精准且快速校准的语音神经假体研究与学习
1. 研究背景
肌萎缩侧索硬化症(ALS)等神经系统疾病俗称 “渐冻症”,会导致患者出现构音障碍,严重影响沟通能力,进而增加患者孤立、抑郁风险,降低生活质量,甚至影响终末期生命维持治疗决策。目前现有的增强和辅助沟通技术(如眼动追踪仪、头部追踪仪)信息传输速率低,且会随患者自主肌肉控制能力丧失而愈发难以使用。脑机接口作为一种极具潜力的沟通技术,可直接从神经信号中解码用户的预期言语,但此前的语音神经假体存在训练需求大、准确率有限等问题。
数据
本次训练中使用的数据集由单个研究参与者所说的 10,948 个句子组成,如 Card 等人所描述的“准确且快速校准的语音神经假体”(2024 年),新英格兰医学杂志。对于每个句子,我们提供参与者试图说的话的记录,以及从言语运动皮层中 256 个微电极记录的相应神经尖峰活动的时间序列。数据集包含预定义的“train”、“val”和“test”分区。train 和 val 分区包括句子标签,如果需要,您可以重新分区它们。“测试”分区不包括句子标签,将用于竞争评估。该数据集可以从此 Kaggle 竞赛页面(见选项卡)或 Dryad 下载。
There are some notable differences between this dataset and the one used in the Brain-to-Text 2024 challenge:
| Brain-to-Text '24 | Brain-to-Text '25 | |
|---|---|---|
| Participant | 'T12' | 'T15' |
| Neural recordings | 128 intracortical electrodes in speech motor cortex, 128 intracortical electrodes in inferior frontal gyrus | 256 intracortical recording electrodes in speech motor cortex |
| Dataset period | 25 sessions spanning 4 months | 45 sessions spanning 20 months |
| Number of Sentences | 12,100 | 10,948 |
| Sentence corpus | Switchboard | 50-word vocabulary, Switchboard, Openwebtext2, Harvard sentences, custom high-frequency word sentences, random word sentences |
