MySQL事务管理(上)(12)
文章目录
- 前言
- 一、什么是事务
- 二、事务的ACID属性
- 三、事务的版本支持
- 四、事务的提交方式
- 五、事务的相关演示
- 总结
前言
来喽!!!
绷不住了,到这里我又把我的 Xshell 设置成黑色的了,白底黑字用了几天快把我眼睛干烂了
一、什么是事务
-
定义:由 一条或者多条 sql语句 构成的 sql集合体 ,这个集合体合在一起共同要完成某种任务。 MySQL 通过多线程实现存储工作,因此在并发访问场景中,事务确保了数据操作的一致性和可靠性。
-
背景:在没有控制的情况下进行 CURD 操作 (创建、更新、读取、删除)可能导致数据不一致的问题。例如,在火车票售票系统中,两个用户同时尝试购买最后一张票,可能造成同一张票被卖出两次的现象。
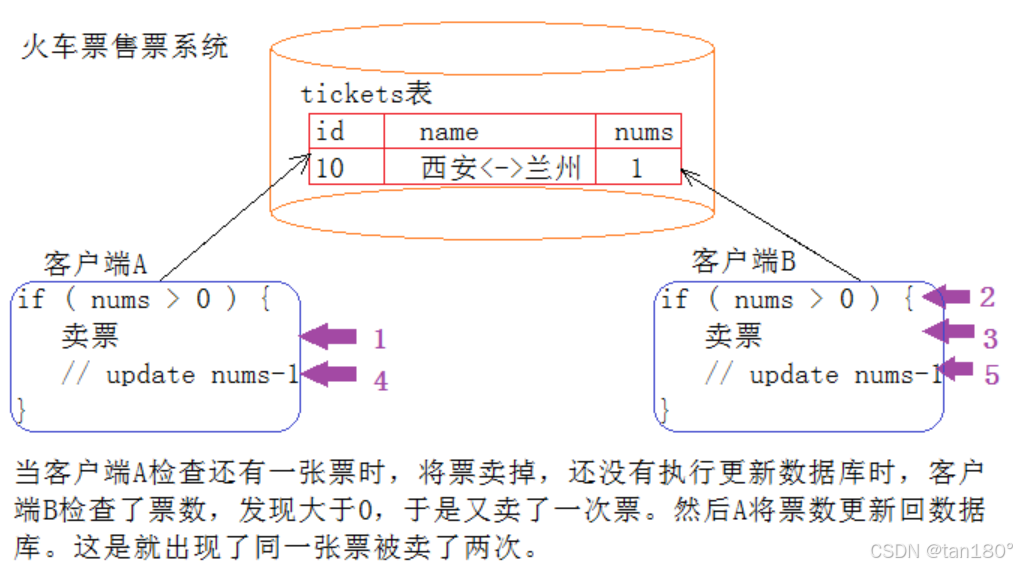
所以说:
- 买票的过程得是原子的吧
- 买票互相应该不能影响吧
- 买完票应该要永久有效吧
二、事务的ACID属性
(要站在MySQL使用者的角度来看,不能站在程序员的角度看)
- 原子性(Atomicity):事务的所有操作要么全部完成,要么完全不执行,任何一部分失败都会导致整个事务的回滚。
- 一致性(Consistency):事务前后,数据库应保持一致的状态,即事务不应破坏数据库的完整性约束。(通过原子性,隔离性,持久性 AND 用户的配合实现一致性)
- 隔离性(Isolation):事务之间的执行是相互隔离的,一个事务的执行不会受到其他事务的影响。
- 持久性(Durability):一旦事务提交,其对数据库所做的改变将是永久性的,即使系统发生故障也不会丢失。
为什么存在事务?
