基于pandas,按日期时间排序,计算每个连续段的开始时间、结束时间,以及时长
1:项目内容:
1.根据所给数据
2. 按日期时间排序
3. 计算相邻两个时间差(分钟),判断是否连续(<=1分钟)
4. 生成连续段编号(连续段内时间差都<=1分钟,一旦大于1分钟就断开)
5. 计算每个连续段的开始时间、结束时间,以及时长(如果开始时间等于结束时间,则时长为1分钟;否则为分钟数)
6. 将每个连续段分配到开始时间所在的日期(注意:这里我们只取日期部分,不取时间)
7. 对每个日期,将该日期的所有连续段按开始时间排序(实际上生成时就是按时间顺序的),然后每个连续段取起、止、时长三个值。
8. 每个日期取全部的连续段
9. 计算每个日期的总时长(该日期所有连续段的时长和)
10. 输出表格:列包括日期,然后依次是每个时间段的起、止、时长,最后是总时长。
2:输入示例
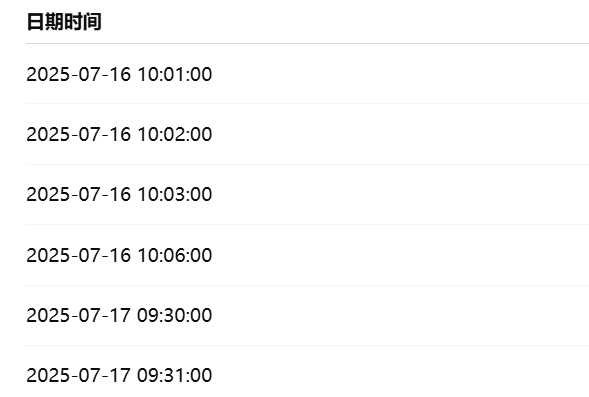
3:输出示例
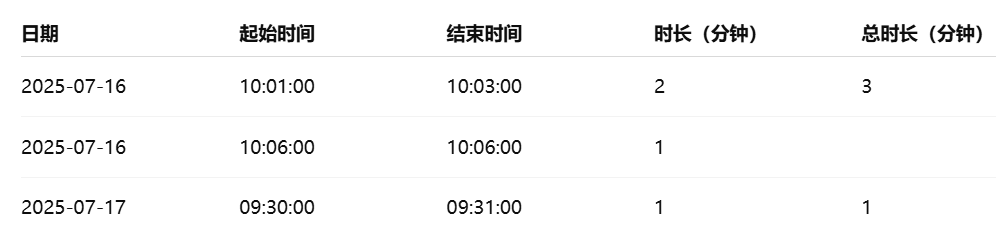
import pandas as pd
import os# 1. 读取数据(确保你使用的是CSV而非Excel)
df = pd.read_csv('C:/Users/Administrator/Desktop/统计/#3.csv', encoding='utf-8-sig')# 2. 筛选平均值范围
df = df[(df['平均值'] > 0) & (df['平均值'] < 11)].copy()# 3. 转换日期时间格式# 4. 排序
df = df.sort_values('日期时间').reset_index(drop=True)# 5. 计算相邻时间差(分钟)
df['时间差'] = df['日期时间'].diff().dt.total_seconds().div(60).fillna(0)# 6. 分段(时间差 >1 分钟视为新段)
df['段编号'] = (df['时间差'] > 1).cumsum()# 7. 聚合段落信息
segments = df.groupby('段编号').agg(起始时间=('日期时间', 'first'),结束时间=('日期时间', 'last')
).reset_index()# 8. 计算时长(分钟)
segments['时长'] = (segments['结束时间'] - segments['起始时间']).dt.total_seconds().div(60).astype(int)
segments['时长'] = segments['时长'].apply(lambda x: 1 if x == 0 else x)# 9. 添加日期字段
segments['日期'] = segments['起始时间'].dt.date# 10. 构造每个段的字符串表示:起始~结束(X分钟)
segments['时间段'] = segments.apply(lambda row: f"{row['起始时间'].strftime('%H:%M')}~{row['结束时间'].strftime('%H:%M')}({row['时长']}分钟)", axis=1)# 11. 每天作为一行,将时间段展开成多列
pivot_data = segments.groupby('日期').agg({'时间段': lambda x: list(x),'时长': 'sum'
}).reset_index()# 12. 拆分每个时间段为独立列
max_len = pivot_data['时间段'].apply(len).max()
for i in range(max_len):pivot_data[f'时段{i+1}'] = pivot_data['时间段'].apply(lambda x: x[i] if i < len(x) else '')# 13. 重命名总时长列
pivot_data.rename(columns={'时长': '总时长(分钟)'}, inplace=True)# 14. 删除原始时间段列
pivot_data.drop(columns='时间段', inplace=True)# 15. 保存结果
output_path = 'C:/Users/Administrator/Desktop/统计/output/#3汇总.xlsx'
os.makedirs(os.path.dirname(output_path), exist_ok=True)
pivot_data.to_excel(output_path, index=False)# 16. 打印前几行结果
print(pivot_data.head())