AI学习和研究——环境部署
快20年在家里没有用过台式机了,网上500块淘了台E5二手电脑,为了能跑动大模型,换掉显卡和电源,加了个1TB硬盘。显示器用被家里淘汰掉的电视。
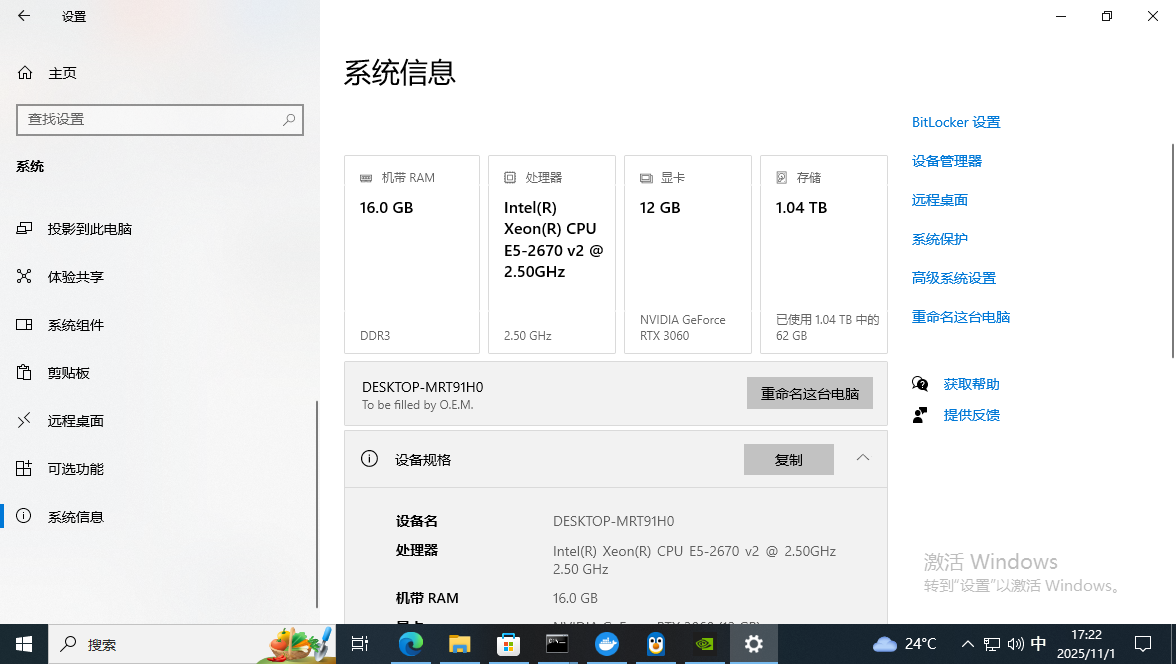
设备名 DESKTOP-MRT91H0
处理器 Intel(R) Xeon(R) CPU E5-2670 v2 @ 2.50GHz 2.50 GHz
机带 RAM 16.0 GB
存储 112 GB SSD Colorful SL300 120GB, 954 GB SSD BIWIN M100 1TB
显卡 NVIDIA GeForce RTX 3060 (12 GB)
设备 ID 68A8B226-3307-467D-A1FF-7396C538A5B5
产品 ID 00391-70000-00000-AA516
系统类型 64 位操作系统, 基于 x64 的处理器
笔和触控 没有可用于此显示器的笔或触控输入
版本 Windows 10 专业工作站版
版本号 22H2
安装日期 2025/10/26
OS 内部版本 19045.6456
然后查阅资料开整:今年最流行的是deepseek
特性 | DeepSeek V3 | DeepSeek R1 | DeepSeekLLM |
|---|---|---|---|
含义 | 高性能信息检索和自然语言处理模型,适用于大规模应用 | 针对特定任务优化的轻量级模型,适用于中小型企业 | 专为大规模语言生成任务设计,适用于对话系统和生成任务 |
模型名称 | DeepSeek V3 | DeepSeek R1 | DeepSeekLLM |
模型大小 | 1.5B、7B、8B、14B、32B、70B、671B | 1.5B、7B、8B、14B | 7B、14B、32B、70B、175B、671B |
重要特效 | - 高效信息检索与语义理解能力 | - 优化的推理速度,低资源消耗 | - 强大语言生成能力,适用于对话生成、文本生成等 |
- 适合大规模文档处理和高并发查询 | - 较轻的计算需求,适用于小型到中型企业应用 | - 强大上下文理解能力,适应复杂对话场景 | |
能力 | - 高效的信息检索、语义理解和大规模文本处理 | - 快速的推理能力,适用于轻量级的企业应用 | - 强大的文本生成、机器翻译、情感分析等 |
- 适应大规模数据库检索、搜索引擎等任务 | - 支持中型规模企业应用,如文档分类、知识图谱查询等 | - 支持生成式对话、文章创作、复杂问答任务 | |
配置建议(1.5B) | CPU:Intel Xeon 或 AMD EPYC 16 核 | CPU:Intel Xeon 或 AMD EPYC 16 核 | CPU:Intel Xeon 或 AMD EPYC 16 核 |
