【统计的思想】基于马尔科夫链的测试
在一般的迁移系统模型里,如果一个状态有多个出迁移,模型里体现不出哪个迁移发生概率大,哪个迁移发生概率小。比如在自助售货机的迁移系统模型里:
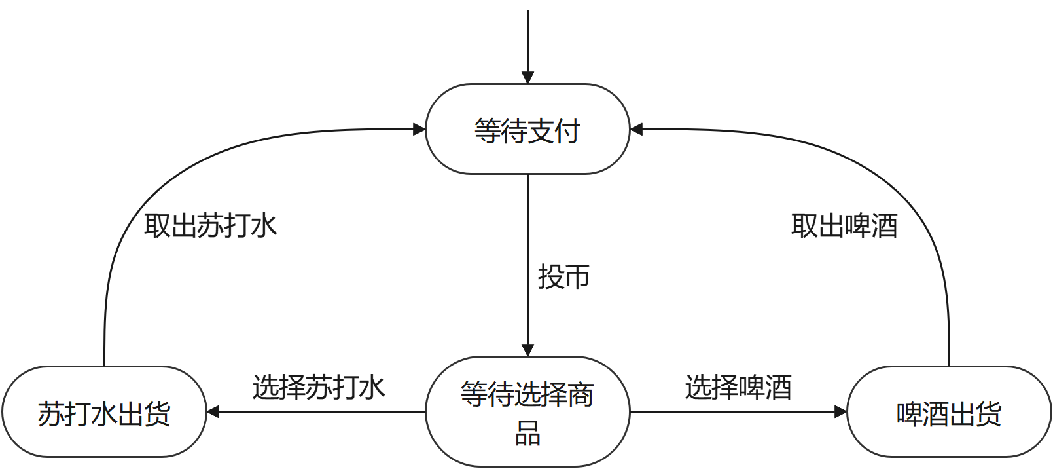
“等待选择商品”这个状态之后,用户有可能选择苏打水,也有可能选择啤酒,迁移系统模型不考虑这两种情况发生的可能性大小。
马尔科夫链在迁移系统的基础上引入了状态迁移概率,是一种典型的统计模型。在马尔科夫链里,节点表示状态,边表示状态迁移,边上标记了迁移的触发条件和发生概率。比如下面这个马尔科夫链模型:
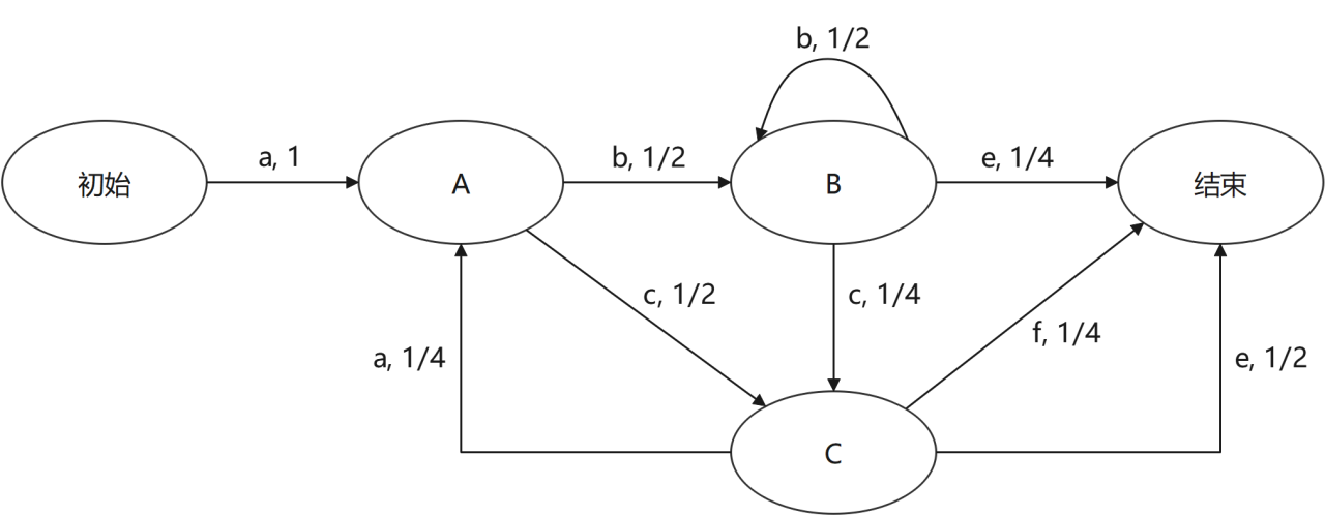
状态A有两个出迁移,输入b的时候会迁移到状态B,这个迁移的发生概率是1/2;输入c的时候会迁移到状态C,这个迁移的发生概率也是1/2。显然,任意一个状态,所有出迁移的发生概率之和为1。
