ElasticSearch:商品SKU+SPU实现join查询,设计及优化
文章目录
一、SPU+SKU
1、商品SPU和SKU
每个店铺中会包含多个商品,每个商品会有多个规格。
红框上面的部分是商品的SPU(Standard Product Unit 标准产品单位),SPU是商品信息聚合的最小单位,是一组可复用、易检索的标准化信息的集合,该集合描述了一个产品的特性。这里会选择对应店铺的名称,填入商品编号、商品名称、上架状态、定时上架时间、商品标签、商品图片等信息。
下面红色的框体是商品的SKU(stock keeping unit 库存量单位),SKU即库存进出计量的单位, 可以是以件、盒、托盘等为单位,SKU是物理上不可分割的最小存货单元。包括商品颜色、商品存储容量、商品价格、商品剩余数量。
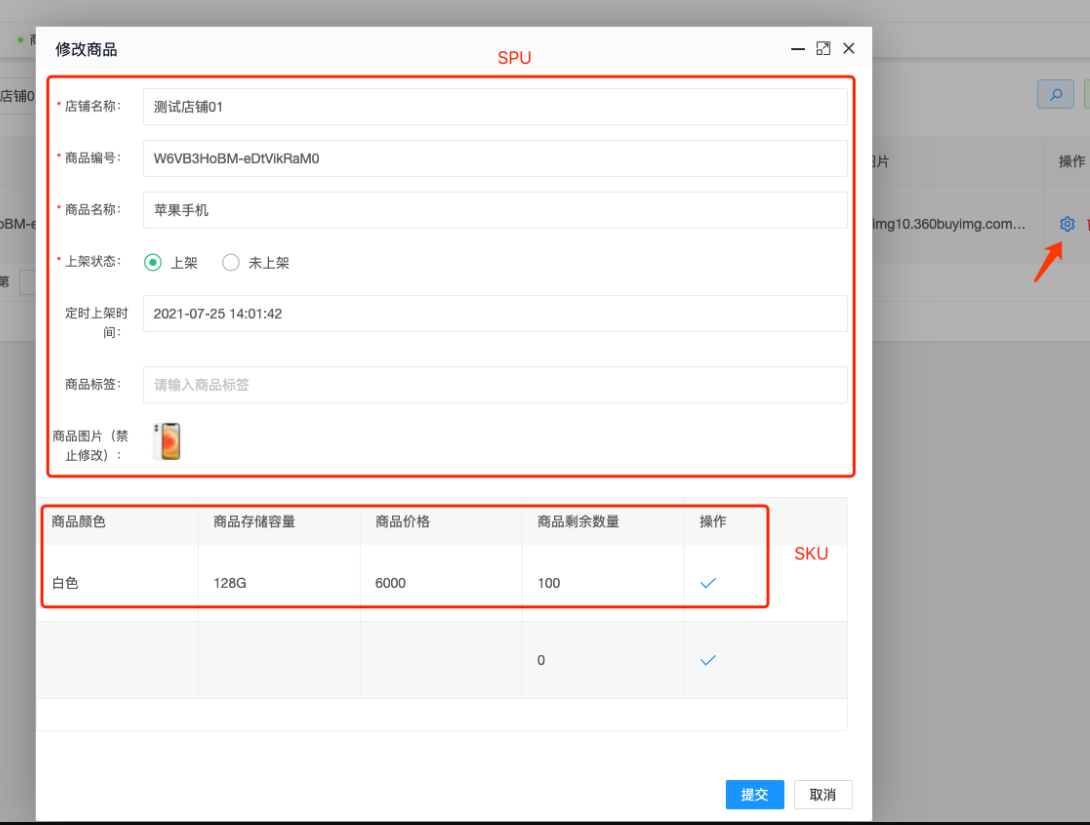
2、SPU和SKU的关系
如图所示,一个店铺会对应多个商品的SPU。同时一个商品的SPU会包含多个商品SKU,以手机为例,一款iPhone12手机就是SPU,如果消费者需要购买该手机的时候,还需要选择手机颜色、内存容量,在商家这边还要查看商品的库存是否足够。因此,一个商品SPU会对
应多个商品SKU的描述。

如果我们建立数据库表的时候会将店铺、商品SPU和商品SKU建立三张表,通过主外键的关系关联。
如果mysql的数据同步到ES中,用户进行搜索的时候,应该怎么实现呢?
