python:讲懂决策树,为理解随机森林算法做准备,以示例带学习,通俗易懂,容易理解和掌握
为什么要讲和学习决策树呢?主要是决策树(包括随机森林算法)不需要数据的预处理。现实世界的数据往往“脏乱差”,决策树让你在数据准备上可以少花很多功夫,快速上手,用起来非常的“省心”。总之,决策树是机器学习领域里最直观易懂、解释性最强、应用最广泛的基础模型之一,学会它,你就掌握了一把打开预测分析大门、理解更高级模型的金钥匙。
下面开始我们的学习吧。
目录
一、什么是决策树
二、具体程序与不同参数运行效果对比
三、小结与建议
一、什么是决策树
决策树是一种在分类与回归中都有非常广泛应用的算法。它的原理是通过对一系列问题进行if/else 的推导,最终实现决策。学过C语言的知道,if/else使用来做判断的,决策树就是对样本数据特征做一些列的判断来实现决策的。
举个例子: 假设要识别斯嘉丽· 约翰逊、泰勒斯威夫特、吴彦祖、威尔·史密斯4 个人中的一个,则决策树的判断流程为:
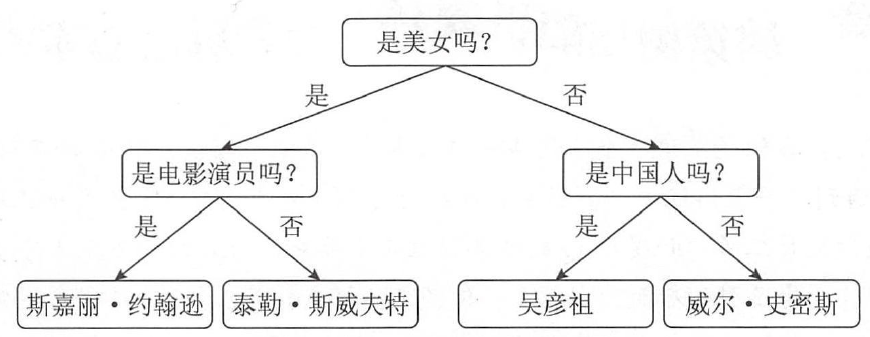
上图中最终的4 个节点,也就是4 个人物的名字,被称为决策树的树叶。例子中的这棵决策树只有4 片树叶,所以通过手动的方式就可以进行建模。但是如果样本的特征特别多, 就不得不使用机器学习的办法来进行建模了。
重点来了,决策树你可以理解为一些列(很多)的if/else判断被打包的一个算法。
我们再给某一个python决策树算法程序的实际决策过程,如下图。是不是决策树实际运行中就是一步步做判断的啊,大家理解了吧。
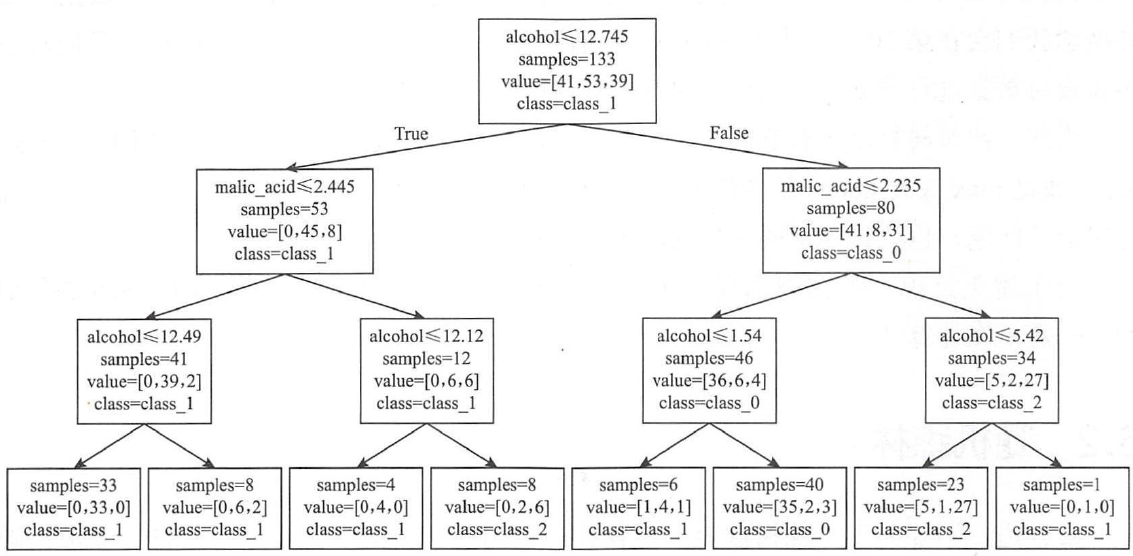
决策树算法运行实际分类过程样例
二、具体程序与不同参数运行效果对比
该程序使用鸢尾花数据集(包含150个样本的4种特征),通过决策树算法根据花萼/花瓣的尺寸特征预测鸢尾花品种(山鸢尾、变色鸢尾、维吉尼亚鸢尾)。程序比较了不同max_depth参数值(1/2/3/无限制)对模型复杂度、准确率和可解释性的影响。
max_depth参数是决策树的重要参数,它是决策树的深度,它的值越大,代表决策树判断的层级越多,的深度越深。
下面是python决策树的具体源程序,运行效果在程序的下面,效果里面展示了不同决策树的判断流程及效果。大家可以更直观的看不同max_depth参数值下的决策过程。
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier, plot_tree
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import matplotlib.pyplot as plt# 加载鸢尾花数据集
iris = load_iris()
X, y = iris.data, iris.target
feature_names = iris.feature_names
