Spring AI Alibaba 【五】
1. 向量化和向量数据库
1.1 向量
Vector 是向量或矢量的意思,向量是数学里的概念,而矢量是物理里的概念,但二者描述的是同一件事。
定义:向量是用于表示具有大小和方向的量。
向量可以在不同的维度空间中定义,最常见的是二维和三维空间中的向量,但理论上也可以有更高维的向量。例如,在二维平面上的一个向量可以写作(x,y),这里x和y分别表示该向量沿两个坐标轴方向上的分量;而在三维空间里,则会有一个额外的z坐标,即(x,y,z)。
1.2 文本向量化
文本向量化(Text Embedding)是自然语言处理中非常重要的一环,它将文本数据转换成向量表示,包括词、句子、文档级别的文本。深度学习向量表征就是通过算法将数据转换成计算机可处理的数字化形式。
1.2.1 词级别向量化
词级别向量化是将单个词汇转换成数值向量,常见的方法包括:
-
独热编码(One-Hot Encoding):为每个词分配一个唯一的二进制向量,其中只有一个位置是1,其余位置是0。
-
TF-IDF:通过统计词频和逆文档频率来生成词向量或文档向量。
-
N-gram:基于统计的n个连续词的频率来生成向量。
-
词嵌入(Word Embeddings):如Word2Vec, GloVe, FastText等,将每个词映射到一个高维实数向量,这些向量在语义上是相关的。
1.2.2 句子向量化
句子向量化是将整个句子转换为一个数值向量,常见的方法包括:
-
简单平均/加权平均:对句子中的词向量进行平均或根据词频进行加权平均。
-
递归神经网络(RNN):通过递归地处理句子中的每个词来生成句子表示。
-
卷积神经网络(CNN):使用卷积层来捕捉句子中的局部特征,然后生成句子表示。
-
自注意力机制(如Transformer):如BERT模型,通过对句子中的每个词进行自注意力计算来生成句子表示;再比如现在的大模型,很多都会有对应的训练好的tokenizer,直接采用对应的tokenizer进行文本向量化。

1.2.3 文档向量化
文档向量化是将整个文档(如一篇文章或一组句子)转换为一个数值向量,常见的方法包括:
-
简单平均/加权平均:对文档中的句子向量进行平均或加权平均。
-
文档主题模型(如LDA):通过捕捉文档中的主题分布来生成文档表示。
-
层次化模型:如Doc2Vec,它扩展了Word2Vec,可以生成整个文档的向量表示。
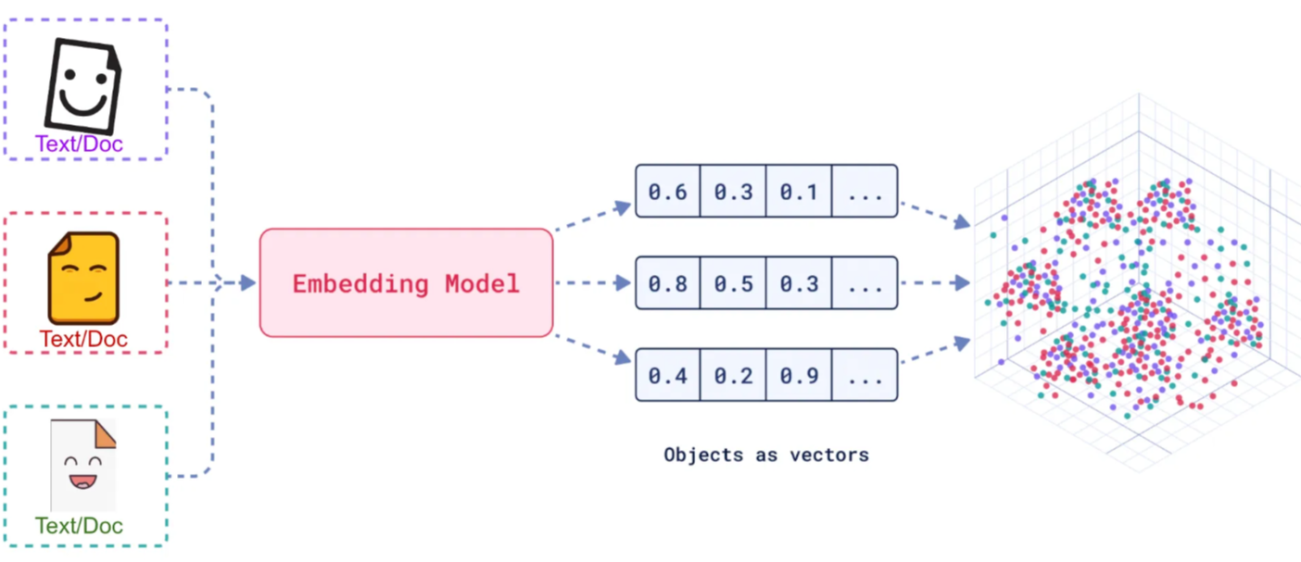
1.3 嵌入模型 (Embedding Model)
1.3.1 定义
嵌入(Embedding)的工作原理是将文本、图像和视频转换为称为向量(Vectors)的浮点数数组。这些向量旨在捕捉文本、图像和视频的含义。嵌入数组的长度称为向量的维度(Dimensionality)。
嵌入模型(EmbeddingModel)是嵌入过程中采用的模型。当前EmbeddingModel的接口主要用于将文本转换为数值向量,接口的设计主要围绕这两个目标展开:
- 可移植性:该接口确保在各种嵌入模型之间的轻松适配。它允许开发者在不同的嵌入技术或模型之间切换,所需的代码更改最小化。这一设计与 Spring 模块化和互换性的理念一致。
- 简单性:嵌入模型简化了文本转换为嵌入的过程。通过提供如
embed(String text)和embed(Document document)这样简单的方法,它去除了处理原始文本数据和嵌入算法的复杂性。这个设计选择使开发者,尤其是那些初次接触 AI 的开发者,更容易在他们的应用程序中使用嵌入,而无需深入了解其底层机制。
1.3.2 API介绍
EmbeddingModel
EmbeddingModel的接口和类。
public interface EmbeddingModel extends Model<EmbeddingRequest, EmbeddingResponse> {@OverrideEmbeddingResponse call(EmbeddingRequest request);/*** Embeds the given document's content into a vector.* @param document the document to embed.* @return the embedded vector.*/List<Double> embed(Document document);/*** Embeds the given text into a vector.* @param text the text to embed.* @return the embedded vector.*/default List<Double> embed(String text) {Assert.notNull(text, "Text must not be null");return this.embed(List.of(text)).iterator().next();}/*** Embeds a batch of texts into vectors.* @param texts list of texts to embed.* @return list of list of embedded vectors.*/default List<List<Double>> embed(List<String> texts) {Assert.notNull(texts, "Texts must not be null");return this.call(new EmbeddingRequest(texts, EmbeddingOptions.EMPTY)).getResults().stream().map(Embedding::getOutput).toList();}/*** Embeds a batch of texts into vectors and returns the {@link EmbeddingResponse}.