北大通用具身导航模型探索!NavFoM:跨实体和跨任务的具身导航基础模型

作者:Jiazhao Zhang, Anqi Li, Yunpeng Qi, Minghan Li, Jiahang Liu, Shaoan Wang, Haoran Liu, Gengze Zhou, Yuze Wu, Xingxing Li, Yuxin Fan, Wenjun Li, Zhibo Chen, Fei Gao, Qi Wu, Zhizheng Zhang, He Wang
单位:北京大学,GalBot,中国科学技术大学,北京智源人工智能研究院,阿德莱德大学,浙江大学,微分机器人
论文标题:Embodied Navigation Foundation Model
论文链接:https://arxiv.org/pdf/2509.12129
项目主页:https://pku-epic.github.io/NavFoM-Web/
主要贡献
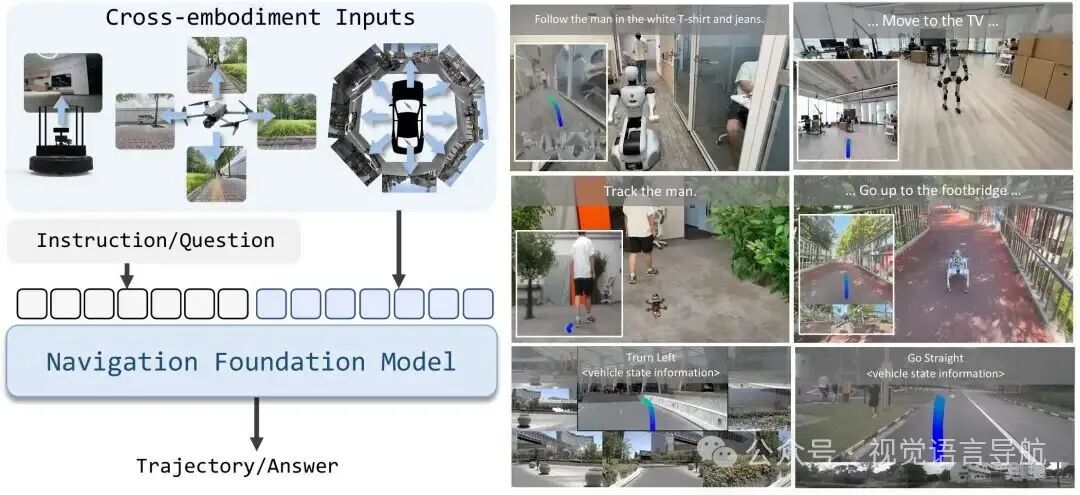
提出了NavFoM模型:跨实体和跨任务的导航基础模型,能够在多种不同的机器人形态(如四足机器人、无人机、轮式机器人和车辆)以及多种任务(如视觉语言导航、目标搜索、目标跟踪和自动驾驶)中实现导航,且无需针对特定任务进行微调,展现出强大的泛化能力。
创新的模型架构与方法:引入了时间-视角指示器(TVI)token来识别不同相机视角和导航时间范围的信息,还提出了基于预算的动态调整采样策略(BATS),在有限的token长度预算下控制所有观测token,以满足实际部署中的硬件内存成本和推理速度要求。
大规模数据集的构建与训练:收集了包含802万导航样本和476万开放世界知识样本的全面且多样化的数据集,涵盖了多种机器人和任务类型,通过端到端的方式联合训练导航数据和图像/视频问答数据,使模型能够学习到通用的导航能力。
