具身导航轨迹规划与主动想象融合!DreamNav:基于轨迹想象的零样本视觉语言导航框架
作者:Yunheng Wang, Yuetong Fang, Taowen Wang, Yixiao Feng, Yawen Tan, Shuning Zhang, Peiran Liu, Yiding Ji, Renjing Xu
单位:香港科技大学(广州),浙江师范大学
论文标题:DreamNav: A Trajectory-Based Imaginative Framework for Zero-Shot Vision-and-Language Navigation
论文链接:https://arxiv.org/pdf/2509.11197
主要贡献
提出 DreamNav 框架,首次将轨迹级规划和主动想象能力统一到零样本视觉语言导航(VLN)系统中,仅使用以自我为中心的输入,实现了在连续环境中的高效导航。
设计了 EgoView Corrector,通过分层方案对齐观察结果并稳定以自我为中心的感知,降低感知成本,解决了以往方法中依赖于昂贵全景感知的问题。
引入 Imagination Predictor,将被动理解转变为积极想象,使智能体能够进行长期规划,从而在零样本 VLN 中实现长视距推理。
提出 Trajectory Predictor,生成与指令语义一致的轨迹级动作策略,确保全局连贯的导航,克服了以往方法中点级决策与指令语义对齐不佳的局限。
研究背景
视觉语言导航(VLN)的重要性:VLN 是指智能体根据自然语言指令感知周围环境并在连续视觉空间中导航至目标位置的任务,是构建能够在非结构化和动态现实环境中可靠运行的具身智能体的关键能力,对于实现将自然语言与具身行为相结合的目标具有重要意义。
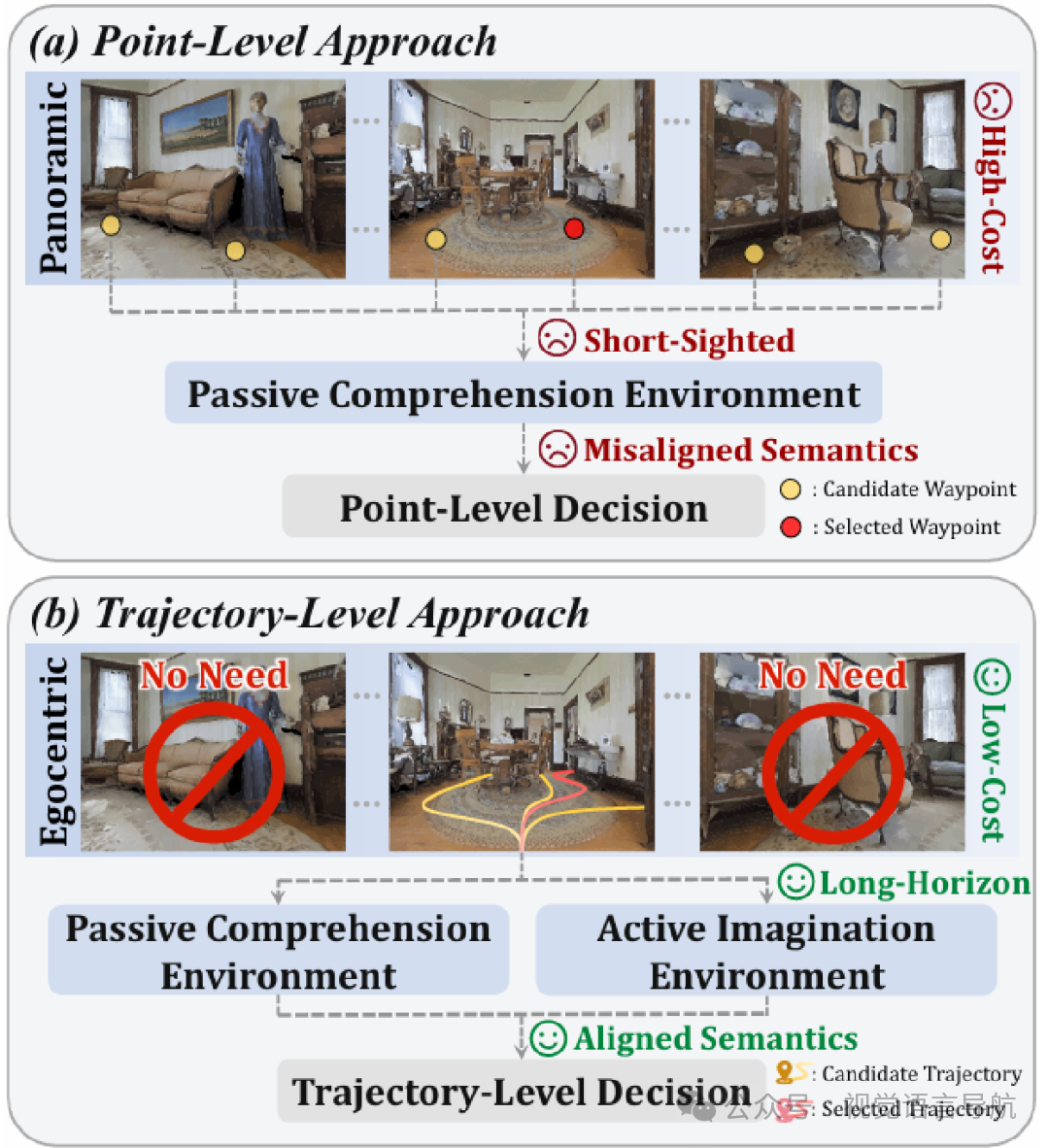
现有零样本 VLN 方法的局限性:尽管利用大规模预训练基础模型实现了零样本 VLN,但现有方法依赖于成本高昂的感知和被动场景理解,且控制局限于点级选择,导致部署成本高、动作语义不一致、规划短视等问题。
方法
问题定义
零样本视觉语言导航(VLN)任务要求智能体在没有针对特定任务的微调的情况下,仅根据自然语言指令 从起始位置导航到目标位置。在每一步 中,智能体感知视觉输入 并预测一个动作 ,从而进入下一个状态并获得新的观测 。
在本工作中,感知空间 严格限制为单目以自我为中心的 RGB-D 流,而动作空间被抽象为轨迹,每条轨迹表示为一系列高级运动,超越了单步动作。
