1 Studying《Is Parallel Programming Hard》14-18
目录
Chapter 14 Advanced Synchronization
14.1 避免锁
14.2 非阻塞性同步
14.3 并行实时计算
Chapter 15 Advanced Synchronization:Memory Ordering
15.1 订购:为什么和如何?
15.2 技巧和陷阱
15.3 编译时间的限制
15.4 高级原语
15.5 硬件细节
15.6 内存模型直觉
Chapter 16 Ease of Use
16.1 什么是简单?
16.2 API设计中的生锈层
16.3 修剪曼德布罗集
Chapter 17 Conflicting Visions of the Future
17.1 CPU技术的未来不是它曾经的样子
17.2 事务内存
17.3 硬件事务内存
17.4 正式回归测试
17.5 并行处理中的函数编程
17.6 概述
Chapter 18 Looking Forward and Back
Chapter 14 Advanced Synchronization
如果一点知识是一件危险的事情,想想你可以用大量的知识做些什么吧!
未知的
本章介绍了用于无锁算法和并行实时系统的同步技术。
尽管无锁算法在面对极端要求时可以非常有用,但它们并不是灵丹妙药。例如,如第5章末尾所指出的,在考虑无锁算法之前,您应该彻底应用分区、批处理和经过良好测试的打包弱api(参见第8章和第9章)。
但在完成所有这些之后,您仍然会发现自己需要本章中描述的高级技术。为此,第14.1节总结了迄今为止用于避免锁的技术,而第14.2节给出了非阻塞同步的简要概述。内存排序也很重要,但它保证了自己的章节,即第15章。
第二种形式的高级同步为并行实时计算提供了所需的更强的前进-进度保证,这是第14.3节的主题。
14.1 避免锁
我们面临着不可克服的机会。
沃尔特凯利
尽管锁定是生产中并行性的主力,但在许多情况下,性能、可伸缩性和实时响应都可以通过使用无锁技术得到大大改进。这种无锁技术的一个特别令人印象深刻的例子是第5.2节中描述的统计计数器,它不仅避免了锁,还避免了读-修改-写原子操作、内存障碍,甚至计数器增量的缓存丢失。我们所介绍的其他例子包括:
1.在第五章中通过许多其他计数算法的快速路径。
2.在第6.4.3节中,通过资源分配器缓存的快速路径。
3.第6.5节中的迷宫求解器。
4.第8章中的数据所有权技术。
6.第10章中的查找代码路径。
7.第13章中的许多技术。
简而言之,无锁技术非常有用,而且会被大量使用。但是,最好是将无锁技术隐藏在一个定义良好的API后面,比如inc_ count()、memblock_alloc()、rcu_read_lock()等等。这样做的原因是,无序地使用无锁技术是创建困难的bug的一个好方法。如果你认为找到和修复这些错误比避免它们更容易,请重新阅读第11章和第12章。
14.2 非阻塞性同步
只要机器能做它应该做的事,就不要担心理论。
罗伯特·海因莱因
术语非阻塞同步(NBS)[Her90]描述了八类具有不同前进进度保证的线性化算法[ACHS13],如下:
1.有界种群-无等待同步:每个线程都将在特定的有限时间内进行,这段时间与线程的数量无关[HS08]。这个级别被广泛认为甚至比有界的无等待同步更难实现。
2.无限制等待同步:每个线程都将在特定的有限时间段内取得进展[Her91]。这一水平被普遍认为是无法实现的,这可能就是为什么Alitarh等人省略了它的原因[ACHS13]。
3.无等待同步:每个线程都会在有限的时间内取得进展。
4.无锁同步:至少有一个线程将在有限的时间内取得进展。
5.无阻塞同步:在没有争议的情况下,每个线程都将在有限的时间内进行[HLM03]。
6.无冲突同步:在没有竞争的情况下,至少有一个线程将在有限的时间内取得进展[ACHS13]。
7.无饥饿同步:在没有故障的情况下,每个线程都将在有限的时间内进行进展[ACHS13]。
8.无死锁同步:在没有故障的情况下,至少有一个线程将在有限的时间内取得进展[ACHS13]。
NBS第1类是在2015年之前制定的,第2、3、4类是在20世纪90年代初首次制定的,第5类是在21世纪初首次制定的,第6类是在2013年首次制定的。最后两门课已经非正式地使用了几十年,但在2013年被重新制定。

理论上,任何并行算法都可以转换为无等待的形式,但通常有一个相对较小的子集。下一节将列出其中的一些内容。
也许最简单的NBS算法是使用获取-添加(原子_add_返回())原语对整数计数器进行原子更新。本节列出了一些常用的国家统计局算法,大致增加复杂性的顺序。
14.2.1.1 NBS集
一个简单的NBS算法实现了一个数组中的一组整数。在这里,数组索引表示可能是集合成员的值,而数组元素表示该值是否实际上是集合成员。国家统计局算法的线性标准要求读取和更新数组使用原子指令或伴随着内存障碍,但在罕见的情况下,线性并不重要,简单的易失性负载和存储足够,例如,使用READ_ONCE()和WRITE_ONCE()。
NBS集也可以使用位图来实现,其中每个可能是集合成员的每个值对应一个位。读取和更新通常必须通过原子位操作指令来执行,尽管也可以使用比较和交换(cmpxchg()或CAS)指令。
14.2.1.2 NBS计数器
在第5.2节中讨论的统计计数器算法可以被认为是无界等待的,但只能通过使用一个可爱的定义技巧,其中和被认为是近似的而不是精确的。1给定足够宽的误差范围,这是read_count()函数求和计数器的时间长度的函数,那么就不可能证明发生了任何非线性化的行为。这肯定是(如果有点人为的话)将统计计数器算法归类为有界无等待。该算法可能是Linux内核中使用最多的NBS算法。
14.2.1.3半NBS队列
另一个常见的国家统计局算法是原子队列元素排队使用原子交换指令[MS98b],其次是一个存储到下>指针的新元素的前身,如清单14.1所示,显示了userspace-RCU库实现[Des09b]。第9行更新尾指针以引用新元素,同时返回对其前身的引用,该引用存储在本地变量old_tail中。然后,第10行更新前任的->下一个指针以引用新添加的元素,最后,第11行返回关于队列最初是否为空的指示。
| 清单14.1:NBS排队算法 |
| 1个静态内联布尔 二 cds_wfcq_append(结构体cds_wfcq_head*头,3 结构cds_wfcq_tail*尾巴, 4 结构体cds_wfcq_node *new_head, 5 结构体cds_wfcq_node *new_tail) 6 { 7 结构体cds_wfcq_node *old_tail;8 9 old_tail = uatomic_xchg(&tail->p,new_tail); 10 CMM_STORE_SHARED(old_tail->下一个,new_head); 11 返回old_tail!=&head->节点;12 } 13 14静态内联布尔 15_cds_wfcq_enqueue(结构体cds_wfcq_head*头, 16 结构cds_wfcq_tail*尾巴, 17 结构体cds_wfcq_node *new_tail) 18 { 19 返回cds_wfcq_append(头,尾, 20 新尾巴,新尾巴);21 } |
尽管删除单个元素需要互斥(这样删除队列就是阻塞),但可以对队列中的整个内容执行非阻塞删除。不可能的是以非阻塞的方式取消任何给定元素的队列:队列者可能在列表的第9行和第10行之间失败,因此有问题的元素只是部分排队。这导致了一个半NBS算法,其中排队是NBS,但去排队是阻塞的。尽管如此,该算法在实践中仍被大量使用,部分原因是大多数生产软件都不需要容忍任意的故障-停止错误。

14.2.1.4 NBS堆栈
清单14.2显示了LIFO推送算法,该算法拥有无锁推送和无界等待pop(lifo-push.c),形成了一个NBS堆栈。该算法的起源尚不清楚,但它在1975年授予的一项专利中被提及[BS75]。这项专利是在1973年申请的,几个月后,你的编辑看到了他的第一台电脑,它只有一个CPU。
第1-4行显示了node_t结构,它包含一个任意的值和一个指向堆栈上的下一个结构的指针,第7行显示了堆栈最顶部的指针。
list_push()函数跨越了第9-20行。第11行分配一个新节点,并且第14行将其初始化。第17行初始化新分配的节点的->的下一个指针,并且第18行尝试将其推到堆栈上。如果第19行检测到cmpxchg()失败,另一个通过循环重试。否则,新节点已被成功推入,并且此函数返回到其调用者。注意,第19行解决了其中list_push()的两个并发实例试图推到堆栈上的竞争。cmpxchg()将为其中一个成功,而为另一个失败,从而导致另一个重试,从而为堆栈上的两个节点选择任意顺序。
list_pop_all()函数跨越了第23-34行。第25行上的xchg()语句原子地删除了堆栈上的所有节点,将结果列表的头放在局部变量p中,并将顶部设置为NULL。这个原子操作会将并发调用序列化到
| 清单14.2:NBS堆栈算法 |
| 1结构node_t { 2 value_t瓦尔; 5 6 // LIFO列表结构 7结构体node_t*顶部;8 11 结构体node_t*新节点=malloc(node_t(*新节点)); 12 结构node_t*桌面;13 15 oldtop=READ_ONCE(顶部); 16 做{ 17 newnode->next = oldtop; 18 oldtop = cmpxchg(&top, newnode->next, newnode); 19 而(新节点->下一个!=旧); 20 } 21 22 23空白list_pop_all(空白(foo)(结构体node_t *p))24 { 25 结构体node_t*p=xchg(&顶部,空);26 27 而(p) { 30 foo (p); 32 下一个p=;33 } 34 } |
list_pop_all():其中一个将得到该列表,另一个将得到一个空指针,至少假设没有对list_push()的并发调用。
一个在p中获得非空列表的list_pop_all()的一个实例在跨越第27-33行的循环中处理这个列表。第28行预取->下一个指针,第30行调用当前节点上的foo()引用的函数,第31行释放当前节点,第32行为下一次通过循环设置p。
但是假设一对list_puss()实例与一个list_ pop_all()同时运行,该列表最初包含一个节点a。以下是这个场景可能发生的一种方式:
1.第一个list_push()实例推送一个新的节点B,通过第17行执行,它刚刚将一个指向节点a的指针存储到节点B的->的下一个指针中。
2.list_pop_all()实例运行完成,将顶部设置为NULL并释放节点A。
3.第二个list_push()实例运行到完成,推送一个新的节点C,但碰巧分配了过去属于节点a的内存。
4.第一个list_push()实例执行第18行执行cmpxchg()。因为新的节点C与新释放的节点A具有相同的地址,所以这个cmpxchg()会成功
并且这个list_push()实例运行到完成。
注意,尽管重用了节点A的内存,推送和弹出都成功运行。这是一个不寻常的特性:大多数数据结构需要保护,防止通常被称为ABA问题。
但是这个属性只适用于用汇编语言编写的算法。可悲的事实是,大多数语言(包括C和C++)不支持指向生命周期结束对象的指针,例如指向节点B的->下一个指针中包含的旧节点A的指针。事实上,编译器有权假设如果从两个不同的调用malloc()返回两个指针(调用它们p和q),那么这些指针不能相等。真正的编译器真的会生成常数假的响应p==q比较。指向已释放的对象,但其内存已为兼容类型的对象重新分配的指针称为僵尸指针。
许多并发应用程序通过仔细地向编译器隐藏内存分配器来避免这个问题,从而防止编译器做出不适当的假设。这种模糊的方法目前在实践中很有效,但很可能有一天会成为越来越激进的优化器的受害者。C和C++标准委员会都在进行一些工作来解决这个问题[MMS19,MMM+ 20]。同时,在编码aba容忍算法时,请非常小心。
![]()
国家统计局最常被引用的好处来自它的进步保证,它对失败阻止错误的容忍度,以及它的线性化。这些内容其中的每一个都将在下面的一节中进行讨论。
14.2.2.1国家银行前进进度保证
国家统计局的进步保证已经使许多人建议在实时系统中使用它,而国家统计局的算法实际上在许多这样的系统中使用。然而,需要注意的是,前进的进度保证在很大程度上与构成实时编程基础的进度保证正交:
1.实时前进进度保证通常有一定的相关时间,例如,“调度延迟必须小于100微秒。”相比之下,最流行的国家统计局的形式只能保证在有限的时间内取得进展,而没有明确的界限。
2.实时前进进度保证通常是概率性的,就像在软实时保证“至少99.9 %的时间下,调度延迟必须小于100微秒一样。”相比之下,国家统计局的许多进步进步保证都是无条件的。
3.实时前进进度保证通常以环境约束为条件,例如,只被尊重: (1)对于最高优先级的任务,
(2)当每个CPU花费至少有一定比例的空闲时间时,以及(3)当I/O速率低于某个指定的最大值时。相比之下,国家统计局的前进进度保证通常是无条件的,尽管最近国家统计局的工作适应了有条件的保证[ACHS13]。
4.实时程序环境的一个重要组成部分是调度器。国家统计局的算法假设一个最坏情况的恶魔调度程序,尽管不管出于什么原因,不是一个恶魔,它只是拒绝运行应用程序
包含NBS算法。相比之下,实时系统假设调度器正在尽最大努力来满足它所知道的任何调度约束,并且,在没有这些约束的情况下,它的级别最好地尊重进程优先级,并为具有相同优先级的进程提供公平的调度。非恶魔调度器允许实时程序使用比NBS更简单的算法[ACHS13,Bra11]。
5.NBS前进进度保证类假设许多底层操作是无锁的,甚至是没有等待的,而实际上这些操作在常见情况的计算机系统上是阻塞的。
6.国家统计局的前进进度保证通常是通过细分业务来实现的。例如,为了避免阻塞脱队列操作,NBS算法可以替代非阻塞轮询操作。这在理论上是很好的,但在实践中对需要一个元素及时地在队列中传播的真实程序没有帮助。
7.实时前进进度保证通常只适用于没有软件错误的情况下。相比之下,许多类的国家统计局保证即使在面对失败阻止错误时也适用。
8.国家统计局的前进进度保证类意味着线性化。相比之下,实时前进进度保证通常独立于排序约束,如线性化。
![]()
重申一下,尽管存在这些差异,但许多国家统计局的算法在实时程序中却非常有用。
14.2.2.2 NBS的基础业务
只有当NBS算法使用的底层操作也是非阻塞的时,它才能真正成为非阻塞。在数量惊人的案例中,实际情况并非如此。
例如,非阻塞算法经常分配内存。理论上,由于存在无锁内存分配器[Mic04b]。但在实践中,大多数环境最终必须从通常使用锁定的操作系统内核中获取内存。因此,除非所有需要的内存都以某种方式预先分配,否则在常见的真实计算机系统上运行时,分配内存的“非阻塞”算法将不是非阻塞的。
这一点显然也适用于执行I/O操作或以其他方式与环境交互的算法。
也许令人惊讶的是,这一点也适用于表面上的非阻塞算法,它们只执行普通加载和存储,如第14.2.1.2节中讨论的计数器。乍一看,那些可以分别编译为单个加载和存储指令的加载和存储,似乎不仅是非阻塞的,而是有限制的人口无关的自由等待。
除了加载和存储指令并不一定是快速的或确定性的。例如,如在第3章中提到的,缓存丢失可能会消耗数千个CPU周期。更糟糕的是,测量的缓存-错过延迟可能是cpu数量的函数,
如图5.1所示。我们只能合理地假设,这些延迟也取决于系统的互连的细节。此外,考虑到硬件供应商通常不会发布缓存错过延迟的上限,在现代计算机系统中假设内存引用指令实际上无需等待似乎是勇敢的。而那些有这种界限的老式系统,总体上却非常缓慢。
此外,硬件并不是内存引用指令运行缓慢的唯一来源。例如,当在典型的计算机系统上运行时,负载和存储都可能导致页面故障。这会导致调用内核内的页面故障处理程序。它可能获得锁,甚至做I/O,甚至可能使用像网络文件系统(NFS)这样的东西。所有这些都是最突出的操作。
页面故障也不是由内核引起的唯一危害。给定的CPU可能在任何时候被中断,中断处理程序可能会运行一段时间。在此期间,表面上非阻塞的用户模式算法将根本不会运行。这种情况提出了一个有趣的问题,即依赖于中断的系统调用所提供的前进进度保证,例如,模态屏障()系统调用。
事情看起来确实很黯淡,但这种算法的非阻塞特性至少可以通过多种方法来部分地弥补:
1.在裸金属上运行,禁用分页。如果您既勇敢又自信地认为您能够编写没有野生指针错误的代码,那么这种方法可能很适合您。
2.运行在非阻塞的操作系统内核上[GC96]。这样的内核非常罕见,部分原因是它们在传统上完全没有提供与基于锁的内核相比,所希望的性能和可伸缩性优势。但也许你应该写一个。
3.使用像()()这样的工具来避免页面故障,同时也确保您的程序预分配了它在启动时所需要的所有内存。这可以很好地工作,但以严重的常见情况下的内存使用不足为代价。在成本有限或功率有限的环境中,这种方法不太可能可行。
4.使用诸如Linux内核的NO_HZ_FULL无标记模式等工具[Cor13]。在Linux内核的最新版本中,这种模式将中断远离指定的cpu。然而,这可能会严重限制在部分操作中受I/O绑定的应用程序的吞吐量。
考虑到这些因素,非阻塞同步在理论上比在实践中更重要也就不足为奇了。
14.2.2.3国家统计局的细分业务
为给定的算法提供NBS排名上更高位置的一个常见技巧是用轮询API替换阻塞操作。例如,与其提供一个可靠的无锁甚至阻塞的脱队列操作,而是提供一个脱队列操作,它将以无等待的方式虚假失败,而不是表现出可怕的无锁或阻塞行为。
这在理论上很好,但在实践中一个常见的效果是仅仅将无锁或锁定行为从特定的算法移到使用该算法的倒霉代码中。在这种情况下,这个技巧不仅没有得到任何好处,而且这个技巧增加了该算法的所有用户的复杂性。
对于其他地方的并行算法,最大化一个特定的度量并不能替代仔细考虑用户的需求。
14.2.2.4 NBS故障-停止容差
在NBS算法的类别中,无等待同步(有界或其他)、无锁同步、无阻塞同步和无冲突同步即使在存在故障停止错误的情况下也能保证向前进展。一个失败停止错误可能会导致一些线程被无限期地抢占。正如我们将看到的,这种故障停止容忍特性可能很有用,但事实是,组成一组故障停止容忍机制并不一定会导致故障停止容忍系统。要了解这一点,请考虑由一系列无等待队列组成的系统,其中元素从系列中的一个队列中删除,进行处理,然后添加到下一个队列中。
如果一个线程在排队操作中被抢占,那么理论上一切都很好,因为该队列的无等待特性将保证向前进行。但是在实践中,正在处理的元素会丢失,因为无等待队列的故障停止容忍特性不会扩展到使用这些队列的代码。
然而,在一些应用程序中,国家统计局相当有限的容错能力是有用的。例如,在一些基于网络或web应用程序中,失败停止事件最终将导致重传,这将重新启动由于失败停止事件而丢失的任何工作。因此,运行此类应用程序的系统可以重载,甚至调度程序不能再提供任何合理的公平保证。相比之下,如果线程在保持锁时失败停止,则可能需要重新启动应用程序。然而,即使在这个限制范围内,国家统计局也不是万灵药,因为纯粹的调度延迟可能会出现虚假的再传输。在某些情况下,减少负载以避免排队延迟可能更有效,这也将提高调度器提供公平访问的能力,减少甚至消除失败停止事件,从而减少重试操作的数量,进而进一步减少负载。
14.2.2.5 NBS Linearizability
需要注意的是,线性化可能非常有用,特别是在分析由严格锁定和完全有序的原子操作组成的并发代码时。2此外,这种对完全有序原子操作的处理自动涵盖了简单的NBS算法。
然而,一个复杂的国家统计局算法的线性化点通常被深埋在该算法中,因此对实现该算法的一部分的库函数的用户不可见。因此,任何声称用户受益于复杂国家统计局算法的线性化性特性的主张都应该被深感怀疑[HKLP12]。
有时会断言,开发人员为其并发代码的正确性证明是必要的。然而,这样的证明是例外,而不是规则,而那些确实在制作证明的现代开发人员经常使用不依赖于线性化的现代证明技术。此外,开发人员经常使用不需要完整规范的现代证明技术
开发人员经常在事后学习他们的规范,一次学习一个错误。在第12.3章中讨论了一些这样的证明技术
人们经常断言,线性性可以很好地映射到顺序规范,这些规范比并发规范更自然[RR20]。但这一断言并不能解释我们这个高度并发的目标宇宙。这个宇宙只能被期望选择应对并发性的能力,特别是对于那些参加团队运动或监督小孩的人。此外,考虑到顺序计算的教学仍然被认为是一种黑色艺术[PBCE20],我们有理由认为并行计算的教学也处于类似的混乱状态。因此,只关注一种证明技术不太可能是一个前进的好方法。
同样,请理解线性化在许多情况下是非常有用的。不过,那把古老的工具,那把锤子也是如此。但在计算领域有一个问题,人们应该放下锤子,拿起键盘。类似地,有时线性化似乎并不是该工作的最佳工具。
值得赞扬的是,有一些线性化的倡导者意识到了它的一些缺点。也有人提出了扩展线性化性的建议,例如,间隔线性化性,它旨在处理需要非零时间来完成[CnRR18]的常见操作情况。这些建议是否会产生能够处理现代并发软件工件的理论还有待观察,特别是考虑到第12章中讨论的一些证明技术已经处理了许多现代并发软件工件。
可以创建完全非阻塞的队列[MS96],但是,这样的队列比上面概述的半nbs算法要复杂得多。这里的教训是要仔细考虑你的实际需求。放松不相关的需求通常可以大大提高其简单性、性能和可伸缩性。
最近的研究指出了另一种放松需求的重要方法。事实证明,提供公平调度的系统可以享受无等待同步的大部分好处,即使运行只提供非阻塞同步的算法,无论是在理论上[ACHS13]还是在实践中[AB13]。因为在生产中使用的大多数调度器实际上都提供了公平性,所以与更简单、更快的非无等待算法相比,更复杂的提供无等待同步的算法通常没有提供实际优势。
有趣的是,公平的日程安排只是在实践中经常得到尊重的一个有益的约束条件。其他的约束集可以允许阻塞算法来实现确定性的实时响应。例如,给定:(1)在给定优先级级别内以FIFO顺序授予的公平锁,(2)优先级反转避免(例如,优先级继承[TS95,WTS96]或优先级上限),(3)有界的线程数,(4)有界关键段持续时间,(5)有界负载,以及(6)没有故障停止错误,基于锁的应用程序可以提供确定性的响应时间[Bra11,SM04a]。这种方法当然模糊了阻塞之间的区别
以及无等待的同步,这一切都是好的。希望理论框架能够继续提高它们描述在实践中实际使用的软件的能力。
那些认为理论应该引领潮流的人指的是独一无二的彼得·丹宁,他说:“理论遵循实践”[Den15],或著名的托尼·霍尔,他说整个工程:“在工程科学的所有分支,工程在科学之前开始;事实上,没有工程的早期产品,科学家就没有什么可研究的!”[Mor07].当然,一旦有了一个合适的理论体系,利用它是明智的。然而,请注意,第一个适当的理论体系通常是一件事,而第一个被提出的理论体系则完全是另一回事。
![]()
国家统计局算法的支持者有时认为实时计算是国家统计局的重要受益者。下一节将更深入地探讨实时系统的向前发展的需求。
14.3 并行实时计算
如果应用得好,人们总是有足够的时间。
约翰沃尔夫冈冯戈特
并行实时计算是计算的一个重要新兴领域。第14.3.1节介绍了“实时计算”的一些定义,超越通常的声音,转向更有意义的标准。第14.3.2节调查了需要实时响应的应用程序的类型。第14.3.3notes节介绍了并行实时计算,并讨论了并行实时计算何时以及为什么会有用。第14.3.4gives节简要概述了如何实现并行实时系统,并分别使用第14.3.5节和第14.3.6focusing节介绍了操作系统和应用程序。最后,第14.3.7outlines节,如何决定您的应用程序是否需要实时工具。
一种传统的实时计算分类方法是分为硬实时和软实时分类,在这两种分类中,大规模庞大的硬实时应用程序永远不会错过它们的截止日期,但软弱的软实时应用程序经常错过它们的截止日期。
14.3.1.1软实时
应该很容易看到软实时定义的问题。首先,根据这个定义,任何一个软件都可以说是一个软实时应用程序:“我的应用程序在半皮秒内计算出百万点傅里叶变换。”决不!!这个系统上的时钟周期超过了300皮秒!”“啊,但这是一个软的实时应用程序!”如果术语“软实时”有任何用处,那么显然需要一些限制。

因此,我们可以说一个给定的软实时应用程序必须至少满足一定比例的时间的响应时间要求,例如,我们可以说它必须在99.9 %的时间内执行不到20微秒。
这当然提出了一个问题:当应用程序不能满足其响应时间要求时,应该做什么。答案随应用程序的不同而不同,但有一种可能性是,被控制的系统具有足够的稳定性和惯性,从而使偶尔发生的后期控制动作变得无害。另一种可能性是,该应用程序有两种计算结果的方法,一种是快速、确定性但不准确的方法,另一种是非常准确的、计算时间不可预测的方法。一种合理的方法是同时启动这两种方法,如果准确的方法不能及时完成,那就杀死它,使用快速但不准确的方法的答案。快速但不准确的方法的一个候选方法是在当前时间段内不采取控制操作,另一个候选是采取与前一个时间段内采取相同的控制操作。
简而言之,如果没有软度,谈论软实时是没有意义的。
14.3.1.2硬实时
相反,硬实时性的定义是相当明确的。毕竟,一个给定的系统要么总是在最后期限内完成,要么就没有完成。
不幸的是,严格应用这一定义将意味着永远不可能有任何困难的实时系统。在图14.1中可以幻想地描述了其原因。尽管你总是可以构建一个更健壮的系统,也许有冗余,你的对手总是可以得到一个更大的锤子。但不要相信我的话:问问恐龙吧。
不过话说回来,把显然不仅仅是硬件问题,而是真正的大型硬件问题归咎于软件,也许是不公平的。这表明,我们将硬实时软件定义为能够在最后期限前完成的软件,但只有在没有硬件故障的情况下。不幸的是,失败并非总是如此


一个选项,如图14.2所示。我们根本不能指望图中描述的可怜的先生放心,我们说:“放心,如果错过最后期限导致你的悲惨死亡,这肯定不是由于软件问题!”硬实时响应是整个系统的特性,而不仅仅是软件的特性。
但如果我们不能要求完美,也许我们可以通过通知,类似于前面提到的软实时方法。如果图14.2中的Life-a-Tron即将错过最后期限,它可以提醒医院工作人员。
不幸的是,这种方法有图14.3中想象中所描述的简单解决方案。一个总是立即发出通知,表示它不能满足其最后期限的系统符合法律条文,但它是完全无用的。显然,还必须要求系统在一定的时间内满足其最后期限,或者可能禁止它在超过一定数量的连续操作中错过其最后期限。
我们显然不能采取硬实时或软实时的可靠的方法。因此,下一节将采用更真实的方法。
14.3.1.3现实世界的实时
尽管像“硬实时系统总是在最后期限前完成!”吸引人,容易记住,现实世界的实时系统需要其他东西。尽管生成的规范很难记住,但它们可以通过对环境、工作负载和实时应用程序本身施加约束来简化实时系统的构建。
环境限制对环境的限制解决了对“硬实时”所隐含的开放式响应时间承诺的反对意见。这些约束条件可能规定允许的工作温度、空气质量、电磁辐射水平和类型,以及图14.1的点,冲击和振动水平。
当然,有些约束比其他约束更容易满足。很多人都已经意识到,商品电脑部件往往拒绝在低于零度的温度下运行,这表明了一套气候控制要求。
一位大学里的老朋友曾经遇到过一个挑战,即在具有一些相当具有攻击性的氯化合物的环境中操作实时系统,他明智地将这一挑战交给了设计硬件的同事。实际上,我的同事对计算机周围的环境施加了大气成分约束,硬件设计师通过使用物理密封来满足这一约束。
另一位大学老朋友研究一个计算机控制系统,该系统在真空中使用工业强度弧溅射钛锭。弧线有时会决定它厌倦了穿过钛锭的路径,并选择一条更短、更有趣的地面路径。正如我们在物理课上学到的,电子流的突然变化会产生电磁波,大电子流的大变化会产生高功率的电磁波。在这种情况下,由此产生的电磁脉冲足以在400米外的一个小“橡胶导管”天线的引线上产生四分之一的伏特电位差。这意味着附近的导体经历了更高的电压,这多亏了相反的平方定律。这包括那些组成计算机的控制溅射过程的导体。特别是,在计算机的重置线上产生的电压足以实际重置计算机,让所有参与的人都感到困惑。这种情况是通过硬件来解决的,包括一些复杂的屏蔽和一个我所听说过的比特率最低的光纤网络,即9600波特。不太壮观的电磁环境通常可以通过软件通过使用错误检测和校正码来处理。也就是说,重要的是要记住,尽管错误检测和校正代码可以降低故障率,但它们通常不能将它们一直降低到零,这可能是实现硬实时响应的另一个障碍。
也有一些情况下,需要最低水平的能量,例如,通过系统的电源引线,通过系统与外部世界的一部分进行通信。

许多系统旨在在具有令人印象深刻的冲击和振动水平的环境中运行,例如,发动机控制系统。当我们从连续的振动转向间歇性的冲击时,可能会发现更剧烈的要求。例如,在我的本科学习期间,我遇到了一台旧的雅典娜弹道学计算机,它被设计成即使附近的手榴弹爆炸,也能继续正常运行。最后,飞机中使用的“黑匣子”必须在坠毁前、期间和之后继续运行。
当然,也有可能使硬件更能抵御环境冲击和侮辱。任意数量的巧妙的机械减震装置都可以减少冲击和振动的影响,多层屏蔽可以减少低能电磁辐射的影响,纠错编码可以减少高能辐射的影响,各种盆栽和密封技术可以降低空气质量的影响,任何数量的加热和冷却系统都可以抵消温度的影响。在极端情况下,三重模冗余可以降低系统某一部分的故障导致整个系统的错误行为的可能性。然而,所有这些方法都有一个共同点:尽管它们可以降低失败的概率,但它们不能将其降低到零。
这些环境挑战通常通过健壮的硬件来解决,但是,接下来两个部分中的工作负载和应用程序约束通常在软件中处理。
工作量限制就像对人一样,通常可以通过超载来阻止实时系统达到最后期限。例如,如果系统被中断得太频繁,那么它可能没有足够的CPU带宽来处理其实时应用程序。解决此问题的硬件解决方案可能会限制将中断传递到系统的速率。可能的软件解决方案包括:如果中断接收得太频繁,则禁用中断一段时间,重置设备产生太频繁的中断,甚至完全避免中断以支持轮询。
由于排队效应,过载也会降低响应时间,因此实时系统过度提供CPU带宽并不罕见,因此正在运行的系统(例如)有80 %的空闲时间。这种方法也适用于存储和网络设备。在某些情况下,可能会保留单独的存储和网络硬件,以便单独使用实时应用程序的高优先级部分。简而言之,考虑到实时系统中的响应时间比吞吐量更重要,这个硬件大多是空闲的并不罕见。

当然,在整个设计和实现过程中,保持足够低的利用率需要良好的纪律。没有什么比一个小功能爬行更能破坏最后期限的了。
应用程序约束为某些操作比为其他操作更容易提供有限的响应时间。例如,看到响应时间是很常见的
针对中断和唤醒操作的规范,但对于(例如)文件系统卸载操作则非常罕见。这样做的一个原因是,很难绑定卸载文件系统操作可能需要做的工作量,因为需要卸载才能将该文件系统的所有内存数据刷新到大容量存储中。
这意味着实时应用程序必须被限制在能够合理地提供有限延迟的操作中。其他操作必须要么推送到应用程序的非实时部分,要么完全放弃。
对应用程序的非实时部分也可能存在限制。例如,非实时应用程序是否被允许使用拟用于实时部分的cpu?是否有一段时间段内应用程序的实时部分将异常繁忙,如果是,应用程序的非实时部分是否允许在这些时间内运行?最后,应用程序的实时部分允许用多少量来降低非实时部分的吞吐量?
从前面几节中可以看出,真实世界的实时规范需要包括对环境、工作负载和应用程序本身的约束。此外,对于允许应用程序的实时部分使用的操作,必须对实现这些操作的硬件和软件有限制。
对于每个这样的操作,这些约束可能包括最大响应时间(也可能还包括最小响应时间)和满足该响应时间的概率。100 %的概率表示相应的操作必须提供硬实时服务。
在某些情况下,响应时间和满足它们的所需概率可能会根据相关操作的参数而有所不同。例如,在本地局域网上的网络操作比在100微秒内完成的同一网络操作更有可能在跨大陆广域网内完成。此外,在铜或光纤局域网上的网络操作可能有极高的概率完成没有耗时的重传输,而在有损的WiFi网络上的同样的网络操作可能有更高的概率错过紧迫的截止日期。类似地,从紧密耦合的固态磁盘(SSD)读取可以比从老式usb连接的旋转锈磁盘驱动器读取速度快得多。6
一些实时应用程序会通过不同的操作阶段。例如,一个实时系统控制胶合板车床,从旋转原木上剥离一张薄薄的木头(称为“贴面”)必须: (1)将原木载入车床,(2)将原木放在车床的卡盘上,使原木中包含的最大圆柱暴露于叶片,(3)开始旋转原木,(4)不断改变刀的位置,将原木剥成单板,(5)去除剩余的原木太小,(6)等待下一个原木。这六个操作阶段的每一个都可能有自己的期限和环境限制,例如,人们预计第四阶段的期限会比阶段6的期限严重得多,即毫秒而不是秒。因此,人们可能期望,低优先级的工作将在阶段6中进行,而不是在阶段4中进行。无论如何,仔细的选择
这种分阶段开发的方法的一个关键优点是,可以分解延迟预算,这样就可以独立开发应用程序的各个组件,每个组件都有自己的延迟预算。当然,与任何其他类型的预算,可能会有偶尔的冲突,组件得到整体预算的一部分,和任何其他类型的预算,强大的领导和共享目标可以帮助及时解决这些冲突。同样,与其他类型的技术预算一样,还需要进行强有力的验证工作,以确保适当地关注延迟,并对延迟问题提供早期预警。一个成功的验证工作几乎总是包括一个好的测试套件,这可能使理论家们不满意,但也有帮助完成工作的优点。事实上,截至2021年初,大多数现实世界的实时系统都使用了验收测试,而不是正式的证明。
然而,广泛使用测试套件来验证实时系统确实有一个非常真实的缺点,即实时软件只在硬件和软件的特定配置上进行验证。添加额外的配置需要额外的昂贵和耗时的测试。也许正式核查领域将充分进展到足以改变这种情况,但到2021年初,还需要相当大的进展。

除了对应用程序的实时部分的延迟要求外,对应用程序的非实时部分可能还有性能和可伸缩性要求。这些额外的需求反映了这样一个事实,即通常可以通过降低可伸缩性和平均性能来实现最终的实时延迟。
软件工程需求也可能很重要,特别是对于必须由大型团队开发和维护的大型应用程序。这些要求通常有利于增加模块化和故障隔离。
这仅仅是为生产实时系统规定最后期限和环境限制所需的工作的大纲。希望这个大纲清楚地说明了基于声音咬合的实时计算方法的不足。
可以说,所有的计算实际上都是实时计算。例如,当你在网上购买生日礼物时,你期望礼物在收件人的生日之前到达。事实上,甚至即使是千年之交的web服务也观察到了亚秒的响应约束[Boh01],而且需求并没有随着时间的推移而得到缓解[DHJ+07]。然而,关注那些通过非实时系统和应用程序无法直接实现响应时间需求的实时应用程序是很有用的。当然,随着硬件成本的降低、带宽和内存大小的增加,实时和非实时之间的界限将继续改变,但这种进展绝不是一件坏事。

实时计算用于工业控制应用,从制造到航空电子设备;科学应用,也许最引人注目的是大型地球望远镜使用的自适应光学;军事应用,包括上述航空电子设备;以及金融服务应用,第一台识别出机会的计算机可能会获得大部分利润。这四个领域可以被描述为“寻找生产”、“寻找生命”、“寻找死亡”和“寻找金钱”。
金融服务应用程序与其他三类应用程序有细微的不同,因为金钱是非物质的,这意味着非计算延迟相当小。相比之下,其他三个类别中固有的机械延迟提供了一个非常真实的收益递减点,超过这个点,应用程序的实时响应的进一步减少将提供很少或没有好处。这意味着金融服务应用程序和其他实时信息处理应用程序将面临一场军备竞赛,而延迟最低的应用程序通常会获胜。尽管由此产生的延迟需求仍然可以按照第460页的“真实世界实时规范”段落中的描述来指定,但这些需求的不寻常性质导致一些人将金融和信息处理应用程序称为“低延迟”而不是“实时”。
不管我们到底选择叫它什么,对实时计算都有巨大的需求[Pet06,Inm07]。
目前还不太清楚谁真的需要并行实时计算,但低成本多核系统的出现却使它更加突出。不幸的是,传统的实时计算的数学基础假设是单cpu系统,只有少数例外证明了这一规则[Bra11]。幸运的是,有几种方法来调整现代计算硬件,以适应实时数学循环,一些linux内核黑客一直在鼓励学者进行这种转变[dOCdO19,Gle10]。
一种方法是认识到许多实时系统类似于生物神经系统,其反应范围从实时反射到非实时策略和规划,如图14.4所示。硬实时反射,从传感器和控制执行器中读取,在单个CPU或特殊用途的硬件上实时运行,如FPGA。应用程序的非实时策略和规划部分将在其余的cpu上运行。战略和规划活动可能包括统计分析、定期校准、用户界面、供应链活动和准备工作。对于高计算负载的准备活动的一个例子,请考虑

回到第460页“真实世界实时规范”段落中讨论的贴面剥离应用。当一个CPU正在处理剥离一个日志所需的高速实时计算时,其他CPU可能会分析下一个日志的大小和形状,以确定如何定位下一个日志,以获得最大的圆柱体的高质量木材。结果表明,许多应用程序都有非实时和实时的组件[BMP08],因此这种方法经常可以用于允许传统的实时分析与现代多核硬件相结合。
另一个简单的方法是只关闭一个硬件线程,以便返回到单处理器实时计算的既定数学过程中。然而,这种方法放弃了潜在的成本和能源效率优势。也就是说,获得这些优势需要克服第3章中所涵盖的并行性能障碍,而不仅仅是平均而言,而是在最坏的情况下。
因此,实现并行实时系统可能是一个相当大的挑战。在下一节中概述了应对这一挑战的方法。
我们将研究两种主要类型的实时系统,事件驱动系统和轮询。事件驱动的实时系统大部分时间都保持空闲状态,并实时响应通过操作系统传递给应用程序的事件。或者,系统可以运行后台非实时工作负载。轮询实时系统的特点是一个受CPU绑定的实时线程,在一个紧密的循环中运行,轮询输入和更新输出。这个紧密的轮询循环通常完全在用户模式下执行,读写到已经映射到用户模式应用程序地址空间的硬件寄存器。或者,一些应用程序将轮询循环放置到内核中,例如,使用可加载的内核模块。
无论选择何种风格,用于实现实时系统的方法都将取决于截止日期,例如,如图14.5所示。从这个图的顶部开始,如果您可以忍受响应时间超过一秒钟,您很可能可以使用脚本语言来实现您的实时应用程序——而且脚本语言实际上经常使用,我不一定推荐这种做法。如果所需的延迟超过几十毫秒,则可以使用旧的2.4Linux内核的版本,但我也不一定推荐这种做法。特殊的实时Java实现可以提供实时响应延迟

只有几毫秒,即使使用了垃圾收集器。Linux2.6。x和3。如果在实时友好的硬件上进行精心配置、调整和运行,x内核可以提供几百微秒的实时延迟。如果小心地避免使用垃圾收集器,特殊的实时Java实现可以提供低于100微秒的实时延迟。(但是请注意,避免垃圾收集器也意味着要避免Java的大型标准库,因此也也避免了Java的生产力优势。)Linux4。x和5。x内核可以提供亚100微秒的延迟,但有与2.6相同的警告。x和3。x内核。包含-rt补丁集的Linux内核可以提供远低于20微秒的延迟,而在没有mmu的情况下运行的专业实时操作系统(RTOSes)可以提供不到10微秒的延迟。实现亚微秒的延迟通常需要手工编码的组装,甚至需要特殊用途的硬件。
当然,在堆栈中一直都需要仔细的配置和调整。特别是,如果硬件或固件不能提供实时延迟,那么软件就无法弥补损失的时间。更糟糕的是,高性能硬件有时会牺牲最坏情况下的行为,以获得更大的吞吐量。事实上,来自已禁用中断的紧密循环运行的计时可以为高质量的随机数生成器提供基础[MOZ09]。此外,一些固件会通过窃取循环来执行各种内务管理任务,在某些情况下,它试图通过重新编程受害者CPU的硬件时钟来掩盖其轨迹。当然,循环窃取在虚拟环境中是预期的行为,但人们仍然是在虚拟环境中努力进行实时响应[Gle12,Kis14]。因此,评估硬件和固件的实时功能至关重要。
但是,对于合格的实时硬件和固件,堆栈上的下一层是操作系统,这将在下一节中介绍。
有许多策略可以用于实现一个实时系统。一种方法是将通用的非实时操作系统移植到专用的实时操作系统(RTOS)之上,如图14.6所示。绿色的“Linux进程”框表示运行在Linux内核上的非实时进程,而黄色的“RTOS进程”框表示运行在RTOS上运行的实时进程。
在Linux内核获得实时功能之前,这是一种非常流行的方法,并且仍在使用中[xen14,Yod04b]。但是,这种方法要求将应用程序分成一个在RTOS上运行的部分和另一个在Linux上运行的部分。虽然可以使这两个环境看起来相似,例如,通过将POSIX系统调用从RTOS转发到运行在Linux上的实用程序线程,但总是有粗糙的边。
此外,RTOS必须同时与硬件和Linux内核进行接口,因此需要对硬件和内核上的更改进行重大维护。此外,每个这样的RTOS通常都有自己的系统调用接口和一组系统库,它们可以简化生态系统和开发人员。事实上,这些问题似乎是推动RTOSes与Linux结合的原因,因为这种方法允许访问RTOS的全部实时功能,同时允许应用程序的非实时代码完全访问Linux的开源生态系统。
尽管在Linux内核具有最小的实时功能期间,将RTOSes与Linux内核配对是一个聪明而有用的短期响应,但它也促使人们向Linux内核添加实时功能。实现这个目标的进展情况如图14.7所示。上面一行显示了禁用抢占的Linux内核的图,因此基本上没有实时功能。中间一行显示了一组图表,显示了启用了抢占的主线Linux内核不断增强的实时能力。最后,最下面一行显示了一个应用了-rt补丁集的Linux内核的图表,从而最大化了实时功能。来自-rt补丁集的功能被添加到主线上,因此随着时间的推移,主线Linux内核的功能也会不断增强。然而,要求最高的实时应用程序继续使用-rt补丁集。
图14.7顶部所示的不可抢占内核是使用CONFIG_抢占=n构建的,因此在Linux内核中的执行不能被抢占。这意味着内核的实时响应延迟受Linux内核中最长代码路径的限制,这确实很长。但是,用户模式执行是可抢占的,因此在用户模式下执行时,右上角显示的一个实时Linux进程可以抢占左上角显示的任何非实时Linux进程。
Figure14.7shows的中间行在Linux的可抢占内核的开发中有三个阶段(从左到右)。在所有这三个阶段中,Linux内核中的大多数进程级代码都可以被抢占。这当然大大提高了实时响应延迟,但是在RCU读侧临界部分、自旋锁临界部分、中断处理程序、中断禁用的代码区域和抢占禁用的代码区域中,抢占仍然被禁用,如图中间一行最左边的图中的红色框所示。抢占RCU的出现允许RCU读侧临界部分被抢占,如中央图所示,线程中断处理程序的出现允许设备中断处理程序被抢占,如最右边的图所示。当然,在这段时间内还添加了许多其他的实时功能,但是,它不能在这个图中那样容易地表示出来。它将在第14.3.5.1节中进行讨论。