在多个基准测试和真实世界实验中验证了模型性能:在七个公共基准测试上取得了最先进的或极具竞争力的性能,并且在真实世界中的多种机器人平台上进行了实验,进一步证实了模型的泛化性和实用性。
研究背景

导航在具身AI中的重要性:导航是具身AI的一个基本能力,它使机器人能够在物理环境中智能地移动以完成指定任务。实现这一能力需要对环境上下文和任务指令有深刻的理解,通常通过视觉和语言观察来实现,这与视觉语言模型(VLMs)的原理相似。
现有方法的局限性:尽管VLMs在大规模开放世界数据的任务中展现出了强大的零样本泛化能力,但现有的具身导航方法大多局限于狭窄的任务领域、特定的机器人形态架构,且缺乏对不同任务和机器人形态的通用导航模型。
方法
通用导航任务
任务定义:考虑一个通用导航设置,移动机器人根据文本指令 和从N个不同相机在时间步 到 捕获的图像序列 ,预测导航轨迹 ,其中每个 表示一个位置和朝向的航点,对于轮式机器人/汽车,;对于无人机(UAV),。
任务目标:模型需要根据输入的视觉观测和语言指令,输出能够完成任务的轨迹,驱动机器人按照指令移动。
基础架构

视频基础的视觉语言模型扩展:NavFoM基于视频基础的视觉语言模型(VLMs)扩展而来,采用双分支架构,分别用于导航和问答任务。
导航任务处理流程:
视觉特征提取:首先使用视觉编码器处理输入的图像序列 ,得到视觉特征 。然后通过一个跨模态投影器(cross-modality projector)将视觉特征投影到与大型语言模型(LLM)兼容的潜在空间中,得到视觉token 。
语言特征嵌入:将文本指令 嵌入到语言token 中,这一步骤遵循现有的语言模型嵌入方法。