刚才说的是多个 sql 在交叉执行可能会出现并发问题,进而导致数据不一致,进而导致数据完整性破坏。但是这样说的太专业了,对事务的理解不能光站在程序员角度理解,一定要站在数据库使用者角度考虑。
- 事务被 MySQL 编写者设计出来,但是事务并不是天然就有的,而是在用一段时间发现要有这个事务。本质是为了当应用程序访问数据库的时候,事务能够简化我们的编程模型,不需要我们去考虑各种各样的潜在错误和并发问题。
- 只需要把告诉我你要干什么,把你的 sql 给我,我帮你封装成事务,帮你去运行。可以想一下当我们使用事务时,要么提交,要么回滚,我们不会去考虑网络异常了,服务器宕机了,同时更改一个数据怎么办对吧?这些问题统统不考虑。
- 因此事务本质上是为了应用层服务的,是为了让上层的应用服务更好的使用数据库。而不是伴随着数据库系统天生就有的。
也就是说,事务的作用在于:
- 解决并发问题:事务的设计初衷是为了应对并发操作带来的数据不一致问题,确保数据的完整性和一致性。
- 服务应用层:事务的本质是为应用层服务的,它简化了开发者的编程模型,使开发者可以专注于业务逻辑,而不用担心底层的数据操作细节。
三、事务的版本支持