图14.7的底部一行显示了-rt补丁集,它为许多设备提供了线程化(因此是可抢占的)中断处理程序,这也允许这些驱动程序的相应的“中断禁用”区域被抢占。这些驱动程序反而使用锁定来协调每个驱动程序的进程级部分及其线程化的中断处理程序。最后,在某些情况下,禁用优先购买权将被禁用迁移所取代。这些度量在许多运行-rt补丁集的系统中产生了极好的响应时间[RMF19,dOCdO19]的响应时间。
最后一种方法是简单地清除实时进程中的所有内容,清除该进程需要的任何cpu中的所有其他处理,如图14.8所示。这是在3.10 Linux内核中通过CONFIG_NO_HZ_全Kconfig参数实现的[Cor13,Wei12]。需要注意的是,这种方法需要至少一个内务管理CPU来进行后台处理,例如运行内核守护进程。然而,当在一个给定的非内务化CPU上只有一个可运行的任务时,该CPU上的调度时钟中断将被关闭,从而消除了干扰和操作系统抖动的一个重要来源。除了少数例外,内核不会强制执行非内务CPU的其他处理,而只是在给定CPU上只有一个可运行任务时提供更好的性能。任意数量的用户空间工具都可以用来强制一个给定的CPU不再有一个可运行的任务。如果配置正确,这是一项重要的任务,CONFIG_NO_HZ_FULL提供了接近裸金属系统的实时线程性能水平[ACA+ 18]。弗雷德里克·魏斯贝克制作了CONFIG_NO_ HZ_FULL配置的实用指南[魏22d、魏22b、魏22e、魏22c、魏22a、魏22f]。
当然,关于这些方法中哪一种最适合实时系统,一直有很多争论,这场争论已经持续了很长一段时间[Cor04a,Cor04c]。和往常一样,答案似乎是“视情况而定”,正如下面几节所讨论的那样。Section14.3.5.1considers事件驱动的实时系统和使用与cpu绑定的轮询循环的Section14.3.5.2considers实时系统。
事件驱动的实时应用程序所需的操作系统支持非常广泛,但是,本节将只关注几个项目,即计时器、线程中断、优先级继承、抢占RCU和抢占自旋锁。
计时器显然对实时操作至关重要。毕竟,如果你不能指定在特定的时间做某件事,那么到那时你将如何回应呢?即使在非实时系统中,也会产生大量的计时器,因此必须非常有效地处理它们。示例包括TCP连接的重传定时器(几乎总是在有机会触发之前被取消)、7个定时延迟(如在睡眠中(1),很少被取消)和轮询()系统调用的超时(通常在有机会触发之前被取消)。因此,这些计时器的良好数据结构将是一个优先队列,该队列的添加和删除原语是快速的,并且发布的计时器数量为O (1)。
为此目的的经典数据结构是日历队列,它在Linux内核中被称为计时器轮。这种古老的数据结构也被大量用于离散事件模拟。其思想是时间是量化的,例如,在Linux内核中,时间量子的持续时间是调度-时钟中断的周期。一个给定的时间可以用一个整数来表示,任何在某个非积分时间发布计时器的尝试都将被四舍五入到一个方便的附近的积分时间量子。
一个简单的实现是分配一个数组,按时间的低阶位进行索引。这在理论上是可行的,但在实践中,系统产生了大量的长时间超时(例如,TCP会话的两小时保持活动超时),这些超时几乎总是被取消。这些长时间超时会导致小阵列造成问题,因为浪费了大量时间跳过尚未过期的超时。另一方面,一个足够大,能够优雅地容纳大量长时间超时的阵列将消耗太多的内存,特别是考虑到性能和可伸缩性问题,每个CPU都需要一个这样的阵列。
解决此冲突的一种常见方法是在一个层次结构中提供多个数组。在此层次结构的最低级别上,每个数组元素代表一个时间单位。在第二层,每个数组元素代表N个时间单位,其中N是每个数组中的元素数量。在第三层,每个数组元素代表n2个时间单位,以此类推。这种方法允许单个数组按不同的位进行索引,如图14.9所示,对于一个不现实的小8位时钟。这里,每个数组有16个元素,因此低阶4位(当前0xf)索引低阶(最右边)数组,后续4位(当前0x1)索引下一级。因此,我们有两个数组,每个数组都有16个元素,总共有32个元素,它们加在一起,比单个数组所需的256个元素数组要小得多。
这种方法非常适用于基于吞吐量的系统。每个计时器操作是O (1)和小常数,每个计时器元素最多被触摸m + 1次,其中m是级别数。
不幸的是,计时器轮不能很好地运行实时系统,有两个原因。第一个原因是在计时器精度和计时器开销之间存在一个严格的权衡,图14.10和14.11充分说明了这一点。在图14.10中,计时器处理每毫秒只发生一次,这是可接受的开销



对很多人来说都很低(但不是全部!)工作负载,但这也意味着不能为超过1毫秒的粒度设置超时。另一方面,图14.11显示了每10微秒进行一次的计时器处理,这为大多数人(但不是所有的人!)提供了可接受的精细计时器粒度工作负载,但它处理计时器如此频繁,系统可能没有时间做其他事情。
第二个原因是需要将计时器从较高级级联到较低级。参考图14.9,我们可以看到,在上(最左)数组中的元素1x上排队的任何计时器都必须级联到下(最右)数组,以便在它们的时间到达时可以调用。不幸的是,可能会有大量的超时等待级联,特别是对于具有更多级别的计时器轮。统计数据的威力使得这种级联对于面向吞吐量的系统来说不是一个问题,但是级联可能会导致实时系统中延迟的有问题的下降。
当然,实时系统可以简单地选择一种不同的数据结构,例如,某种形式的堆或树,放弃插入和删除操作的O (1)边界,以获得数据结构维护操作的O(logn)限制。这对于特殊用途的RTOSes来说是一个很好的选择,但是对于像Linux这样的通用系统时效率低下,它通常支持大量的计时器。
为Linux内核的-rt补丁集选择的解决方案是区分安排稍后活动的计时器和安排TCP包丢失等低概率错误的超时。一个关键的观察结果是,错误处理通常不是特别的时间关键性,因此计时器轮的毫秒级粒度是好的和足够的。另一个关键的观察结果是,错误处理超时通常很早就被取消,通常是在它们可以级联之前。此外,系统通常比处理计时器事件有更多的错误处理超时,因此O(logn)数据结构应该为计时器事件提供可接受的性能。
然而,也有可能做得更好,即通过简单地拒绝级联计时器。而不是级联,否则就会在日历队列中一直被级联的计时器会被适当地处理。这确实会导致在持续时间内出现高达百分之几的错误,但在少数情况出现问题的情况下,可以使用基于树的高分辨率计时器(hr计时器)。

简而言之,Linux内核的-rt补丁集使用计时器轮来进行错误处理超时,使用树来用于计时器事件,为每个类别提供所需的服务质量。
线程中断用于解决降级的实时延迟的一个重要来源,即长时间运行的中断处理程序,如图14.12所示。对于能够通过单个中断传递大量事件的设备来说,这些延迟尤其成问题,这意味着中断处理程序将长时间处理所有这些事件。更糟糕的是,可以将新事件传递到仍在运行的中断处理程序的设备,因为这样的中断处理程序很可能无限期地运行,从而无限期地降低实时延迟。
解决这个问题的一种方法是使用图14.13中所示的线程中断。中断处理程序在可抢占IRQthead上下文中运行,该进程以可配置优先级运行。然后,设备中断处理程序只运行很短的时间,刚好足以使IRQ线程知道新事件。如图所示,线程中断可以大大改善实时延迟,部分原因是在IRQ线程上下文中运行的中断处理程序可能会被高优先级的实时线程抢占。
然而,没有免费的午餐,线程中断也有缺点。其中一个缺点是中断延迟的增加。而不是立即运行中断处理程序,该处理程序的执行将被延迟,直到IRQ线程开始运行它。当然,这不是一个问题,除非生成中断的设备是在实时应用程序的关键路径上。

另一个缺点是,编写得糟糕的高优先级实时代码可能会饿死中断处理程序,例如,阻止网络代码运行,从而使调试问题变得非常困难。因此,开发人员在编写高优先级的实时代码时必须非常小心。这被称为蜘蛛侠原则:巨大的力量会带来巨大的责任。
优先级继承用于处理优先级反转,优先级反转可能是由可抢占中断处理程序获取的锁引起的[SRL90]。假设一个低优先级的线程持有一个锁,但被一组中等优先级的线程抢占,每个CPU至少有一个这样的线程。如果发生中断,一个高优先级的IRQ线程将优先于其中一个中优先级的线程,但只有在它决定获得低优先级线程所持有的锁之前。不幸的是,低优先级的线程在它开始运行之前不能释放锁,而中等优先级的线程阻止它这样做。因此,高优先级的IRQ线程只有在中优先级的一个线程释放其CPU后才能获得锁。简而言之,中等优先级的线程间接地阻塞了高优先级的IRQ线程,这是优先级反转的一个经典情况。
请注意,这种优先级反转不会发生在非线程中断中,因为低优先级线程必须在保持锁时禁用中断,这将防止中优先级线程抢占它。
在优先级继承解决方案中,试图获取锁的高优先级线程将其优先级提供给持有锁的低优先级线程,直到锁被释放,从而防止了长期的优先级倒置。
当然,优先级继承确实有其局限性。例如,如果您可以设计应用程序以完全避免优先级反转,那么您可能会获得更好的延迟[Yod04b]。这并不奇怪,因为优先级继承将一对上下文切换到最坏情况的延迟。也就是说,优先级继承可以将无限期延迟转换为有限的延迟时间的增加,并且在许多应用程序中,优先级继承的软件工程好处可能超过其延迟时间的成本。
另一个限制是,它只处理给定操作系统上下文中的基于锁的优先级倒置。它无法解决的一个优先级反转场景是一个高优先级线程等待网络套接字,等待消息,该低优先级进程被一组cpu绑定的中优先级进程抢占写入。此外,图14.14还幻想地描述了对用户输入应用优先级继承的一个潜在缺点。
最后一个限制涉及到读写器锁定。假设我们有大量的低优先级线程,甚至数千个线程,每个线程读取一个特定的读写器锁。假设所有这些线程都被一组中等优先级的线程所抢占,每个CPU至少有一个中等优先级的线程。最后,假设一个高优先级的线程唤醒并尝试写-获取相同的读写器锁。无论我们多么积极地提高读程读取的优先级——保持这个锁,高优先级线程完成其写获取很可能需要很长一段时间。
对于这个读写锁优先级反转难题,有许多可能的解决方案:
1.一次只允许对一个给定的读写器锁进行一次读取。(这是Linux内核的-rt补丁集传统上采用的方法。)
2.一次只允许N个读写器锁的读取,其中N是cpu的数量。
3.一次只允许N个读获取给定的读写器锁,其中N是开发人员以某种方式指定的数字。
4.禁止高优先级线程来自写获取的读写器锁,这些锁曾经被以较低优先级运行的线程读取。(这是优先级上限协议[SRL90]的一个变体。)

无并发读取器的限制最终变得无法忍受,因此-rt开发人员更仔细地研究了Linux内核是如何使用读取器-编写器的自旋锁的。他们了解到,时间关键代码很少使用内核中写获取读者-作者锁的部分,因此作者饥饿的前景并不会阻碍显示。因此,他们构建了一个实时的读-写器锁,在这个锁中,写端获取彼此之间使用优先级继承,但读端获取绝对优先于写端获取。这种方法在实践中工作得很好,这是清楚了解用户真正需要的重要性的另一个教训。
这个实现的一个有趣的细节是,rt_read_lock()和rt_write_lock()函数都进入一个RCU读侧临界部分,而rt_read_unlock()和rt_write_unlock()函数都退出该临界部分。这是必要的,因为非实时内核的读-写锁定函数禁用了其关键部分的抢占,而且确实有读-写锁定用例依赖于synchronize_rcu()将等待所有已存在的读-写-锁关键部分完成。让这给你一个教训:了解用户真正需要什么对正确操作至关重要,而不仅仅是对性能。不仅如此,用户真正需要改变的东西也会随着时间的推移而改变。
这样做的一个副作用是,所有的a -rt内核的读写器锁定关键部分都受到RCU优先级的提升。这至少为读写器锁定阅读器被抢占很长一段时间的问题提供了部分解决方案。
还可以通过将读写锁转换为RCU来避免读写锁优先级反转,下一节将简要讨论。
| 清单14.3:先发制人的Linux-内核RCU | |
| 1空白2{ 3 4 5 } 6 7空 8 { 9 10 11 12 13 14 15 } | __rcu_read_lock(空白) 电流->rcu_read_lock_nesting++;屏障(); __rcu_read_unlock(空白) 如果--电流->rcu_read_lock_nesting)屏障(); 如果(READ_ONCE(当前->rcu_read_unlock_special.s)){rcu_read_unlock_special(t); } |
优先使用的RCU有时可以用作替代读写器锁定[MW07,MBWW12,McK14f],如第9.5节中所讨论的。在可以使用它的地方,它允许阅读器和更新器并发运行,从而防止低优先级阅读器对高优先级更新器施加任何类型的优先级反转场景。然而,为了实现这一点,有必要能够抢占长期运行的RCU读侧临界部分[GMTW08]。否则,长RCU读侧临界部分将导致过多的实时延迟。
因此,向Linux内核中添加了一个可抢占的RCU实现。该实现通过保留在当前RCU读端关键部分中已被优先处理的任务列表,该实现避免了单独跟踪内核中每个任务的状态的需要。宽限期是允许结束: (1)一旦所有cpu完成任何RCU读边关键部分生效前当前宽限期和(2)一旦所有任务抢占在那些预先存在的关键部分从列表中删除。此实现的一个简化版本如清单14.3所示。__rcu_read_lock()函数跨越第1-5行,而__rcu_read_unlock()函数跨越第7-15行。
__rcu_read_lock()的第3行增加了嵌套rcu_read_lock()调用数量的每个任务计数,第4行防止编译器将RCU读侧关键部分中的后续代码重新排序到rcu_read_lock()之前。
__rcu_read_unlock()的第9行可以防止编译器使用此函数的其余部分重新排序关键部分中的代码。第10行减少了嵌套计数,并检查了它是否已经变为零,换句话说,这是否对应于一个嵌套集的最外层的rcu_read_unlock()。如果是,第11行防止编译器通过第12行检查重新排序嵌套更新。如果需要特殊处理,则在第13行呼叫rcu_read_unlock_special()。
可能需要几种特殊处理类型,但是当RCU读侧关键部分被抢占时,我们将关注所需的处理。在这种情况下,任务必须从其RCU读端关键部分中首次抢占时添加到的列表中删除自己。但是,需要注意的是,这些列表受到锁的保护,这意味着rcu_read_unlock()不再是无锁的。但是,最高优先级的线程将不会被抢占,因此,对于那些最高优先级的线程,rcu_read_unlock()将永远不会尝试获取任何锁。此外,如果仔细实施,锁定可以用于同步实时软件[Bra11,SM04a]。

RCU的另一个重要的实时特性,无论是否具有可抢占性,都是能够将RCU回调执行卸载到内核线程中。要使用这个,您的内核必须使用CONFIG_RCU_NOCB_CPU=y构建,并使用rcu_nocbs=内核引导参数指定要卸载的cpu。或者,由第14.3.5.2will节中描述的nohz_full=内核引导参数指定的任何CPU也都会卸载其RCU回调。
简而言之,这种可抢占的RCU实现允许对读取数据结构——主要是实时响应,不会出现大量读取器优先级提升所固有的延迟,也不会由于回调调用而产生的延迟。
由于Linux内核中存在长时间的基于自旋锁的关键部分,可抢占的自旋锁是-rt补丁集的一个重要部分。这个功能还没有达到主流:尽管它们是一个概念上简单的替代品,但它们已经被证明是相对有争议的。此外,主线Linux内核中的实时功能满足了许多用例,这减缓了2010年代早期-rt补丁集的开发速度[Edg13,Edg14]。然而,抢占自旋锁对于实现数十微秒的实时延迟是绝对必要的。幸运的是,Linux基金会组织了一项努力,以资助将剩余的代码从-rt补丁集转移到主线。
出于性能原因,在Linux内核中大量使用每个cpu变量。不幸的是,对于实时应用程序,每个cpu变量的许多用例需要协调更新多个这样的变量,这通常是通过禁用抢占来提供的,这反过来会降低实时延迟。实时应用程序显然需要其他方式来协调每个cpu变量更新。
一种替代方法是提供每个cpu的自旋锁,如上所述,它们实际上是光滑的,以便它们的关键部分可以被抢占,从而提供优先级继承。在这种方法中,每个CPU变量的代码更新组必须获得当前CPU的自旋锁,执行更新,然后释放任何获得的锁,请记住,抢占可能导致迁移到其他CPU。但是,这种方法同时引入了开销和死锁。
另一种替代方案,即在2021年初开始在-rt补丁集中使用,是将抢占禁用转换为迁移禁用。这确保了一个给定的内核线程在每个CPU变量更新的过程中一直保持在其CPU上,但也可以允许其他一些内核线程对这些相同的变量进行自己的更新。在一些情况下,比如统计数据收集,这不是一个问题。在令人惊讶的罕见情况下,这种中间更新抢占是一个问题,手头的用例必须正确地同步更新,可能通过一组特定于该用例的每个cpu锁。尽管引入锁再次引入了死锁的可能性,但这些锁的每个用例性质使任何此类死锁都更容易管理和避免。
关闭事件驱动的备注。当然,还有许多其他的linux内核组件对于实现世界级的实时延迟至关重要,
例如,截止日期调度[dO18b,dO18a],但是,本节中列出的那些调度对由-rt补丁集增强的Linux内核的工作方式有了一种很好的感觉。
乍一看,使用轮询循环似乎似乎避免了所有可能的操作系统干扰问题。毕竟,如果一个给定的CPU从未进入内核,那么内核就完全消失了。让内核远离内核的传统方法就是没有内核,许多实时应用程序确实可以在裸金属上运行,特别是那些运行在8位微控制器上的应用程序。
人们可能希望通过在给定的CPU上运行单个CPU绑定的用户模式线程,就可以在现代操作系统内核上获得裸金属性能,避免所有干扰原因。虽然现实当然更为复杂,但由于弗雷德里克·韦斯贝克领导的NO_HZ_FULL实现[Cor13],Wei12],该实现已被接受到Linux内核的3.10版本中。然而,正确地设置这样的环境需要相当小心,因为有必要控制许多可能的操作系统抖动来源。下面的讨论涵盖了对操作系统抖动的几个来源的控制,包括设备中断、内核线程和守护进程、调度器的实时限制(这是一个特性,而不是一个bug!),计时器、非实时设备驱动程序、内核内全局同步、调度时钟中断、页面故障,最后,还有非实时硬件和固件。
中断是大量OS抖动的一个极好的来源。不幸的是,在大多数情况下,为了与外部世界通信,绝对需要中断。解决操作系统抖动和与外部世界保持联系之间的冲突的一种方法是保留少量的内务cpu,并强制执行对这些cpu的所有中断。Linux源代码树中的文档/irq关联.txt文件描述了如何将设备中断定向到指定的cpu,截至2021年初,该cpu涉及以下内容
| $ echo 0f > /proc/irq/44/smp_affinity |
这个命令将把中断#44限制为cpu0-3。请注意,调度时钟中断需要特殊处理,这将在本节后面进行讨论。
操作系统抖动的第二个来源是由于内核线程和守护进程。单个内核线程,如RCU的宽限期内核线程(rcu_bh、rcu_preempt和rcu_sched),可以使用任务集命令、sched_setaffinity()系统调用或cgroups强制到任何所需的cpu上。
每个cpu的k线程通常更具挑战性,有时会限制硬件配置和工作负载布局。防止操作系统抖动这些kshowes要求某些类型的硬件不附加到实时系统,所有中断和I/O启动发生在管家cpu,特殊的内核Kconfig或引导参数被选择为了直接工作远离工作cpu,或者工作cpu永远不会进入内核。具体的每个k线程的建议可以在Linux内核源文档目录中的每个cpu-k线程的内核.txt中找到。
对于以实时优先级运行的cpu绑定线程,Linux内核中操作系统抖动的第三个来源是调度程序本身。这是一个有意的调试特性,旨在确保重要的非实时工作每秒至少分配50毫秒,即使在实时应用程序中存在无限循环的bug。但是,当您正在运行一个轮询循环风格的实时应用程序时,您将需要禁用此调试功能。该操作的方法如下:
| $echo-1>/proc/sys/内核/sched_rt_runtime_us |
当然,您需要作为根目录运行来执行此命令,而且您还需要仔细考虑前面提到的蜘蛛侠原则。最小化风险的一种方法是从正在运行与cpu绑定的实时线程的所有cpu中卸载中断和内核线程/守护进程,如上述段落所述。此外,您应该仔细阅读文档/调度程序目录中的材料。sched-rt-group .rst文件中的材料特别重要,特别是当您正在使用由CONFIG_RT_GROUP_SCHED Kconfig参数启用的c组实时特性时。
操作系统抖动的第四个来源来自计时器。在大多数情况下,将给定的CPU排除在内核之外将防止计时器被安排在该CPU上。一个重要的例外是重复计时器,即给定的计时器处理程序会发布稍后出现的同一计时器。如果这样的计时器在给定的CPU上启动,该计时器将继续在该CPU上定期运行,无限期地造成操作系统抖动。卸载循环计时器的一个粗糙但有效的方法是使用CPU热插头离线所有运行CPU绑定的实时应用程序线程的工作CPU,在线这些相同的CPU,然后启动你的实时应用程序。
操作系统抖动的第五个来源是由不打算实时使用的设备驱动程序提供的。对于一个旧的规范示例,在2005年,VGA驱动程序将通过在禁用中断的帧缓冲器来空白屏幕,这导致数十毫秒的操作系统抖动。避免设备驱动程序引起的操作系统抖动的一种方法是仔细选择在实时系统中大量使用,因此修复了实时错误的设备。另一种方法是将设备的中断和使用该设备的所有代码限制在指定的内务cpu中。第三种方法是测试该设备支持实时工作负载和修复任何实时错误的能力。8
操作系统抖动的第六个来源是由一些内核内的全系统同步算法提供的,也许最显著的是全局TLB-flush算法。这可以通过避免内存解映射操作,特别是避免内核内的解映射操作来避免。到2021年初开始,避免内核内解映射操作的方法是避免卸载内核模块。
操作系统抖动的第七个源是由调度时钟中断和RCU回调调用提供的。可以通过构建启用了NO_HZ_ FULL Kconfig参数的内核,然后使用nohz_full=参数指定要运行实时线程的工作cpu列表来避免这些问题。例如,nohz_full=2-7将cpu2、3、4、5、6和7指定为工作cpu,从而将cpu0和1留为内务cpu。只要在每个工作CPU上不存在超过一个可运行的任务,工作CPU就不会发生调度时钟中断,并且每个工作CPU的RCU回调将在其中一个内务管理CPU上被调用。由于CPU上只有一个可运行任务而抑制调度时钟中断的CPU被称为自适应滴答模式或nohz_full模式。重要的是要确保您指定了足够的管理cpu来处理系统其他部分施加的管理负载,这需要仔细的基准测试和调优。
操作系统抖动的第八个来源是页面故障。因为大多数Linux实现都使用MMU来保护内存,所以在这些系统上运行的实时应用程序
8如果你采取这种方法,请提交你的修复程序上游,以便其他人可以受益。毕竟,当您需要将应用程序移植到以后的Linux内核版本时,您将成为那些“其他版本”之一。
| 清单14.4:定位OS抖动的源 | |
| 1 cd /sys/kernel/debug/tracing | |
| 2 | 回声1 > max_graph_depth |
| 3 | |
| 4 | #运行工作量 |
| 5 | 猫per_cpu/cpuN/跟踪 |
可能会出现页面故障。使用mlock()和所有()系统调用将应用程序的页面锁定到内存中,从而避免重大页面故障。当然,蜘蛛侠原理也适用,因为锁定太多的内存可能会阻止系统完成其他工作。
不幸的是,操作系统抖动的第九个来源是硬件和固件。因此,使用已经为实时使用而设计的系统是很重要的。
不幸的是,这个操作系统抖动源的列表永远不会完整,因为它会随着内核的每个新版本而改变。这使得有必要能够跟踪OS抖动的其他源。给定一个运行一个CPU绑定的用户模式线程的CPU N,清单14.4中所示的命令将生成一个包含该CPU进入内核的所有时间的列表。当然,第5行的N必须用有问题的CPU的数量来替换,而第2行的1可以增加以显示内核内额外级别的函数调用。生成的跟踪可以帮助跟踪操作系统抖动的来源。
和往常一样,这里没有免费的午餐,NO_HZ_FULL也不例外。如前所述,NO_HZ_FULL使内核/用户转换更加昂贵,因为需要将转换通知内核子系统(如RCU)。作为一个粗略的经验法则,NO_HZ_FULL有助于处理许多类型的实时和重计算的工作负载,但会损害其他具有高系统调用和I/O [ACA+ 18]率的工作负载。其他的限制、权衡和配置建议可以在文档/计时器/no_hz.rst中找到。
正如您所看到的,在Linux等通用操作系统上运行cpu绑定的实时线程时,要获得裸金属性能,就需要认真关注细节。自动化当然会有所帮助,而且一些自动化已经被应用,但考虑到用户数量相对较少,自动化可能会看起来相对缓慢。然而,在运行通用操作系统时获得几乎裸金属性能的能力承诺可以简化某些类型的实时系统的构建。
开发实时应用程序是一个范围广泛的主题,本节只能涉及以下几个方面。为此,第14.3.6.1looks节介绍了实时应用程序中常用的一些软件组件,第14.3.6.2provides节简要概述了可能是如何实现基于轮询循环的应用程序的,第14.3.6.3节给出了类似的流媒体应用程序的概述,第14.3.6.4节简要介绍了基于事件的应用程序。
在工程的所有领域中,一组健壮的组件对生产率和可靠性至关重要。本节并不是实时软件组件的完整目录。目录将填充多本书,而是对可用组件类型的简要概述。
寻找实时软件组件的一个自然位置将是提供无等待同步的算法[Her91],事实上,无锁算法对实时计算非常重要。然而,无等待同步只能保证在有限的时间内向前进行。虽然一个世纪是有限的,但当你的截止日期以微秒为单位测量时,这是没有帮助的,更不用说毫秒了。
然而,有一些重要的无等待算法确实提供了有限制的响应时间,包括原子测试和设置、原子交换、原子获取和添加、基于循环数组的单生产者/单消费者FIFO队列,以及大量的每线程分区算法。此外,最近的研究证实了一个观察结果,即具有无锁保证的算法在实践中也提供相同的延迟(在无等待的意义上),假设一个随机公平的调度器和没有失败停止bug[ACHS13]。这意味着许多非无等待的堆栈和队列仍然适合实时使用。

在实践中,锁定经常用于实时程序,理论上是不成立的。然而,在更严格的约束下,基于锁的算法也可以提供有限的延迟[Bra11]。这些限制条件包括:
1.公平的调度程序。在固定优先级调度器的常见情况下,有限的延迟只提供给最高优先级的线程。
2.有足够的带宽来支持工作负载。支持这一约束的实现规则可能是“在正常运行期间,所有cpu上至少有50 %的空闲时间”,或者,更正式地说,“提供的负载将足够低,允许工作负载随时可调度。”
3.没有故障停止错误。
4.FIFO锁定原语带有获取、切换和释放延迟的限制。同样,在优先级内的FIFO锁定原语的常见情况下,限制延迟只提供给最高优先级的线程。
5.一种防止无界优先级反转的一些方法。本章前面提到的优先级上限和优先级继承学科就足够了。
6.锁获取的边界嵌套。我们可以有一个无限数量的锁,但只要一个给定的线程一次不能获得超过一些锁(理想情况下只有一个)。
7.线程数。与前面的约束相结合,这个约束意味着在任何给定的锁上都将有有限数量的线程等待。
8.在任何给定的关键部分所花费的限定时间。给定在任何给定锁上等待的线程数量和临界部分持续时间,等待时间将是有限的。

这一结果为实时软件中提供了大量的算法和数据结构,并验证了长期的实时实践。
当然,一个仔细和简单的应用程序设计也非常重要。世界上最好的实时组件无法弥补一个不经过深思熟虑的设计。对于并行实时应用程序,同步开销显然必须是设计的一个关键组成部分。
许多实时应用程序由一个单个cpu绑定的循环组成,该循环读取传感器数据,计算控制律,并写入控制输出。如果提供传感器数据和获取控制输出的硬件寄存器被映射到应用程序的地址空间中,则此循环可能完全没有系统调用。但是要注意蜘蛛侠的原则:强大的力量就会带来巨大的责任,在这种情况下,就有责任避免通过不适当地引用硬件寄存器来损坏硬件。
这种安排通常运行在裸金属上,没有任何好处(或来自)操作系统的干扰。然而,硬件能力的提高和自动化水平的提高推动了软件功能的增加,例如,用户界面、日志记录和报告,所有这些都可以从操作系统中获益。
在裸金属上运行的同时,还可以访问通用操作系统的全部功能的一种方法是使用Linux内核的NO_HZ_FULL功能,如第14.3.5.2节所述。
一种大数据实时应用程序从许多来源获取输入,在内部处理它,并输出警报和摘要。这些流媒体应用程序通常是高度并行的,可以同时处理不同的信息源。
实现流媒体应用程序的一种方法是使用密集阵列循环FIFOs来连接不同的处理步骤[Sut13]。每个这样的FIFO只有一个线程,以及一个(可能不同的)单线程。扇入和扇出点使用线程而不是数据结构,所以如果需要合并几个FIFO的输出,一个单独的线程将从它们输入并输出到另一个FIFO,这个单独的线程是唯一的生产者。类似地,如果一个给定的FIFO的输出需要被拆分,则一个单独的线程将从该FIFO中输入,并根据需要输出到几个FIFO。
这个规程可能看起来很有限制,但它允许以最小的同步开销在线程之间进行通信,并且在试图满足严格的延迟约束时,最小的同步开销非常重要。当每个步骤的处理量很小时,尤其如此,因此同步开销比处理开销更大。
单个线程可能是cpu绑定的,在这种情况下,将适用于第14.3.6.2节中的建议。另一方面,如果单个线程阻塞了等待从其输入的fifo中获得的数据,则适用下一节的建议。
| 清单14.5:定时等待测试程序 | |
| 如果2,则为1 3 4 } 5如果6 7 8 } 9如果10 11 12 } | (clock_gettime(CLOCK_REALTIME,和时间启动)!=0){ 错误(“clock_gettime 1”);退出(-1); (纳米睡眠(&时间等待,空)!=0){perror(“纳米睡眠”); 出口(-1); (clock_gettime(CLOCK_REALTIME,和时间结束)!=0){ 错误(“clock_gettime 2”);退出(-1); |
我们将使用燃料喷射到一个中型工业发动机作为事件驱动应用的一个奇特的例子。在正常工作条件下,该发动机要求在顶部死区中心周围的一度间隔内注入燃料。如果我们假设1500转的转速,我们每秒有25个旋转,或者大约每秒9000度,即每秒111微秒。因此,我们需要将燃油喷射安排在大约100微秒的时间间隔内。
假设一个定时等待将被用来启动燃油喷射,尽管如果你正在建造一个发动机,我希望你提供一个旋转传感器。我们需要测试定时等待功能,也许可以使用清单14.5中所示的测试程序。不幸的是,如果我们运行这个程序,我们可能会得到不可接受的计时器抖动,即使是在a -rt内核中。
奇怪的是,一个问题是,POSIX CLOCK_REALTIME并不能实时使用。相反,它的意思是“实时”,而不是进程或线程所消耗的CPU时间。对于实时使用,您应该使用CLOCK_MONOTONIC。然而,即使有了这种变化,结果仍然是不可接受的。
另一个问题是,必须通过使用sched_setscheduler()系统调用将线程提升到实时优先级。但即使是这种改变也是不够的,因为我们仍然可以看到页面错误。我们还需要使用锁定()系统调用来锁定应用程序的内存,防止页面故障。有了所有这些变化,结果可能最终是可以接受的。
在其他情况下,可能需要进行进一步的调整。可能有必要将时间关键的线程亲和到它们自己的cpu上,也可能有必要亲和中断远离这些cpu。可能需要仔细选择硬件和驱动程序,而且很可能需要仔细选择内核配置。
从这个例子中可以看出,实时计算可能是相当不可原谅的。
假设您正在编写一个并行的实时应用程序,它需要访问可能发生逐渐变化的数据,这可能是由于温度、湿度和气压的变化。这个程序上的实时响应约束是如此严重,以至于不允许旋转或阻塞,因此排除了锁定,也不允许使用重试循环,从而排除了序列锁和危险指针。幸运的是,温度和压力通常是受到控制的,因此一个默认的硬编码数据集通常就足够了。
| 清单14.6:使用RCU进行实时校准 |
| 1结构校准{ 2 短a; 3 短b; 4 短c;5}; 6个结构校准default_cal = { 62,33,88 }; 7结构体校准cur_cal = &default_cal;8 9短calc_control(短t,短h,短压机)10{ 11 结构校准 13 p = rcu_dereference ( cur_cal ); 14 返回do_控制(t,h,按,p->a,p->b,p->c);15 } 16 17 bool update_cal(短a,短b,短c)18 { 19 结构校准 20 结构校准*old_p;21 22 old_p = rcu_dereference ( cur_cal ); 23 p = malloc (sizeof(*p); 24 如果(!p) 25 返回假; 26 p->a = a; 27 p->b = b; 28 p->c = c; 29 rcu_assign_pointer ( cur_cal , p); 30 如果(old_p == &default_cal) 31 返回真; 32 synchronize_rcu() ; 33 自由(old_p); 34 返回真值;35 } |
然而,温度、湿度和压力偶尔会偏离默认值,在这种情况下,有必要提供替代默认值的数据。因为温度、湿度和压力是逐渐变化的,所以提供更新的值并不是一个紧急事项,尽管它必须在几分钟内发生。该程序将使用一个名为cur_cal的全局指针,它通常引用default_cal,这是一个静态分配和初始化的结构,包含了名为a、b和c的字段中的默认校准值。否则,cur_cal指向一个提供当前校准值的动态分配的结构。
清单14.6显示了如何使用RCU来解决这个问题。查找是确定性的,如第9-15行上的calc_control()所示,与实时需求一致。更新更为复杂,如update_cal()在第17-35行所示。

这个示例展示了RCU如何提供对实时程序的确定性读端数据结构访问。

在实时计算和实时快速计算之间的选择可能是一个很困难的问题。因为实时系统经常会对非实时计算造成吞吐量损失,所以在不需要时使用实时计算是不明智的,如图14.15所示。
另一方面,在需要时不使用实时操作也会导致问题,如图14.16所示。这几乎足以让你为老板感到难过了!
其中一个经验法则是使用以下四个问题来帮助你进行选择:
1.平均长期吞吐量是唯一的目标吗?
2.是否允许重负载降低响应时间?
3.是否存在高内存压力,排除使用()()系统调用?
4.应用程序的基本工作项是否需要超过100毫秒才能完成?
如果这些问题的答案都是“是”,你应该选择实时快速而不是实时,否则,实时可能会适合你。
明智地选择,如果你选择实时,确保你的硬件,固件和操作系统的工作!
Chapter 15 Advanced Synchronization:Memory Ordering
进步的艺术是在变化中保持秩序,在秩序中保持变化。
怀德海
因果关系和排序是非常直观的,黑客通常对这些概念有很强的把握。这些直觉在编写、分析和调试顺序代码时不仅非常有用,而且在使用诸如锁定等标准互斥机制的并行代码时也非常有用。不幸的是,这些直觉在代码中完全崩溃,而是使用弱有序的原子操作和内存障碍。这类代码的一个示例实现了标准互斥机制,而另一个示例实现了使用较弱同步的快速路径。尽管侮辱了直觉,但有些人认为弱点是一种美德。美德或缺点,这一章将帮助您理解内存顺序,通过实践,这将足以实现同步原语和性能关键的快速路径。
第15.1节将演示真实的计算机系统可以重新排序内存参考,给出它们这样做的一些原因,并提供一些关于如何防止不希望的重新排序的信息。第15.2节和第15.3节将分别涵盖硬件和编译器可能给粗心的并行程序员带来的痛苦类型。第15.4节概述了在更高的抽象级别上建模内存排序的好处。第15.5节随后将详细介绍一些具有代表性的硬件平台。最后,第15.6节提供了一些可靠的直觉和有用的经验法则。

15.1 订购:为什么和如何?
除非人们控制它,没有什么是有序的。创造中的一切都是松散的。
亨利沃德比彻,更新
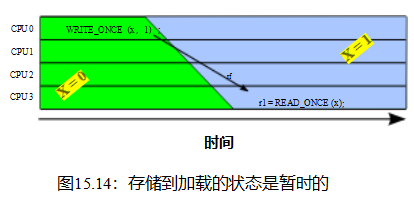
内存排序的一个动机可以在清单15.1(C-SB+o-o+o-o.litmus)中看似简单的试金石中看到,乍一看似乎可以保证
| 清单15.1:内存排序错误:存储缓冲测试 |
| 1 C C-SB+o-o+o-o 2 3 {} 4 5 P0(int *x0, int *x1) 6 { 7 int r2; 8 9 WRITE_ONCE(*x0,2); 10 r2 = READ_ONCE(*x1); 11 } 12 13 P1(int *x0, int *x1) 14 { 15 int r2; 16 18 r2 = READ_ONCE(*x0); 19 } 20 21个已存在(1:r2=0 /\ 0:r2=0) |
| 存在子句永远不会触发。1毕竟,如果0:r2=0存在条款所示,2我们可能希望线程P0()负载从x1到r2必须发生在线程P1()存储x1,这可能提高进一步希望线程P1()负载从x0到r2必须发生在线程P0()存储x0,这样1:r2=2,因此从不触发存在子句。这个例子是对称的,所以类似的推理可能会让我们希望1:r2=0能保证0:r2=2。不幸的是,缺乏记忆障碍粉碎了这些希望。CPU有权重新排序线程P0()和线程P1()中的语句,即使在x86等相对强有序的系统上也是如此。 |
| 快速测试15.2:编译器还可以重新排序清单15.1中的线程P0()和线程P1()的内存访问,对吧? |
| 这种重新排序的意愿可以通过试金石7[AMT14]等工具来证实,该工具发现,在x86笔记本电脑上的10000万次试验中,反直觉的排序发生了314次。奇怪的是,两个负载返回值2发生的频率较低,在这种情况下,只有167次。3这里的教训很清楚:增加反直觉并不一定意味着降低概率! 下面的部分展示了这种直觉是如何分解的,然后提出了一些记忆排序的心理模型,可以帮助你避免这些陷阱。 第15.1.1gives节简要概述了为什么硬件错误排序会导致内存访问,然后第15.1.2节也同样简要地概述了如何阻止这种错误排序。最后,第15.1.3节列出了一些基本的经验法则,它们将在后面的章节中进一步细化。这些部分主要关注硬件的重新排序,但请放心,编译器的重新排序比硬件所梦想的要积极得多。由编译器诱导的重新排序将在第15.3节中进行讨论。 |
纯粹主义者会坚持存在条款永远不会被满足,但我们在这里使用“触发”来类比断言。
2,即线程P0()的局部变量r2的实例等于零。试金石命名法的文件见第12.2.1节。
3请注意,结果对确切的硬件配置、系统加载的程度以及其他许多方面都很敏感。所以为什么不在你自己的系统上尝试一下呢?
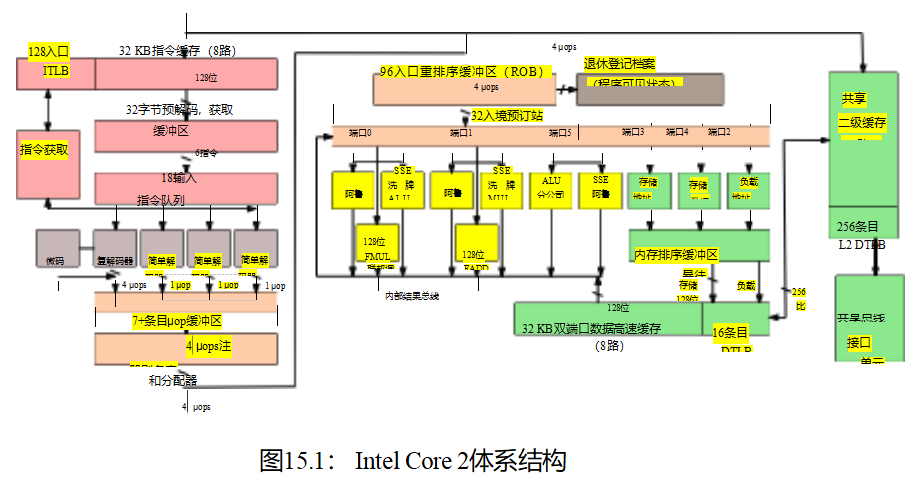
但是为什么记忆排序首先会发生错误呢?难道cpu就不能自己跟踪订购情况吗?这难道不是我们最初就有电脑来记录事情的原因吗?
许多人确实希望他们的电脑能跟踪事情,但也有许多人坚持认为他们要快速跟踪事情。事实上,对性能的关注是如此强烈,以至于现代cpu非常复杂,这从图15.1中的简化方框图中可以看出。那些需要从他们的系统中挤出最后几个百分点的性能的人,反过来,在调整他们的软件时,也需要密切关注这个数字的细节。除了这种对细节的密切关注意味着当一个给定的CPU随着年龄的增长而退化时,软件将不再在它上快速运行。例如,如果最左边的ALU失败,经过调优以充分利用所有ALU的软件可能比未调优的软件运行得更慢。解决这个问题的一个方案是,一旦系统的任何cpu开始退化,就停止服务。
另一种选择是回顾第3章的经验教训,特别是对于许多重要的工作负载,主内存无法跟上现代cpu,而现代cpu可以在从内存中获取单个变量所需的时间内执行数百个指令。对于这样的工作负载,CPU的详细内部结构是无关的,
CPU可以用图15.2中标记的CPU、存储缓冲区和缓存来近似。
因为这些数据密集型工作负载,CPU运动越来越大的缓存,如图3.11,这意味着尽管第一个加载由给定的CPU从一个给定的变量将导致一个昂贵的缓存错过3.1.6节中讨论,随后重复加载变量,CPU可能很快执行,因为初始缓存错过将变量加载到CPU的缓存。
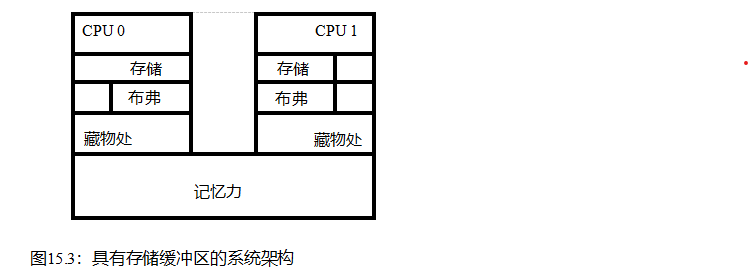
但是,也需要容纳从多个cpu到一组共享变量的频繁并发存储。在缓存相干系统中,如果缓存包含给定变量的多个副本,则该变量的所有副本必须具有相同的值。这对于并发加载工作得非常好,但对于并发存储却不那么好:每个存储必须对旧值的所有副本做一些事情(另一个缓存丢失!),考虑到有限的光速和物质的原子性质,这将比急躁的软件黑客所希望的要慢。而这些存储字符串则是在图15.2中使用蓝色块标记的存储缓冲区的原因。
从图15.2中删除内部CPU复杂度,添加第二个CPU,并在图15.3中显示主内存结果。当给定的CPU存储到该CPU缓存中不存在的变量时,那么新值将被放置在该CPU的存储缓冲区中。然后,CPU可以立即继续操作,而不必等待存储区对位于其他CPU缓存中的该变量的所有旧值进行处理。
尽管存储缓冲区可以极大地提高性能,但它们可能会导致指令和内存引用的执行异常,从而导致严重的混乱,如图15.4所示。

