图解系统-小林coding笔记
整体架构图
一、硬件结构
当CPU要读写内存数据的时候,一般需要通过两个总线:
- 首先要通过
地址总线来指定内存的地址; - 再通过
数据总线来传输数据。
线路位宽与CPU位宽
硬件的64位和32位指的是CPU的位宽,软件的64位和32位指的是指令到位宽。
程序执行的基本过程
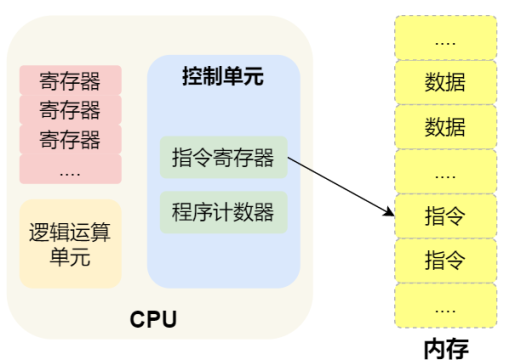
⼀个程序执⾏的时候, CPU 会根据程序计数器⾥的内存地址,从内存⾥⾯把需要执⾏的指令读取到指令寄存器⾥⾯执⾏,然后根据指令⻓度⾃增,开始顺序读取下⼀条指令。
CPU 从程序计数器读取指令、到执⾏、再到下⼀条指令,这个过程会不断循环,直到程序执⾏结束,这个不断循环的过程被称为 CPU 的指令周期。
a=1+2执行具体过程
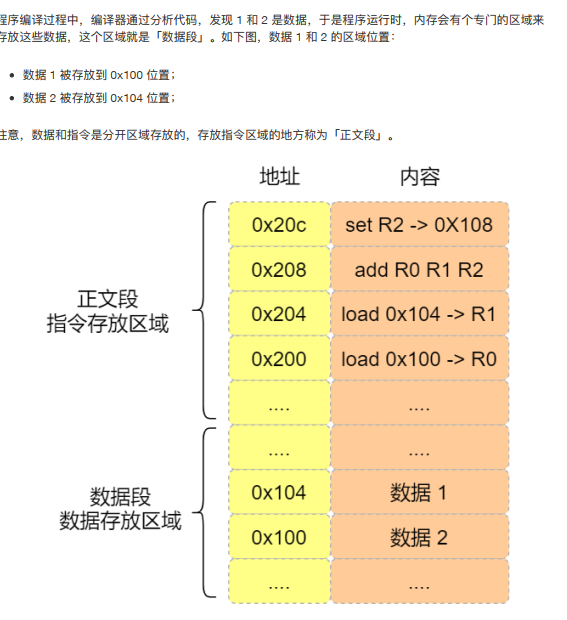
指令
不同的 CPU 有不同的指令集,也就是对应着不同的汇编语⾔和不同的机器码,接下来选⽤最简单的 MIPS指集,来看看机器码是如何⽣成的,这样也能明⽩⼆进制的机器码的具体含义。
编译器在编译程序的时候,会构造指令,这个过程叫做指令的编码。 CPU 执⾏程序的时候,就会解析指令,这个过程叫作指令的解码。
现代⼤多数 CPU 都使⽤来流⽔线的⽅式来执⾏指令,所谓的流⽔线就是把⼀个任务拆分成多个⼩任务,于是⼀条指令通常分为 4 个阶段,称为 4 级流⽔线,如下图:
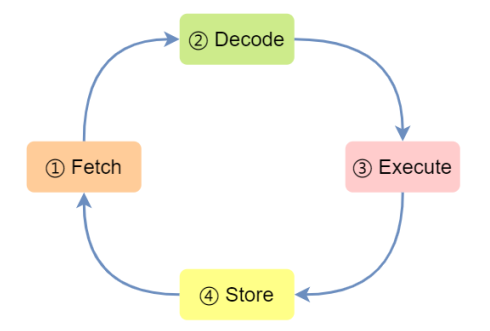 CPU 通过程序计数器读取对应内存地址的指令,这个部分称为 Fetch(取得指令) ;
CPU 通过程序计数器读取对应内存地址的指令,这个部分称为 Fetch(取得指令) ;
2. CPU 对指令进⾏解码,这个部分称为 Decode(指令译码) ;
3. CPU 执⾏指令,这个部分称为 Execution(执⾏指令) ;
4. CPU 将计算结果存回寄存器或者将寄存器的值存⼊内存,这个部分称为 Store(数据回写) ;
上⾯这 4 个阶段,我们称为指令周期(Instrution Cycle) , CPU 的⼯作就是⼀个周期接着⼀个周期,周⽽复始。