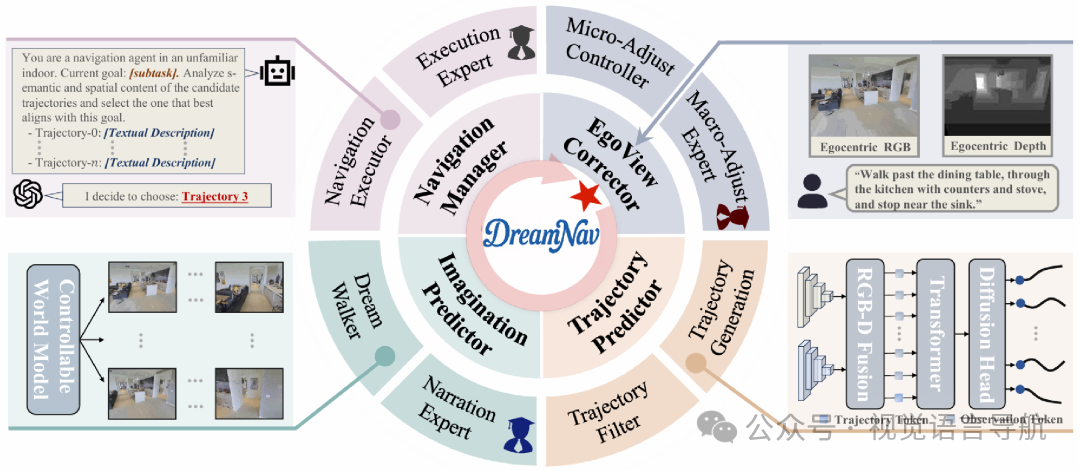
视角校正器
由于以自我为中心的智能体容易受到视角误差的影响,论文引入了两阶段分层方案,包括 Macro-Adjust Expert和 Micro-Adjust Controller,以校正视角并稳定感知。
Macro-Adjust Expert:在初始化阶段,智能体的起始朝向可能与指令指定的方向显著不一致。该专家通过联合推理全局场景布局、可导航性、指令相关线索的存在以及子任务的方向一致性来判断是否需要进行校正旋转。例如,如果初始观测中缺少指令中的地标“餐桌”,则会识别出初始化朝向误差,并执行两次连续的 90° 顺时针旋转以重新对齐智能体。
Micro-Adjust Controller:在执行长期策略后,智能体的终端朝向可能会出现漂移,导致后行动朝向误差。该控制器利用 CLIP 提示的 FastSAM 检测这种误差并触发适当的调整。具体来说,它会根据可行走区域掩码的归一化占用率与固定阈值 进行比较来触发调整。如果当前视图被墙壁主导,则会通过两次校正旋转恢复正确的朝向。

轨迹预测器
该模块负责生成与语义一致、可通行且空间多样化的导航路径。它包含两个部分:Trajectory Generator和 Trajectory Filter。
Trajectory Generator:基于生成扩散策略模型,该模型将输入的 RGB-D 观测编码并融合为统一表示,然后通过条件 U-Net 生成未来轨迹点。具体来说,RGB 图像通过预训练的 DepthAnything ViT 编码,深度图像通过 NavDP 特定的 ViT 编码,然后通过一个两层的 Transformer 编码器捕获空间关系和上下文依赖,形成轨迹生成的条件上下文。最后,扩散策略头通过迭代去噪高斯噪声样本生成轨迹。
Trajectory Filter:由于扩散策略可以一次性生成多个候选轨迹,但其中只有少数对应于真正不同且可通行的分支。为了减少计算和 API 令牌成本,论文通过远点优先遍历算法从候选轨迹中选择一个紧凑的子集,以最大化多样性。具体来说,通过计算成对的不相似度,并使用贪婪选择规则来选择最多样化的候选轨迹。
想象预测器
该模块的目标是为智能体提供前瞻性推理能力,以增强导航决策的可靠性。它包含两个部分:Dream Walker和 Narration Expert。