| Speaking strategy | Attempted vocalized | Attempted vocalized or attempted silent |
| Speaking rate | ~62 words per minute | ~30 words per minute (attempted vocalized) or ~50 words per minute (attempted silent) |
数据格式
该数据集可从以下Kaggle竞赛页面或Dryad平台下载。数据集包含20个月内45个实验会话产生的10,948个句子,以文件形式存储。关于如何使用Python的h5py库加载该数据的示例代码,可在的GitHub仓库https://doi.org/10.5061/dryad.dncjsxm85
您可以使用 Python 库加载数据。请参阅下面的示例代码,以及我们的 GitHub 存储库,请点击此处。
https://github.com/Neuroprosthetics-Lab/nejm-brain-to-text/blob/main/model_training/evaluate_model_helpers.py#L29
import h5pydef load_h5py_file(file_path):data = {'neural_features': [],'n_time_steps': [],'seq_class_ids': [],'seq_len': [],'transcriptions': [],'sentence_label': [],'session': [],'block_num': [],'trial_num': [],}# Open the hdf5 file for that daywith h5py.File(file_path, 'r') as f:keys = list(f.keys())# For each trial in the selected trials in that dayfor key in keys:g = f[key]neural_features = g['input_features'][:]n_time_steps = g.attrs['n_time_steps']seq_class_ids = g['seq_class_ids'][:] if 'seq_class_ids' in g else Noneseq_len = g.attrs['seq_len'] if 'seq_len' in g.attrs else Nonetranscription = g['transcription'][:] if 'transcription' in g else