通过 show engines 命令可以查看数据库引擎
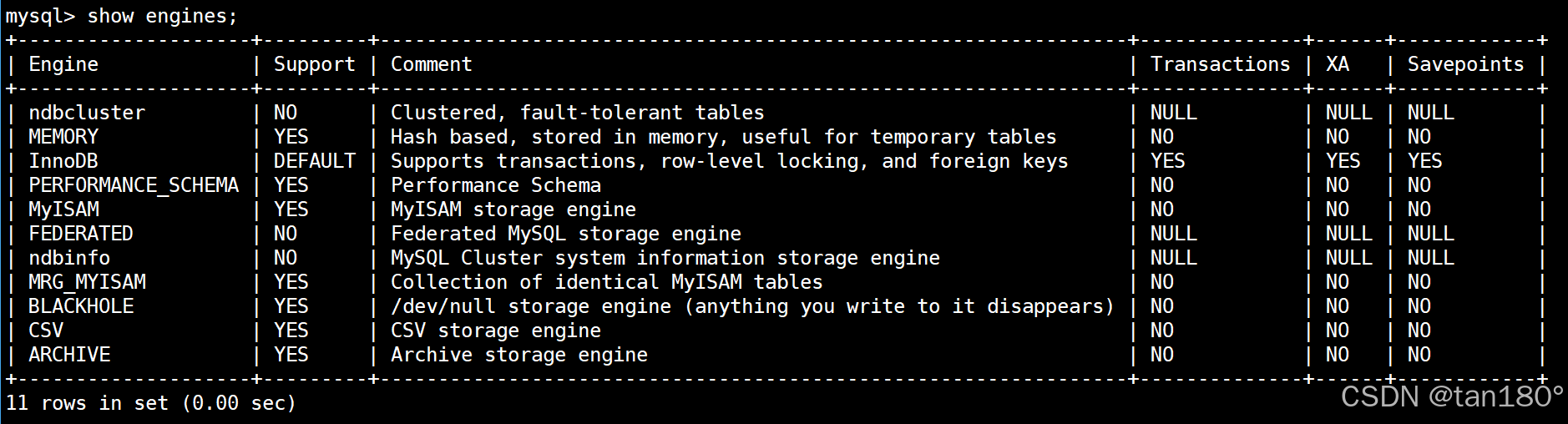
- Engine: 表示存储引擎的名称。
- Support: 表示服务器对存储引擎的支持级别,YES表示支持,NO表示不支持,DEFAULT表示数据库默认使用的存储引擎,DISABLED表示支持引擎但已将其禁用。
- Comment: 表示存储引擎的简要说明。
- Transactions: 表示存储引擎是否支持事务,可以看到InnoDB存储引擎支持事务,而MyISAM存储引擎不支持事务。
- XA: 表示存储引擎是否支持XA事务。
- Savepoints: 表示存储引擎是否支持保存点。
四、事务的提交方式
事务常见的提交方式有两种,分别是 自动提交 和 手动提交 。
通过 show命令 查看 autocommit全局变量 ,可以查看事务的自动提交是否被打开。
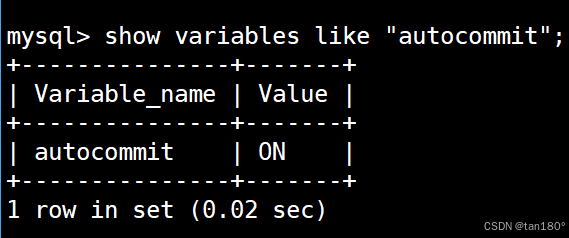
autocommit 的值为 ON 表示自动提交被打开,值为 OFF 表示自动提交被关闭,即事务的提交方式为手动提交。