* @param texts list of texts to embed.* @return the embedding response.*/default EmbeddingResponse embedForResponse(List<String> texts) {Assert.notNull(texts, "Texts must not be null");return this.call(new EmbeddingRequest(texts, EmbeddingOptions.EMPTY));}/*** @return the number of dimensions of the embedded vectors. It is generative* specific.*/default int dimensions() {return embed("Test String").size();}}Embedding Model API提供多种选项,将文本转换为Embeddings,支持单个字符串、结构化的Document对象或文本批处理。
有多种快捷方式可以获得文本Embeddings。例如embed(String text)方法,它接受单个字符串并返回相应的 Embedding 向量。所有方法都围绕着call方法实现,这是调用 Embedding Model的主要方法。
通常,Embedding返回一个float数组,以数值向量格式表示Embeddings。
embedForResponse方法提供了更全面的输出,可能包括有关Embeddings的其他信息。
dimensions方法是开发人员快速确定 Embedding 向量大小的便利工具,这对于理解 Embedding space 和后续处理步骤非常重要。
EmbeddingRequest
EmbeddingRequest是一种ModelRequest,它接受文本对象列表和可选的Embedding请求选项。以下代码片段简要地显示了 EmbeddingRequest 类,省略了构造函数和其他工具方法:
public class EmbeddingRequest implements ModelRequest<List<String>> {
private final List<String> inputs;
private final EmbeddingOptions options;
// other methods omitted
}EmbeddingResponse
EmbeddingResponse类的结构如下:
public class EmbeddingResponse implements ModelResponse<Embedding> {private List<Embedding> embeddings;private EmbeddingResponseMetadata metadata = new EmbeddingResponseMetadata();// other methods omitted
}EmbeddingResponse类保存了AI模型的输出,其中每个 Embedding 实例包含来自单个文本输入的结果向量数据。同时,它还携带了有关 AI 模型响应的EmbeddingResponseMetadata元数据。
Embedding
Embedding表示一个 Embedding 向量。
public class Embedding implements ModelResult<List<Double>> {private List<Double> embedding;private Integer index;private EmbeddingResultMetadata metadata;
// other methods omitted
}1.3.3 维度 Dimensions
如我们所见,每个数值向量都有x和y坐标(或者在多维系统中是x、y、z,...)。x、y、z、...是这个向量空间的轴,称为维度。对于我们想要表示为向量的一些非数值实体,我们首先需要决定这些维度,并为每个实体在每个维度上分配一个值。
例如,在一个交通工具数据集中,我们可以定义四个维度:“轮子数量”、“是否有发动机”、“是否可以在地上开动”和“最大乘客数”。然后我们可以将一些车辆表示为:
| item | number of wheels | has an engine | moves on land | max occupants |
|---|---|---|---|---|
| car | 4 | yes | yes | 5 |
| bicycle | 2 | no | yes | 1 |
| tricycle | 3 | no | yes | 1 |
| motorcycle | 2 | yes | yes | 2 |
| sailboat | 0 | no | no | 20 |
| ship | 0 | yes | no | 1000 |
因此,我们的汽车Car向量将是(4,yes,yes,5),或者用数值表示为(4,1,1,5)(将yes设为1,no设为0)。
向量的每个维度代表数据的不同特性,维度越多对事务的描述越精确,我们可以使用“是否有翅膀”、“是否使用柴油”、“最高速度”、“平均重量”、“价格”等等更多的维度信息。
1.3.4 相似
如何确定哪些是最相似的?
每个向量都有一个长度和方向。例如,在这个图中,p和a指向相同的方向,但长度不同。p和b正好指向相反的方向,但有相同的长度。然后还有c,长度比p短一点,方向不完全相同,但很接近。
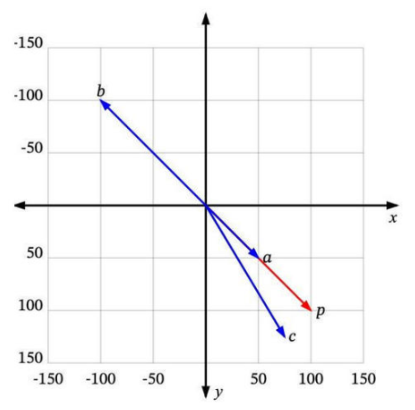
那么,哪一个最接近p呢?
