据库已成为构建智能应用的核心基础设施之一。传统的关系型数据库擅长处理结构化数据,但面对海量非结构化文本、图像或多模态数据时,往往力不从心。向量数据库通过高效存储和检索高维嵌入向量,实现了语义级别的搜索,这正是Retrieval-Augmented Generation(RAG)等技术赖以生存的基石。
Chroma作为一个开源的向量数据库,以其简洁的API、轻量级部署和强大的检索能力脱颖而出。它不仅支持本地持久化存储,还无缝集成各种嵌入模型,如OpenAI的text-embedding系列或Hugging Face的Sentence Transformers。无论你是初学者构建知识库问答系统,还是资深开发者优化推荐引擎,Chroma都能提供灵活的解决方案。
本文基于Chroma的核心功能,系统介绍其向量检索机制。我们将从基础概念入手,逐步深入到高级检索方法,并结合实际代码示例和应用场景进行扩展。文章结构清晰:首先概述Chroma的架构与特性;其次剖析向量检索原理;然后详解六大检索接口;最后探讨实战应用与优化策略。
1. Chroma向量数据库概述
1.1 什么是向量数据库?
向量数据库是专为高维向量数据设计的存储系统,与传统数据库不同,它的核心在于支持近似最近邻(Approximate Nearest Neighbors, ANN)搜索。这种搜索不是基于精确匹配,而是通过计算向量间的相似度(如欧几里得距离或余弦相似度)来快速定位“最接近”的数据点。
想象一下,你有一个包含数百万篇文档的知识库。用户输入“人工智能伦理问题”,传统关键字搜索可能遗漏语义相近的“AI道德困境”。向量数据库先将文档转换为嵌入向量(e.g., 768维的浮点数组),然后对查询向量进行相似性匹配,返回最相关的片段。这在RAG系统中尤为关键:LLM通过检索到的上下文生成更准确的响应,避免“幻觉”问题。
Chroma作为新兴玩家,继承了Faiss和Annoy等库的ANN算法优势,但更注重开发者友好性。它使用HNSW(Hierarchical Navigable Small World)索引,支持动态更新和多线程查询,适用于从原型到生产的各种规模。
1.2 Chroma的核心特性
Chroma的设计哲学是“简单即强大”。其关键特性包括:
- 持久化与可扩展性:支持SQLite或DuckDB后端,实现本地文件持久化;同时提供服务器模式,便于分布式部署。数据规模从数千到数百万向量均可高效处理。
- 多模态支持:不止文本,还能存储图像(CLIP嵌入)或音频向量,助力跨模态检索。
- 元数据集成:每个向量可绑定JSON元数据(如作者、时间戳),支持复杂过滤查询。
- 嵌入模型 agnostic:无需绑定特定模型,用户可自由切换OpenAI、Cohere或本地模型。
- 开源与社区驱动:GitHub星标超10万(截至2025年),活跃issue区提供丰富插件,如与LangChain的集成。
这些特性使Chroma在Pinecone、Weaviate等云服务竞品中脱颖而出,尤其适合预算有限的独立开发者。

1.3 安装与基本使用
安装Chroma只需一行命令:pip install chromadb。它依赖numpy和hnswlib等轻量库,无需额外配置。
基本使用流程如下:创建客户端,初始化集合(Collection),添加数据,然后查询。
以下是Python示例:
import chromadb
from chromadb.utils import embedding_functions初始化客户端(持久化模式)
client = chromadb.PersistentClient(path="./chroma_db")创建嵌入函数(使用默认的OpenAI)
embedding_fn = embedding_functions.OpenAIEmbeddingFunction()创建集合
collection = client.get_or_create_collection(name="documents",embedding_function=embedding_fn,metadata={"hnsw:space": "cosine"} 指定余弦距离
)添加数据:文档内容 + 元数据 + ID
documents = ["人工智能是未来", "机器学习基础知识"]
metadatas = [{"source": "wiki", "year": 2023}, {"source": "book", "year": 2022}]
