1 Studying《Is Parallel Programming Hard》1-5
目录
Chapter 1 How To Use This Book
1.1 路线图
1.2 快速测验
1.3 本书的替代品
1.4 示例源代码
1.5这本书是谁的?
Chapter 2 Introduction
2.1 历史并行编程难题
2.2 并行编程目标
2.3 并行编程的替代方法
2.4 什么是并行编程的难点?
2.5 讨论
Chapter 3 Hardware and its Habits
3.1 概述
3.2 管理费用
3.3 硬件免费午餐?
3.4 软件设计影响
Chapter 4 Tools of the Trade
4.1 脚本语言
4.2 POSIX多进程
4.3 POSIX操作的替代方法
4.4 工作的正确工具:如何选择?
Chapter 5 Counting
5.1 为什么并发计数不是简单的?
5.2 统计计数器
5.3 约定的限位计数器
5.4 精确限位计数器
5.5 并行计数讨论
Chapter 1 How To Use This Book
如果你能认识到生活是艰难的,事情对你来说就会容易得多。
路易斯·d·布兰代斯
本书的目的是帮助您在不危及理智的情况下编写共享内存并行系统。然而,您应该把这本书中的信息看作是构建的基础,而不是一座已经完工的大教堂。如果您选择接受这一使命,那么您的任务就是帮助在令人兴奋的并行编程领域取得进一步的进展——这种进展最终会使这本书过时。
21世纪的并行编程不再仅仅局限于科学、研究和重大挑战项目。这当然是好事,因为这意味着并行编程正逐渐成为一门工程学科。因此,作为一门工程学科,本书考察了具体的并行编程任务,并描述了如何处理这些任务。在一些令人惊讶的常见情况下,这些任务可以实现自动化。
这本书旨在通过展示成功并行编程项目的工程基础,让新一代并行黑客摆脱缓慢而费力地重新发明旧轮子的需要,使他们能够将精力和创造力集中在新的前沿领域。然而,你从这本书中获得什么,取决于你投入多少。希望仅仅阅读这本书就能有所帮助,而快速测验则会更加有帮助。不过,最好的效果来自于将书中教授的技术应用于实际问题。正如一贯所言,实践出真知。
但是,无论你如何处理它,我们真诚地希望并行编程至少能给你带来和它带给我们的乐趣、兴奋和挑战一样多的乐趣!
1.1 路线图
猫:你要去哪里?
爱丽丝:我该往哪个方向走?
猫:这取决于你要去哪里。
爱丽丝:我不知道。
猫:不管你往哪个方向走。
刘易斯·卡罗尔,《爱丽丝梦游仙境》
本书是一本广泛适用和大量使用的设计技术手册,而不是只适用于少数领域的最佳算法集合。您目前正在阅读第1章 ,但你已经知道了。第2章给出了并行编程的高级概述。
第三章介绍了共享内存并行硬件。毕竟,如果不了解底层硬件,编写好的并行代码是很难的。由于硬件不断进化,本章的内容始终会过时。然而,我们仍会尽力跟上时代。第四章则简要概述了常见的共享内存并行编程原语。
第五章深入探讨了并行化一个最简单的问题,即计数。由于几乎每个人对计数都有很好的掌握,本章能够深入讨论许多重要的并行编程问题,而不会受到更常见的计算机科学问题的干扰。我的印象是,这一章在并行编程课程中得到了最大的应用。
第6章介绍了一些设计级别的方法来解决第5章中提到的问题。事实证明,在可行的情况下,设计级别上解决并行性问题非常重要:借用迪杰斯特拉的话[Dij68],“改造后的并行性被认为是严重次优的”[McKee12c]。
接下来的三章将探讨三种重要的同步方法。第七章讨论了锁定技术,这不仅是生产级并行编程的核心工具,也被广泛认为是并行编程中最糟糕的“反派”。第八章简要概述了数据所有权的概念,这是一个常被忽视但极其普遍且强大的方法。最后,第九章介绍了多种延迟处理机制,包括引用计数、危险指针、序列锁定和RCU。
第10章将前几章的教训应用到哈希表上,由于其出色的可分区性,哈希表被大量使用,(通常)导致出色的性能和可扩展性。
正如许多人痛苦地发现,没有验证的并行编程是注定失败的。第11章涵盖了各种测试形式。当然,在事后无法测试程序的可靠性,因此第12章简要概述了几种实用的形式验证方法。
第十三章包含一系列中等规模的并行编程问题。这些问题的难度各不相同,但应该适合那些已经掌握了前面章节内容的人。
第14章探讨了高级同步方法,包括非阻塞同步和并行实时计算,而第15章则涵盖了内存排序这一高级主题。第16章随后提供了一些易用性的建议。第17章展望了几种可能的未来方向,包括共享内存并行系统。
设计、软件和硬件事务性内存以及并行功能编程。最后,第18章回顾了本书的内容及其起源。
本章之后是一些附录。其中最受欢迎的似乎是附录C,它深入探讨了内存排序。附录E包含了臭名昭著的快速测验的答案,将在下一节中讨论。
1.2 快速测验
做些困难的事,否则你永远长不高。
缩写自Ronald E. Osburn
“快速问答”贯穿全书,答案可在第705页开始的附录E中找到。有些问题基于该快速问答出现的内容,但另一些则需要你超越这些部分思考,在某些情况下,甚至超越当前的知识范围。正如大多数努力一样,你从这本书中获得多少收获很大程度上取决于你愿意投入多少。因此,那些在查看答案前真正努力解答问题的读者会发现,他们的付出得到了丰厚的回报,对并行编程的理解也得到了显著提升。

简而言之,如果你需要深入理解材料,那么你应该花些时间回答快速测验。别误会我的意思,被动阅读材料确实很有价值,但要真正掌握解决问题的能力,确实需要练习解题。同样地,要真正具备编写代码的能力,也确实需要练习编写代码。

我在晚年攻读博士学位时通过课程学习才明白这一点。当时我正在研究一个熟悉的话题,但令我惊讶的是,我竟然很少能立即回答出章节练习题。 强迫自己回答问题大大提高了我对材料的保留。所以通过这些快速测验,我并不是要求你做我自己没有做过的事情。
最后,最常见的学习障碍是认为自己已经理解了当前的材料。快速测验可以是一个非常有效的治疗方法。
1.3 本书的替代品
在两个恶人之间,我总是选择以前从未尝试过的那个。
救生背心
正如克努特所深刻体会到的,如果你想让你的书是有限的,就必须聚焦。这本书专注于共享内存并行编程,重点放在软件堆栈底层的软件上,如操作系统内核、并行数据管理系统、低级库等。本书使用的编程语言是C。
如果您对并行处理的其他方面感兴趣,那么您可能会从其他书籍中获得更好的帮助。幸运的是,您可以选择许多其他书籍:
1.如果你更喜欢对并行编程进行学术性和严谨性的探讨,你可能会喜欢赫尔利希和沙维特的教科书[HS08,HSLS20]。这本书从硬件的高度抽象低级原语开始,逐步深入到锁和简单的数据结构,包括列表、队列、哈希表和计数器,最终以事务内存作为结尾,全都是用Java实现的。迈克尔·斯科特的教科书[Sco13]则侧重于软件工程,处理类似的内容,据我所知,这是第一本正式出版的学术教科书,专门有一章讨论RCU。
Herlihy、Shavit、Luchangco和Spear在他们的第二版[HSLS20]中确实增加了关于危险指针和RCU的短节,后者以EBR的形式出现。它们还简要介绍了两者的背景,尽管关于RCU的历史记载较为简略,几乎是在它被纳入Linux内核一年后,以及孔和莱曼的里程碑式论文发表二十多年之后[KL80]。希望深入了解历史的读者可以在本书的第9.5.5节找到相关信息。
然而,那些可能怀疑该教科书的第一作者对RCU持有敌对态度的读者,应该参考他的一篇论文第一页的最后一句[BGHZ16]。这句话是:“QSBR[特定类别的RCU实现]速度快,几乎可以应用于任何数据结构。”这些话显然不是对RCU怀有敌意的人所说的话。
2.如果您想从编程语言实用主义的角度对并行程序设计进行学术处理,您可能会对Scott教科书[Sco06,Sco15]中关于编程语言实用主义的并发章节感兴趣。
3.如果你对面向对象模式处理并行编程感兴趣,特别是关注C++,可以尝试阅读施密特的POSA系列第2卷和第4卷[SSRB00,BHS07]。特别是第4卷中有一些有趣的章节,将这项工作应用于仓库应用。这个例子的真实性通过标题为“分割大泥球”的部分得到了证明,在该部分中
4.如果您想使用Linux内核设备驱动程序,那么Corbet、Rubini和Kroah-Hartman的《Linux设备驱动程序》[CRKH05]是不可或缺的,Linux Weekly News网站(https://lwn.net/)也是如此 关于Linu x内核内部结构这一更广泛的主题,有大量的书籍和资源可供参考。
5.如果你的主要关注点是科学和技术计算,并且你更喜欢模式化的方法,你可以尝试Mattson等人的教科书[MSM05]。它涵盖了Java、C/C++、OpenMP和MPI。它的模式首先专注于设计,然后是实现。
如果你的主要关注点是科学和技术计算,并且对GPU、CUDA和MPI感兴趣,可以参考诺姆·马特洛夫的《并行机器编程》[Mat17]。当然,GPU厂商也提供了相当多的额外信息[ AMD 20,Zel 11,NVi 17a,NVi 17b]。
7.如果你对POSIX线程感兴趣,可以看看大卫·R·布滕霍夫的书[But97]。此外,W·理查德·史蒂文斯的书[ Ste92,Ste13]涵盖了UNIX和POSIX,而斯图尔特·韦斯的讲义[Wei13]则提供了一个详尽且易于理解的介绍,附有一系列很好的示例。
8.如果您对C++11感兴趣,您可能会喜欢Anthony Williams的“C++并发实践:实用多线程”[ Wil 12,Wil 19]。
9.如果您对C++感兴趣,但又想在Windows环境中使用它,您可能会尝试HerbSutter的“Effective Concurrency”系列文章[Sut08]。这个系列很好地介绍了并行处理的常识性方法。
10.如果您想尝试Intel Threading构建块,那么JamesReinders的书[Ri07]可能是您正在寻找的内容。
11.那些对各种类型的多处理器硬件缓存组织如何影响内核内部实现感兴趣的读者应该看看Curt Schimmel对这个主题的经典论述[Sch94]。
12.如果你正在寻找硬件视角的书籍,亨尼斯和帕特森的经典教科书[HP17,HP11]非常值得一读。安德鲁·钱恩的教科书[Chi22]可能是适合科学和技术工作量(处理大型数组)的“读者文摘”版本。如果你希望从更硬件中心的角度寻找关于内存排序的学术教科书,丹尼尔·索林等人[SHW11,NSHW20]的著作非常推荐。对于从Linux内核角度介绍内存排序的教程,保罗·邦齐尼的LWN系列是一个很好的起点[Bon21a,Bon21e,Bon21c,Bon21b,Bon21d,Bon21f]。
13.那些希望了解Rust语言对低级并发支持的读者应该参考Mara Bos的书[Bos23]。
14.最后,使用Java的用户可能会从Doug Lea的教科书中受益[Lea97,GPB+07]。
但是,如果您对低级软件的并行设计原理感兴趣,特别是用C语言编写的软件,请继续阅读!
| git clonegit://git.kernel.org/pub/scm/linux/kernel/git/paulmck/perfbook.git cd perfbook #您可能需要安装字体。请参阅FAQ .txt中的项目1。 make#-jN用于并行构建证据perfbook.pdf& #两列版本 makeperfbook-1c.pdf evinceperfbook-1c .pdf&#One-column versi versi on fore-readers make help#显示其他构建选项 |
1.4 示例源代码
未知的《星球大战》粉丝
本书讨论了相当多的源代码,在许多情况下,这些源代码可以在本书的git树的CodeSamples目录中找到。例如,在UNIX系统上,您应该能够键入以下内容:
| 查找CodeSamples-namercu_rcp ls .c-print |
此命令将查找文件rcu_ rcpls .c,该文件在附录B中被调用。非UNIX系统有自己众所周知的按文件名查找文件的方法。
1.5这本书是谁的?
如果你成为了一名教师,你的学生会教你。
奥斯卡·哈默斯坦二世
正如封面所示,编辑是Paul E. McKenney。然而,编辑确实接受通过theperfbook@vger.kernel.org提交的投稿电子邮件列表。这些贡献可以是任何形式的,流行的方法包括文本邮件、针对书的L A TEX源代码的补丁,甚至git pull请求。使用最适合您的形式。
要创建补丁或git拉取请求,您需要该书的L A TEX源代码,即atgit://git.kernel.org/pub/scm/linux/kernel/git/paulmck/perfbook.git,或,alternati vely,https://git.kernel.org/pub/scm/ linux/kernel/git/paulmck/perfbook.git . 当然,您还需要git和L A TEX,它们是大多数主流Lin ux发行版的一部分。根据您使用的发行版不同,可能还需要其他包。一些流行发行版所需的包列表列在《L A TEX源代码》中的FAQ-BUILD .txt文件里。
要创建并显示此书当前的L A TEX源树,请使用清单1.1中显示的Linux命令列表。 在某些环境下,显示perfbook. pdf的evince命令可能需要替换为acroread。git clone命令只需在首次创建pdf时使用,之后可以运行清单1.2中所示的命令。拉取任何更新并生成一个
| 清单1.2:生成更新的PDF | ||
| git远程更新 | ||
| git checkoutorigin/master | ||
| 制造 | # | -jN用于并行构建 |
| 证明perfbook.pdf& makeperfbook-1c.pdf | # | 两栏版本 |
| evinceperfbook-1c.pdf | &# | 单列版本预览 |
更新的PDF。清单1.2中的命令 必须在清单1.1中所示命令创建的perfbook目录中运行。
这本书的pdf版本偶尔会在https://kernel.org/pub/上发布 linux/kernel/people/paulmck/perfbook/perfbook.html以及athttp:// www.rdrop.com/users/paulmck/perfbook/ .
贡献补丁和发送git pull请求的实际过程与Linux内核类似,即documentedhere:https://www.kernel.org/doc/ html/latest/process/submitting-p atches.html . 一个重要的要求是,每个补丁(或在git拉取请求的情况下,提交)必须包含有效的“已签名的:”行,其格式如下:
| 签名-发布者:My Name < myname@ example. org> |
请seehttps://lkml.org/lkml/2007/1/15/219 例如,一个带有“签名人:”行的补丁。请注意,“签名人:”行有非常特殊的意义,即您正在证明:
(a)该贡献全部或部分由我创建,我有权根据文件中指出的开源许可证提交;或
(b)本贡献基于先前的工作,据我所知,该工作受适当的开源许可保护,我有权根据该许可提交修改后的作品,无论这些修改是全部或部分由我完成的,均需遵循相同的开源许可(除非我被允许以其他许可提交),具体如文件所示;或
(c)该贡献由其他人员直接提供给我,且该人员已进行认证
(a)、(b) or (c)和我没有修改它。
(d)我理解并同意该项目和贡献是公开的,并且会无限期地保存该贡献的记录(包括我提交的所有个人信息,包括我的签名),并且可以按照该项目或所涉及的开源许可证(s)进行重新分发。
这与Linux内核使用的开发者证书(DCO)1.1非常相似。您必须使用您的真实姓名:很遗憾,我们不能接受匿名或假名贡献。
本书的语言是美式英语,然而,本书的开源性质允许翻译,我个人也鼓励这样做。涵盖本书的开源许可还允许您出售您的译本,如果您愿意的话。我确实希望您能寄给我一份译本(如果有实体书的话),但这是出于职业礼貌的要求,并不是您已经根据知识共享和自由软件许可证获得许可的前提条件。请参阅源代码树中的FAQ .txt文件以获取当前可用的译本列表。
进展。我认为,一旦至少有一章被完全翻译,翻译工作就“正在进行中”。
“美式英语”这一术语下有许多风格。这本书的风格在附录D中有所记载。
正如本节开头所述,我是这本书的编辑。但是,如果您选择投稿,那本书也将是您的书。本着这种精神,我向您提供第二章,即我们的引言。
Chapter 2 Introduction
如果并行编程是如此困难,为什么会有这么多并行程序?
未知的
并行编程一直被认为是黑客最难攻克的领域之一。论文和教科书警告过死锁、活锁、竞争条件、非确定性、阿姆达尔定律对扩展性的限制以及过高的实时延迟。这些风险确实存在;我们作者积累了无数年的经验,还有由此带来的心理创伤、白发苍苍和脱发。
然而,新技术在初次使用时往往难以掌握,但随着时间的推移,这些技术会变得越来越容易。例如,曾经罕见的开车能力如今在许多国家已司空见惯。这一巨大变化源于两个基本原因:(1)汽车变得更便宜且更容易获得,因此更多的人有机会学习驾驶;(2)由于自动变速箱、自动节气门、自动起动机、显著提高的可靠性以及一系列其他技术改进,汽车变得更加容易操作。
同样的道理也适用于许多其他技术,包括计算机。如今,编程不再需要手动操作键盘。电子表格让大多数非程序员能够从他们的计算机中获得几十年前需要专家团队才能实现的结果。最引人注目的例子或许是网络冲浪和内容创作,自21世纪初以来,这些活动已经变得轻松,无需培训或教育背景的人们就能使用各种现在常见的社交网络工具轻松完成。就在1968年,这种内容创作还是一项超前的研究项目[ Eng68],当时被描述为“就像不明飞行物降落在白宫草坪上”[Gri00]。
因此,如果您希望论证并行编程仍然像许多人目前所认为的那样困难,那么您将承担证明的负担,同时要记住许多世纪以来在许多领域中出现的反例。
2.1 历史并行编程难题
不是记忆的力量,而是它的对立面,
遗忘的能力,是我们存在的必要条件。
肖勒姆·阿什
正如书名所示,这本书采取了不同的方法。它没有抱怨并行编程的困难,而是研究了为什么
并行编程是困难的,然后工作来帮助读者克服这些困难。正如将要看到的,这些困难历来分为几个类别,包括:
1.并行系统的成本高且相对罕见。
2.研究人员和实践者缺乏并行系统经验。
3.公开可访问的并行代码很少。
4.缺乏广泛理解的并行编程工程学科。
5.通信的开销相对处理而言较高,即使是在紧密耦合的共享内存计算机中也是如此。
许多这些历史性的难题正在逐步被克服。首先,在过去的几十年里,由于摩尔定律的影响,多核系统的成本已经从房屋价格的数倍降到了一顿普通餐食的价格[Mo65]。早在1996年,就有论文指出多核CPU的优势[ONH+96]。IBM在2000年将其高端POWER系列引入了同时多线程技术,并在2001年引入了多核技术。英特尔在2000年11月将其普通Pentium系列引入了超线程技术,而AMD和英特尔则在2005年推出了双核CPU。Sun随后在2005年底推出了多核/多线程的Niagara。事实上,到20 08年,找到单核CPU的台式机系统变得越来越困难,单核CPU主要被用于上网本和嵌入式设备。到2012年,即使是智能手机也开始配备了多个CPU。到2020年,安全关键型软件标准开始关注并发问题。
其次,低成本且易于获取的多核系统的出现意味着曾经罕见的并行编程体验现在几乎对所有研究人员和实践者都可用。事实上,学生和业余爱好者长期以来一直能够负担得起并行系统。因此,我们可以预期围绕并行系统的发明和创新水平将大幅提高,随着时间的推移,这种日益增长的熟悉度将使曾经昂贵得令人望而却步的并行编程领域变得更加友好和平凡。
第三,在20世纪,大型并行软件系统几乎总是被严格保密的专有技术。相比之下,21世纪出现了许多开源(因此公开可用)的并行软件项目,包括Linux内核[Tor03]、数据库系统[Pos08,MS08]以及消息传递系统[ The08,Uni08a]。本书将主要基于Linux内核,但也会提供大量适合用户级应用的材料。
第四,尽管20世纪80年代和90年代的大规模并行编程项目几乎都是专有项目,但这些项目为其他社区培养了一大批了解开发生产级并行代码所需工程学科的开发者。本书的主要目的是介绍这一工程学科。
不幸的是,第五个难题,即通信成本相对于处理成本的高昂,依然普遍存在。这一难题在新世纪受到了越来越多的关注。然而,根据史蒂芬·霍金的观点,光速的有限性和物质的原子性质将限制该领域的进步[Gar07,Moo03]。幸运的是,自20世纪80年代末以来,这一难题一直存在,使得上述工程学科得以发展出实用且有效的解决方案。
处理这些问题的策略。此外,硬件设计者越来越意识到这些问题,因此,也许未来的硬件将对并行软件更加友好,如第3.3节中所讨论的。