token组织与LLM处理:将视觉token (经过时间-视角指示器(TVI)token处理和基于预算的动态调整采样策略(BATS)采样)与语言token 组织在一起,输入到LLM中进行处理。LLM的输出是一个动作token 。
轨迹预测:动作token 通过一个规划模型(如三层MLP)解码,生成轨迹 。由于不同任务(如室内导航、无人机导航、自动驾驶)的轨迹范围差异较大,模型通过任务特定的缩放因子 将轨迹点归一化到 范围内,然后重新缩放到绝对值。
问答任务处理流程:对于问答任务,模型使用LLM以自回归的方式预测下一个token,遵循现有的问答任务处理方法。
导航基础模型
观测编码
输入:模型接收从N个不同相机在时间步T捕获的RGB图像序列 。
视觉特征提取:使用预训练的视觉编码器(如DINOv2和SigLIP)提取视觉特征 ,其中P是patch数量,C是嵌入维度。然后将这些特征沿通道维度拼接,得到更紧凑的表示 。
网格池化:为了进一步压缩特征,使用网格池化策略(Grid Average Pooling),生成细粒度(fine-grained)和粗粒度(coarse-grained)的视觉特征。细粒度特征 用于最新观测和图像问答,粗粒度特征 用于导航历史和视频数据。
跨模态投影:使用一个两层的MLP(多层感知机)将视觉特征投影到大型语言模型(LLM)的潜在空间中,得到视觉token 。
时间-视角指示器
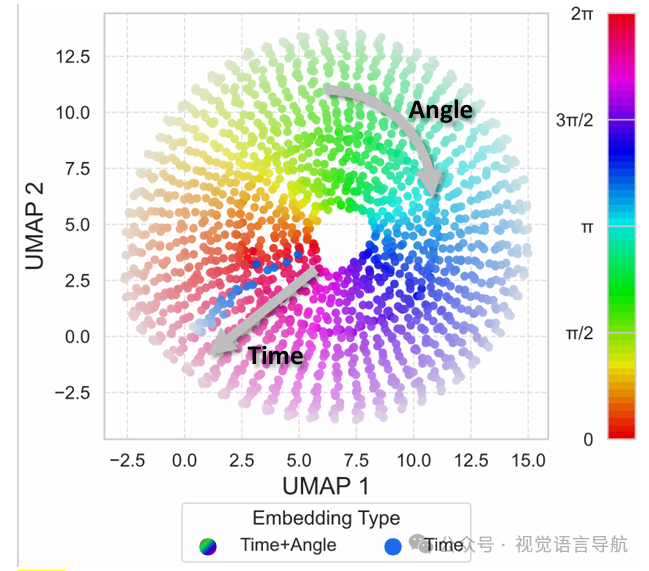
目的:解决视觉token缺乏视角和时间信息的问题,使LLM能够区分不同时间步和不同相机视角的token。
组成:
角度嵌入(AnglePE):使用正弦和余弦值的组合来表示方位角,确保角度的循环连续性(如 )。
时间嵌入(TimePE):使用时间步 的正弦位置编码。
基础嵌入(EBase):一个可学习的嵌入,用于表示视觉token的起始点。