假设系统从初始状态开始,先变成状态A,再变成状态C,最后变成结束状态,这样一整个过程,就是系统从初态到终态的一个状态转换事件,这个事件发生的概率,就是1×(1/2)×(1/4)=1/8。从马尔科夫链上,我们能看出被测对象可能发生哪些状态转换事件,这些事件的发生概率是多少。这跟事件分布列的作用是差不多的。
基于事件分布列的随机测试
所以,基于马尔科夫链的测试,也跟基于事件分布列的随机测试类似,经常用来评估系统的可靠性。具体实施的时候,关键的一点在于,要按照马尔科夫链里的迁移概率,来选择测试用例,构建测试集。比方说这样一个马尔科夫链:
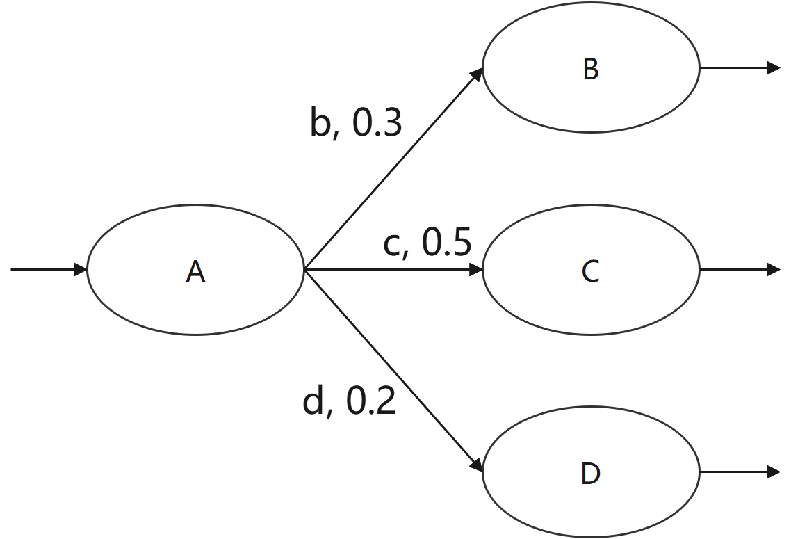
我们就会希望,测试集里覆盖A→B这个迁移的用例占30%,覆盖A→C的用例占50%,覆盖A→D的用例占20%。这样,测试的情况才能比较真实地反映系统实际使用情况。
