面向运维智能的可扩展多智能体AI系统设计
关于AI智能体的讨论已经非常热烈,本文则详细讲解一个实用设计:在这个设计中,由大语言模型(LLM)驱动的多个AI智能体相互协作,只需一个自然语言查询,就能完成日志分析、代码检查、数据库查询乃至自动提报事件等任务。
为何需要模块化智能?
试想当生产环境出错、延迟激增或系统故障时——我们通常需要查阅日志、数据库,翻阅大量文档页面来定位问题根源。这类事件往往一团乱麻。有时问题在日志文件中有所提及,有时则隐藏在代码深处,或是埋没在某人八个月前解决的旧工单里。偶尔,问题性质又清晰到需要立即升级处理。
这类问题很难用传统工具实现自动化。大多数自动化方案只在情况可预测且重复时才有效。
模块化AI系统正是为此而生。它不再试图用一个工具或流程解决所有问题,而是利用一组专门化的智能体。每个智能体专注于一项任务,例如分析日志、扫描代码或文档查找已知模式、查询数据库等。这些智能体能够相互通信,作为一个群体进行智能化的推理和操作。这种模块化方式还有另一个好处:可以轻松地独立替换或测试单个组件。模块化智能不仅锦上添花,更是当今快速应对运营复杂性和速度的必备要素。
什么是智能体AI系统?
智能体AI系统由多个智能体组成,它们能够感知环境、进行推理、制定计划并自主行动。实践中,这类系统通常利用大语言模型(LLM) 来理解上下文、做出决策、使用工具,并通过传递上下文信息相互沟通,从而协作完成任务。它并非由一个单一的“全能”聊天机器人处理一切,而是让一组专业化的AI工作者能够协调各自的努力。
实战解析:智能体AI系统如何处理运维问题
为了更清晰地理解,我们假设用户提出这样一个查询:“任务 ID TID65738 为什么失败了?”下面展示一个模块化智能体系统如何端到端地处理这个查询:
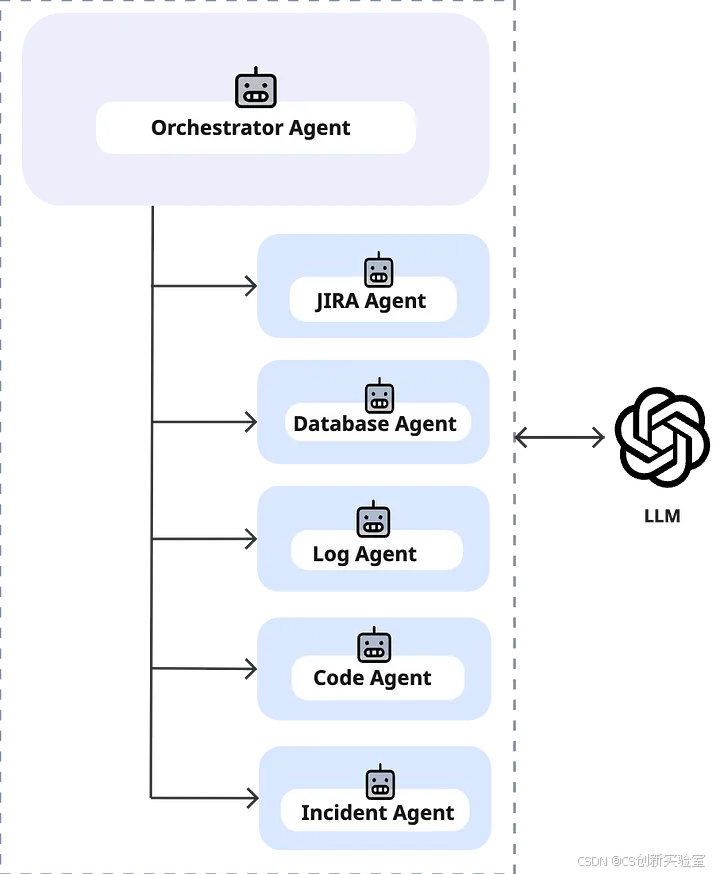
- 系统首先由**协调智能体(Orchestrator Agent)**启动。该智能体解读用户请求,并判断需要调用哪些专业智能体。
- 协调智能体:解读用户请求,决定调用哪些智能体(如日志智能体、数据库智能体、代码智能体等)。
- 示例提示词:“请从日志智能体、数据库智能体、代码智能体等中选择需要调用的智能体。”
随后,各智能体分工协作处理问题的不同环节:
- 日志智能体(Log Agent): 读取日志文件,查找与该任务ID失败相关的线索。它尝试判断失败是由可修复的错误(如异常)还是性能问题(如延迟)引起的。
- 示例提示词:“请检查日志内容,判断该问题是可修复的异常还是延迟问题。”
- 代码智能体(Code Agent): 若日志智能体发现具体错误,代码智能体则调取相关代码(例如从GitLab仓库),将错误与代码进行关联分析,并推测可能的根本原因或修复方案。它可以建议代码更改或指出需要关注的代码库具体部分。
- 示例提示词:“请根据提供的GitLab代码片段和错误信息,推测可能的根本原因和修复建议。”
- 数据库智能体(Database Agent): 若问题与性能相关,数据库智能体则从监控数据库中调取指标和时间戳,检查与该任务相关的瓶颈或延迟。
- 示例提示词:“请返回该任务ID相关的时间戳并检测是否存在性能瓶颈。”
- 事件智能体(Incident Agent): 该智能体可被触发,用于检查历史事件记录,确认过去是否发生过类似问题。它能提供背景信息,例如该错误在过去六个月内发生的次数,或链接到过往的事件报告。
- 示例提示词:“请搜索与此错误相似的过往事件并总结发现。”
- JIRA智能体(JIRA Agent): 若问题需要升级处理(例如,这是一个新发现的Bug或需要跟踪的复发性问题),该智能体将创建新的工单。它会整合其他智能体的分析结果(错误详情、修复建议、上下文信息),并草拟包含摘要的JIRA工单。
- 示例提示词:“请根据其他智能体提供的上下文信息,创建一份包含摘要和链接的JIRA工单。”
这种团队协作模式意味着系统能够动态地将任务路由给最合适的专家智能体,其协作方式非常类似于人类团队解决问题。
智能体工作流场景示例
以下是一些示例查询及其涉及的相关智能体:
-
查询: “任务 ID TID65738 为什么失败了?检查这个问题是否由最近的代码变更引起。”
涉及智能体: 协调 → 日志 → 代码