但是,尽管并行编程可能不像通常所宣传的那样困难,但它通常比顺序编程要费力。
因此,考虑并行编程的替代方案是有意义的。然而,在不了解并行编程目标的情况下,不可能合理地考虑并行编程的替代方案。这一主题将在下一节中讨论。
2.2 并行编程目标
如果你不知道你要去哪里,你就会去别的地方。
尤吉·贝拉
并行编程的三大目标(除了顺序编程的目标之外)如下:
1.性能。
2.生产率。
3.一般性。
不幸的是,考虑到目前的技术水平,对于任何给定的并行程序来说,最多只能实现这三个目标中的两个。因此,这三个目标构成了并行编程的铁三角,一个过于乐观的希望常常在此三角上破灭。

性能是大多数并行编程工作的主要目标。毕竟,如果性能不是问题,为什么不给自己一个机会:直接编写顺序代码,然后开心点?这很可能更容易,而且你可能会更快地完成更多的工作。
请注意,此处对“性能”的解释范围较广,包括可伸缩性(每个CPU的性能)和效率(每瓦的性能)。
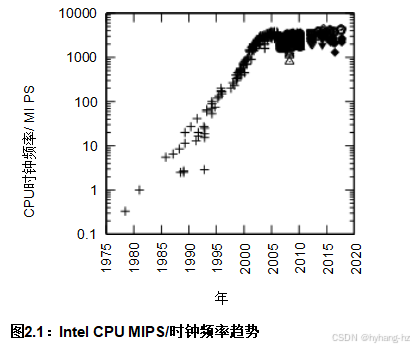
也就是说,性能的重点已经从硬件转移到了并行软件。这种重点的转移是因为,尽管摩尔定律继续带来晶体管密度的增加,但它已不再提供传统的单线程性能提升。这可以从图2.1中看出。 , 2 这表明,编写单线程代码并简单等待一两年让CPU迎头赶上可能已不再是一个选项。鉴于所有主要制造商近期向多核/多线程系统发展的趋势,对于那些希望充分利用系统全部性能的人来说,采用并行化是最佳选择。
即便如此,第一个目标还是性能,而不是可扩展性,特别是考虑到实现线性可扩展性的最简单方法是降低每个CPU的性能[Tor01]。
给定一个四核CPU系统,你更倾向于哪个?是单个CPU每秒提供100笔交易但完全不扩展的程序?还是单个CPU每秒提供10笔交易且完美扩展的程序?第一个程序看起来更好,不过如果你恰好有一个32核CPU系统,答案可能会改变。
话虽如此,仅仅因为拥有多个CPU并不一定意味着需要全部使用,尤其是在多CPU系统价格最近下降的情况下。关键在于,线程编程主要是一种性能优化,因此它是众多优化中的一种。如果你的程序已经足够快,按照当前的编写方式,就没有必要再进行优化了,无论是通过并行化还是应用其他潜在的顺序优化方法。 同样地,如果你打算将并行性作为优化手段应用于顺序程序,那么你需要将并行算法与最佳顺序算法进行比较。这可能需要一些谨慎,因为许多文献在分析并行算法性能时忽略了顺序情况。

近年来,生产力变得越来越重要。试想一下,早期计算机的价格高达数千万美元,而当时工程师的年薪只有几千美元。如果一支由十名工程师组成的团队能够提升这台机器的性能,哪怕只是提高10%,那么他们的工资就能得到数倍的回报。
其中一台机器是CSIRAC,这是最古老的仍保存完好的存储程序计算机,于1949年投入使用[乐04,德06]。由于这台机器是在晶体管时代之前制造的,因此由2000个真空管组成,运行时钟频率为1 kHz,功耗为30 kW,重量超过三公吨。考虑到这台机器只有768字的RAM,可以肯定地说,它没有像当今大型软件项目中常见的生产效率问题。
如今,购买一台计算能力如此之低的机器几乎是不可能的。或许最接近的是8位嵌入式微处理器,以著名的Z80[维基08]为代表,但即使是老款的Z80,其CPU时钟频率也比CSIRAC快1000多倍。Z80 CPU拥有8500个晶体管,在2008年以每台不到2美元的价格购买1000个单位。相比之下,软件开发成本对于Z80来说几乎微不足道。
CSIRAC和Z80是长期趋势中的两个点,如图2.2所示。 该图表展示了过去四十年中每颗芯片计算能力的近似值,在四十年间实现了令人印象深刻的六倍增长。请注意,尽管在2003年遇到了时钟频率墙,但多核CPU的优势使得这种增长得以持续,这得益于每个芯片支持超过50个硬件线程。
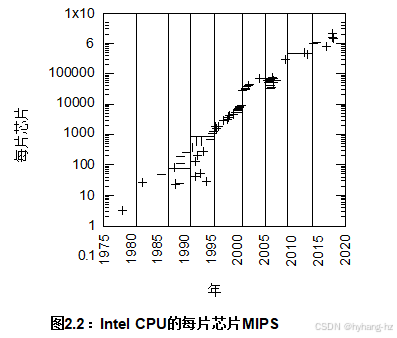
硬件成本迅速下降的一个不可避免的后果是,软件生产力变得越来越重要。仅仅高效利用硬件已不再足够:现在还需要极其高效地利用软件开发人员。这种情况对于顺序硬件来说早已存在,但并行硬件直到最近才成为低成本的商品。因此,只有在最近,高生产力才在创建并行软件时变得至关重要。

也许曾经,平行软件的唯一目的是性能。然而,现在,生产力正在成为焦点。
一种证明开发并行软件高成本合理性的方法是追求最大通用性。在其他条件相同的情况下,更通用的软件艺术的成本可以分摊到更多的用户身上,而不太通用的则不然。事实上,这种经济力量解释了对可移植性的狂热关注,这可以视为通用性的一个重要特例。
不幸的是,通用性往往以牺牲性能、生产力或两者为代价。例如,可移植性通常是通过适应层实现的,这不可避免地会带来性能损失。为了更普遍地理解这一点,请考虑以下流行的并行编程环境:
C/C++“锁定加线程”:这一类别包括POSIX线程(pthreads)[ Ope97]、Windows线程以及众多操作系统内核环境,提供了出色的性能(至少在一个SMP系统中),同时也具有良好的通用性。遗憾的是,其生产率相对较低。
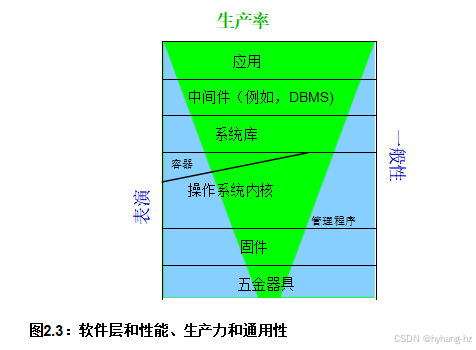
图2.3:软件层和性能、生产力和通用性
Java:这个通用且天生支持多线程的编程环境,被认为比C或C++具有更高的生产率,这得益于自动垃圾回收器和丰富的类库。然而,尽管其性能在21世纪初有了显著提升,但仍落后于C和C++。
MPI:这一消息传递接口[ MPI08]驱动着世界上最大的科学和技术计算集群,提供无与伦比的性能和可扩展性。理论上,它具有通用性,但主要用于科学和技术计算。许多人认为其生产力甚至低于C/C++“锁定加线程”环境。
OpenMP:这组编译器指令可用于并行化循环。因此,它非常适用于此任务,这种特殊性通常会限制其性能。然而,它比MPI或C/C++的“锁定加线程”更容易使用。
SQL:结构化查询语言[Int92]专用于关系数据库查询。然而,其性能相当出色,根据事务处理性能委员会(TPC)基准测试结果[Tra01]衡量。生产力极佳;事实上,这种并行编程环境使得人们即使对并行编程概念知之甚少或一无所知,也能充分利用大型并行系统。
并行编程环境的完美境界,一个能够提供世界级性能、生产力和通用性的环境,目前还不存在。在这样的完美境界出现之前,我们必须在性能、生产力和通用性之间做出工程上的权衡。其中一个权衡可以通过绿色的“铁三角”来表示5 如图2.3所示 这表明,在系统堆栈的高层,生产率变得越来越重要,而在底层,性能和通用性变得越来越重要。在底层产生的巨大开发成本必须分摊到同样庞大的用户群体中
(因此,通用性的重要性不言而喻),较低层的性能损失很难在较高层恢复。在堆栈的上层,对于特定应用的用户可能非常少,在这种情况下,提高生产力至关重要。这解释了为什么在堆栈的上层倾向于“臃肿软件”:额外的硬件通常比额外的开发人员更便宜。本书旨在帮助那些在堆栈底层工作的开发者,那里性能和通用性最为关键。
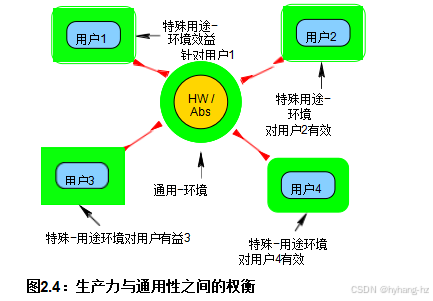
需要注意的是,生产力与通用性之间的权衡在许多领域已经存在了几个世纪。以钉枪为例,它比锤子更适用于钉钉子,但与钉枪不同的是,锤子除了钉钉子外还可以用于许多其他事情。因此,在并行计算领域出现类似的权衡也就不足为奇了。这种权衡如图2.4所示。在这里,用户1、2、3和4有特定的工作需要计算机来帮助他们完成。对于给定的用户来说,最有效的语言或环境是能够直接完成该用户的工作,而不需要任何编程、配置或其他设置。

不幸的是,一个能够完成用户1要求的工作的系统不太可能完成用户2的工作。换句话说,最有效的语言和环境是特定于领域的,因此从定义上来说缺乏通用性。
另一种选择是将给定的编程语言或环境定制到硬件系统(例如,低级语言如汇编、C、C++或Java)或某种抽象(例如,Haskell、Prol og或Snobol),如图2.4中中心附近的圆形区域所示。 这些语言可以被视为通用型,因为它们同样不适合用户1、2、3和4所需的任务。换句话说,它们的通用性是以降低生产率为代价的,与领域特定语言和环境相比。更糟糕的是,一种针对特定需求定制的语言,除非能够高效地映射到实际硬件上,否则可能会面临性能和可扩展性问题。
铁三角的三个相互冲突的目标——绩效、生产力和通用性——难道没有出路吗?
事实证明,通常可以使用一些替代方案来实现并行编程,例如在下一节中讨论的替代方案。毕竟,尽管并行编程可能很有趣,但它并不总是最佳工具。
2.3 并行编程的替代方法
当经验指引道路时,实验就是愚蠢的。
罗杰·M·巴布森
为了正确考虑并行编程的替代方案,您必须首先决定您期望并行性为您做什么。如第2.2节所示,并行编程的主要目标是性能、生产力和通用性。由于本书是为软件堆栈底层的性能关键代码开发人员编写的,因此本节其余部分主要关注性能改进。
请记住,并行处理只是提高性能的一种方法。其他众所周知的方法包括以下几种,大致按难度递增顺序排列:
1.运行多个序列应用程序实例。
2.使应用程序使用现有的并行软件。
3.优化串行应用程序。
以下各节介绍了这些方法。
运行多个顺序应用程序实例可以让你在不实际执行并行编程的情况下进行并行编程。根据应用程序的结构,有大量方法可以实现这一点。
如果你的程序需要分析大量不同的场景,或者需要分析大量独立的数据集,一个简单有效的方法是创建一个单一的顺序程序来执行单一分析,然后使用多种脚本环境(例如bash shell)并行运行该顺序程序的多个实例。在某些情况下,这种方法可以轻松扩展到机器集群中。
这种方法可能看起来像是作弊,事实上有些人贬低这类程序为“令人尴尬的并行”。确实,这种方法存在一些潜在缺点,包括增加内存消耗、浪费CPU周期重复计算常见的中间结果以及数据复制增加。然而,它通常非常高效,几乎无需额外努力就能获得显著的性能提升。
如今,能够提供单线程编程环境的并行软件环境已不再短缺,包括关系数据库[Data82]、Web应用服务器和map-reduce环境。例如,一种常见的设计为每个用户提供一个独立的进程,每个进程根据用户查询生成SQL。这些针对每个用户的SQL会运行在一个通用的关系数据库中,该数据库自动并行执行用户的查询。每个用户的程序仅负责用户界面,而关系数据库则全面负责并行性和持久性相关的复杂问题。
此外,越来越多的并行库函数,特别是用于数值计算的。更好的是,一些库利用了专用硬件,如向量单元和通用图形处理单元(GPGU)。
采用这种方法通常会牺牲性能,至少与精心手工编译一个完全并行的应用程序相比是这样。然而,这种牺牲往往通过大幅减少开发工作量而得到很好的回报。
![]()
直到20世纪初,CPU时钟频率每18个月翻一番。因此,通常更重要的是创造新功能,而不是精心优化性能。如今,摩尔定律“仅仅”增加了晶体管密度,而不是同时增加晶体管密度和每个晶体管的性能,这可能是重新思考性能优化重要性的良机。毕竟,新一代硬件不再带来显著的单线程性能提升。此外,许多性能优化还可以节省能源。
从这个角度来看,并行编程不过是另一种性能优化手段,尽管随着并行系统的成本降低和普及,这种优化变得越来越有吸引力。然而,值得注意的是,通过并行性获得的加速效果大致受限于CPU数量(但参见第6.5节中的一个有趣例外)。相比之下,传统单线程软件优化所能带来的加速效果要大得多。例如,用哈希表或搜索树替换长链表可以将性能提升几个数量级。这样高度优化的单线程程序可能比其未优化的并行版本运行得快得多,使得并行化变得没有必要。当然,高度优化行程序会更好,尽管这需要额外的开发努力。此外,不同的程序可能有不同的性能瓶颈。例如,如果您的程序大部分时间都在等待来自磁盘驱动器的数据,那么使用多个CPU可能只会增加等待磁盘时间。
事实上,如果程序是从一个按顺序排列在旋转磁盘上的大文件中读取数据,那么并行化你的程序可能会因为额外的寻道开销而变得慢得多。你应该优化数据布局,使文件更小(从而更快读取),将文件分割成可以并行访问的不同驱动器的块,频繁访问的数据缓存在主内存中,或者尽可能减少需要读取的数据量。

