1 Studying《Computer Vision: Algorithms and Applications 2nd Edition》6-10
目录
Chapter 6 Recognition
6.1 实例识别
6.2 图像分类
6.3 目标检测
6.4 语义分割
6.5 视频理解
6.6 视觉和语言
6.7 其他阅读材料
6.8 练习
Chapter 7 Feature detection and matching
7.1 点和斑点
7.2 边缘和轮廓
7.3 剖面跟踪
7.4 线与消失点
7.5 分段
7.6 其他阅读材料
Chapter 8 Image alignment and stitching
8.1 两两比对
8.2 图像拼接
8.3 全球协调
8.4 合成
8.5 其他阅读材料
Chapter 9 Motion estimation
9.1 翻译对齐
9.2 参数运动
9.3 光流
9.4 分层运动
9.5 额外阅读
9.6 练习
Chapter 10 Computational photography
10.1 光度校准
10.2 高动态范围成像
10.3 超分辨率、去噪和模糊消除
10.4 图像抠像和合成
10.5 纹理分析与合成
10.6 额外阅读
10.7 练习
Chapter 6 Recognition
6.1实例识别 346
6.2图像分类 349
6.2.1基于特征的方法 350
6.2.2深度网络 358
6.2.3应用:视觉相似性搜索 360
6.2.4人脸识别 363
6.3目标检测 370
6.3.1人脸检测 371
6.3.2行人检测 376
6.3.3一般对象检测 379
6.4语义分割 387
6.4.1应用:医学图像分割 390
6.4.2实例分割 391
6.4.3全景分割 392
6.4.4应用:智能照片编辑 394
6.4.5姿态估计 395
6.5视频理解 396
6.6视觉和语言 400
6.7其他阅读材料 409
6.8练习 413

图6.1各类识别:(a)基于图像结构的人脸识别(Fischler和Elschlager 1973)©1973年IEEE;(b)实例(已知对象)识别(Lowe 1999)©1999年IEEE;(c)实时人脸检测(Viola和Jones 2004)©2004年Springer;(d)基于特征的识别(Fergus、Perona和Zisserman 2007)©2007年Springer;(e)使用Mask R-CNN进行实例分割(He、Gkioxari等人2017)©2017年IEEE;(f)姿态
估计(G ler、Neverova和Kokkinos2018)©2018 IEEE;(g)全景分割
(Kirillov,He等人,2019)©2019 IEEE;(h)视频动作识别(Feichtenhofer,Fan等人,2019);(i)图像描述(Lu,Yang等人,2018)©2018 IEEE。
在这本书涵盖的所有计算机视觉主题中,视觉识别在过去十年经历了最大的变化和最快的发展,部分原因是由于更大规模的标注数据集的可用性以及深度学习方面的突破(图5.40)。在本书的第一版(Szeliski2010)中,识别是最后一章,因为它被认为是一项“高级任务”,需要建立在特征检测和匹配等低级组件之上。事实上,许多入门级的视觉课程仍然在最后教授识别,通常先介绍“经典”(非学习型)视觉算法和应用,然后再转向深度学习和识别。
正如我在前言和引言中提到的,我已将机器学习和深度学习移到了书的开头部分,因为这些是计算机视觉其他领域广泛使用的基础技术。我还决定将识别章节放在深度学习之后,因为大多数现代识别技术都是深度神经网络的自然应用。旧的识别章节大部分已被更新的深度学习技术所取代,因此你有时会看到对经典识别技术的简要描述,以及指向第一版和相关综述或开创性论文的链接。
一个经典的例子是实例识别,我们试图找到特定制造对象的范例,如停车标志或运动鞋(图6.1b)。(更早的例子是使用相对特征位置进行面部识别,如图6.1a所示。)寻找独特特征的同时处理局部外观变化的一般方法(第7.1.2节),然后检查它们在图像中的共现和相对位置,至今仍广泛用于制造3D物体检测(图6.3)、3D结构和姿态恢复(第11章)以及位置识别(第11.2.3节)。高度准确且广泛应用的基于特征的实例识别方法是在2000年代开发的(图7.27),尽管最近出现了基于深度学习的替代方案,但这些方法通常仍然是首选(Sattler,Zhou等,2019)。我们在第6.1节回顾了实例识别,尽管一些必要的组件,如特征检测、描述和匹配(第7章),以及3D姿态估计和验证(第11章),将在后续章节中介绍。
更难的问题是类别或类别的识别(例如,识别高度变化的类别成员,如猫、狗或摩托车),最初也是通过基于特征的方法和相对位置(部分模型)来解决的,如图6.1d所示。我们在第6.2节中讨论图像分类(即全图类别识别)时,首先回顾这些“经典”(尽管现在很少使用)的技术。然后,我们展示前一章中描述的深度神经网络如何非常适合这类分类问题。接下来,我们讨论视觉相似性搜索,在这种情况下,不是将图像归类到预定义的数量中。
在分类中,我们检索出语义相似的其他图像。最后,我们专注于人脸识别,这是计算机视觉研究时间最长的主题之一。
在第6.3节中,我们转向物体检测这一主题,在这里我们不仅对整个图像进行分类,还通过边界框标出了各种物体的位置。这一主题包括更专业的变体,如面部检测和行人检测,以及通用类别的物体检测。在第6.4节中,我们研究了语义分割,任务是精确到像素地标出不同的物体和材料,即为每个像素标注一个物体的身份和类别。与此相关的变体包括实例分割,每个独立的物体获得一个独特的标签;全景分割,物体和背景(例如草地、天空)都得到标注;姿态估计,像素被标记为人体部位和方向。本章最后两节简要涉及视频理解(第6.5节)和视觉与语言(第6.6节)。
在开始描述个体识别算法及其变体之前,我应该简要提及大规模数据集和基准测试在识别系统快速进步中所起的关键作用。虽然像Xerox 10 (Csurka,Dance等人,2006年)和Caltech-101 (Fei-Fei,Fergus,和Perona,2006年)这样的小型数据集在评估物体识别系统方面发挥了早期作用,但PASCAL视觉对象类别(VOC)挑战赛(Everingham,Van Gool等人,2010年;Everingham,Eslami等人,2015年)是第一个足够大且具有挑战性的数据集,显著推动了该领域的发展。然而,PASCAL VOC仅包含20个类别。ImageNet数据集(Deng,Dong等人,2009年;Rusakovsky,Deng等人,2015年)的引入,拥有1,000个类别和超过一百万张标注图像,最终提供了足够的数据,使端到端学习系统得以突破。微软COCO(上下文中的常见对象)数据集进一步促进了发展(Lin,Maire等人,2014年),特别是在精确的对象分割方面,我们将在第6.4节中研究。关于构建此类数据集的人工众包方法的精彩综述见(Kovashka,Russakovsky等人,2016年)。本章将提到其他有时更为专业的数据集。最流行和活跃的数据集和基准测试列表见表6.1至6.4。
6.1 实例识别
一般物体识别分为两类,即实例识别和类别识别。前者涉及重新识别一个已知的二维或三维刚性物体,可能从一个新的视角观察,在杂乱的背景中,并且部分

图6.2在杂乱场景中识别物体(Lowe2004)©2004斯普林格。数据库中的两张训练图像显示在左侧。它们通过SIFT特征与中间的杂乱场景匹配,这些特征以小方块的形式显示在右侧图像中。每个识别出的数据库图像在场景中的仿射变换显示为右侧图像中较大的平行四边形。
闭塞。1后者也被称为类别级或通用对象识别(Ponce,Hebert等人,2006),是识别特定一般类别的任何实例的更具挑战性的问题,如“猫”、“汽车”或“自行车”。
多年来,为实例识别开发了许多不同的算法。Mundy(2006)回顾了早期的方法,这些方法侧重于从图像中提取线条、轮廓或三维表面,并将其与已知的三维物体模型进行匹配。另一种流行的方法是从大量视角和光照条件下获取图像,并使用特征空间分解来表示它们(Murase和Nayar 1995)。更近一些的方法包括Lowe(2004)、Lepetit和Fua(2005)、Rothganger、Lazebnik等人(2006)以及Ferrari,
Tuytelaars和Van Gool2006b;Gordon和Lowe2006;Obdr lek和Matas2006;Sivic
并且Zisserman2009;Zheng,Yang和Tian2018)倾向于使用视角不变的二维特征,例如我们将在第7.1.2节中讨论的那些。从新图像和数据库中的图像中提取出具有信息量的稀疏二维特征后,使用第7.1.3节描述的一种稀疏特征匹配策略,将图像特征与对象数据库进行匹配。每当找到足够数量的匹配项时,通过寻找一个几何变换来对齐两组特征(图6.2)来进行验证。

图6.3使用仿射区域的三维物体识别(Rothganger、Lazebnik等人,2006年)©
2006斯普林格:(a)样本输入图像;(b)五个识别(重投影)的对象及其边界框;(c)几个局部仿射区域;(d)局部仿射区域(补丁)重投影到标准(正方形)框架中,连同其几何仿射变换。
为了识别一个或多个已知对象的实例,如图6.2左栏所示,识别系统首先在每个数据库图像中提取一组兴趣点,并将相关的描述符(及原始位置)存储在一个索引结构中,例如搜索树(第7.1.3节)。在识别时,从新图像中提取特征并与存储的对象特征进行比较。每当找到足够数量的匹配特征(比如三个或更多)时,系统就会调用匹配验证阶段,其任务是确定匹配特征的空间排列是否与数据库图像中的特征一致。
因为图像可能高度杂乱,相似特征可能属于多个对象,原始特征匹配集可能会包含大量异常值。因此,Lowe(2004)建议使用霍夫变换(Section7.4.2)来累积可能的几何变换的投票。在他的系统中,他使用了数据库对象与场景特征集合之间的仿射变换,这种方法对于主要是平面的物体或至少有几个对应特征具有准平面几何形状的物体效果很好。
另一种使用局部仿射框架的系统是由Rothganger、Lazebnik等人(2006)开发的。在他们的系统中,使用了Mikolajczyk和Schmid(2004)提出的仿射区域检测器来校正局部图像块(Figure6.3d),从中计算出SIFT描述子和10×10 UV颜色直方图,并用于匹配和识别。同一物体不同视角下的相应块及其局部仿射变形被用来计算该物体的三维仿射模型,通过扩展的方法实现。
第11.4.1节的分解算法,然后可以升级为欧几里得重建(Tomasi和Kanade1992)。在识别时,使用局部欧几里得邻域约束来过滤潜在匹配,类似于仿射几何
Lowe(2004)和Obdr lek和Matas(2006)使用的限制条件。图6.3显示了使用这种方法识别杂乱场景中的五个物体的结果。
虽然基于特征的方法通常用于检测和定位场景中的已知对象,但也可以根据这些匹配获得场景的像素级分割。法拉利、图特拉尔斯和范古尔(2006b)描述了一种同时识别对象和分割场景的系统,而卡纳拉、拉图等人(2008)则将这种方法扩展到非刚性变形。第6.4节重新审视了在通用类别(类别)识别背景下联合识别和分割的主题。
虽然在2000年代初期到中期,实例识别主要集中在图像中定位已知的三维物体,如图6.2-6.3所示,但注意力逐渐转向了更具挑战性的实例检索问题(也称为基于内容的图像检索),在这种情况下,需要搜索的图像数量可能非常庞大。第7.1.4节回顾了此类技术,其概览可参见图7.27以及郑、杨和田(2018)的综述。这一主题还与视觉相似性搜索(第6.2.3节)和三维姿态估计(第11.2节)相关。
6.2 图像分类
虽然实例识别技术相对成熟,并被用于商业应用,如交通标志识别(Stallkamp,Schlipsing等,2012),但通用类别(类)识别仍然是一个快速发展的研究领域。例如,考虑图6.4a中的照片集,这些照片展示了来自10个不同视觉类别的对象。(我留给你们来命名每个类别。)你将如何编写一个程序,将这些图像分类到适当的类别中,特别是如果你还被提供了“以上都不是”的选项?
从这个例子可以看出,视觉类别识别是一个极其具有挑战性的问题。然而,如果以今天的算法比十年前的算法好多少来衡量,这个领域的进步是相当惊人的。
在本节中,我们回顾了用于全图像分类的主要算法类别。我们首先介绍基于经典特征的方法,这些方法依赖于手工设计的特征及其统计特性,有时还会使用机器学习来进行最终分类(图5.2b)。由于这类技术已不再广泛使用,我们仅简要描述最重要的几种方法。更多细节可参见本书的第一版。

图6.4图像识别的挑战:(a)来自Xerox 10类数据集的样本图像(Csurka,Dance等人,2006年)©2007年施普林格出版社;(b)来自ImageNet数据集的难度和变化轴(Russakovsky,Deng等人,2015年)©2015年施普林格出版社。
(Szeliski2010,第14章)以及引用的期刊论文和综述。接下来,我们描述基于前一章介绍的深度神经网络的现代图像分类系统。然后,我们讨论视觉相似性搜索,其任务是找到视觉上和语义上相似的图像,而不是归类到固定的类别中。最后,我们探讨人脸识别,因为这一主题有着悠久的历史。
6.2.1基于特征的方法
在本节中,我们回顾了基于特征的经典类别识别(图像分类)方法。历史上,基于部件的表示和识别算法(第6.2.1节)是首选方法(Fischler和Elschlager 1973;Felzenszwalb和Huttenlocher 2005;Fergus、Perona和Zisserman 2007),我们首先描述了相似性-

图6.5来自两个广泛使用的图像分类数据集的样本图像:(a) Pascal视觉对象类别(VOC)(Everingham,Eslami等人,2015年)©2015 Springer;(b) ImageNet (Russakovsky,Deng等人,2015年)©2015 Springer。
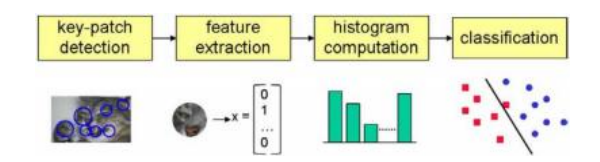
图6.6一个典型的词袋分类系统处理流程(Csurka,Dance等,2006)©2007斯普林格。首先在关键点处提取特征,然后量化以获得学习到的视觉词汇(特征聚类中心)上的分布(直方图)。利用特征分布直方图通过分类算法,如支持向量机,来学习决策面。
特征包方法将对象和图像表示为无序的特征描述子集合。接着,我们回顾了基于部件模型构建的更复杂系统,然后探讨上下文和场景理解以及机器学习如何提升整体识别效果。本节介绍的技术详情可参见早期的综述文章、论文集和课程(Pinz2005;Ponce,Hebert等2006;Dickinson,Leonardis等2007;Fei-Fei,Fergus和Torralba 2009),以及关于帕斯卡和ImageNet识别挑战的两篇综述文章(Everingham,Van Gool等2010;Everingham,Eslami等2015;Russakovsky,Deng等2015)和本书的第一版(Szeliski2010,第14章)。
词袋
类别识别中最简单的算法之一是词袋模型(也称为特征包或关键点包)方法(Csurka,Dance等2004;Lazebnik,Schmid和Ponce 2006;Csurka,Dance等2006;Zhang,Marszalek等2007)。如图6.6所示,该算法仅计算查询图像中视觉词汇的分布(直方图),并将此分布与训练图像中的分布进行比较。我们将在第7.1.4节中详细讨论这种方法。与实例识别最大的不同在于缺少几何验证阶段(第6.1节),因为通用视觉类别的单个实例,如图6.4a所示,其特征之间的空间一致性相对较低(但参见Lazebnik,Schmid和Ponce(2006)的研究)。
Csurka、Dance等人(2004)首次使用“关键点包”一词来描述此类方法,并且是最早证明基于频率的技术的效用的人之一
类别识别。他们最初的系统使用了仿射协变区域和SIFT描述子、k均值视觉词汇构建,以及朴素贝叶斯分类器和支持向量机进行分类。(后者表现
更佳。)他们的新系统(Csurka,Dance等人,2006年)采用了规则的(非仿射的)SIFT补丁和提升方法,而不是支持向量机,并结合了一小部分几何一致性信息。
张、马尔扎莱克等人(2007)对这种特征包系统进行了更详细的研究。他们比较了多种特征检测器(哈里斯-拉普拉斯(米科拉伊奇和施密特2004)和拉普拉斯(林德伯格1998b)、描述子(SIFT、RIFT和SPIN(拉泽比尼克、施密特和庞斯2005))以及SVM核函数。
格劳曼和达雷尔(2007b)没有将特征向量量化为视觉词汇,而是开发了一种直接计算两个大小可变的特征向量集合之间近似距离的技术。他们的方法是将特征向量归类到特征空间中定义的多分辨率金字塔中,并统计落在相应箱内的特征数量。两组特征向量之间的距离(可以视为高维空间中的点)通过对应箱之间的直方图交集计算得出,同时排除在更细层次上已找到的匹配项,并更重地加权更精细的匹配。在后续工作中,格劳曼和达雷尔(2007a)展示了如何使用哈希技术避免显式构建金字塔。
受到这项工作的启发,Lazebnik、Schmid和Ponce(2006)展示了如何利用类似的思想来增强关键点包,引入类似于SIFT(Lowe 2004)和“gist”(Torralba,Murphy等2003)所执行的池化操作的松散二维空间位置概念。在他们的工作中,他们提取了仿射区域描述符(Lazebnik,Schmid和Ponce 2005),并将其量化为视觉词汇。(基于Fei-Fei和Perona(2005)的先前研究,特征描述符在图像上以密集方式(在规则网格上)提取,这有助于描述如天空等无纹理区域。)然后,他们形成一个包含词汇计数(直方图)的空间金字塔,并使用类似的金字塔匹配核以层次方式结合直方图交集计数。
关于是否使用量化特征描述子或连续描述子,以及是否使用稀疏或密集特征的争论持续了多年。Boiman、Shechtman和Irani(2008)指出,如果将查询图像与表示某一类的所有特征进行比较,而不仅仅是每个类别图像单独比较,最近邻匹配
然后是一个na
。而不是我们
在研究通用特征检测器和描述符的同时,一些作者一直在探索学习特定类别特征的方法(Ferencz、Learned-Miller和Malik 2008),通常使用随机森林(Philbin、Chum等2007;Moosmann、Nowak和Jurie 2008;Shotton、Johnson和Cipolla 2008)或结合特征生成和图像分类阶段(Yang,

图6.7使用图像结构定位和跟踪人物(Felzenszwalb和Huttenlocher 2005)©2005斯普林格。该结构由可活动的矩形身体部分(躯干、头部和四肢)组成,这些部分以树状拓扑连接,编码相对部位的位置和方向。为了拟合图像结构模型,首先使用背景减除计算出二值轮廓图像。
Jin等人(2008))。其他研究者,如Serre、Wolf和Poggio(2005)以及Mutch和Lowe(2008)则使用了受生物(视觉皮层)处理启发的密集特征变换层次结构,并结合SVM进行最终分类。
基于部件的模型
通过识别物体的组成部分并测量它们之间的几何关系,是物体识别中最古老的方法之一(Fischler和Elschlager 1973;Kanade 1977;Yuille 1991)。基于部件的方法常用于人脸识别(Moghaddam和Pentland 1997;Heisele、Ho等2003;Heisele、Serre和Poggio 2007),并且继续被用于行人检测(图6.24)(Felzenszwalb、McAllester,
以及Ramanan2008)和姿态估计(G ler、Neverova和Kokkinos2018)。
在这篇综述中,我们讨论了基于部件识别的一些核心问题,即几何关系的表示、单个部件的表示以及学习这些描述并在运行时识别它们的算法。关于基于部件的识别模型的更多细节,可参见Fergus(2009)的课程笔记。
Fischler和Elschlager(1973)将最早用于表示几何关系的方法称为图像结构,它由不同特征位置之间的弹簧式连接组成(图6.1a)。为了将图像结构拟合到图像中,能量函数的形式为
E = Σi Vi(li)+ i Vij(li;lj
) (6.1)
在所有可能的部件位置或姿态{li }和存在边(几何关系)的部件对(i,j)上最小化。请注意,这种能量与用于马尔可夫随机场(4.35–4.38)的能量密切相关,后者可以将图像结构嵌入到一个概率框架中,使参数学习更加容易(Felzenszwalb和Huttenlocher 2005)。
基于部件的模型可以有不同的几何连接拓扑结构(Carneiro和Lowe 2006)。例如,Felzenszwalb和Huttenlocher(2005)将连接限制为树状结构,这使得学习和推理更加可行。树状拓扑结构允许使用递归维特比(动态规划)算法(Pearl 1988;Bishop 2006),其中叶节点首先根据其父节点进行优化,然后将得到的值代入并从能量函数中消除。为了进一步提高推理算法的效率,Felzenszwalb和Huttenlocher(2005)将成对能量函数Vij(li,lj)限制为位置变量函数的马氏距离,并使用快速距离变换算法在接近线性的N时间内最小化每个成对交互。
图6.7展示了使用他们的图像结构算法将关节模型拟合到通过背景分割获得的二值图像的结果。在这个图像结构的应用中,部件由其近似矩形的位置、大小和方向参数化。一元匹配势能Vi(li)是通过计算每个部件所代表的倾斜矩形内外的前景和背景像素百分比来确定的。
许多不同的图形模型已被提出用于基于部件的识别。卡内罗和洛(2006)讨论了其中一些模型,并提出了他们自己的一个模型,称为稀疏灵活模型;该模型涉及对部件进行排序,并且每个部件的位置最多依赖于其k个祖先位置。
最简单的模型是词袋模型,在这种模型中,不同部分或特征之间没有几何关系。虽然这类模型可以非常高效,但它们在表达部件的空间排列方面的能力非常有限。树和星(一种特殊的树,其中所有叶节点都直接连接到一个共同的根)在推理方面最为高效,因此在学习方面也是如此(Felzenszwalb和Huttenlocher 2005;Fergus、Perona和Zisserman2005;Felzenszwalb,McAllester以及Ramanan 2008)。有向无环图在复杂度上紧随其后,仍然能够支持高效的推理,尽管这会强加一个因果结构到部件模型上(Bouchard和Triggs 2005;Carneiro和Lowe 2006)。k-扇形模型中,大小为k的团构成了星形模型的根,其推理复杂度为O(N^k+1),但通过距离变换和高斯先验,这一复杂度可以降低到O(N^k)(Crandall、Felzenszwalb和Huttenlocher

图6.8上下文的重要性(图片由安东尼奥·托拉尔巴提供)。你能说出图像(a-b)中所有物体的名字吗,特别是那些被圈出的(c-d)。仔细观察这些圈出的物体。你是否注意到它们都有相同的形状(旋转后),如列(e)所示?
2005年;Crandall和Huttenlocher2006年)。最后,完全连接的星座模型是最通用的,但是对于中等数量的部件P,特征分配到部件变得难以处理,因为这种分配的复杂度是O(NP)(Fergus、Perona和Zisserman2007年)。
原始星座模型由伯尔、韦伯和佩罗纳(1998)开发,包含多个部分,这些部分的相对位置通过它们的平均位置和一个完整的协方差矩阵来编码,该矩阵不仅表示位置不确定性,还表示不同部分之间的潜在关联。韦伯、韦林和佩罗纳(2000)将这一技术扩展到弱监督设置,在这种设置下,每个部分的外观及其位置都可以根据整个图像标签自动学习。费格斯、佩罗纳和齐瑟曼(2007)进一步将这种方法扩展到从尺度不变的关键点检测中同时学习外观和形状模型。
基于部件的识别方法也被扩展到从少量示例中学习新类别,这建立在为其他类别开发的识别组件之上(Fei-Fei,Fergus和Perona 2006)。可以利用语法的概念开发更复杂的层次化部件模型(Bouchard和Triggs 2005;Zhu和Mumford 2006)。一种更简单的方法是使用关键点,这些关键点被识别为属于估计部件位置的类别投票(Leibe,Leonardis和Schiele 2008)。如图6.9所示,部件也可以成为细粒度类别识别系统中的有用组件。
情境和场景理解
到目前为止,我们主要考虑的是识别和定位物体的任务,而不是理解物体出现的场景(上下文)。这是一个很大的问题。
限制,因为上下文在人类物体识别中扮演着非常重要的角色(Oliva和Tor- ralba2007)。上下文可以极大地提高物体识别算法的性能(Divvala,Hoiem等人2009),同时为一般场景理解提供有用的语义线索(Torralba2008)。
考虑图6.8a-b中的两张照片。你能说出所有物体的名字吗,特别是那些在图像(c-d)中圈出的物体?现在仔细看看这些圈出的物体。你是否发现它们的形状有相似之处?事实上,如果你将它们旋转90°,它们都与图6.8e中所示的“团块”相同。这就是我们通过形状来识别物体的能力!
尽管我们在本章前面没有明确讨论上下文,但我们已经看到了这一普遍概念的几个实例。一种简单的方法是将空间信息融入识别算法中,即在不同区域计算特征统计,如拉泽布尼克、施密德和庞斯(2006)提出的空间金字塔系统。基于部件的模型(图6.7)使用了一种局部上下文,其中各个部件需要以正确的几何关系排列,才能构成一个物体。
基于部件和基于上下文模型之间的最大区别在于,后者将对象组合成场景,而每个类别的组成对象数量事先并不知道。实际上,可以将基于部件和基于上下文的模型结合在同一识别架构中(Murphy,Torralba和Freeman 2003;Sudderth,Torralba等2008;Crandall和Huttenlocher 2007)。
考虑一个包含街道和办公室场景的图像数据库。如果我们有足够的训练图像,并且这些图像中带有标记区域,如建筑物、汽车和道路,或者显示器、键盘和鼠标,我们就可以开发出一种几何模型来描述它们之间的相对位置。苏德斯、托拉尔巴等人(2008)开发了这样一个模型,可以将其视为一个两层星座模型。在顶层,物体之间的相对分布(例如,建筑物相对于汽车)被建模为高斯分布。在底层,物体中心相对于各部分(仿射协变特征)的分布则使用高斯混合模型进行建模。然而,由于场景中的物体数量以及每个物体中的部分数量未知,因此使用潜在狄利克雷过程(LDP)在生成框架中建模物体和部分的创建。所有物体和部分的分布都是从一个大型标注数据库中学习得到的,然后在推理(识别)过程中用于标记场景中的元素。
另一个上下文的例子是在同时分割和识别中(第6.4节和图6.33),场景中各种物体的排列被用作标注过程的一部分。托拉尔巴、墨菲和弗里曼(2004)描述了一种条件随机场,其中建筑物和道路的估计位置影响汽车的检测,并使用增强学习来学习CRF的结构。拉比诺维奇、韦达利等人(2007)
利用上下文改进CRF分割的结果,注意某些相邻关系(关系)比其他关系更可能成立,例如,一个人骑马的可能性比骑狗的大。Galleguillos和Belongie(2010)回顾了为对象分类添加上下文的各种方法,而Yao和Fei-Fei(2012)研究了人与物体的互动。(关于这一问题的最新观点,参见Gkioxari、Girshick等人(2018)。)
上下文在单张图像的三维推断中也起着重要作用(图6.41),利用计算机视觉技术将像素标记为属于地面、垂直表面或天空(Hoiem,Efros,和Hebert 2005a)。这一研究方向已扩展到一种更为全面的方法,同时推理物体的身份、位置、表面方向、遮挡和相机视角参数(Hoiem,Efros,和Hebert 2008)。
许多方法利用场景的大致轮廓(Torralba2003;Torralba,Murphy等2003)来确定特定物体实例可能出现的位置。例如,Murphy、Torralba和Freeman(2003)训练了一个回归器,根据图像的大致轮廓预测行人、汽车和建筑物(或室内办公场景中的屏幕和键盘)的垂直位置。这些位置分布随后与经典对象检测器结合使用,以提高检测器的性能。大体轮廓还可以直接匹配完整图像,正如我们在Hays和Efros(2007)的场景补全工作中所见。
最后,场景理解的一些工作利用了大量标注(甚至未标注)图像的存在,直接对整个图像进行匹配,其中图像本身隐含地编码了物体之间的预期关系(Russell,Torralba等2007;Malisiewicz和Efros 2008;Galleguillos和Belongie 2010)。当然,这是使用深度神经网络的一个核心优势,我们将在下一节中讨论。
正如我们在第5.4.3节中所见,随着Krizhevsky、Sutskever和Hinton(2012)提出的“AlexNet”超级视觉系统在ImageNet大规模视觉识别挑战赛(ILSVRC)上的引入,深度网络开始超越基于学习的“浅层”方法。自那时起,识别准确率继续显著提高(图5.40),很大程度上得益于更深的网络和更优的训练算法。最近,更高效的网络成为研究的重点(图5.45),同时更大的(未标注的)训练数据集也受到关注(第5.4.7节)。现在有诸如Classy Vision3这样的开源框架,可用于训练和微调自己的图像和视频分类模型。
图6.9使用部件进行细粒度类别识别(张、多纳休等,2014)©2014斯普林格。深度神经网络物体和部件检测器经过训练,其输出通过几何约束结合。最终分类使用从提取的部件特征训练的分类器完成。
看看许多流行的计算机视觉模型在自己的图像上表现如何。
除了识别图像网络和COCO数据集中常见的类别外,研究人员还研究了细粒度类别识别问题(段、帕里克等,2012;张、多纳休等,2014;克劳斯、金等,2015),其中子类之间的差异可能非常微妙,且示例数量极少(图6.9)。细粒度子类的例子包括花卉(尼尔斯巴克和齐瑟曼,2006)、猫和狗(帕尔希、韦达利等,2012)、鸟类(瓦赫、布兰森等,2011;范霍恩、布兰森等,2015)以及汽车(杨、罗等,2015)。最近的一个细粒度分类例子是iNaturalist系统(范霍恩、麦克奥达等,2018),该系统允许专家和公民科学家拍摄并标注生物物种,使用细粒度类别识别系统来标注新图像(图6.10a)。 细粒度分类通常通过图像和类别的属性进行攻击(Lampert、Nickisch和Harmeling 2009;Parikh和Grauman 2011;Lampert、Nickisch和Harmeling 2014),如图Figure6.10b所示。提取属性可以实现零样本学习(Xian、Lampert等2019),即使用这些属性的组合来描述以前未见过的类别。然而,为了不

图6.10细粒度类别识别。(a)iNaturalist网站和应用程序允许公民科学家通过手机收集和分类图像(Van Horn,Mac Aodha等,2018)©2018 IEEE。(b)属性可用于细粒度分类和零样本学习(Lampert,Nickisch,和Harmeling,2014)©2014斯普林格。这些图像是“具有属性的动物”数据集的一部分。
学习不同属性之间的虚假关联(Jayaraman、Sha和Grauman 2014)或对象与其共同上下文之间的关联(Singh、Mahajan等2020)。细粒度识别也可以通过度量学习(Wu、Manmatha等2017)或最近邻视觉相似性搜索(Touvron、Sablayrolles等2020)来解决,我们将在下文讨论这些方法。
使用计算机视觉算法自动将图像分类并用属性标记,使得在目录和网络中查找它们变得更加容易。这在图像搜索或图像检索引擎中很常见,这些引擎根据关键词找到可能的图像,就像常规的网络搜索引擎找到相关的文档和页面一样。
然而,有时从图像中找到所需信息更为容易,即使用视觉搜索。例如,我们刚刚看到的细粒度分类,以及实例检索,即找到完全相同的对象(第6.1节)或位置(第11.2.3节)。另一种变体是寻找视觉相似的图像(通常称为视觉相似性搜索或反向图像搜索),当搜索意图无法用简洁的语言表达时,这种方法非常有用。6

图6.11 GrokNet产品识别服务用于产品标记、视觉搜索和推荐©Bell,Liu等人(2020):(a)识别照片中的所有产品;(b)使用弱监督数据增强自动获取数据进行度量学习。
视觉相似性搜索这一主题历史悠久,有多种名称,包括图像内容查询(QBIC)(Flickner,Sawhney等,1995)和基于内容的图像检索(CBIR)(Smeulders,Worring等,2000;Lew,Sebe等,2006;Vasconcelos,2007;Datta,Joshi等,2008)。这些领域的早期研究主要基于简单的全图相似度指标,如颜色和纹理(Swain和Ballard,1991;Jacobs,Finkelstein和Salesin,1995;Manjunathi和Ma,1996)。
后来的架构,如Fergus、Perona和Zisserman(2004)提出的,使用基于特征的学习和识别算法来重新排序传统关键词图像搜索引擎的输出结果。在后续工作中,Fergus、Fei-Fei等人(2005)利用概率最新语义分析(PLSA)(Hofmann 1999)的扩展方法对图像搜索返回的结果进行聚类,然后选择与最高排名结果相关的聚类作为该类别的代表性图像。其他方法则依赖于精心标注的图像数据库,例如LabelMe (Russell、Torralba等人2008)。例如,Malisiewicz和Efros(2008)描述了一个系统,该系统可以根据查询图像找到类似的LabelMe图像;而Liu、Yuen和Torralba(2009)则将基于特征的对应算法与标记数据库结合,以实现同时识别和分割。
新的视觉相似性搜索方法使用了诸如费舍尔核和局部聚合描述子向量(VLAD)(J gou,Perronnin等,2012)或池化卷积神经网络激活(Babenko和Lempitsky,2015a;Tolias
,Sicre和J gou,2016;Cao,Araujo和Sim,2020;Ng,Balntas等,2020;Tolias,Jenicek
和Chum,2020)等整体图像描述符,结合度量学习(Bell和Bala,2015;Song,Xiang等,2016;Gordo,Al- maz n等,2017;Wu,Manmatha等,2017;Berman,J gou等,2019)
,以紧凑的描述符表示每张图像,可用于在大型数据库
中测量相似性(Johnson,Douze和J gou,2021)。还可以将多种技术结合起来,例如深度网络与VLAD的结合(Arandjelovic,Gronat
等,2016),广义均值(GeM)
Radenovi、Tolias和Chum2019
)。
图6.12 GrokNet训练架构使用了7个数据集、一个通用DNN主干、两个分支和83个损失函数(80个分类损失+3个嵌入损失)©Bell,Liu et al.(2020)。
池化(Radenovi、Tolias和Chum2019),
或动态均值池化(DAME)池化(Yang、Kien Nguyen等人2019)被整合到端到端可调的完整系统中。Gordo、Al- maz n等人(2017)对这些技术进行
了全面的综述和实验比较,我们也在第7.1.4节的大规模匹配和检索部分进行了讨论。一些最新的图像检索技术使用局部和全局描述符的组合,在地标识别任务中取得了最先进的性能(Cao、Araujo和Sim2020;Ng、Balntas等人2020;Tolias、Jenicek和Chum2020)。ECCV 2020实例级识别研讨会7提供了该领域的一些最新工作的参考,而即将举行的NeurIPS‘21图像相似性挑战赛8则提供了检测内容篡改的新数据集。
最近的一个商业系统例子是贝尔、刘等人(2020)描述的GrokNet产品识别服务,该系统除了类别识别外还使用了视觉相似性搜索。GrokNet接收用户图像和购物查询作为输入,并返回与查询图像中相似的索引项目(图6.11a)。需要相似性搜索组件的原因在于,世界上的“长尾”商品种类繁多,如“毛绒水槽、电动狗刷或汽油驱动高领毛衣”,使得全面分类变得不切实际。
在训练时,GrokNet同时使用带有类别和/或属性标签的弱标记图像和未标记图像,在这些图像中检测物体中的特征,然后用于度量学习,使用ArcFace损失(Deng,Guo等人,2019)的修改版本和一种新方法。

图6.13人类可以识别熟悉的人的低分辨率人脸(Sinha,Balas等人,2006)©2006 IEEE。
成对边缘损失(图6.11b)。整个系统接收大量未标记和弱标记的图像,并使用类别和属性软最大值损失以及三种不同的嵌入度量损失训练ResNeXt101主干网络(图6.12)。GrokNet只是最近开发的众多商业视觉产品搜索系统中的一个例子。其他系统包括亚马逊(Wu,Manmatha等,2017年)、Pinterest (Zhai,Wu等,2019年)和Facebook (Tang,Borisyuk等,2019年)的系统。除了帮助人们找到他们可能想要购买的商品外,大规模相似性搜索还可以加快网络上有害内容的搜索速度,例如Facebook的SimSearchNet。10
在计算机被要求执行的各种识别任务中,人脸识别可以说是它们最成功的一项。尽管人们甚至无法轻易区分不熟悉的人(O‘Toole,Jiang等,2006;O’Toole,Phillips等,2009),但计算机在区分少数家庭成员和朋友方面的能力已经进入了消费级照片应用。人脸识别还可以用于多种其他应用,包括人机交互(HCI)、身份验证(Kirovski,Jojic,Jancke等,2004)、桌面登录、家长控制和患者监测(Zhao,Chellappa等,2003),但也存在滥用的可能(Chokshi,2019;Ovide,2020)。
| 名称/网址 | 内容/参考 |
| CMU多PIE数据库 http://www.cs.cmu.edu/afs/cs/project/PIE/MultiPie 野外的面孔 http://vis-www.cs.umass.edu/lfw YouTube脸部(YTF) https://www.cs.tau.ac.il/~ wolf/ytfaces 超级脸 https://megaface.cs.washington.edu IARPA Janus基准(IJB) https://www.nist.gov/programs-projects/face-challenges 宽脸型 http://shuoyang1213.me/WIDERFACE | 337张不同姿势的面部照片 Gross、Matthews等人(2010)5,749名网络名人 Huang,Ramesh等人(2007) 3,425个YouTube视频中的1,595人 Wolf、Hassner和Maoz(2011)1M互联网面临的问题 Nech和Kemelmacher-Shlizerman(2017)31,334张3,531人的视频面孔 Maze、Adams等人(2018) 用于人脸检测的32,203张图像,Yang,Luo等人(2016) |
表6.1人脸识别和检测数据集,改编自Maze、Adams等人。
(2018).
姿势、光照和表情(PIE)条件(Phillips,Moon等,2000;Sim,Baker和Bsat,2003;Gross,Shi和Cohn,2005;Huang,Ramesh等,2007;Phillips,Scruggs等,2010)。近年来广泛使用的数据集包括野外标注人脸(LFW)(Huang,Ramesh等,2007;Learned-Miller,Huang等,2016),YouTube面部(YTF)(Wolf,Hassner,和Maoz,2011),MegaFace (Kemelmacher-Shlizerman,Seitz等,2016;Nech和Kemelmacher-Shlizerman,2017),以及IARPA Janus基准(IJB)(Klare,Klein等,2015;Maze,Adams等,2018),详见表6.1。(有关用于训练的其他数据集,请参见Masi,Wu等(2018)。)
一些最早的人脸识别方法涉及找到图像中独特特征的位置,如眼睛、鼻子和嘴巴,并测量这些特征位置之间的距离(Fischler和Elschlager 1973;Kanade 1977;Yuille 1991)。其他方法则依赖于将灰度图像投影到称为特征脸(Section5.2.3)的低维子空间上,并使用主动外观模型联合建模形状和外观变化(同时忽略姿态变化)(第6.2.4节)。关于“经典”(DNN之前)人脸识别系统的描述可以在许多调查报告和书籍中找到(Chellappa、Wilson和Sirohey 1995;Zhao、Chellappa等2003;Li和Jain 2005),以及人脸识别网站。Sinha、Balas等人(2006)关于人类人脸识别的综述也非常值得一读;它包括许多
令人惊讶的结果,比如人类识别熟悉事物的低分辨率图像的能力

图6.14通过形状和颜色操纵面部外观(Rowland和Per- rett1995)©1995 IEEE。通过向输入图像(b)添加或减去性别特异性形状和颜色特征,可以诱导出不同量的性别变化。
添加的数值(从平均值)为:(a)+50%(性别增强)、(b)0%(原始图像)、(c)-50%(接近“两性同体”)、(d)-100%(性别转换),以及(e)-150%(增强相反性别特征)。
(图6.13)以及眉毛在识别中的重要性。研究人员还研究了面部表情的自动识别。参见Chang、Hu等人(2006)、Shan、Gong和McOwan(2009)以及Li和Deng(2020)的一些代表性论文。
活动外观和三维形状模型
使用模块化或基于视图的特征空间进行人脸识别的需求,我们在第5.2.3节中讨论过,这反映了更普遍的一个观察,即面部外观和可识别性不仅依赖于颜色或纹理(这些正是特征脸所捕捉的内容),还同样依赖于形状。此外,在处理三维头部旋转时,进行识别时应忽略人的头部姿态。
事实上,最早的面部识别系统,如菲舍勒和埃尔施拉格(1973)、卡纳德(1977)以及尤尔(1991)所开发的系统,都在面部图像上找到了独特的特征点,并基于这些特征点的相对位置或距离进行识别。后来的技术,如局部特征分析(佩内夫和阿蒂克1996)和弹性聚类图匹配(威斯科特、费洛斯等人1997),将局部滤波器响应(喷流)与形状模型结合,在独特特征位置处进行识别。
一个视觉上引人注目的例子说明了形状和纹理为什么都很重要
罗兰和佩雷特(1995)手动勾勒面部特征的轮廓,然后利用这些轮廓将每张图像标准化(扭曲)为标准形状。通过分析形状和颜色图像与平均值的偏差,他们能够将某些形状和颜色的变形与个人特征如年龄和性别联系起来(图6.14)。他们的研究证明,形状和颜色对这些特征的感知具有重要影响。
大约在同一时期,计算机视觉领域的研究人员开始使用同时的形状变形和纹理插值来建模由身份或表情引起的面部外观变化(Beymer1996;Vetter和Poggio1997),开发了诸如主动形状模型(Lanitis、Taylor和Cootes1997)、3D可变形模型(Blanz和Vetter1999;Egger、Smith等人2020)以及弹性束图匹配(Wiskott、Fellous等人1997)等技术。
库特斯、爱德华兹和泰勒(2001)提出的活动外观模型(AAMs)不仅模拟了图像形状的变化,这种变化通常由图像上关键特征点的位置编码,还模拟了纹理的变化,这些变化在分析前被归一化到一个标准形状。形状和纹理都表示为相对于平均形状和纹理的偏差,
(6.2)
t = + Uta; (6.3)
在Us和Ut中,特征向量已经预先缩放(白化),使得a中的单位向量代表训练数据中观察到的一个标准差的变化。除了这些主要变形外,形状参数还通过全局相似性变换来匹配给定人脸的位置、大小和方向。同样,纹理图像包含尺度和偏移,以最好地适应新的光照条件。
正如你所见,相同的外观参数a(6.2-6.3)同时控制着从平均值出发的形状和纹理变形,这在我们认为它们之间存在关联时是合理的。图6.15展示了沿前四个主方向移动三个标准差如何最终改变一个人外貌中的多个相关因素,包括表情、性别、年龄和身份。
虽然活动外观模型主要是为了准确捕捉面部特征的外观和变形的变化,但它们可以通过计算一个身份子空间来适应面部识别,该子空间将身份变化与其他变化来源如光照、姿势和表情区分开来(Costen,Cootes等。

图6.15主要变化模式在活动外观模型中的表现(Cootes、Edwards和Taylor 2001)©2001 IEEE。四张图片展示了同时改变形状和纹理前四个变化模式的±σ与平均值的影响。你可以清楚地看到面部形状和阴影是如何同时受到影响的。
1999年)。这一基本思想借鉴了特征脸(Belhumeur、Hes- panha和Kriegman 1997;Moghaddam、Jebara和Pentland 2000)等类似研究,旨在计算个体内部和外部变异的独立统计量,然后在这些子空间中找到区分方向。尽管AAMs有时被直接用于识别(Blanz和Vetter 2003),但在识别领域的主要用途是将人脸对齐到标准姿态(Liang、Xiao等2008;Ren、Cao等2014),以便可以使用更传统的人脸识别方法(Penev和Atick 1996;Wiskott、Fellous等1997;Ahonen、Hadid和Pietikinen 2006;Zhao和Pietikinen 2007;Cao、Yin等2010)。
主动外观模型已扩展以处理光照和视角变化(Gross,Baker等,2005)以及遮挡问题(Gross,Matthews和Baker,2006)。其中一个最重要的扩展是构建形状的三维模型(Matthews,Xiao和Baker,2007),这些模型在捕捉和解释面部外观在大幅度姿态变化中的全部变异性方面表现得更好。这样的模型既可以从单目视频序列中构建(Matthews,Xiao和Baker,2007),如图6.16a所示,也可以从多视图视频序列中构建(Ramnath,Koterba等,2008),后者在重建和跟踪中提供了更高的可靠性和准确性(Murphy-Chutorian和Trivedi,2009)。
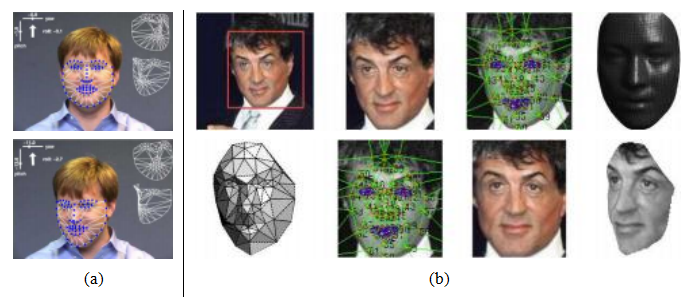
图6.16头部追踪与正面化:(a)使用3D主动外观模型(AAMs)(Matthews,Xiao和Baker 2007)©2007斯普林格出版社,显示视频帧以及估计的偏航、俯仰和滚动参数及拟合的3D可变形网格;(b)使用DeepFace系统中的六个点,随后是67个点(Taigman,Yang等2014)©2014 IEEE,用于正面化面部图像(底部行)。

图6.17 DeepFace架构(Taigman,Yang等人,2014)©2014 IEEE,从正面化阶段开始,随后是几个局部连接(非卷积)层,然后是两个具有K类软性函数的全连接层。
使用深度学习的面部识别
受到深度网络在全图像分类中取得巨大成功的启发,人脸识别研究人员开始在其系统中使用深度神经网络骨干。图6.16b–6.17展示了Taigman、Yang等人(2014)提出的DeepFace系统的两个阶段,这是最早利用深度网络实现显著提升的系统之一。在他们的系统中,采用基于特征点的预处理正面化步骤,将原始彩色图像转换为裁剪良好的正面人脸。然后,深度局部连接网络(其中卷积核可以随空间变化)被输入到两个最终的全连接层,再进行分类。
一些较新的深度人脸识别方法省略了正面化阶段,转而使用数据增强(第5.3.3节)来生成具有更多姿态变化的合成输入(Schroff,Kalenichenko和Philbin 2015;Parkhi,Vedaldi和Zisserman 2015)。Masi、Wu等人(2018)提供了一篇关于深度人脸识别的优秀教程和综述,包括广泛使用的训练和测试数据集列表、正面化和数据增强的讨论,以及一个关于训练损失(Figure6.18)的部分。最后一个主题对于扩展到越来越多的人数至关重要。Schroff、Kalenichenko和Philbin(2015)以及Parkhi、Vedaldi和Zisserman(2015)使用三元组损失构建了一个与受试者数量无关的低维嵌入空间。更近期的系统则采用了受softmax函数启发的对比损失,我们在第5.3.4节中讨论过这一点。例如,Deng、Guo等人(2019)的ArcFace论文在嵌入空间的单位超球上测量角度距离,并增加额外的边缘以使身份聚在一起。这一想法进一步扩展用于视觉相似性搜索(Bell、Liu等人2020)和人脸识别(Huang、Shen等人2020;Deng、Guo等人2020a)。
个人照片集
除了数码相机自动寻找人脸以辅助自动对焦,以及视频会议中摄像机寻找人脸以聚焦演讲者(无论是机械方式还是数字方式),人脸识别技术已经渗透到大多数消费级照片整理软件和照片分享网站中。找到人脸并允许用户标记它们,使得日后更容易找到选定人物的照片,或者自动与朋友分享。事实上,在照片中标记朋友是脸书上最受欢迎的功能之一。
然而,有时人脸很难找到和识别,特别是当他们身材矮小、背对着摄像头或被遮挡时。在这种情况下,将人脸识别与人物检测和衣物识别结合使用可以非常有效,如图6.19所示(Sivic,Zitnick,和Szeliski 2006)。将人物识别与其他技术结合使用可以进一步提高效果。
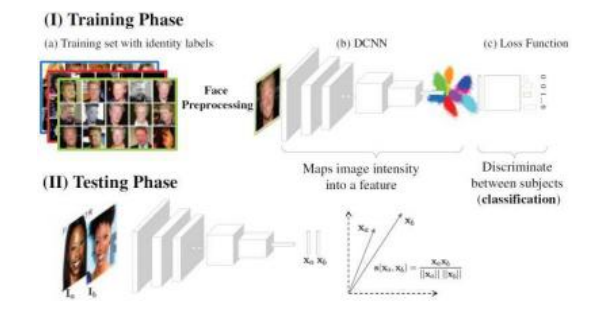
图6.18一个典型的现代深度人脸识别架构,出自Masi、Wu等人(2018)的调查©2018 IEEE。在训练时,使用大量标注的人脸数据集(a)来约束深度卷积神经网络(b)的权重,优化分类任务的损失函数(c)。测试时,通常丢弃分类层,使用DCNN作为特征提取器来比较人脸描述符。
各种上下文,如位置识别(第11.2.3节)或活动或事件识别,也能帮助提高性能(Lin,Kapoor等人,2010)。
6.3 目标检测
如果我们被给予一张图像进行分析,比如图6.20中的集体肖像,我们可以尝试将识别算法应用于该图像中的每一个可能的子窗口。这样的算法可能会既慢又容易出错。相反,构建专门的
目标探测器,它的工作是快速找到特定物体可能出现的可能区域。
我们首先介绍面部检测器,这是最早成功的识别示例之一。这类算法被集成到当今大多数数码相机中,以增强自动对焦功能,并被应用于视频会议系统中,用于控制平移和缩放。接着,我们探讨行人检测器,作为更广泛对象检测方法的一个例子。最后,我们将讨论多类对象检测问题,这一问题如今已通过以下方式解决:

图6.19使用组合面部、头发和躯干模型进行人物检测和识别(Sivic,Zitnick和Szeliski2006)©2006 Springer。(a)仅使用面部检测,有多个头部被遗漏。(b)组合面部和服装模型成功重新找到了所有人。
6.3.1人脸检测
在将人脸识别应用于普通图像之前,必须首先找到任何人脸的位置和大小(图6.1c和6.20)。原则上,我们可以在每个像素和尺度上应用人脸识别算法(Moghaddam和Pentland 1997),但这种过程在实际中会过于缓慢。
在过去四十年中,开发了多种快速人脸检测算法。杨、克里格曼和阿胡贾(2002)以及赵、切拉帕等人(2003)对此领域早期工作的综述进行了全面介绍。根据他们的分类法,人脸检测技术可以分为基于特征、基于模板或基于外观的类型。基于特征的技术试图找到眼睛、鼻子和嘴巴等显著图像特征的位置,然后验证这些特征是否处于合理的几何排列。这些技术包括一些早期的人脸识别方法(菲舍勒和埃尔施拉格1973;卡纳德1977;尤尔1991),以及后来基于模块化特征空间的方法(莫加达姆和彭特兰1997)、局部滤波器喷射(梁、伯尔和

图6.20 Rowley、Baluja和Kanade(1998)产生的面部检测结果©1998 IEEE。您能在57个真阳性结果中找到一个假阳性结果(非人脸的框)吗?
Perona1995;Penev和Atick1996;Wiskott,Fellous等人1997),支持向量机(Heisele,Ho等人2003;Heisele,Serre和Poggio2007)以及提升法(Schneiderman和Kanade2004)。
基于模板的方法,如主动外观模型(AAM)(第6.2.4节),可以处理广泛的姿势和表情变化。通常,它们需要在真实人脸附近进行良好的初始化,因此不适合用作快速人脸检测器。
基于外观的方法会扫描图像中小而重叠的矩形区域,寻找可能的人脸候选对象,然后使用一系列更昂贵但选择性更强的检测算法进行细化(Sung和Poggio 1998;Rowley、Baluja和Kanade 1998;Romdhani、Torr等2001;Fleuret和Geman 2001;Viola和Jones 2004)。为了处理尺度变化,通常将图像转换为次八度金字塔,并在每一层进行单独扫描。大多数基于外观的方法都严重依赖于使用标记的人脸和非人脸区域集来训练分类器。
宋和波吉奥(1998)以及罗利、巴卢贾和卡纳德(1998)提出了两种最早的基于外观的人脸检测器,并引入了许多后来被广泛采用的创新方法。首先,这两个系统收集了一组标记的人脸图像(图6.20),以及一组来自已知不含人脸的图像的图像,例如航拍图像或植被。收集到的人脸图像通过人工镜像、旋转、缩放和轻微平移来增强,以减少这些效果对面部检测器的影响。
接下来的几段将对一些早期出现的基于外观的系统进行快速回顾
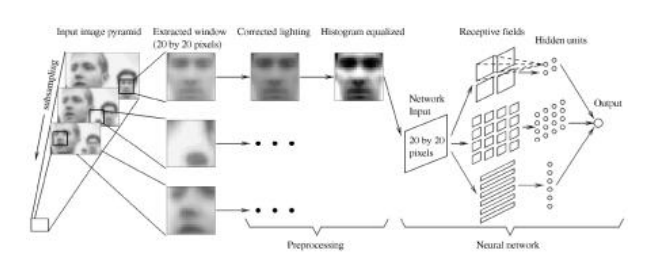
图6.21面部检测神经网络(Rowley、Baluja和Kanade1998)©1998 IEEE。从金字塔的不同层次中提取重叠的补丁,然后进行预处理。然后使用三层神经网络来检测可能的脸部位置。
基于机器算法的面部检测器。这些系统为计算机视觉中机器学习的逐渐采用和进化提供了一个有趣的视角。更详细的描述可以在原始论文以及本书的第一版(Szeliski2010)中找到。
聚类与主成分分析。一旦人脸和非人脸模式经过预处理,Sung和Poggio(1998)使用k-means将每个数据集聚类为六个独立的簇,然后对生成的12个簇分别拟合主成分分析子空间。在检测时,首先使用Moghaddam和Pentland(1997)开发的DIFS和DFFS指标生成24个马氏距离测量值(每个簇两个)。这24个测量值被输入到多层感知器(MLP),即全连接神经网络。
神经网络。Rowley、Baluja和Kanade(1998)没有先对数据进行聚类并计算到聚类中心的马氏距离,而是直接将神经网络(MLP)应用于20×20像素的灰度强度块,使用不同大小的手工设计“感受野”来捕捉大尺度和小尺度结构(图6.21)。由此产生的神经网络直接输出每个重叠块中心出现人脸的可能性,形成一个多分辨率金字塔。由于多个重叠块(在空间和分辨率上)可能在人脸附近触发,因此使用了一个额外的合并网络来合并重叠检测结果。作者还尝试训练多个网络并合并它们的输出。图6.20显示了他们面部检测器的一个样本结果。
支持向量机。与使用神经网络分类图像块不同,Osuna、Freund和Girosi(1997)采用支持向量机(SVM),我们在第5.1.4节中讨论过,来对与Sung和Poggio(1998)相同的预处理图像块进行分类。SVM在特征空间中寻找不同类别(在这种情况下是人脸和非人脸图像块)之间的最大间隔分离平面。当线性分类边界不足时,可以使用核函数将特征空间提升到更高维度的特征(5.29)。SVM已被其他研究人员用于人脸检测和人脸识别(Heisele、Ho等2003;Heisele、Serre和Poggio 2007),以及一般对象识别(Lampert 2008)。
提升。在2000年代开发的所有面部检测器中,由维奥拉和琼斯(2004)引入的可能是最著名的。他们的技术首次将提升的概念引入计算机视觉领域,这一概念涉及训练一系列越来越具区分性的简单分类器,然后融合它们的输出(Bishop 2006,第14.3节;Hastie、Tibshirani和Friedman 2009,第10章;Murphy 2012,第16.4节;Glassner 2018,第14.7节)。
更详细地说,提升涉及构建一个分类器h(x),作为简单弱学习者的总和,
=签名αj hj
(6.4)
其中每个弱学习器hj (x)都是输入的一个极其简单的函数,因此在分类性能中(单独地)预期不会产生太多贡献。
在大多数提升变体中,弱学习器是阈值函数,
这些也被称作决策桩(基本上是决策树最简单的版本)。在大多数情况下,传统上(也是更简单的方法)将aj和bj设为±1,即aj = -sj,bj = +sj,这样只需要选择特征fj、阈值θj以及阈值的极性sj∈±1。14

图6.22基于提升法的人脸检测器中使用的简单特征(Viola和Jones 2004)©2004斯普林格:(a)由2-4个不同矩形组成的矩形特征差异(白色矩形内的像素从灰色矩形中减去);(b)AdaBoost选择的第一和第二特征。第一个特征测量眼睛与脸颊之间的强度差异,第二个特征测量眼睛与鼻梁之间的强度差异。
比单个像素更精细,一旦预计算了累加面积表,它们的计算速度极快,如第3.2.3节(3.31–3.32)所述。实际上,在O(N)预计算阶段的成本下(其中N是图像中的像素数量),后续矩形差值可以通过4r次加法或减法来计算,其中r∈{2;3;4}是特征中矩形的数量。
提升成功的关键在于逐步选择弱学习器的方法以及每个阶段后重新加权训练样本。AdaBoost(自适应提升)算法(Bishop2006;Hastie,Tibshirani和Friedman2009;Murphy2012)通过根据每个阶段是否正确分类来重新加权每个样本,并使用阶段平均分类错误来确定最终的弱分类器权重αj。
为了进一步提高检测器的速度,可以创建一个分类器级联,其中每个分类器使用少量测试(例如,二项式AdaBoost分类器)来拒绝大部分非人脸,同时尝试通过所有潜在的人脸候选(Fleuret和Geman2001;Viola和Jones2004;Brubaker、Wu等人2008)。
深度网络。自20世纪初面部检测研究的初期爆发以来,面部检测算法一直在不断进化和改进(Zafeiriou,Zhang,和Zhang 2015)。研究人员提出了使用特征级联(Li和Zhang 2013)、可变形部件模型(Mathias,Benenson等2014)、聚合通道特征(Yang,Yan等2014)以及神经网络(Li,Lin等2015;Yang,Luo等2015)。更广泛的face基准-

图6.23使用定向梯度直方图检测行人(Dalal和Triggs
2005)©2005 IEEE: (a)训练样本上的平均梯度图像;(b)每个“像素”显示以该像素为中心的块中的最大正SVM权重;(c)同样,负SVM权重也是如此;(d)测试图像;(e)计算出的R-HOG(矩形梯度直方图)描述符;(f)由正SVM权重加权的R-HOG描述符;(g)由负SVM权重加权的R-HOG描述符。
mark15,16(杨、罗等人,2016)包含了来自更近期论文的结果和指向,包括RetinaFace(邓、郭等人,2020b),该方法结合了其他最近的神经网络和目标检测器的思想,如特征金字塔网络(林、多尔等人,2017)和RetinaNet(林、戈亚尔等人,2017),还有一篇关于
其他近期人脸检测器的精彩综述。
虽然早期关于物体检测的研究主要集中在人脸检测上,但行人和汽车等其他物体的检测也受到了广泛关注(Gavrila和Philomin 1999;Gavrila 1999;Papageorgiou和Poggio 2000;Mohan、Papageorgiou和Poggio 2001;Schneiderman和Kanade 2004)。其中一些技术在速度和效率方面保持了与人脸检测相同的关注点。然而,另一些则专注于准确性,将检测视为更具有挑战性的通用类别识别变体(第6.3.3节),旨在尽可能准确地确定物体的位置和范围(Everingham、Van Gool等2010;Everingham、Eslami等2015;Lin、Maire等2014)。一个著名的行人检测器的例子是达拉尔开发的算法。
以及Triggs(2005),他们使用了一组重叠的方向梯度直方图(HOG)
输入支持向量机的描述符(图6.23)。每个HOG都有单元格来累积特定方向梯度的幅度加权投票,就像Lowe(2004)开发的尺度不变特征变换(SIFT)一样,我们将在第7.1.2节和图7.16中描述。然而,与仅在兴趣点位置评估的SIFT不同,HOG是在一个规则重叠网格上评估的,其描述符幅度使用更粗糙的网格进行归一化;它们仅在一个尺度和固定方向上计算。为了捕捉人物轮廓周围细微的方向变化,使用了大量的方向区间,并且在中心差异梯度计算中不进行平滑处理——更多实现细节参见Dalal和Triggs(2005)。图6.23d显示了一个样本输入图像,而图6.23e则显示了相关的HOG描述符。
一旦计算出描述符,支持向量机(SVM)就会在生成的高维连续描述符向量上进行训练。图6.23b-c展示了每个块中(最)正和负的SVM权重图,而图6.23f-g则显示了中心输入图像对应的加权HOG响应。可以看出,在人的头部、躯干和脚周围有相当数量的正响应,而在毛衣的中部和颈部则相对较少的负响应。
与人脸检测类似,行人和一般物体检测领域在2000年代继续迅速发展(Belongie,Malik和Puzicha2002;Mikolajczyk,Schmid和Zisserman2004;Dalal和Triggs2005;Leibe,Seemann和Schiele2005;Opelt,Pinz和Zisserman2006;Torralba2007;Andriluka,Roth和Schiele2009;Maji和Berg2009;Andriluka,Roth和Schiele2010;Doll r,Belongie和Perona2010)。
在人物检测领域的一项重要进展是费尔岑斯瓦尔布、麦克阿莱斯特和拉马南(2008)的工作,他们扩展了方向梯度直方图人物检测器,以纳入灵活的部件模型(第6.2.1节)。每个部件都在整体对象模型下方两个金字塔层级的HOG上进行训练和检测,同时学习并使用部件相对于父节点(即整体边界框)的位置(图6.24b)。为了补偿训练示例边界框中的不准确或不一致(图6.24c中的虚线),“真实”位置的父(蓝色)边界框被视为一个潜在(隐藏)变量,并在训练和识别过程中推断。由于部件的位置也是潜在的,系统可以采用半监督方式训练,无需在训练数据中包含部件标签。该系统的扩展版本(费尔岑斯瓦尔布、吉什克等人,2010年)包括了一个简单的上下文模型改进,在2008年视觉对象类别检测挑战赛中,该系统是表现最好的两个对象检测系统之一(埃弗林厄姆、范古尔等人,2010年)。
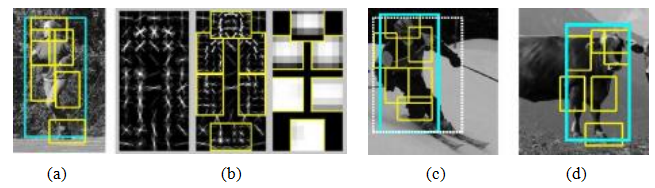
图6.24部件对象检测(Felzenszwalb,McAllester和Ramanan 2008)©2008 IEEE:(a)输入照片及其关联的人物(蓝色)和部件(黄色)检测结果。(b)检测模型由粗略模板、多个高分辨率部件模板以及每个部件位置的空间模型定义。(c)正确检测到一名滑雪者,而(d)错误地检测到一头牛(被标记为人物)。