当然你也可以通过 set命令 设置 autocommit全局变量 的值,可以打开或关闭事务的自动提交
五、事务的相关演示
在这里先展示一些事务的 常规操作 和 ACID 特性
先来准备一个测试表,接着将 MySQL 的隔离级别设置成读未提交,也就是把隔离级别设置的比较低,方便看到实验现象

需要注意的是,设置全局隔离级别后当前会话的隔离级别不会改变,只会影响后续与 MySQL 新建立的连接,因此需要重启终端才能看到会话的隔离级别被成功设置。
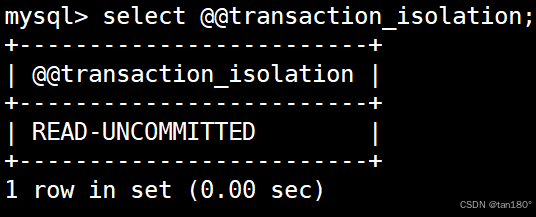
可能你查到的查看会话隔离级别的系统变量是 tx_isolation,但是从MySQL 8.0版本开始,系统变量 tx_isolation 被重命名为 transaction_isolation。若使用旧变量名(如 tx_isolation),会触发错误提示“未知系统变量”。
现在我们创建一个银行用户表,表中包含用户的id、姓名和账户余额。如下:

先来展示一下事务的常规操作

左终端中的事务向表中插入一条记录,由于我们将隔离级别设置成了读未提交,因此在左终端中的事务使用 commit 提交之前,在右终端中就能查看到事务向表中插入的记录。