并行化可以是一种强大的优化技术,但并非唯一,也不适用于所有情况。当然,程序越容易并行化,这种优化就越有吸引力。并行化被认为相当困难,这引出了一个问题:“究竟是什么让并行编程如此困难?”
2.4 什么是并行编程的难点?
真正的困难可以克服,而想象中的困难是无法克服的。
西奥多·N·韦尔
需要注意的是,并行编程的难度既是一个人为因素问题,也是一个并行编程问题的技术属性。我们需要人类来告诉并行系统该做什么,这也就是编程。但并行编程涉及双向通信,程序的性能和可扩展性是机器向人类传达的信息。简而言之,人编写程序告诉计算机该做什么,而计算机则通过最终的性能和可扩展性来评估这个程序。因此,诉诸抽象或数学分析通常会非常有限效用。
在工业革命中,人机界面通过人为因素研究进行评估,这些研究被称为时间和动作研究。尽管有一些人为因素研究考察了并行编程[ENS05,ES05,HCS+05,SS94],但这些研究过于狭隘,因此无法得出普遍结论。此外,鉴于程序员生产力的正常范围跨越了一个数量级,期望一项经济的研究能够检测到(例如)10%的生产力差异是不现实的。虽然这类研究能够可靠地检测到多个数量级的差异极其宝贵,但最显著的改进往往基于一系列10%的改进。
因此,我们必须采取不同的办法。
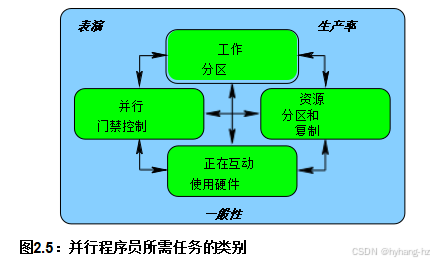
一种方法是仔细考虑并行程序员必须完成而顺序程序员不需要完成的任务。然后我们可以评估给定的编程语言或环境在多大程度上帮助开发人员完成这些任务。这些任务可以分为图2.5中所示的四个类别。 以下各节对每种情况进行了说明。
工作划分对于并行执行是绝对必要的:如果只有一个“全局”工作,则最多只能由一个CPU同时执行,这按定义就是顺序执行。然而,工作划分需要非常谨慎。例如,不均匀的划分可能导致小分区完成时才进行顺序执行[Amd67]。在不太极端的情况下,可以使用负载均衡来充分利用可用硬件,恢复性能和可扩展性。
尽管分区可以显著提高性能和可扩展性,但也可能增加复杂性。例如,分区会使得处理全局错误和事件变得更加复杂:一个并行程序可能需要执行非平凡的同步操作,以安全地处理这些全局事件。更广泛地说,每个分区都依赖某种形式的通信:毕竟,如果某个线程不进行通信,它将毫无作用,也就无需执行。然而,由于通信会产生开销,粗心的分区选择可能导致严重的性能下降。
此外,必须经常控制并发线程的数量,因为每个线程都会占用公共资源,例如CPU缓存中的空间。如果允许过多的线程同时执行,CPU缓存将会溢出,导致高缓存未命中率,从而降低性能。相反,为了充分利用I/O设备,通常需要大量线程来重叠计算和I/O操作。
![]()
最后,允许线程并发执行大大增加了程序的状态空间,这使得程序难以理解和调试,降低了生产效率。在其他条件相同的情况下,状态空间更小且结构更规则的程序更容易理解,但这既是一个人因工程问题,也是一个技术和数学问题。好的并行设计可能具有极其庞大的状态空间,但由于其结构规律而易于理解;而糟糕的设计即使状态空间相对较小也可能难以理解。最好的设计利用了令人尴尬的并行性,或将问题转化为一个有令人尴尬的并行解决方案的问题。在这两种情况下,“令人尴尬的并行”实际上是一种丰富的资源。目前的技术已经列举了一些好的设计;需要更多的工作来对状态空间的大小和结构做出更普遍的判断。
给定一个单线程的顺序程序,该单线程可以完全访问程序的所有资源。这些资源通常是内存中的数据结构,但也可以是CPU、内存(包括缓存)、I/O设备、计算加速器、文件以及其它资源。
第一个并行访问控制问题在于,对给定资源的访问形式是否依赖于该资源的位置。例如,在许多消息传递环境中,局部变量访问通过表达式和赋值实现,而远程变量访问则使用完全不同的语法,通常涉及消息传递。POSIX线程环境[Ope97]、结构化查询语言(SQL)[Int92]以及分区全局地址空间(PGAS)环境如通用并行C(UPC)[ EGCD03,CBF13]提供隐式访问,而消息传递接口(MPI)[ MPI08]提供显式访问,因为对远程数据的访问需要显式的消息传递。
另一个并行访问控制的问题是如何协调线程对资源的访问。这种协调通过各种并行语言和环境提供的大量同步机制来实现,包括消息传递、锁定、事务、引用计数、显式定时、共享原子变量和数据所有权。许多传统的并行编程问题,如死锁、活锁和事务回滚,都源于这种协调。该框架可以进一步扩展,以比较这些同步机制,例如锁定与事务内存[MMW07],但这种扩展超出了本节的范围。(有关事务内存的更多信息,请参见第17.2节和第17.3节。)
![]()
最有效的并行算法和系统充分利用资源并行性,因此通常明智的做法是通过分区写密集型资源和复制频繁访问的读为主资源来开始并行化。这里提到的资源主要是数据,可能分布在计算机系统、大容量存储设备、NUMA节点、CPU核心(或芯片或硬件线程)、页面、缓存行、同步原语实例或代码的关键部分。例如,基于锁定原语的分区被称为“数据锁定”[BK85]。
资源划分通常依赖于具体应用。例如,数值应用经常按行、列或子矩阵划分矩阵,而商业应用则经常划分写密集型数据结构和读主要数据结构。因此,一个商业应用可能会将特定客户的资料分配给大型集群中的少数几台计算机。应用可能静态地划分数据,也可能随时间动态改变划分方式。
资源分区非常有效,但对于复杂的多链接数据结构来说却相当具有挑战性。
硬件交互通常是操作系统、编译器、库或其他软件环境基础设施的领域。然而,开发人员在处理新型硬件特性和组件时,往往需要直接与这些硬件打交道。此外,在榨取给定系统性能的最后一丝提升时,可能也需要直接访问硬件。在这种情况下,开发人员可能需要根据目标硬件的缓存几何结构、系统拓扑或互连协议来定制或配置应用程序。
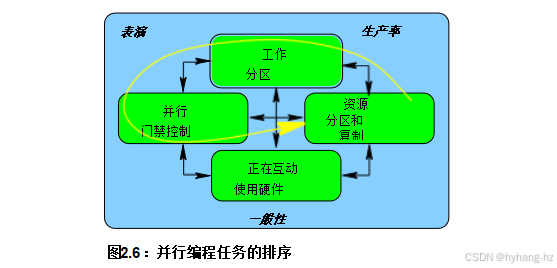
在某些情况下,硬件可能被视为一种受分区或访问控制的资源,如前几节所述。
尽管这四种能力是基础,良好的工程实践会利用这些能力的组合。例如,数据并行方法首先将数据分区以减少跨分区通信的需求,然后相应地划分代码,最后映射数据分区和线程,以最大化吞吐量同时最小化线程间通信,如图2.6所示。 开发人员可以单独考虑每个分区,大大减少相关状态空间的大小,从而提高生产率。尽管有些问题无法分区,但巧妙地转换为允许分区的形式有时可以显著提升性能和可扩展性[Met99]。
2.4.6语言和环境如何帮助这些任务?
尽管许多环境要求开发人员手动处理这些任务,但也有长期存在的环境能够显著提高自动化水平。SQL就是这类环境的典型代表,其许多实现可以自动并行化单个大型查询,并且还能自动化独立查询和更新的并发执行。
这四个任务类别必须在所有并行程序中执行,但这当然并不意味着开发人员必须手动执行这些任务。随着并行系统的成本降低和可用性提高,我们可以预期这四个任务将越来越自动化。
![]()
2.5 讨论
在你尝试之前,你不知道自己不能做什么。
亨利·詹姆斯
本节概述了并行编程的困难、目标及替代方案。随后讨论了并行编程为何难以实现,并提出了一种高层次的方法来应对并行编程的难题。那些仍然坚持认为并行编程不可能实现的人,应该回顾一些较早的并行编程指南[Seq88,Bir 89,BK 85,Inm 85]。安德鲁·比雷尔在其专著中的一段话尤其发人深省[比雷尔89]:
编写并发程序被认为既奇特又困难。我认为并非如此。你需要一个提供良好原语和合适库的系统,需要基本的谨慎和细心,需要掌握一系列有用的技巧,并且需要了解常见的陷阱。希望本文能帮助你认同我的观点。
这些较早的指南的作者在20世纪80年代就已经很好地应对了并行编程挑战。因此,在21世纪,拒绝迎接并行编程挑战是没有任何借口的!
现在我们准备进入下一章,该章节深入探讨了并行软件底层并行硬件的相关特性。
Chapter 3 Hardware and its Habits
过早抽象是一切罪恶的根源。
成千上万的人
大多数人直觉地认为,在系统之间传递消息比在一个系统内部执行简单的计算要昂贵得多。但同样,单共享内存系统中线程之间的通信也可能非常昂贵。因此,本章探讨了在共享内存系统中同步和通信的成本。这几页内容最多只能触及共享内存并行硬件设计的表面;希望了解更多细节的读者最好从亨尼斯和帕特森的经典著作的最新版本开始阅读[HP17,HP95]。

3.1 概述
机械同感:硬件和软件协同工作。
马丁·汤普森
对计算机系统规格表的粗心阅读可能会让人相信CPU性能是一条清晰赛道上的赛跑,如图3.1所示,比赛总是由跑得最快的人获胜。
尽管有一些CPU限制的基准测试接近图3.1中显示的理想情况 典型的程序更像是一项障碍赛跑,而不是一条跑道。这是因为过去几十年里,由于摩尔定律的推动,CPU的内部架构发生了巨大变化。这些变化将在接下来的部分中详细描述。
20世纪80年代,典型的微处理器获取一条指令,解码并执行它,通常至少需要三个时钟周期来完成一条指令,甚至在开始下一条指令之前。相比之下,20世纪90年代末和21世纪初的CPU可以同时执行多条指令,利用流水线、超标量技术和乱序执行技术。
指令和数据处理;推测执行等[HP17,HP11],以优化指令和数据通过CPU的流动。某些核心拥有多个硬件线程,这被称为同时多线程(SMT)或超线程(HT)[ Fen73],每个线程在软件看来都是一个独立的CPU,至少从功能角度来看是这样。这些现代硬件特性可以显著提升性能,如图3.2所示。
要实现具有长流水线的CPU的全性能,需要程序中高度可预测的控制流。合适的控制流可以通过主要执行紧密循环的程序来提供,例如对大型矩阵或向量进行算术运算。这样,CPU几乎可以在所有情况下正确预测循环结束时会执行分支,从而使流水线保持满载状态,CPU能够以全速运行。
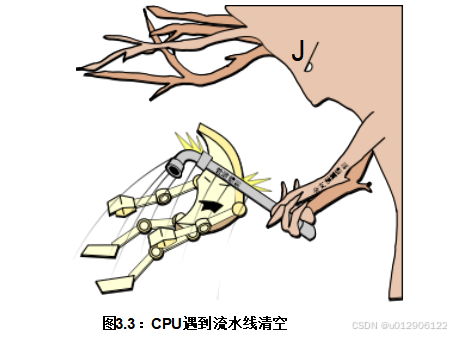
然而,分支预测并非总是那么简单。例如,考虑一个包含许多循环的程序,每个循环迭代次数虽少但随机。再比如,考虑一个传统的面向对象程序,其中有许多虚拟对象可以引用多个不同的真实对象,这些对象频繁调用成员函数时实现各不相同,导致通过指针进行大量调用。在这种情况下,CPU难以甚至无法预测下一个分支会指向何处。因此,CPU必须等待执行足够长的时间以确定分支指向的位置,或者只能猜测并使用推测执行继续前进。尽管对于控制流可预测的程序,猜测效果非常好,但对于不可预测的分支(如二分查找中的分支),猜测结果经常出错。错误的猜测代价高昂,因为CPU必须丢弃相应分支之后的所有推测执行指令,导致流水线清空。如果流水线清空过于频繁,会大幅降低整体性能,如图3.3所示。
这种情况在超线程(或SMT,如果你喜欢的话)中变得更加普遍,尤其是在具有推测执行功能的流水线超标量乱序CPU上。在这种越来越常见的情况下,共享同一核心的所有硬件线程也共享该核心的资源,包括寄存器、缓存、执行单元等。指令通常被解码为微操作,并使用共享的执行单元。
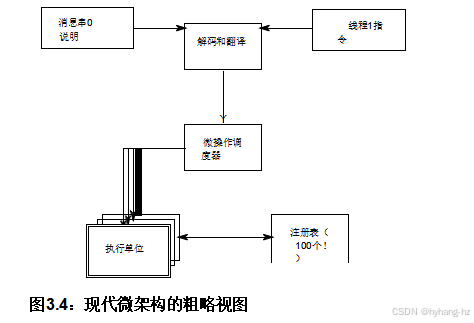
单元和数百个硬件寄存器通常由微操作调度器协调。图3.4给出了这样一个双线程核心的粗略示意图, 教科书和学术论文中提供了更精确(因而更复杂)的图表。 因此,一个硬件线程的执行可以而且经常会被共享该核心的其他硬件线程的操作所干扰。
即使只有一个硬件线程处于活动状态(例如,在旧式学校CPU设计中只有一个线程),反直觉的结果也相当常见。执行单元通常具有重叠的功能,因此CPU选择的执行单元可能会导致管道停滞,因为后续指令会争夺该执行单元。理论上,这种竞争是可以避免的,但在实际操作中,CPU必须迅速做出选择,而没有先见之明的好处。特别是,在紧致循环中添加一条指令有时实际上可以加快执行速度。
不幸的是,管道冲洗和共享资源竞争并不是现代CPU必须运行的障碍赛程中的唯一危险。下一节将介绍引用内存的危险。
在20世纪80年代,微处理器从内存中加载一个值的时间通常比执行一条指令要少。近年来,微处理器可能在访问内存所需的时间内执行数百甚至数千条指令。这种差异是由于摩尔定律使得CPU性能的增长速度远超内存延迟的减少速度,部分原因是内存容量的增长速度。例如,典型的20世纪70年代小型计算机可能只有4KB(没错,是千字节,而不是兆字节,更不用说吉字节或太字节)的主存,并且单周期访问。 当今的CP U设计者仍然可以构建一个4 KB的单周期访问内存,即使是在多GHz时钟频率的系统上。事实上,他们经常构建这样的内存,但现在称其为“0级缓存”,而且它们可以比4 KB大一些。
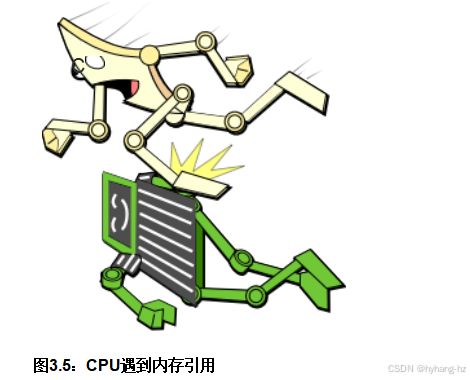
尽管现代微处理器上的大缓存可以显著减少内存访问延迟,但这些缓存需要高度可预测的数据访问模式才能成功隐藏这些延迟。不幸的是,常见的操作如遍历链表具有极其不可预测的内存访问模式——毕竟,如果模式是可预测的,我们这些软件类型岂不是就不用费心去处理指针了?因此,如图3.5所示 ,内存引用通常会给现代cpu带来严重的障碍。
到目前为止,我们只考虑了在单线程代码执行过程中可能出现的障碍。多线程为CPU带来了额外的障碍,如下几节所述。
其中一个障碍是原子操作。问题在于,原子操作的概念与CPU流水线逐件处理的操作理念相冲突。值得称赞的是,现代CPU使用了多种极其巧妙的技巧,使得这些操作看起来像是原子性的,尽管实际上它们是逐件执行的。一种常见的技巧是识别出所有包含待原子操作数据的缓存行,确保这些缓存行由执行原子操作的CPU拥有,然后在确保这些缓存行仍由该CPU拥有的情况下进行原子操作。由于所有数据都是私有的,其他CPU无法干扰原子操作,尽管CPU流水线的逐件处理特性。可想而知,这种技巧可能需要延迟甚至清空流水线,以完成允许特定原子操作正确完成的设置操作。
相比之下,在执行非原子操作时,CPU可以加载缓存行中的值,并将结果放入存储缓冲区,而无需等待缓存行所有者。尽管有许多硬件优化
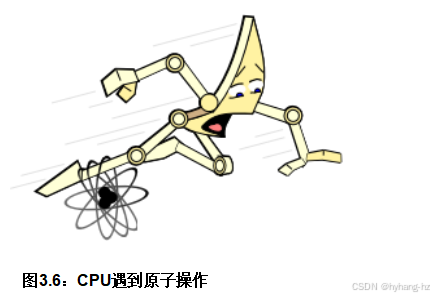
图3.6:CPU遇到原子操作
这有时会隐藏缓存延迟,对性能的影响往往如图3.6所示。
不幸的是,原子操作通常只适用于数据中的单个元素。由于许多并行算法要求在多个数据元素更新之间保持顺序约束,大多数CPU提供了内存屏障。这些内存屏障也作为性能消耗障碍,如下一节所述。

将在第15章和附录C中更详细地讨论内存屏障。与此同时,请考虑以下基于锁的简单临界区:
| spin_lock(&mylock);a= a+1; spin_unlock(&mylock); |
如果CPU不按所示顺序执行这些语句,那么变量“a”会在没有“mylock”保护的情况下递增,这显然违背了获取它的初衷。为了防止这种破坏性的重排序,锁定原语包含显式或隐式的内存屏障。由于这些内存屏障的全部目的是防止CPU为了提高性能而进行的重排序,因此内存屏障几乎总是会降低性能,如图3.7所示。
与原子操作一样,CPU设计者一直在努力减少内存屏障开销,并取得了实质性的进展。
一个越来越常见的令人沮丧的经历是,仔细地微优化一个关键的代码路径,大大减少了该代码路径消耗的时钟周期数,结果却发现该代码消耗的实际时间实际上增加了。



欢迎来到现代热节流。
如果你通过更有效地利用CPU的功能单元来减少时钟周期的数量,那么你将增加该CPU的功耗。这反过来又会增加该CPU散发的热量。如果这种散热超过了冷却系统的容量,系统将对CPU进行热管理,例如通过降低其时钟频率,就像图3.8中雪企鹅所描绘的那样。
如果性能是关键,正确的解决方法就是改进冷却,这是严肃玩家和超频爱好者的最爱。但是,如果你无法修改计算机的冷却系统,可能是因为你从云服务提供商那里租用了它,那么你就需要采取其他优化方法。例如,你可能需要应用算法优化,而不是依赖硬件的微优化。或者,你可以并行化你的代码,将工作(以及热量)分散到多个CPU核心上。
额外的多线程障碍是“缓存未命中”。如前所述,现代CPU配备了大容量缓存,以减少因高内存延迟而产生的性能损失。然而,对于频繁在不同CPU之间共享的变量而言,这些缓存实际上适得其反。这是因为当某个CPU希望修改某个变量时,很可能其他CPU最近已经对该变量进行了修改。在这种情况下,该变量可能存在于另一个CPU的缓存中,但不在当前CPU的缓存中,从而导致昂贵的缓存未命中(详见附录C.1)。这种缓存未命中是CPU性能的主要障碍,如图3.9所示。 ![]()
图3.10:CPU等待I/O完成
缓存未命中可以视为一种CPU到CPUI/O的操作,因此是可用的最便宜的I/O操作之一。涉及网络、大容量存储或(更糟糕的是)人类的I/O操作比前几节提到的内部障碍要困难得多,如图3.10所示。
这是共享内存与分布式系统并行性之间的区别之一:共享内存并行程序通常不会遇到比缓存未命中更严重的障碍,而分布式并行程序则会因较大的网络通信延迟而受到影响。在这两种情况下,相关的延迟可以视为通信成本——这种成本在顺序程序中是不存在的。因此,通信开销与实际工作量之间的比例是一个关键的设计参数。并行硬件设计的主要目标之一是根据需要降低这一比例,以实现相关性能和可扩展性的目标。同样地,正如将在第六章中看到的,并行软件设计的主要目标之一是减少诸如通信缓存未命中等昂贵操作的频率。
当然,说某项操作是障碍是一回事,而证明该操作是重大障碍则是另一回事。这种区别将在下面的章节中讨论。
3.2 管理费用
不要在不了解材料的情况下设计桥梁,也不要以不了解底层硬件为由设计低级软件。
未知的
本节介绍前一节中列出的性能障碍的实际开销,但首先有必要对硬件系统架构有一个大致的了解,这是下一节的主题。
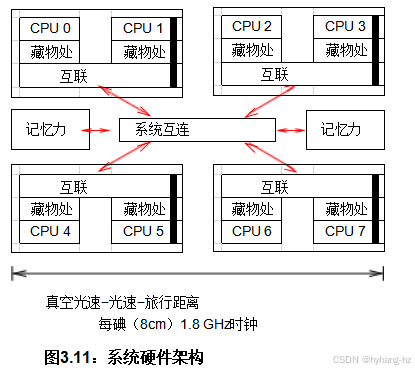
图3.11 显示了一个八核计算机系统的粗略示意图。每个芯片都有一对CPU核心,每个核心都有自己的缓存,以及一个互连,允许这对CPU相互通信。系统互连使得四个芯片能够互相通信,并与主内存通信。
数据以“缓存行”的单位通过该系统移动,这些缓存行是固定大小的对齐内存块,通常大小在3²到256字节之间。当CPU从内存中加载一个变量到其寄存器时,必须首先将包含该变量的缓存行加载到其缓存中。同样地,当CPU将一个寄存器中的值存储到内存中时,也必须将包含该变量的缓存行加载到其缓存中,并且还必须确保没有其他CPU拥有该缓存行的副本。
例如,如果CPU 0要写入一个缓存行位于CPU 7缓存中的变量,则可能会出现以下过于简化的事件序列:
1. CPU 0检查其本地缓存,没有找到该缓存行。因此,它将写入记录在其存储缓冲区中。
2.请求此缓存行被转发到CPU 0和1的互连,检查CPU1的本地缓存,但没有找到该缓存行。
3.此请求被转发到系统互连,该互连与另外三个芯片进行检查,得知缓存内由包含CPU 6和7的芯片持有。
4.此请求被转发到CPU6和7的互连,该互连检查两个CPU的缓存,在CPU 7的缓存中找到值。
5. CPU 7将缓存行转发到其互连,并且从其缓存中清除该缓存行。
6. CPU 6和7的互连将缓存行转发到系统互连。
7.系统互连将缓存行转发至CPU0的and1互连。
8. CPU 0和1的互连将缓存行转发到CPU0的缓存。
9. CPU 0现在可以完成写入,更新新到达的缓存行的相关端口离子,从存储缓冲区中先前记录的值。