图6.25使用随机森林进行姿态检测(Rogez,Rihan等人,2008)©2008 IEEE。估计的姿态(运动学模型的状态)绘制在每个输入帧上。
基于部件的人体检测和姿态估计的改进包括Andriluka、Roth和Schiele(2009)以及Kumar、Zisserman和Torr(2009)的工作。
罗热兹、里汉等人(2008)提出了一个更精确的人体姿态和位置估计方法,他们使用基于HOG构建的随机森林计算了人在行走周期中的相位以及各个关节的位置(图6.25)。由于他们的系统能够生成完整的三维姿态信息,因此其应用领域更接近于三维人体跟踪器(西登布拉德、布莱克和弗利特2000;安德里卢卡、罗斯和席勒2010),我们将在第13.6.4节中讨论。当有视频序列可用时,光流和运动不连续性中的额外信息可以大大帮助检测任务,这一点由埃夫罗斯、伯格等人(2003)、维奥拉、琼斯和斯诺(2003)以及达拉尔、特里格斯和施密德(2006)讨论过。
自2000年代以来,行人和一般人物检测一直在积极开发中,通常是在更广泛的多类物体检测的背景下进行(Everingham,Van Gool等人,2010;Everingham,Eslami等人,2015;Lin,Maire等人,2014)。Cal-
技术行人检测基准17和多尔、贝尔戈和佩罗纳(2010)的调查介绍了一个新的数据集
,并提供了截至2012年的算法综述,包括积分通道特征(多尔、图等人2009)、西方最快的行人检测器(多尔、贝尔戈和佩罗纳2010
),以及3D姿态估计算法如姿态小部件(布尔德夫和马利克2009)。自其最初
构建以来,该基准继续发布并评估更近期的检测器,包括多尔、阿佩尔和基恩兹勒(2012)、多尔、阿佩尔等人(2014)以及基于深度神经网络的更近期算法(塞曼内特、卡武库奥卢等人2013;欧阳和王2013;田、
罗等人2015;张
、林等人2016)。城市行人数据集(张、本森和席勒2017)和更广泛的面部与人物挑战18也报告了最近算法的结果。
虽然人脸和行人检测算法是最早被广泛研究的,但计算机视觉一直致力于解决一般的物体检测和标注问题,而不仅仅是全图像分类。帕斯卡视觉对象类别(VOC)挑战赛(Everingham,Van Gool等人2010)包含20个类别,既包括分类也包括检测挑战。早期在检测挑战中表现良好的参赛作品包括Chum和Zisserman(2007)基于特征的检测器和空间金字塔匹配SVM分类器、Felzenszwalb、McAllester和Ramanan(2008)的星型拓扑可变形部件模型以及Lampert、Blaschko和Hofmann(2008)的滑动窗口SVM分类器。该竞赛每年重新举行,2012年检测挑战赛的前两名参赛者(Everingham,Eslami等人2015)使用了滑动窗口空间金字塔匹配(SPM)SVM (de Sande,Uijlings等人2011)和牛津大学重新实现的可变形部件模型(Felzenszwalb,Girshick等人2010)。
图像净大规模视觉识别挑战赛(ILSVRC)于2010年发布,将数据集从帕斯卡VOC 2010的大约2万张图像扩展到ILSVRC 2010的超过140万张图像,并从20个物体类别增加到1000个物体类别(Russakovsky等人,2015)。与帕斯卡类似,它也有一个物体检测任务,但包含更广泛的具有挑战性的图像(图6.4)。微软COCO(上下文中的常见对象)数据集(Lin等人,2014)每张图像中包含更多的物体,以及多个物体的像素级分割,这使得不仅能够研究语义分割(第6.4节),还能研究单个物体实例分割(第6.4.2节)。表6.2列出了用于训练和测试通用物体检测算法的一些数据集。
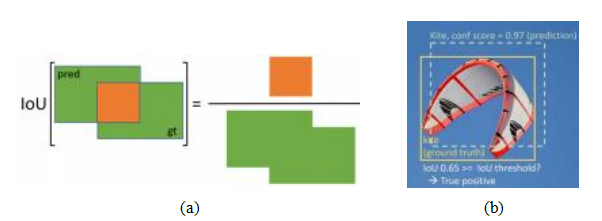
图6.26交并比(IoU):(a)示意图,(b)实际例子©2020 Ross Girshick。
COCO的发布恰逢图像分类、目标检测和分割领域向深度网络的全面转型(Jiao,Zhang et al.2019;Zhao,Zheng et al. 2019)。图6.29显示了COCO目标检测任务中平均精度(AP)的快速提升,这与深度神经网络架构的进步密切相关(图5.40)。
精确度与召回率
在描述现代物体检测器的要素之前,我们首先需要讨论它们试图优化的指标。如图6.5a和6.26b所示,物体检测的主要任务是为所有感兴趣的物体放置精确的边界框,并正确地标记这些物体。为了衡量每个边界框的准确性(既不太小也不太大),常用的指标是交并比(IoU),也称为杰卡德指数或杰卡德相似系数(Rezatofighi,Tsoi等,2019)。IoU通过计算预测边界框Bpr和真实边界框Bgt的交面积与并面积之比来得出,
IoU =
(6.6)
如图6.26a所示。
正如我们即将看到的,目标检测器首先提出多个合理的矩形区域(检测结果),然后对每个检测进行分类,并生成置信度评分(图6.26b)。这些区域随后会经过某种非极大值抑制(NMS)阶段,该阶段使用贪婪的最自信优先算法移除与较强检测重叠过多的较弱检测。
为了评估一个对象检测器的性能,我们遍历所有的检测结果,
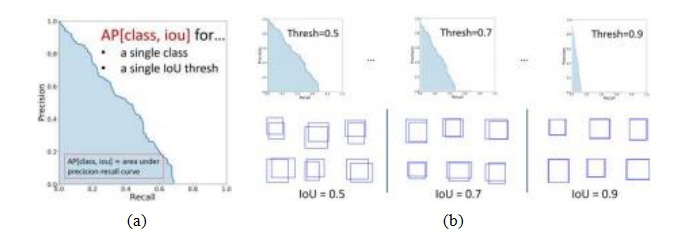
图6.27目标检测器平均精度©2020 Ross Girshick:单个类别和IoU阈值下的(a) a精度-召回率曲线,其中AP是P-R曲线下面积;(b)平均精度是在多个IoU阈值(从宽松到严格)上取平均值。
从最自信到最不自信,将它们分类为真阳性TP(正确标签且IoU足够高)或假阳性FP(错误标签或真实对象已匹配)。对于每个新的递减置信度阈值,我们可以计算精确率和召回率
精确度=
(6.7)
记住=
(6.8)
其中P是正例的数量,即测试图像中标注的真值检测的数量。19(关于特征匹配的其他术语,可参见第7.1.3节,这些术语常用于测量和描述错误率。)
计算每个置信阈值下的精确率和召回率,可以生成一个精确率-召回率曲线,如图6.27a所示。该曲线下面积称为平均精确率(AP)。对于检测到的每个类别,可以分别计算AP分数,并取这些分数的平均值以得到平均精确率(mAP)。另一种广泛使用的度量是平均精确率。早期的基准测试,如PASCAL VOC使用单一IoU阈值0.5来确定mAP(Everingham,Eslami等,2015),而COCO基准测试(Lin,Maire等,2014)则在一系列IoU阈值下平均mAP,即IoU∈{0.50;0.55;...;0.95},如图6.27a所示。尽管这一AP分数仍被广泛使用,但最近提出了一种基于概率的检测质量(PDQ)分数(Hall,Dayoub等,2020)。还提出了一种更平滑的平均精确率版本,称为Smooth-AP,并证明其在大规模图像检索任务中具有优势(Brown,Xie等,2020)。
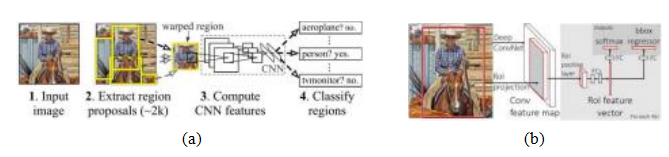
图6.28 R-CNN和Fast R-CNN目标检测器。(a) R-CNN重新缩放每个提议区域内的像素,并执行CNN + SVM分类(Girshick,Donahue等,2015)©2015 IEEE。(b) Fast R-CNN重采样卷积特征,并使用全连接层进行分类和边界框回归(Girshick2015)©2015 IEEE。
现代物体探测器
检测图像中物体的第一阶段是提出一组合理的矩形区域,以便运行分类器。这类区域提议算法的发展在20世纪初是一个活跃的研究领域(Alexe,Deselaers和Ferrari 2012;Uijlings,Van De Sande等2013;Cheng,Zhang等2014;Zitnick和Doll 2014)。
基于神经网络的最早物体检测器之一是R-CNN,即由Girshick、Donahue等人(2014)开发的区域卷积网络。如图6.28a所示,该检测器首先使用Uijlings、Van De Sande等人(2013)的选择性搜索算法提取大约2,000个区域提议。每个提议的区域随后被重新缩放(扭曲)到一个224平方的图像,并通过AlexNet或VGG神经网络,最终由支持向量机(SVM)分类器进行分类。
吉什克(2015)的后续论文《快速R-CNN》中,交换了卷积神经网络和区域提取阶段,并用一些全连接(FC)层替换了SVM,这些层同时计算对象类别和边界框精炼(图6.28b)。这重新利用了CNN的计算,使得训练和测试时间大大加快,与之前的网络相比,精度显著提高(图6.29)。从图6.28b可以看出,快速R-CNN是一个具有共享主干和两个独立头部的深度网络示例,因此也有两种不同的损失函数,尽管这些术语直到何、吉奥查里等人(2017)的《掩码R-CNN》论文中才被引入。
几个月后,Ren、He等人(2015)引入了更快的R-CNN系统,用卷积区域提议网络(RPN)替换了相对较慢的选择性搜索阶段,从而实现了更快的推理速度。计算出卷积特征后,RPN在每个粗略位置建议多个潜在的锚框,这些锚框在形状和大小上各不相同。
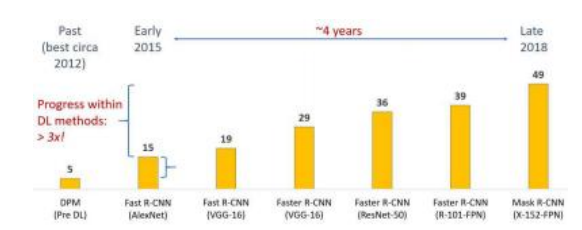
图6.29按年份划分的COCO目标检测任务的最佳平均精度(AP)结果(Lin,Maire等人,2014)©2020 Ross Girshick。
以适应不同的潜在对象。然后,通过Fast R-CNN头部的实例对每个提案进行分类和细化,并使用非最大抑制对最终检测结果进行排序和合并。
R-CNN、Fast R-CNN和Faster R-CNN都在单一分辨率的卷积特征图(Figure6.30b)上操作。为了获得更好的尺度不变性,最好是在一系列分辨率上操作,例如,在每个图像金字塔层级计算特征图,如图6.30a所示,但这计算成本高昂。我们也可以从卷积网络内部的不同层级开始(图6.30c),但这些层级具有不同程度的语义抽象,即较高/较低的层级更倾向于抽象结构。最佳解决方案是构建特征金字塔网络(FPN),如图6.30d所示,通过自上而下的连接赋予高分辨率(低)金字塔层级以在更高层级推断出的语义(Lin,Doll r等2017)。这种额外信息显著提升了目标检测器(及其他下游任务)的性能,并使其行为对物体大小的敏感度大大降低。
DETR (Carion,Massa等,2020)采用了一种更简单的架构,消除了非极大值抑制和锚点生成的使用。他们的模型由一个ResNet主干网络组成,该主干网络连接到一个变压器编码器-解码器。大致来说,它生成N个边界框预测,其中一些可能包括“无对象类别”。真实边界框也用“无对象类别”边界框填充,以获得总共N个边界框。在训练过程中,二分匹配用于建立每个预测边界框与真实边界框之间的一对一映射,所选映射导致
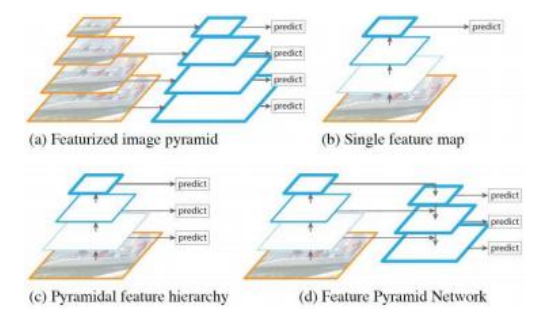
图6.30特征金字塔网络及其前身(Lin,Doll等人,2017)©
2017 IEEE:(a)在图像金字塔的每个层次提取的深度特征;(b)单个低分辨率特征图;(c)深度特征金字塔,其中较高层次具有更高的抽象性;(d)特征金字塔网络,具有自上而下的上下文信息。
以最低的成本进行训练。整体的训练损失是匹配的边界框之间的损失之和。他们发现他们的方法在COCO上的性能与最先进的目标检测方法具有竞争力。
单级网络
在我们迄今为止研究的架构中,区域提议算法或网络会选择要考虑的检测位置和形状,然后使用第二个网络对每个区域内的像素或特征进行分类和回归。另一种方法是使用单阶段网络,该网络通过单一神经网络输出多个位置的检测结果。例如,Liu、Anguelov等人(2016)提出的SSD(单次多盒检测器)和Redmon、Divvala等人(2016)、Redmon和Farhadi(2017)以及Redmon和Farhadi(2018)描述的YOLO(你只需看一次)系列检测器。RetinaNet (Lin、Goyal等人,2017)也是一种基于特征金字塔网络构建的单阶段检测器。它利用焦点损失来集中训练,通过降低正确分类样本的损失权重,防止大量容易的负样本压倒训练过程。这些以及更近期的卷积物体检测器在Jiao、Zhang等人(2019)的最新综述中有所描述。图6.31展示了截至2017年初发布的检测器的速度和准确性。
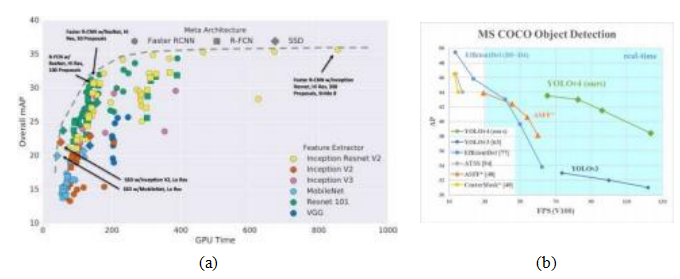
图6.31卷积物体检测器的速度/精度权衡:(a) (Huang,Rathod等人,2017)©2017 IEEE;(b) YOLOv4©Bochkovskiy,Wang和Liao(2020)。
最新的YOLO检测器家族成员是Bochkovskiy、Wang和Liao(2020)提出的YOLOv4。除了在性能上超越其他近期的快速检测器如EfficientDet(Tan、Pang和Le,2020),如图Figure6.31b所示,该论文还将处理流程分为几个阶段,包括一个颈部模块,该模块执行特征金字塔网络中的自上而下的特征增强。此外,论文还评估了许多不同的组件,这些组件被归类为“免费工具包”,可以在训练时使用,以及“特殊工具包”,可以在检测时以最小的额外成本使用。
虽然大多数边界框目标检测器继续在COCO数据集(Lin,Maire等人,2014)上评估其结果,但较新的数据集如Open Images (Kuznetsova,Rom等人,2020)和LVIS:大规模词汇实例分割(Gupta,Doll r,和Girshick,2019)现在也被使用(见表6.2)。最近的两个研讨会重点介绍了使用这些数据集的最新成果,分别是Zendel等人(2020)和Kirillov,Lin等人(2020),并且还涉及了与实例分割、全景分割、关键点估计和密集姿态估计相关的挑战,这些主题我们将在本章后面讨论。用于训练和微调目标检测器的开源框架包括TensorFlow object Detection。
| 名称/网址 | 范围 | 内容/参考 | ||
| 对象识别 | ||||
| 牛津建筑数据集 建筑物图片 https://www.robots.ox.ac.uk/~ vgg/data/oxbuildings INRIA假期 假日场景 https://lear.inrialpes.fr/people/jegou/data.php 帕斯卡 分割,框 http://host.robots.ox.ac.uk/pascal/VOC 图像网 完成图片 https://www.image-net.org 时尚MNIST 完成图片 https://github.com/zalandoresearch/fashion-mnist | 5062张图像 Philbin、Chum等人(2007)1,491张图像 J gou、Douze和Schmid (2008)11k张图像(2.9k张带分割的图像) Everingham、Eslami等人(2015)21k(WordNet)类别,14M张图像 邓、董等(2009)70k时尚产品 Xiao、Rasul和Vollgraf(2017) | |||
| 物体检测和分割 | ||||
| 加州理工学院行人数据集边界框 http://www.vision.caltech.edu/Image-Datasets/CaltechPedestrians MSR剑桥 每像素分割 https://www.microsoft.com/en-我们/研究/项目/图像理解 LabelMe数据集 多边形边界 http://labelme.csail.mit.edu 微软COCO 分割,框 https://cocodataset.org 城市景观 多边形边界 https://www.cityscapes-dataset.com 布罗登 分割掩模 http://netdissect.csail.mit.edu 布罗登+ 分割掩模 https://github.com/CSAILVision/unifiedparsing 利兹 实例分割 https://www.lvisdataset.org 打开图片 段落,关系 https://g.co/dataset/openimages | 行人 Doll r,Wojek等人( 2009)23类 Shotton、Winn等人(2009)>500个类别 Russell、Torralba等人(2008)330k张图像 Lin,Maire等人(2014)30个类别,25,000张图像 Cordts、Omran等人(2016)多种视觉概念 Bau、Zhou等人(2017)多种视觉概念 Xiao,Liu等人(2018) 1000类,220万张图片 Gupta、Doll r和Girshick(2019
)478k张图像,3M个关系 库兹涅佐娃、Rom等人(2020) | |||


图6.32图像分割示例(Kirillov,He等人,2019)©2019 IEEE:(a)原始图像;(b)语义分割(逐像素分类);(c)实例分割(划分每个对象);(d)全景分割(标注所有物体和物品)。
6.4 语义分割
一个具有挑战性的通用物体识别和场景理解版本是同时执行识别和精确边界分割(Fergus2007)。在本节中,我们探讨了一些相关问题,即语义分割(逐像素类别标注)、实例分割(准确划分每个独立对象)、全景分割(标注对象和背景)以及密集姿态估计(标注属于人体及其身体部位的像素)。图6.32和6.43展示了这些类型的分割示例。
同时识别和分割的基本方法是将问题表述为给图像中的每个像素标注其类别归属。早期的方法通常使用能量最小化或贝叶斯推断技术来实现这一点,即条件随机场(第4.3.1节)。Shotton、Winn等人(2009年)的TextonBoost系统基于特定图像的颜色分布(第4.3.2节)、位置信息(例如,前景物体更可能位于图像中央,天空更可能较高,道路更可能较低)以及使用共享提升训练的新颖纹理布局分类器,采用一元(像素级)势能。它还使用传统的成对势能,考虑图像颜色梯度。纹理布局特征首先通过一系列17个方向滤波器组过滤图像,然后聚类响应以将每个像素分类为30种不同的纹理类别(Malik、Belongie等人,2001年)。随后,响应使用经过联合提升训练的偏移矩形区域进行过滤(Viola和Jones,2004年),生成用作一元势能的纹理布局特征。图6.33展示了一些成功使用TextonBoost标记和分割的图像示例。
TextonBoost条件随机场框架已被扩展到LayoutCRFs

图6.33使用TextonBoost (Shotton,Winn等人,2009)同时识别和分割©2009 Springer。
温恩和肖顿(2006)引入了额外的约束条件,以识别多个对象实例并处理遮挡问题;霍伊姆、罗瑟和温恩(2007)则引入了完整的三维模型。条件随机场继续被广泛使用,并扩展到同时进行识别和分割的应用中,如本书第一版所述(Szeliski2010,第14.4.3节),以及那些首先执行低级或层次化分割的方法(第7.5节)。
全卷积网络(Long、Shelhamer和Darrell 2015)的发展,我们在第5.4.1节中有所介绍,使得使用单一神经网络实现逐像素语义标注成为可能。尽管早期的网络分辨率较低(边界非常模糊),但在最终阶段加入条件随机场(Chen、Papandreou等2018;Zheng、Jayasumana等2015)、反卷积上采样(Noh、Hong和Han 2015)以及U-Net中的精细连接(Ronneberger、Fischer和Brox 2015),这些改进都有助于提高准确性和分辨率。
现代语义分割系统通常基于诸如特征金字塔网络(Lin,Doll等人,2017)等架构构建,这些架构具有自上而下的连接,有助于将语义
信息传递到更高分辨率的地图中。例如,赵、石等人(2017)提出的金字塔场景解析网络(PSPNet)使用空间金字塔池化(He,Zhang等人,2015)来聚合不同分辨率级别的特征。肖、刘等人(2018)提出的统一感知解析网络(UPerNet)则同时使用特征金字塔网络和金字塔池化模块,不仅标注图像像素的对象类别,还
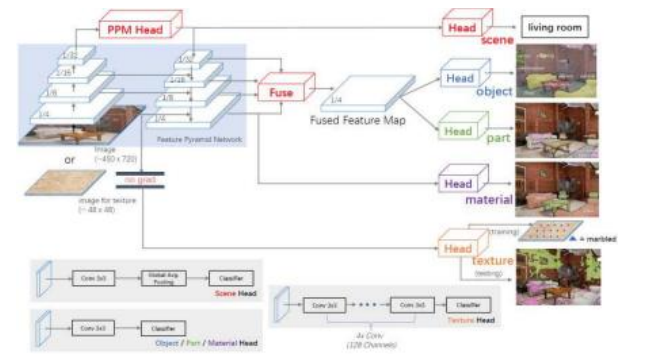
图6.34统一感知解析(Xiao,Liu等,2018)的UPerNet框架©2018斯普林格。特征金字塔网络(FPN)主干在输入到FPN的自上而下的分支之前,附加了一个金字塔池化模块(PPM)。FPN和/或PPM的各个层被输入到不同的头部,包括用于图像分类的场景头、来自融合FPN特征的对象和部分头、在FPN最细粒度级别操作的材料头,以及不参与FPN微调的纹理头。底部灰色方块提供了某些头部的更多细节。
材料、部件和纹理,如图6.34所示。HRNet(王、孙等人,2020)在整个管道中保留了特征图的高分辨率版本,并在不同分辨率层之间偶尔交换信息。此类网络还可以用于估计图像中的表面法线和深度(黄、周等人,2019;王、格拉吉蒂等人,2020)。
语义分割算法最初是在MSRC (Shotton,Winn等,2009)和PASCAL VOC (Everingham,Eslami等,2015)等数据集上进行训练和测试的。近年来的数据集包括用于城市场景理解的城市景观数据集(Cordts,Omran等,2016)和ADE20K (Zhou,Zhao等,2019),后者标注了150个不同类别和部分标签的更广泛的室内和室外场景像素。Bau,Zhou等(2017)创建的广泛且密集标注数据集(Broden)整合了多个此类密集标注数据集,包括ADE20K、Pascal-Context、Pascal-Part、OpenSur- faces和可描述纹理,以获得材料和纹理等广泛标签。
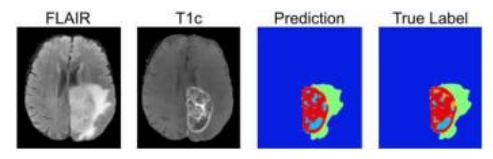
图6.35使用深度网络的三维体积医学图像分割(Kamnitsas,Ferrante等人,2016)©2016 Springer。
除了基本的对象语义之外,该数据集最初是为了帮助解释深度网络而开发的,但也已被证明(经过扩展后)对于训练统一多任务标注系统如UPerNet (Xiao,Liu等,2018)非常有用。表6.2列出了用于训练和测试语义分割算法的一些数据集。
最后一点。虽然语义图像分割和标注在图像理解中有着广泛的应用,但将场景的语义草图或绘画转化为逼真图像的问题也受到了广泛关注(Johnson,Gupta和Fei-Fei 2018;Park,Liu等2019;Bau,Strobelt等2019;Ntavelis,Romero等2020b)。我们将在第10.5.3节中详细讨论这一主题,涉及语义图像合成。
图像分割最有前景的应用之一是在医学影像领域,可以用于分割解剖组织以供后续定量分析。图4.21展示了一个带有方向边的二值图割,用于分割肝脏组织(浅灰色)与其周围的骨骼(白色)和肌肉(深灰色)组织。图6.35展示了脑部扫描中用于检测脑肿瘤的分割过程。在现代图像分割算法中使用的成熟优化和深度学习技术发展之前,这种处理需要对单个X光切片进行更为繁琐的手动追踪。
最初,医学图像分割使用了诸如马尔可夫随机场(第4.3.2节)和区分性分类器如随机森林(第5.1.5节)等优化技术(Criminisi、Robertson等人,2013)。最近,该领域转向了深度学习方法(Kamnitsas、Ferrante等人,2016;Kamnitsas、Ledig等人,2017;Havaei、Davy等人,2017)。
医学图像分割(McInerney和Terzopoulos1996)和医学图像配准(Kybic和Unser2003)(第9.2.3节)是研究领域丰富

图6.36使用Mask R-CNN进行实例分割(He、Gkioxari等人,2017年)©2017
IEEE:(a)系统架构,附加分割分支;(b)样本结果。
他们自己专门举办的会议,如医学影像计算和计算机辅助介入(MICCAI),以及期刊,如医学影像分析和IEEE医学影像学杂志。这些可以成为该领域研究的参考和灵感来源。
实例分割是寻找图像中所有相关对象并为其可见区域生成像素级掩模的任务(图6.36b)。一种潜在的方法是执行已知对象实例识别(第6.1节),然后将对象模型反投影到场景中(Lowe2004),如图6.1d所示,或者将新场景的部分与预学习的(分割的)对象模型匹配(Ferrari,Tuytelaars,和Van Gool2006b;Kannala,Rahtu等2008)。然而,这种方法仅适用于已知的刚性3D模型。
对于更复杂的(灵活的)对象模型,如人类模型,一种不同的方法是将图像预分割成更大或更小的部分(第7.5节),然后将这些部分与模型的部分进行匹配(Mori,Ren等,2004;Mori2005;He,Zemel,和Ray2006;Gu,Lim等,2009)。对于一般高度可变的类别,一种相关的方法是根据特征对应关系投票确定潜在的对象位置和尺度,然后推断对象的范围(Leibe,Leonardis,和Schiele2008)。
随着深度学习的出现,研究人员开始将区域建议或图像预分割与卷积第二阶段结合,以推断最终实例分割(Hariharan,Arbel ez等人2014;Hariharan,Arbel ez等人2015;Dai,He和Sun2015
;Pinheiro,Lin等人2016
;Dai,He和Sun2016;Li,Qi等人2017)。
实例分割的突破是Mask R-CNN的引入

图6.37使用Mask R-CNN进行人物关键点检测和分割(He,Gkioxari et al.2017)©2017 IEEE
(He,Gkioxari等,2017)。如图6.36a所示,Mask R-CNN使用了与Faster R-CNN (Ren,He等,2015)相同的区域提议网络,但在此基础上增加了一个额外的分支用于预测对象掩码,除了现有的边界框精炼和分类分支外。与其他具有多个分支(或头)和输出的网络一样,每个监督输出对应的训练损失需要仔细平衡。还可以添加其他分支,例如,用于检测人体关键点位置的分支(通过关键点掩码图像实现),如图6.37所示。
自引入以来,Mask R-CNN及其扩展的性能随着骨干架构的进步而持续提升(Liu,Qi等2018;Chen,Pang等2019)。最近两个突出展示该领域最新成果的工作坊是COCO + LVIS联合识别挑战赛(Kirillov,Lin等2020)和鲁棒视觉挑战赛(Zendel等2020)。此外,还可以用时间演化的闭合轮廓,即“蛇”(第7.3.1节),来替代大多数实例分割技术生成的像素掩码,如Peng,Jiang等(2020)所述。为了鼓励更高质量的分割边界,Cheng,Girshick等(2021)提出了一种新的边界交并比(Boundary IoU)指标,以替代常用的掩码交并比(Mask IoU)指标。
如我们所见,语义分割将图像中的每个像素分类为其语义类别,即每个像素对应什么。实例分割关联
具有单独对象的像素,即有多少个对象以及它们的范围

图6.38使用Panoptic特征金字塔网络(Kirillov,Girshick等人,2019)生成的全景分割结果©2019 IEEE。

图6.39 Detectron2对一些我个人照片的全景分割结果。(点击https://github.com/facebookresearch/detectron2and上的“Colab Notebook”链接,然后编辑输入图像URL来尝试自己的。)
(图6.32)。将这两个系统结合起来一直是语义场景理解的目标(Yao,Fidler和Urtasun 2012;Tighe和Lazebnik 2013;Tu,Chen等2005)。在像素级别上实现这一点,可以得到一个全景分割的场景,其中所有物体都被正确分割,剩余的部分也被正确标注(Kir- illov,He等2019)。设计一个合理的全景质量(PQ)指标,同时平衡两个任务的准确性,需要精心设计。在他们的论文中,Kirillov,He等(2019)描述了他们提出的指标,并分析了人类(以一致性为标准)和最近算法在三个不同数据集上的表现。
COCO数据集现已扩展,包括一个全景分割任务,最近的一些成果可以在ECCV 2020工作坊上找到(Kirillov,Lin等2020)。图6.38显示了由Kirillov,Girshick等(2019)描述的全景特征金字塔网络生成的一些分割结果,该网络在特征金字塔网络中增加了两个分支,分别用于实例分割和语义分割。

图6.40使用数百万张照片完成场景(Hays和Efros2007)©
2007年ACM:(a)原始图像;(b)去除不需要的前景后;(c)合理的场景匹配,用户选择的场景以红色突出显示;(d)替换和混合后的输出图像。
物体识别和场景理解的进步极大地增强了智能(半自动)照片编辑应用的能力。一个例子是Lalonde、Hoiem等人(2007年)的“照片剪辑艺术”系统,该系统能够识别并分割互联网照片集合中的感兴趣对象,如行人,然后允许用户将它们粘贴到自己的照片中。另一个例子是Hays和Efros(2007年)的场景补全系统,它解决了我们在第10.5节将要研究的同一修复问题。给定一张图像,我们希望擦除并填充一大块区域(图6.40a-b),那么你从哪里获取填补编辑后图像空白的像素呢?传统方法要么使用平滑连续法(Bertalmio、Sapiro等人,2000年),要么从图像的其他部分借用像素(Efros和Leung,1999;Criminisi、P rez和Toyama,2004;Efros和Freeman,2001)。随着网络上大量图像的可用性,通常更有意义的是找到另一张图像作为缺失像素的来源。
在他们的系统中,海斯和埃夫罗斯(2007)计算每张图像的要点(奥利瓦和托拉尔巴2001;托拉尔巴、墨菲等人2003),以找到颜色和构图相似的图像。然后他们运行一个图割算法,该算法最小化图像梯度差异,并使用泊松图像融合(第8.4.4节)(普雷兹、甘格内特和布莱克2003)将新的替换部分合成到原始图像中。图6.40d显示了结果图像,其中
被擦除的前景屋顶区域被帆船所替代。由阿维丹、贝克和山编辑的特别期刊专刊(2010)中,还可以找到更多由所谓的“互联网计算机视觉”支持的照片编辑和计算摄影应用示例。
图像识别和分割的另一种应用是通过识别特定场景结构从单张照片中推断出三维结构。例如,Criminis,Reid,

图6.41自动照片弹出窗口(Hoiem、Efros和Hebert2005a)©2005 ACM:
(a)输入图像;(b)超像素被分为(c)多个区域;(d)标签表示地面(绿色)、垂直方向(红色)和天空(蓝色);(e)结果分段平面3D模型的新视角。
齐瑟曼(2000)检测消失点,并让用户绘制基本结构,如墙壁,以推断三维几何(第11.1.2节)。霍伊姆、埃夫罗斯和赫伯特(2005a)则处理更“有机”的场景,例如图6.41所示。他们的系统使用多种分类器和从标记图像中学习到的统计方法,将每个像素分类为地面、垂直或天空(图6.41d)。为此,他们首先计算超像素(图6.41b),然后将其分组为可能具有相似几何标签的合理区域(图6.41c)。所有像素被标记后,可以利用垂直像素与地面像素之间的边界来推断图像沿哪些三维线折叠成“弹出”效果(移除天空像素后),如图6.41e所示。在相关工作中,萨克森、孙和吴(2009)开发了一种系统,直接推断每个像素的深度和方向,而不仅仅是使用三个几何类别标签。我们将在第12.8节中详细探讨从单张图像推断深度的技术。
6.4.5姿态估计
从单张图像推断人体姿态(头部、身体和四肢的位置和姿态)可以看作是另一种分割任务。我们已经讨论过
第6.3.2节中给出了行人检测部分的一些姿态估计技术,如图所示
图6.25.自Felzenszwalb和Huttenlocher(2005)的开创性工作开始,二维和三维姿态检测与估计迅速发展成为活跃的研究领域,并取得了重要的进展和数据集(Sigal和Black2006a;Rogez、Rihan等人2008;Andriluka、Roth和Schiele2009;Bourdev和Malik2009;Johnson和Everingham2011;Yang和Ramanan2011;Pishchulin、Andriluka等人2013;Sapp和Taskar2013;Andriluka、Pishchulin等人2014)。
最近,深度网络已成为识别人体关键点的首选技术,以便将其转换为姿态估计(Tompson,Jain等人,2014;

图6.42 OpenPose实时多个人2D姿态估计(Cao,Simon et al.2017)©2017 IEEE。
Toshev和Szegedy 2014;Pishchulin、Insafutdinov等人2016;Wei、Ramakrishna等人2016;Cao、Simon等人2017;He、Gkioxari等人2017;Hidalgo、Raaj等人2019;Huang、Zhu等人2020)。图6.42显示了OpenPose系统(Cao、Hidalgo等人2019)生成的一些令人印象深刻的实时多人2D姿态估计结果。
在人体姿态估计中,最新的、最具挑战性的任务是DensePose任务
由G ler、Neverova和Kokkinos(2018)提出,其中任务是将每个像素与之关联
图6.43展示了基于表面模型的人体3D点RGB图像。作者为COCO图像中出现的50,000个人提供了密集注释,并评估了多种对应网络,包括他们自己的DensePose-RCNN及其几种扩展。关于3D人体建模和跟踪的更深入讨论,请参见第13.6.4节。
6.5 视频理解
正如我们在本章前面几节中所看到的,图像理解主要关注于命名和描述图像中的物体和物品,尽管物体与人之间的关系有时也会被推断出来(Yao和Fei-Fei2012;Gupta

图6.43密集姿态估计旨在映射RGB图像中所有的人体像素
至人体3D表面(G ler、Neverova和Kokkinos2018)©2018 IEEE。
本文描述了DensePose-COCO,一个大规模的真实数据集,包含50K个人的手动注释的图像到表面对应关系,以及DensePose-RCNN,训练以每秒多个帧密集回归UV坐标。
以及Malik2015;Yatskar、Zettlemoyer和Farhadi2016;Gkioxari、Girshick等人2018)。(我们将在关于视觉与语言的下一节中讨论描述完整图像的主题。)
那么,什么是视频理解呢?对于许多研究者来说,它始于对人类动作的检测和描述,这些动作被视为视频的基本原子单位。当然,就像图像一样,这些基本的原语可以被链接成更完整的对较长视频序列的描述。
人类活动识别研究始于20世纪90年代,同时期还涉及了人体运动跟踪等相关课题,相关内容将在第9.4.4节和第13.6.4节中讨论。阿加瓦尔和蔡(1999)对这两个领域进行了全面综述,他们称之为人体运动分析。他们调查的一些技术包括点跟踪、网格跟踪以及时空特征。
在2000年代,研究重点转向了时空特征,例如巧妙利用小区域中的光流来识别体育活动(Efros,Berg等人,2003年),或用于电影中动作分类的时空特征检测器(Laptev,Marszalek等人,2008年),后来结合图像上下文(Marszalek,Laptev,和Schmid,2009年)和跟踪特征轨迹(Wang和Schmid,2013年)。Poppe(2010年)、Aggarwal和Ryoo(2011年)以及Weinland、Ronfard和Boyer(2011年)提供了本十年算法的综述。一些
本研究使用的数据集包括KTH人体运动数据集(Sch ldt,Laptev,
以及Caputo2004)、UCF体育动作数据集(Rodriguez、Ahmed和Shah2008)、好莱坞人体动作数据集(Marszalek、Laptev和Schmid2009)、UCF-101(Soomro、Zamir和Shah2012)和HMDB人体运动数据库(Kuehne、Jhuang等人2011)。近十年来,视频理解技术已转向使用深度网络。
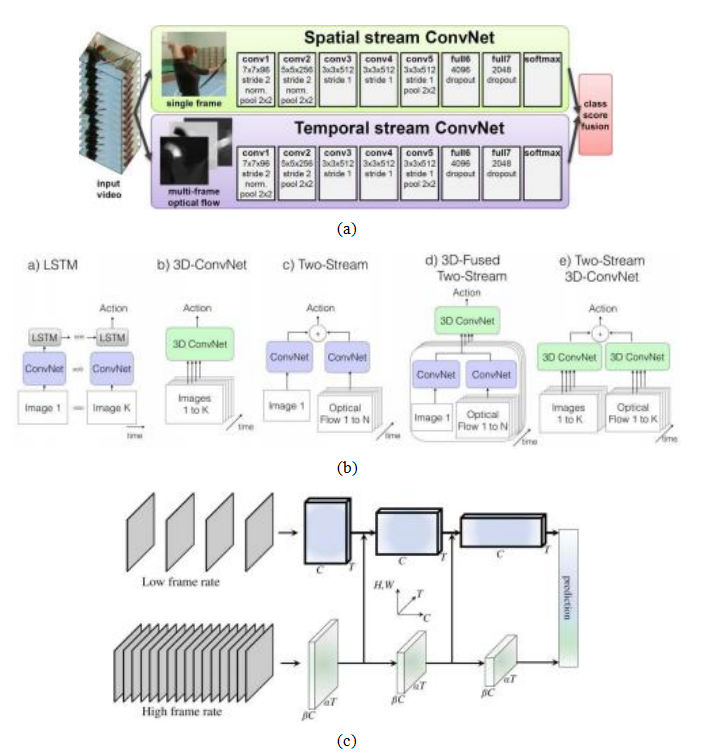
视频分类©Simonyan和Zisserman(2014a);(b)一些替代的视频处理架构(Carreira和Zisserman 2017)©2017 IEEE;(c)一种低帧率、低时间分辨率的慢路径和高帧率、高时间分辨率的快路径的SlowFast网络(Feichtenhofer,Fan等2019)©2019 IEEE。
(Ji,Xu等人,2013;Karpathy,Toderici等人,2014;Simonyan和Zisserman,2014a;Tran,Bourdev等人,2015;Feichtenhofer,Pinz和Zisserman,2016;Carreira和Zisserman,2017;Varol,Laptev和Schmid,2017;Wang,Xiong等人,2019;Zhu,Li等人,2020),有时与时间模型如LSTM结合(Baccouche,Mamalet等人,2011;Donahue,Hendricks等人,2015;Ng,Hausknecht等人,2015;Srivastava,Mansimov和Salakhudinov,2015)。
虽然可以直接将这些网络应用于视频流中的像素,例如使用三维卷积(第5.5.1节),研究人员还探讨了使用光流(第9.3章)作为额外输入。由此产生的双流架构由西蒙尼安和齐瑟曼(2014a)提出,并如图6.44a所示。卡雷拉和齐瑟曼(2017)后来的一篇论文将这种架构与像素流上的三维卷积以及两流和三维卷积的混合体进行了比较(图6.44b)。
最新的视频理解架构已回归到在原始像素流上使用3D卷积(Tran,Wang等2018,2019;Kumawat,Verma等2021)。Wu,Feichtenhofer等(2019)将3D卷积特征存储到他们称为长期特征库中,以提供更广泛的时间上下文用于动作识别。Feichtenhofer,Fan等(2019)提出了一种双流SlowFast架构,其中慢路径以较低帧率运行,并与快速路径结合,后者具有更高的时间采样但通道数较少(图6.44c)。表6.3总结了一些广泛用于评估这些算法的数据集。它们包括Charades(Sigurdsson,Varol等2016)、YouTube8M(Abu-El-Haija,Kothari等2016)、Kinetics(Carreira和Zisserman 2017)、“Something-something”(Goyal,Kahou等2017)、AVA (Gu,Sun等2018)、EPIC-厨房(Damen,Doughty等2018)和AVA-Kinetics (Li,Thotakuri等2020)。关于这些及其他视频理解算法的精彩介绍可以在Johnson (2020,第18讲)中找到。
与图像识别一样,研究人员也开始使用自监督算法来训练视频理解系统。与图像不同,视频片段通常是多模态的,即除了像素外还包含音频轨道,这可以成为未标记监督信号的极佳来源(Alwassel,Mahajan等2020;Patrick,Asano等2020)。当在推理时可用时,音频信号可以提高此类系统的准确性(Xiao,Lee等2020)。
最后,虽然动作识别是最近视频理解工作的主要焦点,但也可以将视频分类为不同的场景类别,如“海滩”、“烟花”或“下雪”。这个问题被称为动态场景识别,可以
使用时空CNN进行处理(Feichtenhofer,Pinz和Wildes,2017)。
| 名称/网址 元数据 | 内容/参考 |
| 猜字谜 动作、对象、描述 https://prior.allenai.org/projects/charades YouTube 800万 实体 https://research.google.com/youtube8m 动力学 行动类别 https://deepmind.com/research/open-source/kinetics “某物-某物”与对象的交互 https://20bn.com/datasets/something-something 阿瓦 行动 https://research.google.com/ava 史诗厨房 操作和对象 https://epic-kitchens.github.io | 9.8k视频 Sigurdsson,Varol等人(2016)4.8k视觉实体,8M视频 Abu-El-Haija、Kothari等人(2016) 700个动作类别,65万视频Carreira和Zisserman(2017) 174个动作,220k个视频 Goyal、Kahou等人(2017) 80个动作,430个15分钟视频,Gu,Sun等人(2018) 100小时以自我为中心的视频Damen,Doughty等人(2018) |
表6.3视频理解与动作识别数据集。
6.6 视觉和语言
计算机视觉研究的最终目标不仅仅是解决诸如构建世界三维模型或寻找相关图像等简单任务,而是成为人工智能(AGI)的重要组成部分。这要求视觉与其他人工智能组件如语音和语言理解与合成、逻辑推理以及常识和专业知识表示与推理相融合。
语音和语言处理技术的进步使得基于语音的智能虚拟助手如Siri、Google Assistant和Alexa得以广泛应用。在本章前面,我们已经了解了计算机视觉系统如何命名图像中的单个对象,并通过外观或关键词找到相似的图像。接下来自然而然地与其它人工智能组件集成的一步是将视觉和语言结合起来,即自然语言处理(NLP)。
尽管这一领域已经研究了很长时间(Duygulu,Barnard等,2002;Farhadi,Hejrati等,2010),但过去十年中,其性能和能力有了迅速提升(Mogadala,Kalimuthu和Klakow,2021;Gan,Yu等,2020)。一个例子是库尔卡尼、普雷姆拉杰等人(2013)开发的BabyTalk系统,该系统首先检测物体、它们的属性及其位置关系,然后推断出这些物体可能的兼容标签,最后生成图像描述,如图6.45a所示。

图6.45图像描述系统:(a) BabyTalk检测物体、属性和位置关系,并将这些信息组合成图像描述(Kulkarni,Premraj等2013)©2013 IEEE;(b-c)DenseCap将词语短语与区域关联,然后使用RNN构建合理的句子(Johnson,Karpathy和Fei-Fei 2016)©2016 IEEE。

图6.46注意力图像描述:(a)“展示、关注和讲述”系统,利用硬注意力将生成的词语与图像区域对齐©胸,Ba等人(2015);(b)使用不同检测器生成的神经婴儿对话描述,展示了词语与基础区域之间的关联(Lu,Yang等人,2018)©2018 IEEE。
视频字幕
接下来的几年里,关于图像描述和标注的论文如雨后春笋般涌现,包括(陈和劳伦斯·齐特尼克2015;多纳休、亨德里克斯等人2015;方、古普塔等人2015;卡帕西和费-菲2015;维尼亚尔、托舍夫等人2015;徐、巴等人2015;约翰逊、卡帕西和费-菲2016;杨、何等人2016;尤、金等人2016)。许多系统将基于CNN的图像理解组件(主要是物体和人物动作检测器)与RNN或LSTM结合,以生成描述,通常与其他技术如多实例学习、最大熵语言模型和视觉注意力相结合。一个令人惊讶的早期结果是,最近邻技术,即找到具有相似标题的图像集并创建共识标题,表现得非常出色(德夫林、古普塔等人2015)。
近年来,基于注意力机制的系统一直是图像描述系统的重要组成部分(Lu,Xiong等,2017;Anderson,He等,2018;Lu,Yang等,2018)。图6.46展示了两篇相关论文的例子,其中生成的每个字都与相应的图像区域相对应。CVPR 2020教程(Zhou 2020)总结了过去五年中二十多篇相关的论文,包括使用变压器(第5.5.3节)进行描述的论文。该教程还涵盖了视频描述的

图6.47©Goh、Camarata等人(2021)发现的针对CLIP的对抗性打字攻击(Radford、Kim等人,2021)。与预测场景中存在的对象不同,CLIP根据对抗性的手写标签来预测输出。
以及密集视频字幕(Aafaq,Mian等,2019;Zhou,Kalantidis等,2019)和视觉-语言预训练(Sun,Myers等,2019;Zhou,Palangi等,2020;Li,Yin等,2020)。教程还包含关于视觉问答和推理(Gan2020)、文本到图像合成(Cheng2020)以及视觉-语言预训练(Yu,Chen,和Li 2020)的讲座。
对于图像分类任务(第6.2节),一个主要限制是模型只能预测其训练时使用的离散预定义标签集中的一个标签。CLIP (Radford,Kim等,2021)提出了一种替代方法,该方法依赖于图像描述,以实现零样本迁移至任何可能的标签集。给定一张带有标签集的图像(例如,{狗;猫;……;房子}),CLIP预测能够最大化图像被描述为“一张{标签}的照片”的概率的标签。第5.4.7节讨论了CLIP的训练方面,该方法收集了4亿个文本-图像对,并使用对比学习来确定图像与描述配对的可能性。
令人惊讶的是,CLIP在没有见过或微调过许多流行图像分类基准(如ImageNet、Caltech 101)的情况下,能够超越独立微调的ResNet-50模型在每个特定数据集上的表现。此外,与最先进的分类模型相比,CLIP的零样本泛化能力对数据分布的变化更为稳健,在ImageNet Sketch(Wang,Ge等2019)、ImageNetV2(Recht,Roelofs等2019)和ImageNet-R(Hendrycks,Basart等2020)等数据集上均表现出色,而无需针对这些数据集进行专门训练。事实上,Goh,Cammarata等人(2021)发现,CLIP单元对不同模态呈现的概念(例如,蜘蛛侠的图片、“蜘蛛”一词的文字以及蜘蛛侠的画作)的反应相似。图6.47显示了他们发现的一种对抗性打字攻击,可以欺骗CLIP。通过简单地将手写类别标签(例如,iPod)放在现实物体(例如,苹果)上,CLIP经常预测出标签上所写的类别。
与其他视觉识别和基于学习的系统领域一样,数据集在视觉和语言系统的开发中发挥了重要作用。一些广泛使用的带有标题的图像数据集包括概念性标题(Sharma,Ding等人,2018),

图6.48来自Visual Genome数据集的图像和数据(Krishna,Zhu等人,2017)©
2017斯普林格。(a)一个示例图像及其区域描述符。(b)每个区域都有一个对象、属性和两两关系的图表示,这些图被组合成场景图,在这个图中所有对象都与图像关联,并且还关联了问题和答案。(c)一些样本问题和答案对,涵盖了从识别到高级推理的各种视觉任务。
| 名称/网址 元数据 | 内容/参考 |
| Flickr30k(实体)图片说明(基于地面) https://shannon.cs.illinois.edu/DenotationGraph http://bryanplummer.com/Flickr30kEntities COCO字幕 全部图片说明 https://cocodataset.org/#captions-2015 概念性字幕完整图像字幕 https://ai.google.com/research/ConceptualCaptions 100米远场 Flickr元数据 http://projects.dfki.uni-kl.de/yfcc100m 视觉基因组 密集注释 https://visualgenome.org VQA v2.0 问题/回答对 https://visualqa.org 视频通话 多项选择题 https://visualcommonsense.com 广岛县 Compositional QA https://visualreasoning.net 视控 聊天机器人的对话框 https://visualdialog.org | 30k张图像(+边界框)Young,Lai等人(2014) Plummer、Wang等人(2017)150万字幕,33万张图像 Chen、Fang等人(2015)3.3M图像说明对 Sharma、Ding等人(2018)100M张带元数据的图像 Thomee、Shamma等人(2016)108k张图像,带区域图 Krishna、Zhu等人(2017)265k张图像 Goyal、Khot等人(2017)110k电影片段,290k问答 Zellers、Bisk等人(2019) 关于视觉基因组的220万问题 Hudson和Manning(2019)120k COCO图像+对话 Das,Kottur等人(2017) |
UIUC帕斯卡句子数据集(法哈迪、赫尔拉蒂等人,2010年)、SBU带注释图片数据集(奥多涅兹、库尔卡尼和伯格,2011年)、Flickr30k(杨、莱等人,2014年)、COCO标题(陈、方等人,2015年),以及每张图像包含50个句子的扩展版本(韦丹塔姆、劳伦斯·齐特尼克和帕里克,2015年)(见表6.4)。更密集标注的数据集如视觉基因组(克里希纳、朱等人,2017年)描述了图像的不同子区域及其各自的短语,即提供密集的标题,如Figure6.48所示。YFCC100M(托米、沙玛等人,2016年)包含来自Flickr的大约1亿张图片,但仅包括每个图片的原始用户上传元数据,如标题、上传时间、描述、标签和(可选地)图片位置。
衡量句子相似性的指标在图像描述和其他视觉与语言系统的发展中也发挥着重要作用。一些广泛使用的指标包括:BLEU:双语评估(Papineni等,2002年),ROUGE:基于召回的摘要评价(Lin,2004年),METEOR:显式排序翻译评估指标(Banerjee和Lavie,2005年),CIDEr:共识基础的
图6.49 DALL·E的定性文本生成图像结果,展示了广泛的泛化能力©Ramesh,Pavlov等(2021)。右下角的例子提供了一个部分完成的猫的图像提示,以及文字,模型会填充其余部分。其他三个例子仅以文字提示作为输入,模型生成整个图像。
图像描述评价(Vedantam、Lawrence Zitnick和Parikh2015)和香料:语义命题图像描述评价(Anderson、Fernando等人2016)。27
文本生成图像
文本生成图像的任务是视觉字幕的逆过程,即给定一个文本提示,生成相应的图像。由于图像具有如此高的维度,使其看起来连贯历来都十分困难。从文本提示生成图像可以视为从少量类别标签生成图像的一种泛化(第5.5.4节)。由于可能的文本提示几乎是无限的,成功的模型必须能够从训练中看到的相对较少的部分进行泛化。
早期关于这一任务的研究,如Mansimov、Parisotto等人(2016)的工作,使用RNN从头开始迭代地生成图像。他们的结果与文本提示有些相似,但生成的图像相当模糊。次年,Reed、Akata等人(2016)将GAN应用于该问题,未见过的文本提示开始显示出有希望的结果。他们生成的图像相对较小(64×64),后来的研究在这方面有所改进,通常首先生成小规模图像,然后基于该图像和文本输入生成更高分辨率的图像(Zhang、Xu等人,2017,2018;Xu、Zhang等人,2018;Li、Qi等人,2019)。
DALL·E(Ramesh,Pavlov等人,2021)使用了数量级更多的数据(2.5亿
互联网上的图像-文本对)并计算以实现惊人的定性结果(图6.49)。他们的方法在超越训练数据泛化方面产生了有希望的结果,甚至能够组合不常相关的对象(例如,扶手椅和牛油果),生成多种风格(例如,绘画、卡通、炭笔画),并且在处理困难对象时表现得相当不错(例如,镜子或文字)。
DALL·E的模型由两个组件构成:VQ-VAE-2(第5.5.4节)和解码器变压器(第5.5.3节)。文本被分词为256个标记,每个标记是16,384个可能向量之一,使用BPE编码(Sennrich,Haddow和Birch 2015)。VQ-VAE-2使用大小为8,192的代码本(显著大于原始VQ-VAE-2论文中使用的512代码本),将图像压缩为32×32的向量标记网格。在推理时,DALL·E使用变压器解码器,从256个文本标记开始,自回归预测32×32的图像标记网格。给定这样的网格,VQ-VAE-2能够利用其解码器生成最终的256×256大小的RGB图像。为了获得更好的实验结果,DALL·E生成512张图像候选,并使用CLIP (Radford,Kim等2021)重新排序这些图像,CLIP决定给定标题与给定图像关联的可能性。
一个引人入胜的DALL·E扩展是使用VQ-VAE-2编码器来预测压缩图像令牌的一部分。例如,假设我们有一个文本输入和一张图片。文本输入可以被分解为其256个令牌,然后可以使用VQ-VAE-2编码器获得32×32的图像令牌。如果我们丢弃图像令牌的下半部分,变压器解码器就可以自回归地预测哪些令牌可能存在于那里。这些令牌,连同未被丢弃的原始图像中的令牌,可以传递给VQ-VAE-2解码器以生成完整的图像。图6.49(右下角)展示了如何使用这样的文本和部分图像提示应用于图像到图像转换(第5.5.4节)。
视觉问题回答和推理
图像和视频字幕是有助于我们构建人工智能系统的有用任务,因为它们展示了将视觉线索如物体身份、属性和动作组合起来的能力。然而,系统是否真正理解了场景的深层含义,以及能否对构成部分及其组合方式进行推理,目前仍不清楚。
为了解决这些问题,研究人员一直在构建视觉问答(VQA)系统,该系统需要视觉算法来回答关于开放式问题
图像,如图6.48c所示。许多这项工作始于视觉问答(VQA)数据集的创建(Antol,Agrawal等,2015),这激发了大量后续研究。次年,VQA v2.0通过创建平衡的图像对集改进了这一数据集,每个问题在两个图像中有不同的答案(Goyal,Khot等,2017)。该数据集进一步扩展,以减少先前假设和数据分布的影响,并鼓励答案基于图像(Agrawal,Batra等,2018)。
自那时起,许多额外的VQA数据集被创建。这些包括用于视觉常识推理的VCR数据集(Zellers,Bisk等人,2019年)以及用于评估视觉推理和组合问题回答的GQA数据集和指标(Hudson和Manning,2019年),后者基于通过视觉基因组场景图提供的关于对象、属性和关系的信息(Krishna,Zhu等人,2017年)。关于这些及其他VQA数据集的讨论可以在Gan(2020年)在CVPR 2020教程中找到,其中包括测试视觉定位和指称表达理解、视觉蕴含、使用外部知识、阅读文本、回答子问题和使用逻辑的数据集。部分数据集总结见表6.4。
与图像和视频字幕处理一样,VQA系统使用各种形式的注意力机制来关联像素区域与语义概念(杨、何等,2016)。然而,不同于使用RNN、LSTM或变压器等序列模型生成文本,自然语言问题首先被解析以产生编码,然后与图像嵌入融合,生成所需答案。
图像语义特征可以基于粗网格计算,或者结合“自下而上”的对象检测器和“自上而下”的注意力机制来提供特征权重(Anderson,He等,2018)。近年来,使用自下而上区域和网格化特征描述符的技术之间来回摇摆,最近表现最佳的两种算法又回到了更简单(且速度快得多)的网格化方法(Jiang,Misra等,2020;Huang,Zeng等,2020)。Gan(2020)在CVPR 2020教程中讨论了这些以及其他数十种VQA系统及其子组件,如多模态融合变体(双线性池化、对齐、关系推理)、神经模块网络、鲁棒VQA和多模态预训练。Mogadala、Kalimuthu和Klakow(2021)的综述以及年度VQA挑战研讨会(Shri-vasava,Hudson等,2020)也是获取更多信息的极佳来源。如果您想测试当前VQA系统的状态,可以将您自己的图像上传到https://vqa.cloudcv.org,并向系统提出您的问题。
视觉对话。VQA的一个更具挑战性的版本是视觉对话,在这种对话中,聊天机器人会收到一张图片,并被要求回答关于该图片的开放式问题,同时还要参考之前的对话元素。VisDial数据集是最早广泛用于此任务的数据集(Das,Kottur等,2017)。你可以在视觉对话研讨会和挑战赛中找到为此任务开发的系统指南(Shrivastava,Hudson等,2020)。此外,在https://visualchatbot.cloudcv.org上还有一个聊天机器人,你可以上传自己的图片并开始对话,有时这会导致幽默(或奇怪)的结果(Shane2019)。
视觉-语言预训练。与许多其他识别任务一样,预训练在过去几年中取得了显著的成功,例如ViLBERT (Lu,Batra等,2019年)、Oscar (Li,Yin等,2020年),以及CVPR 2020关于视觉-语言自监督学习教程中描述的许多其他系统(Yu,Chen,和Li,2020年)。
6.7 其他阅读材料
与机器学习或深度学习不同,近期没有专门针对图像识别和场景理解的一般主题的教科书或综述。一些早期的综述(Pinz2005;Andreopoulos和Tsotsos2013)和论文集(Ponce,Hebert等2006;Dickinson,Leonardis等2007)回顾了“经典”(深度学习前)的方法,但鉴于过去十年的巨大变化,许多这些技术已不再使用。目前,除了本章和大学计算机视觉课程外,主要视觉会议如ICCV (Xie,Girshick等2019)、CVPR (Girshick,Kirillov等2020)和ECCV (Xie,Girshick等2020)上的教程也是获取最新材料的最佳来源之一。表6.1–6.4that中列出的图像识别数据集的活跃排行榜也可以成为获取最新论文的良好来源。
例如,实例识别算法,即检测外观变化微小但可能在三维姿态上有所差异的静态制造对象,仍然经常基于检测二维兴趣点并使用视点不变描述符来描述它们,如第7章和(Lowe2004)、Rothganger、Lazebnik等人(2006)以及Gordon和Lowe(2006)所讨论的那样。近年来,注意力转向了更具挑战性的实例检索问题(也称为基于内容的图像检索),其中需要搜索的图像数量可以非常大(Sivic和Zisserman2009)。下一章第7.1.4节回顾了此类技术,Zheng、Yang和Tian(2018)的综述也是如此。这一主题还与视觉相似性搜索有关(Bell和Bala2015;Arandjelovic、Gronat等人。
Al.2016;Song,Xiang et al.2016;Gordo,Almaz n et al.2017
;Rawat and Wang2017;Bell,Liu et al.2020),这些研究均在Section6.2.3中进行了报道。
关于基于特征的全图(单对象)类别识别,已有大量调查、论文集和课程笔记被撰写(Pinz2005;Ponce,Hebert等2006;Dickinson,Leonardis等2007;Fei-Fei,Fergus和Torralba 2009)。其中一些论文使用了词袋或关键点(Csurka,Dance等2004;Lazebnik,Schmid和Ponce 2006;Csurka,Dance等2006;Grauman和Darrell 2007b;Zhang,Marszalek等2007;Boiman,Shechtman和Irani 2008;Ferencz,Learned-Miller和Malik 2008)。其他论文则基于对象轮廓进行识别,例如使用形状上下文(Belongie,Malik和Puzicha 2002)或其他技术(Shotton,Blake和Cipolla 2005;Opelt,Pinz和Zisserman 2006;Ferrari,Tuytelaars和Van Gool 2006a)。
许多物体识别算法使用基于部件的分解方法,以提高对关节和姿态的不变性。早期算法主要关注部件之间的相对位置(Fischler和Elschlager 1973;Kanade 1977;Yuille 1991),而后期算法则采用了更复杂的外观模型(Felzenszwalb和Huttenlocher 2005;Fergus、Perona和Zisserman2007;Felzenszwalb,McAllester以及Ramanan 2008)。关于基于部件模型的识别,Fergus(2009)的课程笔记提供了很好的概述。Carneiro和Lowe(2006)讨论了用于基于部件识别的多种图形模型,包括树形图、星型图、k-扇形图和星座图。
经典识别算法通常将场景上下文作为其识别策略的一部分。该领域的代表性论文包括托拉尔巴(2003年)、托拉尔巴、墨菲等人(2003年)、拉比诺维奇、韦达利等人(2007年)、拉塞尔、托拉尔巴等人(2007年)、苏德斯、托拉尔巴等人(2008年)和迪瓦拉、霍伊姆等人(2009年)。机器学习也成为经典物体检测和识别算法的关键组成部分(费尔岑斯瓦尔布、麦克阿莱斯特和拉马南2008年;西维奇、拉塞尔等人2008年),利用大型人工标注数据库也是如此(拉塞尔、托拉尔巴等人2007年;托拉尔巴、弗里曼和弗格斯2008年)。
克里维斯基、苏特塞弗和欣顿(2012)的“AlexNet”超级视觉系统取得了突破性成功,这使得类别识别研究的重点从基于特征的方法转向了深度神经网络。如图5.40所示,识别准确率的快速提升在很大程度上得益于更深的网络和更优的训练算法,部分还归功于更大(未标注)的训练数据集(第5.4.7节)。
更专业的识别系统,如人脸识别系统,经历了类似的演变。虽然最早的一些人脸识别方法涉及找到独特的图像特征并测量它们之间的距离(Fischler和Elschlager 1973;Kanade 1977;Yuille 1991),但后来的方法则依赖于比较灰度-
图像通常投影到低维子空间(Turk和Pentland 1991;Belhumeur、Hespanha和Kriegman 1997;Heisele、Ho等2003),或局部二值模式(Ahonen、Hadid和Pietikinen 2006)。还开发了多种
形状和姿态变形模型(Beymer 1996;Vetter和Poggio 1997),包括活动形状模型(Cootes、Cooper等1995)、3D可变形模型(Blanz和Vetter 1999;Egger、Smith等2020)以及活动外观模型(Cootes、Edwards和Taylor 2001;Matthews和Baker 2004;Ramnath、Koterba等2008)。关于经典人脸识别算法的更多信息,可以在许多调查报告和书籍中找到(Chellappa、Wilson和Sirohey 1995;Zhao、Chellappa等2003;Li和Jain 2005)。
形状模型的概念在社区转向深度神经网络方法时继续被使用(Taigman,Yang等,2014)。然而,一些较新的深度人脸识别系统省略了正面化阶段,转而使用数据增强来生成具有更多姿态变化的合成输入(Schroff,Kalenichenko和Philbin,2015;Parkhi,Vedaldi和Zisserman,2015)。Masi,Wu等(2018)提供了一篇关于深度人脸识别的优秀教程和综述,包括广泛使用的训练和测试数据集列表、正面化和数据增强的讨论,以及训练损失的部分。
随着全图(单个对象)类别识别问题逐渐“解决”,研究重点转向了多对象轮廓划分和标注,即物体检测。物体检测最初是在特定类别如人脸、行人、汽车等的背景下进行研究的。人脸识别领域的开创性论文包括奥苏纳、弗伦德和吉罗西(1997年);宋和波吉奥(1998年);罗利、巴卢贾和卡纳德(1998年);维奥拉和琼斯(2004年);海塞勒、霍等人(2003年),杨、克里格曼和阿胡贾(2002年)则提供了该领域早期工作的全面综述。行人和汽车检测的早期工作由加夫里拉和菲洛明(1999年);加夫里拉(1999年);帕帕乔治奥和波吉奥(2000年);施耐德曼和卡纳德(2004年)完成。后续论文包括(米科拉伊奇克、施密德和齐瑟曼2004年;达拉尔和特里格斯2005年;莱贝、塞曼和席勒2005年;安德里卢卡、罗思和席勒2009年;多尔、贝隆吉和佩罗纳2010年;费尔岑斯瓦尔布、吉什克等人2010年)。
现代通用物体检测器通常采用区域提议算法(Uijlings,Van De Sande等,2013;Zitnick和Doll,2014)构建,该算法将图像中选定的区域(无论是
像素还是预计算的神经特征)输入多路分类器,从而形成如R-CNN (Girshick,Donahue等,2014)、Fast R-CNN (Girshick,2015)、Faster R-CCNN (Ren,He等,2015)和FPN (Lin,Doll等,2017)等架构。这种两阶段方法的另一种替代方案是单阶段网络,它使用单一网络在
多个位置输出检测结果。此类架构的例子包括
SSD (Liu,Anguelov等人,2016)、RetinaNet (Lin,Goyal等人,2017)和YOLO (Redmon,Divvala等人,2016;Redmon和Farhadi2017,2018;Bochkovskiy,Wang,以及Liao,2020)。这些以及更近期的卷积物体检测器在Jiao,Zhang等人(2019)的最新综述中进行了描述。
虽然在许多计算机视觉应用中,如计数汽车或行人甚至描述图像,对象检测已经足够,但详细的像素级标注可能更有用,例如用于照片编辑。这种标注有多种类型,包括语义分割(这是什么?)、实例分割(这是哪个可数对象?)、全景分割(这是什么或什么对象?)。早期解决这一问题的方法之一是将图像预分割成块,然后将这些块与模型的部分匹配(Mori,Ren等2004;Russell,Efros等2006;Borenstein和Ullman 2008;Gu,Lim等2009)。另一种流行的方法是使用
条件随机场(Kumar和Hebert2006;He,Zemel和Carreira-Perpi n2004;
温恩和肖顿2006;拉比诺维奇、韦达利等人2007;肖顿、温恩等人2009)。这些方法在当时在帕斯卡VOC分割挑战中取得了最佳结果之一。现代语义分割算法使用金字塔形全卷积架构,将输入像素映射到类别标签(龙、谢尔哈默和达雷尔2015;赵、石等人2017;肖、刘等人2018;王、孙等人2020)。
实例分割这一更具挑战性的任务,每个不同的对象都需要一个独特的标签,通常通过结合物体检测器和逐对象分割来解决,这在He、Gkioxari等人(2017)的开创性论文《Mask R-CNN》中得到了体现。后续研究使用了更复杂的主干架构(Liu、Qi等人,2018;Chen、Pang等人,2019)。最近两个突出展示该领域最新成果的工作坊是COCO + LVIS联合识别挑战赛(Kirillov、Lin等人,2020)和鲁棒视觉挑战赛(Zendel等人,2020)。
将语义分割和实例分割结合在一起一直是语义场景理解的目标(Yao,Fidler,和Urtasun 2012;Tighe和Lazebnik 2013;Tu,Chen等2005)。在像素级别上实现这一点可以得到一个全景分割,其中所有物体都被正确分割,剩余的部分也被正确标注(Kirillov,He等2019;Kirillov,Girshick等2019)。COCO数据集现已扩展以包含全景分割任务,在ECCV 2020工作坊中可以找到一些最近的结果(Kirillov,Lin等2020)。
视频理解的研究,或更具体地说,人类活动识别,可以追溯到20世纪90年代;一些优秀的综述包括(Aggarwal和Cai 1999;Poppe 2010;Aggarwal和Ryoo 2011;Weinland、Ronfard和Boyer 2011)。在过去十年中,视频理解技术转向使用深度网络(Ji、Xu等2013;Karpathy、Toderici等
Al.2014;Simonyan和Zisserman2014a;Donahue、Hendricks等人2015;Tran、Bourdev等人2015;Feichtenhofer、Pinz和Zisserman2016;Carreira和Zisserman2017;Tran、Wang等人2019;Wu、Feichtenhofer等人2019;Feichtenhofer、Fan等人2019)。表6.3总结了一些广泛用于评估这些算法的数据集。
虽然将文字与图像关联的研究已经进行了很长时间(Duygulu,Barnard等,2002),但对用标题和完整句子描述图像的持续研究始于2010年代初(Farhadi,Hejrati等,2010;Kulkarni,Premraj等,2013)。过去十年间,这类系统的性能和能力迅速提升(Mogadala,Kalimuthu和Klakow,2021;Gan,Yu等,2020)。最早被广泛研究的子问题之一是图像描述(Donahue,Hendricks等,2015;Fang,Gupta等,2015;Karpathy和Fei-Fei,2015;Vinyals,Toshev等,2015;Xu,Ba等,2015;Devlin,Gupta等,2015),随后的系统开始使用注意力机制(Anderson,He等,2018;Lu,Yang等,2018)。最近,研究人员开发了用于视觉问答(Antol,Agrawal等,2015)和视觉常识推理(Zellers,Bisk等,2019)的系统。
CVPR 2020关于视觉字幕最新进展的教程(Zhou2020)总结了过去五年中二十多篇相关论文,包括使用Transformer进行字幕生成的论文。该教程还涵盖了视频描述和密集视频字幕(Aafaq,Mian等2019;Zhou,Kalantidis等2019)以及视觉-语言预训练(Sun,Myers等2019;Zhou,Palangi等2020;Li,Yin等2020)。此外,该教程还包括关于视觉问答和推理(Gan2020)、文本到图像合成(Cheng2020)以及视觉-语言预训练(Yu,Chen,和Li2020)的讲座。
6.8 练习
例6.1:预训练识别网络。为图像分类、分割或其他任务如人脸识别或行人检测寻找一个预训练网络。
运行网络后,你能描述出网络最常见的错误类型吗?创建一个“混淆矩阵”,显示哪些类别被归类为其他类别。现在用网络处理你自己的数据,无论是来自网络搜索还是个人照片集。有令人惊讶的结果吗?
我自己最喜欢尝试的代码是Detectron2,31,我用它生成了图6.39所示的全视图分割结果。
31点击“Colab Notebook”链接athttps://github.com/facebookresearch/detectron2,然后编辑输入图像URL,尝试自己的。
例6.2:重新训练识别网络。在分析了预训练网络的性能之后,尝试在原始数据集上对其进行重新训练,但参数(层数、通道数、训练参数)进行了修改,或者使用了额外的例子。你能让网络表现得更符合你的期望吗?
许多在线教程,如上述提到的Detectron2协作笔记本,都附有如何从头开始在不同数据集上重新训练网络的说明。你能创建自己的数据集吗?例如,通过网络搜索并弄清楚如何标注示例?一种低投入(但不太准确)的方法是信任网络搜索的结果。Russakovsky、Deng等人(2015年)、Kovashka、Russakovsky等人(2016年)以及其他关于图像数据集的论文讨论了获取准确标签的挑战。
训练你的网络,尝试优化它的架构,并报告你所面临的挑战和你所发现的。
注:以下练习由Matt Deitke提出。
例6.3:图像扰动。下载ImageNet或Imagenette。32现在,通过在图像的左上角添加一个小方块来扰动每个图像,该方块的颜色对于每个标签都是唯一的,如下图所示:

使用任意图像分类模型,例如ResNet、EfficientNet或ViT,在扰动后的图像上从头开始训练模型。模型是否会过度拟合到正方形的颜色而忽略图像的其他部分?在训练和验证数据上评估模型时,尝试在不同标签之间对抗性地交换颜色。
例6.4:图像归一化。使用之前练习中下载的相同数据集,取一个ViT模型并移除所有中间层的归一化操作。你能否训练网络?利用Li、Xu等人(2018)的技术,有无中间层归一化操作时,损失景观图会呈现什么变化?
例6.5:语义分割。解释实例分割、语义分割和全景分割之间的区别。对于每种分割类型,是否可以进行后处理以获得其他类型的分割?
例6.6:类别编码。神经网络中的分类输入,如单词或对象,可以使用独热编码向量进行编码。然而,通常会将独热编码向量通过嵌入矩阵,然后输出结果传递给神经网络的损失函数。与使用独热编码相比,向量嵌入有哪些优势?
例6.7:目标检测。对于目标检测,DETR、Faster-RCNN和YOLOv4的参数数量如何比较?尝试在MS COCO上训练每个模型。哪一个训练速度最慢?每个模型在推理时评估单个图像需要多长时间?
例6.8:图像分类与描述。对于图像分类,列出使用分类标签和自然语言描述之间的至少两个显著差异。
例6.9:ImageNet Sketch。尝试使用几个预训练模型在ImageNet上进行评估,不进行任何微调,在ImageNet Sketch上进行评估(Wang,Ge et al.2019)。对于这些模型中的每一个,由于分布的变化,性能下降的程度有多大?
例6.10:自监督学习。为以下每种数据类型提供自监督学习预设任务的例子:静态图像、视频和视觉-语言。
例6.11:视频理解。对于许多视频理解任务,我们可能对跟踪一个物体在时间上的变化感兴趣。为什么这比为每一帧独立做出预测更受欢迎呢?假设推理速度不是问题。
例6.12:微调新头部。使用为对象分类训练的网络的主干,并用YOLO的一个变体对其进行对象检测微调。为什么可能希望冻结网络的早期层?
例6.13:电影理解。目前,大多数视频理解网络,如本章讨论的那些,往往只处理作为输入的短视频片段。为了在更长的序列上运行,例如整个电影,可能需要进行哪些修改?
Chapter 7 Feature detection and matching
7.1点和斑点 419
7.1.1特征检测器 422
7.1.2特征描述符 434
7.1.3特征匹配 441
7.1.4大规模匹配和检索 448
7.1.5特征跟踪 452
7.1.6应用:性能驱动动画 454
7.2边缘和轮廓 455
7.2.1边缘检测 456
7.2.2轮廓检测 461
7.2.3应用:边缘编辑和增强 465
7.3剖面跟踪 466
7.3.1蛇与剪刀 467
7.3.2水平集 474
7.3.3应用:轮廓跟踪和转描 476
7.4线与消失点 477
7.4.1连续逼近 477
7.4.2 Hough变换 477
7.4.3消失点 481
7.5分段 483
7.5.1基于图的分割 486
7.5.2平均偏移 487
7.5.3标准化切割 489
7.6其他阅读材料 491
7.7练习 495

图7.1特征检测器和描述子可用于分析、描述和匹配图像:(a)点状兴趣算子(Brown,Szeliski和Winder 2005)©2005 IEEE;(b) GLOH描述子(Mikolajczyk和Schmid 2005);(c)边缘(Elder和Goldberg 2001)©2001 IEEE;(d)直线(Sinha,Steedly等2008)©2008 ACM;(e)图基合并(Felzenszwalb和Huttenlocher 2004)©2004 Springer;(f)均值漂移(Comaniciu和Meer 2002)©2002 IEEE。
特征检测与匹配是许多计算机视觉应用中的关键组成部分。考虑图7.2中展示的两组图像。对于第一组,我们可能希望将两张图像对齐,以便无缝拼接成一个复合马赛克(第8.2节)。对于第二组,我们可能希望建立一组密集的对应关系,以便构建3D模型或生成中间视图(第12章)。无论哪种情况,你应该检测并匹配哪些类型的特征来建立这种对齐或对应关系?在继续阅读之前,请花点时间思考这个问题。
你可能首先注意到的是图像中的特定位置,如山峰、建筑角落、门道或形状有趣的雪地。这些局部特征通常被称为关键点特征或兴趣点(甚至角点),通常通过该位置周围像素块的外观来描述(第7.1节)。另一类重要的特征是边缘,例如山峦与天空的轮廓(第7.2节)。这类特征可以根据其方向和局部外观(边缘轮廓)进行匹配,也是图像序列中物体边界和遮挡事件的良好指标。边缘可以组合成长曲线和环线,然后进行跟踪(第7.3节)。它们也可以组合成直线段,可以直接匹配或分析以找到消失点,从而确定内部和外部相机参数(第7.4节)。
在本章中,我们描述了一些检测这些特征的实际方法,并讨论了如何在不同图像之间建立特征对应关系。点特征现在被广泛应用于各种场景,因此阅读并实现第7.1节中的一些算法是很好的做法。边缘和线条提供了与关键点和基于区域的描述符互补的信息,非常适合描述制造物体的边界。这些替代描述符虽然非常有用,但在简短的入门课程中可以跳过。
本章的最后一部分(第7.5节)讨论了自下而上的非语义分割技术。尽管这些技术曾广泛用作识别和匹配算法的重要组成部分,但它们大多已被我们在第6.4节中研究的语义分割技术所取代。这些技术偶尔仍被用于将像素聚类在一起,以实现更快或更可靠的匹配。
7.1 点和斑点
点特征可用于在不同图像中找到一组稀疏的对应位置,通常作为计算相机姿态(第11章)的前体,而计算相机姿态是使用立体匹配(第12章)计算更密集对应位置的前提条件。