特别是,存储缓冲区会导致如清单15.1所示的内存排序错误。
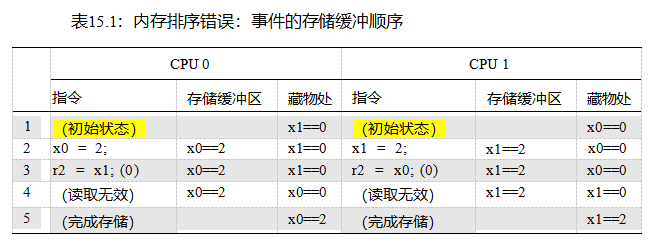
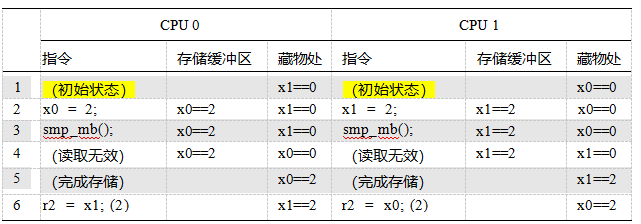
表15.1显示了导致这种错误排序的步骤。第1行显示了初始状态,其中CPU 0在缓存中有x1,CPU1在缓存中有x0,这两个变量的值都为零。第2行显示了由于每个CPU的存储区而引起的状态变化(清单15.1中的第9行和第17行)。因为两个CPU在缓存中都没有存储到变量,所以两个CPU都在各自的存储缓冲区中记录它们的存储。

第3行显示了两个加载项(清单15.1中的第10行和第18行)。因为每个CPU加载的变量在该CPU的缓存中,所以每个加载立即返回缓存值,在这两种情况下都为零。
但是cpu还没有完成:它们迟早必须清空存储缓冲区。
因为缓存移动数据在相对较大的块称为数据线,因为每个数据线可以持有几个变量,每个CPU必须得到数据线到自己的缓存,这样它可以更新的部分数据线对应的变量的存储缓冲区,但不干扰任何数据线的其他部分。每个CPU还必须确保弹轴线不存在于任何其他CPU的缓存中,为此使用读取无效操作。如第4行所示,在两个读取无效操作完成后,两个CPU交换了粗线,因此CPU0的缓存现在包含x0,而CPU1的缓存现在包含x1。一旦这两个变量进入了它们的新家,每个CPU就可以将其存储缓冲区刷新到相应的缓存行中,并保留每个变量的最终值,如第5行所示。

总之,需要存储缓冲区来允许cpu有效地处理存储指令,但它们可能会导致违反直觉的内存排序错误。
但是如果你的算法真的需要它的内存引用,你会怎么做呢?例如,假设您正在使用一对标志与一个驱动程序进行通信,一个标志表示驱动程序是否在运行,另一个标志表示是否在运行
| 清单15.2:内存排序:存储缓冲试金石 |
| 1 C C-SB+o-mb-o+o-mb-o 2 3 {} 4 5 P0(int *x0, int *x1) 6 { 7 int r2; 8 10 smp_mb(); 11 r2 = READ_ONCE(*x1); 12 } 13 14 P1(int *x0, int *x1) 15 { 16 int r2; 17 20 r2 = READ_ONCE(*x0); 21 } 22 23已存在(1:r2=0 /\ 0:r2=0) |
对该驱动程序有一个未决的请求。请求者需要设置请求-挂起的标志,然后检查驱动程序正在运行的标志,如果为false,则唤醒驱动程序。一旦驱动程序服务了它知道的所有挂起请求,它需要清除驱动程序运行标志,然后检查请求挂起标志以查看ifit需要重新启动。这种非常合理的方法不能工作,除非有一些方法来确保硬件处理存储和加载的顺序。这是下一节的主题。
事实证明,有一些编译器指令和同步原语(如锁定和RCU)负责通过使用内存障碍(例如,Linux内核中的smp_mb())来维护排序的错觉。这些记忆障碍可以是显式指令,因为它们在手臂、权力、安定和阿尔法上,或者它们可以被其他指令暗示,因为它们通常在x86上。由于这些标准的同步原语保留了排序的错觉,因此您的阻力最小的路径是简单地使用这些原语,从而允许您停止阅读本节。
但是,如果您需要实现同步原语本身,或者如果您只是对了解内存顺序的工作原理感兴趣,请继续阅读吧!这个旅程的第一站是清单15.2(C-SB+o-mb-o+o-mb-o.litmus),它在P0()和P1()中的存储和加载之间放置了一个smp_mb()linux内核的全内存障碍,但在其他方面与清单15.1相同。这些障碍阻止了在我的x86笔记本电脑上的1亿次试验中发生反直觉的结果。有趣的是,由于这些障碍而增加的开销导致法律结果,两个负载返回值2超过80万次,而清单15.1中的无障碍代码只有167次。
这些障碍对排序有深刻的影响,如表15.2所示。虽然前两行与表15.1中相同,尽管smp_mb()
第3行上的说明本身不会改变状态,它们确实会导致存储在加载(第6行)之前完成(第4行和第5行),这排除了表15.1中所示的反直觉的结果。注意,变量x0和x1仍然有大于
表15.2:内存排序:事件的存储-缓冲顺序
然而,第2行的一个值,正如前面承诺的那样,smp_mb()调用最终会解决问题。
尽管像smp_mb()这样的完全障碍具有非常强的排序保证,但它们的优势在放弃的硬件和编译器优化方面具有很高的价格。许多情况可以用更弱的排序来处理,保证使用更便宜的内存排序指令,或者,在某些情况下,根本没有内存排序指令。
表15.3提供了Linux内核的排序原语及其保证的廉价表。每一行对应于一个可能提供或不提供排序的原语或类别,标记为“先前排序操作”和“后续排序操作”的列是可能(或可能不)排序的操作。包含“Y”的单元格表示无条件地提供排序,而其他字符表示只部分或有条件地提供排序。空白单元格表示没有提供订单。
“存储”行还涵盖了原子RMW操作的存储部分。此外,“负载”行覆盖了一个成功的值返回的_放松的()RMW原子操作的负载组件,尽管组合的“_放松的()RMW操作”行在值返回的情况下提供了一个方便的组合引用。执行不成功的值返回RMW操作原子的CPU必须使所有其他CPU缓存中的相应变量无效。因此,不成功的值返回原子RMW操作具有存储的许多属性,这意味着“_放松的()RMW操作”行也适用于不成功的值返回原子RMW操作。
*_获取行覆盖smp_load_acquire(),cmpxchg_acquire(),xchg_获取(),等等;*_释放行覆盖smp_store_release(),rcu_分配指针(),cmpxchg_release(),xchg_release(),等;而“成功的全强度非无效RMW”行包括原子_添加_返回(),原子_添加_,除非(),atomic_dec_and_test(),cmpxchg(),xchg(),等等。“成功”限定符适用于原子_add_,除非()、cmpxchg_acquire()和cmpxchg_release(),当它们指示失败时,它们对内存或排序都没有影响,如前面的“_放松()RMW操作”行所示。
列“C”表示累积量和传播量,如第15.2.7.1节和第15.2.7.2节所述。同时,当涉及最多有两个线程时,通常可以忽略此列。
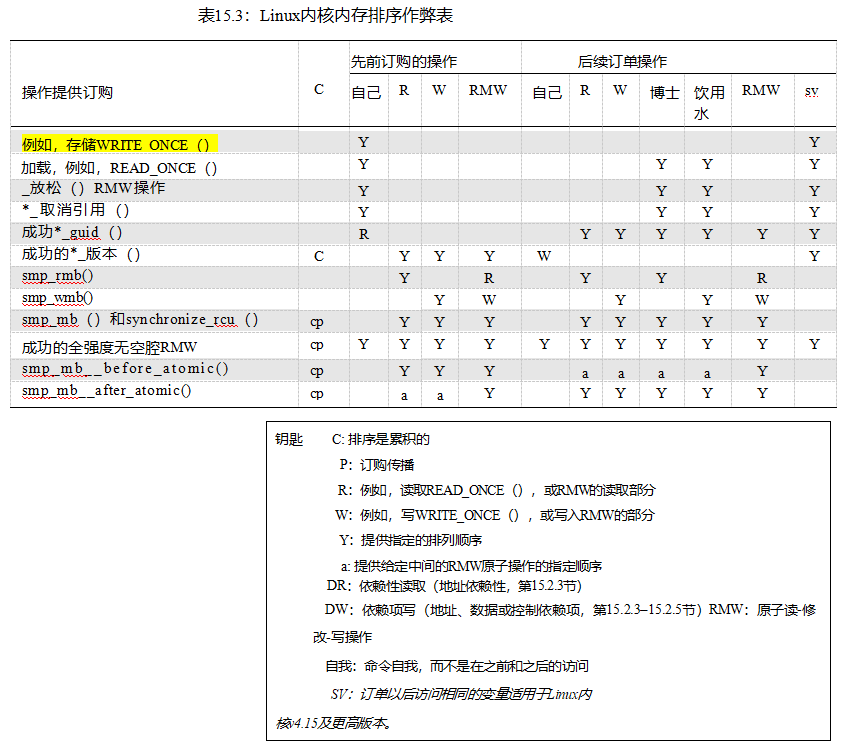
需要注意的是,这个表只是一个备忘表,因此绝对不能替代对内存顺序的良好理解。为了开始建立这样的理解,下一节将介绍一些基本的经验法则。
本节介绍了一些“好且足够”的基本经验规则。实际上,您可以编写大量具有出色性能和可伸缩性的并发代码,而不需要任何这些经验规则。更复杂的经验规则将在第15.6节中介绍。

一个给定的线程会按顺序查看它自己的访问权限。此规则假设从/到共享变量的加载和存储分别使用READ_ONCE()和WRITE_ONCE()。否则,编译器可能会深刻地打乱您的代码,有时CPU也会做一些打乱,如第15.5.4节中所讨论的。
中断处理程序和信号处理程序是线程的一部分。中断处理程序和信号处理程序都发生在一个线程中的一对相邻指令之间。这意味着给定的处理程序似乎从中断线程的角度进行原子执行,至少在汇编语言级别上是这样。但是,C和C++语言并没有定义共享普通变量的处理程序和中断线程的结果。相反,这些共享变量必须是sig_atomic_t、无锁原子或易失性原子。
另一方面,由于处理程序在中断的线程的上下文中执行,因此用于同步处理程序和线程之间通信的内存顺序可能非常轻量级。例如,获取负载的对应是READ_ONCE(),后面是()编译器指令,发布存储的对应是屏障(),后面是WRITE_ONCE()。一个完整的内存障碍的对应物是障碍()。最后,在线程内禁用中断或信号(视情况而定)不包括处理程序。
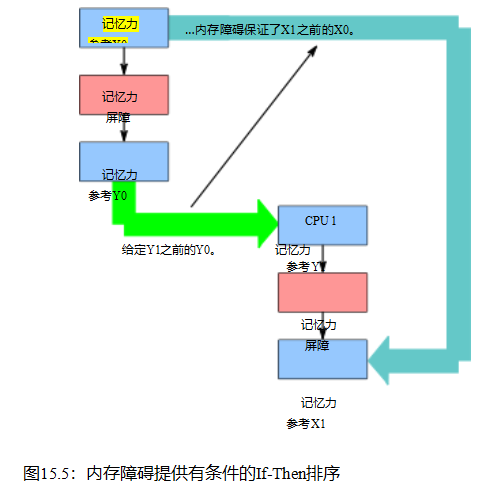
排序具有有条件的if-then语义。图15.5illustrates,这是内存障碍。假设两个存储障碍都足够强,如果CPU 1,s访问Y1发生在CPU 0,s访问Y0之后,那么CPU 1,s访问X1保证发生在CPU 0,s访问X0之后。当你怀疑哪些记忆障碍足够强大时,smp_mb()总是会做这项工作,尽管要付出代价。

清单15.2就是一个很恰当的例子。第10和19行上的smp_mb()作为屏障,第9行的x0存储为X0,第11行的x1的负载为Y0,第18行的x1存储为Y1,第20行的x0的负载为X1。逐步应用if-then规则,我们知道如果P10()的局部变量r2被设置为值0,则在第11行从x1到x1加载之后发生。if-then规则将声明从第20行的x0的加载发生在存储到第9行的x0之后。换句话说,只有当P0()的局部变量r2以值0结尾时,P1()的局部变量r2才保证以值2结尾。这强调了内存排序保证是有条件的,而不是绝对的。
虽然图15.5特别提到了内存障碍,但同样的if-then规则也适用于Linux内核的其他排序操作。
订购操作必须进行配对。如果您在一个线程中仔细地排序操作,但在另一个线程中没有这样做,那么就没有排序。这两个线程都必须为应用if-then规则提供排序。
订购操作几乎永远不会加快运行速度。如果您发现自己试图添加一个内存障碍,试图迫使之前的存储更快地刷新到内存,请抵制!增加订购量通常会减慢工作速度。当然,在某些情况下,添加指令会加速运行,如图254页上的图9.22所示,但在这种情况下,需要进行仔细的基准测试。即便如此,很有可能虽然你在系统上加快了一些速度,但你很可能在用户的系统上大大放慢了速度。或者关于你未来的系统。
订购操作并不神奇。当您的程序由于某些竞争条件而失败时,通常很容易加入一些内存排序操作,试图阻止您的bug不存在。一个更好的反应是以一种精心设计的方式使用更高级级的原语。在并发编程中,设计不存在的错误几乎总是比将它们压缩到更低的概率更好。
这些都只是粗略的经验法则。尽管这些经验法则涵盖了在实际实践中看到的绝大多数情况,就像任何一套经验法则一样,它们确实有它们的局限性。下一节将通过引入试金石测试来演示这些限制,这些测试旨在侮辱你的直觉,同时增加你的理解。这些试金石测试还将阐明表15.3中所示的linux内核内存排序备忘单所代表的许多概念,并可以在适当的工具下自动分析[AMM+ 18]。第15.6节将回到这个小抄,根据所有干预的干预技巧和陷阱,展示一套更复杂的经验规则。

| 清单15.3:软件逻辑分析器 |
| 1个状态。变量= mycpu; |
| 2 lasttb = oldtb = firsttb = gettb(); |
| 3而(状态变量== mycpu){ |
| 4 lasttb = oldtb; |
| 5 oldtb = gettb(); |
| 6 如果(首先第一个> 1000) |
| 7 破碎 |
| 8 } |
15.2 技巧和陷阱
知道陷阱在哪里,这是逃避它的第一步。
莱托·阿特雷德斯公爵,沙丘,弗兰克·赫伯特
现在您知道硬件可以重新排序内存访问,并且可以阻止它这样做,下一步就是让您承认您的直觉有问题。第15.2.1节介绍了这个痛苦的任务,第15.2.1节,该节展示了一些代码,表明标量变量可以同时接受多个值,第15.2.2到15.2.7节展示了一系列直观正确的代码片段,这些代码片段在实际硬件上严重失败。一旦你的直觉通过了悲伤的过程,后面的部分将总结记忆排序所遵循的基本规则。
但是首先,让我们快速看看单个变量在单个时间点上可能有多少个值。
很自然地认为一个变量是按照定义良好的全局顺序接受定义良好的值序列。不幸的是,旅程中的下一站会对这个安慰人的小说说“再见”。希望您已经开始对表15.1和表15.2的第2行说“再见”,如果是这样的话,本节的目的是要强调这一点。
为此,请考虑清单15.3中所示的程序片段。这个代码片段由多个cpu并行执行。第1行为当前CPU的ID设置一个共享变量,第2行初始化gettb()函数中的几个变量,该函数提供一个细粒度硬件“时间基”计数器的值,在所有CPU之间同步(不幸的是,不是所有CPU架构都可用),从第3-8行开始的循环记录了变量保留这个CPU分配给它的值的时间长度。当然,其中一个cpu将“赢”,因此如果没有因为第6-7行的检查,就永远不会退出循环。

在退出循环,firsttb将持有一个时间戳后不久分配和lasttb将持有一个时间戳之前的最后采样共享变量仍然保留分配值,或值等于firsttb如果共享变量已经改变之前进入循环。这使得我们可以在532纳秒的时间段内绘制每个CPU的状态值的视图,如图15.6所示。该数据是在2006年在1.5 GHz POWER5系统上收集的
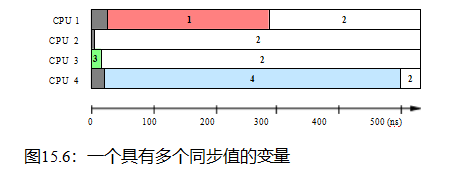
有8个核,每个核包含一对硬件线程。CPu1、2、3、4记录这些值,CPU 0控制测试。时间基计数器周期约为5.32 ns,足够细粒度,允许观察中间缓存状态。
每个水平条表示给定CPU随时间变化的观察结果,左边的灰色区域表示相应CPU第一次测量之前的时间。在前5 ns中,只有CPU 3对该变量的值有一个意见。在接下来的10 ns中,cpu2和3对变量的值存在不一致,但随后同意该值是“2”,这实际上是最终商定的值。然而,CPU 1认为近300 ns的值是“1”,而CPU 4认为近500 ns的值是“4”。

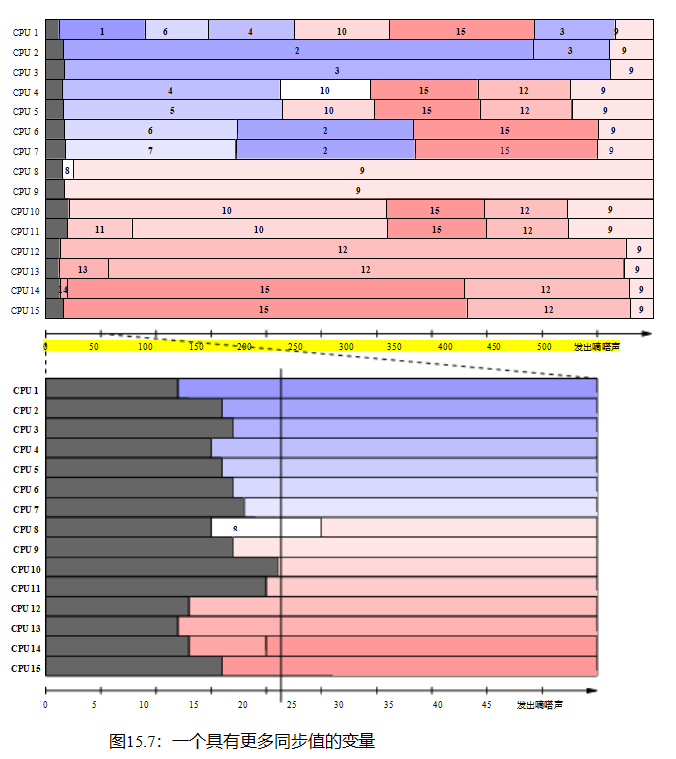
如果您认为有四个cpu的情况很有趣,那么考虑图15.7,它显示了相同的情况,但是在时间t = 0时,每个都有15个cpu将它们的数量分配给单个共享变量。图中的两个图的绘制方式与图15.6相同。唯一的区别是,横轴的单位是时间基蜱,每个蜱持续约5.3纳秒。因此,整个序列比图15.6中记录的事件要长一些,这与cpu数量的增加相一致。上面的图表显示了整体图片,而下面的图表放大了前50个时间基。同样,CPU 0协调测试,因此不记录任何值。
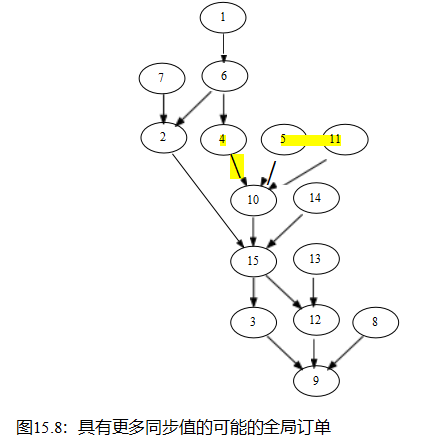
所有cpu最终对最终值9达成一致,但在值15和12提前领先之前。请注意,对于下图中垂直线所示的时间21时变量的值有14种不同的观点。还要注意,所有cpu看到的序列的顺序与图15.8中所示的有向图一致。然而,这些数字强调了正确使用内存排序操作的重要性。
一个变量在单个时间点上可以承担多少个值?在系统中,每个存储缓冲区多达一个!因此,我们进入了一种制度,在那里我们必须告别关于变量值和时间流逝的舒适直觉。这是需要进行内存排序操作的机制。
但是请记住第三章和第六章的经验教训。将所有cpu并发存储到同一个变量是设计并行程序的方法,至少如果性能和可伸缩性对您很重要的话是这样的。
不幸的是,内存排序有许多其他方式可以侮辱你的直觉,而且并不是所有这些方式都与性能和可伸缩性相冲突。下一节将详细介绍对不相关的内存引用的重新排序。
| 1 C C-MP+o-wmb-o+o-o 2 3 {} 4 5 P0(int* x0, int* x1) { 6 WRITE_ONCE(*x0,2); 7 smp_wmb(); 8 WRITE_ONCE(*x1,2); 9 } 10 11 P1(int* x0, int* x1) { 12 int r2; 13 int r3; 14 15 r2 = READ_ONCE(*x1); 16 r3 = READ_ONCE(*x0); 17 } 18 19个已存在(1:r2=2 /\ 1:r3=0) |
第15.1.1节显示,即使是像x86这样相对强排序的系统,也可以在以后的加载中重新排序之前的存储,至少当存储和加载是针对不同的变量时是这样。本节建立在该结果的基础上,我们将查看负载和存储的其他组合。
清单15.4(C-MP+o-wmb-o+o-o.litmus)显示了经典的消息传递试金石,其中x0是消息,x1是指示消息是否可用的标志。在此测试中,smp_wmb()强制订购P0()存储,但没有为负载指定排序。相对强排序的架构,如x86,确实会强制排序。然而,弱有序的体系结构通常不是[AMP+ 11]。因此,清单的第19行上的存在子句可以触发。
| 清单15.5:执行消息传递试金石的顺序 |
| 1 C C-MP+o-wmb-o+o-rmb-o 2 3 {} 4 5 P0(int* x0, int* x1) { 6 WRITE_ONCE(*x0,2); 7 smp_wmb(); 8 WRITE_ONCE(*x1,2); 9 } 10 11 P1(int* x0, int* x1) { 12 int r2; 13 int r3; 14 16 smp_rmb(); 17 r3 = READ_ONCE(*x0); 18 } 19 20已存在(1:r2=2 /\ 1:r3=0) |
| 清单15.6:装载缓冲石试金石(不订购) |
| 1 C C-LB+o-o+o-o 2 3 {} 4 5 P0(int *x0, int *x1) 6 { 7 int r2; 8 9 r2 = READ_ONCE(*x1); 10 WRITE_ONCE(*x0,2); 11 } 12 13 P1(int *x0, int *x1) 14 { 15 int r2; 16 17 r2 = READ_ONCE(*x0); 18 WRITE_ONCE(*x1,2); 19 } 20 |
从不同位置重新排序加载的一个基本原理是,当早期的加载缺少缓存,但后期加载的值已经存在时,这样做允许继续执行。

因此,依赖于有序加载的便携式代码必须添加显式排序,例如,清单15.5(C-MP+o-wmb-o+o-rmb-o.litmus中第16行所示的smp_rmb()),这可以防止存在子句的触发。
15.2.2.2加载之后是存储
清单15.6(C-LB+o-o+o-o.litmus)显示了经典的负载缓冲试金石。尽管相对强排序的系统,如x86或IBM大型机不会与后续存储一起重新排序之前的加载,但许多弱排序的架构确实可以
| 清单15.7:执行负荷缓冲石试试验 |
| 1 C C-LB+o-r+a-o 2 3 {} 4 5 P0(int *x0, int *x1) 6 { 7 int r2; 8 9 r2 = READ_ONCE(*x1); 10 smp_store_release (x0, 2); 11 } 12 13 P1(int *x0, int *x1) 14 { 15 int r2; 16 17 r2 = smp_load_acquire (x0); 18 WRITE_ONCE(*x1,2); 19 } 20 |
| 清单15.8:消息传递试金石,无作者订购(无订购) |
| 1 C C-MP+o-o+o-rmb-o 2 3 {} 4 5 P0(int* x0, int* x1) { 6 WRITE_ONCE(*x0,2); 7 WRITE_ONCE(*x1,2); 8 } 9 10 P1(int* x0, int* x1) { 11 int r2; 12 int r3; 13 14 r2 = READ_ONCE(*x1); 15 smp_rmb(); 16 r3 = READ_ONCE(*x0); 17 } 18 19个已存在(1:r2=2 /\ 1:r3=0) |
允许这样的重新排序[AMP+ 11]。因此,第21行上的存在子句确实可以触发。
虽然实际硬件很少出现这种重新排序[3月17日],但需要这样做的一种情况是,当加载缺少缓存,存储缓冲区几乎已满,后续存储的轴线已经准备就绪。因此,可移植代码必须强制执行任何必需的排序,例如,如清单15.7(C-LB+o-r+a-o.litmus)所示。smp_store_release()和smp_load_acquire()保证第21行上的存在子句永远不会触发。
清单15.8(C-MP+o-o+o-rmb-o.litmus)再次显示了经典的消息传递试金石测试,smp_rmb()提供了对P1(),s加载的订购,但对P0(),s存储没有任何订购。同样,相对强有序的体系结构确实强制排序,但弱有序的体系结构并不一定这样做[AMP+ 11],这意味着存在子句可以触发。这种重新排序可能是有益的一种情况是,当存储缓冲区已满时,另一个存储已准备好执行,但最老的商店所需的粗线还不可用。在这种情况下,
| 清单15.10:消息传递地址相关性试金石测试的强制排序(在v4.15之前) |
| 1 C C-MP+o-wmb-o+ld-addr-o 2 3 { 4 y=1; 5 x1=y; 6 } 7 8 P0(int* x0, int** x1) { 9 WRITE_ONCE(*x0,2); 10 smp_wmb(); 11 WRITE_ONCE(*x1,x0); 12 } 13 14 P1(int** x1) { 15 int *r2; 16 int r3; 17 19 r3 = READ_ONCE(*r2); 20 } 21 22已存在(1:r2=x0 /\ 1:r3=1) |
7请注意,在v4.15及更高版本上不需要无锁的_去引用(),因此在这些以后的Linux内核中不可用。在包含这个脚注的这本书的版本中也不需要它。
| 清单15.12:负载缓冲数据相关的试金石 |
| 1CC-LB+-r+数据-o2 3 {} 4 5 P0(int *x0, int *x1) 6 { 7 int r2; 8 9 r2 = READ_ONCE(*x1); 10 smp_store_release (x0, 2); 11 } 12 13 P1(int *x0, int *x1) 14 { 15 int r2; 16 18 WRITE_ONCE(*x1,r2); 19 } 20 21个已存在(1:r2=2 /\ 0:r2=2) |

然而,需要注意的是,地址依赖关系可能是脆弱的,并且很容易被编译器优化破坏,如第15.3.2节中所讨论的。
当加载指令返回的值用于计算稍后存储指令存储的数据时,就会发生数据依赖关系。请注意上面的“数据”:如果负载返回的值被用来计算以后的存储指令使用的地址,这将是一个地址依赖项,这在第15.2.3节中涉及。然而,数据依赖关系的存在意味着,在单线程代码中用于更新链接数据结构的完全相同的指令序列在并发代码中提供了较弱但非常有用的排序。
清单15.12(C-LB+o-r+o-data-o.litmus)与清单15.7类似,只是P1()在第17行和第18行之间的排序不是通过获取加载强制执行的,而是通过数据依赖关系强制执行的:第17行加载的值是第18行存储的值。此数据依赖项提供的顺序足以防止存在子句的触发。
与地址依赖一样,数据依赖是脆弱的,很容易通过编译器优化破坏,如第15.3.2节中讨论的。事实上,数据依赖可能比地址依赖更加脆弱。其原因是,地址依赖关系通常涉及到指针值。相比之下,如清单15.12所示,很容易通过积分值携带数据依赖关系,编译器有更多的自由将其优化为不存在。只有一个例子,如果加载的整数乘以常数零,编译器就会
| 清单15.13:负载缓冲控制相关的试金石 |
| 1CC-LB+o-r+-ctrl-o2 3 {} 4 5 P0(int *x0, int *x1) 6 { 7 int r2; 8 9 r2 = READ_ONCE(*x1); 10 smp_store_release (x0, 2); 11 } 12 13 P1(int *x0, int *x1) 14 { 15 int r2; 16 19 WRITE_ONCE(*x1,2); 20 } 21 22已存在(1:r2=2 /\ 0:r2=2) |
知道结果是零,因此可以用常数零替换加载的值,从而破坏依赖关系。

简而言之,只有在防止编译器破坏数据时,才能依赖数据依赖关系。
当测试负载指令返回的值以确定是否执行以后的存储指令时,就会发生控制依赖关系。换句话说,一个简单的条件分支或条件移动指令可以作为一个弱但低开销的内存障碍指令。但是,请注意“稍后的存储指令”:尽管所有平台都尊重负载到存储的依赖关系,但许多平台并不尊重负载到负载的控制依赖关系。
清单15.13(C-LB+o-r+o-ctrl-o.litmus)显示了另一个负载缓冲检查,这次使用控制依赖项(第18行)来排序第17行加载和第19行存储。排序足以防止存在的触发。
然而,控制依赖比数据依赖更容易被优化,而第15.3.3describes节是为了防止编译器破坏控制依赖而必须遵循的一些规则。
值得重申的是,控制依赖关系只提供从负载到存储的排序。因此,在Listing15.14(C-MP+o-r+o-ctrl-o.litmus的第14-16行)上显示的负载到控制依赖关系不提供排序,因此不阻止存在子句的触发。
总之,控制依赖项可能是很有用的,但它们是高维护项。
因此,只有在性能考虑因素不允许使用其他解决方案时,您才应该使用它们。
| 清单15.14:消息传递控制相关的试金石(不订购) |
| 1 C C-MP+o-r+o-ctrl-o 2 3 {} 4 5 P0(int* x0, int* x1) { 6 WRITE_ONCE(*x0,2); 7 smp_store_release (x1, 2); 8 } 9 10 P1(int* x0, int* x1) { 11 int r2; 12 int r3 = 0; 13 14 r2 = READ_ONCE(*x1); 15 如果(r2 >= 0) 17 } 18 19个已存在(1:r2=2 /\ 1:r3=0) |

在缓存一致性平台上,所有cpu都对给定变量的负载和存储顺序达成一致。幸运的是,当使用READ_ONCE()和WRITE_ONCE()时,几乎所有的平台都是缓存一致的,如表15.3所示的备忘单中的“SV”列所示。不幸的是,这个属性是如此流行,以至于它已经被多次命名,“单变量SC”,8“单拷贝原子”[SF95],而只是简单的“相干性”[AMP+ 11]已经看到使用。这本书并没有通过为这个概念发明另一个术语来进一步加剧混淆,而是交替使用了“缓存一致性”和“一致性”。
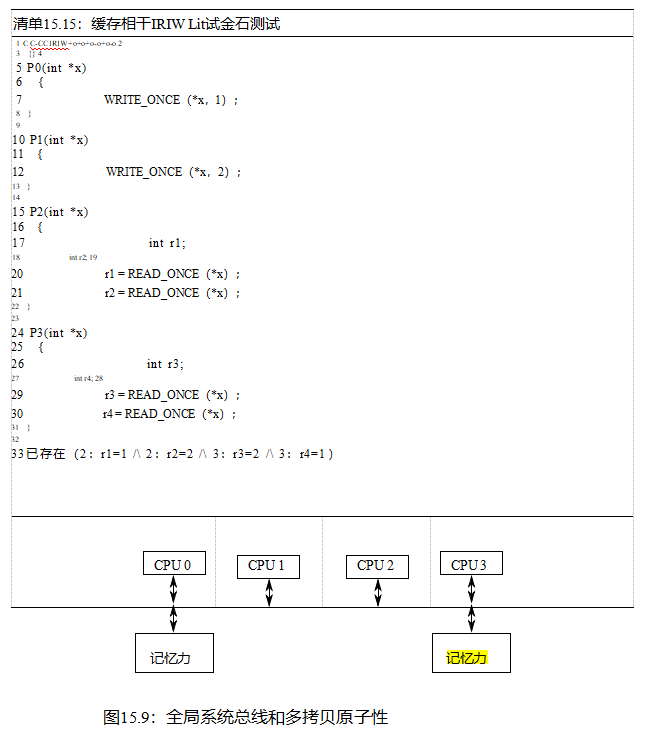
清单15.15(C-CCIRIW+o+o+o-o+o-o.litmus)显示了一个测试缓存一致性的快速测试,其中“IRIW”代表“独立写数的独立读取”。因为这个石试测试只使用一个变量,P2()和P3()必须与P0()9和P1()9存储的顺序一致。换句话说,如果P2()认为P0()9商店是先位的,那么P3()最好不要相信P1()9商店是先位。事实上,如果出现这种情况,第33行上的存在子句就会触发。

我们很容易推测,不同大小的重叠负载和存储到单个内存区域(可能使用c语言联合关键字设置)将提供类似的排序保证。然而,Flur等人[FSP+ 17]发现了一些令人惊讶的简单金石测试,证明在实际硬件上可以违反这种保证。因此,有必要将代码限制在对给定变量的相同大小的对齐访问上,至少在考虑可移植性时是这样。
添加更多的变量和线程会增加重新排序和其他反直觉行为的范围,如下一节所讨论的。
运行在完全多拷贝原子[SF95]平台上的线程保证与存储的顺序一致,即使是对不同的变量。这种系统的一个有用的心理模型是图15.9所示的单总线体系结构。如果每个商店在公交车上都有一条信息,如果公交车一次只能容纳一个商店,那么任何一对cpu都会同意他们观察到的所有商店的顺序。不幸的是,构建一个如图所示的计算机系统,如果没有存储缓冲区,甚至是缓存,将会导致非常缓慢的计算。因此,大多数对提供多拷贝原子性感兴趣的CPU供应商反而提供了稍弱的其他多拷贝原子性[ARM17,第B2.3节],它将执行给定存储的CPU排除在
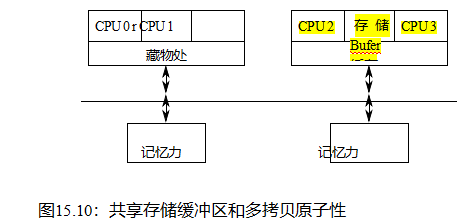
| P0() | P0() & P1() | P1() | P2() | |||||
| 指令 | 存储 | 缓冲区 | 藏物处 | 指令 | 指令 | 存储缓冲区 | 藏物处 | |
|
|
|
y==0 |
|
|
x==0 | |||
| 2 | x = 1; | x==1 | y==0 | x==0 | ||||
|
| (读取无效x) | x==1 | y==0 | r1 = x (1) | x==0 | |||
| 4 | x==1 | y==1 | y==0 | y = r1 | r2 = y | x==0 | ||
|
| x==1 | y==1 | (完成存储) | (准备就绪) | x==0 | |||
| 6 | (响应y) | x==1 | y==1 | (r2==1) | x==0 y==1 | |||
|
| x==1 | y==1 | smp_rmb() | x==0 y==1 | ||||
| 8 | x==1 | y==1 | r3 = x (0) | x==0 y==1 | ||||
|
| x==1 | x==0 y==1 | (响应x) | y==1 | ||||
| 10 | (完成存储) | x==1 y==1 | y==1 | |||||










cpu2和3也一样。这意味着CPU 1可以从存储缓冲区中加载一个值,从而可能立即看到由CPU 0存储的值。相比之下,cpu2和3将不得不等待相应的缓存行将这个新值带给它们。

表15.4显示了可能导致清单15.16中存在子句触发的事件序列。这个事件序列将严重依赖于P0()和P1(),它们以图15.10所示的方式共享缓存和存储缓冲区。

第1行显示初始状态,P0()和P1()共享缓存中初始值y,P2()共享缓存中初始值x。
第2行显示了P0()在第7行执行其存储的即时效果。因为包含x的数据线不在P0()和P1()的共享缓存中,所以新值(1)存储在共享存储缓冲区中。
第3行显示了两个转换。首先,P0()发出一个读取无效操作来获取包含x的粗线轴,以便它可以将x的新值从共享存储缓冲区中冲出。第二,P1()从x加载(第14行)加载,这一操作立即完成,因为x的新值立即从共享存储缓冲区立即可用。
第4行还显示了两个转换。首先,它显示了P1()执行其存储到y(第15行)的即时效果,将新值放到共享存储缓冲区中。第二,它显示了P2()的开始(第23行)。
第五行延续了显示两个过渡的传统。首先,它显示P1()完成其存储到y,从共享存储缓冲区刷新到缓存。其次,它显示P2()请求包含y的轴线。
第6行显示P2()接收包含y的粗线,允许它完成加载到r2,其值为1。
第7行显示P2()执行它的smp_rmb()(第24行),从而保持它的两个加载顺序。
第8行显示P2()从x执行其负载,x立即从P2()的缓存中返回值为0。
第9行显示了P2()最终响应了P0()对包含x的粗毛线的请求,并重新回到了第3行。
最后,第10行显示P0()完成其存储,将其x值从共享存储缓冲区刷新到共享缓存。
请注意,第28行上的存在子句已经触发。r1和r2的值都是值1,r3的最终值都是值0。出现这个奇怪的结果是因为P0()的新值x早在通信到P2()之前就被通信到了P1()。

这种反直觉的结果,因为依赖项提供了排序,但它们只在自己线程的范围内提供排序。这个三线程示例需要更强的排序,这是第15.2.7.1至15.2.7.4节的主题。
清单15.16中所示的三线程示例需要累积排序或累积性。累积内存排序操作不仅命令它之前的任何给定访问,还命令任何线程对同一变量的早期访问。
依赖项不提供累积性,这就是为什么在第492页的表15.3中的READ_ONCE()行的“C”列为空的原因。然而,正如其“C”列中的“C”所示,释放操作确实提供了累积性。因此,清单15.17(C-WRC+o+o-r+a-o.litmus)将发布操作替换为Listing15.16的数据依赖关系。因为释放操作是累积的,它的排序不仅适用于清单15.17从P1()加载第14行,也适用于存储P0()到第7行,但只有当该加载返回存储的值,这与第27行存在子句中的1:r1=1匹配。这意味着P2()的负载获取足以迫使第24行x的负载在第7行存储之后发生,因此返回的值是1,这与2:r3=0不匹配,这反过来阻止了存在子句的触发。
这些排序约束如图15.11所示。还要注意,累积性并不局限于时间上的某一步。如果从第7行存储之前的任何线程从x或存储到x有另一个加载,那么该优先加载或存储也将在第24行加载之前订购,尽管只有当r1和r2最终都包含值1时。
| 清单15.17: WRC试金石与发布 |
| 1 C C-WRC+o+o-r+a-o 2 3 {} 4 5 P0(int *x) 6 { 8 } 9 10 P1(int *x, int* y) 11 { 12 int r1; 13 14 r1 = READ_ONCE(*x); 15 smp_store_release (y, r1); 16 } 17 18 P2(int *x, int* y) 19 { 20 int r2; 21 int r3; 22 24 r3 = READ_ONCE(*x); 25 } 26 |
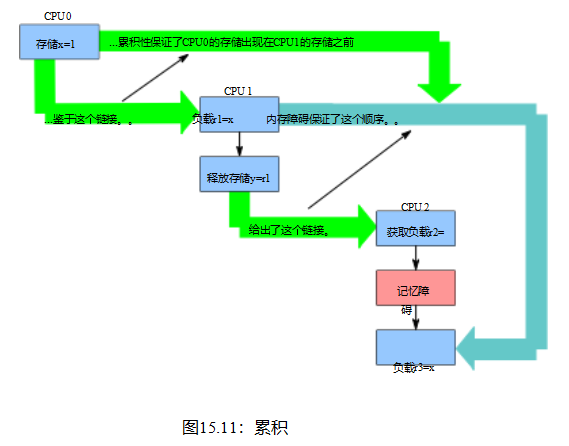
图15.11:累积
| 清单15.18: W+RWC试金石测试与发布(无订购) |
| 1 C C-W+RWC+o-r+a-o+o-mb-o 2 3 {} 4 5 P0(int *x, int *y) 6 { 7 WRITE_ONCE(*x,1); 8 smp_store_release (y, 1); 9 } 10 11 P1(int *y, int *z) 12 { 13 int r1; 14 int r2; 15 17 r2 = READ_ONCE(*z); 18 } 19 20 P2(int *z, int *x) 21 { 22 int r3; 23 24 WRITE_ONCE(*z,1); 26 r3 = READ_ONCE(*x); 27 } 28 |
简而言之,在某些情况下,使用累积排序操作可以抑制非多拷贝原子行为。然而,累积性也有限制,这将在下一节中讨论。
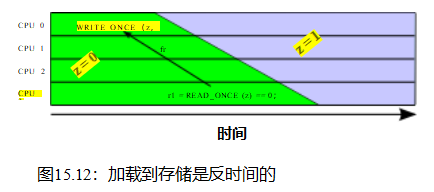
清单15.18(C-W+RWC+o-r+a-o+o-mb-o.litmus)显示了累积量和存储释放的局限性,即使有一个完整的内存障碍。问题是,尽管第8行的smp_store_release()具有累积性,尽管累积性确实排序了第26行的P2()9s加载,但smp_store_release()9s排序不能通过P1()9s加载(第17行)和P2()9s存储(第24行)的组合来传播。这意味着第29行上的存在子句确实可以触发。

这种情况可能看起来完全违反直觉,但请记住,光速是有限的,计算机的大小是非零的。因此,P2()9s存储到z的影响需要时间才能传播到P1(),这又意味着P1()9s从z读取可能发生的时间要晚得多,但仍然可以看到
| 1 C C-W+RWC+o-mb-o+a-o+o-mb-o 2 3 {} 4 5 P0(int *x, int *y) 6 { 7 WRITE_ONCE(*x,1); 8 smp_mb(); 9 WRITE_ONCE(*y,1); 10 } 11 12 P1(int *y, int *z) 13 { 14 int r1; 15 int r2; 16 17 r1 = smp_load_acquire (y); 18 r2 = READ_ONCE(*z); 19 } 20 21 P2(int *z, int *x) 22 { 23 int r3; 24 25 WRITE_ONCE(*z,1); 26 smp_mb(); 27 r3 = READ_ONCE(*x); 28 } 29 30已存在(1:r1=1 /\ 1:r2=0 /\ 2:r3=0) |
旧的值为零。图15.12所示:仅仅因为加载看到了旧值并不意味着这个加载比新值存储的执行时间更早。
请注意,清单15.18还显示了内存障碍配对的限制,因为没有两个进程,而是三个进程。这些更复杂的试金石测试可以说是有循环,其中记忆障碍配对是双线程循环的特殊情况。清单15.18中的循环经过P0()(第7和8行)、P1()(第16和17行)、P2()(第24、25和26行),然后返回P0()(第7行)。存在子句描述了此循环:1:r1=1表示第16行的smp_load_acquire()返回第8行smp_store_release()存储的值,1:r2=0表示第24行的WRITE_ONCE()来得太晚,无法影响第17行READ_ONCE()返回的值,最后2:r3=0表示第7行的WRITE_ONCE()来得太晚,无法影响第26行READ_ONCE()返回的值。在这种情况下,存在子句可以触发的事实意味着循环是允许的。相反,在存在的子句不能触发的情况下,该循环被称为被禁止的。
但是,如果我们需要禁止与清单15.18第29行中的存在子句对应的循环呢?一种解决方案是用smp_mb()替换P0()的smp_store_release(),表15.3显示,smp_mb()不仅具有累积性,而且还具有传播性。其结果如清单15.19(C-W+RWC+o-mb-o+a-o+o-mb-o.litmus)所示。