Nonesentence_label = g.attrs['sentence_label'][:] if 'sentence_label' in g.attrs else Nonesession = g.attrs['session']block_num = g.attrs['block_num']trial_num = g.attrs['trial_num']data['neural_features'].append(neural_features)data['n_time_steps'].append(n_time_steps)data['seq_class_ids'].append(seq_class_ids)data['seq_len'].append(seq_len)data['transcriptions'].append(transcription)data['sentence_label'].append(sentence_label)data['session'].append(session)data['block_num'].append(block_num)data['trial_num'].append(trial_num)return data
数据字段
neural_features:每次试验的时间分箱(20 毫秒)神经特征 (512 X T)。n_time_steps:每次试验的时间步长数。seq_class_ids:每个试验的整数音素序列标签。整数使用以下映射对应于音素:
LOGIT_TO_PHONEME = [
'BLANK', # "BLANK" = CTC blank symbol
'AA', 'AE', 'AH', 'AO', 'AW',
'AY', 'B', 'CH', 'D', 'DH',
'EH', 'ER', 'EY', 'F', 'G',
'HH', 'IH', 'IY', 'JH', 'K',
'L', 'M', 'N', 'NG', 'OW',
'OY', 'P', 'R', 'S', 'SH',
'T', 'TH', 'UH', 'UW', 'V',
'W', 'Y', 'Z', 'ZH',
' | ', # "|" = silence token
]
seq_len:每次试验的音素标签数。transcriptions:每个试验的句子标签的 ASCII 表示。sentence_label:每个试验的原始文本句子标签。session:收集试验数据的日期。每个日期都有多个区块,每个区块都有多个试验。block_num:试验来源的研究区块号。trial_num:试用源自的试用号。
2. 研究对象