图7.2两对要匹配的图像。可以使用哪些特征来建立这些图像之间的对应关系?
对应点还可以用于对齐不同的图像,例如,在拼接图像马赛克(第8.2节)或高动态范围图像(第10.2节),以及执行视频稳定(第9.2.1节)。它们还广泛用于对象实例识别(第6.1节)。关键点的一个重要优势是,即使在存在遮挡(如被遮挡)和大规模及方向变化的情况下,也能进行匹配。
基于特征的对应技术自立体匹配早期就已使用(Hannah1974;Moravec1983;Hannah1988),随后在图像拼接应用中(Zoghlami、Faugeras和Deriche1997;Brown和Lowe 2007)以及全自动三维建模中(Beardsley、Torr和Zisserman1996;Schaf-falitzky和Zisserman2002;Brown和Lowe2005;Snavely、Seitz和Szeliski2006)也获得了广泛的应用。
寻找特征点及其对应关系主要有两种方法。第一种是在一张图像中找到可以使用局部搜索技术(如相关性或最小二乘法)准确跟踪的特征点(第7.1.5节)。第二种是独立检测所有待考虑图像中的特征点,然后根据它们的局部外观进行匹配(第7.1.3节)。前者更适合于从附近视角拍摄或快速连续拍摄的图像(例如视频序列),而后者则更适合于预期会有大量运动或外观变化的情况,例如拼接全景图(Brown和Lowe 2007年)、在宽基线立体中建立对应关系(Schaffalitzky和Zisserman 2002年)或执行物体识别。

图7.3图片对,提取的补丁如下。注意一些补丁可以比其他补丁更精确地定位或匹配。
(Fergus,Perona和Zisserman2007)。
在本节中,我们将关键点检测和匹配流程分为四个独立阶段。在特征检测(提取)阶段(Section7.1.1),每张图像都会搜索出可能与其他图像良好匹配的位置。在特征描述阶段(第7.1.2节),每个检测到的关键点周围区域会被转换成一个更紧凑且稳定的(不变的)描述符,以便与其他描述符进行匹配。特征匹配阶段(Sections7.1.3and 7.1.4)高效地搜索其他图像中可能的匹配候选。特征跟踪阶段(Section7.1.5)是第三阶段的替代方案,仅搜索每个检测到特征的小邻域,因此更适合视频处理。
一个很好的例子可以在大卫·洛(2004)的论文中找到,该论文描述了他尺度不变特征变换(SIFT)的发展和完善过程。关于替代技术的全面描述可以在一系列综述和评估论文中找到,这些论文涵盖了特征检测(施密德、莫尔和鲍克哈格2000;米科拉伊奇克、图特拉尔斯等人2005;图特拉尔斯和米科拉伊奇克2008)和特征描述子(米科拉伊奇克和施密德2005;巴尔纳斯、伦斯等人2020)。石和托马西(1994)以及特里格斯(2004)也提供了经典(神经网络前)特征检测的良好综述。
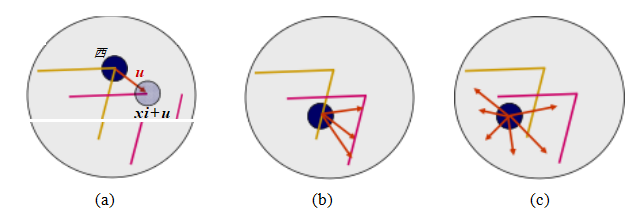
图7.4不同图像区域的孔径问题:(a)稳定(“角状”)流动;(b)经典孔径问题(梳状幻象);(c)无纹理区域。两幅图像I0(黄色)和I1(红色)叠加在一起。红色向量u表示区域中心之间的位移,w(xi)加权函数(区域窗口)以深色圆圈显示。
7.1.1特征检测器
我们如何找到可以与其他图像可靠对应的位置,即哪些是好的特征来跟踪(Shi和Tomasi 1994;Triggs 2004)?再次查看图7.3中显示的图像对和三个样本补丁,看看它们匹配或跟踪的效果如何。你可能会注意到,无纹理的补丁几乎无法定位。具有大对比度变化(梯度)的补丁更容易定位,尽管单一方向上的直线段会受到孔径问题的影响(Horn和Schunck 1981;Lucas和Kanade 1981;Anandan 1989),也就是说,只能沿边缘方向的法线方向对齐补丁(图7.4b)。至少在两个(显著)不同方向上有梯度的补丁最容易定位,如图7.4a所示。
这些直觉可以通过查看比较两个图像块的最简单的匹配标准来形式化,即它们的(加权)平方差之和,
其中,I0和I1是要比较的两幅图像,u =(u,v)是位移向量,w(x)是空间变化的加权(或窗口)函数,求和i涵盖了补丁中的所有像素。请注意,这与我们后来用于估计完整图像之间运动的公式相同(第9.1节)。
在执行特征检测时,我们不知道该特征最终会与哪些其他图像位置匹配。因此,我们只能通过将图像块与之对比,来计算这一指标相对于位置△u的小变化的稳定性。

图7.5三个自相关表面EAC(Δu)以灰度图像和表面图的形式显示:(a)原始图像用三个红色十字标记,表示计算自相关表面的位置;(b)这个区域来自花坛(良好的唯一
最小);(c)这个斑块来自屋顶边缘(一维孔径问题);(d)这个斑块来自云层(没有好的峰值)。图b-d中的每个网格点都是Δu的一个值。
(图7.5)。1注意纹理花坛的自相关表面(图7.5b和图7.5a右下角的红色十字)表现出强烈的最小值,表明它可以很好地定位。屋顶边缘对应的关联表面(图7.5c)在一个方向上具有强烈的模糊性,而云区对应的关联表面(图7.5d)则没有稳定的最小值。
利用图像函数的泰勒级数展开,我们可以将自相关面近似为I0(xi+△u)≈I0(xi)+▽I0(xi)·△u(Lucas和Kanade1981;Shi和Tomasi1994),
(7.5)
= △uTA△u, (7.6)
在哪里
(7.7)
是图像在xi处的梯度。该梯度可以通过多种技术计算(Schmid,Mohr和Bauckhage 2000)。经典的“哈里斯”检测器(Harris和Stephens 1988)使用[–2–1 0 1 2]滤波器,但更现代的变体(Schmid,Mohr和Bauckhage 2000;Triggs 2004)则用高斯函数的水平和垂直导数对图像进行卷积(通常σ = 1)。
A = w *
我们用权重核w的离散卷积替换了加权求和。这个矩阵可以解释为一个张量(多带)图像,其中梯度▽I的外积与权重函数w卷积,以提供每个像素
自相关函数的局部(二次)形状估计。
1严格来说,相关性是两个补丁的乘积(3.12);我在这里使用这个术语是更定性的。加权平方差之和通常被称为SSD表面(第9.1节)。
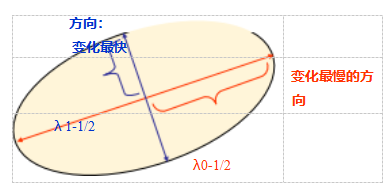
正如Anandan(1984;1989)首次指出,并在Section9.1.3and方程(9.37)中进一步讨论,矩阵A的逆提供了匹配区域位置不确定性的下限。因此,它是判断哪些区域可以可靠匹配的有效指标。最直观地理解和分析这种不确定性的方法是对自相关矩阵A进行特征值分析,这会产生两个特征值(λ0;λ 1)和两个特征向量方向(图7.6)。由于较大的不确定性依赖于较小的特征值,即λ0-1/2,因此找到较小特征值的最大值来定位要跟踪的良好特征是有意义的(Shi和Tomasi 1994)。
弗斯特纳
-哈里斯。虽然阿南丹(1984)和卢卡斯与卡纳德(1981)是最早分析自相关矩阵不确定性结构的人,但他们是在将确定性与光流测量关联的背景下进行的。弗斯特纳(1986)和哈里斯与斯蒂芬斯(1988)首次提出使用从自相关矩阵
导出的旋转不变标量度量中的局部最大值来定位关键点,以实现稀疏特征匹配。这两种技术还建议使用高斯加权窗口代替之前使用的正方形块,这使得检测器响应对平面内图像旋转不敏感。
最小特征值λ0(Shi和Tomasi1994)不是唯一可以计算的量
用于寻找关键点。Harris和Stephens(1988)提出的一个更简单的量是
det(A)—Q轨迹(A)2=λ0λ1—Q(λ0 + λ1)2 (7.9)
与Q = 0.06不同,这个量不需要使用平方根,但仍然具有旋转不变性,并且还降低了边缘特征的权重
Schmid、Mohr和Bauckhage(2000)以及Triggs(2004)对特征检测算法进行了更详细的历史回顾。
图7.7流行的关键点检测函数的等值线(Brown、Szeliski和Winder 2004)。每个检测器都寻找特征值λ0,λ1均为较大的点。
λ1≥λ0. Triggs(2004)建议使用该数量
λ0 — Qλ 1 (7.10)
(例如,当Q=0.05时),这也会减少一维边缘处的响应,在这些位置上,混叠误差有时会放大较小的特征值。他还展示了如何将基本的2×2赫斯矩阵扩展到参数运动中,以检测在尺度和旋转方面也能准确定位的点。另一方面,布朗、泽利斯基和温德(2005)使用了调和平均值
(7.11)
在λ0≈λ1的区域内,这是一个更平滑的函数。图7.7显示了各种兴趣点算子的等值线,从中我们可以看到两个特征值是如何混合以确定最终的兴趣值的。图7.8展示了经典哈里斯检测器以及下面讨论的高斯差分(DoG)检测器的结果兴趣点响应。
自适应非极大值抑制(ANMS)。大多数特征检测器仅寻找兴趣函数中的局部最大值,这可能导致图像中特征点分布不均,例如,在高对比度区域特征点会更密集。为了缓解这一问题,Brown、Szeliski和Winder(2005)仅检测那些既是局部最大值且其响应值显著(10%)高于其半径r内所有邻居的特征点(图7.9c-d)。他们设计了一种有效的方法,通过首先按响应强度对所有局部最大值进行排序,然后创建

图7.8兴趣点运算器响应:(a)样本图像,(b) Harris响应,以及(c) DoG响应。圆圈的大小和颜色表示每个兴趣点检测的尺度。注意两个检测器往往在互补的位置响应。

图7.9自适应非极大值抑制(ANMS)(Brown,Szeliski和Winder 2005)©2005 IEEE:上两幅图像显示了最强的250个和500个兴趣点,而下两幅图像则展示了通过自适应非极大值抑制选择的兴趣点及其对应的抑制半径r。请注意,后者在图像中的空间分布更加均匀。

图7.10在五个金字塔层次上提取的多尺度定向补丁(MOPS)(Brown、Szeliski和Winder 2005)©2005 IEEE。方框显示了特征的方向和描述符向量采样的区域。
第二列表按抑制半径递减排序(Brown,Szeliski和Winder 2005)。图7.9展示了选择前n个特征与使用ANMS的定性比较。请注意,非极大值抑制现在也是基于DNN的目标检测器的重要组成部分,如第6.3.3节所述。
测量重复性。鉴于计算机视觉中已开发出大量特征检测器,我们如何决定使用哪些?Schmid、Mohr和Bauckhage(2000)首次提出了测量特征检测器的重复性,他们将其定义为在一个图像中检测到的关键点在变换后图像中相应位置∈(例如,∈= 1.5)像素内的出现频率。在他们的论文中,他们通过应用旋转、尺度变化、光照变化、视角变化以及添加噪声来转换平面图像。他们还测量了每个检测到的特征点可用的信息量,定义为一组旋转不变局部灰度描述符的熵。在他们调查的技术中,发现改进版(高斯导数)的Harris操作符,其中σd=1(导数高斯的尺度)和σi=2(积分高斯的尺度),效果最佳。
尺度不变性
在许多情况下,检测尽可能精细的稳定尺度特征可能不合适。例如,在匹配具有少量高频细节的图像(如云)时,
细粒度特征可能不存在。
解决这一问题的一个方法是在不同尺度上提取特征,例如,在金字塔结构中以多种分辨率执行相同操作,然后在相同层级匹配特征。当待匹配的图像没有发生大规模变化时,这种方法尤为适用,比如从飞机上连续拍摄的航拍图像或使用固定焦距相机拍摄的全景图拼接。图7.10展示了这种方法的一个输出:布朗、斯泽利斯基和温德(2005)提出的多尺度定向块检测器,显示了五个不同尺度下的响应。
然而,对于大多数物体识别应用而言,图像中物体的尺度是未知的。与其在多个尺度上提取特征,然后匹配所有这些特征,不如提取在位置和尺度上都稳定的特征(Lowe 2004;Mikolajczyk和Schmid 2004)。
早期关于尺度选择的研究由林德伯格(1993;1998b)进行,他首次提出使用高斯拉普拉斯(LoG)函数的极值作为兴趣点位置。基于这项工作,洛(2004)提出了计算一组次八度高斯差分滤波器(图7.11a),寻找结果结构中的三维(空间+尺度)最大值(图7.11b),然后使用二次拟合计算亚像素空间+尺度位置(布朗和洛2002)。经过仔细的经验调查,确定次八度级别的数量为三个,这对应于四分之一八度金字塔,与特里格斯(2004)使用的相同。
与Harris算子一样,对于指示函数(在这种情况下,是DoG)的局部曲率存在强烈不对称性的像素被拒绝。这是通过首先计算差异图像D的局部Hessian实现的
(7.12)
然后拒绝那些关键点
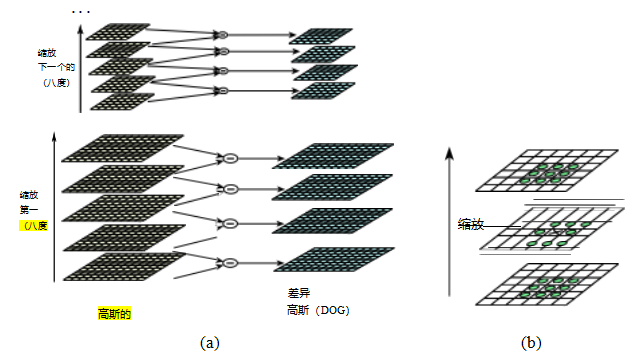
图7.11使用次八度高斯金字塔差分(Lowe2004)检测尺度空间特征©2004斯普林格:(a)相邻的次八度高斯金字塔层级相减,生成高斯差分图像;通过将像素与其26个邻近像素进行比较,检测出结果三维体积中的(b)极值(最大值和最小值)。
或小于其粗略和精细级别的值)。还提出了并评估了对尺度和位置的可选迭代优化。米科拉伊奇克、图特拉尔斯等人(2005)和图特拉尔斯与米科拉伊奇克(2008)讨论了其他尺度不变区域检测器的例子。
旋转不变性和方向估计
除了处理尺度变化外,大多数图像匹配和物体识别算法还需要应对(至少)平面内的图像旋转。一种解决方法是设计旋转不变的描述子(Schmid和Mohr 1997),但这些描述子的区分能力较差,即它们会将外观不同的区域映射到相同的描述子上。
更好的方法是估计每个检测到的关键点的主导方向。一旦估计了关键点的局部方向和尺度,就可以提取出一个围绕检测点的缩放和定向的补丁,并用于形成特征描述符(图7.10和7.15)。
最简单的方向估计是关键点周围区域内的平均梯度。如果使用高斯加权函数(Brown、Szeliski和Winder2005),
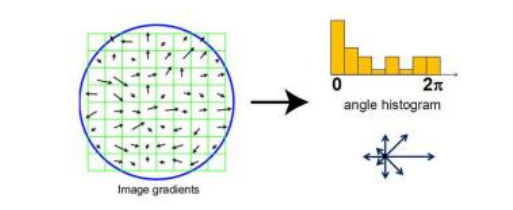
图7.12通过创建所有梯度方向的直方图(按其大小加权或在阈值化小梯度后)并找到该分布中的显著峰值,可以计算出主导方向估计值(Lowe2004)©2004 Springer。
这个平均梯度相当于一阶可调滤波器(第3.2.3节),即可以使用高斯滤波器的水平和垂直导数进行图像卷积来计算(Freeman和Adelson 1991)。为了使这一估计更加可靠,通常建议使用比检测窗口更大的聚合窗口(高斯核大小)(Brown、Szeliski和Winder 2005)。图7.10中所示的方框方向是通过这种方法计算得出的。
然而,有时一个区域内的平均(带符号)梯度可能很小,因此作为方向的指标不可靠。更可靠的方法是查看围绕关键点计算的方向直方图。Lowe(2004)计算了一个由边缘方向组成的36个区间直方图,该直方图根据梯度大小和到中心的高斯距离加权,并找到全局最大值80%范围内的所有峰值,然后使用三个区间的抛物线拟合计算出更准确的方向估计(图7.12)。
仿射不变性
虽然尺度不变性和旋转不变性非常理想,但对于许多应用,如宽基线立体匹配(Pritchett和Zisserman1998;Schaffalitzky以及Zisserman 2002)或位置识别(Chum、Philbin等2007),完全仿射不变性更为优选。仿射不变检测器不仅在尺度和方向变化后能在一致的位置响应,还能在仿射变形如(局部)透视缩短(图7.13)中保持一致的响应。事实上,对于足够小的图像块,任何连续的图像扭曲都可以很好地近似为仿射变形。
为了引入仿射不变性,一些作者提出了拟合椭圆到自动-

图7.13用于匹配从截然不同的视角拍摄的两幅图像的仿射区域探测器(Mikolajczyk和Schmid2004)©2004 Springer。

图7.14从多幅图像中提取并匹配的最大稳定极限区域(MSERs)(Matas,Chum et al.2004)©2004 Elsevier。
相关性或Hessian矩阵(使用特征值分析),然后使用该拟合的主要轴和比率作为仿射坐标系(Lindeberg和G rding1997;Baumberg 2000;Mikolajczyk
和Schmid2004;Mikolajczyk、Tuytelaars等2005;Tuytelaars和Mikolajczyk2008)。
另一个重要的仿射不变区域检测器是由马塔斯、楚姆等人(2004年)开发的最大稳定极值区域(MSER)检测器。为了检测MSERs,通过在所有可能的灰度级别上对图像进行阈值处理来计算二值化区域(因此该技术仅适用于灰度图像)。这一操作可以通过首先按灰度值对所有像素进行排序,然后随着阈值的变化逐步向每个连通组件中添加像素来高效完成(Nist r和Stew nius2008)。随着阈值的变化,监测每个组件(区域)的面积;那些相对于阈值面积变化率最小的区域被定义
为最大稳定的。因此,这些区域对仿射几何和光度(线性偏置增益或平滑单调)变换具有不变性(Figure7.14)。如有需要,可以使用其矩矩阵将每个检测到的区域拟合到一个仿射坐标系。
特征点检测领域依然非常活跃,每年在主要的计算机视觉会议上都会发表论文。Mikolajczyk、Tuytelaars等人(2005)和Tuytelaars和Mikolajczyk(2008)综述了多个流行的(DNN之前)仿射区域检测器,并提供了它们对常见图像变换不变性的实验比较。
最近十年发表的论文包括:
SURF (Bay,Ess等人,2008),使用积分图像进行更快的卷积;
•FAST和FASTER(Rosten、Porter和Drummond2010),最早的学会检测器之一;
•BRISK(Leutenegger、Chli和Siegwart2011),它使用尺度空间FAST检测器和位串描述符;
ORB (Rublee、Rabaud等人,2011年),为FAST添加了方向性;以及
KAZE (Alcantarilla、Bartoli和Davison,2012)和Accelerated-KAZE (Alcantarilla、Nuevo和Bartoli,2013),使用非线性扩散来选择特征的尺度
察觉
虽然FAST引入了机器学习用于特征检测器的想法,但最近的论文使用卷积神经网络来执行检测。这些包括:
学习协变特征检测器(Lenc和Vedaldi2016);
学习为特征点分配方向(Yi,Verdie等人,2016);
•LIFT,学习不变特征变换(Yi,Trulls等,2016),SuperPoint,自监督兴趣点检测与描述(DeTone,Malisiewicz和Rabi- novich,2018),以及LF-Net,从图像中学习局部特征(Ono,Trulls等,2018),这三种方法共同优化了检测器和描述符。
(多头)管道;
AffNet(Mishkin、Radenovic和Matas2018),用于检测可匹配的仿射协变区域;
Key.Net (Barroso-Laguna,Riba等人,2019),它使用手工制作和学习的CNN特征的组合;
D2-Net (Dusmanu、Rocco等人,2019)、R2D2 (Revaud、Weinzapfel等人,2019)和D2D (Tian、Balntas等人,2020),均提取密集的局部特征描述符
然后保留那些具有高显著性或可重复性的数据。
最后两篇论文也包含了对其他最近特征检测器的很好的回顾,Balntas、Lenc等人(2020)的论文也是如此。
当然,关键点并不是唯一可用于图像配准的特征。佐格拉米、福热拉斯和德里奇(1997)使用线段以及点状特征来估计图像对之间的单应性,而巴托利、科克雷尔和斯特姆(2004)则利用沿边缘的局部对应关系提取三维结构和运动。图特拉尔斯和范古尔(2004)使用仿射不变区域检测宽基线立体匹配中的对应关系,而卡迪尔、齐瑟曼和布雷迪(2004)则检测局部最大化的显著区域,这些区域的块熵及其随尺度变化的速率达到最大值。科索和哈格(2005)使用相关技术将二维定向高斯核拟合到同质区域。关于寻找和匹配曲线、直线和区域的技术的更多细节将在本章后面部分介绍。
检测到关键点特征后,我们必须进行匹配,即确定不同图像中相应位置的特征。在某些情况下,例如视频序列(Shi和Tomasi 1994)或已校正的立体对(Zhang、Deriche等1995;Loop和Zhang 1999;Scharstein和Szeliski 2002),每个特征点周围的局部运动可能主要是平移。在这种情况下,可以使用简单的误差度量,如平方差之和或归一化互相关,这些方法在第9.1节中有所描述,用于直接比较每个特征点周围小区域的强度。(Mikolajczyk和Schmid(2005)的研究,下文讨论,使用了互相关。)由于特征点可能无法精确定位,可以通过执行增量运动精化来计算更准确的匹配分数,如第9.1.3节所述,但这可能会耗时较长,有时甚至会降低性能(Brown、Szeliski和Winder 2005)。
然而,在大多数情况下,特征的局部外观会改变方向和尺度,有时甚至会发生仿射变形。因此,通常更倾向于提取局部尺度、方向或仿射框架估计值,然后使用这些信息重新采样补丁,再形成特征描述符(图7.15)。
即使补偿了这些变化,图像块的局部外观通常仍会因图像而异。我们如何使图像描述符对这种变化更加不变,同时仍能保持不同(非对应)图像块之间的可区分性?Mikolajczyk和Schmid(2005)回顾了多种视图不变的局部图像描述符,并实验比较了它们的性能。最近,Balntas、Lenc等人(2020)和Jin、Mishkin等人(2021)比较了过去十年开发的大量学习特征描述符。下面,我们将介绍其中的一些描述符。
3最近的许多出版物,如Tian,Yu等人(2019)使用他们的HPatches数据集来比较他们的性能

图7.15一旦确定了局部尺度和方向估计,就会使用偏置和增益归一化的强度值的8×8采样来形成MOPS描述符,采样间距为检测尺度的五像素(Brown,Szeliski,和Winder 2005)©2005 IEEE。这种低频采样使特征对兴趣点位置误差具有一定的鲁棒性,是通过在高于检测尺度的金字塔层级进行采样实现的。
更多细节。
偏置和增益归一化(MOPS)。对于不表现出大量前景缩短的任务,如图像拼接,简单的归一化强度块表现良好且易于实现(Brown,Szeliski和Winder 2005)(Figure7.15)。为了补偿特征点检测器(位置、方向和尺度)的轻微不准确,多尺度定向块(MOPS)以相对于检测尺度的五像素间距采样,使用图像金字塔的较粗层次以避免混叠。为了补偿仿射光度变化(线性曝光变化或偏置和增益,(3.3)),块强度被重新缩放,使其均值为零,方差为一。
尺度不变特征变换(SIFT)。SIFT特征(Lowe2004)是通过计算检测到的关键点周围16×16窗口中每个像素的梯度形成的,使用的是检测到关键点时所对应的高斯金字塔层级。梯度幅度通过高斯衰减函数(图7.16a中以蓝色圆圈表示)进行下权重处理,以减少远离中心的梯度的影响,因为这些梯度更容易受到小失配的影响。
在每个4×4象限中,通过(概念上)将梯度值乘以高斯衰减函数后加到八个方向直方图的一个区间内,形成梯度方向直方图。为了减少位置和主要方向估计错误的影响,每个原始的256个加权梯度幅度被柔和地添加到2×2×2相邻的区域。
与以前的方法相反。
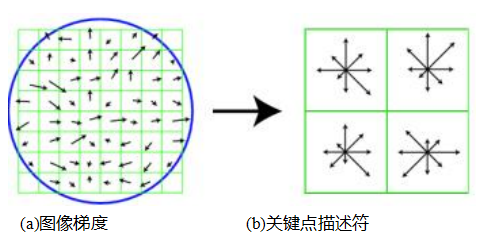
图7.16洛(2004)尺度不变特征变换(SIFT)的示意图:(a)在每个像素处计算梯度的方向和强度,并通过高斯衰减函数加权(蓝色圆圈)。(b)然后在每个子区域中使用三线性插值计算加权梯度方向直方图。虽然此图显示了一个8×8像素的补丁和一个2×2的描述符数组,但洛的实际实现使用了16×16的补丁和一个4×4的八区间直方图数组。
使用三线性插值在(x;y;θ)空间中绘制直方图区间。在计算直方图的任何应用中,例如霍夫变换(第7.4.2节)或局部直方图均衡化(第3.1.4节),将值柔和地分配到相邻的直方图区间通常是个好主意。
四维数组中的八个区间直方图生成了128个非负值,构成了SIFT描述子向量的原始版本。为了减少对比度或增益的影响(梯度已经去除了加性变化),128维向量被归一化为单位长度。为进一步提高描述子对其他光度变化的鲁棒性,值被裁剪至0.2,然后再次归一化为单位长度。
PCA-SIFT。Ke和Sukthankar(2004)提出了一种更简单的计算描述子的方法,该方法受到SIFT的启发;它在39×39的补丁上计算x和y(梯度)导数,然后使用主成分分析(PCA)将结果的3042维向量降维至36维(第5.2.3节和附录A.1.2)。另一种流行的SIFT变体是SURF (Bay,Ess等2008),该方法使用盒滤波器来近似SIFT中使用的导数和积分。
RootsSIFT.Arandjelovi和Zisserman(2012
)观察到,通过使用L1度量重新归一化SIFT描述符,然后取每个分量的平方根,可以显著提高性能(可区分性)。
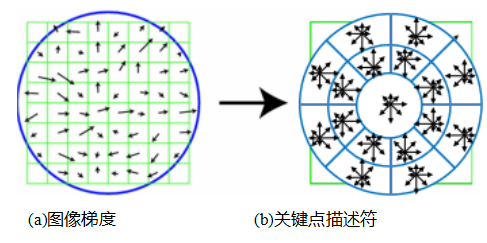
图7.17梯度位置-方向直方图(GLOH)描述符使用对数极坐标区间而不是正方形区间来计算方向直方图(Mikolajczyk和Schmid,2005)。GLOH在每个区间内使用16个梯度方向,尽管该图仅显示了8个以减少混乱。
梯度位置-方向直方图(GLOH)。这一描述符由米科拉伊奇克和施密德(2005)开发,是SIFT的一种变体,使用了对数极坐标分箱结构,而不是洛厄(2004)使用的四个象限(图7.17)。空间分箱范围为半径0.. .6、6.. .11和11.. .15,共有八个角度分箱(除了单个中心区域),总计17个空间分箱,而GLOH使用了16个方向分箱,而不是SIFT中的8个。然后,272维直方图通过在大型数据库上训练的主成分分析投影到128维描述符上。在他们的评估中,米科拉伊奇克和施密德(2005)发现,总体表现最佳的GLOH比SIFT略胜一筹。
可转向滤波器。可转向滤波器(第3.2.3节)是高斯滤波器的导数组合,允许快速计算所有可能方向上的偶数和奇数(对称和反对称)边缘特征和角特征(Freeman和Adelson1991)。由于它们使用了相当宽的高斯函数,因此对定位和方向误差也较为不敏感。
局部描述子的性能。在Mikolajczyk和Schmid(2005)比较的局部描述子中,他们发现GLOH表现最好,紧随其后的是SIFT。他们还给出了许多本书未涉及的其他描述子的结果。
特征描述子领域继续迅速发展,一些技术关注局部颜色信息(van de Weijer和Schmid 2006;Abdel-Hakim和Farag 2006)。Winder和Brown(2007)开发了一个多阶段框架,用于计算特征描述子,该框架涵盖了SIFT和GLOH(图7.18a),并且还允许它们
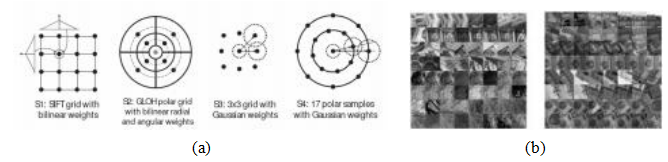
图7.18 SIFT、GLOH及一些相关特征描述子的空间求和块(Winder和Brown 2007)©2007 IEEE: (a)特征参数,例如高斯权重,是从互联网照片集合中应用鲁棒结构从运动得到的(b)匹配真实图像块训练数据库中学习而来的(Hua、Brown和Winder 2007)。
学习新的描述子以获得优于先前手动调优的描述子的最佳参数。Hua、Brown和Winder(2007)通过学习具有最佳区分能力的高维描述子的低维投影扩展了这一工作,而Brown、Hua和Winder(2011)进一步扩展了这项工作,学习池化区域的最佳放置。所有这些论文都使用了一个由真实世界图像补丁组成的数据库(图7.18b),这些图像是在互联网照片集合中使用稳健的结构从运动算法可靠匹配的位置采样的(Snavely、Seitz和Szeliski 2006;Goesele、Snavely等2007)。在同期研究中,Tola、Lepetit和Fua(2010)开发了一种类似的菊花描述子用于密集立体匹配,并根据真实立体数据优化了其参数。
虽然这些技术构建了优化所有对象类别重复性的特征检测器,但也有可能开发出针对特定类别或实例的特征检测器,以最大化与其他类别的区分度(Ferencz,Learned-Miller和Malik 2008)。如果可以在匹配图像中确定平面表面的方向,则还可以提取视角不变的补丁(Wu,Clipp等2008)。
最近的趋势是开发二进制位字符串特征描述子,这些描述子可以利用现代计算机架构中的快速汉明距离运算。简短描述子(Calonder,Lepetit等,2010)通过比较关键点周围散落的128对像素值(图7.19a中表示为线段)来获得一个128位向量。ORB (Rublee,Rabaud等,2011)在计算定向简短描述子之前,在fast检测器中添加了方向组件。BRISK(Leutenegger,Chli,和Siegwart,2011)在fast检测器中加入了尺度空间分析和径向对称采样模式(图7.19b),以生成二进制描述子。FREAK (Alahi,
图7.19二进制位串特征描述符:(a)简短的描述符比较了128对像素值(用线段表示),并将比较结果存储在一个128位向量中(Calonder,Lepetit等,2010)©2010 Springer;(b)快速采样模式和高斯模糊半径;(Leutenegger,Chli和Siegwart,2011)©2011 IEEE;(c) FREAK视网膜采样模式(Alahi,Ortiz和Vandergheynst,2012)©2012 IEEE。
Ortiz和Vandergheynst2012)使用了更明显的“视网膜”(对数极坐标)采样模式,并结合一系列位比较,以实现更高的速度和效率。Mukherjee、Wu和Wang(2015)的调查和评估比较了所有这些“经典”特征检测器和描述符。
自2015年以来,大多数新的特征描述符都是使用深度学习技术构建的,如Balntas、Lenc等人(2020)和Jin、Mishkin等人(2021)所调查的。其中一些描述符,例如LIFT(Yi、Trulls等人,2016)、TFeat(Balntas、Riba等人,2016)、HPatches (Balntas、Lenc等人,2020)、L2-Net (Tian、Fan、Wu,2017)、HardNet (Mishchuk、Mishkin等人,2017)、Geodesc (Luo、Shen等人,2018)、LF-Net (Ono、Trulls等人,2018)、SOSNet (Tian、Yu等人,2019)和Key.Net (Barroso-Laguna、Riba等人,2019),都是基于补丁操作的,类似于经典的SIFT方法。因此,它们需要一个初始的局部特征检测器来确定补丁的中心,并在构建网络输入时使用预设的补丁大小。
相比之下,诸如DELF (Noh,Araujo等,2017)、SuperPoint (DeTone,Malisiewicz和Rabinovich,2018)、D2-Net (Dusmanu,Rocco等,2019)、ContextDesc (Luo,Shen等,2019)、R2D2 (Revaud,Weinzaepfel等,2019)、ASLFeat(Luo,Zhou等,2020)和CAPS(Wang,Zhou等,2020)等方法使用整个图像作为描述子计算的输入。这还有一个额外的好处,即用于计算描述子的感受野可以从数据中学习,而不需要指定块大小。理论上,这些CNN模型可以学习到使用图像中所有像素的感受野,尽管在

图7.20 HPatches局部描述符基准测试(Balntas,Lenc等人,2020)©2019
IEEE:(a)特征描述符的年代学;(b)数据集中的典型补丁(按Easy、Hard和Tough分组);(c)不同描述符的大小和速度。
他们倾向于使用高斯样感受野(Zhou,Khosla等人,2015;Luo,Li等人,2016;Selvaraju,Cogswell等人,2017)。
在HPatches基准测试(图7.20)中,Balntas等人(2020)评估了补丁匹配,HardNet和L2-net平均表现最佳。另一篇论文(Wang,Zhou等人,2020)显示CAPS和R2D2表现最佳,而S2DNet (Germain,Bourmaud和Lepetit,2020)和LISRD (Pautrat,Larsson等人,2020)也声称达到了最先进水平,而WISW基准测试(Bellavia和Colombo,2020)则表明,传统的描述符如SIFT结合更近期的思想表现最好。在Jin,Mishkin等人(2021)的宽基线图像匹配基准测试中,HardNet、Key.Net和D2-Net是顶级表现者(例如,D2-Net具有最多的地标),尽管结果相当依赖于任务,高斯差异检测器仍然是最佳选择。这些描述符在大光照差异(昼夜)下匹配特征的表现也得到了研究(Radenovi,Sch nberger等人,2016;Zhou,Sattler和Jacobs,2016;Mishkin,2021)。最近在宽基线匹配领域的一个趋势是,在没有检测器阶段的情况下密集提取特征,然后匹配并优化对应关系集(江、特鲁尔斯等人2021;萨林、乌纳加尔等人2021;孙、沈等人2021;张、达内利扬等人2021;周、萨特勒和莱亚尔-泰克斯2021)。这些较新的技术中的一些已经
一旦我们从两张或多张图像中提取了特征及其描述符,下一步就是在这几张图像之间建立初步的特征匹配。我们采取的方法部分取决于应用,例如,对于已知重叠的图像(如图像拼接)与可能完全没有对应关系的图像(如尝试从数据库中识别对象时),不同的策略可能是更优的选择。
在本节中,我们将这个问题分为两个独立的部分。第一部分是选择匹配策略,这决定了哪些对应关系会被传递到下一阶段进行进一步处理。第二部分是设计高效的数据结构和算法,以尽可能快地完成这种匹配,相关内容将在第7.1.4节中详细展开。
匹配策略和错误率
确定哪些特征匹配是合理的进一步处理取决于匹配执行的上下文。假设我们有两张图像,它们有相当程度的重叠(例如,在图像拼接或视频中跟踪物体时)。我们知道一张图像中的大多数特征很可能与另一张图像匹配,尽管有些可能不匹配,因为它们被遮挡了或者外观变化太大。
另一方面,如果我们要识别一个杂乱场景中出现的已知物体数量(图6.2),大多数特征可能不匹配。此外,必须搜索大量潜在匹配的物体,这需要更有效的策略,如下所述。
首先,我们假设特征描述子已经设计得当,使得特征空间中的欧几里得(向量大小)距离可以直接用于潜在匹配的排序。如果发现某个描述子中的某些参数(轴)比其他参数更可靠,通常最好提前重新缩放这些轴,例如通过确定它们与其他已知良好匹配之间的差异(Hua,Brown,和Winder 2007)。一个更通用的过程是将特征向量转换到一个新的缩放基中,这被称为白化,在基于特征脸的人脸识别中会有更详细的讨论(第5.2.3节)。
给定欧几里得距离度量,最简单的匹配策略是设置一个阈值(最大距离),并返回该阈值范围内的所有其他图像的匹配结果。如果阈值设置过高,则会产生过多的假阳性,即返回错误的匹配结果。如果阈值设置过低,则会产生过多的假阴性,即错过太多正确的匹配结果(图7.21)。
我们可以通过以下方法量化匹配算法在特定阈值下的性能
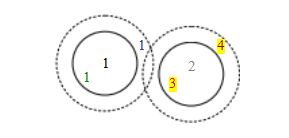
图7.21假阳性和假阴性:黑色数字1和2是在与其他图像特征数据库匹配的特征。在当前阈值设置(实心圆圈)下,绿色1是真阳性(匹配成功),蓝色1是假阴性(未匹配),红色3是假阳性(匹配错误)。如果我们提高阈值(虚线圆圈),蓝色1会变成真阳性,但棕色4会成为额外的假阳性。
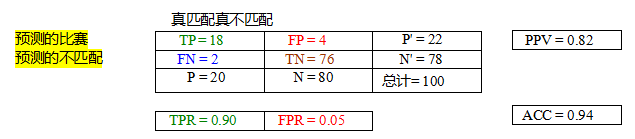
表7.1特征匹配算法正确估计和错误估计的匹配数量,显示了真正例(TP)、假正例(FP)、假反例(FN)和真反例(TN)的数量。各列之和等于实际的正例(P)和负例(N),而各行之和等于预测的正例(P9)和负例(N9)。文中给出了真正例率(TPR)、假正例率(FPR)、阳性预测值(PPV)和准确率(ACC)的计算公式。
首先计算正确和错误匹配以及匹配失败的数量,使用以下定义(Fawcett2006),我们在Section6.3.3中已经讨论过:
TP:真阳性,即正确匹配的数量;
FN:假阴性,未正确检测到的匹配;
FP:假阳性,错误的匹配建议;
TN:真阴性,正确拒绝的非匹配。
表7.1显示了包含此类数字的样本混淆矩阵(列联表)。
我们可以通过定义以下量将这些数字转换为单位率(Fawcett
真阳性率(TPR),
假阳性率(FPR),
阳性预测值(PPV),
准确度(ACC),
在信息检索(或文档检索)文献中(Baeza-Yates和Ribeiro-Neto 1999;Manning、Raghavan和Schtze 2008),使用了精确率(返回的文档中有多少是相关的)这一术语,而不是阳性预测值。召回率(找到的相关文档的比例)则被用作真正率(参见第6.3.3节)。精确率和召回率可以结合成一个称为F值的单一指标,这是它们的调和平均值。这个单一指标常用于对视觉算法进行排名(Knapitsch、Park等2017)。
任何特定的匹配策略(在特定阈值或参数设置下)都可以通过真阳性率和假阳性率来评估;理想情况下,真阳性率接近1,假阳性率接近0。随着我们改变匹配阈值,会得到一系列这样的点,这些点统称为受试者工作特征(ROC)曲线(Fawcett2006)(图7.22a)。这条曲线越接近左上角,即曲线下面积(AUC)越大,其性能越好。图7.22b展示了如何根据特征间距离绘制匹配数和非匹配数的关系图。这些曲线可以用来绘制ROC曲线(练习7.3)。ROC曲线还可以用于计算平均精度,这是在选择最佳结果时改变阈值的平均精度(PPV),然后是两个最佳结果等(见第6.3.3节和图6.27)。
使用固定阈值的问题在于难以设定;随着我们进入特征空间的不同部分,有用的阈值范围可能会有很大变化(Lowe2004;Mikolajczyk和Schmid2005)。在这种情况下,更好的策略是直接匹配特征空间中的最近邻。由于某些特征可能没有匹配项(例如,在物体识别中它们可能是背景杂波的一部分,或者在另一张图像中被遮挡),因此仍然需要使用阈值来减少假阳性的数量。
理想情况下,该阈值本身将适应特征空间的不同区域。如果可用的训练数据充足(Hua,Brown,and Winder2007),有时可以学习
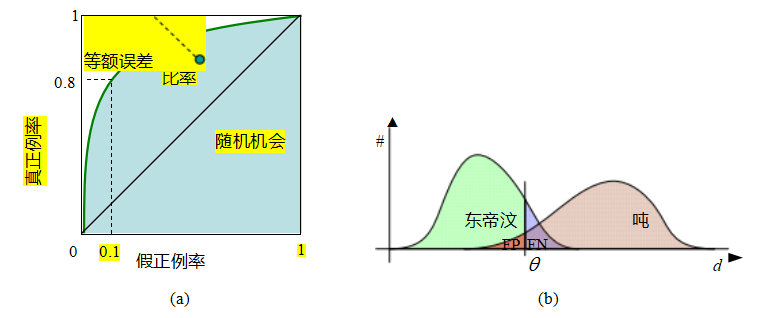
图7.22 ROC曲线及其相关率:(a)ROC曲线绘制了特征提取和匹配算法特定组合下的真正率与假正率。理想情况下,真正率应接近1,而假正率接近0。ROC曲线下面积(AUC)常被用作算法性能的单一(标量)度量。或者,有时也会使用等错误率。(b)正例(匹配)和负例(非匹配)随特征间距离的变化分布。随着阈值θ的增加,真正例(TP)和假正例(FP)的数量也随之增加。
不同的特征有不同的阈值。然而,通常我们只是得到一组图像需要匹配,例如,在拼接图像或从无序的照片集合构建3D模型时(Brown和Lowe 2007,2005;Snavely、Seitz和Szeliski 2006)。在这种情况下,一个有用的启发式方法是将最近邻距离与次近邻距离进行比较,最好是从已知不匹配目标的图像中获取(例如,数据库中的不同对象)(Brown和Lowe 2002;Lowe 2004;Mishkin、Matas和Perdoch 2015)。我们可以定义这个最近邻距离比(Mikolajczyk和Schmid 2005)为
NNDR =
(7.18)
其中,d1和d2分别是最近邻和次近邻距离,DA是目标描述符,DB和DC是其最近的两个邻居(图7.23)。近期研究表明,互NNDR(或至少带有交叉一致性检查的NNDR)明显优于单向NNDR (Bellavia和Colombo 2020;Jin、Mishkin等2021)。
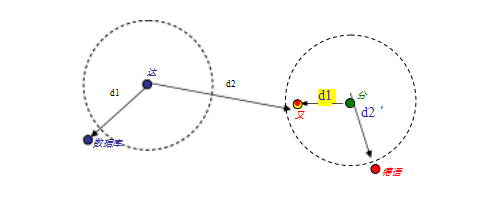
图7.23固定阈值、最近邻和最近邻距离比匹配。在固定距离阈值(虚线圆圈)下,描述符DA无法正确匹配DB,而DD错误地匹配了DC和DE。如果我们选择最近邻,DA正确地匹配了DB,但DD错误地匹配了DC。使用最近邻距离比(NNDR)匹配,
小NNDR d1 /d2正确匹配DA与DB,大NNDR
d/d正确
拒绝与DD匹配。
一旦我们确定了匹配策略,仍需高效地寻找潜在候选者。最简单的方法是将每对可能匹配图像中的所有特征与其他所有特征进行比较。虽然传统上这种方法计算成本过高,但现代GPU已经使得这种比较成为可能。
一种更高效的方法是设计一种索引结构,如多维搜索树或哈希表,以快速查找给定特征附近的其他特征。这些索引结构可以独立为每张图像构建(这在我们只想考虑某些潜在匹配时非常有用,例如寻找特定对象),也可以全局地为给定数据库中的所有图像构建,这样可能会更快,因为它消除了遍历每张图像的需要。对于极其庞大的数据库(数百万张或更多图像),甚至可以使用基于文档检索思想的更高效的结构,例如词汇树(Nist r和Stew nius2006)、产品量化(J gou,Douze和Schmid2010;Johnson,Douze和J gou2021)或倒排多索引(Babenko和Lempitsky2015b),具体讨论见第7.1.4节。
实现较为简单的一种技术是多维哈希,它根据应用于每个描述符向量的函数,将描述符映射到固定大小的桶中。匹配时,每个新特征都会被哈希到一个桶中,通过搜索附近的桶来返回潜在候选者,然后对这些候选者进行排序或评分,以确定哪些是有效的匹配。
哈希的一个简单例子是Brown、Szeliski和Winder使用的Haar小波
(2005)在他们的MOPS论文中。在匹配结构构建过程中,每个8×8缩放、定向和归一化的MOPS封面被转换为一个三元素索引,通过对封面的不同象限求和实现。生成的三个值根据其预期的标准差进行归一化,然后映射到两个(b=10)最近的一维区间。由这三个量化值连接形成的三维索引用于索引存储(添加)特征的23 = 8区间。查询时,仅使用主要(最近)索引,因此只需检查单个三维区间。然后可以利用该区间的系数选择k个近似最近邻以进行进一步处理(如计算NNDR)。
一种更复杂但适用范围更广的哈希方法称为局部敏感哈希,它使用独立计算的哈希函数的联合来索引特征(Gionis,Indyk和Motwani 1999;Shakhnarovich,Darrell和Indyk 2006)。Shakhnarovich、Viola和Darrell(2003)将这一技术扩展,使其对参数空间中点的分布更加敏感,他们称之为参数敏感哈希。最近的研究将高维描述子向量转换为二进制码,这些码可以通过汉明距离进行比较(Torralba,Weiss和Fergus 2008;Weiss,Torralba和Fergus 2008),或者可以适应任意核函数(Kulis和Grauman 2009;Raginsky和Lazebnik 2009)。
另一种广泛使用的索引结构是多维搜索树。其中最著名的是k-d树,也常写作kd树,它通过交替的轴对齐超平面分割多维特征空间,在每个轴上选择阈值以最大化某个标准,例如搜索树平衡(Samet 1989)。图7.24展示了一个二维k-d树的例子。这里,八个不同的数据点A至H以小菱形形式排列在二维平面上。k-d树递归地沿轴对齐(水平或垂直)切割平面分割这个平面。每次分割可以用维度编号和分割值来表示(图7.24b)。分割的安排旨在尽量平衡树,即尽可能减小其最大深度。查询时,经典的k-d树搜索首先定位查询点(+)在其相应的箱(D)中,然后在树中搜索附近的叶子节点(C,B,.. .),直到可以保证找到最近邻。最佳的箱优先(BBF)搜索(Beis和Lowe 1999)按空间距离顺序搜索箱,因此通常更高效。
许多额外的数据结构已被开发出来,用于解决精确和近似最近邻问题(Arya,Mount等,1998;Liang,Liu等,2001;Hjaltason和Samet,2003)。例如,Nene和Nayar(1997)开发了一种称为切片的技术,该技术通过沿不同维度排序的点列表进行一系列一维二分搜索。
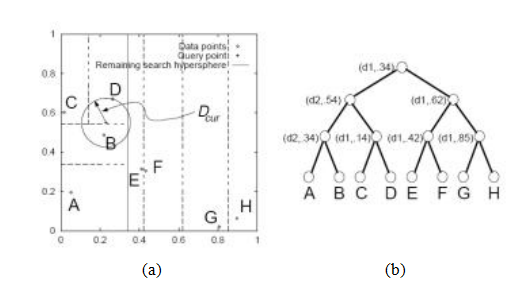
图7.24 K-d树和最佳先验(BBF)搜索(Beis和Lowe 1999)©1999 IEEE: (a)轴向切割平面的空间排列用虚线表示。单个数据点以小菱形显示。(b)相同的细分可以表示为一棵树,其中每个内部节点代表一个轴向切割平面(例如,顶部节点沿维度d1切割值为.34),每个叶节点是一个数据点。在BBF搜索过程中,查询点(记作“+”)首先在其所属的箱(D)中查找,然后在其最近的相邻箱(b)中查找,而不是在树(C).中的最近邻节点。
为了高效地筛选出位于查询点超立方体内的候选点列表。Grauman和Darrell(2005)在索引树的不同层级重新加权匹配项,这使得他们的技术对树构建中的离散化误差不那么敏感。Nist和Stew nius(2006)使用度量树,该树在层次结构的每一层将特征描述符与少量原型进行比较。由此产生
的量化视觉词汇可以与经典的信息检索(文档相关性)技术结合使用,快速从数百万图像数据库中筛选出潜在候选者(第7.1.4节)。Muja和Lowe(2009)比较了这些方法中的几种,并引入了一种新的方法(基于层次k均值树的优先搜索),并得出结论认为多重随机化k-d树通常提供最佳性能。现代计算近似最近邻的库包括FLANN (Muja和Lowe 2014)和Faiss (Johnson、Douze和J gou 2021),相关内容在Section5.1.1and附录C.2中讨论。
特征匹配验证和密集化
一旦我们有一些候选匹配,我们可以使用几何对齐(第8.1节)来验证哪些匹配是内点,哪些是外点。例如,如果我们预期整个图像在匹配视图中被平移或旋转,我们可以拟合一个全局几何
图7.25从椭圆归一化仿射区域获得的视觉词汇(Sivic和Zis- serman2009)©2009 IEEE。(a)从每一帧中提取仿射协变区域,并使用基于学习到的马氏距离的k均值聚类方法,将这些区域聚类为视觉词汇。(b)每个网格中的中心补丁显示查询点,周围的补丁显示最近邻。
转换并保留那些与估计变换足够接近的特征匹配。选择一小部分种子匹配,然后验证更大一组的过程通常称为随机抽样或RANSAC(第8.1.4节)。一旦建立了初始的一组对应关系,一些系统会寻找更多的匹配,例如沿着极线寻找额外的对应关系(第12.1节)或基于全局变换在估计位置附近寻找。还可以使用深度神经网络进行特征匹配和过滤,如Sarlin、DeTone等人(2020年)的SuperGlue系统所示。这些主题将在第8.1节和第12.2节中进一步讨论。
随着数据库中对象数量的增加(比如数十亿个对象或视频帧),将新图像与每个数据库图像匹配所需的时间可能会变得难以承受。与其逐一比较图像,需要采用技术手段快速缩小搜索范围,锁定少数可能的图像,然后通过更严格的验证阶段进行比对。
快速查找文档之间的部分匹配问题是信息检索(IR)中的一个核心问题(Baeza-Yates和Ribeiro-Neto1999;Manning,
Raghavan和Sch tze2008)。在计算机视觉中,寻找特定对象的问题
在大型集合中,称为基于内容的图像检索(CBIR)(Smeulders,Worring等,2000;Lew,Sebe等,2006;Vasconcelos,2007;Datta,Joshi等,2008)或实例检索(Zheng,Yang,和Tian,2018)。快速文档检索算法的基本方法是预先计算单个词与它们出现的文档(或网页或新闻故事)之间的倒排索引。更具体地说,特定词出现的频率
文档中的单词用于快速查找与特定查询匹配的文档。
西维克和齐瑟曼(2009)首次将红外技术应用于视觉搜索。在他们的视频谷歌系统中,首先在所有待索引的视频帧中检测仿射不变特征,这些特征既包括哈里斯特征点周围的形状适应区域(沙法利茨基和齐瑟曼2002;米科拉伊奇克和施密特2004),也包括最大稳定极值区域(马塔斯、楚姆等人2004;Section7.1.1),如图7.25a所示。接下来,从每个归一化区域计算出128维SIFT描述子(即图7.25b中的补丁)。然后,通过累积从一帧到另一帧跟踪的特征统计信息,估计这些描述子的平均协方差矩阵。随后,使用特征描述子协方差Σ定义特征描述子之间的马氏距离(5.32)。实际上,特征描述子通过预乘以Σ-1/2进行白化处理,以便可以使用欧几里得距离。5
为了将快速信息检索技术应用于图像,首先需要将每张图像中出现的高维特征描述符映射到离散的视觉词汇。Sivic和Zisserman(2003)使用k-均值聚类来完成这一映射,而一些后来的方法(Nist r和Stew nius 2006;Philbin,Chum等2007)则采用了其他技术,如词汇树或随机森林。为了使聚类时间可控,仅使用几百帧视频来学习聚类中心,这仍然涉及从大约300,000个描述符中估计数千个聚类,尽管后续研究大大扩展了这一能力(Nist r和Stew nius 2006;Philbin,Chum等2007;Mikulik,Perdoch等2013)。在视觉查询时,新查询区域中的每个特征(例如图7.25a,这是从较大视频帧裁剪出来的区域)都会映射到其对应的视觉词汇。为了防止非常常见的模式污染结果,创建了一个最常见的视觉词汇停止列表,并将这些词汇从进一步考虑中剔除。
一旦查询图像或区域被映射为其构成的视觉词汇,就需要从数据库中检索出可能匹配的图像。具体操作方法可参见Sivic和Zisserman(2009)、Nist r和Stew nius(2006)、Philbin、Chum等人(2007)、Chum、Philbin等人(2007)、Philbin、Chum
等人(2008),以及本书第一版(Szeliski2010,第14.3.2节)。由于量化和评分特征的高效性,Nist r和Stew nius(2006)构建的基于词汇树的识别系统能够实时处理来自40,000张CD封面的数据库,并以1赫兹的速度匹配包含一百万帧的数据库。
5注意,从匹配的特征点计算特征协方差比在描述子空间上简单地执行PCA要合理得多(Winder和Brown2007)。这大致相当于我们在第5.2.3节中研究的类内散射矩阵。

图7.26使用随机树进行位置或建筑物识别(Philbin,Chum等人,2007)©2007 IEEE。左图是查询,其他图是最高排名的结果。
取自六部故事片。
实例识别系统在2000年代继续迅速改进。Philbin、Chum等人(2007)展示了随机森林k-d树在大规模位置识别任务中表现优于词汇树(图7.26)。他们还比较了验证阶段使用不同二维运动模型的效果(第2.1.1节)。后续工作中,Chum、Philbin等人(2007)应用了信息检索中的另一个概念,即查询扩展,这涉及将初始查询中排名靠前的图像重新提交作为额外查询,以生成更多的候选结果。Philbin、Chum等人(2008)展示了如何通过软分配来缓解视觉词汇选择中的量化问题,其中每个特征描述符映射到多个附近的视觉词汇,类似于J gou、Harzallah和Schmid(2007)之前提出的多分配想法。然而,这些技术往往会减少视觉词汇向量的稀疏性并增加内存和计算成本。J gou、Douze和Schmid(2008)在初始大规模图像排序阶段引入了部分几何信息和局部描述符之间的显式
匹配方案。综上所述,这些算法帮助实例识别算法实现了网络规模的检索、匹配和三维重建任务(Agarwal、Furukawa等人,2010,2011;Frahm
自2012年的“深度学习革命”以来,研究人员开始开发神经特征检测器和描述符(第7.1.1节和第7.1.2节),有时将它们组合成端到端匹配系统。图7.27展示了实例检索的一些主要里程碑,而图7.28则展示了各种不同的经典和基于CNN的检索架构。郑、杨和田(2018)的综述论文更详细地描述并对比了这些不同的算法,还提供了
6查询扩展的另一种方法是数据库端增强(Arandjelovi和Zisserman2012)。
但请注意,一些流行的开源大规模重建系统,如COLMAP,仍然使用传统特征和索引方案(Sch nberger和Frahm2016)。
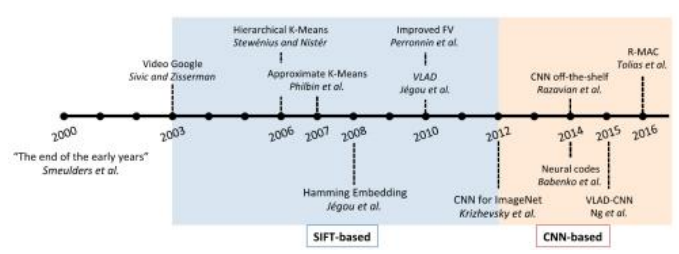
图7.27实例检索中的里程碑(Zheng、Yang和Tian2018)©2018 IEEE,显示了从手工制作的基于特征的检索到基于CNN的方法的转变。
图7.28基于特征的实例检索典型管道(Zheng、Yang和Tian,2018),©2018 IEEE,显示了特征提取、编码和索引部分,这些部分在使用深度学习框架时通常被合并。
这些算法在图像检索数据集上的实验比较。您还可以在第6.2.3节关于视觉相似性搜索的部分找到更多相关技术和系统的详细信息,该部分讨论了用单个向量表示图像的全局描述符(Arandjelovic,Gronat等2016;Radenovi,Tolias和Chum 2019;Yang,Kien Nguyen等2019;Cao,Araujo和Sim 2020;Ng,Balntas等2020
;Tolias,Jenicek和Chum 2020),作为局部特征包的替代方案;第11.2.3节关于位置识别的部分;以及第11.4.6节关于从社区(互联网)照片中进行大规模3D重建的部分。
一种替代方法是,在第一张图像中找到一组可能的特征位置,然后在后续图像中搜索这些位置对应的特征。这种检测后跟踪的方法更广泛应用于视频跟踪场景,预期相邻帧之间的运动和外观变形量较小。
选择好的特征进行跟踪的过程与为更广泛的识别应用选择好的特征密切相关。实际上,包含双向高梯度的区域,即在自相关矩阵(7.8)中具有高特征值的区域,提供了稳定的位置来寻找对应关系(Shi和Tomasi 1994)。
在后续帧中,寻找对应补丁平方差较低的位置(7.1)通常效果良好。然而,如果图像发生亮度变化,则明确补偿这种变化(9.9)或使用归一化互相关(9.11)可能更为合适。如果搜索范围较大,使用层次搜索策略通常更高效,该策略利用低分辨率图像中的匹配来提供更好的初始猜测,从而加快搜索速度(第9.1.1节)。替代策略包括学习被跟踪补丁的外观特征,然后在其预测位置附近进行搜索(Avidan2001;Jurie和Dhome 2002;Williams、Blake和Cipolla2003)。这些主题在第9.1.3节中有更详细的讨论。
如果特征在较长的图像序列中被跟踪,其外观可能会发生更大的变化。这时你需要决定是继续与最初检测到的补丁(特征)匹配,还是在每个后续帧的匹配位置重新采样。前者容易失败,因为原始补丁可能会发生外观变化,如缩短。后者则存在特征从其原始位置漂移到图像中其他位置的风险(Shi和Tomasi 1994)。(从数学上讲,小的失配误差会累积形成马尔可夫随机游走,导致随时间推移更大的漂移。)

图7.29使用仿射运动模型进行特征跟踪(Shi和Tomasi 1994)©1994 IEEE,上排:跟踪特征位置周围的图像块。下排:使用仿射变换回拉回第一帧后的图像块。尽管速度标志从一帧到另一帧逐渐变大,但仿射变换仍保持了原始帧与后续跟踪帧之间的良好相似性。
一个理想的解决方案是使用仿射运动模型(第9.2节)将原始补丁与后续图像位置进行比较。Shi和Tomasi(1994)首先使用平移模型比较相邻帧中的补丁,然后利用这一步骤产生的位置估计值初始化当前帧中补丁与首次检测到特征的基帧之间的仿射配准(图7.29)。在他们的系统中,特征仅在跟踪失败的区域偶尔被检测到。通常情况下,会在特征当前预测位置周围搜索一个区域,并使用增量配准算法(第9.1.3节)。由此产生的跟踪器常被称为Kanade-Lucas-Tomasi(KLT)跟踪器。
自他们最初进行特征跟踪研究以来,石和托马西的方法已经催生了大量后续论文和应用。比尔斯利、托尔和齐瑟曼(1996)利用扩展特征跟踪结合运动结构(第11章)从视频序列中逐步构建稀疏3D模型。康、斯泽利斯基和舒姆(1997)将相邻(规则网格化)补丁的角点连接起来,以提高跟踪的稳定性,但代价是处理遮挡时表现较差。托马西尼、富西埃洛等人(1998)为基本的石和托马西算法提供了一个更好的虚假匹配拒绝标准,柯林斯和刘(2003)提供了改进的特征选择机制和应对长时间内较大外观变化的方法,沙菲克和沙(2005)开发了适用于大量移动对象或点的视频特征匹配(数据关联)算法。勒佩蒂和富亚(2005)以及伊尔马兹、贾韦德和沙(2006)综述了更广泛的物体跟踪领域,该领域不仅包括基于特征的技术,还包括基于轮廓和区域的替代技术(第7.3节)。

图7.30使用快速训练分类器进行实时头部跟踪(Lepetit、Pilet和Fua
特征跟踪的最新发展是使用学习算法构建专用识别器,以快速搜索图像中的匹配特征(Lepetit、Pilet和Fua2006;Hinterstoisser、Benhimane等人2008;Rogez、Rihan等人。
2008;zuysal,Calonder等人2010)。通过花时间在样本补丁上训练分类器
并且通过仿射变形,可以构建极其快速且可靠的特征检测器,从而支持更快的运动(图7.30)。将这些特征与可变形模型(Pilet、Lepetit和Fua2008)或从运动中构建结构的算法(Klein和Murray2008)相结合,可以实现更高的稳定性。
虽然基于特征的跟踪在实时应用中仍被广泛使用,如SLAM、自主导航和增强现实(第11.5节),但目前许多关于跟踪的研究集中在整体物体跟踪上(Chellappa,Sankaranarayanan等2010;Smeulders,Chu等2014),我们将在Section9.4.4中详细探讨这一主题。
快速特征跟踪最引人注目的应用之一是性能驱动的动画,即基于跟踪用户运动的3D图形模型的交互变形(Williams1990;Litwinowicz和Williams1994;Lepetit、Pilet和Fua2004)。
巴克、芬克尔斯坦等人(2000)提出了一种系统,该系统能够跟踪用户的面部表情和头部动作,并利用这些信息在一系列手绘草图之间进行变形。动画师首先提取每个草图的眼睛和嘴巴区域,并在每张图像上绘制控制线(图7.31a)。运行时,面部跟踪系统(Toyama 1998)确定这些特征的当前位置(图7.31b)。动画系统决定哪个

图7.31表现驱动的手绘动画(Buck,Finkelstein等2000)©2000 ACM:(a) eye和嘴部部分的手绘草图及其叠加的控制线;(b)输入视频帧中叠加了跟踪特征;(c)不同的输入视频帧及其对应的(d)手绘动画。
输入图像根据最近邻特征外观匹配和三角形重心插值进行变形。它还从跟踪的特征中计算头部的整体位置和方向。最终变形的眼睛和嘴巴区域被重新合成到整体头部模型中,生成手绘动画的一帧(图7.31d)。
在最近的研究中,巴恩斯、雅各布斯等人(2008)观察用户在桌面上用纸剪动画,然后将这些动作和图画转化为无缝的二维动画。基于特征的人脸追踪器继续被广泛使用(佐尔费尔、蒂斯等人,2018),不仅在视觉特效行业,还用于实时智能
手机增强现实效果,如脸书的Spark AR面具。
7.2 边缘和轮廓
虽然兴趣点对于找到可以在二维中精确匹配的图像位置很有用,但边缘点更为丰富,通常携带重要的语义关联。例如,物体的边界,在三维中也对应于遮挡事件,通常由可见轮廓界定。其他类型的边缘则对应于阴影边界或折痕边缘,这些地方表面方向迅速变化。孤立的边缘点也可以组合成长曲线或轮廓,以及直线段(第7.4节)。有趣的是,即使是年幼的孩子也能轻松识别出熟悉的物体或动物,即使它们只是简单的线条画。

图7.32人边界检测(Martin、Fowlkes和Malik2004)©2004 IEEE。边缘的暗度对应于有多少人标记了该位置的对象边界。
给定一张图像,我们如何找到显著的边缘?考虑图7.32中的彩色图像。如果有人让你指出最“显著”或“最强”的边缘或物体边界,你会追踪哪些?你的感知与图7.32中显示的边缘图像有多接近?
定性地说,边缘出现在不同颜色、强度或纹理区域的边界处(Martin,Fowlkes和Malik 2004;Arbel ez,Maire等2011;Pont-Tuset,Arbel ez等2017
)。不幸的是,将图像分割
成连贯的区域是一项艰巨的任务,我们将在第7.5节中讨论。通常,最好仅使用局部信息来检测边缘。
在这种情况下,一种合理的方法是将边缘定义为强度或颜色变化迅速的位置。可以将图像看作是一个高度场。在这样的表面上,边缘出现在陡峭斜坡的位置,或者等效地,在密集的等高线区域(地形图上)。
定义曲面斜率和方向的数学方法是通过它的梯度,
(7.19)
局部梯度向量J指向强度函数中上升最快的方位。其大小表示变化的斜率或强度,而其方向则指向与局部轮廓垂直的方向。
不幸的是,取图像导数会突出高频部分,从而放大噪声,因为噪声与信号的比例在高频部分更大。因此,这是明智的做法
为了在计算梯度之前用低通滤波器平滑图像。由于我们希望边缘检测器的响应与方向无关,因此需要一个圆形对称的平滑滤波器。正如我们在第3.2节中所见,高斯滤波器是唯一可分离的圆形对称滤波器,因此它被用于大多数边缘检测算法。Canny(1986)讨论了其他滤波器,许多研究人员回顾了不同的边缘检测算法并比较了它们的性能(Davis 1975;Nalwa和Binford 1986;Nalwa 1987;Deriche 1987;Freeman和Adelson 1991;Nalwa 1993;Heath、Sarkar等1998;Crane 1997;Ritter和Wilson 2000;Bowyer、Kranenburg和Dougherty 2001;Arbel ez、Maire等2011;Pont-Tuset、Arbel ez等2017)。
由于微分是一个线性运算,因此它与其他线性滤波运算可以互换。因此,平滑图像的梯度可以写为
Jσ (x) = ▽[Gσ (x) * I(x)] = [▽Gσ ](x) * I(x), (7.20)
即,我们可以将图像与高斯核函数的水平和垂直导数进行卷积,
▽Gσ (x
)
= , (x) = [—x — y
] exp (— ,
(7.21)
参数σ表示高斯函数的宽度。这与Freeman和Adelson(1991)在第3.2.3节中已经介绍的第一阶可导向滤波器的计算相同。
然而,对于许多应用而言,我们希望将这种连续的梯度图像简化为仅包含孤立的边缘,即沿边缘轮廓在离散位置上的单个像素。这可以通过寻找与边缘方向垂直的方向上的最大值来实现,即沿着梯度方向。
找到这个最大值相当于沿着梯度方向对强度场求方向导数,然后寻找零交叉点。所需的向量导数等同于第二个梯度算子与第一个结果之间的点积,
Sσ (x) = ▽ · Jσ (x) = [▽2 Gσ ](x) * I(x). (7.22)
▽2 Gσ
(7.23)
因此,该核被称为高斯(LoG)拉普拉斯核(Marr和Hildreth1980)。该核可以分为两个可分离的部分,
▽2 Gσ (x) = —
Gσ
(y)Gσ (x) (7.24)
(Wiejak、Buxton和Buxton1985),这允许使用可分离过滤实现更高效的实施(第3.2.1节)。
在实际应用中,通常会用高斯差分(DoG)计算来替代高斯卷积的拉普拉斯算子,因为它们的核形状在定性上是相似的(Figure3.34)。如果已经计算了“拉普拉斯金字塔”(第3.5节),这种方法尤为方便。
事实上,在计算边缘场时,并不一定非要区分相邻层次之间的差异。想想“广义”高斯差分图像中的零交叉点代表什么。更精细(小核)的高斯函数是原始图像的降噪版本。较粗(大核)的高斯函数则是较大区域平均强度的估计值。因此,每当DoG图像改变符号时,这对应于(略微模糊的)图像从相对暗处变为相对亮处,相对于该邻域内的平均强度而言。
一旦我们计算了符号函数S(x),就必须找到其零交叉点,并将其转换为边缘元素(edgels)。检测和表示零交叉点的一个简单方法是寻找相邻像素位置xi和xj,其中符号值发生变化,即[S(xi)> 0] [S(xj)> 0]。
这个交叉点的子像素位置可以通过计算连接S(xi)和S(xj)的“线”的“x轴截距”来获得,
(7.25)
通过线性插值在原始像素网格上计算的梯度值,可以获得这种边缘的方向和强度。
通过将对偶网格上的相邻边缘连接到由四个相邻像素组成的原始像素网格中的每个正方形内的形成边缘,可以获得一种替代的边缘表示。这种表示的优势在于,边缘现在位于比原始像素网格偏移半个像素的网格上,因此更容易存储和访问。与之前一样,可以通过插值梯度场或从高斯图像差异中估计这些值来计算边缘的方向和强度(见练习7.7)。
在对边缘方向的准确性要求较高的应用中,可以使用高阶可转向滤波器(Freeman和Adelson1991)(参见Section3.2.3)。这种滤波器对更细长的边缘具有更高的选择性,并且有可能更好地建模曲线。
8回顾Burt和Adelson(1983a)的“拉普拉斯金字塔”实际上计算高斯滤波水平的差异。
9该算法是三维行进立方体等值面提取算法(Lorensen和Cline)的二维版本
图7.33边缘检测尺度选择(Elder和Zucker 1998)©1998 IEEE:((a))原始图像;(b-c)调整至更精细(模特)和更粗略(阴影)尺度的Canny/Deriche边缘检测器;(d)梯度估计的最小可靠尺度;(e)二阶导数估计的最小可靠尺度;(f)最终检测到的边缘。
交点,因为它们可以表示同一像素上的多种方向(图3.16)。它们的缺点是计算成本更高,且边缘强度的方向导数没有简单的闭式解。10
尺度选择和模糊估计
正如我们之前提到的,导数、拉普拉斯和高斯差分滤波器(7.20-7.23)都需要选择一个空间尺度参数σ。如果我们只关注检测锐利边缘,滤波器的宽度可以从图像噪声特性中确定(Canny1986;Elder和Zucker1998)。然而,如果我们希望检测不同分辨率下的边缘(图7.33b-c),可能需要采用一种尺度空间方法,该方法能够检测并选择不同尺度下的边缘(Witkin1983;Lindeberg1994,1998a;Nielsen,Florack和Deriche1997)。
埃尔德和祖克(1998)提出了一种解决此问题的原则方法。给定已知的图像噪声水平,他们的技术计算每个像素可以可靠检测到边缘的最小尺度(图7.33d)。该方法首先通过选择不同尺度下计算的梯度估计值中的梯度幅度来密集地计算图像上的梯度。然后,它对有向二阶导数进行类似的最小尺度估计,并利用这一量的零交叉点稳健地选择边缘(图7.33e-f)。作为可选的最后一步,可以从二阶导数响应中极值之间的距离减去高斯滤波器的宽度来计算每条边的模糊宽度。
色彩边缘检测
虽然大多数边缘检测技术都是为灰度图像开发的,但彩色图像可以提供额外的信息。例如,不同亮度的颜色(具有相同亮度的颜色)之间的明显边缘是有用的线索,但是不能被灰度边缘运算符检测到。
一种简单的方法是将每个颜色通道单独运行的灰度检测器的输出结合起来。然而,需要注意一些事项。例如,如果我们简单地将每个颜色通道中的梯度相加,带符号的梯度可能会相互抵消!(比如考虑一个纯红到绿的边缘。)我们也可以独立地在每个通道中检测边缘,然后取这些边缘的并集,但这可能导致难以连接的粗化或重叠的边缘。
更好的方法是在每个频带中计算定向能量(Morrone和Burr 1988;Perona和Malik 1990a),例如使用二阶可导向滤波器(第3.2.3节)(Freeman和Adelson 1991),然后将定向加权能量相加,找到它们的联合最佳方向。不幸的是,这种能量的方向导数可能没有封闭形式的解(如带符号的一阶可导向滤波器的情况),因此不能使用简单的零交叉策略。然而,Elder和Zucker(1998)描述的技术可以用来数值计算这些零交叉点。
一种替代方法是在每个像素周围估计局部颜色统计(Ruzon和Tomasi 2001;Martin、Fowlkes和Malik 2004)。这种方法的优点在于可以使用更复杂的技术(例如,三维颜色直方图)来比较区域统计,并且还可以考虑其他指标,如纹理。图7.34显示了此类检测器的输出。
多年来,为了检测颜色边缘,人们开发了许多其他方法,可以追溯到Nevatia(1977)的早期工作。Ruzon和Tomasi(2001)以及Gevers、van de Weijer和Stokman(2006)对这些方法进行了很好的综述,其中包括融合多通道输出、使用多维梯度和基于向量的方法等思想。
结合边缘特征线索
如果边缘检测的目标是匹配人类边界检测的性能(Bowyer,Kranenburg和Dougherty 2001;Martin,Fowlkes和Malik 2004;Arbel ez,Maire等2011;Pont-Tuset,Arbel ez等2017),而
不仅仅是寻找用于匹配的稳定特征,
那么通过结合亮度、颜色和纹理等多低级线索,可以构建出更好的检测器。
马丁、福尔克斯和马利克(2004)描述了一个系统,该系统结合了亮度、颜色和纹理边缘,以在手段分割的自然彩色图像数据库上实现最先进的性能(马丁、福尔克斯等人,2001)。首先,他们构建并训练了独立的方向半圆检测器,用于测量亮度(亮度)、颜色(a*和b*通道,总响应)和纹理(未归一化的滤波器组响应,来自马利克、贝隆吉等人(2001)的工作)中的显著差异。然后,使用软非极大值抑制技术对某些响应进行锐化。最后,利用多种机器学习技术将三个检测器的输出结合起来,其中逻辑回归被发现具有速度、空间和准确性之间的最佳平衡。结果系统(见图7.34的一些示例)显示出优于先前开发的技术。梅尔、阿尔贝莱兹等人(2008)通过结合基于局部外观的检测器与光谱(基于分割的)检测器(贝隆吉和马利克,1998)改进了这些结果。在后续工作中,阿尔贝莱兹、梅尔等人(2011)建立了层次化分割。
7.2.2轮廓检测
虽然孤立的边缘对于各种应用很有用,例如线检测(第7.4节)和稀疏立体匹配(第12.2节),但当它们被链接到连续轮廓时,它们变得更加有用。
如果边缘是通过某个函数的零交叉点检测到的,那么将它们连接起来就很简单了,因为相邻的边缘点共享共同的端点。将这些边缘点链接成链涉及拾取一个未连接的边缘点,并沿着其邻居双向追踪。可以使用一个排序后的边缘点列表(首先按x坐标排序,然后按y坐标排序,以