内存:32GB RAM | 内存:32GB RAM | 内存:32GB RAM | |
显卡:NVIDIA T4 / V100 / A100,16GB 显存 | 显卡:NVIDIA T4,16GB 显存 | 显卡:NVIDIA A100,16GB 显存 | |
Python 版本:Python 3.7+ | Python 版本:Python 3.7+ | Python 版本:Python 3.7+ | |
配置建议(7B) | CPU:Intel Xeon 或 AMD EPYC 16 核 | CPU:Intel Xeon 或 AMD EPYC 16 核 | CPU:Intel Xeon 或 AMD EPYC 16 核 |
内存:64GB RAM | 内存:64GB RAM | 内存:64GB RAM | |
显卡:NVIDIA A100,16GB 显存 | 显卡:NVIDIA A100 / V100,16GB 显存 | 显卡:NVIDIA A100 / V100,16GB 显存 | |
Python 版本:Python 3.7+ | Python 版本:Python 3.7+ | Python 版本:Python 3.7+ | |
配置建议(8B) | CPU:Intel Xeon 或 AMD EPYC 24 核 | CPU:Intel Xeon 或 AMD EPYC 24 核 | CPU:Intel Xeon 或 AMD EPYC 24 核 |
内存:128GB RAM | 内存:128GB RAM | 内存:128GB RAM | |
显卡:2 x A100,32GB 显存 | 显卡:2 x A100,32GB 显存 | 显卡:2 x A100,32GB 显存 | |
Python 版本:Python 3.7+ | Python 版本:Python 3.7+ | Python 版本:Python 3.7+ | |
配置建议(14B) | CPU:Intel Xeon 或 AMD EPYC 32 核 | CPU:Intel Xeon 或 AMD EPYC 32 核 | CPU:Intel Xeon 或 AMD EPYC 32 核 |
内存:128GB - 256GB RAM | 内存:128GB - 256GB RAM | 内存:128GB - 256GB RAM | |
显卡:2 x A100,40GB 显存 | 显卡:2 x A100,40GB 显存 | 显卡:2 x A100,40GB 显存 | |
Python 版本:Python 3.7+ | Python 版本:Python 3.7+ | Python 版本:Python 3.7+ | |