指令的类型
指令从功能⻆度划分,可以分为 5 ⼤类:
数据传输类型的指令,⽐如 store/load 是寄存器与内存间数据传输的指令, mov 是将⼀个内存地
址的数据移动到另⼀个内存地址的指令;
运算类型的指令,⽐如加减乘除、位运算、⽐较⼤⼩等等,它们最多只能处理两个寄存器中的数据;
跳转类型的指令,通过修改程序计数器的值来达到跳转执⾏指令的过程,⽐如编程中常⻅的 ifelse 、 swtich-case 、函数调⽤等。
信号类型的指令,⽐如发⽣中断的指令 trap ;
闲置类型的指令,⽐如指令 nop ,执⾏后 CPU 会空转⼀个周期
指令的执行速度
CPU 的硬件参数都会有 GHz 这个参数,比如⼀个 1 GHz 的 CPU,指的是时钟频率是 1 G,代表着 1 秒会产⽣ 1G 次数的脉冲信号,每⼀次脉冲信号⾼低电平的转换就是⼀个周期,称为时钟周期。
对于 CPU 来说,在⼀个时钟周期内, CPU 仅能完成⼀个最基本的动作,时钟频率越⾼,时钟周期就越短,⼯作速度也就越快。

CPU时钟周期:指令数 ×\times× 每条指令的平均时钟周期数(CPI),于是:

要想程序跑得更快,优化这三者即可:
- 指令数,表示执⾏程序所需要多少条指令,以及哪些指令。这个层⾯是基本靠编译器来优化,毕竟同样的代码,在不同的编译器,编译出来的计算机指令会有各种不同的表示⽅式。
- 每条指令的平均时钟周期数CPI,表示⼀条指令需要多少个时钟周期数,现代⼤多数 CPU 通过流⽔
线技术(Pipline),让⼀条指令需要的 CPU 时钟周期数尽可能的少; - 时钟周期时间,表示计算机主频,取决于计算机硬件。有的 CPU ⽀持超频技术,打开了超频意味着把 CPU 内部的时钟给调快了,于是 CPU ⼯作速度就变快了,但是也是有代价的, CPU 跑的越快,散热的压⼒就会越⼤, CPU 会很容易奔溃。
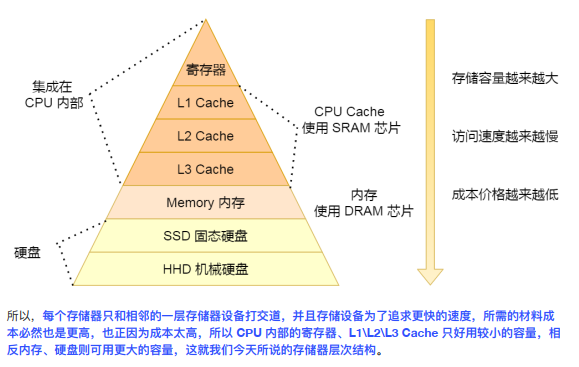
存储器金字塔
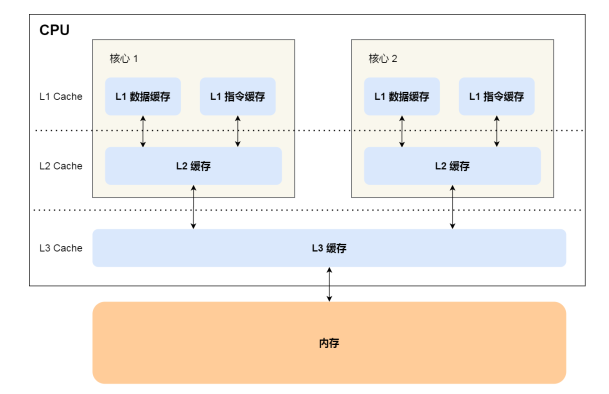
CPU Cache的数据结构和读取过程是什么样的?
