给运维插上 AI 的翅膀:我的 Dify AIOps 探索之旅
从手动救火到智能洞察,一个运维工程师的自我进化。
曾几何时,运维工作像是“数字世界的消防员”。Kubernetes 集群一个莫名的告警,就能让我在深夜从床上弹起,一头扎进浩如烟海的日志和指标中,试图从无数条数据里找到那颗导致雪崩的“石子”。监控图表令人眼花缭乱,知识库文档分散各处,资产信息更新不及时……这些问题每天都在消耗着团队的精力。
直到我遇见了 Dify 和它强大的工作流功能,我决定,是时候为我的运维工作插上一双 AI 的翅膀了。这不是要取代运维,而是要增强我们。以下便是我的探索之旅。
启航:为什么是 Dify 工作流?
传统的运维脚本和工具往往是“孤岛式”的,一个脚本查日志,一个工具看监控,另一个平台管资产。而 Dify 的工作流以一种可视化的方式,将这些孤岛连接了起来。它允许我将不同的“原子能力”(如 API 调用、代码执行、AI 模型推理)像搭积木一样组合成一个完整的、智能的解决方案。
为什么不考虑用n8n 工作流?
核心原因:
内置RAG:Dify的知识库功能开箱即用,n8n需要自己搭建向量数据库和嵌入流程
LLM集成:Dify原生支持多模型切换和优化,n8n需要通过各种插件和自定义代码
提示词工程:Dify提供可视化的提示词编排,n8n需要手动构建和管理prompt模板
我的核心构想是:快速创建一个智能运维中心,能够理解我的自然语言提问,并自动调动后端的各种资源,给出综合性的、有洞察的答案。在这个构想下选择了dify作为实现AIOps的基座
开放能力
第一站:智能 K8s 问题分析——告别 `kubectl` 地狱
场景:收到告警“Pod 重启频繁”,传统流程需要我手动执行一系列 kubectl 命令,对比事件、日志和资源状态,耗时耗力。
Dify 解决方案:
我构建了一个名为 “K8s 故障侦探” 的工作流:
- :我只需在聊天界面输入 分析某个环境 pod [pod-name] 在命名空间 [namespace] 频繁重启的原因。
- :Dify 通过自然语言理解我的意图,并提取出关键实体(Pod 名、命名空间,环境名称)。
- K8s API:工作流中的一个节点通过 Service Account 权限,安全地调用 Kubernetes API,获取该 Pod 的详细信息(describe pod)、最近事件(get events)和日志(logs)。
- 分析引擎:获取到的原始文本信息(通常是杂乱无章的)被送入 LLM 分析节点。我在这里给 设定了一个清晰的“运维专家”角色提示词:
你是一个资深的 K8s 运维专家。请根据提供的 Pod 详情、事件和日志,分析该 Pod 频繁重启的根本原因。请用清晰的逻辑列出可能的原因,并按可能性排序。如果是资源不足,请指出是 CPU 还是内存;如果是探针失败,请指出是存活探针还是就绪探针,并关联相关日志片段。
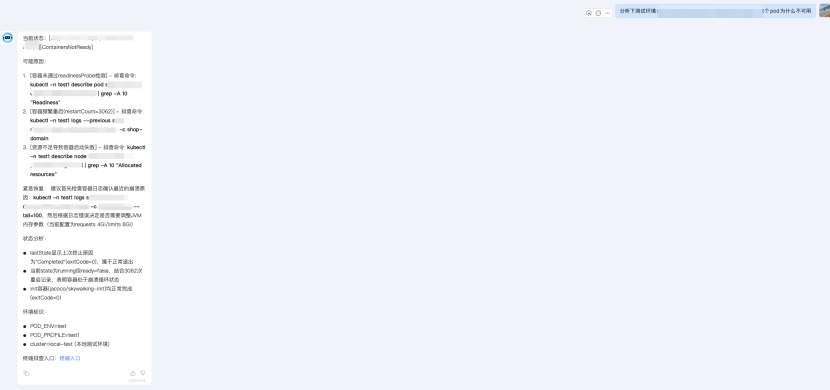
输出:短短几秒钟,AI 会给我返回一个结构化的报告:
- 根本原因:OOMKilled(内存不足)。
- 证据:在事件中发现 Reason: OOMKilled,在日志中发现应用在崩溃前正在处理一个大型文件。
- 建议操作:调整 Pod 的 resources.limits.memory 值,或优化应用的内存使用。
从此,初步的问题诊断从原来的 15-30 分钟缩短到了 5 秒钟。
分析案例如图:
此外我们也开放了
- 域名路由异常分析
- 应用级别分析pod 通过应用名称反查业务pod是否存在异常 这个在pod过多的情况下非常好用可以快速定位问题pod
第二站:多维度监控分析——从“看图表”到“听结论”
场景:Grafana 仪表盘上堆满了曲线和面板,我需要同时关注 CPU、内存、网络 I/O 等多个指标,才能判断系统是否真正健康。
Dify 解决方案:
我构建了 “监控洞察官” 工作流:
- 输入:总结过去一小时内 [服务名] 的性能表现和异常。
- 数据聚合:工作流并行地调用 Prometheus API 和 Elasticsearch API,分别获取该服务在过去一小时的关键指标(CPU、延迟、错误率)和相关的应用日志(错误、异常堆栈)。