(系统通过日志智能体检查错误,然后通过代码智能体查看最近的代码变更。) -
查询: “请提供任务 ID TID65738 的处理时间和延迟。”
涉及智能体: 协调 → 日志 → 数据库
(日志智能体从日志中找到任务运行位置,数据库智能体则从任何Azure服务上的存储数据库检索指标。) -
查询: “创建一个包含任务 ID TID65738 失败详情的 JIRA 工单。”
涉及智能体: 协调 → 日志 → 代码 → JIRA
(系统从日志和代码智能体收集错误详情,然后由JIRA智能体创建JIRA工单。) -
查询: “任务 ID TID65738 的工作流中哪一步耗时最长?”
涉及智能体: 协调 → 数据库 → 代码
(数据库智能体识别耗时步骤,代码智能体将这些步骤与代码文件关联分析。) -
查询: “本月发生了多少起类似事件?”
涉及智能体: 协调 → 事件
(事件智能体在事件数据库中搜索过去一个月内的类似问题。) -
查询: “生成报告并升级处理此任务问题。”
涉及智能体: 协调 → 日志 → 数据库 → 事件 → JIRA
(这是一个综合性请求:系统分析日志、收集指标、检查过往事件,然后创建JIRA报告。) -
查询: “列出过去一天中最慢的10个任务。”
涉及智能体: 协调 → 数据库
(数据库智能体直接处理此请求,查询性能指标并返回最慢的任务列表。) -
查询: “总结任务失败的原因及过往类似事件。”
涉及智能体: 协调 → 日志 → 事件
(日志智能体找出任务失败的错误原因,事件智能体则补充有关类似失败的历史背景信息。)
这些场景展示了协调智能体如何根据查询灵活组装智能体工作流。用户只需用自然语言提问,系统便能判断需要哪些组件协同工作来提供答案或解决方案。
支持多智能体系统的流行框架
如今,支持基于LLM的多智能体系统的框架众多。一些流行的开源框架包括:
- LangGraph: 由 LangChain Inc 开发的基于图的工作流框架,支持工作流编排,并能实时掌握智能体的推理与操作动态。
- CrewAI: 一个 Python 框架,通过为智能体定义清晰的角色来支持自主运行。
- Semantic Kernel: 支持模块化、插件式智能体,可轻松集成到现有代码中,有助于快速构建可扩展、生产就绪的多智能体编排系统。
在本文中,我们将探讨如何使用 Semantic Kernel 框架和 Azure 平台来设计一个多智能体系统。
基于 Semantic Kernel 与 Azure 工具的技术设计
在本项目中,我们使用了 Semantic Kernel。这是一个轻量级开源 SDK,可轻松集成 AI 服务并通过插件(我们将其用于实现智能体)构建复杂工作流。它提供了内置支持,用于在多个智能体之间编排 LLM 提示词,并能与 Azure 服务(如 Functions、Azure OpenAI、Blob 存储、Cosmos DB 等)无缝集成。例如,我们使用了 AzureChatCompletion 服务将 Azure OpenAI (GPT-4) 连接到我们的智能体提示词。
以下是一个简单示例:
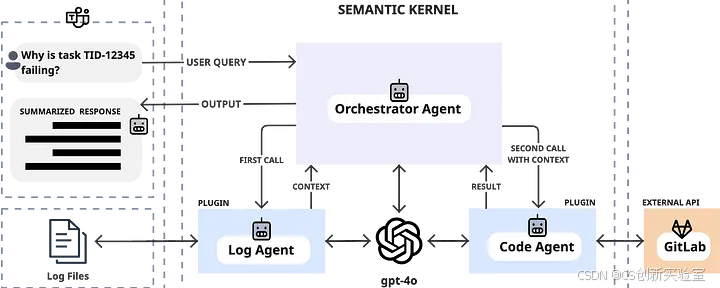
假设我们已在 Semantic Kernel 中将日志智能体(Log Agent)和代码智能体(Code Agent)构建为插件,每个智能体都有自己的提示词逻辑。这类系统的一个挑战在于如何让智能体之间相互通信。例如,将日志智能体提取的错误摘要传递给代码智能体的提示词,用于根本原因分析。Semantic Kernel 的编排能力让我们能够以清晰、异步的方式实现这种链式调用。这使得每个智能体可以专注于自身任务,同时在各步骤之间顺畅地共享信息。
使用 Semantic Kernel 实现智能体链式调用
在 Semantic Kernel 中,我们设置了一个协调器函数(我们称之为 ClassifyAgents),它读取用户查询并决定需要调用哪些智能体。
以下是一个展示其工作原理的简化 Python 示例:
首先,我们初始化内核(Kernel),注册 AI 模型,并将智能体作为插件加载:
# 初始化 Semantic Kernel
kernel = Kernel()# 添加 Azure OpenAI (GPT-4o) 作为 LLM 服务