CPU怎么知道要访问的内存数据,是否在Cache里,如果在的话,如何找到Cache对应的数据呢?
直接映射Cache
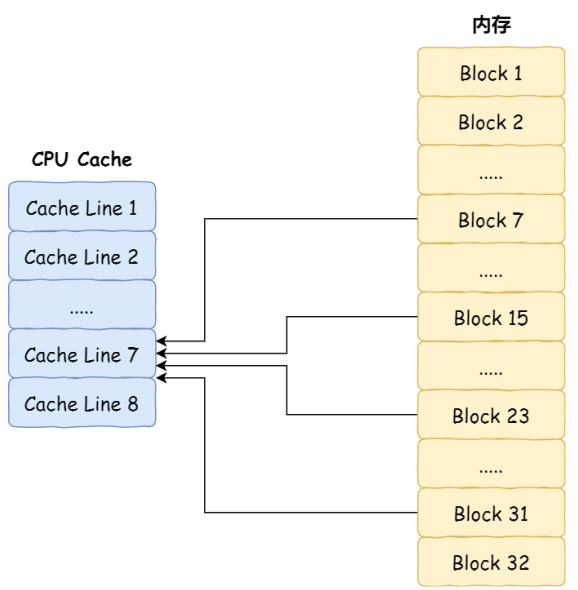
CPU 访问内存数据时,是⼀⼩块⼀⼩块数据读取的,具体这⼀⼩块数据的⼤⼩,取决于coherency_line_size 的值,⼀般 64 字节。在内存中,这⼀块的数据我们称为内存块(Block) ,读取的时候我们要拿到数据所在内存块的地址。
直接映射Cache采用取模运算策略,取模运算的结果就是内存块地址对应的 CPU Line(缓存块) 的地址。
CPU 在从 CPU Cache 读取数据的时候,并不是读取 CPU Line 中的整个数据块,⽽是读取 CPU 所需要的
⼀个数据⽚段,这样的数据统称为⼀个字(Word) 。那怎么在对应的 CPU Line 中数据块中找到所需的字
呢?答案是,需要⼀个偏移量(Offset) 。
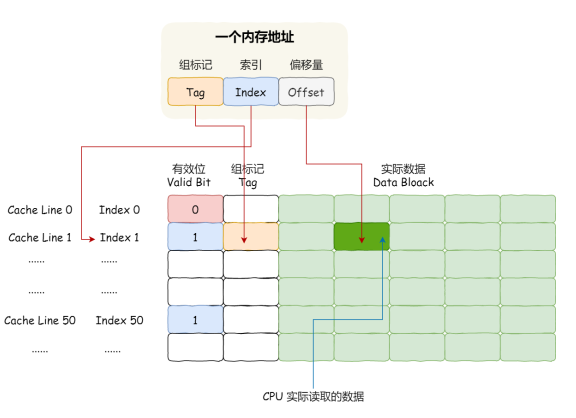
⼀个内存的访问地址,包括组标记、 CPU Line 索引、偏移量这三种信息,于是 CPU 就能通过这些信息,在 CPU Cache 中找到缓存的数据。⽽对于 CPU Cache ⾥的数据结构,则是由索引 + 有效位 + 组标记 + 数据块组成。
全相连Cache(可了解)
组相连Cache(可了解)
CPU缓存一致性
在什么时机才把Cache中的数据写回到内存中:
- 写直达( 把数据同时写⼊内存和 Cache 中,效率问题)
- 写回(在把数据写⼊到 Cache 的时候,只有在缓存不命中,同时数据对应的 Cache 中的 Cache Block 为<>脏标记的情况下,才会将数据写到内存中,⽽在缓存命中的情况下,则在写⼊后 Cache后,只需把该数据对应的 Cache Block 标记为脏即可,⽽不⽤写到内存⾥。)
解决写回引起的一致性问题:
1、写传播:某个 CPU 核⼼⾥的 Cache 数据更新时,必须要传播到其他核⼼的 Cache;
2、事务的串形化:某个 CPU 核⼼⾥对数据的操作顺序,必须在其他核⼼看起来顺序是⼀样的。
要实现事务串行化:
CPU 核⼼对于 Cache 中数据的操作,需要同步给其他 CPU 核⼼;
要引⼊「锁」的概念,如果两个 CPU 核⼼⾥有相同数据的 Cache,那么对于这个 Cache 数据的更新,只有拿到了「锁」,才能进⾏对应的数据更新。
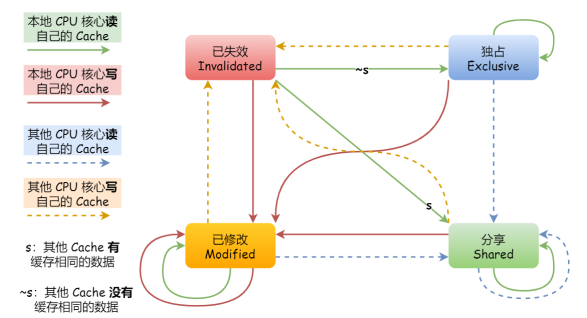
MESI协议
MESI协议其实是 4 个状态单词的开头字⺟缩写,分别是:
- Modified,已修改(脏标记)
- Exclusive,独占
- Shared,共享
- Invalidated,已失效
这四个状态来标记 Cache Line 四个不同的状态。
CPU是如何执行任务的?