如果相似似似意味着指向相似的方向,那么a是最接近p的。接下来是c。b是最不相似的,因为它正好指向与p相反的方向。如果相似意味着相似的长度,那么b是最接近p的(因为它有相同的长度),接下来是c,然后是a
由于向量通常用于描述语义意义,仅仅看长度通常无法满足需求。大多数相似度测量要么仅依赖于方向,要么同时考虑方向和大小。
示例

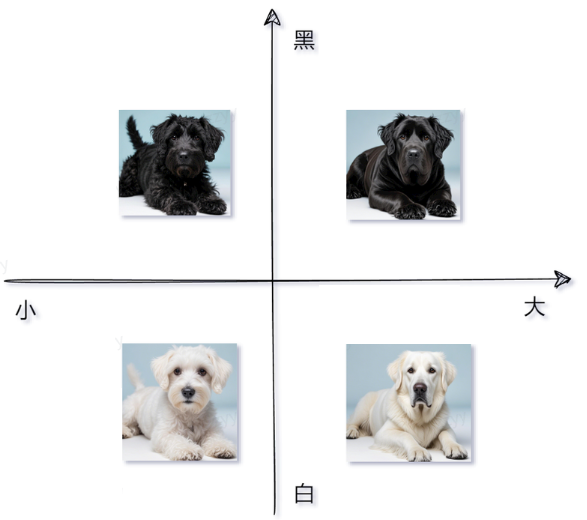
从不同的维度去分析相似度,得到的结果是不一定相同的。
1.3.5 总结
嵌入模型是什么?
嵌入模型是一种机器学习模型,旨在将数据(如文本、图像或其他形式的信息)表示为连续的低维向量空间。这些嵌入能够捕捉数据之间的语义或上下文相似性,使机器能够更有效地执行比较、聚类或分类等任务。
想象一下,你想描述不同的水果,与其使用冗长的描述,不如使用数字来表示甜度、大小和颜色等特征。例如,一个苹果可以表示为 [8,5,7],而香蕉是 [9,7,4]。这些数字使得比较或分组相似水果变得更加容易。
1.4 向量数据库
1.4.1 定义
向量数据库是一种专门类型的数据库,在 AI 应用中扮演着重要角色。
在向量数据库中,查询与传统关系型数据库不同。 它们不是进行精确匹配,而是执行相似性搜索。 当给定一个向量作为查询时,向量数据库会返回与查询向量”相似”的向量。 关于这种相似性如何在高层次上计算的更多细节,请参见 向量相似性。
向量数据库用于将你的数据与 AI 模型集成。 使用它们的第一步是将数据加载到向量数据库中。 然后,当用户查询要发送到 AI 模型时,首先检索一组相似的文档。 这些文档随后作为用户问题的上下文,与用户的查询一起发送到 AI 模型。 这种技术被称为 检索增强生成 (RAG)。
简单来说,向量数据库是一种专门用于存储、管理和检索向量数据(即高维数值数组)的数据库系统。其核心功能是通过高效的索引结构和相似性计算算法,支持大规模向量数据的快速查询与分析,向量数据库维度越高,查询精准度也越高,查询效果也越好。
1.4.2 用途
将文本、图像和视频转换为称为向量(Vectors)的浮点数数组在 VectorStore中,查询与传统关系数据库不同。它们执行相似性搜索,而不是精确匹配。当给定一个向量作为查询时,VectorStore 返回与查询向量“相似”的向量。
1.4.3 指征特点
- 捕捉复杂的词汇关系(如语义相似性、同义词、多义词)
- 向量嵌入为检索增强生成 (RAG) 应用程序提供支持
1.4.4 通俗理解
将文本映射到高维空间中的点,使语义相似的文本在这个空间中距离较近。例如,“肯德基”和”麦当劳”的向量可能会比”肯德基”和”新疆大盘鸡”的向量更接近。
1.5 Redis Stack
Redis Stack 扩展了 Redis OSS 的核心功能,为调试等提供了完整的开发人员体验。
Redis Stack 是使用 Redis 的最佳起点。我们将我们必须提供的最佳技术捆绑到一个易于使用的软件包中。
除了 Redis OSS 的所有功能外,Redis Stack 还支持:
- 概率数据结构
- 可查询的 JSON 文档
- 跨哈希和 JSON 文档进行查询
- 时序数据支持(引入和查询),包括全文搜索
- 使用 Cypher 查询语言绘制数据模型
Redis Stack 是Redis Labs 推出的一个增强版Redis,不是Redis的替代品,而是在原生 Redis基础上的功能扩展包,专为构建现代实时应用而设计。
简单来说:RedisStack = 原生Redis + 搜索 + 图 + 时间序列 + JSON + 概率结构 + 可视化工具 + 开发框架支持
1.5.1 Redis Stack相比原生Redis的优势
| 功能维度 | 原生Redis | Redis Stack增强功能 |
|---|---|---|
| 数据结构 | 字符串、列表、集合、哈希等 | 增加JSON、图、时间序列、概率结构等高级类型 |
| 查询能力 | 仅限键值查询 | 支持全文搜索、向量搜索、图查询、JSON 查询 |
| 使用场景 | 缓存、消息队列、计数器等 | 实时推荐、时序分析、知识图谱、文档数据库、AI 向量检索 |
| 开发体验 | 命令行操作,需手动拼装逻辑 | 提供 RedisInsight和对象映射库,开发效率更高 |
1.5.2 RedisStack核心组件
- RediSearch:提供全文搜索能力,支持复杂的文本搜索、聚合和过滤,以及向量数据的存储和检索。
- RedisJSON:原生支持JSON数据的存储、索引I和查询,可高效存储和操作嵌套的JSON文档。
- RedisGraph:支持图数据模型,使用Cypher查询语言进行图遍历查询。
- RedisBloom:支持 Bloom、Cuckoo、Count-Min Sketch等概率数据结构。
1.5.3 RedisStack 的安装
要在 Windows 上安装 Redis Stack,您需要安装 Docker。
有关在Windows上安装Docker,可以参考如下教程:
Windows 环境下安装 Docker 的详细教程(超详细图文)_docker安装windows-CSDN博客
【保姆级教程】windows 安装 docker 全流程 - 美码师 - 博客园
Windows装Docker至D盘/其他盘(最新,最准确,直接装)_docker安装到d盘-CSDN博客
docker window安装(附D盘安装) - 知乎
在安装好 Docker后,启动 Docker Desktop,打开cmd命令行窗口,运行如下命令:
docker pull docker.m.daocloud.io/redis/redis-stack-server:latest即可在无需其他任何额外操作的前提下使用镜像站完成对该镜像的拉取。
运行如下命令就可以成功运行redis stack:
docker run -d --name redis-stack-server -p 6379:6379 redis/redis-stack-server
1.5.4 主要ReJSON-RL命令列表
ReJSON- RL提供的主要命令包括:
- JSON.SET 设置JSON值
- JSON.GET 获取JSON值
- JSON.DEL 删除 JSON值
- JSON.MGET 批量获取多个键的JSON值
- JSON.TYPE 获取JSON值的类型
- JSON. NUMINCRBY 对JSON中的数字进行增量操作
- JSON.STRAPPEND 追加字符串到JSON字符串
- JSON. STRLEN 获取JSON字符串的长度
1.6 矢量数据库
矢量数据库是一种特殊类型的数据库,在人工智能应用中发挥着至关重要的作用。
在向量数据库中,查询与传统的关系数据库不同。 他们执行相似性搜索,而不是完全匹配。 当给定向量作为查询时,向量数据库返回与查询向量“相似”的向量。 有关如何在高级上计算此相似性的更多详细信息,请参阅向量相似度。
矢量数据库用于将您的数据与 AI 模型集成。 使用它们的第一步是将数据加载到矢量数据库中。 然后,当用户查询要发送到 AI 模型时,首先检索一组相似的文档。 然后,这些文档作为用户问题的上下文,并与用户的查询一起发送到 AI 模型。 这种技术被称为检索增强生成 (RAG)。
1.7 编码实战
本文中的向量模型选择为阿里云百炼平台通义大模型类别下的通用文本向量-v3
1.7.1 新建Module
可以命名为 Embed2vector
1.7.2 修改POM文件
在依赖配置节点修改为以下配置:
<dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><!--spring-ai-alibaba dashscope--><dependency><groupId>com.alibaba.cloud.ai</groupId><artifactId>spring-ai-alibaba-starter-dashscope</artifactId></dependency><!-- 添加 Redis 向量数据库依赖 --><dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-starter-vector-store-redis</artifactId></dependency><!--lombok--><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><version>1.18.38</version></dependency><!--hutool--><dependency><groupId>cn.hutool</groupId><artifactId>hutool-all</artifactId><version>5.8.22</version></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency></dependencies><build><plugins><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId></plugin><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><version>3.11.0</version><configuration><compilerArgs><arg>-parameters</arg></compilerArgs><source>21</source><target>21</target></configuration></plugin></plugins></build><repositories><repository><id>spring-milestones</id><name>Spring Milestones</name><url>https://repo.spring.io/milestone</url><snapshots><enabled>false</enabled></snapshots></repository></repositories>1.7.3 编写配置文件
在resources目录下新建application.properties配置文件,内容如下:
server.port=8011# 设置响应的字符编码
server.servlet.encoding.charset=utf-8
server.servlet.encoding.enabled=true
server.servlet.encoding.force=truespring.application.name=Embed2vector# ====SpringAIAlibaba Config=============
spring.ai.dashscope.api-key=${DASHSCOPE_API_KEY}
spring.ai.dashscope.chat.options.model=qwen-plus
spring.ai.dashscope.embedding.options.model=text-embedding-v3# =======Redis Stack==========
spring.data.redis.host=localhost
spring.data.redis.port=6379
spring.data.redis.username=default
spring.data.redis.password=
spring.ai.vectorstore.redis.initialize-schema=true
spring.ai.vectorstore.redis.index-name=custom-index
spring.ai.vectorstore.redis.prefix=custom-prefix此处的配置参数来源于Redis :: Spring AI Reference
Properties starting with are used to configure the :spring.ai.vectorstore.redis.*RedisVectorStore
| Property | Description | Default Value |
|---|---|---|
|
| Whether to initialize the required schema |
|
|
| The name of the index to store the vectors |
|
|
| The prefix for Redis keys |
|
1.7.4 编写主启动类
新建主启动类,并编写如下内容:
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;@SpringBootApplication
public class Embed2vectorApplication {public static void main(String[] args){SpringApplication.run(Embed2vectorApplication.class, args);}}1.7.5 编写业务类
新建子包controller,并在其中新建业务类 Embed2VectorController
import com.alibaba.cloud.ai.dashscope.embedding.DashScopeEmbeddingOptions;
import jakarta.annotation.Resource;
import lombok.extern.slf4j.Slf4j;
import org.springframework.ai.document.Document;
import org.springframework.ai.embedding.EmbeddingModel;
import org.springframework.ai.embedding.EmbeddingRequest;
import org.springframework.ai.embedding.EmbeddingResponse;
import org.springframework.ai.vectorstore.SearchRequest;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;import java.util.Arrays;
import java.util.List;@RestController
@Slf4j