为了完整性起见,图15.13显示了在相同变量的一组存储之间的“获胜”存储不一定是最后开始的存储。对于任何仔细检查497页图15.7的人来说,这不应该感到惊讶。
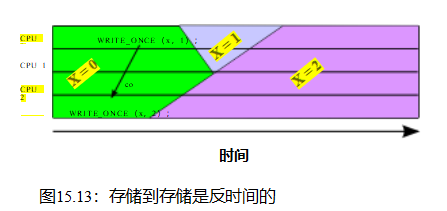
| 清单15.20: 2+2W带写障碍的试金石 |
| 1 C C-2+2W+o-wmb-o+o-wmb-o 2 3 {} 4 5 P0(int *x0, int *x1) 6 { 7 WRITE_ONCE(*x0,1); 8 smp_wmb(); 9 WRITE_ONCE(*x1,2); 10 } 11 12 P1(int *x0, int *x1) 13 { 14 WRITE_ONCE(*x1,1); 15 smp_wmb(); 16 WRITE_ONCE(*x0,2); 17 } 18 |
| 合理化加载到存储和存储对存储排序的一种方法是明确区分存储指令执行的时间顺序,以及相应的恶作剧访问执行这些指令的cpu的顺序。正是快速访问顺序定义了实际商店的外部可见顺序。这个快速访问顺序对执行存储指令的代码不直接可见,这导致了加载到存储和存储到存储排序的反直觉的反时间性质。11 |
| 快速测试15.27:但对于只有订购存储的石蕊测试,如清单15.20(C-2+2W+o-wmb-o+o-wmb-o.litmus)所示,研究表明,即使是在弱有序系统,如Arm和+11][SSA+11]也是如此。鉴于此,商店对商店总是反时的?? |
| 但有时时间真的是站在我们这边的。继续阅读! 如图15.14所示,在平台上没有用户可见的投机,如果一个负载返回的值从一个特定的存储,然后,由于有限的光速和非零的现代计算系统的大小,存储绝对必须在比这更早的时间执行的负载。这意味着精心构建的程序可以依赖于时间的流逝本身作为一个内存排序操作。 |
| 1+-++-+数据-数据-2 3 {} 4 5 P0(int *x0, int *x1) 6 { 7 int r2; 8 9 r2 = smp_load_acquire (x0); 10 WRITE_ONCE(*x1,2); 11 } 12 13 P1(int *x1, int *x2) 14 { 15 int r2; 16 17 r2 = READ_ONCE(*x1); 18 WRITE_ONCE(*x2,r2); 19 } 20 21 P2(int *x2, int *x0) 22 { 23 int r2; 24 25 r2 = READ_ONCE(*x2); 26 WRITE_ONCE(*x0,r2); 27 } 28 29已存在(0:r2=2 /\ 1:r2=2 /\ 2:r2=2) |
当然,仅仅流逝时间本身是不够的,就像在Listing15.6on 499页中看到的那样,它只有存储加载链接,而且因为它绝对没有排序,仍然可以触发它的存在子句。但是,只要每个线程提供最弱的顺序,存在子句就无法触发。例如,清单15.21(C-LB+a-o+o-data-o+o-data-o.litmus)显示了使用smp_load_acquire()排序的P0(),以及使用数据依赖性排序的P1()和P2()。这些顺序接近表15.3的顶部,这就足以防止现有子句的触发。

下一节将介绍对内存访问排序的重要使用。
在Listing15.7on第500页中显示了一个最小的释放-获取链,但是这些链可以要长得多,如清单15.22(C-LB+a-r+a-r+a-r+a-r.litmus)所示。释放-获取链越长,从通道中获得的排序就越多
| 清单15.22:长LB释放-收购链 |
| 1 C C-LB+a-r+a-r+a-r+a-r 2 3 {} 4 5 P0(int *x0, int *x1) 6 { 7 int r2; 8 9 r2 = smp_load_acquire (x0); 10 smp_store_release (x1, 2); 11 } 12 13 P1(int *x1, int *x2) 14 { 15 int r2; 16 17 r2 = smp_load_acquire (x1); 18 smp_store_release (x2, 2); 19 } 20 21 P2(int *x2, int *x3) 22 { 23 int r2; 24 25 r2 = smp_load_acquire (x2); 26 smp_store_release (x3, 2); 27 } 28 29 P3(int *x3, int *x0) 30 { 31 int r2; 32 33 r2 = smp_load_acquire (x3); 34 smp_store_release (x0, 2); 35 } 36 37已存在(0:r2=2 /\ 1:r2=2 /\ 2:r2=2 /\ 3:r2=2) |
因此,无论涉及多少个线程,相应的存在子句都不能触发。
尽管释放-获取链本质上是存储到加载的生物,但事实证明,它们可以容忍一个加载到存储的步骤,尽管这些步骤是反时间的,如图511页的15.12所示。例如,清单15.23(C-ISA2++-r+-r+a-o.litmus)显示了一个三步释放-获取链,但P3()的最终访问是x0的READ_ONCE(),P0()通过WRITE_ONCE()访问,形成这两个进程之间的非时间加载到存储链接。但是,由于P0()的smp_store_release()(第8行)是累积的,如果P3()的READ_ONCE()返回零,这个累积性将迫使READ_ONCE()在P0()的smp_store_发布()之前被排序。此外,释放-获取链(第8、15、16、23、24和32行)迫使P3()的READ_ONCE()在P0()‘s smp_store_release()之后订购。因为P3()的READ_ONCE()不能同时在P0()的smp_store_release()之前和之后,所以两件事中的任何一个或两个都必须是正确的:
1.P3()的READ_ONCE()来自于P0()的WRITE_ONCE()之后,所以READ_
ONCE()返回值2,因此存在子句的3:r2=0为false。
2.释放-获取链没有形成,即存在子句的1:r2=2、2:r2=2或3:r1=2中有一个或多个为false。
| 清单15.23:长ISA2发布-收购链 |
| 1 C C-ISA2+o-r+a-r+a-r+a-o 2 3 {} 4 5 P0(int *x0, int *x1) 6 { 8 smp_store_release (x1, 2); 9 } 10 11 P1(int *x1, int *x2) 12 { 13 int r2; 14 15 r2 = smp_load_acquire (x1); 16 smp_store_release (x2, 2); 17 } 18 19 P2(int *x2, int *x3) 20 { 21 int r2; 22 23 r2 = smp_load_acquire (x2); 24 smp_store_release (x3, 2); 25 } 26 27 P3(int *x3, int *x0) 28 { 29 int r1; 30 int r2; 31 32 r1 = smp_load_acquire (x3); 33 r2 = READ_ONCE(*x0); 34 } 35 36已存在(1:r2=2 /\ 2:r2=2 /\ 3:r1=2 /\ 3:r2=0) |
无论哪种方式,存在子句都不能触发,尽管这个试金石包含了P3()和P0()之间臭名昭著的加载到存储链接。但是永远不要忘记,释放-获取链只能容忍一个加载到商店的链接,如清单15.18所示。
发布-获取链也可以容忍一个单一的店间步骤,如清单15.24(C-Z6.2+o-r+a-r+a-r+a-o.litmus)所示。与前面的例子一样,smp_store_release()的累积性结合了释放-获取链的时间性质,阻止了第35行中存在的子句的触发。

但是请注意:添加第二个存储到存储的链接允许相应更新的存在子句被触发。要了解这一点,请查看清单15.26和15.27,它们具有相同的P0()和P1()进程。唯一的代码区别是,清单15.27有一个额外的P2(),它对P0()发布和P1()获取的x2变量执行一个smp_store_release()。存在子句也被调整,以排除P2()的smp_store_release()先于P0()的执行。
运行清单15.27中的试金石测试表明,添加P2()可以完全破坏来自释放-获取链的排序。因此,在构建释放-获取链时,请注意正确地构建它们。

| 清单15.24:长Z6.2发行-收购链 |
| 1 C C-Z6 .2+o-r+a-r+a-r+a-o 2 3 {} 4 5 P0(int *x0, int *x1) 6 { 7 WRITE_ONCE(*x0,2); 8 smp_store_release (x1, 2); 9 } 10 11 P1(int *x1, int *x2) 12 { 13 int r2; 14 15 r2 = smp_load_acquire (x1); 16 smp_store_release (x2, 2); 17 } 18 19 P2(int *x2, int *x3) 20 { 21 int r2; 22 23 r2 = smp_load_acquire (x2); 24 smp_store_release (x3, 2); 25 } 26 27 P3(int *x3, int *x0) 28 { 29 int r2; 30 31 r2 = smp_load_acquire (x3); 32 WRITE_ONCE(*x0,3); 33 } 34 |
| 1 C C-Z6 .2+o-r+a-o+o-mb-o 2 3 {} 4 5 P0(int *x, int *y) 6 { 7 WRITE_ONCE(*x,1); 8 smp_store_release (y, 1); 9 } 10 11 P1(int *y, int *z) 12 { 13 int r1; 14 15 r1 = smp_load_acquire (y); 16 WRITE_ONCE(*z,1); 17 } 18 19 P2(int *z, int *x) 20 { 21 int r2; 22 23 WRITE_ONCE(*z,2); 24 smp_mb(); 25 r2 = READ_ONCE(*x); 26 } 27 28已存在(1:r1=1 /\ 2:r2=0 /\ z=2) |
| 1 C C-MP+o-r+a-o 2 3 {} 4 5 P0(int* x0, int* x1, int* x2) { 6 int r1; 7 8 WRITE_ONCE(*x0,2); 9 r1 = READ_ONCE(*x1); 10 smp_store_release (x2, 2); 11 } 12 13 P1(int* x0, int* x1, int* x2) { 14 int r2; 15 int r3; 16 17 r2 = smp_load_acquire (x2); 18 WRITE_ONCE(*x1,2); 19 r3 = READ_ONCE(*x0); 20 } 21 22已存在(1:r2=2 /\(1:r3=0 \/ 0:r1=2)) |
| 1 C C-MPO+o-r+a-o+o 2 3 {} 4 5 P0(int* x0, int* x1, int* x2) { 6 int r1; 7 8 WRITE_ONCE(*x0,2); 9 r1 = READ_ONCE(*x1); 10 smp_store_release (x2, 2); 11 } 12 13 P1(int* x0, int* x1, int* x2) { 14 int r2; 15 int r3; 16 17 r2 = smp_load_acquire (x2); 18 WRITE_ONCE(*x1,2); 19 r3 = READ_ONCE(*x0); 20 } 21 22 P2(int* x2) { 23 smp_store_release (x2, 3); 24 } 25 26已存在(1:r2=3 /\ x2=3 /\(1:r3=0 \/ 0:r1=2)) |
简而言之,正确构建的释放-获取链形成了一个和平的直觉幸福岛,被更复杂的记忆排序约束的强烈反直觉海洋所包围。
本节将重新讨论第845页的清单E.12,它在快速测验15.25的回答中提出。这个试金石只有两个线程,P0()的存储由smp_wmb()订购,P1()的访问由smp_mb()订购。尽管这个试金石规模小,顺序重,但在存在条款中显示的反直觉的结果实际上是允许的。
快速测试15.25的答案是,即从P0()到P1()的链接是商店到商店的链接,而从P1()到P0()的链接是商店到商店的链接。这两个链接都是反时间的,因此在这两个过程中都需要完整的记忆障碍。重新访问图15.13和15.14显示,这些反时态链接给了硬件相当大的自由度。
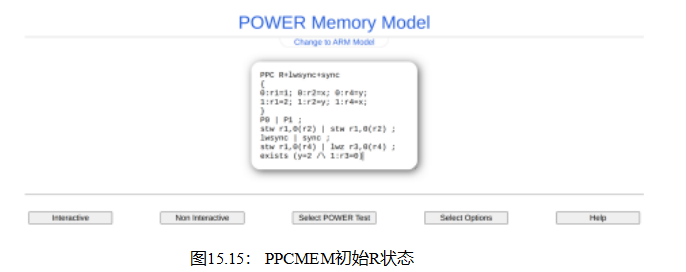
但这就提出了一个问题,即硬件将如何使用这个纬度来满足清单E.12中的存在子句。没有已知的“玩具”硬件实现可以实现这一点,所以让我们来研究PowerPC架构为实现这一点所经历的步骤序列。
本研究的第一步是将清单E.12翻译为PowerPC汇编语言试金石(第403页的第12.2.1节):
| PPC R+lwsync+sync { 0:r1=1; 0:r2=x; 0:r4=y; 1:r1=2; 1:r2=y; 1:r4=x; } stw r1,0(r2) | stw r1,0(r2) ; lwsync |同步 ; |
第一行标识测试的类型(PPC),并给出测试的名称。第3行和第4行分别初始化P0()和P1()的寄存器。第6-9行显示了与清单E.12中的C代码对应的PowerPC汇编语句,第一列是P0()的代码,第二列是P1()的代码。第7行显示了两列中的初始WRITE_ONCE()调用;第8行列分别显示了P0()和P1()的smp_wmb()和smp_mb();第9行列分别显示了P0()的WRITE_ONCE()和P1()的READ_ONCE();最后第10行显示了存在子句。
为了满足这一存在子句,P0()的stw到y必须先于P1()的,而P1()之后的后lwz必须先于P0()的stw到x。要了解这是如何发生的,需要粗略理解以下PowerPC术语。
指令提交:
这可以被认为是该指令的执行,而不是执行该指令的内存系统结果。
写入达到一致性点:
这可以看作是被写入到相应的缓存行中的值。
这可以被认为是系统已经计算出了所写入的一对值将被存入相应的缓存行的顺序,但很可能是在该缓存行到达之前。有些人可能会说,图15.7中的数据表明,真正的PowerPC硬件实际上使用了部分一致性提交来处理单个核心内的多个硬件线程的并发存储。
写入传播到线程:
当第二个硬件线程意识到第一个硬件线程的写入时,就会发生这种情况。写传播到给定线程的时间可能与缓存行移动没有任何关系。例如,如果一对线程共享一个存储缓冲区,它们可能会在涉及缓存行之前就看到彼此的写操作。另一方面,如果一对硬件线程被广泛地分开,那么第一个线程的写值可能在第二个线程知道该写之前就已经存储到相应的缓存行中。
屏障传播到线程:
硬件线程通过相互传播内存障碍指令,使彼此意识到所需要的这些指令。
确认同步:
PowerPC同步指令实现了Linux内核的smp_mb()全障碍。同步指令提供如此强的顺序的一个原因是,每个同步不仅被传播到其他硬件线程,而且这些其他线程还必须承认每个同步。这种双向通信允许硬件线程协同产生所需的强全局排序。
我们现在已经准备好逐步通过满足上述存在子句的PowerPC事件序列。
为了更好地理解这一点,请跟随https://www.cl.cam.ac.uk/ ~pes20/ppcmem/index.html,仔细地将上述汇编语言的试金石复制到窗格中。结果应该如图15.15所示,给出或取空格字符。点击左下角的“互动”按钮,在短暂的延迟后,应该会产生一个如图15.16所示的显示。如果“交互式”按钮拒绝做任何事情,这通常意味着存在语法错误,例如,在复制-粘贴操作过程中可能引入了一个虚假的换行字符。
这个显示器在每个显示线程状态的部分中都有一个可单击的链接,正如每个链接中的“提交”所暗示的那样,这些链接提交每个线程的第一个stw
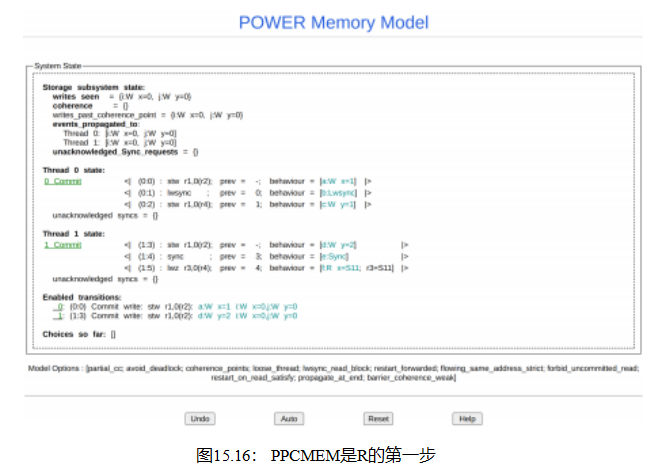
指示如果你愿意,你可以点击屏幕底部附近的“启用转换”下列出的相应链接。请注意,稍后的一些内存-系统转换将出现在此显示的上部“存储子系统状态”部分。
以下单击顺序演示了如何满足现有子句:
1.提交P0()的第一个stw指令(到x)。
2.提交P1()的stw指令。
3.提交P0()的lwsync指令。
4.提交P0()的第二条stw指令(到y)。
5.提交P1()的同步指令。
6.此时,在显示线程状态的两个部分中都应该没有可点击的链接,但应该有不少链接处于“存储子系统状态”。以下步骤告诉您要单击哪一个。
7.部分相干性提交: c:W y=1 ->d:W y=2。这将系统提交到处理P0()的存储到y,即使两个存储都没有达到一致性点或任何其他线程。人们可能会想象,部分一致性提交发生在一个存储缓冲区中,该缓冲区由正在写入同一变量的多个硬件线程共享。
8.将写入传播到线程: d:W y=2传播到线程0。这对于允许P1()的同步指令传播到P0()是必要的。
9.屏障传播到线程:e:同步到线程0。
10.写达到相干点: a:W x=1。
11.写达到相干点: c:W y=1。
12.写达到相干点: d:W y=2。为了让P0()确认P1()9s同步指令,需要这三个操作。
13.确认同步:同步e:同步。
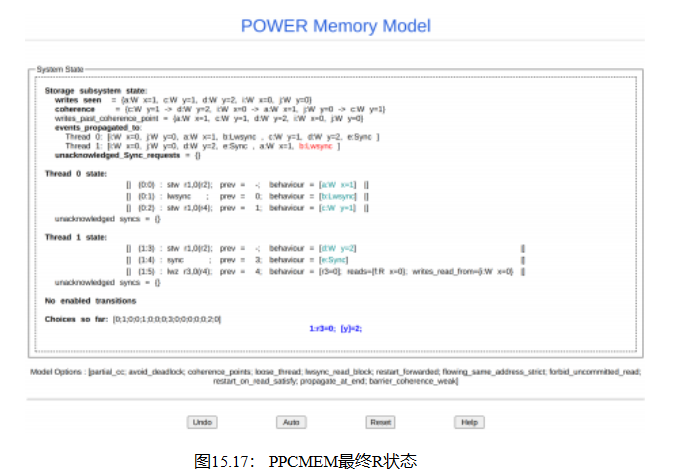
14.在线程P1()9s状态下返回,单击Read i:W x=0,它加载值为零,从而满足存在子句。剩下的只是清理工作,可以按任何顺序进行。
15.提交P1()9s lwz指令。
16.写入传播到线程: a:W x=1到线程1。
17.屏障传播到线程:b:Lwsync传播到线程1。
此时,您应该会看到类似于图15.17的东西。注意,满意的存在子句在底部用蓝色显示,证实了这种反直觉真的可能发生。如果你愿意,你可以点击“撤销”来探索其他选项,或点击“重置”来重新开始。为了更好地理解非多拷贝原子体系结构是如何操作的,以不同的顺序执行这些步骤是非常有用的。
![]()
虽然要想完全理解这种反直觉的结果是如何发生的,就需要超出本书范围的硬件细节,但这个练习应该是
提供一些有用的直觉。或者更准确地说,摧毁了一些适得其反的直觉。
15.3 编译时间的限制
科学既增加了我们的力量,也降低了我们的骄傲。
克劳德伯纳德
大多数语言,包括C语言,都是由很少或没有并行编程经验的人在单处理器系统上开发的。因此,除非明确说明,否则这些语言假设当前CPU是唯一读写内存的东西。这反过来意味着这些语言的“编译器”优化器已经准备好、愿意,并且能够对程序执行的内存引用的顺序、数量和大小进行戏剧性的更改。事实上,相比之下,由硬件进行的重新排序似乎相当平淡。
本节将帮助您驯服编译器,从而避免大量编译时的恐慌。Section15.3.1describes如何防止编译器对代码的内存引用进行破坏性优化,第15.3.2节描述了如何保护地址和数据依赖关系,最后,第15.3.3节描述了如何保护这些微妙的控制依赖关系。
如第4.3.4节所述,除非另有说明,编译器假定没有其他内容影响代码正在访问的变量。此外,这个假设不仅仅是一些设计错误,而是被庄严载入了各种标准中。12在准备以下章节时,值得总结本材料。
普通访问,如在普通访问的c-语言赋值语句中,如“r1=a”或“b=1”,都受到Section4.3.4.1中描述的共享变量骗局的影响。避免这些恶作剧的方法在第4.3.4.2–4.3.4.4节中描述:
1.普通访问可以撕裂,例如,编译器可以选择一次访问一个字节的8字节指针。通过使用READ_ONCE()和WRITE_ONCE(),可以防止撕裂对齐的机器大小的访问。
2.普通负载可以融合,例如,如果来自同一对象的早期加载的结果仍然在机器寄存器中,编译器可能会选择重用该寄存器中的值,而不是从内存重新加载。可以通过使用READ_ONCE()或通过使用屏障()、smp_rmb()和表15.3中所示的其他方法在两个负载之间强制排序来防止负载融合。
3.普通存储可以融合,因此如果有相同变量的后续存储,存储可以完全省略。可以通过使用WRITE_ONCE()或通过使用屏障()、smp_wmb()和表15.3中所示的其他方法在两个商店之间强制排序来防止存储融合。
4.可以通过现代优化编译器以令人惊讶的方式重新排序普通访问。这种重新排序可以通过强制执行上面所调用的排序来防止。
5.可以发明普通负载,例如,寄存器压力可能会导致编译器从其寄存器中丢弃以前加载的值,然后稍后重新加载它。可以通过使用READ_ONCE()或通过在负载和以后使用屏障()使用其值之间强制执行上述要求的顺序来防止发明的负载。
6.商店可以在普通商店之前发明,例如,通过使用存储到位置作为临时存储。这可以通过使用WRITE_ONCE()来预防。
7.存储可以转换为负载检查存储序列,这可以击败控制依赖关系。这可以通过使用smp_load_acquire()来预防。

请注意,所有这些共享内存的骗局都可以通过避免普通访问上的数据竞争来避免,如第4.3.4.4节所述。毕竟,如果没有数据竞争,那么上面提到的每一个编译器优化都是完全安全的。但是对于包含数据竞争的代码,随着编译器优化不断变得越来越激进,这个列表可能会在没有注意的情况下发生变化。
简而言之,使用READ_ONCE()、WRITE_ONCE()、屏障()、易失性和第492页表15.3中调用的其他原语是防止编译器优化并行算法消失的有价值的工具。编译器开始提供其他机制来避免加载和存储撕裂,例如,内存_order_放松原子加载和存储,但是,仍然需要工作[Cor16b]。此外,除了编译器问题之外,仍然需要挥发性来避免融合和发明的访问,包括C11原子访问。
请注意,您可以过度使用READ_ONCE()和WRITE_ONCE()。
例如,如果您阻止了给定变量的更改(可能是通过保持锁来保护该变量的所有更新),那么使用READ_ONCE()就没有意义了。类似地,如果您阻止任何其他CPU或线程读取给定变量(可能是因为您在任何其他CPU或线程访问它之前初始化该变量),那么使用WRITE_ONCE()就没有意义了。然而,根据我的经验,开发人员需要使用READ_ONCE()和WRITE_ONCE()比他们认为的更频繁,而且不必要的使用开销相当低。相比之下,在需要时不使用它们的惩罚可能相当高。
第15.2.3节和15.2.4节分别讨论的地址和数据依赖关系的低开销,使得它们的使用非常具吸引力。不幸的是,编译器既不理解地址,也不理解数据依赖关系,尽管人们正在努力教授它们,或者至少,标准化它们的教学过程[MWB+ 17,MRP+ 17]。与此同时,必须非常小心,以防止编译器破坏依赖关系。
| 清单15.28:与比较的可中断的依赖关系 |
| 1因特reserve_int; |
| 2 int *gp; |
| 3 int *p; |
| 4 |
| 5 p = rcu_dereference(gp); |
| 7 处理储备金(p); |
| 8做些事!*/ |
| 清单15.29:与比较的依赖关系 |
| 1因特reserve_int; 2 int *gp; 3 int *p; 4 6如果(p == &reserve_int){ 7 处理_preft(&reserve_int); 9}其他{ 10 一起做些什么,好的!*/ 11 } |
15.3.2.1给你的依赖链一个好的开始
引导依赖链的负载必须使用正确的顺序,例如rcu_dereference()或READ_ONCE()。不遵守此规则可能会产生严重的副作用:
1.在DEC Alpha上,依赖负荷,如第15.5.1节所述。
2.如果依赖链的加载标题是C11非易失性内存_order_放松加载,编译器可以省略加载,例如,通过使用它过去加载的值。
3.如果依赖链的负载标题是普通负载,编译器可以省略负载,同样是使用过去加载的值。更糟糕的是,它可以加载两次而不是一次,因此代码的不同部分使用不同的值——编译器确实可以这样做,特别是在寄存器压力下。
4.由依赖链的头加载的值必须是一个指针。理论上,是的,您可以加载一个整数,也许是为了将它用作数组索引。在实践中,编译器对整数了解太多了,因此有太多的机会来打破你的依赖链[MWB+ 17]。
15.3.2.2避免了算术依赖关系的破坏
虽然对依赖链中的指针进行一些算术运算只是很好的,但您需要小心地避免给编译器提供太多的信息。毕竟,如果编译器学会了足够的知识来确定指针的精确值,那么它就可以使用这个精确的值,而不是指针本身。一旦编译器这样做,依赖关系就会被破坏,所有的顺序也会丢失。
1.虽然允许从指针中计算偏移量,但这些偏移量不能导致完全抵消。例如,给定一个字符指针cp,cp-(uintptr_ t)cp将取消,并可以允许编译器破坏您的依赖链。
另一方面,相互取消偏移值是完全安全和合法的。例如,如果a和b相等,cp+a-b是一个恒等函数,包括保留依赖关系。
2.比较可以打破依赖关系。清单15.28显示了这是如何发生的。
这里全局指针gp指向动态分配的整数,但如果内存低,它可能指向reserve_int变量。这个reserve_int案例可能需要特殊处理,如清单的第6行和第7行所示。但是编译器可以合理地将这段代码转换为Listing15.29中所示的形式,特别是在那些具有绝对地址的指令比使用寄存器中提供的地址的指令运行得更快的系统上。然而,在第5行的指针加载和第8行的解引用之间显然没有顺序。请注意,这只是一个例子:有很多其他的方法可以通过比较来打破依赖链。
请注意,当将一系列的不等式比较放在一起时,可能会为编译器提供足够的信息来确定指针的确切值,此时依赖关系将被破坏。此外,编译器可能能够将来自单一不等式比较的信息与其他信息结合起来,以学习确切的值,再次打破依赖关系。指向数组中元素的指针特别容易受到后一种依赖关系破坏的影响。
15.3.2.3依赖指针的安全比较
事实证明,有几种安全的方法来比较依赖的指针:
1.与NULL指针的比较。在这种情况下,编译器只能了解到指针是NULL,在这种情况下,无论如何都不允许对它的引用。
2.无论是在比较之前还是之后,依赖点从未被解引用。
3.将依赖指针与引用很久以前最后修改的对象的指针进行比较,其中“很久以前”的唯一无条件安全值是“在编译时”。关键是,除了地址或数据依赖关系之外,其他东西保证了排序。
4.两个指针之间的比较,每个指针都带有适当的依赖性。例如,您有一对指针,每个指针都包含一个依赖关系,每个指针都包含一个锁,并且您希望通过按地址顺序获取锁来避免死锁。
5.比较是不相等的,并且编译器没有足够的其他信息来推断携带依赖关系的指针的值。
| 清单15.30:破坏了具有指针比较的依赖关系 |
| 1结构foo { 2 int a; 3 int b; 5 }; 7结构为foo *gp2;8 9空白更新程序(空白) 10 { 11 结构foo *p;12 14 BUG_ON (!p); 15 p->a = 42; 17 p->c = 44; 19 WRITE_ONCE(p->b,143); 21 rcu_assign_pointer(gp2,p); 22 } 23 25 { 26 结构foo *p; 27 结构foo *q; 28 int r1, r2 = 0; 29 30 p = rcu_dereference(gp2); 32 返回 34 q = rcu_dereference(gp1); 35 如果(p == q){ 37 } 39 } |
指针比较可能相当棘手,因此非常值得浏览清单15.30中所示的示例。这个示例使用了在第1-5行上显示的简单结构foo,以及两个全局指针,gp1和gp2,分别显示在第6行和第7行上。这个示例使用了两个线程,即第9-22行的更新器()和第24-39行的读取器()。
更新程序()线程在第13行分配内存,如果没有可用的内存,则在第14行痛苦地抱怨。第15-17行初始化新分配的结构,然后第18行将指针分配给gp1。第19行和第20行然后更新结构的两个字段,并在第18行使这些字段对读者可见之后这样做。请注意,读取器可见字段的不同步更新经常构成一个错误。尽管有合法的用例只是这样做,但这样的用例需要比本例中执行的更小心。
最后,第21行将指针分配给gp2。
读取器()线程首先在第30行获取gp2,用第31行和第32行检查是否为空,如果是空则返回。第33行获取字段->b,第34行获取gp1。如果第35行看到在第30行和第34行上获取的指针相等,则第36行获取p->c。注意,第36行使用在第30行读取的指针p,而不是在第34行读取的指针q。
但这种差异可能并不重要。在第35行上进行相同的比较可能会导致编译器(错误地)得出结论,认为两个指针是等价的,而实际上它们携带不同的依赖关系。这意味着编译器很可能会进行转换
将第36行改为r2 = READ_ONCE(q->c),这很可能导致加载值44,而不是期望值144。

简而言之,需要非常小心地确保源代码中的依赖链在编译器生成的汇编代码中仍然是依赖链。
第15.2.5节中描述的控制依赖关系由于其开销较低而具有吸引力,但也特别棘手,因为当前的编译器不理解它们,并且很容易破坏它们。本节中的规则和示例旨在帮助您防止编译器的无知破坏您的代码。
负载-负载控制依赖关系需要一个完整的读取内存障碍,而不仅仅是一个数据依赖关系障碍。考虑以下代码:
| 问= READ_ONCE (x);如果(q) { <数据依赖性障碍>q=READ_ONCE(y); } |
这不会产生预期的效果,因为没有实际的数据依赖,而是一个控制依赖,CPU可能通过尝试提前预测结果而短路,这样其他CPU看到y的负载发生在x的负载之前。在这种情况下,实际需要的是:
| 问= READ_ONCE (x);如果(q) { <read barrier> q = READ_ONCE (y);} |
然而,商店并没有被猜测。这意味着为负载存储控件依赖项提供了排序,如下示例所示:
| q = READ_ONCE (x); 如果(q) WRITE_ONCE(y,1); |
控制依赖关系通常与其他类型的排序操作配对。也就是说,请注意,READ_ONCE()和WRITE_ONCE()都不是可选的!如果没有READ_ONCE(),编译器可能会将来自x的负载与来自x的其他负载融合。如果没有WRITE_ONCE(),编译器可能会将存储与y与其他存储与y融合,或者,更糟糕的是,读取值,比较它,并且只有条件地执行存储。其中任何一种都可能对排序产生高度反直觉的影响。
更糟糕的是,如果编译器能够证明(比如说)变量x的值总是非零的,那么它就有权通过消除以下“if”语句来优化原始示例:
| q = READ_ONCE (x); WRITE_ONCE(y,1);/* BUG: CPU可以重新订购!!!*/ |

在“if”语句的两个分支上对相同的商店强制订购是很诱人的:
| q = READ_ONCE (x); 如果(q) { 屏障 WRITE_ONCE(y,1);做一些事情,(); }其他{ 屏障 WRITE_ONCE(y,1); do_sote_else(); } |
不幸的是,当前的编译器将在高优化级别上转换如下:
| q = READ_ONCE (x); 屏障 WRITE_ONCE(y,1);/* BUG:未订购!!!*/如果(q) { 做什么();}其他{ 做_oth_else();} |
现在,从x和存储到y的加载之间没有条件,这意味着CPU有其重新排序它们的权限:条件是绝对必需的,即使在应用了所有编译器优化之后,也必须出现在汇编代码中。因此,如果在本例中需要排序,则需要显式的内存排序操作,例如,发布存储:
| 问= READ_ONCE (x);如果(q) { smp_store_release(&y,1);做一些事情,(); }其他{ smp_store_release(&y,1);做一些事,(); } |
仍然需要初始的READ_ONCE(),以防止编译器猜测x的值。此外,您需要小心如何处理局部变量q,否则编译器可能能够猜测它的值,并再次删除所需的条件。例如:
| 问= READ_ONCE (x);如果(q % MAX){ WRITE_ONCE(y,1); 做什么();}其他{ WRITE_ONCE(y,2); 做_oth_else();} |
如果MAX被定义为1,那么编译器知道(q%MAX)等于零,在这种情况下,编译器有权将上述代码转换为以下内容:

给定这个转换,CPU不需要尊重从变量x和存储到变量y的负载之间的排序。添加一个障碍()来限制编译器是很诱人的,但这并没有帮助。条件消失了,障碍()不会把它带回来。因此,如果您依赖于此排序,您应该确保MAX大于1,可能如下:
| q = READ_ONCE (x); BUILD_BUG_ON(MAX <= 1);如果(q % MAX){ WRITE_ONCE(y,1); 做什么();}其他{ WRITE_ONCE(y,2); 做_oth_else();} |
请再次注意,y的商店有所不同。如果它们是相同的,如前面所述,编译器可以将此存储拉到“if”语句之外。
您还必须避免过度依赖布尔短路计算。考虑此示例:
| q = READ_ONCE (x); if (q || 1 > 0) WRITE_ONCE(y,1); |
因为第一个条件不能出错,而第二个条件总是为真的,所以编译器可以将这个示例转换为如下,从而击败了控制依赖关系:
| q = READ_ONCE (x);WRITE_ONCE(y,1); |
这个示例强调了需要确保编译器不能超出猜测您的代码。永远不要忘记,尽管READ_ONCE()确实强制编译器实际发出给定负载的代码,但它不会强制编译器使用已加载的值。
此外,控制依赖项仅适用于所讨论的if语句的然后子句和else子句。特别是,它并不一定适用于if-语句后面的代码:

人们很容易认为这实际上是排序的,因为编译器不能重新排序挥发性访问,也不能用条件对y的写入重新排序。不幸的是,对于这种推理,编译器可能会将这两个写操作编译为条件移动指令,就像在这种奇特的伪汇编语言中一样:
| 清单15.31:具有控制相关的LB试金石 |
| 1 C C-LB+o-cgt-o+o-cgt-o 2 3 {} 4 5 P0(int *x, int *y) 6 { 7 int r1; 8 9 r1 = READ_ONCE(*x); 10 如果(r1 > 0) 11 WRITE_ONCE(*y,1); 12 } 13 14 P1(int *x, int *y) 15 { 16 int r2; 17 18 r2 = READ_ONCE(*y); 19 如果(r2 > 0) 20 WRITE_ONCE(*x,1); 21 } 22 23已存在(0:r1=1 /\ 1:r2=1) |
| ld r1,x cmp r1,$0 cmov, ne r4,$1 cmov, eq r4,$2 st r4,y st $1,z |
一个弱排序的CPU在从x和存储到z的负载之间没有任何类型的依赖性。控制依赖项将只扩展到一对cmov指令和依赖于它们的存储区。简而言之,控制依赖项只适用于“if”的“then”和“else”中的存储(包括这两个子句调用的函数),而不一定适用于“if”之后的代码。
最后,控制依赖关系不提供累积性。这可以通过两个相关的石蕊蕊试验来证明,即清单15.31和15.32,x和y的初始值都为零。
清单15.31(C-LB+-cgt-o+-cgt-o.litmus)的双线程示例中的存在子句将永远不会触发。如果控件依赖保证了累积性(它们不保证),那么在清单15.32(C-WWC+-cgt-o+o-cgt-o+o.litmus)中向示例添加一个线程将保证相关的存在子句永远不会触发。
但是由于控制依赖不提供累积性,三线程试金石中的存在子句可以触发。如果您需要三线程示例来提供排序,那么您将需要在P0()中的加载和存储之间进行smp_mb(),也就是说,就在“if”语句之前或之后。此外,原来的双线程示例非常脆弱,应该避免使用。
![]()
以下规则列表总结了本节的经验教训:
1.编译器不理解控制依赖关系,所以您的工作是确保
编译器不能破坏您的代码。
| 1 C C-WWC+o-cgt-o+o-cgt-o+o 2 3 {} 4 5 P0(int *x, int *y) 6 { 7 int r1; 8 9 r1 = READ_ONCE(*x); 10 如果(r1 > 0) 11 WRITE_ONCE(*y,1); 12 } 13 14 P1(int *x, int *y) 15 { 16 int r2; 17 18 r2 = READ_ONCE(*y); 19 如果(r2 > 0) 20 WRITE_ONCE(*x,1); 21 } 22 23 P2(int *x) 24 { 25 WRITE_ONCE(*x,2); 26 } 27 28已存在(0:r1=2 /\ 1:r2=1 /\ x=2) |
2.控制依赖项可以根据以后的存储来排序预先加载。但是,它们不保证任何其他类型的订购:不保证对后期加载的优先加载,也不保证对后期加载的优先存储。如果您需要这些其他形式的订购,请使用smp_rmb()、smp_wmb(),或者,在以前的存储和以后的加载情况下,使用smp_mb()。
3.如果“if”语句的两个腿都以相同变量的相同存储开始,那么控件依赖项将不会对这些存储进行排序,如果需要排序,则在它们之前使用smp_mb()或使用smp_store_release()。请注意,在“if”语句的每一段的开头使用障碍()是不够的,因为如上面的例子所示,优化编译器可以在尊重障碍()定律的同时破坏控制依赖关系。
4.控制依赖关系要求在之前的加载和后续存储之间至少有一个运行时条件,而此条件必须涉及之前的加载。如果编译器能够优化条件删除,它也将优化删除排序。仔细使用READ_ONCE()和WRITE_ONCE()可以帮助保存所需的条件。
5.控制依赖关系要求编译器避免将依赖关系重新排序为不存在。仔细使用READ_ONCE()、brorom_read()或atomic64_ read()可以帮助保留您的控件依赖关系。
6.控件依赖项只适用于包含控件依赖项的“if”中的“then”和“else”,包括这两个子句调用的任何函数。控件依赖项不适用于包含控件依赖项的“if”语句结束后的代码。
7.控制依赖关系通常与其他类型的内存排序操作配对。
8.控制依赖关系不提供累积性。如果你需要累积量,请使用
一些提供它的东西,比如smp_store_release()或smp_mb()。
同样,许多流行语言的设计都考虑到了单线程的使用。
成功的多线程使用这些语言需要您特别注意内存引用和依赖关系。
15.4 高级原语
方法会教你赢得时间。
约翰沃尔夫冈冯歌德
第12.3.1节中的一个快速小测验的答案表明,由于验证了在更高的抽象级别上建模的程序,因此实现了指数级增长。本节将探讨更高级的抽象如何提供对同步原语本身更深入的理解。15.4.1takes节是内存分配,15.4.2examines节是锁定的不同语义,15.4.3digs节更深入地了解RCU。
第6.4.3.2节涉及到内存分配,本节扩展了相关的内存排序问题。
关键的要求是,在释放该块之前在给定内存块上执行的任何访问必须在重新分配该块后执行的任何访问之前被命令。毕竟,如果一个免费之前的商店在另一个商店之后重新订购,这将是一个残酷和不寻常的内存分配错误!但是,要求开发人员使用READ_ONCE()和WRITE_ONCE()来访问动态分配的内存也是残酷和不寻常的。因此,尽管在第4.3.4.1节中提到了所有共享变量的诡计,但仍必须为普通的访问提供完整的订购。
当然,每个CPU看到自己的访问顺序,编译器总是完全考虑到CPU内部的恶作剧,偶尔会出现编译器错误。这些事实使得memblock_alloc()和memblock_自由()中的无锁快速路径可能,分别用Listings6.10和6.11显示。然而,这也是为什么开发人员在发布一个指向新分配的内存块的指针时,负责提供适当的顺序(例如,通过使用smp_store_release())。毕竟,在cpu-本地的情况下,分配器不一定提供任何跨cpu排序。
这意味着分配器在重新平衡其每个线程池时必须提供排序。这个顺序是由从memblock_alloc()和memblock_free()调用spin_lock()和spin_ulocok()提供的。对于任何从一个线程迁移到另一个线程的块,旧线程在将块放置在全局池之后执行spin_ unlock(&globalmem.mutex),而新线程在将块移动到每个线程池之前执行spin_lock(&globalmem.mutex)。这个spin_olocko()和spin_lock()确保新旧线程看到旧线程的访问发生在新线程的访问之前。