Dream Walker:基于可控世界模型,该模型将静态图像转化为可探索的 3D 世界。给定一个 RGB 观测和一条轨迹,模型作为以自我为中心的模拟器,生成与轨迹对齐的连贯视觉序列。每个轨迹元素被映射到一个相对相机姿态,从而将轨迹转换为姿态序列。通过在截断的姿态序列上条件化模型,确保生成的每一帧与预期的以自我为中心的运动对齐。
Narration Expert:将 Dream Walker 生成的像素级序列抽象为简洁的语义叙述,以提高效率和可解释性。通过设计针对性的提示问题,引导模型关注与任务相关的关键语义信息,从而为下游基础模型提供易于理解和利用的文本描述。
导航管理器
该模块负责从多个想象的候选轨迹中选择最适合当前子任务的轨迹,并确保任务的完成。
Navigator:将 Imagination Predictor 生成的轨迹描述与子任务规范进行语义比较分析,评估它们的相关性。每个描述作为预测信号,允许导航器评估与子任务目标的一致性,并优先选择最有助于完成任务的候选轨迹。
Execution Expert:由于单个导航子任务可能需要多个运动步骤,这使得细粒度动作与高层进度之间的对应关系变得模糊。该专家通过结构化推理链,准确判断每个轨迹步骤是否推进了子任务的完成,确保导航过程的准确性和连贯性。
实验
实验细节
评估基准:
模拟环境:使用 Habitat 模拟器中的 R2R-CE 数据集的 Val-Unseen 分割进行评估,包含 613 条轨迹和 11 个未见过的环境。
真实环境:设计了一个包含办公室、走廊、教室和礼堂四种室内场景的综合基准,每个环境设计五个任务,每个任务执行三次。
评估指标:
模拟环境:使用轨迹长度(TL)、导航误差(NE)、预言成功率(OSR)、成功率(SR)和路径长度加权成功率(SPL)等指标。
真实环境:以停止在目标点 2 米范围内作为成功标准,主要评估成功率(SR)。
实现细节:
EgoView Corrector:Micro-Adjust Controller 执行 30° 旋转,最多两次,阈值为 ;Macro-Adjust Expert 执行 90° 旋转,最多三次。
Trajectory Predictor:候选轨迹数量(CTN)设置为 4。
Imagination Predictor:想象展开长度(IRL)设置为 18,图像分辨率为 320×448。
