PySpark 窗口函数row_number、lag、lead的使用简述
本篇文章How PySpark Window Functions Helped Me Analyze Data 10x Faster适合数据科学新手学习如何利用PySpark的窗口函数进行高效数据分析。文章的亮点在于通过使用row_number、rank、lag和lead等函数,简化了复杂的数据聚合和比较操作,使得分析过程更清晰、可重复。
文章目录
- 1 引言
- 2 数据集背景
- 2 使用 `row_number()` 获取每位作者的 Top-N 图书
- 3 按平均评分对所有图书进行排名
- 4 使用 `lag()` 和 `lead()` 进行顺序比较
- 5 评分的累计总和
- 6 实际应用中的性能优势
- 7 结论

1 引言
作为一名数据科学家,我经常发现传统的聚合和连接在从大型数据集中提取细微洞察时显得力不从心。在我早期的 PySpark 经验中,我发现像排名、计算运行总计或比较连续行等任务往往需要多次连接或嵌套聚合,这既低效又繁琐。
探索 PySpark 的窗口函数提供了一个优雅的解决方案。像 row_number、rank、lag 和 lead 这样的函数让我可以在不重复重组或连接的情况下,对数据集进行分区、排序和计算指标。
本文将演示我如何使用窗口函数来加速对图书数据集的分析,包括:
- 检索每位作者评分最高的图书
- 计算随时间变化的累计评分
- 比较连续的出版指标
通过本文,您将了解如何优化 PySpark 工作流,同时保持其清晰和可复现。
2 数据集背景
为了说明这些技术,我使用了一个流行科学图书数据集,其中包含以下字段:书名、作者、出版年份、平均评分和总评分。
Jupyter Notebook 单元格:数据集创建
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, row_number, rank, lag, lead, sum
from pyspark.sql.window import Windowspark = SparkSession.builder \.appName("PySpark Window Functions for Data Science") \.getOrCreate()data = { "Title": [ "A Brief History of Time", "The Selfish Gene", "Sapiens", "Astrophysics for People in a Hurry", "Guns, Germs, and Steel", "The Gene", "Cosmos", "Homo Deus", "The Blind Watchmaker", "The Origin of Species" ], "Author": [ "Stephen Hawking", "Richard Dawkins", "Yuval Noah Harari", "Neil deGrasse Tyson", "Jared Diamond", "Siddhartha Mukherjee", "Carl Sagan", "Yuval Noah Harari", "Richard Dawkins", "Charles Darwin" ], "Year": [1988, 1976, 2011, 2017, 1997, 2016, 1980, 2015, 1986, 1859], "Avg_Rating": [4.21, 4.16, 4.34, 4.08, 4.02, 4.30, 4.36, 4.25, 4.15, 4.11], "Total_Ratings": [469860, 189857, 1215588, 201503, 285674, 100231, 285199, 301991, 75642, 200345]
}df = spark.createDataFrame( [tuple(x) for x in zip(*data.values())], schema=list(data.keys())