因此,传统使用的内存分配所需的排序可以仅通过非快速路径锁定来提供,从而允许快速路径保持无同步性。
锁定是一个众所周知的同步原语,并行编程社区已经有了几十年的经验。因此,锁定的语义非常简单。
也就是说,它们非常简单,直到你开始尝试对它们进行数学建模。
简单的部分是,任何持有给定锁的CPU或线程都可以保证看到CPU或线程在之前持有相同的锁时执行的任何访问。类似地,任何持有给定锁的CPU或线程都保证在随后持有同一锁时不会看到由其他CPU或线程将执行的访问。那还有什么呢?
事实证明,很多人:
1.是否允许cpu、线程或编译器将内存访问拉到给定的基于锁的关键部分?
2.持有给定锁的CPU或线程是否也能保证在CPU和线程最后一次获得同一锁之前看到它们执行的访问,反之亦然?
3.假设一个给定的CPU或线程执行一个访问(称之为“a”),释放一个锁,重新获得那个相同的锁,然后执行另一个访问(称之为“B”)。是否其他CPU或线程没有保证看到A和B?
4.如上所述,但是由其他CPU或线程执行?
5.如上所述,但是当锁的重新获取是其他的锁了吗?
6.spin_is_lock()提供了什么排序保证?
对这些问题甚至所有问题的反应可能是“为什么有人会这么做?”然而,任何完整的锁定数学定义都必须有解决所有这些问题的答案。因此,下面的部分将在Linux内核的上下文中解决这些问题。
15.4.2.1是否进入关键部分?
内存访问是否可以被重新排序为基于锁的关键部分?
在linux-内核内存模型的上下文中,简单的答案是“是的”。
这可以通过运行清单15.33和15.34(分别锁定.石蕊和锁定.石蕊)所示的石蕊试验来验证,两者都会产生有时的结果。这个结果表明,可以满足存在子句,即P0()和P1()的r1变量的最终值都可以为零。这意味着spin_lock()和spin_解锁()都不需要作为一个完整的内存屏障。
| 1C锁定前进入2 3 {} 4 5 P0(int *x, int *y, spinlock_t *sp) 6 { 7 int r1; 8 9 WRITE_ONCE(*x,1); 10 自旋锁(sp); 11 r1 = READ_ONCE(*y); 12 spin_解锁(sp); 13 } 14 15 P1(int *x, int *y) 16 { 17 int r1; 18 19 WRITE_ONCE(*y,1); 20 smp_mb(); 21 r1 = READ_ONCE(*x); 22 } 23 24个已存在(0:r1=0 /\ 1:r1=0) |
| 1C锁定后进入2 3 {} 4 5 P0(int *x, int *y, spinlock_t *sp) 6 { 7 int r1; 8 9 自旋锁(sp); 10 WRITE_ONCE(*x,1); 11 spin_解锁(sp); 12 r1 = READ_ONCE(*y); 13 } 14 15 P1(int *x, int *y) 16 { 17 int r1; 18 19 WRITE_ONCE(*y,1); 20 smp_mb(); 21 r1 = READ_ONCE(*x); 22 } 23 24个已存在(0:r1=0 /\ 1:r1=0) |
然而,其他环境可能会做出其他选择。例如,仅在x86 CPU系列上运行的锁定实现将具有锁定获取原语,它们对任何之前和任何后续访问的锁获取进行完全排序。因此,在这样的系统上,清单15.33中所示的订购都是免费的。有x86个锁发布实现是弱顺序的,因此无法提供清单15.34中所示的顺序,但是实现仍然可以选择保证这种顺序。
对于弱有序系统来说,它们很可能会选择执行保证两种排序所需的内存屏障指令,这可能简化了对锁定和无锁访问组合的高级使用的代码。但是,如前所述,LKMMM选择不提供这些额外的订单,部分原因是为了避免对更简单和更普遍的锁定用例施加性能惩罚。相反
,smp_mb__after_spinlock()和smp_mb__after_unlock_lock()原语提供于15.5节中讨论的更复杂的用例,如15.5节所述。
到目前为止,本节只讨论了硬件的重新排序。编译器是否也可以将内存引用重新排序为基于锁的关键部分?
在Linux内核中,这个问题的答案是一个响亮的“不!”
硬件重新排序优于编译器优化的原因无法解释的一个原因是,硬件将避免重新排序对基于锁的关键部分的页面错误访问。相比之下,编译器对页面故障没有任何线索,因此它会很高兴地将页面故障重新排序为一个关键部分,这可能会使内核崩溃。编译器也无法可靠地确定哪些访问将导致缓存丢失,因此编译器重新排序到关键部分也可能导致过度的锁争用。因此,Linux内核禁止编译器(而不是CPU)将访问移动到基于锁的关键部分。
关键部分以外的15.4.2.2访问?
如果一个给定的CPU或线程持有一个给定的锁,它可以保证看到在同一锁的所有之前的关键部分中执行的访问。类似地,这样的CPU或线程保证不会看到将在同一锁的所有后续关键部分中执行的访问。
但是在之前的关键部分和随后的关键部分之后的访问如何呢?
对于Linux内核,可以参考Linux内核的清单15.35(C-Lock-outside-across.litmus)来回答这个问题。运行这个试金石测试会产生永不结果,这意味着导致之前的关键部分的代码访问对持有相同锁的当前CPU或线程也是可见的。类似地,放置在后续关键部分之后的代码对于当前持有相同锁的CPU或线程是不可见的。
因此,Linux内核不能允许在整个给定的关键部分上移动访问。其他环境很可能也希望允许这样的代码运动,但请注意,这样做很可能会产生严重违反直觉的结果。
简而言之,由spin_lock()提供的顺序不仅扩展到整个临界部分,而且还无限期地超过了该临界部分的末尾。类似地,spin_ulooke()提供的顺序不仅扩展了整个临界部分,而且无限期地超出了临界部分的开始。
| 清单15.35:关键部分以外的访问 | ||
| 1 | C跨外部锁定 | |
| 2 | ||
| 3 4 | {} | |
| 5 | P0(int *x, int *y, spinlock_t | *sp) |
| 6 | { | |
| 7 8 | int r1; | |
| 9 | WRITE_ONCE(*x,1); | |
| 10 | 自旋锁(sp); | |
| 11 | r1 = READ_ONCE(*y); | |
| 12 | spin_解锁(sp); | |
| 13 14 | } | |
| 15 | P1(int *x, int *y, spinlock_t | *sp) |
| 16 | { | |
| 17 18 | int r1; | |
| 19 | 自旋锁(sp); | |
| 20 | WRITE_ONCE(*y,1); | |
| 21 | spin_解锁(sp); | |
| 22 | r1 = READ_ONCE(*x); | |
| 23 24 | } | |
| 25 | 存在(0:r1=0 /\ 1:r1=0) | |
15.4.2.3订购非锁的支架?
一个没有持有给定锁的CPU或线程是否看到该锁的关键部分已被命令?
对于Linux内核,这个问题可以通过参考清单15.36(C-Lock-across-unlock-lock-1.litmus)来回答,其中显示了一个示例,其中P (0)将它的写和读取放在同一锁的两个不同的关键部分中。运行这个试金石表明,可以满足存在,这意味着答案是“不”,并且cpu可以跨连续的临界部分重新排序访问。换句话说,当单独考虑时,不仅自旋锁()和自旋解锁()更弱,当它们加在一起时,它们也比一个全屏障弱。
如果要观察到给定锁的临界部分的顺序,那么观察者必须一方面保持该锁,或者必须在第二次锁定获取后立即执行smp_mb__after_spinlock()或smp_mb__after_unlock_lock()。
但是,如果这两个临界部分在不同的cpu或线程上运行呢?
Linux内核引用Listing15.37(C-Lock- across-unlock-lock-2.litmus),其中第一次锁获取由P0()执行,第二次锁获取由P1()执行。请注意,P1()必须读取x才能拒绝在P0()执行之前由P1()执行的执行。运行这个试金石表明,可以满足存在,这意味着答案是“不”,CPU可以跨连续的关键部分重新排序访问,即使每个关键部分运行在不同的CPU或线程上。

如前面一样,如果要观察到给定锁的临界部分的顺序,那么观察者必须持有该锁,或者必须在P1()的锁获取之后立即执行smp_mb__after_spinlock()或smp_mb__after_unlock_lock()。
| 1C解锁锁1 | ||
| 2 | ||
| 3 {} 4 | ||
| 5 P0(int 6 { | *x, int *y, spinlock_t | *sp) |
| 7 8 | int r1; | |
| 9 | 自旋锁(sp); | |
| 10 11 12 | WRITE_ONCE(*x、1)、spin_解锁(sp)、spin_lock(sp); | |
| 13 14 15 } 16 | r1 = READ_ONCE(*y);spin_ulook(sp); | |
| 17 P1(int 18 { | *x, int *y, spinlock_t | *sp) |
| 19 20 | int r1; | |
| 21 22 | WRITE_ONCE(*y,1);smp_mb(); | |
| 23 24 } 25 | r1 = READ_ONCE(*x); | |
| 26存在 | (0:r1=0 /\ 1:r1=0) | |
| 1C解锁锁2 2 3 {} 4 5 P0(int *x, spinlock_t *sp) 6 { 7 自旋锁(sp); 8 WRITE_ONCE(*x,1); 9 spin_解锁(sp); 10 } 11 12 P1(int *x, int *y, spinlock_t *sp) 13 { 14 int r1; 15 int r2; 16 17 自旋锁(sp); 18 r1 = READ_ONCE(*x); 19 r2 = READ_ONCE(*y); 20 spin_解锁(sp); 21 } 22 23 P2(int *x, int *y, spinlock_t *sp) 24 { 25 int r1; 26 27 WRITE_ONCE(*y,1); 28 smp_mb(); 29 r1 = READ_ONCE(*x); 30 } 31 32已存在(1:r1=1 /\ 1:r2=0 /\ 2:r1=0) |
如果当两个关键部分都被同一锁保护时,就不能保证排序,那么当使用不同的锁时,就不希望有任何排序保证了。然而,我们鼓励读者构建相应的试金石,并自己看看。
这种情况似乎违反直觉,但代码很少需要关心。这种方法还允许某些弱有序系统更有效地实现锁。
15.4.2.4订购为spin_is_锁定的()?
如果保留指定的锁,Linux内核的自pin_锁定()原语返回true,否则返回false。注意,当其他CPU或线程持有该锁时,spin_is_lock()返回true,而不仅仅是当当前CPU或线程持有该锁时。这就提出了一个问题,即()可能提供什么对spin_is_锁定的排序保证。
在Linux内核中,答案会随着时间的推移而变化。最初,spin_is_锁定的()是无序的,但一些有趣的用例激发了强排序。后来围绕linux内核内存模型的讨论得出结论,spin_is_锁定的()应该只用于调试。部分原因是,即使是一个完全有序的spin_is_锁定的()也可能返回true,因为其他一些CPU或线程即将释放有问题的锁。在这种情况下,可以从true的返回值中学到的东西很少,这意味着spin_is_锁定()的可靠使用非常复杂。其他方法几乎总是工作得更好,例如,使用显式共享变量或spin_trylock()原语。
这种情况导致了当前状态,即spin_is_lock()没有提供排序保证,除了如果它返回false,当前的CPU或线程不能保持相应的锁。

15.4.2.5为什么是数学模型锁定?
考虑到所有这些可能的选择,为什么模型一般会被锁定呢?为什么不简单地建模一个简单的实现呢?
原因之一是建模性能,如第825页上的表E.5所示。直接建模锁定通常比模拟甚至是一个简单的实现都要快几个数量级。这并不奇怪,考虑到现在的正式验证工具所经历的组合爆炸,即由被建模的代码所执行的内存访问数量的增加。因此,在API边界上分割建模可能会导致组合内爆。
另一个原因是,一个简单的实现可能会不必要地约束真实的实现或真实的用例。相比之下,建模一个柏拉图式的锁允许最广泛的实现,同时为锁的用户提供具体的指导。
如9.5.2节所述,RCU宽限期的基本属性是这个简单的两部分保证: (1)如果任何给定的RCU阅读的关键部分之前给定的宽限期的开始,那么整个的关键部分之前宽限期的结束。(2)如果一个给定的RCU读取侧的任何部分
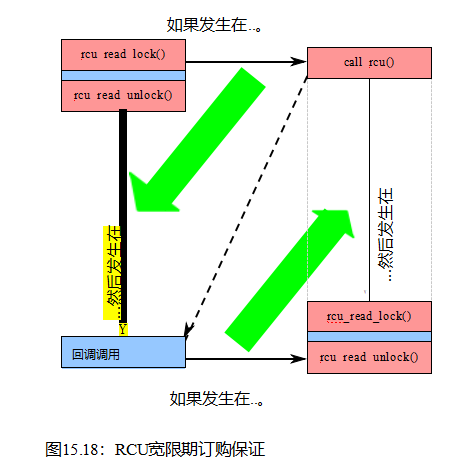
当然,依赖关系会限制在RCU读取侧临界部分内重新排序访问的能力。
其中一些是由杰德·Alglave在LKMM的早期工作中介绍给保罗的,还有一些来自其他LKMM参与者[AMM+ 18]。
| 1 C C-LB+rl-o-o-rul+rl-o-o-rul 2 3 {} 4 5 P0(uintptr_t *x0, uintptr_t *x1) 6 { 7 rcu_read_lock() ; 8 uintptr_t r1 = READ_ONCE(*x0); 9 WRITE_ONCE(*x1,1); 10 rcu_read_unlock() ; 11 } 12 13 P1(uintptr_t *x0, uintptr_t *x1) 14 { 15 rcu_read_lock() ; 16 uintptr_t r1 = READ_ONCE(*x1); 17 WRITE_ONCE(*x0,1); 18 rcu_read_unlock() ; 19 } 20 21个已存在(0:r1=1 /\ 1:r1=1) |
| 清单15.41: RCU阅读器不提供类似障碍的订购 |
| 1 C C-LB+o-rl-rul-o+o-rl-rul-o 2 3 {} 4 5 P0(uintptr_t *x0, uintptr_t *x1) 6 { 7 uintptr_t r1 = READ_ONCE(*x0); 8 rcu_read_lock() ; 9 rcu_read_unlock() ; 10 WRITE_ONCE(*x1,1); 11 } 12 13 P1(uintptr_t *x0, uintptr_t *x1) 14 { 15 uintptr_t r1 = READ_ONCE(*x1); 16 rcu_read_lock() ; 17 rcu_read_unlock() ; 18 WRITE_ONCE(*x0,1); 19 } 20 21个已存在(0:r1=1 /\ 1:r1=1) |
| 这些原语也没有类似障碍的排序属性,至少在混合中有一个宽限期,如清单15.41(C-LB+-+-rul-+-rl-rul-o.litmus)所示。这个石蕊试金石的循环也是允许的。(试一试!) 当然,鉴于rcu_read_lock()和rcu_read_unlock()在RCU的QSBR实现中都是不操作的,这两个金石测试中缺乏排序绝对不令人惊讶。 15.4.3.2 RCU更新端订购 与RCU阅读器相比,RCU更新端函数synchronize_rcu()和synchronize_rcu_expedited()提供的内存排序至少与smp_mb()一样强,这可以在清单15.42中所示的试金石测试中看到。这个测试的周期是被禁止的,就像它使用smp_mb()一样。考虑到表15.3中提供的信息,这并不令人惊讶。 |
| 清单15.42: RCU更新器提供完整的订购 |
| 1 C C-SB+o-rcusync-o+o-rcusync-o 2 3 {} 4 5 P0(uintptr_t *x0, uintptr_t *x1) 6 { 7 WRITE_ONCE(*x0,2); 8 synchronize_rcu() ; 9 uintptr_t r2 = READ_ONCE(*x1); 10 } 11 12 P1(uintptr_t *x0, uintptr_t *x1) 13 { 14 WRITE_ONCE(*x1,2); 15 synchronize_rcu() ; 16 uintptr_t r2 = READ_ONCE(*x0); 17 } 18 19个已存在(1:r2=0 /\ 0:r2=0) |
| 1 C C-SB+o-rcusync-o+o-rl-o-rul 2 3 {} 4 5 P0(uintptr_t *x0, uintptr_t *x1) 6 { 7 WRITE_ONCE(*x0,2); 8 synchronize_rcu() ; 9 uintptr_t r2 = READ_ONCE(*x1); 10 } 11 12 P1(uintptr_t *x0, uintptr_t *x1) 13 { 14 WRITE_ONCE(*x1,2); 15 rcu_read_lock() ; 16 uintptr_t r2 = READ_ONCE(*x0); 17 rcu_read_unlock() ; 18 } 19 20已存在(1:r2=0 /\ 0:r2=0) |
15.4.3.3 RCU的读者:前后的
在阅读本节之前,最好先考虑一下可用的保证和可维护软件应该依赖的保证之间的区别。请记住这一点,本节介绍了一些更奇特的RCU保证。
清单15.43(C-SB+o-rcusync-o+o-rl-o-rul.litmus)显示了一个与清单15.38类似的试金石,但是RCU阅读器的第一次访问是在RCU读取侧关键部分之前,而不是更传统的(和可维护的!)被包含在其中的方法。也许令人惊讶的是,在这个试金石测试中给出的结果与清单15.38中的相同:循环是禁止的。
为什么会是这样的情况呢?
由于P1()的两个访问都是不稳定的,如第4.3.4.2节中所讨论的,编译器不允许对它们重新排序。这意味着,为P1()的WRITE_ONCE()发出的代码将先于为P1()的READ_ONCE()发出的代码。因此,在rcu_read_lock()和rcu_read_unlock()中放置内存屏障指令的RCU实现将保持P1()的两次访问的顺序,一直保持到硬件级别。另一方面,依赖于基于中断的状态机的RCU实现也将完全保持这种相对于优雅的排序
| 1 C C-SB+o-rcusync-o+rl-o-rul-o 2 3 {} 4 5 P0(uintptr_t *x0, uintptr_t *x1) 6 { 7 WRITE_ONCE(*x0,2); 8 synchronize_rcu() ; 9 uintptr_t r2 = READ_ONCE(*x1); 10 } 11 12 P1(uintptr_t *x0, uintptr_t *x1) 13 { 14 rcu_read_lock() ; 15 WRITE_ONCE(*x1,2); 16 rcu_read_unlock() ; 17 uintptr_t r2 = READ_ONCE(*x0); 18 } 19 20已存在(1:r2=0 /\ 0:r2=0) |
| 1 C C-SB+o-rcusync-o+o-rl-rul-o 2 3 {} 4 5 P0(uintptr_t *x0, uintptr_t *x1) 6 { 7 WRITE_ONCE(*x0,2); 8 synchronize_rcu() ; 9 uintptr_t r2 = READ_ONCE(*x1); 10 } 11 12 P1(uintptr_t *x0, uintptr_t *x1) 13 { 14 WRITE_ONCE(*x1,2); 15 rcu_read_lock() ; 16 rcu_read_unlock() ; 17 uintptr_t r2 = READ_ONCE(*x0); 18 } 19 20已存在(1:r2=0 /\ 0:r2=0) |
由于中断发生在执行被中断代码时的精确位置而导致的周期。
这反过来意味着,如果WRITE_ONCE()遵循一个给定的RCU宽限期的结束,那么在该RCU读取侧临界部分内和之后的访问必须遵循相同的宽限期的开始。类似地,如果READ_ONCE()先于宽限期的开始,则在该临界部分内和之前的所有内容都必须先于同一宽限期的结束。
清单15.44(C-SB+o-rcusync-o+rl-o-rul-o.litmus)与此类似,但它会查看RCU读侧关键部分之后的访问。这个测试9s周期也被禁止了,因为可以用群体工具进行检查。其推理与清单15.43类似,并留给读者进行练习。
清单15.45(C-SB+o-rcusync-o+o-rl-rul-o.litmus)更进一步,将P1()9的WRITE_ONCE()移动到RCU读侧临界部分之前,并将P1()9的READ_ONCE()移动到它之后,导致一个空的RCU读侧临界部分。
也许令人惊讶的是,尽管临界部分很空,但RCU仍然设法阻止了这个循环。这可以再次使用群体工具进行检查。此外
| 清单15.46:没有RCU阅读器会发生什么? |
| 1 C C-SB+o-rcusync-o+o-o 2 3 {} 4 5 P0(uintptr_t *x0, uintptr_t *x1) 6 { 7 WRITE_ONCE(*x0,2); 8 synchronize_rcu() ; 9 uintptr_t r2 = READ_ONCE(*x1); 10 } 11 12 P1(uintptr_t *x0, uintptr_t *x1) 13 { 14 WRITE_ONCE(*x1,2); 15 uintptr_t r2 = READ_ONCE(*x0); 16 } 17 18个已存在(1:r2=0 /\ 0:r2=0) |
推理再次类似于清单15.43的重述,如果P1()的WRITE_ONCE()遵循给定宽限期的结束,那么P1()的RCU读侧关键部分——以及之后的一切——都必须遵循相同宽限期的开始。类似地,如果P1()的READ_ONCE()先于给定宽限期的开始,那么P1()的RCU读侧临界部分——以及它之前的所有部分——必须先于相同宽限期的结束。在这两种情况下,临界部分的空性都是无关紧要的。

这种情况导致了一个问题,即如果完全省略rcu_read_lock()和rcu_read_uloke()会发生什么,如清单15.46(+-+-+-o+o-o.litmus)所示。可以用群体来检查,这个石试试验的周期是允许的,也就是说,r2的两个实例的最终值都可以为零。
鉴于空的RCU读侧关键部分可以提供排序,这可能看起来很奇怪。的确,RCU的QSBR实现实际上会禁止这种结果,因为在P1()的函数体中的任何地方都没有静止状态,因此P1()将在隐式的RCU读侧临界部分中运行。然而,RCU也有非QSBR实现,它们没有隐含的RCU读侧关键部分,反过来,RCU也没有办法强制排序。因此,这个石蕊试金石的周期是允许的。

15.4.3.4多重RCU读取器和更新器
因为synchronize_rcu()的排序语义至少和smp_ mb()一样强,无论在SB试金石测试中有多少进程(如Listing15.42),在每个进程的访问之间放置synchronize_rcu()都禁止循环。此外,在SB测试中,一个进程使用syaan_rcu(),另一个进程使用rcu_read_lock()和rcu_read_unlock(),如图所示
特别是考虑到保罗在与Jade Alglave一起去概括RCU排序语义时,多次改变了他对这个特殊的试金石测试的想法。
| 1 C C-SB+o-rcusync-o+o-rcusync-o+rl-o-o-rul+rl-o-o-rul 2 3 {} 4 5 P0(uintptr_t *x0, uintptr_t *x1) 6 { 7 WRITE_ONCE(*x0,2); 8 synchronize_rcu() ; 9 uintptr_t r2 = READ_ONCE(*x1); 10 } 11 12 P1(uintptr_t *x1, uintptr_t *x2) 13 { 14 WRITE_ONCE(*x1,2); 15 synchronize_rcu() ; 16 uintptr_t r2 = READ_ONCE(*x2); 17 } 18 19 P2(uintptr_t *x2, uintptr_t *x3) 20 { 21 rcu_read_lock() ; 22 WRITE_ONCE(*x2,2); 23 uintptr_t r2 = READ_ONCE(*x3); 24 rcu_read_unlock() ; 25 } 26 27 P3(uintptr_t *x0, uintptr_t *x3) 28 { 29 rcu_read_lock() ; 30 WRITE_ONCE(*x3,2); 31 uintptr_t r2 = READ_ONCE(*x0); 32 rcu_read_unlock() ; 33 } 34 35已存在(3:r2=0 /\ 0:r2=0 /\ 1:r2=0 /\ 2:r2=0) |
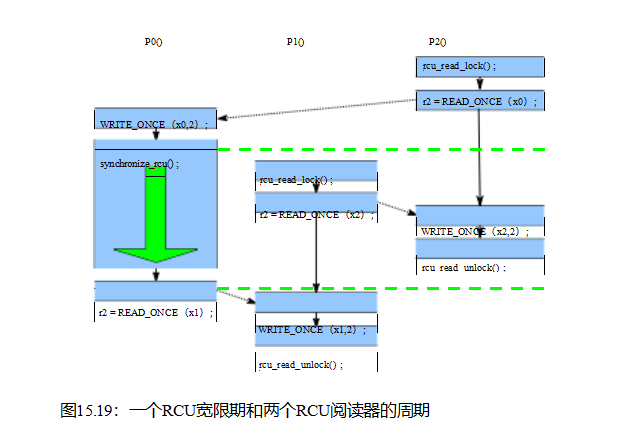
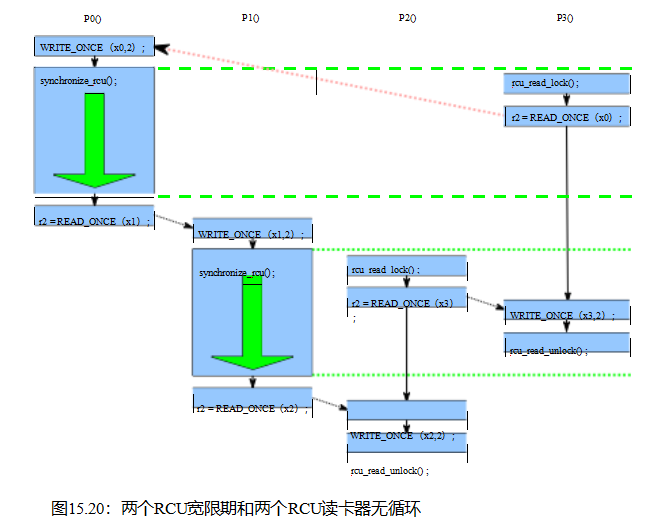
P2()和P3()都有RCU阅读器。同样,cpu可以在RCU读取侧临界部分内重新排序访问,如图15.20所示。为了形成这个循环,P2()的临界部分必须在P1()的宽限期之后结束,而P3()的临界部分必须在同一宽限期开始之后结束,这也是在P0()的宽限期结束之后。因此,P3()的临界部分必须在P0()的宽限期开始后开始,这反过来意味着P3()从x0中的读取不可能先于P0()的写入。因此,禁止该循环,因为RCU读取侧临界部分不能跨越完整的RCU宽限期。
但是,仔细看看图15.20就可以清楚地看出,添加第三个阅读器将允许这个循环。这是因为这第三个读者可以在P0()的宽限期结束之前结束,因此在相同的宽限期开始之前开始。这反过来又表明了一般的规则:在这些RCU-only试金石测试中,如果至少有许多RCU宽限期作为RCU读侧临界部分,那么这个循环是被禁止的。
15.4.3.5 RCU和其他排序机制
但是,将RCU与其他排序机制结合起来的试金石测试怎么办呢?一般的规则是,它只需要一种机制来禁止一个循环。
例如,请参考清单15.40。应用前一节中的一般规则,因为这个试金石有两个RCU读侧临界部分,没有RCU宽限期,因此允许该循环。但是如果P0()的WRITE_ONCE()是呢
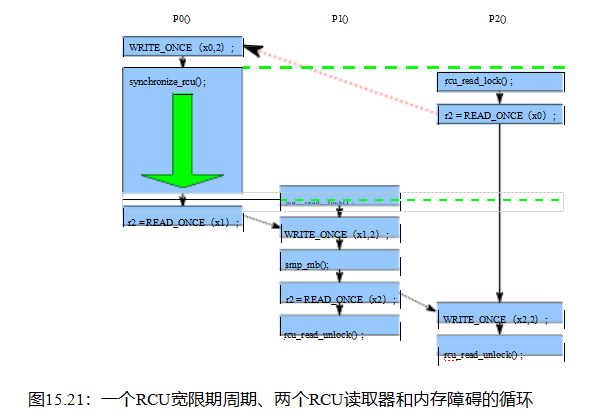
被smp_store_release()取代,P1()的READ_ONCE()被smp_load_acquire()取代?
RCU仍然允许这个循环,但发行-收购对将禁止它。因为只需要一个机制就可以禁止一个循环,所以释放-获取对将占上风,从而禁止这个循环。
关于另一个例子,请参考清单15.47。因为这个试金石有两个RCU阅读器,但只有一个宽限期,所以它的周期是允许的。但假设一个smp_mb()被放置在P1()的一对访问之间。在这个新的试金石测试,因为添加smp_mb(),P2()以及P1()的临界部分将超出P0()的宽限期,这反过来会防止P2()读x0前P0()写,如Figure15.21的红色虚线箭头。在这种情况下,RCU和全内存屏障共同工作来禁止循环,RCU在P0()和P1()和P2()之间保持顺序,以及与smp_mb()一起

简而言之,RCU的语义曾经是纯粹实用的,现在已经完全形式化了[MW05,DMS+ 12,GRY13,AMM+ 18]。
用高级原语来验证代码,而不是在该原语的特定实现中使用的低级内存访问,这是非常有益的。首先,这允许使用“这些原语”的代码根据这些原语的抽象表示进行验证,从而使这些代码不太容易受到实现更改的影响。其次,在API边界上划分验证会导致组合内爆,大大减少了形式验证的开销。
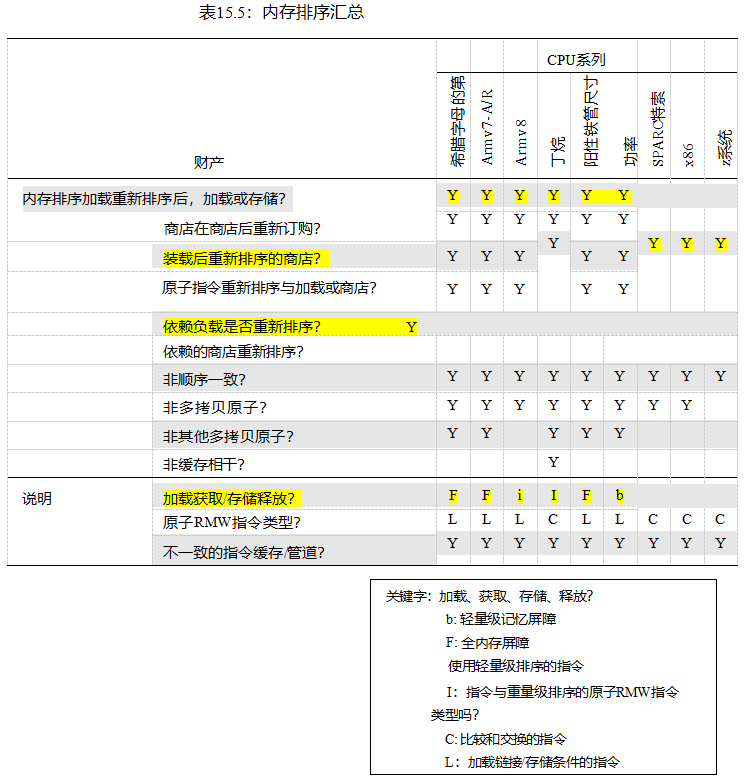
希望通过对高级原语的详细语义进行验证,将大大提高静态分析和模型检验的有效性。
15.5 硬件细节
摇滚拍纸!
德里克威廉姆斯
每个CPU家族都有其独特的内存排序方法,这可能使可移植性成为一个挑战,如表15.5所示。
事实上,一些软件环境只是禁止直接使用内存排序操作,从而将程序员限制在需要时合并它们的互斥原语中。请注意,本节并不是要成为涵盖每个CPU家族的所有(甚至是大部分)方面的参考手册,而是要成为参考手册
提供粗略比较的高级概述。有关详细信息,请参阅相关CPU的参考手册。
回到表15.5,第一组行查看内存顺序属性,第二组行查看指令属性。请注意,这些属性保持在机器指令级别。编译器可以并且可以比硬件更积极地进行排序。使用有标记的访问,如READ_ONCE()和WRITE_ONCE(),来约束编译器的优化,并防止不合理的重新排序。
前三行指示给定的CPU是否允许重新排序四种可能的加载和存储组合,如第15.2.1节和第15.2.1-15.2.2.3节中讨论的。下一行(“使用加载或存储重新排序的原子指令?”)指示给定的CPU是否允许使用原子指令重新排序加载和存储。
第五行和第六行包括重新排序和依赖关系,这在第15.2.3–15.2.5节中涉及,并在第15.5.1节中有更详细的解释。简而言之,Alpha需要阅读器的内存障碍,以及链接数据结构的更新者的内存障碍,然而,这些内存障碍是由v4.15和以后的Linux内核中特定于Alpha架构的代码提供的。
下一行,“非顺序一致”,表示CPU的正常负载和存储指令是否受到顺序一致性的限制。对性能的考虑要求没有一个现代主流系统是顺序一致的。
接下来的三行覆盖了在第15.2.7节中定义的多拷贝原子性。
第一个是完整的(和罕见的)多拷贝原子性,第二个是较弱的其他多拷贝原子性,第三个是最弱的非多拷贝原子性。
下一行,“非缓存相干”,涵盖了从多个线程到单个变量的访问,这一点在第15.2.6节中进行了讨论。
最后三行包括指令级别的选择和问题。第一行表示每个CPU如何实现负载-获取和存储-释放,第二行按原子-指令类型对CPU进行分类,第三行和最后一行表示一个给定的CPU是否有一个不连贯的指令缓存和管道。这样的cpu需要执行针对自修改代码的特殊指令。
常见的处理内存排序操作的“只是说不”方法在适用的地方可能非常合理,但也有一些环境,比如Linux内核,需要直接使用内存排序操作。因此,Linux提供了一个精心选择的最小共分母内存排序原母集,如下所示:
smp_mb()(全内存障碍),同时订购加载和存储。这意味着在内存屏障之前的加载和存储将在内存屏障之后的任何加载和存储之前提交到存储中。
仅排序为加载的smp_rmb()(读取内存障碍)。
只订购存储空间的smp_wmb()(写内存屏障)。
smp_mb__before_atomic(),强制在smp_mb__之前的访问和之后的RMW原子操作之后的访问。这是对完全排序原子RMW操作的系统的操作。
smp_mb__after_atomic(),强制对早期RMW原子操作之前的访问对对smp_mb__after_atomic()之后的访问进行排序。这也是对完全排序原子RMW操作的系统的一个建议。
smp_mb__after_spinlock(),强制锁访问之前的访问命令对smp_mb__after_spinlock()之后的访问。这也是对完全订购锁定收购的系统的一个建议。
mmiowb()强迫MMIO命令,由全球旋锁保护,
在2016年LWN关于MMIO [MDR16]的文章中进行了更详细的描述。
smp_mb()、smp_rmb()和smp_wmb()原语还迫使编译器避免任何可能产生跨越障碍重新排序内存优化效果的优化。

这些原语只在SMP内核中生成代码,但是,有几个版本有UP版本(分别为mb()、rmb()和wmb()),即使在UP内核中也会产生内存障碍。在大多数情况下都应该使用smp_版本。然而,后一个原语在编写驱动程序时很有用,因为即使在UP内核中,MMIO访问也必须保持有序。在没有内存排序操作的情况下,cpu和编译器都会愉快地重新安排这些访问,这充其量会使设备的行为很奇怪,并可能导致内核崩溃,甚至损坏硬件。
因此,大多数内核程序员不需要担心每个CPU的内存顺序特性,只要他们坚持使用这些接口和完全有序的原子操作。当然,如果您深入研究给定CPU的特定架构的代码,所有的赌注都不了。
此外,所有Linux的锁定原语(自旋锁、读写锁、内存锁、RCU、……)都包括任何需要的排序原语。因此,如果您正在使用正确使用这些原语的代码,那么您就不必担心Linux的内存排序原语。
也就是说,在调试时,深入了解每个CPU的内存一致性模型会非常有用,更不用说编写特定于架构的代码或同步原语了。
此外,他们还说,稍微掌握一点知识是一件非常危险的事情。想象一下,用很多知识会造成的伤害!对于那些希望更多地了解单个cpu的记忆一致性模型的人,下一节将介绍一些流行的和突出的cpu的cpu。虽然没有任何办法可以替代实际读取给定的CPU文档,但这些部分确实给出了一个很好的概述。
对于一个生命的终结已经结束的CPU,这似乎很奇怪,但是Alpha很有趣,因为它是唯一一个重新排序依赖负载的主流CPU,因此对并发api有巨大的影响,包括在Linux内核中。核心Linux内核代码需要适应Alpha的版本v4.15结束,并且在版本5.9中删除了smp_read_barrier_depends()和()api的所有跟踪。然而,这部分仍然保留在第三版中,因为在2023年初,仍有一些Linux内核黑客仍在开发Linux版本之前的Linux内核。此外,还将其修改到
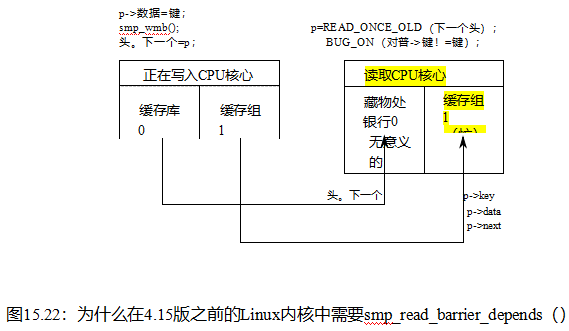
人们可以在指针获取和解引用之间放置一个smp_rmb()原语,以迫使Alpha使用稍后的依赖负载对指针获取进行排序。然而,这对尊重读取侧数据依赖性的系统(如Arm、Itanium、PPC和SPARC)带来了不必要的开销。因此,在Linux内核中添加了一个smp_read_barrier_depends()原语,以消除这些系统上的开销,但在Linux内核的v5.9中被删除,以增强Alpha,READ_ONCE()的定义。因此,在v5.9中,核心内核代码不再需要关注DEC Alpha的这方面。但是,最好使用rcu_dereference(),如清单15.50中的第16行和第21行所示,它对于所有最近的内核版本都能安全有效地工作。
也可以实现一种软件机制,可以用来代替smp_store_release()来强制所有读取CPU查看写入CPU,s按顺序写。这个软件障碍可以通过向所有其他cpu发送处理器间中断(ipi)来实现。在收到这样的IPI后,CPU将执行内存障碍指令,实现类似于Linux内核提供的sys_membarrier()系统调用提供的系统范围内存障碍。需要额外的逻辑来避免死锁。当然,尊重数据依赖性的cpu将把这样一个障碍定义为简单的smp_store_release()。然而,Linux社区认为这种方法造成了过多的开销[McK01],就他们的观点而言,这完全不适合于具有积极的实时响应需求的系统。
Linux内存障碍原语的名称来源于Alpha指令,所以smp_mb()是mb,smp_rmb()是rmb,smp_wmb()是wmb。Alpha是唯一一个其READ_ONCE()包含一个smp_mb()的CPU。

有关Alpha的更多信息,请参阅其参考手册[Cor02]。
| 清单15.50:安全插入和无锁定搜索 | ||
| 1 | 结构 | 电子插入(长键、长数据) |
| 2 | { | |
| 3 | 结构el *p; | |
| 4 | p=kmalloc(尺寸(*p),GFP_ATOMIC); | |
| 5 | spin_lock(&mutex); | |
| 6 | 下一个=头。下一个; | |
| 7 | p->键=键; | |
| 8 | p->数据=数据; | |
| 9 | smp_store_release(&head.next , p); | |
| 10 | spin_解锁(&mutex); | |
| 11 | } | |
| 12 | ||
| 13 | 结构 | el*搜索(长搜索键) |
| 14 | { | |
| 15 | ||
| 16 | p=rcu_dereference(下头); | |
| 17 | 而(p != &head){ | |
| 18 | 如果(p->键==搜索键){ | |
| 19 | 返回(p); | |
| 20 | } | |
| 21 | ||
| 22 | }; | |
| 23 | 返回(空); | |
| 24 | } | |
Arm家族在深度嵌入式应用中很流行,特别是对于功率受限的微控制器。它的内存模型类似于功率模型(见第15.5.6节),但Arm使用了一组不同的内存屏障指令[ARM10]:
DMB(数据内存障碍)导致指定类型的操作在相同类型的任何后续操作之前已经完成。操作的“类型”可以是所有操作,也可以限制为仅写操作(类似于Alpha wmb和功率eieio指令)。此外,Arm允许缓存一致性具有三个范围中的一个:单处理器、处理器的一个子集(“内部”)和全局(“外部”)。
DSB(数据同步屏障)会使指定类型的操作在执行任何后续(任何类型)操作之前实际完成。操作的“类型”与DMB的操作相同。在Arm架构的早期版本中,DSB指令被称为DWB(漏极写缓冲区或数据写屏障,这是您的选择)。
ISB(指令同步屏障)会刷新CPU管道,因此只有在ISB完成之后,所有的指令才会在ISB完成后获取。例如,如果您正在编写一个自修改的程序(例如JIT),那么您应该在生成代码和执行代码之间执行一个ISB。
这些指令都没有与Linux的rmb()原语的语义完全匹配,因此它必须实现为一个完整的DMB。DMB和DSB指令对屏障之前和之后排序的访问有递归定义,其效果类似于功率的累积性,两者都比第15.2.7.1节中描述的LKMM累积性强。
Arm还实现了控制依赖关系,因此如果条件分支依赖于负载,那么在该条件分支之后执行的任何存储都将在加载之后排序。但是,跟在条件分支之后的负载将不能保证是
除非在分支和负载之间有一个ISB指令。请考虑以下示例:
| r1 = x; nop(); y = 1; r2 = z; ISB(); |
在这个例子中,加载-存储控制依赖排序导致从第1行x的加载在第4行y的存储之前被排序。但是,Arm不尊重负载-负载控制依赖关系,因此第1行上的负载很可能发生在第5行上的负载之后。另一方面,第2行上的条件分支和第6行上的ISB指令的组合确保了第7行上的负载发生在第1行上的负载之后。请注意,在第2行和第5行之间插入一个额外的ISB指令将在第1行和第5行之间强制排序。
Arm的Armv8 CPU系列[ARM17]包含64位功能,与Section15.5.2中描述的仅32位CPU相比。Armv8的内存模型与Armv7非常相似,但添加了负载获取(LDLARB、LDLARH和LDLAR)和存储释放(STLLRB、STLLRH和STLLR)指令。这些指令充当“半内存障碍”,因此Armv8cpu可以用以后的LDLAR指令重新排序以前的访问,但禁止用以后的访问重新排序早期的LDLAR指令,如图15.23所示。类似地,Armv8cpu可以使用后续的访问重新排序早期的STLLR指令,但禁止使用以后的STLLR指令重新排序以前的访问。正如人们所料,这意味着这些指令直接支持C11的加载-获取和存储-释放的概念。
然而,Armv8远远超出了C11内存模型,它要求存储释放和加载获取的组合在某些情况下作为一个完整的障碍
境况例如,在Armv8中,给定一个存储,之后存储发布,接着加载获取,之后加载,所有不同的变量,所有来自一个CPU,所有CPU都同意初始存储在最终加载之前。有趣的是,大多数TSO架构(包括x86和大型机)并不能保证这一点,因为这两个加载可以在两个存储之前重新订购。
Armv8是仅有的两种需要smp_mb__after_spinlock()原语成为完全障碍的架构之一,因为它在Linux内核中的锁获取实现相对较弱。
Armv8的区别还在于,它是第一个由供应商公开定义其内存顺序的CPU[ARM17]。
安腾提供了一个弱一致性模型,因此在没有显式的记忆障碍指令或依赖关系的情况下,安腾有权任意重新排序记忆引用[Int02a]。Itanium有一个名为mf的内存栅栏指令,但也有“半内存栅栏”修改器来加载、存储和处理其一些原子指令[Int02b]。acq修改器可以防止后续的内存-引用指令在acq之前被重新排序,但允许先前的内存-引用指令在acq之后被重新排序,类似于Armv8加载-获取指令。类似地,rel修改器可以防止先前的内存参考指令在rel之后被重新排序,但允许后续的内存参考指令在rel之前被重新排序。
这些半记忆围栏对临界区域是有用的,因为将操作推到临界区域是安全的,但如果让它们出血,可能是致命的。然而,作为为数不多的具有这种特性的cpu之一,Itanium曾经定义了与锁获取和发布相关的内存顺序的语义。奇怪的是,据传实际的安腾硬件将同时实现负载-获取和存储-发布指令作为全部障碍。然而,Itanium是第一个将加载获取和存储释放的概念(如果不是现实的话)引入其指令集的主流CPU。

