用AI写了一个文档拼音标注工具 中文+拼音一键生成
在日常学习、教学或资料整理中,我们经常需要给中文文字加上拼音标注。
传统方法要么用 Word 插件、要么手工标注,效率低又容易出错。
最近发现一款 AI 拼音标注工具,它能自动识别整段中文内容,并精准地为每个汉字加上拼音,只需一键即可生成标注版文本或文档。
支持网页端和桌面端使用,完全免安装,使用体验非常丝滑。
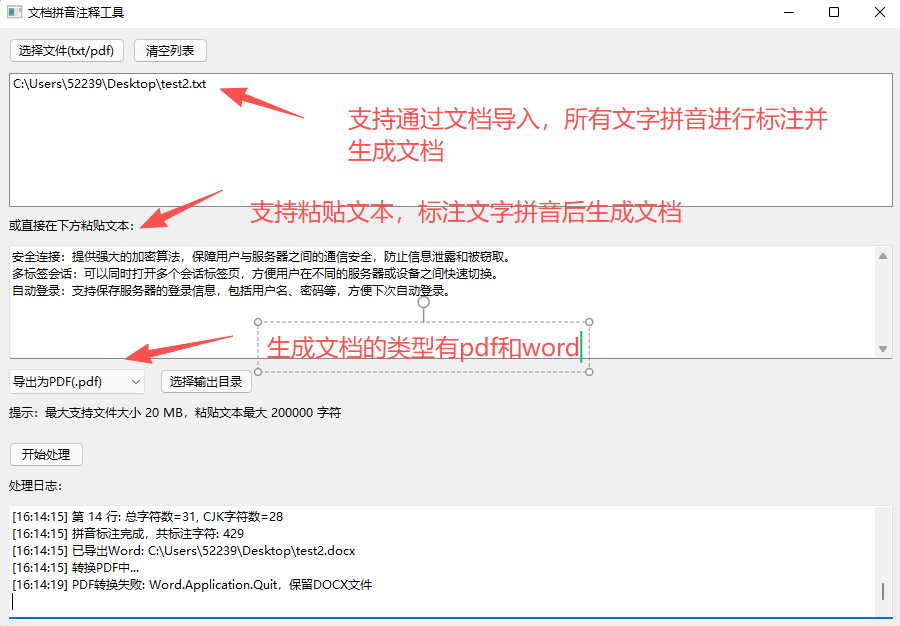
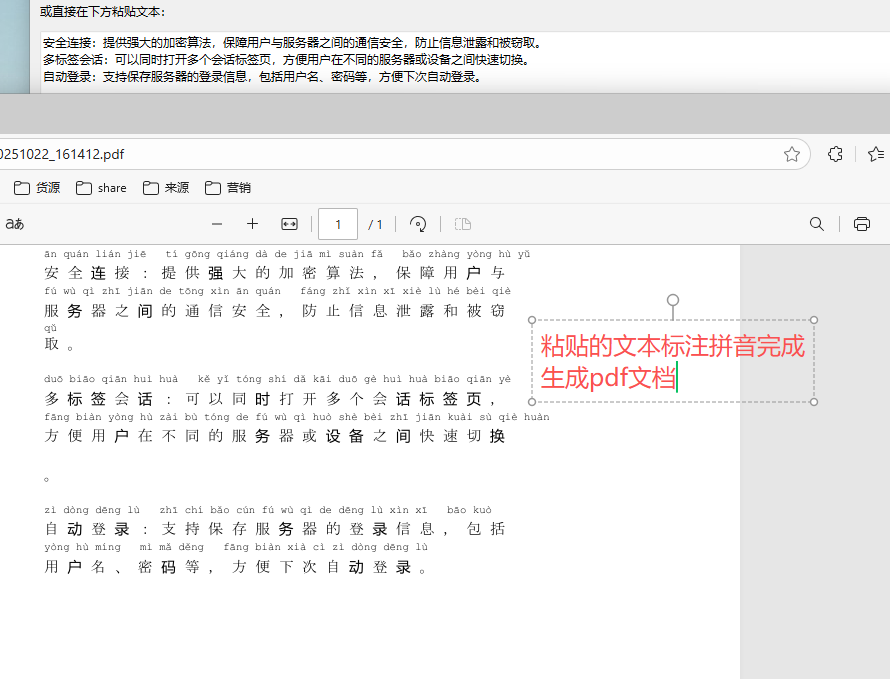
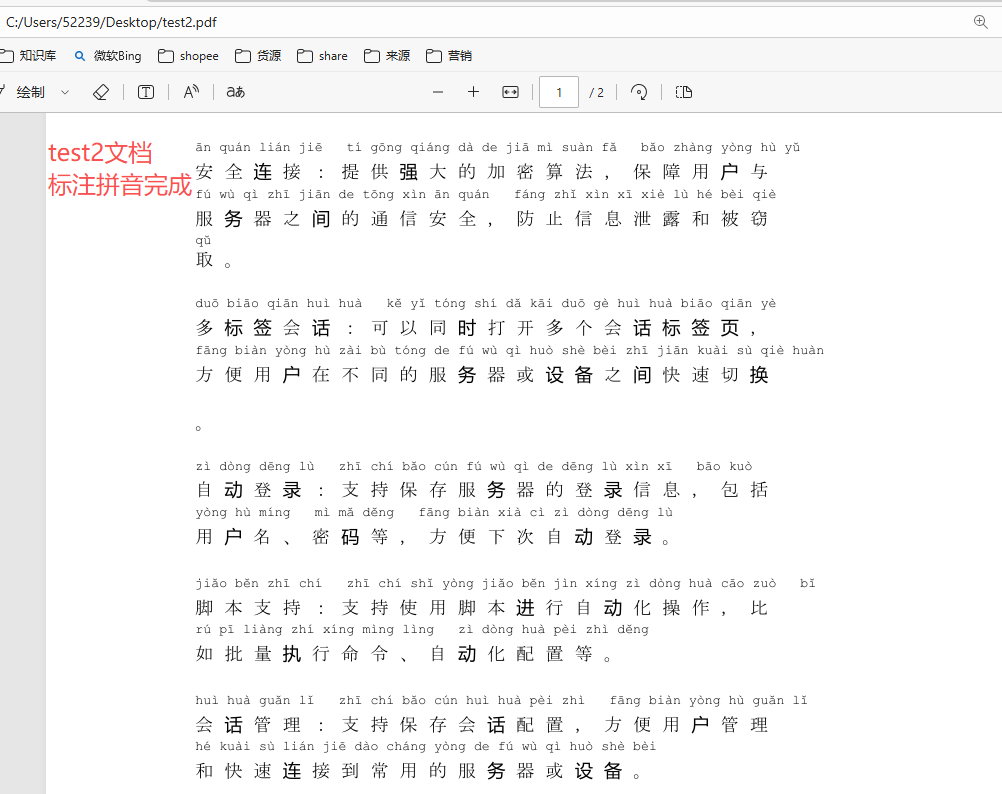
主要功能
- 自动拼音标注:粘贴或上传文本,AI 自动识别并生成拼音。
- 格式智能排版:拼音在汉字上方或括号中显示,排版清晰美观。
- 支持多种输出格式:支持复制、导出为 Word / PDF / TXT 文件。
- 批量处理文本:可一次性对整篇文章、课文或文档进行标注。
- 多音字智能识别:基于 AI 模型自动判断正确读音,准确率高。
- 中英混排识别:自动跳过英文部分,输出干净整齐。
使用步骤
- 双击
pinyin_tools.exe工具即可。 - 将需要标注拼音的文本粘贴到输入框中;或者需要标注拼音的文档导入进来即可。
使用场景
- 教育教学:语文老师准备拼音版课件或试题时的高效助手。
- 儿童学习:家长打印带拼音的故事书、诗词读物。
- 办公文档:需要制作双语或拼音资料的培训讲师、HR 等。
- 语言学习:为国际学生制作带拼音的中文教材。
使用总结
这款 AI 拼音标注工具真正实现了输入中文,秒出拼音,
准确率高、排版美观,对老师、学生和创作者都非常实用。
尤其在中文教育、拼音教学场景下,它能显著提高文档制作效率。
如果你经常需要加拼音,不妨试试看,让 AI 帮你省下大量时间!