这个简化的序列仅仅是缓存一致性协议[HP95,CSG99,MHS12,SHW11]这一学科的开端,更多细节请参见附录C。从事件序列中可以看出,由a触发CAS操作,一条指令可引起大量的协议流量,这会显著降低并行程序的性能。
幸运的是,如果某个变量在一段时间内频繁读取但从未更新,该变量可以复制到所有CPU的缓存中。这种复制使得所有CPU都能以极快的速度访问这个主要读取的变量。第9章介绍了同步机制,充分利用了这一重要的硬件读取优化。
一些对并行程序很重要的常见操作的开销如表3.1所示。 该系统的时钟周期四舍五入为0.5纳秒。尽管现代微处理器通常能够在每个时钟周期内完成多条指令的执行,但操作的成本仍然在第三列“比率”中以时钟周期为单位进行了标准化。关于这张表,首先需要注意的是许多比率的值非常大。
相同的CPU比较交换(CAS)操作大约需要十秒的时间,这一时间是时钟周期的十倍多。CAS是一种原子操作,其中硬件会将指定内存位置的内容与指定的“旧”值进行比较,如果它们相等,则存储一个指定的“新”值,此时CAS操作成功。如果不相等,内存位置保持其(意外的)值,CAS操作失败。该操作具有原子性,因为硬件保证在比较和存储之间不会改变内存位置。CAS功能由x86中的锁;cmpxchg指令提供。
“相同CPU”前缀表示当前执行CAS操作的CPU也是最后一个访问该变量的CPU,因此对应的缓存行已经存在于该CPU的缓存中。同样地,“相同CPU”锁操作(由一次获取和释放组成的“往返”对)耗时超过十五纳秒,或超过三十个时钟周期。锁操作比CAS更昂贵,因为它需要对锁数据结构进行两次原子操作,一次用于获取,另一次用于释放。
涉及共享单个核心的硬件线程之间交互的内核操作的成本与asm-eCPU操作的成本大致相同。这并不令人惊讶,因为这两个硬件线程还共享完整的缓存层次结构。
对于盲CAS,软件在不查看内存位置的情况下指定旧值。当尝试获取锁时,这种方法是合适的。
表3.1:CPU 0视图:8插槽系统上使用Intel Xeon Platinum 81 76个CPU的同步机制@2.10 GHz
| 操作 | 成本(ns) | 比率(成本/时钟) | 中央处理器 |
| 时钟周期 | 0.5 | 1.0 | |
| 相同CPU的CAS 锁上 | 7.0 15.4 | 14.6 32.3 | 0 |
| 在核心 盲法CAS CAS | 7.2 18.0 | 15.2 37.7 | 224 |
| 离线 盲法CAS CAS | 47.5 101.9 | 99.8 214.0 | 1–27225–251 |
| 离线 盲法CAS CAS | 148.8 442.9 | 312.5 930. 1 | 28–111252–335 |
| 交叉互连盲CAS CAS | 336.6 944.8 | 706.8 1,984.2 | 112–223336–447 |
| 系统外 Comms Fabric全球通信 | 5,000 195,000,000 | 10,500 409,500,000 |
如果解锁状态用零表示,锁定状态用值一表示,那么对锁执行指定旧值为零、新值为一的CAS操作,如果锁尚未被持有,则该操作将成功获取锁。关键在于,内存位置的访问仅限于一次,即CAS操作本身。
相比之下,CAS操作的旧值是从某个早期加载中获取的。例如,为了实现原子增量操作,会先加载该位置的当前值,然后将该值加一以生成新值。在CAS操作中,实际加载的值会被指定为旧值,而加一后的值则作为新值。如果在这次加载和CAS之间没有改变该值,这将导致内存位置的增量。然而,如果该值确实发生了变化,则旧值不会匹配,从而导致比较失败。关键在于,现在内存位置有两次访问,一次是加载,另一次是CAS。
因此,核心盲CAS仅消耗约7纳秒,而核心CAS则消耗约18纳秒也就不足为奇了。核心盲CAS的额外负载并非免费获得。也就是说,这些操作的开销分别类似于相同CPU的CAS和锁。

表3.2:配备Intel Xeon Platinum 8176 CPU的8插槽系统的缓存几何结构@2.10 GHz
| 等级 | 范围 | 线条大小 | 集锦 | 方式 | 尺寸 |
|
|
|
|
|
|
|
| L1 | 核心 | 64 | 64 | 8 | 32K |
| L2 | 核心 | 64 | 1024 | 16 | 1024K |
| L3 | 插座 | 64 | 57,344 | 11 | 39,424K |






盲CAS涉及同一插槽内不同核心的CPU,耗时近五十纳秒,或接近一百个时钟周期。用于此缓存未命中测量的代码会在一对CPU之间来回传递缓存行,因此这种缓存未命中的满足不是来自内存,而是来自另一台CPU的缓存。非盲CAS操作,如前所述,必须查看变量的旧值并存储新值,耗时超过一百纳秒,或超过两百个时钟周期。仔细思考一下。在一秒钟内完成一次CAS操作的时间,CPU可以执行超过两百条正常指令。这不仅展示了细粒度锁定的局限性,也揭示了任何依赖于细粒度全局一致性的同步机制的局限性。
如果这对CPU位于不同的插槽上,操作的代价就大得多。盲CAS操作消耗近150纳秒,或超过300个时钟周期。正常CAS操作消耗超过400纳秒,或近1000个时钟周期。
更糟糕的是,并非所有社会契约对都是一样的。这个特定系统似乎是由四个插槽组件组成的,当CPU位于不同组件时会产生额外的延迟惩罚。在这种情况下,盲CAS操作需要超过三百纳秒,即超过七百个时钟周期。而一个CAS操作几乎需要整整一微秒,即接近两千个时钟周期。

不幸的是,内核和内核间通信的高速度并非免费。首先,在给定的核心中只有两个CPU,在给定的套接字中只有56个,而整个系统中有448个。其次,如表3.2所示,与theon-socket缓存相比,theon-core缓存要小得多,而后者又比该系统配置的1.4 TB内存要小。第三,再次参考图示,缓存被组织成一个硬件表,每个桶中的项目数量有限。例如,L3缓存(“大小”)的原始大小接近40MB,但每个桶(“行”)只能容纳11块内存(“路”),每块最多64字节(“行大小”)。这意味着只需12字节的内存(当然是在精心选择的地址处)就能溢出这40MB的缓存。另一方面,同样谨慎地选择地址可能会充分利用整个40MB的内存。
I/O操作更加昂贵。如“通信结构”一栏所示,高性能(且昂贵!)的通信结构,如InfiniBand或任何专有互连,在端到端往返过程中大约有五微秒的延迟时间,在此期间可能执行了超过一千条指令。基于标准的通信网络通常需要某种协议处理,这进一步增加了延迟。当然,地理距离也会增加延迟,全球光纤传输的速度大约为195毫秒,相当于超过4亿个时钟周期,如“全球通信”一栏所示。

很自然地会问硬件是如何帮助的,答案是“相当多!”
一种硬件优化是大缓存行。这可以显著提升性能,尤其是在软件按顺序访问内存时。例如,假设一个64字节的缓存行,软件访问64位变量,首次访问仍然会因为光速延迟而较慢(如果其他方面没有问题的话),但随后的七次访问可以非常快。然而,这种优化也有其阴暗面,即虚假共享,当同一缓存行中的不同变量被不同的CPU更新时,会导致较高的缓存未命中率。软件可以利用许多编译器提供的对齐指令来避免虚假共享,添加此类指令是调优并行软件的常见步骤。
第二个相关的硬件优化是缓存预取,即硬件通过预取后续的缓存行来应对连续访问,从而避免这些后续缓存行的光速延迟。当然,硬件必须使用简单的启发式方法来确定何时预取,而这些启发式方法可能会被许多应用程序中的复杂数据访问模式所误导。幸运的是,一些CPU家族通过提供特殊的预取指令来实现这一点。不幸的是,这些指令在一般情况下的有效性仍存在争议。
第三项硬件优化是存储缓冲区,它使得即使在存储地址不连续且所需缓存行不在CPU缓存中时,也能快速执行一串存储指令。这项优化的阴暗面是内存乱序,详见第15章。
第四项硬件优化是推测执行,这可以让硬件充分利用存储缓冲区,而不会导致内存乱序。然而,这种优化的阴暗面可能是能耗不高效和性能下降,如果推测执行出错并需要回滚重试。更糟糕的是,Spectre和Meltdown的出现[Ho r18]表明,硬件推测还可能引发侧信道攻击,这些攻击可以绕过内存保护硬件,使非特权进程能够读取它们本不应访问的内存。显然,推测执行与云计算的结合需要更多的改进!
第五个硬件优化是大缓存,允许单个CPU在不产生昂贵的缓存未命中的情况下操作更大的数据集。尽管大缓存
会降低能效和缓存未命中延迟,生产微处理器上不断增长的缓存大小证明了这种优化的力量。
最后一种硬件优化是读取-主要复制,其中经常被读取但很少被更新的数据存在于所有CPU的缓存中。这种优化使读取-主要数据能够极其高效地访问,是第9章的主题。
简而言之,硬件和软件工程师是站在同一边的,他们都试图让计算机运行得更快,尽管物理定律尽了最大努力,如图3.12所示 我们的数据流正竭尽全力超越光速。下一节将讨论一些额外的事情,这些事情取决于最近的研究成果能否顺利转化为实际应用,硬件工程师可能(或不可能)能够做到。本书后续章节将概述软件对这一崇高目标的贡献。
3.3 硬件免费午餐?
今天的大麻烦是,有太多的
人们总是在寻找别人替他们做事。解决我们大多数问题的办法就是每个人都为自己做点什么。
亨利·福特,更新
近年来,并发受到了如此多的关注的主要原因是摩尔定律所导致的单线程性能提升(或“免费午餐”[Sut08])的终结,如第12页图2.1所示。本节简要回顾了硬件设计者可能有几种方法可以带来“免费午餐”。
然而,前一节介绍了一些利用并发的实质性硬件障碍。硬件设计者面临的一个严重的物理限制是光速的有限性。如图3.11所示第34页 光在1.8 GHz时钟周期内,在真空中只能传播大约8厘米的距离。这一距离在5 GHz时钟周期下降至约3厘米。与现代计算机系统的规模相比,这两个距离都相对较小。
更糟糕的是,硅中的电波移动速度比真空中光的速度慢3到30倍,而常见的时钟逻辑结构仍然运行
例如,内存引用可能需要等待本地缓存查找完成,才能将请求传递给系统其余部分。此外,为了将电信号从一个硅片传输到另一个硅片,例如在CPU和主内存之间通信,需要相对低的速度和高功率驱动器。

尽管如此,仍有一些技术(包括硬件和软件)可以帮助改善情况:
1. 3D集成,
2.新型材料和工艺,
3.用光代替电,
4.专用加速器,以及
5.现有并行软件。
这些内容在以下各节中进行了描述。
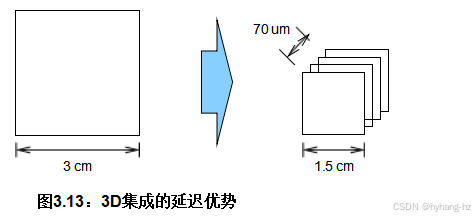
三维集成(3DI)是将非常薄的硅片垂直堆叠在一起的实践。这种做法提供了潜在的好处,但也带来了显著的制造挑战[Kni08]。
也许3DI最重要的好处是减少了系统中的路径长度,如图3.13所示。用four1.5-centimeter层叠硅片替代了3厘米的硅片,在理论上可以将系统中的最大路径减少一半,同时要记住每一层都非常薄。此外,只要设计和布局得当,长水平电气连接(既慢又耗电)可以被短垂直电气连接所取代,后者不仅更快,而且更节能。
然而,由于时钟逻辑水平导致的延迟不会因3D集成而减少,且为了使3D集成在生产中仍能兑现其承诺,必须解决重大的制造、测试、电源供应和散热问题。散热问题可能通过基于半导体的方法来解决。
金刚石是良好的热导体,但却是电绝缘体。因此,要生长出大单晶金刚石已经相当困难,更不用说将其切割成晶圆了。此外,这些技术似乎不太可能实现一些人所习惯的指数级增长。话虽如此,它们可能是通往吉姆·格雷晚年所说的“冒烟的毛球”[Gra02]的必要步骤。
据说斯蒂芬·霍金曾声称,半导体制造者面临两个基本问题:(1)光速有限和(2)物质的原子性质[Gar07]。尽管半导体制造商可能正在接近这些极限,但仍有几条研究和发展路径专注于绕过这些基本限制。
一种解决物质原子性质的方法是所谓的“高介电常数”材料,这些材料使得较大的设备能够模拟出微小设备的电学特性。这些材料带来了一些严重的制造挑战,但仍然可能帮助将前沿推进得更远一些。另一种更为奇特的方法是在单个电子中存储多个比特,利用给定电子可以存在于多个能级这一事实。这种特定方法是否能在生产中的半导体器件中可靠地实现,还有待观察。
另一种提出的变通方法是“量子点”方法,它允许更小的设备尺寸,但仍然处于研究阶段。
一个挑战是,许多最近的硬件设备级突破需要非常精确地控制哪些原子被放置在哪里[Kel17]。因此,似乎可以肯定的是,无论谁找到一种好方法将原子手工放置在芯片上的数十亿个设备中的每一个上,即使没有其他优势,也将拥有极高的竞争权!
尽管光速是一个难以突破的极限,但事实是半导体器件的速度受限于电的速度而非光速,因为半导体材料中的电波传播速度仅为真空中光速的3%到30%。在硅器件上使用铜连接是一种提高电速的方法,未来的技术进步可能会进一步接近光速。此外,一些实验已经使用微小的光纤作为芯片内部和之间的互连,基于玻璃中光速超过真空中光速60 %的事实。然而,这种光纤的一个障碍在于电与光之间转换效率低下,导致功耗和散热问题。
也就是说,在物理学领域没有一些基本的进展的情况下,数据流速度的指数级增长将受到真空中光速的实际速度的严格限制。
通用CPU在处理特定问题时,往往会花费大量时间和精力去做与当前问题只有间接关系的工作。例如,在计算一对向量的点积时,通用CPU通常会使用带有循环计数器的循环(可能是展开的)。解码指令,
增加循环计数器、测试这个计数器并返回到循环顶部,在某种程度上是浪费精力:真正的目标是将两个向量中的对应元素相乘。因此,专门设计用于向量相乘的硬件可以更快地完成任务,同时消耗更少的能量。
事实上,这是许多通用微处理器中向量指令存在的动机。因为这些指令同时对多个数据项进行操作,所以它们允许以更少的指令解码和循环开销来计算点积。
同样,专用硬件可以更高效地进行加密和解密、压缩和解压、编码和解码等众多任务。遗憾的是,这种效率并非免费获得。集成这些专用硬件的计算机系统将包含更多的晶体管,即使在不使用时也会消耗一些电力。软件必须被修改以利用这种专用硬件,同时这些专用硬件必须足够通用,使得高层硬件设计成本能够分摊到足够多的用户身上,从而使专用硬件变得负担得起。由于这些经济因素,迄今为止,专用硬件仅出现在少数应用领域,包括图形处理(GPU)、矢量处理器(MMX、SSE和VMX指令),以及在较小程度上的加密。即使在这些领域中,实现预期的性能提升也并非总是那么容易,例如,由于热限制[Kra17,Lem18,Dow20]。
与服务器和PC领域不同,智能手机长期以来一直使用各种各样的硬件加速器。这些硬件加速器通常用于媒体解码,以至于高端MP3播放器可能在CPU完全关闭的情况下播放音频几分钟。这些加速器的目的是提高能效,从而延长电池寿命:专用硬件往往比通用CPU计算效率更高。这是第2.2.3节中提到的原则的另一个例子:通用性几乎从来不是免费的。
然而,考虑到摩尔定律引起的单线程性能增加的结束,似乎可以安全地假设特殊目的硬件的种类会增加。
尽管多核CPU似乎让计算行业大吃一惊,但事实是共享内存并行计算机系统已经商用超过四分之一个世纪了。这足以让重要的并行软件出现,而它确实做到了。并行操作系统非常普遍,同时并行线程库、并行关系数据库管理系统和并行数值软件也十分常见。利用现有的并行软件可以在很大程度上解决我们可能遇到的任何并行软件危机。
也许最常见的例子是并行关系数据库管理系统。单线程程序,通常用高级脚本语言编写,同时访问中央关系数据库并不罕见。在这种高度并行的系统中,只有数据库需要直接处理并行性。当这一技巧奏效时,真是妙不可言!
3.4 软件设计影响
一艘船向东驶去,另一艘向西驶去,而同样的微风在吹拂着;
是帆的集合,而不是风向标指引他们去哪里。
埃拉·惠勒·威尔科克斯
表3.1中比率的值 至关重要,因为它们限制了给定并行应用程序的效率。要了解这一点,假设并行应用程序使用CAS操作用于线程之间的通信。这些CAS操作通常会涉及缓存未命中,也就是说,假设线程主要是在相互之间进行通信而不是与自身通信。进一步假设每次CAS通信操作对应的工作单元需要300纳秒,这足以计算多个浮点超越函数。那么大约一半的执行时间将被CAS通信操作消耗!这意味着运行此类并行程序的双CPU系统不会比单CPU上运行的顺序实现更快。
分布式系统的情况更糟,单个通信操作的延迟可能长达数千甚至数百万次浮点运算。这说明了通信操作必须极其不频繁,并且能够支持大量处理的重要性。

课程应该非常明确:并行算法必须在设计时充分考虑这些硬件特性。一种方法是运行几乎独立的线程。线程之间的通信越少,无论是通过原子操作、锁还是显式消息,应用程序的性能和可扩展性就越好。这种方法将在第五章中简要讨论,在第六章中深入探讨,并在第八章中推向极致。
另一种方法是确保任何共享数据都是读取优先的,这样可以允许CPU的缓存复制读取优先的数据,进而允许所有CPU快速访问。这种方法在第5.2.4节中有所提及,并在第9章中进行了更深入的探讨。
简而言之,实现优秀的并行性能和可扩展性意味着努力实现令人尴尬的并行算法和实现,无论是通过仔细选择数据结构和算法,使用现有的并行应用程序和环境,还是将问题转换为令人尴尬的并行形式。

所以,总结一下:
1.好消息是多核系统价格低廉,而且很容易获得。
2.更多的好消息:许多同步操作的过热广告比21世纪初并行系统上的要低得多。
3.坏消息是缓存mi的开销仍然很高,特别是在大型系统上。
本书的其余部分描述了处理这个坏消息的方法。
特别是,第4章将介绍一些用于并行编程的低级工具,第5章将研究并行计数的问题和解决方案,第6章将讨论促进性能和可伸缩性的设计学科。
Chapter 4 Tools of the Trade
你的好坏取决于你的工具,而你的工具的好坏也取决于你。
未知的
本章简要介绍了并行编程的一些基本工具,主要关注运行在类似于Linux的操作系统上的用户应用程序可用的那些工具。第4.1节从脚本语言开始,第4.2节描述了POSIX API支持的多进程并行性以及对POSIX线程的讨论,参见第4.3节在其他环境中呈现模拟操作,最后,第4.4节帮助选择完成工作的工具。