iummf指令用于Linux内核中的smp_rmb()、smp_mb()和smp_wmb()原语。尽管一直有相反的谣言,“mf”助记符代表“记忆栅栏”。
安腾还提供了一个全球释放操作的总订单,包括mf指令。这提供了传递性的概念,如果给定的代码片段看到给定的访问已经发生了,任何以后的代码片段也会看到较早的访问已经发生了。假设,所有涉及的代码片段都正确地使用了内存障碍。
最后,Itanium是唯一支持Linux内核的架构,它可以将正常加载重新排序到相同的变量。Linux内核避免了这个问题,因为READ_ ONCE()发出一个易失性负载,它被编译为ld,acq指令,强制给定CPU对所有READ_ ONCE()调用进行排序,包括对相同变量的排序。
MIPS内存模型[Wav16,第479页]似乎类似于Arm、安定和功率,默认情况下是弱排序的,但尊重依赖关系。MIPS有各种各样的内存障碍指令,但它们与硬件考虑无关,而是与Linux内核和C++11标准[Smi19]提供的用例有关,其方式类似于Armv8的添加:
同时
除了内存引用之外,还有许多硬件操作,用于实现OCTEON系统的v4.13 Linux内核的smp_mb()。
sync_wmb
写内存障碍,它可以在OCTEON系统上使用,通过同步助记符来实现v4.13 Linux内核中的smp_wmb()原语。其他系统则使用纯同步系统。
sync_mb
全内存障碍,但仅用于内存操作。这可以用于实现C++原子_线程_栅栏(memory_order_seq_cst)。
同步获取
获取内存障碍,可用于实现C++的原子线程栅栏(内存顺序获取)。理论上,它也可以用于实现v4.13linux内核smp_load_acquire()原语,但在实际中使用同步。
同步释放
释放内存障碍,它可能用于实现C++的原子线程栅栏(内存顺序释放)。理论上,它也可以用于实现v4.13linux内核smp_store_release()原语,但在实际中使用同步。
sync_rmb
读取内存障碍,这在理论上可以用于实现Linux内核中的smp_rmb()原语,除了由v4.13 Linux内核支持的当前MIPS实现不需要显式指令来强制排序。因此,smp_rmb()只是约束编译器。
辛奇
指令-缓存同步,它与其他指令一起使用,以允许自修改代码,例如由即时(JIT)编译器生成的代码。
与MIPS架构师的非正式讨论表明,MIPS对传递性或累积性的定义类似于手臂和权力。然而,似乎不同的MIPS实现可能具有不同的内存顺序属性,因此查阅有关您正在使用的特定MIPS实现的文档是很重要的。
POWER和PowerPC CPU系列有各种各样的内存屏障指令[IBM94,LHF05]:
同步使所有上述操作在启动任何后续操作开始之前已经完成。因此,这个指令是相当昂贵的。
lwsync(轻量级同步)根据后续加载和存储订购加载,也为存储订购。但是,它不会根据后续负载订购存储。lwsync指令可用于实现负载-获取和存储-释放操作。有趣的是,lwsync指令强制执行了与x86、z系统相同的cpu内部排序,巧合的是,还有SPARC TSO。但是,将lwsync指令放置在每对内存引用指令之间并不会导致x86、z系统或SPARC TSO内存排序。在这些其他系统上,如果一对cpu独立地执行对不同变量的存储,那么所有其他cpu都将就这些存储的顺序达成一致。而在PowerPC上则不是这样,即使在每对内存引用指令之间都有一条lwsync指令,因为PowerPC是非多副本原子的。
Eieio(强制执行I/O的顺序执行)导致所有之前的可缓存存储似乎都在所有后续存储之前已经完成。但是,可缓存内存的存储是分开从存储到不可缓存存储的,这意味着eieio不会强制MMIO存储在旋锁发布之前。这条指令很可能是一个独特的五元音助记符。
isync强制所有之前的指令在任何子任务指令开始执行之前似乎已经完成。这意味着前面的指令必须进展得足够远,以致它们可能产生的任何陷阱已经发生或保证不会发生,并且这些指令的任何副作用(例如,页表更改)都可以在随后的指令中看到。但是,它并不强制对所有的内存引用进行排序,而只强制对指令本身的实际执行。因此,加载可能会返回旧的仍然缓存的值,并且isync指令不会强制将以前存储的值从存储缓冲区中刷新。
不幸的是,这些指令都没有完全符合Linux的wmb()原语,它要求排序所有存储,但不需要同步指令的其他高开销操作。rmb()原语也没有匹配的轻量级指令。但是没有选择: ppc64版本的wmb()、rmb()和mb()被定义为重量级同步指令。然而,Linux的smp_wmb()原语从未用于MMIO(毕竟,驱动程序必须仔细地在UP和SMP内核中的MMIOs),因此它被定义为较轻的eieio或lwsync指令[MDR16]。smp_mb()原语也被定义为同步指令,而smp_rmb()被定义为重量较轻的lwsync指令。
功率特征为“累积性”,可以用来获得传递性。当正确使用时,任何看到早期代码片段结果的代码也将看到这个早期代码片段本身所看到的访问。更多的细节可从麦肯尼和西尔维拉[MS09]。
功率尊重控制依赖的方式与Arm非常相同,除了功率异步指令取代了Arm ISB指令。
和Armv8一样,电源需要smp_mb__after_spinlock()成为一个完整的内存障碍。此外,电源是唯一需要smp_mb__after_uloko_lock()成为完整内存障碍的架构。在这两种情况下,这都是因为功率锁定原语的排序属性较弱,因为使用了lwsync指令来为获取和释放提供排序。
电源体系结构的许多成员都有不一致的指令缓存,因此内存的存储不一定反映在指令缓存中。值得庆幸的是,现在很少有人编写自我修改的代码,但是jit和编译器一直在这样做。此外,从CPU的角度来看,重新编译最近运行的程序就像自我修改代码。icbi指令(指令缓存块无效)会使指令缓存中的指定的缓存行无效,并且可以在这些情况下使用。
尽管Linux和Solaris都使用了SPARC的TSO(总存储顺序),但该体系结构还定义了PSO(部分存储顺序)和RMO(放松内存顺序)。任何在RMO中运行的程序也将在PSO或TSO中运行,类似地,在PSO中运行的程序也将在TSO中运行。向另一个方向移动共享内存并行程序可能需要仔细地插入内存障碍。
尽管SPARC的PSO和RMO模式最近并没有被大量使用,但它们确实产生了一个非常灵活的内存障碍指令[SPA94],允许对顺序进行细粒度控制:
在后续商店之前的订单。(此选项由Linux smp_wmb()原语使用。)
加载存储订单在加载之前的后续存储。
在后续加载之前的存储加载订单。
加载在后续加载之前的加载订单。(此选项由Linux smp_rmb()原语使用。)
在启动任何后续操作之前,同步将完全完成所有之前的操作。
MemIssue会在随后的内存操作之前完成之前的内存操作,这对于某些内存映射的I/O实例来说非常重要。
Lookaside与MemIssue相同,但只适用于之前的存储和后续加载,甚至只适用于访问相同内存位置的存储和加载。
那么,为什么需要“记忆问题”呢?因为“模条#存储加载”可以允许后续加载从存储缓冲区获取其值,如果写入MMIO寄存器会对要读取的值产生副作用,这将是灾难性的。相反,“membar#MemIssue”会等到存储缓冲区被刷新后才允许执行负载,从而确保负载实际上从MMIO寄存器获得其值。驱动程序可以使用“记忆#同步”,但在不需要更昂贵的“记忆#同步”的附加功能的情况下,更轻的“记忆#记忆问题”是首选。
“看吧”是“记忆问题”的一个较轻的版本,
当写入给定的MMIO寄存器时,影响下一个值是有用的
要从那个寄存器中读取。但是,当对给定MMIO寄存器的写入影响下次从其他MMIO寄存器读取的值时,必须使用较重的“内存问题”。
SPARC要求在指令流被修改和执行任何这些指令的时间之间使用刷新指令[SPA94]。这需要从SPARC的指令缓存中刷新该位置的任何优先值。请注意,刷新将接受一个地址,并且将只从指令缓存中刷新该地址。在SMP系统上,所有cpu的缓存都被刷新,但是没有方便的方法来确定cpu外刷新何时完成,尽管有一个实现注释。
但是,Linux内核在TSO模式下运行SPARC,所以上面所有的成员栏变体都具有严格的历史意义。特别是,smp_mb()原语只需要使用#StoreLoad,因为TSO禁止使用其他三个重新排序。
历史上,x86CPU提供了“进程排序”,以便所有CPU都同意给定CPU写入内存的顺序。这允许smp_wmb()原语没有CPU [Int04b]。当然,还需要一个编译器指令来防止跨smp_wmb()原语重新排序的优化。在古代,某些x86cpu没有对负载提供排序保证,所以smp_mb()和smp_rmb()原语扩展到锁定;addl。这种原子指令是加载和存储的障碍。
但那已经是古代了。最近,英特尔发布了一个针对x86的内存模型[Int07]。事实证明,英特尔的现代cpu比以前的规范中声称的更严格,所以这个模型只是要求了这种现代行为。甚至在最近,英特尔发布了x86更新的内存模型[Int11,8.2节],它要求商店的总全球订单,尽管个别cpu仍然被允许看到自己的商店比总全球订单显示的更早。为了允许涉及存储缓冲区的重要硬件优化,需要对总排序进行此例外。此外,x86提供了其他多副本原子性,例如,如果CPU 0看到CPU 1的存储,那么CPU 0保证看到CPU 1在其存储之前看到的所有存储。软件可能会使用原子操作来覆盖这些硬件优化,这也是原子操作往往比非原子操作更昂贵的原因之一。
同样重要的是,要注意,在给定的内存位置上操作的原子指令都应该是相同的大小[Int16,第8.1.2.2节]。例如,如果您编写一个程序,其中一个CPU的原子增量为一个字节,而另一个CPU在同一位置执行一个4字节的原子增量,那么您就是自己。
一些SSE指令是弱有序的(clflush和非时间移动指令[Int04a])。使用这些非时间移动指令的代码也可以使用mfence表示smp_mb(),lfence表示smp_rmb(),sfence表示smp_wmb()。一些旧版本的x86 CPU有一个模式位,支持无序存储,对于这些CPU,smp_wmb()也必须被定义为锁定;addl。
尽管更新的x86实现适应了没有任何特殊指令的自修改代码,为了与过去和未来潜在的x86实现完全兼容,给定的CPU必须在修改代码和执行它之间执行一个跳转指令或序列化指令(例如,cpuid)[Int11,第8.1.3节]。
z系统机器构成了IBM大型机系列,以前被称为360、370、390和zSeries [Int04c]。并行性在z系统中来得太晚了,但考虑到这些大型机在20世纪60年代中期首次发布,这并不能说明什么。“bcr15,0”指令用于Linux smp_mb()原语,但是编译器约束足以满足smp_rmb()和smp_wmb()原语。它还具有很强的内存排序语义,如表15.5所示。特别是,所有的CPU都将同意来自不同CPU的不相关存储的顺序,即z系统CPU家族是完全多副本原子的,并且是唯一具有这种特性的商用系统。
与大多数cpu一样,z系统体系结构并不能保证缓存一致性 指令流,因此,自修改代码必须在更新指令和执行指令之间执行序列化指令。也就是说,许多实际的z系统机器实际上可以适应自修改的代码,而不需要序列化指令。z系统指令集提供了大量的序列化指令集, 包括比较和交换、一些类型的分支(例如,前面提到的“bcr15,0”指令)和测试和设置。
在这些CPU家族之间存在相当大的差异,这一节只是触及了少数被大量使用或具有历史意义的家族的表面。对于那些希望有更多细节的人,请查阅参考手册。
但是Linux-内核内存模型的一个很大的好处是,在编写独立于架构的Linux-内核代码时,您可以忽略这些细节。
15.6 内存模型直觉
几乎所有的人都很聪明。这是他们所缺乏的方法。
F.W.尼科尔
本节将回顾表15.3和第15.1.3节,总结了中间的讨论,包括一些呼吁传递直觉和更复杂的经验规则。
但是首先,当使用内存作为通信介质时,有必要回顾从一个线程到另一个线程的时间和非时间性质,如第15.2.7节中详细讨论的。关键是,尽管负载和存储在概念上很简单,但在真正的多核硬件上,需要大量的时间才能对所有其他线程可见。
当一个线程加载其他线程存储的值时,就会发生简单而直观的情况。这个简单的因果关系案例显示了时间行为,因此软件可以安全地假设存储指令在加载指令开始之前就已经完成了。在现实生活中,加载指令可能在存储指令之前已经开始了一段时间,但所有现代硬件都必须小心地对软件隐藏这些情况。因此,当一个线程加载一个其他线程存储的值时,软件将看到预期的时间因果行为,如第15.2.7.3节所述。
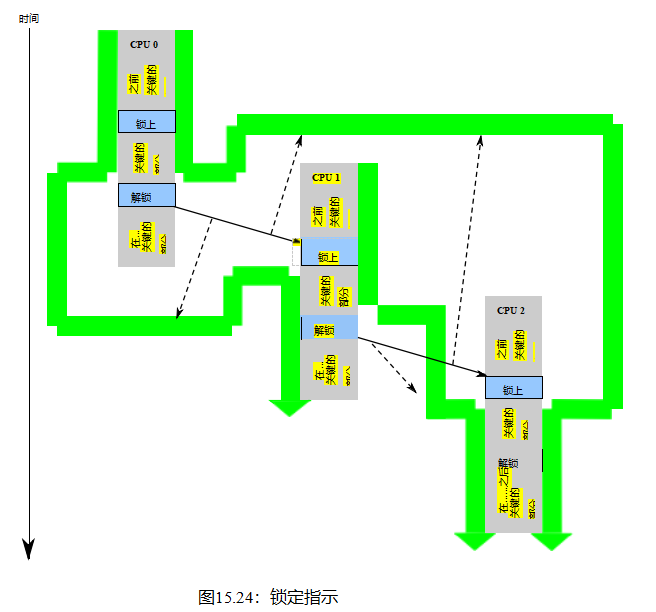
这种时间行为为下一节的传递直觉提供了基础。
本节总结了关于单个线程或变量、锁定、释放-获取链、RCU和完全有序的代码的直觉。
一个只有一个变量或只有一个线程的程序将按顺序查看所有的访问。当在现代计算机系统上运行单线程时,有相当多的代码可以获得足够的性能,但这本书主要是关于需要多个cpu的软件。然后,再讲到下一节。
另一种传递直觉涉及到备受诟病的主力,锁定,在第15.4.2节中有更详细的描述,更不用说第7章了。本部分包含一个图形描述,后面是一个口头描述。
图形描述显示在Figure15.24中,它显示了由cpu0、1和2按该顺序获取和释放的一个锁。实心的黑色箭头表示
解锁锁定顺序。从它们到绿色箭头的虚线显示了对排序的影响。特别是:
1.CPU 0的解锁先于CPU 1的锁定,这一事实确保了CPU 0在其临界部分内或之前执行的任何访问都将被CPU 1在其临界部分内和之后执行的访问所看到。
2.CPU 0的解锁先于CPU 2的锁定,这一事实确保了CPU 0在其临界部分内或之前执行的任何访问都将被CPU 2在其临界部分内和之后执行的访问所看到。
3.CPU 1的解锁先于CPU 2的锁定这一事实确保了CPU 1在其临界段内或之前执行的任何访问将被CPU 2在其临界部分内和之后执行的访问看到。
简而言之,基于锁的排序是通过cpu0、1和2进行传递的。关键是,这种顺序超出了临界部分,因此,早期锁释放之前的所有内容都可以被后期锁获取之后的所有内容所看到。
对于那些喜欢单词而不是图表的人,持有给定锁的代码将看到同一锁的所有先前关键部分的传递访问。如果这样的代码在给定的关键部分中看到了访问,它也会在该关键部分之前看到所有CPU代码中的访问。换句话说,当CPU释放给定的锁时,该锁的后续所有关键部分将在锁释放之前看到该CPU所有代码的访问。
相反,持有给定锁的代码将被保护,不会在同一锁的任何后续关键部分看到访问,同样是传递的。如果这样的代码被保护,以防止在给定的关键部分中看到访问,那么它也将被保护,以防止看到在该关键部分之后的所有CPU代码中的访问。换句话说,当一个CPU获得一个给定的锁时,该锁之前的所有关键部分将受到保护,不会在获得锁之后看到该CPU的所有代码的访问。
但是“看到访问”是什么意思?到底看到了是什么访问?
首先,访问是加载或存储,可能作为读-修改-写操作的一部分发生。
如果一个CPU在释放给定锁之前的代码包含对给定变量的访问a,那么对于在稍后获取同一锁之后对任何CPU代码中包含的同一变量的访问B:
1.如果A和B都是负载,那么B将返回与A相同的值或稍后的一些值。
2.如果A是负载,而B是存储,那么B将覆盖A加载的值或以后的值。
3.如果A是一个存储,B是一个负载,那么B将返回A存储的值或稍后的值。
4.如果A和B都是存储区,那么B将覆盖A存储的值或以后的一些值。
在这里,“一些后期值”是“由某些介入访问存储的值”的缩写。
锁定是强烈的直觉,这也是它存活如此多尝试消除它的原因之一。这也是为什么你应该在它适用的地方使用它的原因之一。
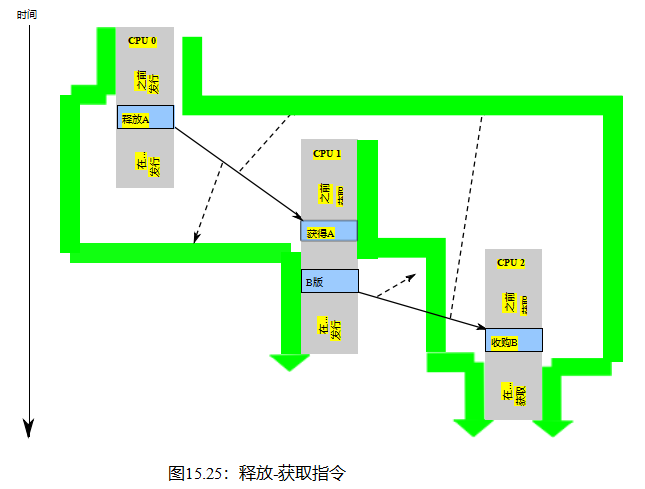
释放-获取链也以一种过渡直观的方式运行。本节还包含一个图形描述,后面是一个口头描述。
图形描述如图15.25所示,它显示了一个通过cpu0、1和2扩展的释放-获取链。黑色箭头描述了释放-获取的顺序。从它们到绿色箭头的虚线显示了对排序的影响。
1.CPU 0,s对A的释放被CPU 1,s获取A的事实确保了CPU 0在其发布之前执行的任何访问将被CPU 1在其获取之后执行的任何访问所看到。
2.CPU1,B的释放是由CPU 2读取的,这确保了CPU 1在发布之前执行的任何访问将被CPU 2执行的任何访问看到。
3.还要注意,CPU 0,A的释放由CPU1获取A,先于CPU1,由CPU 2释放B。总之,所有这些确保CPU 0执行的任何访问将在获取后被CPU 2执行的任何访问看到。
对于那些喜欢文字而不是图表的人,当一个获取加载一个版本存储的值时,如第15.2.7.4节中讨论的那样,那么该版本之后的代码将看到获取之前的所有访问。更准确地说,如果CPU 0进行了加载CPU1所存储的值的获取,那么CPU 0执行的所有后续访问将在发布之前看到所有CPU1的访问。
类似地,该释放访问之前的访问将被保护,不会看到获取访问之后的访问。(更精确的部分是留给读者的一个练习。)
发布和获取可以被链接,例如CPU0,发布存储CPU 1加载的值,CPU 1以后的发布存储CPU2加载的值,获取,等等。给定获取之后的访问将看到链中每个先前发布之前的访问,相反,给定发布之前的访问将受到保护,不会看到链中每个后续获取之后的访问。一些长链的例子说明了清单15.22,15.23,和15.24。
看见和看不见的访问的工作方式与第15.6.1.2节中描述的工作方式相同。
但是,如清单15.27所示,获取访问必须完全加载发布访问所存储的内容。任何本身不属于同一释放-收购连锁店的干预商店都将打破这条连锁店。
然而,适当构建的释放-获取链是可传递的、直观的和有用的。
15.6.1.4 RCU的直觉
如第228页第9.5.2节所述,RCU提供了一些订购保证。
第一个机制是在第228页的第9.5.2.1节中描述的发布-订阅机制。这类似于上一节中讨论的获取-释放链,但替代了smp_load_获取()的rcu_dereference()原语族的一个成员。与smp_load_acquire()不同,rcu_取消引用()所暗示的顺序只适用于取消引用该rcu_ dereference()返回的指针的后续访问,如图229页上的9.10所示。
第二个保证说,如果RCU读侧临界部分的任何部分先于一个宽限期的开始,那么整个临界部分先于该宽限期的结束,如第231页的图9.11所示。
第三个保证说,如果RCU读侧临界部分的任何部分在宽限期结束之后,那么整个临界部分在宽限期开始之后,如图232页的9.12所示。
这两种保证都在第230页的第9.5.2.2节中进行了讨论,在第233页和第234页的图9.13和9.14中显示了更多的例子。这两个保证有进一步的版本维护后果,这将在第235页的第9.5.2.3节中讨论。
这些保证在第15.4.3节中进行了更正式的讨论。
RCU的许多复杂性不在于它的保证,而在于它的用例,这是从第251页开始的第9.5.4节的主题。
一个更极端的例子是,每对传递性之间至少有一个smp_mb()
的访问。任何给定访问所看到的所有访问也将被以后的所有访问所看到。
由此产生的程序将被完全订购,如果有点慢。这样的程序将依次保持一致,并深受专门从事20世纪80年代可靠验证技术的正式验证专家的喜爱。但是不管是不是慢,当你需要它的时候,smp_mb()总是在那里!
然而,在有些情况下,我们还是不能用这些直观的计算方法来解决的。因此,下一节介绍了一组更完整的,如果不少传递的经验规则。
前一节中提出的传递直觉非常吸引人,至少在记忆模型中是这样。不幸的是,当一个线程的存储覆盖一个由其他线程加载或存储的值时,硬件没有义务提供时间上的因果错觉。从软件的角度来看,较早的存储很可能会覆盖较晚的存储的值,但前提是这两个存储是由不同的线程执行的,如图15.13所示。类似地,稍后的加载很可能读取被早期存储覆盖的值,但同样只有当该加载和存储由不同的线程执行时,如图15.12所示。如第15.2.7.2节所述,为了实现足够的性能,需要缓冲存储,从而导致这种反直觉的行为。
因此,一个线程读取其他线程编写的值的情况,比一个线程覆盖其他线程加载或存储的值的顺序要弱得多。这些差异可以通过以下的经验法则来捕获。
第一条经验法则是,只有在至少两个线程之间共享的至少两个变量之间的交互时,才需要内存排序操作,这是Section15.6.1.1中呈现的单一直观幸福的基础。根据中间的材料,这句话包含了第15.1.3节的许多基本经验法则,例如,请记住,“记忆障碍配对”是“循环”的一个双线程特例。而且,像往常一样,如果一个单线程程序能够提供足够的性能,为什么还要使用并行性呢?毕竟,避免并行性也避免了内存排序操作增加的成本和复杂性。
第二条经验法则涉及到加载缓冲情况:如果给定周期中的所有线程之间的通信都使用存储到加载链接(即,下一个线程的负载返回前一个线程存储的值),那么最小排序就足够了。最小排序包括依赖关系和获取以及所有更强的排序操作。因为锁获取必须加载该锁的任何预先释放所存储的锁字值,所以这个经验法则是Section15.6.1.2中呈现的锁直觉的基础。
第三条经验法则涉及释放-获取链:如果给定周期中除了一个链接都是存储到加载链接,那么对每个存储到加载链接使用释放-获取对就足够了,如清单15.23和15.24所示。本规则是第15.6.1.3节中提出的释放-获取直觉的基础。
您可以在允许的环境中使用依赖关系来替换给定的获取,请记住,C11标准的内存模型并不完全尊重依赖关系。因此,导致负载的依赖关系必须由READ_ ONCE()或rcu_dereference()引导:普通c语言负载是不够的。此外,请仔细检查第15.3.2节和第15.3.3节,因为一个依赖项被打破
您的编译器将不会订购任何东西。共享唯一的非存储到加载链接的两个线程有时一方面可以用WRITE_ONCE()+smp_wmb()代替smp_store_版本(),另一方面可以用READ_ONCE()+smp_rmb()代替smp_load_获得()。然而,明智的开发人员将仔细检查这些替代品,例如,使用第12.3节中所述的群体工具。

第四条也是最后一条经验法则确定了需要完整内存障碍(或更强)的位置:如果给定循环包含两个或两个以上非存储到加载链接(即总共两个或多个加载到存储或存储到存储链接),则该循环中每对非存储到加载链接之间至少需要一个完整障碍,如清单15.19以及快速测试15.25的答案所示。完整的障碍包括smp_mb()、成功的全强度非空原子RMW操作,以及在_smp_mb__()或smp_mb__after_atomic()之前结合的其他原子RMW操作。RCU的任何宽限期等待原语(synchronize_rcu()和朋友)也充当了完整的障碍,但代价比smp_mb()大得多。强度带来代价,尽管完全障碍对性能的影响通常大于可伸缩性。这一经验法则的极端逻辑终点是在第15.6.1.5节中提出的完全有序的直觉的基础。
正在重新捕获规则:
1.只有当至少两个线程共享了至少两个变量时,才需要进行内存排序操作。
2.如果一个循环中的所有链接都是存储到加载的链接,那么最小排序就足够了。
3.如果一个循环中除了一个链接之外的所有链接都是存储到加载链接,那么每个存储到加载链接都可以使用一个释放-获取对。
4.否则,在每对非存储到加载的链接之间至少需要一个完整的屏障。
请注意,如第15.5节中所讨论的,体系结构被允许提供更强的保证,但这些保证只能在仅为该体系结构运行的代码中使用。此外,更精确的内存模型[AMM+ 18]可能比这些经验法则以更低的开销操作提供更强的保证,尽管代价是牺牲更大的复杂性。在这些更正式的内存排序文件中,存储到加载链接是从读取(rf)链接的例子,加载到存储链接是从读取(fr)链接的例子,存储到存储链接是一致性(co)链接的例子。
最后一个建议是:使用原始内存排序原语是最后的手段。使用现有的原语几乎总是更好的,比如锁定或RCU,从而让这些原语为您执行内存排序。
Chapter 16 Ease of Use
16.1 什么是简单?
创建一个完美的API就像犯下一件完美的罪行。至少有50件事可以发生
错了,如果你是个天才,你可能能预见到其中的25个。
向可能还活着的凯瑟琳·特纳的粉丝们道歉。
当有人说“我想编程
我只需要说我想做的事,”给他们一颗棒棒糖。
Alan J. Perlis,更新
如果你倾向于轻视易用性要求,请考虑Linux内核RCU中的一个易用性错误导致了使用RCU时的可利用内核安全漏洞[McK19a]。因此,即使是在内核中的API也必须易于使用这一点显然非常重要。
不幸的是,“简单”是一个相对的概念。例如,许多人会觉得15小时的飞机飞行有点煎熬——除非他们停下来考虑其他交通方式,特别是游泳。这意味着创建一个易于使用的API需要你足够了解你的目标用户,知道对他们来说什么是简单。这可能与对你而言什么是简单无关。
以下问题说明了这一点:“在今天活着的所有人中随机选择一个人,有什么改变可以改善那个人的生活?”
没有一项单一的改变能够保证帮助所有人的生活。毕竟,人们有着极其广泛的需求、愿望和抱负。一个饥饿的人可能需要食物,但额外的食物可能会加速一个病态肥胖者的死亡。许多年轻人热切渴望的高度兴奋,对正在从心脏病发作中恢复的人来说可能是致命的。对某人成功至关重要的信息,可能会导致因信息过载而受苦的人失败。简而言之,如果你正在开发一个旨在帮助你完全不了解的人的软件项目,当这些人对你的项目提出批评时,你不必感到惊讶。
如果你真的想帮助某个特定群体,长期与他们紧密合作是无可替代的,这可能需要数年时间。然而,你可以做一些简单的事情来提高用户对软件满意的可能性,这些内容将在下一节中讨论。
16.2 API设计中的生锈层
因此,找到合适的测量方法不是数学上的练习,而是一种冒险的判断。
彼德·德拉科
本节内容改编自Rusty Russell 2003年渥太华Linux研讨会主题演讲的部分内容[Rus03,幻灯片39-57]。Rusty的核心观点是,目标不仅是要让API易于使用,更重要的是要让API难以被误用。为此,Rusty提出了他的“Rusty量表”,按这一重要不易误用属性的递减顺序排列。
以下列表试图将Rusty Scale推广到Linux内核之外:
1.不可能出错。尽管这是所有API设计者都应该努力达到的标准,但只有神话般的dwim()1命令才能接近这个标准。
2.编译器或链接程序不会让你出错。
3.如果编译器或链接程序出错,它会警告你。BUILD_BUG_ON()是用户的朋友。
4.最简单的用法就是正确的用法。
5.名称告诉您如何使用它。但是,名称可能是一把双刃剑。尽管对于从读写锁定转换代码的人来说,rcu_read_lock()非常简单,但对于从引用计数转换代码的人来说,它可能会引起一些困扰。
6.如果做不好,它在运行时就会崩溃。WARN_ON_ONCE()是用户的朋友。
7.遵循常见惯例,你就能做对。`malloc()`库函数就是一个很好的例子。尽管内存分配很容易出错,但许多项目确实能够做到正确,至少大多数时候是这样。结合使用`Valgrind`[The11]和`malloc()`,几乎可以将`malloc()`的错误率降到“要么正确执行,否则运行时总会出问题”的地步。
8.阅读文档,你就会做对。
9.阅读实现,你就会做对。
10.阅读正确的邮件列表存档,你就会得到正确的答案。
11.阅读正确的邮件列表存档,你就会弄错。
12.阅读实现,你就会犯错。rcu_read_lock()最初的非CONFIG_抢占实现[McK07a]是这个例子的典型代表。
13.阅读文档,你就会出错。例如,DEC Alpha的wmb指令文档[Cor02]曾误导许多开发人员,让他们误以为该指令的内存顺序语义比实际情况要强得多。后来的文档澄清了这一点[Com01,Pug00],将wmb指令提升到了“阅读文档,你就会做对”的级别。
14.遵循常见的惯例,你就会犯错。在这一尺度上,printf()语句就是一个例子,因为开发人员几乎总是没有检查printf()的错误返回值。
15.如果做对了,它会在运行时崩溃。
16.名字告诉你如何不使用它。
17.明显的用法是错误的。Linux内核中的smp_mb()函数就是一个例子,说明了这一点。许多开发人员认为这个函数具有比实际更强的顺序语义。第15章包含了避免这种错误所需的信息,Linux内核源代码树的文档和工具/内存模型目录也是如此。
18.如果编译器或链接程序正确地处理了它,它们会警告你。
19.编译器或链接程序不会让你得到正确的结果。
20.不可能完全正确。gets()函数是这个尺度上的一个著名例子。事实上,gets()可能最好被描述为一个无条件的缓冲区溢出安全漏洞。
16.3 修剪曼德布罗集
简单并不先于复杂,
但要遵循它。
艾伦·珀利斯
这套有用的程序类似于曼德布罗集(见图16.1),因为它没有明确的平滑边界——如果有,停机问题就能解决。但我们需要的是普通人可以使用的API,而不是每个潜在用途都需要完成博士论文才能使用的API。因此,我们“修剪了曼德布罗集”,将API的使用限制在一个易于描述的子集中。
这种剃须似乎适得其反。毕竟,如果一个算法有效,为什么不用呢?
要了解为什么至少需要一些剃须操作,可以考虑一种锁定设计,这种设计避免了死锁,但可能是最糟糕的方式。该设计使用了一个循环双向链表,其中包含系统中每个线程的一个元素以及一个头部元素。当新线程被创建时,父线程必须将新元素插入到这个列表中,这需要某种形式的同步。

保护列表的一种方法是使用全局锁。但是,如果频繁创建和删除线程,这可能会成为瓶颈。另一种方法是使用哈希表并锁定各个哈希桶,但按顺序扫描列表时,这种方法的性能可能较差。
第三种方法是锁定单个列表元素,并要求在插入时同时持有前驱和后继的锁。由于需要获取两个锁,我们需要决定以何种顺序来获取它们。两种传统的方法是按地址顺序获取锁,或者按照列表中出现的顺序获取锁,这样当头部作为被锁定的两个元素之一时,总是先获取头部的锁。然而,这两种方法都需要特殊的检查和分支。
要实现的剃须解决方案是无条件地按列表顺序获取锁。但是,死锁怎么办?
不会发生死锁。
要实现这一点,从零开始给列表中的元素编号,起始为表头,结束于列表最后一个元素(即表头前的一个元素,因为列表是循环的)。同样地,将线程从零到N - 1进行编号。如果每个线程都尝试锁定一对连续的元素,至少有一个线程能够同时获得这两个锁。
为什么
因为没有足够的线程来完成整个列表的访问。假设线程0获取了元素0的锁。要被阻塞,其他线程必须已经获取了元素1的锁,因此我们假设线程1已经这样做了。同样地,对于线程1来说,要被阻塞,其他线程必须已经获取了元素2的锁,依此类推,直到线程N - 1,它获取了元素N - 1的锁。对于线程N - 1来说,要被阻塞,其他线程必须已经获取了元素N的锁。但没有更多的线程了,所以线程N - 1无法被阻塞。因此,死锁不会发生。
那么,为什么我们要禁止使用这个令人愉快的小算法呢?
事实上,如果您真的想要使用它,我们无法阻止您。但是,我们可以建议不要将这样的代码包含在我们关心的任何项目中。


事实上,这个算法极其专门化(仅适用于特定大小的列表),并且相当脆弱。任何意外未能向列表中添加节点的错误都可能导致死锁。实际上,仅仅是在稍晚一点时添加节点就可能引发死锁,增加线程数量也是如此。
此外,上述其他算法都是“良好且充分”的。例如,按地址顺序获取锁既简单又快速,同时允许使用任意大小的列表。只是要注意空列表和仅包含一个元素的列表带来的特殊情况!

总之,我们使用算法并不是因为它们碰巧有效。相反,我们会选择那些足够有用、值得学习的算法。算法越复杂难懂,它必须越普遍有用,才能让学习和修复其错误的过程变得有价值。
![]()
除例外情况外,我们必须继续削减软件“曼德布罗集”,以便我们的程序保持可维护性,如图16.2所示。
Chapter 17 Conflicting Visions of the Future
预测是非常困难的,尤其是关于未来的。
尼尔斯·玻尔
本章呈现了一些关于并行编程未来的相互冲突的愿景。这些愿景中哪一个会成为现实尚不清楚,事实上,甚至不清楚它们是否会实现。然而,这些愿景都很重要,因为每个愿景都有其忠实的支持者,如果足够多的人对某件事深信不疑,你将不得不面对它对其支持者的思想、言语和行为产生的影响。此外,一个或多个这样的愿景最终将会实现。但大多数都是虚假的。分辨出哪些是哪些,你就会变得富有[Spi77]!
因此,以下章节将概述事务内存、硬件事务内存、回归测试中的形式验证以及并行函数编程。但首先,我们将讲述一个来自21世纪初的关于预测的警示故事。
17.1 CPU技术的未来不是它曾经的样子
他身后有一个伟大的未来。
大卫·马兰尼斯
多年过去,透过多年的经验之眼,一切似乎都显得如此简单和纯真。而21世纪初,在很大程度上,人们对于摩尔定律即将失效、无法继续提供当时传统的CPU时钟频率提升这一前景还抱有天真。当然,偶尔也会有关于技术极限的警告,但这些警告已经持续了几十年。鉴于此,请考虑以下情景:
1.单处理器Uber Alles(图17.1),2.多线程狂热(图17.2),
3.更多相同(图17.3),以及
4.碰撞假人撞击记忆墙(图17.4)。
5.惊人的加速器(图17.5)。
以下各节将介绍这些情形。
正如在2004年所述[McK04]:
在这种情况下,CPU时钟速率的摩尔定律增长和横向扩展计算的持续进步使得SMP系统变得无关紧要。因此,这种情况被称为“单处理器至上”,字面意思是单处理器至高无上。
这些单处理器系统仅受指令开销的影响,因为内存屏障、缓存抖动和争用不会影响单CPU系统。在这种情况下,RCU仅适用于特定应用,如与NMI的交互。尚不清楚缺乏RCU的操作系统是否会认为采用它有必要,尽管已经实现RCU的操作系统可能
会继续这样做。
然而,最近多线程cpu的发展似乎表明这种情况不太可能。
确实不太可能!但更大的软件社区不愿意接受他们需要拥抱并行计算的事实,因此过了好一阵子,这个社区才意识到摩尔定律带来的CPU核心频率提升的“免费午餐”已经彻底结束了。永远不要忘记:信念是一种情感,不一定是理性技术思考的结果!
同样来自2004年[McK04]:
一种较为温和的单处理器Uber Alles变体采用了硬件多线程技术,事实上,多线程CPU现在已成为许多台式机和笔记本电脑系统的标准配置。最激进的多线程CPU共享所有级别的缓存层次结构,从而消除了CPU到CPU的内存延迟,进而大大减少了传统同步机制带来的性能损失。然而,多线程CPU仍然会因竞争和由内存屏障引起的流水线停滞而产生开销。此外,由于所有硬件线程共享所有级别的缓存,给定硬件线程可用的缓存量仅为等效单线程CPU的一小部分,这可能会降低具有大缓存需求的应用程序的性能。还有一种可能性是,有限的缓存可用性会导致基于RCU的算法因宽限期引起的额外内存消耗而产生性能损失。研究这一可能性将是未来的工作。
然而,为了避免性能下降,许多多线程CPU和多CPU芯片会根据硬件线程至少部分地划分缓存层级。这增加了每个硬件线程可用的缓存量,但同时也重新引入了从一个硬件线程传递到另一个硬件线程时的内存延迟。
我们都知道这个故事的结局,即在一个芯片上插入多个多线程核心,每个核心连接到一个插槽,针对每核活动线程数较少的情况进行了不同程度的优化。问题在于未来的共享内存系统是否总是能适应单个插槽。
再次引用2004年文献[McK04]:
More-of-the-Same方案假设内存延迟比率将保持在今天的大致水平。
这一情景实际上代表了一种变化,因为要实现更多的相同效果,互连性能必须跟上摩尔定律核心CPU性能的增长。在这种情况下,由于流水线停顿、内存延迟和争用导致的开销仍然显著,而RCU仍保持其目前的高度适用性。
而变化是摩尔定律仍在提供的不断增加的集成水平。但从长远来看,会是更多的CPU/芯片?还是更多的I/O、缓存和内存?
服务器似乎选择了前者,而芯片上的嵌入式系统(SoC)继续选择后者。
还有2004年的一段话[McK04]:
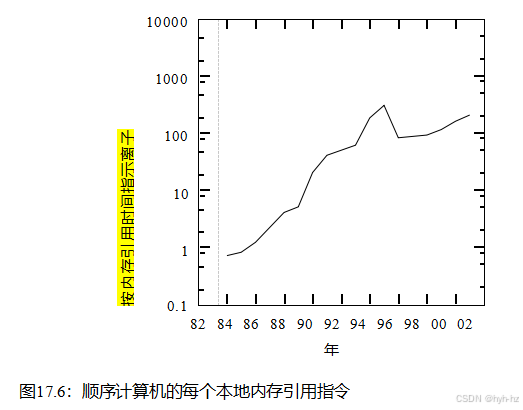
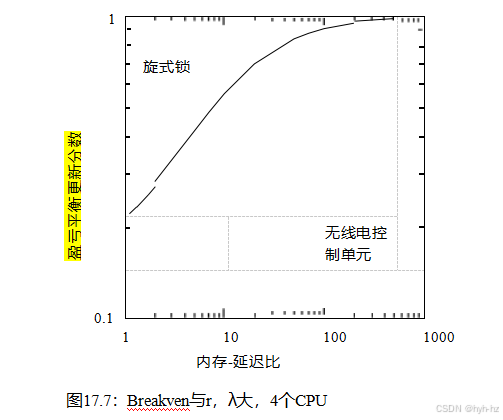
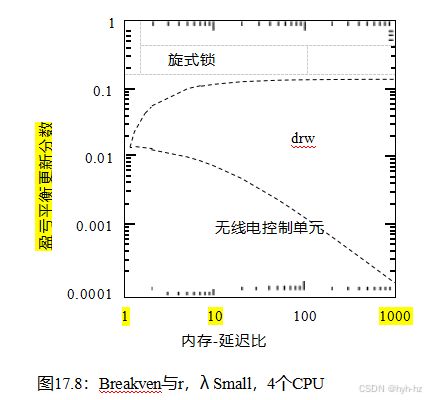
如果图17.6中显示的内存延迟趋势继续存在,那么相对于指令执行开销,内存延迟将继续增长。
像Linux这样的系统,如果大量使用RCU,将会发现额外使用RCU是有利可图的,如图17.7所示。从该图可以看出,如果RCU被大量使用,增加内存延迟比会使RCU相对于其他同步机制的优势逐渐增大。相反,对于少量使用RCU的系统,需要越来越高的读取强度才能使RCU发挥作用,如图17.8所示。从该图可以看出,如果RCU使用较少,增加内存延迟比会使RCU相对于其他同步机制的优势逐渐减弱。由于在高负载下观察到Linux每个宽限期有超过1,600次回调[SM04b],可以认为Linux属于前者。
一方面,这段文字未能预见RCU在更新强度显著的工作负载中可能遇到的缓存热问题,部分原因是当时认为RCU不太可能用于此类工作负载。然而,在实际应用中,SLAB_TYPESAFE_BY_RCU在多个情况下被用于解决这些缓存热问题,序列锁定也是如此。另一方面,这段文字也未能预见RCU会被用于减少调度延迟或提高安全性。
本书生成的大部分数据是在一个八插槽系统上收集的,每个插槽有28个核心,每个核心有两个硬件线程,总计448个硬件线程。空闲系统的内存延迟小于一微秒,这并不比2004年类似规模系统的延迟差。有人声称这些延迟接近一微秒只是因为x86 CPU家族相对较强的内存排序机制,但这一特定论点可能还需要一段时间才能得到解决。
硬件加速器的潜力在2004年并不像2021年那样清晰,因此本节没有引用。然而,2020年11月的Top 500榜单[MDSS20]中包含了许多加速器,所以可以说这一部分反映的是现状而非未来。同样的情况也适用于前面的大多数部分。
硬件加速器被用于许多其他用途,包括加密、压缩和机器学习。
简而言之,要警惕预测,包括本章其余部分的预测。
17.2 事务内存
一切都应该尽可能简单,但不能更简单。
路易斯·祖科夫斯基笔下的阿尔伯特·爱因斯坦
使用数据库外事务的想法可以追溯到几十年前[Lom77,Kni86,HM93],数据库与非数据库事务之间的关键区别在于,非数据库事务省略了定义数据库事务的“ACID”1属性中的“D”。支持基于内存的事务,或称为“事务性内存”(TM)的概念则更为近期[HM93],但遗憾的是,尽管提出了其他一些类似建议[SSHT93],商品硬件中对此类事务的支持并未立即实现。不久之后,沙维特和图伊图提出了一种仅软件实现的事务性内存(STM),能够在商品硬件上运行,尽管存在内存排序问题[ST95]。这一提议沉寂多年,可能是因为研究界的注意力被非阻塞同步所吸引(见第14.2节)。
但到世纪之交,TM开始受到更多关注[MT01,RG01],到本世纪中叶,人们的兴趣水平只能被称为“炽热的”[Her05,Gro07],只有少数人持谨慎态度[BLM05,MMW07]。
TM的基本思想是原子地执行一段代码,使得其他线程看不到中间状态。因此,TM的语义可以通过简单地用递归获取和释放全局锁来实现每个事务,尽管性能和可扩展性极差。无论是硬件还是软件实现,TM实现中固有的大部分复杂性在于高效检测并发事务何时可以安全并行运行。由于这种检测是动态进行的,冲突的事务可以被中止或“回滚”,在某些实现中,这种失败模式对程序员是可见的。
由于事务回滚随着事务规模的减小而变得越来越不可能,TM对于基于内存的小型操作可能非常有吸引力,例如用于栈、队列、哈希表和搜索树的链表操作。然而,目前要为大型事务,特别是包含非内存操作如输入输出和进程创建的事务,提供理由则困难得多。接下来的部分将探讨“事务内存无处不在”这一宏伟愿景当前面临的挑战[McK09b]。第17.2.1节考察了与外部世界交互所面临的挑战,第17.2.2looks节讨论了与进程修改的交互。
原始语句,第17.2.3节探讨了与其他同步原始语句的交互,最后是第17.2.4closes节的一些讨论。
用唐纳德·克努斯的智慧之言:
许多计算机用户觉得输入和输出实际上不是“真正的编程”的一部分,它们仅仅是(不幸的是)为了将信息输入和输出到机器中而必须做的事情。
无论我们是否相信输入和输出是“真正的编程”,事实是软件绝对必须处理外部世界。因此,本节对事务内存的外部世界能力进行批评,重点是I/O操作、时间延迟和持久存储。
17.2.1.1输入/输出操作
可以在基于锁的关键区中执行I/O操作,同时持有危险指针,在序列锁定的读侧关键区中执行,也可以在用户空间RCU读侧关键区中执行,甚至必要时可以同时进行。当你尝试在一个事务内执行I/O操作时会发生什么?
底层问题在于交易可能会因冲突而回滚。大致来说,这意味着任何给定交易中的所有操作都必须可撤销,即执行两次的操作与只执行一次的效果相同。不幸的是,I/O通常是最典型的不可撤销操作,这使得将一般的I/O操作包含在交易中变得困难。事实上,一般I/O是不可撤销的:一旦按下启动核弹头的按钮,就无法回头了。
以下是处理事务内I/O的一些选项:
1.限制事务中的I/O操作,使用内存缓冲区进行缓冲I/O。这些缓冲区可以像其他任何内存位置一样包含在事务中。这似乎是首选机制,在许多常见情况下,如流I/O和大容量存储I/O,它确实表现良好。然而,在多个进程将多条记录导向输出流合并到单个文件时,需要特殊处理,例如使用fopen()的“a+”选项或open()的O_APPEND标志。此外,正如将在下一节中看到的,常见的网络操作无法通过缓冲来处理。
2.禁止在事务中执行I/O,这样任何尝试执行I/O操作的行为都会使包含该操作的事务(以及可能的多个嵌套事务)中止。这种方法似乎是针对非缓冲I/O的常规TM方法,但要求TM与其他能够容忍I/O的同步原语进行互操作。
3.禁止在事务中进行输入/输出,但请让编译器协助执行此禁令。
4.仅允许在任何给定时间进行一个特殊的不可撤销事务[SMS08],从而允许不可撤销事务包含I/O操作。2这种方法可以实现
总体而言,这种方法严重限制了I/O操作的可扩展性和性能。鉴于可扩展性和性能是并行处理的一等目标,这种做法的通用性似乎有些自我局限。更糟糕的是,使用不可撤销性来容忍I/O操作似乎极大地限制了手动事务回滚操作的使用。最后,如果存在一个不可撤销的事务正在操作某个数据项,那么任何其他操作该相同数据项的事务都不能具有非阻塞语义。
5.创建新的硬件和协议,以便将I/O操作拉入事务性基底。在输入操作的情况下,硬件需要正确预测操作的结果,并且如果预测失败,则中止事务。
输入/输出操作是TM的一个众所周知的弱点,而且尚不清楚支持事务中的输入/输出问题是否有一个合理的通用解决方案,至少如果“合理”包括可用的性能和可伸缩性的话。然而,继续投入时间和精力解决这个问题可能会产生更多的进展。
17.2.1.2 RPC操作
可以在基于锁的关键区中执行RPC,同时持有危险指针,在序列锁定的读侧关键区中执行,也可以在用户空间RCU读侧关键区中执行,甚至必要时可以同时进行。当你尝试在一个事务中执行RPC时会发生什么?
如果RPC请求及其响应都包含在事务中,并且事务的某些部分依赖于响应返回的结果,那么就无法使用缓冲I/O时可以使用的内存缓冲技巧。任何尝试采用这种缓冲方法都会导致事务死锁,因为请求无法传输,直到事务被保证成功为止,但事务的成功可能要等到收到响应后才能确定,如下例所示:
| begin_trans(); rpc_request() ; i = rpc_response(); a[i]++; end_trans(); |
事务的内存占用量在接收到RPC响应后才能确定,在无法确定事务的内存占用量之前,无法判断该事务是否可以提交。唯一符合事务语义的操作是无条件中止事务,这至少可以说是毫无帮助的。
以下是TM可选择的一些选项:
1.禁止在事务中执行RPC,以防止任何尝试执行RPC操作的行为
中止包围的事务(也许还有多个嵌套事务)。Alter-
首先,让编译器强制执行无RPC事务。这种方法可以
2.仅允许一个特殊的不可撤销事务[SMS08]在任何给定时间进行,从而允许不可撤销事务包含RPC操作。这通常可行,但严重限制了RPC操作的可扩展性和性能。鉴于可扩展性和性能是并行处理的一等目标,这种方法的通用性似乎有些自我限制。此外,使用不可撤销事务来允许RPC操作会限制一旦RPC操作开始后手动事务回滚的操作。最后,如果有不可撤销事务正在操作某个数据项,那么其他任何操作该相同数据项的事务都必须具有阻塞语义。
3.识别那些在收到RPC响应之前就能确定交易成功的特殊情况,并在发送RPC请求前自动将其转换为不可撤销的交易。当然,如果多个并发交易以这种方式尝试RPC调用,可能需要回滚除一个之外的所有交易,这会导致性能和可扩展性的下降。然而,对于以RPC结束的长时间运行交易而言,这种方法仍然有价值。此方法仍需限制手动交易中止操作。
4.确定RPC响应可能移出事务的特殊情况,然后使用类似于缓冲I/O所用的技术继续执行。
5.扩展事务底层架构,包括RPC服务器及其客户端。理论上这是可行的,分布式数据库已经证明了这一点。然而,考虑到基于内存的事务处理没有慢速磁盘驱动器可以隐藏延迟,分布式数据库技术是否能满足所需的性能和可扩展性要求尚不清楚。当然,随着固态硬盘的出现,数据库可能需要重新设计其延迟隐藏方法。
如前一节所述,输入/输出是TM的已知弱点,而RPC只是I/O的一个特别有问题的情况。
17.2.1.3时间延迟
一个重要的特例是事务访问与额外事务访问之间的交互涉及事务内的显式时间延迟。当然,事务内的时间延迟与TM的原子性属性相悖,但这种特性可以说是弱原子性的核心所在。此外,正确地与内存映射I/O交互有时需要精心控制的时间,而应用程序通常会出于各种目的使用时间延迟。最后,在基于锁的关键区段中,可以在持有危险指针的情况下执行时间延迟;在序列锁定读侧关键区段中执行时间延迟;在用户空间RCU读侧关键区段中执行时间延迟,甚至可以在必要时同时进行。这样做可能从竞争或可扩展性的角度来看并不明智,但这样做并不会引发任何根本性的概念问题。
那么,TM对于事务中的时间延迟能做些什么呢?
1.忽略事务中的时间延迟。这看起来很优雅,但像许多其他“优雅”的解决方案一样,在与旧代码接触时无法生存。这种代码在关键部分很可能有重要的时间延迟,在被事务化时会失败。
2.遇到延迟操作时中止事务。这很有吸引力,但不幸的是,自动检测延迟操作并不总是可能的。这是在执行关键计算的紧致循环,还是仅仅在等待时间流逝?
3.要求编译器禁止事务中的时间延迟。
4.让时间延迟正常执行。不幸的是,一些TM实现只在提交时发布修改,这可能会破坏时间延迟的目的。
不清楚是否存在唯一正确的答案。具有弱原子性的TM实现,如果在事务中立即发布更改(并在中止时回滚这些更改),可能更适合最后一种选择。即使在这种情况下,事务另一端的代码(或可能是硬件)也可能需要大幅重新设计,以容忍中止的事务。这种重新设计的需求会使将事务内存应用于遗留代码变得更加困难。
17.2.1.4持久性
有许多不同类型的锁定原语。一个有趣的区别是持久性,换句话说,锁是否可以独立于使用锁的进程的地址空间存在。
非持久锁包括pthread_mutex_lock()、pthread_rwlock_ rdlock()和大多数内核级别的锁定原语。如果实现非持久锁的数据结构中的内存位置消失,那么该锁也会随之消失。对于pthread_mutex_lock()的典型使用情况,这意味着当进程退出时,其所有锁都会消失。这一特性可以被利用来简化程序关闭时的锁清理过程,但同时也使得不相关的应用程序更难共享锁,因为这种共享需要应用程序共享内存。

