FlashAttention whl本地快速安装
FlashAttention 是一种高性能 attention 加速库,在大模型推理与训练中广泛应用。在很多项目中都有应用,当我们部署或者复现项目的时候,使用:
pip install flash-attn
pip install flash-attn --no-build-isolation
会发现编译时间极其漫长,甚至长达 3-5 个小时,特别是没有 GPU 驱动适配好或依赖缺失的服务器环境下,容易出现中途失败或资源耗尽的问题。试过的都知道。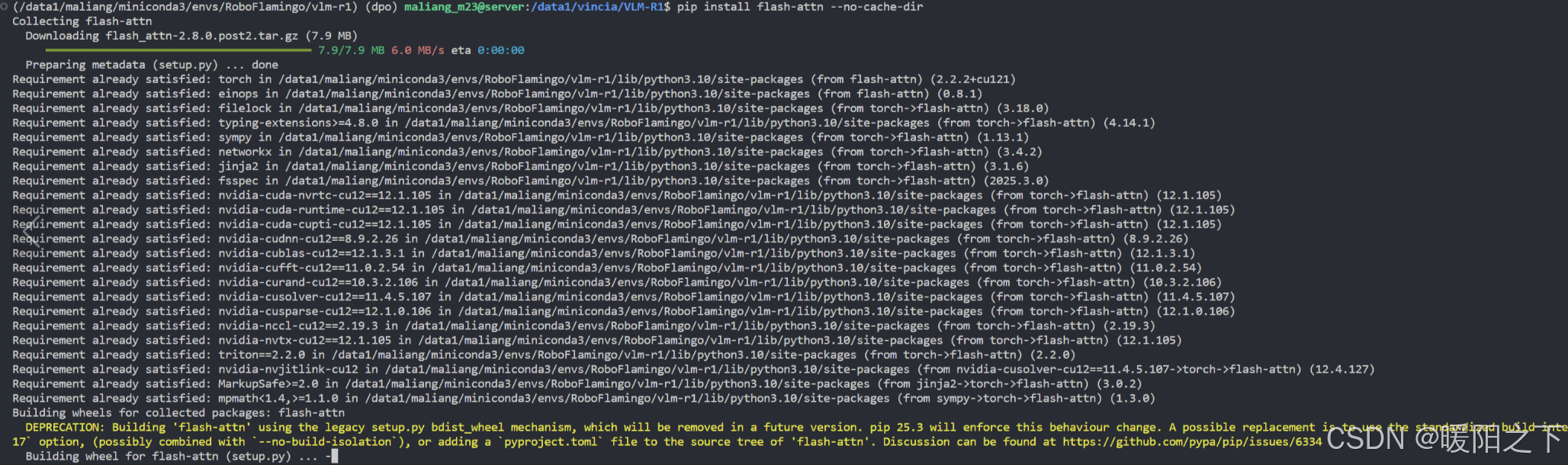
为此,推荐使用预编译的 .whl 安装包,绕过本地编译,秒速完成部署。
1️⃣ 进入预编译 wheel 文件仓库,下载对应的.whl 安装包
点击下方链接进入文件仓库:
🔗 flash-attention-wheels仓库
页面如下图所示:
随便选择版本,然后观察python、pytorch和CUDA版本是否有你想要的:
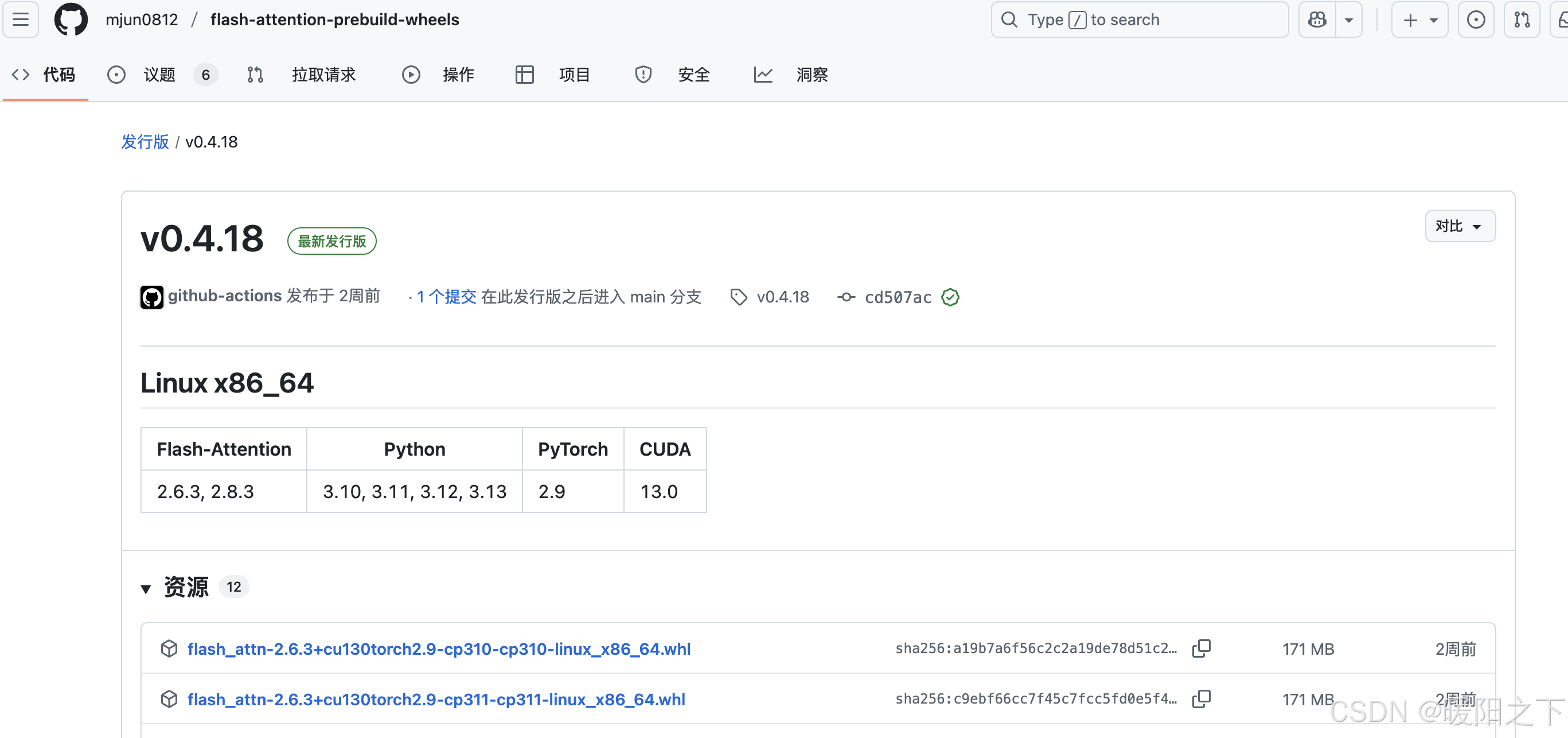
当前版本有你所需的版本之后再选择下方具体资源进行下载。
2️⃣ 确认系统环境
Python 版本:可通过 python --version 获取,如 3.10 → 对应 cp310
PyTorch 版本:torch.version,如 2.4.0 → 对应 torch2.4