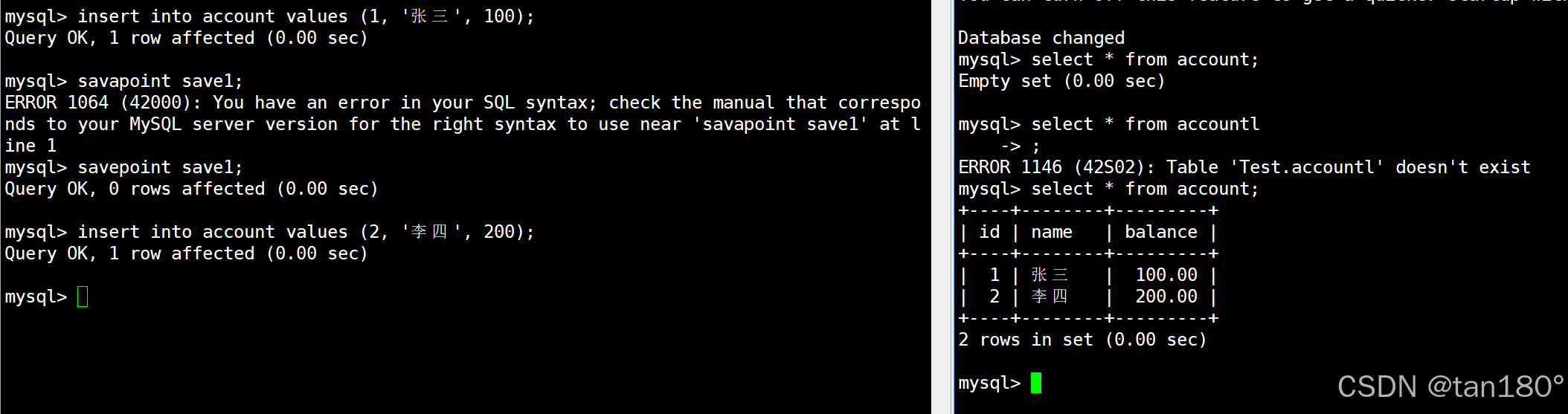
左终端中的事务使用 rollback命令 回滚到保存点,这时右终端在查看表中数据时就看不到刚才插入的第二条记录了

左终端中的事务使用 rollback命令 回滚到事务最开始,这时右终端在查看表中数据时就看不到任何记录了。如下:

总结一下:
- 使用 begin 或 start transaction 命令,可以启动一个事务。
- 使用 savepoint 保存点 命令,可以在事务中创建指定名称的保存点。
- 使用 rollback to 保存点 命令,可以让事务回滚到指定保存点。
- 使用 rollback 命令,可以直接让事务回滚到最开始。
- 使用 commit 命令,可以提交事务,提交事务后就不能回滚了。
接着我们再来看看原子性
在左终端中启动一个事务,在右终端查看银行用户表中的信息

左终端中的事务向表中插入一条记录,由于隔离级别是读未提交,因此在右终端中能够查询到插入的这条记录。
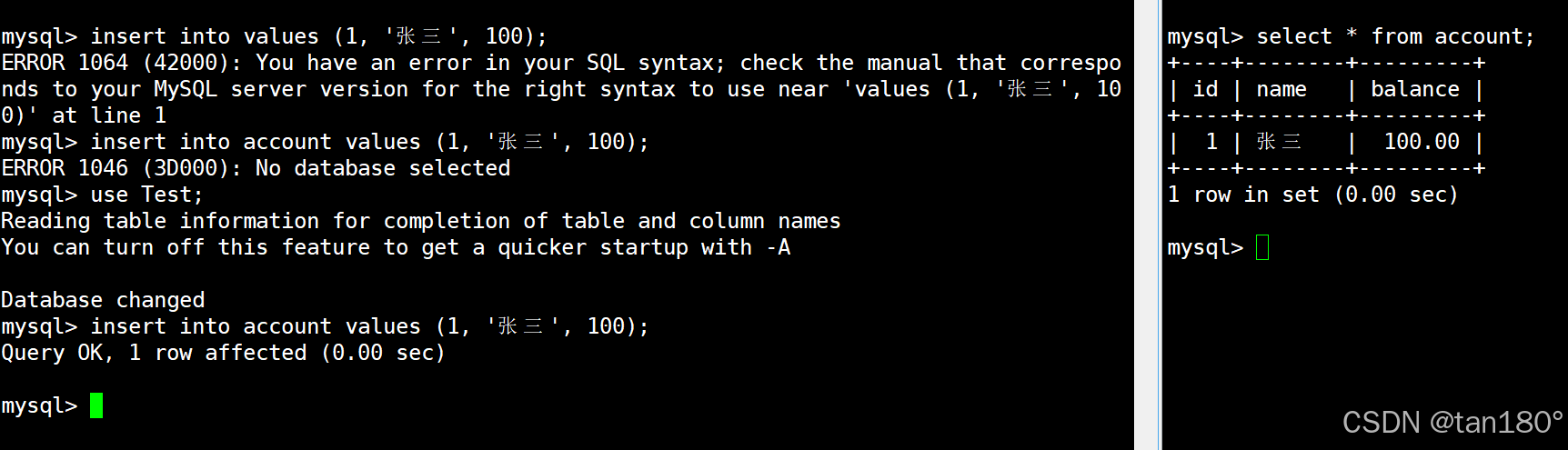