请注意,本章仅提供简要介绍。更多细节可参见参考文献(和因特网),并在后续章节中提供更多信息。
4.1 脚本语言
至高无上的美德是简单。
亨利·沃兹沃斯·朗费罗,简化
Linux命令行脚本语言提供了简单而有效的并行处理方法。例如,假设您有一个需要使用两组不同的参数运行两次的程序compute_it。可以使用UNIX命令行脚本来实现这一点:
| compute_it 1 > compute_it .1 .out &compute_it 2 > compute_it .2.out & |
第1行 和2 启动此程序的两个实例,将它们的输出重定向到两个单独的文件中,并使用&字符将shell指向在后台运行此程序的两个实例。第3行 等待两个实例完成,以及第4行 和5 显示它们的输出。结果执行如图4.1所示 :compute_它执行的两个实例并行执行,等待在它们都完成后完成,然后cat的两个实例依次执行。
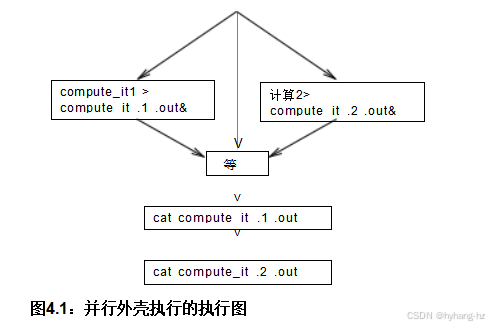

希望这些简单的例子能让你相信并行编程并不总是复杂或困难的。

4.2 POSIX多进程
骆驼是委员会设计的马。
未知的
本节简要介绍了POSIX环境,其中包括线程[ Ope97],因为该环境易于使用且广泛实现。第4.2.1节提供了对POSIX fork()和相关原语的简要介绍,第4.2.2节涉及线程创建和销毁,第4.2.3节 简要介绍了POSIX锁定,最后是第4.2.4节 描述了一个特定的锁,可用于读取由多个线程读取且仅偶尔更新的数据。
进程使用fork()原语创建,可以使用kill()原语销毁,可以使用exit()原语销毁自身。一个进程
| 清单4.1:使用叉形()基本图形 |
| 1 pid=fork(); 5/*有错误时,父级*/ 7退出(EXIT_FAILURE);8} else{ 10} |
| 1静态2{ 3 4 5 6 7 8 9 10 11 12 13 14 15} | __inline__ void waitall(void) intpid; intstatus; pid=wait(&status);如果(pid==-1){ 如果(errno== ECHILD) perror("wait"); }} |
执行fork()原语被称为新创建进程的“父”进程。父进程可以使用wait()原语等待其子进程。
请注意,本节中的示例相当简单。实际应用中使用这些基本组件时,可能需要处理信号、文件描述符、共享内存段以及其他多种资源。此外,某些应用程序在某个子进程终止时需要采取特定行动,并且可能还需要关注子进程终止的原因。这些问题当然会大大增加代码的复杂性。如需更多信息,请参阅相关教科书[Ste92,Wei13]。
如果fork()成功,它会返回两次,一次给父进程,一次给子进程。fork()返回的值允许调用者区分两者,如清单4.1所示。 (forkjoin .c)。第1行 执行fork()原语,并将其返回值保存在局部变量pid中。第2行 检查pid是否为零,如果是,则这是子进程,继续执行第3行。 如前所述,子进程可能通过exit()原语终止。否则,这是父进程,在第4行检查fork()原语返回的错误 ,打印错误信息并在第5行退出 – 7 如果是,否则fork()已成功执行,父进程因此执行第9行 变量pid包含子进程的进程ID。
父进程可以使用wait()原语等待其子进程完成。然而,使用此原语比其外壳脚本对应物更为复杂,因为每次调用wait()仅等待一个子进程。因此,通常会将wait()封装到类似于清单4.2中所示的waitall()函数的功能中。 (api-pthreads.h),通过这个waitall()函数具有类似于shell脚本wait命令的语义。每个循环遍历第6行 – 14等待一个子进程。第7行 调用wait()原语,该原语会阻塞直到子进程退出,并返回该子进程的进程ID。如果进程ID为-1,则表示wait()原语无法等待子进程。如果是这样,请参见第9行 支票
第48章第4节工具
清单4.3:通过fork()创建的过程,不共享内存
1 int x=0; 2
3 int main(int argc,char*argv[])4{
5 intpid; 6
7 pid=fork();
9 x =1;
11退出( EXIT_成功);12}
13 if(pid< 0){/* parent,出错时*/
14perror("fork");
15退出(EXIT_FAILURE);16}
17
18/* parent*/ 19
23返回EXIT_成功;24}
对于ECHILD errno,它表示没有更多的子进程,所以第10行 退出循环。否则,行11 和12 打印错误并退出。

必须注意的是,父母和孩子并不共享记忆。这可以通过清单4.3中所示的程序来说明。 (forkjoinvar.c),其中子进程在第9行将全局变量x设置为1 在第10行打印一条消息, 并在第11行退出。 父类在第20行继续 ,它在那儿等着孩子,在第21行 发现变量x的副本仍然是零。因此,输出如下:
| 子进程setx=1 父进程看到x=0 |
![]()
最细粒度的并行需要共享内存,这一点在第4.2.2节中进行了介绍。 也就是说,共享内存并行处理可能比分叉-连接并行处理复杂得多。
要在现有进程中创建一个线程,可以调用pthread_create()原语,例如,如第16行所示 和17见清单4.4 (pcreate.c)。第一个参数是指向一个pthread_t的指针,用于存储要创建的线程ID;第二个参数NULL是指向可选pthread_attr_t的指针;第三个参数是新线程将要调用的函数(在此例中为mythread());最后一个参数NULL将传递给mythread()。
在本例中,mythread()只是返回,但它也可以调用pthread_ exit()。
清单4.4:通过pthread_创建的线程create()Share Memory
1 int x=0; 2
3 void *mythread(void *arg)4{
5 x =1;
6printf(“子进程setx=1\n”);
7 returnNULL; 8}
9
10 int main(int argc,char*argv[])11{
12级;
13pthread_ttid;
14 void*vp; 15
16if ((en =pthread_create(&tid,NULL,
17 mythread,NULL ))!= 0) {
18 fprintf(stderr,“pthread_create:%s\n”,strerror(en));
19退出(EXIT_FAILURE);20}
21
22/* parent*/ 23
24 if((en=pthread_join(tid,&vp))!= 0){
25 fprintf(stderr,“pthread_join:%s\n”,strerror(en));
26退出(EXIT_FAILURE);27}
28printf(“父进程看到x=%d\n”,x);29
30返回EXIT_成功;31}

pthread_join()原语,如第24行所示 ,类似于叉连接等待()原语。它会阻塞直到由tid变量指定的线程完成执行,无论是通过invokingpthread_exit()还是从线程的顶级函数返回。线程的退出值将通过传递给pthread_ join()的第二个参数的指针存储。线程的退出值要么是传递给pthread_ exit()的值,要么是从线程的顶级函数返回的值,具体取决于该线程的退出方式。
清单4.4中所示程序 按以下顺序生成输出,证明两个线程之间确实共享内存:
| 子进程setx=1 父进程看到x=1 |
请注意,该程序仔细确保每次只有一个线程将值存储到变量x中。任何情况下,如果一个线程可能向某个变量存储值,而另一个线程要么从中加载数据,要么向该变量存储数据,则这种情况被称为数据竞争。由于C语言不保证数据竞争的结果会合理,我们需要某种方法来安全地并发访问和修改数据,例如下一节讨论的锁定原语。
但是你说你的数据竞赛是良性的?也许它们是。但是请帮大家(包括你自己)一个大忙,阅读第4.3.4.1节非常谨慎。随着编译器越来越积极地进行优化,真正良性数据竞争的数据越来越少。

POSIX标准允许程序员通过“POSIX锁定”来避免数据竞争。POSIX锁定包含多个基本操作,其中最基础的是arepthread_mutex_lock()和pthread_mutex_unlock()。这些基本操作作用于pthread_mutex_t类型的锁。这些锁可以静态声明并用PTHREAD_MUTEX_INITIALIZER初始化,也可以动态分配并使用pthread_ mutex_ init()基本操作初始化。本节的示例代码将采用前者。
Thepthread_mutex_lock()获取指定的锁,而thepthread_mutex_unlock()释放指定的锁。由于这些是“独占”锁定原语,任何时候只有一个线程可以“持有”给定的锁。例如,如果一对线程同时尝试获取同一个锁,其中一个线程会先被“授予”锁,另一个线程则等待第一个线程释放锁。一个简单且相当实用的编程模型允许在持有相应锁的情况下访问给定的数据项[Ho74]。
![]()
使用清单4.5中所示的代码演示了这种独占锁定属性。 (lock .c)第1行 定义并初始化名为lock_a的POSIX锁,而第2行同样定义并初始化名为lock_b的锁。第4行 定义并初始化共享变量x。
第6行 – 33 定义一个函数lock_ reader(),它在保持由arg指定的锁的同时反复读取共享变量x。第12行 将参数arg赋值给指向pthread_ mutex_t的指针,这是pthread_ mutex_ lock()和pthread_mutex_unlock()原语所要求的。

第14行–18获取specifiedpthread_mutex_t,检查错误,如果出现错误则退出程序。第19行 – 26反复检查x的值,每次改变时打印新的值。第25行 睡眠一毫秒,这使得该演示在单处理器机器上运行良好。第27行 – 31 释放thepthread_mutex_t,再次检查错误,如果出现任何错误则退出程序。最后,第32行 返回NULL,再次与所需函数类型bypthread_create()匹配。

第35行–56 见清单4.5 显示锁_writer(),它在持有指定的pthread_ mutex_t时定期更新共享变量x。与锁_reader()一样,第39行将参数arg赋值给指向pthread_ mutex_t的指针,第41行 – 45 获得
| 清单4.5:独占锁的演示 |
| 1 pthread_ mutex_ t lock_a = PTHREAD_ MUTEX_初始化器; 2 pthread_ mutex_ t lock_b = PTHREAD_ MUTEX_初始化器;3 6 void *lock_reader(void *arg)7{ 8级; 9 inti; 10 int newx=-1; 11 int oldx=-1; 12 pthread_mutex_t *pmlp =(pthread_mutex_t *)arg;13 14if((en =pthread_mutex_lock(pmlp))!= 0){ 15fprintf(stderr,“lock_reader:pthread_mutex_lock:%s\n”, 16strerror(en)); 17退出(EXIT_FAILURE);18} 20 newx =READ_ONCE(x); 21如果(newx!= oldx){ 22printf(“lock_reader():x=%d\n”,newx);23} 24 oldx = newx; 27if((en =pthread_mutex_unlock(pmlp))!= 0){ 28fprintf(stderr,“lock_reader:pthread_mutex_unlock:%s\n”, 29错误(en); 32 returnNULL; 33} 34 35 void*lock_writer(void *arg)36{ 37分; 38 inti; 39 pthread_mutex_t *pmlp =(pthread_mutex_t *)arg;40 41if((en =pthread_mutex_lock(pmlp))!= 0){ 42 fprintf(stderr,“lock_writer:pthread_mutex_lock:%s\n”, 43strerror(en); 44退出(EXIT_FAILURE);45} 47 WRITE_ONCE(x,READ_ONCE(x) + 1); 48票(NULL,0.5);49票 50if((en =pthread_mutex_unlock(pmlp))!= 0){ 51fprintf(stderr,“lock_writer:pthread_mutex_unlock:%s\n”, 52strerror(en)); 53退出(EXIT_FAILURE);54} |
| 清单4.6:同一独占锁的演示 |
| 1printf(“使用samelock创建两个线程:\n”); 2 en=pthread_create(&tid1,NULL,lock_reader,&lock_a); 如果(en!= 0){ 4 fprintf(stderr,“pthread_create:%s\n”,strerror(en)); 5退出(EXIT_FAILURE);6} 7 en=pthread_create(&tid2,NULL,lock_writer,&lock_a); 8如果(en!= 0){ 9fprintf(stderr,“pthread_create:%s\n”,strerror(en); 10退出(EXIT_FAILURE);11} 12 if((en=pthread_jo in(tid1,&vp))!= 0){ 13 fprintf(stderr,“pthread_join:%s\n”,strerror(en); 14退出(EXIT_FAILURE);15} 16如果((en=pthread_jo在(tid2,&vp))!=0){ 17 fprintf(stderr,“pthread_join:%s\n”,strerror(en); |
| 1printf(“创建两个线程sw/differentlocks:\n”); 2x = 0; 3 en=pthread_create(&tid1,NULL,lock_reader,&lock_a); 4如果(en!= 0){ 5 fprintf(stderr,“pthread_create:%s\n”,strerror(en); 6退出(EXIT_FAILURE);7} 8 en=pthread_create(&tid2,NULL,lock_writer,&lock_b); 9如果(en!= 0){ 10fprintf(stderr,“pthread_create:%s\n”,strerror(en); 11退出(EXIT_FAILURE);12} 13如果((en=pthread_jo在(tid1,&vp))!=0){ 14 fprintf(stderr,“pthread_join:%s\n”,strerror(en)); 15退出(EXIT_FAILURE);16} 17 if((en=pthread_jo in(tid2,&vp))!= 0){ 18 fprintf(stderr,“pthread_join:%s\n”,strerror(en)); 19退出(EXIT_FAILURE);20} |
指定的锁,以及第50行 – 54 释放它。在保持锁的情况下,行46 – 49 增加共享变量x,在每次增量之间休眠5毫秒。最后,第50行 – 54松开锁。
清单4.6显示了一个代码片段,它使用同一个锁lock_a以线程的形式运行lock_reader()和lock_writer()。第2行 – 6创建一个运行锁_reader()的线程,然后是第7行 – 11创建一个运行锁_writer()的线程。第12行 – 19 等待两个线程都完成。此代码片段的输出如下:
| 使用同一个锁创建两个线程:lock_reader():x=0 |
由于两个线程都使用同一个锁,thelock_reader()线程在保持锁的同时无法看到lock_writer()生成的x的所有中间值。

清单4.7 显示了类似的代码片段,但这次使用了不同的锁:lock_a forlock_reader()andlock_b forlock_wr iter()。此代码片段的输出如下:
| 创建两个threadsw/differentlocks: 锁读器():x=0lock_reader():x=1lock_reader():x=2lock_reader():x=3 |
由于这两个线程使用不同的锁,它们不会相互排斥,并且可以并发运行。因此,lock_reader()函数可以查看lock_writer()存储的x的中间值。