怎么做到这一点呢?可以采用如下算法:
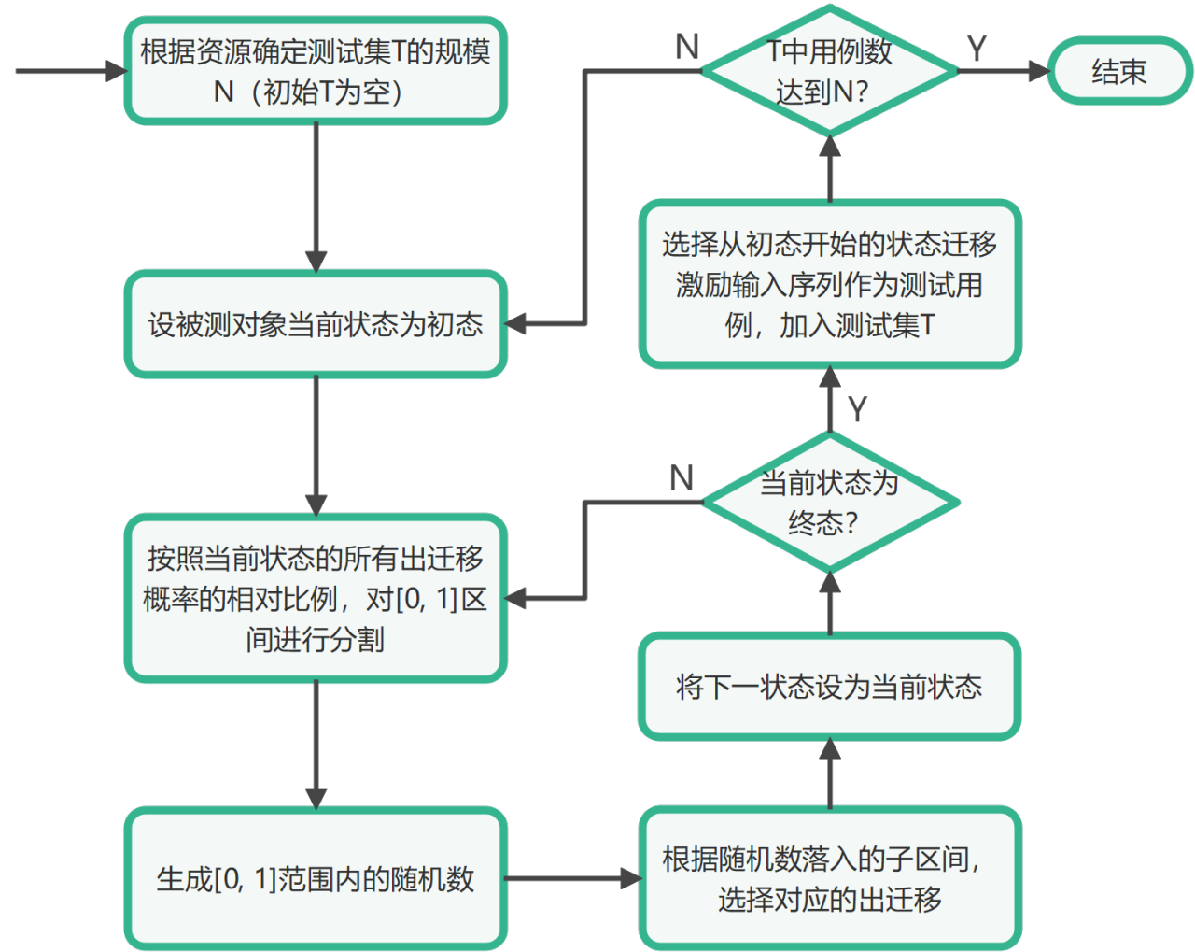
首先根据资源约束,确定测试集的规模,然后就是测试选择的过程,每一个用例都是让系统从初态开始,接受一系列测试输入,发生一系列状态迁移,最后达到终态。
假设系统现在处于状态A,接下来的测试输入可以是b、c或d。应该选哪一个呢?我们按照所有出迁移概率的相对比例,把[0,1]区间分割成这样三个部分:

然后生成一个[0,1]范围内的随机数,如果这个随机数落在[0.3, 0.8]这个范围内,接下来的输入就是c。这样,系统状态就有50%的可能会从A迁移到C。
每一个测试输入,都用这样的方法去选择,一直到终态为止,这样形成的输入序列,就是一个完整的用例。所有用例都按这样的方法来设计,最后就能保证,整个测试集里,每个迁移出现的频率,跟马尔科夫链里定义的概率是基本一致的。