public class Embed2VectorController {@Resourceprivate EmbeddingModel embeddingModel;@Resourceprivate VectorStore vectorStore;/*** 文本向量化* http://localhost:8011/text2embed?msg=射雕英雄传** @param msg* @return*/@GetMapping("/text2embed")public EmbeddingResponse text2Embed(String msg){//EmbeddingResponse embeddingResponse = embeddingModel.call(new EmbeddingRequest(List.of(msg), null));EmbeddingResponse embeddingResponse = embeddingModel.call(new EmbeddingRequest(List.of(msg),DashScopeEmbeddingOptions.builder().withModel("text-embedding-v3").build()));System.out.println(Arrays.toString(embeddingResponse.getResult().getOutput()));return embeddingResponse;}/*** 文本向量化 后存入向量数据库RedisStack*/@GetMapping("/embed2vector/add")public void add(){List<Document> documents = List.of(new Document("i study LLM"),new Document("i love java"));vectorStore.add(documents);}/*** 从向量数据库RedisStack查找,进行相似度查找* http://localhost:8011/embed2vector/get?msg=LLM* @param msg* @return*/@GetMapping("/embed2vector/get")public List getAll(@RequestParam(name = "msg") String msg) {SearchRequest searchRequest = SearchRequest.builder().query(msg).topK(2).build();List<Document> list = vectorStore.similaritySearch(searchRequest);System.out.println(list);return list;}
}1.7.6 测试
启动主启动类后,在浏览器中请求如下地址:
http://localhost:8011/text2embed?msg=射雕英雄传

能看到有如上图输出。
http://localhost:8011/embed2vector/add
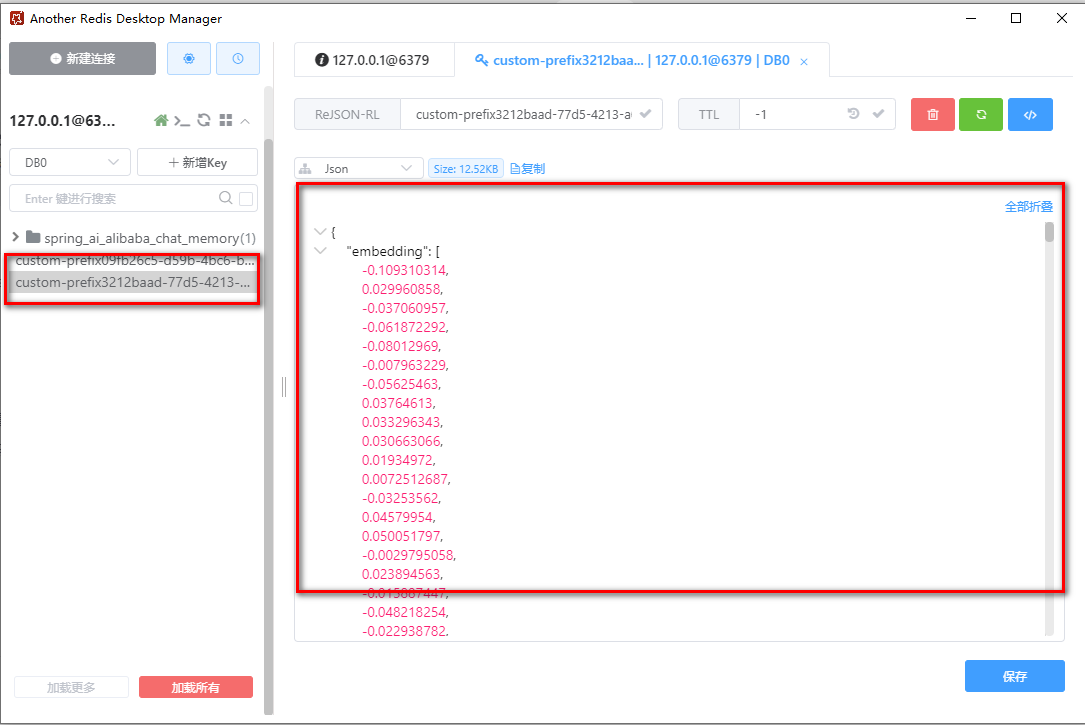
数据已成功添加到redis satck中。
http://localhost:8011/embed2vector/get?msg=LLM
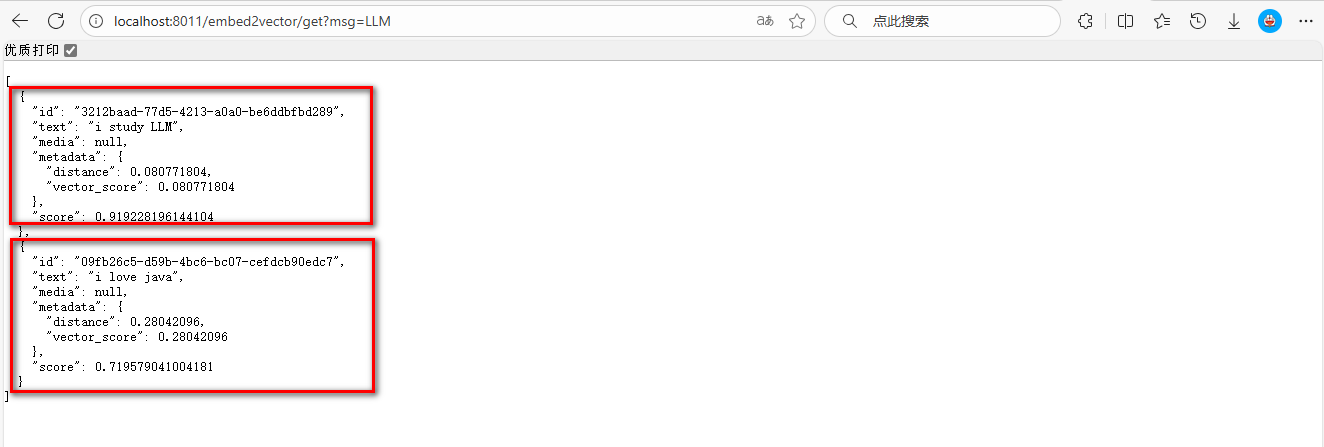
可以看到返回的数据根据给定的关键词LLM查找到了两条数据,其中score表示的是于关键词的相关度,亦即前文中提到的相似度。
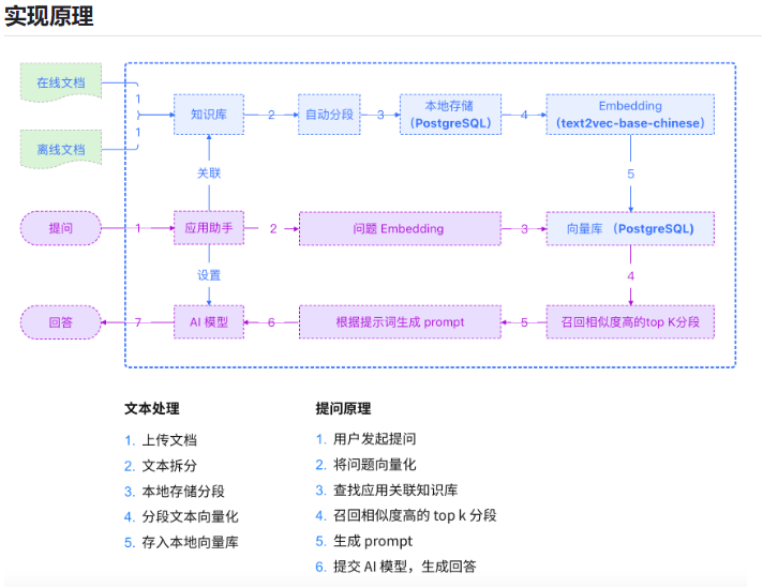
1.8 实现原理
2. RAG(Retrieval Augmented Generation)检索增强生成
2.1 LLM的缺陷
- LLM的知识不是实时的,不具备知识更新。
- LLM可能不知道你私有的领域/业务知识。
- LLM有时会在回答中生成看似合理但实际上是错误的信息。
LLM 的知识仅限于它所接受的训练数据。如果你想让一个 LLM 了解特定领域的知识或专有数据,可以采用:
- 使用 RAG
- 使用你的数据对 LLM 进行微调
- 将 RAG 和微调结合使用
2.2 定义
RAG(Retrieval Augmented Generation,检索增强生成)是一种结合信息检索和文本生成的技术范式。
简单来说,RAG(检索增强生成)是一种从你的数据中查找相关信息,并在将提示发送给LLM之前将其注入到提示中的方法。这样一来,LLM就能获得(希望是)相关的信息,并基于这些信息进行回答,从而降低产生幻觉的概率。
2.2.1 幻觉
- 已读乱回
- 已读不回
- 似是而非
2.3 核心设计理念
RAG技术就像给AI大模型装上了「实时百科大脑」,为了让大模型获取足够的上下文,以便获得更加广泛的信息源,通过先查资料后回答的机制,让AI摆脱传统模型的”知识遗忘和幻觉回复”困境。
2.4 四大核心步骤
2.4.1 文档切割 → 建立智能档案库
- 核心任务: 将海量文档转化为易检索的知识碎片
- 实现方式:
- 就像把厚重词典拆解成单词卡片
- 采用智能分块算法保持语义连贯性
- 给每个知识碎片打标签(如”技术规格”、“操作指南”)
关键价值:优质的知识切割如同图书馆分类系统,决定了后续检索效率
2.4.2 向量编码 → 构建语义地图
- 核心转换:
- 用AI模型将文字转化为数学向量
- 使语义相近的内容产生相似数学特征
- 数据存储:
- 所有向量存入专用数据库
- 建立快速检索索引(类似图书馆书目检索系统)
🎯 示例效果:“续航时间”和”电池容量”会被编码为相似向量
2.4.3 相似检索 → 智能资料猎人
应答触发流程:
- 将用户问题转为”问题向量”
- 通过多维度匹配策略搜索知识库:
- 语义相似度
- 关键词匹配度
- 时效性权重
- 输出指定个数最相关文档片段
2.4.4 生成增强 → 专业报告撰写
应答构建过程:
- 将检索结果作为指定参考资料
- AI生成时自动关联相关知识片段。
- 输出形式可以包含:
- 自然语言回答
- 附参考资料溯源路径
输出示例:
“根据《产品手册v2.3》第5章内容:该设备续航时间为…”
2.5 文档检索 (Document Retriever)
文档检索(DocumentRetriever)是一种信息检索技术,旨在从大量未结构化或半结构化文档中快速找到与特定查询相关的文档或信息。文档检索通常以在线(online)方式运行。
类似考试时有不懂的,给你准备了小抄,对大模型知识盲区的一种补充。
DocumentRetriever通常基于向量搜索。它将用户的查询问题(query)转化为Embeddings后,在存储文档中进行相似性搜索,返回相关的片段。片段的用途之一是作为提示词(prompt)的一部分,发送给大模型(LLM)汇总处理后,作为答案呈现给用户。
DocumentRetriever API提供了简单、灵活的方式,供开发者使用自定义的检索系统。
2.6 作用
通过引入外部知识源来增强LLM的输出能力,传统的LLM通常基于其训练数据生成响应,但这些数据可能过时或不够全面。RAG允许模型在生成答案之前,从特定的知识库中检索相关信息,从而提供更准确和上下文相关的回答。
2.7 流程
RAG 流程分为两个不同的阶段:索引和检索
2.7.1 索引
索引(Indexing):索引首先清理和提取各种格式的原始数据,如PDF、HTML、Word和
Markdown,然后将其转换为统一的纯文本格式。为了适应语言模型的上下文限制,文本被分割成更小的、可消化的块(chunk)。然后使用嵌入模型将块编码成向量表示,并存储在向量数据库中。这一步对于在随后的检索阶段实现高效的相似性搜索至关重要。知识库分割成chunks,并将chunks向量化至向量库中。