现成工具自取,已打包好exe程序:
夸克下载链接:https://pan.quark.cn/s/3d52da2faa62
迅雷下载链接:https://pan.xunlei.com/s/VOcA6WSqXxYeuKLUjqXO3OcvA1?pwd=9txy#
源码
#!/usr/bin/env python3
# -*- coding: utf-8 -*-"""
Pinyin Annotation Tool (Windows, Python 3.7.x)Features:
- wxPython UI: pick .docx/.txt/.pdf files; paste text; live logs
- Add Pinyin above Simplified/Traditional Chinese via Word Phonetic Guide (ruby)
- Options: ignore English/digits and punctuation
- Export: Word (.docx) or PDF (.pdf) using Microsoft Word (COM)Install on Python 3.7.8 (Windows):pip install wxPython==4.1.1 pypinyin==0.49.0 pdfminer.six==20220524 pywin32==305 python-docx==0.8.11 opencc-python-reimplemented==0.1.7
"""import os
import sys
import threading
import time
import tracebackimport wx # wxPython 4.1.1
from pypinyin import pinyin, Style # 0.49.0try:from opencc import OpenCC # 0.1.7_opencc = OpenCC('t2s')
except Exception:_opencc = Nonetry:import docx # python-docx 0.8.11
except Exception:docx = Nonetry:from pdfminer.high_level import extract_text as pdf_extract_text # pdfminer.six 20220524
except Exception:pdf_extract_text = Nonetry:import win32com.client as win32 # pywin32 305
except Exception:win32 = Nonedef is_cjk_char(ch: str) -> bool:code = ord(ch)return (0x3400 <= code <= 0x9FFF or0xF900 <= code <= 0xFAFF or0x20000 <= code <= 0x2FA1F)def is_xml_compatible_char(ch: str) -> bool:"""检查字符是否与XML兼容"""code = ord(ch)# 允许的字符范围:# 0x20-0xD7FF: 基本可打印字符和各种语言字符# 0xE000-0xFFFD: 私有用途和其他字符# 0x10000-0x10FFFF: 补充字符# 排除控制字符 (0x00-0x1F 除了 \t \n \r) 和 0xFFFE, 0xFFFFif ch in ('\t', '\n', '\r'):return Trueif code < 0x20:return Falseif 0x20 <= code <= 0xD7FF:return Trueif 0xE000 <= code <= 0xFFFD:return Trueif 0x10000 <= code <= 0x10FFFF:return Truereturn Falsedef clean_text_for_xml(text: str) -> str:"""清理文本中的不兼容XML字符"""if not isinstance(text, str):text = str(text)# 使用列表推导式过滤掉不兼容的字符cleaned = ''.join(ch for ch in text if is_xml_compatible_char(ch))# 清理多个连续的空行cleaned = cleaned.replace('\r\n', '\n').replace('\r', '\n')lines = cleaned.split('\n')# 移除过多的连续空行(最多保留2个)result_lines = []empty_count = 0for line in lines:if not line.strip():empty_count += 1if empty_count <= 2:result_lines.append(line)else:empty_count = 0result_lines.append(line)return '\n'.join(result_lines)def generate_pinyin_for_text(text: str):if not isinstance(text, str):text = str(text)# 在处理前先清理不兼容的字符text = clean_text_for_xml(text)annotated = []for ch in text:if is_cjk_char(ch):# 对单个字符转换,避免转换后字符数改变导致索引错位simp_ch = _opencc.convert(ch) if _opencc is not None else chpys = pinyin(simp_ch, style=Style.TONE, strict=False, heteronym=False)py_txt = pys[0][0].strip() if pys and pys[0] else ''annotated.append((ch, py_txt or None))else:# 非中文字符保持原样,不标注拼音annotated.append((ch, None))return annotateddef read_file_text(path: str) -> str:ext = os.path.splitext(path)[1].lower()if ext == '.txt':with open(path, 'rb') as f:data = f.read()# 尝试多种编码for encoding in ['utf-8', 'gbk', 'gb2312', 'utf-16']:try:return data.decode(encoding)except Exception:pass# 如果都失败,使用 utf-8 with ignorereturn data.decode('utf-8', 'ignore')if ext == '.docx':raise RuntimeError('暂不支持 .docx,请使用 .txt 或 .pdf')if ext == '.pdf' and pdf_extract_text is not None:return pdf_extract_text(path)if ext == '.pdf' and pdf_extract_text is None:raise RuntimeError('pdfminer.six not installed; cannot read PDF')raise RuntimeError('Unsupported file type: %s' % ext)def export_with_word_ruby(output_path: str, text: str, export_pdf: bool, log=None) -> str:if docx is None:raise RuntimeError('python-docx not available')def _log(msg: str):if