图7.34综合亮度、颜色、纹理边界检测器(Martin,Fowlkes和Malik 2004)©2004 IEEE。连续几行显示了亮度梯度(BG)、颜色梯度(CG)、纹理梯度(TG)以及综合(BG+CG+TG)检测器的输出结果。最后一行显示了从手段分割图像数据库中的人工标注边界(Martin,Fowlkes等2001)。
图7.35链接轮廓的一些编码替代方案。(a)网格对齐的链接边缘链的链码表示。该代码以一系列方向码的形式表示,例如0 1 0 7 6 5,这些方向码可以进一步使用预测编码和行程长度编码进行压缩。(b–c)轮廓的弧长参数化。沿轮廓(b)的离散点首先被转换为沿弧长的(c)(x,y)对。然后,这条曲线可以定期重新采样或转换为其他(例如傅里叶)表示形式。
例如),可以使用二维数组来加速邻居查找。如果边缘不是通过零交叉检测到的,那么找到边缘的延续会变得很棘手。在这种情况下,比较相邻边缘的方向(以及可选的相位)可以用于消除歧义。连接组件计算的一些想法有时也可以用来使边缘链接过程更快(见练习7.8)。
一旦边缘像素被连接成链,我们可以应用一个可选的具有滞后性的阈值处理,以去除强度较低的轮廓段(Canny1986)。滞后性的基本思想是设置两个不同的阈值,允许被跟踪的曲线在高于较高阈值的情况下强度下降到较低阈值。
连接的边缘列表可以使用多种替代表示方法更紧凑地编码。链码使用三位代码对应于点与其后继点之间的八个基本方向(北、东北、东、东南、南、西南、西、西北),来编码位于N8网格上的连接点列表(图7.35a)。虽然这种表示比原始的边缘列表更为紧凑(特别是当使用预测可变长度编码时),但它不太适合进一步处理。
一个更有用的表示方法是轮廓的弧长参数化,x(s),其中s表示沿曲线的弧长。考虑图7.35b中所示的边集。我们从一个点开始(图7.35c中的(1.0,0.5)的点),并在坐标s = 0处绘制它(图7.35c)。下一个点(2.0,0.5)在s = 1处绘制,再下一个点(2.5,1.0)在s = 1.7071处绘制,即我们以每个边段的长度递增。最终的图可以在进一步处理之前,在规则的(例如,整数)s网格上重新采样。
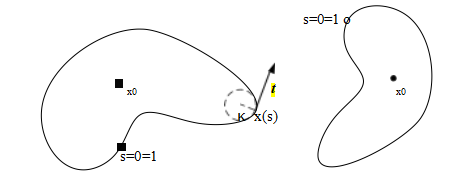
图7.36使用弧长参数化匹配两条轮廓。如果两条曲线都归一化到单位长度,s∈[0,1]并以它们的质心x0为中心,它们将具有相同的描述符,直到一个整体的“时间”偏移(由于s=0的不同起点)和相位(x-y)偏移(由于旋转)。
图7.37使用高斯核进行曲线平滑(Lowe1988)©1998 IEEE:(a)不使用收缩校正项;(b)使用收缩校正项。
处理
弧长参数化的优点在于它使得匹配和处理(例如平滑)操作变得更加容易。考虑图7.36中描述相似形状的两条曲线。为了比较这两条曲线,我们首先从每个描述符中减去平均值x0 = ,sx(s)。接下来,我们将每个描述符重新缩放,使s从0到1而不是从0到S,即x(s)除以S。最后,我们将每个归一化的描述符进行傅里叶变换,将每个x =(x,y)值视为复数。如果原始曲线相同(仅相差未知的比例和旋转),那么最终的傅里叶变换结果应该只在幅度上有所不同,加上由于旋转引起的恒定复相位偏移,以及由于s的不同起点而在域内产生的线性相位偏移(见练习7.9)。
弧长参数化也可用于平滑曲线以去除数字化

图7.38不影响曲线扫掠的曲线特性变化(Finkelstein和Salesin1994)©1994 ACM:高频小波可以用风格库中的示例替换,以产生不同的局部外观。
噪声。然而,如果我们仅仅应用一个常规平滑滤波器,曲线往往会向内收缩(图7.37a)。Lowe(1989)和Taubin(1995)描述了通过基于二阶导数估计或更大的平滑核添加偏移项来补偿这种收缩的技术(图7.37b)。芬克尔斯坦和塞利辛(1994)提出了一种基于小波分解中选择性修改不同频率的替代方法。除了控制收缩而不影响其“范围”外,小波还允许交互式地修改曲线的“特征”,如图7.38所示。
曲线的平滑和简化过程与“草火”(距离)变换和区域骨架(第3.3.3节)(Tek和Kimia 2003)有关,可用于根据轮廓形状识别物体(Sebastian和Kimia 2005)。此外,还可以使用更局部的曲线形状描述符,如形状上下文(Belongie、Malik和Puzicha 2002),这些描述符在识别过程中可能对因遮挡导致的部分缺失更为鲁棒。
轮廓检测与链接领域持续快速进化,现在包括全局轮廓分组、边界完成和节点检测(Maire,Arbelaez等2008),以及将轮廓分组到可能的区域(Arbel ez,Maire等2011)和宽基线对应(Meltzer和Soatto 2008)。一些涉及轮廓检测的其他论文包括Xiaofeng和Bo
(2012),Lim,Zitnick和Doll r(2013),Doll r和Zitnick(2015),Xie和Tu(2015),以及Pont-Tuset,Arbel ez等(2017)。
虽然边缘可以作为对象识别或匹配特征的组件,但它们也可以直接用于图像编辑。
事实上,如果在保留每个边缘的同时保留边缘的幅度和模糊估计值,视觉上

图7.39在轮廓域中的图像编辑(Elder和Goldberg2001)©2001 IEEE:
(a)和(d)原始图像;(b)和(e)提取的边缘(要删除的边缘用白色标记);(c)和(f)重建的编辑图像。
可以从这些信息中重建出类似的图像(Elder1999)。基于这一原理,Elder和Goldberg(2001)提出了一种“轮廓域图像编辑”系统。该系统允许用户选择性地移除与不需要的特征相对应的边缘,如镜面反射、阴影或分散注意力的视觉元素。通过从剩余的边缘重建图像,不希望的视觉特征已被移除(图7.39)。
另一个潜在应用是增强感知显著的边缘,同时简化底层图像以生成卡通或“钢笔画”风格化图像(DeCarlo和Santella2002)。该应用在第10.5.2节中进行了更详细的讨论。
7.3 剖面跟踪
虽然直线、消失点和矩形在人造世界中很常见,但对应于物体边界的曲线更为常见,尤其是在自然环境中。在本节中,我们将介绍一些定位图像中边界曲线的方法。
第一个曲线最初由其发明者(Kass、Witkin和Terzopoulos1988)称为蛇形曲线(第7.3.1节),是一种能量最小化二维样条曲线,可演化(移动)
朝向图像特征,如强边缘。第二种智能剪刀(Mortensen和Barrett 1995)(Section7.3.1),允许用户实时勾勒出一条贴合物体边界的曲线。最后,水平集技术(第7.3.2节)通过将曲线作为特征函数的零集来演化,这使得它们能够轻松改变拓扑结构并融入基于区域的统计信息。
这三种方法都是活动轮廓的例子(Blake和Isard 1998;Mortensen 1999),因为这些边界检测器在图像和可选用户引导力的共同作用下,逐步向最终解移动。下面的介绍大幅简化了本书第一版中第5.1节的内容(Szeliski 2010),感兴趣的读者可以查阅更多细节。
蛇形曲线是第4.2节中首次介绍的一维能量最小化样条的二维推广,
εint = ∫ α(s)Ⅱfs (s)Ⅱ2 + β(s)Ⅱfss (s)Ⅱ2 ds, (7.26)
其中s是沿曲线f(s) =(x(s),y(s))的弧长,α(s)和β(s)是类似于(4.24–4.25)中引入的s(x,y)和c(x,y)项的一阶和二阶连续性加权函数。我们可以通过沿初始曲线位置均匀采样来离散化这一能量(图7.35c),以获得
(7.27)
+ β(i)Ⅱf(i + 1) - 2f(i) + f(i - 1)Ⅱ2 /h4 ,
其中是步长,如果我们在每次迭代后沿着弧长重采样曲线,就可以忽略它。
除了这种内部的样条能量之外,蛇同时最小化基于图像和基于约束的外部势能。基于图像的势能是几个项的总和
εimage = wline εline + wedge εedge + wterm εterm, (7.28)
其中,线项将蛇吸引到暗色的脊上,边缘项将蛇吸引到强烈的梯度(边缘)上,而项则将蛇吸引到线的末端。随着蛇的进化,
为了减少能量,它们经常“扭动”和“滑行”,这就是它们的流行名称。
图7.40弹性网络:开放的方块表示城市,封闭的方块通过直线段连接的是游览点。蓝色圆圈表示每个城市的吸引力范围,这种吸引力会随时间减弱。根据弹性网络的贝叶斯解释,蓝色圆圈对应于从某个未知游览点生成每个城市的圆形高斯分布的一个标准差。
因为普通蛇形模型有收缩的趋势,通常最好通过将蛇形模型绘制在要跟踪的对象外部来初始化。或者,可以向动力学中加入膨胀力(Cohen和Cohen 1993),即沿每个点的法线向外移动。此外,还可以用深度神经网络替代能量最小化变分演化方程,以显著提高性能(Peng、Jiang等2020)。
弹性网和滑动弹簧
一个有趣的蛇形变体,最初由杜宾和威尔肖(1987)提出,后来杜宾、斯泽利斯基和尤尔(1989)在能量最小化框架下重新表述,是旅行商问题(TSP)的弹性网公式。回想一下,在TSP中,旅行商必须访问每个城市一次,同时尽量减少总行走距离。一条被限制通过每个城市的蛇可以解决这个问题(尽管没有最优性保证),但事先无法确定每条蛇控制点应与哪个城市关联。
而不是在蛇节点和城市之间设置固定的约束,假设城市会在游览路线(Figure7.40)上的某个点附近经过。从概率的角度来看,每个城市都是以每个游览点为中心的高斯混合生成的,
p
ij与pij = e-d
| 469 | |
| 其中σ是高斯分布的标准差 | |
| dij = Ⅱf(i) - d(j)Ⅱ | (7.30) |
是巡游点f(i)和城市位置d(j)之间的欧几里得距离。相应的数据拟合能量(负对数似然)是
这种能量的名称来源于,与普通的弹簧不同,普通弹簧将给定的蛇形点与给定的约束条件耦合,而这种替代能量定义了一个滑动弹簧,使得约束条件(城市)和曲线(路线)之间的关联随时间演变(Szeliski1989)。请注意,这是广受欢迎的迭代最近点数据约束的一种软变体,通常用于拟合或对齐表面到数据点或彼此之间(第13.2.1节)(Besl和McKay1992;Chen和Medioni1992;Zhang1994)。
为了计算出一个良好的TSP解决方案,滑动弹簧数据关联能量与常规的一阶内部平滑能量(7.27)相结合,以定义一条路径的成本。路径f(s)最初被初始化为围绕城市点平均值的小圆圈,而σ逐渐降低(图7.40)。当σ值较大时,路径试图靠近点的质心;但随着σ的减小,每个城市对其最近的路径点的吸引力越来越强(Durbin,Szeliski,和Yuille 1989)。当σ→0时,每个城市至少会捕获一个路径点,且后续城市的路径变得直线。
虽然蛇在捕捉许多真实世界轮廓的细微和不规则细节方面非常擅长,但它们有时会表现出太多的自由度,这使得它们在进化过程中更容易陷入局部最小值。
解决此问题的一个方法是通过使用B样条近似来控制具有较少自由度的蛇形曲线(Menet、Saint-Marc和Medioni1990b,a;Cipolla和Blake1990)。由此产生的B蛇形曲线可以表示
(7.32)
如果被跟踪或识别的对象在位置、尺度或方向上有很大的变化,这些可以建模为控制点上的附加变换,例如,
x = sRxk + t(2.18),该值可与对照组的值同时进行估计
或者,可以运行单独的检测和对准阶段,首先定位和定向感兴趣对象(Cootes、Cooper等人,1995)。
图7.41活动形状模型(ASM):(a)改变一组面部的前四个形状参数的效果(Cootes,Taylor等人,1993年)©1993 IEEE;(b)沿每个控制点法线寻找最强梯度(Cootes,Cooper等人,1995年)©1995 Elsevier.
在B型蛇形线中,由于蛇形线受控自由度较少,因此不需要使用原始蛇形线的内部平滑力,尽管这些平滑力仍可以通过有限元分析推导和实现,即对B样条基函数求导和积分(Terzopoulos1983;Bathe2007)。
在实际应用中,通常会估计一组关于控制点{xk }的形状先验分布(Cootes,Cooper等,1995)。描述这一分布的一种方法是通过每个单独点xk的位置x-k和二维协方差Ck来表示。这些可以转化为对点位置的二次惩罚(先验能量)。然而,在实践中,点位置的变化通常是高度相关的。
一种优选的方法是同时估计所有点的联合协方差。首先,将所有点的位置{xk }连接成一个向量x,例如通过交错每个点的x和y位置。这些向量在所有训练样本中的分布可以用均值x和协方差来描述。
(7.33)
其中,xp是P个训练样本。使用特征值分析(附录A.1.2),可以得到
也称为主成分分析(PCA)(Section5.2.3和附录B.1),协方差矩阵可以写为,
C = Φ diag(λ0... λK - 1) ΦT . (7.34)
在大多数情况下,可以使用具有最大特征值的少数几个特征向量来模拟点的可能出现。所得点分布模型(Cootes、Taylor等人,1993;Cootes、Cooper等人,1995)可表示为
x = x- + b, (7.35)
其中b是M冬K元素形状参数向量,是Φ的前m列。
为了将形状参数限制在合理的值,我们可以使用形式如下的二次惩罚
或者,允许的bm值范围可以限制在某个范围内,例如,jbmj≤3√λm(Cootes,Cooper等,1995)。Isard和Blake(1998)回顾了推导一组形状向量的替代方法。通过在-2√λm≤2√λm的范围内变化各个形状参数bm,可以很好地表示预期的外观变化,如图7.41a所示。
为了使点分布模型与图像对齐,每个控制点会在垂直于轮廓的方向上搜索,以找到最可能对应的图像边缘点(图7.41b)。这些单独的测量结果可以与形状参数(以及位置、尺度和方向参数,如需)的先验知识结合,来估计一组新的参数。由此产生的活动形状模型(ASM)可以通过迭代最小化来拟合非刚性变形物体的图像,例如医学图像或身体部位,如手部(Cootes,Cooper等,1995)。ASM还可以与底层灰度分布的主成分分析相结合,创建活动外观模型(AAM)(Cootes,Edwards,和Taylor,2001),我们在Section6.2.4中对此进行了更详细的讨论。
动态蛇形线和冷凝
在许多活动轮廓的应用中,感兴趣的对象在变形和演化过程中从一帧到另一帧被跟踪。在这种情况下,使用前一帧的估计值来预测和限制新的估计值是有意义的。
一种方法是使用卡尔曼滤波,这将产生一个称为卡尔曼蛇的公式(Terzopoulos和Szeliski1992;Blake、Curwen和Zisserman1993)。卡尔曼滤波基于形状参数演化的线性动态模型,
xt = Axt - 1 + wt , (7.37)
其中xt和xt - 1是当前和前一状态变量,A是线性转换矩阵,w是一个噪声(扰动)向量,通常建模为高斯(Gelb
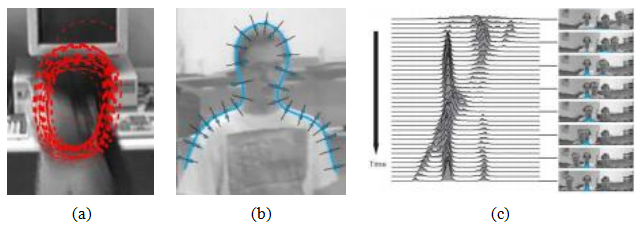
图7.42使用冷凝进行头部跟踪(Isard和Blake,1998)©1998
Springer:(a)头部估计分布的样本集表示;(b)每个控制顶点位置的多个测量值;(c)多假设跟踪随时间变化。
1974)。矩阵A和噪声协方差可以通过观察被跟踪对象的典型序列提前学习(Blake和Isard1998)。
然而,在许多情况下,例如在杂乱环境中跟踪时,如果我们移除假设分布为高斯分布这一前提,可以得到更好的轮廓估计。在这种情况下,传播的是一个通用的多模态分布。为了建模这种多模态分布,Isard和Blake(1998)将粒子滤波技术引入了计算机视觉领域。粒子滤波技术通过一组加权点样本来表示概率分布(Andrieu、de Freitas等2003;Bishop 2006;Koller和Friedman 2009)。
为了根据线性动力学(确定性漂移)更新样本的位置,首先更新样本的中心,并为每个点生成多个样本。然后对这些样本进行扰动以考虑随机扩散,即它们的位置由从w分布中抽取的随机向量移动。最后,将这些样本的权重乘以测量概率密度,即根据当前(新的)测量结果,计算每个样本的似然性。由于点样本代表并传播了多模态密度的条件估计,Isard和Blake(1998)将其算法称为条件密度传播或凝聚。 图7.42a显示了头部跟踪器的一个分解样本可能的样子,为被跟踪的(子集)粒子绘制红色B样条轮廓。图7.42b显示了为什么测量密度本身通常是多模态的:边缘的位置
12多模态分布建模的替代方法包括高斯混合(第5.2.2节)和多重假设跟踪(Bar-Shalom和Fortmann1988;Cham和Rehg1999)。
13注意,由于这些步骤的结构,可以使用非线性动力学和非高斯噪声。
图7.43智能剪刀:(a)当鼠标追踪白色路径时,剪刀沿着物体边界跟随橙色路径(绿色曲线显示中间位置)(Mortensen和Barrett 1995)©1995 ACM;(b)常规剪刀有时会跳到更强(错误的)边界;(c)经过前一段训练后,更倾向于相似的边缘轮廓(Mortensen和Barrett 1998)©1995 Elsevier。
由于背景杂乱,与样条曲线垂直的条件密度(头部和肩部跟踪器质心的x坐标)可能有多个局部最大值。最后,图7.42c显示了在一段时间内跟踪几个人时条件密度的时间演变。
剪刀
活动轮廓允许用户大致指定感兴趣的边界,并让系统将轮廓演化到更精确的位置,同时跟踪其随时间的变化。然而,这种曲线演化的结果可能是不可预测的,可能需要额外的用户提示才能达到预期效果。
一种替代方法是让系统在用户绘制时实时优化轮廓(Mortensen 1999)。Mortensen和Barrett(1995)开发的智能剪刀系统正是这样做的。当用户绘制粗略轮廓(图7.43a中的白色曲线)时,系统会计算并绘制出更优的曲线,该曲线紧贴高对比度边缘(橙色曲线)。
为了计算最优曲线路径(活线),首先对图像进行预处理,将低成本与边缘(即相邻的水平、垂直和对角线,即N8邻域)关联起来,这些边缘可能是边界元素。他们的系统使用零交叉、梯度幅度和梯度方向的组合来计算这些成本。
接下来,当用户绘制一条粗略的曲线时,系统会使用迪杰斯特拉算法不断重新计算从起始种子点到当前鼠标位置之间的最低成本路径。
为了防止系统不可预测地跳跃,系统会在一段时间的不活动后“冻结”到目前为止的曲线(重置起始点)。为了防止导线跳到相邻的高对比度轮廓上,系统还会“学习”当前优化曲线下的强度分布,并利用这一点优先让导线沿着相同的(或相似的)边界移动(图7.43b-c)。
已提出几种扩展基本算法的方法,即使在原始形式下也能表现出色。莫滕森和巴雷特(1999)使用了滑板法,这是一种简单的分水岭区域分割方法,用于预先将图像分割成边界成为优化曲线路径候选的区域。这些区域边界被转换成一个更小的图,在该图中,节点位于三个或四个区域交汇的地方。然后在这一简化图上运行迪杰斯特拉算法,从而实现更快(且通常更稳定)的性能。智能剪刀的另一种扩展是采用概率框架,考虑边界当前的轨迹,从而形成一个名为JetStream的系统(普雷兹、布莱克和甘格内特2001)。
与在每个时间点重新计算最优曲线不同,可以通过简单地将当前鼠标位置“抓取”到最近的可能边界点来开发一个更简单的系统(Gleicher1995)。这些边界提取技术在图像切割中的应用
7.3.2水平集
基于参数曲线形式的主动轮廓,例如蛇形、B-蛇形和凝聚,其局限性在于,在曲线演化过程中改变其拓扑结构具有挑战性(McInerney和Terzopoulos 1999,2000)。此外,如果形状发生剧烈变化,可能还需要重新参数化曲线。
对于这些闭合轮廓,另一种表示方法是使用水平集,其中特征函数(或带符号距离(第3.3.3节))的零交叉点定义了曲线。水平集通过修改底层嵌入函数(即这个二维函数的另一个名称)φ(x;y),而不是曲线f(s),来适应和跟踪感兴趣的物体(Malladi、Sethian和Vemuri 1995;Sethian 1999;Sapiro 2001;Osher和Paragios 2003)。为了减少所需的计算量,只需在当前零交叉点周围更新一小段区域(边界),这导致了所谓的快速行进方法(Sethian 1999)。
一个演化方程的例子是卡塞勒斯提出的测地线活动轮廓,
图7.44测地线活动轮廓的水平集演化。嵌入函数φ根据底层表面的曲率更新,该曲率由边缘/速度函数g(I)调制,并且还根据g(I)的梯度进行更新,从而将其吸引到强边缘。
Kimmel和Sapiro(1997)以及Yezzi、Kichenassamy等人(1997),
· ▽φ, (7.38)
其中g(I)是蛇边势能的广义版本。为了直观地理解曲线的行为,假设嵌入函数φ是一条与曲线相距的带符号距离函数(图7.44),在这种情况下jφj = 1。方程(7.38)中的第一项使曲线沿其曲率方向移动,即在调制函数g(I)的影响下,它起到拉直曲线的作用。第二项使曲线沿着g(I)的梯度向下移动,促使曲线向g(I)的最小值迁移。
虽然这种水平集公式可以轻松改变拓扑结构,但它仍然容易受到局部最小值的影响,因为它是基于图像梯度等局部测量的。另一种方法是将问题重新表述为分割框架,在该框架中,能量衡量的是分割区域内外图像统计特性(如颜色、纹理、运动)的一致性(Cremers,Rousson和Deriche 2007;Rousson和Paragios 2008;Houhou,Thiran和Bresson 2008)。这些方法建立在Leclerc(1989)、Mumford和Shah(1989)以及Chan和Vese(2001)引入的早期基于能量的分割框架之上,相关内容详见Section4.3.2。
有关水平集及其应用的更多信息,请参见由Osher和Paragios编辑的论文集(2003年)以及关于变分和水平集方法在计算机视觉中的研讨会系列(Paragios,Faugeras等2005年)和关于尺度空间和变分方法在计算机视觉中的特刊(Paragios和Sgallari。

图7.45基于关键帧的转描(Agarwala,Hertzmann等人,2004)©2004
ACM: (a)原始画面;(b)转描轮廓;(c)重新上色的上衣;(d)转描手绘动画。
2009).
活动轮廓可用于多种物体跟踪应用(Blake和Isard 1998;Yilmaz、Javed和Shah 2006)。例如,它们可以用于追踪面部特征以实现性能驱动的动画(Terzopoulos和Waters 1990;Lee、Terzopoulos和Waters 1995;Parke和Waters 1996;Bregler、Covell和Slaney 1997)。它们还可以用于追踪头部和人物,如图7.42所示,以及移动车辆(Paragios和Deriche 2000)。其他应用包括医学图像分割,在计算机断层扫描中可以从一个切片到另一个切片追踪轮廓(Cootes和Taylor 2001),或随时间变化,如超声波扫描。
一个有趣的应用是转描技术,它利用跟踪轮廓来变形一组手绘动画(或修改或替换原始视频frames).14Agarwala,赫茨曼等人(2004)提出了一种基于跟踪选定关键帧的手绘B样条轮廓的系统,结合了几何和外观标准(图7.45)。他们还对之前的转描技术和基于图像的轮廓跟踪系统进行了出色的综述。
14这个术语来自于一种装置(arotoscope),它将真人电影的画面投射到醋酸纤维素下面,这样艺术家就可以直接在演员的形状上绘制动画。
477节介绍了将对象从一张照片剪切并粘贴到另一张照片中,参见第10.4节。
7.4 线与消失点
虽然边缘和一般曲线适合描述自然物体的轮廓,但人造世界充满了直线。检测和匹配这些直线在多种应用中都有用处,包括建筑建模、城市环境中的姿态估计以及打印文档布局的分析。
在本节中,我们介绍了一些从前一节计算的曲线中提取分段线性描述的技术。首先,我们介绍一些算法,用于将曲线近似为分段线性折线。接着,我们描述了霍夫变换,该变换可以将边缘点聚集成线段,即使在间隙和遮挡的情况下也能做到这一点。最后,我们描述了如何将具有共同消失点的三维线段聚类在一起。这些消失点可用于校准相机,并确定其相对于矩形场景的方向,如第11.1.1节所述。
正如我们在第7.2.2节中所见,将曲线描述为一系列二维位置xi=x(s)提供了一种通用表示方法,适用于匹配和进一步处理。然而,在许多应用中,更倾向于用更简单的表示来近似这种曲线,例如,作为分段线性折线或B样条曲线(Farin2002)。
多年来,人们开发了多种技术来实现这种近似,也称为线简化。其中最古老且简单的方法之一是由拉默(1972年)和道格拉斯与佩克(1973年)提出的,他们通过递归地将曲线在距离连接两个端点的直线(或当前粗略折线近似)最远的点处细分。赫舍伯格和斯诺因克(1992年)提供了一种更高效的实现方法,并引用了该领域的其他一些相关工作。
一旦计算出线简化,就可以用来近似原始曲线。如果需要更平滑的表示或可视化,可以使用近似或插值样条或曲线(第3.5.1节和第7.3.1节)(Szeliski和Ito1986;Bartels、Beatty和Barsky1987;Farin2002)。
虽然使用多段线进行曲线近似通常可以成功提取直线,但现实世界中的直线有时会被分解成不连通的组件或由许多直线组成
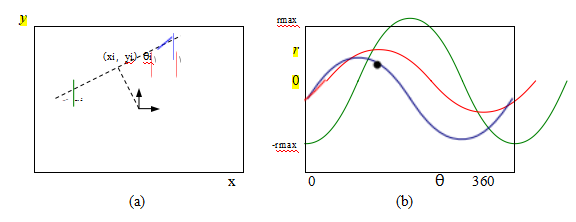
图7.46原始霍夫变换:(a)每个点投票选出一组完整的潜在直线;ri(θ)=xi cos θ + yi sin θ;(b)每组线扫出一个正弦波(r;θ);它们的交点提供了所需的直线方程。
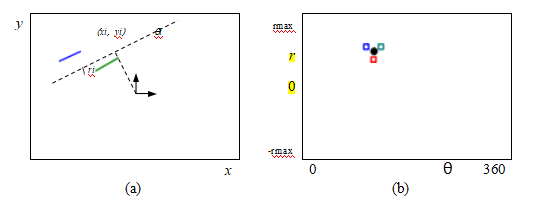
图7.47偏向霍夫变换:(a)在极坐标(r;θ)中参数化,其中i =(cos θi;sin θi)和ri = i·xi;(b)(r;θ)积累数组,显示了标记为红色、绿色和蓝色的三个边缘的投票结果。
共线线段。在许多情况下,将这些共线线段组合成延长线是可取的。在进一步处理阶段(第7.4.3节中描述),我们可以将这些线组合成具有共同消失点的集合
霍夫变换,以其原始发明者(Hough1962)命名,是一种著名的边缘“投票”技术,用于确定可能的线位置(Duda和Hart1972;Ballard 1981;Illingworth和Kittler1988)。在其最初的表述中(图7.46),每个边缘点都会对所有通过它的可能线条进行投票,而与高累加器或箱值相对应的线条则被检查以寻找潜在的线拟合。除非线上的点确实是孤立的,否则更好的方法是利用每个边缘点处的局部方向信息来投票给一个单独的累加器单元(图7.47),如下所述。一种混合策略,即每个边缘点投票
15Hough变换也可以推广到寻找其他几何特征,如圆(Ballard
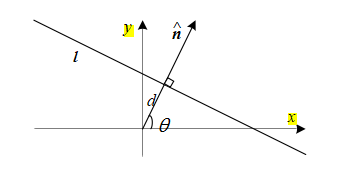
在一些情况下,对于以估计方向为中心的多个可能的方向或位置对来说可能是可取的。
在我们投票支持线性假设之前,我们必须首先选择一个合适的表示。
图7.48(从图2.2a复制)显示了正常距离(d)参数化
一条直线。由于直线由边段组成,我们采用以下约定:直线的法线
与图像梯度J(x) =▽I(x)方向相同(即,具有相同的符号)的点
(7.19)为了获得直线的最小两个参数表示,我们将法向量转换为角度
θ = tan-1 ny /nx, (7.39)如图7.48所示。可能的(θ,d)值范围为[-180.,180.]×[-√2,√2],假设我们使用的是归一化的像素坐标(2.61),这些坐标位于[-1,1]内。每个轴上的区间数量取决于位置和方向估计的精度以及预期的线密度,并且最好通过在样本图像上进行一些测试运行来实验确定。
实现霍夫变换时有许多细节需要注意,包括在投票过程中使用边缘段长度或强度,在累加器数组中保存构成边的列表以便于后处理,以及可选地将不同“极性”的边合并为同一线段。这些细节最好通过编写实现并在样本数据上测试来解决。
对于线的二维极坐标(θ,d)表示法,另一种方法是使用完整的三维m=
(d)直线方程,投影到单位球上。虽然球可以参数化
使用球坐标(2.8),
=(cosθcosφ,sinθcosφ,sinφ), (7.40)
这并不能均匀地对球体进行采样,仍然需要使用三角学。
通过使用立方体映射,可以得到另一种表示方法,即将m投影到
单位立方体的表面(图7.49a)。计算三维向量的立方体坐标
图7.49线方程和消失点的立方体地图表示:(a)围绕单位球体的立方体地图;(b)将半立方体投影到三个子空间(Tuyte- laars、Van Gool和Proesmans1997)©1997 IEEE。
首先,找到m的最大(绝对值)分量,即m = ± max(jnxj,jny j,jdj),并用它来选择六个立方体面中的一个。将剩余的两个坐标除以m,并用这些坐标作为立方体面的索引。虽然这种方法避免了使用三角函数,但确实需要一些决策逻辑。
使用立方体图的一个优势,首先由图特拉尔斯、范古尔和普罗斯曼斯(1997)指出,是所有通过某一点的线都对应于立方体面上的线段,这在使用原始(全投票)霍夫变换时非常有用。在他们的研究中,他们表示直线方程为ax + b + y = 0,这并不对x和y轴进行对称处理。需要注意的是,如果我们通过忽略边缘方向(梯度符号)的极性来限制d≥0,就可以使用半立方体,仅需用三个立方体面即可表示,如图7.49b所示(图特拉尔斯、范古尔和普罗斯曼斯1997)。
基于RANSAC的线检测。霍夫变换的另一种替代方法是随机样本一致性(RANSAC)算法,该算法在第8.1.4节中详细描述。简而言之,RANSAC随机选择边对来形成一条线假设,然后测试有多少其他边落在这条线上。(如果边的方向足够准确,单个边就可以产生这个假设。)具有足够多内点(匹配的边)的线段随后被选为所需的线段。
RANSAC的一个优点是不需要累加器数组,因此算法可以更加节省空间,并且可能更少受到箱大小选择的影响。缺点是需要生成和测试的假设远多于通过在累加器数组中找到峰值所获得的假设。
自下而上的分组。另一种线段检测方法是将具有相似方向的边沿迭代地分组为有向矩形线支持区域(Burns,Han-

图7.50实际消失点:(a) architecture (Sinha,Steedly等人,2008),(b) furniture (Mi u k,Wildenauer和Ko eck,2008)©2008 IEEE,以及(c)校准模式(Zhang,2000)。
儿子,以及里斯曼1986)。然后可以使用统计分析来确定这些区域的有效性,如格罗蓬·冯·乔伊、雅库博维奇等人(2008)在LSD论文中所述。该算法非常快速,能够很好地区分线段和纹理,并因其性能和开源可用性而在实践中广泛使用。最近,已经开发出深度神经网络算法,可以同时提取线段及其连接点(黄、王等人2018;张、李等人2019;黄、秦等人2020;林、平特亚和范·格默特2020)。
一般来说,对于哪种线估计技术表现最佳并没有明确的共识。因此,仔细考虑问题并尝试几种方法(连续逼近、Hough和RANSAC)来确定最适合您应用的方法是个好主意。
在许多场景中,结构重要的线条因为三维空间中的平行性而具有相同的消失点。例如水平和垂直的建筑边缘、斑马线、铁路轨道、家具如桌子和衣柜的边缘,当然还有常见的校准图案(图7.50)。找到这些线条集合的共同消失点可以帮助精确定位它们在图像中的位置,在某些情况下,还可以帮助确定相机的内外方位(第11.1.1节)。
多年来,已经开发出大量技术来寻找消失点(Quan和Mohr 1989;Collins和Weiss 1990;Brillaut-O‘Mahoney 1991;McLean和Kotturi 1995;Becker和Bove1995;Shufelt1999;Tuytelaars,Van Gool,以及Proesmans 1997;Schaffalitzky和Zisserman 2000;Antone和Teller 2002;Rother 2002;Ko eck和Zhang
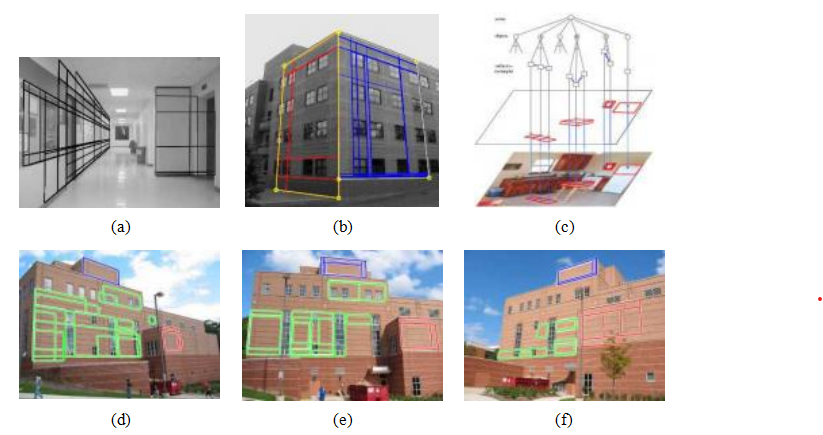
图7.51矩形检测:(a)室内走廊和(b)建筑物外部
分组立面(Ko eck和Zhang2005)©2005 Elsevier;基于(c)语法的识别
(Han和Zhu2005)©2005 IEEE;(d-f)使用平面扫描算法进行矩形匹配
(Mi u k、Wildenauer和Ko eck 2008)©2008 IEEE。
2012;Antunes和Barreto2013;Kluger、Ackermann等人2017;Zhou、Qi等人2019a)——请参阅一些较新的论文以获取更多参考文献和替代方法。
在本书的第一版(Szeliski2010,第4.3.3节)中,我介绍了一种基于线对投票潜在消失点位置的简单霍夫技术,随后进行稳健的最小二乘拟合阶段。虽然我的方法分为两个独立阶段,但通过交替分配线条到消失点和重新拟合消失点位置,可以取得更好的结果(Antone和Teller2002;Ko eck和Zhang2005;Pflugfelder2008)。检测单个消失点的结果也可以通过同时搜索相互正交的消失点对或三元组来提高
鲁棒性(Shufelt1999;Antone和Teller2002;Rother2002;Sinha、Steedy等人2008;Li、Kim等人2020)。图7.50展示了此类消失点检测算法的一些结果。还可以使用神经网络同时检测线段及其连接点(Zhang、Li等人2019),然后利用这些信息构建完整的3D线框模型(Zhou、Qi和Ma2019;Zhou、Qi等人2019b)。
矩形检测
一旦检测到一组相互正交的消失点,就可以在图像中搜索三维矩形结构(图7.51)。已经开发出多种技术来寻找这样的矩形,主要集中在建筑场景中。
(Ko eck和Zhang2005;Han
以及Ko eck
2008;Schindler,Krishnamurthy等人2008)。
检测到正交消失方向后,Ko eck和Zhang(2005)改进了拟合线方程
,寻找靠近线段交点的角点,然后通过校正相应区域并寻找大量水平和垂直边缘来验证矩形假设(图7.51a-b)。在后续工作中,Mi u k、Wilder和Ko eck(2008)使用马尔可夫随机场(MRF)来区分可能重叠的矩形假设。他们还使用平面扫描算法在不同视图之间
匹配
矩形(图7.51d-f)。
韩和朱(2005)提出了一种不同的方法,他们利用矩形形状的潜在语法和嵌套结构(矩形与消失点之间)来推断线段最可能分配给矩形的方式(图7.51c)。现在,使用规则、重复结构作为建模过程的一部分被称为整体3D重建(周、古川和马2019;周、古川等2020;平托雷、穆拉等2020),将在Section13.6.1on建模3D建筑中详细讨论。
7.5 分段
图像分割的任务是找到“组合在一起”的像素组。在统计学和机器学习中,这个问题被称为聚类分析或更简单的聚类,是一个广泛研究的领域,有数百种不同的算法(Jain和Dubes 1988;Kaufman和Rousseeuw 1990;Jain、Duin和Mao 2000;Jain、Topchy等2004;Xu和Wunsch 2005)。我们已经在第5.2.1节讨论了一般向量空间聚类算法。聚类与分割的主要区别在于,前者通常忽略像素布局和邻域,而后者则高度依赖空间线索和约束。
在计算机视觉中,图像分割是最古老且研究最为广泛的问题之一(Brice和Fennema 1970;Pavlidis 1977;Riseman和Arbib 1977;Ohlander、Price和Reddy 1978;Rosenfeld和Davis 1979;Haralick和Shapiro 1985)。早期技术通常采用区域分割或合并的方法(Brice和Fennema 1970;Horowitz和Pavlidis 1976;Ohlander、Price和Reddy 1978;Pavlidis和Liow 1990),这些方法对应于分裂算法和聚类算法(Jain、Topchy等2004;Xu和Wunsch 2005),我们在此介绍
在第5.2.1节中进行了减少。最近的算法通常优化一些全局标准,例如区域内的一致性和区域间边界长度或不相似性(Leclerc1989;Mumford和Shah1989;Shi和Malik2000;Comaniciu和Meer2002;Felzenszwalb和Huttenlocher2004;Cremers、Rousson和Deriche2007;Pont-Tuset、Arbel ez等人2017)。
我们已经看到了使用图像形态学(第3.3.3节)、马尔可夫随机场(第4.3节)、活动轮廓(第7.3节)和水平集(第7.3.2节)进行图像分割的例子。在识别章节(第6.4节)中,我们研究了语义分割,其目标是将图像分解为具有语义标签的区域,如天空、草地以及个人和动物。在本节中,我们将回顾一些用于自下而上通用(非语义)图像分割的额外技术。这些技术包括基于区域分割和合并的算法、基于图的分割、概率聚合(第7.5.1节)、均值漂移模式查找(第7.5.2节)以及基于像素相似度度量的归一化切割分割(第7.5.3节)。由于许多这些算法已不再广泛使用,因此很多描述已经大大缩短,与本书第一版(Szeliski2010,第5章)中的描述相比,后者提供了更详细的说明。
由于图像分割领域的文献非常丰富,了解一些表现较好的算法的一个好方法是查看人类标注数据库上的实验比较(Arbel ez,Maire等2011;Pont-Tuset,Arbel ez等2017)。其中最著名的是伯克利分割数据
集和基准(Martin,Fowlkes
等2001),该数据集包含来自Corel图像数据集的1,000张图像,由30名人类受试者手动标注。Unnikrishnan、Pantofaru和Hebert(2007)提出了新的度量标准来比较分割算法,而Estrada和Jepson(2009)则比较了四种知名分割算法。Alpert、Galun等人(2007)还提供了一个更新的前景和背景分割数据库。
如第3.3.3节所述,分割灰度图像的最简单技术是选择一个阈值,然后计算连通分量。不幸的是,由于光照和对象内部统计变化,单个阈值很少足以处理整个图像。
区域分割(分裂聚类)。将图像逐步细分为更小的区域是计算机视觉中最古老的技术之一。Ohlander、Price和Reddy(1978)提出了一种这样的技术,首先计算整个图像的直方图,然后找到最佳阈值以分离直方图中的大峰值。这一过程会重复进行,直到区域变得相对均匀或低于某个特定大小。近年来的分割算法通常优化某些区域内相似性和区域间差异性的度量。这些内容将在第4.3.2节和第7.5.3节中讨论。
区域合并(凝聚聚类)。区域合并技术可以追溯到计算机视觉的早期。Brice和Fennema(1970)使用双网格来表示像素之间的边界,并根据相对边界长度和这些边界处可见边缘的强度来合并区域。
一种非常简单的基于像素的合并方法结合了平均颜色差异低于阈值或区域过小的相邻区域。将图像分割成这样的超像素(Mori,Ren等,2004),这些超像素没有语义意义,可以作为有用的预处理阶段,使立体匹配(Zitnick,Kang等,2004;Taguchi,Wilburn和Zitnick,2008)、光流(Zitnick,Jojic和Kang,2005;Brox,Bregler和Malik,2009)以及识别(Mori,Ren等,2004;Mori,2005;Gu,Lim等,2009;Lim,Arbel ez等,2009)等高级算法更快且更稳健。还可以通过从中粒度分割
(以四叉树表示)开始,然后允许合并和分裂操作来结合分割和合并(Horowitz和Pavlidis,1976;Pavlidis和Liow,1990)。
分水岭。一种与阈值处理相关的技术,因为它作用于灰度图像,即分水岭计算(Vincent和Soille 1991)。该技术将图像分割成多个集水区,这些区域是图像中的部分(可以解释为高度场或地形),雨水会流入同一个湖泊。计算这些区域的一种有效方法是从所有局部最小值开始淹没地形,并在不同演化组件相遇的地方标记山脊。整个算法可以使用像素优先队列和广度优先搜索来实现(Vincent和Soille1991).16
由于图像中很少有被较亮的脊线分隔的暗区,因此通常将分水岭分割应用于梯度幅值图像的平滑版本,这使得它也能用于彩色图像。作为替代方案,可以使用可导向滤波器(3.28–3.29)中的最大方向能量(Freeman和Adelson 1991)作为Arbel ez、Maire等人(2011)开发的方向分水岭变换的基础。这些技术最终会找到由可见(高梯度)边界分隔的平滑区域。由于这些边界通常是活动轮廓
通常跟随的目标,因此活动轮廓算法(Mortensen和Barrett 1999;Li、Sun等人2004)通常会预先计算这种分割,使用分水岭或
16相关算法可用于高效计算最大稳定极限区域(MSER)(第7.1.1节)(Nist r和Stew nius2008)。

图7.52基于图的合并分割(Felzenszwalb和Huttenlocher 2004)©2004斯普林格:(a)输入灰度图像成功分割为三个区域,尽管较小矩形内的变化大于中间边缘的变化;(b)输入灰度图像;(c)使用N8像素邻域的结果分割。
7.5.1基于图的分割
虽然许多合并算法只是简单地应用一个固定的规则来将像素和区域聚类在一起,但费尔岑斯瓦尔布和胡滕洛赫(2004)提出了一种使用区域间相对不相似性来确定哪些区域应该合并的合并算法;该算法能够证明优化全局聚类度量。他们首先使用像素间的不相似性度量w(e),例如测量N8邻域之间的强度差异。或者,他们可以使用科马尼丘和梅尔(2002)引入的联合特征空间距离,我们将在Sections7.5.2和7.5.3中讨论。图7.52显示了使用他们的技术分割的两个图像示例。
概率聚合
阿尔珀特、加伦等人(2007)开发了一种基于灰度相似性和纹理相似性的概率合并算法。区域Ri和Rj之间的灰度相似性基于与其他相邻区域的最小外部差异,该差异与平均强度差异进行比较,以计算两个区域应合并的可能性pij。合并过程采用层次化方式,受到代数多重网格技术(布兰特1986;布里格斯、亨森和麦考密克2000)的启发,并由阿尔珀特、加伦等人(2007)在其加权聚合分割(SWA)算法中使用过(沙伦、加伦等人2006)。图7.56显示了该算法生成的分割结果。
7.5.2平均偏移
均值移位和模式查找技术,如k-均值和高斯混合,将与每个像素相关的特征向量(例如,颜色和位置)建模为来自未知概率密度函数的样本,然后尝试在该分布中查找聚类(模式)。
考虑图7.53a所示的彩色图像。仅凭颜色,你如何分割这幅图像?图7.53b展示了L*u*v*空间中像素的分布,这相当于忽略空间位置的视觉算法所看到的情况。为了简化可视化,我们只考虑L*u*坐标,如图7.53c所示。你看到了多少明显的(拉长的)聚类?你会如何找到这些聚类?
我们在第5.2.2节中研究的k均值和高斯混合技术使用密度函数的参数模型来回答这个问题,即假设密度是由少量较简单的分布(例如高斯分布)的叠加而成,这些分布的位置(中心)和形状(协方差)可以被估计。而均值漂移则平滑分布并找到其峰值以及特征空间中对应每个峰值的区域。由于建模的是完整的密度,这种方法被称为非参数方法(Bishop 2006)。
均值漂移的关键在于一种高效地在高维数据分布中找到峰值的技术,而无需显式计算完整的函数(Fukunaga和Hostetler 1975;Cheng 1995;Comaniciu和Meer 2002)。再次考虑图7.53c中显示的数据点,可以认为这些数据是从某个概率密度函数中抽取的。如果我们能够计算出这个密度函数,如图7.53e所示,我们就能找到其主要峰值(模式),并识别出输入空间中达到相同峰值的区域属于同一区域。这与第7.5节描述的分水岭算法相反,后者是沿着山谷向下寻找吸引盆地的过程。
那么,第一个问题是如何根据稀疏样本集估计密度函数。最简单的方法之一是平滑数据,例如通过用宽度为h的固定核进行卷积,正如我们在Section4.1.1中所见,这是密度估计中的帕森窗口方法(Duda,Hart和Stork 2001,第4.3节;Bishop 2006,第2.5.1节)。一旦我们计算出f (x),如Figure7.53e所示,就可以使用梯度上升或其他优化技术找到其局部最大值。
这种方法的问题在于,对于更高维度的情况,评估整个搜索空间上的f (x)在计算上变得不可行。相反,均值漂移采用了一种优化文献中称为多次重启梯度下降的变体。从某个局部最大值的猜测点yk开始,该点可以是随机输入数据点xi,均值漂移计算f (x)在yk处的密度估计梯度,并取一个
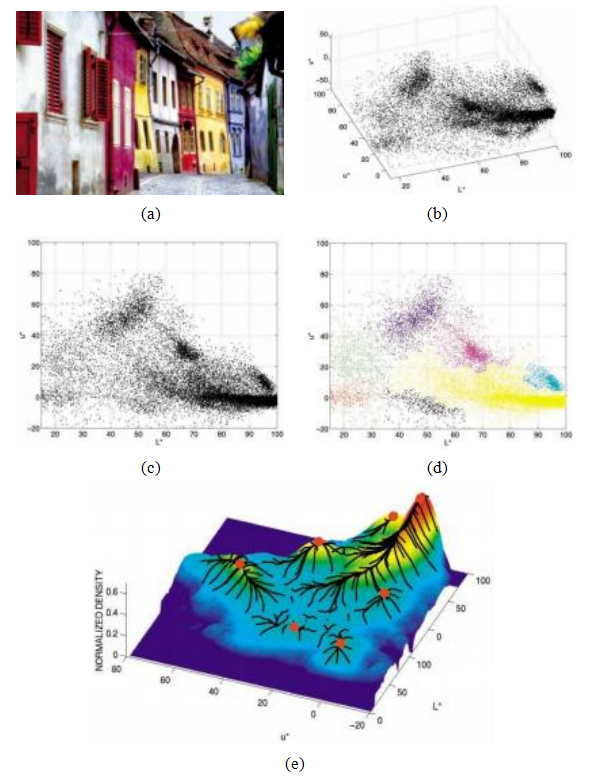
图7.53均值偏移图像分割(Comaniciu和Meer2002)©2002 IEEE:
(a)输入彩色图像;(b)在L*u*v*空间中绘制的像素;(c) L*u*空间分布;(d)经过159次均值漂移处理后的聚类结果;(e)相应轨迹,峰值用红点标记。
朝这个方向迈出一步。有关如何高效地实现这一点的详细信息,可参见关于均值漂移的论文(Comaniciu和Meer2002;Paris和Durand2007)以及本书第一版(Szeliski2010,第5.3.2节)。
图7.53所示的颜色分割仅在确定最佳聚类时考虑像素颜色。因此,可能会将具有相同颜色的小孤立像素聚在一起,这可能不符合图像的语义分割。通常通过在颜色和位置的联合域中进行聚类可以获得更好的结果。在这种方法中,图像的空间坐标xs =(x,y),称为空间域,与颜色值xr,称为范围域,被连接起来,并在五维空间xj中应用均值漂移聚类。由于位置和颜色可能有不同的尺度,核函数分别调整,就像第3.3.2节讨论的双边滤波器核(3.34–3.37)一样。然而,均值漂移与双边滤波的区别在于,在均值漂移中,每个像素的空间坐标与其颜色值一起调整,使得该像素更快地向具有相似颜色的其他像素迁移,从而可以用于后续的聚类和分割。
均值漂移算法已应用于计算机视觉中的多个不同问题,包括人脸跟踪、二维形状提取和纹理分割(Comaniciu和Meer 2002),立体匹配(Wei和Quan 2004),非真实感渲染(第10.5.2节)(DeCarlo和Santella 2002),以及视频编辑(第10.4.5节)(Wang,Bhat等2005)。Paris和Durand(2007)对这些应用进行了很好的综述,同时提供了更高效地求解均值漂移方程和生成层次分割的技术。
7.5.3标准化切割
而自下而上的合并技术将区域聚合为连贯的整体,并进行平均移位
技术试图使用模式查找和归一化切割来寻找相似像素的簇
Shi和Malik(2000)提出的技术检查了邻近像素之间的亲缘关系(相似性),并试图分离由弱亲缘关系连接的组。
考虑图7.54a所示的简单图。A组中的像素都以高亲和力紧密相连,用粗红线表示;B组中的像素也是如此。这两组之间的连接,用细蓝线表示,要弱得多。一个归一化的切割线,用虚线表示,将它们分为两个簇。
两组A和B之间的切割定义为所有权重被切割的总和,其中两个像素(或区域)i和j之间的权重衡量它们的相似度。然而,使用最小切割作为分割标准并不能产生合理的聚类,因为最小切割通常涉及隔离单个像素。
图7.54样本加权图及其归一化切割:(a)小样本图及其最小归一化切割;(b)该图关联和切割的表格形式。关联和切割条目是通过相关权重矩阵W的面积之和计算得出的。通过行或列求和对表格条目进行归一化,得到归一化的关联和切割Nassoc和Ncut。
更好的分割度量是归一化切割,定义为
N切割
(7.41)
其中assoc(A,A)=εi∈A;j∈A wij表示A内的关联(所有权重之和)
聚类和关联(A,V)=关联(A,A)+切割(A,B)是与节点A中的所有权重之和。图7.54b展示了如何将切割和关联视为权重矩阵W = [wij ]中的面积之和,其中矩阵的条目已排列为节点A在前,节点B在后。将这些面积除以相应的行和(图7.54b最右列)得到归一化的切割和关联值。这些归一化值更好地反映了特定分割的适应性,因为它们寻找的是相对于特定区域内部和外部所有边而言较弱的边集合。
不幸的是,计算最优归一化切割是NP完全问题。因此,Shi和Malik(2000)建议使用归一化亲和矩阵的广义特征值分析来计算节点到组的实值分配(Weiss1999),具体细节参见归一化切割论文和(Szeliski2010,第5.4节)。由于这些特征向量可以解释为弹簧-质量系统中的大振动模式,归一化切割是一种用于图像分割的谱方法。在计算出实值特征向量后,与正负特征向量值相对应的变量被关联到两个切割组件。这一过程可以进一步重复,以层次方式细分图像,如图7.55所示。
Shi和Malik(2000)提出的原始算法使用了空间位置和图像

图7.55归一化切割分割(Shi和Malik2000)©2000 IEEE:输入图像和归一化切割算法返回的组件。
特征差异用于计算像素间的相似度。在后续的研究中,Malik、Belongie等人(2001)寻找像素i和j之间的中间轮廓,定义中间轮廓权重,然后将这些权重与基于纹理块的纹理相似度度量相乘。他们随后使用基于局部像素特征的初始过度分割,以区域为基础重新估计中间轮廓和纹理统计。图7.56展示了该改进算法在多个测试图像上的运行结果。
由于需要求解大型稀疏特征值问题,归一化切割可能相当缓慢。Sharon、Galun等人(2006)提出了一种加速归一化切割计算的方法,该方法受到代数多重网格(Brandt1986;Briggs,Henson,and McCormick2000)的启发。
图7.56展示了加权聚合(SWA)产生的分割示例,以及Alpert、Galun等人(2007)提出的最新概率自下而上的合并算法。在更近期的研究中,Pont-Tuset、Arbel ez等人(2017)加速了归一化切割,并将其扩展到多个尺度,从而在伯克利分割
数据集上取得了最先进的结果,同时在VOC和COCO数据集上也实现了对象建议的最先进成果。
7.6 其他阅读材料
关于特征检测、描述和匹配的开创性论文之一是Lowe(2004)。Schmid、Mohr和Bauckhage(2000)、Mikolajczyk和Schmid(2005)、Mikolajczyk、Tuytelaars等人对这些技术进行了全面的调查和评估。
图7.56比较分割结果(Alpert,Galun等人,2007)©2007 IEEE。“我们的方法”指的是Alpert等人开发的概率自下而上的合并算法。
al.(2005)和Tuytelaars和Mikolajczyk(2008),而Shi和Tomasi(1994)和Triggs
(2004)也提供了很好的评论。
在特征检测器领域(Mikolajczyk,Tuytelaars等2005),除了经典的Frstner-Harris(F rstner1986;Harris
和Stephens1988
)和高斯差分(Lindeberg1993,1998b;Lowe2004)方法外,最大稳定极值区域(MSERs)也被广泛用于需要仿射不变性的应用(Matas,Chum等2004;Nist r和Stew nius2008)。最近的兴趣点检测器由Xiao和Shah(2003)、Koethe
(2003)、Carneiro和Jepson(2005)、Kenney,Zuliani和Manjunath(2005)、Bay,Ess等(2008)、Platel,Balmachnova等(2006)以及Rosten,Porter和Drummond(2010)讨论,基于线匹配的技术(Zoghlami,Faugeras和Deriche1997;Bartoli,Coquerelle和Sturm2004)和地区检测(Kadir,Zisserman和Brady2004;Matas,Chum等2004;Tuytelaars和Van Gool2004;Corso和Hager 2005)也是如此。三篇关于基于DNN的特征检测器的优秀综述论文分别由Balntas,Lenc等(2020)、Barroso-Laguna,Riba等(2019)和Tian,Balntas等(2020)撰写。
米科拉伊奇克和施密德(2005)调查并比较了多种局部特征描述符(及匹配启发式方法)。该领域的较新出版物包括范德韦杰尔和施密德(2006)、阿卜杜勒-哈基姆和法拉格(2006)、温德和布朗(2007)以及华、布朗和温德(2007)的著作,还有巴尔恩塔斯、伦茨等人(2020)和金、米什金等人(2021)的最新评估。高效匹配特征的技术包括k-d树(贝斯和洛厄1999;洛厄2004;穆贾和洛厄2009)、金字塔匹配核(格劳曼和达雷尔2005)、度量(词汇)树(尼斯特和斯图尼乌斯2006),
多种多维哈希技术(Shakhnarovich、Viola和Darrell 2003;Torralba、Weiss和Fergus 2008;Weiss、Torralba和Fergus 2008;Kulis和Grauman 2009;Raginsky和Lazebnik 2009),以及产品量化(J gou、Douze和Schmid 2010;Johnson、Douze和J
gou 2021)。关于大规模系统用于
实例检索的综述,可参考Zheng、Yang和Tian(2018)。
关于特征检测和跟踪的经典参考文献是Shi和Tomasi(1994)。该领域的最新研究集中在为特定特征学习更好的匹配函数(Avidan2001;Jurie和Dhome2002;Williams、Blake和Cipolla2003;Lepetit和Fua 2005;Lepetit、Pilet和Fua2006;Hinterstoisser、Benhimane等人2008;Rogez、Rihan等人。
Al.2008;zuysal,Calonder等人2010)。
一个被广泛引用和使用的边缘检测器是由Canny(1986)开发的。关于替代边缘检测器以及实验比较的研究,可以在Nalwa和Binford(1986)、Nalwa(1987)、Deriche(1987)、Freeman和Adelson(1991)、Nalwa(1993)、Heath、Sarkar等人(1998)、Crane(1997)、Ritter和Wilson(2000)、Bowyer、Kranenburg和Dougherty(2001)、Arbel ez、Maire等人(2011)以及Pont
-Tuset、Arbel ez等人(2017
)的出版物中找到。边缘检测中的尺度选择问题由Elder和Zucker(1998)进行了很好的处理,而颜色和纹理边缘检测的方法则可以在Ruzon和Tomasi(2001)、Martin、Fowlkes和Malik(2004)以及Gevers、van de Weijer和Stokman(2006)的著作中找到。边缘检测器还与区域分割技术结合使用,以进一步提高对语义显著边界检测的效果(Maire、Arbel ez等人2008;Arbel ez、Maire等人2011;Xiaofeng和Bo2012;Pont-Tuset、Arbel
ez等人2017)。连接成轮廓的边缘可以平滑和操作以
产生艺术效果(Lowe1989;Finkelstein和Salesin1994;Taubin1995),并用于识别(Belongie、Malik和Puzicha2002;Tek和Kimia2003;Sebastian和Kimia2005)。
活动轮廓的主题有着悠久的历史,始于关于蛇和其他能量最小化变分方法的开创性工作(Kass、Witkin和Terzopoulos 1988;Cootes、Cooper等1995;Blake和Isard 1998),继而发展到智能剪刀技术(Mortensen和Barrett 1995,1999;P rez、Blake和Gangnet 2001),最终演变为水平集方法(Malladi、Sethian和Vemuri 1995;Caselles、Kimmel和Sapiro 1997
;Sethi an 1999;Paragios和Deriche 2000;Sapiro 2001;Osher和Paragios 2003;Paragios、Faugeras等2005;Cremers、Rousson和Deriche 2007;Rousson和Paragios 2008;Paragios和Sgallari 2009),这些方法目前是最广泛使用的活动轮廓方法。
Burns、Hanson和Riseman(1986)撰写了一篇关于图像中直线提取的早期、备受推崇的论文。Grompone von Gioi、Jakubowicz等人(2008)扩展了他们的自下而上的线支持区域概念,构建了流行的LSD线段。
检测器。关于消失点检测的文献非常丰富且仍在不断发展中(Quan和Mohr 1989;Collins和Weiss 1990;Brillaut-O‘Mahoney 1991;McLean和Kotturi 1995;Becker和Bove 1995;Shufelt 1999;Tuytelaars、Van Gool和Proesmans 1997;Schaffalitzky和Zisserman 2000;Antone和Teller 2002;Rother 2002;Ko eck和Zhan
2005;Denis、Elder和Estrada2008;Pflugfelder2008;Tardif2009;Bazin,Seo等2012;Antunes和Barreto 2013;Zhou、Qi等2019a)。同时,线段和节点检测技术也已开发出来(Huang、Wang等2018;Zhang、Li等2019)。
图像分割这一主题与聚类技术密切相关,这在许多专著和综述文章中都有论述(Jain和Dubes 1988;Kaufman和Rousseeuw 1990;Jain、Duin和Mao 2000;Jain、Topchy等2004)。一些早期的分割技术包括Brice和Fennema(1970)、Pavlidis(1977)、Rise-man和Arbib(1977)、Ohlander、Price和Reddy(1978)、Rosenfeld和Davis(1979)以及Haralick和Shapiro(1985)所描述的技术,而较新的技术则由Leclerc(1989)、Mumford和Shah(1989)、Shi和Malik(2000)以及Felzenszwalb和Hutten- locher(2004)开发。
Arbel ez、Maire等人
2011)和Pont-Tuset、Arbel ez等
人(2017)对自动分割技术进行了很好的综述,并在Berkeley分割数据集和基准测试(Martin、Fowlkes等人,2001)上比较了它们的性能。17其他比较论文和数据库包括Unnikrishnan、Pantofaru和Hebert(2007)、Alpert、Galun等人(2007)以及Estrada和Jepson(2009)。
基于局部像素相似性的图像分割技术结合聚合或分裂方法包括分水岭(Vincent和Soille1991;Beare2006;Arbel ez,Maire等人2011),区域分裂(Ohlander,Price,and Reddy1978
),区域合并(Brice和Fennema1970;Pavlidis和Liow1990;Jain,Topchy等人2004),以及基于图和概率的多尺度方法(Felzenszwalb和Huttenlocher2004;Alpert,Galun等人2007)。
均值移位算法,用于在像素的密度函数表示中找到模式(峰值),由Comaniciu和Meer(2002)以及Paris和Durand(2007)提出。高斯混合参数化也可用于表示和分割此类像素密度(Bishop2006;Ma,Derksen等2007)。
关于图像分割的谱(特征值)方法的开创性工作是石和马利克(2000)提出的归一化切割算法。相关研究还包括韦斯(1999)、梅尔和石(2000)、梅尔和石(2001)、马利克、贝隆
吉等人(2001)、吴、乔丹和韦斯(2001)、余和石(2003)、库尔、布尼茨和石(2005)、沙伦、加伦等人(2006)、托利弗和米勒(2006)以及王和奥利恩斯(2010)。
Chapter 8 Image alignment and stitching
8.1双向比对 503
8.1.1使用最小二乘法进行2D对齐 504
8.1.2应用:全景 506
8.1.3迭代算法 507
8.1.4稳健的最小二乘法和RANSAC 510
8.1.5 3D对齐 513
8.2图像拼接 514
8.2.1参数化运动模型 516
8.2.2应用:白板和文档扫描 517
8.2.3旋转全景图 519
8.2.4缺口闭合 520
8.2.5应用:视频摘要和压缩 522
8.2.6圆柱坐标和球坐标 523
8.3全球协调 526
8.3.1捆绑调整 527
8.3.2消除视差 531
8.3.3识别全景图 533
8.4合成 536
8.4.1选择合成表面 536
8.4.2像素选择和加权(去鬼影) 538
8.4.3应用:照片拼贴 544
8.4.4混合 544
8.5其他阅读材料 547
8.6练习 549

图8.1图像拼接:(a)二维图像的几何对齐以实现拼接(Szeliski和Shum 1997)©1997 ACM;(b)由54张照片构建的球面全景图(Szeliski和Shum 1997)©1997 ACM;(c)从无序的照片集合中自动组装的多图像全景图;多图像拼接(d)无移动物体去除和(e)有移动物体去除(Uyttendaele、Eden和Szeliski 2001)©2001 IEEE。