尽管POSIX排他锁还有更多的内容,但这些基本操作提供了良好的开端,并且在许多情况下是足够的。下一节将简要介绍POSIX读写锁。
The POSIX API provides a reader-wr iter lock, which is represented by apthread_rwlock_t.As with pthread_mutex_t,pthread_rwlock_t may be statically initial-ized via PTHREAD_RWLOCK_INITIALIZER or dynamically initialized via the pthread_rwlock_init() primitive. Thepthread_rwlock_rdlock() primitiveread-acquiresthe specified pthread_rwlock_t, the pthread_rwlock_wrlock() primitive write- acquires it , and the pthread_ rwlock_ unlock () primitive releases it . Only a single thread maywrite-hold agiven pthread_rwlock_t at any given time, but multiple threads may read- hold a given pthread_ rwlock_t, at least while there is no thread currently write- holding it .
正如你可能预料的那样,读写锁是为大多数读取情况设计的。在这种情况下,读写锁比独占锁具有更高的可扩展性,因为独占锁按定义只能由一个线程持有,而读写锁允许多个读者同时持有锁。然而,在实际应用中,我们需要了解读写锁能提供多少额外的可扩展性。
清单4.8 (rwlockscale .c)显示了测量读写锁可伸缩性的方法之一。第1行 显示了读写锁的定义和初始化,第2行 显示holdtime参数控制每个线程持有读写锁的时间,第3行 显示了t hinktime参数,它控制读写锁释放和下一次获取之间的时间,第4行 定义了读取计数数组,每个读取线程将它获得锁的次数放入该数组,以及第5行 定义thenreadersrunning变量,它确定所有读取器线程是否已开始运行。
| 清单4.8:测量读写锁的可扩展性 |
| 1 pthread_ rwlock_ t rwl = PTHREAD_ RWLOCK_ INITIALIZER; 2个未签名的长保持时间=0; 4个很长的读数; 5 int nreadersrunning=0; 6 7#定义GOFLAG_ INIT 0 8#defineGOFLAG_RUN 1 9#defineGOFLAG_STOP 2 10个字符goflag = GOFLAG_ INIT;11 14分; 15 inti; 16 long long loopcnt=0;17 long me=(long)arg;18 19sync_fetch_and_add(和nreadersrunning,1); 20 while(READ_ ONCE(goflag)== GOFLAG_ INIT){ 21继续;22} 23 while(READ_ONCE(goflag)== GOFLAG_RUN){ 24if((en =pthread_rwlock_rdlock(&rwl))!= 0){ 25 fprintf(stderr, 26“pthread_rwlock_rdlock:%s\n”,strerror(en)); 27退出(EXIT_FAILURE);28} 30wait_microseconds(1); 31} 32if((en =pthread_rwlock_unlock(&rwl))!= 0){ 33 fprintf(stderr, 34“pthread_rwlock_unlock:%s\n”,strerror(en)); 35退出(EXIT_FAILURE);36} 38wait_microseconds(1); 39} 42readcounts[me]=loopcnt; |
第7行 – 10定义goflag,它同步测试的开始和结束。此变量最初设置为GOFLAG_INIT,然后在所有读取器线程启动后设置为toGOFLAG_RUN,最后设置为GOFLAG_STOP以终止测试运行。
第12行 – 44 定义读取器(),即读取器线程。第19行 原子式地增加nreadersrunning变量,以指示此线程现在正在运行,并且行20 – 22 等待测试开始。TheREAD_ONCE()原始函数迫使编译器在每次循环中获取goflag——否则编译器有权假设goflag的值永远不会改变。
跨越线路23的环 – 41执行性能测试。行24 – 28 获取锁,第29行 – 31保持锁住指定的微秒数,第32行 – 36 释放锁,行37 – 39在获取锁之前,等待指定的微秒数。第40行计算此位置的采集。
第42行 将锁获取计数移动到此线程的readcounts[]数组元素中,第43行返回,终止此线程。
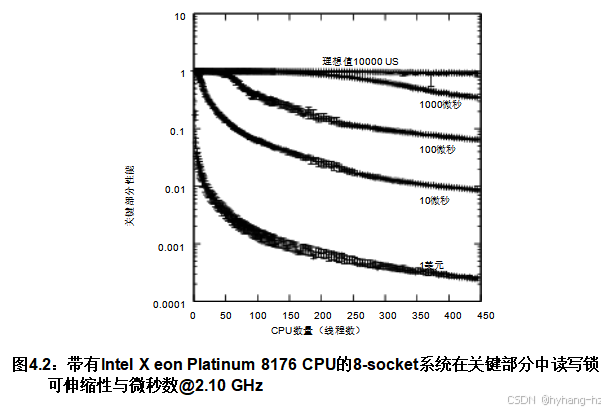
图4.2 展示了在配备224个核心的Xeon系统上运行此测试的结果,每个核心有两个硬件线程,总计448个软件可见CPU。所有这些测试中,思考时间参数均为零,而保持时间参数则设置为从一微秒(图中标记为“1us”)到一万微秒(图中标记为“10000us”)不等。
![]()
其中N是当前运行中的线程数,L N是当前运行中所有N个线程获取的锁总数,L 1是单线程运行中获取的锁数。在硬件和软件可扩展性理想的情况下,这个值总是1.0。
如图所示,读写锁的可扩展性显然不够理想,特别是对于较小的关键部分。要了解为什么读取操作如此缓慢,可以考虑所有获取线程都必须更新pthread_ rwlock_t数据结构。因此,如果所有448个执行线程同时尝试读取-获取读写锁,它们必须一个接一个地更新底层的pthread_ rwlock_t。幸运的线程可能几乎立即完成,但最不幸运的线程则必须等待其他447个线程完成更新。随着CPU数量的增加,这种情况只会变得更糟。请注意对数轴。尽管10,000微秒的轨迹看似理想,但实际上已经下降了约10%。
 尽管存在这些限制,读写锁定在许多情况下仍然非常有用,例如当读取器必须执行高延迟的文件或网络I/O时。还有其他替代方案,其中一些将在第5章和第9章中介绍。
尽管存在这些限制,读写锁定在许多情况下仍然非常有用,例如当读取器必须执行高延迟的文件或网络I/O时。还有其他替代方案,其中一些将在第5章和第9章中介绍。
图4.2显示了读写锁的开销在最小的关键段中最严重,因此最好有其他方法来保护这些微小的关键段。一种这样的方法是使用原子操作。我们已经见过一个原子操作,即第19行的__sync_fetch_and_add()原语。 见清单4.8。 这个原始原子操作会将其第二个参数的值加到第一个参数引用的值上,返回旧的值(在这种情况下被忽略)。如果两个线程同时对同一个变量执行__sync_fetch_and_add(),那么该变量的结果将包含两次加法的值。
GNU C编译器提供了一系列额外的原子操作,包括__ sync_ fetch_和sub()、__ sync_ fetch_和or()、__ sync_ fetch_和and()、__ sync_ fetch_和xor()以及__ sync_ fetch_和nand(),这些操作都返回旧值。如果您需要新值,则可以使用 同步添加和提取()、__同步子和提取()、__同步或和提取()、__同步_和_和提取()、__同步_xor_和_提取()、__同步_与_和提取()等原语。
![]()
| 清单4.9:编译器屏障原语(用于GCC) | |
| #define#define #define #define | ACCESS_ONCE(x)(*volatiletypeof(x)*)&(x))READ_ONCE(x) ({ typeof (x) x = ACCESS_ ONCE (x);x;})WRITE_ ONCE(x,val)\ do { ACCESS_ ONCE(x) =(val);}while(0)barrier()__asmvolatile__(“”:::“memory”) |
经典 比较交换操作由一对原语提供, 同步操作`()`和`__`,比较和交换`val_`。这两种原语原子地将一个位置更新为新值,但前提是该位置的先前值必须等于指定的旧值。第一个变体如果操作成功返回1,失败则返回0,例如,如果先前值不等于指定的旧值。第二个变体返回该位置的先前值,如果等于指定的旧值,则表示操作成功。比较-交换操作具有“通用性”,即任何对单个位置的原子操作都可以通过比较-交换来实现,尽管早期的操作在适用时通常更高效。比较-交换操作还可以作为更广泛原子操作的基础,但这些更复杂的操作往往存在复杂性、可扩展性和性能问题[Her90]。
 __的同步_()原语会发出一个“内存屏障”,这限制了编译器和CPU重新排序操作的能力,如第15章所述。在某些情况下,只需限制编译器重新排序操作的能力,而让CPU自由操作,此时可以使用barrier()原语。在某些情况下,只需确保编译器不会优化掉某个内存读取,此时可以使用READ_ONCE()原语,正如第20行所示。 见清单4.5。 同样,WRITE_ONCE()原语可用于防止编译器优化掉给定的内存写入。GCC并不直接提供最后三个原语,但可以如清单4.9所示进行简单实现。 ,这三者都在第4.3.4节中进行了详细讨论。 另外,READ_ONCE(x)与GCC内含函数__atomic_load_n(&x有许多共同之处, ATOMIC_RELAXED) andWRITE_ONCE()与GCC intrinsic__原子_store_n(&x,v,__ATOMIC_relaxed)有μch的共同点。
__的同步_()原语会发出一个“内存屏障”,这限制了编译器和CPU重新排序操作的能力,如第15章所述。在某些情况下,只需限制编译器重新排序操作的能力,而让CPU自由操作,此时可以使用barrier()原语。在某些情况下,只需确保编译器不会优化掉某个内存读取,此时可以使用READ_ONCE()原语,正如第20行所示。 见清单4.5。 同样,WRITE_ONCE()原语可用于防止编译器优化掉给定的内存写入。GCC并不直接提供最后三个原语,但可以如清单4.9所示进行简单实现。 ,这三者都在第4.3.4节中进行了详细讨论。 另外,READ_ONCE(x)与GCC内含函数__atomic_load_n(&x有许多共同之处, ATOMIC_RELAXED) andWRITE_ONCE()与GCC intrinsic__原子_store_n(&x,v,__ATOMIC_relaxed)有μch的共同点。
![]()
C 11标准增加了原子操作,包括加载(atomic_ load())、存储(atomic_store())、内存屏障(atomic_thread_f ence()和atomic_ signal_ fence())以及读-改-写原子操作。读-改-写原子操作包括atomic_fetch_add()、atomic_fetch_sub(),atomic_fetch_and(),atomic_fetch_xor(),atomic_exchange()、atomic_ compare_ exchange_ weak()和atomic_compare_exchange_strong()。这些操作的机制与第4.2.5节中描述的类似。 ,但是为所有操作的_显式变体添加了内存顺序参数。没有内存顺序
参数,所有操作都是完全有序的,参数允许较弱的排序。对于example,“atomic_load_explicit(&a,memory_order_relaxed)”is与Linux内核的“READ_ONCE()”大致类似。1
C11原子操作的一个限制是它们仅适用于特定类型的原子,这可能会带来问题。因此,GNU C编译器提供了原子内核函数,如including__atomic_load(),__atomic_load_n(),__atomic_store(),__ atomic_ store_n()、__atomic_thread_fence_()等。这些内核函数提供与其C11对应函数相同的语义,但也可以用于普通的非原子对象。其中一些内核函数可以从以下列表中传递一个内存顺序参数: ATOMIC_RELAXED、atomic_consume、atomic_acquire、atomic_release ATOMIC_ACQ_REL, andATOMIC_SEQ_CST .
线程变量,也称为线程特定数据、线程局部存储和其他不太礼貌的名字,在并发代码中被极其频繁地使用,这将在第5章和第8章中探讨。POSIX提供了pthread_ key_ create()函数来创建一个线程变量(并返回相应的键),pthread_key_delete()用于删除与键对应的线程变量,pthread_setspecific()用于设置当前线程中与指定键对应的变量值,andpthread_getspecific()用于返回该值。
许多编译器(包括GCC)提供了一个线程标识符,可以在变量定义中使用,以指定该变量是按线程分配的。然后可以正常使用变量名来访问当前线程实例的值。当然,线程比POSIX头文件特有的数据更容易使用,因此对于仅使用GCC或其他支持线程的编译器构建的代码,通常更倾向于使用线程。
幸运的是,C11标准引入了一个_thread_local关键字,可以用来代替thread。随着时间的推移,这个新关键字应该结合了thread的易用性和POSIX特定于线程数据的可移植性。
4.3 POSIX操作的替代方法
开源的战略营销范式是一个被过滤了的大量并行醉汉的行走
达尔文主义过程。
布鲁斯·佩伦斯
不幸的是,在各种标准委员会着手处理线程操作、锁定原语和原子操作之前,这些操作早已被广泛使用。因此,这些操作的支持方式存在相当大的差异。至今仍常见的是,这些操作以汇编语言实现,这要么是出于历史原因,要么是为了在特定情况下获得更好的性能。例如,GCC‘ssync_系列的原语都提供了完整的
| 清单4.10:Thread API |
| intsmp_thread_id(音调) thread_id_tcreate_thread(void(*func)(void*),void*arg)for_each_thread(t) for_each_running_thread(t) void*wait_thread(thread_id_t tid)voidwait_all_threads(void) |
| 内存排序语义,过去曾促使许多开发人员为不需要完整内存排序语义的情况创建自己的实现。以下各节将展示一些来自Linux内核的替代方案以及本书示例代码中使用的一些历史原始语句。 4.3.1组织和初始化 虽然许多环境不需要任何特殊的初始化代码,但本书中的代码示例都以调用smp_init()开头,该函数初始化一个映射frompthread_t到连续的整数。用户空间RCU库2 同样需要调用rcu_init()。尽管这些调用可以在支持构造函数的环境(如GCC环境)中隐藏,但大多数由用户空间RCU库支持的RCU版本也要求每个线程在创建时调用rcu_register_thread(),并在退出前调用rcu_unregister_thre ad()。 对于Linux内核而言,是否不需要调用特殊初始化代码或者内核的启动时间代码实际上是必需的初始化代码,这是一个哲学问题。 4.3.2线程创建、销毁和控制 Linux内核使用struct task_struct指针来跟踪kthreads,kthread_ create()创建它们,kthread_should_stop()外部建议它们停止(没有POSIX等效函数),3 kthread_停止()等待它们停止,并为定时等待调度timeout_interruptible()。还有一些额外的kthread管理API,但这个提供了很好的开始,以及好的搜索术语。 CodeSamples API专注于“线程”,它们是控制的中心。4 每个这样的线程都有一个类型为thread_id_t的标识符,而且在给定时间运行的两个线程不会有相同的标识符。线程共享除每个线程的本地状态外的所有内容,5 其中包括程序计数器和堆栈。 线程API如清单4.10所示 ,成员在下面的章节中描述。 4.3.2.1 API成员 create_thread()原语创建新线程,启动新线程的 |
在创建线程()的第一个参数指定的函数中执行,并传递创建线程()的第二个参数指定的参数。新创建的线程将在从由函数指定的启动函数返回时终止。create_thread()原语返回新创建子线程对应的thread_id_t。
如果创建了更多的thanNR_THREADS线程,这个原始函数将终止程序,其中包括运行程序时隐式创建的线程。NR_THREADS是一个编译时常量,可以修改,但有些系统可能对允许的线程数有一个上限。
smp_线程id()
由于从create_ thread()返回的thread_ id_ t是系统依赖的,smp_thread_id()的p原语返回一个与请求该线程的线程索引相对应的索引。这个索引保证小于自程序启动以来存在的最大线程数,因此对于位掩码、数组索引等非常有用。
for_each_thread()
for_each_thread()宏遍历所有存在的线程,包括如果创建的话将存在的所有线程。此宏对于处理第4.2.8节中介绍的每个线程变量很有用。
for_each_running_thread()
for_ each_ running_ thread()宏只循环当前存在的线程。如果需要,调用者有责任在创建和删除线程时进行同步。
等待()
wait_thread()原语等待由thread_id__t传递给它的线程指定的读取完成。这不会干扰指定线程的执行;相反,它只是等待该线程。请注意,wait_thread()返回的是相应线程返回的值。
等待所有线程()
Thewait_all_threads()原语等待所有当前正在运行的线程完成。如果需要,调用者有责任与线程的创建和删除进行同步。然而,这个原语通常不用于在运行结束时清理,因此这种同步通常不需要。
4.3.2.2示例用法
清单4.11 (threadcreate .c)展示了一个类似hello-world的子线程示例。如前所述,每个线程都会分配自己的栈,因此每个线程都有自己的私有参数和myarg变量。每个子线程在退出前仅打印其参数和itssmp_thread_id()。请注意第7行的返回语句。 终止该线程,将NULL返回给在此线程上调用wait_t hread()的用户。
父程序如清单4.12所示。 它在第6行调用smp_init()来初始化线程系统 ,解析第8行的参数 – 15,并宣布它出现在第16线。 它在第18行创建指定数量的子线程 – 19 ,并等待它们在第21行完成。 请注意,wait_ all_ threads()会丢弃线程返回值,因为在这种情况下它们都是NULL,这并不十分有趣。
1 void *thread_test(void*arg)2{
3 int myarg= (intptr_t)arg; 4
5printf(“子线程%d:smp_thread_id()=%d\n”,
7 returnNULL; 8}
1个主参数(int argc,char*argv[]) 2{
3 inti;
4 int nkids=1; 5
9 nkids=strtoul(argv[1],NULL,0);
10如果(nkids > NR_ THREADS){
11fprintf(stderr,“nkids=%d太大,最大值=%d\n”,
12名儿童,NR_THREADS);
15}
16printf(“父线程正在创建%d个线程。\n”,nkids);17
18个(i=0;i<nkids;i++)
19create_thread(thread_test,(void*)(intptr_t)i);20
21wait_all_threads(); 22
23printf(“所有生成的线程已完成。\n”);24
25退出(0);26}
| voidspin_lock_init(spinlock_t*sp);voidspin_lock(spinlock_t*sp); intspin_trylock(spinlock_t*sp);voidspin_unlock(spinlock_t*sp); |
Linux内核锁定API的一个好的初始子集如清单4.13所示, 每个API元素在下面的章节中都有描述。本书的CodeSamples锁定API与Linux内核紧密地遵循了这一过程。
4.3.3.1 API成员
spin_lock_init()
spin_lock_init()原语初始化指定的spinlock_t变量,并且必须在该变量传递给任何其他spinlock原语之前调用。
自旋锁()
spin_lock()原语如果需要,会获取指定的自旋锁并等待
| 清单4.14:过着危险的早期1990年代风格 | ||||
| 1 | ptr | =global_ptr; | ||
| 2 | 如果 | ( ptr!= NULL&& ptr | < | 高地址) |
| 3 | ||||
| 清单4.15:C编译器可以发明加载 | |
| 1如果 | |
| 2 | |
| 3 | do_low(global_ptr); |
直到自旋锁可用为止。在某些环境中,例如pthr线程中,等待将涉及阻塞,而在其他环境中,例如Linux内核中,则可能涉及CPU周期的自旋循环。
关键在于任何时候只有一个线程可以持有自旋锁。
spin_trylock()
spin_trylock()原语获取指定的自旋锁,但仅在它立即可用时才获取。如果它能够获取自旋锁,则返回true,否则返回false。
旋转解锁()
spin_ unlock()原语释放指定的自旋锁,允许其他线程获取它。
4.3.3.2示例用法
可以使用名为mutex的自旋锁来保护变量counter,如下所示:
| spin_lock(&mutex);counter++; spin_unlock(&mutual); |

但是,spin_lock()和spin_unlock()这两个原语确实存在性能问题,这将在C第10章中看到。
直到2011年,C标准才定义了并发读写共享变量的语义。然而,至少在四分之一个世纪前[BK85,Inm85],就已经有人编写并发C代码了。这不禁让人思考,如今的老前辈们在遥远的C11之前的日子里做了些什么。简短的回答是“他们活得危险”。
至少,如果他们使用的是2021年的编译器,他们的生活将会非常危险。在(比如说)20世纪90年代初,编译器进行的优化较少,部分原因是编译器编写者较少,部分原因在于那个时代的内存相对较小。尽管如此,问题还是出现了,如清单4.14所示。 编译器有权将其转换为清单4.15。 如您所见,临时在线1 见清单4.14 已经被优化掉,所以global_ptr将被加载到3次。

第4.3.4.1节 描述了普通访问引起的其他问题,第4.3.4.2节 和4.3.4.3 描述一些C11之前的解决方案。当然,如果可行,直接C语言内存引用应该被第4.2.5节中描述的原语所取代 或(特别是)第4.2 .6节。 使用这些原语可以避免数据竞争,即确保如果多个并发的C语言访问给定变量,所有这些访问都是加载。
给定一个执行普通加载和存储的代码,6编译器有权假设受影响的变量既未被其他线程访问也未被修改。这一假设使得编译器能够执行大量转换操作,包括加载拆分、存储拆分、加载融合、存储融合、代码重排序、虚拟加载、虚拟存储、存储到加载转换以及消除死代码,这些操作在单线程代码中都能正常工作。但并发代码可能会因这些转换或共享变量的花招而失效,如下所述。
加载撕裂发生在编译器为单个访问使用多个加载指令时。例如,理论上编译器可以编译从global_ ptr中加载的指令(见第1行见清单4.14 )作为一系列逐字节加载。如果其他线程同时将global_ptr设置为NULL,结果可能是指针除一个字节外全部被置零,从而形成一个“野指针”。使用这种野指针进行存储可能会损坏任意内存区域,导致罕见且难以调试的崩溃。
更糟糕的是,在(比如说)一个8位系统中,使用16位指针时,编译器可能别无选择,只能使用一对8位指令来访问给定的指针。由于C标准必须支持所有类型的系统,因此标准不能排除在一般情况下发生加载撕裂的可能性。
存储撕裂发生在编译器为单次访问使用多个存储指令时。例如,一个线程可能同时将0x12345678存储到一个四字节整型变量中,而另一个线程则存储了0xabcdef00。如果编译器在这两种访问中都使用了16位存储,结果可能会是0x1234ef00,这可能会让从这个整型加载代码感到非常意外。这也不是纯粹的理论问题。例如,有些CPU具有小的即时指令字段,在这样的CPU上,编译器可能会将一个64位存储拆分为两个32位存储,以减少显式形成寄存器中64位常量的开销,即使是在64位CPU上也是如此。有历史报告指出这种情况实际上已经发生(例如[KM13]),但也有最近的一份报告[Dea19]。
当然,编译器别无选择,只能在通用中撕裂一些存储器
在这种情况下,考虑到代码使用64位整数在32位系统上运行的可能性。
| 清单4.16:邀请负载熔断 |
| 1,同时(need_to_stop) 2do_something_quickly(); |
| 1如果(!need_to_stop) 2 for(;;){ 3do_something_quickly(); 4do_something_quickly(); 5do_something_quickly(); 6do_something_quickly(); 7do_something_quickly(); 8do_something_quickly(); 9do_something_quickly(); 10do_something_quickly(); 11do_something_quickly(); 12do_something_quickly(); 13do_something_quickly(); 14do_something_quickly(); 15do_something_quickly(); 16do_something_quickly(); 17do_something_quickly(); 18do_something_quickly(); 19} |
| 但对于机器大小的正确对齐存储器,WRITE_ONCE()将防止存储器撕裂。 加载融合发生在编译器使用先前从给定变量加载的结果而不是重复加载时。这种优化不仅在单线程代码中效果很好,在多线程代码中也常常有效。不幸的是,“通常”这个词掩盖了一些真正令人烦恼的例外情况。 例如,假设一个实时系统需要快速调用一个名为do_ something_的函数()重复执行,直到设置变量need_ to_ stop,而编译器可以发现do_something_quick()不存储toneed_to_stop。一种(不安全的)编码方法如清单4.16所示。 编译器可能会合理地将这个循环展开十六次,以减少循环末尾反向分支的每次调用。更糟糕的是,由于编译器知道`do_ something_ quickly`()不需要存储`to_ stop`,因此编译器可以合理地决定只检查一次这个变量,从而产生如清单4.17所示的代码。 一旦进入,第2行的循环 – 19 无论其他线程存储了多少次非零值need_to_stop,它都不会退出。结果最坏的情况是令人困惑,而且很可能还会造成严重的物理损坏。 编译器可以将跨代码的大量代码的加载合并在一起。例如,在清单4.18中, t0()和t 1()同时运行,do something()和do something_ else()是内联函数。第1行 声明指针gp,C默认初始化为NULL。在某一点,第5行 t0()存储一个指向gp的非NULL指针。同时,t1()在第10行从gp加载三次, 12 ,和15。 鉴于第13行 发现gp是非空的,人们可能会希望第15行的解引用 将保证永远不会出错。不幸的是,编译器有权将第10行的读取合并 和15, 这意味着如果第10行 加载NULL和第12行 load&myvar,第15行 可以加载NULL,导致故障。8 |
| 1 int*gp; 2 3 void t0(void)4{ 7 8 void t1(void)9{ 10p1 = gp; 13如果(p2){ 15 p3 = * gp; 16} 17} |
| 1空2{ 3 4 5 6 7 8 9 10} 11 12空13{ 14 15 16 17} | shut_it_down(void) 状态= SHUTTING_ DOWN;/*有缺陷的!!!*/start_shutdown(); 在(!other_task_ready)/*buggy!!!*/继续; 完成shutdown(); 状态=SHUT_DOWN;/*buggy!!!*/do_something_else(); 工作至关闭(voi d) 而(状态!=SHUTTING_DOWN)/*buggy!!!*/do_more_work(); other_task_ready = 1;/*BUGGY!!! */ |
请注意,中间的READ_ONCE()不会阻止另外两个加载融合,尽管这三个加载都是从同一个变量加载。

