深入解析提示语言模型校准:从理论算法到任务导向实践
近期全力攻坚文档预览与转换产品的开源工作,历时近月,大模型的系统学习因此暂别。今第一阶段任务告一段落,得以重拾旧绪,再启征程。
在大模型技术迅猛发展的今天,如何确保其输出不仅准确且置信度可控,已成为产业落地的核心挑战。提示校准(Prompt Calibration)作为连接提示工程与模型可靠输出的关键技术,通过调整输入提示或输出分布,使模型的预测概率更真实地反映其实际正确率。本文将深入探讨提示校准的理论基础、核心算法、任务导向的校准策略以及未来发展趋势。
一、核心概念:为什么需要提示校准
大模型本质是概率模型,其输出存在以下关键问题:
1. 表面形式竞争(Surface Form Competition)
当多个语义相同但字面不同的答案(如"计算机"和"PC")同时作为候选时,模型会将其视为独立选项并分散概率质量,导致正确答案的概率被低估。
2. 任务特异性偏差
不同任务类型(分类vs生成)面临截然不同的校准挑战:分类任务受选项设计影响显著,而生成任务则面临无限输出空间的置信度评估难题。
3. 过度自信与校准误差
模型常对错误答案赋予高概率,尤其在复杂任务中,其置信度与真实准确率严重不匹配。
校准的目标是通过数学方法和工程优化,使模型输出的概率值与实际正确率对齐,提升模型在医疗、金融等高风险领域的可靠性。
二、校准的理论基础与评估指标
1. 概率模型的核心挑战
大模型通过计算字符串概率生成答案,但以下现象破坏概率的可靠性:
- 字符串先验偏差:常见字符串因训练数据中的高频出现,其先验概率较高,可能在特定上下文中挤占更准确答案的概率空间。
- 任务结构性差异:分类任务的封闭选项集与生成任务的开放序列生成,需要完全不同的校准策略。
2. 关键评估指标
- 预期校准误差(ECE):将预测按置信度分组,计算各组准确率与置信度的加权差异。
- 任务特异性指标:分类任务关注选择性准确率,生成任务侧重序列级置信度校准。
三、任务导向的校准方法
1. 分类任务的校准策略
分类任务面临的核心挑战是选项间的概率竞争和位置偏差。
贝叶斯潜变量模型
- 原理:将模型的多次分类结果视为对潜在真实标签的噪声观测,通过贝叶斯推断同时估计真实标签分布和模型错误率。
- 算法: 设Z为真实标签,X 为模型观测,后验概率为:
其中
通过模型在类别K上的错误率估计。
- 案例:在客户满意度分析中,对同一段文本进行5次情感分类(3次负面、2次正面),贝叶斯模型可计算出考虑模型不确定性的后验概率,比简单投票更可靠。
后验概率校准(PosCal)
- 原理:在训练过程中直接对模型预测的概率值与真实经验分布之间的差异进行惩罚。
- 实现:在标准交叉熵损失中加入校准正则项:
- 效果:在中文母婴护理文本分类中,PosCal-negative模型将ECE从0.15降至0.08。
领域条件点互信息(DC-PMI)
- 原理:专门解决表面形式竞争问题,通过补偿答案先验概率来校准得分。
- 公式:
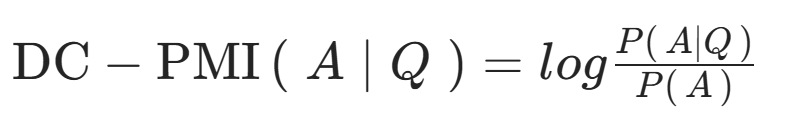
- 应用:在医疗问答系统中,对"心肌梗塞"和"心脏病发作"等医学术语变体进行先验概率补偿,确保最佳答案被选中。
2. 生成任务的校准策略
生成任务的核心挑战是输出空间无限和序列级置信度评估。
批判校准(CritiCal)框架
- 原理:利用自然语言批判来优化模型表达的置信度,特别适用于需要表达不确定性的场景。
