【AI论文】VL-Cogito:面向高级多模态推理的渐进式课程强化学习
摘要:强化学习已证明其在提升大型语言模型推理能力方面的有效性。近期研究逐步将这一范式拓展至多模态推理任务。然而,由于多模态任务在语义内容和问题设定上具有内在复杂性与多样性,现有模型在不同领域和难度层次上常表现出性能不稳定的问题。为解决这些局限,我们提出VL-Cogito——一种基于新型多阶段渐进式课程强化学习(PCuRL)框架训练的高级多模态推理模型。PCuRL通过系统引导模型逐步攻克难度递增的任务,显著提升其在多样化多模态场景下的推理能力。该框架引入两项关键创新:(1)在线难度软加权机制,可在连续强化学习训练阶段动态调整训练难度;(2)动态长度奖励机制,鼓励模型根据任务复杂度自适应调节推理路径长度,从而平衡推理效率与准确性。实验评估表明,在涵盖数学、科学、逻辑及通用理解能力的主流多模态基准测试中,VL-Cogito始终达到或超越现有推理导向型模型的表现,验证了本方法的有效性。Huggingface链接:Paper page,论文链接:2507.22607
研究背景和目的
研究背景:
近年来,强化学习(Reinforcement Learning, RL)在提升大型语言模型(Large Language Models, LLMs)的推理能力方面取得了显著成效。特别是在代码生成、数学问题解决和科学推理等复杂任务中,基于可验证奖励的强化学习(RL with Verifiable Rewards, RLVR),如GRPO(Group Relative Policy Optimization)方法,通过利用基于规则的奖励机制,促进了多推理路径的生成和迭代优化,显著提高了LLMs解决复杂推理任务的能力。然而,随着研究从单模态语言模型扩展到多模态大语言模型(Multimodal Large Language Models, MLLMs),新的挑战随之而来。
多模态任务在语义内容和问题设定上具有高度的复杂性和多样性,导致现有模型在不同领域和难度层次上常表现出性能不稳定的问题。例如,在图表解读、复杂几何问题和科学分析等领域,由于任务类型的异质性,模型在跨领域推理时面临显著困难。传统的强化学习方法在处理这些多模态任务时,往往难以在不同难度和类型的任务间实现稳定的性能提升。因此,如何设计一种能够有效适应多模态任务复杂性和多样性的强化学习框架,成为当前研究的重要课题。
研究目的:
本研究旨在提出一种新型的强化学习框架,以解决现有模型在处理多模态推理任务时面临的性能不稳定问题。具体而言,研究目的包括:
- 提升多模态推理能力:通过设计一种能够适应不同难度和类型多模态任务的强化学习框架,提升模型在复杂多模态环境中的推理能力。
- 稳定模型性能:解决现有模型在不同领域和难度层次上性能不稳定的问题,确保模型在各种多模态任务中都能保持稳定的推理性能。
- 优化推理效率与准确性:通过引入动态调整机制,平衡推理效率与准确性,使模型能够根据任务复杂度自适应调节推理路径长度。
研究方法
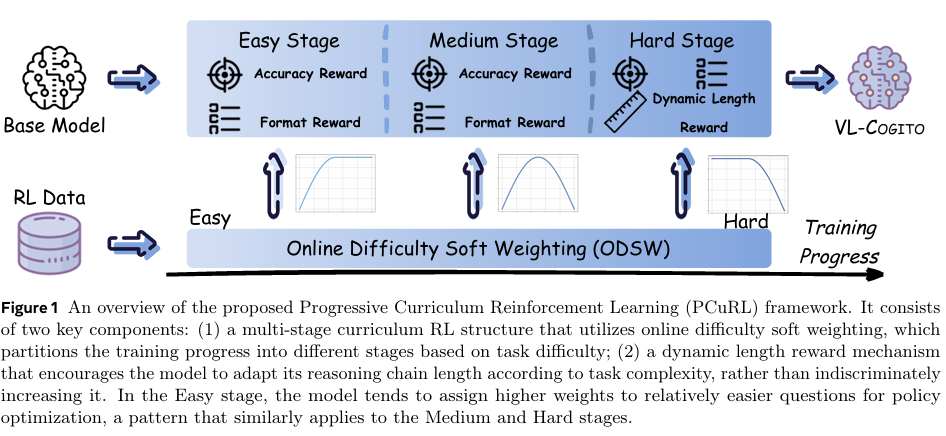
为实现上述研究目的,本研究提出了VL-Cogito模型,并设计了一种基于多阶段渐进式课程强化学习(Progressive Curriculum Reinforcement Learning, PCuRL)框架的训练方法。具体研究方法如下:
- 数据收集与预处理:
- 收集了涵盖数学、逻辑推理、计数、科学推理、图表理解和通用图像理解等六大类任务的23个多模态数据集。
- 对数据集进行筛选和预处理,将大多数样本 reformulate 为开放式的问答格式,以避免模型依赖特定答案格式的浅层线索。
- 采用基于难度的采样方法,剔除那些通过Qwen2.5-VL-7B-Instruct模型在8次试验中准确率超过50%的问题,以增强训练样本的难度和覆盖范围。