存储融合可能发生在编译器注意到对某个变量的一对连续存储操作而没有来自该变量的加载操作时。在这种情况下,编译器有权省略第一个存储操作。这在单线程代码中从来不是问题,事实上,在正确编写的并发代码中通常也不是问题。毕竟,如果两个存储操作迅速连续执行,其他线程几乎不可能从第一个存储操作中加载值。
但是,也有例外,例如清单4 .19所示。 函数shut_ it_ down()在第3行将状态存储到共享变量中 和8, 因此,假设neither start_shutdown()nor finish_shutdown()访问状态,编译器可以合理地删除第3行上的store到状态。 不幸的是,这意味着work_until_shut_dow n()将永远无法退出跨越第14行的循环 和15, 因此,它永远不会设置other_task_ready,这反过来意味着shut_it_down()永远不会退出跨越第5行的循环 和6 ,即使编译器选择不合并第5行的连续加载fromother_task_ready。
| 清单4.21:编译器发明了一个邀请存储 | |
| 1 a=1; | |
| 2如果 | |
| 3 | a =0; |
| 4 | do abunch_of_stuff(&a); |
| 5} | |
| 清单4.22:邀请商店到装载转换 | |
| 1 r1=p; | |
| 2如果(不太可能(r1)) | |
| 3 | |
| 4 | 屏障 |
| 5 | |
不是负载。这种情况可能表明使用smp_ store_ release()而不是smp_wmb()。
死码消除可能发生在编译器发现加载的值从未被使用,或者变量被存储但从未被加载时。这当然可以消除对共享变量的访问,进而破坏内存排序原语,导致并发代码以令人惊讶的方式运行。迄今为止的经验表明,这样的意外很少会让人感到愉快。特别是当外部代码通过符号表定位变量时,仅存取变量的情况尤为危险:编译器必然不知道这些外部代码的访问,因此可能会消除外部代码所依赖的变量。
可靠的并发代码显然需要一种方法,使编译器保存对共享内存的重要访问的数量、顺序和类型,第4.3.4.2节讨论了这个主题 和4.3.4.3 ,接下来是这些。
4.3.4.2易挥发溶液
尽管现在备受诟病,在C11和C++11[ Bec11]问世之前,volatile关键字是并行编程者工具箱中不可或缺的工具。这引发了一个问题,即volatile究竟意味着什么,即使是最新的版本也未能给出精确的答案[Smi19]。 此版本保证了“通过易失性值的访问严格根据抽象机的规则进行评估”,易失性访问是副作用,它们是四个向前推进指标之一,其确切语义由实现定义。或许最清晰的指导来自这一非规范注释:
易失性是指实现中避免对对象进行激进优化的提示,因为对象的值可能通过实施者无法检测到的方式发生变化。此外,对于某些实现,易失性可能意味着访问对象需要特殊的硬件指令。详细语义参见6.8.1。一般来说,C++中易失性的语义与C中相同。
这段措辞或许会让编写低级代码的人感到安心,但编译器开发者可以完全忽略非规范注释。相比之下,程序员可能会更加确信编译器开发者会尽量避免破坏设备驱动程序(尽管这可能需要与设备驱动开发人员进行几次坦诚而开放的讨论),并且设备驱动程序至少施加了以下约束[M WPF18]:
1.当可用该访问大小和类型的机器指令时,禁止实现撕裂对齐的易失性访问。12 当前代码依赖于此约束以避免不必要的加载和存储撕裂。
| 1ptr =READ_ONCE(global_ptr); | |||||
| 2 | 如果 | (ptr | != NULL&& ptr | < | 高地址) |
| 3 | do_low(ptr); | ||||
| 1,同时(!READ_ ONCE(need_ to_ stop)) 2do_something_quickly(); |
| 清单4.27:取消邀请一个虚构的商店 | |
| 1如果(条件) | |
| 2 | WRITE_ONCE(a,1); |
| 否则 | |
| 4 | |
| 清单4.28:防止C编译器融合负载 | |
| 1小时 | |
| 2 | 屏障 |
| 3 | |
| 4 | 屏障 |
| 5} | |
但是,这并不能阻止代码的重新排序,这需要一些额外的技巧,这些技巧在第4.3.4.3节中进行了介绍。
最后,可以使用WRITE_ONCE()来防止清单4.20中所示的存储发明 ,结果代码如清单4.27所示。
总之,易失性关键字可以在加载和存储操作为机器大小且正确对齐的情况下防止加载撕裂和存储撕裂。它还可以防止加载融合、存储融合、虚拟加载和虚拟存储。然而,尽管它可以阻止编译器重新排序易失性访问,但无法阻止CPU重新排序这些访问。此外,它也无法阻止编译器或CPU重新排序非易失性访问与易失性访问之间的关系。要防止这类重排序,需要采用下一节中描述的技术。
传统上,通过使用汇编语言来提供额外的排序,例如GCC的asm指令。奇怪的是,这些指令实际上并不需要包含汇编语言,如清单4.9中所示的barrier()宏。
在屏障()宏中,__ asm__引入了asm指令,__ volatile防止编译器优化掉asm,空字符串表示不生成实际指令,而最终的“内存”告诉编译器这个无操作的asm可以任意改变内存。作为回应,编译器会避免在屏障()宏中移动任何内存引用。这意味着实时销毁循环的展开如清单4.17所示。 可以通过添加barrie r()调用来防止,如第2行所示 和4 见清单4.28。 这两行代码防止编译器从任一方向将load from need_to_stop推入或越过do_something_quickly()。
然而,这并不能阻止CPU重新排序引用。在许多情况下,这不是问题,因为硬件只能进行一定量的重排序。然而,也有像清单4.19这样的情况 硬件必须受到限制。清单4.26 防止了存储器熔断和发明,以及清单4.29 通过在第4行添加smp_mb()进一步防止剩余的重新排序, 8 ,10 , 18 , 和21。 smp_ mb()宏与清单4.9中所示的屏障()类似, 但是,用一个包含完整内存屏障指令的字符串替换空字符串,例如,在x86上使用“mfence”或在Po werPC上使用“sync”。

一些读-改写原子操作也提供了排序,其中一些在第4.3.5节中介绍。 在一般情况下,内存排序可能相当微妙,如第15章所述。下一节介绍内存排序的替代方法,即限制甚至完全避免数据竞争。
“医生,当我同时访问共享变量时,我的头很痛!”
“然后停止同时访问共享变量!!!”
医生的建议可能看似无济于事,但一种经过验证的方法是避免当前访问共享变量——即只有在持有特定锁时才能访问这些变量,这将在第七章中讨论。另一种方法是从特定的CPU或线程访问给定的“共享”变量,这将在第八章中讨论。 可以将这两种方法结合起来,例如,某个变量可能仅由特定的CPU或线程在持有某个锁的情况下修改,并且可以从同一CPU或线程读取,也可以从其他CPU或线程在持有同一锁的情况下读取。在所有这些情况下,对共享变量的所有访问都可能是普通的C语言访问。
以下是一些允许对给定变量进行普通加载和存储访问的情况,而对其他访问该变量则需要标记(例如READ_O NCE()andWRITE_ONCE()):
1.共享变量仅由指定的拥有CPU或线程修改,但会被其他CPU或线程读取。所有存储操作都必须使用WRITE_ONCE()。拥有CPU或线程可以使用普通加载。其他所有操作都必须使用READ_ONCE()进行加载。
2.共享变量仅在持有给定锁时被修改,但未持有该锁的代码可以读取。所有存储操作都必须使用WRITE_ONCE()。持有锁的CPU或线程可以使用普通的加载操作。其他所有操作都必须使用READ_ONCE()进行加载。
3.共享变量仅在持有特定锁的CPU或线程修改时才会被修改,但其他CPU或线程,或者不持有该锁的代码可以读取。所有存储操作都必须使用WRITE_ONCE()。持有锁的CPU或线程可以使用普通加载,任何持有锁的CPU或线程也可以这样做。其他所有操作都必须useREAD_ONCE()for loads。
共享变量仅由特定的CPU或线程以及该CPU或线程上下文中运行的信号或中断处理程序访问。处理程序可以使用普通的加载和存储操作,任何阻止了处理程序被调用的代码也可以这样做,即那些阻塞了信号和/或中断的代码。所有其他代码必须使用READ_ONCE()和WRITE_ONCE()。
5.共享变量仅由特定的CPU或线程访问,以及由该CPU或线程上下文中运行的信号或中断处理程序访问,且处理程序在返回前总是会恢复其写入的所有变量的值。处理程序可以使用普通的加载和存储操作,任何阻止处理程序被调用的代码也可以这样做,即那些阻止信号和/或中断的代码。所有其他代码可以使用普通的加载操作,但必须useWRITE_ONCE()以防止存储撕裂、存储融合和虚构的存储。

在大多数其他情况下,对共享变量的加载和存储必须分别使用useREAD_ONCE()和WRITE_ONCE()或更高级别的操作。但需要重申的是,neitherREAD_ONCE()和WRITE_ONCE()除了在编译器内部之外,不提供任何顺序保证。参见上述第4.3.4.3节。 或第15章,以了解有关此类担保的信息。
第5章介绍了许多避免数据竞争的模式。
Linux内核提供了多种原子操作,但type atomic_t上定义的原子操作是一个很好的起点。byatomic_read()和atomic_set()分别提供了普通的非撕裂读取和存储。bysmp_load_acquire()提供了获取加载,smp_store_release()提供了释放存储。
提供了一些非值返回的获取和添加操作,如byatomic_add()、atomic_sub()、atomic_inc()、andatomic_de c()等。bothatomic_dec_和_test()以及atomic_ sub_和_test()提供了返回零指示的原子递减操作。atomic_add_return()则提供了一个返回新值的原子加法操作。atomic_add_unless()和atomic_inc_not_zero()提供了条件性的原子操作,除非原子变量的原始值与指定值不同,否则不会发生任何操作(这些操作对于管理引用计数器非常有用)。
原子交换操作由atomic_xchg()提供,而受推崇的比较交换(CAS)操作则由atomic_cmpxchg()提供。这两种操作都会返回旧值。Linux内核中还有许多其他原子RMW原语,详见Linux内核源代码树中的Documentation/ atomic_t. txt文件。14 本书的CodeSamples API与Linux内核的API非常相似。
| DEFINE_PER_THREAD(计数器); |
必须按照以下方式初始化计数器:
| init_per_thread(计数器,0); |
可以按如下方式递增此计数器的实例:
| p_counter=&__get_thread_var(计数器);WRITE_ ONCE(*p_计数器,*p_计数器+ 1); |
计数器的值是其实例的总和。因此,可以按如下方式收集计数器值的快照:
| for_each_thread(t) sum+=READ_ONCE(per_thread(counter,t)); |
同样,也可以使用其他机制获得类似的效果,但每线程变量结合了方便性和高性能,将在第5.2节中详细说明。
![]()
4.4 工作的正确工具:如何选择?
如果你陷入困境,改变你的工具;它可能会解放你的思维。
保罗·阿登,缩写
作为一个粗略的经验法则,使用最简单的工具来完成任务。如果可以的话,直接按顺序编程。如果这还不够,尝试使用shell脚本来协调并行性。如果生成的shell脚本fork()/ exec()开销(对于英特尔酷睿双核笔记本电脑上的最小C程序大约为480微秒)过大,可以尝试使用C语言中的fork()和wait()原语。如果这些原语的开销(对于最小子进程大约为80微秒)仍然过大,则可能需要使用POSIX线程原语,并选择合适的锁和/或原子操作原语。如果POSIX线程原语的开销(通常小于微秒级)过大,则可能需要使用第9章介绍的原语。当然,实际的开销不仅取决于你的硬件,更重要的是你如何使用这些原语。此外,始终记住,进程间通信和消息传递可以是共享内存多线程执行的良好替代方案,尤其是在你的代码充分利用了第6章中提到的设计原则时。
![]() 由于并发是在C语言首次用于构建并发系统后的几十年才被添加到C语言中的,因此存在多种并发方式
由于并发是在C语言首次用于构建并发系统后的几十年才被添加到C语言中的,因此存在多种并发方式
访问共享变量。在其他条件相同的情况下,第4.2.6节中描述的C11标准操作 应该是你的第一站。如果你需要以普通访问和原子访问两种方式访问某个共享变量,那么现代GCC原子性操作如第4.2.7节所述可能对你很有用。如果你正在处理使用经典的GCC同步API的旧代码库,那么你应该查看第4.2.5节 以及相关的GCC文档。如果您正在处理Linux内核或类似的代码库,该代码库结合使用volatile关键字和内联汇编,或者您需要依赖项来提供排序,请参阅第4.3.4节中介绍的材料 以及第15章中的内容。
无论你采取何种方法,请记住,随意破解多线程代码是一个极其糟糕的主意,特别是考虑到共享内存并行系统会利用你的智慧来对付你:你越聪明,就越容易为自己挖一个更深的坑,直到意识到自己陷入了困境[Pok16]。因此,有必要做出正确的设计选择以及正确的个体原语选择,这将在后续章节中详细讨论。
Chapter 5 Counting
简单如1、2、3!
未知的
计数或许是计算机最简单、最自然的功能。然而,在大型共享内存多处理器上高效且可扩展地进行计数却颇具挑战。此外,计数这一概念的简洁性使我们能够探索并发的基本问题,而无需受复杂数据结构或同步原语的干扰。因此,计数为并行编程提供了一个极好的入门。
本章介绍了一些具有简单、快速和可扩展计数算法的特殊案例。但是首先,让我们了解您对并发计数已经了解了多少。

5.1 为什么并发计数不是简单的?
追求简单,但不要轻信。
怀德海
让我们从一些简单的事情开始,例如,清单5.1中所示的算术运算的直接使用 (count_ nonatomic .c)。这里,我们在第1行有一个计数器, 我们在第5行增加它, 我们在第10行读出了它的价值。 还有什么比这更简单呢?

这种方法还有一个额外的优点,如果你做了大量的阅读,几乎没有增量,它是快速的,而且在小型系统上,性能非常好。
只有一个大问题:这种方法可能会丢失计数。在我的六核x86笔记本电脑上,运行了invokedinc_count()285,824,000次,但最终计数器的值只有35,385,525。尽管近似计算在计算中确实有其重要性,但87 %的计数丢失还是有些过分了。

准确计数的直接方法是使用原子操作,如清单5.2所示(count_ atomic .c)。第1行 定义原子变量,第5行 原子级递增它,以及第10行 读出来。因为这是原子,所以它能保持完美的计数。
| 清单5.2:原子级计数! |
| 1atomic_t计数器=ATOMIC_INIT(0);2 3静态__inline__void inc_count(void)4{ 7 8静态__inline__ longread_coun t(void)9{ |
然而,它的速度较慢:在我的六核x86笔记本电脑上,它比非原子增量慢二十多倍,即使只有一个线程在增加。
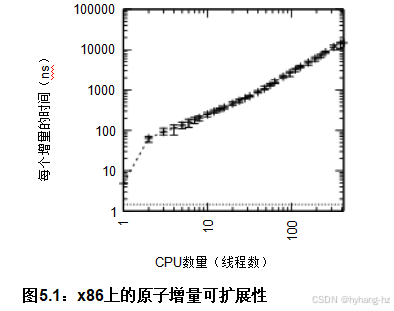
考虑到第3章中的讨论,这种糟糕的性能不应该令人惊讶,同样,随着CPU和线程数量的增加,原子增量的性能变慢也不应该令人惊讶,如图5.1所示。 在这个图中,位于x轴上的水平虚线代表了一个完全可扩展算法的理想性能:使用这样的算法,给定的增量将产生与单线程程序相同的开销。显然,对单个全局变量进行原子增量操作远非理想,而且随着额外CPU的增加,这种开销会成倍增长。

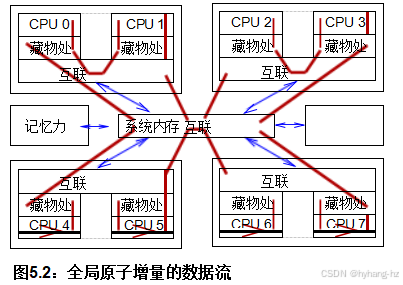
关于全球原子增量的另一个观点,可参考图5.2。 为了使每个CPU都有机会增加给定的全局变量,包含该变量的缓存行必须在所有CPU之间循环,如红色箭头所示。这种循环需要相当长的时间,导致图5.1中看到的性能较差。,可以认为如图5.3所示。 以下各节讨论了高性能计数,它避免了这种循环中固有的延迟。

| 清单5.3:基于数组的每个线程统计计数器 | |
| 1DEFINE_PER_THREAD(未签名的长计数器);2 3静态__inline__void inc_count(void)4{ 5个未签名的长*p_cou nter=&__get_thread_var(计数器);6 7 WRITE_ ONCE(*p_ counter,*p_ counter +1);8} 9 10静态__inline__ unsigned longread_count(void)11{ 12 intt; 13未签名长和=0;14 15for_each_thread(t) 16sum +=READ_ONCE(per_thr ead(counter,t)); 17返回总和;18} |
5.2 统计计数器
事实是顽固的,但统计数据是可以改变的。
马克·吐温
本节介绍统计计数器的常见特殊情况,即计数更新频率极高而读取值的频率极低。这些计数器将用于解决快速问答5.2中提出的网络包计数问题。
统计计数通常通过为每个线程(或在内核中运行时为每个CPU)提供一个计数器来处理,这样每个线程都会更新自己的计数器,这一点在第73页的4.3.6节中有所提及。通过简单地将所有线程的计数器相加,可以读取这些计数器的总值,这依赖于加法的交换性和结合性。这是将在第135页的6.3.4节中介绍的数据所有权模式的一个例子。

提供每个线程变量的一种方法是为每个线程指定一个元素的数组(假定缓存对齐并填充以避免错误共享)。
![]()
这样的数组可以被包装成每个线程的原始数据,如清单5.3所示(count_ stat .c)第1行 定义一个包含一组名为counter的、类型为unsigned long的线程计数器的数组。
第3行 – 8 展示一个函数,用于递增计数器,使用get_thread_ var()原语定位当前运行线程的计数器数组元素。由于该元素仅由相应线程修改,因此非原子递增就足够了。然而,这段代码usesWRITE_ONCE()防止破坏性
编译器优化。举个例子,编译器有权将要存储的位置用作临时存储,因此在实际存储之前,会将实际上相当于垃圾的数据写入该位置。这当然会让试图读取计数的人感到困惑。使用ofWRITE_ONCE()可以防止这种优化以及其他类似的优化。
第10行 – 18 展示一个函数,该函数使用for_ each_ thread()原语遍历当前运行的线程列表,并使用per_ thread()原语获取指定线程的计数器。此代码还使用READ_ONCE()以确保编译器不会将这些加载操作优化得毫无意义。例如,在两个连续调用read_ count()的情况下,可能会被内联,而一个谨慎的优化器可能会注意到相同的位置正在被累加,从而错误地认为只需一次累加并使用结果值两次就足够了。这种优化对于期望后续read_ count()调用考虑其他线程活动的人来说可能会相当令人沮丧。使用READ_ONCE()可以防止这种优化以及其他类型的优化。