配置建议(32B) | CPU:Intel Xeon 或 AMD EPYC 32-48 核 | CPU:Intel Xeon 或 AMD EPYC 32-48 核 | CPU:Intel Xeon 或 AMD EPYC 32-48 核 |
内存:256GB RAM | 内存:256GB RAM | 内存:256GB RAM | |
显卡:4 x A100,40GB 显存 | 显卡:3-4 x A100,40GB 显存 | 显卡:4 x A100,40GB 显存 | |
Python 版本:Python 3.7+ | Python 版本:Python 3.7+ | Python 版本:Python 3.7+ | |
配置建议(70B) | CPU:Intel Xeon 或 AMD EPYC 64 核 | CPU:Intel Xeon 或 AMD EPYC 64 核 | CPU:Intel Xeon 或 AMD EPYC 64 核 |
内存:512GB RAM | 内存:512GB RAM | 内存:512GB RAM | |
显卡:4-6 x A100,80GB 显存 | 显卡:4 x A100,80GB 显存 | 显卡:6-8 x A100,80GB 显存 | |
Python 版本:Python 3.7+ | Python 版本:Python 3.7+ | Python 版本:Python 3.7+ | |
配置建议(671B) | CPU:Intel Xeon 或 AMD EPYC 96 核 | CPU:Intel Xeon 或 AMD EPYC 96 核 | CPU:Intel Xeon 或 AMD EPYC 96 核 |
内存:1TB RAM | 内存:1TB RAM | 内存:1TB RAM | |
显卡:10 x A100,80GB 显存 | 显卡:8 x A100,80GB 显存 | 显卡:16 x A100,80GB 显存 | |
Python 版本:Python 3.7+ | Python 版本:Python 3.7+ | Python 版本:Python 3.7+ | |
使用场景 | - 大规模信息检索、搜索引擎优化、大数据文档检索 | - 知识图谱、文档分类、轻量级NLP任务 | - 对话生成、内容创作、情感分析、复杂问答任务 |
性能需求 | - 高性能计算需求,适合大规模应用和高负载任务 | - 较低计算需求,适用于中小型企业或小型应用 | - 极高计算需求,适用于大型计算集群和超高并发任务 |
1. 安装docker:
其中碰到默认镜像源无法下载问题(设置国内镜像源);
WINDOWS环境下使用docker要搭载WSL虚拟环境,Windows功能要打开“Hyper-V”功能;