2.7.2 检索
检索(Retrieval):在收到用户查询(Query)后,RAG系统采用与索引阶段相同的编码模型将查询转换为向量表示,然后计算索引语料库中查询向量与块向量的相似性得分。该系统优先级和检索最高k(Top-k)块,显示最大的相似性查询。
检索阶段通常在线进行,此时用户提交的问题应使用索引文档来回答。
此过程可能因所使用的信息检索方法而异。对于向量搜索,这通常涉及嵌入用户的查询(question)以及在嵌入存储中执行相似性搜索。 然后将相关句段(原始文档的片段)注入到提示中并发送到LLM。
以下是检索阶段的简化图:
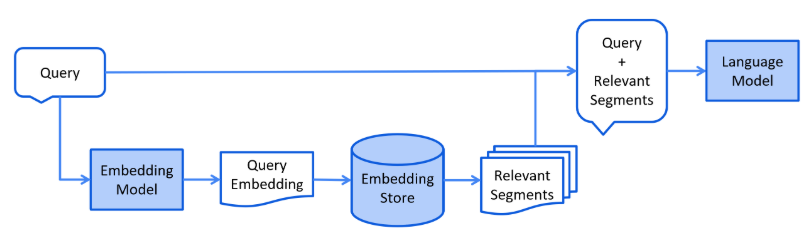
2.8 编码实战
需求:AI智能运维助手,通过提供的错误编码,给出异常解释辅助运维人员更好的定位问题和维护系统。
方案:SpringAI Alibaba + 阿里百炼嵌入模型text-embedding-v3 + 向量数据库 + RedisStack + DeepSeek 来实现RAG功能。
2.8.1 新建Module
可以命名为 RAG4AiOps
2.8.2 修改POM文件
在依赖配置节点修改为以下配置:
<dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><!--spring-ai-alibaba dashscope--><dependency><groupId>com.alibaba.cloud.ai</groupId><artifactId>spring-ai-alibaba-starter-dashscope</artifactId></dependency><!-- 添加 Redis 向量数据库依赖 --><dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-starter-vector-store-redis</artifactId></dependency><!--lombok--><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><version>1.18.38</version></dependency><!--hutool--><dependency><groupId>cn.hutool</groupId><artifactId>hutool-all</artifactId><version>5.8.22</version></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency></dependencies><build><plugins><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId></plugin><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><version>3.11.0</version><configuration><compilerArgs><arg>-parameters</arg></compilerArgs><source>21</source><target>21</target></configuration></plugin></plugins></build><repositories><repository><id>spring-milestones</id><name>Spring Milestones</name><url>https://repo.spring.io/milestone</url><snapshots><enabled>false</enabled></snapshots></repository></repositories>2.8.3 编写配置文件
在resources目录下新建application.properties配置文件,内容如下:
server.port=8012# 设置全局编码格式
server.servlet.encoding.enabled=true
server.servlet.encoding.force=true
server.servlet.encoding.charset=UTF-8spring.application.name=RAG4AiDatabase# ====SpringAIAlibaba Config=============
spring.ai.dashscope.api-key=${DASHSCOPE_API_KEY}
spring.ai.dashscope.chat.options.model=deepseek-r1
spring.ai.dashscope.embedding.options.model=text-embedding-v3# =======Redis Stack==========
spring.data.redis.host=localhost
spring.data.redis.port=6379
spring.data.redis.username=default
spring.data.redis.password=
spring.ai.vectorstore.redis.initialize-schema=true
spring.ai.vectorstore.redis.index-name=user-index
spring.ai.vectorstore.redis.prefix=user-prefix2.8.4 编写主启动类
新建主启动类,并编写如下内容:
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;@SpringBootApplication
public class Rag4AiOpsApplication {public static void main(String[] args) {SpringApplication.run(Rag4AiOpsApplication.class, args);}}2.4.5 编写配置类
新建子包config,并在其中新建配置类 SaaLLMConfig
package com.atguigu.study.config;import com.alibaba.cloud.ai.dashscope.api.DashScopeApi;
import com.alibaba.cloud.ai.dashscope.chat.DashScopeChatModel;
import com.alibaba.cloud.ai.dashscope.chat.DashScopeChatOptions;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.model.ChatModel;
import org.springframework.ai.chat.prompt.ChatOptions;
import org.springframework.ai.rag.advisor.RetrievalAugmentationAdvisor;
import org.springframework.ai.rag.retrieval.search.VectorStoreDocumentRetriever;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;/*** @Description ChatModel+ChatClient+多模型共存*/
