推荐算法召回:架构理解
🔍 一、召回服务的定位与挑战
召回层是推荐系统的第一道漏斗,负责从亿级候选集中筛选出千级别的相关项,其效果直接决定推荐效果的天花板。核心挑战包括:
- 低延迟约束:需在50ms内完成海量候选检索;
- 高召回率要求:98%的召回率需覆盖用户多样化兴趣;
- 数据漂移应对:实时用户行为分布变化需动态适应;
- 误杀控制:避免优质内容被过度过滤引发用户投诉。
⚙️ 二、召回服务核心架构
1. 多路召回并行
| 召回策略 | 实现方式 | 适用场景 |
|---|---|---|
| 规则召回 | 基于标签/热度/CTR/复购规则(如电商新人冷启动用Top-Sale召回) | 冷启动、高解释性需求 |
| 协同过滤 | Item-CF(余弦相似度计算物品关联)、User-CF(Jaccard系数用户分群) | 用户行为丰富场景 |
| 向量召回 | 双塔模型生成User/Item Embedding,通过Faiss进行ANN检索 | 长尾Query、语义匹配需求 |
2. 特征工程优化
- 实时特征:用户实时行为序列(点击、停留)通过Redis流式更新;
- 上下文特征:时间/地理位置/设备信息增强场景适配性;
- Embedding服务:BERT预训练文本特征,SIM模型处理长期行为序列。
3. 分层融合机制
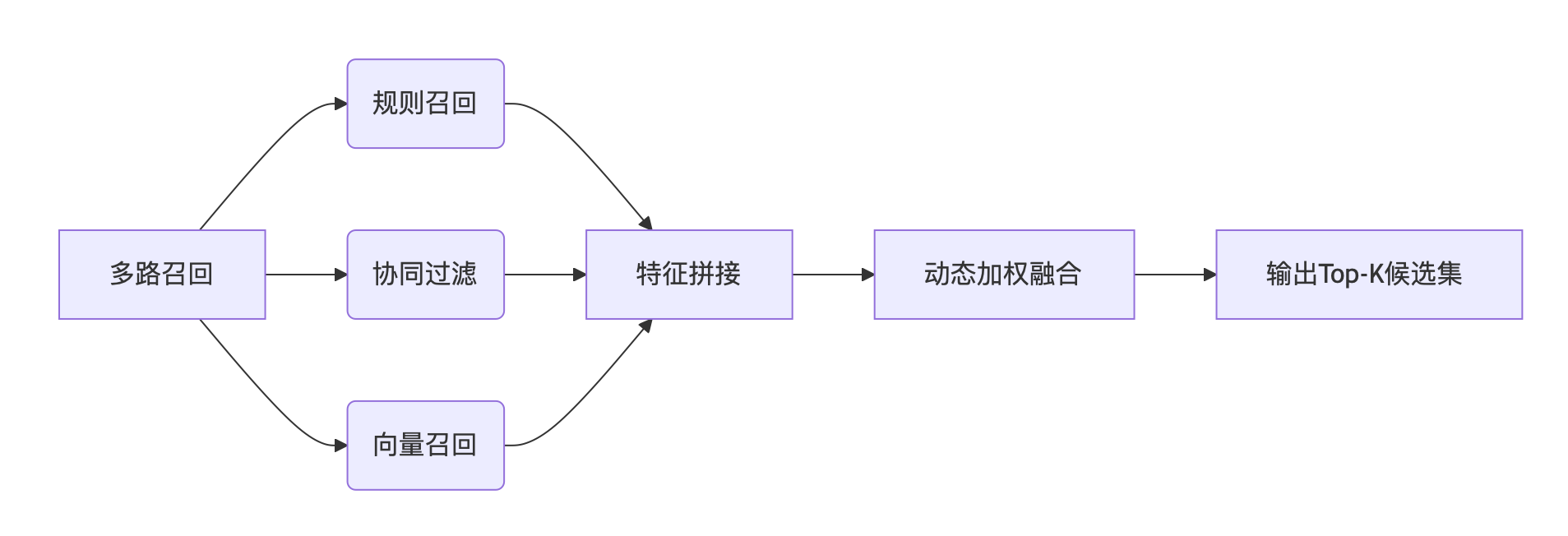
- 动态权重:根据AB测试反馈调整各策略权重(如电商场景提升复购策略权重);
- 去重抽样:
same_key_positions记录重复项位置,以1/n概率替换保障公平性。
🚀 三、高性能召回关键技术
1. 模型轻量化
- 知识蒸馏:将教师模型(如Transformer)知识迁移至轻量学生模型;
- 量化剪枝:FP32→INT8量化降低70%推理耗时,稀疏注意力减少计算量。
2. 工程优化
| 技术 | 收益 | 案例 |
|---|---|---|
| 分布式缓存 | Redis Cluster缓存热点特征,命中率>95% | 千万QPS下延迟<10ms |
| Faiss+GPU加速 | 亿级向量检索提速5倍 | 电商场景50ms召回千万商品 |
| 异步流处理 | Kafka实时更新行为特征 | 数据漂移响应时间<1s |
3. 误杀控制方案
- 多模型投票:协同过滤+向量召回融合降低单一模型误判率;
- 损失函数优化:引入稀疏惩罚项,提升长尾物品曝光权重;
- 实时反馈闭环:用户投诉触发策略动态降级。
📊 四、行业最佳实践
1. 电商场景(某头部平台)
- 策略组合:30%复购召回(生鲜)+ 40%向量召回(长尾商品)+ 30%规则召回(新人);
- 效果:召回率98.2%,误杀率下降60%。
2. 内容平台(短视频推荐)
- 序列建模:Transformer编码用户观看序列,捕捉多峰兴趣;
- 冷启动优化:Top-CTR召回保障新内容曝光。
🔮 五、未来演进方向
- RAG增强召回:结合LLM理解用户Query语义,生成检索增强指令;
- 端云协同:边缘设备实时生成用户Embedding,降低云端压力;
- 多场景自适应:通过Domain Adaptation技术实现跨场景知识迁移。
架构设计箴言:召回层的本质是“在相关性、多样性、时效性间寻找动态平衡”6。在50ms的极限挑战下,需通过 轻量模型+智能路由+硬件加速 构建技术护城河,而多路召回融合仍是应对数据漂移与误杀风险的终极方案。