kernel.add_chat_service("gpt-4o",AzureChatCompletion(deployment_name="gpt-4o", # 部署名称endpoint="https://your-endpoint.openai.azure.com/", # 终端节点api_key="your-azure-api-key" # Azure API 密钥)
)# 导入智能体(插件)
log_agent = kernel.import_semantic_skill_from_directory("./LogAgent", "LogAgent") # 日志智能体
code_agent = kernel.import_semantic_skill_from_directory("./CodeAgent", "CodeAgent") # 代码智能体
orchestrator_agent = kernel.import_semantic_skill_from_directory("./OrchestratorAgent", "OrchestratorAgent") # 协调智能体
假设协调器的提示词设计为根据查询返回一个逗号分隔的智能体名称列表。例如,如果用户询问“任务 TID-12345 为什么失败了?”,协调器可能返回类似 "log_agent, code_agent" 的结果。
以下是在代码中运行协调器的过程:
# 创建一个包含用户查询的上下文
context = kernel.create_new_context()
context["input"] = "Why is task TID-12345 failing?" # 用户查询# 使用协调器决定调用哪些智能体
orchestrator_result = await kernel.run_async(orchestrator_agent["ClassifyAgents"], input_vars=context)# 将结果解析为 Python 列表
agents_to_call = [agent.strip() for agent in orchestrator_result.result.split(",")] # 待调用智能体列表
一旦获得待调用的智能体列表,我们就可以依次调用它们。每个智能体运行时,都可以将其结果放入共享上下文(context)中供其他智能体使用。
# 如果需要日志智能体,首先调用它
if "log_agent" in agents_to_call:# 获取该任务ID的相关日志context["log_data"] = fetch_logs("TID-12345") # 日志数据context["task_id"] = "TID-12345" # 任务ID# 运行 LogAgent 插件(包含分类日志错误的函数)log_result = await kernel.run_async(log_agent["ClassifyLogError"], input_vars=context)# 将日志中的错误摘要保存到上下文中,供其他智能体使用context["error_summary"] = log_result.result # 错误摘要# 如果协调器建议调用代码智能体且问题似乎可修复
if "code_agent" in agents_to_call and "error_summary" in context:# 从仓库检索相关代码片段(例如,基于错误或堆栈跟踪)context["code_snippet"] = fetch_gitlab_code("TaskProcessor.java", context["error_summary"]) # 代码片段# 运行 CodeAgent 插件分析代码并建议修复方案code_result = await kernel.run_async(code_agent["SuggestFix"], input_vars=context)suggested_fix = code_result.result # 建议的修复方案