一名45岁左利手ALS男性患者,患病5年,研究入组时已无法行走,依赖他人协助控制电动轮椅、穿衣、进食及个人卫生,存在严重构音障碍,ALS功能评定量表修订版(ALSFRS-R)评分为23分(满分48分,分数越高功能越好)。患者保留眼球和颈部活动能力,但口面部活动受限,存在混合性上下运动神经元构音障碍,非日常照护者无法理解其言语,Frenchay构音障碍评估第二版评分为E级(表示严重构音障碍,A级为正常,E级为完全丧失功能)。患者夜间需无创呼吸支持,无气管切开术史,认知功能正常(简易精神状态检查修订版评分为27分,满分27分)。
3. 研究方法
3.1 手术植入
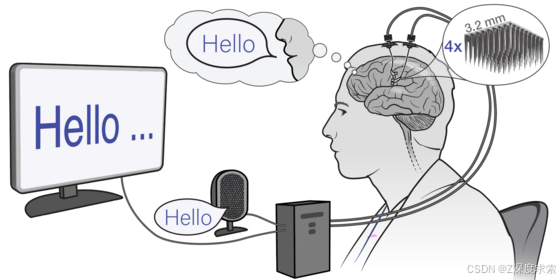
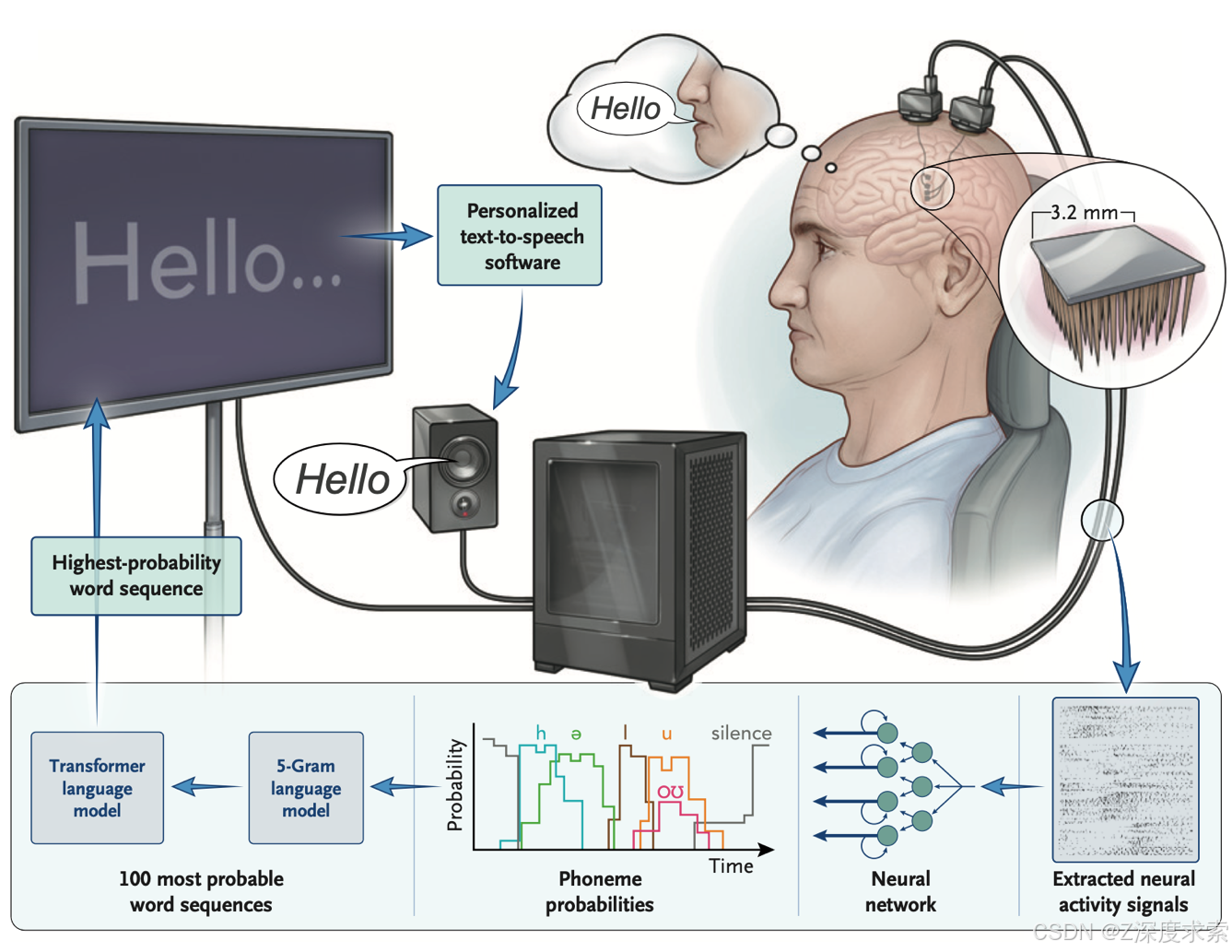
2023年7月为患者实施手术,在其左侧中央前回(协调言语相关运动活动的重要皮质区域)植入4个微电极阵列(Blackrock Neurotech公司NeuroPort阵列),每个阵列尺寸为3.2mm×3.2mm,含64个电极(8×8网格排列),通过专用高速气动植入器插入皮质1.5mm深处。4个阵列通过两个经皮连接器(基座)传输神经信号,共实现256个位点的记录。手术持续5小时,术后3天出院,无严重不良事件。
3.2 植入定位
术前通过磁共振成像(MRI)识别中央沟,结合功能磁共振成像(fMRI)及标准临床fMRI任务(句子完成、无声单词生成、无声动词生成、物体命名)确认患者为左半球语言优势。利用人类连接组计划多模态MRI皮质分区技术精准定位植入靶点,包括语言相关区域55b(与语音表征相关)以及腹侧中央前回的三个言语产生相关区域:腹侧前运动皮质背侧和腹侧部分、初级运动皮质(布罗德曼4区)。
3.3 数据采集与处理
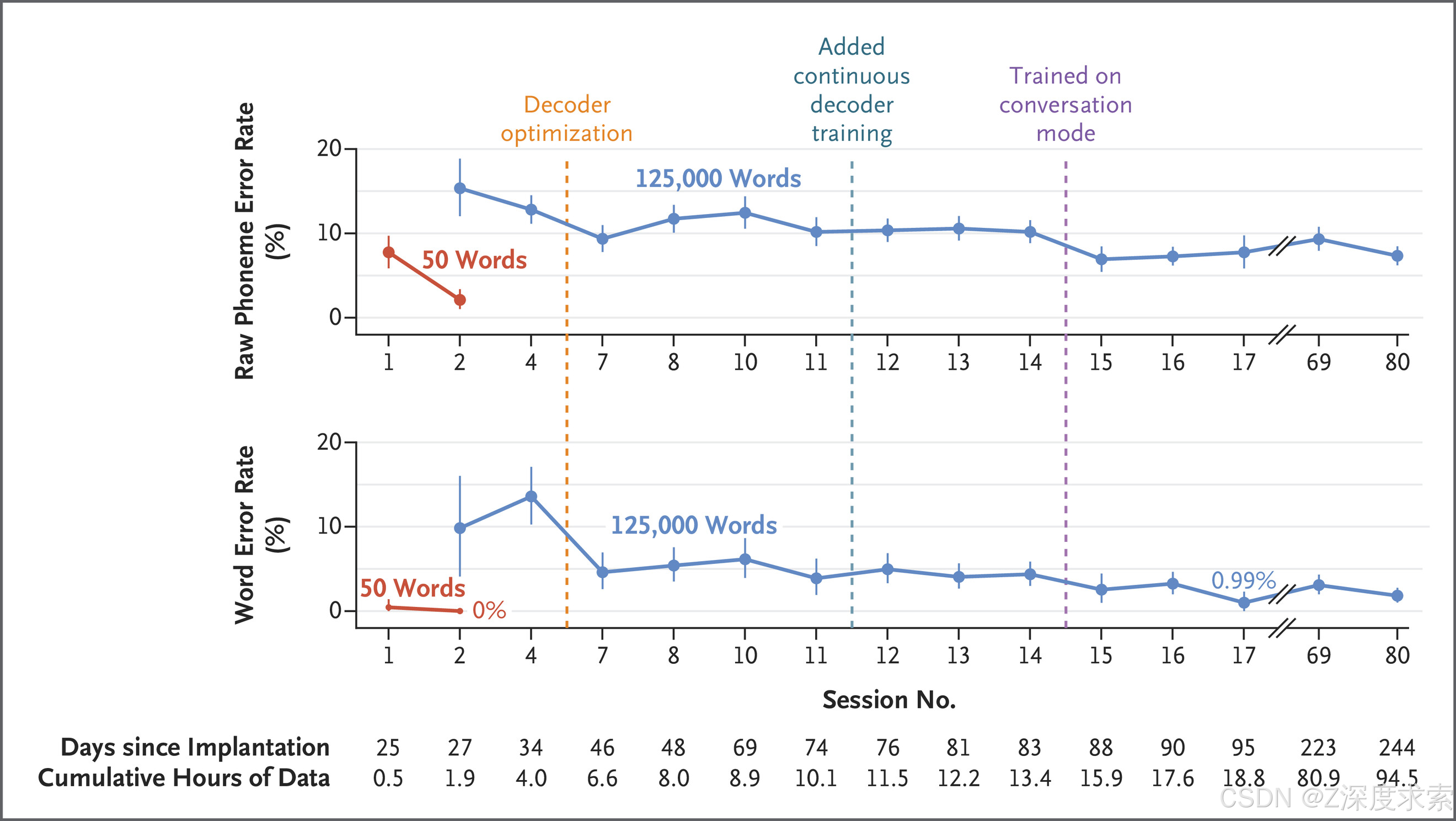
2023年8月(术后25天)开始数据采集,在患者家中进行84个疗程,持续32周。每个疗程包含多个任务模块(时长5-30分钟),患者在模块间休息。任务包括指令延迟复制任务(屏幕显示单词,患者在视觉或听觉提示后尝试说出单词)和患者自定节奏对话模式(患者尝试说出任意内容,系统词汇量限制为12.5万个)。采用Blackrock Neurotech公司NeuroPort系统采集信号,通过公开软件进行实时信号处理和解码,每80毫秒将皮质记录活动预测为最可能的英语音素,结合开源语言模型将音素序列组合为单词并生成句子。
3.4 评估指标
采用音素错误率和单词错误率评估解码性能,计算方式为错误音素/单词数量与预期解码音素/单词总数的比值(百分比)。错误定义为使解码句子与预期句子匹配所需的插入、删除或替换操作。对话模式中通过术后询问患者、患者使用眼动追踪仪选择输出文本准确性(“100%正确”“基本正确”“错误”)等方式确认预期句子。
4. 研究结果
结果
在线语音解码性能