如果左终端中的事务在提交之前因为某些原因与 MySQL 断开连接,那么 MySQL 会自动让事务回滚到最开始,这时右终端中就看不到之前插入的记录了

我们再来看看持久性
在左终端中启动一个事务,在右终端查看银行用户表中的信息,现在在左终端中的事务向表中插入一条记录,由于隔离级别是读未提交,因此在右终端中能够查询到插入的这条记录

左终端中的事务在提交后与 MySQL 断开连接,这时右终端中仍然可以看到之前插入的记录,因为事务提交后数据就被持久化了
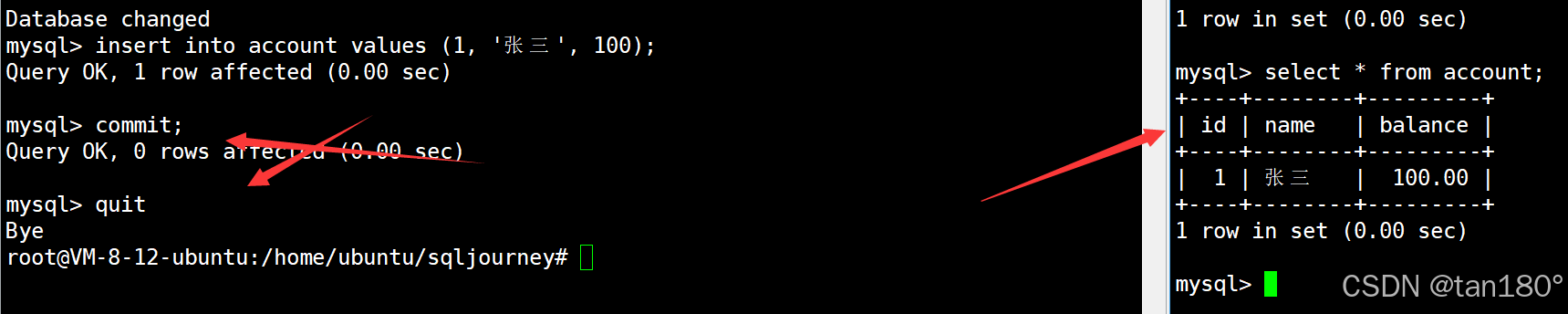
接着我们再来验证一下 begin 或者 start transaction 都必须使用 commit 才能持久化
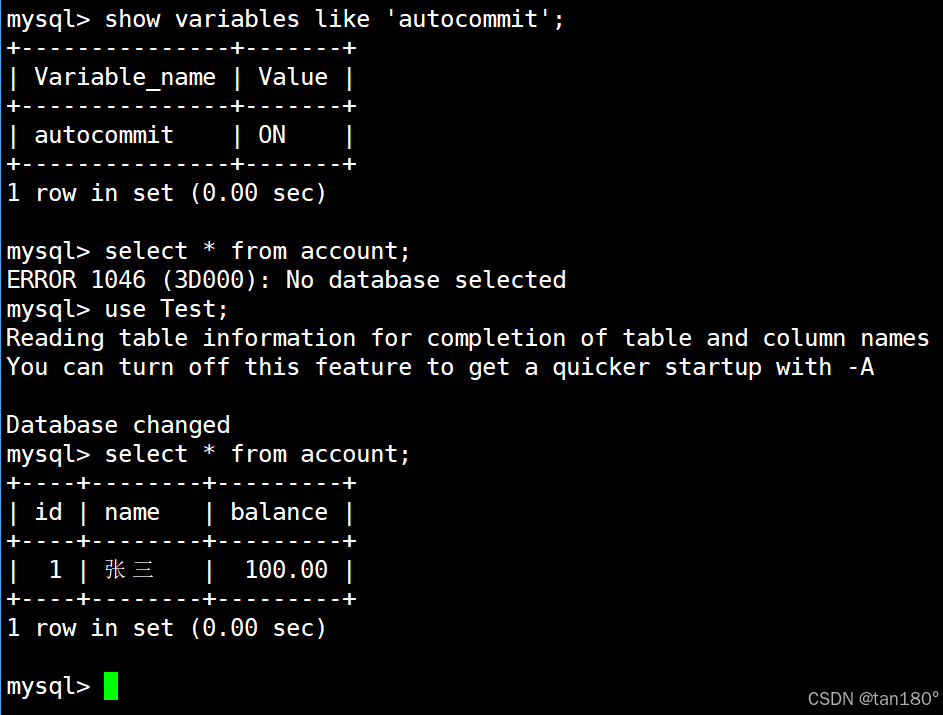
通过 show命令 查看 autocommit 的值为 ON ,表示事务的提交方式是 自动提交 ,此时银行用户表中有一条记录
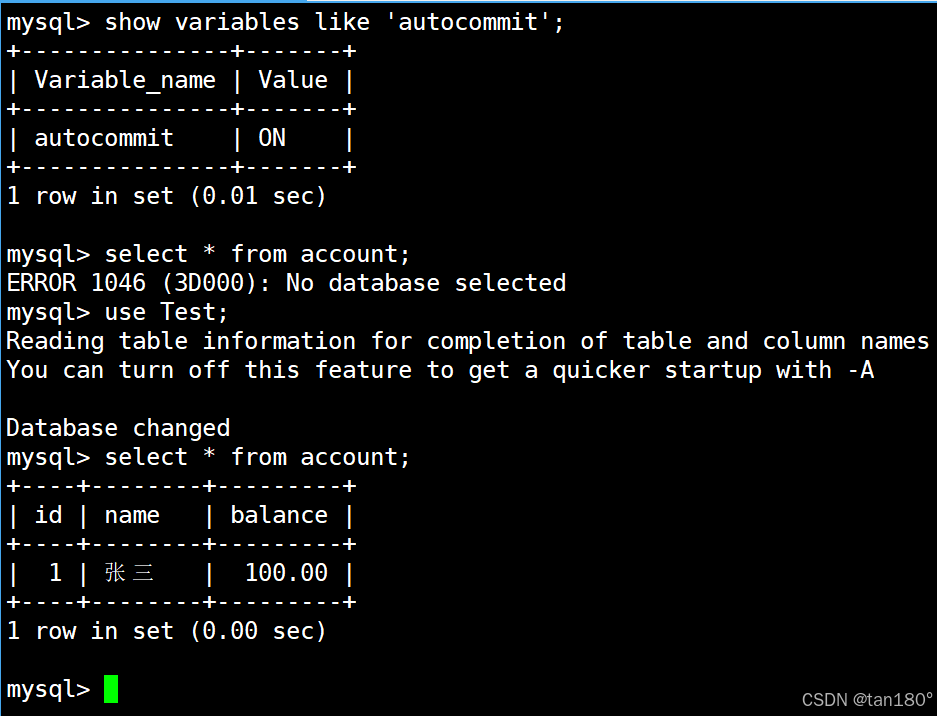
在左终端中启动一个事务并向表中新插入一条记录,由于隔离级别是读未提交,因此在右终端中能够查询到新插入的这条记录
