Leetcode 43
1 题目
102. 二叉树的层序遍历
给你二叉树的根节点 root ,返回其节点值的 层序遍历 。 (即逐层地,从左到右访问所有节点)。
示例 1:
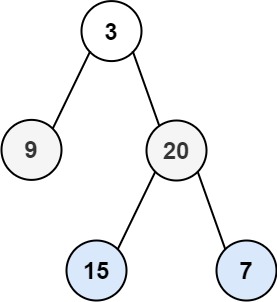
输入:root = [3,9,20,null,null,15,7] 输出:[[3],[9,20],[15,7]]
示例 2:
输入:root = [1] 输出:[[1]]
示例 3:
输入:root = [] 输出:[]
提示:
- 树中节点数目在范围
[0, 2000]内 -1000 <= Node.val <= 1000
2 代码实现
cpp
class Solution {
public:vector<vector<int>> levelOrder(TreeNode* root) {vector <vector <int>> ret;if (!root) {return ret;}queue <TreeNode*> q;q.push(root);while (!q.empty()) {int currentLevelSize = q.size();ret.push_back(vector <int> ());for (int i = 1; i <= currentLevelSize; ++i) {auto node = q.front(); q.pop();ret.back().push_back(node->val);if (node->left) q.push(node->left);if (node->right) q.push(node->right);}}return ret;}
};整体逻辑
层序遍历的核心是按 “层” 访问节点:先访问第 1 层(根节点),再访问第 2 层(根的左右子节点),以此类推。实现时需要用队列来暂存节点,确保按顺序访问。
代码逐句解释
1. 函数定义
vector<vector<int>> levelOrder(TreeNode* root)
- 返回值
vector<vector<int>>:这是 C++ 的二维动态数组(类似 C 语言的int**),用于存储每层的节点值(外层数组的每个元素是一层的所有值)。 - 参数
TreeNode* root:二叉树根节点指针(和 C 语言的struct TreeNode*含义相同)。
2. 初始化返回结果
vector <vector <int>> ret; // 定义二维数组,用于存最终结果
if (!root) { // 如果根节点为空(空树)return ret; // 直接返回空结果
}
- 这一步和 C 语言类似:先判断树是否为空,空则返回空结果。
3. 初始化队列(核心工具)
queue <TreeNode*> q; // 定义一个队列,存储 TreeNode* 类型(节点指针)
q.push(root); // 先把根节点入队(从根开始遍历)
- 队列(queue) 的作用:暂存 “待访问的节点”,确保按 “先进先出” 的顺序处理(符合层序遍历的顺序)。
- 相当于 C 语言中用数组模拟队列的
queue[rear++] = root。
4. 层序遍历主循环
while (!q.empty()) { // 只要队列不为空,就继续处理(还有节点没访问)int currentLevelSize = q.size(); // 当前层的节点数量(队列中现存的节点数)ret.push_back(vector <int> ()); // 给结果集新增一个空的子数组(用于存当前层的结果)// 遍历当前层的所有节点for (int i = 1; i <= currentLevelSize; ++i) {auto node = q.front(); q.pop(); // 取出队头节点,并从队列中移除(类似C的queue[front++])ret.back().push_back(node->val); // 把当前节点的值存入结果集的“最后一个子数组”(即当前层)// 把下一层的节点入队(左子树优先,再右子树)if (node->left) q.push(node->left); // 左子节点存在则入队if (node->right) q.push(node->right); // 右子节点存在则入队}
}
关键逻辑拆解:
-
currentLevelSize = q.size():每次进入循环时,队列中剩下的节点都是 “当前层” 的节点(因为上一层的节点已经全部处理完了)。这个值决定了当前层要遍历多少个节点。 -
ret.push_back(vector <int> ()):在结果集中新增一个空的一维数组,用于存放当前层所有节点的值(相当于 C 语言中给result[returnSize]分配内存)。 -
auto node = q.front(); q.pop():q.front():取队头节点(类似 C 的queue[front])。q.pop():移除队头节点(类似 C 的front++)。
-
ret.back().push_back(node->val):ret.back():获取结果集中的最后一个子数组(即当前层的数组)。push_back(node->val):把当前节点的值添加到这个子数组中(类似 C 语言中currentLevel[i] = node->val)。