如果数据库智能体(Database Agent)或事件智能体(Incident Agent)也在 agents_to_call 列表中,我们可以遵循相同的模式调用它们。每次智能体运行时,都会用新数据(如指标或事件历史)更新上下文,供后续智能体使用。通过使用协调器和上下文共享,每个智能体的输出可以作为下一个智能体的输入。
这种分步式链式调用由 LLM 自身驱动编排(通过协调器智能体利用 LLM 来决定调用哪个智能体的能力)。协调器智能体处理结果,并使用正确的数据调用这些工具(我们的自定义插件)。
代码智能体如何驾驭大型代码库**
为了克服设计挑战,使代码智能体(Code Agent)能在大型代码库中高效搜索相关代码片段,可采用以下策略:
- 静态过滤(Static Filtering): 第一步是通过文件过滤缩小搜索范围。例如,如果错误看起来是 Java 异常,我们仅关注
.java文件。如果错误提及特定模块,则将搜索限制在该模块的目录内。 - 利用错误上下文(Use Error Context): 我们还利用错误本身的线索,如堆栈跟踪、错误消息、函数名或行号,来识别代码库中最相关的部分。例如,如果日志显示
TaskProcessor中发生异常,智能体就知道查看与该类相关的文件。 - 语义搜索(Semantic Search): 为了超越基本的关键词匹配,我们使用嵌入(embeddings) 执行语义搜索。将错误描述和代码文件都嵌入到向量数据库中(例如使用 Azure Cognitive Search 或类似的向量数据库 [5])。代码智能体随后可以执行相似性搜索,检索与错误可能相关的前 K 个(top-K)最相关的代码片段或文件。
- 针对性代码分析(Targeted Code Analysis): 智能体仅提取少量最可能相关的代码片段(而非整个文件),并将这些片段连同错误上下文一起输入给 LLM。这确保了提示词的高效性和针对性。然后,LLM 分析这些片段,识别根本原因,甚至可能建议代码更改。
通过结合静态过滤、错误上下文和语义搜索,代码智能体可以在庞大的代码库中聚焦于相关部分,避免用无关代码淹没 LLM。
通过 UI 和 Power Automate 实现系统操作化**
为了让这个多智能体系统能在现实世界中使用,一个简洁的界面至关重要。其模块化设计使得系统可以轻松接入不同的前端,并能独立测试各个组件。在我们的案例中,我们使用 Power Automate 将智能体工作流集成到了 Microsoft Teams 的聊天界面中。
工作流程如下:
我们在 Teams 中设置了一个 Power Automate 流程,用于监听特定命令或关键词。该流程随后获取用户的自然语言查询,并将其发送到运行着 Semantic Kernel 协调器(在 Azure 上托管为 API)的后端。由于许多运维团队和开发人员已经将 Teams 用于日常协作,这使他们能在日常使用的工具中查询 AI 系统,无需切换上下文。
查询到达后端后,协调器接管处理。它如前所述运行必要的智能体(日志分析、代码查找等),链式组合它们的结果,并生成响应。该响应可能包含错误诊断、修复建议、性能指标,甚至是新创建的 JIRA 工单链接。Power Automate 随后将此响应发布回 Teams 频道,有时会 “@提及” 相关用户或团队。
通过将 LLM 驱动的智能体与 Semantic Kernel(用于编排)和 Power Automate(用于用户交互)等工具集成,我们构建的原型不仅能响应查询,还能主动推理多步骤问题并执行操作(如记录事件)。使用自然语言界面意味着用户几乎无需额外培训,只需像平常一样提问即可。
结论
这种智能体系统的模块化设计,只是协作式智能如何应用于高压环境的一个示例。它通过直接从日志文件和代码中精确定位根本原因,甚至自动生成包含摘要和链接的 JIRA 工单,可以将问题定位时间(triage time)从数小时缩短至数秒。用户无需花费时间查阅日志文件或文档,而可以专注于审阅解决方案并解决问题。
通过将 LLM 与 Semantic Kernel(用于编排)和 Power Automate(用于用户交互)等企业级工具结合,我们构建的系统更像一个乐于助人的队友,而非传统的自动化脚本。随着技术系统日益复杂,这类模块化、AI 驱动的工具可能在改进团队管理运维和大规模解决问题的方式上发挥重要作用。