【CVPR2025】计算机视觉|AnomalyNCD:让工业异常分类“脱胎换骨”!

论文地址:https://arxiv.org/pdf/2410.14379
代码地址:https://github.com/HUST-SLOW/AnomalyNCD
关注UP CV缝合怪,分享最计算机视觉新即插即用模块,并提供配套的论文资料与代码。
https://space.bilibili.com/473764881
摘要
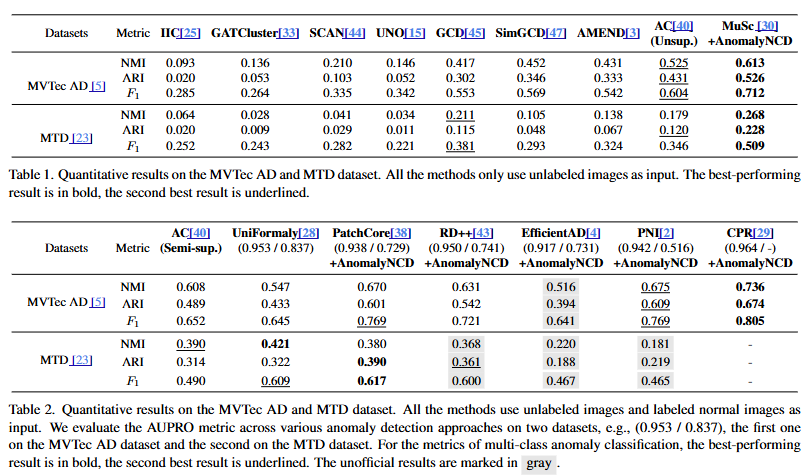
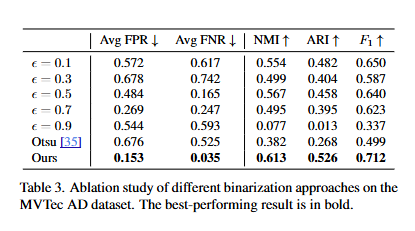
近年来,多类别异常分类越来越受到关注。以前的方法直接对异常进行聚类,但由于缺乏异常先验知识,往往难以奏效。获取这些知识面临两个问题:非显著异常和弱语义异常。本研究提出了一种名为 AnomalyNCD 的多类别异常分类网络,它与不同的异常检测方法兼容。为了解决异常的非显著性问题,本研究设计了主要元素二值化(MEBin)方法来获取以异常为中心的图像,确保在学习异常的同时避免错误检测的影响。接下来,为了学习弱语义的异常,本研究设计了掩码引导的表征学习方法,该方法侧重于由掩码引导的孤立异常,并通过校正后的伪标签减少来自错误输入的混淆。最后,为了实现区域和图像级别的灵活分类,本研究开发了一种区域合并策略,根据分类的异常区域确定整体图像类别。本研究的方法在 MVTec AD 和 MTD 数据集上的性能优于最先进的方法。与现有方法相比,AnomalyNCD 与零样本异常检测方法相结合,在 MVTec AD 上实现了 10.8% 的 F1 增益、8.8% 的 NMI 增益和 9.5% 的 ARI 增益,在 MTD 上实现了 12.8% 的 F1 增益、5.7% 的 NMI 增益和 10.8% 的 ARI 增益。
引言
本研究致力于解决工业场景中多类别异常分类的难题,特别是对未曾见过的新异常类别进行识别和归类。 当前的工业异常检测技术虽然在定位异常方面取得了显著进展,但通常缺乏对异常类型的细粒度识别能力,这对于后续的异常处理至关重要。现有的异常聚类方法尝试通过定位异常区域并提取特征进行聚类来识别异常类别。然而,由于缺乏对异常类型的先验知识,这些方法在处理外观、形状和位置各异的同质异常模式时效果有限。本研究旨在利用已知异常的先验知识对未知异常进行分类,从而克服现有方法的局限性。
本研究深入探讨了利用已知异常先验知识所面临的两大主要障碍:异常的非显著性和低语义性。 与自然场景中的图像分类不同,工业场景中的异常通常不会位于图像中心,这使得网络难以提取其语义特征。此外,工业异常通常比自然物体具有更弱的语义信息,导致网络难以集中关注于异常本身,而更容易受到背景信息的干扰。这两种特性使得直接套用自然场景下的图像分类或新类别发现方法难以奏效。
为了克服这些挑战,本研究提出了一种名为 AnomalyNCD 的多类别异常分类网络,它与新类别发现(NCD)的概念相符。该网络通过将模型的注意力集中在真实的异常区域来学习对孤立异常进行分类。为了解决异常的非显著性问题,本研究提出了一种主要元素二值化(MEBin)方法。MEBin 通过从异常检测(AD)结果中提取主要异常区域,并将这些区域从原始图像中分离出来。这个二值化过程减轻了异常检测结果中错误检测对后续多类别异常学习的负面影响,并使得 AnomalyNCD 能够与不同的异常检测算法兼容。
