2025年10月AGI月评|OmniNWM/X-VLA/DreamOmni2等6大开源项目:自动驾驶、机器人、文档智能的“技术底座”全解析
〔更多精彩AI内容,尽在 「魔方AI空间」 ,引领AIGC科技时代〕
本文作者:猫先生
知识库主页:https://oizxc9sdhbc.feishu.cn/wiki/FGS5wST0Hiy6xJklyPTcTVOqnAd
引言
本月项目的焦点明显指向了更高维度的智能:从自动驾驶的全景环境模拟,到机器人的跨平台通用控制,再到文档与图像的深度理解与生成。
这些项目不再满足于单一任务的卓越,而是致力于构建统一、可推理、可行动的“全能型”AI基础设施,预示着AI技术正从“工具化”迈向“体系化”的新阶段。
一、 智能驾驶新纪元:OmniNWM——构建自动驾驶的“数字孪生”世界
项目概览OmniNWM(Omniscient Navigation World Model)由上海交通大学、PhiGent Robotics、清华大学等机构联合推出,是一个开创性的全景导航世界模型。其核心突破在于,能够以一个统一的框架,同时预测未来一段时间内的全景RGB视频、语义分割视频、度量深度视频、3D语义占据栅格(3D Semantic Occupancy)以及车辆的规划轨迹。
项目主页:https://arlo0o.github.io/OmniNWM/

技术深度点评
-
“世界模型”的真正践行者:世界模型(World Model)的概念源于AI对环境进行模拟和推理的理想,但过往许多模型仅能预测RGB像素,缺乏对物理世界结构和语义的理解。OmniNWM首次在自动驾驶领域大规模、高质量地实现了多模态联合预测。其生成的3D语义占据栅格尤为重要,它提供了一个稠密、带类别标签的3D环境表示,是进行安全合规决策(如碰撞检测)的直接依据。
-
精准控制与泛化能力:项目提出了归一化全景Plücker射线图这一新颖的轨迹编码表示,将未来路径转化为图像空间中的像素级信号。这使得模型能够以前所未有的精度控制生成视频中车辆的行驶轨迹,甚至能处理“倒车”等分布外(Out-of-Distribution)动作,展现了强大的泛化性。
-
内生奖励函数:OmniNWM摒弃了依赖外部模型计算奖励的传统做法,直接利用自身生成的3D占据栅格来定义基于规则的稠密奖励(如是否压线、是否可能碰撞)。这为在模拟环境中进行高效、可靠的闭环评估和强化学习训练铺平了道路,是实现全栈自动驾驶仿真的关键一步。
行业应用前瞻
-
自动驾驶仿真测试:可生成海量、高保真、长时序的极端场景(Corner Cases),极大降低实车测试成本和风险。
-
自动驾驶规控算法训练:提供高质量的环境预测和内生奖励,成为训练和验证决策规划算法的“沙盒”。
-
高精地图生成与更新:通过对现实世界的大量模拟,可辅助生成或验证高精地图的语义信息。
二、 具身智能新范式:X-VLA——软提示学习实现机器人“一通百通”