任务特定的TVItoken:
导航任务:包含时间、视角和基础嵌入。
视频问答任务:包含时间嵌入和基础嵌入。
图像问答任务:仅包含基础嵌入。
优势:通过这种方式,模型可以灵活处理不同类型的样本(如图像QA、视频QA和导航),并且在训练过程中能够更好地组织视觉token,从而提高模型的性能。
基于预算的动态调整采样策略
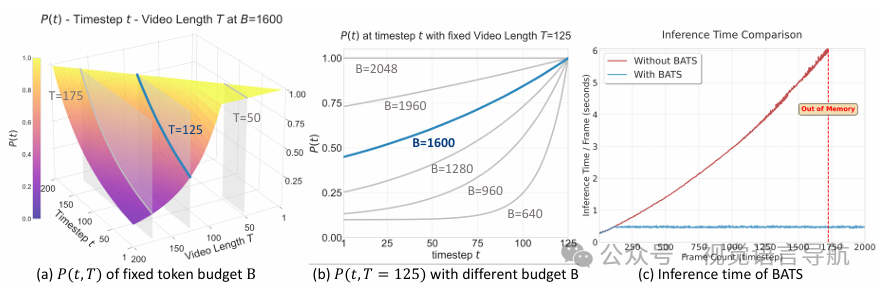
问题:在导航过程中,实时捕获的视频会产生大量的视觉token,这会增加推理和训练时间,不利于实际部署。
策略:给定一个token预算 和多视图视频序列 ,使用基于指数增长的采样概率 来动态采样帧,该概率受“遗忘曲线”启发。
采样概率公式:
其中, 确保采样概率的下界, 是指数衰减率。
期望采样帧数:
约束:确保期望的token数量不超过token预算 。
优势:BATS策略能够在不同的token预算和时间步下平滑地获得合理的采样概率,同时保持稳定的推理速度,适应不同的相机数量和任务需求。
LLM前向传播
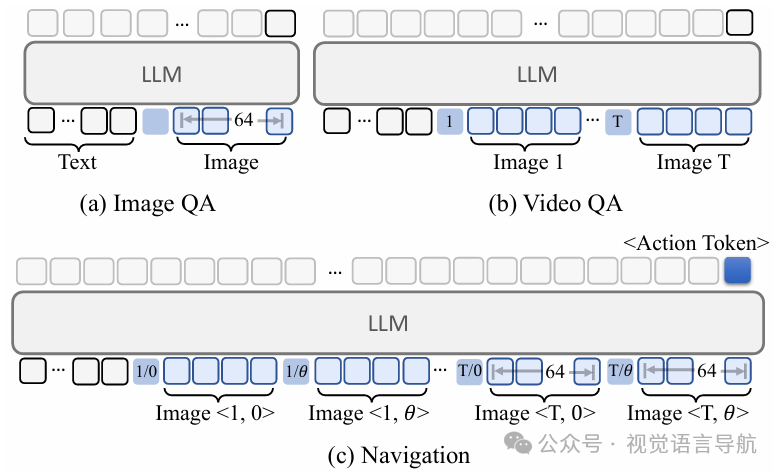
token组织:将视觉token (通过BATS采样)和语言token 组织起来,使用TVItoken进行转发。对于不同的任务(如图像QA、视频QA和导航),采用不同的token组织策略,以增强LLM对输入token的理解。
轨迹预测:对于导航任务,使用LLM的前向传播结果 ,通过一个三层MLP(规划模型)提取轨迹信息 。由于原始轨迹的范围可能从几米到几十米不等,为了防止轨迹点分布的发散,将轨迹点归一化到 范围内,然后通过任务特定的缩放因子 将其重新缩放到绝对值。
损失函数:导航任务的损失函数使用均方误差(MSE)计算轨迹预测误差,问答任务的损失函数使用交叉熵损失 。总损失函数是导航损失和问答损失的加权和,其中导航损失通过一个常数缩放因子 (设为10)放大,以补偿其数值较小的问题。