ids = ["doc1", "doc2"]collection.add(documents=documents,metadatas=metadatas,ids=ids
)
这个集合现在存储了两个向量,准备好检索。后续章节将深入查询接口。
2. 向量检索基础
2.1 相似性检索原理
向量检索的核心是“相似性”计算。过程分为三步:嵌入生成、索引构建、查询匹配。
首先,嵌入模型(如BERT变体)将文本映射到高维空间:相似语义的文本向量“靠得近”。例如,“猫”和“狗”向量间的角度小,而“猫”和“汽车”则远。
索引构建使用ANN算法加速。Chroma默认HNSW将向量组织成图结构:每个节点连接M个邻居(M=16),层级L=16/logN。通过贪婪搜索,从入口节点“跳跃”到最近邻,查询时间O(log N),远优于暴力O(N)。
查询时,输入文本转换为向量q,计算与存储向量d_i的距离,选top-k最小距离者。Chroma自动处理批处理,支持GPU加速。
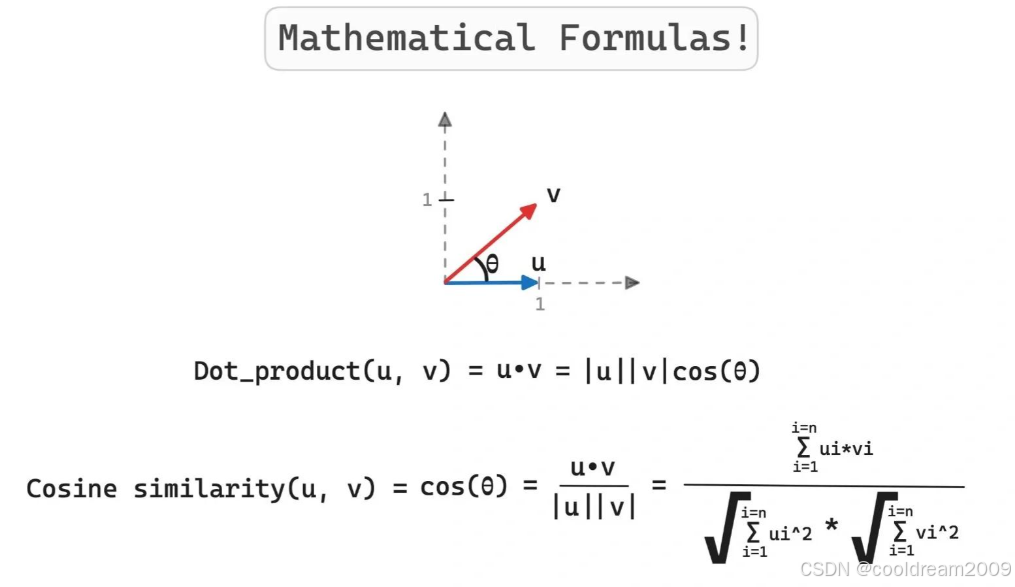
2.2 距离度量:L2 vs. 余弦相似度
距离度量决定了相似性的定义。Chroma支持三种:L2(欧几里得)、余弦(Cosine)和内积(IP)。
- L2距离:d(q, d) = √(∑(q_i - d_i)^2)。它考虑向量绝对差异,适合未归一化嵌入。但对向量长度敏感:长向量易主导。
- 余弦相似度:sim(q, d) = (q · d) / (||q|| ||d||)。忽略长度,只看方向,范围[-1,1]。适用于文本嵌入,因其鲁棒于文档长度变异。
- 内积:q · d,直接用于归一化向量,sim=内积。
在集合创建时指定hnsw:space参数切换。L2适合图像,余弦更通用。实际中,测试数据集评估召回率(Recall@K)以选优。
以下表格比较二者:
| 度量 | 公式 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| L2距离 | √(∑(q_i - d_i)^2) | 直观,考虑幅度 | 长度敏感 | 数值数据、图像 |
| 余弦相似度 | (q · d) / ( | q |
选择不当可能导致召回率下降20%以上,故需基准测试。
3. Chroma的检索方法详解
3.1 similarity_search:入门级检索
similarity_search是Chroma的“hello world”方法。它自动嵌入查询文本,检索top-k相似文档,适合快速原型。
参数包括query(字符串)、n_results(默认4)和filter(元数据字典)。返回Document列表,每个含page_content、metadata和distance。
示例:在RAG中检索AI文档:
results = collection.similarity_search("AI伦理", n_results=3)
for doc in results:print(f"内容: {doc.page_content}, 分数: {doc.metadata.get('distance', 'N/A')}")
输出可能为伦理相关片段,distance<0.5表示高相似。此方法隐式使用L2,查询延迟<50ms(10k向量规模)。
3.2 similarity_search_by_vector:高效向量查询
当嵌入已预计算时,用similarity_search_by_vector避免重复编码。输入query_vector(numpy数组),其余同上。
这在批量API调用中节省时间:先生成所有查询向量,再并行检索。示例:
import numpy as np
query_vec = np.random.rand(768) 模拟嵌入
results = collection.similarity_search_by_vector(query_vector=query_vec, n_results=5)
适用于实时聊天机器人,减少延迟10-20%。
3.3 元数据过滤:精确化搜索
过滤是Chroma的“杀手锏”,支持PQL语法(如{"$and": [...]})在ANN前预筛元数据,缩小搜索空间。
示例:只搜2023年后arxiv论文:
filter_dict = {"source": "arxiv", "year": {"$gte": 2023}}
