openpyxl 流式读取xlsx文件(read_only=true)读不到sheet页中所有行
问题
最近用openpyxl读取一个xlsx文件时,文件sheet页中明明有多行数据,就是读取不到,仅仅读取了最前面的一行数据。定位发现openpyxl 流式读取xlsx文件(read_only=true,代码示例如下)时,
from openpyxl import load_workbook# 以只读模式加载工作簿
wb = load_workbook(filename='example.xlsx', read_only=True)# 选择要读取的工作表,这里假设选择第一个工作表
sheet = wb.active# 逐行遍历工作表中的数据
for row in sheet.rows:data_row = [cell.value for cell in row]print(data_row)# 关闭工作簿(虽然在这种模式下,openpyxl会自动管理资源,但显式关闭是个好习惯)
wb.close()首先会解析 xlsx文件名\xl\worksheets 目录下的*.xml文件中的dimension参数,根据dimension参数判断sheet页有多少行内容,然后按照这个行数信息逐行读取sheet页内容。出问题的xlsx文件用java的poi包流式写出的,使用了SXSSFSheet的flushRows()方法(无参数)手动刷新缓存的数据到磁盘,导致dimension没有更新。
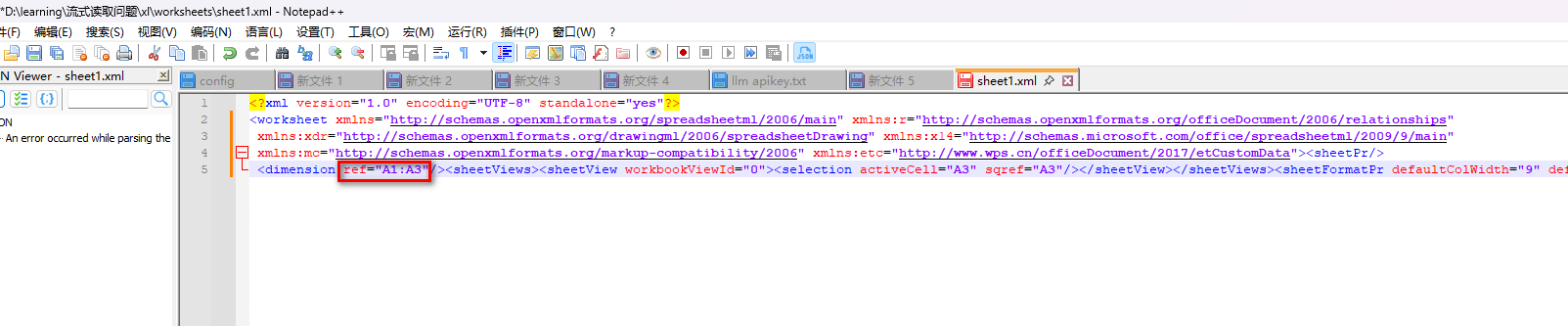
PS: xlsx文件其实是一个压缩包,可以将文件扩展名改成zip,进行解压,解压后可看到上面所说的xml文件信息。
详细原因分析
我们之前讨论过flushRows()和dimension的关系,现在更深入探讨一下。在Apache POI中,SXSSFSheet的flushRows()方法(无参数)会将内存中所有行刷新到磁盘临时文件,并清空内存中的行缓存。这会导致一个问题:当所有行都被刷新到磁盘后,内存中就没有行数据了,此时POI在调用write方法将数据写出到磁盘时计算dimension时可能会出错。
具体原因如下
sheet的dimension(即<dimension ref="A1:D10"/>)表示该Sheet的数据区域。POI在计算dimension时,通常依赖于sheet中缓存的行的信息(如第一个有数据的行和最后一个有数据的行)。对于SXSSFSheet,当行在内存中时,POI可以直接访问这些行来计算dimension;当行被刷新到磁盘后,POI需要依赖其他机制来记录或计算dimension。
问题发生时机
如果在写入数据后调用了SXSSFSheet.flushRows()(无参数)将所有行手动刷新到磁盘,那么内存中就没有行数据了。此时,如果POI在调用write方法生成最终的sheet.xml文件到磁盘,会因为缓存中没有该sheet页内容,导致dimension计算错误。
常见错误表现:
dimension被错误地设置为一个很小的范围(比如只包含一行或一列)。
或者dimension属性在sheet.xml中完全缺失。
解决方案
方法1) 避免在写入所有行后立即调用无参flushRows():除非必要,否则让POI自动管理刷新。在关闭工作簿之前,不需要手动刷新所有行,因为关闭工作簿时会自动处理。
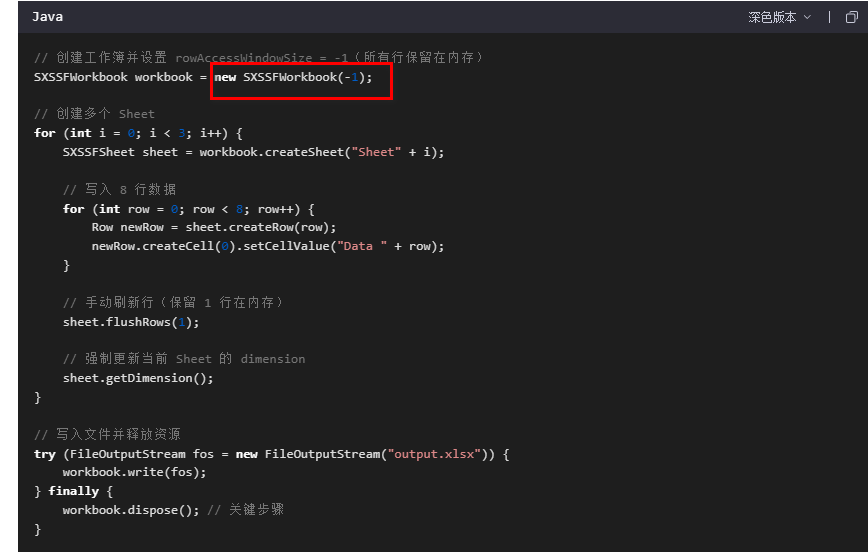
方法2)在调用flushRows()之前确保至少有一行留在内存中:使用带参数的flushRows(remaining)并确保remaining>0,这样至少有一行留在内存中,POI可以基于这一行和已刷新的行信息正确计算dimension。
方法3)使用randomWindowSize参数,将其设置成非零值,让POI自动刷新xlsx数据到磁盘。
参考信息:
randomWindowSize参数含义
- 正值:表示内存中将保留最近写入的行数。例如,如果设置为100,则内存中会保留最近写入的100行数据,当超过这个数量时,旧的行会被刷新到磁盘上。
- 0:表示不使用窗口大小限制,所有行都将保留在内存中,这与普通的
XSSFWorkbook行为类似,但可能会导致内存溢出问题。 - -1:表示完全禁用窗口大小限制,并且不会自动刷新行到磁盘。这意味着所有的行都会保留在内存中,直到显式调用
flushRows()方法或关闭工作簿。这种设置适用于需要对所有行进行随机访问的情况,但需要注意内存消耗。
remainning参数含义
remaining:指定刷新后保留在内存中的最近行数
作用:手动触发刷新时,系统会:
将所有早于最近 remaining 行的数据写入磁盘临时文件
从内存中移除这些已刷新的行