现代CPU的架构图:
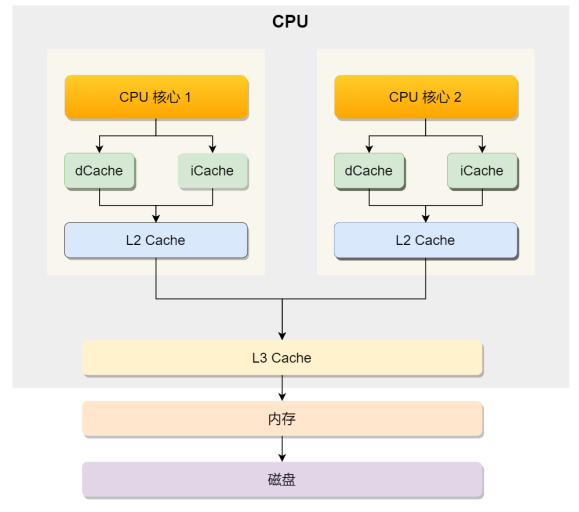
CPU 从内存中读取数据到 Cache 的时候,并不是⼀个字节⼀个字节读取,⽽是⼀块⼀块的⽅式来读取数
据的,这⼀块⼀块的数据被称为 CPU Line(缓存⾏),所以 CPU Line 是 CPU 从内存读取数据到 Cache的单位。
伪共享
伪共享:因为多个线程同时读写同一个Cache Line的不同变量时,而导致CPU Cache失效的现象。
解决办法:用空间换时间,对齐地址。
有⼀个 Java 并发框架 Disruptor 使⽤「字节填充 + 继承」的⽅式,来避免伪共享的问题。
CPU如何选择线程的?
调度类
由于任务有优先级之分, Linux 系统为了保障⾼优先级的任务能够尽可能早的被执⾏,于是分为了这⼏种调度类:
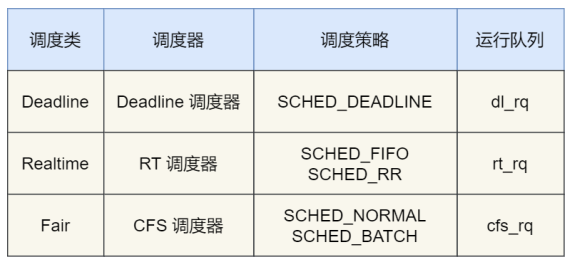
Deadline 和 Realtime 这两个调度类,都是应⽤于实时任务的,这两个调度类的调度策略合起来共有这三种,它们的作⽤如下:
- SCHED_DEADLINE:是按照 deadline 进⾏调度的,距离当前时间点最近的 deadline 的任务会被优先调度;
- SCHED_FIFO:对于相同优先级的任务,按先来先服务的原则,但是优先级更⾼的任务,可以抢占低优先级的任务,也就是优先级⾼的可以「插队」;
- SCHED_RR:对于相同优先级的任务,轮流着运⾏,每个任务都有⼀定的时间⽚,当⽤完时间⽚的任务会被放到队列尾部,以保证相同优先级任务的公平性,但是⾼优先级的任务依然可以抢占低优先级的任务;
而 Fair 调度类是应⽤于普通任务,都是由 CFS 调度器管理的,分为两种调度策略:
- SCHED_NORMAL:普通任务使⽤的调度策略;
- SCHED_BATCH:后台任务的调度策略,不和终端进⾏交互,因此在不影响其他需要交互的任务,可以适当降低它的优先级。
完全公平调度
我们平⽇⾥遇到的基本都是普通任务,对于普通任务来说,公平性最重要,在 Linux ⾥⾯,实现了⼀个基于 CFS 的调度算法,也就是完全公平调度(Completely Fair Scheduling) 。
这个算法的理念是想让分配给每个任务的 CPU 时间是⼀样,于是它为每个任务安排⼀个虚拟运⾏时间vruntime,如果⼀个任务在运⾏,其运⾏的越久,该任务的 vruntime ⾃然就会越⼤,⽽没有被运⾏的任务, vruntime 是不会变化的。