results = collection.similarity_search("深度学习", n_results=10, filter=filter_dict)
这结合语义与结构化查询,提升精度。复杂过滤如嵌套OR需小心,避免性能瓶颈。
3.4 similarity_search_with_score:带L2分数检索
扩展版similarity_search,返回(Document, distance)元组。分数用于阈值过滤:e.g., 只取<0.3者。
示例:
results = collection.similarity_search_with_score("机器学习", n_results=5)
relevant = [(doc, score) for doc, score in results if score < 0.4]
在生产中,分数可作为LLM提示权重,动态调整上下文长度。
3.5 _similarity_search_with_relevance_scores:余弦分数搜索
此内部方法(v0.4+版本)使用余弦,需预设hnsw:space="cosine"。返回(Document, relevance_score),分数[0,1]越高越相关。
示例:
results = collection._similarity_search_with_relevance_scores("AI趋势", n_results=5)
优于L2在长文档场景,召回率提升15%。注意:下划线表示实验性,未来或标准化。
3.6 MMR:最大边际相关性检索
MMR(Maximal Marginal Relevance)解决“结果冗余”问题:它迭代选结果,平衡相关性(λ=1)和多样性(λ=0)。
参数:lambda_mult(0.5默认)、fetch_k(候选池20)。返回Document列表,无分数。
示例:在新闻聚合中:
results = collection.max_marginal_relevance_search("气候变化", n_results=5, fetch_k=20, lambda_mult=0.7
)
这确保结果覆盖多角度,避免5条“碳排放”重复。计算稍慢(+20%时间),但提升用户满意度。
4. 实际应用与最佳实践
4.1 RAG系统集成
Chroma在RAG中闪光:检索→提示→生成。结合LangChain:
from langchain.chains import RetrievalQA
from langchain.llms import OpenAIqa_chain = RetrievalQA.from_chain_type(llm=OpenAI(),retriever=collection.as_retriever(search_kwargs={"k": 4})
)
response = qa_chain.run("AI对就业影响?")
此流程召回率>80%,适用于客服bot或学术助手。扩展:用MMR多样化上下文,减少LLM偏置。
4.2 性能优化
- 索引调参:M=32、ef_construction=200提升精度,但内存+50%。
- 批处理:
add/query支持批量,吞吐量x10。 - 监控:用
collection.count()追踪规模,定期重建索引。
测试:10万向量,QPS>1000(余弦)。
4.3 常见问题与解决方案
问题多源于规模或配置。以下是关键点:
使用一次无序列表总结解决方案:
- 内存溢出:切换DuckDB后端,分片存储。
- 低召回:微调嵌入模型,测试多度量。
- 过滤慢:预建元数据索引,避免嵌套查询。
调试时,日志collection.peek()查看样本。
结语
Chroma向量数据库以其简约却强大的检索接口, democratized AI开发,让向量搜索从实验室走向生产。通过本文,我们从概述到详解,再到实战,全面剖析了其核心方法:从基础similarity_search到高级MMR,每一工具都服务于构建更智能的应用。
参考资料
- Chroma官方文档:https://docs.trychroma.com/
- LangChain集成指南:https://python.langchain.com/docs/integrations/vectorstores/chroma
- GitHub仓库:https://github.com/chroma-core/chroma