MySQL之SQL 优化全攻略:从原理到实战
大家好呀!今天来跟大家好好聊聊 MySQL 的 SQL 优化~不管是开发还是运维,写得一手高效的 SQL 都是必备技能,毕竟谁也不想让系统卡成 PPT 对吧😂 这篇文章会从 MySQL 的底层逻辑讲到实际优化技巧,全是干货,赶紧码住!
目录
一、先搞懂 MySQL 的 "五脏六腑"—— 逻辑架构 🧠
1. 四层架构拆解
2. 两大存储引擎 PK:MyISAM vs InnoDB 🆚
二、SQL 执行顺序:别被书写顺序骗了!📝
三、索引为啥快?揭秘 B+Tree 的 "黑科技" 🌳
1. 各种结构的 "坑"
2. B+Tree 的优势 ✅
四、Explain:SQL 的 "体检报告" 🩺
1. type:执行类型(越左越好)
2. extra:额外信息
3. id:查询序号
4. key:实际使用的索引
5. key_len:索引使用的字节长度
6. ref:索引关联的内容
五、SQL 优化实战:避开这些 "坑" 🚫
1. 全字段匹配最棒 ✨
2. 最佳左前缀法则 📏
3. 索引列别计算 🧮
4. 范围条件右边失效 ➡️
5. 别用%开头的 like ❌
6. 字符串加单引号 📌
7. 少用 or,用 union 替代 🤝
8. 覆盖索引:把 "目录" 变 "全书" 📚
9. 批量操作:少点外卖,多囤粮 🚚
10. 拒绝 SELECT *:只取所需,不搬全家 🏠
六、总结:优化口诀走一波 🌟
一、先搞懂 MySQL 的 "五脏六腑"—— 逻辑架构 🧠
MySQL 的逻辑架构就像一个工厂,每个环节各司其职,搞懂它才能明白优化的根源~
1. 四层架构拆解
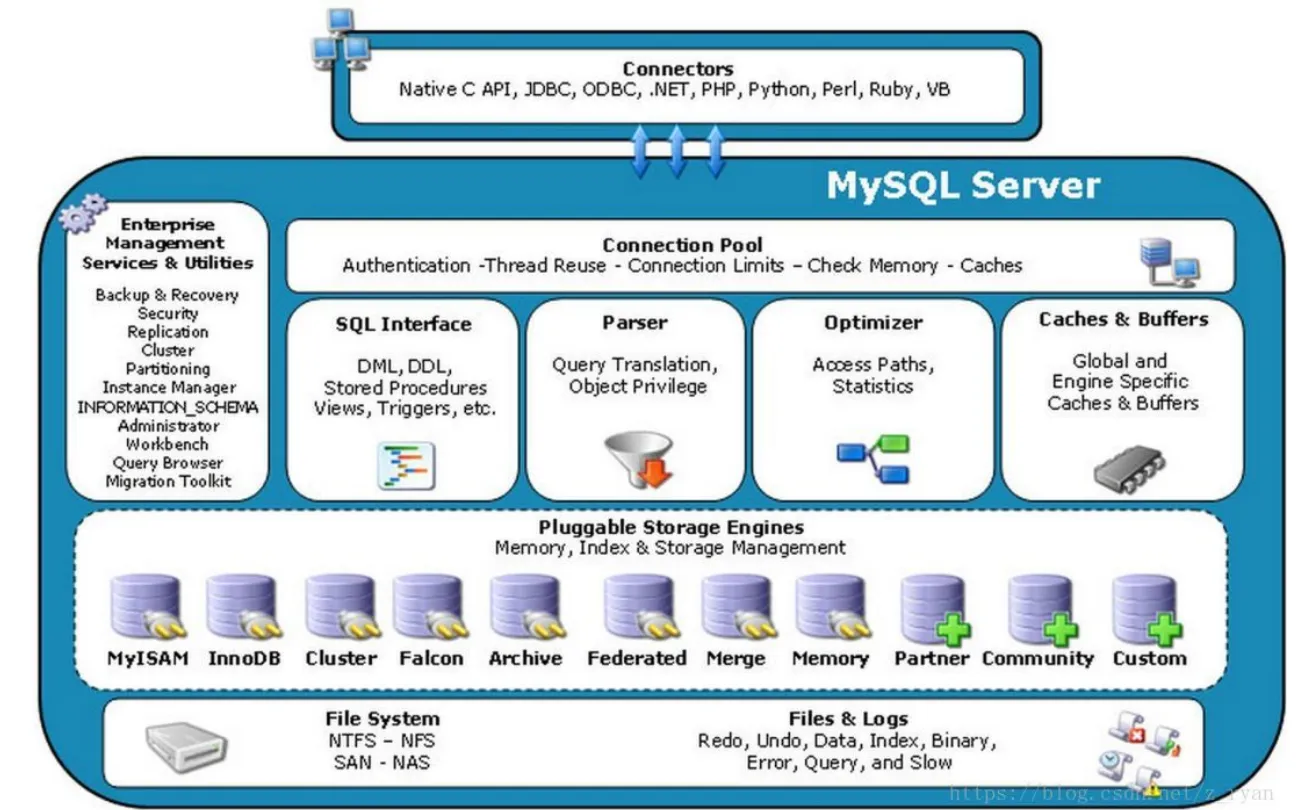
- 连接层:最上层的 "门卫",负责客户端连接(比如 TCP/IP、本地 sock),处理认证、线程池管理。比如我们用 Navicat 连数据库,就是在这一层建立连接啦~
- 服务层:"核心车间",负责 SQL 的解析、优化、缓存等。比如 SQL 语句进来后,先由解析器处理,再由优化器找最优执行方案。
- 引擎层:"存储引擎",数据怎么存、怎么取全看它!MySQL 支持多种引擎,最常用的是 MyISAM 和 InnoDB。
- 存储层:"仓库",把数据存在磁盘上(比如 NTFS、NFS 文件系统)。
2. 两大存储引擎 PK:MyISAM vs InnoDB 🆚
| 对比项 | MyISAM | InnoDB |
|---|---|---|
| 主外键 | 不支持 | 支持 |
| 事务 | 不支持 | 支持(ACID 特性) |
| 锁机制 | 表锁(操作一条记录锁全表) | 行锁(只锁操作的行) |
| 缓存 | 只缓存索引 | 缓存索引 + 真实数据 |
| 表空间 | 小 | 大 |