数据
数据集规模:为了训练NavFoM,论文收集了1270万训练样本,包括802万导航样本、315万图像问答样本和161万视频问答样本。这些样本涵盖了多种机器人(如轮式机器人、四足机器人、无人机和汽车)和多种任务(如视觉语言导航、目标搜索、目标跟踪和自动驾驶)。
导航样本:
视觉语言导航(VLN):包括室内环境(如VLN-CE R2R和RxR)和室外环境(如OpenUAV)的数据,要求机器人根据自然语言指令和视觉观测来规划轨迹。
目标搜索:要求机器人在未见过的环境中探索并识别目标,数据来自HM3D ObjectNav。
目标跟踪:要求机器人在动态和拥挤的环境中区分目标并保持适当的距离,数据来自EVT-Bench。
自动驾驶:要求机器人在复杂动态的真实世界环境中生成安全、舒适且运动学上可行的轨迹,数据来自nuScenes和OpenScene。
网络视频导航:利用Sekai数据集中的YouTube视频、指令和轨迹,尽管这些样本可能存在不完美的指令和轨迹,但有助于引入真实世界的导航场景。
开放世界问答样本:收集了图像问答和视频问答样本,为模型提供丰富的开放世界知识。
实现细节
训练配置:模型在配备56个NVIDIA H100 GPU的集群服务器上训练了大约72小时,总共使用了4032 GPU小时。对于问答数据,所有帧以1 FPS采样以减少连续帧之间的冗余。对于离散导航数据,每一步机器人执行离散动作后采样一次。对于连续导航环境,数据以2 FPS采样。
视觉编码器和语言模型初始化:视觉编码器(DINOv2和SigLIP)和大型语言模型(Qwen2-7B)使用其默认的预训练权重进行初始化。
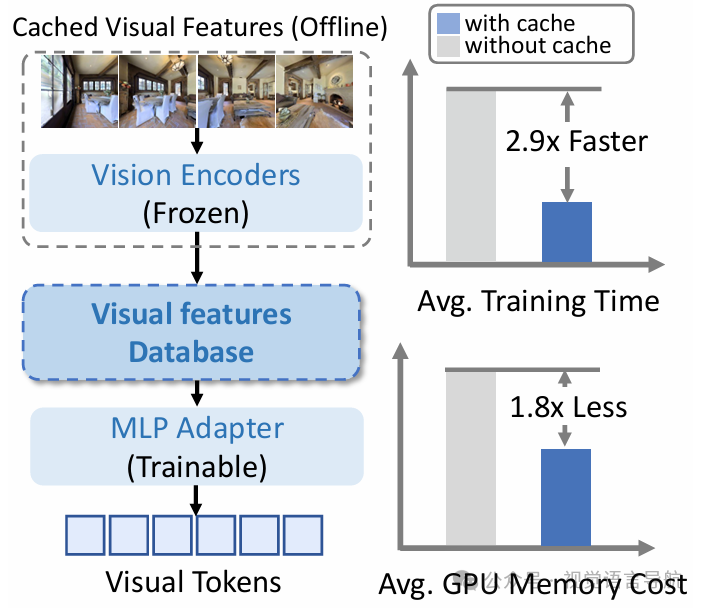