一旦我们从图像中提取了特征,许多视觉算法的下一个阶段就是将这些特征在不同图像之间进行匹配(第7.1.3节)。这一匹配过程中的一个重要环节是验证匹配特征集是否几何一致,例如,特征位移是否可以用简单的二维或三维几何变换来描述。计算出的运动随后可以用于其他应用,如图像拼接(第8.2节)或增强现实(第11.2.2节)。
在本章中,我们探讨了几何图像配准这一主题,即计算将一幅图像中的特征映射到另一幅图像的二维和三维变换(第8.1节)。在第11章中,我们将研究姿态估计的相关问题,即将相机相对于已知的三维物体或场景的位置确定下来,以及运动结构,即如何同时估计三维几何和相机运动。
8.1 两两比对
基于特征的对齐问题是估计两组或多组匹配的二维或三维点之间的运动。在本节中,我们仅限于全局参数变换,如第2.1.1节所述,并在表2.1和图8.2中展示,或用于曲面的高阶变换(Shashua和Toelg1997;Can、Stewart等人2002)。非刚性或弹性变形的应用(Bookstein1989;Kambhamettu、Goldgof等人1994;Szeliski和Lavall e1996;Torresani、Hertzmann和Bregler2008)将在第9.2.2节和第13.6.4节中讨论。
|
表8.1表2.1中所示的二维坐标变换x,= f(x;p)的雅可比矩阵,其中我们重新参数化了运动,使得当p = 0时,它们是恒等的。 8.1.1使用最小二乘法进行2D对齐 给定一组匹配的特征点{(xi,xi,)}和一个平面参数变换1的形式 x, = f(x; p), (8.1) 如何才能得到运动参数p的最佳估计值呢?通常的做法是使用最小二乘法,即最小化残差平方和 在哪里 ri = xi,- f(xi;p)= i, -i, (8.3) 是测量位置i与其对应的当前预测值之间的残差 |

1关于非平面参数模型的示例,如二次方程,请参见Shashua和Toelg(1997)和Shashua和Wexler(2001)的工作。
第2.1.1节和表2.1中介绍的许多运动模型,即平移、相似性和仿射,都具有运动量△x=x,-x与未知参数p之间的线性关系,
△x = x, - x = J(x)p, (8.4)
其中J=∂f/∂p是变换f关于运动参数p的雅可比矩阵(见表8.1)。在这种情况下,可以将简单的线性回归(线性最小二乘问题)表述为
-△xi
Ⅱ2 (8.5)
= pTAp - 2pT b + c. (8.7)
最小值可通过求解对称正定(SPD)的正规方程组来找到2
Ap = b, (8.8)
(8.9)
称为Hessian和b = Σi JT(xi)△xi。对于纯平移的情况,得到的方程具有特别简单的形式,即,平移是对应点之间的平均平移,或者等价地,点质心的平移。
不确定性权重。上述最小二乘公式假设所有特征点都以相同的精度匹配。这通常不是情况,因为某些点可能落在
比其他区域更具有纹理。如果我们把标量方差估计σ与之联系起来
EWLS =
2 Ⅱri Ⅱ2 . (8.10)
2对于条件较差的问题,最好使用线性方程组J(xi)p =△xi的QR分解,而不是正规方程(Bj rck1996;Golub和Van Loan1996)。然而,在图像配准中很
3每个测量值的方差或不确定度可能不同的问题称为异方差模型。

图8.3由三个图像组成的简单全景图,这些图像自动与平移模型对齐,然后平均在一起。
如第9.1.3节所示,可以通过将补丁Hessian Ai(9.48)的逆与每个像素的噪声协方差相乘来获得基于补丁匹配的协方差估计值
σ(9.37)。用其逆协方差Σi-1 = σn-2Ai来加权每个平方残差(
称为信息矩阵),我们得到
图像对齐最简单(也是最有趣)的应用之一是称为全景图的特殊形式的图像拼接。在全景图中,图像被平移,有时还会旋转和缩放,然后通过简单的平均法融合(图8.3)。这一过程模仿了艺术家大卫·霍克尼创作的照片拼贴画,尽管他的作品使用的是不透明叠加模型,由普通照片组成。
在大多数网络上看到的例子中,图像都是手工对齐以达到最佳的艺术效果。4但是,也可以使用特征匹配和对齐技术自动执行配准(Nomura,Zhang和Nayar2007;Zelnik-Manor和Perona2007)。
考虑一个简单的平移模型。我们希望不同图像中的所有对应特征尽可能对齐。设tj为第j个图像坐标系在全球复合坐标系中的位置,xij为第i个匹配特征在第j个图像中的位置。
EPLS =
Ⅱ -
xi Ⅱ2, (8.12)
其中,xi是特征i在全局坐标系中的共识(平均)位置。(另一种方法是分别对每一对重叠图像进行配准,然后计算每个帧的共识位置——见练习8.2。)
上述最小二乘问题无法确定(可以向所有帧和点位置tj和xi添加一个常数偏移)。为了解决这个问题,要么选择一个帧作为原点,要么添加一个约束条件使平均帧偏移为0。
添加旋转和缩放变换的公式很简单,可以作为练习(练习8.2)来完成。看看你是否能创建一些拼贴画,并且愿意与他人在网上分享。
虽然线性最小二乘法是估计参数的最简单方法,但是计算机视觉中的大多数问题在测量值和未知数之间没有简单的线性关系。在这种情况下,得到的问题被称为非线性最小二乘法或非线性回归。
例如,考虑估计两组点之间刚性的欧几里得二维变换(平移加旋转)的问题。如果我们用平移量(tx,ty)和旋转角θ来参数化这一变换,如表2.1所示,那么该变换的雅可比矩阵,见表8.1,将依赖于当前的θ值。请注意,在表8.1中,我们重新参数化了运动矩阵,使其在原点p = 0时始终为单位矩阵,这使得初始化运动参数变得更加容易。
为了最小化非线性最小二乘问题,我们通过最小化来迭代地找到当前参数估计p的更新△p
Ⅱ2
(8.13) ⅡJ△p - ri Ⅱ2 (8.14)
= △pTA△p - 2△pT b + c, (8.16)
508 计算机视觉:算法和应用,第2版(最终草稿,2021年9月),其中“Hessian”5 A与公式(8.9)相同,右侧向量
(8.17)
现在是残差向量的雅可比加权和。这在直觉上是有意义的,因为参数被拉向预测误差的方向,其强度与雅可比成正比。
计算出A和b后,我们用以下公式求解△p:
(A + λdiag(A))△p = b, (8.18)
并相应地更新参数向量p←p+△p。参数λ是一个额外的阻尼参数,用于确保系统在能量(平方误差)上采取“下降”步骤,是莱文贝格-马夸特算法(详见附录A.3)的重要组成部分。在许多应用中,如果系统成功收敛,可以将其设置为0。
对于我们的二维平移+旋转问题,最终得到一组未知数(δtx,δty,δθ)的3×3标准方程组。可以通过拟合一个四参数相似变换(tx,ty,c,s),然后设置θ = tan-1(s/c),来获得(tx,ty,θ)的初始估计值。另一种方法是使用二维点的质心来估计平移参数,再利用极坐标估计旋转角度(练习8.3)。
对于其他二维运动模型,表8.1中的导数都相当直接,除了投影二维运动(单应性),它出现在图像拼接应用中(第8.2节)。这些方程可以从(2.21)重新写成新的参数形式:
以
及y、=
(8.19)
因此雅可比矩阵为
可以通过乘法得到八个未知数{h00,h01,...,h21 }的初始估计值
通过分母将(8.19)中的等式两边相乘,得到线性
5“Hessian”A不是非线性最小二乘问题(8.13)的真正Hessian(二阶导数)。相反,它是近似Hessian,它忽略了off(xi;p+△p)的二阶(和更高阶)导数。
然而,从统计学的角度来看,这并不是最佳的,因为用于乘以每个方程的分母D在各点之间可能相差很大。
一种补偿方法是根据当前估计的分母D的倒数重新加权每个方程,
虽然这看起来与(8.21)是一样的方程组,因为最小二乘法被用来求解一组超定方程,但权重确实很重要,并产生了一组不同的正规方程,在实践中表现更好。
然而,进行估计的最合理的方法是直接使用高斯-牛顿近似法最小化平方残差方程(8.13),即执行p的一阶泰勒级数展开,如(8.14)所示,从而得到一组方程
虽然这些看起来与(8.22)相似,但它们在两个重要方面有所不同。首先,左侧由未加权的预测误差组成,而不是点位移,且解向量是参数向量p的扰动。其次,J内的量涉及
预测特征位置,而不是感知特征
位置(,,,)。这两种方法都
差异虽细微,却导向了一种算法,当与适当的下坡步检查(如莱文贝格-马夸特算法)结合时,该算法能够收敛到局部最小值。请注意,迭代方程(8.22)并不能保证收敛,因为它并不是最小化一个明确定义的能量函数。
6哈特利和齐瑟曼(2004)将这种从有理方程形成线性方程的策略称为直接线性变换,但这一术语通常与姿态估计相关(第11.2节)。还需注意的是,我们对h参数的定义与他们书中使用的不同,因为我们定义h ii为单位差,且不将h22设为自由参数,这意味着我们无法处理某些极端的单应性。
方程(8.23)类似于直接基于强度的配准的加法算法(第9.2节),因为全变换的变化正在被计算。如果我们先在当前的单应矩阵前加上一个增量单应矩阵,即使用组合算法(第9.2节中描述),则得到D=1(因为p = 0),上述公式简化为,,y,),为了简洁起见,用(x,y)表示。
虽然对于噪声遵循正态(高斯)分布的测量,常规最小二乘法是首选方法,但在对应点中存在异常值时(这种情况几乎总是存在),需要使用更稳健的最小二乘法版本。在这种情况下,最好使用M估计器(Huber1981;Hampel、Ronchetti等1986;Black和Rangarajan 1996;Stewart 1999),该方法涉及对残差应用一个稳健的惩罚函数P(r)。
埃尔尔斯
(8.25)
而不是平方它们。7
(8.26)
其中ψ(r) = P,(r)是P的导数,称为影响函数。如果我们引入权重函数w(r) = ψ(r)/r,我们观察到使用(8.26)求解(8.25)的驻点等价于最小化迭代重加权最小二乘法(IRLS)问题。
EIRLS =
Ⅱri Ⅱ2 , (8.27)
其中w(Ⅱri Ⅱ)在(8.10)中扮演与σi-2相同的局部加权角色。IRLS算法在计算影响函数w(Ⅱri Ⅱ)和求解由此产生的加权最小二乘问题(固定w值)之间交替进行。其他增量鲁棒最小二乘法
7一些常用稳健惩罚函数ρ的图见图4.7。
算法可以在Sawhney和Ayer(1996)、Black和Anandan(1996)、Black和Rangarajan(1996)以及Baker、Gross等人(2003)的工作中找到,也可以在关于稳健统计的教科书和教程中找到(Huber1981;Hampel、Ronchetti等人1986;Rousseeuw和Leroy1987;Stewart1999)。
虽然M估计器确实有助于减少异常值的影响,但在某些情况下,从过多的异常值开始会阻止IRLS(或其他梯度下降算法)收敛到全局最优。更好的方法通常是找到一组初始内点对应关系,即与主导运动估计一致的点。8
两种广泛使用的方法分别称为随机样本一致性(简称RANSAC,Fischler和Bolles 1981年提出)和最小中位数平方(LMS)(Rousseeuw 1984年提出)。这两种技术首先随机选择k个对应关系的子集,然后用这些子集来计算p的初始估计值。接着,计算所有对应关系的残差。
ri = i,
(xi;p)- i,; (8.28)
地点。9
RANSAC技术随后计算出预测位置∈范围内的内点数量,即Ⅱri Ⅱ≤∈的点数。(∈值取决于具体应用,通常在1到3像素之间。)最小二乘法找到Ⅱri Ⅱ2值的中位数。随机选择过程重复S次,样本集中数量最多的
将内点(或具有最小中值残差)作为最终解保留下来。然后,将初始参数猜测p或计算出的全部内点传递给下一个数据拟合阶段。
当测量数量相当大时,可能更倾向于在初始轮次中仅对部分测量进行评分,以选择最合理的假设进行进一步的评分和选择。这种对RANSAC的修改可以显著提高其性能,称为预取RANSAC(Nist r2003)。另一种RANSAC变体称为PROSAC(PROgressive SAmple Consensus),通过从最“自信”的匹配中随机添加样本
,从而加快找到一组(统计上)可能良好的内点集的过程(Chum和Matas2005)。Raguram、Chum等人(2012)提供了一个统一的框架,从中可以推导出大多数这些技术,并进行了很好的实验比较。
RANSAC的其他变体包括MLESAC(Torr和Zisserman2000)、DSAC
8对于基于像素的对齐方法(第9.1.1节),通常使用分层(粗到细)技术锁定场景中的主要运动。
9对于诸如极点几何估计之类的问题,残差可能是点与直线之间的距离。
| k | p | S |
| 3 | 0.5 | 35 |
| 6 | 0.6 | 97 |
| 6 | 0.5 | 293 |
表8.2试验次数S,以达到99%的成功概率(Stewart1999)。
(布拉赫曼、克鲁尔等人,2017),图割RANSAC(巴拉特和马塔斯,2018),MAGSAC(巴拉特、马塔斯和诺斯科娃,2019),以及ESAC(布拉赫曼和罗瑟,2019)。其中一些算法,如DSAC(可微RANSAC),设计为可微,以便用于特征检测和匹配管道的端到端训练(第7.1节)。巴拉特、诺斯科娃等人(2020)的MAGSAC++论文比较了这些变体中的许多。杨、安托南特等人(2020)声称,使用具有递减异常参数的鲁棒惩罚函数,即渐进非凸性(布雷克和齐瑟曼,1987;巴拉特,2019),可以在许多几何对应和姿态估计问题中超越RANSAC。为了确保随机采样有很好的机会找到一组真实的内点,必须评估足够多的试验次数S。设p为任意给定对应有效概率,P为S次试验后的成功概率。一次试验中所有k个随机样本均为内点的概率为pk。因此,S次试验全部失败的概率为
1 - P = (1 - pk )S (8.29)和所需的最小试验次数为
(8.30)
斯图尔特(1999)给出了达到99%成功概率所需的试验次数S的例子。如表8.2所示,随着所用样本点数量的增加,试验次数迅速增长。这强烈建议在任何给定试验中使用尽可能少的样本点k,这也是RANSAC在实际应用中的常规做法。
不确定性建模
除了稳健地计算出一个好的对齐外,一些应用还需要计算不确定性(见附录B.6)。对于线性问题,可以通过求解Hessian矩阵(8.9)并乘以特征位置噪声来获得这一估计值,如果这些
尚未用于对单个测量值进行加权,如公式(8.10)和(8.11)所示。在统计学中,Hessian是逆协方差,有时也称为(Fisher)信息矩阵(附录B.1)。
当问题涉及非线性最小二乘法时,海森矩阵的逆提供了协方差矩阵的克拉美-罗下界,即它提供了给定解中协方差的最小量。如果能量在远离局部最小值的地方趋于平坦,最优解所在的区域可能会出现更宽的分布(“更长的尾部”)。
许多计算机视觉应用需要对齐3D点,而不是对齐2D图像特征集。如果3D变换在运动参数中是线性的,例如,对于平移、相似性和仿射,可以使用常规最小二乘法(8.5)。
ER3D =
Ⅱx
- Rxi - tⅡ2 ; (8.31)
这更常见,并常被称为绝对定向问题(Horn 1987),需要稍有不同的技术。如果仅使用标量加权(而不是完整的三维每点各向异性协方差估计),则可以利用两个点云的加权质心来估计平移t=c,-Rc。然后我们面临的问题是估计两组点之间的旋转{i = xi - c}和
{i,=xi,-c}都是以原点为中心的。
一种常用的技术称为正交Procrustes算法(Golub和Van Loan,1996年,第601页),涉及计算3×3相关矩阵的奇异值分解(SVD)
T = UΣVT
. (8.32)
然后,旋转矩阵就得到R = UVT。(当=R时,你自己验证一下。)
另一种技术是用于估计对应于旋转矩阵R的单位四元数的绝对定向算法(Horn1987),该算法包括从C中的条目形成4×4矩阵,然后找到与最大正特征值相关的特征向量。
10当使用完全协方差时,它们会通过旋转进行转换,因此无法得到平移的闭式解。
Lorusso、Eggert和Fisher(1995)将这两种技术与文献中提出的另外两种技术进行了实验比较,但发现准确度差异微乎其微(远低于测量噪声的影响)。
在这些闭式算法不适用的情况下,例如使用完整的三维协方差或三维对齐是更大优化的一部分时,可以采用第2.1.3节(2.35–2.36)中介绍的增量旋转更新方法,该方法由瞬时旋转矢量参数化(有关图像拼接的应用,请参见第8.2.3节)。
在某些情况下,例如合并范围数据地图时,数据点之间的对应关系事先并不已知。在这种情况下,可以使用迭代算法,这些算法首先匹配附近的点,然后更新最可能的对应关系(Besl和McKay 1992;Zhang 1994;Szeliski和Lavall e 1996;Gold、Rangarajan等1998;Davi
、DeMenthon等2004;Li和Hartley 2007;Enqvist、Josephson和Kahl 2009)。这些技术在第13.2.1节中有更详细的讨论。
8.2 图像拼接
用于对齐图像并将其无缝拼接成照片马赛克的算法是计算机视觉中最古老且最广泛使用的技术之一(Milgram 1975;Peleg 1981)。图像拼接算法生成高分辨率的照片马赛克,用于制作当今的数字地图和卫星照片。这些算法现在也是智能手机摄像头的标准模式,可用于创建美丽的超广角全景图。
图像拼接起源于摄影测量学界,长期以来,该领域一直使用基于地面控制点或手动注册的连接点的手动密集方法来将航拍照片拼接成大规模的照片马赛克(Slama1980)。该领域的一个关键进展是束调整算法的发展(第11.4.2节),该算法可以同时求解所有相机位置,从而获得全局一致的解决方案(Triggs,McLauchlan等1999)。在创建照片马赛克时,另一个反复出现的问题是消除可见接缝,为此多年来开发了多种技术(Milgram1975,1977;Peleg 1981;Davis1998;Agarwala,Dontcheva等2004)。
在电影摄影中,20世纪90年代开发了特殊的相机来拍摄超广角全景图,通常通过在相机绕轴旋转时通过垂直狭缝曝光胶片(Meehan 1990)。90年代中期,图像对齐技术开始应用于从普通手持相机构建无缝宽角全景图(Mann和Picard 1994;Chen 1995;Szeliski 1996)。随后的算法解决了需要
计算全局一致的对齐(Szeliski和Shum1997;Sawhney和Kumar1999;Shum和Szeliski2000),以消除由于视差和物体运动引起的“幽灵”(Davis 1998;Shum和Szeliski2000;Uyttendaele、Eden和Szeliski2001;Agarwala、Dontcheva等人2004),并处理不同的曝光(Mann和Picard1994;Uyttendaele、Eden和Szeliski2001;Levin、Zomet等人2004;Eden、Uyttendaele和Szeliski2006;Kopf、Uyttendaele等人2007)。11
早期的技术通过直接最小化像素间的差异来工作,而如今的算法则提取一组稀疏特征并相互匹配,如第7章所述。基于特征的方法(Zoghlami、Faugeras和Deriche 1997;Capel和Zisserman 1998;Cham和Cipolla 1998;Badr、Qumsieh和Dudek 1998;McLauchlan和Jaenicke 2002;Brown和Lowe 2007)具有更强的鲁棒性,能够更好地应对场景移动,并且通常更快。然而,它们最大的优势在于能够“识别全景图”,即自动发现一组无序图像之间的相邻(重叠)关系,这使得它们非常适合用于由普通用户拍摄的全景图的全自动拼接(Brown和Lowe 2007)。
那么,图像拼接中的核心问题是什么?与图像对齐一样,我们必须首先确定一个合适的数学模型,将一张图像中的像素坐标与另一张图像中的像素坐标联系起来;第8.2.1reviews节介绍了我们研究的基本模型,并提出了一些新的运动模型,专门针对全景图像拼接。接下来,我们必须设法估计各种图像对(或集合)之间的正确对齐关系。第七章讨论了如何在每张图像中找到独特的特征,然后高效地匹配这些特征,以快速建立图像对之间的对应关系。第九章讨论了如何结合直接的像素对像素比较以及梯度下降(和其他优化技术)来估计这些参数。当全景图中存在多张图像时,可以使用全局优化技术计算一组全局一致的对齐关系,并高效地发现哪些图像相互重叠。在第8.3节中,我们将探讨如何修改这些先前开发的技术,以利用通常用于创建全景图的成像设置。
在对图像进行对齐之后,我们必须选择一个最终合成表面,用于对对齐后的图像进行变形(第8.4.1节)。我们还需要算法来无缝剪切和混合重叠的图像,即使存在视差、镜头畸变、场景运动和曝光
11Benosman和Kang(2001)汇编了其中一些论文,Szeliski(2006a)对这些论文进行了综述。
12有关直接技术与基于功能的技术的优缺点,请参见Triggs、Zisserman和Szeliski的讨论。
(2000)和本书第一版(Szeliski2010,第8.3.4节)。

8.2.1参数化运动模型
在我们能够注册和对齐图像之前,需要建立将像素坐标从一张图像映射到另一张图像的数学关系。可以采用多种参数化运动模型,包括简单的二维变换、平面透视模型、三维相机旋转、镜头畸变以及映射到非平面(例如圆柱面)表面。
我们已经在第2.1节和第8.1节中讨论了这些模型中的几个。特别是,在第2.1.4节中,我们看到如何用八个参数的单应性(2.71)来描述从不同位置观察到的平面表面变形的参数运动(Mann和Picard 1994;Szeliski 1996)。我们还看到了纯旋转的相机如何诱导出另一种类型的单应性(2.72)。
在本节中,我们将回顾这两种模型,并展示它们如何应用于不同的拼接情况。我们还将介绍球面和圆柱复合表面,并说明在有利条件下,如何使用纯平移进行对齐(第8.2.6节)。选择最适合特定情况或数据集的对齐模型是一个模型选择问题(Torr2002;Bishop2006;Robert 2007;Hastie、Tibshirani和Friedman2009;Murphy2012),这是我们书中未涉及的重要话题。
平面透视运动
最简单的图像对齐运动模型是简单地在二维空间中平移和旋转图像(图8.4a)。这与你处理重叠照片时所使用的运动方式完全相同。这也是大卫·霍克尼用来创作他称之为拼贴画的作品的技术(泽尔尼克-马诺和佩罗纳2007;野村、张和奈亚尔2007)。这种拼贴画通过展示可见的接缝和不一致之处来增强艺术效果,在像Flickr这样的网站上非常流行,这些作品
更常见的是使用“全景”(Section8.1.2)这一名称。在诸如照片和视频稳定以及合并等应用中,平移和旋转通常也是足够的运动模型,可以补偿小的摄像机运动(练习8.1和第9.2.1节)。
在第2.1.4节中,我们看到了如何使用一个3×3的单应矩阵(2.71)来描述两个相机观察同一平面之间的映射。考虑矩阵M10,它是在将一个图像中的像素映射到三维点,然后再映射回第二个图像时产生的,
1 ~
1 0-10
(8.33)
当P0矩阵的最后一行被平面方程0·p + c0和点所取代时
假设这些点位于该平面上,即它们的视差d0 = 0,我们可以忽略M10的最后一列及其最后一行,因为我们不关心最终的缓冲深度。由此得到的单应矩阵H10(M10的左上3×3子矩阵)描述了两幅图像中像素之间的映射关系, ~
1 ~
H100 .
最近的拼接算法首先提取特征,然后进行匹配,通常使用稳健的技术如RANSAC(第8.1.4节)来计算一组良好的内点。最终计算单应性(8.34),即给定对应特征对时最小二乘拟合问题的解,
(8.36)
采用迭代最小二乘法,如第8.1.3节和公式(8.21–8.23)所述。
最简单的图像拼接应用是将平板扫描仪拍摄的多张图像拼接在一起。假设你有一张大地图,或者一件儿童的艺术作品,太大而无法放入你的扫描仪中。只需多次扫描该文档,确保每次扫描之间有足够的重叠部分,以确保有足够多的共同特征。接下来,选取已知重叠的一对图像,提取特征,进行匹配,然后

图8.5纯3D摄像机旋转。单应(映射)的形式特别简单,仅取决于3D旋转矩阵和焦距。
xk+1 = Rk xk + tk ; (8.37)
最匹配特征的方法是使用两点RANSAC,必要时找到一组好的内点。然后,在最终合成表面(例如与第一次扫描对齐)上重新采样图像(第3.6.1节),并将它们平均在一起。你是否看到了这个方案的潜在问题?
一个复杂之处在于,二维刚性变换在旋转角度θ上是非线性的,因此您必须使用非线性最小二乘法或约束R为正交正规矩阵,如第8.1.3节所述。
更大的问题在于成对对齐过程。随着你对越来越多的对进行对齐,解决方案可能会偏离,不再全局一致。在这种情况下,可能需要采用第8.3节中描述的全局优化方法。这种全局优化通常需要求解一个庞大的非线性方程组,尽管在某些情况下,如线性化单应矩阵(第8.2.3节)或相似变换(第8.1.2节),可以使用正规最小二乘法作为选项。
稍微复杂一些的情况是,当你拍摄多张重叠的手持照片时,这些照片可以是白板或其他大型平面物体(He和Zhang 2005;Zhang和He 2007)。在这种情况下,可以使用单应性模型来表示自然运动,尽管也可以采用更复杂的模型来估计相对于平面的三维刚性运动(如果焦距未知,则还需考虑焦距)。
全景图像拼接最典型的情况是相机经历纯旋转。想象一下站在大峡谷边缘。相对于场景中的远处几何结构,当你快门启动时,相机正在经历纯旋转,这相当于假设所有点都远离相机,即位于无穷远平面上(图8.5)。13将t0设为= t1 = 0,我们得到简化的3×3单应矩阵
10 = K1 R1 R0-1K0-1 = K1 R10 K0-1 , (8.38)
其中,Kk = diag(fk,fk,1)是简化的相机内矩阵(2.59),假设cx = cy = 0,即从图像中心开始索引像素(Szeliski1996)。这也可以重写为
(8.39)
或
(8.40)
这揭示了映射方程的简洁性,并使所有运动参数变得明确。因此,我们不再使用一对图像的一般八参数单应性,而是得到了与焦距f已知、固定或变化情况相对应的三参数、四参数或五参数三维旋转运动模型(Szeliski和Shum 1997)。估计每个图像相关的三维旋转矩阵(以及可选地,焦距)本质上比估计具有完整八个自由度的单应性更稳定,这使得这种方法成为大规模图像拼接算法的首选方法(Szeliski和Shum 1997;Shum和Szeliski 2000;Brown和Lowe 2007)。
根据这个表示,我们如何更新旋转矩阵以使两个重叠的图像对齐?给定当前估计的同态H10(8.38),最好的方法是
13在更一般的场景(例如室内),如果我们希望确保没有视差(不同深度物体之间的可见相对移动),我们需要围绕镜头的前无视差点旋转相机(Littlefield2006)。这可以通过使用带有内置平移台的专业全景旋转头来实现(Houghton2013),或者通过观察共线点来确定前节点——参见Debevec、Wenger等人(2002)和Szeliski(2010,图6.7)。
14可以使用第11.1.3节中所述的内在校准技术或从EXIF标签获得焦距的初步估计值。
更新R10是将增量旋转矩阵R(!)前置到当前估计值R10(Szeliski和Shum1997;Shum和Szeliski2000),
(!) = K1 R(!)R10 K0-1 = [K1 R(!)K1][K1 R10 K0-1] = D10 . (8.41)
注意,这里我们以组合形式写出了更新规则,其中增量更新D被加到了当前的单应矩阵H10前面。利用(2.35)给出的R(!)的小角度近似,我们可以将增量更新矩阵写成
注意,现在D矩阵中的条目与表8.1和公式(8.19)中使用的h00、...、h21参数之间存在一个很好的对应关系,即:
(h00 , h01 , h02 , h00 , h11 , h12 , h20 , h21 ) = (0, -ωz , f1ωy , ωz, 0, -f1ωx, -ωy /f1 , ωx /f1 ). (8.43)
因此,我们可以将链式法则应用于方程(8.24和8.43)以得到
这为我们提供了线性化的更新方程,用于估计=(ωx,ωy,ωz)。请注意,这个更新规则依赖于目标视图的焦距f1,而与模板视图的焦距f0无关。这是因为组合算法本质上是对目标进行了微小的扰动。一旦增量旋转向量!计算完成,R1旋转矩阵就可以通过R1←R(!)R1进行更新。
更新焦距估计的公式稍微复杂一些,具体见舒姆和泽利斯基(2000)。这里不再重复,因为另一种基于最小化反投影三维光线差异的更新规则已在第8.3.1节给出。图8.1a展示了四张图像在三维旋转运动模型下的对齐情况。
本节介绍的技术可以用来估计一系列旋转矩阵和焦距,这些矩阵可以串联起来创建大型全景图。不幸的是,
15这与瞬时刚性流的旋转分量(Bergen,Anandan等人,1992)以及Szeliski和Shum(1997)和Shum和Szeliski(2000)给出的更新方程相同。

图8.6缺口闭合(Szeliski和Shum1997)©1997 ACM:(a)当焦距不正确时(f = 510),可见缺口。(b)对于正确的焦距(f = 468),看不到缺口。
由于累积的误差,这种方法很少能产生封闭的360°全景图。相反,总是会出现间隙或重叠(图8.6)。
我们可以通过将序列中的第一张图像与最后一张图像匹配来解决这个问题。两个旋转矩阵估计值之间的差异表明了错位的程度。通过取这两个旋转对应的四元数的商,并将这个“误差四元数”除以序列中的图像数量(Szeliski和Shum 1997),可以将这一误差均匀分布在整条序列中。我们还可以根据错位的程度更新估计的焦距。为此,我们首先将误差四元数转换为间隙角θg,然后使用公式fI = f(1 - θg /360o)更新焦距。
图8.6a显示了注册图像序列的末尾和第一张图像。最后一张图像与第一张图像之间存在较大差距,实际上它们是同一张图像。这一差距为32°,因为使用了错误的焦距估计(f = 510)。图8.6b展示了通过使用正确的焦距(f = 468)填补这一差距后的注册结果。请注意,两个马赛克图像的视觉错位非常小(除了在缺口处),但图8.6a是使用了有9%误差的焦距计算得出的。哈特利(1994b)、麦克米伦和毕晓普(1995)、斯坦(1995)以及康和韦斯(1997)开发了相关方法,利用纯平移运动和圆柱图像来解决焦距估计问题。
遗憾的是,这种填补空白的启发式方法只适用于“一维”全景图,即相机在相同方向上连续转动。在第8.3节中,我们将介绍一种不同的填补空白和重叠的方法,该方法适用于任意相机运动。

图8.7将背景场景进行视频拼接,创建一个可以传输并用于在每一帧中重新创建背景的单个精灵图像(Lee,Chen等人,1997)©1997 IEEE。
图像拼接的一个有趣应用是能够总结和压缩用平移摄像机拍摄的视频。这一应用最早由特奥多西奥和本德(1993)提出,他们称这种基于马赛克的摘要为显著静帧。随后,伊兰尼、许和阿南丹(1995)以及伊兰尼和阿南丹(1998)将这些想法扩展到其他应用领域,如视频压缩和视频索引。尽管这些早期方法使用了仿射运动模型,因此仅限于长焦距,但李、陈等人(1997)将这些技术推广到完整的八参数单应式,并将其纳入MPEG-4视频压缩标准中,在该标准中,拼接的背景层被称为视频精灵(图8.7)。
虽然视频拼接在许多方面是多图像拼接(Steedly,Pal和Szeliski 2005;Baudisch,Tan等2006)的直接推广,但大量独立运动、相机变焦以及希望可视化动态事件的潜在存在带来了额外的挑战。例如,移动的前景物体通常可以通过中值滤波去除。或者,可以将前景物体提取到一个单独的图层(Sawhney和Ayer 1996),然后重新合成回拼接全景图中,有时作为多个实例以营造“时间照片”的效果(Massey和Bender 1996),有时则作为视频叠加(Irani和Anandan 1998)。视频还可以用于创建动画全景视频纹理(Section14.5.2),其中全景场景的不同部分通过独立移动的视频循环进行动画处理(Agar-
例如,wala、Zheng等人(2005年)、Rav-Acha、Pritch等人(2005年)、Joshi、Mehta等人(2012年)、Yan、Liu和Furukawa(2017年)、He、Liao等人(2017年)、Oh、Joo等人(2017年)),或对场景的复合马赛克照射“视频手电筒”(Sawhney、Arpa等人,2002年)。
视频也可以为创建从移动摄像机拍摄的全景图提供有趣的内容来源。尽管这否定了通常假设的单一点观(视中心),但仍可获得有趣的结果。例如,Sawhney、Kumar等人(1998)的VideoBrush系统使用从图像中心提取的细条带,以创建水平移动摄像机拍摄的全景图。这一想法可以推广到其他摄像机运动和合成表面,利用自适应流形上的马赛克概念(Peleg、Rousso等人,2000),并用于生成全景立体图(Ishiguro、Yamamoto和Tsuji,1992;Peleg、Ben-Ezra和Pritch2001).16)。类似的想法已被用于为多平面赛璐珞动画创建全景背景画(Wood、Finkelstein等人,1997),创建具有视差的场景拼接图像(Kumar、Anandan等人,1995),以及使用多投影中心图像(Rademacher和Bishop,1998)和多视角全景图(Rom n、Garg和Levoy,2004;Rom n和Lensch,2006;Agarwala、Agrawala等人,2006;Kopf、Chen等人,2010)作为更复杂场景的3D表示。
另一种基于视频的全景图变体是同心马赛克(第14.3.3节)(Shum和He 1999)。这里,不是试图生成单一的全景图像,而是保留完整的原始视频,并使用光线重映射(光场渲染)重新合成视图(来自不同摄像机位置),从而赋予全景图三维深度感。同一数据集还可以用于通过多基线立体重建深度(Ishiguro、Yamamoto和Tsuji 1992;Peleg、Ben-Ezra和Pritch 2001;Li、Shum等2004;Zheng、Kang等2007)。
使用仿射变换或三维运动对齐图像的另一种方法是首先将图像转换为圆柱坐标系,然后使用纯平移模型进行对齐(Chen1995;Szeliski1996)。遗憾的是,这种方法仅适用于所有图像均在水平相机下拍摄或已知倾斜角度的情况。
假设相机处于标准位置,即其旋转矩阵为单位矩阵R = I,使得光轴与z轴对齐,而y轴垂直。因此,对应于(x,y)像素的3D光线为(x,y,f)。
16类似的技术可能被用于谷歌Cardboard Camera,https://blog.google/products/google-vr/ cardboard-camera-ios。
图8.8从3D到(a)圆柱坐标和(b)球坐标系的投影。
我们希望将此图像投影到半径为1的圆柱表面上(Szeliski1996)。该表面上的点由角度θ和高度参数化,三维圆柱坐标对应于(θ,h),由下式给出:
(sin θ,h,cosθ)/(x,y,f), (8.45)
如图8.8a所示。通过这种对应关系,我们可以计算出扭曲或映射坐标的公式(Szeliski和Shum1997),
x,= sθ = stan-1
(8.46)
y, = sh = s
(8.47)
其中s是任意的缩放因子(有时称为圆柱的半径),可以设置为s = f以最小化图像中心附近的失真(缩放)。该映射方程的逆为
图像也可以投影到球面上(Szeliski和Shum 1997),这在最终全景图包含完整的球面或半球视图时非常有用,而不仅仅是圆柱形条带。在这种情况下,球面由两个角度(θ,φ)参数化,三维球坐标表示为
(sinθcosφ,sinφ,cosθcosφ)/(x,y,f), (8.50)
17根据所需的全景输出分辨率,也可以将该比例设置为更大的或更小的值,以用于最终合成表面——请参见第8.4节。

图8.9圆柱全景图(Szeliski和Shum1997)©1997 ACM:(a)两个圆柱扭曲的图像通过水平平移相关联;(b)由一系列图像合成的圆柱全景图的一部分。
如图8.8b.18所示,坐标之间的对应关系现在由(Szeliski和Shum1997)给出:
而其逆为
(8.51) (8.52)
(8.53) (8.54)
请注意,从公式(8.50)生成一个缩放的(x,y,z)方向,然后通过z进行透视分割和通过f进行缩放可能更简单。
圆柱图像拼接算法最常用于相机已知水平且仅绕垂直轴旋转的情况(Chen1995)。在这种条件下,不同旋转角度的图像通过纯水平平移相关联。这使得它成为计算机视觉入门课程中的初始项目非常有吸引力,因为可以避免透视对齐算法(第8.1节、第9.2节和第8.2.3节)的全部复杂性。图8.9展示了两个来自水平旋转的圆柱变形图像如何拼接。
专业全景摄影师通常使用云台,这种设备便于控制倾斜角度,并能在特定的旋转角度处停止。有时也会使用电动旋转头来拍摄更大的全景图(Kopf,Uyttendaele等,2007)。这些设备不仅确保了视野的均匀覆盖和所需图像重叠量,还使得可以使用圆柱坐标或球面坐标以及纯平移来拼接图像。在这种情况下,像素坐标(x,y,f)首先需要根据已知的倾斜角和平移角进行旋转,然后再投影到圆柱坐标或球面坐标中(Chen 1995)。大致已知的平移角也有助于计算对齐,因为所有输入图像的大致相对位置事先已经确定,从而减少了对齐范围的搜索。图8.1b显示了一个完整的三维旋转全景图,将其展开到球面上(Szeliski和Shum 1997)。
最后值得一提的坐标映射是极坐标映射,其中北极位于光轴上而不是垂直轴上,
(cosθsinφ,sinθsinφ,cosφ)=s(x,y,z)。 (8.55)
在这种情况下,映射方程变为
(8.56)
y,= sφ sin θ = s tan-1
(8.57)
其中r=√x²++y²是(x,y)平面上的径向距离,而sφ在(x,y,)平面上起类似的作用。这种映射为某些类型的广角全景图提供了一个吸引人的可视化表面,同时也是鱼眼镜头引起的畸变的良好模型,如第2.1.5节所述。请注意,对于小值的(x,y),映射方程简化为x,≈sx/z,这表明s的作用类似于焦距f。
8.3 全球协调
到目前为止,我们已经讨论了如何使用各种运动模型来配准图像对。在大多数应用中,我们得到的不仅仅是单个图像对需要配准。因此,目标是找到一组全局一致的对齐参数,以最小化所有图像对之间的错配(Szeliski和Shum 1997;Shum和Szeliski 2000;Sawhney和Kumar 1999;Coorg和Teller 2000)。
在本节中,我们将成对匹配标准(8.2、9.1和9.43)扩展到一个全局能量函数,该函数涉及所有图像的姿态参数(第8.3.1节)。计算出全局对齐后,我们通常需要进行局部调整,例如消除视差,以减少因局部错配导致的重影和模糊(第8.3.2节)。最后,如果我们被给予一组无序的图像进行配准,我们需要发现哪些图像可以组合成一个或多个全景图。这一全景识别过程在第8.3.3节中有所描述。
一种注册大量图像的方法是逐个向全景图中添加新图像,将最近的图像与集合中已有的图像对齐(Szeliski和Shum 1997),并在必要时发现哪些图像重叠(Sawhney和Kumar 1999)。对于360°全景图,累积误差可能导致全景图两端出现间隙(或过度重叠),可以通过使用称为“闭合间隙”的过程来拉伸所有图像的对齐来解决(第8.2.4节)。然而,更好的方法是同时使用最小二乘框架对所有图像进行对齐,以正确分布任何错位误差。
在摄影测量学领域,同时调整大量重叠图像的姿态参数和3D点位置的过程被称为束调整(Triggs,McLauchlan等1999)。在计算机视觉中,这一方法最初被应用于一般结构从运动问题(Szeliski和Kang 1994),随后专门用于全景图像拼接(Shum和Szeliski 2000;Sawhney和Kumar 1999;Coorg和Teller 2000)。
在本节中,我们采用基于特征的方法来构建全局对齐问题,因为这种方法可以简化系统。等效的直接方法可以通过将图像分割成块并为每个块创建虚拟特征对应关系(Shum和Szeliski 2000)或通过用像素级误差度量替代特征级误差度量来实现(Irani和Anandan 1999)。
在我们详细描述之前,需要指出的是,虽然这种方法较为简单,但准确性较低。具体来说,可以计算重叠图像之间的两两旋转估计值,然后使用旋转平均法来估算每个相机的整体旋转(Hartley,Trumpf等2013)。然而,由于每个特征点位置的测量误差没有被正确计数,就像束调整中那样,因此该解决方案不会具有相同的理论最优性。
Epairwise-LS
= Ⅱri Ⅱ2 = Ⅱ
(8.58)
对于多图像对齐,而不是有一个成对的特征对应集合
对应关系,{(xi,i9)},我们有一个n个特征的集合,其中第i个特征的位置
第j幅图像中的点,用xij表示,其标量置信度(即方差的倒数)用cij表示。21每幅图像还具有某些相关的姿态参数。
在本节中,我们假设该姿态由旋转矩阵Rj和焦距fj组成,尽管也可以使用单应式进行表述(Szeliski和Shum 1997;Sawhney和Kumar 1999)。将三维点xi映射到第j帧中的点xij的方程可以从公式(2.68)和(8.38)重新写为
ij
~ KjRjxi和xi ~ Rj-1Kj-1ij,
(8.59)
其中,Kj = diag(fj,fj,1)是校准矩阵的简化形式。将帧j中的点xij映射到帧k中的点xik的运动同样由下式给出
ik ~ kj ij
= KkRk
Rj-1Kj-1ij .
(8.60)
给定从成对比对中获得的初始估计值{(Rj,fj)},我们如何改进这些估计值?
一种方法是直接将成对能量Epairwise-LS(8.58)扩展到多视图公式,
k
比最小二乘法更复杂的技术来解决(Van Huffel和Lemmerling 2002;Matei和Meer 2006)。然而,在实际应用中,如果我们有足够的特征,可以直接使用常规的非线性最小二乘法最小化上述量,从而获得准确的多帧对齐。
虽然这种方法工作得很好,但它有两个潜在的缺点。首先,
因为求和是在所有具有相应特征的对上进行的,这些特征是
图像中看不到的特征,其cij = 0。我们也可以用2×2逆协方差矩阵Σi1代替cij,如公式(8.11)所示。
在最终的解中,观察到多次的特征被赋予了过重的权重。(实际上,一个特征被观察到m次会被计为()到{(
Rj,fj)},这虽然有些繁琐,但使用第8.2.3makes节中引入的Rj增量校正方法可以使其更加可行。
优化的另一种方法是使用真正的束调整,即不仅求解姿态参数{(Rj,fj)},而且求解三维点位置{xi },
EBA-2D = cij
Ⅱij Ⅱ
2 , (8.62)
i
j(xi;Rj,fj)由公式(8.59)给出。完全束调整的缺点是需要求解的变量更多,因此每次迭代以及整体收敛速度可能会更慢。(想象一下每次更新旋转矩阵时,三维点需要如何“移动”。)然而,使用稀疏矩阵技术可以降低每个线性化高斯-牛顿步的计算复杂度(第11.4.3节)(Szeliski和Kang1994;Triggs、McLauchlan等人1999;Hartley和Zisserman2004)。
另一种方法是将三维投影射线方向的误差最小化(Shum和Szeliski2000),即,
EBA-3D = cij
xi Ⅱ2, (8.63)
i
但是,如果我们消除三维射线xi,我们可以在三维射线空间中推导出成对的能量(Shum和Szeliski2000),
这导致了最简单的更新方程组(Shum和Szeliski 2000),因为fk可以折叠到同质坐标向量的创建中,如公式(8.40)所示。因此,尽管该公式对更频繁出现的特征赋予了更高的权重,但这是Shum和Szeliski(2000)以及Brown、Szeliski和Winder(2005)所使用的方法。为了减少对较长焦距的偏倚,我们将每个残差(3D误差)乘以√fjfk,这类似于将3D光线投影到一个“虚拟相机”中,焦距为中间值。
向上选择向量。如上所述,上述方法计算的3D摄像机的姿态存在全局模糊性。虽然这看起来无关紧要,但人们
希望最终拼接的图像“正立”而不是扭曲或倾斜。具体来说,人们习惯于看到照片中垂直(重力)轴线指向图像中的正上方。想想你通常如何拍摄照片:虽然你可以随意摇动和倾斜相机,但通常会保持相机的水平边缘(其x轴)与地面平行(垂直于世界重力方向)。
从数学上讲,对旋转矩阵的这种约束可以表示如下。从公式(8.59)中可以得知,三维到二维投影由下式给出:
基~ KkRk
xi。 (8.65)
我们希望将每个旋转矩阵Rk乘以一个全局旋转RG,使得全局y轴的投影= (0,1,0)与图像x轴的投影= (1,0,0)垂直。22
该约束可以写为
TRkRG= 0 (8.66)
(注意,校准矩阵的缩放在这里是无关紧要的)。这相当于重新
要求Rk的第一行rk0 = TRk与RG的第二列垂直,
rG1 = RG。这组约束条件(每个输入图像一个)可以写成最小二乘法
问题
因此,rG1是散射矩阵或矩矩阵的最小特征向量,该矩阵由单个摄像机旋转x向量展开,当摄像机直立时,该矩阵通常具有形式(c,0,s)。
为了完全指定RG全局旋转,我们需要指定一个额外的约束条件。这与第8.4.1节讨论的视图选择问题有关。一个简单的启发式方法是
到世界z轴,rG2 = RG。因此,我们可以计算完整的旋转矩阵RG
三个步骤:
1. rG1 =最小特征向量(Σk rk0r0);
2. rG0 = N((Σk rk2) × rG1 );
3. rG2 = rG0 × rG1 ,
22注意,这里我们采用计算机图形学中常见的惯例,即垂直世界轴对应于y。如果我们希望与水平拍摄的“常规”图像相关的旋转矩阵是单位矩阵,而不是绕x轴旋转90°,这是一个自然的选择。
8.3.2消除视差
一旦我们优化了相机的全局方向和焦距,我们可能会发现
或者在某些地方出现幽灵。这可能是由多种因素造成的,包括未建模的径向畸变、三维视差(未能围绕相机前节点旋转)、小场景运动如摇动的树枝,以及大规模场景运动如人物进出画面。
每个问题都可以用不同的方法来解决。径向畸变可以使用第2.1.5节中讨论的技术之一进行估算(可能提前)。例如,铅垂线法(Brown1971;Kang2001;El-Melegy和Farag2003)通过调整径向畸变参数,使略微弯曲的线条变得笔直;而基于马赛克的方法则通过减少图像重叠区域的错位来调整这些参数(Stein 1997;Sawhney和Kumar1999)。
三维视差可以通过进行完整的三维束调整来处理,即用方程(2.68)替换方程(8.62)中使用的投影方程(8.59),该方程模拟了相机的平移。然后可以同时恢复匹配特征点和相机的三维位置,尽管这可能比无视差图像配准要昂贵得多。一旦恢复了三维结构,场景(理论上)可以投影到一个包含没有视差的单一(中心)视角。然而,要做到这一点,需要执行密集立体对应(第12.3节)(Li,Shum等人,2004;Zheng,Kang等人,2007),如果图像只有部分重叠,则可能无法实现。在这种情况下,可能只需要在重叠区域校正视差,这可以通过多视角平面扫描(MPPS)算法(Kang,Szeliski,和Uyttendaele2004;Uyttendaele,Criminisi等人,2004)来完成。
当场景中的运动非常大,即物体完全出现和消失时,一个合理的解决方案是每次仅从一张图像中选择像素作为最终合成的源(Milgram1977;Davis1998;Agarwala,Dontcheva等2004),如第8.4.2节所述。然而,当运动相对较小(大约几个像素)时,可以使用通用的二维运动估计(光流)来执行适当的校正,然后再通过局部对齐过程进行混合(Shum和Szeliski 2000;Kang,Uyttendaele等2003)。同样的过程也可以用来补偿径向畸变和三维视差,尽管它使用的运动模型比明确建模误差源的模型更弱,因此可能更容易失败或引入不必要的畸变。
Shum和Szeliski(2000)提出的局部对齐技术从全局束调整(8.64)开始,用于优化相机姿态。一旦这些已经完成

图8.10用运动视差对马赛克进行去鬼影处理(Shum和Szeliski2000)©2000
IEEE:(a)复合视差;(b)单个去鬼步骤后(补丁大小为32);(c)多个步骤后(大小分别为32、16和8)。
估计地,三维点xi的期望位置可以被估计为后投影三维位置的平均值,
ij ; (8.68)
可以将这些投影到每个图像j中,以获得目标位置ij。目标位置ij与原始特征
xij之间的差异提供了一组局部运动估计
uij = ij - xij ;
(8.69)
可以插值形成一个密集的校正场uj(xj)。在他们的系统中,舒姆和斯泽利斯基(2000)使用了一种逆变形算法,其中稀疏的-ujj值被放置在新的目标位置x-ij处,利用双线性核函数(尼尔森1993)进行插值,然后在计算变形(校正)图像时将其添加到原始像素坐标中。为了获得一组较为密集的特征以供插值,舒姆和斯泽利斯基(2000)在每个补丁的中心放置了一个特征点(补丁大小控制局部对齐阶段的平滑度),而不是依赖于兴趣算子提取的特征(图8.10)。
康、乌特恩代尔等人(2003)提出了一种基于运动去鬼影的替代方法,该方法估计每个输入图像与中心参考图像之间的密集光流。在考虑某个扭曲像素之前,会使用照片一致性度量检查光流向量的准确性,并用于计算高动态范围辐射估计值,这是他们整体算法的目标。由于需要参考图像,这种方法不太适用于一般的图像拼接,尽管可以设想对此情况进行扩展。
在最近的一些论文中,已经对结合全局参数扭曲与局部网格扭曲或多个运动模型来补偿视差的想法进行了改进
(Zaragoza,Chin等人,2013;Zhang和Liu,2014;Lin,Pankanti等人,2015;Lin,Jiang等人,2016;Herrmann,Wang等人,2018b;Lee和Sim,2020)。其中一些论文使用了内容保持变形(Liu,Gleicher等人,2009)来实现局部变形,而其他论文则采用了滚动快门模型(Zhuang和Tran,2020)。
完成全自动图像拼接所需的最后一步是识别哪些图像可以拼接在一起,布朗和洛(2007)称之为全景图识别。如果用户按顺序拍摄图像,使得每张图像与其前一张重叠,并且指定了要拼接的第一张和最后一张图像,那么束调整结合拓扑推断过程可以自动组装全景图(萨韦尼和库马尔1999)。然而,用户在拍摄全景图时常常跳跃操作,例如,他们可能在前一排的基础上开始新的一排,跳回来重新拍摄重复镜头,或者创建360°全景图,需要发现端到端的重叠部分。此外,能够发现用户在长时间内拍摄的多个全景图会非常方便。
为了识别全景图,布朗和洛(2007)首先使用基于特征的方法找到所有图像之间的重叠部分,然后在重叠图中寻找连通组件以“识别”各个全景图(图8.11)。基于特征的匹配阶段首先从所有输入图像中提取尺度不变特征变换(SIFT)特征位置和特征描述子(洛2004),并将它们放入索引结构中,具体方法见第7.1.3节。对于每一对待考虑的图像,使用索引结构快速找到第一个图像中每个特征的最近匹配邻居,然后比较特征描述子以找到最佳匹配。RANSAC算法用于生成一组内点匹配;通过匹配对假设相似运动模型,进而计算内点的数量。布朗、哈特利和尼斯特(2007)专门针对旋转全景图描述了一种RANSAC算法。
在实际操作中,让全自动拼接算法顺利运行的最难点在于确定哪些图像对实际上对应于场景的同一部分。重复结构如窗户(图8.12)在使用基于特征的方法时可能导致错误匹配。一种缓解此问题的方法是通过直接像素级比较已注册的图像,以判断它们是否确实是同一场景的不同视角。不幸的是,如果场景中有移动物体(图8.13),这种启发式方法可能会失效。虽然没有解决这一问题的灵丹妙药,但在达到全面场景理解之前,通过应用特定领域的启发式方法,例如对典型相机运动的先验假设以及机器学习技术,仍有可能进一步改进。

图8.11认识全景(Brown,Szeliski和Winder2005),图例
Matthew Brown提供的: (a)输入成对匹配的图像;(b)将图像分组为连通组件(全景图);(c)将单独的全景图注册并混合成拼接合成图。

图8.12匹配错误(Brown、Szeliski和Winder2004):几个特征的偶然匹配可能导致图像对之间实际上没有重叠的匹配。

图8.13直接像素误差比较验证图像匹配可能失败,当场景包含移动物体时(Uyttendaele、Eden和Szeliski2001)©2001 IEEE。
8.4 合成
一旦我们完成了所有输入图像的相互注册,就需要决定如何生成最终的拼接马赛克图像。这包括选择最终的合成表面(平面、圆柱形、球形等)和视图(参考图像)。同时,还需要确定哪些像素参与最终合成,以及如何最优地混合这些像素以减少可见接缝、模糊和重影。
在本节中,我们回顾了解决这些问题的技术,即表面参数化合成、像素和接缝选择、混合以及曝光补偿。我们的重点是完全自动化的解决方案。由于高质量全景图和合成图的创建既是一项计算任务,也是一项艺术创作,因此开发了各种交互工具来辅助这一过程(Agarwala,Dontcheva等,2004;Li,Sun等,2004;Rother,Kolmogorov和Blake,2004)。其中一些工具将在第10.4节中详细讨论。
首先需要决定的是如何呈现最终图像。如果只有几张图片拼接在一起,一种自然的方法是选择其中一张作为参考,然后将其他所有图片变形到其参考坐标系中。这种合成图像有时被称为平面全景图,因为投影到最终表面仍然是透视投影,因此直线仍然保持直线(这通常是所希望的attribute).23
然而,对于较大的视场,我们无法在不过度拉伸图像边缘像素的情况下保持平面表示。(实际上,一旦视场超过约90°,平面全景图就会开始严重失真。)通常用于合成较大全景图的方法是使用圆柱投影(Chen 1995;Szeliski 1996)或球面投影(Szeliski和Shum 1997),如第8.2.6节所述。事实上,计算机图形中用于环境映射的任何表面都可以使用,包括立方体贴图,它用立方体的六个正方形面表示整个观察球体(Greene 1986;Szeliski和Shum 1997)。制图学家还开发了多种替代方法来表示
全球(Bugayevskiy和Snyder1995)。
参数化的选择在一定程度上取决于具体应用,并涉及保持局部外观不变(例如,保持直线不变)与提供环境的均匀采样之间的权衡。Kopf、Uyttendaele等人(2007)讨论了根据全景图的范围自动选择并平滑过渡到不同表示的方法。近年来,全景摄影的一个趋势是使用俯视地面的立体投影(在户外场景中)来创建“小行星”渲染图。24
视图选择。一旦我们选择了输出参数化,还需要确定场景中哪一部分将在最终视图中居中。如前所述,对于平面合成图像,我们可以选择其中一张作为参考。通常,一个合理的选项是几何上最居中的那张。例如,对于表示为一组三维旋转矩阵的旋转全景图,我们可以选择其z轴最接近平均z轴的图像(假设视野合理)。或者,我们可以使用平均z轴(或四元数,但这更复杂)来定义参考旋转矩阵。
对于较大的全景图,例如圆柱形或球形全景图,如果已拍摄了视场的一部分,我们可以使用相同的启发式方法。对于完整的360°全景图,更好的选择是从输入序列中选取中间图像,有时甚至是第一张图像,假设其中包含最感兴趣的物体。在所有这些情况下,让用户控制最终视图通常是非常理想的。如果第8.3.1节中描述的“向上向量”计算正确无误,这可以简单到在图像上平移或设置垂直的“中心线”作为最终全景图。
坐标变换。在选择参数化和参考视图之后,我们仍然需要计算输入和输出像素坐标之间的映射。
如果最终合成表面是平面(例如单个平面或立方体贴图的面)且输入图像没有径向畸变,则坐标变换就是由公式(8.38)描述的简单透视变换。这种变形可以通过适当设置纹理映射坐标并在图形硬件中渲染一个四边形来实现。
24这些灵感来自安托万·德·圣埃克苏佩里的《小王子》。去https://www.flickr.comand搜索“小行星投影”。
例如,将圆柱坐标或球坐标映射到三维坐标所需的局部三角函数,或者每个像素处的径向畸变场。也可以通过在较粗的网格上计算精确的像素映射,然后插值这些值来加速这一过程。
当最终合成表面是一个纹理映射的多面体时,必须使用稍微复杂一些的算法。不仅需要正确处理三维坐标和纹理映射坐标,还需要在纹理映射的三角形足迹之外进行少量的过度绘制,以确保在三维渲染过程中插值的纹理像素具有有效的值(Szeliski和Shum 1997)。
采样问题。虽然上述计算可以得出每个输入图像中的正确(分数)像素地址,但我们仍需关注采样问题。例如,如果最终全景图的分辨率低于输入图像,则需要预滤波输入图像以避免混叠。这些问题已在图像处理和计算机图形学领域得到了广泛研究。基本问题是计算适当的预滤波器,这取决于源图像中相邻样本之间的距离(和排列)。如第3.5.2节和第3.6.1节所述,图形学界已开发出多种近似解决方案,如MIP映射(Williams 1983)或椭圆加权高斯平均(Greene和Heckbert 1986)。为了获得最高的视觉质量,可能需要使用更高阶(例如三次)插值器结合空间自适应预滤波器(Wang,Kang等2001)。在某些条件下,还可以通过超分辨率过程生成比输入图像更高分辨率的图像(第10.3节)。
一旦源像素被映射到最终的合成表面,我们仍需决定如何将它们融合,以创建一个美观的全景图。如果所有图像都完美对齐且曝光相同,这将是一个简单的问题,即任何像素或组合都可以。然而,对于真实图像而言,可能会出现可见的接缝(由于曝光差异)、模糊(由于对齐错误)或重影(由于移动物体)。
创建干净、美观的全景图既涉及选择哪些像素,也涉及如何加权或混合这些像素。这两个阶段之间的区别有些模糊,因为每个像素的加权可以被视为选择和混合的结合。在本节中,我们将讨论空间变化的加权、像素选择(接缝放置),以及更复杂的混合方法。

图8.14通过各种算法计算的最终复合材料(Szeliski2006a):(a)
平均值,(b)中位数,(c)羽化平均值,(d) p-norm p = 10,(e) Voronoi,(f)带羽化的加权ROD顶点覆盖,(g)带有泊松混合的图切割缝合,以及(h)带有金字塔混合。
羽化和中心加权。创建最终合成的最简单方法是在每个像素处取平均值,
(8.70)
(x)是扭曲的(重采样的)图像,wk (x)在有效像素处为1,在其他地方为0。在计算机图形硬件上,这种求和可以在累加缓冲区中执行(使用A通道作为权重)。
简单平均通常效果不佳,因为曝光差异、误注册和场景移动都非常明显(图8.14a)。如果唯一的问题是快速移动的物体,可以使用中值滤波器(这是一种像素选择操作符)来去除它们(图8.14b) (Irani和Anandan 1998)。相反,中心加权(下文讨论)和最小似然选择(Agarwala,Dontcheva等2004)有时可用于保留移动物体的多个副本(Figure8.17)。
一种更好的平均方法是更重地加权图像中心附近的像素,而减少边缘像素的权重。当图像中存在一些缺失区域时,减少缺失区域和图像边缘像素的权重更为理想。这可以通过计算距离图或草火变换来实现,
wk (x) = arg mk
(x + y)无效}, (8.71)
每个有效像素都标记了它与最近的无效像素之间的欧几里得距离(第3.3.3节)。欧几里得距离图可以使用两遍光栅算法高效地计算(Danielsson1980;Borgefors1986)。
加权平均与距离图结合通常被称为羽化(Szeliski和Shum 1997;Chen和Klette 1999;Uyttendaele、Eden和Szeliski 2001),在融合曝光差异方面表现良好。然而,模糊和重影仍然是问题(图8.14c)。请注意,加权平均与使用经典叠加操作合成各个图像并不相同(Porter和Duff 1984;Blinn 1994a),即使使用权重值(归一化为总和为一)作为透明度通道也是如此。这是因为叠加操作会减弱来自较远表面的值,因此与直接求和不等效。
提高羽化效果的一种方法是将距离图值提高到某个大幂次,
即,在公式(8.70)中使用w(x)。加权平均值随后被主导。
较大的值,即它们的作用类似于p-norm。由此产生的复合体通常可以提供可见的曝光差异和模糊之间的合理折衷(图8.14d)

图8.15差异区域(RODs)的计算(Uyttendaele、Eden和Szeliski
2001)©2001 IEEE:(a)三个重叠的带有移动人脸的图像;(b)相应的ROD;(c)重合ROD的图。
当p→∞时,仅选择权重最大的像素。这种硬像素选择过程产生了一种熟悉的沃罗诺伊图的可见性掩模敏感变体,它将每个像素分配给集合中最近的图像中心(Wood,Finkelstein等1997;Peleg,Rousso等2000)。生成的复合图虽然在艺术指导和高重叠全景图(多面马赛克)中有用,但在曝光变化时,边缘往往非常粗糙且有明显的接缝(图8.14e)。
Xiong和Turkowski(1998)使用Voronoi概念(草地火灾变换的局部最大值)来选择用于拉普拉斯金字塔混合的接缝(下文将讨论)。但是,
由于接缝选择是按顺序进行的,因此在添加新图像时可能会出现一些伪影。
最优接缝选择。计算沃罗诺伊图是选择不同图像贡献最终合成图像之间接缝的一种方法。然而,沃罗诺伊图完全忽略了接缝下方的局部图像结构。更好的方法是在图像一致的区域放置接缝,以避免从一个源到另一个源的过渡变得可见。这样,算法可以避免“切割”移动物体,因为接缝看起来会很不自然(Davis1998)。对于一对图像,这一过程可以表述为一个简单的动态规划问题,从重叠区域的一边开始,到另一边结束(Milgram1975,1977;Davis1998;Efros和Freeman 2001)。
当多个图像被合成时,动态程序思想并不容易推广。(对于顺序合成的方形纹理瓷砖,Efros和Freeman(2001)沿着每个瓷砖的四个边运行动态程序。)
为了克服这一问题,乌特恩代尔、埃登和谢利斯基(2001)观察到,在图像注册良好的情况下,移动物体会产生最明显的伪影,即透明的幽灵。因此,他们的系统会决定保留哪些物体以及删除哪些物体。首先,算法比较所有重叠的输入图像对,以确定图像不一致的区域(RODs)。接下来,构建一个图,其中包含

图8.16拼贴(Agarwala、Dontcheva等,2004)©2004 ACM。从五张源图像中(其中四张显示在左侧),拼贴软件能够快速生成一张全家福肖像,每个人都在微笑并看着镜头(右侧)。用户只需翻阅图像堆栈,并使用指定的源图像对象粗略地勾勒出他们希望添加到合成图像中的人物轮廓。用户应用的线条和计算出的区域(中间部分)根据左侧源图像的边框进行了颜色编码。
顶点表示ROD,边代表最终合成图像中重叠的ROD对(图8.15)。由于存在一条边意味着存在分歧区域,因此必须从最终合成图像中移除顶点(区域),直到没有一条边连接剩余的顶点对。最小的此类集合可以通过顶点覆盖算法计算得出。由于可能存在多个这样的覆盖集,因此使用加权顶点覆盖算法,其中顶点权重通过汇总ROD中的羽化权重来计算(Uyttendaele,Eden,和Szeliski 2001)。因此,该算法更倾向于移除靠近图像边缘的区域,这减少了部分可见物体出现在最终合成图像中的可能性。(还可以通过ROD边界上的“边缘性”(像素差异)推断出差异区域中的哪个物体是前景物体,当有物体存在时,这种边缘性应该更高(Herley 2005)。)一旦移除了所需的多余差异区域,最终合成图像就可以通过羽化创建(图8.14f)。
Agarwala、Dontcheva等人(2004)描述了一种不同的像素选择和接缝放置方法。他们的系统计算标签分配,以优化两个目标函数的总和。第一个是每个像素的图像目标,确定哪些像素可能产生良好的合成,
ED = D (x; l(x)); (8.72)
其中D(x;l)是选择像素x处的图像l的数据惩罚。在他们的系统中,用户可以通过“绘制”图像来选择使用哪些像素,以获得所需的对象或

图8.17一组五张照片追踪一名滑雪板运动员的跳跃,拼接成一个无缝的合成图像。因为算法更喜欢靠近图像中心的像素,所以保留了多名滑雪板运动员的多份副本。
外观,使得除用户选定标签外的所有标签的D(x,l)值都很大(图8.16)。或者,可以使用自动选择标准,例如最大似然法,该方法偏好在背景中反复出现的像素(用于对象去除),或最小似然法,适用于不频繁出现的对象,即移动对象保留。使用更传统的中心加权数据项则倾向于支持输入图像中居中的对象(图8.17)。
(8.73)
其中S(x,y,lx,ly)是图像依赖的交互惩罚或缝合成本,用于在像素x和y之间放置缝合线,N是N4邻近像素的集合。例如,Kwatra、Sch dl等人(2003)和Agarwala、Dontcheva等人(2004)使用的基于颜色的简单缝合惩罚可以表示为
S (x, y, lx , ly) = lx (x)
- ly (
x)Ⅱ + lx
(y) - ly
(y)Ⅱ . (8.74)
更复杂的接缝惩罚还可以考虑图像梯度或图像边缘的存在(Agarwala,Dontcheva等,2004)。接缝惩罚在其他计算机视觉应用中也被广泛使用,例如立体匹配(Boykov,Veksler,和Zabih,2001),以赋予标签函数连贯性或平滑度。另一种方法是通过分水岭计算,在重叠图像中的强一致边缘处放置接缝,这一方法由Soille(2006)描述。
这两个目标函数的和产生了一个马尔可夫随机场(MRF),关于其优化算法的详细描述见第4.3节、4.3.2节和附录B.5。对于此类标签计算,Boykov、Veksler和Zabih(2001)开发的α展开算法表现尤为出色(Szeliski、Zabih等人,2008)。
对于图8.14g所示的结果,Agarwala、Dontcheva等人(2004)对无效像素使用了较大的数据惩罚,而对有效像素则设为0。请注意,接缝放置算法如何避开差异区域,包括那些可能使物体被切割的边界区域。图割(Agarwala、Dontcheva等人2004)和顶点覆盖(Uytten- daele、Eden和Szeliski2001)通常会产生相似的结果,尽管前者由于优化所有像素而显著较慢,后者则更敏感于用于确定差异区域的阈值。最近的接缝选择方法包括海鸥(Lin、Jiang等人2016),该方法联合优化局部对齐和接缝选择,以及以对象为中心的图像拼接(Herrmann、Wang等人2018a),该方法使用现成的对象检测器以避免切割物体。
虽然图像拼接通常用于合成部分重叠的照片,但它也可以用于合成重复拍摄的场景,目的是获得每个元素的最佳组合和外观。
图8.16展示了由Agarwala、Dontcheva等人(2004)开发的Photomontage系统,用户可以在一组预先对齐的图像上绘制线条,以指示他们希望保留每个图像中的哪些区域。一旦系统解决了生成的多标签图割(8.72–8.73),来自每张源照片的不同部分就会使用泊松图像融合(8.75–8.77)的一种变体进行混合。他们的系统还可以用于自动合成一系列焦点调整后的图像(Hasinoff、Kutulakos等人,2009),或从一组照片中移除电线和其他不需要的元素。练习8.14要求你实现该系统并尝试其一些变体。
一旦确定了图像之间的接缝并去除了不需要的物体,我们仍然需要融合这些图像以补偿曝光差异和其他错位。之前讨论的空间变化权重(羽化)通常可以用来实现这一点。然而,在实际操作中,要在平滑低频曝光变化与保持足够清晰的过渡之间找到令人满意的平衡是困难的(尽管使用较高的羽化指数可以帮助)。