| 适合场景 | 读多写少(如博客列表) | 写多 / 需事务(如订单) |
这两个引擎,MyISAM 注重性能,读取数据的速度非常的快,InnoDB注重事务,注重安全,读取速度比较慢。
我们企业中,一般会做一个MySQL主从复制 可以将主的MySQL服务器,配置为InnoDB, 从服务器可以配置为MyISAM ,因为它负责读。
可以做到读写分离。
👉 举个栗子:电商系统的订单表必须用 InnoDB(支持事务,防止下单时数据错乱);而商品列表页查询多,可用 MyISAM 提升读速度。实际中常搞 "主从复制":主库用 InnoDB(负责写),从库用 MyISAM(负责读),实现读写分离~
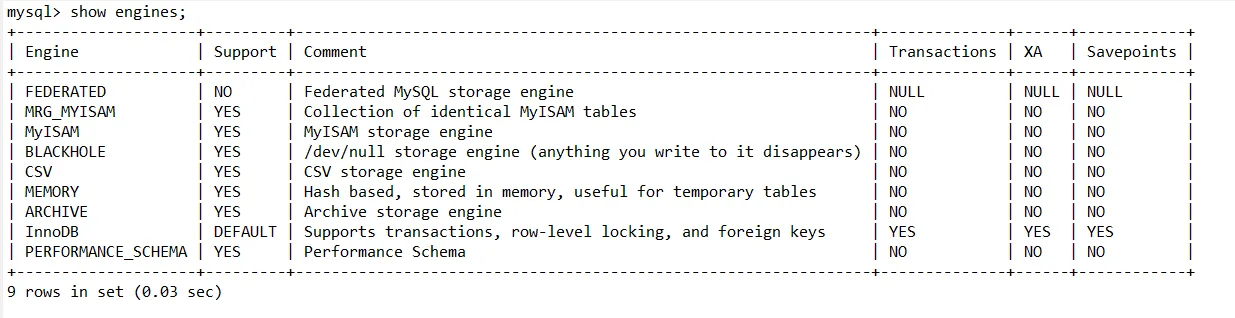
我们可以使用show engines的sql命令来查看当前数据库支持哪些存储引擎

二、SQL 执行顺序:别被书写顺序骗了!📝
我们写 SQL 的顺序是:SELECT → FROM → WHERE → GROUP BY → HAVING → ORDER BY,但 MySQL 执行时完全不一样!正确顺序是:
FROM:先确定要查的表(比如从 user 表和 order 表开始)ON:处理表连接的条件(比如 user.id = order.user_id)JOIN:关联表(把符合 ON 条件的记录拼起来)WHERE:过滤行(比如 age > 18)GROUP BY:分组(比如按部门分组)HAVING:过滤组(比如分组后取平均工资 > 10k 的组)SELECT:提取字段(比如选 name、salary)DISTINCT:去重(比如去掉重复的 name)ORDER BY:排序(比如按 salary 降序)LIMIT:限制结果条数(比如取前 10 条)
👉 例子:查 "部门 30 中,工资 > 5k 的员工,按工资排序取前 3"
SELECT DISTINCT name, salary
FROM employee
JOIN department ON employee.dept_id = department.id
WHERE department.id = 30 AND salary > 5000
GROUP BY name -- 假设按姓名分组(实际可能按id更合理)
HAVING COUNT(*) = 1 -- 排除重复记录
ORDER BY salary DESC
LIMIT 3;执行时先关联表,再过滤部门和工资,分组后过滤,最后选字段、排序、限制条数~
三、索引为啥快?揭秘 B+Tree 的 "黑科技" 🌳
索引就像书的目录,能快速定位数据。但为啥 MySQL 偏爱 B+Tree 而不是其他结构?
1. 各种结构的 "坑"
- Hash:快是快,但只支持等值查询(比如
