深度学习笔记002-引言--日常生活总的机器学习、训练模型的过程、关键组件、各种机器学习问题
一、日常生活中的机器学习
假如需要我们编写程序来响应一个“唤醒词”(比如“Alexa”“小爱同学”和“Hey Siri”)。 我们试着用一台计算机和一个代码编辑器编写代码。 问题看似很难解决:麦克风每秒钟将收集大约44000个样本,每个样本都是声波振幅的测量值。而该测量值与唤醒词难以直接关联。那又该如何编写程序,令其输入麦克风采集到的原始音频片段,输出是否{是,否}(表示该片段是否包含唤醒词)的可靠预测呢?我们对编写这个程序毫无头绪,这就是需要机器学习的原因。
通常,即使我们不知道怎样明确地告诉计算机如何从输入映射到输出,大脑仍然能够自己执行认知功能。 换句话说,即使我们不知道如何编写计算机程序来识别“Alexa”这个词,大脑自己也能够识别它。 有了这一能力,我们就可以收集一个包含大量音频样本的数据集(dataset),并对包含和不包含唤醒词的样本进行标记。 利用机器学习算法,我们不需要设计一个“明确地”识别唤醒词的系统。 相反,我们只需要定义一个灵活的程序算法,其输出由许多参数(parameter)决定,然后使用数据集来确定当下的“最佳参数集”,这些参数通过某种性能度量方式来达到完成任务的最佳性能。
参数:参数可以被看作旋钮,旋钮的转动可以调整程序的行为。
模型:任一调整参数后的程序被称为模型(model)。
模型族:通过操作参数而生成的所有不同程序(输入-输出映射)的集合称为“模型族”。
学习算法:使用数据集来选择参数的元程序被称为学习算法(learning algorithm)
二、训练模型过程
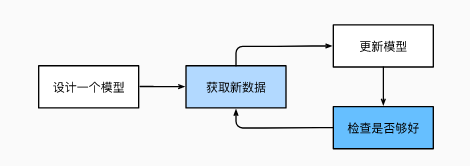
在机器学习中,学习(learning)是一个训练模型的过程。 通过这个过程,我们可以发现正确的参数集,从而使模型强制执行所需的行为。 换句话说,我们用数据训练(train)模型。训练过程通常包含如下步骤:
-
从一个随机初始化参数的模型开始,这个模型基本没有“智能”;
-
获取一些数据样本(例如,音频片段以及对应的是或否标签);
-
调整参数,使模型在这些样本中表现得更好;
-
重复第(2)步和第(3)步,直到模型在任务中的表现令人满意。
三、机器学习中的关键组件
首先介绍一些核心组件。无论什么类型的机器学习问题,都会遇到这些组件:
-
可以用来学习的数据(data);
-
如何转换数据的模型(model);
-
一个目标函数(objective function),用来量化模型的有效性;
-
调整模型参数以优化目标函数的算法<