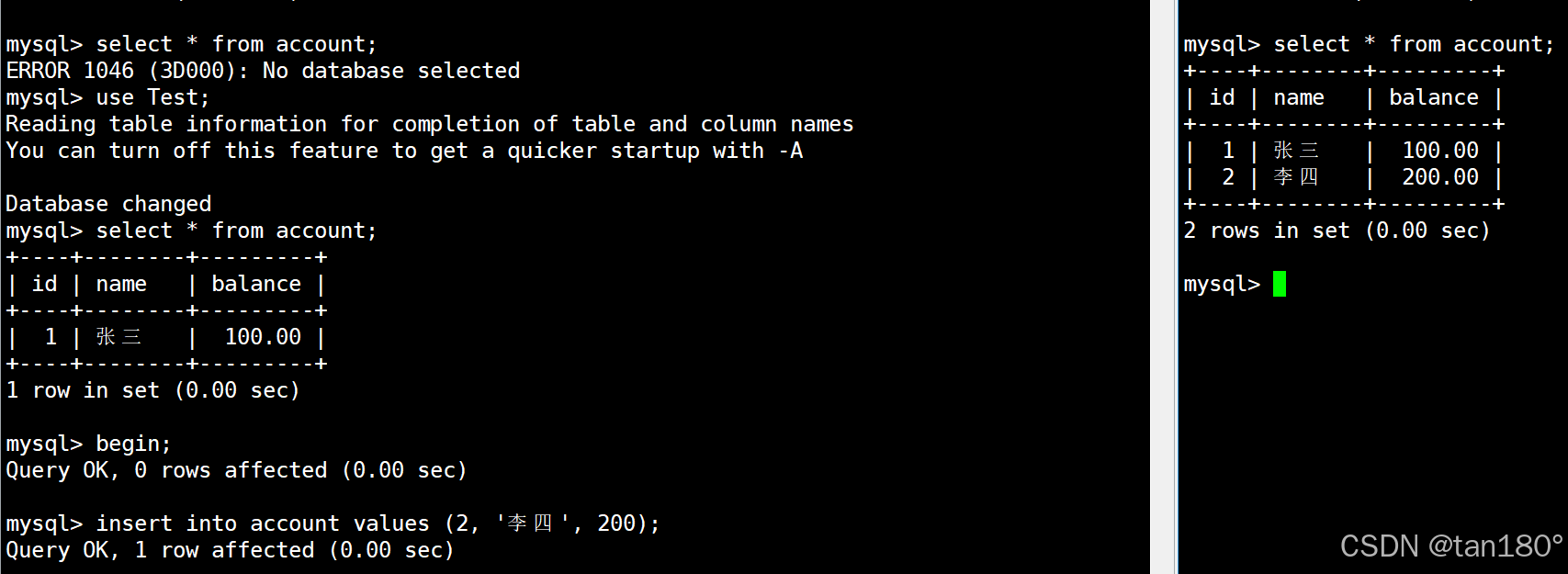
如果左终端中的事务在提交之前与 MySQL 断开连接,那么 MySQL 依旧会自动让事务回滚到最开始,这时右终端中就看不到之前新插入的记录了
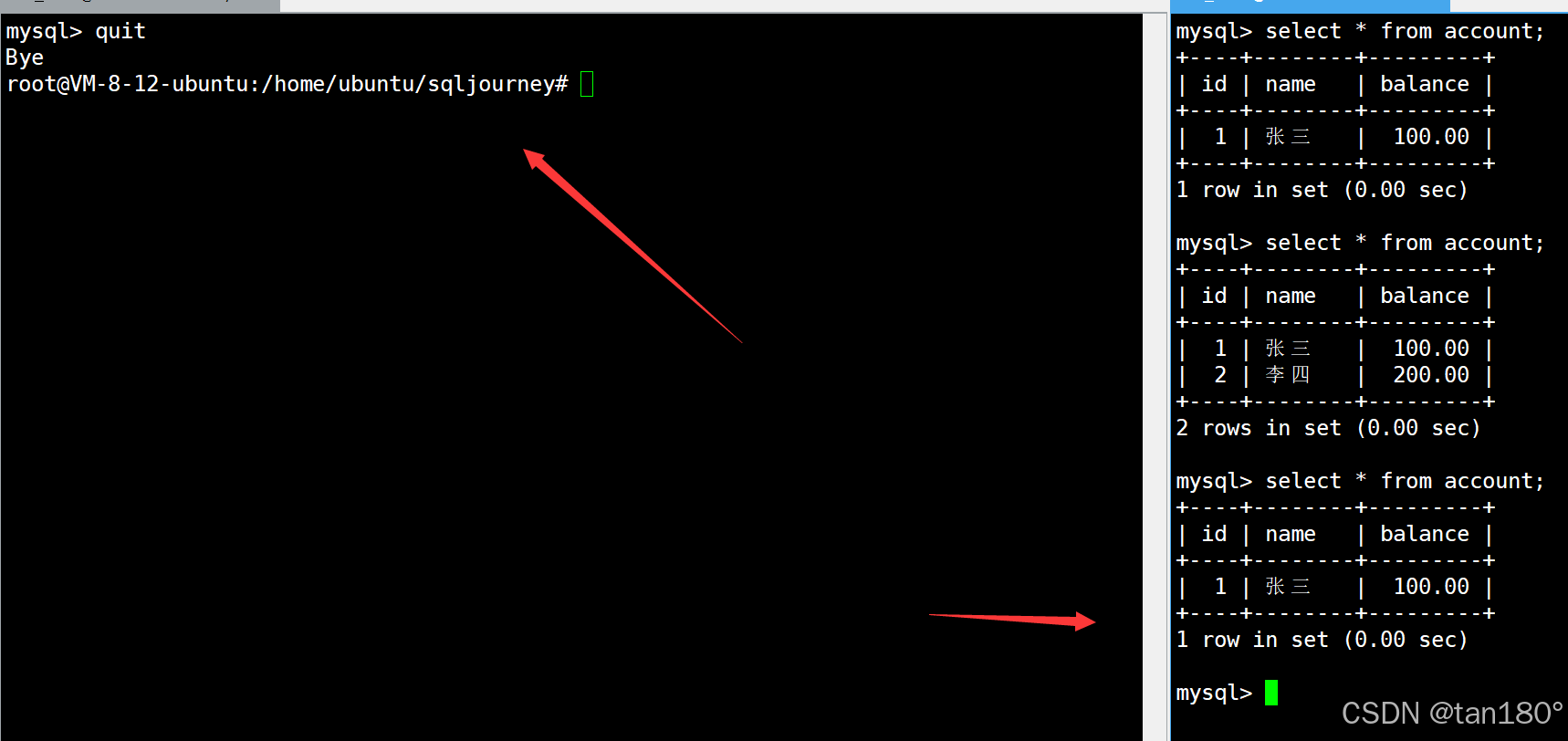
接下来我想演示一下 单条SQL 与 事务 的关系
- 实际 全局变量autocommit 是否被设置影响的是 单条SQL语句 ,InnoDB 中的每一条 SQL 都会默认被封装成事务。
- autocommit 为 ON ,则 单条SQL语句 执行后会自动被提交,如果为 OFF ,则 SQL语句 执行后需要使用commit 进行手动提交。
比如通过 show命令 查看 autocommit 的值为 ON ,表示事务的提交方式是 自动提交 ,此时银行用户表中有一条记录
在左终端中直接向表中新插入一条记录,由于隔离级别是读未提交,因此在右终端中肯定能够查询到新插入的这条记录