id=10),范围查询(id>10)直接歇菜❌ - 二叉树 / 平衡二叉树:数据多了树会很高(比如 100 万数据可能要 20 层),查一次要读 20 次磁盘,太慢❌
- B Tree:每个节点存索引 + 数据,导致一次读(16KB)能存的索引少,范围查询不方便❌
2. B+Tree 的优势 ✅
- 非叶子节点只存索引,不存数据,16KB 能存更多索引(比如一次读 1000 个索引)
- 叶子节点连起来(像链表),范围查询超方便(比如
id>10 and id<20直接扫叶子节点) - 所有数据存在叶子节点,查询更稳定
👉 例子:查id between 100 and 200,B+Tree 直接定位到 100 的叶子节点,顺着链表读到 200,效率拉满!
四、Explain:SQL 的 "体检报告" 🩺
写了 SQL 不知道快不快?用EXPLAIN分析一下就知道!它能告诉你 SQL 的执行细节,重点看这几个字段:
1. type:执行类型(越左越好)
system > const > eq_ref > ref > range > index > all
- System:表只有一行记录(等于系统表),这是const类型的特列,平时不会出现,这个也可以忽略不计,单表单记录可以出现。
- const:主键 / 唯一索引查询,一次到位!比如
select * from user where id=1✅ - Eq_ref: 唯一性索引扫描,对于每个索引键,表中只有一条记录与之匹配。常见于主键或唯一索引扫描
- ref:非唯一索引,返回匹配单值的多行。比如
select * from user where name='张三'(name 是普通索引) ✅ - range:范围查询(between、in、> 等)。比如
select * from user where age between 18 and 30✅ - Index: 称之为覆盖索引
- all:全表扫描!数据量大时巨慢,必须优化❌(比如
select * from user where age>18没建 age 索引)
2. extra:额外信息
- Using filesort:排序用了磁盘文件,慢!(比如
order by age但 age 没索引)❌ - Using temporary:用了临时表,慢!(比如
group by name但 name 没索引)❌ - Using index:覆盖索引,只查索引不读数据,快!✅(比如索引是
(name, age),查询select name, age from user where name='张三')
👉 例子:分析下面的 SQL
EXPLAIN SELECT * FROM user WHERE age > 18 ORDER BY name;如果type=ALL且extra=Using filesort,说明没建 age 索引,且 name 排序用了文件,得优化!
