为什么 MySQL utf8 存不下 Emoji?utf8mb4 实战演示
目录
- 一、MySQL utf8 与 utf8mb4 区别详解
- 1. utf8 与 utf8mb4 的区别
- 2. 常见字符及字节数示例
- 3. 实际测试案例
- 建表(utf8)
- 建表(utf8mb4)
- 4. 如何选择?
- 5. 总结
- 6. MySQL和PostgreSQL对比
一、MySQL utf8 与 utf8mb4 区别详解
在使用 MySQL 时,很多人会遇到 中文/Emoji 存储变成问号 (?) 的问题。表面看似是「编码问题」,实际上是因为 MySQL 的 utf8 并不是真正的 UTF-8,而是阉割版,只能存 3 字节字符。
如果要完整支持 Unicode,包括 emoji、冷僻汉字、少数民族文字、历史文字,就必须使用 utf8mb4。
1. utf8 与 utf8mb4 的区别
| 特性 | utf8 (MySQL) | utf8mb4 |
|---|---|---|
| 最大字节 | 3 字节 | 4 字节 |
| 支持范围 | 基本多文种平面 (BMP),常见汉字、英文、符号 | 全部 Unicode,包括 emoji、冷僻汉字、特殊符号 |
| 是否推荐 | ❌ 不推荐 | ✅ 推荐 |
| 出现问题 | 存 emoji 报错或变成 ? | 可正常存储 |
👉 mb4 = most bytes 4,代表最多可用 4 字节存储字符,才是真正的 UTF-8 实现。
2. 常见字符及字节数示例
| 字符 | Unicode 编码 | UTF-8 字节数 | 说明 |
|---|---|---|---|
A | U+0041 | 1 | 英文 |
中 | U+4E2D | 3 | 常用汉字 |
ༀ | U+0F00 | 3 | 藏文 |
😄 | U+1F604 | 4 | Emoji |
𠮷 | U+20BB7 | 4 | 冷僻汉字(扩展 B 区) |
𠀀 | U+20000 | 4 | 甲骨文(历史文字) |
3. 实际测试案例
建表(utf8)
CREATE TABLE utf8_test (id INT AUTO_INCREMENT PRIMARY KEY,char_test VARCHAR(10) CHARACTER SET utf8
);
插入数据:
INSERT INTO utf8_test (char_test) VALUES
('A'),
('中'),
('ༀ'),
('😄'),
('𠮷'),
('𠀀');
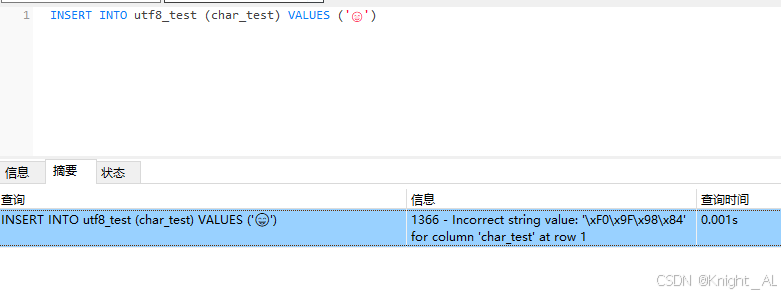
结果:前 3 个字符能正常显示,后 3 个会变成 问号 ? 或报错。
建表(utf8mb4)
CREATE TABLE utf8mb4_test (id INT AUTO_INCREMENT PRIMARY KEY,char_test VARCHAR(10) CHARACTER SET utf8mb4
);
插入同样数据:
INSERT INTO utf8mb4_test (char_test) VALUES
('A'),
('中'),
('ༀ'),
('😄'),
('𠮷'),
('𠀀');
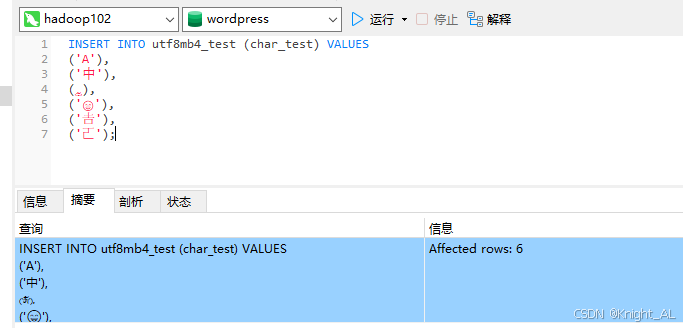
结果:所有字符都能正确显示 ✅。
4. 如何选择?
- 新项目:一律使用 utf8mb4(未来安全,不怕 emoji 报错)。
- 老项目:如需兼容 emoji,需要将数据库/表/字段从
utf8迁移到utf8mb4。
迁移方式:
ALTER DATABASE db_name CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci;
ALTER TABLE table_name CONVERT TO CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;
5. 总结
- MySQL 的
utf8并不是标准 UTF-8,只能存 3 字节字符。 utf8mb4才是完整 UTF-8,能存 emoji、冷僻汉字、历史文字。- 新系统建议直接使用
utf8mb4,避免未来存储字符时出现问号或报错。
6. MySQL和PostgreSQL对比
| 特性 | MySQL | PostgreSQL |
|---|---|---|
| 编码指定 | 数据库 / 表 / 字段都可以设 | 只能在数据库级别设 |
utf8 | 阉割版(3字节) ❌ | 真正 UTF-8(1~4字节) ✅ |
utf8mb4 | 真正 UTF-8(推荐) | 不需要(UTF8 就是完整的) |
| emoji 存储 | 需要 utf8mb4 | UTF8 直接支持 |
| 排序规则 | 内置 general_ci / unicode_ci 等 | 依赖操作系统 locale (LC_COLLATE) |