那么, 在 CFS 算法调度的时候,会优先选择 vruntime 少的任务,以保证每个任务的公平性。

CPU运行队列
⼀个系统通常都会运⾏着很多任务,多任务的数量基本都是远超 CPU 核⼼数量,因此这时候就需要排队。
事实上,每个 CPU 都有⾃⼰的运⾏队列(Run Queue, rq) ,⽤于描述在此 CPU 上所运⾏的所有进程,其队列包含三个运⾏队列, Deadline 运⾏队列 dl_rq、实时任务运⾏队列 rt_rq 和 CFS 运⾏队列 csf_rq,其中 csf_rq 是⽤红⿊树来描述的,按 vruntime ⼤⼩来排序的,最左侧的叶⼦节点,就是下次会被调度的任务。
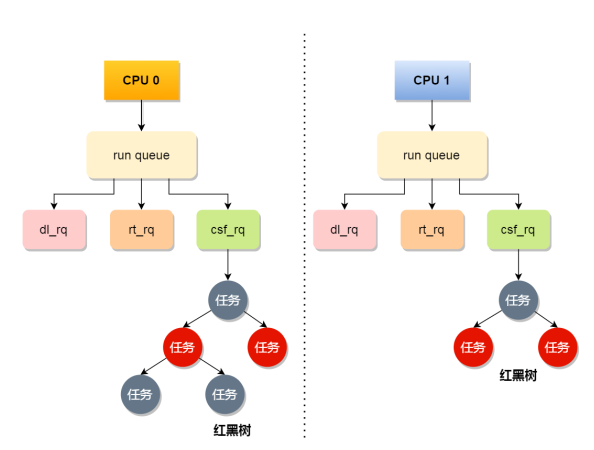
Deadline > Realtime > Fair
实时任务总是会⽐普通任务优先被执⾏
调整优先级
如果我们启动任务的时候,没有特意去指定优先级的话,默认情况下都是普通任务,普通任务的调度类是Fail,由 CFS 调度器来进⾏管理。 CFS 调度器的⽬的是实现任务运⾏的公平性,也就是保障每个任务的运⾏的时间是差不多的。
如果你想让某个普通任务有更多的执⾏时间,可以调整任务的 nice 值,从⽽让优先级⾼⼀些的任务执⾏更多时间。 nice 的值能设置的范围是 -20~19 , 值越低,表明优先级越⾼,因此 -20 是最⾼优先级, 19则是最低优先级,默认优先级是 0。
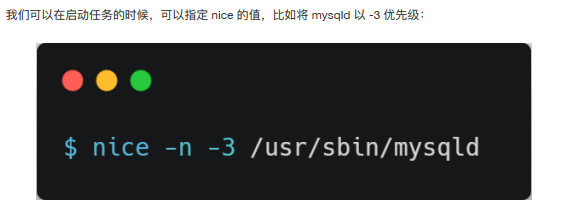
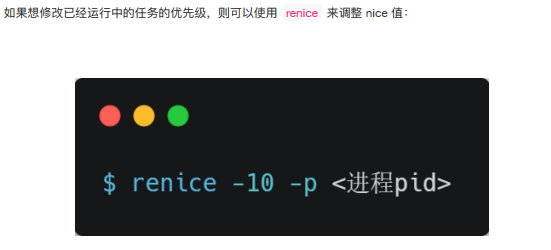
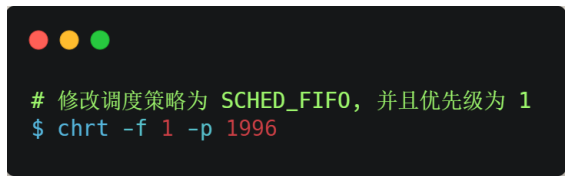
nice 调整的是普通任务的优先级,所以不管怎么缩⼩ nice 值,任务永远都是普通任务,如果某些任务要求实时性⽐较⾼,那么你可以考虑改变任务的优先级以及调度策略,使得它变成实时任务,⽐如:
软中断
中断
在计算机中,中断是系统⽤来响应硬件设备请求的⼀种机制,操作系统收到硬件的中断请求,会打断正在执⾏的进程,然后调⽤内核中的中断处理程序来响应请求。
中断请求的响应程序,也就是中断处理程序,要尽可能快的执⾏完,这样可以减少对正常进程运⾏调度地影响。
什么是软中断?