- PCuRL框架设计:
- 多阶段渐进式课程学习:将训练过程分为简单、中等和困难三个阶段,每个阶段采用不同的难度加权机制,逐步引导模型攻克难度递增的任务。
- 在线难度软加权机制(ODSW):根据每个问题的滚动准确率动态调整其权重,使模型在训练过程中能够聚焦于适当难度的任务,从而实现平稳的训练过渡。
- 动态长度奖励机制(DyLR):根据任务复杂度自适应调节推理路径长度,鼓励模型在复杂任务上生成更长的推理路径,在简单任务上保持简洁。通过定义目标推理长度,并根据模型生成的响应长度与目标长度的差异给予奖励或惩罚。
- 模型训练与优化:
- 使用Qwen2.5-VL-Instruct-7B作为骨干模型,采用AdamW优化器进行训练。
- 在每个训练阶段,根据验证性能选择最优检查点作为下一阶段的起点。
- 引入KL散度损失系数和响应采样温度等超参数,以控制策略更新的幅度和响应的多样性。
研究结果
通过一系列实验评估,本研究验证了VL-Cogito模型和PCuRL框架的有效性。主要研究结果如下:
- 性能提升:
- 在涵盖数学、科学、逻辑和通用理解能力的主流多模态基准测试中,VL-Cogito模型始终达到或超越现有推理导向型模型的表现。具体而言,VL-Cogito在Geometry@3K、MathVista和LogicVista等数学基准测试中,绝对增益分别达到7.6%、5.5%和4.9%;在ScienceQA、EMMA和MMStar等科学和通用理解基准测试中,也有显著提升。
- 稳定性增强:
- PCuRL框架通过渐进式课程学习策略,有效解决了模型在不同领域和难度层次上性能不稳定的问题。实验结果表明,随着训练难度的逐步增加,模型的验证准确率持续提高,且未出现显著的性能波动。
- 推理效率与准确性的平衡:
- 动态长度奖励机制使模型能够根据任务复杂度自适应调节推理路径长度。在简单任务上,模型保持简洁的推理路径;在复杂任务上,模型生成更长的推理路径以提高准确性。这种自适应调节机制有效平衡了推理效率与准确性。
研究局限
尽管本研究在提升多模态推理能力方面取得了显著成效,但仍存在以下局限:
- 数据依赖性:
- 模型性能高度依赖于训练数据的质量和覆盖范围。尽管本研究收集了涵盖多个领域的多模态数据集,但仍可能存在某些特定领域或任务类型的数据缺失问题。
- 计算资源需求:
- PCuRL框架需要分阶段进行模型训练,且每个阶段都需要大量的计算资源。特别是困难阶段的动态长度奖励机制,需要更长的训练时间和更多的计算资源来优化模型性能。
- 超参数调整:
- PCuRL框架涉及多个超参数(如在线难度软加权机制中的权重计算函数、动态长度奖励机制中的目标长度和奖励系数等),这些超参数的调整对模型性能有显著影响。目前,这些超参数主要依赖于经验调整,缺乏系统的优化方法。
未来研究方向
针对上述研究局限,未来研究可以从以下几个方面展开:
- 扩展数据集:
- 进一步收集和整理涵盖更多领域和任务类型的多模态数据集,特别是那些目前数据缺失的领域。同时,探索数据增强和合成技术,以增加训练数据的多样性和覆盖范围。
- 优化计算资源利用:
- 研究更高效的模型训练和优化算法,以减少计算资源的需求。例如,可以采用模型并行化、分布式训练和混合精度训练等技术来加速模型训练过程。
- 自动化超参数优化:
- 探索自动化超参数优化方法,如贝叶斯优化、强化学习优化等,以减少人工调整超参数的工作量,并提高模型性能的稳定性。
- 跨模态交互与融合:
- 深入研究跨模态交互与融合机制,以进一步提升模型在多模态推理任务中的性能。例如,可以探索更有效的注意力机制、图神经网络和Transformer架构等,以增强模型对不同模态信息的理解和利用能力。
- 可解释性与鲁棒性:
- 加强模型的可解释性和鲁棒性研究。通过可视化技术、注意力机制分析和错误分析等方法,深入理解模型的推理过程,并探索提高模型鲁棒性的方法,以应对实际应用中的各种挑战。