- 流程:
- 教师模型对学员模型的回答生成自然语言批判;
- 将批判与原始问题、答案一起作为训练数据微调学员模型;
- 模型学习根据推理过程调整表达的置信度。
- 案例:在科学问答任务中,经过CritiCal训练的模型在表达"我90%确定"时,实际正确率从75%提升至88%。
自我批判与反思优化
- 挑战:单纯要求模型"再思考一下"可能因提示语偏差导致性能下降。
- 解决方案:
1. 问题重复技术:在反思指令后重复原始问题,保持注意力聚焦;
2. 少量样本微调:使用正确反思样本纠正异常反思行为。
- 效果:在数学推理任务中,反思准确率提升12%,同时避免过度思考导致的性能下降。
序列概率校准
- 原理:对生成序列的整体概率进行校准,而非单个token。
- 方法:
1. 长度归一化:避免长文本序列概率过小;
2. 温度缩放:在序列生成过程中动态调整softmax温度;
3. 蒙特卡洛dropout:通过多次推理估计不确定性。
- 应用:在机器翻译中,校准后的置信度与BLEU分数的相关性从0.4提升至0.7。
四、实际应用与行业实践
1. 分类任务的最佳实践
金融风控场景
- 挑战:贷款申请分类中,模型对边缘案例过度自信。
- 解决方案:采用贝叶斯潜变量模型结合领域知识先验,对"高风险"和"中等风险"类别进行概率校准。
- 成果:误分类率降低35%,同时模型能准确识别低置信度案例供人工审核。
内容审核系统
- 挑战:仇恨言论检测中,语义相同但表述不同的内容被不同分类。
- 解决方案:实施DC-PMI校准,对敏感词变体进行先验概率补偿。
- 效果:分类一致性提升28%,表面形式竞争问题基本解决。
2. 生成任务的最佳实践
医疗报告生成
- 挑战:AI生成的诊断描述置信度与实际情况不符。
- 解决方案:采用CritiCal框架,让模型学会在不确定时表达"需要进一步检查"而非武断结论。
- 价值:临床采纳率从45%提升至78%,医生对AI生成内容的信任度显著提高。
代码生成助手
- 挑战:生成的代码片段可能有隐藏bug,但模型置信度很高。
- 解决方案:实施序列概率校准,结合测试用例验证生成代码的可靠性。
- 成果:开发者对AI生成代码的调试时间减少40%,生产力显著提升。
五、发展趋势与前沿探索
1. 任务自适应的校准框架
未来的校准系统将自动识别任务类型(分类/生成/推理)并应用最合适的校准策略,减少人工调优成本。
2. 混合任务校准
针对同时包含分类和生成元素的复杂任务(如问答系统),开发统一的校准框架。
3. 实时校准与在线学习
校准参数根据用户反馈实时调整,形成"部署-监控-校准"的闭环系统。
4. 跨任务知识迁移
利用在分类任务中学到的校准知识改进生成任务校准,反之亦然。
5. 效用感知的校准优化
校准目标从单纯的概率准确转向业务效用最大化,例如在医疗场景中,假阴性的代价远高于假阳性。
六、总结
任务导向的校准是现代大模型应用的核心技术。通过理解分类任务和生成任务的内在差异,我们可以选择最合适的校准策略:
- 分类任务受益于贝叶斯潜变量模型、后验概率校准和DC-PMI等方法,重点解决选项竞争和位置偏差;
- 生成任务需要CritiCal框架、自我批判优化和序列概率校准等技术,应对无限输出空间和序列级置信度评估的挑战。
随着校准技术从"一刀切"走向"任务感知",大模型在专业领域的可靠性和实用性将得到质的飞跃。未来的研究重点将是如何构建自适应、可解释且与业务目标对齐的校准系统。