- 数据预处理与关联:一个 Python 代码节点对获取到的指标数据进行简单的计算(如最大值、最小值、平均值、同比变化),并将异常时间点与日志中的错误时间进行关联。
- 综合研判:将处理后的指标趋势、关键日志片段一并交给 LLM。提示词如下:
请基于以下时间序列指标和应用日志,对服务 [服务名] 的健康状况进行总结。指出是否存在性能瓶颈或错误,并推测可能导致该问题的模块或外部依赖。
- 输出:AI 会生成一份简洁的监控报告:整体状态:健康 / 存在风险 / 不健康。关键发现:在 14:30 左右,服务延迟从 50ms 飙升至 500ms,同时段日志中发现大量数据库连接超时异常。关联分析:推测可能与底层数据库实例的 CPU 使用率饱和有关。
分析案例如图:

第三站:资产管理-从人工到自动化分析
场景:研发同学定位问题 通常需要从微服务的异常调用链以及日志中获取到的ip地址 服务名称来判断哪个pod出问题了,传统架构下研发同学需要去cmdb资产管理系统里获取相应信息之后 再通过应用名称找到故障节点。
Dify 解决方案:
我打造了一个 “运维万事通” 智能资产管理:
- 数据准备:将所有资产信息录入cmdb系统中。
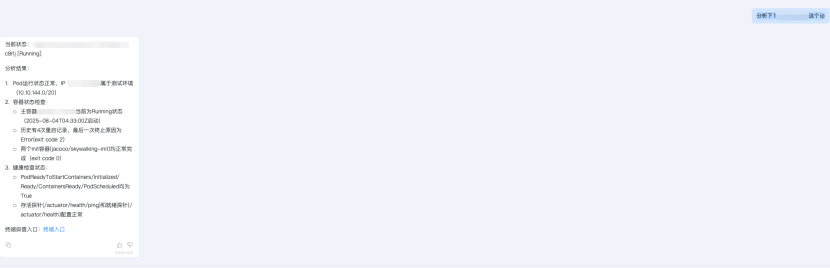
- 输入:例如分析下192.168.1.1这个ip 或者 分析下192.168.1.1 这个ip 昨天使用的pod是那个
- 智能检索与回答:Dify 会先从cmdb里获取ip信息判断ip地址类型,pod还是ecs还是slb还是历史pod使用的ip 通过不同类型分析该资源是否处于正常状态
分析案例如图:
第四站 知识库检索——唤醒沉睡的文档
打造一个 “运维万事通” 智能知识库助手:
- 数据准备:
- 将敏感信息隐藏或者通过在线文档超链接的形式展示在知识库中 保证敏感信息不被大模型记录 其次修改文档结构 保证dify分段正常
- 数据库 网络 安全 基础架构领域的文档全部录入 Dify 的知识库
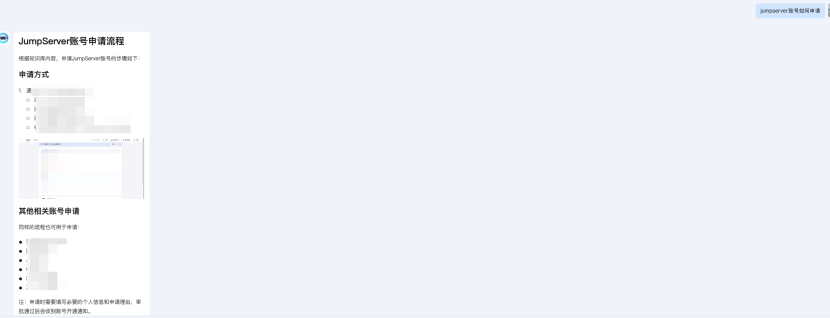
- 输入:jumpserver账号如何申请
- 智能检索与回答:Dify 的 RAG 引擎会从知识库中精准检索到与 dms系统如何使用” 和 dms” 相关的所有文档片段。LLM 基于这些检索到的片段信息,根据你的问题 生成一个流畅、完整的答案。
检索案例如图:
这不仅是知识的检索,更是知识的理解和整合,极大地降低了信息获取的门槛和成本。
迷雾与灯塔
量化数据库选型:
我们在一开始尝试做RAG的时候 用的是默认的Weaviate数据库作为RAG的数据源,但是在实际测试过程中发现整体检索效率偏慢,在文档数不多的情况下知识库检索平均耗时1.2秒左右,考虑到后续大量的数据库 我们决定尝试其他向量数据库,于是,我们决定探索一个性能更优的解决方案,最终将目光投向了 Elasticsearch + 官方向量搜索插件 的方案。压测结果令人振奋:平均耗时从1.2秒大幅降至260毫秒,性能提升了近5倍!
通信协议选型(mcp or http):
这是一个“内置快速开发”与“标准化生态集成”之间的选择。
一开始,我们尝试接入了 MCP,初衷是希望更好地融入标准化生态。对于尚不具备 MCP 能力的场景,我们也计划通过 HTTP 转 MCP 的方式实现快速集成。然而,在实际测试过程中,我们发现基于 MCP 的问答响应效率明显偏低。
经过分析,我们发现 MCP 在工具选择与模型推理阶段均采用了深度思考模式。该模式下系统不支持流式输出,必须等待整个分析流程完全结束后,才能一次性返回结果。这种机制导致用户在等待过程中体验较差,响应迟滞感明显。
旅程感悟与未来展望
通过 Dify 工作流,我成功地将 AI 能力无缝嵌入到了运维的日常工作中。这趟探索之旅让我深刻体会到:
- 效率的质变:从被动的、手动的操作,转变为主动的、智能的洞察。
- 能力的平民化:复杂的运维分析能力,现在任何一个团队成员都可以通过简单的对话来获取。
- 平台的统一:Dify 成为了一个强大的运维AI中台,整合了分散的工具和数据。
总结:
给运维插上 AI 的翅膀,不是为了飞翔得更高傲,而是为了飞翔得更从容、更远。Dify 让我看到了未来 AIOps 的模样,一个运维工程师与 AI 智能体协同作战、共同守护系统稳定性的新时代。
这场旅程,才刚刚开始。