@Configuration
public class SaaLLMConfig
{// 模型名称常量定义private final String DEEPSEEK_MODEL = "deepseek-v3";private final String QWEN_MODEL = "qwen-plus";@Bean(name = "deepseek")public ChatModel deepSeek(){return DashScopeChatModel.builder().dashScopeApi(DashScopeApi.builder().apiKey(System.getenv("DASHSCOPE_API_KEY")).build()).defaultOptions(DashScopeChatOptions.builder().withModel(DEEPSEEK_MODEL).build()).build();}@Bean(name = "qwen")public ChatModel qwen(){return DashScopeChatModel.builder().dashScopeApi(DashScopeApi.builder().apiKey(System.getenv("DASHSCOPE_API_KEY")).build()).defaultOptions(DashScopeChatOptions.builder().withModel(QWEN_MODEL).build()).build();}@Bean(name = "deepseekChatClient")public ChatClient deepseekChatClient(@Qualifier("deepseek") ChatModel deepSeek){return ChatClient.builder(deepSeek).defaultOptions(ChatOptions.builder().model(DEEPSEEK_MODEL).build()).build();}@Bean(name = "qwenChatClient")public ChatClient qwenChatClient(@Qualifier("qwen") ChatModel qwen){return ChatClient.builder(qwen).defaultOptions(ChatOptions.builder().model(QWEN_MODEL).build()).build();}
}新建配置类 RedisConfig
import lombok.extern.slf4j.Slf4j;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.redis.connection.RedisConnectionFactory;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.serializer.GenericJackson2JsonRedisSerializer;
import org.springframework.data.redis.serializer.StringRedisSerializer;@Configuration
@Slf4j
public class RedisConfig
{/*** RedisTemplate配置* redis序列化的工具配置类,下面这个请一定开启配置* 127.0.0.1:6379> keys ** 1) "ord:102" 序列化过* 2) "\xac\xed\x00\x05t\x00\aord:102" 野生,没有序列化过* this.redisTemplate.opsForValue(); //提供了操作string类型的所有方法* this.redisTemplate.opsForList(); // 提供了操作list类型的所有方法* this.redisTemplate.opsForSet(); //提供了操作set的所有方法* this.redisTemplate.opsForHash(); //提供了操作hash表的所有方法* this.redisTemplate.opsForZSet(); //提供了操作zset的所有方法* @param redisConnectionFactor* @return*/@Beanpublic RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory redisConnectionFactor){RedisTemplate<String,Object> redisTemplate = new RedisTemplate<>();redisTemplate.setConnectionFactory(redisConnectionFactor);//设置key序列化方式stringredisTemplate.setKeySerializer(new StringRedisSerializer());//设置value的序列化方式json,使用GenericJackson2JsonRedisSerializer替换默认序列化redisTemplate.setValueSerializer(new GenericJackson2JsonRedisSerializer());redisTemplate.setHashKeySerializer(new StringRedisSerializer());redisTemplate.setHashValueSerializer(new GenericJackson2JsonRedisSerializer());redisTemplate.afterPropertiesSet();return redisTemplate;}
}新建配置类 InitVectorDatabaseConfig
import cn.hutool.crypto.SecureUtil;
import jakarta.annotation.PostConstruct;
import org.springframework.ai.document.Document;
import org.springframework.ai.reader.TextReader;
import org.springframework.ai.transformer.splitter.TokenTextSplitter;
import org.springframework.ai.vectorstore.AbstractVectorStoreBuilder;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.io.Resource;
import org.springframework.data.redis.core.RedisTemplate;import java.io.IOException;
import java.io.StringReader;
import java.nio.charset.Charset;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.time.Duration;