仅保留最新的 remaining 行在内存中
// 示例:保留最近50行在内存
sheet.flushRows(50); // 内存行变化示意图
Before: [行0, 行1, ..., 行99] // 内存中有100行
After: [行50, 行51, ..., 行99] // 仅保留最后50行POI测试代码
下面的代码可以复现dimension写入错误问题。
要想写出正确的dimension参数,可以修改第35行代码为
xssfSheet.flushRows(1); // 保留1行数据在内存中
package org.example;import org.apache.poi.xssf.streaming.SXSSFWorkbook;
import org.apache.poi.xssf.streaming.SXSSFSheet;
import org.apache.poi.ss.usermodel.Row;import java.io.FileOutputStream;
import java.util.Arrays;
import java.util.List;public class ExcelWriter {protected final SXSSFWorkbook xssfWorkbook;SXSSFSheet xssfSheet;public ExcelWriter(String sheetName) {// 禁用自动刷新xssfWorkbook = new SXSSFWorkbook(-1);// 创建一个新的工作表xssfSheet = xssfWorkbook.createSheet(sheetName);}public void writeData(List<List<String>> data) throws Exception {int rowNum = 0;for (List<String> rowData : data) {// 创建一行Row row = xssfSheet.createRow(rowNum++);int colNum = 0;for (String cellData : rowData) {// 在当前行中创建单元格并设置值row.createCell(colNum++).setCellValue(cellData);}// 如果需要,你可以在这里调用flushRows方法来手动刷新行到磁盘if (rowNum % 5 == 0) { // 每写入5行就刷新一次xssfSheet.flushRows(); // 不保留数据在内存中}}}public void saveToFile(String filePath) throws Exception {// 将工作簿写入文件try (FileOutputStream fileOut = new FileOutputStream(filePath)) {xssfWorkbook.write(fileOut);} finally {// 清理临时文件xssfWorkbook.dispose();}}public static void main(String[] args) throws Exception {ExcelWriter writer = new ExcelWriter("Sample Sheet");List<List<String>> data = Arrays.asList(Arrays.asList("Header1", "Header2", "Header3"),Arrays.asList("Row1-Col1", "Row1-Col2", "Row1-Col3"),Arrays.asList("Row2-Col1", "Row2-Col2", "Row2-Col3"),Arrays.asList("Row3-Col1", "Row3-Col2", "Row3-Col3"),Arrays.asList("Row4-Col1", "Row4-Col2", "Row4-Col3"));writer.writeData(data);writer.saveToFile("流式读取问题测试.xlsx");}
}运行上面的代码需要添加maven依赖项如下
<dependency><groupId>org.apache.poi</groupId><artifactId>poi</artifactId><version>5.2.4</version>
</dependency>
<dependency><groupId>org.apache.poi</groupId><artifactId>poi-ooxml</artifactId><version>5.2.4</version>
</dependency>