【推荐系统9】重排模型:基于贪心、个性化的重排
目录
基于贪心的重排
MMR: 最大边际相关
DPP:行列式点过程
代码层面的使用
基于个性化的重排
PRM: 基于Transformer的个性化重排模型
PRS
PMatch:基于排列组合的重排模型
PRank阶段:排列评估
召回阶段从海量物品中筛选出数百到数千候选,精排阶段利用复杂模型对候选集精准打分,输出按预估分数降序排列的候选列表。
重排(Re-ranking) 阶段作为推荐流程的最终优化环节,其作用是对精排输出的高质量候选列表进行全局优化,生成更能满足用户体验需求和业务目标的最终推荐列表。
本文为funrec推荐系统学习笔记,整合自己的理解和网络其他资料写成。
本节介绍重排阶段的核心算法策略:
基于贪心的重排
关于贪心的重排算法主要有两个:
MMR: 最大边际相关
最大边际相关(Maximal Marginal Relevance, MMR)
精排输出的按CTR降序排列的列表中,头部物品往往具有高度相似性,这样会导致用户产生审美疲劳、优质内容曝光不足的现象
MMR算法的核心目标是在保留高相关性物品的前提下,通过主动引入多样性打破同质化
DPP:行列式点过程
行列式点过程(Determinantal Point Process, DPP)
MMR通过候选内容和已选内容计算两两相似度,贪心的选择一个和已选所有内容相似度最低的内容。但MMR无法捕捉多个物品间的复杂排斥关系
行列式如何度量多样性? 相似度矩阵的行列式值较大时,对应物品的多样性越高,反之行列式的值越低,多样性越低(当行列式值=0时,向量共面),因此相似矩阵的行列式可以度量多样性
如何融合相关性和多样性? 核矩阵可以融合相关性和多样性,
核矩阵的行列式值同时反映相关性和多样性:
- 相关性越高(物品精排得分越高),行列式值越大;
- 多样性越好(物品间相似度越低,越接近正交),行列式值越大。
最后通过对核矩阵行列式取对数,将优化目标拆解为 “相关性项” 和 “多样性项” 的线性组合。再加上超参数调节两者的权重
最后的贪心求解过程:
核心目标是从候选物品中选择一个子集,使得核矩阵(融合了相关性和多样性)的行列式值最大,使用的贪心策略:每次挑一个能让当前推荐列表变得更好(更相关且更多样)的物品,逐步凑出最优推荐结果,这里用到了数学技巧(Cholesky 分解)降低了 DPP 求解的复杂度
代码层面的使用
调用开源库(如`dppy`),只需传入核矩阵和推荐数量,快速验证效果。
from dppy.finite_dpps import FiniteDPP# 构造核矩阵K(已提前计算好相关性和相似度)
K = np.array([[1.0, 0.2, 0.1], [0.2, 1.0, 0.3], [0.1, 0.3, 1.0]])
# 初始化DPP,指定核矩阵
dpp = FiniteDPP('likelihood', **{'K': K})
# 贪心选择2个物品
selected = dpp.sample_exact_k_dpp(size=2, mode='greedy')
print("选中的物品索引:", selected)基于个性化的重排