加速训练:由于视频的长跨度(数百帧),在线编码所有图像在大批次中计算成本较高。为了缓解这一问题,论文使用视觉特征缓存机制,构建了一个视觉特征数据库。在训练过程中,仅缓存粗粒度视觉token(每帧4个token),这比存储完整视频所需的磁盘空间要少得多。对于图像问答和导航的最新观测,仍然在线使用视觉编码器提取细粒度视觉token(每帧64个token)。这种方法将训练时间减少了2.9倍,同时减少了GPU内存使用。
实验
实验设置
评估目标
评估NavFoM在不同导航任务和基准测试上的性能。
验证NavFoM在真实世界环境中的表现。
分析NavFoM的关键设计组件(如TVItoken和BATS策略)的有效性。
基准测试
视觉语言导航:在VLN-CE R2R和RxR基准测试上评估,要求机器人在未见过的室内环境中根据指令导航。此外,在OpenUAV基准测试上评估,要求无人机在未见过的室外环境中根据指令导航。
目标搜索:在HM3D-OVON数据集上评估,这是一个零样本(zero-shot)的开放词汇目标导航基准测试。
目标跟踪:在EVT-Bench基准测试上评估,要求机器人在拥挤的环境中识别并跟踪目标。
自动驾驶:在nuScenes和NAVSIM基准测试上评估,评估机器人在复杂动态环境中的自动驾驶能力。
评估指标
使用标准的导航性能评估指标,包括成功率(SR)、路径长度加权成功率(SPL)、动态时间规整(nDTW)和目标导航误差(NE)。
对于跟踪任务,使用跟踪率(TR)来衡量成功跟踪的步骤比例。
部署环境
在多个模拟器上部署NavFoM,包括Habitat-Lab等,这些模拟器提供了不同的环境和任务设置。
在真实世界环境中,使用多种机器人平台(如四足机器人、人形机器人、无人机和轮式机器人)进行实验,验证模型的实际应用能力。

基准测试结果
视觉语言导航