图8.18 Poisson图像编辑(P rez、Gangnet和Blake2003)©2003 ACM:(a)
狗和两个孩子被选为源图像,粘贴到目标游泳池中。(b)简单粘贴无法匹配边界处的颜色,而(c) Poisson图像混合可以掩盖这些差异。
拉普拉斯金字塔融合。一个吸引人的解决方案是伯特和阿德森(1983b)开发的拉普拉斯金字塔融合技术,我们在第3.5.5节中讨论过。该方法不是使用单一的过渡宽度,而是通过创建带通(拉普拉斯)金字塔来使用频率自适应宽度,并使每个层级内的过渡宽度成为该层级的函数,即像素宽度相同。实际上,少量的层级,例如最少两个(布朗和洛厄2007),可能足以补偿曝光差异。应用这种金字塔融合的结果如图8.14h所示。
梯度域融合。多波段图像融合的一种替代方法是在梯度域中执行操作。从梯度场重建图像在计算机视觉领域有着悠久的历史(Horn1986),最初的研究集中在亮度恒定性(Horn1974)、阴影中的形状(Horn和Brooks1989)以及光度立体(Woodham1981)。类似的思想也被用于从边缘重建图像(Elder和Goldberg2001)、去除图像中的阴影(Weiss2001)、从单个图像中分离反射(Levin、Zomet和Weiss2004;Levin和Weiss 2007),以及通过减少图像边缘(梯度)的幅度来映射高动态范围图像(Fattal、Lischinski和Werman2002)。
普雷兹、甘格内特和布莱克(
2003)展示了如何在图像编辑应用中使用梯度域重建实现无缝对象插入(图8.18)。他们不是复制像素,而是复制新图像片段的梯度。然后通过求解泊松方程来计算复制区域的实际像素值,该方程局部匹配
在缝合边界处遵守固定的狄利克雷(精确匹配)条件的同时,梯度变化。P rez、Gangnet和Blake(2003)指出,这
相当于计算源图像和目标图像沿边界不匹配部分的加性膜插值。25在早期研究中,Peleg(1981)也提出添加一个平滑函数以确保缝合曲线的一致性。
阿加瓦拉、唐切娃等人(2004)将这一概念扩展到多源公式中,在这种情况下,不再需要讨论一个目标图像,其精确像素值必须在接缝处匹配。相反,每个源图像贡献自己的梯度场,并使用诺伊曼边界条件求解泊松方程,即排除任何涉及图像边界外像素的方程。
Agarwala、Dontcheva等人(2004)没有求解泊松偏微分方程,而是直接最小化一个变分问题,
x)(x)Ⅱ2。 (8.75)
C(x)
该方程的离散形式是一组梯度约束方程
x)(x +)-
l(x)(x)和 (8.76) C(x + ) l(x)
(x + ) - l(x)
(x), (8.77)
其中=(1,0)和=(0,1)是x和y方向上的单位向量。然后他们求解相关的稀疏最小二乘问题。由于这个方程组仅在加性约束下定义,Agarwala、Dontcheva等人(2004)要求用户选择一个像素的值。实际上,更好的选择可能是弱偏向于重现原始颜色值的解。
为了加速求解这个稀疏线性系统,法塔尔、利辛斯基和沃曼(2002)使用了多重网格方法,而阿加瓦拉、唐切娃等人(2004)则采用了层次基预处理共轭梯度下降法(斯泽利斯基1990b,2006b;克里希南和斯泽利斯基2011;克里希南、法塔尔和斯泽利斯基2013)(附录A.5)。在后续的研究中,阿加瓦拉(2007)展示了如何使用四叉树表示来进一步加速计算,同时几乎不损失精度;而斯泽利斯基、乌特恩代勒和斯特迪(2008)则表明,使用较粗的样条表示每幅图像的偏移场可以更快。后者的工作还指出,在对数域中混合,即使用乘法而非加法偏移,更为理想,因为它更接近于接缝边界处的纹理对比度。
结果缝合在实践中效果很好(图8.14h),尽管需要小心。
25膜插值器已知对于任意形状的约束具有比频域插值器更好的插值特性(Nielson1993)。
在接缝位置,右侧由两个源图像的梯度平均值替换。
在复制靠近接缝处的大型梯度值时必须小心,以免引入“双边缘”。
直接从源图像中放置接缝后复制梯度只是梯度域融合的一种方法。Levin、Zomet等人(2004)的论文探讨了这种方法的几种不同变体,他们称之为梯度域图像拼接(GIST)。他们研究的技术包括对源图像中的梯度进行羽化(混合),以及使用L1范数从梯度场重建图像,而不是使用公式(8.75)中的L2范数。他们偏好的技术是对原始图像梯度上的羽化(混合)成本函数进行L1优化(他们称之为GIST1-l1 )。由于使用线性规划的L1优化可能较慢,他们在多网格框架中开发了一种更快的基于中值的迭代算法。他们偏好的方法与所谓的最优梯度接缝(这相当于Agarwala、Dontcheva等人(2004)的方法)之间的视觉比较显示了类似的结果,同时显著改进了金字塔融合和羽化算法。
曝光补偿。金字塔和梯度域混合可以很好地补偿图像之间的中等程度的曝光差异。但是,当曝光差异变得很大时,可能需要采用其他方法。
乌特恩代尔、伊登和谢利斯基(2001)迭代地估计每个源图像与混合合成图像之间的局部校正。首先,在每个源图像与初始羽化合成图像之间拟合一个基于块的二次传递函数。接下来,将传递函数与其邻近值平均,以获得更平滑的映射,并通过样条(插值)在相邻块值之间计算出逐像素传递函数。一旦每个源图像都得到了平滑调整,就会计算一个新的羽化合成图像,并重复此过程(通常三次)。乌特恩代尔、伊登和谢利斯基(2001)展示的结果表明,这种方法在曝光补偿方面比简单的羽化效果更好,能够处理由于镜头暗角等效应引起的局部曝光变化。
然而,处理曝光差异的最合理方法是将图像拼接在辐射度域中,即使用每个图像的曝光值将其转换为辐射度图像,然后创建一个拼接的高动态范围图像,如第10.2节和Eden、Uyttendaele和Szeliski(2006)所述。
8.5 其他阅读材料
Hartley和Zisserman(2004)对基于特征的对齐和最优运动估计等主题进行了精彩的介绍,讨论了稳健估计技术
详见附录B.3以及关于此主题的专著和综述文章(Huber 1981;Hampel,Ronchetti等1986;Rousseeuw和Leroy 1987;Black和Rangarajan 1996;Stewart 1999)。计算机视觉中最常用的鲁棒初始化技术是随机样本一致性(RANSAC)(Fischler和Bolles 1981),这一技术催生了一系列更高效的变体(Torr和Zisserman 2000;Nist 2003;Chum和Matas 2005;Raguram,Chum等2012;Brachmann
,Krull等2017;Barath和Matas 2018;Barath,Matas和Noskova 2019;Brachmann和Rother 2019)。Barath、Noskova等人(2020)在MAGSAC++论文中比较了这些变体中的许多。
关于图像拼接的文献可以追溯到20世纪70年代摄影测量学界的早期工作(Milgram1975,1977;Slama1980)。在计算机视觉领域,相关论文始于20世纪80年代初(Peleg1981),而全自动技术的发展则是在十年后才开始出现(Mann和Picard1994;Chen1995;Szeliski1996;Szeliski和Shum 1997;Sawhney和Kumar1999;Shum和Szeliski2000)。这些技术最初采用基于像素的直接对齐方法,但如今以特征为基础的方法更为普遍(Zoghlami,Faugeras和Deriche1997;Capel和Zisserman1998;Cham和Cipolla1998;Badra,Qumsieh和Dudek1998;McLauchlan和Jaenicke2002;Brown和Lowe2007)。本章所依据的内容部分收录于Benosman和Kang(2001)编著的书中。Szeliski(2006a)对图像拼接进行了全面综述,本章内容即基于此研究。近期的出版物包括Zaragoza、Chin等人(2013)、Zhang和Liu(2014)、Lin、Pankanti等人(2015)、Lin、Jiang等人(2016)、Herrmann、Wang等人(2018b)、Lee和Sim(2020)以及Zhuang和Tran(2020)。
高质量的接缝寻找和融合技术是图像拼接系统中的另一个重要组成部分。该领域的重要进展包括米尔格拉姆(1977年)、伯特和阿德森(1983b)、戴维斯(1998年)、乌特恩代尔、埃登和斯泽利斯基(2001年)、普雷兹、甘格内特和布莱克(2003年)、莱文、佐梅特等人(2004年
)、阿加瓦拉、唐切娃等人(2004年)、埃登、乌特恩代尔和斯泽利斯基(2006年)、科普夫、乌特恩代尔等人(2007年)、林、江等人(2016年)以及赫尔曼、王等人(2018a)的工作。
除了用于创建航拍或地面全景图像的多张重叠照片合并外,拼接技术还可用于自动白板扫描(He和Zhang 2005;Zhang和He 2007)、鼠标扫描(Nakao、Kashitani和Kaneyoshi 1998)以及视网膜图像马赛克(Can、Stewart等人2002)。这些技术还可以应用于视频序列(Teodosio和Bender 1993;Irani、Hsu和Anandan 1995;Kumar、Anandan等人1995;Sawhney和Ayer 1996;Massey和Bender 1996;Irani和Anandan 1998;Sawhney、Arpa等人2002;Agarwala、Zheng等人2005;Rav-Acha、Pritch等人2005;Steedy、Pal和Szeliski 2005;Baudisch、Tan等人2006),甚至可用于视频压缩(Lee、Chen等人1997)。
Chapter 9 Motion estimation
9.1翻译对齐 558
9.1.1分层运动估计 562
9.1.2基于傅立叶的对齐 563
9.1.3逐步完善 566
9.2参数运动 570
9.2.1应用:视频稳定 573
9.2.2基于样条线的运动 575
9.2.3应用:医学图像配准 577
9.3光流 578
9.3.1深度学习方法 584
9.3.2应用:卷帘窗防晃动 587
9.3.3多帧运动估计 587
9.3.4应用:视频降噪 589
9.4分层运动 589
9.4.1应用:帧插值 593
9.4.2透明层和反射 594
9.4.3视频对象分割 597
9.4.4视频对象跟踪 598
9.5额外阅读 600
9.6练习 602

图9.1运动估计:(a-b)基于正则化的光流(Nagel和Enkel- mann1986)©1986 IEEE;(c-d)分层运动估计(Wang和Adelson1994)©1994 IEEE;(e-f)来自评估数据库的样本图像和真实流(Butler、Wulff等人2012)©2012 Springer。
用于对视频序列中的图像进行对齐和估计运动的算法是计算机视觉中最广泛使用的算法之一。例如,帧率图像对齐被广泛用于数字摄像机中以实现其图像稳定(IS)功能。
早期广泛使用的图像配准算法的一个例子是卢卡斯和卡纳德(1981)开发的基于块的平移对齐(光流)技术。该算法的变体几乎被所有运动补偿视频压缩方案所采用,如MPEG/H.263(勒加尔1991)和HEVC/H.265(苏利文、奥姆等人2012)。类似的参数化运动估计算法也被广泛应用于视频摘要(特多西奥和本德1993;伊拉尼和阿南丹1998)、视频稳定(汉森、阿南丹等人1994;斯里尼瓦桑、切拉帕等人2005;松下、奥费克等人2006)以及视频压缩(伊拉尼、许和阿南丹1995;李、陈等人1997)。更复杂的图像配准算法也已开发用于医学成像和遥感。布朗(1992)、齐托娃和弗卢瑟(2003)、戈斯塔斯比(2005)和泽利斯基(2006a)对图像配准技术进行了综述。
为了估计两幅或多幅图像之间的运动,首先需要选择一个合适的误差度量来比较这些图像(第9.1节)。确定了这一点后,必须设计一种合适搜索技术。最简单的方法是穷尽所有可能的对齐方式,即进行全面搜索。实际上,这可能会太慢,因此通常使用基于图像金字塔的层次化粗到精技术(第9.1.1节)。或者,可以使用傅里叶变换(第9.1.2节)来加速计算。
为了在对齐中获得亚像素精度,通常使用基于图像函数泰勒级数展开的增量方法(第9.1.3节)。这些方法也可以应用于参数化运动模型(第9.2节),这些模型用于建模全局图像变换,如旋转或剪切。通过学习被跟踪场景或物体的典型动态或运动统计特性,例如行走人的自然步态(第9.2节),可以提高运动估计的可靠性。对于更复杂的运动,可以使用分段参数样条运动模型(Section9.2.2)。
在存在多个独立(且可能非刚性)运动的情况下,需要使用通用光流(或光学流)技术,如第9.3节所述。近年来,性能最佳的技术开始采用深度神经网络(第9.3.1节)。对于包含大量遮挡的更复杂运动,分层运动模型(第9.4节)可以很好地工作,该模型将场景分解为连贯移动的层次。这些表示还可以用于视频对象分割(第9.4.3节)和对象跟踪(第9.4.4节)。
在本章中,我们将更详细地描述这些技术。更多细节可以在运动估计的综述和比较评估论文中找到(Barron,
Fleet和Beauchemin1994;Mitiche和Bouthemy1996;Stiller和Konrad1999;Szeliski
2006a;Baker,Scharstein等人,2011;Sun,Yang等人,2018;Janai,G等人,2020;Hur
和Roth2020)。
9.1 翻译对齐
建立两幅图像或图像块之间的一致性的最简单方法是将一幅图像相对于另一幅进行平移。给定一个模板图像I0 (x),在离散像素位置{x=(xi,yi)}处采样,我们希望找到它在图像I1 (x)中的位置。解决这个问题的最小二乘法是找到平方差(SSD)函数的最小值。
其中u =(u,v)表示位移,ei = I1(xi + u)- I0(xi)称为残差误差(或视频编码文献中的位移帧差异)。1(我们暂时忽略I0的某些部分可能位于I1边界之外或不可见的情况。)假设两幅图像中对应的像素值保持不变,通常称为亮度恒定约束。2
一般来说,位移u可以是分数形式,因此需要应用合适的插值函数来处理图像I1 (x)。实际上,双线性插值经常被使用,但双三次插值可以产生略好的结果(Szeliski和Scharstein2004)。彩色图像可以通过累加所有三个颜色通道的差异来进行处理,尽管也可以首先将图像转换到不同的颜色空间,或者仅使用亮度(这在视频编码器中经常这样做)。
稳健的误差度量。我们可以通过用稳健函数P(ei)(Huber1981;Hampel,Ronchetti等1986;Black和Anandan1996;Stewart1999)替换平方误差项,使上述误差度量对异常值更加稳健,以获得
强规范P(e)是一个增长速度慢于二次惩罚的函数
用最小二乘法求解。其中一种函数,有时用于视频运动估计
1使用最小二乘法的通常理由是,它是高斯噪声下的最佳估计。请参见下面关于稳健误差度量的讨论以及附录B.3。
2亮度恒定(Horn1974)是指物体在不同光照条件下保持其感知亮度的趋势。
由于其速度,编码是绝对差值(SAD)度量3或L1范数的总和,即:
然而,由于该函数在原点处不可导,因此不适合使用第9.1.3节中介绍的梯度下降方法。
相反,通常使用一个平滑变化的函数,该函数在小值时是二次的,但在远离原点时增长得更慢。Black和Rangarajan(1996)讨论了各种这样的函数,包括Geman-McClure函数,
(9.4)
其中a是一个常数,可以视为异常值阈值。合适的阈值可以通过稳健统计方法(Huber1981;Hampel,Ronchetti等1986;Rousseeuw和Leroy 1987)得出,例如通过计算中位绝对偏差MAD=medij,并乘以1.4来获得内点噪声过程的标准差的稳健估计(Stewart1999)。Barron(2019)提出了一种广义稳健损失函数,能够建模各种异常分布和阈值,具体讨论见第4.1.3节和附录B.3,该方法还包含一种贝叶斯方法来估计损失函数参数。
空间变化的权重。上述误差指标忽略了这样一个事实:对于给定的对齐,某些被比较的像素可能位于原始图像边界之外。此外,我们可能希望部分或完全降低某些像素的贡献。例如,在拼接马赛克时,当不需要的前景物体已被裁剪掉时,我们可能希望有选择地“删除”图像中的一些部分。对于背景稳定等应用,我们可能希望降低中间部分的权重。
图像的一部分,通常包含被摄像机跟踪的独立移动物体。
所有这些任务都可以通过将空间变化的每个像素权重与两个匹配的图像关联起来来完成。误差度量就变成了加权(或窗口)SSD函数,3在视频压缩中,例如H.264标准(https://www.itu.int/rec/T-REC-H.264),通常使用绝对变换差之和(SATD),其测量频率变换空间中的差异,例如使用哈达玛变换,因为其更准确地预测质量(Richardson2003)。
如果允许大量的潜在运动,则上述度量可能会偏向于较小的重叠解决方案。为了抵消这种偏差,可以将窗口SSD分数除以重叠面积
(9.6)
计算每个像素(或平均)的像素误差EWSSD /A。该量的平方根是均方根强度误差
RMS =√
(9.7)
经常在比较研究中报告。
偏移和增益(曝光差异)。通常,被对齐的两幅图像并非以相同的曝光度拍摄。两个图像之间线性(仿射)强度变化的简单模型是偏移和增益模型,
I1 (x + u) = (1 + Q)I0 (x) + β, (9.8)
其中,β是偏置,Q是增益(Lucas和Kanade 1981;Gennert 1988;Fuh和Maragos1991;Baker、Gross和Matthews 2003;Evangelidis和Psarakis 2008)。最小二乘法公式如下
与其简单地计算对应区域之间的平方差,有必要进行线性回归(附录A.2),这会稍微增加成本。请注意,对于彩色图像,可能需要为每个颜色通道估计不同的偏置和增益,以补偿某些数码相机自动执行的颜色校正(第2.3.2节)。偏置和增益补偿在视频编解码器中也有应用,称为加权预测(Richardson2003)。
一种更通用(空间变化、非参数)的强度变化模型,在配准过程中作为计算的一部分,被Negahdaripour(1998)、Jia和Tang(2003)以及Seitz和Baker(2009)使用。这有助于处理局部变化,例如广角镜头、大光圈或镜头外壳引起的暗角。此外,还可以在比较图像值之前对其进行预处理,例如使用带通滤波图像(Anandan 1989;Bergen,Anandan等1992),或梯度(Scharstein 1994;Papenberg,Bruhn等2006),或其他局部变换,如直方图或秩。
变换(Cox、Roy和Hingorani 1995;Zabih和Woodfill 1994),或最大化互信息(Viola和Wells III 1997;Kim、Kolmogorov和Zabih 2003)。Hirschm ller和Scharstein(2009)比较了这些方法中的几种,并报告了它们在曝光差异场景中的相对性能。
相关性。除了计算强度差之外,还可以进行相关性分析,即最大化两个对齐图像的乘积(或互相关),
(9.10)
乍一看,这似乎使得偏差和增益建模变得不必要,因为图像将倾向于对齐,而不管它们的相对尺度和偏移。然而,实际上
不正确。如果I1 (x)中存在一个非常亮的区域,那么最大乘积可能实际上位于该区域内。
在哪里
(9.13)
是相应补丁的平均图像,N是补丁中的像素数。归一化互相关得分始终保证在[-1,1]范围内,这使得在某些高级应用中更容易处理,例如判断哪些补丁真正匹配。当匹配不同曝光度拍摄的图像时,归一化相关性表现良好,例如在创建高动态范围图像时(第10.2节)。然而,需要注意的是,如果两个补丁中的任何一个方差为零,则NCC得分是未定义的(实际上,其性能在噪声低对比度区域会下降)。
NCC的变体与匹配分数(9.9)中隐含的偏置-增益回归有关,即归一化SSD分数
由Criminisi、Shotton等人(2007)提出。在他们的实验中,他们发现它产生的结果与NCC相当,但当使用移动平均技术应用于大量重叠的补丁时,它更有效率(第3.2.2节)。
既然我们有了一个明确的对齐成本函数需要优化,如何找到其最小值呢?最简单的办法是在某个范围内的平移上进行全面搜索,使用整数或亚像素步长。这通常是用于运动补偿视频压缩中块匹配的方法,其中探索了一系列可能的运动(例如,±16像素)。4
为了加快这一搜索过程,通常采用层次运动估计:构建图像金字塔(第3.5节),首先在较粗的层级上对较少数量的离散像素(对应相同的运动范围)进行搜索(Quam1984;Anandan1989;Bergen,Anandan等1992)。然后利用金字塔某一层的运动估计来初始化下一层更精细的局部搜索。或者,可以从粗层中使用多个种子(好的解决方案)来初始化细层搜索。虽然这不能保证产生与完整搜索相同的结果,但通常效果几乎一样好,而且速度快得多。
更正式地说,设
Ik (l)(xj) ← k (l-1)(
2xj ) (9.15)
是通过子采样(下采样)在第l级的平滑图像版本得到的被削减的图像。有关如何执行所需的下采样(金字塔构造),而不引入过多混叠,请参见第3.5节。
在最粗略的层面上,我们寻找最佳位移u(l),以最小化图像I0(l)和I1(l)之间的差异。这通常通过在位移u(l)的某个范围内进行全面搜索来完成,范围为∈2-l[-S;S]²,其中S是最精细(原始)分辨率水平下的期望搜索范围,之后可选择进行第9.1.3节中描述的增量细化步骤。
一旦估计出合适的运动矢量,就用它来预测可能的位移
(l-1) ← 2u(l)
(9.16)
4在立体匹配(第12.1.2节)中,由于潜在位移的1D特性,搜索假设的数量要小得多,因此几乎总是对所有可能的视差进行显式搜索(即平面扫描)。
对于下一个更精细的层次。5在更精细的层次上,位移搜索会在一个更窄的位移范围内重复进行,例如(l—1)士1,再次可选择与增量细化步骤结合(Anandan 1989)。或者,可以使用当前运动估计对图像进行变形(重采样),在这种情况下,只需在更精细的层次上计算小幅度的增量运动。Bergen、Anandan等人(1992)提供了整个过程的详细描述,扩展到了参数化运动估计(第9.2节)。
当搜索范围对应于较大图像的显著部分(如图像拼接的情况,见第8.2节),层次方法可能效果不佳,因为通常无法在重要特征被模糊之前过度细化表示。在这种情况下,基于傅里叶的方法可能更为合适。
基于傅里叶的对齐依赖于移位信号的傅里叶变换这一事实
与原始信号具有相同的幅度,但相位线性变化(第3.4节),即F {I1(x + u)} = F {I1 (x)} e—ju·!=I1(!)e—ju·!, (9.17)
其中,!是傅里叶变换的向量值角频率,我们使用符号I1(!)= F {I1 (x)}来表示信号的傅里叶变换(第3.4节)。
傅里叶变换的另一个有用特性是,空间域中的卷积对应于傅里叶域中的乘法(第3.4节)。因此,交叉相关函数ECC的傅里叶变换可以写为
在哪里
(9.19)
是相关函数,即一个信号与另一个信号的反向的卷积,而I(!)是I1(!)的复共轭。这是因为卷积被定义为
一个信号与另一个信号的反向相加(第3.4节)。
5这种位移加倍仅在位移以整数像素坐标定义时才必要,这是文献中常见的做法(Bergen,Anandan等,1992)。如果使用归一化的设备坐标(Section2.1.4),则各层级的位移(和搜索范围)无需改变,尽管步长需要调整,以保持搜索步长大致不超过一个像素。
事实上,傅里叶移位性质(9.17)是从卷积定理中得出的,因为观察到移位等同于与一个位移的delta函数δ(x - u)进行卷积。
为了高效地评估ECC在所有可能的u值范围内,我们对图像I0 (x)和I1 (x)分别进行傅里叶变换,将两个变换相乘(在将第二个变换取共轭后),然后取结果的逆变换。快速傅里叶变换算法可以在O(NM log NM)次操作中计算出一个N×M图像的变换(Bracewell1986)。这比考虑图像重叠范围全貌所需的O(N^2 M^2)次操作要快得多。
虽然基于傅里叶的卷积常用于加速图像相关性的计算,但它也可以用于加速平方差函数(及其变体)的计算。考虑公式(9.1)给出的平方差公式。其傅里叶变换可以表示为
(9
.20)
因此,SSD函数可以通过取相关函数的两倍并从两个图像(或补丁)的能量之和中减去它来计算。
窗口相关。遗憾的是,傅里叶卷积定理仅适用于在两个图像的所有像素上进行求和的情况,当访问超出原始边界外的像素时,需要使用图像的循环移位。虽然对于小偏移和大小相当的图像来说这是可以接受的,但当图像重叠很小或一个图像是另一个的小子集时,这种方法就毫无意义了。
在这种情况下,交叉相关函数应被窗口(加权)交叉相关函数所取代,
(9.22)
其中加权函数w0和w1在图像的有效范围之外为零,并且两个图像都被填充,使得循环移位返回原始图像边界之外的0值。
一个更有趣的例子是计算方程(9.5)中引入的加权SSD函数,
将此展开为相关性的总和并推导出适当的傅里叶变换集,留待练习9.1。
同样的推导方法也可以应用于偏差-增益校正后的平方差函数EBG(9.9)。同样地,可以使用傅里叶变换高效计算所有相关性,以进行偏差和增益参数的线性回归,从而估计每个潜在位移下的曝光补偿差异(练习9.1)。此外,还可以利用傅里叶变换来估计两个中心位于同一像素上的区域之间的旋转和尺度,如De Castro和Morandi(1987)以及Szeliski (2010,第8.1.2节)所述。
相位相关。一种用于运动估计的常规相关(9.18)的变体是相位相关(Kuglin和Hines 1975;Brown 1992)。在这里,两个待匹配信号的谱通过将(9.18)中每个频率乘积除以傅里叶变换的幅度来白化,
(9.24)
在进行最终逆傅里叶变换之前。对于具有完美(循环)移位的无噪声信号,我们有I1(x + u)= I0 (x),因此,根据公式(9.17),我们得到
F{I1(x+u)}=I1(!)e—2πju·! = I0(!)和
F {EPC (u)} = e —2πju·! . (9.25)
因此,相位相关(在理想条件下)的输出是一个位于u的正确值处的单个尖峰(脉冲),这(原则上)使得更容易找到正确的估计。
相位相关在某些领域被认为优于常规相关,但这种表现取决于信号和噪声的特性。如果原始图像受到窄频带噪声(例如低频噪声或峰值频率“嗡嗡”声)的影响,白化过程实际上会减弱这些区域的噪声。然而,如果原始信号在某些频率上的信噪比非常低(比如两张模糊或纹理粗糙且高频噪声较多的图像),白化过程反而可能降低性能(见练习9.1)。
梯度交叉相关已成为相位相关的一种有前途的替代方法(Argyriou和Vlachos,2003),尽管可能需要进一步的系统研究。Fleet和Jepson(1990)也研究了相位相关作为估计的方法。
图9.2函数的泰勒级数近似和光流校正量增量计算。J1(xi + u)是(xi + u)处的图像梯度,ei是当前强度差。
9.1.3逐步完善
到目前为止所描述的技术可以估计与最近像素的对齐(如果使用更小的搜索步骤,则可以估计与潜在的分数像素的对齐)。一般来说,图像稳定和拼接应用需要更高的精度才能获得可接受的结果。
为了获得更好的亚像素估计,我们可以采用天和胡恩斯(1986)描述的几种技术之一。一种方法是在找到的最佳值周围评估几个离散(整数或分数)的(u,v)值,并通过插值匹配得分来找到解析最小值(Szeliski和Scharstein 2004)。
更常用的方法是,首先由Lucas和Kanade(1981)提出,在SSD能量函数(9.1)上进行梯度下降,使用图像函数的泰勒级数展开(图9.2),
(9.27)
(9.28)
在哪里
ei = I1(xi + u)- I0(xi), (9.30)
在(9.1)中首次介绍的是电流强度误差。7在特定子像素处的梯度
位置(xi + u)可以使用多种技术计算,其中最简单的是
7我们遵循机器人学中常用的惯例,以及Baker和Matthews(2004)的惯例,即关于(列)向量的导数结果为行向量,因此公式中需要的转置更少。
仅仅是为了获取像素x和x +(1,0)或x +(0,1)之间的水平和垂直差异。更复杂的导数有时会导致明显的性能改进。
SSD误差(9.28)增量更新的线性化形式通常被称为
光流约束或亮度恒定约束方程(Horn和Schunck1981)Ixu + Iy v + It = 0, (9.31)
其中Ix和Iy中的下标表示空间导数,而It称为时间导数,如果我们在计算视频序列中的瞬时速度,这是有意义的。当平方并求和或在区域上积分时,它可以用来计算光流(Horn和Schunck1981)。
上述最小二乘问题(9.28)可通过求解相关正规方程(附录A.2)来最小化,
A△u = b (9.32)
(9.33)
分别称为(高斯-牛顿近似)Hessian矩阵和梯度加权残差向量。8这些矩阵也常写为
以
及
(9.35)
所需用于J1(xi + u)的梯度可以在估计I1(xi + u)所需的图像变形同时计算(第3.6.1节(3.75)),实际上,这些梯度通常作为图像插值的副产品被计算。如果效率是关注点,可以使用模板图像中的梯度来替代这些梯度,
J1(xi + u)≈J0(xi), (9.36)
因为接近正确的对齐,模板和位移目标图像应该看起来相似。这具有允许预计算Hessian和Jacobi矩阵的优点
8真正的Hessian是误差函数E的完整二阶导数,它可能不是正定的-请参见第8.1.3节和附录A.3。
图像处理可以显著节省计算资源(Hager和Belhumeur 1998;Baker和Matthews 2004)。通过将用于计算(9.30)中ei的变形图像I1(xi + u)表达为子像素插值滤波器与I1中离散样本的卷积,可以进一步减少计算量(Peleg和Rav-Acha 2006)。预先计算梯度场与I1移位版本之间的内积,使得ei的迭代重新计算可以在常数时间内完成(与像素数量无关)。
上述增量更新规则的有效性取决于泰勒级数近似的质量。当远离真实位移(例如,1-2像素)时,可能需要多次迭代。然而,可以通过最小二乘法拟合一系列较大的位移来估计J1的值,以扩大收敛范围(Jurie和Dhome2002),或者为给定的补丁“学习”一个专用识别器(Avidan2001;Williams、Blake和Cipolla2003;Lepetit、Pilet和Fua2006;Hinterstoisser、Benhimane
(如Section7.1.5中所讨论的,et al.2008;zuysal,Calonder et al.2010)。
常用的增量更新停止标准是监测位移校正ⅡuⅡ的大小,当其降至某个阈值以下(例如,1/10像素)时停止。对于较大的运动,通常会将增量更新规则与分层的粗到精搜索策略结合使用,具体如第9.1.1节所述。
条件性和孔径问题。有时,由于待对齐区域缺乏二维纹理,线性系统(9.32)的逆运算可能会变得条件不良。一个常见的例子是孔径问题,最早在一些早期关于光流的研究论文中被识别(Horn和Schunck 1981),后来由Anandan进行了更深入的研究(1989)。考虑一个图像块,其中包含一条向右移动的斜边(图7.4)。在这种情况下,只有速度(位移)的法向分量可以可靠地恢复。这在(9.32)中表现为秩亏矩阵A,即其较小的特征值非常接近零。
当方程(9.32)求解时,沿边缘的位移分量条件非常差,在小噪声扰动下可能导致离谱的猜测。一种缓解此问题的方法是在预期运动范围内添加先验(软约束)(Simoncelli,Adelson,和Heeger1991;Baker,Gross,和Matthews2004;Govindu2006)。这可以通过向A的对角线添加一个小值来实现,这实际上使解偏向于较小的△u值,但仍(大部分)最小化平方误差。 然而,当使用简单的(固定的)二次先验时,如Simoncelli、Adelson和Heeger(1991)所假设的纯高斯模型,在实践中并不总是成立,例如,因为
矩阵A在构造上总是保证是对称半正定的,即它具有非负实特征值。
即沿强边界的混叠(Triggs2004)。因此,在进行矩阵求逆之前,可以谨慎地将较大特征值的一小部分(例如5%)添加到较小的特征值中。
不确定性建模。特定基于补丁的运动估计的可靠性可以通过不确定性模型更正式地捕捉。最简单的模型是协方差矩阵,它捕捉了运动估计在所有可能方向上的预期方差。如第8.1.4节和附录B.6所述,在少量加性高斯噪声下,可以证明协方差矩阵Σu与海森矩阵A的逆成正比,
Σu = σA —1 , (9.37)
其中σ是加性高斯噪声的方差(Anandan1989;Matthies,Kanade,
和Szeliski1989;Szeliski1989)。
对于较大的噪声量,卢卡斯-坎纳德算法在(9.28)中进行的线性化只是近似的,因此上述量成为真实协方差的克拉美罗下界。因此,海森矩阵A的最小和最大特征值现在可以解释为运动最不确定和最确定方向上的(缩放后的)逆方差。(Steele和Jaynes(2005)给出了使用更现实的图像噪声模型的更详细分析。)图7.5显示了图像中三个不同像素位置的局部SSD表面。如你所见,表面在高纹理区域有一个明显的最小值,并且在强边缘附近受到光圈问题的影响。
偏差和增益、加权和鲁棒误差度量。Lucas-Kanade更新规则也可应用于偏差-增益方程(9.9)
(Lucas和Kanade1981;Gennert1988;Fuh和Maragos1991;Baker、Gross和Matthews 2003)。由此得到的4×4方程组可以同时求解,以估计平移位移更新△u和偏置和增益参数β和Q。
对于具有线性外观变化的图像(模板),可以推导出类似的公式,
λj Bj
9.39)
其中Bj (x)是基图像,λj是未知系数(Hager和Belhumeur1998;Baker、Gross等人2003;Baker、Gross和Matthews2003)。潜在
线外观变化包括光照变化(Hager和Belhumeur1998)和
小非刚性变形(Black和Jepson1998;Kambhamettu、Goldgof等人2003)。也可以使用加权(窗口)版本的Lucas-Kanade算法:请注意,在从原始加权SSD函数(9.5)推导Lucas-Kanade更新时,我们忽略了对w1(xi + u)加权函数关于u的导数,这在实践中通常是可接受的,特别是当加权函数是一个具有相对较少过渡的二进制掩模时。
贝克、格罗斯等人(2003)仅使用了w0 (x)项,如果两幅图像具有相同的范围且重叠区域没有(独立的)遮挡,则这一方法是合理的。他们还讨论了将权重与▽I(x)成比例的想法,这有助于处理非常嘈杂的图像,其中梯度本身也是噪声。类似的观点,以总最小二乘法的形式表述(范胡菲尔和范德瓦尔1991;范胡菲尔和莱默林2002),也被其他研究光流的研究者提出(韦伯和马利克1995;巴巴-哈迪亚沙尔和
Suter1998b;M hlich和Mester1998)。Baker、Gross等人(2003)展示了如何进行评估
对于足够大的图像,即使只使用了5-10%的像素,方程(9.40)在最可靠(最高梯度)的像素处也不会显著降低性能。(这一想法最初由Dellaert和Collins(1999)提出,他们使用了更复杂的选取标准。)
Lucas-Kanade增量细化步骤也可以应用于第9.1节中介绍的稳健误差度量,
ELK—SRD
(9.41)
可使用第8.1.4节中描述的迭代加权最小二乘法技术解决。
9.2 参数运动
许多图像对齐任务,例如手持相机拍摄的图像拼接,需要使用更复杂的运动模型,如第2.1.1节所述。这些模型,例如仿射变形,通常比纯平移具有更多的参数,因此在整个可能值范围内进行完整搜索是不切实际的。相反,增量卢卡斯-坎纳德算法可以推广到参数化运动模型,并与层次搜索算法结合使用(Lucas和Kanade 1981;Rehg和Witkin 1991;Fuh和Maragos 1991;
Bergen、Anandan等人1992;Shashua和Toelg1997;Shashua和Wexler2001;Baker和Matthews2004)。
对于参数化运动,我们不再使用单一的常数平移向量u,而是采用空间变化的运动场或对应图x(x;p),该图由低维向量p参数化,其中x可以是第2.1.1节中介绍的任何运动模型。参数化的增量运动更新规则现在变为
即,图像梯度▽I1与对应场的雅可比矩阵Jx,=∂x/∂p的乘积。
表8.1给出了第2.1.1节和表2.1中介绍的二维平面变换的运动雅可比矩阵Jx。请注意,我们重新参数化了这些运动矩阵,使其在原点p = 0时始终为单位矩阵。这在后续讨论组合算法和逆组合算法时会非常有用。(这也使得对运动施加先验条件变得更加容易。)
对于参数化运动,(高斯-牛顿)Hessian和梯度加权残差向量变为
(9.46)
(9.47)
注意方括号内的表达式与简单平移运动情况(9.33–9.34)中计算出的相同。
基于块的近似。参数化运动的海森矩阵和残差向量的计算可能比平移情况下的计算成本高得多。对于具有n个参数和N个像素的参数化运动,A和b的累积需要O(n^2 N)次操作(Baker和Matthews 2004)。一种显著减少这种计算量的方法是
该方法是将图像划分为更小的子块(补丁)Pj,并且仅在像素级别上累积方括号内的简单2×2量(Shum和Szeliski,2000),
(9.48)
ei ▽I
(9.49)
然后可以近似地得到完整的Hessian和残差
和
其中,j是每个补丁Pj的中心(Shum和Szeliski2000)。这相当于用分段常数近似代替真实运动雅可比矩阵。实际上,这种方法效果很好。
组合方法。对于像单应性这样的复杂参数运动,计算运动雅可比矩阵变得复杂,并可能涉及逐像素除法。Szeliski和Shum(1997)观察到,这可以通过首先根据当前运动估计xI(x;p)对目标图像I1进行变形来简化,
1 (x)
= I1 (xI (x; p)), (9.52)
然后将这个扭曲的图像与模板I0 (x)进行比较。随后,Hager和Belhumeur(1998)建议用I0 (x)的梯度替换I1 (x)的梯度,如前所述的(9.36),这使得可以预计算(并求逆)给定在(9.46)中的海森矩阵A。残差向量b(9.47)也可以部分预计算,即最速下降法图像▽I0可以预先计算并存储,以便稍后与e(x) = I1 (x)—I0 (x)误差图像相乘,如(Szeliski 2010,第8.2节)和(Baker和Matthews 200
)所述,这种方法称为逆加法方案。Baker和Matthews(2004)还介绍了一种变体,他们称之为逆组合算法,在该算法中,他们对模板图像I0 (x)进行扭曲,并预计算逆海森矩阵和最速下降法图像,使其成为首选方法。他们还讨论了使用高斯-牛顿迭代的优势(即一阶展开)。
与最速下降法和Levenberg-Marquardt等其他方法相比,最小二乘法(如上所述)具有优势。
后续系列文章(Baker,Gross等,2003;Baker,Gross和Matthews,2003,2004)讨论了更高级的主题,如逐像素加权、效率优化的像素选择、稳健度量和算法的深入探讨、线性外观变化以及参数先验。这些内容对于任何希望实现高度调优的增量图像配准的人来说都是极其宝贵的读物,并且已被广泛用作后续目标跟踪器的组件,相关内容将在第9.4.4节中讨论。Evan Evangelidis和Psarakis(2008)提供了这些及其他相关方法的一些详细实验评估。
学习运动模型
参数化运动场的一种替代方法是学习一组针对特定应用定制的基础函数(Black,Yacoob等,1997)。首先,从一组训练视频中计算出一组密集的运动场(第9.3节)。接着,对运动场堆栈ut (x)应用奇异值分解(SVD),以计算前几个奇异向量vk (x)。最后,对于新的测试序列,使用粗到精算法估计参数化流场中的未知系数ak,从而计算出新的流场。
u (x) = akvk (x). (9.53)
图9.3a展示了通过观察行走视频学习到的一组基场。图9.3b显示了基系数的时间演变以及几个恢复的参数化运动场。请注意,类似的思想也可以应用于特征轨迹(Torresani、Hertzmann和Bregler 2008),这一主题我们将在第7.1.5节和第13.6.4节中详细讨论,同时还有视频稳定技术(Yu和Ramamoorthi 2020)。
视频稳定是参数运动估计最广泛的应用之一(Hansen,Anandan等,1994;Irani,Rousso和Peleg,1997;Morimoto和Chellappa,1997;Srinivasan,Chellappa等,2005;Grundmann,Kwatra和Essa,2011)。用于稳定性的算法既可以在硬件设备中运行,如摄像机和静态相机,也可以在软件包中运行,以提高抖动视频的视觉质量。

图9.3学习的参数化运动场对于一个行走序列(Black,Yacoob等人
(Al.1997)©1997 IEEE:(a)学习基流场;(b)随时间变化的运动系数图和相应的估计运动场。
在关于全帧视频稳定性的论文中,松下、奥费克等人(2006)对稳定性的三个主要阶段进行了很好的概述,即运动估计、运动平滑和图像变形。运动估计算法通常使用相似变换来处理相机的平移、旋转和变焦。难点在于让这些算法锁定背景运动,这是由相机移动引起的,而不被独立移动的前景物体所干扰(余和拉马莫尔蒂2018,2020;余、拉马莫尔蒂等2021)。运动平滑算法恢复运动的低频部分(缓慢变化的部分),然后估计需要消除的高频抖动成分。虽然常用的运动导数二次惩罚,但通过导数的L1最小化可以实现更真实的虚拟相机运动(锁定且线性)(格伦德曼、夸特拉和埃萨2011)。最后,图像变形算法应用高频校正,使原始帧看起来像是相机仅经历了平滑运动。
生成的稳定算法可以显著改善抖动视频的外观,但它们通常仍包含视觉伪影。例如,图像扭曲可能导致图像边缘缺失,这些边缘需要裁剪、使用其他帧的信息填充或通过修复技术(第10.5.1节)来补全。此外,在快速运动中捕捉到的视频帧往往模糊不清。可以通过使用去模糊技术(第10.3节)或从运动较少或对焦更好的其他帧中借用更清晰的像素来改善其外观(松下、奥费克等人,2006年)。练习9.3要求你实现并测试这些想法。
在摄像机大量翻译3D的情况下,例如,当摄像师在
步行时,更好的方法是从相机运动和三维场景的运动重建中计算出完整的结构。然后可以计算一条或多条平滑的三维相机路径,并使用插值后的三维点云作为代理几何,通过视图插值重新渲染原始视频,同时保留显著特征,这有时被称为内容保持变形(Liu,Gleicher等2009,2011;Liu,Yuan等2013;Kopf,Cohen和Szeliski 2014)。如果你有多个摄像头阵列而不是单个摄像机,可以采用光场渲染方法(第14.3节)(Smith,Zhang等2009)来实现更佳效果。
虽然参数化运动模型在各种应用中都很有用(如视频稳定和映射到平面表面上),但大多数图像运动太复杂,无法被这样的低维模型捕捉。
传统上,光流算法(第9.3节)为每个像素计算一个独立的运动估计值,即计算出的流向量数等于输入像素数。因此,一般光流方程(9.1)可以写成
经
济、社会和文化事务部 (9.54)
注意,在上面的方程式中,变量的数量{ui }是测量数量的两倍,所以问题是没有约束的。
我们将在第9.3节中研究的两种经典方法是,在重叠区域(基于补丁或窗口的方法)上进行求和,或者使用正则化或马尔可夫随机场(第四章)在{ui }场中添加平滑项。在本节中,我们将介绍一种介于一般光流(每个像素独立的运动)和参数化流(少量全局参数)之间的替代方法。该方法是将运动场表示为二维样条函数。
j Bj
j wi;
j , (9.55)
其中,Bj(xi)称为基函数,仅在有限的支撑区间内非零(Szeliski和Coughlan1997)。我们称wij = Bj(xi)为权重,以强调{ui }是{j }的已知线性组合。
将单个像素流向量ui(9.55)的公式代入SSD误差度量(9.54),得到一个类似于方程(9.43)的参数运动公式。最大的
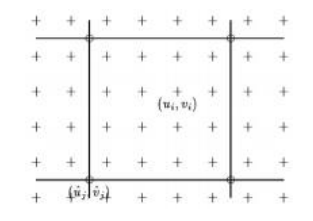
图9.4样条运动场:位移向量ui=(ui,vi)以加号(+)表示,由较少的控制顶点j =(i,j)控制,以圆圈(.)表示。
不同之处在于,雅可比矩阵J1(xi9)(9.45)现在由权重矩阵W = [wij ]中的稀疏项组成。
在我们对运动场有更多的了解的情况下,例如当运动是由静态场景中的摄像机移动引起的时,我们可以使用更专业的运动模型。例如,平面加视差模型(第2.1.4节)可以自然地与基于样条的运动表示相结合,其中平面内的运动由同态(8.19)表示,而平面外的视差d则由每个样条控制点上的标量变量表示(Szeliski和Kang 1995;Szeliski和Coughlan 1997)。
在许多情况下,少量的样条顶点会导致一个条件良好的运动估计问题。然而,如果在多个样条区域中存在大片无纹理区域(或受孔径问题影响的拉长边缘),可能需要添加正则化项以使问题变得适定(第4.2节)。最简单的方法是直接在样条控制网格{j }中相邻顶点之间添加平方差惩罚项,如公式(4.24)所示。如果采用多分辨率(粗到细)策略,则在逐层转换时重新缩放这些平滑项非常重要。
与基于样条的运动估计器相对应的线性系统是稀疏且规则的。由于其通常规模适中,因此可以使用直接技术如乔列斯基分解(附录A.4)来求解。或者,如果问题变得过大并受到过多填充的影响,则可以使用迭代技术,如层次预条件共轭梯度法(Szeliski1990b,2006b;Krishnan和Szeliski2011;Krishnan、Fattal和Szeliski2013)(附录A.5)。
由于其稳健性,基于样条的运动估计已被用于许多应用,包括视觉效果(Roble1999)和医学图像配准(Sec-
图9.5基于四叉树样条的运动估计(Szeliski和Shum1996)©1996
IEEE:(a)四叉树样条表示,(b)这可能导致裂缝,除非白色节点被限制依赖于其父节点;(c)变形的四叉树样条网格叠加在灰度图像上;(d)流场以针图形式可视化。
第9.2.3条)(Szeliski和Lavall
e1996;Kybic和Unser2003)。
然而,基本技术的一个缺点是,在运动不连续处模型表现不佳,除非使用过多的节点。为了改善这一状况,Szeliski和Shum(1996)提出在样条控制网格中嵌入四叉树表示(图9.5a)。大单元用于呈现平滑运动区域,而小单元则添加在运动不连续的区域(图9.5c)。
为了估计运动,采用了一种从粗到精的策略。首先,在低分辨率图像上施加一个规则样条,获得初始运动估计。对于运动不一致的样条区域,即残差平方(9.54)超过阈值的部分,将其细分为更小的区域。为了避免在最终的运动场中出现裂纹(图9.5b),需要限制某些节点的值,这些节点位于细化网格中,即靠近较大单元的节点,使其依赖于其父节点的值。这最简单的方法是使用四叉树样条的层次基表示(Szeliski 1990b),并选择性地将一些层次基函数设为0,如(Szeliski和Shum 1996)所述。
因为样条基运动模型擅长表示平滑的弹性变形场,在医学图像配准中得到了广泛应用(Bajcsy和Kovacic 1989;Szeliski和Lavalle 1996;Christensen、Joshi和Miller1997).10。配准技术既可用于跟踪个体
患者随时间的发展或进展(alon-
纵向研究)或将不同的患者图像匹配在一起,以发现共同点和去
10在计算机图形学中,这种弹性体积变形被称为自由形式变形(Sederberg和Parry1986;Coquillart1990;Celniker以及Gossard1991)。
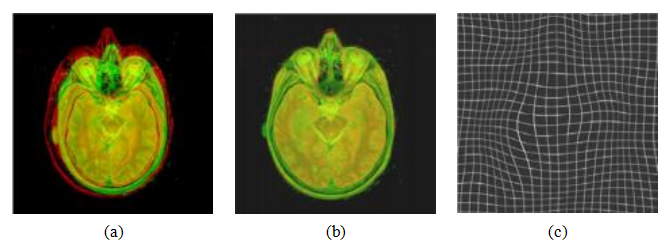
图9.6弹性脑配准(Kybic和Unser 2003)©2003 IEEE:(a)原始脑图谱和患者MRI图像以红绿叠加;(b)弹性配准后,使用八个用户指定的标志点(未显示);(c)立方B样条变形场,显示为变形网格。
结构变异或病理(横断面研究)。当不同成像模式进行配准时,例如计算机断层扫描(CT)和磁共振成像(MRI),通常需要相似性互信息测量(Viola和Wells III 1997;Maes,Collignon等1997)。
Kybic和Unser(2003)提供了一篇很好的文献综述,并描述了一个完整的系统,该系统通过将图像和变形场表示为多分辨率样条来实现。图9.6展示了Kybic和Unser系统用于将患者的脑部MRI与标记的脑图谱图像配准的一个例子。该系统可以完全自动运行,但通过定位几个关键标志点可以获得更准确的结果。关于可变形医学图像配准的最新论文,包括性能评估,包括Klein、Staring和Pluim(2007)、Glocker、Komodakis等人(2008)以及Sotiras、Davatzikos和Paragios(2013)的综述。
与其他应用程序一样,常规体积样条可以通过选择性细化来增强。在三维体积图像或表面配准的情况下,这些被称为八叉树样条(Szeliski和Lavall 1996),已用于配准不同患者的医学表面模型,如椎骨和面部图9.7)。
9.3 光流
运动估计最普遍(也是最具挑战性)的版本是计算每个像素的独立运动估计,这通常被称为光流(或视流)。
图9.7基于八叉树样条的两个椎体表面模型的图像配准(Szeliski
以及Lavall e1996)©1996 Springer:(a)在初始刚性对齐后;(b)在弹性对齐后;(c)穿过适应的八叉树样条变形场的横截面。
我们在上一节中提到,这通常涉及到最小化图像中对应像素的亮度或颜色差异,
经
济、社会和文化事务部 (9.56)
由于变量数量{ui }是测量次数的两倍,问题变得欠约束。解决这一问题的两种经典方法是:在重叠区域(基于补丁或窗口的方法)上局部求和,或者使用正则化或马尔可夫随机场(第4章)对{ui }场添加平滑项,并寻找全局最小值。关于最近光流算法的良好综述,可参见Baker、Scharstein等人(2011年)、Sun、Yang等人(2018年)、Janai、Gnei等人(2020年)以及Hur和Roth(2020年)。
基于补丁的方法通常涉及使用位移图像函数(9.28)的泰勒级数展开来获得亚像素估计值(Lucas和Kanade 1981)。Anand(1989)展示了如何在粗到细的金字塔方案中,将一系列局部离散搜索步骤与Lucas-Kanade的增量细化步骤交织在一起,这使得可以估计大运动,如第9.1.1节所述。他还分析了局部运动估计的不确定性与局部海森矩阵Ai(9.37)的特征值之间的关系,如图7.4和7.5所示。
伯根、阿南丹等人(1992)开发了一个统一的框架,用于描述参数化(第9.2节)和基于补丁的光流算法,并对这一主题进行了很好的介绍。在粗到精的金字塔中每次迭代光流估计后,他们重新校正其中一张图像,以便仅计算增量光流估计(第9.1.1节)
当使用重叠的补丁时,一种有效的实现方法是首先计算每个像素处梯度和强度误差(9.33–9.34)的外积,然后使用移动平均滤波器执行重叠窗口求和。11
霍恩和舒克(1981)没有独立求解每个运动(或运动更新),而是开发了一个基于正则化的框架,在该框架中,(9.56)在所有流向量{ui }上同时最小化。为了约束问题,增加了平滑性约束,即对流导数的平方惩罚,加入到基本的逐像素误差度量中。由于该技术最初是在变分(连续函数)框架下为小运动开发的,因此与(9.28)相对应的线性化亮度恒定约束,即(9.31),通常被写成一个解析积分。
EHS =∫(Ixu + Iy v + It)2 dx dy, (9.57)
其中(Ix,Iy)=▽I1=J1,It = ei表示时间导数,即图像之间的亮度变化,而u(x,y)和v(x,y)是二维光流函数。Horn和Schunck模型也可以视为基于样条的运动估计的极限情况,当样条变为1×1像素块时。
也可以将局部和全局流量估计的思想结合到一个单一框架中,方法是使用局部聚合(而非单像素)的海森矩阵作为亮度恒定项(Bruhn,Weickert和Schn rr 2005)。考虑离散形式的解析全局能量(9.57),即(9.28),
EHSD = ui + 2eiJui
+ e
(9.58)
如果我们用面积代替每个像素(秩1)的Hessian Ai = [JiJ]和残差bi = Jiei
通过聚合版本(9.33–9.34),我们得到了一个全局最小化算法,其中使用了基于区域的亮度约束。
对基本光流模型的另一种扩展是结合全局(参数化)和局部运动模型。例如,如果我们知道运动是由相机在静态场景中移动引起的(刚体运动),我们可以重新定义问题,即估计每个像素的深度以及全局相机运动的参数(Adiv1989;Hanna 1991;Bergen,Anandan等1992;Szeliski和Coughlan 1997;Nir,Bruckstein和Kim- mel 2008;Wedel,Cremers等2009)。这些技术与立体匹配密切相关(第12章)。或者,我们也可以估计每幅图像或每段的仿射运动模型,并结合每个像素的残差校正(Black和Jepson 1996;Ju,Black和
11在此阶段也可使用其他平滑或聚合过滤器(Bruhn、Weickert和Schn rr 2005)。
Jepson1996;Chang、Tekalp和Sezan1997;M min和P rez2002)。我们
将在第9.4节中重新讨论这个话题。
当然,图像亮度可能并不总是衡量外观一致性的一个合适指标,例如当图像中的光照变化时。如第9.1节所述,匹配梯度、滤波图像或其他指标,如图像赫西安(二阶导数测量)可能更为合适。还可以局部计算图像中可转向滤波器的相位,这不受偏置和增益变换的影响(Fleet和Jepson 1990)。Papenberg、Bruhn等人(2006)回顾并探讨了这些约束条件,并提供了在增量流计算过程中迭代重配图像的详细分析和理由。
由于亮度恒定性约束是在每个像素独立评估的,而不是在可能违反恒定流假设的区域求和,因此全局优化方法在运动不连续处表现更好。特别是当使用鲁棒度量作为平滑性约束时(Black和Anandan 1996;Bab-Hadiashar和Suter1998a).12),L1范数,即总变差(TV)是一种流行的鲁棒度量选择,它产生了一个凸能量函数,可以找到其全局最小值(Bruhn,Weickert,和Schn rr2005;Papenberg,Bruhn等2006;Zach,Pock,和Bischof2007b;Zimmer,Bruhn,和Weickert2011)。各向异性平滑性先验是另一种流行的选择,它在图像梯度平行和垂直方向上应用不同的平滑
性(Nagel和Enkelmann 1986;Sun,Roth等2008;Werlberger,Trobin等2009;Werlberger,Pock,和Bischof2010)。还可以从一组配对的流场和强度图像中学习一组更好的平滑性约束(导数滤波器和鲁棒函数)(Sun,Roth等2008)。这些技术在Baker,Scharstein等人(2011)和Sun,Roth和Black(2014)的文章中进行了更详细的讨论。 由于估计流体时存在较大的二维搜索空间,大多数算法采用梯度下降和粗到精的连续方法来最小化全局能量函数。这与立体匹配形成了鲜明对比,后者是一个“更简单”的一维视差估计问题,在深度神经网络出现之前,组合优化技术是首选方法。一种应对这种复杂性的方法是从高效的基于块的对应关系开始(Kroeger,Tim-oft et al.2016)。另一种处理大二维搜索空间的方法是将稀疏特征匹配整合到变分公式中,这一方法最初由Brox和Malik(2010a)提出。后来,包括几位作者在内的多个研究者对此进行了扩展。
12稳健的亮度指标(第9.1节,(9.2))也可帮助提高基于窗口的方法的性能(Black和Anandan1996)。
13在Xu、Ranftl和Koltun中可以找到一些例外,这些例外情况表明,没有探索完整的4D成本量。
(2017)和Teed和Deng(2020b)。
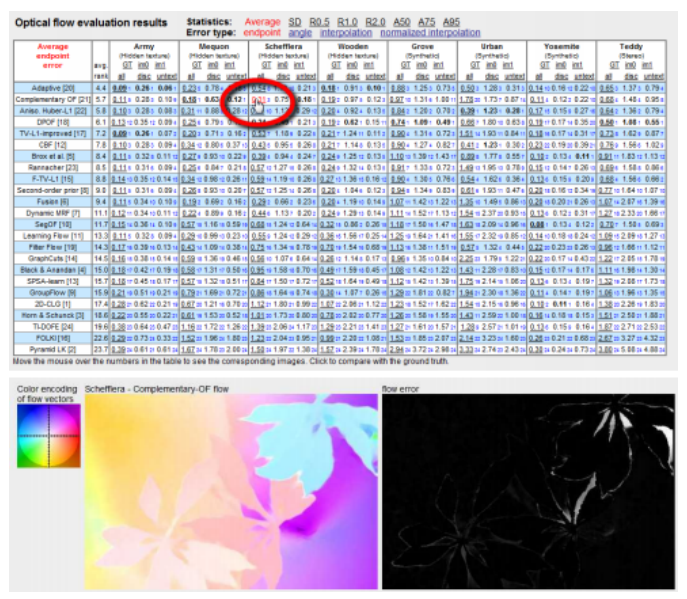
图9.8 24种光流算法结果评估,2009年10月,https://vision.middlebury.edu/flow,(Baker,Scharstein等,2009)。通过将鼠标指针移到带下划线的性能评分上,用户可以交互式地查看相应的流场和误差图。点击评分可以在计算结果和真实值之间切换。每个评分旁边都有一个较小的蓝色数字,表示当前列中的相应排名。每列中的最低(最佳)评分以粗体显示。表格按平均排名排序(总体计算了24列,每八个序列各三个区域掩模)。平均排名作为所选度量/统计指标下的性能近似度量。
Weinzaepfel,Revaud等人(2013)的DeepFlow系统使用手工设计(非学习)卷积网络计算初始准密集对应关系,Revaud,Weinza- epfel等人(2015)的EpicFlow系统在变分优化之前添加了边缘和遮挡感知插值步骤。
基于马尔可夫随机场的组合优化方法在贝克、沙尔斯坦等人(2011)最初发布的光流数据库中表现良好,但如今已被深度神经网络超越。这类技术的例子包括格洛克、帕拉吉奥斯等人(2008)开发的方法,他们采用粗到精的策略,使用逐像素的二维不确定性估计,然后用于指导下一层次的细化和搜索。莱姆皮茨基、罗思和罗瑟(2008)利用融合移动(莱姆皮茨基、罗瑟和布莱克2007)来寻找好的解决方案,这些移动是基于基本流算法(霍恩和舒恩克1981;卢卡斯和卡纳德1981)生成的提案。
对这些“经典”的粗到精的能量最小化方法进行了细致的经验分析,详见孙、罗思和布莱克(2014)精心撰写的论文。图9.9a展示了他们研究框架的主要组成部分,包括基于前一层次流动的初始变形(或在最粗层次进行网格搜索),随后是能量最小化的流动更新,最后是一个可选的后处理步骤。在他们的论文中,作者不仅回顾了从1980年代(霍恩和舒恩克1981)到2013年开发的数十种变分(能量最小化)方法,还指出诸如中值滤波后处理等算法细节,往往被先前的研究者忽略,但对结果有重要影响。除了在米德尔伯里流数据集(贝克、沙尔斯坦等人2011)上进行分析外,他们还在较新的Sintel数据集(巴特勒、沃尔夫等人2012)上进行了评估。
精确运动估计领域正以惊人的速度发展,每年都有显著的性能提升。虽然米德尔伯里光流网站(图9.8)仍然是高性能算法的良好资源,但最近的出版物更多地关注(无论是训练还是评估)由巴特勒、沃尔夫等人(2012)开发的MPI Sintel数据集,其中一些样本如Figure9.1e-f所示。一些算法还在KITTI流基准上进行训练和测试(盖格、伦兹和乌尔塔苏恩2012),尽管该数据集侧重于从行驶车辆获取的视频。总体而言,基于学习的算法在使用一个数据集训练后,应用于另一个数据集时仍会遇到困难。17
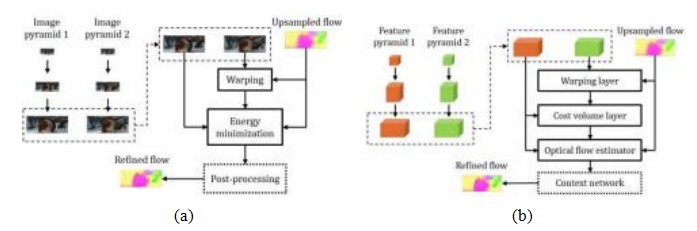
图9.9迭代粗到精光流估计(Sun,Yang等,2018)©2018 IEEE:(a)“经典”变分(能量最小化)方法(Sun,Roth和Black,2014);(b)较新的神经网络方法,通过端到端深度学习训练(Sun,Yang等,2018)。两幅图均展示了单个层级的粗到精金字塔处理过程,输入为前一层(较粗)计算出的光流,并将细化后的光流传递给下一层更精细的层级。
在过去的十年里,深度神经网络已经成为所有高度智能的组成部分
高效的光流算法,如Janai、G ney等人在综述文章中所述。
(2020,第11章)和Hur和Roth(2020)。一种早期的方法是使用受深度卷积网络启发的非线性聚合,即Weinzaepfel、Revaud等人(2013)的DeepFlow系统,该系统采用手工设计(非学习)的卷积和池化来计算多级响应图(匹配成本),然后使用经典的能量最小化变分框架进行优化。
首个在编码器-解码器网络中使用全深度端到端学习的系统是FlowNetS (Dosovitskiy,Fischer等,2015),该系统基于作者合成的FlyingChairs数据集进行训练。论文还介绍了FlowNetC,该方法采用关联网络(局部成本卷积)。后续的FlowNet 2.0系统利用初始流估计来扭曲图像,然后通过级联编码器-解码器网络进一步优化流估计(Ilg,Mayer等,2017),而后续的研究还涉及遮挡和不确定性建模(Ilg,Saikia等,2018;Ilg,C¸ic¸ek等,2018)。
一种替代方法是将全分辨率网络串联起来,同时使用图像金字塔和流金字塔,并结合粗到精的变形和细化,这一方法最早由Ranjan和Black(2017)在SPyNet论文中提出。Sun、Yang等人(2018,2019)提出的较新的PWC-Net如图Figure9.9b所示,通过首先从每一帧计算特征金字塔,再根据从前一分辨率插值得到的流变形第二组特征,扩展了这一思路。
图9.10迭代残差优化光流估计(Hur和Roth 2019)©2019 IEEE。Sun、Yang等人(2018)在Figure9.9bis中提出的从粗到精的级联方法被替换为循环神经网络(RNN),该网络将插值后的较粗层次的光流估计作为下一层更精细层次的变形输入,但每层使用相同的卷积权重。
层级,然后通过特征图之间的点积计算出成本体积,这些特征图最多偏移了d=士4像素。当前层级的精细光流估计是使用多层卷积神经网络生成的,该网络的输入包括成本体积、图像特征以及前一层次插值的光流。最终的情境网络以倒数第二层的光流估计和特征作为输入,并利用扩张卷积赋予网络更广泛的上下文。如果你比较图9.9a–b,你会看到经典和深度粗到精光流估计算法各个处理阶段之间令人愉悦的一致性。18
赫尔和罗斯(2019)开发的一种粗到精的PWC-Net变体是图9.10所示的迭代残差细化网络。与FlowNet 2.0和PWC-Net不同,IRR在每一层都重用了相同的结构和卷积权重,这使得网络可以被“卷起”绘制,如图所示。因此,该网络可以被视为一个简单的递归神经网络(RNN),在每个阶段后对输出流估计进行上采样。除了参数更少外,这种权重共享还提高了准确性。在他们的论文中,作者还展示了如何扩展(加倍)此网络以同时计算前向和后向流以及遮挡情况。
在最近的研究中,Jonschkowski、Stone等人(2020)以PWC-Net为基础架构,系统地研究了训练流估计器的所有组件,采用无监督的方式,即使用没有真实流的常规现实视频,这可以使用更大的训练集(Ahmadi和Patras 2016;Meister、Hur和Roth 2018)。在他们的论文中,Jonschkowski等人系统地比较了光度损失、遮挡估计、自监督和平滑性约束,并分析了
18注意,与其他粗略到精细的变形方法一样,这些算法难以处理快速移动的细小结构,而这些结构在较粗的层次上可能不可见(Brox和Malik2010a)。
其他选择的影响,如预训练、图像分辨率、数据增强和批量大小。他们还提出了四个改进措施,包括成本体积归一化、遮挡估计的梯度停止、在原生流分辨率下应用平滑性以及用于自监督的图像缩放。另一篇近期明确处理遮挡问题的论文是江、坎贝尔等人(2021)。
最近的一个趋势是建模由于均匀和遮挡区域导致的流场估计中的不确定性(Ilg,C¸ic¸ek等,2018)。Yin、Darrell和Yu(2019)开发的HD3网络在多个分辨率级别之间建模对应分布,而Hui和Loy(2020)的LiteFlowNet3网络扩展了他们的小型快速LiteFlowNet2网络(Hui、Tang和Loy,2021),通过成本体积调制和流场变形模块显著提高了精度,同时成本极低。在同一时期的工作中,Hofinger、Rota Bul等人(2020)引入了新的组件,如用采样代替扭曲、智能梯度阻塞和知识蒸馏,这些不仅提高了其流估计的质量,还
可以用于其他应用,例如立体匹配。Tee和Deng(2020b)基于循环网络的思想(Hur和Roth,2019),但不是扭曲特征图,而是预计算一个完整的(W×H)²多分辨率相关体积(循环全对流场变换或RAFT),每次迭代时根据当前的流估计访问该体积。计算一个稀疏的相关体积,仅存储每个参考图像特征的k个最近匹配,可以进一步加速计算(Jiang、Lu等,2021)。
鉴于光流技术的快速演变,哪种方法最好使用?答案高度依赖于具体问题。一种评估方法是跨多个数据集进行测试,如鲁棒视觉挑战赛中所做的那样。在这个综合基准上,RAFT、IRR和PWCall的变体表现良好。另一种方法是根据其特定用途专门评估一种光流算法,并尽可能在特定问题的数据上微调网络。Xue、Chen等人(2019)描述了他们如何在合成降质的Vimeo-90K数据集上微调SPyNet从粗到精的网络以估计任务导向的光流(TOFlow),该方法在三个不同的视频处理任务中优于“更高精度”的网络(甚至优于真实流),这三个任务分别是帧插值(第9.4.1节)、视频去噪(第9.3.4节)和视频超分辨率。通过将合成训练数据定制为目标数据集,也可以显著提高基于学习的光流算法的性能(Sun,
为了节省硅电路并提高光敏度或填充因子,许多移动电话中的CMOS成像传感器采用滚动快门技术,即不同行或列依次曝光。在拍摄快速场景或相机运动时,这可能导致直线变得倾斜或弯曲(例如飞机或直升机的螺旋桨叶片),或者场景中的刚性部分摇晃(也称为果冻效应),例如在动作摄影中相机快速振动时。
为了补偿这些由不同扫描线曝光时间造成的失真,必须精确估计每个像素的光流,而不是有时用于慢动作视频稳定化的全帧参数运动(第9.2.1节)。Baker、Bennett等人(2010年)和Forss n、Ringaby(2010年)是最早研究这一问题的计算机视觉研究人员之一。在他们的论文中,Baker、Bennett等人(2010年)从低频帧间运动
中恢复高频运动场,并用其重新采样每个输出扫描线。Forss n和Ringaby(2010年)使用相机旋转模型进行类似的计算,这需要内参镜头校准。Grundmann、Kwatra等人(2012年)通过混合单应性来建模相机和场景运动,从而消除了这种校准的需求;而Liu、Gleicher
等人(2011年)则使用子空间约束。为了生成高质量的图像拼接结果,还需要精确的滚动快门校正(Zhuang和Tran 2020)。
在一些现代成像系统中,如运动相机,惯性测量单元(IMU)可以提供相机运动的高频估计,但它们无法直接提供深度依赖视差和独立物体运动的估计。因此,最佳的相机内图像稳定器使用IMU数据和复杂的图像处理相结合。20模型化滚动快门对于从运动中获取结构的准确姿态估计也非常重要(Hedborg,Forss n等2012;Kukelova,Albl等2018;Albl,Kukelova等2020;Kukelova,Albl等2020),以及视觉-惯性融合在SLAM中的应用(Patron-Perez,Lovegrove
和Sibley 2015;Schubert,Demmel等2018),这些内容将在第11.4.2节和第11.5节中讨论。
到目前为止,我们已经将运动估计看作是一个两帧问题,目标是计算出一个运动场,使一个图像中的像素与另一个图像中的像素对齐。实际上,运动估计通常应用于视频中,在视频中可以使用一整序列的帧来执行这个任务。
图9.11空间-时间体积的切片(Szeliski1999a)©1999 IEEE:(a-b)花园序列中的两帧;(c) a横向切片穿过完整的时空体积,箭头指示估计流动的关键帧位置。请注意,花园序列的颜色不正确;正确的颜色(黄色花朵)显示在图9.13中。
一种经典的多帧运动处理方法是使用定向或可转向滤波器(Heeger1988)对时空体进行滤波,类似于定向边缘检测(第3.2.3节)。图9.11展示了常用花园序列中的两帧,以及通过堆叠所有视频帧创建的三维体积的水平切片。由于像素运动主要为水平方向,因此可以清楚地看到各个(纹理)像素轨迹的斜率,这对应于它们的水平速度。时空滤波利用每个像素周围的三维体积来确定其在时空中的最佳方向,这直接对应于像素的速度。
不幸的是,为了在图像的各个位置获得相对准确的速度估计,时空滤波器具有较大的范围,这严重降低了其在运动不连续处的估计质量。(这个问题同样存在于基于二维窗口的运动估计器中。)一种替代全时空滤波的方法是估算更多的局部时空导数,并在全局优化框架内使用这些导数来填补无纹理区域(Bruhn,Weickert,和Schn rr2005;Govindu2006)。
另一种选择是同时估计多个运动估计,同时可选地推理遮挡关系(Szeliski 1999a)。图9.11c示意性地展示了一种潜在的方法。水平箭头表示关键帧s的位置,在这些位置进行运动估计,而其他切片则表示视频帧,其颜色与通过插值关键帧预测的颜色相匹配。运动估计可以被表述为一个全局能量最小化问题,该问题同时最小化关键帧与其他帧之间的亮度兼容性和流兼容性项,此外还使用了稳健的平滑项。
多视图框架对于刚性场景运动来说可能更加合适
(多视图立体)(第12.7节),其中每个像素的未知数是视差和遮挡关系,可以直接从像素深度确定(Szeliski1999a;Kol- mogorov和Zabih2002)。然而,它也适用于一般运动,通过增加遮挡关系模型,如Hur和Roth(2017)的MirrorFlow系统所示。
以及多帧版本(Janai、Guney等人,2018;Neoral、ochman和Matas2018;
Ren、Gallo等人,2019)。
视频降噪是去除电影和视频中的噪声和其他伪影(如划痕)的过程(Kokaram2004;Gai和Kang2009;Liu和Freeman2010)。与单张图像降噪不同,后者仅能利用当前画面的信息,而视频降噪器可以从相邻帧中平均或借用信息。然而,为了在不引入模糊或抖动(不规则运动)的情况下实现这一目标,它们需要精确的逐像素运动估计。一种方法是使用任务导向的流,其中流网络被专门调整以端到端提供最佳降噪性能(Xue,Chen等2019)。
练习9.6列出了所需的一些步骤,包括判断当前运动估计是否足够准确,可以与其他帧进行平均。尽管一些最近的论文继续将流估计作为多帧去噪流程的一部分(Tassano、Delon和Veit 2019;Xue、Chen等2019),但其他研究要么将不同帧中的相似块拼接在一起(Maggioni、Boracchi等2012),要么将小部分帧组合成一个深度网络,该网络从未明确估计运动表示(Claus和van Gemert 2019;Tassano、Delon和Veit 2020)。一种更通用的视频增强和恢复方法——视频质量映射——也最近开始受到关注(Fuoli、Huang等2020)。
9.4 分层运动
在许多情况下,视觉运动是由场景中不同深度的少量物体的移动引起的。在这种情况下,如果将像素分组为适当的物体或层,则可以更简洁地描述(并更可靠地估计)像素运动(Wang和Adelson1994)。
图9.12示意性地展示了这种方法。这一序列中的运动是由棋盘背景的平移和前景手部的旋转引起的。完整的运动序列可以从前景和背景元素的外观中重建,这些元素可以表示为透明抠像图像(精灵或视频