基于贪心策略的重排序方法。这些方法通过显式定义多样性、相关性或覆盖度的优化目标,在初始排序列表上进行局部调整。它们计算效率高且可解释性强,但在处理复杂的物品间相互影响和深度个性化方面存在局限:目标函数往往需要手工设计,难以捕捉高阶、非线性的交互模式;同时,将用户个性化信息深度融入列表级优化也颇具挑战。
本节介绍两个个性化重排模型:
PRM: 基于Transformer的个性化重排模型
(Personalized Re-Ranking Model)
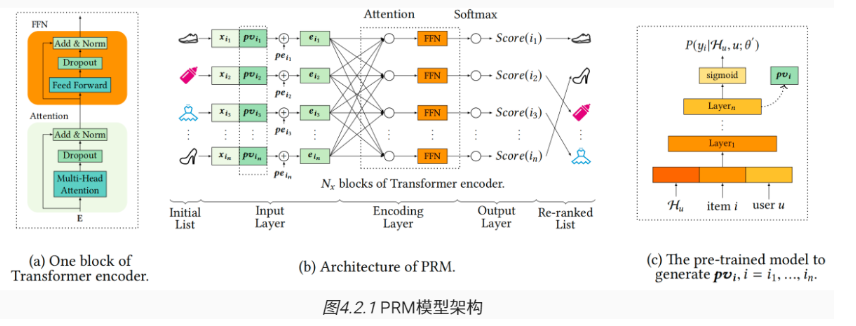
PRM 利用 Transformer 通过多头自注意力机制让每个物品关注列表中所有其他物品,捕捉长距离、复杂的物品间相互影响,融入用户个性化信息,无需依赖预设多样性公式,直接从数据中学习最优物品组合。
输入层输入 PV、物品自身特征、位置嵌入
关键创新:个性化向量(PV)生成
- 利用预训练点击率预估模型,输入用户历史行为数据学习用户对物品的点击概率预测能力。
- 提取预训练模型输出层前隐藏层的激活值作为 PV
PRS
(Permutation Retrieve System)
传统的重排序方法(包括PRM)主要关注单个物品的分数优化,却忽略了物品排列顺序本身对用户行为的影响。
> 想象这样一个场景:用户面对商品列表 [A, B, C] 时毫无购买欲望,但当看到 [B, A, C] 这个排列时却购买了商品A。这种现象被称为 排列变异影响 (Permutation-Variant Influence)。一个可能的解释是:将价格较高的商品B放在前面,会让用户觉得商品A相对便宜,从而激发购买欲望。
PRS的设计思路是:评估所有可能的物品排列组合,并选择其中用户体验最佳的那一个。在计算效率上PRS提供了两阶段解决方案:
1. PMatch阶段:通过搜索算法快速筛选出少数几个候选排列
2. PRank阶段:使用神经网络模型评估这些候选排列的质量,选出最优解
如图为PRS的框架结构
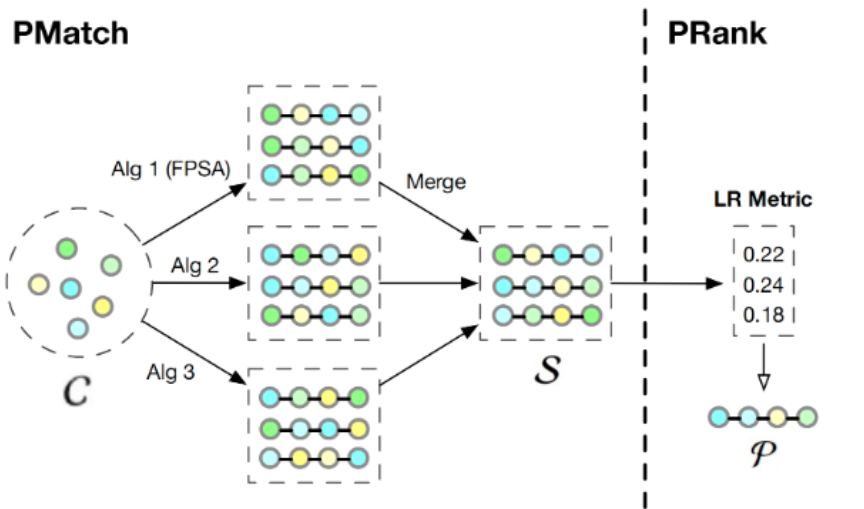
PMatch:基于排列组合的重排模型
离线训练:双模型预测体系
PMatch阶段需要两个point-wise预测模型的支持:
1. CTR模型:预测用户点击某个物品的概率 PCTR
2. Next模型:预测用户在浏览完当前物品后继续浏览下一个物品的概率
在线服务:FPSA算法
将用户的浏览行为建模为一个序列决策过程。
PRank阶段:排列评估
PRank (Permutation-Ranking) 阶段接收PMatch生成的候选排列,使用神经网络模型DPWN (Deep Permutation-Wise Network) 来评估每个排列的质量。
DPWN的设计理念是:排列中每个物品的价值不仅取决于它自身的特征,更取决于它在整个序列上下文中的位置和作用。为了捕捉这种复杂的序列依赖关系,DPWN采用了Bi-LSTM架构。
PRank阶段的核心评估指标是List Reward(LR) ,它被定义为排列中所有物品预测点击概率的总和:这个简单而有效的指标反映了整个排列的预期收益。在线服务时,PRank会计算每个候选排列的LR值,并选择LR最高的排列作为最终输出。