为了解决异常的低语义性问题,本研究设计了一种掩码引导的表征学习方法。该方法利用 MEBin 生成的异常掩码将网络的注意力引导到单个异常区域,确保网络学习到更具区分性的异常特定特征,并对每个单独的异常进行分类。此外,本研究还在这种学习方法中使用了修正的伪标签,以防止训练过程中受到假阳性异常的影响。最后,为了在区域和图像级别实现更灵活的分类,本研究提出了一种区域合并策略,该策略根据图像中每个区域的分类结果来确定图像的整体类别。在 MVTec AD 和 MTD 数据集上的实验结果证明了 AnomalyNCD 的有效性,其性能优于现有的异常聚类方法和自然场景下的 NCD 方法。
论文创新点
✨ AnomalyNCD:一种新型多类别异常分类方法 ✨
本研究提出了一种名为 AnomalyNCD 的新型多类别异常分类方法,该方法能够与现有的异常检测方法兼容,以发现并识别工业异常的视觉类别。 其核心优势在于能够将检测到的未见异常分类到同质组中,极大提升了工业异常识别的效率和准确性。
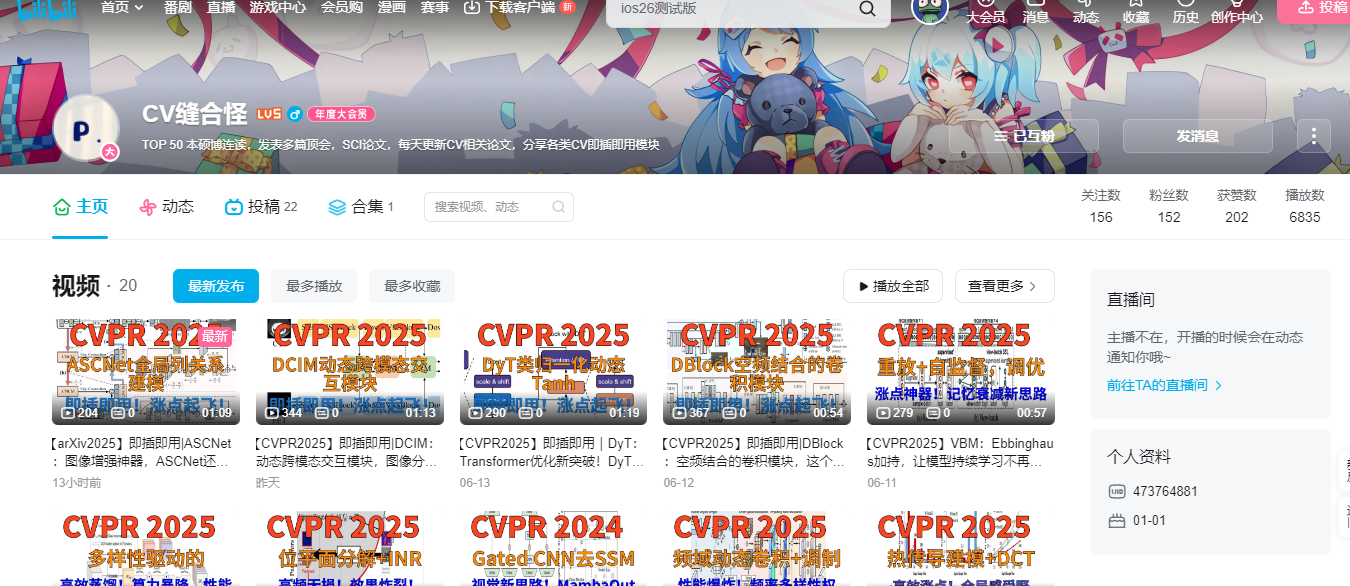
1. ⚙️ 主要元素二值化(MEBin):自适应阈值,精准定位 ⚙️
- 目标: 从异常检测结果中分离出主要的异常结构。
- 方法: 通过从小阈值变化中提取稳定的区域。
- 优势:
- 减轻了异常检测结果中错误对后续多类别异常学习的负面影响。
- 确保了与各种异常检测算法的兼容性。
- 相比传统方法,MEBin 能自适应地为每张图像确定最佳阈值,减少误报和漏报,尤其是在正常图像上。
2. 🧭 掩码引导的表征学习:聚焦异常区域,提取细粒度特征 🧭
- 目标: 学习特定于异常的更具辨别力的特征。
- 方法: 利用 MEBin 生成的异常掩码,将网络的注意力引导到单个异常区域。
- 优势:
- 确保网络能够对每个单独的异常进行分类。
- 使用修正的伪标签,以防止训练中包含假阳性异常。
- 更好地关注图像中的局部异常,学习更细粒度的特征,从而提高分类性能。
3. 🧩 区域合并策略:灵活分类,结果更稳健 🧩
- 目标: 实现更灵活的子图像和图像级别分类。
- 方法: 根据图像中每个区域的分类结果来确定图像的异常类别。
- 优势:
- 相比简单平均子图像预测或使用异常分数作为权重,本研究的区域合并方法根据面积为多个子图像预测分配权重。
- 获得更稳健的合并预测,并有效地减少了过度检测区域对图像分类的误导。
4. 🏆 实验结果:性能优越,显著优势 🏆
- 数据集: MVTec AD 和 MTD 数据集
- 结果: 性能优于现有的工业异常聚类方法和自然场景中的 NCD 方法。
- 总结: AnomalyNCD 的自适应二值化方法、关注局部异常的表征学习以及鲁棒的区域合并策略,使其在多类别异常分类任务中具有显著优势,即使 AnomalyNCD 的性能通常受异常检测方法质量的影响。
论文实验