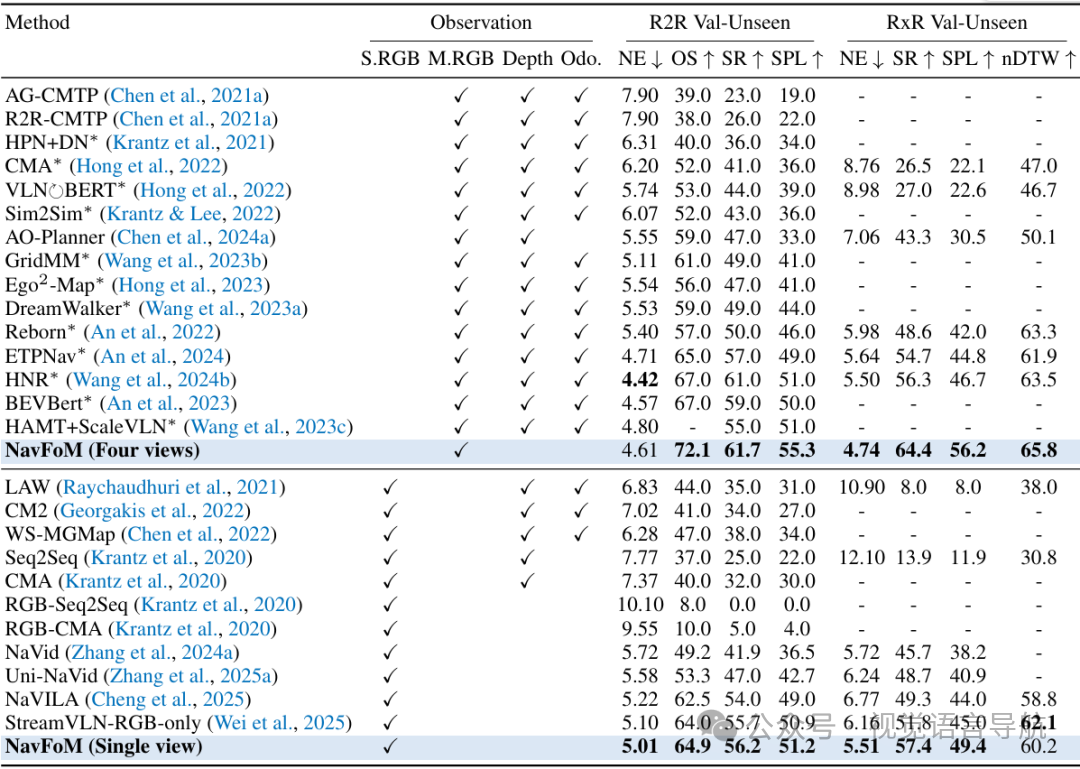
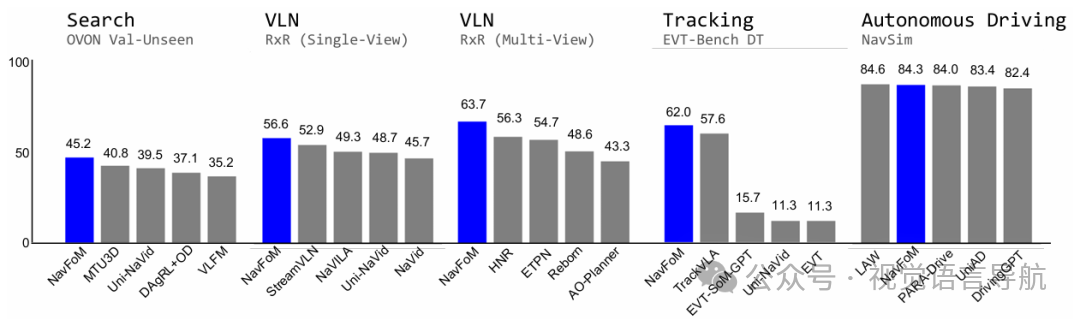
在VLN-CE R2R和RxR基准测试上,NavFoM在单视图和多视图设置下均取得了最先进的性能。例如,在VLN-CE RxR的多视图设置中,成功率从56.3%提高到64.4%。
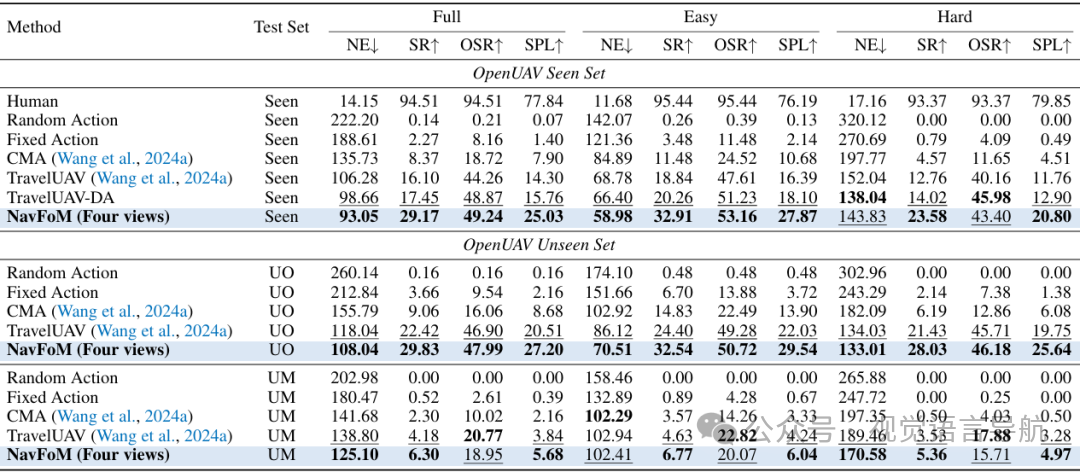
在OpenUAV基准测试上,NavFoM在未见过的地图和目标设置中取得了29.83%的成功率,超过了之前的最佳方法。

目标搜索
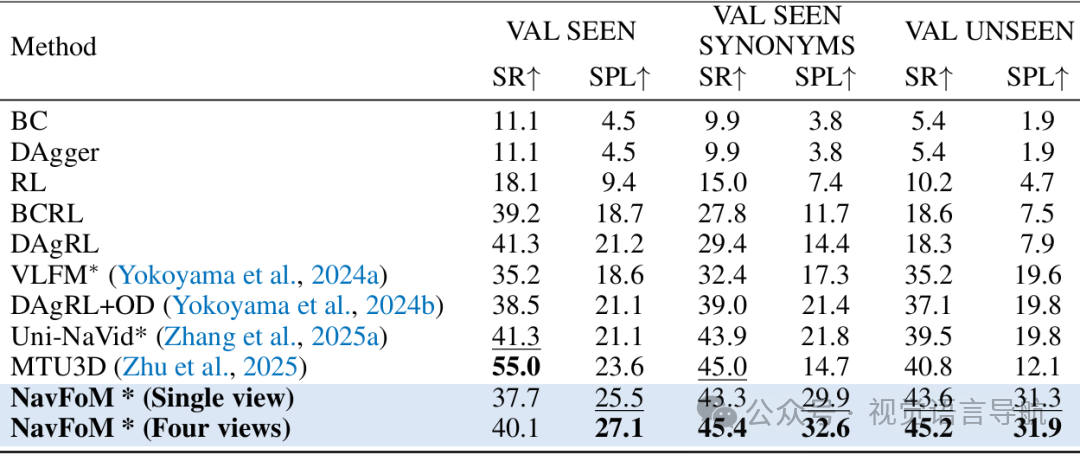
在HM3D-OVON基准测试上,NavFoM在单视图和多视图设置下均取得了优异的性能。在零样本设置中,成功率从40.8%提高到45.2%。
主动目标跟踪
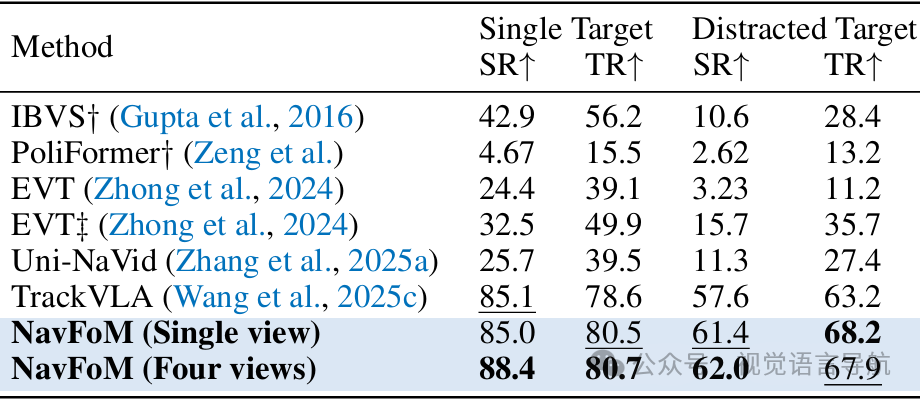
在EVT-Bench基准测试上,NavFoM在单视图和多视图设置下均取得了最先进的性能。例如,在单视图设置中,成功率达到了85.0%,在多视图设置中,成功率进一步提高到88.4%。
自动驾驶
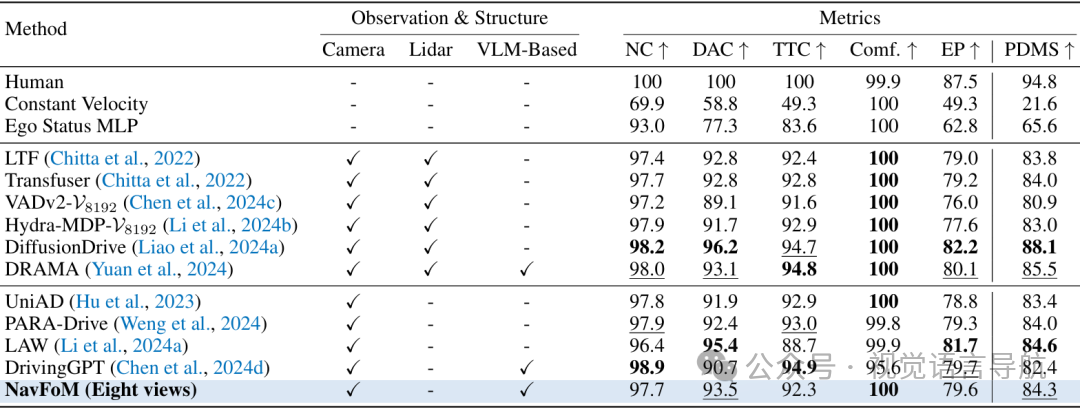
在nuScenes和NAVSIM基准测试上,NavFoM取得了与专门针对自动驾驶设计的基线方法相当的性能。例如,在NAVSIM的八视图设置中,NavFoM的PDM分数达到了84.3。

真实世界实验结果
真实世界测试案例

设计了110个可复现的测试案例,包括50个VLN样本、30个搜索样本和30个跟踪样本。NavFoM在这些复杂场景中表现出色,正确理解周围环境并规划出合适的轨迹。
挑战性真实世界实验