3. id:查询序号
- id 相同:执行顺序由上至下(比如多表连接时,先执行上面的表操作)。
- id 不同:序号越大优先级越高,先执行(比如子查询,内层查询 id 更大,会先跑)。
👉 例子:select * from user where id in (select user_id from order)中,子查询select user_id from order的 id 更大,会先执行。
4. key:实际使用的索引
- 显示 SQL 真正用到的索引名称(如果为
NULL,说明没用到索引)。 - 注意:
possible_keys是 "可能用到的索引",但key才是 "实际用到的",两者不一致时说明索引没被正确使用(比如索引失效)。
👉 例子:possible_keys显示有age_idx,但key为NULL,说明查询时age_idx索引失效了(可能因为用了age+1>18这类计算)。
5. key_len:索引使用的字节长度
- 表示索引字段使用的字节数,可判断索引是否被完整使用(长度越短,说明用到的索引字段越少,在满足需求的前提下越优)。
👉 例子:复合索引(name, age),若key_len只计算了name的长度,说明age字段的索引没被用到。
6. ref:索引关联的内容
- 表示索引是和什么关联的(比如常量、其他表的字段),反映索引的具体使用场景。
👉 例子:ref=const说明是常量等值查询(如where id=1);ref=order.user_id说明是表连接时,用了order表的user_id字段关联索引。
五、SQL 优化实战:避开这些 "坑" 🚫
索引虽好,但一不小心就会失效,记住这些原则:
1. 全字段匹配最棒 ✨
创建索引(name, age, pos),查询where name='张三' and age=20 and pos='开发',索引全用上!
2. 最佳左前缀法则 📏
索引顺序是name→age→pos,查询时必须从左往右用,不能跳!
- 有效:
where name='张三'、where name='张三' and age=20 - 失效:
where age=20(跳过 name)、where name='张三' and pos='开发'(跳过 age,pos 索引失效)
3. 索引列别计算 🧮
where id+1=10会让索引失效!改成where id=9
4. 范围条件右边失效 ➡️
where name='张三' and age>20 and pos='开发'中,age 是范围查询,后面的 pos 索引失效
5. 别用%开头的 like ❌
where name like '%张三'索引失效!改成where name like '张三%'(前缀匹配)
6. 字符串加单引号 📌
where name=123会隐式转换类型,索引失效!改成where name='123'
7. 少用 or,用 union 替代 🤝
where id=1 or id=2可能失效,改成:
select * from user where id=1
union
select * from user where id=2;8. 覆盖索引:把 "目录" 变 "全书" 📚
如果查询的字段全部包含在索引中,就无需回表查询数据,这种索引称为覆盖索引。
👉 例子:
创建复合索引(name, age),查询select name, age from user where name='张三'时,索引直接包含所有字段,查询速度飞起!
注意:覆盖索引要求索引包含SELECT、WHERE、ORDER BY等子句中的所有字段。
9. 批量操作:少点外卖,多囤粮 🚚
- 批量插入:用
INSERT INTO ... VALUES (1,'a'),(2,'b')代替逐条插入,减少网络交互。 - LOAD DATA INFILE:从文件导入数据,速度比
INSERT快 10 倍以上!
LOAD DATA INFILE '/path/data.csv' INTO TABLE user;- INSERT SELECT:从其他表复制数据时,用一条语句搞定:
INSERT INTO target_table (col1, col2) SELECT col1, col2 FROM source_table;10. 拒绝 SELECT *:只取所需,不搬全家 🏠
- 反例:
SELECT * FROM user会读取所有字段,包括大字段(如TEXT),增加 IO 和网络传输。 - 正例:
SELECT id, name FROM user只取需要的字段,减少内存和带宽消耗。
额外好处:使用覆盖索引时,SELECT *会导致回表,而明确字段可直接走索引。
六、总结:优化口诀走一波 🌟
全字段匹配好,左前缀要记牢;
索引不列计算,范围右边失效了;
% 开头 like 别用,字符串加引号;
or 换 union,explain 常检查;
type 避开 ALL,extra 无 filesort~
希望这篇文章能帮你写出飞一般的 SQL!有问题欢迎留言讨论哦~😊