图9.12分层运动估计框架(王和阿德森1994)©1994 IEEE:最上面两行描述了两个层次,每个层次包含一个强度(颜色)图像、一个透明度(黑色=透明)的遮罩以及一个参数化的运动场。这些层次通过不同量的运动合成,以重现视频序列。
(对象)和对应于每一层的参数化运动。将这些层按从后向前的顺序置换和合成(第3.1.3节)可重现原始视频序列。
分层运动表示不仅能够生成紧凑的表示(Wang和Adelson 1994;Lee、Chen等1997),还能充分利用多个视频帧中的信息,并准确建模运动不连续处像素的外观。这使得它们特别适合用于基于图像的渲染(第14.2.1节)(Shade、Gortler等1998;Zitnick、Kang等2004),以及对象级别的视频编辑。
为了计算视频序列的分层表示,王和阿德森(1994)首先在一组非重叠的块上估计仿射运动模型,然后使用k均值聚类这些估计值。接着,他们交替进行像素分配到各层和使用分配的像素重新计算每层的运动估计,这一技术最初由达雷尔和彭特兰(1991)提出。一旦每个帧的参数化运动和逐像素层分配独立计算完成,通过将所有帧中的不同层部分进行扭曲和合并来构建分层。中值滤波用于生成对小强度变化具有鲁棒性的清晰复合层,

图9.13分层运动估计结果(Wang和Adelson1994)©1994 IEEE。
以及推断各层之间的遮挡关系。图9.13展示了这一过程在花园序列上的结果。你可以看到其中一个帧的初始和最终层分配,以及合成流和带有相应流矢量叠加的透明遮罩层。
在后续研究中,魏斯和阿德森(1996)使用正式的概率混合模型来推断最优层数和每像素的层分配。魏斯(1997)进一步推广了这种方法,用平滑正则化的每像素运动估计替换了每层的仿射运动模型,这使得系统能够更好地处理弯曲和起伏的层,如大多数真实世界序列中所见。
然而,上述方法仍然区分了先估计运动和层分配,然后再估计层颜色。在贝克、斯泽利斯基和阿南丹(1998)描述的系统中,生成模型被推广以适应现实世界的刚性运动场景。每一帧的运动使用三维相机模型来描述,而每一层的运动则通过三维平面方程加上每个像素的残余深度偏移(即平面加视差表示(第2.1.4节))来描述。初始层估计的过程类似于王和阿德森(1994)的方法,只是使用了刚性平面运动(单应矩阵)而不是仿射运动模型。然而,最终的模型优化通过最小化重新合成的运动序列与观察到的运动序列之间的差异,联合重新优化层像素颜色和不透明度值Ll以及三维深度、平面和运动参数zl、nl和Pt(贝克、斯泽利斯基和阿南丹1998)。
图9.14展示了使用该算法获得的最终结果。如你所见,运动边界和层分配比图9.13中的要清晰得多。由于每个像素的深度偏移,单个层的颜色值也比使用仿射或平面运动模型得到的更锐利。而贝克、斯泽利斯基的原始系统,
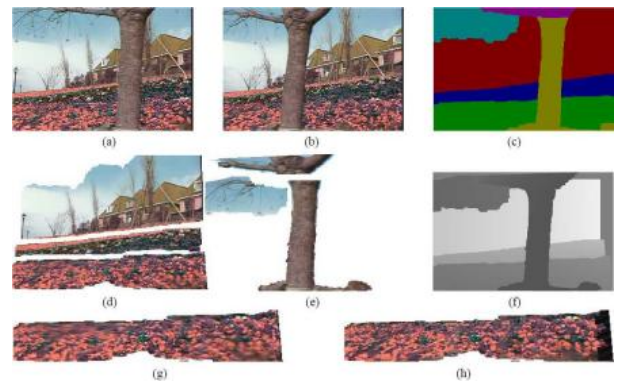
图9.14分层立体重建(Baker、Szeliski和Anandan1998)©1998
IEEE: (a)第一张输入图像;(b)最后一张输入图像;(c)初始分割为六层;(d)和(e)六层精灵;(f)平面精灵的深度图(颜色越深表示距离越近);前一层(g)残差深度估计前;(h)残差深度估计后。请注意,花园序列的颜色不正确;正确的颜色(黄色花朵)如图9.13所示。
Anandan(1998)要求对像素进行粗略的初始分层,Torr、Szeliski和Anandan(2001)描述了用于初始化该系统并确定最佳层数的自动贝叶斯技术。
层次运动估计仍然是一个活跃的研究领域。2000年代的代表性论文包括(Sawhney和Ayer 1996;Jojic和Frey 2001;Xiao和Shah 2005;Kumar、Torr和Zisserman 2008;Thayananthan、Iwasaki和Cipolla 2008;Schoenemann和Cremers 2008),而更近期的论文则包括(Sun、Sudderth和Black 2012;Sun、Wulff等2013;Sun、Liu和Pfister 2014;Wulff和Black 2015)以及(Sevilla-Lara、Sun等2016),这些研究共同实现了语义分割和运动估计。
层次并不是将分割引入运动估计的唯一方法。已经开发了大量算法,在估计光流向量和将其分割为连贯区域之间交替进行(Black和Jepson 1996;Ju、Black和Jepson 1996;Chang、Tekalp和Sezan 1997;M min和P rez 2002;Cremers和Soatto 2005)。其中一些技术依赖于首先分割输入的颜色图像,然后
估计每个片段的运动,以生成连贯的运动场,同时建模遮挡(Zitnick,Kang等2004;Zitnick,Jojic和Kang 2005;Stein,Hoiem和Hebert 2007;Thayananthan,Iwasaki和Cipolla 2008)。事实上,视频中连贯运动部分的分割已经发展成为一个独立的主题,即视频对象分割,我们将在第9.4.3节中研究。
帧插值是运动估计的一个广泛应用,通常在硬件中实现,以匹配输入视频与显示器的实际刷新率,在这种情况下,需要从前后帧中插值出新颖的中间帧信息。如果能够在每个未知像素位置计算出准确的运动估计,可以获得最佳效果。然而,除了计算运动外,遮挡信息也至关重要,以防止移动前景物体污染特定像素的颜色,这些物体可能会遮挡前一帧或后一帧中的某个像素。
更详细地考虑图9.11c,并假设箭头表示我们希望插值的帧之间的关键帧。该图中条纹的方向编码了各个像素的速度。如果在图像I0中的位置x0处获得的运动估计u0与在图像I1中的位置x0 + u0处获得的运动估计相同,则称这些流向量是一致的。这个运动估计可以转移到生成图像It中的位置x0 + tu0,其中t∈(0;1)是插值的时间。最终的颜色值可以在像素x0 + tu0处通过线性混合计算得出,
它(x0 + tu0)=(1 - t)I0(x0)+ tI1(x0 + u0)。 (9.59)
然而,如果对应位置的运动矢量不同,则必须使用某种方法来确定哪个是正确的,以及哪张图像包含被遮挡的颜色。实际的推理过程比这更为复杂。例如,基于Shade、Gortler等人(1998)和Zitnick、Kang等人(2004)早期深度图插值工作的插值算法,被Baker、Scharstein等人(2011)在流评估论文中采用。Mahajan、Huang等人(2009)提出了一种更高质量的帧插值算法,该算法基于梯度重建。帧插值任务的准确性有时也被用来衡量运动估计算法的质量(Szeliski 1999b;Baker、Scharstein等人2011)。
最近的帧插值技术使用深度神经网络作为其架构的一部分。一些方法使用时空卷积(Niklaus,Mai和Liu 2017),而其他方法则使用DNN计算双向光流(Xue,Chen等人2019)。
图9.15深度特征视频插值网络(Niklaus和Liu 2020)©2020 IEEE。该多阶段网络首先计算双向流,使用特征金字塔编码每一帧,然后通过软并融合这些特征进行变形和组合。组合后的特征随后输入最终的图像合成网络(解码器)。
然后使用上下文特征(Niklaus和Liu 2018)或软可见性图(Jiang、Sun等2018)将两个原始帧的贡献结合起来。Niklaus和Liu(2020)的系统将输入帧编码为深度多分辨率神经特征,通过双向流前向扭曲这些特征,使用softmax分散法结合这些特征,最后使用一个最终的深度网络解码这些组合特征,如图9.15所示。类似的架构也可以用于从单张静态图像创建具有时间纹理的循环视频(Holynski、Curless等2021)。其他最近开发的帧插值网络包括Choi、Choi等(2020)、Lee、Kim等(2020)、Kang、Jo等(2020)和Park、Ko等(2020)。
层状运动的特殊情况是透明运动,通常由窗户和相框中看到的反射引起(图9.16和9.17)。
该领域的早期研究中,一些工作通过估计运动成分(Shizawa和Mase 1991;Bergen、Burt等1992;Darrell和Simoncelli 1993;Irani、Rousso和Peleg 1994)或将单个像素分配到竞争的运动层来处理透明运动,这适用于部分被精细遮挡物(如树叶)遮挡的场景。然而,为了准确分离真正透明的层次,需要一个更好的反射运动模型。由于光线既从玻璃表面反射又透过玻璃表面传播,正确的反射模型是累加式的,每个移动层都会对最终图像贡献一定的强度(Szeliski、Avidan和Anandan 2000)。

图9.16光线从相框透明玻璃反射:(a)输入序列中的第一张图像;(b)主导运动层最小合成;(c)次要运动残差层最大合成;(d–e)最终估计的图像和反射层原始图像来自Black和Anandan(1996),而分离的层来自Szeliski、Avidan和Anandan(2000)©2000 IEEE。
如果已知各层的运动,恢复各层图像就变成了一个简单的约束最小二乘问题,其中各层图像被限制为正值,饱和像素则对总和值提供了不等式约束。然而,这个问题可能会受到长时间低频模糊的影响,特别是当某一层缺乏暗(黑色)像素或运动是单向时。在他们的论文中,Szeliski、Avidan和Anandan(2000)指出,通过交替稳健计算运动层并随后对层强度做出保守(上限或下限)估计,可以同时估计运动和层值。最终的运动和层估计可以通过梯度下降法在类似于Baker、Szeliski和Anandan(1998)提出的联合约束最小二乘公式上进行优化,其中过度合成算子被替换为加法。
图9.16和9.17显示了将这些技术应用于两个具有反射的图像帧的结果。请注意,在第二个序列中,反射光的量与透射光(女孩的照片)相比非常低,然而算法仍然能够恢复两层。

图9.17透明运动分离(Szeliski、Avidan和Anandan2000)©2000
IEEE:(a)输入序列的第一幅图像;(b)主导运动层最小合成;(c)第二-
最大复合的动态残差层;(d-e)最终估计的图像和反射层。注意,(c)和(e)中的反射层的强度被加倍,以更好地显示其结构。
不幸的是,Szeliski、Avidan和Anand(2000)使用的简单参数化运动模型仅适用于平面反射器和浅景深场景。这些技术扩展到曲面反射器和深度显著的场景的研究也已开展(Swaminathan、Kang等2002;Criminisi、Kang等2005;Jacquet、Hane等2013),以及更复杂三维深度场景的扩展研究(Tsin、Kang和Szeliski 2006)。虽然用于评估光流技术的运动序列也开始包括反射和透明度(Baker、Scharstein等2011;Butler、Wulff等2012),但它们提供的地面真实流估计仅包含每个像素的主要运动,例如忽略雾气和反射。
在最近的研究中,辛哈、科普夫等人(2012)使用两层具有不同深度和反射率的相机捕捉到的三维场景中的反射进行建模,然后利用这些反射生成基于图像的渲染(新颖视图合成),我们将在第14.2.1节中详细讨论。科普夫、兰古特等人(2013)扩展了该系统的建模和渲染组件,以恢复每层的彩色图像梯度,然后使用梯度域渲染重建新颖视图。薛、鲁宾斯坦等人(2015)通过引入梯度稀疏先验,扩展了这些模型,以实现透过窗户和围栏时的无障碍摄影。关于这一主题的更近期论文包括杨、李等人(2016)、南多里亚、埃尔加里布等人(2017)和刘、赖等人(2020a)。双像素成像传感器的出现,最初设计用于快速对焦,也可以通过将梯度分离到不同的深度平面来消除反射(普纳普拉特和布朗2019)。

图9.18来自密集标注视频分割(DAVIS)数据集的样本序列©Pont-Tuset,Perazzi等人(2017)。DAVIS 2016数据集(a)仅包含前景-背景分割(红色区域),而DAVIS 2017数据集(b)则在每个序列中包含多个标注对象(亮色区域)。
虽然所有这些技术对于分离或消除作为相干图像出现的反射都很有用,但更复杂的三维几何形状通常会产生空间分布的镜面反射(第2.2.2节),这不适合基于层的表示。在这种情况下,表面光场(第14.3.2节和图14.13)和神经光场(第14.6节和图14.24b)等光场表示可能更为合适。
正如我们在本章中所见,准确估计运动通常需要将视频分割成连贯移动的区域或对象,并正确建模遮挡。将视频片段分割成连贯的对象是静态图像分割的时间类比,我们在第7.5节中研究过。除了提供更准确的运动估计外,视频对象分割还支持多种编辑任务,如对象移除和插入(第10.4.5节),以及视频理解和解释。
虽然前景和背景层的分割研究已经进行了很长时间(Bergen,Anandan等,1992;Wang和Adelson,1994;Gorelick,Blank等,2007;Lee和Grauman,2010;Brox和Malik,2010b;Lee,Kim和Grauman,2011;Fragkiadaki,Zhang和Shi,2012;Papazoglou和Ferrari,2013;Wang,Shen和Porikli,2015;Perazzi,
王等人(2015)引入了戴维斯(密集注释视频分割),佩拉齐、庞特-图塞等人(2016)的贡献极大地加速了该领域的研究。图9.18a展示了原始戴维斯2016数据集的一些帧,其中第一帧带有前景像素掩模(显示为红色),任务是估计其余帧的前景掩模。戴维斯2017数据集(庞特-图塞、佩拉齐等人,2017)将视频片段数量从50增加到150,增加了更多具有挑战性的元素,如运动模糊和前景遮挡,并且最重要的是,每个序列中添加了一个以上的标注对象(图9.18b)。
视频对象分割算法,如OSVOS (Caelles,Maninis等,2017)、FusionSeg (Jain,Xiong,和Grauman,2017)、MaskTrack (Perazzi,Khoreva等,2017)和SegFlow (Cheng,Tsai等,2017),通常包括一个深度逐帧分割网络以及用于连接和优化分割的运动估计算法。一些方法(Caelles,Maninis等,2017;Khoreva,Benenson等,2019)还基于第一帧注释对分割网络进行微调。最近的方法则侧重于提高流水线的计算效率(Chen,Pont-Tuset等,2018;Cheng,Tsai等,2018;Wug Oh,Lee等,2018;Wang,Zhang等,2019;Meinhardt和Leal-Taix,2020)。
自2017年起,每年都会与CVPR联合举办关于DAVIS数据集的挑战赛和研讨会。近年来,挑战赛新增了带有较弱注释/涂鸦的分割任务(Caelles,Montes等人,2018年),以及完全未监督的分割任务,算法能够计算视频帧的时间关联分割(Caelles,Pont-Tuset等人,2019年)。此外,还有一个更新、更大的数据集,名为YouTube-VOS (Xu,Yang等人,2018年),该数据集也有自己的挑战赛和排行榜。关于这一主题发表的论文数量持续很高。最近工作的最佳来源是https://davischallenge.org和https://youtube-vos.org上的挑战排行榜,这些排行榜附有简短的技术描述文章,还有大量会议论文,通常标题中包含“视频对象分割”。
计算机视觉在视频分析中最广泛的应用之一是视频对象跟踪。这些应用包括监控(Benfold和Reid2011)、动物和细胞跟踪(Khan、Balch和Dellaert2005)、运动员跟踪(Lu、Ting等人2013)以及汽车安全(Janai、G ney等人2020,第6章)。
我们在前面的章节中已经讨论了更简单的跟踪示例,包括第7.1.5节中的特征(补丁)跟踪和第7.3节中的轮廓跟踪。
图9.19视觉目标跟踪(Smeulders,Chu等人,2014)©2014 IEEE:(a)高级模型显示主要跟踪器组件;(b)一些跟踪区域表示,包括单个边界框、轮廓、斑点、基于块的、稀疏特征、部件和多个边界框。
此类技术的实验评价包括Lepetit和Fua(2005)、Yilmaz、Javed和Shah(2006)、Wu、Lim和Yang(2013)以及Janai、Gnei等人(2020,第6章)。
了解跟踪技术的一个很好的起点是斯梅尔德斯、朱等人(2014)的调查和教程,这也是最早的大规模跟踪数据集之一,包含超过300个视频片段,时长从几秒到几分钟不等。图9.19a展示了在线跟踪系统中通常存在的几个主要组件,包括选择形状、运动、位置和外观的表示方法,以及相似度测量、优化和可选的模型更新。图9.19b展示了一些用于表示形状和外观的选择,包括单个边界框、轮廓、补丁、特征和部分。
论文包括对先前调查和技术的讨论,以及数据集、评估指标和上述模型选择。随后,它将一些知名和较新的算法分类到一个分类体系中,该体系包括固定模板的简单匹配、扩展和约束(稀疏)外观模型、判别分类器和基于检测的跟踪。所讨论和评估的算法包括由贝克和马修斯(2004年)实现的KLT、均值漂移(科马尼丘和米尔2002年)和片段基(亚当、里夫林和辛莫尼2006年)跟踪、在线PCA外观模型(罗斯、林等人2008年)、稀疏基(梅和凌2009年)以及使用核化结构输出支持向量机的Struct(哈雷、戈洛杰茨等人2015年)。
大约在同一时期(2013年),一系列关于单目标短期跟踪的年度挑战和研讨会开始,称为VOT(视觉对象跟踪)。21在他们描述评估方法的期刊论文中,Kristan、Matas等人(2016)评估了最近的跟踪器,并发现结构化变体以及核化相关滤波器(KCF)的扩展,
最初由亨里克斯、卡塞罗等人(2014)开发,表现最佳。这一时期的其他具有高度影响力的论文包括(贝尔蒂内托、瓦尔马德雷等人2016a,b;丹内尔詹、罗宾逊等人2016)。自那时起,深度网络在视觉物体跟踪中发挥了关键作用,通常使用孪生网络(第5.3.4节;布罗姆利、居约等人1994;乔普拉、哈德塞尔和勒昆2005)将被跟踪的区域映射到神经嵌入中。关于更近期跟踪算法的列表和描述,可以在伴随VOT挑战赛和研讨会的年度报告中找到,最近的一份是克里斯坦、莱昂德尼斯等人(2020)。
与单目标VOT挑战和研讨会并行,多目标跟踪作为KITTI视觉基准的一部分被引入(Geiger,Lenz,和Urtasun 2012),Leal-Taix,Milan等人(2015)也开发了一个独立的基准,并推出了一系列挑战,最近的结果由Dendorfer,O ep等人(202)描述。Luo,Xing等人(2021)对2016年之前的多目标跟踪论文进行了综述。简单快速的多目标
跟踪器包括Bergmann、Meinhardt和Leal-
Taix(2019
)和Zhou、Koltun和Kr henb hl(2020)
。然而,直到最近,追踪
数据集主要关注人、车辆和动物。为了扩大可追踪对象的范围,Dave、Khurana等人(2020)创建了TAO(跟踪任何物体)数据集,包含2,907个视频,这些视频首先由用户标记所有移动的物体,然后将这些物体分类到833个类别中。
虽然在本节中,我们主要关注的是物体跟踪,其主要目标是在连续的视频帧中定位一个物体,但也可以同时进行跟踪和分割(Voigtlaender,Krause等2019;Wang,Zhang等2019),或者使用可变形模型跟踪非刚性变形物体,如T恤(Kambhamettu,Goldgof等2003;White,Crane和Forsyth 2007;Pilet,Lepetit和
Fua2008;Furukawa和Ponce2008;Salzmann和Fua2010)或RGB-D流(Bo i,
Zollh等人,2020年
;Bo i等人,Palafox等人,2020
年,2021年)。最近的TrackFormer论文
Meinhardt、Kirillov等人(2021)对多目标跟踪和分割的最新工作进行了很好的综述。
9.5 额外阅读
一些最早的运动估计算法是为运动补偿视频编码开发的(Netravali和Robbins,1979),这些技术继续被用于现代编码标准,如MPEG、H.263和H.264 (Le Gall,1991;Richardson
2003年)。在计算机视觉领域,这一分支最初被称为图像序列分析(黄1981)。一些早期的开创性论文包括霍恩和舒恩克(1981)以及纳格尔和恩克尔曼(1986)开发的变分方法,以及卢卡斯和卡纳德(1981)开发的基于块的平移对齐技术。这些算法的层次化(从粗到细)版本由昆(1984)、阿南丹(1989)和伯根、阿南丹等人(1992)开发,尽管它们也长期用于视频编码中的运动估计。
Rehg和Witkin(1991)、Fuh和Maragos(1991)以及Bergen、Anandan等人(1992)将平移运动模型推广到仿射运动,Shashua和Toelg(1997)以及Shashua和Wexler(2001)则将其推广到二次参考曲面——详见Baker和Matthews(2004)的综述。这些参数化运动估计算法在视频摘要(Teodosio和Bender 1993;Irani和Anandan 1998)、视频稳定(Hansen、Anandan等人1994;Srinivasan、Chellappa等人2005;Matsushita、Ofek等人2006)和视频压缩(Irani、Hsu和Anandan 1995;Lee、Chen等人1997)中得到了广泛应用。关于参数化图像配准的综述包括Brown(1992)、Zitov‘aa和Flusser(2003)、Goshtasby(2005)以及Szeliski(2006a)的研究。
光学流算法的总体调查和比较包括Aggar- wal和Nandhakumar(1988)、Barron、Fleet和Beauchemin(1994)、Otte和Nagel(1994)、Mitiche和Bouthemy(1996)、Stiller和Konrad(1999)、McCane、Novins等人(2001)等人的研究,
Szeliski(2006a)、Baker、Scharstein等人(2011)、Sun、Yang等人(2018)、Janai、G ney等人
等(2020),以及赫尔和罗斯(2020)。匹配基元的主题,即在匹配前使用滤波或其他技术预处理图像,在多篇论文中有所讨论(阿南丹1989;伯根、阿南丹等人1992;沙尔斯坦1994;扎比和伍德菲尔1994;考克斯、罗伊和欣戈拉尼1995;维奥拉和威尔斯三世1997;内加达里普尔1998;金、科洛莫戈罗夫和扎比2003;贾和唐2003;帕彭贝格、布鲁恩等人2006;塞茨和贝克
2009年)。Hirschm ller和Scharstein(2009年)比较了其中一些方法并报告
根据他们在曝光差异场景中的相对表现。
贝克、沙尔斯坦等人(2011)首次发布了用于评估光流算法的大规模基准测试,这促进了估计算法质量的迅速提升。尽管大多数表现最佳的算法使用了稳健的数据和平滑度规范,如L1或TV以及连续变分优化技术,但一些算法采用了离散优化或分割方法(帕彭贝格、布鲁恩等人2006;特罗宾、波克等人2008;徐、陈和贾2008;莱姆皮茨基、罗斯和罗瑟2008;维尔伯格、特罗宾等人2009;雷和杨2009;韦德尔、克雷默斯等人2009)。
Sintel (Butler,Wulff等人,2012)和KITTI (Geiger,Lenz,and Urta-
太阳2012)数据集进一步加速了光流算法的进步。过去十年中发表的重要论文包括温扎普费尔、雷沃等人(2013),孙、罗斯和布莱克(2014),雷沃、温扎普费尔等人(2015),伊尔格、迈耶等人(2017),徐、兰夫特和科尔图恩(2017),孙、杨等人(2018,2019),赫尔和罗斯(2019),以及蒂德和邓(2020b)。关于过去十年光流论文的综述,可参见孙、杨等人(2018),贾奈、格内伊等人(2020),以及赫尔和罗斯(2020)。
关于视频对象分割和视频对象跟踪的阅读起点是最近与这些主题的主要数据集和挑战相关的研讨会(Pont-Tuset,Perazzi等人,2017;Xu,Yang等人,2018;Kristan,Leonardis等人,2020;Dave,Khurana等人,2020;Dendorfer,O ep等人,2021)。
9.6 练习
例9.1:相关性。实现并比较以下相关性算法的性能:
平方差之和(9.1)
稳健差异的总和(9.2)
绝对差值之和(9.3)
•偏置增益补偿平方差(9.9)
•常规交叉相关(9.11)
?上述版本的窗口(9.22–9.23)
基于傅里叶的上述措施的实现(9.18–9.20)
·相位相关(9.24)
?梯度互相关(Argyriou和Vlachos,2003)。
比较几种算法在不同运动序列上的表现,这些序列包含不同程度的噪声、曝光变化、遮挡和频率变化(例如,高频纹理如沙子或布料,以及低频图像如云朵或运动模糊视频)。一些具有光照变化和真实对应关系(水平运动)的数据集可以在https://vision.middlebury.edu/stereo/data网站上找到(2005年和2006年的数据集)。
Chapter 10 Computational photography
10.1光度校准 610
10.1.1辐射响应函数 611
10.1.2噪声水平估计 614
10.1.3暗角 615
10.1.4光学模糊(空间响应)估计 616
10.2高动态范围成像 620
10.2.1色调映射 627
10.2.2应用:闪光灯摄影 634
10.3超分辨率、去噪和模糊消除 637
10.3.1彩色图像去马赛克 646
10.3.2镜头模糊(散景) 648
10.4图像抠像和合成 650
10.4.1蓝屏遮罩 651
10.4.2自然图像遮罩 653
10.4.3基于优化的抠像 656
10.4.4烟雾、阴影和闪光垫 661
10.4.5视频遮罩 662
10.5纹理分析与合成 663
10.5.1应用:孔洞填充和图像修复 665
10.5.2应用:非真实感渲染 667
10.5.3神经风格转换和语义图像合成 669
10.6额外阅读 671
10.7练习 674

图10.1计算摄影:(a)合并多张曝光以创建高动态范围图像(Debevec和Malik 1997)©1997 ACM;(b)合并闪光灯和非闪光灯照片;(Petschnigg、Agrawala等2004)©2004 ACM;(c)图像抠图和合成;(Chuang、Curless等2001)©2001 IEEE;(d)用修复技术填充孔洞
(Criminisi,P rez,和Toyama2004)©2004 IEEE。
在过去十年中,计算机视觉的所有进步中,计算摄影无疑具有最广泛的商业影响。2010年,亚当斯、塔尔瓦拉等人(2010)发表了开创性的《弗兰肯相机》论文,同时发布了一款最早广泛使用的相机内全景图像拼接应用。1纵观到2020年,每部智能手机都内置了全景拼接、高动态范围(HDR)曝光合并以及多图像去噪和超分辨率功能(哈辛诺夫、夏莱特等人2016;罗夫斯基、加西亚-多拉多等人2019;利巴、穆尔蒂等人2019),最新的手机还通过多个镜头或双像素模拟浅景深(散景)效果(巴伦、亚当斯等人2015;瓦德瓦、加尔格等人2018;加尔格、瓦德瓦等人2019;张、瓦德瓦等人2020)。
在第8.2节中,我们描述了如何将多张图像拼接成宽广视野的全景图,使我们能够创建普通相机无法捕捉的照片。这只是计算摄影的一个例子,在计算摄影中,图像分析和处理算法被应用于一张或多张照片,以生成超越传统成像系统能力的图像。
在本章中,我们将介绍一些额外的计算摄影算法。首先回顾光度图像校准(第10.1节),即相机和镜头响应的测量,这是后续许多算法的前提条件。接着讨论高动态范围成像(第10.2节),通过多次曝光捕捉场景中的全部亮度范围(图10.1a)。我们还介绍了色调映射操作符,这些操作符将宽色域图像重新映射到常规显示设备如屏幕和打印机上,以及合并闪光灯和普通图像以获得更好曝光的算法(图10.1b)。
接下来,我们将讨论如何通过合并多张照片或使用复杂的图像先验或深度网络来提高图像的分辨率和视觉质量(第10.3节)。这包括从大多数相机中存在的图案化拜耳马赛克中提取全彩色图像的算法。
在第10.4节中,我们讨论了从一张照片中切割图像片段并将其粘贴到其他照片中的算法(图10.1c)。在第10.5节中,我们描述了如何从真实世界的样本生成新颖的纹理,用于填补图像中的孔洞等应用(图10.1d)。最后,我们简要概述了非写实渲染(第10.5.2节),这种技术可以将普通照片转化为类似传统绘画的艺术渲染,并讨论了神经网络在风格迁移和语义图像合成中的应用(第10.5.3节)。
本书没有详细讨论的一个主题是新型计算传感器、光学和摄像机。Nayar(2006)的一篇文章可以找到一个很好的综述,这本书
Raskar和Tumblin(2010)以及Levin、Fergus等人(2007)的研究论文中也讨论了相关问题。第10.2节和第14.3节中也有相关讨论。
一篇面向大众的计算摄影入门文章可以在海耶斯(2008)的文章中找到,此外,奈亚尔(2006)、科恩和塞尔斯基(2006)、莱沃伊(2006)以及德贝韦克(2006).2Raskar和图姆布林(2010)的文章也对此领域进行了广泛覆盖,特别强调了计算相机和传感器。高动态范围成像这一子领域有专门讨论该研究的书籍(莱因哈德、海德里希等人,2010),还有一本更面向专业摄影师的优秀书籍(弗里曼,2008)。王和科恩(2009)提供了一篇关于图像抠图的良好综述。
还有几门计算摄影课程,讲师们提供了大量的在线资料,例如卡内基梅隆大学的扬尼斯·格基乌莱卡斯的课程,伯克利大学的阿廖沙·埃夫罗斯的课程,麻省理工学院的弗尔多·杜兰德的计算摄影课程,斯坦福大学的马克·莱沃伊的课程,以及一系列关于计算摄影的SIGGRAPH课程。
10.1 光度校准
在成功合并多张照片之前,我们需要分析将入射辐照度映射到像素值的功能,以及每张图像中存在的噪声量。在本节中,我们将考察影响这种映射的成像流程中的三个组成部分(图10.2)。关于现代数字相机处理流程的更全面、可调模型,请参见Tseng、Yu等人(2019)的最新论文。
第一种是辐射响应函数(Mitsunaga和Nayar 1999),它将到达透镜的光子映射为存储在图像文件中的数字值(第10.1.1节)。第二种是暗角,它会使图像边缘附近的像素值变暗,尤其是在大光圈下(第10.1.3节)。第三种是点扩散函数,它描述了由透镜、抗锯齿滤波器和有限传感器面积引起的模糊(第10.1.4节)。本节的内容基于第2.2.3节中描述的成像过程。
以及2.3.3,所以如果您已经有一段时间没有查看这些部分,请返回并重新查看它们。
如图10.2所示,许多因素影响到达透镜的光强度如何映射到存储的数字值中。我们暂时忽略透镜内部可能发生的非均匀衰减,这将在第10.1.3节中讨论。
影响这一映射的第一个因素是光圈和快门速度(第2.3节),可以将其建模为入射光的全局乘数,最方便的是以曝光值(对数亮度比)来衡量。接下来,感光芯片上的模数(A/D)转换器应用电子增益,通常由相机上的ISO设置控制。理论上这种增益是线性的,但任何电子设备都可能存在非线性(无论是无意还是有意)。暂且忽略光子噪声、片上噪声、放大器噪声和量化噪声,我们稍后会讨论这些内容,通常可以假设入射光与RAW相机文件中存储的值之间的映射大致呈线性关系(如果您的相机支持这一点)。
如果图像以常见的JPEG格式存储,相机的图像信号处理器(ISP)接下来会执行拜耳模式去马赛克处理(第2.3.2节和第10.3.1节),这是一个主要线性的(但通常非平稳的)过程。在此阶段,通常还会应用一些锐化处理。接下来,颜色值会被乘以不同的常数(有时是一个3×3的颜色扭曲矩阵),以进行色彩平衡,即使白点更接近纯白色。最后,每个颜色通道的强度都会应用标准伽玛校正,并将颜色转换为YCbCr格式,然后通过DCT变换、量化,最后压缩成JPEG格式(第2.3.3节)。图10.2以图形形式展示了所有这些步骤。
鉴于所有这些处理的复杂性,很难从原理上建模相机响应函数(图10.3a),即入射辐照度与数字RGB值之间的映射关系。更实际的方法是通过测量入射光与最终值之间的对应关系来校准相机。
最精确但最昂贵的方法是使用积分球,这是一种大型(通常直径为1米)的球体,内部仔细涂上白色哑光漆。顶部有一个精确校准的光源,控制着球体内辐射量(由于球体的辐射特性,其辐射强度在任何地方都是恒定的),侧面有一个小开口,可以安装相机/镜头组合。通过缓慢调节进入光源的电流,可以建立入射辐射与测量像素值之间的准确对应关系。此外,还可以研究相机的暗角和噪声特性。
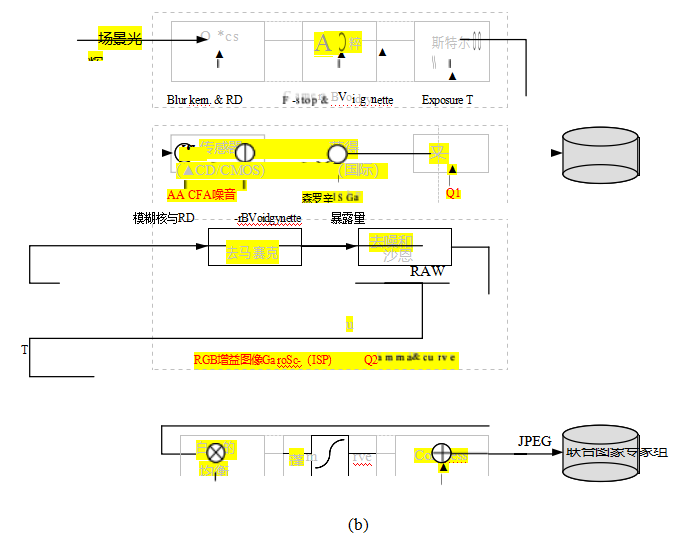
图10.2图像传感流程:(a)方框图展示了各种噪声源以及典型的数字后处理步骤;(b)等效信号变换,包括卷积、增益和噪声注入。缩写如下:RD =径向畸变,AA=抗混叠滤波器,CFA =彩色滤光阵列,Q1和Q2 =量化噪声。
图10.3辐射响应校准:(a)典型相机响应函数,显示入射日志辐照度(曝光)与输出8位像素值之间的映射关系,针对一个颜色通道(Debevec和Malik1997)©1997 ACM;(b)颜色检查表。
simultaneously determined.
同时确定。
更实用的替代方法是使用校准图表(图10.3b),例如Mac- beth或Munsell色卡。这种方法最大的问题是确保照明均匀。一种方法是在远离图表且与图表垂直的大暗室中使用高质量光源。另一种方法是将图表放置在户外,远离任何阴影。(在这两种条件下,结果会有所不同,因为光源的颜色不同。)
最简单的方法可能是使用三脚架拍摄同一场景的多个曝光,并通过同时估计每个像素的入射辐照度和响应曲线来恢复响应函数(Mann和Picard 1995;Debevec和Malik 1997;Mitsunaga和Nayar 1999)。这种方法在第10.2节关于高动态范围成像中进行了更详细的讨论。
如果为JPEG图像,则对每个RGB通道应用√= 2.2非线性(加上裁剪)。
图10.4从单张彩色照片中获得的噪声水平函数估计值(Liu,Szeliski等,2008)©2008 IEEE。彩色曲线是测量到的带噪分段平滑图像之间偏差的概率下包络线,即估计的NLF拟合。通过平均29张图像得到的真实NLF以灰色显示。
10.1.2噪声水平估计
除了了解相机响应函数外,通常还需要知道在特定相机设置下(例如ISO/增益级别)注入的噪声量。最简单的噪声表征是单个标准差,通常以灰度级测量,与像素值无关。更精确的模型可以通过估计噪声水平作为像素值的函数来获得(图10.4),这被称为噪声水平函数(Liu,Szeliski等,2008)。
与相机响应函数一样,估计这些量最简单的方法是在实验室中使用积分球或校准图。噪声可以通过独立地在每个像素处进行多次曝光并计算测量值的时间方差来估算(Healey和Kondepudy 1994),或者通过假设某个区域内(例如,在颜色检查方块内)所有像素值都相同来计算空间方差。
这种方法可以推广到图像中存在强度恒定或缓慢变化区域的情况(Liu,Szeliski等,2008)。首先,将图像分割成这样的区域,并在每个区域内拟合一个常数或线性函数。接下来,在远离大梯度和区域边界的情况下,测量噪声输入像素与平滑拟合函数之间的差异的(空间)标准差。如图10.4所示,将这些差异作为输出级别的函数绘制出来。最后,拟合一个较低的包络线以忽略异常值或偏离。Liu,Szeliski等(2008)提出了一种完全贝叶斯的方法来建模每个量的统计分布。一种更简单的方法,在大多数情况下应该会产生有用的结果,即拟合低维

图10.5单图像暗角校正(郑、余等,2008)©2008 IEEE:(a)原始图像有明显的可见暗角;(b)郑、周等(2006)描述的暗角补偿;(c–d)郑、余等(2008)描述的暗角补偿。
将函数(例如,正值B样条)与下限包络线进行比较(见练习10.2)。
松下和林(2007b)提出了一种技术,基于水平依赖噪声分布的偏斜(不对称性),同时估计相机响应和噪声水平函数。他们的论文还包含了这些领域中先前工作的大量参考文献。
使用广角和大光圈镜头时常见的问题是图像在角落处会变暗(图10.5a)。这个问题通常被称为暗角,有多种形式,包括自然暗角、光学暗角和机械暗角(第2.2.3节)(Ray2002)。与辐射响应函数校准一样,最准确的暗角校准方法是使用积分球或均匀着色且照明良好的空白墙面的照片。
一种替代方法是拼接全景场景,并假设每个像素的真实辐射来自每张输入图像的中心部分。如果辐射响应函数已知(例如,通过RAW模式拍摄)且曝光保持恒定,则这种方法更容易实现。如果响应函数、图像曝光和暗角函数未知,仍可以通过优化大规模最小二乘拟合问题来恢复这些参数(Litvinov和Schechner 2005;Goldman 2010)。图10.6展示了一个同时估计暗角、曝光和辐射响应函数的例子,该例子基于一组重叠的照片(Goldman 2010)。请注意,除非对暗角进行建模并补偿,否则常规梯度域图像融合(第8.4.4节)将无法生成吸引人的图像。
如果只有一个图像可用,可以通过在径向方向上寻找缓慢一致的强度变化来估计暗角。Zheng、Lin和Kang(2006)提出的原始算法首先将图像预分割成平滑变化的区域,然后

图10.6同时估计暗角、曝光和辐射响应
(Goldman2010)©2011 IEEE:(a)原始输入图像的平均值;(b)补偿暗角后的平均值;(c)仅使用梯度域混合(注意剩余的斑点状外观);(d)补偿暗角和混合后的平均值。
在每个区域内进行了分析。郑、余等人(2008)没有预先分割图像,而是计算所有像素的径向梯度,并利用这种分布的不对称性(因为远离中心的梯度平均来说略为负)来估计暗角效应。图10.5展示了将这些算法应用于具有大量暗角效应的图像的结果。练习10.3要求你实现上述的一些技术。
最后一个需要校准的成像系统特性是空间响应函数,它编码了与入射图像卷积以生成点采样图像时产生的光学模糊。卷积核的形状,也称为点扩散函数(PSF)或光学传递函数,取决于多个因素,包括镜头模糊和径向畸变(第2.2.3节),传感器前的抗混叠滤波器,以及每个活动像素区域的形状和范围(第2.3节)(图10.2)。对于多图像超分辨率和去模糊等应用,准确估计该函数是必需的(第10.3节)。
理论上,可以通过在图像中任意位置观察一个无限小的点光源来估计PSF。实际上,通过钻穿一块暗板并用一个非常亮的光源进行背光照射来创建样本阵列是困难的。
一个更实用的方法是观察由长直线组成的图像或

图10.7校准图案,边缘在所有方向上均匀分布,可用于PSF和径向畸变估计(Joshi、Szeliski和Kriegman2008)©2008 IEEE。中间显示了实际感知图像的一部分,右侧是理想图案的放大图。
条形,因为这些可以精确到任意精度。由于水平或垂直边缘的位置在采集过程中可能会产生混叠,因此稍微倾斜的边缘更为理想。这种边缘的轮廓和位置可以估计到亚像素精度,这使得在亚像素分辨率下估计点扩散函数成为可能(Reichenbach,Park和Narayanswamy 1991;Burns和Williams 1999;Williams和Burns 2001;Goesele,Fuchs和Seidel 2003)。Murphy(2005)的论文对相机校准的所有方面进行了很好的综述,包括空间频率响应(SFR)、空间均匀性、色调再现、色彩再现、噪声、动态范围、色彩通道注册和景深。该论文还描述了一种称为sfrmat2的斜边校准算法。
斜边技术可用于恢复二维点扩散函数的一维投影,例如,利用略微垂直的边缘来恢复水平线扩展函数(LSF)(Williams 1999)。随后,LSF通常转换到傅里叶域,并将其幅度绘制为一维调制传递函数(MTF),这表明了在采集过程中丢失(模糊)和混叠的图像频率(第2.3.1节)。对于大多数计算摄影应用而言,直接估计完整的二维点扩散函数更为理想,因为从其投影中恢复可能较为困难(Williams 1999)。
图10.7展示了一种包含所有方向边缘的图案,可以直接用于恢复二维PSF。首先,通过提取感知图像中的边缘、连接这些边缘并找到圆弧的交点来定位图案中的角点。接下来,将已知解析形式的理想图案(使用单应性变换)扭曲以适应输入图像的中心部分,并调整其强度以匹配感知图像中的强度。如果需要,可以将图案渲染为比输入图像更高的分辨率,这使得PSF的估计能够达到亚像素分辨率(图10.8a)。最后

图10.8使用校准目标估计点扩散函数(Joshi,Szeliski和Kriegman 2008)©2008 IEEE。(a)随着分辨率逐渐提高,次像素点扩散函数的变化(注意方形传感区域与圆形镜头模糊之间的相互作用)。(b)还可以估计并消除径向畸变和色差。(c)不聚焦(模糊)镜头的点扩散函数显示了角落处的一些衍射和暗角效应。
K = arg
n ⅡB - D
(10.1)
其中,B是感知(模糊)图像,I是预测(清晰)图像,D是一个可选的下采样算子,用于匹配理想图像和感知图像的分辨率(Joshi,Szeliski和Kriegman 2008)。另一种解决方案是首先估计一维点扩散函数文件,然后使用拉东变换将它们组合起来(Cho,Paris等2011)。
如果在图像的重叠区域局部估计PSF,也可以用来估计由镜头引起的径向畸变和色差(图10.8b)。由于理想目标到感知图像的单应性映射是在图像中心(未畸变)部分估计的,因此任何(每个通道)由光学系统引起的位移都会表现为PSF中心的偏移。补偿这些位移可以消除无色径向畸变和导致不可见色差的各通道位移。色差引起的依赖颜色的模糊(图2.21)也可以使用讨论中的去模糊技术来去除。
12这个过程混淆了几何校准和光度校准之间的区别。原则上,任何几何畸变都可以通过空间变化的位移PSF来建模。实际上,将任何大的位移折叠到几何校正部分更容易。
图10.9不使用校准图案估计PSF(Joshi、Szeliski和
Kriegman2008)©2008 IEEE:(a)输入图像,蓝色横截面(轮廓)位置,(b)检测和预测的台阶边缘轮廓,(c-d)边缘位置附近的预测颜色的位置和值。
第10.3节。图10.8b显示了径向畸变和色差如何表现为拉长和位移的PSF,以及在校准目标区域中消除这些效应的结果。
局部二维PSF估计技术也可用于估算暗角。图10.8c展示了机械暗角如何表现为图像角落处的PSF剪切。为了正确捕捉与暗角相关的整体变暗,需要从中心推断理想图案的修改强度,这最好通过均匀照明的目标来完成。
在处理RAW拜耳阵列图像时,正确估计点扩散函数的方法是仅在检测像素值处评估公式(10.1)中的最小二乘项,同时将理想图像插值到所有值。对于JPEG图像,应首先线性化强度,例如,移除伽马和其他任何非线性因素,以获得估计的辐射响应函数。
如果你有一个用未经校准的相机拍摄的图像,你仍然可以恢复PSF并用它来校正图像吗?事实上,通过稍作修改,之前的

图10.10展示了室内图像的样本,其中窗外区域曝光过度,而室内区域则太暗。
算法仍然有效。
不是假设已知的校准图像,你可以检测出强烈的拉长边缘,并在这些区域拟合理想的阶梯边缘(图10.9b),从而得到如图10.9d所示的清晰图像。对于每个被完整有效估计邻居包围的像素(图10.9c中的绿色像素),应用最小二乘公式(10.1)来估计核K。由此产生的局部估计PSF可用于校正色差(因为可以计算各通道PSF之间的相对位移),正如Joshi、Szeliski和Kriegman(2008)所展示的那样。
练习10.4提供了更多关于实现和测试基于边缘的PSF估计算法的详细说明。Fergus、Singh等人(2006)提出了一种替代方法,该方法不需要明确检测边缘,而是使用图像统计(梯度分布)。
10.2 高动态范围成像
正如我们在本章前面提到的,不同曝光度拍摄的注册图像可以用来校准相机的辐射响应函数。更重要的是,它们可以帮助你在具有挑战性的条件下创建曝光良好的照片,例如在明亮场景中,任何单一曝光都包含饱和(过曝)和暗部(欠曝)区域(图10.10)。这个问题相当普遍,因为自然界中的辐射值范围远大于任何摄影传感器或胶片所能捕捉到的范围(图10.11)。通过一组包围曝光(相机在自动包围曝光(AEB)模式下故意欠曝和过曝拍摄的曝光)来获得材料,从而创建正确曝光的照片,如图10.12所示(Freeman2008;Gulbins和Gulbins2009;Hasinoff,Durand,和Freeman

图10.11不同场景的相对亮度,从暗室里由显示器照亮的1到看太阳的200万。照片由Paul Debevec提供。

图10.12使用相机自动曝光包围(AEB)模式拍摄的一组带有括号的图像和由此产生的高动态范围(HDR)合成图像。
2010;Reinhard,Heidrich等人,2010)。
虽然可以直接将不同曝光的像素组合成最终合成图像(Burt和Kolczynski 1993;Mertens、Kautz和Reeth 2007),但这种方法有可能产生对比度反转和光晕。相反,更常见的方法是分三个阶段进行:
1.从对齐的图像中估计辐射响应函数。
2.通过选择或混合来自不同曝光的像素来估算辐射度图。
3.将生成的高动态范围(HDR)图像转换回可显示的色域。
估计辐射响应函数的想法相对简单(Mann和Picard 1995;Debevec和Malik 1997;Mitsunaga和Nayar 1999;Reinhard、Heidrich等2010)。假设你拍摄了三组不同曝光度(快门速度)的图像,比如±2个曝光值。如果我们能够确定每个像素点的辐射度(曝光)Ei(2.102),就可以将其与每个曝光时间tj测量的像素值zij进行对比,如图10.13所示。
改变快门速度比改变光圈更可取,因为后者会影响暗角和对焦。使用±2个“光圈值”(技术上称为曝光值或EV,因为光圈值指的是光圈)通常是捕捉良好动态范围与确保所有像素曝光正确之间的最佳折衷。
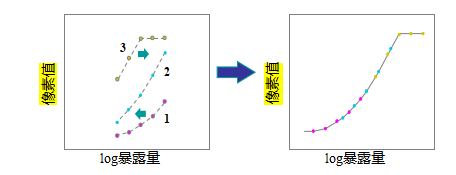
图10.13使用多次曝光进行辐射校准(Debevec和Malik1997)。将相应的像素值作为对数曝光(辐照度)的函数绘制出来。左图中的曲线被移动,以考虑每个像素的未知辐射度,直到它们全部排列成一条平滑曲线。
不幸的是,我们不知道它们的辐射值Ei,因此必须在估计辐射响应函数f的同时估计这些值,该函数可以写为(Debevec和Malik 1997)
zij = f (Ei tj ), (10.2)
其中,tj是第j张图像的曝光时间。逆响应曲线f-1由f-1(zij)= Ei tj给出。 (10.3)
两边取对数(以2为底是方便的,因为现在我们可以用ev来测量量),我们得到
g(zij)= log f-1(zij)= logEi + log tj, (10.4)
其中g = log f-1(将像素值zij映射到logirradiance)是我们在估计的曲线(图10.13侧视)。
贝德韦克和马利克(1997)假设曝光时间tj是已知的。(请注意,这些时间可以从相机的EXIF标签中获得,但它们实际上是按2的幂次递增……,1/128,1/64,1/32,1/16,1/8,……而不是标记的……,1/125,1/60,1/30,1/15,1/8,……——见练习2.5。)因此,未知数是每个像素的曝光时间Ei和响应值gk = g(k),其中g可以根据八位图像中常见的256个像素值进行离散化。(响应曲线分别针对每个颜色通道进行了校准。)
为了使响应曲线平滑,Debevec和Malik(1997)添加了二阶平滑约束
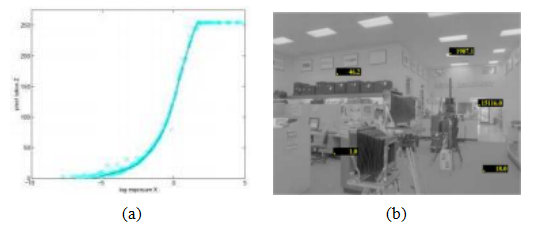
图10.14实际数码相机(DCS460)的恢复响应函数和辐射图像(Debevec和Malik1997)©1997 ACM。
这与蛇中使用的函数(7.27)类似,因为像素值在其范围的中间部分更可靠(并且g函数在饱和值附近变得奇异),因此它们还添加了一个加权(hat)函数w(k),该函数在像素值的两端衰减为零
一系列
(10.6)
将所有这些项放在一起,他们得到了一个未知数{gk }和{Ei }的最小二乘问题,
(为了消除响应曲线和辐照度值的整体偏移模糊性,将响应曲线的中间设置为0。)Debevec和Malik(1997)展示了如何在21行MATLAB代码中实现这一点,这在一定程度上解释了他们技术的流行。
虽然Debevec和Malik(1997)假设暴露时间tj是精确已知的,但没有理由认为这些附加变量不能被加入到最小二乘法中
问题,限制他们的最终估计值接近他们的名义值j
附加项η Σj
图10.14展示了数字相机的恢复辐射响应函数以及整体辐射图中选定(相对)辐射值。图10.15显示了彩色胶片拍摄的括号内输入图像及其对应的辐射图。请注意,尽管大多数关于高动态范围成像的研究假设辐射响应函数(或相机响应函数)与曝光无关,但实际情况并非如此。罗德里格斯,

图10.15用胶片相机拍摄的带有括号的曝光集,以及以伪彩色显示的结果辐射图像(Debevec和Malik1997)©1997 ACM。
Vazquez-Corral和Bertalm o(2019)描述了如何考虑这一点以获得更好的结果。
Debevec和Malik(1997)使用一般二阶平滑曲线g来参数化他们的响应曲线,而Mann和Picard(1995)使用三参数函数
f (E) = α + βE , (10.8)
虽然三浦和奈亚(1999)使用低阶(N≤10)多项式作为逆响应函数g。帕尔、泽利斯基等人(2004)推导出一个贝叶斯模型,该模型为每张图像估计一个独立的平滑响应函数,能够更好地模拟当今数码相机中更复杂(因此也更不可预测)的自动对比度和色调调整。
一旦响应函数被估计出来,创建高动态范围照片的第二步就是将输入图像合并成一个复合辐射图。如果响应函数和图像完全已知,即没有噪声,你可以使用任何非饱和像素值通过逆响应曲线E = g(z)来估算相应的辐射值。
不幸的是,像素存在噪声,尤其是在低光条件下,到达传感器的光子较少。为了补偿这一点,Mann和Picard(1995)使用响应函数的导数作为权重来确定最终的辐射度估计值,因为曲线中“更平坦”的区域告诉我们关于入射辐照度的信息较少。Debevec和Malik(1997)使用了一个帽函数(10.6),该函数强调中间色调像素,同时避免饱和值。Mitsunaga和Nayar(1999)表明,为了最大化信噪比(SNR),

图10.16合并多个曝光以创建高动态范围合成
(Kang,Uyttendaele等人,2003年):(a-c)三种不同的曝光;(d)使用经典算法合并曝光(注意由于马头移动造成的重影);(e)使用运动补偿合并曝光。
加权函数必须强调传输函数中的较高像素值和较大梯度,即,
w(z) = g(z)/g, (z), (10.9)
其中权重w用于形成最终辐照度估计值
logEi =
(10.10)
练习10.1要求您实现一种辐射响应函数校准技术,然后使用它创建辐射度图。
在实际条件下,随意获取的图像可能无法完美对齐,并且可能包含移动物体。Ward(2003)使用全局(参数)变换来对齐输入图像,而Kang、Uyttendaele等人(2003)提出了一种算法,该算法结合了全局配准与局部运动估计(光流),以准确对齐图像,然后融合它们的辐射估计(图10.16)。由于图像的曝光可能差异很大,在估计运动时必须谨慎,这些运动本身也必须检查一致性,以避免产生鬼影和物体碎片。
然而,即使这种方法,在摄像机同时进行大幅度的平移运动和曝光变化时也可能不起作用,这是随意拍摄全景图时常见的现象。在这种情况下,图像的不同部分可能在一处被看到。

图10.17 HDR与大量运动的合并(Eden、Uyttendaele和Szeliski
2006)©2006 IEEE: (a)注册括号内的输入图像;(b)第一次图像选择后的结果:参考标签、图像和色调映射图像;(c)第二次图像选择后的结果:最终标签、压缩HDR图像和色调映射图像
或者更多的曝光。设计一种方法来融合所有这些不同的来源,同时避免急剧的过渡并处理场景运动是一个具有挑战性的问题。一种方法是首先找到一个共识马赛克,然后有选择地计算欠曝和过曝区域的辐射度(Eden,Uyttendaele和Szeliski 2006),如图Figure10.17所示。关于构建和显示高动态范围视频的其他技术,在Myszkowski、Mantiuk和Krawczyk(2008)、Tocci、Kiser等人(2011)、Sen、Kalantari等人(2012)、Dufaux、Le Callet等人(2016)、Banterle、Artusi等人(2017)以及Kalantari和Ramamoorthi(2017)中有所讨论。另一种方法是使用深度学习技术从单个低动态范围图像推断出高动态范围辐射度图像(Liu、Lai等人2020b)。
一些相机,如索尼α550和宾得K-7,已经开始将多重曝光合并和色调映射直接集成到相机机身中。未来,随着相机传感器技术的进步,可能不再需要通过计算多张曝光来生成高动态范围图像(杨、埃尔·加马尔等,1999;奈亚尔和米茨纳加,2000;奈亚尔
以及Branzoi2003;Kang、Uyttendaele等人2003;Narasimhan和Nayar2005;Tumblin、Agrawal和Raskar2005)。然而,将这些图像混合并将其色调映射到低色域显示器的需求可能仍然存在。
HDR图像格式。在我们讨论将HDR图像映射回可显示色域的技术之前,我们应该讨论用于存储HDR图像的常用格式。
如果存储空间不是问题,将每个红、绿、蓝值分别存储为32位IEEE浮点数是最佳解决方案。常用的便携式像素图(.ppm)格式支持未压缩的ASCII和原始二进制编码,通过修改头部可以扩展为便携式浮点图(.pfm)格式。TIFF也支持完整的浮点值。
更紧凑的表示形式是Radiance格式(.pic,.hdr)(Ward1994),它
使用一个共同的指数和每个通道的尾数。中间编码,ILM的OpenEXR,14为每个通道使用16位浮点数,这是大多数系统原生支持的格式
现代GPU。Ward(2004)对这些以及其他数据格式如LogLuv(Larson 1998)进行了更详细的描述,Freeman(2008)和Reinhard、Heidrich等人(2010)的书籍也对此进行了详细描述。一种更近的HDR图像格式是JPEG XR标准。
一旦计算出一个光辉图,通常需要将其显示在较低色域(即八位)的屏幕或打印机上。为此,已经开发了多种色调映射技术,这些技术要么计算空间变化的传输函数,要么减少图像梯度以适应可用的动态范围(Reinhard,Heidrich等,2010)。
将高动态范围辐射图像压缩到低动态范围色域的最简单方法是使用全局转移曲线(Larson,Rushmeier和Piatko 1997)。图10.18显示了一个这样的例子,其中使用了伽马曲线将HDR图像映射回可显示的色域。如果对每个通道分别应用伽马(图10.18b),颜色会变得暗淡(饱和度降低),因为高值颜色通道对最终颜色的贡献较少(按比例减少)。通过使用公式(2.104)从彩色图像中提取亮度通道,然后对亮度通道应用全局映射,再用公式(10.19)重建彩色图像,效果更好(图10.18c)。
不幸的是,当图像具有非常宽的曝光范围时,这种全局方法仍然无法在曝光范围广泛变化的区域中保留细节。需要的是,在-
稳住,这有点像摄影师在黑暗中躲闪和燃烧

图10.18全局色调映射:(a)输入HDR图像,线性映射;(b)对每个颜色通道独立应用gamma;(c)对强度应用gamma(颜色不那么褪色)。原始HDR图像由Paul Debevec,https://www.pauldebevec.com/提供
研究/HDR。处理过的图像由Frdo Durand提供,MIT 6.815/6.865课程
计算摄影。
从数学上讲,这与将每个像素除以该像素周围区域的平均亮度类似。
图10.19显示了这一过程的工作原理。与之前一样,图像被分解为其亮度和色度通道。对数亮度图像
H(x,y)= log L(x,y) (10.11)
然后进行低通滤波,生成基础层
HL (x, y) = B (x, y) * H (x, y), (10.12)和高通细节层
HH (x, y) = H (x, y) - HL (x, y). (10.13)然后通过缩放至所需的对数亮度范围来降低基底层的对比度,
HH, (x, y) = s HH (x, y) (10.14)
并添加到细节层以生成新的对数亮度图像
我(x,y) = HH,(x,y) + HL (x,y), (10.15)
然后可以进行指数运算,生成色调映射(压缩)的亮度图像。注意,这个过程等同于将每个亮度值除以(该像素周围区域的平均对数亮度值的单调映射)。

图10.19使用线性滤波器进行局部色调映射:(a)低通和高通滤波后的对数亮度图像及彩色(色度)图像;(b)经过处理的色调映射图像(在衰减低通对数亮度图像后)显示树木周围有可见的光环。处理过的图像由MIT 6.815/6.865计算摄影课程的Frdo Durand提供。

图10.20使用双边滤波器进行局部色调映射(Durand和Dorsey2002):(a)低通和高通双边滤波的对数亮度图像和彩色(色度)图像;(b)色调映射后的结果图像(在衰减低通对数亮度图像后)
没有显示光环。经过处理的图像由Frdo Durand提供,MIT 6.815/6.865课程
计算摄影。
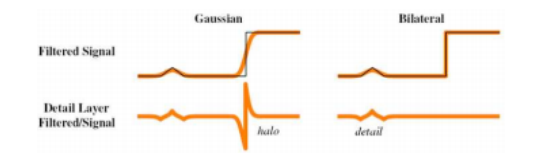
图10.21高斯滤波与双边滤波对比(Petschnigg,Agrawala等,2004)©2004 ACM:高斯低通滤波会在所有边缘上产生模糊效果,因此在细节图像中形成强烈的峰值和谷值,导致光环效应。而双边滤波不会平滑强边缘,从而减少光环效应,同时仍能捕捉到细节。
图10.19展示了低通和高通对数亮度图像以及最终的色调映射彩色图像。请注意,高对比度边缘处的细节层出现了可见的光环,这些光环在最终的色调映射图像中仍然可见。这是因为线性滤波不保留边缘特征,导致细节层中产生了光环(图10.21)。
解决这个问题的方法是使用边缘保持滤波器来创建基础层。杜兰德和多尔西(2002)研究了多种这样的边缘保持滤波器,包括各向异性和鲁棒各向异性扩散,并选择了双边滤波(第3.3.1节)作为他们的边缘保持滤波器。(法布曼、法塔尔等人(2008)的文章主张使用加权最小二乘(WLF)滤波器作为双边滤波器的替代方案,而帕里斯、科尔普罗斯特等人(2008)则回顾了双边滤波及其在计算机视觉和计算摄影中的应用。)图10.20展示了用双边滤波器替换线性低通滤波器后,生成的色调映射图像中没有可见的光晕。图10.22总结了这一过程中的完整信息流,从分解为对数亮度和色度图像开始,经过双边滤波、对比度降低,最后重新组合成最终输出图像。
压缩基础层的替代方法是压缩其衍生物,即对数亮度图像的梯度(Fattal、Lischinski和Werman 2002)。图10.23illus-
处理此过程。对对数亮度图像进行微分以获得梯度图像
H, (x, y) = ▽H(x, y). (10.16)
然后,该梯度图像通过空间变化衰减函数Φ(x,y)而衰减,
G(x, y) = H, (x, y) Φ(x, y). (10.17)
衰减函数I(x,y)旨在衰减大规模亮度变化(图10.24a),并考虑不同空间尺度的梯度(Fattal,
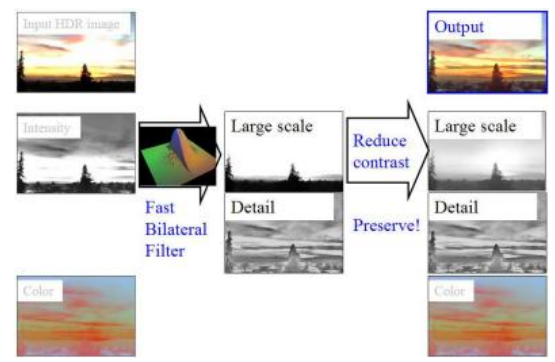
图10.22使用双边滤波器的局部色调映射(Durand和Dorsey2002):sum-
算法工作流程的玛丽。图片由MIT 6.815/6.865课程的Frdo Durand提供
计算摄影。
Lischinski和Werman2002)。
衰减后,通过求解一阶变分(最小二乘法)问题重新整合所得梯度场,
最小值∫∫Ⅱ▽I(x,y)-G(x,y)Ⅱ2 dx dy (10.18)
为了获得压缩的对数亮度图像I(x,y)。这个最小二乘问题与用于泊松混合的问题相同(第8.4.4节),并且首次在我们关于正则化的研究中引入(第4.2,4.24节)。可以使用多网格和层次基预处理等技术高效地解决这个问题(Fattal、Lischinski和Werman 2002;Szeliski 2006b;Farbman、Fattal等2008;Krishnan和Szeliski 2011;Krishnan、Fattal和Szeliski 2013)。一旦新的亮度图像计算完成,它将与原始彩色图像结合使用。
Cout = s Lout,
(10.19)
其中C =(R,G,B)和Lin、Lout分别是原始和压缩后的亮度图像。指数控制颜色的饱和度,通常在s∈[0.4,0.6]范围内(Fattal,Lischinski,和Werman 2002)。图10.24b显示了最终的色调映射颜色。
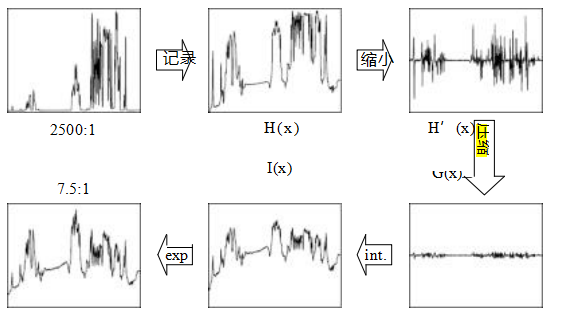
图10.23梯度域色调映射(Fattal、Lischinski和Werman 2002)©2002 ACM。原始图像的动态范围为2415:1,首先转换到对数域H(x),并计算其梯度H(x)。这些梯度根据局部对比度G(x)进行衰减(压缩),然后积分生成新的对数曝光图像I(x),再进行指数运算生成最终强度图像,其动态范围为7.5:1。
图像,尽管输入辐射值的差异极大,但没有可见的光环。
另一种替代方法是使用局部尺度选择算子进行局部遮挡和烧录(Reinhard,Stark等,2002)。图10.25展示了这种尺度选择算子如何确定一个半径(尺度),仅包含内圈内的相似颜色值,同时避免周围圈中更亮的值。实际上,在一系列尺度上评估由内高斯响应归一化的高斯差异,并选择其度量值低于阈值的最大尺度(Reinhard,Stark等,2002)。
另一种最近开发的基于多分辨率分解的色调映射方法是局部拉普拉斯滤波器(Paris、Hasinoff和Kautz 2011),我们在第3.5.3节中介绍过。拉普拉斯金字塔中的系数由局部对比度调整的补丁构建而成,这使得该技术不仅能够对HDR图像进行色调映射,还能增强局部细节并实现风格转换(Aubry、Paris等2014)。
所有这些技术的共同点是,它们能够自适应地减弱或增强图像的不同区域,从而可以在有限的色域内显示而不会损失对比度。Lischinski、Farbman等人(2006)介绍了一种交互式技术,该技术执行

图10.24梯度域色调映射(Fattal、Lischinski和Werman2002)©
2002 ACM:(a)衰减图,数值越深表示衰减越大;(b)最终色调映射图像。
图10.25声调映射的尺度选择(Reinhard、Stark等人,2002)©2002 ACM。

图10.26交互式局部色调映射(Lischinski,Farbman等人,2006)©2006
ACM:(a)用户绘制的笔画,带有相关的曝光值g(x,y);(b)相应的分段平滑曝光调整图f (x,y)。
该操作是通过将一组稀疏的用户绘制的调整(笔画和相关的曝光值校正)插值到分段连续的曝光校正图中(图10.26)。插值是通过最小化局部加权最小二乘法(WLS)变分问题来完成的,
min∫∫wd(x,y)Ⅱf(x,y)- g(x,y)Ⅱ2 dx dy + λ∫∫ws(x,y)Ⅱ▽f(x,y)Ⅱ2 dx dy,
(10.20)其中g(x,y)和f(x,y)分别是输入和输出的对数曝光(衰减)图(图10.26)。数据加权项wd(x,y)在刻痕位置为1,其他地方为0。平滑度加权项ws(x,y)与对数亮度梯度成反比,
(10.21)
因此,鼓励f(x,y)映射在低梯度区域比高梯度不连续处更加平滑。同样的方法也可以用于完全自动化的色调映射,通过为每个像素设置目标曝光值,并允许加权最小二乘法将这些值转换为分段平滑的调整图。
加权最小二乘算法最初是为图像色彩校正应用开发的(Levin,Lischinski和Weiss 2004),后来被应用于一般的边缘保持平滑处理,例如对比度增强(Bae,Paris和Du-Rand 2006)和色调映射(Farbman,Fattal等2008),其中之前使用了双边滤波。该算法还可以同时执行HDR合并和色调映射(Raman和Chaudhuri 2007,2009)。
鉴于已经开发出多种局部自适应色调映射算法,实际应用中应该选择哪一种?弗里曼(2008)对市面上可用的算法、它们产生的伪影以及可用于控制这些伪影的参数进行了深入讨论。他还提供了大量关于HDR摄影和工作流程的建议。我强烈推荐这本书给任何考虑在此领域进行进一步研究(或个人摄影)的人。
虽然高动态范围成像结合了在不同曝光下拍摄的场景图像,但也可以结合闪光灯和非闪光灯图像以实现更好的曝光和色彩平衡,并减少噪声(Eisemann和Durand2004;Petschnigg、Agrawala等人2004)。
15在实践中,x和y离散导数分别进行加权(Lischinski、Farbman等人,2006)。它们的默认参数设置为λ = 0.2、Q = 1和∈= 0.0001。