在不同的机器人平台上进行了更具有挑战性的实验,包括四足机器人、人形机器人、无人机和轮式机器人。NavFoM能够处理复杂的现实世界环境,并完成长距离的指令。
消融研究
多任务训练的协同效应
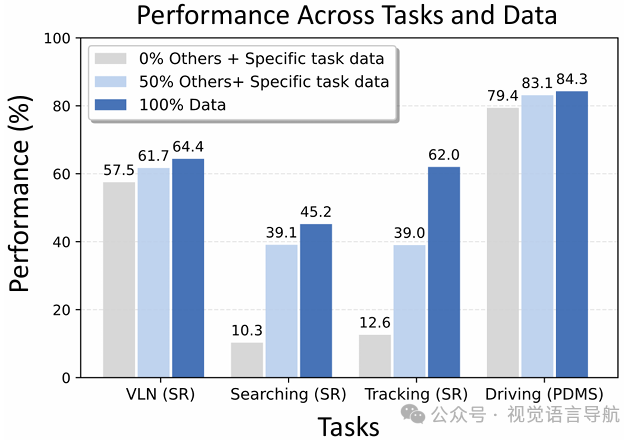
比较了单任务训练和多任务协同训练的性能。结果表明,多任务协同训练能够显著提高模型在不同任务上的性能。例如,在目标搜索任务中,成功率从10.3%提高到45.2%。
不同相机数量的性能
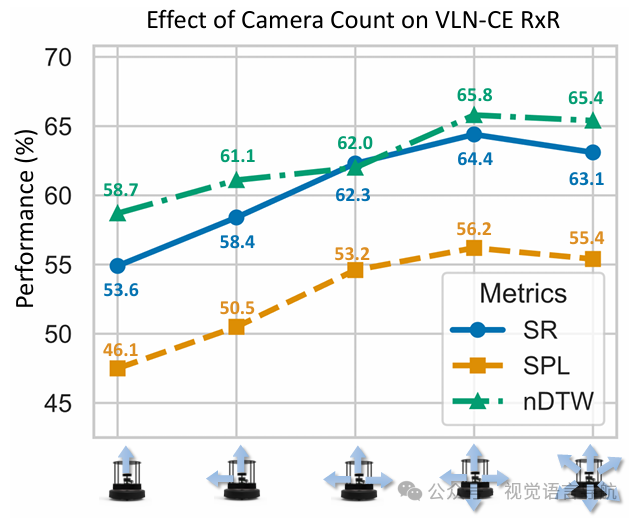
在VLN-CE RxR基准测试上评估了不同数量的相机对性能的影响。结果表明,增加相机数量可以提高性能,但当相机数量从四个增加到六个时,性能略有下降。
BATS和TVItoken的有效性
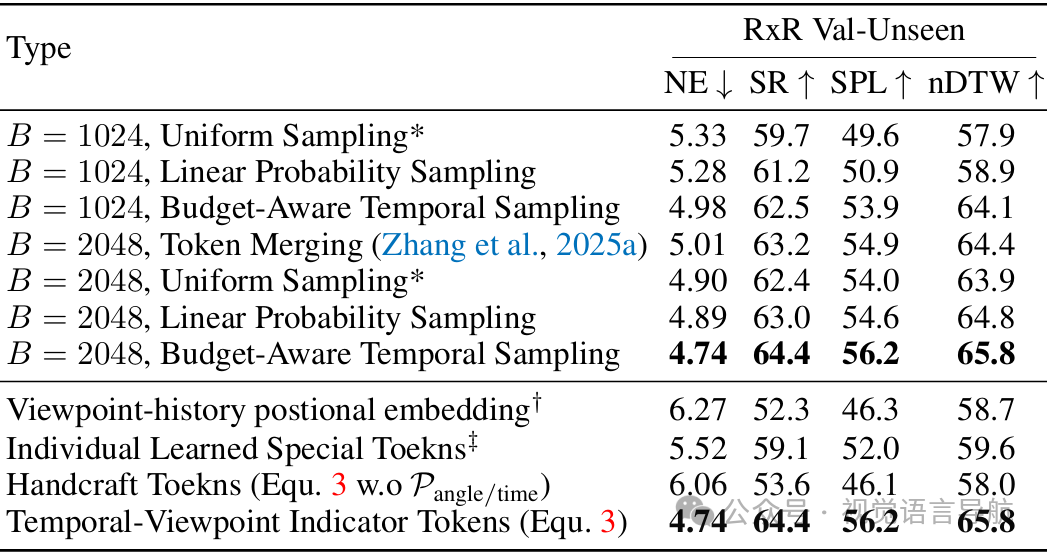
通过在VLN-CE RxR四视图设置上的实验,验证了BATS策略和TVItoken的有效性。BATS策略在不同的token预算下均优于其他采样策略,而TVItoken在性能上显著优于其他替代方案。
结论与未来工作
结论:
NavFoM作为一个跨实体和跨任务的导航基础模型,在多个基准测试和真实世界实验中展现了强大的泛化能力和实际应用潜力。
它通过引入TVItoken和BATS策略,有效地解决了多视图导航和实际部署中的挑战,并通过大规模数据集的训练学习到了通用的导航能力。
未来工作:
尽管NavFoM取得了一定的成果,但论文认为它只是一个起点。未来的工作可能会探索更先进的技术或更高质量的数据来进一步提升模型的性能,例如开发新的方法来更有效地整合视角和时间信息,或者在模型中加入对更多机器人形态和任务的支持。
此外,还可以考虑将模型应用于更复杂的现实世界场景,以进一步验证其泛化能力和实用性。