)
df.show()
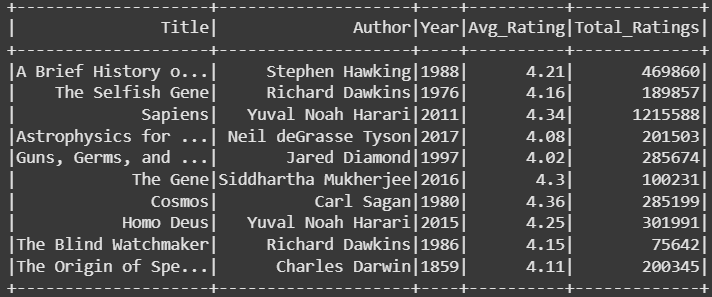
PySpark DataFrame 中的图书数据集,展示了书名、作者、出版年份、平均评分和总评分。(作者图片)
2 使用 row_number() 获取每位作者的 Top-N 图书
在我的工作中,我经常执行的第一个分析任务是识别每个类别中评分最高或评论最多的图书;在本例中,是每位作者。使用 row_number() 在窗口分区上可以让我高效地实现这一点。
window_spec = Window.partitionBy("Author").orderBy(col("Total_Ratings").desc())df_top_n = df.withColumn("row_num", row_number().over(window_spec))df_top_n.filter(col("row_num") == 1).show()
输出:
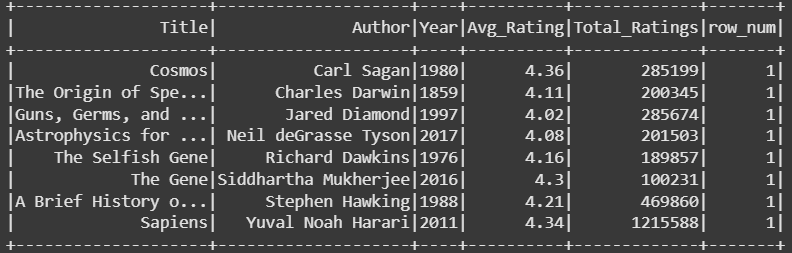
使用 row_number() 窗口函数计算的每位作者评分最高的图书。
3 按平均评分对所有图书进行排名
为了全局比较图书,我使用 rank() 函数。与 row_number() 不同,rank() 会考虑并列情况,这在多本图书具有相同评分时至关重要。
window_spec_rank = Window.orderBy(col("Avg_Rating").desc())df_ranked = df.withColumn("Rank", rank().over(window_spec_rank))
df_ranked.show()
输出:
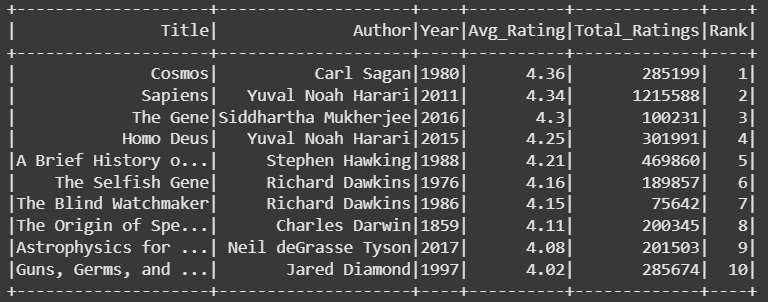
使用 rank() 函数按所有作者的平均评分对图书进行排名。
4 使用 lag() 和 lead() 进行顺序比较
我经常需要观察随时间变化的趋势。lag() 和 lead() 函数允许我将一本书的评分与前一年或后一年的出版物进行比较:
window_spec_seq = Window.orderBy("Year")df_seq = df.withColumn("Prev_Rating", lag("Avg_Rating").over(window_spec_seq)) \.withColumn("Next_Rating", lead("Avg_Rating").over(window_spec_seq))
df_seq.show()
输出:
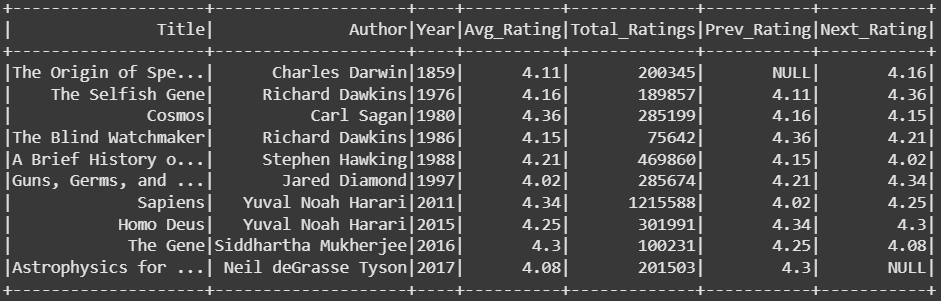
使用 lag() 和 lead() 函数对多年平均评分进行顺序分析。
5 评分的累计总和
对于累计分析,例如随时间变化的累计总评分,窗口函数消除了对重复连接或复杂聚合的需求:
window_spec_cumsum = Window.orderBy("Year")df_running_total = df.withColumn( "Cumulative_Ratings", sum("Total_Ratings").over(window_spec_cumsum)
)
df_running_total.show()
输出:
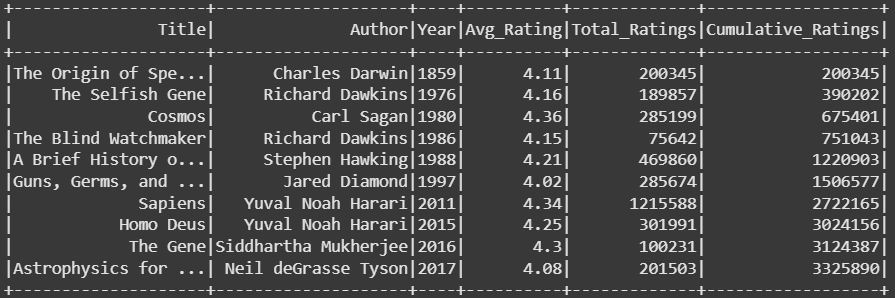
使用基于窗口的运行总计计算的随时间变化的累计总评分。
6 实际应用中的性能优势
根据我的经验,与标准的连接-聚合工作流相比,窗口函数显著减少了所需的计算量。它们最大限度地减少了数据混洗并允许分区级别的计算。对于大型数据集,这种差异转化为显著的运行时节省和更易于维护的代码。
7 结论
作为一名数据科学家,我发现 PySpark 窗口函数对于高级分析来说是不可或缺的。通过利用 row_number、rank、lag、lead 和累计函数,我可以高效地计算 Top-N 项、跟踪趋势以及对大型数据集进行顺序比较。这些技术不仅简化了代码,还加速了分析工作流,让我能够专注于生成可操作的洞察,而不是管理复杂的查询逻辑。