系统盘空间不够(重新分配原配电脑空间,一个硬盘作系统盘,然后把docker存储空间放在1T硬盘空间)
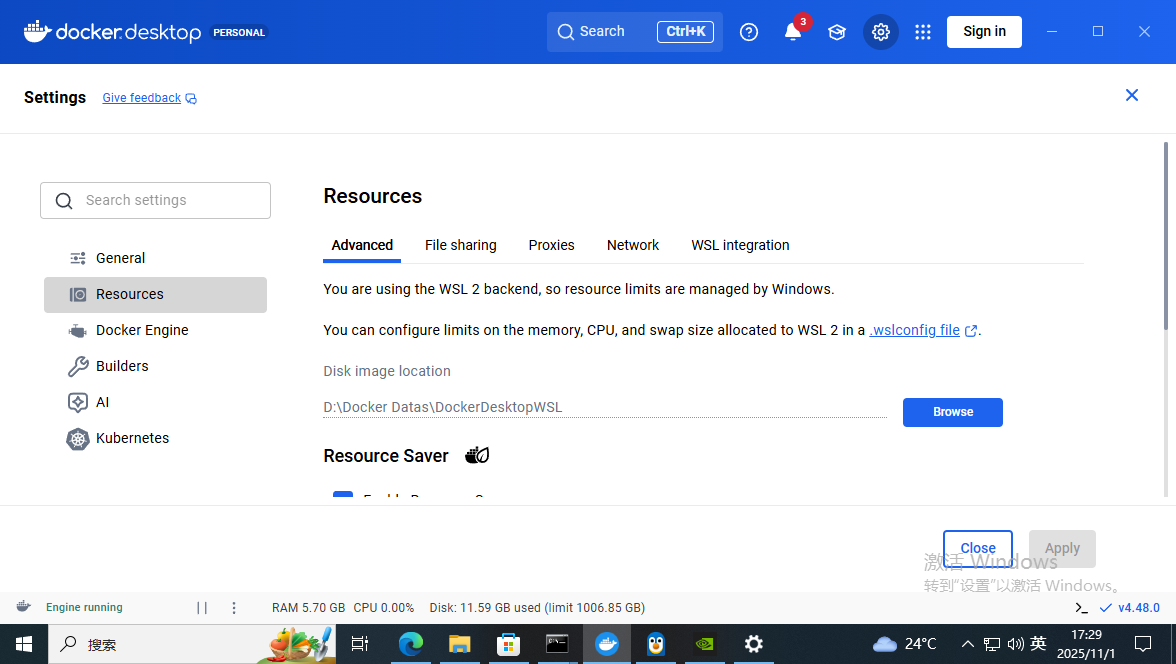
2. 下载安装ollama
docker pull ollama/ollama网络有些问题,让它自己下载,自己去午饭了,吃完午饭刚刚好
启动ollama
docker run -itd -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollamadocker run 运行一个新的 Docker 容器
-itd 组合多个选项:
✅ -i(保持标准输入)
✅ -t(分配终端)
✅ -d(后台运行容器)
-v ollama:/root/.ollama 挂载数据卷,把 ollama 这个 Docker 数据卷 绑定到容器的 /root/.ollama 目录,确保数据持久化(如下载的模型不会丢失)。
-p 11434:11434 端口映射,把 宿主机(本机)的 11434 端口 映射到 容器 内部的 11434 端口,这样宿主机可以通过 http://localhost:11434 访问 Ollama 服务。
--name ollama 指定 容器名称 为 ollama,方便管理和启动。
ollama/ollama 使用的 Docker 镜像,这里是 官方的 Ollama 镜像。
如果是使用GPU运行,则用下面的命令启动
docker run -itd --name ollama --gpus=all -v ollama:/root/.ollama -p 11434:11434 ollama/ollama3. 拉取Deepseek大模型
docker exec -it ollama /bin/bash
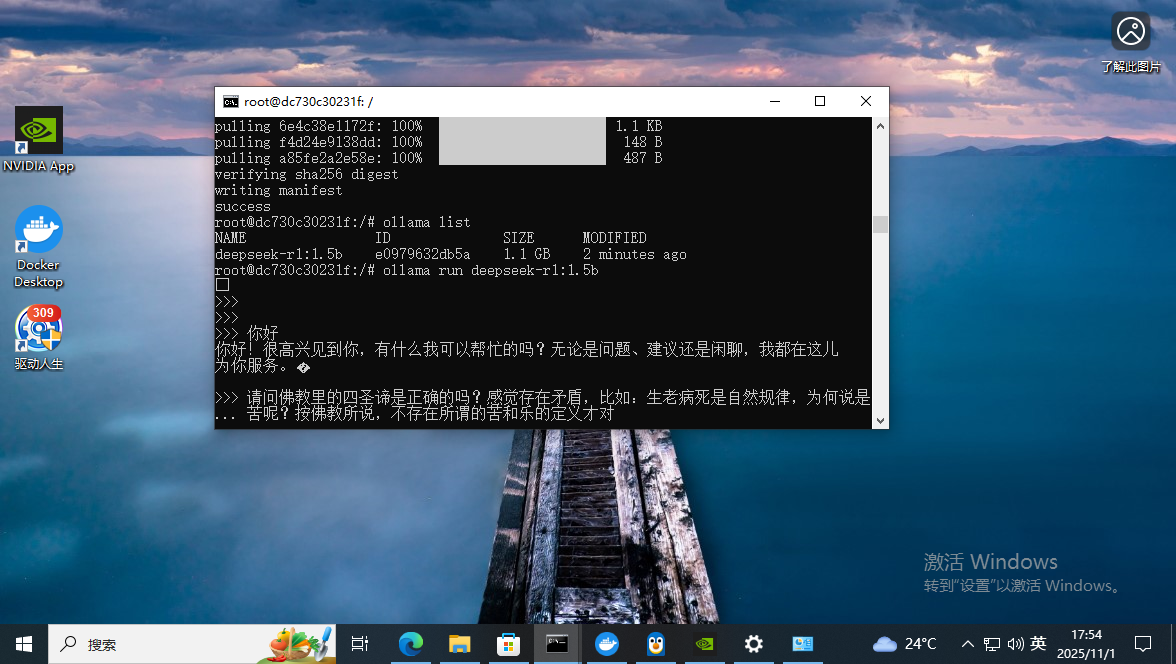
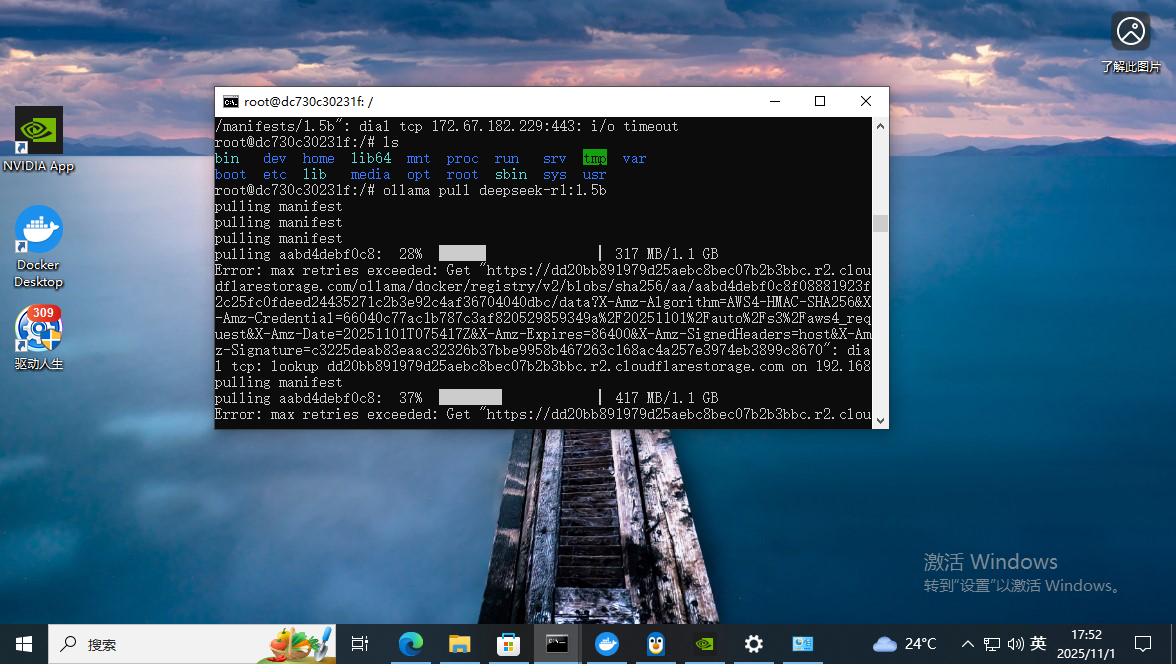
ollama pull deepseek-r1:1.5b先从最小的模型开始吧
网络不好,拉了好几次,一个小时后总算拉下来了。接着继续拉7B的模型
root@dc730c30231f:/# ollama list
NAME ID SIZE MODIFIED
deepseek-r1:7b 755ced02ce7b 4.7 GB 24 minutes ago
deepseek-r1:1.5b e0979632db5a 1.1 GB About an hour ago
root@dc730c30231f:/#拉好后赶快体验吧^0^
root@dc730c30231f:/# ollama run deepseek-r1:1.5b