import java.util.List;@Configuration
public class InitVectorDatabaseConfig
{@Autowiredprivate VectorStore vectorStore;@Autowiredprivate RedisTemplate<String,String> redisTemplate;@Value("classpath:ops.txt")private Resource opsFile;@PostConstructpublic void init(){//1 读取文件TextReader textReader = new TextReader(opsFile);textReader.setCharset(Charset.defaultCharset());//2 文件转换为向量(开启分词)List<Document> list = new TokenTextSplitter().transform(textReader.read());//3 写入向量数据库RedisStack//vectorStore.add(list);// 解决上面第3步,向量数据重复问题,使用redis setnx命令处理//4 去重复版本// 先读取原始文件内容byte[] rawBytes;try {rawBytes = Files.readAllBytes(Paths.get(opsFile.getURI()));} catch (IOException e) {throw new RuntimeException(e);}String content = new String(rawBytes, Charset.defaultCharset());String contentHash = SecureUtil.md5(content);// String sourceMetadata = (String)textReader.getCustomMetadata().get("source");
//
// String textHash = SecureUtil.md5(sourceMetadata);
// String redisKey = "vector-xxx:" + textHash;String redisKey = "vector-content:" + contentHash;// 判断是否存入过,redisKey如果可以成功插入表示以前没有过,可以加入向量数据
// Boolean retFlag = redisTemplate.opsForValue().setIfAbsent(redisKey, "1");Boolean retFlag = redisTemplate.opsForValue().setIfAbsent(redisKey, "1", Duration.ofDays(30));System.out.println("****retFlag : "+retFlag);if(Boolean.TRUE.equals(retFlag)){//键不存在,首次插入,可以保存进向量数据库vectorStore.add(list);}else {//键已存在,跳过或者报错//throw new RuntimeException("---重复操作");System.out.println("------向量初始化数据已经加载过,请不要重复操作");}}}2.4.6 编写业务类
新建子包controller,并在其中新建业务类 RagController
import jakarta.annotation.Resource;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.rag.advisor.RetrievalAugmentationAdvisor;
import org.springframework.ai.rag.retrieval.search.VectorStoreDocumentRetriever;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
import reactor.core.publisher.Flux;/*** @Description 知识出处:* https://docs.spring.io/spring-ai/reference/api/retrieval-augmented-generation.html#_advanced_rag*/
@RestController
public class RagController
{@Resource(name = "qwenChatClient")private ChatClient chatClient;@Resourceprivate VectorStore vectorStore;/*** http://localhost:8012/rag4aiops?msg=00000* http://localhost:8012/rag4aiops?msg=C2222* @param msg* @return*/@GetMapping("/rag4aiops")public Flux<String> rag(String msg){String systemInfo = """你是一个运维工程师,按照给出的编码给出对应故障解释,否则回复找不到信息。""";RetrievalAugmentationAdvisor advisor = RetrievalAugmentationAdvisor.builder().documentRetriever(VectorStoreDocumentRetriever.builder().vectorStore(vectorStore).build()).build();return chatClient.prompt().system(systemInfo).user(msg).advisors(advisor).stream().content();}
}2.4.7 新建数据文件
在resources目录下新建 ops.txt文件,并向文件写入如下实例内容
00000 系统OK正确执行后的返回
A0001 用户端错误一级宏观错误码
A0100 用户注册错误二级宏观错误码
B1111 支付接口超时
C2222 Kafka消息解压严重
D3333 数据库连接失错误
E4444 文件读取权限不足
F5555 网络请求失败2.4.8 测试
启动主启动类
首次启动后,可以在控制台看到如下输出:
****retFlag : true表示该文件是首次加载,同时会在redis stack中看到生成的类似于如下的key
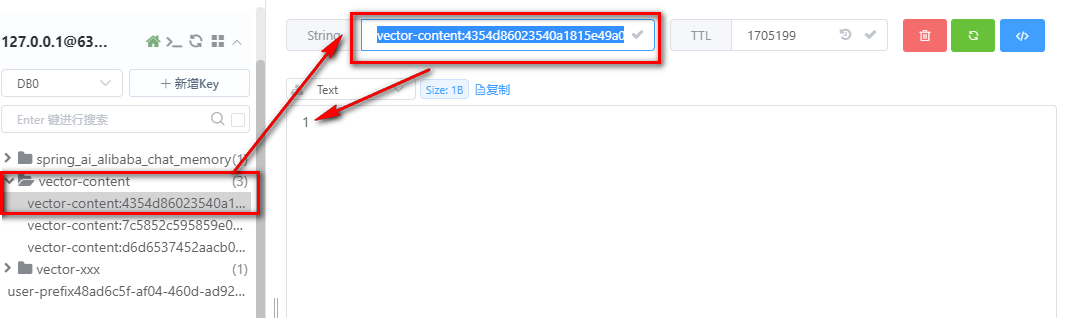
在浏览器中依次请求如下地址:
http://localhost:8012/rag4aiops?msg=00000

http://localhost:8012/rag4aiops?msg=C2222

http://localhost:8012/rag4aiops?msg=Q2333

并且,在 InitVectorDatabaseConfig 类中设置了对ops.txt文件内容的md5加密,使用RedisSetNX去重,以此来检测是否属于同一文件的重复加载行为。
Spring AI Alibaba 【六】-CSDN博客