持久锁有助于避免在不相关的应用程序之间共享内存。持久锁定API包括flock系列、lockf()、System V信号量或O_CREAT标志的open()。这些持久API可用于保护跨越多个应用程序运行的大规模操作,在O_CREAT的情况下甚至能经受住操作系统重启。如有需要,通过分布式锁管理器和分布式文件系统,锁甚至可以跨越多台计算机系统,并且能够在任何或所有这些计算机系统的重启中持续存在。
任何应用程序都可以使用持久锁,包括用多种语言和软件环境编写的程序。事实上,一个用C语言编写的程序可以获取一个持久锁,而另一个用Python语言编写的程序可以释放这个持久锁。
如何为TM提供类似的持久性功能?
1.将持久性事务限制在专门设计来支持它们的特殊用途环境中,例如SQL。鉴于数据库系统已有几十年的历史,这显然可行,但不能提供与持久锁相同的灵活性。
2.使用某些存储设备和/或文件系统提供的快照功能。
不幸的是,它不处理网络通信,也不处理对不提供快照功能的设备的I/O,例如内存棒。
3.建造一台时间机器。
4.通过使用现有的持久性设施来完全避免问题,大概会避免在事务中使用这些设施。
当然,之所以称之为事务内存,应该让我们有所顾虑,因为名称本身与持久化事务的概念相冲突。然而,考虑这种可能性是值得的,因为它是一个重要的测试案例,可以探测事务内存固有的局限性。
进程不是永恒的:它们被创建和销毁,其内存映射被修改,它们与动态库链接,并且它们被调试。这些部分将探讨事务性内存如何处理不断变化的执行环境。
17.2.2.1多线程事务
在持有锁的情况下创建进程和线程是完全合法的,同样地,在序列锁定读侧临界区和用户空间RCU读侧临界区内持有危险指针时也是如此,必要时甚至可以同时进行。这不仅合法,而且非常简单,从以下代码片段可以看出:
| pthread_mutex_lock ( ...); 对于(i = 0;i < ncpus;i++) pthread_create(&tid[i],.. .);for(i = 0;i < ncpus;i++) pthread_join(tid[i],.. .);pthread_mutex_unlock(.. .); |
这段伪代码片段使用`pthread_create()`每个CPU周围生成一个线程,然后使用`pthread_join()`等待每个线程完成,整个过程都在`pthread_mutex_lock()`的保护下进行。其效果是并行执行基于锁的临界区,也可以通过`fork()`和`wait()`实现类似的效果。当然,为了抵消线程生成开销,临界区需要相当大,但在生产软件中有很多大型临界区的例子。
TM对事务中的线程生成会做些什么?
1.声明pthread_create()在事务中是非法的,最好通过中止事务来实现。或者,让编译器强制执行pthread_创建无()事务。
2.允许pthread_create()在一个事务中执行,但只有父线程被视为该事务的一部分。这种方法似乎与现有的和假设的TM实现相当兼容,但对于不谨慎的人来说似乎是一个陷阱。这种方法还引发了进一步的问题,例如如何处理冲突的子线程访问。
3.将pthread_create()转换为函数调用。这种方法虽然有吸引力,但也有其不便之处,因为它无法处理子线程之间相互通信的常见情况。此外,它也不允许事务主体的并发执行。
4.扩展事务以覆盖父线程和所有子线程。这种方法引发了关于冲突访问本质的有趣问题,因为假设父线程和子线程可以相互冲突,但不能与其他线程冲突。同样引人关注的是,如果父线程在提交事务前没有等待其子线程会发生什么。更有趣的是,如果父线程根据参与事务的变量值有条件地执行pthread_join()会怎样?对于锁定情况,这些问题的答案相对简单明了。而对于事务处理,答案留给读者自行思考。
鉴于事务处理在数据库领域中并行执行已司空见惯,当前的事务管理提案未能提供相应的支持或许令人惊讶。另一方面,上述示例展示了较为复杂的锁定机制,这在简单的教科书案例中并不常见,因此其缺失也情有可原。尽管如此,一些研究人员正在利用事务自动并行化代码[RKM+ 10],并且有传言称其他事务管理研究者也在探索事务内的分叉/合并并行性,因此这一主题可能很快会得到更深入的研究。
17.2.2.2exec()系统调用
可以在基于锁的关键区中执行exec()系统调用,同时持有危险指针,在序列锁定的读侧关键区中,以及在用户空间RCU读侧关键区中,甚至必要时可以同时进行。具体语义取决于原语类型。
对于非持久性原语(包括pthread_mutex_lock()、pthread_rwlock_rdlock()和用户空间RCU),如果exec()成功,整个地址空间将消失,同时持有的任何锁也会随之失效。当然,如果exec()失败,地址空间仍然存在,因此相关的锁也会继续有效。这可能有点奇怪,但定义明确。
另一方面,持久性原语(包括flock家族、lockf()、System V信号量和用于打开的O_CREAT flag to open())无论exec()成功还是失败都会存活,因此被exec()的程序可能会释放它们。

当您尝试在事务中执行exec()系统调用时,会发生什么情况?
1.在事务中不允许执行exec(),这样当遇到exec()时,包含的事务就会中止。这一点是明确的,但显然需要使用非TM同步原语与exec()配合使用。
2.在事务中不允许执行exec(),由编译器强制执行此禁止。
C++中有一个TM的草案规范,它采用了这种方法,允许函数用transaction_safe和transaction_unsafe进行装饰
属性。4这种方法比在运行时中止事务有一些优点,但是同样需要使用非TM同步原语与exec()结合使用。一个缺点是需要对许多库函数进行transaction_safe和transaction_unsafe属性的装饰。
3.以类似于非持久锁定原语的方式处理事务,使得如果exec()失败,事务仍然存活;如果exec()成功,则自动提交。仅部分受事务影响的变量驻留在mmap()的内存中(因此可以在成功的exec()系统调用后存活)的情况留给读者自行思考。
4.如果exec()系统调用将会成功,那么就中止事务(以及exec()系统调用),但如果exec()系统调用会失败,则允许事务继续。这在某种意义上是“正确”的方法,但需要大量的工作才能得到一个相当不令人满意的结果。
exec()系统调用或许是通用图灵机应用障碍中最奇特的例子,因为尚不清楚哪种方法是合理的,有些人可能认为这只是现实生活中与exec()交互风险的反映。话虽如此,禁止在事务中使用exec()的两种选项可能是最合乎逻辑的选择。
类似的错误也出现在exit()和kill()系统调用中,以及会导致事务退出的longjmp()或异常。(long jmp()或异常是从哪里来的?)
17.2.2.3动态链接和加载
基于锁的关键区、持有危险指针的代码、顺序锁定的读侧关键区以及用户空间RCU的读侧关键区(单独或组合)可以合法地包含调用动态链接和加载函数的代码,包括C/C++共享库和Java类库。当然,这些库中的代码在编译时是无法预知的。那么,如果在一个事务中调用了动态加载的函数会发生什么?
这个问题分为两部分:(a)如何在事务中动态链接并加载一个函数,以及(b)对于该函数内的代码不可知性该如何处理?公平地说,(b)项对锁定和用户空间-RCU也提出了一些挑战,至少理论上是这样。例如,动态链接的函数可能会导致锁定时出现死锁,或者(错误地)将用户空间-RCU读侧临界区引入静止状态。不同之处在于,虽然锁定和用户空间-RCU临界区允许的操作类别已经非常明确,但在TM的情况下似乎仍存在相当大的不确定性。事实上,不同的TM实现似乎有不同的限制。
那么,TM对于动态链接和加载的库函数可以做些什么呢?关于实际加载代码的选项(a)部分包括以下内容:
1.以类似于处理页面错误的方式处理动态链接和加载,以便加载并链接函数,可能在过程中中止事务。如果事务被中止,则重试将发现该函数已经存在,因此可以预期事务正常进行。
2.禁止在事务处理中动态链接和加载函数。
对于选项(b),无法检测尚未加载函数中的TM不友好操作的可能性包括以下内容:
1.只需执行代码:如果函数中存在任何与TM不兼容的操作,直接中止事务。不幸的是,这种方法使得编译器无法判断一组事务是否可以安全组合。一种允许组合性的方法是不可撤销事务,然而,当前实现仅允许在任意给定时间进行单个不可撤销事务,这会严重限制性能和可扩展性。不可撤销事务还限制了手动事务中止操作的使用。最后,如果有不可撤销事务正在操作某个数据项,其他任何操作该相同数据项的事务都不能具有非阻塞语义。
2.装饰函数声明,指示哪些函数是TM友好的。
这些装饰可以通过编译器的类型系统来强制执行。当然,对于许多语言而言,这需要提出、标准化并实现语言扩展,伴随着相应的时间延迟,以及对大量原本无关的库函数进行相应的装饰。尽管如此,标准化工作已经在进行中[ATS09]。
3.如上所述,禁止在事务中动态链接和加载函数。
输入输出操作当然是TM的一个已知弱点,动态链接和加载可以被视为输入输出的另一种特殊情况。然而,TM的支持者要么解决这个问题,要么接受一个世界,在这个世界里,TM只是并行程序员工具箱中的众多工具之一。(公平地说,许多TM的支持者早已接受了包含更多工具的世界。)
17.2.2.4内存映射操作
在基于锁的关键区中执行内存映射操作(包括mmap()、shmat()和munmap()[Gro01]),同时持有危险指针,在序列锁定读侧关键区中,以及在用户空间RCU读侧关键区中,甚至同时执行这些操作都是完全合法的。当你尝试在一个事务内执行这样的操作时会发生什么?更具体地说,如果被重映射的内存区域包含当前线程事务中的某些变量,会发生什么?如果这个内存区域包含其他线程事务中的变量又会怎样?
由于大多数锁定原语不定义重映射其锁定变量的结果,因此没有必要考虑TM系统元数据被重新映射的情况。
以下是一些TM内存映射选项:
1.事务中的内存重映射是非法的,这将导致所有包含的事务被中止。这在一定程度上简化了事情,但也要求TM与同步原语互操作,这些同步原语能够容忍在它们的关键部分内进行重映射。
2.事务中内存重映射是非法的,编译器负责强制执行此禁令。
3.内存映射在事务中是合法的,但是会终止该区域映射的所有其他包含变量的事务。
4.内存映射在事务中是合法的,但如果被映射的区域与当前事务的足迹重叠,则映射操作将失败。
5.所有内存映射操作,无论是在事务内部还是外部,都检查被映射的区域是否与系统中所有事务的内存占用空间相重叠。如果存在重叠,则内存映射操作失败。
6.系统中任何事务的内存占用范围重叠的内存映射操作的效果由TM冲突管理器决定,它可能会动态地确定是否要使内存映射操作失败或中止任何冲突的事务。
值得注意的是,munmap()将相关内存区域未映射,这可能具有其他有趣的含义。
17.2.2.5调试
通常的调试操作,如断点,在基于锁的关键区和用户空间-RCU读侧关键区中都能正常工作。然而,在最初的事务内存硬件实现[DLMN09]中,事务内的异常会终止该事务,这意味着断点会终止所有包含的事务。
那么如何调试事务呢?
1.在包含断点的事务中使用软件仿真技术。当然,当在任何事务范围内设置断点时,可能需要对所有事务进行仿真。如果运行时系统无法确定某个断点是否位于事务范围内,则为了安全起见,可能需要对所有事务进行仿真。然而,这种方法可能会带来显著的开销,从而掩盖正在追踪的错误。
2.仅使用能够处理断点异常的硬件TM实现。不幸的是,截至本文撰写时(2021年3月),所有此类实现都是研究原型。
3.仅使用软件TM实现,(粗略地说)比简单的硬件TM实现更容许异常。当然,软件TM的开销往往高于硬件TM,因此在所有情况下,这种方法可能不可接受。
4.更仔细地编写程序,以避免一开始就出现交易中的错误。一旦你弄清楚如何做到这一点,请务必让每个人都知道这个秘密!
有理由相信,事务内存相比其他同步机制能够提高生产效率,但如果传统调试技术无法应用于事务中,这些改进很容易丧失。这在新手处理大型事务时尤为明显。相比之下,那些自诩为“顶尖高手”的程序员可能无需使用此类调试工具,尤其是在处理小型事务时。
因此,如果事务内存要向新手程序员兑现其生产率承诺,那么调试问题确实需要解决。
如果事务内存有一天证明它可以满足所有人的需求,它将不再需要与其他任何同步机制交互。在此之前,它需要与那些无法实现其功能或在特定情况下更自然地工作的同步机制合作。以下部分概述了该领域的当前挑战。
17.2.3.1锁定
获取锁时同时持有其他锁是常见的做法,这通常效果很好,至少只要采用众所周知的软件工程技巧来避免死锁。从RCU读侧临界区获取锁也不罕见,因为RCU读侧原语不会参与基于锁的死锁循环,从而缓解了死锁问题。此外,在持有危险指针和序列锁读侧临界区时获取锁也是可行的。但当你试图在一个事务中获取锁时会发生什么?
理论上,答案很简单:只需在事务中操作表示锁的数据结构,一切都能完美解决。实际上,根据TM系统的实现细节,可能会出现一些不明显的问题[VGS08]。这些问题可以解决,但代价是,在事务外部获取锁的开销增加了45 %,而在事务内部获取锁的开销则增加了300 %。虽然对于包含少量锁定的事务程序来说,这些开销可能是可以接受的,但对于希望偶尔使用事务的生产质量基于锁的程序而言,这些开销通常是完全不可接受的。
1.仅使用对锁定友好的TM实现。不幸的是,对锁定不友好的实现具有一些吸引人的特性,包括成功事务的低开销和能够容纳非常大的事务。
2.在向基于锁定的程序引入TM时,仅“在小范围内”使用TM,从而适应对锁定友好的TM实现的限制。
3.完全放弃基于锁定的旧系统,重新实现所有功能以事务形式。这种方法不乏支持者,但需要解决本系列中描述的所有问题。在解决问题期间,竞争同步机制当然也有机会改进。
4.严格地将TM用作基于锁的系统的优化,正如TxLinux [RHP+07]组和许多事务锁省略所做的那样
项目[PD11、Kle14、FIMR16、PMDY20]。这种方法似乎很合理,但仍然保留了锁定设计约束(例如避免死锁的需要)。
5.努力减少锁定基本元素所造成的开销。
可能在TM接口和锁定方面存在问题这一事实让许多人感到意外,这突显了在实际生产软件中尝试新机制和基本组件的必要性。幸运的是,开源的出现意味着现在有大量此类软件可以免费提供给所有人,包括研究人员。
17.2.3.2读写锁定
读取-获取读者-写入锁并同时持有其他锁是常见的做法,只要采用众所周知的软件工程技术来避免死锁,这种方法就有效。在RCU读侧临界区中读取-获取读者-写入锁也是可行的,这样做可以缓解死锁问题,因为RCU读侧原语无法参与基于锁的死锁循环。同时,也可以在持有危险指针和序列锁读侧临界区中获取锁。但当你试图在一个事务内读取-获取读者-写入锁时会发生什么?
不幸的是,直接尝试在一个事务中读取并获取传统的基于计数器的读写锁的做法违背了读写锁的目的。要理解这一点,可以考虑两个事务同时尝试读取并获取同一个读写锁的情况。由于读取操作涉及修改读写锁的数据结构,这将导致冲突,其中一个事务会被回滚。这种行为完全不符合读写锁允许并发读取的目标。
以下是TM可选择的一些选项:
1.使用每CPU或每线程的读写锁定[HW92],这允许给定的CPU(或线程)在获取锁时仅操作本地数据。这样可以避免两个事务同时获取锁时产生的冲突,使它们能够按预期进行。不幸的是,(1)每CPU/线程锁定的写入获取开销可能非常高,(2)每CPU/线程锁定的内存开销可能难以承受,
(3)只有在您能够访问相关源代码时,此转换才可用。其他更新的可扩展读写锁[LLO09]可能会避免一些或所有这些问题。
2.在向基于锁的程序引入TM时,仅“在小范围内”使用TM,从而避免在事务中获取读取-获取读者-写入锁。
3.完全放弃基于锁定的旧系统,重新实现所有功能以事务形式进行。这种方法不乏支持者,但需要解决本系列中描述的所有问题。在这些问题得到解决期间,竞争的同步机制当然也有机会改进。
4.严格地将TM用作基于锁的系统的优化,就像TxLinux [RHP+07]组所做的那样,并且像最近使用TM来省略读写锁的工作[FIMR16]所做的那样。这种方法似乎是合理的,至少在
POWER8 CPU[LGW+15],但保留了锁定设计约束(例如避免死锁的需要)。
当然,将TM与读写锁定结合在一起可能会有其他不明显的问题,就像独占锁定一样。
本节主要讨论RCU。当TM与其他延迟回收机制如引用计数器和危险指针结合时,会出现类似的问题和可能的解决方案。在下面的文本中,特别指出已知的差异。
如第9.5.5节和第9.6.3节所述,引用计数、危险指针和RCU都被大量使用。这意味着任何选择不克服本节中提到的每一个挑战的TM实现都需要与所有这些同步机制干净且高效地互操作。
来自德克萨斯大学奥斯汀分校的TxLinux小组似乎成为了应对RCU/TM互操作性挑战的团队[RHP+07]。由于他们将TM应用于使用RCU的Linux 2.6内核,因此不得不将TM与RCU集成,用TM代替锁定来处理RCU更新。遗憾的是,尽管论文指出RCU实现中的锁(例如rcu_ctrlblk.lock)被转换为事务,但对基于RCU的更新所使用的锁(如dcache_lock)的具体处理方式却只字未提。
最近,迪米特里奥斯·西亚卡瓦拉斯等人将HTM和RCU应用于搜索树[SNGK17,SBN+ 20],克里斯蒂娜·吉安努拉等人使用HTM和RCU对图进行着色[GGK18],而朴成宰等人则利用HTM和RCU优化了NUMA系统上的高竞争锁定[PMDY20]。
需要注意的是,RCU允许读取器和更新器并行运行,进一步使得RCU读取器能够访问正在被更新的数据。当然,无论RCU的性能、可扩展性和实时响应优势如何,这一特性都与TM的原子性属性相悖,尽管POWER8 CPU系列的暂停事务功能[LGW+ 15]使其成为这一规则的例外。
那么,基于TM的更新应该如何与并发的RCU读取器交互呢?以下是一些可能性:
1. RCU的读者会中止并发冲突的TM更新。这实际上是TxLinux项目采取的方法。这种方法确实保留了RCU的语义,同时也保持了RCU的读取端性能、可扩展性和实时响应特性,但不幸的是,它会导致不必要的冲突更新中止。最坏的情况下,一长串RCU读者可能会使所有更新者陷入饥饿状态,理论上可能导致系统挂起。此外,并非所有TM实现都提供了实现此方法所需的强原子性,这是有充分理由的。
2. RCU读取器在运行时会从任何冲突的RCU加载中获取旧(事务前)值。这不仅保留了RCU的语义和性能,还防止了RCU更新饥饿。然而,并非所有TM实现都能及时访问由正在进行的事务暂时更新的变量的旧值。特别是那些基于日志的TM实现,在日志中维护旧值(从而提供出色的TM提交性能),可能不会对此方法感到满意。也许
rcu_dereference()原始方法可以用来允许RCU访问TM实现范围内的旧值,尽管性能可能仍然是一个问题。然而,有一些流行的TM实现已经以这种方式与RCU集成[PW07,HW11,HW14]。
3.如果RCU读取器执行的访问与正在进行的事务冲突,则该RCU访问将被延迟,直到冲突的事务提交或中止。这种方法保留了RCU的语义,但牺牲了RCU的性能和实时响应,尤其是在存在长时间运行的事务时。此外,并非所有TM实现都能延迟冲突访问。然而,对于仅支持小事务的硬件TM实现而言,这种方法似乎非常合理。
4. RCU的读者被转换为事务。这种方法几乎可以保证RCU与任何TM实现兼容,但同时也将TM的回滚强加于RCU的读侧临界区,破坏了RCU的实时响应保证,并且还降低了RCU的读侧性能。此外,在RCU的读侧临界区内包含TM实现无法处理的操作时,这种方法是不可行的。对于危险指针和引用计数器而言,由于没有明确界定的读取代码段概念,这种方法更难以应用。
5.许多使用RCU的更新操作会修改一个指针以发布新的数据结构。在某些情况下,只要事务遵守内存顺序,并且回滚过程使用call_rcu()释放相应的结构,RCU可以安全地看到随后被撤销的事务指针更新。不幸的是,并非所有TM实现都尊重事务内的内存屏障。显然,人们认为由于事务应该是原子性的,因此事务内部访问的顺序不应受到影响。
6.禁止在RCU更新中使用TM。这可以保证工作,但会限制TM的使用。
似乎很可能会发现更多的方法,特别是考虑到用户级RCU和危险指针实现的出现。有趣的是,许多性能更好且扩展性强的STM实现内部都使用了类似RCU的技术[Fra04,FH07,GYW+ 19,KMK+ 19]。
![]()
在基于锁的关键区中,完全合法地操作那些在同一锁的关键区内被同时访问甚至修改的变量,一个常见的例子就是统计计数器。同样的情况也适用于RCU读侧关键区,事实上这是常见的情况。
考虑到在生产数据库系统中普遍存在的所谓“脏读”机制,事务管理的支持者对事务外访问给予了极大的关注也就不足为奇了,弱原子性[BLM06]的概念就是一个很好的例子。
以下是一些非交易选项:
1.由于事务外访问而产生的冲突总是会中止事务。这是强原子性。
2.忽略事务外访问引起的冲突,因此只有事务之间的冲突才能中止事务。这是弱原子性。
3.允许事务在特殊情况下执行非事务操作,例如分配内存或与基于锁的关键区交互。
4.生产允许执行某些操作(例如,添加)的硬件扩展
由多个事务同时对单个变量执行。
5.引入弱语义到事务内存中。一种方法是与第17.2.3.3节中描述的RCU结合使用,而格拉莫利和古埃拉乌伊则调查了其他多种弱事务方法[GG14],例如,将大型“弹性”事务限制分割为较小的事务,从而降低冲突概率(尽管性能和可扩展性较差)。或许进一步的经验会表明,某些额外事务访问的使用可以被弱事务所替代。
看起来事务是在真空中构思出来的,无需与其他任何同步机制进行交互。如果真是这样,那么当将事务与非事务访问结合时,产生大量混乱和复杂性也就不足为奇了。但除非事务仅限于对孤立数据结构的小更新,或者被限制在不与庞大的现有并行代码体互动的新程序中,否则如果要在短期内实现大规模的实际影响,事务必须如此结合。
普遍采用TM的障碍导致了以下结论:
1.TM的一个有趣特性是事务可以回滚和重试。这一特性导致了TM在处理不可逆操作时遇到困难,包括未缓冲的I/O、RPC、内存映射操作、时间延迟以及exec()系统调用。此外,这一特性还带来了所有可能失败带来的复杂性,这些复杂性往往以开发人员可见的方式显现出来。
2.另一个有趣的特性是,TM与它保护的数据交织在一起,这一点由Shpeisman等人指出[SATG+09]。这一特性导致了TM在I/O、内存映射操作、跨事务访问和调试断点方面的问题。相比之下,传统的同步原语,如锁和RCU,保持了同步原语与其保护的数据之间的明确分离。

3.TM领域的许多工作人员的既定目标之一是简化大型顺序程序的并行化。因此,通常期望单个事务串行执行,这可能在很大程度上解释了TM在多线程事务方面的问题。

TM研究人员和开发人员应该对这一切做些什么呢?
一种方法是专注于小事务,即关注那些硬件辅助可能比其他同步原语提供显著优势的小型事务,以及有证据表明结合使用TM锁定方法可以提高生产力的小程序[PAT11]。Sun在其Rock研究CPU中采用了小事务的方法[DLMN09]。一些TM研究人员似乎同意这两种“小即是美”的方法[SSHT93],另一些人则对TM寄予更高的期望,还有一些人暗示高期望可能是TM最大的敌人[Att10,第6节]。尽管如此,TM仍有可能应对更大的问题,本节列出了若要实现这一宏伟目标必须解决的一些问题。
当然,所有参与的人都应该把这当作一次学习经验。看来,TM研究者们可以从那些成功地使用传统同步原语构建大型软件系统的实践者那里学到很多东西。

但就目前而言,STM的现状可以用一系列漫画来概括。首先,图17.9显示了STM的愿景。和往常一样,现实有点不同。



如图17.10,17.11和17.12.7所示,更加细致入微。不太夸张的STM回顾也可获得[Duf10a,Duf10b]。
一些商用硬件支持HTM的受限变体,将在下文进行说明。
17.3 硬件事务内存
在自动化之前,确保您的报告系统是合理干净且高效的。否则,您的新计算机只会加速混乱。
罗伯特·汤森
截至2021年,硬件事务内存(HTM)已在多种类型的商用商品计算机系统上使用多年[YHLR13,Mer11,JSG12,Hay20]。本节试图确定HTM在并行程序员工具箱中的位置。
从概念的角度来看,HTM使用处理器缓存和推测执行,使得一组指定的语句(称为“事务”)能够从其他处理器上运行的任何其他事务的角度来看,以原子方式生效。该事务由一个开始事务机器指令启动,并通过一个提交事务机器指令完成。通常还存在一个中止事务机器指令,它会取消推测(就像开始事务指令及其后续所有指令都没有执行一样),并在失败处理程序处开始执行。失败处理程序的位置通常由开始事务指定。
指令,既可以作为显式的失败处理程序地址,也可以通过指令本身设置的条件代码。每个事务都与其他事务原子性地执行。
HTM有许多重要的优点,包括自动动态分区数据结构、减少同步原语缓存缺失以及支持相当多的实用应用程序。
然而,仔细阅读细则总是值得的,HTM也不例外。本节的一个主要观点是,在什么条件下,HTM的好处能够超过其细则中隐藏的复杂性。为此,第17.3.1describes节讨论了HTM的好处,而第17.3.2describes节则探讨了它的弱点。这种方法与之前论文[MMW07,MMTW10]以及前一节所采用的方法相同。
第17.3.3then节描述了HTM在Linux内核(以及许多用户空间应用程序)中使用的同步原语组合方面的弱点。Section17.3.4looks部分讨论了HTM如何最好地融入并行程序员的工具箱,而第17.3.5节列出了可能大幅扩展HTM范围和吸引力的一些事件。最后,第17.3.6presents节是结论性评述。
HTM的主要优势在于(1)避免了其他同步原语常遇到的缓存未命中问题,(2)能够动态地划分数据结构,以及(3)它拥有相当数量的实际应用。我打破传统,没有单独列出易用性,原因有二。首先,易用性应源于HTM的主要优势,本节将重点讨论这些优势。其次,围绕测试编程天赋[Bo06,DBA09,PBCE20]甚至在面试中使用小型编程练习[Bra07]的做法存在相当大的争议。这表明我们实际上并不清楚什么使编程变得容易或困难。因此,本节余下部分将集中讨论上述三项优势。
17.3.1.1避免同步缓存未命中
大多数同步机制都基于由原子指令操作的数据结构。由于这些原子指令通常首先使相关的缓存行被其运行的CPU拥有,因此在同一实例的后续执行中,在其他CPU上将导致缓存未命中。这种通信缓存未命中的问题严重降低了传统同步机制的性能和可扩展性[ABD+ 97,第4.2.3节]。
相比之下,HTM通过使用CPU的缓存来同步,避免了需要单独的同步数据结构和由此产生的缓存未命中。当锁数据结构放置在单独的缓存行中时,HTM的优势最为明显,在这种情况下,将给定的关键区转换为HTM事务可以完全减少该关键区的开销,实现一次缓存未命中。对于常见的短关键区情况,至少在省略锁不与经常写入的变量共享缓存行的情况下,这些节省是非常显著的。

使用某些传统同步机制的主要障碍在于需要静态划分数据结构。有许多数据结构可以轻松划分,最典型的例子是哈希表,每个哈希链构成一个分区。为每个哈希链分配锁,从而可以轻松地将哈希表的操作并行化到特定的链上。同样,数组、基数树、跳跃表等其他几种数据结构的划分也非常简单。
然而,对于许多类型的树和图进行分区相当困难,结果通常非常复杂[Ell80]。尽管可以使用两阶段锁定和哈希锁数组来分区一般数据结构,但其他技术已被证明更为优越[Mil06],相关内容将在第17.3.3节中讨论。鉴于其避免了同步缓存未命中问题,HTM因此成为大型不可分区数据结构的一个非常现实的选择,至少假设更新相对较小的情况下是这样。

17.3.1.3实用价值
HTM的实际价值已在多个硬件平台上得到证明,包括Sun Rock [DLMN09]、Azul Vega [Cli09]、IBM Blue Gene/Q [Mer11]、Intel Haswell TSX [RD12]和IBM System z [JSG12]。
预期的实际效益包括:
1.锁定省略以实现内存数据访问和更新[MT01,RG02]。
2.对大型不可分区数据结构的并发访问和小的随机更新。
然而,HTM也有一些非常真实的缺点,将在下一节中讨论。
HTM的概念非常简单:一组访问和更新内存的操作是原子性的。但是,就像许多简单的想法一样,当您将其应用于现实世界中的实际系统时,会出现一些复杂的情况。这些复杂情况如下:
1.事务大小限制。
2.冲突处理。
3.中止和回退。
6.语义差异。
以下章节将对每种并发症进行描述,随后为总结。
当前HTM实现的事务大小限制源于处理器缓存用于存储受事务影响的数据。尽管这使得特定CPU可以通过在其缓存范围内执行事务,使其对其他CPU显得原子化,但也意味着任何无法适应的事务都无法提交。此外,改变执行上下文的事件,如中断、系统调用、异常、陷阱和上下文切换,要么必须中止该CPU上的任何正在进行的事务,要么由于其他执行上下文的缓存占用而进一步限制事务大小。
当然,现代CPU倾向于拥有大容量缓存,许多事务所需的数据可以轻松地存储在一个兆字节的缓存中。不幸的是,对于缓存而言,仅仅大小并不是决定因素。问题在于,大多数缓存可以被视为硬件实现的哈希表。然而,硬件缓存不会链接它们的桶(通常称为集),而是为每个集提供固定数量的缓存行。给定缓存中每个集提供的元素数量被称为该缓存的关联性。
尽管缓存关联度各不相同,但我正在使用的笔记本电脑中,一级缓存的八路关联度并不罕见。这意味着,如果某个事务需要访问九个缓存行,并且这九个缓存行都映射到同一组,则该事务根本无法完成,更不用说该缓存中可能有多余的兆字节空间了。是的,给定数据结构中的随机选择的数据元素,该事务能够提交的概率相当高,但无法保证[McK11c]。
已经有一些研究工作旨在缓解这一限制。完全关联的受害者缓存可以减轻关联度的约束,但目前对受害者缓存大小存在严格的性能和能效要求。尽管如此,未修改的缓存行的HTM受害者缓存可以非常小,因为它们只需要保留地址:数据本身可以写入内存或由其他缓存影射,而地址本身足以检测到冲突写入[RD12]。
无界事务内存(UTM)方案[AAKL06,MBM+06]使用DRAM作为极其庞大的受害者缓存,但将此类方案集成到生产质量的缓存一致性机制中仍然是一个未解决的问题。此外,使用DRAM作为受害者缓存可能会带来不幸的性能和能效后果,特别是当受害者缓存需要完全关联时。最后,“无界”特性假设所有DRAM都可以用于受害者缓存,而实际上分配给特定CPU的大量但仍固定的DRAM会限制该CPU的事务大小。其他方案结合了硬件和软件事务内存[KCH+06],可以设想使用STM作为HTM的备用机制。
然而,据我所知,除了简化TM读集的表示之外,目前可用的系统没有实现这些研究想法中的任何一个,也许是有充分的理由。
17.3.2.2冲突处理
第一个复杂性是冲突的可能性。例如,假设事务A和B定义如下:
| 交易 x = 1; y = 3; | A | 交易 y = 2; x = 4; | B |
假设每个事务在其自身的处理器上并发执行。如果事务A同时向x存储数据,而事务B向y存储数据,那么两个事务都无法继续进行。为了理解这一点,假设事务A执行了向y的存储操作。那么事务A将在事务B中交错执行,这违反了事务之间必须原子性执行的要求。同样地,允许事务B执行向x的存储操作也违反了原子性执行的要求。这种情况被称为冲突,当两个并发事务访问同一个变量时,至少有一个访问是存储操作,就会发生冲突。因此,系统有义务中止一个或两个事务以允许执行继续进行。具体选择哪个事务中止是一个有趣的话题,很可能在未来一段时间内仍能成为博士论文的研究课题,例如参见[ATC+11]。对于本节的目的,我们可以假设系统随机做出选择。
另一个复杂的问题是冲突检测,至少在最简单的情况下相对直接。当处理器执行事务时,它会标记该事务触及的每一个缓存行。如果处理器的缓存接收到涉及已被当前事务标记为已触及的缓存行的请求,则可能发生潜在冲突。更复杂的系统可能会尝试将当前处理器的事务安排在发送请求的处理器之前,优化这一过程很可能会在未来很长一段时间内继续产生博士学位论文。然而,本节假设了一个非常简单的冲突检测策略。
然而,为了使HTM有效工作,冲突的概率必须非常低,这反过来要求数据结构的组织方式能够维持足够低的冲突概率。例如,具有简单插入、删除和搜索操作的红黑树符合这一描述,但维护树中元素数量准确计数的红黑树则不符合。另一个例子是,在单次事务中枚举树中所有元素的红黑树将有较高的冲突概率,从而降低性能和可扩展性。因此,许多串行程序在HTM能够有效工作之前需要进行一些重构。在某些情况下,实践者可能会选择采取额外的步骤(在红黑树的情况下,可能切换到可分区的数据结构,如基数树或哈希表),并仅使用锁定机制,尤其是在HTM能够在所有相关架构上轻松实现之前[Cli09]。

此外,并发事务之间的冲突访问可能会导致失败。下节将讨论如何处理此类失败。
因为任何事务都可能在任何时候被中止,所以事务中不应包含无法回滚的语句。这意味着事务不能执行输入/输出操作、系统调用或调试断点(对于HTM事务!!!,不允许单步执行)。相反,事务必须限制在访问常规缓存内存。此外,在某些系统上,中断、异常、陷阱、TLB未命中等事件也会导致事务中止。鉴于错误条件处理不当所引发的大量错误,我们有理由质疑中止和回滚对易用性的影响。

当然,中止和回滚引发了关于HTM是否适用于硬实时系统的问题。HTM的性能优势是否超过了中止和回滚的成本?如果是的话,在什么条件下可以实现这一点?事务能否使用优先级提升?或者高优先级线程的事务应该优先中止低优先级线程的事务?如果是这样,硬件如何高效地得知优先级?关于HTM在实时环境中的应用文献非常稀少,可能是因为在非实时环境中让HTM正常工作已经存在足够多的问题。
由于当前的HTM实现可能会确定性地中止某个事务,软件必须提供回退代码。这种回退代码必须使用某种其他形式的同步机制,例如锁定。如果使用基于锁的回退方法,那么锁定的所有限制,包括死锁的可能性,都会重新出现。当然,可以希望回退方法不常被使用,这可能允许采用更简单且不易发生死锁的锁定设计。但这引发了系统如何从使用基于锁的回退方法过渡到事务的问题。一种方法是采用“测试-再测试-设置”原则[MT02],即所有人在锁释放之前都暂停操作,这样系统可以在那时以干净的状态进入事务模式。然而,这可能导致大量的自旋,如果锁持有者已经阻塞或被抢占,这样做可能是不明智的。另一种方法是允许事务并行处理,同时由一个线程持有锁[MT02],但这在维护原子性方面带来了困难,特别是当线程持有锁的原因是因为相应的事务无法放入缓存时。
最后,处理中止和回滚的可能性似乎给开发人员带来了额外的负担,他们必须正确地处理所有可能的错误条件组合。
很明显,HTM的用户必须投入大量的验证工作来测试备用代码路径以及从备用代码返回事务性代码的过程。也没有理由相信HTM硬件的验证要求会少一些。
尽管事务大小、冲突以及中止或回滚都可能导致事务中止,但人们可能希望足够小且持续时间短暂的事务最终能够成功。这将允许事务无条件重试,就像使用这些指令实现原子操作的代码中,比较交换(CAS)和加载链接/存储条件(LL/SC)操作会被无条件重试一样。
不幸的是,除了低时钟速率的学术研究原型[SBV10]外,目前可用的HTM实现拒绝提供任何形式的前向进展保证。如前所述,因此HTM无法用于避免这些系统中的死锁。希望未来的HTM实现能够提供某种形式的前向进展保证。在此之前,HTM在实时应用中必须极其谨慎地使用。
截至2021年,这一黯淡景象中唯一的例外是IBM大型机,它提供受限交易[JSG12]。这些限制相当严格,详见第17.3.5.1节。HTM向前推进保证能否从大型机迁移到普通CPU家族将十分有趣。
17.3.2.5不可撤销的业务
另一个后果是,HTM事务无法支持不可撤销的操作。当前的HTM实现通常通过要求事务中的所有访问都必须是可缓存内存(从而禁止MMIO访问)以及在中断、陷阱和异常时中止事务(从而禁止系统调用)来强制执行这一限制。
请注意,只要缓冲区填充/刷新操作发生在事务之外,HTM事务就可以支持缓冲I/O。之所以可行,是因为向缓冲区添加数据和从中移除数据是可撤销的:只有实际的缓冲区填充/刷新操作是不可撤销的。当然,这种缓冲I/O方法会导致I/O被计入事务的开销中,增加事务的大小,从而提高失败的可能性。
尽管在许多情况下,HTM可以作为锁定的直接替代品(因此得名事务锁省略(TLE)[DHL+08]),但
在语义上存在细微差别。布伦德尔[BLM06]给出了一个特别恶劣的例子,涉及协调的基于锁的关键区段,在事务执行时会导致死锁或活锁;但一个更简单的例子是空关键区段。
在基于锁的程序中,一个空的关键区段会保证所有先前持有该锁的进程现在都已释放了它。这种惯用法被2.4版本的Linux内核网络堆栈用于协调配置变更。但如果将这个空的关键区段转换为事务,则结果是一个空操作。所有先前关键区段终止的保证就丧失了。换句话说,事务锁省略保留了锁定的数据保护语义,但失去了锁定的时间消息传递语义。
![]()
| 清单17.1:利用优先级提升 |
| 1个空载增压器(空载) 2 { 3 i = 0;4 5 acquire_lock(&boost_lock[i]); 6 while(;){ 7 acquire_lock(&boost_lock[! i]); 8 release_lock(&boost_lock[i]); 9 i = i ^ 1; 10 do_something(); 11 } 12 } 13 15 { 16 i = 0;17 18 while(;){ 19 usleep(500);/* sleep 0 .5 ms. */ 20 acquire_lock(&boost_lock[i]); 21 release_lock(&boost_lock[i]); 22 i = i ^ 1; 24 } |