-
子节点入队:处理完当前节点后,把它的左右子节点(如果存在)加入队列,作为 “下一层” 的节点等待处理(和 C 语言中
queue[rear++] = node->left逻辑相同)。
5. 返回结果
return ret; // 返回存储好的层序遍历结果
和 C 语言版本的对比
| 功能 | C 语言实现 | C++ 代码实现 |
|---|---|---|
| 存储结果 | 用int**和int*手动管理内存 | 用vector<vector<int>>自动管理 |
| 队列实现 | 用数组 +front/rear指针模拟 | 用queue<TreeNode*>容器 |
| 动态扩容 | 需手动调用realloc | vector和queue自动扩容 |
| 访问当前层结果 | 用result[returnSize] | 用ret.back() |
核心思想总结
- 用队列记录 “待访问的节点”,保证按层顺序处理。
- 每次循环先确定 “当前层的节点数量”,然后遍历这些节点。
- 遍历节点时,把节点值存入结果集,同时把它们的子节点加入队列(作为下一层)。
c
int** levelOrder(struct TreeNode* root, int* returnSize, int** returnColumnSizes) {// 开辟返回数组空间,最大为2000int** ans = (int**)malloc(sizeof(int*) * 2000);// *returnColumnSizes数组记录每一层节点的个数*returnColumnSizes = malloc(sizeof(int) * 2000);*returnSize = 0;// 若树为空,直接返回ansif(root == NULL) return ans;// 模拟队列数组struct TreeNode* queue[2000];// head、tail分别指向队列的头部和尾部int head = 0, tail = 0;// 初始先将根节点入队queue[tail++] = root;// 结束条件为队列为空,即tail==headwhile(head != tail){/*每一次循环,都会将树当前层(可用*returnSize表示)节点全部入队,因此头部到尾部的节点数即为当前层的全部节点*/int len = tail - head;// 开辟当前层的一维数组空间ans[*returnSize] = malloc(sizeof(int) * len);/*当前层的节点个数统计完成之后,需要出队,若节点全部出队,队列里存在下一层的全部节点,因此在出队之前,用临时变量start记录之前的head值,移动head到下一层节点的起始位置(即tail的位置),相当于当前层节点出队,*/int start = head;head = tail;// start被赋值后变为当前层的头部,head被赋值后变为当前层的尾部for(int i = start; i < head; i++){// 逐个访问当前层的节点值ans[*returnSize][i - start] = queue[i]->val;// 访问完一个节点后,将此节点的左右孩子入队if(queue[i]->left) queue[tail++] = queue[i]->left;if(queue[i]->right) queue[tail++] = queue[i]->right;}// *returnColumnSizes赋值,并将层数加1(*returnColumnSizes)[(*returnSize)++] = len;}return ans;
}整体逻辑梳理
层序遍历的本质是 “按层次依次访问节点”:先访问根节点(第 1 层),再访问根的左右子节点(第 2 层),接着访问第 2 层节点的子节点(第 3 层),以此类推。实现时需要用队列暂存节点,保证 “先进先出” 的访问顺序。
代码逐句解释
1. 初始化内存与返回值
// 开辟返回数组空间,最大为2000(假设树最多2000层)
int** ans = (int**)malloc(sizeof(int*) * 2000);
// returnColumnSizes数组记录每一层的节点个数(长度同样预设2000)
*returnColumnSizes = malloc(sizeof(int) * 2000);
*returnSize = 0; // 初始化层数为0
// 若树为空,直接返回空结果
if(root == NULL) return ans;
ans是二维数组:外层存储 “每一层的结果”,内层存储 “某一层的所有节点值”。*returnColumnSizes是一维数组:记录每一层有多少个节点(例如returnColumnSizes[0]是第 1 层的节点数)。*returnSize用于记录总层数(最终返回给调用者)。
2. 初始化队列(核心工具)
// 用数组模拟队列,最多存储2000个节点(预设最大值)
struct TreeNode* queue[2000];
// head:队头指针(指向队的位置);tail:队尾指针(入队的位置)
int head = 0, tail = 0;// 根节点入队(初始时队列只有根节点)