项目概览X-VLA来自清华大学AIR研究院和上海AI实验室,是一个基于软提示(Soft Prompt)技术的跨实体(Cross-Embodiment)视觉-语言-动作模型。它旨在解决不同机器人(如机械臂形态、关节数、动作空间各异)数据难以联合训练的异构性问题,让一个模型能理解和操控多种机器人平台。
项目主页:https://thu-air-dream.github.io/X-VLA/
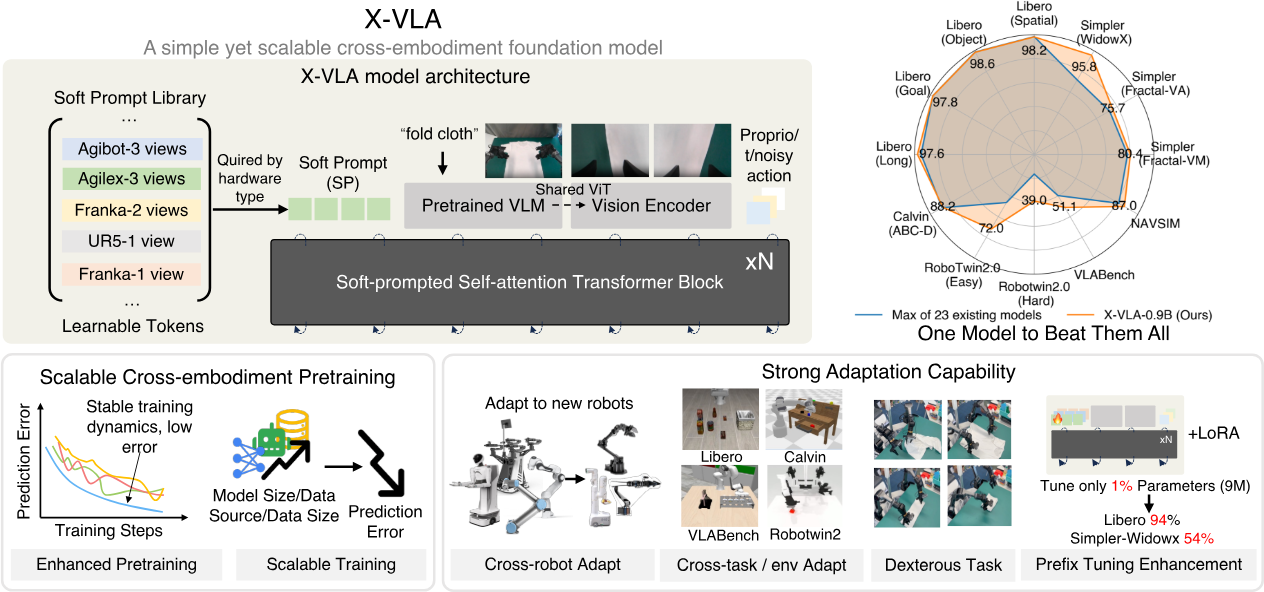
技术深度点评
-
软提示:化解跨实体异构性难题:X-VLA的创新核心是为每个不同的数据源(即每种机器人)引入一组独立的、可学习的嵌入(Embedding),作为实体特定的提示。在训练时,模型通过这部分参数来适应不同机器人的动力学特性和观察空间,从而在不显著增加参数量的前提下,有效融合异构数据。这好比为模型配备了可切换的“驱动程序”,使其能驾驭不同“硬件”。
-
简洁而强大的架构:X-VLA完全基于标准的Transformer编码器,结合流匹配(Flow Matching)技术来生成动作,架构清晰,易于扩展和优化。其在AgiBot世界挑战赛(IROS 2025)中夺冠,以及在6个模拟环境和3个真实机器人上展现的SOTA性能,验证了该范式的有效性。
-
高效微调与快速适应:由于主体参数是共享的,当遇到新的机器人或任务时,仅需对少量的软提示参数或适配器进行微调,即可快速适应,这大大降低了机器人部署的门槛和成本。
行业应用前瞻
-
柔性制造与物流分拣:在产线上,机器人型号和任务可能频繁变更,X-VLA的快速适应能力能大幅提高生产效率。
-
家庭服务机器人:面对非结构化的家庭环境,机器人需要处理多样化的任务,跨实体通用模型是实现这一目标的基石。
-
机器人算法研发:为学术界和工业界提供了一个强大的、可泛化的基础模型,加速机器人智能算法的研究。
三、 多模态内容生成与理解:DreamOmni2与Nanonets-OCR2的精准化突破
本章节聚焦于在图像生成和文档理解两大应用领域实现“精准控制”和“深度理解”的开源项目。
3.1 DreamOmni2:指令驱动的“全能”图像编辑
项目概览DreamOmni2是DreamOmni系列的最新升级,一个开源的多模态指令驱动图像编辑与生成模型。它能够根据用户以图像和文本组合而成的复杂指令,进行极其精细和多样化的编辑操作,如物体替换、光影渲染、风格迁移、姿势模仿、表情移植等。
项目主页:https://pbihao.github.io/projects/DreamOmni2/index.html

技术深度点评
-
超越“文生图”的精确引导:DreamOmni2的核心优势在于多图参考输入能力。用户可以提供一张目标图和多张参考图,并组合复杂的指令(如“将图A中人物的姿势换成图B的,发型换成图C的,背景风格换成图D的”)。这种基于视觉示例的引导远比纯文本描述更精确,解决了AIGC应用中的“控制精度”痛点。
-
统一框架解决多种任务:它将过去需要多个专门模型(如换脸、换装、风格化)才能完成的任务,统一到一个端到端的框架中,极大地提升了实用性和易用性。
行业应用前瞻
-