在 Elasticsearch(ES)中实现关联查询(join)的方式与传统关系型数据库不同,因为 ES 是分布式搜索引擎,其设计初衷并非处理复杂关联。以下是几种常见的 ES 关联实现方法:
3、实现SPU+SKU父子嵌套查询
1. 嵌套对象(Nested Objects)
场景:SPU 与 SKU 强关联,查询时需同时检索。
示例:一款手机(SPU)有多个颜色和配置(SKU)。
映射与数据:
PUT /products
{"mappings": {"properties": {"spu_id": {"type": "keyword"},"spu_name": {"type": "text"},"brand": {"type": "keyword"},"skus": {"type": "nested", // 嵌套类型"properties": {"sku_id": {"type": "keyword"},"color": {"type": "keyword"},"size": {"type": "keyword"},"price": {"type": "double"},"stock": {"type": "integer"}}}}}
}PUT /products/_doc/1
{"spu_id": "SPU001","spu_name": "苹果 iPhone 14","brand": "Apple","skus": [{"sku_id": "SKU001","color": "黑色","size": "128GB","price": 5999.00,"stock": 100},{"sku_id": "SKU002","color": "蓝色","size": "256GB","price": 6799.00,"stock": 50}]
}
查询示例:
- 需求:查找所有品牌为 Apple 且有蓝色 256GB 的手机。
- 实现:
{"query": {"bool": {"must": [{"term": {"brand": "Apple"}},{"nested": { // 嵌套查询"path": "skus","query": {"bool": {"must": [{"term": {"skus.color": "蓝色"}},{"term": {"skus.size": "256GB"}}]}}}}]}}
}
2. 父子关系(Parent-Child)
场景:SPU 与 SKU 生命周期独立,需灵活管理(如动态添加 SKU)。
示例:一款手机(SPU)的 SKU 库存需实时更新。
映射与数据:
PUT /products
{"mappings": {"properties": {"join_field": {"type": "join","relations": {"spu": "sku" // 定义父子关系}}}}
}// 索引 SPU(父文档)
PUT /products/_doc/SPU001
{"spu_id": "SPU001","name": "苹果 iPhone 14","brand": "Apple","join_field": {"name": "spu"}
}// 索引 SKU(子文档)
PUT /products/_doc/SKU001?routing=SPU001 // 必须使用父 ID 作为路由
{"sku_id": "SKU001","color": "黑色","size": "128GB","price": 5999.00,"stock": 100,"join_field": {"name": "sku", "parent": "SPU001"}
}PUT /products/_doc/SKU002?routing=SPU001
{"sku_id": "SKU002","color": "蓝色","size": "256GB","price": 6799.00,"stock": 50,"join_field": {"name": "sku", "parent": "SPU001"}
}
查询示例:
- 需求:查找价格低于 6000 的 SKU 所属的 SPU 信息。
- 实现:
{"query": {"has_child": {"type": "sku","query": {"range": {"price": {"lt": 6000}}},"inner_hits": {} // 返回匹配的子文档}}
}
3. 应用层关联(Application-Side Join)(推荐)
场景:SPU 和 SKU 存储在不同索引,需跨索引关联。
示例:SPU 数据在 spu_index,SKU 数据在 sku_index。
数据结构:
// SPU 索引
PUT /spu_index/_doc/SPU001
{"spu_id": "SPU001","name": "苹果 iPhone 14","brand": "Apple","category": "手机","description": "2023年新款智能手机..."
}// SKU 索引
PUT /sku_index/_doc/SKU001
{"sku_id": "SKU001","spu_id": "SPU001", // 关联字段"color": "黑色","size": "128GB","price": 5999.00,"stock": 100,"sales": 2000
}
查询流程(Python):
from elasticsearch import Elasticsearches = Elasticsearch()# 1. 查询手机分类下的所有 SPU
spu_result = es.search(index="spu_index",body={"query": {"term": {"category": "手机"}},"_source": ["spu_id", "name", "brand"]},size=100
)# 2. 提取 SPU IDs
spu_ids = [hit["_source"]["spu_id"] for hit in spu_result["hits"]["hits"]]# 3. 批量查询 SKU(按价格排序)
sku_result = es.search(index="sku_index",body={"query": {"terms": {"spu_id": spu_ids}},"sort": {"price": "asc"},"_source": ["spu_id", "color", "size", "price"]},size=1000
)# 4. 应用层组装结果(SPU + 最低价格 SKU)
spu_sku_map = {}
for sku in sku_result["hits"]["hits"]["_source"]:spu_id = sku["spu_id"]if spu_id not in spu_sku_map or sku["price"] < spu_sku_map[spu_id]["price"]:spu_sku_map[spu_id] = sku# 5. 合并 SPU 和 SKU 信息
merged_result = []
for spu_hit in spu_result["hits"]["hits"]:spu = spu_hit["_source"]sku = spu_sku_map.get(spu["spu_id"], {})merged_result.append({"spu": spu,"lowest_price_sku": sku})
4. 预连接数据(Denormalization)(推荐)
场景:读多写少,需快速查询(如商品列表页)。
示例:将常用 SKU 信息冗余到 SPU 文档中。
数据结构:
PUT /products/_doc/SPU001
{"spu_id": "SPU001","name": "苹果 iPhone 14","brand": "Apple","category": "手机","min_price": 5999.00, // 预计算:最低价格"max_price": 6799.00, // 预计算:最高价格"default_sku": { // 预定义:默认 SKU"sku_id": "SKU001","color": "黑色","size": "128GB","price": 5999.00},"sku_summary": [ // 预聚合:SKU 摘要{"color": "黑色", "size": "128GB", "price": 5999.00},{"color": "蓝色", "size": "256GB", "price": 6799.00}]
}
查询示例:
- 需求:查找价格区间在 5000-6500 的手机,返回 SPU 及默认 SKU。
- 实现:
{"query": {"range": {"min_price": {"gte": 5000, "lte": 6500}}},"_source": ["spu_id", "name", "brand", "default_sku"]
}
方案对比
| 方法 | 查询性能 | 写入性能 | 数据一致性 | 适用场景 |
|---|---|---|---|---|
| 嵌套对象 | 高 | 中 | 强 | SKU 数量少,需原子性操作 |
| 父子关系 | 中 | 低 | 中 | SKU 动态变化,需独立管理 |
| 应用层关联 | 低 | 高 | 弱 | 跨索引关联,数据量大 |
| 预连接数据 | 最高 | 低 | 弱 | 读多写少,实时性要求低 |
优化建议
- 嵌套对象深度限制:避免超过 1000 个嵌套文档,否则性能下降。
- 父子关系分片一致性:父子文档必须在同一分片(通过
routing参数保证)。 - 应用层关联批量查询:使用
terms查询替代循环单条查询。 - 预连接数据更新策略:通过异步任务(如消息队列)更新冗余字段。
根据实际业务场景(如 SKU 数量、读写比例、实时性要求)选择合适的方案,或组合使用多种方案。