但就算左终端在执行单条SQL后不使用commit进行提交,而直接与MySQL断开连接,这时右终端仍然可以看到之前新插入的记录了,因为单条SQL在执行后被自动提交持久化了

相反,如果将autocommit设置为OFF,表示事务执行后需要手动提交,此时银行用户表中有两条记录
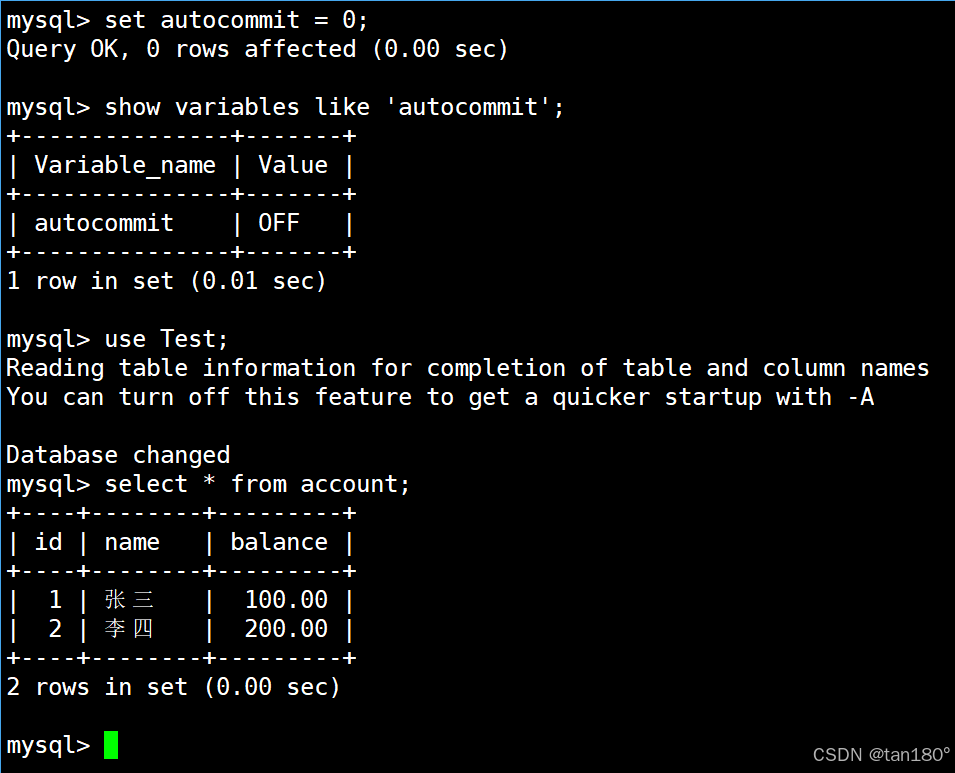
在左终端中直接向表中新插入一条记录,由于隔离级别是读未提交,因此在右终端中肯定能够查询到新插入的这条记录
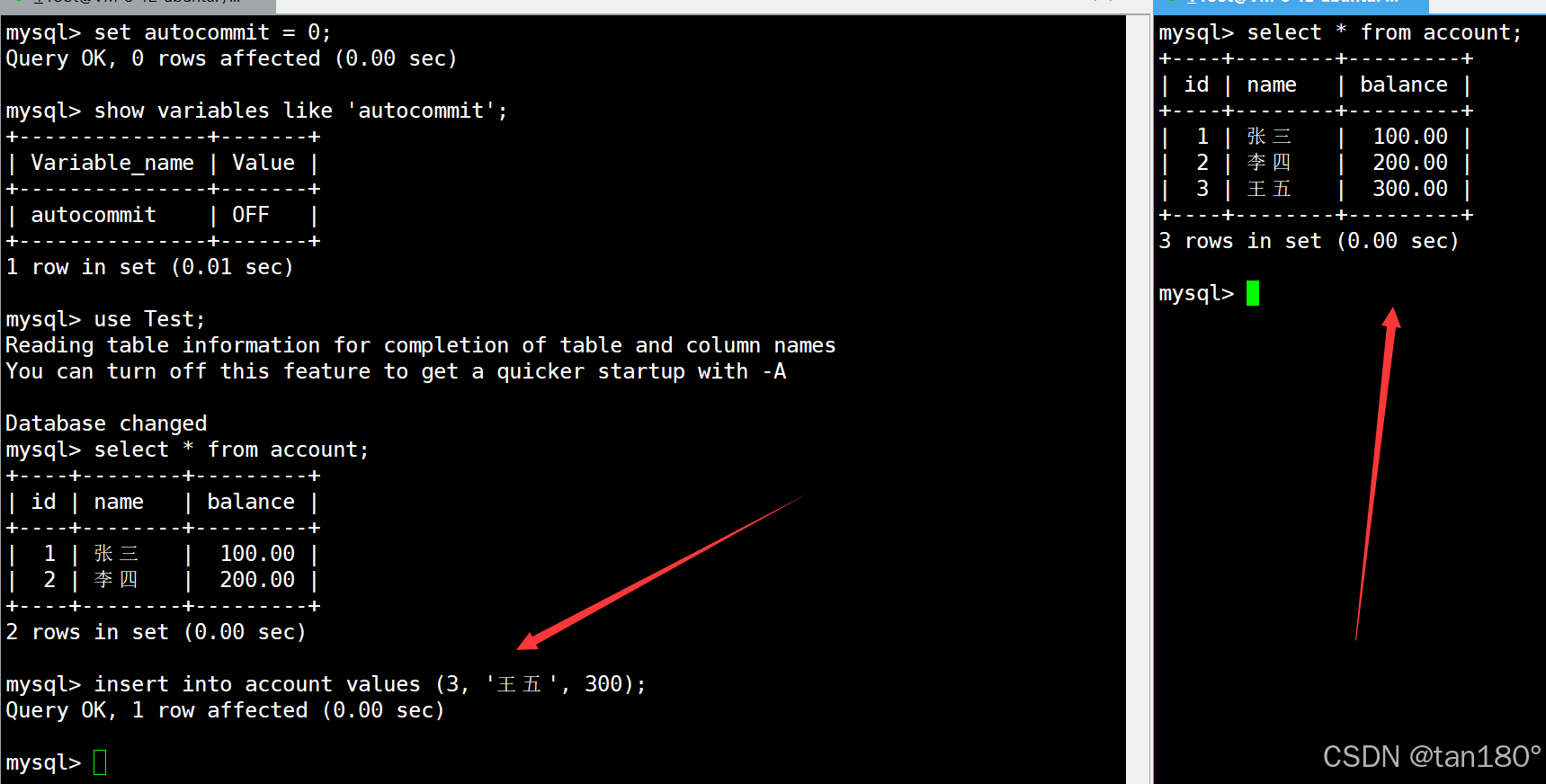
但如果此时左终端在执行 单条SQL 后不使用 commit 进行提交,而直接与 MySQL 断开连接,那么这时右终端中就看不到之前新插入的记录了,因为这时 单条SQL 执行后需要使用 commit手动提交 后才会持久化,在 commit之前 与 MySQL 断开连接则会自动进行回滚操作
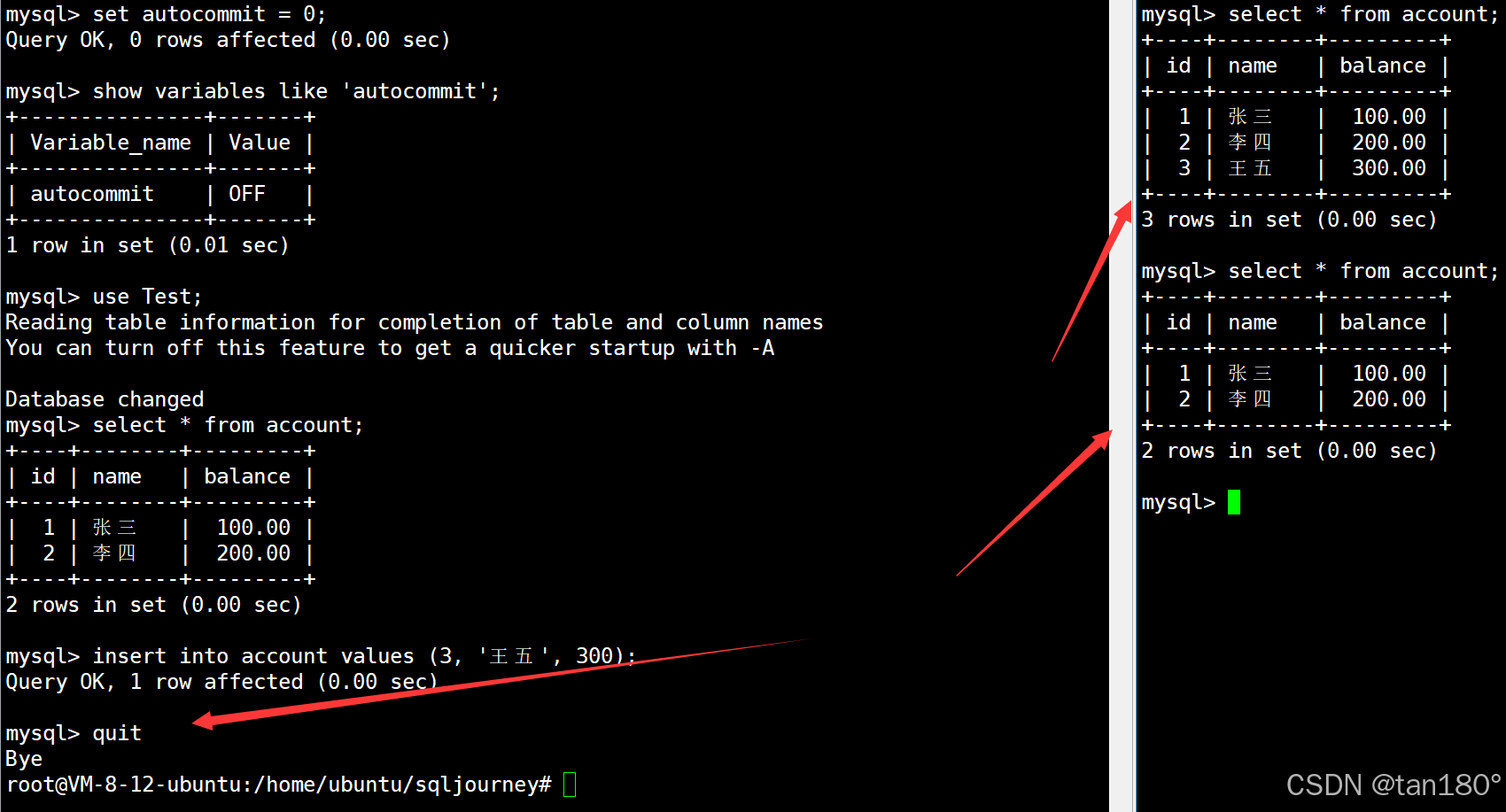
也就是说,实际我们之前一直都在使用 单SQL事务 ,只不过 autocommit 默认是打开的,因此 单SQL事务 执行后自动就被提交了。
总结
上篇完结,现在开始下篇!!!