电商与广告:快速生成商品换装、换场景的营销图片;为模特统一姿势或表情。
-
娱乐与游戏:快速进行角色概念设计、生成宣传素材。
-
专业设计:为设计师提供强大的灵感辅助和素材生成工具。
3.2 Nanonets-OCR2:下一代文档智能的“认知”引擎
项目概览Nanonets-OCR2是一个先进的视觉-语言模型,专为文档理解而优化。它不仅能高精度地将文档图像转换为结构化的Markdown文本,还具备视觉问答(VQA)能力,能直接回答关于文档内容的问题。
项目主页:https://nanonets.com/research/nanonets-ocr-2/

技术深度点评
-
从“识别”到“理解”的跃迁:传统OCR止于文字提取,而Nanonets-OCR2能理解文档的逻辑结构和视觉元素。它可以智能区分正文、水印、签名、页眉页脚,准确提取表格、公式(并转为LaTeX)、复选框状态,甚至能生成流程图和架构图的Mermaid代码。其VQA功能经过特殊训练,对文档内容之外的问题会回答“未提及”,有效减少了幻觉(Hallucination)。
-
大规模高质量数据集:其在超过300万页多样化文档数据上进行训练,覆盖多语言、多领域,这是其强大泛化能力的根本保证。
行业应用前瞻
-
金融与法律:自动化处理合同、报告、票据,实现非结构化数据的秒级归档与查询。
-
医疗与科研:快速数字化病历、研究论文,提取关键信息。
-
企业数字化:构建企业内部的智能文档知识库,提升信息检索和决策效率。
四、 技术趋势总结
10月的开源项目清晰地勾勒出三大技术趋势:
统一化:模型正从“单点开花”走向“多任务统一”,如OmniNWM统一了自动驾驶的感知、预测与规划,X-VLA统一了不同机器人的控制接口,DreamOmni2统一了多种图像编辑任务。这降低了AI系统的复杂度和部署成本。
具身化:AI不再局限于虚拟世界,而是通过与物理环境(驾驶、机器人操作)的交互来学习和进化,“感知-推理-行动”的闭环成为前沿研究的核心。
精准化:无论是图像生成还是文档理解,对结果的“可控性”和“可靠性”要求越来越高。通过多模态指令、软提示、规则奖励等技术,AI正变得越发可信和可用。
这些开源项目的涌现,不仅为研究者和开发者提供了强大的工具,更深刻地影响着自动驾驶、机器人、内容创作和企业数字化等行业的未来图景。
我们有理由期待,在这些基础之上,11月将带来更多激动人心的突破。
推荐阅读
► AGI新时代的探索之旅:2025 AIGCmagic社区全新启航
► 技术资讯: 魔方AI新视界
► 项目应用:开源视界
► 技术专栏: 多模态大模型最新技术解读专栏 | AI视频最新技术解读专栏 | 大模型基础入门系列专栏 | 视频内容理解技术专栏 | 从零走向AGI系列
► 技术综述: 一文掌握视频扩散模型 | YOLO系列的十年全面综述 | 人体视频生成技术:挑战、方法和见解 | 一文读懂多模态大模型(MLLM)|一文搞懂RAG技术范式演变及Agentic RAG|强化学习技术全面解读 SFT、RLHF、RLAIF、DPO|一文搞懂DeepSeek的技术演进之路