硬中断:主要是负责耗时短的⼯作,特点是快速执⾏;
软中断:主要是负责上半部未完成的⼯作,通常都是耗时⽐较⻓的事情,特点是延迟执⾏;
系统里有哪些软中断?
在 Linux 系统⾥,我们可以通过查看 /proc/softirqs 的 内容来知晓「软中断」的运⾏情况,以及/proc/interrupts 的 内容来知晓「硬中断」的运⾏情况。
每个 CPU核⼼都对应着⼀个内核线程。
如何定位软中断CPU使用率过高的问题?
每⼀个 CPU 都有各⾃的软中断内核线程,我们还可以⽤ ps 命令来查看内核线程,⼀般名字在中括号⾥⾯到,都认为是内核线程。
如果在 top 命令发现, CPU 在软中断上的使⽤率⽐较⾼,⽽且 CPU 使⽤率最⾼的进程也是软中断ksoftirqd 的时候,这种⼀般可以认为系统的开销被软中断占据了。
这时我们就可以分析是哪种软中断类型导致的,⼀般来说都是因为⽹络接收软中断导致的,如果是的话,可以⽤ sar 命令查看是哪个⽹卡的有⼤量的⽹络包接收,再⽤ tcpdump 抓⽹络包,做进⼀步分析该⽹络包的源头是不是⾮法地址,如果是就需要考虑防⽕墙增加规则,如果不是,则考虑硬件升级等。
为什么0.1+0.2不等于0.3?
由于计算机的资源是有限的,所以是没办法⽤⼆进制精确的表示 0.1,只能⽤「近似值」来表示,就是在有限的精度情况下,最⼤化接近 0.1 的⼆进制数,于是就会造成精度缺失的情况。
为什么负数要用补码表示?
补码:所谓的补码就是把正数的⼆进制全部取反再加 1。
负数之所以⽤补码的⽅式来表示,主要是为了统⼀和正数的加减法操作⼀样,毕竟数字的加减法是很常⽤的⼀个操作,就不要搞特殊化,尽量以统⼀的⽅式来运算。
计算机是怎么存小数的?

二、操作系统结构
什么是内核?
对于内核的架构⼀般有这三种类型:
- 宏内核,包含多个模块,整个内核像⼀个完整的程序;
- 微内核,有⼀个最小版本的内核,⼀些模块和服务则由⽤户态管理;
- 混合内核,是宏内核和微内核的结合体,内核中抽象出了微内核的概念,也就是内核中会有⼀个小型的内核,其他模块就在这个基础上搭建,整个内核是个完整的程序;
Linux 的内核设计是采⽤了宏内核, Window 的内核设计则是采⽤了混合内核。
这两个操作系统的可执⾏⽂件格式也不⼀样, Linux 可执⾏⽂件格式叫作 ELF, Windows 可执⾏⽂件格式叫作 PE。
三、内存管理
四、进程与线程
五、调度算法
六、文件系统
七、设备管理
八、网络系统
九、Linux命令
后记
持续更新积累。