log:log(msg)try:# 创建新文档doc = docx.Document()_log('文本长度: %d 字符' % len(text))# 逐行处理normalized = text.replace('\r\n', '\n').replace('\r', '\n')lines = normalized.split('\n')applied = 0_log('总行数: %d' % len(lines))for idx, line in enumerate(lines):if not line.strip():continueannotated_line = generate_pinyin_for_text(line)chars = [ch for ch, _ in annotated_line]pys = [(py if (py and is_cjk_char(ch)) else '') for ch, py in annotated_line]if not chars:continue# 调试日志cjk_count = sum(1 for ch in chars if is_cjk_char(ch))_log('第 %d 行: 总字符数=%d, CJK字符数=%d' % (idx + 1, len(chars), cjk_count))# 按行宽限制分段处理(每行最多25个字符)max_chars_per_line = 20line_start = 0while line_start < len(chars):line_end = min(line_start + max_chars_per_line, len(chars))# 构建拼音行和字符行pinyin_parts = []chars_parts = []for i in range(line_start, line_end):ch = chars[i]py = pys[i]py_padded = (py if py else '').ljust(max(len(py) if py else 0, 1))ch_padded = chpinyin_parts.append(py_padded)chars_parts.append(ch_padded)# 构建完整的行pinyin_line = ' '.join(pinyin_parts) # 用空格分隔chars_line = ' '.join(chars_parts)# 再次清理以确保XML兼容性pinyin_line = clean_text_for_xml(pinyin_line)chars_line = clean_text_for_xml(chars_line)# 添加到文档(使用等宽字体)# 拼音行p1 = doc.add_paragraph()r1 = p1.add_run(pinyin_line)r1.font.name = 'Courier New'r1.font.size = docx.shared.Pt(8)p1.paragraph_format.space_before = docx.shared.Pt(0)p1.paragraph_format.space_after = docx.shared.Pt(0)p1.paragraph_format.line_spacing = 1.0# 字符行p2 = doc.add_paragraph()r2 = p2.add_run(chars_line)r2.font.name = 'Courier New'r2.font.size = docx.shared.Pt(11)p2.paragraph_format.space_before = docx.shared.Pt(0)p2.paragraph_format.space_after = docx.shared.Pt(0) # 行间距p2.paragraph_format.line_spacing = 1.0applied += sum(1 for i in range(line_start, line_end) if is_cjk_char(chars[i]))line_start = line_end# 行间空行if idx < len(lines) - 1:p_empty = doc.add_paragraph()p_empty.paragraph_format.space_before = docx.shared.Pt(0)p_empty.paragraph_format.space_after = docx.shared.Pt(0)_log('拼音标注完成,共标注字符: %d' % applied)# 保存文档docx_path = output_path if output_path.lower().endswith('.docx') else (output_path + '.docx')doc.save(docx_path)_log('已导出Word: %s' % docx_path)# 如果需要 PDFif export_pdf:pdf_path = output_path if output_path.lower().endswith('.pdf') else (output_path + '.pdf')if win32 is not None:try:_log('转换PDF中...')word = win32.Dispatch('Word.Application')try:word.Visible = Falseword_doc = word.Documents.Open(docx_path)word_doc.SaveAs2(pdf_path, FileFormat=17)word_doc.Close(False)_log('已导出PDF: %s' % pdf_path)return pdf_pathfinally:word.Quit()except Exception as e:_log('PDF转换失败: %s,保留DOCX文件' % str(e))return docx_pathelse:_log('pywin32 不可用,无法转换PDF')return docx_pathreturn docx_pathexcept Exception as e:_log('导出失败: %s' % str(e))_log(traceback.format_exc())raiseclass MainFrame(wx.Frame):def __init__(self):super(MainFrame, self).__init__(parent=None, title='文档拼音注释工具', size=(920, 640))self.CenterOnScreen()panel = wx.Panel(self)vbox = wx.BoxSizer(wx.VERTICAL)hbox1 = wx.BoxSizer(wx.HORIZONTAL)self.btn_files = wx.Button(panel, label='选择文件(txt/pdf)')self.btn_files.Bind(wx.EVT_BUTTON, self.on_pick_files)hbox1.Add(self.btn_files, 0, wx.RIGHT, 8)self.btn_clear = wx.Button(panel, label='清空列表')self.btn_clear.Bind(wx.EVT_BUTTON, self.on_clear_list)hbox1.Add(self.btn_clear, 0)vbox.Add(hbox1, 0, wx.ALL, 10)self.list_files = wx.ListBox(panel, style=wx.LB_EXTENDED)vbox.Add(self.list_files, 1, wx.EXPAND | wx.LEFT | wx.RIGHT, 10)vbox.Add(wx.StaticText(panel, label='或直接在下方粘贴文本:'), 0, wx.LEFT | wx.RIGHT | wx.TOP, 10)self.text_input = wx.TextCtrl(panel, style=wx.TE_MULTILINE)vbox.Add(self.text_input, 1, wx.EXPAND | wx.ALL, 10)opt_box = wx.BoxSizer(wx.HORIZONTAL)self.choice_format = wx.Choice(panel, choices=['导出为Word(.docx)', '导出为PDF(.pdf)'])self.choice_format.SetSelection(0)opt_box.Add(self.choice_format, 0, wx.RIGHT, 15)self.btn_outdir = wx.Button(panel, label='选择输出目录')self.btn_outdir.Bind(wx.EVT_BUTTON, self.on_pick_outdir)opt_box.Add(self.btn_outdir, 0)vbox.Add(opt_box, 0, wx.LEFT | wx.RIGHT | wx.BOTTOM, 10)# 限制提示self.max_file_mb = 20 # 最大文件大小(MB)self.max_paste_chars = 200000 # 粘贴文本最大字符数vbox.Add(wx.StaticText(panel, label='提示:最大支持文件大小 %d MB,粘贴文本最大 %d 字符' % (self.max_file_mb, self.max_paste_chars)), 0, wx.LEFT | wx.RIGHT | wx.BOTTOM, 10)self.btn_run = wx.Button(panel, label='开始处理')self.btn_run.Bind(wx.EVT_BUTTON, self.on_run)vbox.Add(self.btn_run, 0, wx.ALL, 10)vbox.Add(wx.StaticText(panel, label='处理日志:'), 0, wx.LEFT | wx.RIGHT, 10)self.log = wx.TextCtrl(panel, style=wx.TE_MULTILINE | wx.TE_READONLY)vbox.Add(self.log, 1, wx.EXPAND | wx.ALL, 10)panel.SetSizer(vbox)self.files = []# 默认保存目录:桌面self.outdir = os.path.join(os.path.expanduser('~'), 'Desktop')if not os.path.exists(self.outdir):os.makedirs(self.outdir)def append_log(self, msg: str):ts = time.strftime('%H:%M:%S')self.log.AppendText('[%s] %s\n' % (ts, msg))def on_pick_files(self, event):dlg = wx.FileDialog(self, message='选择文件', wildcard='文档|*.txt;*.pdf',style=wx.FD_OPEN | wx.FD_FILE_MUST_EXIST | wx.FD_MULTIPLE)if dlg.ShowModal() == wx.ID_OK:paths = dlg.GetPaths()self.files = list(paths)self.list_files.Clear()for p in self.files:self.list_files.Append(p)dlg.Destroy()def on_clear_list(self, event):self.files = []self.list_files.Clear()def on_pick_outdir(self, event):dlg = wx.DirDialog(self, message='选择输出目录', style=wx.DD_DEFAULT_STYLE | wx.DD_DIR_MUST_EXIST)if dlg.ShowModal() == wx.ID_OK:self.outdir = dlg.GetPath()self.append_log('输出目录: %s' % self.outdir)dlg.Destroy()def on_run(self, event):export_pdf = self.choice_format.GetSelection() == 1if not self.files and not self.text_input.GetValue().strip():wx.MessageBox('请选择文件或粘贴文本', '提示', wx.OK | wx.ICON_WARNING)returnself.btn_run.Disable()self.log.Clear()def worker():try:pasted = self.text_input.GetValue().strip()if pasted and len(pasted) > self.max_paste_chars:raise RuntimeError('粘贴文本超出最大限制(%d 字符)' % self.max_paste_chars)if pasted:name = 'pasted_%s' % time.strftime('%Y%m%d_%H%M%S')out_path = os.path.join(self.outdir, name)self.append_log('处理粘贴文本...')export_with_word_ruby(out_path, pasted, export_pdf, self.append_log)for idx, f in enumerate(self.files, 1):self.append_log('[%d/%d] 处理 %s' % (idx, len(self.files), f))try:# 文件大小限制try:size_mb = os.path.getsize(f) / (1024.0 * 1024.0)if size_mb > self.max_file_mb:raise RuntimeError('文件超过大小限制(%.2f MB > %d MB)' % (size_mb, self.max_file_mb))except Exception:passtext = read_file_text(f)base = os.path.splitext(os.path.basename(f))[0]out_path = os.path.join(self.outdir, base)export_with_word_ruby(out_path, text, export_pdf, self.append_log)except Exception:self.append_log('处理失败: %s' % f)self.append_log(traceback.format_exc())wx.CallAfter(wx.MessageBox, '处理完成', '提示', wx.OK | wx.ICON_INFORMATION)except Exception as e:self.append_log('发生错误: %s' % str(e))self.append_log(traceback.format_exc())wx.CallAfter(wx.MessageBox, str(e), '错误', wx.OK | wx.ICON_ERROR)finally:wx.CallAfter(self.btn_run.Enable)t = threading.Thread(target=worker, daemon=True)t.start()def main():app = wx.App(False)frame = MainFrame()frame.Show()app.MainLoop()if __name__ == '__main__':main()