导航管理器:使用 GPT-4o 实现 Macro-Adjust Expert、Navigator 和 Execution Expert,使用 Qwen-VL-MaxLatest 实现 Narration Expert。
Habitat 模拟器设置:水平视场角(HFOV)为 69°,智能体高度为 1.25 米,图像分辨率为 480×640,相机向下倾斜 15°。
真实环境测试平台:使用 AgileX LIMO 平台进行测试。
计算资源:所有实验在单个 NVIDIA RTX 4090 GPU 上进行。
模拟环境中的评估
与现有方法的比较:
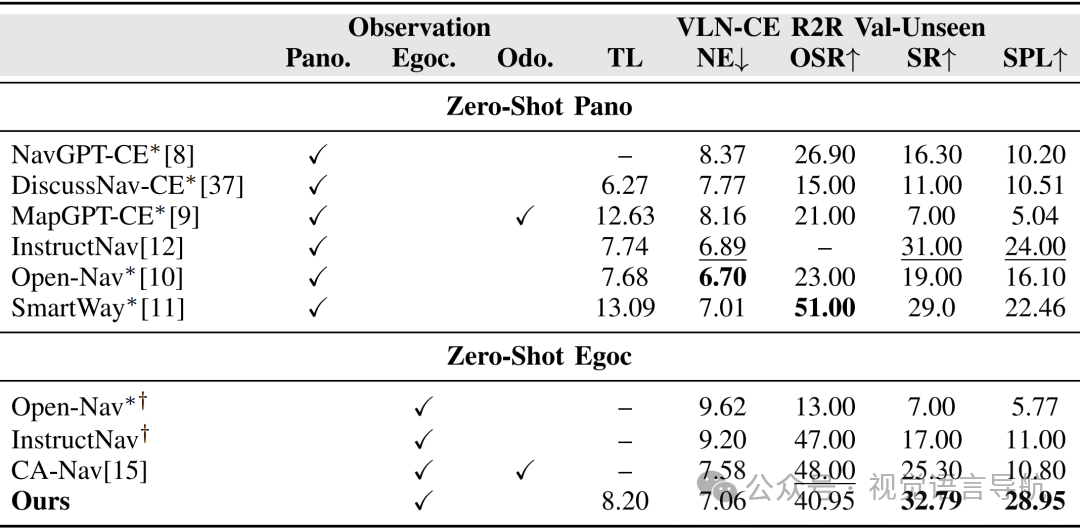
评估结果:如上表所示,DreamNav 在零样本 VLN 方法中表现出色,与使用全景输入的最强方法 InstructNav 相比,SR 提高了 1.79%,SPL 提高了 4.95%;与依赖里程信息的最强以自我为中心的基线 CA-Nav 相比,SR 提高了 7.49%,SPL 提高了 18.15%。
性能分析:DreamNav 的优势在于其以自我为中心的输入方式,降低了感知成本,同时通过轨迹级规划和主动想象能力,显著提升了导航性能。
关键结论:
以自我为中心的输入优势:DreamNav 证明了仅使用以自我为中心的输入即可实现强大的性能,超越了使用全景输入的方法。
人类类似能力的增强:轨迹级策略和主动想象能力进一步增强了零样本 VLN 的性能。
真实环境中的评估
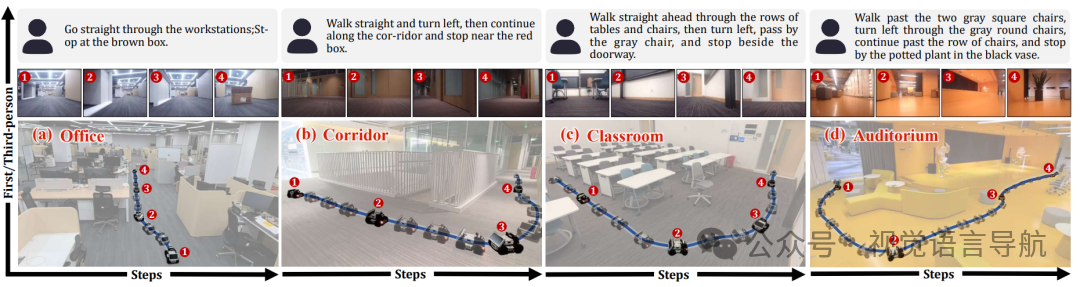

与现有方法的比较:
评估结果:如表所示,DreamNav 在真实环境中的表现优于 Open-Nav 和 Navid。DreamNav 的整体成功率达到了 12/20,而 Open-Nav 为 6/20,Navid 为 3/20。
性能分析:DreamNav 在不同场景中均表现出稳定的性能,而监督学习基线 Navid 对新环境的适应能力较差,成功率较低。
关键结论:
鲁棒性和有效性:DreamNav 在真实环境中展示了较高的鲁棒性和有效性,能够稳定地完成导航任务。
零样本方法的优势:零样本 VLN 方法在新环境中表现出色,而监督学习方法对新环境的适应能力较差。
消融研究
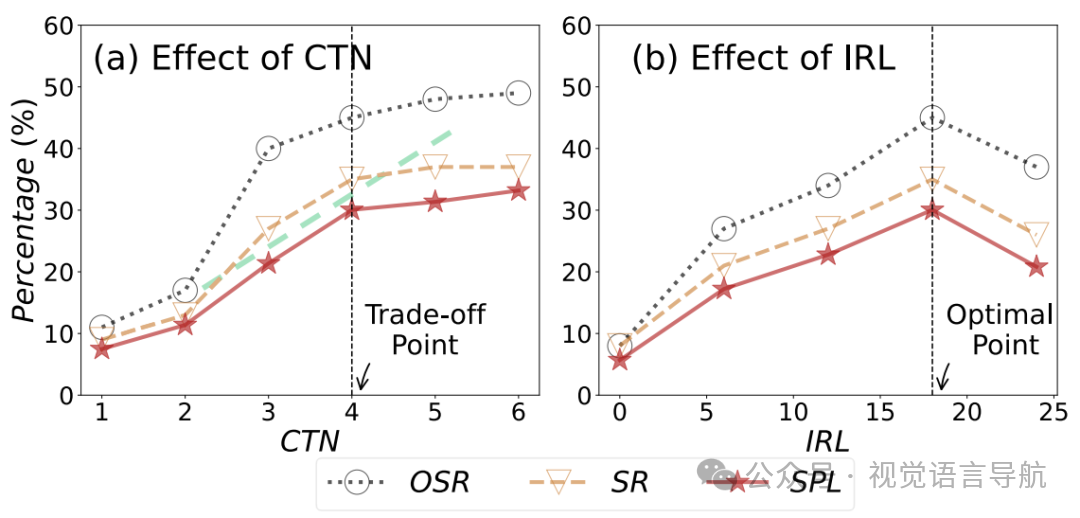
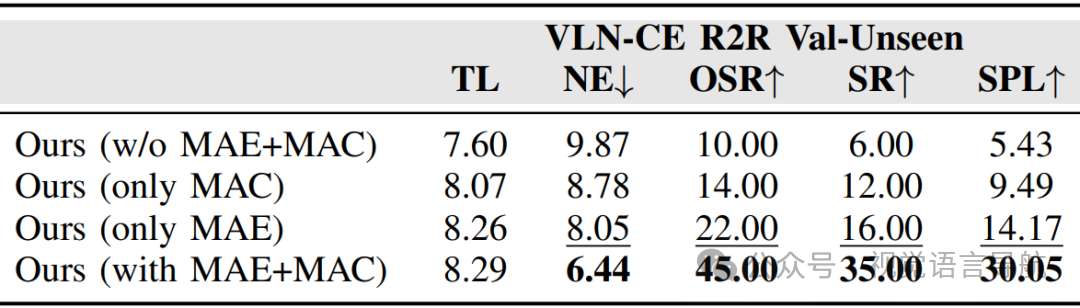
EgoView Corrector 的影响:
实验配置:通过对比完全移除、仅保留 Macro-Adjust Expert、仅保留 Micro-Adjust Controller 和使用完整模块四种配置。
实验结果:如上表所示,完整模块(SR: 35%,SPL: 30.05%)表现最佳。仅保留 Macro-Adjust Expert(SR: 16%,SPL: 14.17%)和仅保留 Micro-Adjust Controller(SR: 12%,SPL: 9.49%)均优于完全移除模块(SR: 6%,SPL: 5.43%)。
结论:Macro-Adjust Expert 和 Micro-Adjust Controller 均对性能有显著提升,且二者协同作用效果最佳。
候选轨迹数量(CTN)的影响:
实验结果:如上图 (a) 所示,CTN 设置为 4 时,在计算成本和导航性能之间达到了最佳平衡。当 CTN 从 1 增加到 4 时,性能提升最为显著,而超过 4 后性能提升趋于平缓。
结论:CTN 设置为 4 是最优的,进一步增加候选轨迹数量只会带来微小的性能提升。
想象展开长度(IRL)的影响:
实验结果:如上图(b) 所示,IRL 设置为 18 时,性能达到最优。当 IRL 小于 18 时,更长的前瞻性模拟可以增强智能体的决策能力;而当 IRL 大于 18 时,性能开始下降。
结论:IRL 设置为 18 是最优的,进一步增加想象展开长度会导致性能下降。
结论与未来工作
结论:
DreamNav 作为首个将轨迹级规划和主动想象能力相结合的零样本 VLN 框架,在仅使用以自我为中心的观测的情况下,通过 EgoView Corrector 降低感知成本,Trajectory Predictor 解决语义不一致问题,Imagination Predictor 缓解短视问题。
实现了在连续环境中的高效导航,并在模拟环境和真实环境中均取得了优异的性能,超越了使用全景输入的零样本 VLN 方法以及现有的以自我为中心的基线方法。
未来工作:
尽管 DreamNav 在降低感知成本和提升导航性能方面取得了显著进展,但仍然存在一些可以进一步探索的方向。
例如,可以研究如何进一步提高以自我为中心导航中的重定向能力,以更好地应对目标丢失后的情况;还可以探索如何将 DreamNav 的能力扩展到更复杂、动态变化的环境中,以增强其在现实世界中的适用性和鲁棒性。
此外,随着基础模型的不断发展和优化,DreamNav 也可以与更先进的模型相结合,以进一步提升其性能和泛化能力。