图10.27闪光/非闪光摄影中的细节转移(Petschnigg,Agrawala等人。
2004)©2004 ACM:输入环境A和闪光F图像的细节;(b)联合双边滤波无闪光图像ANR;(c)细节层F从闪光图像F计算出的细节;(d)最终合并图像AFinal。
闪光灯照片的问题在于色彩往往不自然(无法捕捉环境光线),可能存在强烈的阴影或镜面反射,且远离相机处亮度呈径向衰减(图10.1b和10.27a)。在低光条件下拍摄的非闪光灯照片通常会受到过多噪点的影响(因为高ISO增益和低光子计数),以及模糊(由于曝光时间较长)。是否有一种方法可以将闪光前拍摄的非闪光灯照片与闪光灯照片结合,以产生色彩值良好、清晰度高且噪点低的图像?事实上,已停产的富士胶片FinePix F40fd相机可以快速连续拍摄一对闪光和非闪光的照片;然而,它只允许你选择保留其中一张。
Petschnigg、Agrawala等人(2004)首先使用一种称为联合双边滤波器16的双边滤波器变体对无闪光(环境)图像A进行滤波,其中范围核(3.36)
=
exp
(10.22)
评估基于闪光图像F而非环境图像A,因为闪光图像是噪声较少,因此边缘更可靠(图10.27b)。由于阴影和镜面反射区域内的内容可能不可靠,这些部分会被检测出来,从而使用经过常规双边滤波的环境图像ABase(图10.28)。
他们的算法的第二阶段计算一个闪光细节图像
(10.23)
16 Eisemann和Durand(2004)称其为交叉双边滤波器。
图10.28闪光/非闪光摄影算法(Petschnigg,Agrawala等,2004)©2004 ACM。环境(非闪光)图像A通过常规双边滤波器过滤生成ABase,用于阴影和镜面区域,以及一个联合双边滤波降噪图像ANR。闪光图像F通过双边滤波生成基础图像F base和细节(比例)图像F detail,后者用于调制去噪后的环境图像。阴影/镜面掩模M通过比较闪光和非闪光图像的线性化版本计算得出。
其中F Base是闪光图像F的双边滤波版本,∈= 0.02。这个细节图像(图10.27c)编码了可能被降噪后的无闪光图像ANR滤除的细节,以及由闪光相机产生的额外细节,这些细节通常增加了清晰度。细节图像用于调制降噪后的环境图像ANR,以生成最终结果。
最终=(1 - M)ANRF详细+ MABase (10.24)
如图10.1和10.27d所示。
Eisemann和Durand(2004)提出了一种替代算法,该算法与上述基本概念有相似之处。两篇文章都值得阅读并进行对比(练习10.6)。
闪光图像还可以用于多种其他应用,例如提取更可靠的物体前景遮罩(Raskar,Tan等2004;Sun,Li等2006)。给定足够大的训练集,也可以将单张闪光图像分解为其环境光和闪光光照成分,这些成分可用于调整其外观(Aksoy,Kim等2018)。闪光摄影只是主动照明这一更广泛主题的一个实例,该主题由Raskar和Tumblin(2010)以及Ikeuchi,Matsushita等(2020)进行了更详细的讨论。
10.3 超分辨率、去噪和模糊消除
虽然高动态范围成像技术使我们能够获得比单个普通图像具有更大动态范围的图像,但超分辨率技术使我们能够创建空间分辨率更高、噪声更少的图像(Chaudhuri 2001;Park等2003;Capel和Zisserman 2003;Capel 2004;van Ouwerkerk 2006;Anwar等2020)。通常情况下,超分辨率指的是通过对齐和组合多个输入图像来生成高分辨率合成图像的过程(Irani和Peleg 1991;Cheeseman等1993;Pickup等2009;Wronski等2019)。然而,一些技术可以对单个图像进行超分辨率处理(Freeman等2002;Baker和Kanade 2002;Fattal 2007;Anwar等2020),因此与去模糊技术密切相关(第3.4.1节和第3.4.2节)。Anwar、Khan和Barnes(2020)提供了关于单图像超分辨率技术的全面综述,特别关注最近基于深度学习的方法。
一种传统的超分辨率问题的表述方法是写出随机图像形成方程和图像先验,然后使用贝叶斯推断来恢复超分辨率(原始)清晰图像。我们可以通过推广用于图像去模糊的图像形成方程(第3.4.1节),以及用于模糊核(PSF)估计的图像形成方程(第10.1.4节)来实现这一点。在这种情况下,我们有多个观测图像{ok (x)},以及
作为每个观察图像的图像扭曲函数k(x)(图3.46)。组合所有
在这些元素中,我们得到(有噪声的)观测方程17
ok (x) = D{b(x) * s(k (x))} + nk (x), (10.25)
其中D是下采样算子,它在超分辨(清晰)扭曲图像s(k (x))与模糊核b(x)卷积之后进行操作。上述图像形成方程导致以下最小二乘问题,
(10.26)
在大多数超分辨率算法中,对齐(变形)k是使用其中一个输入帧作为参考帧来估计的;可以采用基于特征(Section8.1.3)或直接(图像基础)(第9.2节)参数化对齐技术。(一些算法,如舒尔茨和史蒂文森(1996)、卡佩尔(2004)以及沃恩斯基、加西亚-多拉多等人(2019)所描述的,使用密集(逐像素流)估计。)更好的方法是重新计算
17也可以向每个观测值添加未知的偏置增益项(Capel2004),如在(9.8)中对运动估计所做的那样。
在计算出s(x)的初始估计值后,通过直接最小化(10.26)进行对齐(Hardie、Barnard和Armstrong1997),或者完全边缘化运动参数(Pickup、Capel等人2007)。
点扩散函数(模糊核)bk是根据图像形成过程的知识推断出来的(例如,运动或失焦模糊的程度以及相机传感器光学特性),或者通过测试图像或观察到的图像{ok }使用第10.1.4节中描述的技术之一进行校准。同时推断模糊核和清晰图像的问题被称为盲图像去卷积(Kundur和Hatzinakos 1996;Levin 2006;Levin,Weiss等2011;Campisi和Egiazarian2017).18
给定k和bk (x)的估计值,可以使用矩阵/向量符号重新编写公式(10.26)。
Ⅱ
ok - DBkWksⅡ2 . (10.27)
(回忆(3.75),一旦变形函数k已知,s(k (x))的值就取决于
线性地处理s(x)中的值。)解决这个最小二乘问题的有效方法是使用预条件共轭梯度下降法(Capel2004),尽管一些早期算法,如Irani和Peleg(1991)开发的算法,使用了常规梯度下降法(在计算机断层扫描文献中也称为迭代反投影(IBP))。
上述公式假设变形可以表示为超分辨率锐利图像的简单(sinc或bicubic)插值重采样,随后是静态(空间不变)模糊(PSF)和面积积分过程。然而,如果表面严重缩短,我们必须考虑在图像变形过程中发生的空间变化滤波(第3.6.1节),然后才能建模由光学系统和相机传感器引起的PSF(王、康等2001;Capel 2004)。
这种最小二乘(MLE)方法在超分辨率中的表现如何?实际上,这很大程度上取决于相机光学系统的模糊和混叠程度,以及运动和点扩散函数估计的准确性(Baker和Kanade 2002;Jiang、Wong和Bao 2003;Capel 2004)。较少的模糊和更多的混叠意味着有更多(混叠的)高频信息可供恢复。然而,由于最小二乘(最大似然)公式不使用图像先验,因此可能会引入大量高频噪声到解决方案中(图10.29c)。
为此,经典超分辨率算法假设某种形式的图像先验。其中最简单的方法是像公式(4.29)那样对图像导数施加惩罚。
请注意,如果模糊核和超分辨率图像都未知,就会出现鸡生蛋还是蛋生鸡的问题。这个问题可以通过使用关于清晰图像的结构假设来“解决”,例如边缘的存在(Joshi、Szeliski和Kriegman 2008),或者使用图像的先验模型,如边缘稀疏性(Fergus、Singh等2006)。

图10.29使用各种图像先验的超分辨率结果(Capel2001):(a)
低分辨率ROI(双三次3倍放大);(b)平均图像;(c)MLE@1.25倍像素放大;(d)简单2x2先验(λ = 0.004);(e) GMRF(λ = 0.003);(f) HMRF(λ = 0.01,α = 0.04)。使用10张图像作为输入,在每种情况下生成一张3倍超分辨率图像,但不包括(c)中的MLE结果。
(4.42), e.g.,
(10.28)
正如第4.3节所述,当Pp是二次时,这属于Tikhonov正则化(第4.2节),整体问题仍然是线性最小二乘法。由此产生的先验图像模型是一个高斯马尔可夫随机场(GMRF),可以扩展到其他(例如对角)差异,如Capel(2004)和Figure10.29所述。
不幸的是,GMRFs生成的解往往带有可见的波纹,这也可以解释为中频噪声敏感度增加。更好的图像先验是一种稳健的先验,鼓励分段连续的解(Black和Rangarajan 1996),详见附录B.3。这类先验的例子包括Huber势函数(Schultz和Stevenson 1996;Capel和Zisserman 2003),它是高斯分布与长尾拉普拉斯分布的混合体,以及Levin、Fergus等人(2007)和Krishnan和Fergus(2009)使用的更稀疏(重尾)的超拉普拉斯分布。此外,还可以通过交叉验证学习这些先验的参数(Capel 2004;Pickup 2007)。
而稀疏(稳健)的导数先验可以减少波动效应并增加边缘

图10.30基于示例的超分辨率:(a)原始32×32低分辨率图像;(b)基于示例的超分辨率256×256图像(Freeman,Jones,和Pasztor 2002)©2002 IEEE;(c)通过施加边缘统计进行上采样(Fattal 2007)©2007 ACM。
清晰度方面,它们无法产生更高频率的纹理或细节。为此,可以使用一组训练样本图像来寻找低频原始图像与缺失的高频部分之间的合理映射关系。受我们在第10.5节讨论的一些基于示例的纹理合成算法启发,弗里曼、琼斯和帕斯特(2002)开发的基于示例的超分辨率算法利用训练图像学习局部纹理块与缺失的高频细节之间的映射关系。为了确保重叠的纹理块在外观上相似,使用了马尔可夫随机场,并通过信念传播(弗里曼、帕斯特和卡迈克尔2000)或光栅扫描确定性变体(弗里曼、琼斯和帕斯特2002)进行优化。图10.30展示了使用这种方法生成缺失细节的结果,并将其与法塔尔(2007)提出的更近期算法进行了比较。后者算法能够根据像素相对于最近检测到的边缘的位置及其相应的边缘统计信息(幅度和宽度),预测精细分辨率图像中的方向梯度幅度。此外,还可以将稀疏(鲁棒)导数先验与基于示例的超分辨率相结合,如塔彭、拉塞尔和弗里曼(2003)所示。
一种替代(但密切相关)的幻觉形式是识别训练图像数据库中低分辨率像素可能对应的部分。在他们的研究中,贝克和卡纳德(2002)使用局部高斯导数滤波器响应作为特征,然后以类似于德博内特(1997)的方式匹配父结构向量。每个识别出的训练图像位置的高频梯度随后被用作超分辨率图像的约束条件,同时结合常规的重建(预测)公式(10.26)。
19对于全超分辨率,其中所有图像都是预先对齐的,只检查不同图像中的对应像素。

图10.31基于识别的超分辨率(Baker和Kanade2002)©2002 IEEE。幻觉列显示了基于识别的算法与Hardie、Barnard和Armstrong(1997)的正则化方法的结果对比。
图10.31显示了从低分辨率输入中产生高分辨率人脸的幻觉结果;Baker和Kanade(2002)也展示了已知字体文本的超分辨率示例。练习10.7提供了更多关于如何实现和测试这些超分辨率技术之一或多个的详细信息。
超分辨率领域的最新趋势是使用深度神经网络直接预测超分辨率图像。这一方法始于Dong、Loy等人(2016)的开创性工作,已经产生了数十种不同的深度神经网络和架构,包括最新NVIDIA显卡中嵌入的深度学习超采样硬件(Burnes2020)。Anwar、Khan和Barnes(2020)最近关于单图像超分辨率的综述将这些算法分类为一个分类法(Figure10.32a),提供了网络架构的图示总结(图10.32b),并在无噪声已知双三次核降采样图像数据集上对超分辨率结果进行了数值和视觉比较。尽管图10.33所示的结果显示了算法之间的显著差异,但尚不清楚这些算法在面对未知模糊核的真实世界噪声输入时表现如何。由Cai、Zeng等人(2019)开发的RealSR真实世界超分辨率数据集,使用数码相机上的变焦镜头拍摄,提供了一种测试(和训练)算法在真实成像退化情况下的方法。该数据集构成了NTIRE的基础。
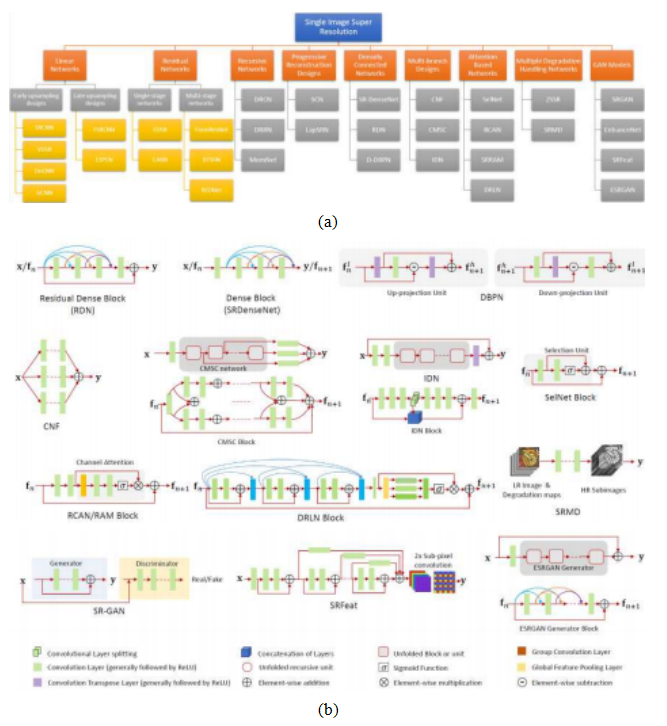
图10.32最近的单图像超分辨率深度神经网络算法(Anwar、Khan和Barnes,2020)©2020 ACM:基于其一般方法的算法分类;(b)部分算法的示意图。

图10.33一些超分辨率算法的视觉比较(Anwar、Khan和Barnes2020)©2020 ACM。

图10.34 Gu和Timofte(2019)的去噪算法时间线©2019
蹦跳的人
真实图像超分辨率的挑战(Cai,Gu等人,2019),20提供了最近基于深度网络算法的经验比较。
虽然单图像超分辨率技术很有趣,但通过在智能手机摄像头中直接构建多帧超分辨率算法,可以取得更加令人印象深刻(且实用)的结果,这样处理过程可以与图像去马赛克同时进行。我们在Section10.3.1和图10.38中讨论了Wronski、Garcia-Dorado等人(2019年)关于彩色图像去马赛克的最新工作。此外,还可以使用帧插值在时间维度上提升视频质量(第9.4.1节),使用视频超分辨率在空间维度上提升视频质量(Liu和Sun 2013;Kappeler、Yoo等人2016;Shi、Caballero等人2016;Tao、Gao等人2017;Nah、Timo-ftp等人2019;Isobe、Jia等人2020;Li、Tao等人2020),或同时在空间和时间维度上提升视频质量(Kang、Jo等人2020)。
图像去噪是图像处理和计算机视觉中的经典问题之一(Per- ona和Malik 1990b;Rudin、Osher和Fatemi 1992;Buades、Coll和Morel 2005b)。在过去的四十年里,已经开发了数百种算法,该领域仍在积极研究中,最近的算法都基于深度神经网络。
最新的图像去噪算法比较基准,NTIRE 2020实际图像去噪挑战赛(Abdelhamed,Afifi等2020),基于智能手机图像去噪数据集(SIDD)(Abdelhamed,Lin和Brown 2018),其中无噪声的真实图像通过平均150张带噪图像获得。这比大多数先前基准中使用的合成带噪图像提供了更加真实多样的实际噪声和图像处理模型(除了(Pl tz和Roth 2017))。
Gu和Timofte(2019)最近(简短)的图像去噪调查包括以下开创性的去噪论文21(请参见图10.34的时间线):
总变差(TV)(Rudin、Osher和Fatemi1992;Chan、Osher和Shen2001;Chambolle2004;Chan和Shen2005),
高斯尺度混合(GSM)(Lyu和Simoncelli2009),
专家小组(FoE)(Roth和Black2009),
非局部方法(NLM)(Buades、Coll和Morel,2005a、b),
BM3D (Dabov,Foi等人,2007),
稀疏过完备字典(K-SVD)(Aharon,Elad和Bruckstein2006),
?预期补丁日志似然性(EPLL)(Zoran和Weiss2011),
MLP降噪器(Burger、Schuler和Harmeling,2012),
加权核范数最小化(WNNM)(Gu,Zhang等人,2014),
•收缩场(脑脊液)(Schmidt和Roth,2014),
?可训练的非线性反应扩散(TNRD)(Chen和Pock2016),
彩色图像的跨通道噪声模型(Nam,Hwang等人,2016),
20https://data.vision.ee.ethz.ch/cvl/ntire20/,https://data.vision.ee.ethz.ch/cvl/aim20/
21我添加了更多来自Brown(2019)的ICCV教程的论文,以及Abdelrahman Abdelhamed的几个额外建议。
•去噪残差CNN(DnCNN)(Zhang,Zuo等人,2017),现在被认为是DNN去噪的基线,以及
学习在黑暗中看东西(陈,陈等人,2018)。
尽管这些结果随着时间显著改善,但如今的成像传感器大多能产生相对干净的图像,除非在低光环境下,此时需要增加ISO相机增益,读取和光子噪声会与信号强度相当。在这种情况下,如果可能的话,最好快速拍摄一系列低ISO(增益)的照片,然后将这些照片合并以获得去噪后的图像(Hasinoff,Kutulakos等2009;Hasinoff,Durand和Freeman 2010;Liu,Yuan等2014)。这种方法被推广并应用于低光摄影中,例如Hasinoff、Sharlet等人的HDR+系统(2016)。近年来,在这一领域的一些研究结合了低光摄影、马赛克消除以及某些情况下的超分辨率技术,包括Godard、Matzen和Uyttendaele(2018)、Chen、Chen等(2018)、Mildenhall、Barron等(2018)、Wronski、Garcia-Dorado等(2019)以及Rong、Demandolx等(2020)的研究。Liba、Murthy等(2019)描述了谷歌夜间视图功能背后的技术,该功能不仅能够在嘈杂条件下稳健地对齐和合并不同的移动区域,还引入了“运动测光”概念来确定最佳帧数和曝光时间。
消除模糊
在有利条件下,超分辨率及相关上采样技术可以提高拍摄良好图像或图像集合的分辨率。当输入图像本身模糊时,通常所能期望的是减少模糊的程度。这个问题与超分辨率密切相关,最大的不同在于模糊核b通常要大得多(且未知),而下采样因子D为1。
关于图像去模糊的文献非常丰富;一些优秀的文献综述包括Fergus、Singh等人(2006年)、Yuan、Sun等人(2008年)和Joshi、Zitnick等人(2009年)。通过将清晰(但有噪声)的图像与更模糊(但更干净)的图像结合,也可以减少模糊(Yuan、Sun等人,2007年),快速多次曝光(Hasinoff和Kutulakos,2011年;Hasinoff、Kutulakos等人,2009年;Hasinoff、Durand和Freeman,2010年),或使用编码光圈技术同时估计深度并减少模糊(Levin、Fergus等人,2007年;Zhou、Lin和Nayar,2009年)。当可用时,机载惯性测量单元(IMU)的数据可用于确定模糊核(Joshi、Kang等人,2010年)。还可以利用双像素传感器的信息来辅助失焦图像的去模糊(Abuolaim和Brown,2020年)。
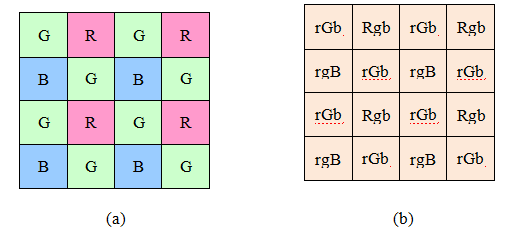
图10.35 Bayer RGB模式:(a)彩色滤光片阵列布局;(b)插值像素值,未知(猜测)值显示为小写字母。
过去十年间,大量基于学习的去模糊算法被引入(孙、曹等人2015;舒勒、希施等人2016;纳赫、金贤、李穆2017;库平、布德赞等人2018;陶、高等人2018;张、戴等人2019;库平、马尔蒂纽克等人2019)。此外,还有一些研究致力于在去模糊图像中人工重新引入纹理,以更好地匹配预期的图像统计特性(赵、乔希等人2012),即现在通常所说的感知损失(Section5.3.4)。
超分辨率的一个特例是日常大多数数码相机中使用的去马赛克过程,即将来自彩色滤光阵列(CFA)的样本转换为全彩RGB图像。图10.35展示了最常用的CFA,即拜耳模式,其中绿色(G)传感器的数量是红色和蓝色传感器的两倍。
从已知的CFA像素值转换到完整的RGB图像的过程相当具有挑战性。与常规超分辨率不同,后者中猜测未知值的小误差通常表现为模糊或混叠,而去马赛克伪影往往会产生虚假的颜色或高频图案化的拉链效应,这些现象肉眼可见(Figure10.36b)。
多年来,人们开发了多种图像去马赛克技术(Kim- mel1999)。Longere等人(2002)、Tappen、Russell和Freeman(2003)以及Li、Gunturk和Zhang(2008)对这一领域进行了综述,并使用感知动机指标比较了先前开发的技术。为了减少锯齿效应,大多数技术利用绿色通道的边缘或梯度信息,该信息更可靠,因为采样密度更高,来推断红色和蓝色通道的合理值,这些通道的采样更为稀疏。

图10.36 CFA去马赛克结果(Bennett,Uyttendaele等2006)©2006斯普林格:(a)原始全分辨率图像(算法输入使用了彩色子采样版本);(b)双线性插值结果,显示蓝色蜡笔尖端附近有色彩边缘效应,左侧(垂直)边缘处有锯齿状现象;(c)Malvar,He和Cutler(2004)的高质量线性插值结果(注意黄色蜡笔上的强烈晕圈/棋盘格伪影);(d)使用Bennett,Uyttendaele等(2006)的局部双色先验。
为了减少色彩边缘效应,一些技术会进行色彩空间分析,例如,在颜色对立通道上使用中值滤波(Longere,Delahunt等人,2002)。Bennett、Uyttendaele等人(2006)的方法是从初始去马赛克结果计算局部双色模型,使用移动的5×5窗口来找到两种主要颜色(图10.37)。22
一旦在每个像素处估计了局部颜色模型,就会使用贝叶斯方法来鼓励像素值沿着每条颜色线分布,并围绕主导颜色值聚集,这可以减少光晕(图10.36d)。贝叶斯方法还支持同时应用去马赛克、降噪和超分辨率处理,即多个彩色滤光阵列输入可以合并成高质量的全彩图像。最近结合去马赛克和降噪的研究包括查特吉、乔希等人(2011年)和加尔比、肖拉西亚等人(2016年)的论文。NTIRE 2020实际图像降噪挑战赛(阿卜杜勒哈迈德、阿菲菲等人2020年)包括一个关于去噪RAW(即彩色滤光阵列)图像的赛道。此外,金、法奇奥洛和莫雷尔(2020年)还有一篇有趣的研究,探讨了是否
22先前关于局部线性颜色模型的研究(Klinker、Shafer和Kanade 1990;Omer和Werman 2004)主要关注单个材料内的颜色和光照变化,而Bennett、Uyttendaele等人(2006)则使用双色模型来描述颜色(材料)边缘的变化。
图10.37从局部5×5邻域集合计算出的双色模型(Bennett,Uyttendaele等,2006)©2006斯普林格。经过两均值聚类和沿两种主要颜色连线的重投影后,大多数像素集中在拟合线上。沿该线分布,沿RGB轴投影,在0和1这两个主要颜色处达到峰值。
在去马赛克之前或之后应用去噪。
正如我们之前提到的,爆发摄影(Cohen和Szeliski 2006;Hasinoff、Kutu- lakos等2009;Hasinoff和Kutulakos 2011),即快速获取图像序列的组合,在智能手机相机中变得越来越普遍。一个最近系统执行联合去马赛克和多帧超分辨率的例子是Wronski、Garcia-Dorado等人(2019)的论文,该论文基于局部适应核函数(图10.38),并支持谷歌Pixel智能手机中的“超级变焦”功能。
使用大光圈拍摄浅景深照片的能力(第2.2.3节)一直是大画幅相机,例如单反(SLR)相机的一大优势。人工模拟可重新对焦的浅景深相机的愿望是计算摄影(Levoy2006)背后的驱动力之一,并促成了光场相机的发展(Ng,Levoy等,2005),我们在Section14.3.4中对此进行了讨论。尽管一些商用型号,如Lytro已经问世,但用智能手机相机创建此类图像的能力直到最近才变得普遍。23
苹果iPhone 7 Plus配备了双镜头(广角/长焦),是首款引入这一功能的智能手机,他们称之为人像模式。尽管该功能背后的技术细节从未公布,但估计深度图像的算法(可以从人像图像的元数据中读取)可能使用了一些组合技术。
图10.38手持式多帧超分辨率(Wronski,Garcia-Dorado等人。
2019)©2019 ACM。处理管道,显示:(a)捕获的原始(拜耳
CFA)图像;(b)用于计算方向核的局部梯度(c);(d)运动估计,结合局部统计(e)以计算混合权重(f)。结果来自(i)Hasinoff、Sharlet等人(2016)的方法和(j)Wronski、Garcia-Dorado等人(2019)的方法。
立体匹配和深度学习的国度。不久之后,谷歌推出了自己的肖像模式,该模式利用了最初设计用于聚焦相机光学系统的双像素技术,结合人物分割计算深度图,正如瓦德瓦、加尔等人(2018)在论文中所述。一旦估计出深度图,就会使用一种快速近似的方法来实现从后向前模糊合成操作,从而正确地模糊背景而不包含前景颜色。最近,加尔、瓦德瓦等人(2019)通过使用深度网络提高了深度估计的质量,并且还使用了两个镜头(以及双像素)生成了更高品质的深度图(张、瓦德瓦等人,2020)。
关于散景,这是摄影师用来描述图像中出现的光斑或亮点形状的术语。这种形状由控制进入镜头光线量的光圈叶片配置决定(在大画幅相机上)。传统上,这些叶片是用直金属片制成的,导致形成了多边形光圈,但后来大多被弯曲的叶片取代,以产生更圆形的形状。使用计算摄影时,我们可以选择任何让摄影师满意的形状,但最好不是高斯模糊,因为高斯模糊不对应任何实际光圈,会产生模糊的亮点。Wadhwa、Garg等人(2018年)的论文中使用了圆形散景来实现景深效果,而最近的一个版本则在计算中采用了
图10.39软化硬分割边界(边界遮罩)(Rother、Kolmogorov和Blake 2004)©2004 ACM:(a)是指分割边界周围区域,其中像素具有混合的前景和背景颜色;(b)沿边界的像素值用于计算软透明度遮罩;(c)在曲线t的每一点上,估计出位移△和宽度σ。
10.4 图像抠像和合成
图像抠像和合成是将前景物体从一张图片中分离出来并粘贴到新背景上的过程(Smith和Blinn 1996;Wang和Cohen 2009)。它常用于电视和电影制作中,将真人演员与计算机生成的图像如天气图或3D虚拟角色和场景叠加在一起(Wright 2006;Brinkmann 2008),并且最近已成为视频会议系统中的一个流行功能。
我们已经看到许多用于图像中对象交互分割的工具,包括蛇形工具(第7.3.1节)、剪刀工具(第7.3.1节)和GrabCut分割(第4.3.2节)。虽然这些技术可以生成合理的像素级分割结果,但它们无法捕捉到边界处混合像素中前景和背景颜色之间的微妙相互作用(Szeliski和Golland 1999)(Figure10.39a)。
为了成功地将前景对象从一张图像复制到另一张图像中,而不产生明显的离散化伪影,我们需要提取一个遮罩,即从输入的合成图像C中估计出一个软不透明度通道α和未受污染的前景颜色F。回顾第3.1.3节(图3.4),合成方程(3.8)可以表示为
C = (1 - α)B + αF. (10.29)
该运算符以因子(1 - α)减弱背景图像B的影响,然后添加与前景元素F对应的(部分)颜色值。
虽然合成操作很容易实现,但反向遮罩操作,即根据输入图像C估计F、α和B则更具挑战性(图10.40)。要了解原因,请观察到,虽然合成像素颜色C提供了三个测量值,

图10.40自然图像遮罩(Chuang,Curless等人,2001)©2001 IEEE:(a)输入图像具有“自然”(非恒定)背景;(b)手绘三色图——灰色表示
未知区域;(c)提取的alpha图;(d)提取的(预乘)前景颜色;(e)在新背景上合成。
F、α和B未知数共有7个自由度。设计技术来估计这些未知数,尽管问题的约束不足,这是图像抠图的本质。
在本节中,我们回顾了多种图像抠图技术。首先介绍蓝幕抠图,该方法假设背景是已知的固定颜色,并讨论其变体,包括双屏抠图(当可以使用多个背景时)和差异抠图(已知背景为任意)。接着,我们讨论自然图像抠图的局部变体,在这些应用中,前景和背景都是未知的。通常情况下,首先指定一个三色标签,即将图像分为前景、背景和未知区域(图10.40b)。接下来,我们介绍一些用于自然图像抠图的全局优化方法。最后,我们讨论抠图问题的其他变体,包括阴影抠图、闪光灯抠图和环境抠图。
蓝幕抠像技术涉及在恒定的彩色背景前拍摄演员(或物体)。虽然最初首选的颜色是亮蓝色,但现在更常用的是亮绿色(Wright2006;Brinkmann2008)。Smith和Blinn(1996)讨论了多种
蓝屏遮罩技术,大多在专利中描述,而不是公开的研究文献。早期的技术使用对象颜色通道的线性组合和用户调整的参数来估计不透明度α。
创、柯尔斯等人(2001)描述了一种称为三岛算法的新技术,该技术涉及拟合两个多面体表面(以平均背景颜色为中心),分离前景和背景颜色分布,然后测量新颜色与这些表面之间的相对距离来估计α(Figure10.41e)。尽管这项技术在许多工作室环境中表现良好,但仍可能受到蓝色溢出的影响,即物体边缘的半透明像素会获得一些背景的蓝色色调。
双屏幕遮罩。在他们的论文中,Smith和Blinn(1996)还介绍了一种称为三角化遮罩的算法,该算法使用多个已知背景颜色来过度约束用于估计不透明度α和前景颜色F的方程。
例如,考虑在合成方程(10.29)中将背景颜色设置为黑色,即B = 0。因此,合成图像C等于αF。如果将背景颜色替换为不同的已知非零值B,则结果如下
C - αF = (1 - α)B; (10.30)
这是一组用于估计α的(颜色)方程,但约束过多。实际上,B的选择不应使C饱和,为了达到最佳精度,应使用多个B值。此外,在处理前对颜色进行线性化也很重要,这是所有图像抠图算法的共同做法。生成用于评估的真实alpha遮罩的论文通常会使用这些技术来获得准确的遮罩估计(Chuang,Curless等,2001;Wang和Cohen,2007a;Levin,Acha和Lischinski,2008;Remann,Rother等,2008,2009).25练习10.8也要求你这样做。
差异抠像。当背景不规则但已知时,一种相关的方法称为差异抠像(Wright 2006;Brinkmann 2008)。这种方法最常用于演员或物体在静态背景前拍摄的情况,例如办公室视频会议、人物跟踪应用(Toyama,Krumm等1999),或用于生成体积3D重建技术所需的轮廓(第12.7.3节)(Szeliski 1993;Seitz和Dyer 1997;Seitz,Curless等2006)。它也可以用于带有摇摄镜头的情况,其中背景是从前景被移除的帧中合成的,使用垃圾抠像(第10.4.5节)(Chuang,Agarwala等2002)。另一个应用是检测视图-
25请访问http://alphamatting.com上的alpha matting评估网站。
影片中的视觉连续性错误,即在稍后重新拍摄镜头时背景的差异(Pickup和Zisserman2009)。
在前景和背景运动都可以通过参数变换来指定的情况下,可以使用三角定位的推广方法(Wexler,Fitzgibbon和Zisserman 2002)提取高质量的遮罩。然而,当帧需要独立处理时,结果往往质量较差(图10.42)。在这种情况下,使用一对立体相机作为输入可以显著提高结果的质量(Criminisi,Cross等2006;Yin,Criminisi等2007)。
图像抠图最通用的版本是,在对背景一无所知的情况下,仅通过场景的粗略分割来区分前景、背景和未知区域,这被称为三色图(Figure10.40b)。然而,一些技术放宽了这一要求,允许用户在图像中画几笔或涂鸦:参见图10.45和10.46(王和科恩2005;王、阿格拉瓦拉和科恩2007;莱文、利辛斯基和韦斯2008;雷曼、罗瑟等人2008;雷曼、罗瑟和盖劳茨2008)。全自动单图像抠图的结果也已报道(莱文、阿查和利辛斯基2008;辛加拉朱、罗瑟和雷曼2009)。王和科恩(2009)的综述文章详细描述并比较了所有这些技术,下面简要介绍其中的一些,而网站http://alphamatting.com则提供了最新算法的最新列表和数值比较。
一种相对简单的自然图像抠图算法是Knockout,如Chuang、Curless等人(2001)所描述,并在图10.41f中展示。该算法首先确定最近的已知前景和背景像素(在图像空间中),然后与邻近的已知像素混合,以生成每个像素的前景F和背景B颜色估计值。接着调整背景颜色,使测量的颜色C位于F和B之间的直线上。最后,按通道估计不透明度α,并根据各通道的颜色差异将三个估计值结合在一起。(这是对α的最小二乘解的一种近似。)图10.42显示,当背景包含多个主导局部颜色时,Knockout存在问题。
如果我们把前景和背景颜色视为在某个区域内采样的分布(图10.41g-h),可以获得更准确的遮罩效果。Ruzon和Tomasi(2000)将局部颜色分布建模为(不相关的)高斯混合,并在条带中计算这些模型。然后,他们找到最能描述观察到的颜色C的混合成分F和B的配对,计算α作为这些均值之间的相对距离,并调整F和B的估计值,使其与C共线。
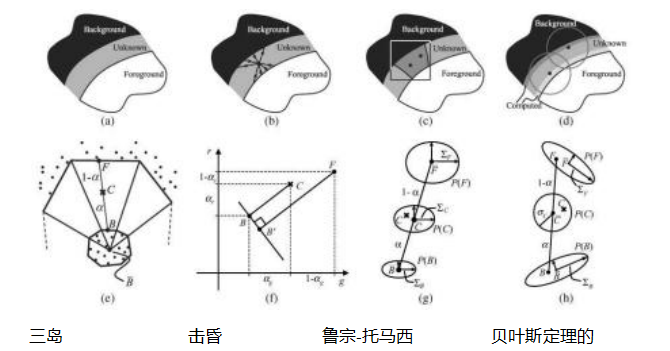
图10.41图像抠图算法(Chuang,Curless等,2001)©2001 IEEE。Mishima的算法将全局前景和背景颜色分布建模为以平均背景色(蓝色)为中心的多面体表面。Knockout使用每个像素的局部前景和背景颜色估计,并沿每个颜色轴计算Q。Ruzon和Tomasi的算法局部建模前景和背景的颜色及其变化。Chuang等人的贝叶斯抠图方法根据局部前景和背景分布计算(部分)前景颜色和不透明度的最大后验概率估计。
创、柯尔斯等人(2001)和希尔曼、汉娜、伦肖(2001)使用完整的3×3颜色协方差矩阵来建模相关高斯混合,并独立计算每个像素的估计值。马特提取以已知颜色值为起点,逐步扩展到未知区域,以便最近计算出的F和B颜色可以在后续阶段使用。
估计未知像素的不透明度和(未混合)前景的最可能值
在背景颜色方面,Chuang等人使用了最大化全贝叶斯公式
P (F, B, Q jC) = P (CjF, B, Q)P (F)P (B)P (Q)/P (C). (10.31)
这相当于最小化负对数似然
L (F, B, Q jC) = L (CjF, B, Q) + L (F) + L (B) + L (Q) (10.32)
(去掉L(C)项,因为它为常数)。
让我们依次检查这些术语。第一个是L(CjF,B,Q),即在未知值(F,B,Q)给定的情况下观察到像素颜色C的可能性。如果我们假设高斯分布

图10.42自然图像抠图结果(Chuang,Curless等人,2001)©2001 IEEE。差异抠图和遮罩效果在这类背景上表现不佳,而较新的自然图像抠图技术则表现出色。Chuang等人的结果略显平滑,更接近真实情况。
在我们的观测中存在方差σ的噪声,这个负对数似然(数据项)是
L(C) = 1/2ⅡC - [αF + (1 - α)B]Ⅱ2 /σ , (10.33)
如图10.41h所示。
第二项,L(F),对应于特定前景颜色F来自高斯混合模型的可能性。在将样本前景颜色聚类后,计算加权均值F和协方差ΣF,其中权重与给定前景像素的不透明度和与未知像素的距离成正比。因此,每个聚类的负对数似然值为
L(F) =
(F - F)T ΣF-1 (F - F). (10.34)
使用类似的方法来估计未知的背景颜色分布。如果背景已经已知,即对于蓝屏或差异遮罩应用,那么使用其测量的颜色值和方差代替。
除了将前景和背景颜色分布建模为高斯混合外,还可以保留原始颜色样本并计算最可能的配对来解释观察到的颜色C (Wang和Cohen2005,2007a)。这些技术在(Wang和Cohen2009)中进行了更详细的描述。
在他们的贝叶斯抠图论文中,Chuang、Curless等人(2001)假设L(α)的分布是恒定的(非信息性的)。后续的研究则假设该分布更集中在0和1附近,有时使用马尔可夫随机场(MRF)来定义P (α)的整体相关先验(Wang和Cohen 2009)。
为了计算最可能的估计值(F,B,α),贝叶斯抠图算法在计算(F,B)和α之间交替进行,因为这些问题都是二次方程,因此可以作为小型线性系统求解。当估计多个颜色簇时,使用前景和背景颜色簇的最可能配对。
贝叶斯图像抠图产生的结果比Ruzon和Tomasi(2000)的原始自然图像抠图算法有所改进,如Figure10.42所示。然而,与后来的技术(Wang和Cohen2009)相比,其在复杂背景或不准确的三色图上的表现并不好(图10.44)。
估计每个像素的不透明度和前景颜色的独立方法的替代方法是使用全局优化来计算一个考虑了邻近像素之间的相关性的遮罩。
图10.43颜色线遮罩(Levin,Lischinski和Weiss 2008):(a)局部3×3颜色块;(b)潜在的Q值分配;(c)前景和背景颜色线,连接它们最近交点的向量ak,以及恒定Q值的平行平面族,Qi = ak·(Ci - B0);(d)两个样本颜色Ci和Cj的散点图及其与平均值μk的偏差。
无聊的Q值。两个例子是GrabCut交互式分割系统(Rother、Kolmogorov和Blake2004)中的边界遮罩和Poisson遮罩(Sun、Jia等人2004)。
边界垫片首先扩展由Grab-Cut(第4.3.2节)生成的二值分割区域,然后为边界上的每个点求解亚像素边界位置△和模糊宽度σ(图10.39)。通过正则化强制这些参数沿边界平滑,并使用动态规划进行优化。虽然这种方法可以为平滑的边界,如人脸,获得良好的结果,但在处理精细细节时,如头发,则存在困难。
Poisson matting (Sun,Jia等,2004)假设每个像素在三值图中具有已知的前景和背景颜色(与贝叶斯matting相同)。然而,它不是独立估计每个Q值,而是假设alpha遮罩的梯度与彩色图像的梯度之间存在关联。
· ▽C; (10.35)
可以通过对式(10.29)两边求梯度并假设前景和背景变化缓慢来推导。然后,使用第4.2节(4.24)首次描述的正则化(最小二乘法)技术,将每个像素的梯度估计值整合到一个连续的Q(x)场中,该技术随后在泊松混合(第8.4.4节,公式(8.75))和基于梯度的动态范围压缩映射(第10.2.1节,公式(10.18))中得到应用。当有良好的前景和背景颜色估计且这些颜色变化缓慢时,该技术效果良好。
莱文、利辛斯基和韦斯(2008)假设这些颜色分布可以局部近似为两种颜色的混合,这被称为颜色线模型(Figure10.43a-c)。在此假设下,对于窗口Wk中的每个像素i(例如,3×3),α的闭式估计值由下式给出:
αi = ak · (Ci — B0) = ak · C + bk , (10.36)
其中,Ci是被视为三向量的像素颜色,B0是背景色线上的任意像素,ak是连接前景和背景色线上最近两点的向量,如图10.43c所示。(请注意,图中所示的几何推导是Levin、Lischinski和Weiss(2008)提出的代数推导的替代方案。)最小化图像中所有重叠窗口Wk上的α值αi与其各自颜色线模型(10.36)之间的偏差,从而产生成本函数。
(10.37)
其中∈项用于在两种颜色分布重叠的情况下(即在常数α区域)对ak的值进行正则化。
因为这个公式是未知数{(ak,bk)}的二次方,所以它们可以在每个窗口Wk内被消除,从而得到最终的能量
Eα = αTLα, (10.38)
L矩阵中的条目由下式给出
其中,M = jWkj是每个(重叠的)窗口中的像素数,μk是窗口Wk中像素的平均颜色,k是像素颜色的3×3协方差加上∈/MI。
图10.43d展示了这个亲和矩阵背后的直觉,该矩阵被称为遮罩拉普拉斯矩阵。请注意,当Wk中的两个像素Ci和Cj指向远离均值μk的相反方向时,它们的加权点积接近—1,因此它们的亲和力接近0。颜色空间中相近的像素(因此具有相似的预期α值)将具有接近—2/M的亲和力。
最小化受已知值α = {0,1}限制的二次能量(10.38)仅需求解一组稀疏线性方程,因此作者称其技术为自然图像抠图的闭式解。一旦α已知,

图10.44中等精度trimap的比较着色结果。Wang和Co- hen(2009)描述了所比较的各个技术。

图10.45基于涂鸦输入的对比着色结果。Wang和Cohen
(2009)描述了正在比较的各个技术。
计算后,使用最小二乘法最小化合成方程(10.29),并用空间变化的一阶平滑度进行正则化来估计前景和背景颜色,
其中,j▽αij权重分别应用于F和B导数的x和y分量(Levin,Lischinski和Weiss2008)。
拉普拉斯(闭式)遮罩只是Wang和Cohen(2009)所审查和比较的众多基于优化的技术之一。其中一些技术使用α遮罩上的亲和力或平滑度项的替代公式,以及替代估计

图10.46基于血流的分割结果(Rhemann,Rother et al. 2008)©2008
电器和电子工程师学会
诸如信念传播等技术,或用于建模局部前景和背景颜色分布的替代表示(例如,局部直方图)(王和科恩2005,2007a,b)。这些技术中的一些还能够在用户绘制轮廓线或稀疏的涂鸦集时提供实时结果(王、阿格拉瓦拉和科恩2007;雷曼、罗瑟等人2008),甚至可以预先将图像分割成少量的区域,用户可以通过简单的点击选择(莱文、阿查和利辛斯基2008)。
图10.44展示了在指定了一个三值图的玩具动物毛皮区域上运行多个调查算法的结果,而图10.45则显示了仅需少量涂鸦作为输入即可生成哑光效果的技术的结果。图10.46展示了一种更为近期的算法(Rhemann,Rother等,2008)的结果,该算法声称优于王和科恩(2009)调查的所有技术。
最新的自然图像遮罩结果可以在Remann、Rother等人(2009)创建的http://alphamatting.com网站上找到。该网站目前列出了超过60种不同的算法,其中大多数较新的算法使用了深度神经网络。Xu、Price等人(2017)的《深度图像遮罩》论文提供了一个更大的数据库,包含49,300张训练图像和1,000张测试图像,这些图像是通过在各种背景上叠加手动创建的颜色前景遮罩构建的。27
粘贴。一旦从图像中提取出一个哑光,通常会直接将其合成到新背景上,除非需要隐藏抠图区域与背景区域之间的接缝,在这种情况下可以使用泊松混合(P rez、Gangnet和Blake2003)(第8.4.4节)。
在后一种情况下,如果哑光边界通过的区域在旧图像和新图像中纹理很少或看起来相似,则是有帮助的。Jia、Sun等人(2006)的论文

图10.47烟雾垫(Chuang,Agarwala等人,2002)©2002 ACM:(a)输入视频
框架;(b)移除前景对象后;(c)估计的透明度;(d)将新对象插入背景。
除了用分数边界遮罩实物体之外,还可以遮罩半透明介质,如烟雾(Chuang,Agarwala等,2002)。从视频序列开始,每个像素被建模为其(未知的)背景颜色和所有像素共有的恒定前景(烟雾)颜色的线性组合。通过颜色空间投票来估计这种前景颜色,并沿每条颜色线的距离用于估计每个像素的时间变化透明度(图10.47)。
提取并重新插入阴影也是可能的,这需要使用一种相关技术(Chuang,Goldman等2003;Wang,Curless和Seitz 2020)。这里,不是假设前景颜色是恒定的,而是假设每个像素在其完全光照和完全阴影的颜色之间变化,这些颜色可以通过在阴影经过场景时(练习10.9)取(稳健的)最小值和最大值来估计。由此产生的部分阴影遮罩可以用于将阴影重新投影到新场景中。如果目标场景具有非平面几何结构,可以通过挥动一根直棍的阴影扫描整个场景。然后,新的阴影遮罩可以根据计算出的变形场进行扭曲,使其正确地覆盖在新场景上(图10.48)。还可以通过扩展视频对象分割算法(第9.4.3节)来从视频流中提取阴影和其他效果,如烟雾(Lu,Cole等2021)。照片中有用的阴影处理示例包括去除或柔化人物肖像中的强烈阴影(Sun,Barron等2019;Zhou,Hadap等2019;Zhang,Barron等2020),这一功能可在Google Photos中作为“肖像光”功能提供。28
使用更复杂的采集系统也可以提高马特算法的质量和可靠性。例如,拍摄闪光灯和非闪光灯图像对支持
可靠地提取前景遮罩,这些遮罩显示为大光照区域

图10.48阴影遮罩(Chuang,Goldman等人,2003)©2003 ACM。阴影遮罩不是简单地用阴影(c)使新场景变暗,而是正确地用新阴影使已照明的场景变暗,并将阴影覆盖在3D几何体(d).上。
两种图像之间的转换(Sun,Li等人,2006)。同时聚焦于不同距离的视频流(McGuire,Matusik等人,2005)或使用多摄像头阵列(Joshi,Matusik和Avidan,2006)也是生成高质量母版的好方法。这些技术在(Wang和Cohen,2009)中有更详细的描述。
最后,拍摄一个折射物体在多个图案背景前,可以将该物体置于新颖的三维环境中。这些环境遮罩技术(Zongker,Werner等人,1999;Chuang,Zongker等人,2000)将在第14.4节中讨论。
虽然可以将常规单帧遮罩技术,如蓝幕或绿幕遮罩(Smith和Blinn1996;Wright2006;Brinkmann2008)应用于视频序列,但移动物体的存在有时会使遮罩过程变得更容易,因为背景的某些部分可能在前一帧或后一帧中被揭示出来。
创、阿加瓦拉等人(2002)提出了一种处理视频抠像问题的巧妙方法,首先使用保守的垃圾遮罩去除前景物体,然后对剩余的背景图进行对齐和合成,以获得高质量的背景估计。他们还描述了如何利用稀疏关键帧绘制的三张图通过双向光流插值到中间帧。关于视频抠像的其他方法,如旋转描边法,即在视频序列的关键帧中绘制曲线或线条(阿加瓦拉、赫茨曼等人,2004;王、巴特等人,2005),在王和科恩(2009)的抠像综述论文中有所讨论。此外,还有由埃罗费耶夫、吉特曼等人(2015)创建的一个精心抠像的定格动画视频的新数据集。
自从视频遮罩技术最初开发以来,改进的算法已经出现
已经开发了交互式和全自动视频对象分割,如dis-

图10.49纹理合成:(a)给定一小块纹理,任务是合成一个看起来相似的较大块;(c)其他半结构化的纹理,这些纹理很难合成。(图片由Alyosha Efros提供。)
在第9.4.3节中讨论。Sengupta、Jayaram等人(2020)的论文使用深度学习和对抗损失,以及运动先验,从小动作手持视频中提供高质量的抠图,同时捕捉到背景中的干净画面。Wang、Curless和Seitz(2020)描述了一个系统,通过观察场景中的人行走来确定阴影和遮挡,从而能够在正确的时间尺度和光照条件下插入新人。后续工作中,Lin、Ryabtsev等人(2021)描述了一种高分辨率实时视频抠图系统,并提供了两个新的视频和图像抠图数据集。最后,Lu、Cole等人(2021)描述了如何提取视频中被跟踪和分割对象相关的阴影、反射和其他效果。
10.5 纹理分析与合成
虽然纹理分析和合成乍看之下似乎不是计算摄影技术,但事实上,它们被广泛用于修复图像中的缺陷,如小洞,或从普通照片中创建非逼真的绘画渲染。
纹理合成问题可以表述如下:给定一个小样本
“纹理”(图10.49a)生成一个更大的相似图像(图10.49b)。可以想象,对于某些样本纹理,这个问题可能相当具有挑战性。
传统的纹理分析和合成方法试图匹配光谱
在生成形状噪声时,匹配频率特性本身并不充分,这相当于匹配空间相关性。不同频率下的响应分布也必须匹配。Heeger和Bergen(1995)开发了一种算法,在多尺度(可转向金字塔)响应直方图和最终图像直方图之间交替匹配。Portilla和Simoncelli(2000)改进了这一技术,通过在尺度和方向上进行成对统计匹配。De Bonet(1997)采用从粗到细的策略,寻找源纹理中具有相似父结构的位置,即类似的多尺度定向滤波器响应,然后随机选择其中一个匹配位置作为当前样本值。Gatys、Ecker和Bethge(2015)也使用了金字塔式的精细到粗再到精细的算法,但使用了为对象识别训练的深度网络。在深度网络的每一层,他们收集各种特征之间的相关统计信息。在生成过程中,他们迭代更新随机图像,直到这些更符合感知的统计量(Zhang,Isola等,2018)得到匹配。我们将在Section10.5.3上关于神经风格转换的神经纹理合成的其他神经方法,如Shaham、Dekel和Michaeli(2019),提供更多细节。
基于范例的纹理合成算法通过寻找与当前合成图像相似的源纹理邻域来依次生成纹理像素(Efros和Leung 1999)。考虑图10.50左侧部分构建的纹理上的未知像素pin。由于其一些相邻像素已经合成,我们可以在右侧的样本纹理图像中寻找类似的局部邻域,并随机选择其中一个作为新的p值。此过程可以沿着新图像重复进行,无论是以光栅方式还是在填充孔洞时绕着边缘扫描(“洋葱剥皮”),如第10.5.1节所述。在实际实现中,Efros和Leung(1999)找到最相似的邻域,然后包括所有距离在d=(1+∈)范围内的其他邻域,其中∈= 0.1。他们还可选地根据相似度度量d来加权随机像素选择。
为了加快这一过程并提高其视觉质量,Wei和Levoy(2000)扩展了该技术,采用了一种从粗到精的生成过程,在匹配过程中还会考虑金字塔中已经合成的较粗层次(De Bonet 1997)。为了加速最近邻查找,使用了树状向量量化。一种更快的最近邻搜索版本是广泛使用的随机补丁匹配迭代更新算法,由Barnes、Shechtman等人(2009)开发。
Efros和Freeman(2001)提出了一种替代的加速和视觉质量提升技术。他们没有一次合成一个像素,而是根据与先前合成区域的相似性选择重叠的方形块(图10.51)。一旦选择了合适的块,新重叠块之间的接缝就会被确定。

图10.50使用非参数采样进行纹理合成(Efros和Leung1999)。最新像素p的值是从源纹理(输入图像)中相似的局部(部分)区域中随机选择的。(图由Alyosha Efros提供。)
图10.51图像拼接的纹理合成(Efros和Freeman2001)。与一次生成一个像素不同,从源纹理中复制较大的块。然后使用动态编程优化所选块之间重叠区域的过渡。(图由Alyosha Efros提供。)
使用动态规划。(无需进行完整的图割缝选择,因为垂直边界只需要每行一个缝的位置。)由于这一过程涉及选择小块并将其拼接在一起,Efros和Freeman(2001)将其系统称为图像绗缝。Komodakis和Tziritas(2007)提出了一种基于MRF的块合成算法版本,该算法使用他们称为“优先BP”的新高效循环信念传播方法。Wei、Lefebvre等人(2009)对2009年之前的基于示例的纹理合成工作进行了全面综述。
填补从照片中切除物体或缺陷后留下的孔洞,即所谓的修复,是纹理合成最常见的应用之一。

图10.52图像修复(孔洞填充):(a-b)沿等光度方向传播(Bertalmio,Sapiro等人,2000年)©2000 ACM;(c-d)基于示例的修复,采用基于置信度的填充顺序(Criminisi,P rez和Toyama,2004年)。
技术不仅用于从照片中移除不想要的人或入侵者(King1997),还用于修复旧照片和电影中的小缺陷(如去除划痕)或移除拍摄过程中悬挂在空中的道具或演员的钢丝(如去除钢丝)。Bertalmio、Sapiro等人(2000)通过沿等光度(恒定值)方向传播像素值并穿插一些各向异性扩散步骤来解决问题(图10.52a-b)。Telea(2004)开发了一种更快的技术,利用了来自水平集的快速行进方法(第7.3.2节)。然而,这些技术不会在缺失区域中产生纹理幻觉。Bertalmio、Vese等人(2003)通过向填充区域添加合成纹理来增强他们早期的技术。
前一节讨论的基于示例(非参数)纹理生成技术也可以通过从外部向内填充孔洞(“洋葱皮”顺序)来使用。然而,这种方法可能无法传播强烈的定向结构。克里米尼西、普雷兹和富山(2004)采用基于示例的纹理合成方法,其中合成的顺序由区域边界上的梯度强度
决定(图10.1d和10.52c-d)。孙、袁等人(2004)提出了一种相关的方法,用户可以绘制交互式线条以指示应优先传播的结构位置。与这些方法相关的其他技术包括多里、科恩-奥尔和耶舒伦(2003)、夸特拉、施德尔等人(2003)、夸特拉、埃萨等人(2005)、威尔奇科维亚克、布罗斯托等人(2005)、科莫达基斯和齐里塔斯(2007)以及韦克斯勒、谢赫特曼和伊拉尼(2007)所开发的技术。
大多数孔洞填充算法借用原始图像的小片段来填补孔洞。当有大量源图像数据库可用时,例如从照片分享网站或互联网获取的图像,有时可以复制一个连续的图像区域来填补孔洞。Hays和Efros(2007)提出了一种这样的技术,该技术利用图像上下文和边界兼容性选择源图像,然后使用图割和泊松混合方法将其与原始(有孔洞的)图像融合。这一技术被讨论如下:
与其他图像处理领域一样,深度神经网络被应用于所有最新的技术中(杨、陆等,2017;余、林等,2018;刘、雷达等,2018;曾、付等,2019;余、林等,2019;张、刘等,2019;纳泽里、吴等,2019;任、余等,2019;施、苏等,2020;易、唐等,2020)。其中一些论文介绍了神经网络架构的一些有趣的新扩展,如部分卷积(刘、雷达等,2018)和部分卷积(余、林等,2019),边缘结构的传播(纳泽里、吴等,2019;任、余等,2019),多分辨率注意力机制和残差(易、唐等,2020),以及迭代置信反馈(曾、林等,2020)。图像修复也被应用于视频序列(例如,高、萨拉夫等,2020)。关于图像修复最近挑战的结果可以在AIM 2020研讨会和挑战中找到(恩塔维利斯、罗梅罗等,2020a)。
基于示例的纹理合成思想还有两个应用,即纹理转移(Efros和Freeman2001)和图像类比(Hertzmann、Jacobs等人2001),它们都是非照相真实渲染的例子(Gooch和Gooch2001)。
除了使用源纹理图像外,纹理传递还采用参考(或目标)图像,并尝试将目标图像的某些特征与新合成的图像相匹配。例如,图10.53c中渲染的新图像不仅试图满足与图10.53b中的源纹理通常相似性的约束,还尝试匹配参考图像的亮度特性。Efros和Freeman(2001)提到,模糊图像强度或局部图像方向角是可替代的匹配量。
Hertzmann、Jacobs等人(2001年)提出了以下问题:
给定一对图像A和A(分别为未过滤的源图像和已过滤的源图像),以及一些额外的未过滤的目标图像B,合成一个新的已过滤的目标图像B,使得
A : A, :: B : B,.
用户无需对非真实感渲染效果进行编程,只需向系统提供前后图像示例,然后让系统使用基于示例的合成来合成新图像,如图10.54所示。
用于解决图像类比的算法以类似于Efros和Leung(1999)以及Wei和Levoy(2000)的纹理合成算法的方式进行。一旦Gaus-
图10.53纹理转移(Efros和Freeman2001)©2001 ACM:(a)参考(目标)图像;(b)源纹理;(c)使用纹理(部分)渲染的图像。

图10.54图像类比(Hertzmann,Jacobs等人,2001年)©2001 ACM。给定源图像A及其渲染(过滤)版本A的一对示例,从另一个未过滤的源图像B生成渲染版本B。
对于所有源图像和参考图像的金字塔,算法会在A生成的源过滤金字塔中寻找与B中部分构建的邻域相似的区域,同时这些区域在A和B的相应位置具有类似的多分辨率外观。与纹理传递类似,外观特征不仅包括(模糊)颜色或亮度值,还包括方向。
这一通用框架允许图像类比应用于各种渲染任务。除了基于示例的非真实感渲染外,图像类比还可用于传统的纹理合成、超分辨率和纹理迁移(使用同一张纹理图像作为A和A)。如果只有经过滤波(渲染)的图像A可用,如绘画的情况,缺失的参考图像A可以通过智能(边缘保持)模糊操作来“幻觉”生成。最后,可以训练系统通过手动用伪颜色覆盖自然图像来执行“数字纹理”,这些伪颜色对应于像素的语义含义,例如水、树和草(图10.55a-b)。最终得到的系统

图10.55图像纹理与数字(Hertzmann,Jacobs等人,2001)©2001 ACM。给定一个纹理图像A和一个手工标记的(绘制的)版本A,仅根据绘制的版本B合成一个新的图像B。
然后可以将一个简略的草图转换为完全渲染的合成照片(图10.55c-d)。在最近的研究中,程、维什瓦纳坦和张(2008)将图像拼接(埃夫罗斯和弗里曼2001)和MRF推理(科莫达基斯、齐里塔斯和帕拉吉奥斯2008)的思想加入到基本的图像类比算法中,而拉马纳拉亚南和巴拉(2007)则将这一过程重新表述为能量最小化,这意味着它可以被视为条件随机场(第4.3.1节),并设计了一种高效的算法来找到一个好的最小值。
传统的滤波和特征检测技术也可用于非真实感渲染。例如,钢笔画(温肯巴赫和塞利辛1994)和绘画渲染技术(利特维诺维奇1997)使用局部颜色、强度和方向估计作为其程序化渲染算法的输入。风格化和简化照片及视频的技术(德卡洛和桑特拉2002;温内勒、奥尔森和古奇2006;法布曼、法塔尔等人2008),如Figure10.56中所述,结合了边缘保持模糊(第3.3.1节)和边缘检测与增强(第7.2.3节)。
随着深度学习的兴起,基于图像引导示例的纹理合成大多已被深度网络中的统计匹配所取代(Gatys,Ecker,和Bethge 2015)。图10.57展示了神经风格迁移网络的基本思想。在Gatys、Ecker和Bethge(2016)的原始工作中,风格图像ys和内容图像yc(见图10.58以获取示例)被输入到一个损失网络中,该网络比较从风格和目标图像中提取的特征与从正在生成的图像中提取的特征。这些损失通常包括感知损失。这些损失的梯度用于迭代地调整生成的图像,这使得这一过程
30有关论文的精选,请参见非真实感动画和渲染研讨会(NPAR)。

图10.56非照相抽象照片:(a) (DeCarlo和Santella
2002)©2002 ACM和(b) (Farbman,Fattal等人,2008)©2008 ACM。
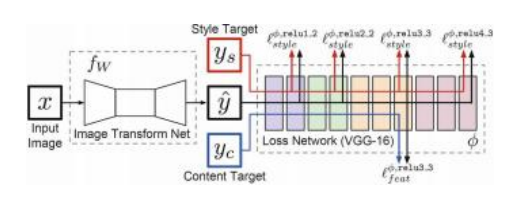
图10.57神经风格迁移的网络架构,该架构学习将图像转换为特定风格(Johnson,Alahi,和Fei-Fei 2016)©2016斯普林格。在训练过程中,内容目标图像yc被输入到图像变换网络作为输入x,同时输入风格图像ys,网络权重会更新以最小化感知损失,即风格重建损失lstyle和特征重建损失lfeat。早期由Gatys、Ecker和Bethge(2015)提出的网络没有图像
转换网络,而不是利用损失来优化转换后的图像。
为了加速这一过程,约翰逊、阿拉希和费-菲(2016)训练了一个前馈图像变换网络,该网络使用固定风格的图像和多个不同的内容目标,调整网络权重,使得由目标yc生成的风格化图像符合所需的统计特性。当新的图像x需要进行风格化时,只需将其通过图像变换网络即可。图10.58a展示了Gatys、埃克尔和贝特格(2016)与约翰逊、阿拉希和费-菲(2016)之间的一些比较。
感知损失现在已成为图像合成系统(Doso- vitskiy和Brox 2016)的标准组件,通常作为生成对抗损失的附加组件(第5.5.4节)。它们有时也被用作替代旧的图像质量指标,如SSIM (Zhang、Isola等2018;Talebi和Milanfar 2018;Tariq、Tursun等2020;Czolbe、Krause等2020)。
约翰逊、阿拉希和费-菲(2016)的基本架构由乌里亚诺夫、韦达利和莱姆皮茨基(2017)扩展,他们发现使用实例归一化而非批量归一化显著提升了结果。杜穆林、什伦斯和库德勒(2017)以及黄和贝隆吉(2017)进一步扩展了这些想法,通过条件实例归一化和自适应实例归一化来训练一个网络以模仿不同的风格,如图10.58b所示。
神经风格迁移仍然是一个活跃的研究领域,相关方法致力于更广泛的图像到图像转换(Isola,Zhu等,2017)和语义照片生成(Chen和Koltun,2017;Park,Liu等,2019;Bau,Strobelt等,2019;Ntavelis,Romero等,2020b)应用——详见Tewari,Fried等(2020,第6.1节)的最新综述。大多数较新的架构使用生成对抗网络(GANs)(Kotovenko,Sanakoyeu等,2019;Shaham,Dekel和Michaeli,2019;Yang,Wang等,2019;Svoboda,Anoosheh等,2020;Wang,Li等,2020;Xia,Zhang等,2020;H rk nen,Hertzmann等,2020),我们在Section5.5.4中讨论过。此外,最近还有一门关于基于学习的图像合成更广泛
主题的课程(Zhu,2021)。
10.6 额外阅读
关于计算摄影第一个十年的优秀综述可以在Raskar和Tumblin(2010)的书中找到,以及Nayar(2006)、Cohen和Szeliski(2006)、Levoy(2006)、Debevec(2006)和Hayes(2008)的调查文章中。此外,还有Bimber(2006)和Durand与Szeliski(2007)编辑的两期特刊。本章开头提到的计算摄影课程笔记也是了解这一领域的另一重要来源。

图10.58两个神经风格迁移的例子:(a)约翰逊、阿拉希和费-菲(2016)的预训练网络©2016斯普林格(标记为“我们的”)与(加蒂斯、埃克尔和贝特格2016)(标记为“[11]”);(b)一个使用条件实例归一化的网络,用于模仿不同风格(上排)应用于各种内容(左列)©(杜穆林、什伦斯和库德勒2017)。
最近的材料和参考文献。31
高动态范围成像的子领域有专门讨论该领域研究的书籍(Reinhard,Heidrich等,2010),以及一些描述相关摄影技术的书籍(Freeman,2008;Gulbins和Gulbins,2009)。校准相机射电响应函数的算法可以在Mann和Picard(1995)、Debevec和Malik(1997)以及Mitsunaga和Nayar(1999)的文章中找到。
色调映射的主题在(Reinhard,Heidrich等人,2010)中得到了广泛讨论。关于这一主题的大量文献中,具有代表性的论文包括(Tumblin和Rushmeier,1993;Larson,Rushmeier和Piatko,1997;Pattanaik,Ferwerda等人,1998;Tum-blin和Turk,1999;Durand和Dorsey,2002;Fattal,Lischinski和Werman,2002;Reinhard,Stark等人,2002;Lischinski,Farbman等人,2006;Farbman,Fattal等人,2008;Paris,Hasinoff和Kautz,2011;Aubry,Paris等人,2014)。
关于超分辨率的文献相当丰富(Chaudhuri2001;Park,Park和Kang2003;Capel和Zisserman 2003;Capel 2004;van Ouwerkerk2006)。超分辨率通常指通过对多张图像进行配准和合并,以生成更高分辨率合成图像的技术(Keren,Peleg和Brada1988;Irani和Peleg1991;Cheese-man,Kanefsky等1993;Mann和Picard1994;Chiang和Boult1996;Bascle,Blake和Zisserman1996;Capel和Zisserman1998;Smelyanskiy,Cheese-man等2000;Capel和Zisserman2000;Pickup,Capel等2009;Gulbins和Gulbins2009;Hasinoff,Sharlet等2016;Wronski,Garcia-Dorado等2019)。然而,单图像超分辨率技术也已开发(Freeman,Jones和Pasztor2002;Baker和Kanade 2002;Fattal2007;Dong,Loy等2016;Cai,Gu等2019;Anwar,Khan和Barnes 2020)。这些技术与去噪(Zhang,Zuo等2017;Brown 2019;Liba,Murthy等2019;Gu和Timofte2019)、去模糊和盲图像反卷积(Campisi和Egiazarian2017;Zhang,Dai等2019;Kupyn,Martyniuk等2019)以及去马赛克(Chatterjee,Joshi等2011;Gharbi,Chaurasia等2016;Abdelhamed,Afifi等2020)密切相关。
王和科恩(2009)对图像抠图进行了很好的综述。代表性论文包括与先前工作的广泛比较,如(Chuang,Curless等2001;Wang和Cohen 2007a;Levin,Acha和Lischinski 2008;Rhemann,Rother等2008,2009;Xu,Price等2017)。您可以在Rhemann,Rother等(2009)创建的http://alphamatting.comwebsite上找到最近的论文和结果的链接。抠图理念
也可用于操纵阴影(Chuang,Goldman等人,2003;Sun,Barron等人。
31 CMU 15-463,http://graphics.cs.cmu.edu/courses/15-463/2008秋季,伯克利CS194-26/294-26,https:// inst.eecs.berkeley.edu/~ cs194-26/fa20,MIT 6.815/6.865,https://stellar.mit.edu/S/course/6/sp08/6.815/materials. html,斯坦福CS 448A,https://graphics.stanford.edu/courses/cs448a-08-spring,CMU 16-726,https:// learning-image-synthesis.github.io,以及SIGGRAPH课程,https://web.media.mit.edu/~raskar/photo。
2019;Zhou,Hadap等人2019;Zhang,Barron等人2020;Wang,Curless和Seitz2020)和视频(Chuang,Agarwala等人2002;Wang,Bhat等人2005;Erofeev,Gitman等人2015;Sengupta,Jayaram等人2020;Lin,Ryabtsev等人2021)。
关于纹理合成和孔洞填充的文献包括传统的纹理合成方法,这些方法试图匹配源图像和目标图像之间的统计特性(Heeger和Bergen 1995;De Bonet 1997;Portilla和Simoncelli 2000),以及寻找源样本内部匹配邻域或块的方法(Efros和Leung 1999;Wei和Levoy 2000;Efros和Freeman 2001;Wei、Lefebvre等2009)或使用神经网络(Gatys、Ecker和Bethge 2015;Shaham、Dekel和Michaeli 2019)。类似地,传统的孔洞填充方法涉及解决局部变分(平滑延续)问题(Bertalmio、Sapiro等2000;Bertalmio、Vese等2003;Telea 2004)。下一波技术采用数据驱动的纹理合成方法(Drori、Cohen-Or和Yeshurun 2003;Kwatra、Sch dl等2003;Criminisi、P rez和Toyama 2004;Sun、Yuan等2004;Kwatra、Essa等2005;Wilczkowiak、Brostow等2005;Komodakis和Tziritas 2007;Wexler、Shechtman和Irani 2007)。最新的图
和视频修复算法使用深度
神经网络(Yang、Lu等2017;Yu、Lin等2018;Liu、Reda等2018;Shih、Su等2020;Yi、Tang等2020;Gao、Saraf等2020;Ntavelis、Romero等2020a)。除了生成孤立的纹理块或修复缺失区域外,相关技术还可以用于将图像或绘画的风格转移到另一张图像(Efros和Freeman2001;Hertzmann,Jacobs等人2001;Gatys,Ecker和Bethge2016;Johnson,Alahi和Fei-Fei2016;Dumoulin,Shlens和Kudlur2017;Huang和Belongie2017;Shaham,Dekel和Michaeli2019)。
10.7 练习
例10.1:辐射校准。实现第10.2节中描述的多曝光辐射校准算法之一(Debevec和Malik 1997;Mitsunaga和Nayar 1999;Reinhard、Heidrich等人2010)。这种校准将在多种不同应用中发挥作用,例如拼接图像或使用不同曝光和阴影形状进行立体匹配。
1.使用三脚架拍摄一系列带有包围曝光的图像。如果你的相机有自动包围曝光(AEB)模式,拍摄三张照片可能就足以校准相机的大部分动态范围,特别是当场景中有很多明暗区域时。(在晴天户外或透过窗户拍摄效果最佳。)