CUDA 版本:nvcc --version 或 nvidia-smi 查看,CUDA 12.4 → 对应 cu124
⚠️ 注意三者必须严格对应,不然会报错或运行异常!
3️⃣ 示例文件选择
假设你本地环境如下:
| 环境项 | 版本 |
|---|---|
| Python | 3.10 |
| PyTorch | 2.4.0 |
| CUDA | 12.4 |
则你应选择如下文件:
flash_attn-2.8.0+cu124torch2.4-cp310-cp310-linux_x86_64.whl
每一部分说明如下:
| 部分 | 含义 |
|---|---|
| 2.8.0 | FlashAttention 版本 |
| cu124 | 使用 CUDA 12.4 编译 |
| torch2.4 | 适配 PyTorch 2.4 |
| cp310 | CPython 3.10 |
| linux_x86_64 | 64位 Linux 系统 |
4️⃣ 下载 wheel 文件
使用 wget 命令下载(鼠标移动到下载链接 → 右键复制链接地址):
wget https://github.com/mjun0812/flash-attention-prebuild-wheels/releases/download/v0.3.12/flash_attn-2.8.0+cu124torch2.4-cp310-cp310-linux_x86_64.whl
或者直接点击进行下载:
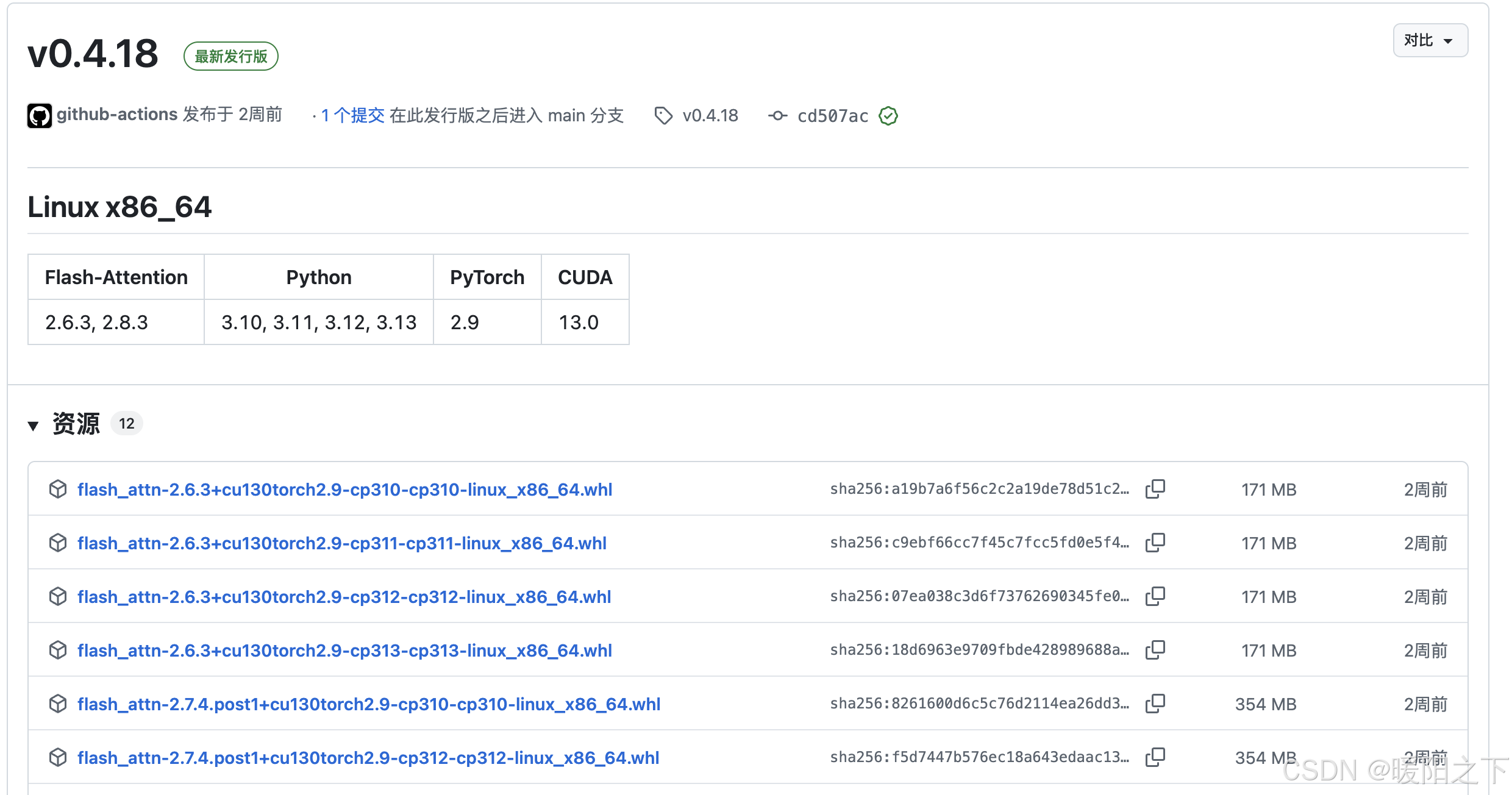
5️⃣ 安装 wheel 包
进入项目的conda虚拟环境,在本地 .whl 文件目录下使用 pip 直接安装本地 .whl 文件:
pip install flash_attn-2.8.0+cu124torch2.4-cp310-cp310-linux_x86_64.whl
几秒钟即可完成安装,无需编译!
🛠️ 常见问题及说明
Q1: pip 安装报错 “no matching distribution found”?
这是因为没有找到与你系统环境匹配的 .whl 文件。请仔细核对:
Python 对应 cp3xx 是否正确
CUDA 是否安装,版本是否一致(如 cu118 vs cu124)
PyTorch 是否与你指定的版本完全一致(如 torch 2.4.0)
Q2: 有 Apple M 系列(macOS)版本吗?
当前 FlashAttention 尚不支持 macOS 系统的 GPU 加速,仅 Linux x86_64 版本有官方编译。
Q3: 支持多 GPU 吗?
是的,FlashAttention 完整支持分布式环境,前提是 CUDA 环境配置正确。
建议配合 torchrun 或 accelerate 使用。
Reference
https://vincia-jun.blog.csdn.net/article/details/149260168