锁定与事务之间的一个重要语义差异在于优先级提升,这是为了避免基于锁的实时程序中出现优先级反转。优先级反转可能发生的情况是,一个持有锁的低优先级线程被一个中等优先级的CPU绑定线程抢占。如果每个CPU至少有一个这样的中等优先级线程,低优先级线程将永远没有机会运行。如果一个高优先级线程现在尝试获取锁,它会阻塞。它无法获取锁,直到低优先级线程释放锁,而低优先级线程又无法释放锁,直到它有机会运行,而它也无法有机会运行,直到其中一个中等优先级线程放弃其CPU。因此,中等优先级线程实际上阻塞了高优先级进程,这就是“优先级反转”这一名称的由来。
避免优先级反转的一种方法是优先级继承,即高优先级线程在锁定时暂时将其优先级让给锁的持有者,这也可以称为优先级提升。然而,优先级提升不仅可用于防止优先级反转,如清单17.1所示。该清单的第1-12行展示了一个低优先级进程,尽管如此,它仍需每隔一毫秒左右运行一次;而同一清单的第14-24行则展示了一个高优先级进程,通过优先级提升确保受提升()按需定期运行。
boost_()函数通过始终保持两个boost_ lock[]锁中的一个来安排这一点,这样,boost_()的第20-21行就可以根据需要提升优先级。

这种安排要求boosted()在系统变得繁忙之前在线5上获得第一个锁定,但即使是现代硬件也很容易安排。
不幸的是,这种安排在事务锁定省略的情况下可能会崩溃。`boostee()`函数的重叠关键区段会变成一个无限事务,迟早会被中止,例如,在运行`boostee()`函数的线程首次被抢占时。此时,`boostee()`将回退到锁定模式,但由于其优先级较低且安静初始化期已经结束(这正是`boostee()`被抢占的原因),该线程可能再也没有机会运行。
如果增强线程()没有持有锁,那么增强线程()在Listing17.1will的第20和21行上的空临界区就会变成一个无效的事务,从而导致增强线程()永远不会运行。这个例子说明了事务内存的一些微妙后果及其回滚重试的语义。
鉴于这种经验可能会揭示出更多的细微语义差异,因此在大型程序中应用基于HTM的锁省略时应谨慎行事。话虽如此,在适用的情况下,基于HTM的锁省略可以消除与锁变量相关的缓存未命中问题,这已在2015年初的大规模实际软件系统中带来了数十个百分点的性能提升。因此,我们可以预期这种技术将在提供可靠支持的硬件上得到广泛应用。

17.3.2.7摘要
尽管HTM似乎有令人信服的应用场景,但当前的实现存在严重的事务大小限制、冲突处理复杂性、回滚问题以及需要谨慎处理的语义差异。表17.1总结了HTM在锁定方面的现状。可以看出,虽然HTM目前的状态缓解了一些锁定的严重缺陷,但它也引入了许多自身的问题。这些问题已被TM社区的领导者所承认[MS12]。
此外,这并不是全部。锁定通常不会单独使用,而是通常与其他同步机制结合使用,包括引用计数、原子操作、非阻塞数据结构、危险指针[Mic04a,HLM02]和RCU [MS98a,MAK+01,HMBW07,McK12b]。下一节将探讨这种增强如何改变这一方程。
实践者长期以来一直使用引用计数、原子操作、非阻塞数据结构、危险指针和RCU来避免锁定的一些缺点。
表17.2:锁定(RCU或危险点增强)与HTM (优势、劣势、严重劣势)的比较
例如,在许多情况下,通过使用引用计数、危险指针或RCU来保护数据结构,特别是对于只读关键部分[Mic04a,HLM02,DMS+ 12,GMTW08,HMBW07],可以避免死锁。这些方法还减少了对数据结构进行分区的需求,如第10章所述。RCU进一步提供了无竞争且有界等待的读侧原语[MS98a,DMS+ 12],而危险指针则提供了无锁读侧原语[Mic02,HLM02,Mic04a]。将这些考虑因素加入表17.1中,得到了增强锁定与HTM之间的更新比较,如表17.2所示。两表之间的差异总结如下:
1.使用非阻塞读侧机制可以缓解死锁问题。
2.诸如危险指针和RCU等读取侧机制可以高效地处理不可分区的数据。
3.危险指针和RCU不会相互竞争,也不会与更新器竞争,这使得读取为主的负载具有出色的性能和可伸缩性。
4.危险指针和RCU提供了前向进展保证(分别锁自由和有界等待自由)。
5.危险指针和RCU的私有化操作很简单。

当然,也可以增强HTM,如下一节中所讨论的。
尽管HTM的应用范围可能还需要一段时间才能像第276页图9.33中所示的RCU那样清晰地界定,但这并不是不朝这个方向前进的理由。
HTM最适合用于更新密集型工作负载,涉及对运行在大型多处理器上的相对较大的内存数据结构的不同部分进行相对较小的更改。这既满足了当前HTM实现的大小限制,又最大限度地减少了冲突及随之而来的中止和回滚的可能性。鉴于当前同步原语,这种情况也相对难以处理。
使用锁定与HTM结合似乎可以克服HTM在不可撤销操作上的困难,而使用RCU或危险指针可能缓解HTM在只读操作中遇到的事务大小限制,这些操作会遍历数据结构的大部分[PMDY20]。当前的HTM实现会在冲突时无条件地中止更新事务,但未来的HTM实现可能会更顺畅地与这些同步机制互操作。在此期间,更新与大型RCU或危险指针读侧临界区冲突的概率应该远小于
表17.3:锁定(普通和增强)与HTM (优点、缺点、严重缺点)的比较
与等效的只读事务冲突。然而,由于相应的冲突流,持续不断的RCU或危险指针读取者可能会饿死更新者。这种漏洞可以通过给非事务读取提供加载内存位置的预事务副本来消除(这需要显著的硬件成本和复杂性)。
HTM事务必须有回退机制这一事实,在某些情况下可能会迫使数据结构的静态分区性回归到HTM。如果未来的HTM实现能够提供前向进展保证,这种限制或许可以缓解,这可能在某些情况下消除对回退代码的需求,从而允许HTM在冲突概率较高的场景中高效使用。
简而言之,尽管HTM可能具有重要的用途和应用,但它只是并行程序员工具箱中的另一个工具,而不是整个工具箱的替代品。
能够大大增加对HTM需求的游戏改变者包括以下内容:
1.前向进展保证。
2.事务大小增加。
3.改进的调试支持。
4.原子性弱。
在以下章节中对此进行了扩展。
正如第17.3.2.4节所讨论的,当前的HTM实现缺乏前向进展保证,这要求有备用软件来处理HTM故障。当然,提出保证很容易,但提供这些保证并不总是那么容易。对于HTM而言,阻碍保证的因素可能包括缓存大小和关联性、TLB大小和关联性、事务持续时间和中断频率以及调度器实现。
缓存大小和关联性在第17.3.2.1节中进行了讨论,同时提出了一些旨在克服当前限制的研究。然而,HTM前向推进保证会受到大小限制,尽管这些限制将来可能会变得更大。那么,为什么目前的HTM实现不为小事务提供前向推进保证呢?例如,仅限于缓存的关联性?一个可能的原因是需要处理硬件故障。例如,一个失效的缓存SRAM单元可以通过停用该单元来处理,从而降低缓存的关联性,进而减少可以保证前向推进的最大事务大小。鉴于这只会减少保证的事务大小,似乎还有其他原因在起作用。也许,在生产质量的硬件上提供前向推进保证比想象中要困难得多。
考虑到在软件中很难做出前进保证,这是一个完全可信的解释。将问题从软件转移到硬件并不一定会使它更容易解决[JSG12]。
对于一个物理标记和索引的缓存,事务能够适应缓存是不够的。它的地址转换也必须适应TLB。因此,任何前向进展保证都必须考虑TLB大小和关联性。
鉴于当前HTM实现中中断、陷阱和异常会中止事务,必须确保给定事务的执行时间短于预期的中断间隔。无论给定事务涉及的数据多么少,如果运行时间过长,也会被中止。因此,任何向前推进的保证不仅取决于事务大小,还取决于事务持续时间。
前向进展保证的关键在于能够确定多个冲突事务中哪一个应该被中止。很容易想象出一个无尽的事务序列,每个事务都会中止前面的一个事务,而这个前面的事务又会被后续的事务中止,结果是没有任何事务真正提交。冲突处理的复杂性体现在已提出的大量HTM冲突解决策略[ATC+ 11,LS11]上。布伦德尔指出,额外的事务外访问也会引入更多复杂性[BLM06]。虽然很容易将所有这些问题归咎于这些额外的事务外访问,但这种思维方式的愚蠢之处可以通过将每个额外的事务外访问放入单独的单次访问事务中来轻易证明。问题在于访问模式,而不是它们是否恰好包含在一个事务中。
最后,任何事务的前向进展保证也取决于调度程序,它必须让执行事务的线程运行足够长的时间以成功提交。
因此,HTM供应商提供前向进展保证存在重大障碍。然而,如果其中任何一家能够做到这一点,其影响将是巨大的。这意味着HTM交易将不再需要软件回退,从而最终实现TM承诺的死锁消除。
然而,2012年底,IBM大型机宣布了一种HTM实现方案,该方案除了常规的最佳努力HTM实现外,还包含了受限事务[JSG12]。受限事务从tbeginc指令开始,而不是用于最佳努力事务的tbegin指令。受限事务保证总是能够完成(最终),因此如果事务中止,硬件不会跳转到回退路径(这是最佳努力事务的做法),而是从tbeginc指令重新启动事务。
大型机架构师需要采取极端措施来实现这一前瞻性的保证。如果某个受限事务反复失败,CPU可能会禁用分支预测、强制执行顺序,甚至禁用流水线。如果重复的失败是由于高竞争,CPU可能会禁用推测性 获取、引入随机延迟,甚至序列化冲突CPU的执行。“有趣”的前向进展场景涉及少至两个CPU或多至一百个CPU。也许这些极端措施提供了一些见解,解释了为什么其他CPU到目前为止没有提供受限事务。
顾名思义,受限事务实际上受到严重限制:
1.最大数据占用空间为四个内存块,每个内存块不能大于32字节。
2.最大代码占用空间为256字节。
3.如果给定的4K页面包含受限事务代码,则该页面可能不包含该事务的数据。
4.可执行的汇编指令的最大数量为32。
5.禁止反向分支。
尽管如此,这些约束支持许多重要的数据结构,包括链表、栈、队列和数组。因此,受限HTM似乎有可能成为并行程序员工具箱中的一个重要工具。
请注意,这些前向推进保证不必是绝对的。例如,假设使用HTM时使用全局锁作为回退机制。如果回退机制已经精心设计以避免第17.3.2.3节中讨论的“羊群效应”,那么如果HTM回滚足够不频繁,全局锁就不会成为瓶颈。话虽如此,系统越大、临界区越长、从“羊群效应”中恢复所需的时间越长,“足够不频繁”就越需要罕见。
17.3.5.2事务大小增加
前向进展保证很重要,但正如我们所见,它们将是基于交易规模和持续时间的条件性保证。已经取得了一些进展,例如,一些商用HTM实现使用近似技术来支持极其庞大的HTM读集[RD12]。另一个例子是,POWER8 HTM支持挂起事务,这可以避免向挂起事务的读写集添加无关访问[LGW+ 15]。这一功能已被用于生成高性能的读写锁[FIMR16]。
需要注意的是,即使是小规模的保证也非常有用。例如,对于栈、队列或出队操作,两个缓存行的保证就足够了。然而,更大的数据结构需要更大的保证,比如遍历一棵树时,所需的保证等于树中的节点数。因此,即使保证的大小有适度增加,也会提高HTM的实用性,从而增加了CPU提供这种保证或提供足够好的替代方案的需求。
17.3.5.3改进的调试支持
另一个制约交易规模的因素是调试交易的需求。当前机制的问题在于,单个步骤的异常会终止整个包围的交易。针对这一问题有许多变通方法,包括模拟处理器(速度慢!)、用STM替代HTM(速度慢且语义略有不同!)、使用重试技术回放以模拟向前进展(奇怪的故障模式!),以及全面支持调试HTM交易(复杂!)。
如果某家HTM供应商能够开发出一种HTM系统,允许在事务中直接使用传统的调试技术,包括断点、单步执行和打印语句,这将使HTM更具吸引力。一些事务内存研究者早在2013年就开始意识到这个问题,至少有一项提案涉及硬件辅助调试设施[GKP13]。当然,这一提议依赖于现有硬件具备此类功能[Hay20,Int20b]。更糟糕的是,一些尖端调试工具与HTM不兼容[OHOC20]。
17.3.5.4弱原子性
鉴于HTM在未来一段时间内可能会面临某种规模限制,HTM需要与其他机制顺畅互操作。如果额外的事务外读取不会无条件中止带有冲突写入的事务,而只是提供预事务值,那么HTM与主要读取机制如危险指针和RCU的互操作性将会得到改善。这样,危险指针和RCU可以用来让HTM处理更大的数据结构,并减少冲突概率。
这并非易事。最直接的实现方式是在每个缓存行和总线上增加一个状态,这是一项不小的额外开销。然而,这种开销带来的好处是允许大容量读取器运行,而不会因持续冲突导致更新者饥饿的风险。另一种方法是由Siakavaras等人[SNGK17]在二叉搜索树中广泛应用的方法,即只在实际更新时使用HTM,而在只读遍历时使用RCU。这种方法的性能比其他事务内存技术高出多达220 %,这一加速效果与Howard和Walpole [HW11]将RCU与STM结合时观察到的结果相似。在这两种情况下,弱原子性都是通过软件而非硬件实现的。尽管如此,如果能在硬件和软件中同时实现弱原子性,可能会获得更多的加速效果,这仍然值得研究。
尽管当前的HTM实现确实在某些情况下带来了实际的性能提升,但也存在显著的不足。最突出的问题包括事务大小受限、需要处理冲突、需要回滚和中止、缺乏向前推进的保证、无法处理不可撤销操作以及与锁定相比细微的语义差异。此外,关于HTM实现可靠性仍有许多令人担忧的原因[JSG12,Was14,Int20a,Int21,Lar21,Int20c]。
这些不足之处在未来的实现中可能会有所缓解,但似乎仍需继续努力,使HTM能够与多种其他同步机制良好配合,正如前面所提到的[MMW07,MMTW10]。尽管已经有一些研究使用HTM与RCU结合[SNKG17,SBN+20,GGK18,PMDY20],但在HTM如何更好地与RCU及其他延迟回收机制协同工作的方面,进展甚微。
简而言之,目前的HTM实现似乎是并行程序员工具箱中受欢迎且有用的补充,但要充分利用它们还需要做大量有趣和具有挑战性的工作。然而,它们不能被视为挥动就能解决所有并行编程问题的魔杖。
17.4 正式回归测试
没有实验的理论:我们走得太远了吗?
迈克尔·米岑马赫
形式验证在多个生产环境中早已证明其价值[LBD+04,BBC+ 10,Coo18,SAE+ 18,DFLO19]。然而,核心形式验证是否会被纳入用于复杂并发代码库如Linux内核的持续集成自动化回归测试套件中,仍是一个开放的问题。尽管已经有一个针对Linux内核SRCU的概念验证[Roy17],但该测试仅针对最简单的RCU实现的一小部分,并且难以跟上不断变化的Linux内核的步伐。因此,值得探讨的是,要将形式验证作为Linux内核回归测试的第一级成员需要具备哪些条件。
以下列表是一个很好的开始[McK15a,幻灯片34]:
1.任何需要的翻译都必须是自动化的。
2.必须正确处理环境(包括内存排序)。
3.内存和CPU开销必须适中。
4.必须提供导致漏洞位置的具体信息。
5.除了源代码和输入之外,信息的范围必须适度。
6.必须找到与代码的用户相关的漏洞。
这个列表建立在Richard Bornat的格言之上,但比它更谦虚:“形式验证研究人员应该验证开发人员编写的代码 他们用语言编写它,在运行环境中运行,就像他们编写它一样。”以下各节讨论上述每项要求,然后介绍一个记分卡,说明几个工具在多大程度上符合这些要求。

尽管Promela和spin是无价的设计辅助工具,但如果你需要正式回归测试你的C语言程序,每次重新验证代码时都必须手动翻译成Promela。如果代码恰好位于每60到90天发布一次的Linux内核中,那么每年你需要手动翻译四到六次。随着时间推移,人为错误会逐渐累积,这意味着验证结果将无法与源代码匹配,从而使验证变得毫无意义。显然,重复验证要么要求形式验证工具直接输入你的代码,要么需要有无bug的自动翻译功能,将你的代码转换为验证所需的形式。
PPCMEM和herd理论上可以直接输入汇编语言和C++代码,但这些工具只适用于非常小的测试,这通常意味着你必须手动提取你的机制的核心。就像Promela和spin一样,两者都
PPCMEM和herd非常有用,但是它们不适合回归套件。
相比之下,cbmc
和Nidhugg可以输入规模合理(尽管仍然相当有限)的C程序,如果它们的能力继续增长,很可能会成为回归测试套件中的优秀补充。Coverity的静态分析工具也可以输入C程序,而且是大规模的,包括Linux内核。当然,与cbmc和Nidhugg相比,Coverity的静态分析要简单得多。另一方面,Coverity对“C程序”的定义非常全面,这带来了特殊的挑战[BBC+ 10]。亚马逊网络服务使用了多种形式验证工具,包括cbmc,并将其中一些工具应用于回归测试[Coo18]。谷歌直接在其大型Java代码库上使用了一些相对简单的静态分析工具,这些代码库可能不如C代码库多样化[SAE+ 18]。脸书对其代码库进行了更为激进的形式验证,包括并发分析[DFLO19,O‘H19],但尚未应用于Linux内核。最后,微软长期以来一直在其代码库上使用静态分析[LBD+04]。
有了这个列表,显然可以创建复杂的正式验证工具,直接使用生产质量的源代码。
然而,使用C代码作为输入的一个缺点是它假设编译器是正确的。另一种方法是使用C编译器生成的二进制文件作为输入,从而考虑到任何相关的编译器错误。这种方法已在多个验证工作中被采用,最著名的是SEL4项目[SM13]。

但是,直接从源代码或二进制文件进行验证都有消除人为翻译错误的优点,这对于可靠的回归测试至关重要。
这并不是说具有专用语言的工具毫无用处。相反,它们对于设计时验证非常有用,如第12章中所讨论的那样。然而,这些工具对于自动回归测试并不特别有用,而这正是本节的主题。
正确建模环境对于形式验证工具至关重要。一个常见的遗漏是内存模型,许多形式验证工具,包括Promela/spin,都局限于顺序一致性。第12.1.4.6is节中提到的QRCU经验是一个重要的警示故事。
普拉梅拉和自旋假设顺序一致性,这与现代计算机系统不匹配,正如第15章所见。相比之下,PPCMEM和herd的一大优势在于它们对各种CPU系列内存模型的详细建模,包括x86、Arm、Power,以及在herd中的Linux内核内存模型[AMM+ 18],该模型已被接受到Linux内核版本v4.17中。
cbmc和Nidhugg工具提供了一些选择内存模型的能力,但没有PPCMEM和herd提供的多样性。然而,随着时间的推移,更大规模的工具可能会采用更多样化的内存模型。
从长远来看,将I/O包含在形式验证工具中[MDR16]是有帮助的,但可能还需要一段时间才能实现。
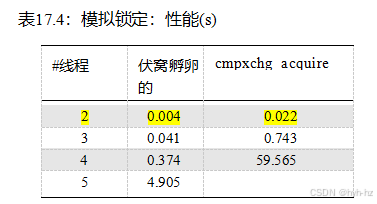
然而,无法匹配环境的工具仍然有用。例如,在一个假设的顺序一致系统中,许多并发错误仍然是错误,这些错误可以通过过度近似系统内存模型并采用顺序一致性的工具来定位。不过,这些工具将无法发现涉及缺少内存排序指令的错误,正如第12.1.4.6节所述的警示故事所指出的那样。
几乎所有硬核形式验证工具本质上都是指数型的,这可能看起来令人沮丧,直到你考虑到许多最有趣的软件问题实际上是不可判定的。然而,即使在指数型之间也有程度上的差异。
PPCMEM旨在未优化,以确保感兴趣的内存模型能够准确表示。而herd工具则更积极地进行优化,如第12.3节所述,因此比PPCMEM快几个数量级。然而,无论是PPCMEM还是herd,都针对非常小的测试用例,而不是较大的代码库。
相比之下,Promela/spin、cbmc和Nidhugg是为(相对)较大的代码体设计的。Promela/spin被用于验证好奇号漫游车的文件系统[GHH+ 14],正如前面提到的,cbmc和Nidhugg都被应用于Linux内核RCU。
如果启发式方法继续以过去三十年的速度进步,我们可以期待形式验证的开销大幅减少。话虽如此,组合爆炸仍然是组合爆炸,这将显著限制可验证程序的规模,无论是否继续改进启发式方法。
然而,组合爆炸的另一面是马其顿的菲利普二世那句永恒的忠告:“分而治之。”如果一个大型程序可以被分解并验证各个部分,那么结果可能会出现组合内爆[McK11e]。一个自然的划分点是在API边界上,例如锁定原语的边界。一次验证过程可以确认锁定实现的正确性,而后续的验证过程则可以确保锁定API的正确使用。
这种方法的性能优势可以通过使用Linux内核内存模型[AMM+ 18]来展示。该模型提供了spin_lock()和spin_unlock()原语,但这些原语也可以通过cmpxchg_acquire()和smp_store_release()模拟实现,如清单17.2(C-SB+l-o-o-u+l-o-o- *u .litmus和C-SB+l-o-o-u+l-o-o-u*-C.litmus)所示。表17.4比较了使用模型中的spin_lock()和spin_unlock()与模拟这些原语的性能和可扩展性。差异在于
| 清单17.2:使用cmpxchg_acquire()模拟锁定 |
| 1 C C-SB+l-o-o-u+l-o-o-u-C 2 3 {} 4 5 P0(int *sl, int *x0, int *x1) 6 { 7 int r2; 8 int r1; 9 10 r2 = cmpxchg_acquire(sl,0,1); 11 WRITE_ONCE(*x0,1); 12 r1 = READ_ONCE(*x1); 13 smp_store_release(sl,0); 14 } 15 16 P1(int *sl, int *x0, int *x1) 17 { 18 int r2; 19 int r1; 20 21 r2 = cmpxchg_acquire(sl,0,1); 22 WRITE_ONCE(*x1,1); 23 r1 = READ_ONCE(*x0); 24 smp_store_release(sl,0); 25 } 26 存在28(0:r1=0/1:r1=0) |

当然,工具能够自动划分大型程序、验证各个部分,然后验证这些部分的组合是非常有用的。与此同时,大型程序的验证仍需要大量的手动干预。这种干预最好通过脚本来实现,以便在每次发布时可靠地进行重复验证,并最终以适合持续集成的方式进行。Facebook的Infer工具已经在这方面迈出了重要一步,通过组合性和抽象化实现了这一目标[BGOS18,DFLO19]。
无论如何,我们可以预期形式验证能力会随着时间的推移而继续增加,任何这样的增加反过来都会增加形式验证对回归测试的适用性。
任何大小的软件制品都包含错误,因此只报告错误存在与否的形式验证工具并无特别用途,需要的是至少提供一些关于错误所在位置和错误性质的信息的工具。
cbmc的输出包括回溯映射到源代码,类似于Promela/spin的方法,Nidhugg也是如此。当然,这些回溯可能相当长,分析起来也可能非常繁琐。然而,这样做通常比传统方式查找错误要快得多,也更令人愉快。
此外,形式验证工具最简单的测试之一是漏洞注入。
毕竟,我们中的任何人都可以编写`printf(“verified\n”)`,但事实是,形式验证工具的开发者和其他人一样容易出错。因此,那些仅仅声明存在错误的形式验证工具本质上更不可靠,因为它们在真实代码上的验证难度更大。
除此之外,编写形式验证工具的人可以利用现有的工具。例如,一个旨在仅确定是否存在严重但罕见错误的工具可能会使用二分法。如果测试程序的老版本中没有该错误,而新版本中有,则可以使用二分法快速定位插入错误的提交,这可能足以找到并修复错误。当然,这种策略对于常见错误并不适用,因为在这种情况下,由于所有提交至少包含一次常见错误,二分法会失败。
因此,许多形式验证工具提供的执行轨迹将继续具有价值,特别是对于复杂且难以理解的错误。此外,最近的研究应用了类似于传统Hoare逻辑的不正确性逻辑形式化方法,用于完整的正确性证明,但其唯一目的是发现错误[O‘H19]。
在过去,形式验证研究人员要求有一个完整的规范来验证软件。不幸的是,一个数学上严格的规范可能比实际代码还要大,而且每行规范中包含错误的可能性与每行代码一样高。证明代码忠实实现了规范的形式验证努力,实际上只是证明了两者之间逐个错误的兼容性,这可能并没有多大帮助。
更糟糕的是,包括Linux内核RCU在内的许多软件组件的要求是基于经验的[McK15h,McK15e,McK15f].16对于这种常见的软件类型,完整的规范是一种礼貌的虚构。硬件的完整规范同样不减少这种虚构性,这一点在2017年末的Meltdown和Spectre侧信道攻击中得到了明确体现[Hor18]。
这种情况可能会让人放弃对真实世界软件和硬件工件进行正式验证的所有希望,但事实证明,还有很多可以做的事情。例如,设计和编码规则可以作为部分规范,代码中包含的断言也可以。实际上,像cbmc和Nidhugg这样的形式验证工具都会检查可以触发的断言,隐式地将这些断言视为规范的一部分。然而,这些断言也是代码的一部分,这使得它们不太可能过时,特别是当代码还接受压力测试时。17 cbmc工具还会检查数组越界引用,从而隐式地将其添加到规范中。上述不正确逻辑也可以被视为使用了一个隐式的“不存在错误”的规范[O‘H19]。
这种隐式指定的方法相当合理,特别是当你不把形式验证视为完全正确的证明,而是将其视为一种具有不同优势和劣势的验证方式时,即测试。从这个角度来看,软件总是会有缺陷,因此任何有助于发现这些缺陷的工具都是非常有益的。
发现错误并修复它们当然是任何类型的验证工作的全部要点。显然,要避免出现假阳性。但是即使没有假阳性,也有错误和错误。
例如,假设一个软件工件恰好有100个剩余的bug,每个bug平均每百万运行时间出现一次。再假设一个全知的正式验证工具找到了这100个bug,开发人员随后修复了它们。这个软件工件的可靠性会发生什么变化?
答案是可靠性降低了。
要理解这一点,请记住历史经验表明,大约有7%的修复会引入新的错误[BJ12]。因此,修复这100个平均故障时间(MTBF)约为10,000年的错误,将会引入另外七个错误。历史统计数据显示,每个新错误的MTBF将远低于70,000年。这反过来意味着,这七个新错误的总MTBF很可能远低于10,000年,从而导致原本100个错误的修复实际上降低了整个软件的可靠性。

更糟糕的是,想象另一个软件制品,它平均每天有一个错误,每百万年有99个错误。假设一个形式验证工具找到了这99个百万年的错误,但未能发现那个每天出现一次的错误。修复这99个已定位的错误需要时间和精力,会降低可靠性,而对每天频繁发生的错误却无能为力,这种错误可能会带来尴尬,甚至更加严重的问题。
因此,最好有一个验证工具能够优先定位最棘手的bug。然而,正如第17.4.4节所述,可以利用其他工具。一个强大的工具就是传统的测试。鉴于对bug的了解,应该可以构建特定的测试来发现它,可能还需要使用第11.6.4节中描述的一些技术来增加bug显现的概率。这些技术应能计算出bug原始失败率的大致估计值,进而用于优先处理bug修复工作。

最近有一些形式验证工作优先考虑执行次数较少的执行,基于一个合理的假设,即较少的预占更有可能发生。
识别相关的漏洞听起来可能要求过高,但如果我们真的要提高软件的可靠性,这就是真正需要的。
表17.5显示了所涵盖的正式验证工具的简易记分卡
在本章中,较短的波长比较长的波长更好。

Promela需要手动翻译,并且仅支持顺序一致性,因此它的前两个单元格是红色的。它有合理的开销(至少对于形式验证而言),并且提供了回溯功能,所以接下来的两个单元格是黄色的。尽管需要手动翻译,但Promela以自然的方式处理断言,因此第五个单元格是绿色的。
PPCMEM通常需要手动翻译,因为它支持的测试用例规模较小,所以它的第一个单元格是橙色。它处理多种内存模型,因此第二个单元格是绿色。其开销相当高,所以第三个单元格是红色。它提供了操作之间关系的图形显示,虽然不如回溯法有帮助,但仍然非常有用,因此第四个单元格是黄色。它需要构建一个存在子句,并且不能接受进程内部断言,所以第五个单元格也是黄色。
群集工具的大小限制与PPCMEM类似,因此其第一个单元格也是橙色。它支持多种内存模型,所以第二个单元格是蓝色。它的开销合理,因此第三个单元格是黄色。它的错误定位和断言功能与PPCMEM非常相似,因此接下来的两个单元格也是黄色。
cbmc工具直接输入C代码,因此它的第一个单元格是蓝色的。它支持几种内存模型,所以第二个单元格是黄色的。它的开销合理,因此第三个单元格也是黄色的,不过也许求解器性能会继续提升。它提供回溯功能,因此第四个单元格是绿色的。它直接从C代码中获取断言,所以第五个单元格是蓝色的。
Nidhugg还直接输入C代码,因此它的第一个单元格也是蓝色。它仅支持几种内存模型,所以第二个单元格是橙色的。它的开销相当低(对于形式验证而言),因此第三个单元格是绿色的。它提供回溯功能,所以第四个单元格也是绿色的。它直接从C代码中获取断言,所以第五个单元格是蓝色的。
那么第六行和最后一行呢?现在还为时过早,无法判断这些工具在查找正确漏洞方面表现如何,所以它们都标有问号。

请注意,此表再次对这些工具在回归测试中的使用进行了评级。
仅仅因为它们中的许多不适合回归测试,并不意味着它们毫无用处,事实上,其中许多已经多次证明了它们的价值。18只是不适合回归测试。
然而,这种情况可能会改变。毕竟,形式验证工具在2010年代取得了令人印象深刻的进展。如果这种进步继续下去,形式验证很可能成为并行程序员验证工具箱中不可或缺的工具。
17.5 并行处理中的函数编程
功能编程在并行应用程序中的奇怪失败。
马尔特·斯卡鲁普克
当我上世纪80年代初上第一堂函数式编程课时,教授断言无副作用的函数式编程风格非常适合简单的并行化和分析。三十年后,这一观点依然成立,但主流生产中并行函数语言的使用却很少,这种情况可能与教授的另一主张不无关系,即程序既不应维护状态也不应进行输入输出。尽管像Erlang这样的函数式语言有小众用途,且其他几种函数式语言也增加了多线程支持,但在主流生产中,这些语言仍主要由C、C++、Java和Fortran等过程性语言主导(通常会结合OpenMP、MPI或协数组)。
这种情况自然会引出一个问题:“如果分析是目标,为什么不在进行分析之前将过程语言转换为函数语言呢?”当然,对于这种方法有许多反对意见,我只列举其中的三个:
1.过程语言通常大量使用全局变量,这些变量可以由不同的函数独立更新,更糟糕的是,还可以被多个线程更新。请注意,Haskell的单子是为了处理单线程的全局状态而发明的,而多线程访问全局状态则对函数模型造成了额外的破坏。
2.多线程过程语言通常使用诸如锁、原子操作和事务等同步原语,这给函数模型带来了额外的暴力。
3.过程语言可以别名函数参数,例如通过两个不同的参数向同一函数调用传递同一个结构的指针。这可能导致函数在不知情的情况下通过两个不同的(可能重叠的)代码序列更新该结构,从而大大增加了分析的复杂性。
当然,考虑到全局状态、同步原语和别名的重要性,聪明的函数编程专家已经提出了许多尝试来调和函数编程模型与它们的关系,单子就是一个很好的例子。
另一种方法是将并行过程程序编译成函数式程序,然后使用函数式编程工具分析结果。但可以做得更好,因为任何实际计算都是一个具有有限输入的大型有限状态机,在有限的时间间隔内运行。这意味着任何实际程序都可以转换为表达式,尽管这个表达式可能非常庞大[DHK12]。
然而,许多并行算法的低级内核可以转换为足够小的表达式,轻松地适应现代计算机的内存。如果这样的表达式与一个断言结合,检查该断言是否会触发就变成了一个可满足性问题。尽管可满足性问题是NP完全问题,但它们通常可以在远少于生成完整状态空间所需的时间内解决。此外,解决方案时间似乎仅弱依赖于底层的内存模型,因此运行在弱有序系统上的算法也可以进行验证[AKT13]。
总体方法是将程序转换为单静态赋值(SSA)形式,使得每个变量的赋值都会创建该变量的一个独立版本。这适用于所有活动线程中的赋值,从而使最终表达式包含该代码的所有可能执行方式。添加断言意味着询问任何输入和初始值组合是否会导致断言触发,正如上文所述,这正是可满足性问题。
一个可能的反对意见是它不能优雅地处理任意循环结构。
然而,在许多情况下,这可以通过展开循环有限次来处理。此外,也许一些循环也将被证明适合通过归纳方法进行折叠。
另一个可能的反对意见是,自旋锁涉及任意长的循环,任何有限的展开都无法完全捕捉到自旋锁的行为。事实证明,这一反对意见很容易克服。与其建模一个完整的自旋锁,不如建模一个尝试获取锁的尝试锁,并在无法立即成功时中止。断言必须精心设计,以避免在自旋锁因未立即可用而中止的情况下触发。由于逻辑表达式与时间无关,所有可能的并发行为都将通过这种方法被捕捉到。
最后一个反对意见是,这种技术不太可能处理像Linux内核这样庞大的软件实体,其中包含数百万行代码。这可能是事实,但重要的是,对Linux内核中每个较小的并行原语进行详尽验证仍然非常有价值。事实上,领导这一方法的研究人员已经将其应用于非平凡的实际代码,包括Linux内核中的Tree RCU实现[LMKM16,KS17a]。
这项技术的应用范围还有待观察,但它是形式验证领域中较为有趣的创新之一。尽管函数式编程的支持者们最终可能正确地断言函数式编程的必然主导地位,但显然,这种长期被推崇的方法论开始在其形式验证的主场受到可信的竞争。因此,我们有理由继续怀疑函数式编程主导地位的必然性。
17.6 概述
本章简要探讨了多种可能的未来,包括多核、事务内存、形式验证作为回归测试以及并发函数式编程。这些未来中的任何一个都可能发生,但更有可能的是,正如过去一样,未来会比我们所能想象的更加奇异。
Chapter 18 Looking Forward and Back
历史是那些本可以避免的事情的总和。
康拉德·阿登纳
你已经读完了这本书,干得好!我希望你的旅程是愉快的、充满挑战的和值得的。
对于编辑和撰稿人来说,这是第二版的终点,但对于那些愿意加入的人来说,这也是第三版的起点。无论如何,回顾一下过去的旅程是很好的。
第1章介绍了本书的内容,以及对那些对低级并行编程以外的其他内容感兴趣的人的一些替代方案。
第2章讨论了并行编程的挑战和解决这些挑战的高级方法,还讨论了如何避免这些挑战,同时仍然获得大部分并行的好处。
第三章对多核硬件进行了高层次的概述,特别是那些给并发软件带来挑战的方面。本章将这些挑战归咎于物理定律,而不是固执的硬件架构师和设计者。然而,硬件架构师和工程师可以采取一些措施,本章讨论了其中的一些方法。与此同时,软件架构师和工程师也必须尽自己的一份力来应对这些挑战,相关内容将在本书后续章节中讨论。
第4章简要介绍了低级并发交易的工具。
第5章演示了这些工具的使用,更重要的是并行编程设计技术在并发计数这一简单但令人惊讶地具有挑战性的任务中的应用。事实上,并发计数算法非常具有挑战性,因此许多并发计数算法被广泛使用,每种算法都针对不同的用例进行了专门化。
第6章深入探讨了最重要的并行编程设计技术,即在尽可能高的层次上对问题进行划分。本章还概述了该设计空间中的许多要点。
第7章阐述了并行编程的工作主力(和恶棍),锁定。
本章介绍了多种类型的锁定,并提出了一些工程解决方案,以解决许多众所周知且被大肆宣传的锁定缺陷。
第8章讨论了数据所有权的用途,其中同步是由给定数据项与特定线程的关联提供的。在适用的情况下,这种方法将出色的性能和可伸缩性与深刻的简单性结合在一起。
第9章展示了如何通过一点点拖延来显著提升性能和可扩展性,同时在许多令人惊讶的情况下还能简化代码。本章介绍的一些机制利用了CPU缓存复制只读数据的能力,从而绕过了物理定律的残酷限制。
限制光速和原子的微小。第10章讨论了并发数据结构,重点是哈希表,它在并行程序中有着悠久而光荣的历史。
第十一章深入探讨了代码审查和测试方法,第十二章概述了形式验证。无论你处于形式验证/测试的哪一边,如果代码没有经过彻底验证,它就不起作用。对于并发代码来说,这一点至少是双重的。
第13章介绍了一些情况,其中将并发机制相互结合或与其他设计技巧相结合可以大大简化并行程序员的工作。第14章探讨了高级同步方法,包括无锁编程、非阻塞同步和并行实时计算。第15章深入研究了至关重要的内存排序问题,介绍了技术和工具,不仅帮助你解决内存排序问题,还能完全避免这些问题。第16章简要概述了一个令人惊讶的重要话题——易用性。
最后,但绝对不是最不重要的,第17章阐述了关于未来的许多相互冲突的愿景,包括CPU技术趋势、事务内存、硬件事务内存、回归测试中形式验证的使用,以及长期预测并行编程的未来属于函数式编程语言。
但是现在我们已经回顾了这第二版的内容,这本书是如何开始的呢?
保罗的并行编程之旅始于1990年,当时他加入了Sequent计算机系统公司。Sequent采用了一种类似学徒制的项目,新招聘的工程师被安排在由经验丰富的工程师组成的隔间中,这些资深工程师指导他们,审查他们的代码,并就各种主题提供了大量建议。由于当时没有片上缓存,逻辑分析仪可以轻松显示特定CPU的指令流和内存访问,包括精确的时间信息,这使得一些新入职的工程师受益匪浅。当然,这种透明度的缺点是CPU核心时钟频率比21世纪慢了100倍。通过学徒制和硬件性能透明化,这些新入职的工程师在两到三个月内就成为了高效的并行程序员,有些人在几年内就开始了开创性的研究工作。
序列公司意识到,它能够迅速培训新工程师掌握并行计算的奥秘是不同寻常的,因此出版了一本精简的书籍,凝聚了公司的并行编程智慧[Seq88],这与几年前发表的两篇开创性论文[BK85,Inm85]相辅相成。已经深谙这些奥秘的人士对这本书和这些论文表示赞赏,但新手通常无法从中获益良多,往往会犯下极具创意却相当破坏性的错误,而这些错误并未被书或论文明确禁止。1当然,这种情况促使保罗开始考虑编写一本改进版的书,但他在这段时间的努力仅限于内部培训材料和已发表的论文。
到1999年IBM收购Sequent时,世界上许多最大的数据库实例都在Sequent硬件上运行。但时代变了,到了2001年,许多Sequent的并行程序员已将重点转向Linux内核。经过最初的犹豫,Linux内核社区热情而有效地拥抱了并发技术[BWCM+ 10,McK12a],带来了许多优秀的创新。
还有来自整个社区的改进。保罗时不时地想到要写一本书,但生活太快了,所以他没有在这个项目上取得任何进展。
2006年,保罗受邀参加了一个关于Linux可扩展性的会议,并获得了向尊敬的并行编程专家小组提出最后一个问题的机会。保罗开始提问时指出,在1991年至2006年的15年间,一个并行系统的成本已经从一栋房子的价格降到了一辆中档自行车的价格,显然在未来15年内,直到2021年,还有很大的降价空间。他还提到,价格的下降应该会带来更高的熟悉度和更快地解决并行编程问题的进展。这引出了他的问题:“到2021年,为什么并行编程还没有成为常规?”
第一位发言者似乎对提出如此荒谬问题的人相当不屑,迅速用简短的回答回应。对此,保罗也给出了简短的回应。他们来回争论了一段时间,例如,发言者的简短回答“僵局”引发了保罗的简短回应“锁定依赖检查器”。
这位专家最终没有更多的发言权,即兴说了一句最后的话:“像你这样的人应该用锤子敲打!”
保罗的回答当然是“你得排队等着!”
保罗把注意力转向下一位小组成员,这位成员似乎在赞同第一位小组成员和不愿面对保罗的一连串回答之间左右为难。因此,他发表了一段简短的、不置可否的讲话。小组剩下的时间里都是这样。
直到轮到最后一位小组成员发言,他是一位你可能听说过的名字叫林纳斯·托瓦兹的人。林纳斯指出,三年前(即2003年),任何与并发相关的补丁的初始版本通常都很糟糕,存在设计缺陷和许多错误。即使经过清理后被接受,错误仍然存在。林纳斯将此与2006年的现状进行了对比,他说当时并发相关补丁的第一个版本往往设计良好,几乎没有或根本没有错误。随后,他建议如果工具继续改进,那么或许到2021年并行编程将成为常规。
会议随后结束。保罗并不惊讶许多观众,特别是那些与第一位小组成员观点相同的人,对他避而远之。他也毫不意外地听到几位观众感谢他提出了问题。然而,当有位男士泪流满面地走上前来,几乎说不出话来地哭泣时,他感到非常惊讶。
你看,这个人曾在Sequent工作了几年,因此非常擅长并行编程。此外,他目前被分配到一个团队,负责编写并行代码。但进展并不顺利。你看,问题不在于他们难以理解他对并行编程的解释。
而是他们根本不听他的。
简而言之,他的团队对待这个人的态度与第一位小组成员试图对待保罗的方式相同。因此,在那一刻,保罗从“我总有一天要写一本书”变成了“我会尽一切努力写出这本书”。保罗不好意思承认他不记得那个人的名字,事实上,他可能从未知道过这个名字。

这本书毕竟是给那个人的。
这本书也适合那些想要将低级并发添加到自己的技能集中的其他人。如果你从这本书中记住的唯一一件事是图18.1中的教训,那就这样吧。
这本书也是对那位未具名的小组成员及其未具名雇主的一种致敬。几年后,这位雇主选择任命了一个更有用经验且言辞更少的人。这个人也曾是小组的一员,在那次讨论中,他直视着我说,平行编程可能比顺序编程难5%。
对于我们其他人来说,当有人试图向我们展示一个解决紧迫问题的方案时,也许我们至少应该对他们表示礼貌,倾听他们!