class_names = iris.target_names# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# 测试不同max_depth值
depth_values = [1, 2, 3, None] # None表示不限制深度
results = {}for depth in depth_values:# 创建决策树模型tree_model = DecisionTreeClassifier(max_depth=depth, random_state=42)# 训练模型tree_model.fit(X_train, y_train)# 预测并评估y_pred = tree_model.predict(X_test)accuracy = accuracy_score(y_test, y_pred)# 存储结果results[depth] = {'model': tree_model,'accuracy': accuracy,'n_nodes': tree_model.tree_.node_count}# 可视化决策树plt.figure(figsize=(12, 8))plot_tree(tree_model, feature_names=feature_names,class_names=class_names,filled=True, rounded=True)plt.title(f"Decision Tree (max_depth={depth}, Accuracy={accuracy:.2f})")plt.show()# 打印结果比较
print("深度 vs 准确率 vs 节点数:")
for depth, data in results.items():print(f"max_depth={depth}: 准确率={data['accuracy']:.4f}, 节点数={data['n_nodes']}")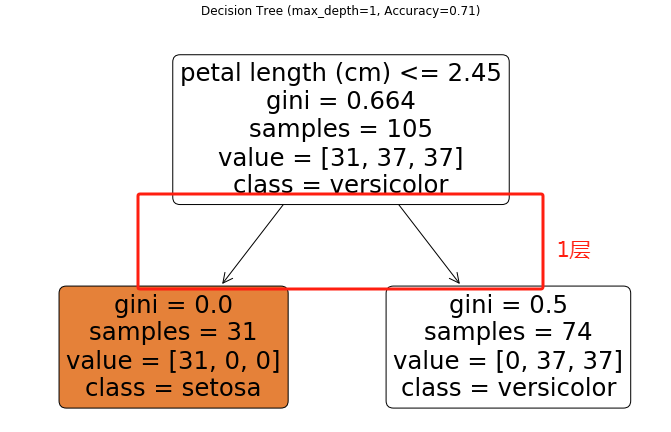
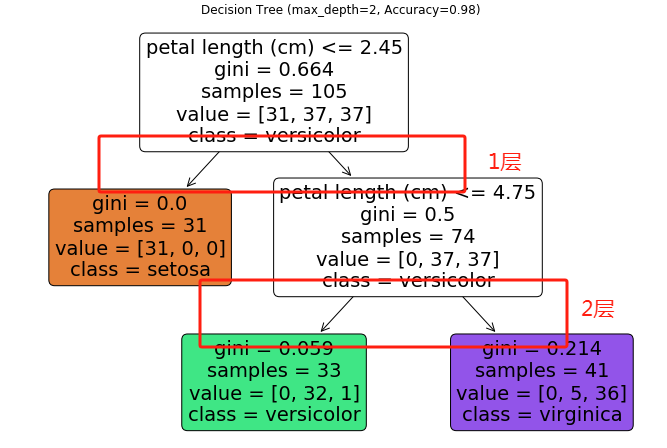
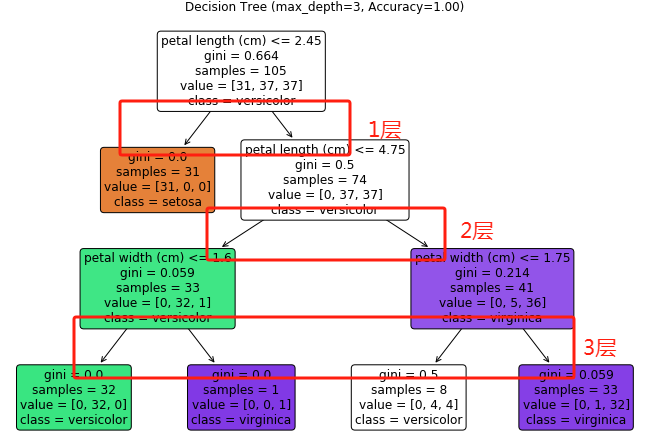
程序的运行效果如下:

通过运行效果,我们可以看出,max_depth参数的值越大,深度越深,准确率越高,但是要避免过拟合。
三、小结与建议
-
深度与复杂度:深度增加会提升模型复杂度(节点数增加),但过深会导致过拟合
-
准确率曲线:本例中深度3达到最佳平衡(98%准确率),继续加深不提升精度
-
实践建议:
-
从深度3-5开始调试
-
使用交叉验证选择最优深度
-
配合
min_samples_split/min_samples_leaf防过拟合 -
高深度树可考虑转换为随机森林
-
-
业务场景:
-
需要解释性:选择深度≤3
-
追求精度:尝试深度5-8
-
医疗/金融领域:优先选择深度≤4的可解释模型
-
以上就是本文的内容, 希望大家能够有收获。
请大家点赞、收藏和加关注吧。