queue[tail++] = root;
- 队列的作用:暂存 “待访问的节点”,确保按层次顺序处理(先入队的节点先被访问)。
- 初始状态:
head=0,tail=1(根节点存入队列第 0 位,tail指向队尾的下一个空位)。
3. 层序遍历主循环(核心逻辑)
// 队列不为空时循环(head == tail 表示队空,遍历结束)
while(head != tail){// 当前层的节点数量 = 队尾 - 队头(队列中现存的节点都是当前层的)int len = tail - head;// 为当前层分配存储空间(存储len个节点值)ans[*returnSize] = malloc(sizeof(int) * len);// 记录当前层的起始位置(后续出队时用)int start = head;// 移动head到tail位置(相当于当前层的节点全部出队,下一次循环处理下一层)head = tail;// 遍历当前层的所有节点(从start到head-1,共len个节点)for(int i = start; i < head; i++){// 存储当前节点的值到结果数组:当前层的第(i - start)个位置ans[*returnSize][i - start] = queue[i]->val;// 若当前节点有左子节点,入队(作为下一层的节点)if(queue[i]->left) queue[tail++] = queue[i]->left;// 若当前节点有右子节点,入队(作为下一层的节点)if(queue[i]->right) queue[tail++] = queue[i]->right;}// 记录当前层的节点数量,并将层数+1(*returnColumnSizes)[(*returnSize)++] = len;
}
关键步骤拆解:
-
len = tail - head:每次进入循环时,队列中从head到tail-1的节点都是 “当前层” 的节点(因为上一层的节点已经全部处理完并出队),len就是当前层的节点总数。 -
ans[*returnSize] = malloc(...):为当前层(第*returnSize层)分配一个能存len个整数的数组,用于存储当前层的所有节点值。 -
start = head; head = tail:start记录当前层节点在队列中的起始位置(方便后续遍历)。- 直接将
head移到tail位置,相当于 “当前层的所有节点全部出队”(简化了逐个出队的操作)。
-
遍历当前层节点:循环从
start到head-1(即当前层的所有节点):- 把节点值存入
ans[*returnSize][i - start](i - start是当前层内的索引,从 0 开始)。 - 把节点的左右子节点入队(
tail后移),这些子节点会作为 “下一层” 的节点在后续循环中处理。
- 把节点值存入
-
记录当前层信息:
(*returnColumnSizes)[(*returnSize)++] = len表示:第*returnSize层有len个节点,然后层数加 1(*returnSize自增)。
4. 返回结果
return ans; // 返回存储好的层序遍历结果
核心设计亮点
- 用数组模拟队列:避免了动态分配队列内存的麻烦,通过
head和tail指针控制入队 / 出队,效率高。 - 一次性出队当前层:通过
start = head; head = tail直接将当前层节点全部标记为 “已出队”,简化了循环逻辑。 - 预设最大空间:假设树的最大层数和节点数不超过 2000(实际场景中需根据题目约束调整,避免越界)。
示例理解(以简单二叉树为例)
假设二叉树为:
plaintext
3/ \9 20/ \15 7
-
初始队列:
[3](head=0, tail=1),*returnSize=0。 -
第 1 次循环(处理第 0 层):
len=1,为ans[0]分配 1 个空间。遍历节点 3,存入ans[0][0] = 3。3 的左右子节点 9、20 入队,队列变为[9,20](tail=3)。returnColumnSizes[0] = 1,*returnSize=1。 -
第 2 次循环(处理第 1 层):
len=2(tail-head=3-1=2),为ans[1]分配 2 个空间。遍历节点 9 和 20,存入ans[1][0]=9、ans[1][1]=20。9 无子女,20 的子女 15、7 入队,队列变为[15,7](tail=5)。returnColumnSizes[1] = 2,*returnSize=2。 -
第 3 次循环(处理第 2 层):
len=2(tail-head=5-3=2),为ans[2]分配 2 个空间。遍历节点 15 和 7,存入ans[2][0]=15、ans[2][1]=7。15 和 7 无子女,队列不变(tail=5)。returnColumnSizes[2] = 2,*returnSize=3。 -
最终结果:
ans = [[3], [9,20], [15,7]],returnSize=3,returnColumnSizes=[1,2,2]。
这段代码通过清晰的队列操作和内存管理,高效实现了二叉树的层序遍历,逻辑简洁且易于理解。