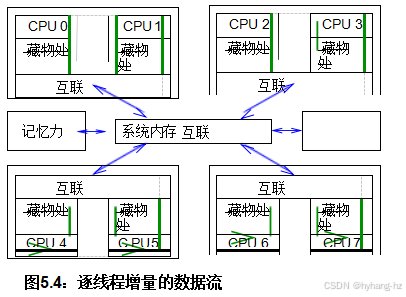
这种方法随着更新线程数量的增加而线性扩展invokinginc_count()。如图5.4中每个CPU上的绿色箭头所示,这样做的原因是,每个CPU都可以快速地增加其线程的变量,而无需进行昂贵的跨系统通信。因此,本节解决了本章开头提出的网络包计数问题。

但是,许多实现提供了更便宜的机制来处理线程数据,而且不受任意数组大小限制。这是下一节的主题。
| 清单5.4:逐线程统计计数器 |
| 1个未签名的长Thread_local计数器=0; 2个未签名的长* counterp[ NR_ THREADS] = { NULL }; 3个未签名的长最终计数=0; 4DEFINE_SPINLOCK(最终锁);5 10 11静态内联无符号longread_count(void)12{ 13 intt; 14个未签名的长字节;15 16spin_lock(&final_mutex); 18for_each_thread(t) 20 sum+=READ_ONCE(*counterp[t]; 22返回总和;23} 24 25 void count_register_thread(unsigned long *p)26{ 27年,平均指数=smp_thread_id();28 29spin_lock(&final_mutex);30counterp[idx]=&counter;31spin_unlock(&final_mutex);32} 33 34 void count_unregister_thread(int nthreadsexpected)35{ 36个内部索引=smp_thread_id();37 38spin_lock(&final_mutex); 40counterp[idx]=NULL; 41spin_unlock(&final_mutex);42} |
| 自C11起,C语言中引入了_Thread_local存储类,提供线程间存储。如清单5.4所示,可以使用此方法 (count_end.c)实现一个统计计数器,它不仅扩展性好,避免了任意线程数的限制,而且与简单的非原子增量相比,对增量器的性能影响很小或没有影响。 第1行– 4 定义需要的变量:counter是每个线程的计数器变量,counterp[]数组允许线程访问彼此的计数器,finalcount在各个线程退出时累积总值,final_mutex在累积计数器总值和退出线程之间进行协调。 |
| 快速测试5.18:清单5.4中没有明确的counter array吗 重新施加一个任意的线程数限制?为什么C语言不提供aper_thread()接口,类似于Linux内核的per_cpu()原语,以便线程更容易地访问彼此的每个线程变量? |
Theinc_count()更新器使用的函数非常简单,如第6行所示 – 9 .
读取器使用的read_count()函数更为复杂。第16行 获取锁以排除退出的线程,以及第21行 释放它。第17行 将sum初始化为那些已经退出的线程累积的计数,并行18 – 20 汇总当前正在运行的线程累积的计数。最后,行22 返回总和。

第25行 – 32 显示count_ register_ thread()函数,每个线程在首次使用此计数器之前都必须调用此函数。此函数只是将该线程的counterp[]数组元素设置为指向其线程计数器变量。

第34行– 42 显示thecount_unregister_thread()函数,每个先前调用count_register_thread()的线程必须在退出前调用该函数。第38行 获取锁,并行41 释放它,从而排除任何调用toread_count()以及对count_unregister_ thread()的其他调用。第39行 将此线程的计数器添加到全局最终计数,然后行40 NULL会删除其counterp[]数组条目。随后调用read_count()将看到全局finalcount中退出线程的计数,并在遍历counterp[]数组时跳过退出线程,从而获得正确的总数。
这种方法几乎与非原子加法具有相同的性能,并且线性扩展。另一方面,并发读取争夺单一全局锁,因此性能低下,扩展极差。然而,对于统计计数器而言,这并不是问题,因为增量操作频繁而读取操作几乎不存在。当然,这种方法比基于数组的方案复杂得多,因为给定线程的每线程变量在该线程退出时会消失。

基于数组和基于Thread_local的方法都提供了出色的更新侧性能和可伸缩性。然而,这些优点导致大量线程的读取侧开销较大。下一节将介绍一种方法,在保留更新侧可伸缩性的同时减少读取侧开销。
一种在大幅提高读取性能的同时保持更新侧可扩展性的方法是降低一致性要求。前一节中的计数算法保证返回一个值,该值介于理想计数器在执行read_count()开始时可能达到的值和结束时可能达到的值之间。
| 清单5.5:基于数组的逐线程最终一致计数器 |
| 1DEFINE_PER_THREAD(未签名的长计数器); 3 intstopflag; 4 5静态__inline__void inc_count(void)6{ 7个未签名的长*p_coun ter=&__get_thread_var(计数器);8 9 WRITE_ ONCE(*p_ counter,*p_ counter +1);10} 11 12静态__inline__ unsigned longread_count(void)13{ 14返回READ_ ONCE(global_ count);15} 16 17 void *eventual(void *arg)18{ 20个未签名的长字节;21 22 while(READ_ ONCE(stopflag)< 3){ 23 sum=0; 24for_each_thread(t) 25sum+=READ_ONCE(per_thread(counter,t)); 26 WRITE_ ONCE(global_ count,sum); 27个投票(NULL,0,1); 28如果(READ_ONCE(stopflag)) 29smp_store_release(&stopflag,stopflag+ 1);30} 31 returnNULL; 32} 33 36分; 37pthread_ttid; 38 39 en =pthread_create(&tid,N ULL,最终,NULL); 40如果(en!= 0){ 41 fprintf(stderr,“pthread_create:%s\n”,strerror(en)); 42退出(EXIT_FAILURE);43} 44} 45 46 void count_cleanup(void)47{ 48 WRITE_一次(停止标志,1); 49当(smp_load_acquire(停止标志)<3)时 |
read_ count()的执行。最终一致性[ Vog09]提供了更弱的保证:在没有调用inc_ count()的情况下,调用read_ count()最终会返回一个准确的计数。
我们通过维护一个全局计数器来实现最终一致性。然而,更新器仅操作其每个线程的计数器。提供了一个单独的线程来将每个线程的计数器中的计数值传递给全局计数器。读取者只需访问全局计数器的值。如果更新器处于活跃状态,读取者使用的值将会过时,但一旦更新停止,全局计数器最终会收敛到真实值——因此这种方法可以称为最终一致。
实现如清单5.5所示 (count_ stat_ eventual .c)。第1行 – 2 显示跟踪计数器值的每个线程变量和全局变量,以及第3行 显示停止标志,用于协调终止(在以下情况下
我们希望用一个精确的计数器值来终止程序)。Theinc_count()函数显示在第5行 – 10 与清单5.3中的对应项类似。 第12行所示的read_ count()函数 – 15仅返回global_ count变量的值。
然而,count_ init()函数在第34行 – 44创建最终的()线程,如第17行所示 – 32,它会遍历所有线程,将每个线程的局部计数器相加,并将总和存储到global_count变量中。最终的()线程会在两次遍历之间等待任意选择的一毫秒。
第46行的count_cleanup()函数 – 51坐标终止。这里的调用tosmp_load_acquire()和eventual()中的调用smp_store_release()确保了所有对global_ count的更新都对call count_cleanup()之后的代码可见。
这种方法在支持线性计数器更新能力的同时,提供了极快的计数器读出速度。然而,这种出色的读侧性能和更新侧可扩展性是以额外运行最终()的线程为代价的。

快速测试5.26:鉴于清单5.5中所示的最终一致算法读取和更新操作的开销极低,且具有极高的可扩展性,为什么还要考虑第5.2.2节中描述的实现方式呢 考虑到其昂贵的读取端代码?

这三种实现表明,尽管运行在并行机器上,统计计数器仍有可能获得接近单程过程的性能。

根据本节介绍的内容,您现在应该能够回答本章开头关于网络统计计数器的快速测验了。
5.3 约定的限位计数器
对正确问题的近似答案比对一个精确答案更有价值
近似问题。
约翰·图基
计数的另一个特殊情况是限位检查。例如,正如快速测试5.3中提到的近似结构分配限位问题 假设你需要维护一个计数,记录分配的结构数量,一旦使用中的结构数量超过某个限制,在这种情况下是10,000个。进一步假设这些结构是短暂的,这个限制很少被超出,而且这个限制是近似的,即有时超出这个限制是一个有限度,而有时未能达到这个限制也是一个有限度。参见第5.4节 如果你需要精确的限制。
一种可能的限制造计设计是将10,000的限制除以线程数量,然后给每个线程分配一个固定的结构池。例如,如果有100个线程,每个线程将管理自己的100个结构池。这种方法简单,在某些情况下效果很好,但无法处理常见的场景,即某个结构由一个线程分配而另一个线程释放[MS93]。一方面,如果某个线程负责释放任何结构,则执行大部分分配操作的线程会耗尽结构,而执行大部分释放操作的线程则会有大量无法使用的信用。另一方面,如果释放的结构被归功于分配它们的CPU,则需要CPU之间互相操作计数器,这将需要昂贵的原子指令或其他线程间通信的方式。
简而言之,对于许多重要的工作负载,我们无法完全划分计数器。鉴于分区计数器是第5.2节讨论的三种方案中带来优秀更新侧性能的原因 ,这可能是悲观的理由。然而,第5.2.4节中提出的最终一致算法 提供了一个有趣的提示。回想一下,该算法维护了两组书,一个用于更新器的每线程计数变量和一个用于读取器的全局计数变量,最终由一个()线程定期更新全局计数,以最终与每个线程的计数值保持一致。每个线程的计数完美地划分了计数值,而全局计数则保留了完整的值。
对于限幅计数器,我们可以使用这个主题的一个变体,其中我们部分地对计数器进行分区。例如,考虑四个线程,每个线程不仅有一个线程计数器,而且还有一个线程最大值(称为count ermax)。
但是,如果某个线程需要增加其计数器,但计数器等于最大值怎么办?这里的关键是将该线程计数值的一半移动到全局计数器,然后增加计数器。例如,如果某个线程的计数器和最大值变量都等于10,我们这样做:
3.为了平衡增加的分数,从这个线程的计数器中减去5。
4.释放全局锁。
5.增加此线程的计数器,结果为6。
尽管此过程仍需全局锁定,但每次五次增量操作只需获取一次锁,大大减少了该锁的竞争度。我们可以通过增加countermax的值来将这种竞争度降低到最低。然而,增加countermax值的相应代价是全局计数的准确性降低。要了解这一点,请注意,在四核系统中,如果countermax等于十,全局计数最多会出错40次。相比之下,如果countermax增加到100,全局计数可能会出错多达400次。
这引发了我们对全局计数与计数器总值偏差的关注,其中总值是全局计数和每个线程计数变量之和。这个问题的答案取决于总值与计数器上限(称为全局计数最大值)之间的差距。这两个值之间的差异越大,计数器最大值可以设置得越高而不超过全局计数最大值。这意味着可以根据这一差异来设置给定线程的计数器最大值。当远未达到上限时,线程的计数器最大值被设置为较大值以优化性能和可扩展性;而当接近上限时,这些变量则被设置为较小值,以减少对全局计数最大值检查时的误差。
此设计是并行快速路径的一个示例,这是一种重要的设计模式,在这种模式中,常见情况无需执行昂贵指令且线程之间没有交互,但偶尔也会使用一种更为保守设计(且开销更高)的全局算法。该设计模式在第6.4节中有更详细的介绍。
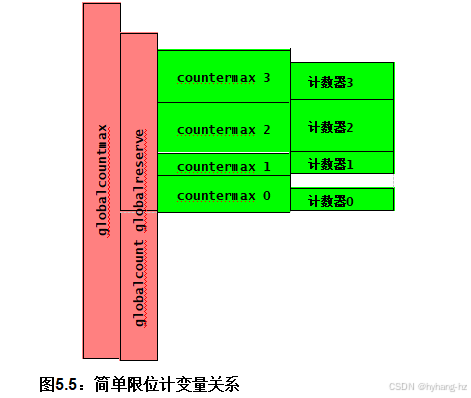
清单5.6 显示了此实现所使用的每个线程变量和全局变量。per-thread反计数器和countermax变量分别是相应线程的局部计数器及其上限。第3行中的全局countermax变量 包含聚合计数器的上限以及第4行上的全局计数变量 是全局计数器。全局计数器与每个线程的计数器之和给出了整体计数器的总值。第5行中的全局保留变量 至少是所有线程计数器变量的最大值之和。这些变量之间的关系如图5.5所示:
1.globalcount和globalreserve的总和必须小于或等于globalcountmax。
2.所有线程的countermax值之和必须小于或等于全局保留量。
3.每个线程的counter必须小于或等于该线程的countermax。
| 清单5.6:简单限位计变量 | |
| 1个未签名的长线程计数器=0; | |
| 2个未签名的长线程计数器,最大值=0; | |
| 3 | |
| 4 | 未签名的长全局计数=0; |
| 5 | 未签名的长期全球储备=0; |
| 6 | 未签名的长* counterp[ NR_ THREADS] = { NULL }; |
| 7 | |
counter[]数组的每个元素都引用了相应线程的计数变量,最后,gblcnt_互斥锁spinlock保护所有全局变量,换句话说,除非线程已经获得了gblcnt_ mutex,否则任何线程都不允许访问或修改任何全局变量。
清单5.7 显示了add_ count()、sub_ count()和read_ count()函数(count_lim.c)。

第1行 – 18显示add_count(),它将指定的值delta添加到计数器中。行3 检查这个线程的计数器是否有空间给delta,如果有,就执行第4行 添加并行5 返回成功。这是add_ counter()fastpath,它不执行原子操作,仅引用每个线程变量,并且不应该发生任何缓存未命中。

如果第3行有测试失败时,我们必须访问全局变量,因此必须在第7行acquiregblcnt_mutex, 我们在第11行发布 在故障情况下或在线16 在成功案例中,第8行 调用全局变量globalize_ count(),如清单5.9所示,它清除了线程局部变量,并根据需要调整全局变量,从而简化了全局处理。(但不要只听我的,自己试着写一下吧!)
| 1静态2{ 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18} 19 20静态21{ 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36} 37 38静态39{ 40 41 42 43 44 45 46 47 48 49 50 51} | __inline__intadd_count(未签名的长delta) 如果(countermax - counter>= delta){ WRITE_ONCE(计数器,计数器+ delta);返回1; } spin_lock(&gblcnt_mutex);globalize_count(); 如果(全局计数最大值- globalcount- globalreserve< delta){spin_unlock(&gblcnt_mutex); return0; } globalcount+=delta;balance_count(); spin_unlock(&gblcnt_mutex);返回1; __inline__intsub_count(未签名的长delta) WRITE_ONCE(计数器,计数器-增量); return1;} spin_lock(&gblcnt_mutex);globalize_count(); 如果(globalcount< delta){ spin_unlock(&gblcnt_mutex);返回0; } globalcount-=delta;balance_count(); spin_unlock(&gblcnt_mutex);return1; __inline__无符号longread_coun t(void) intt; 未签名的长和; spin_lock(&gblcnt_mutex); for_each_thread(t){ 如果(counterp[t]!= NULL) sum+=READ_ONCE(*counterp[t];) |
| 3 | 如果 | (counter+ delta<= countermax){ | |||
| 4 | 一次写入(计数器, | 柜台 | + | 希腊语字母表第四字母δ | |
| 5 | return1; | ||||
| 6 | } | ||||
第9行 和10 检查是否可以容纳delta的添加,表达式小于号前的意义如图5.5所示 为两个红色(最左边)条形的高度差。如果不能容纳delta的增加,则行11 (如上所述)发布gblcnt_mutex和第12行 返回值表示失败。
否则,我们走慢路。第14行 将delta加到globalcount中,然后行15 调用balance_ count()(如清单5.9所示 )用于更新全局变量和每个线程的变量。调用balance_count()通常会将thisthread的countermax设置为重新启用快速路径。第16行 然后释放gblcnt_mutex(如前所述),最后,第17行 返回表明成功。

第20行 – 36 显示sub_ count(),它从计数器中减去指定的delta。第22行 检查per-thread count er是否可以容纳这个减法,如果是,则行23 做减法和第24行 返回成功。这些行构成sub_count()的快速路径,和add_count()一样,此快速路径不执行任何代价操作。
如果快速路径不能容纳delta的减法,执行程序将在第26行进入慢路径 – 35 . 因为慢路径必须访问全局状态,行26acquiresgblcnt_mutex,由第29行释放 (如发生故障)或通过线路34 (如成功)。第27行 调用全局变量globalize_ count(),如清单5.9所示, 这再次清除了线程局部变量,根据需要调整全局变量。第28行 检查计数器是否可以容纳减去的delta,如果不是,则行29 发布gblcnt_mutex(如前面所述)和第30行返回失败。
另一方面,如果第28行 发现计数器可以容纳减法delta,我们完成了慢路径。第32行 减去33,然后划线 invokesbalance_count()(见清单5.9 )更新全局变量和每个线程的变量(希望重新启用快速路径)。然后第34行 发布gblcnt_mutex,第35行 返回成功。

第38行– 51showread_count(),返回计数器的总值。它acquiresgblcnt_mutex在第43行 并在第49行释放它 ,不包括add_ count()和sub_ count()中的全局操作,以及,正如我们将看到的,也不包括线程创建和退出。第44行 将局部变量sum初始化为globalcount的值,然后循环跨越第45行 – 48汇总每个线程的计数器变量。第50行 然后返回总和。
清单5.9 显示了add_ count()、sub_ count()和read_ count()这些在清单5.7中显示的primitives所使用的许多实用函数。
| 清单5.9:简单限幅计数器实用函数 |
| 1静态__inline__ voidglobalize_count(void)2{ 3 globalcount+=counter; 5 globalreserve-=countermax; 8 9静态__inline__ voidbalance_count(void)10{ 11 countermax = globalcountmax - 13个countermax/=num_online_threads(); 14 globalreserve += countermax; 15个计数器=计数器最大值/2; 17 counter=globalcount; 20 21 void count_register_thread(void)22{ 23年11月=smp_thread_id();24日 25spin_lock(&gblcnt_mutex);26counterp[idx]=&counter;27spin_unlock(&gblcnt_mutex);28} 29 30 void count_unregister_thread(int nthreadsexpected)31{ 32 int idx=smp_thread_id();33 34spin_lock(&gblcnt_mutex); 36counterp[idx]=NULL; |
第1行 – 7 显示全局变量globalize_ count(),该函数将当前线程的每线程计数器清零,并适当调整全局变量。需要注意的是,此函数不会改变计数器的总值,而是改变计数器当前值的表示方式。第3行将线程的计数变量添加到全局计数器中,第4行 零位计数器。同样,第5行 从全局保留中减去每线程计数器max,行6 计数器最大值为零。参考图5.5很有帮助 在读取此函数和下一个的balance_ count()时。
第9行 – 19 显示balance_ count(),大致来说是globalize_count()的逆数。此函数的作用是将当前线程的countermax变量设置为最大值,以避免计数器超过全局最大限制。当然,更改当前线程的countermax变量需要相应调整counter、globalcount和globalreserve,这可以通过参考图5.5来了解。 通过这样做,balance_ count()最大化使用ofadd_count()的低优先级快速路径和sub_count()。由于withglobalize_count(),balance_ count()不被允许更改计数器的聚合值。
第11行 – 13 计算此线程对未被全局计数或全局保留覆盖的全局计数最大值部分的份额,并将计算出的数量分配给此线程的计数最大值。第14行 对全局储备进行相应的调整。第15行 将此线程的计数器设置为中间
从零到countermax的范围。第16行 检查全局计数器是否确实可以容纳这个计数器值,如果不是,则执行第17行 相应地减少计数器。最后,在任何情况下,行18 对全局计数进行相应的调整。

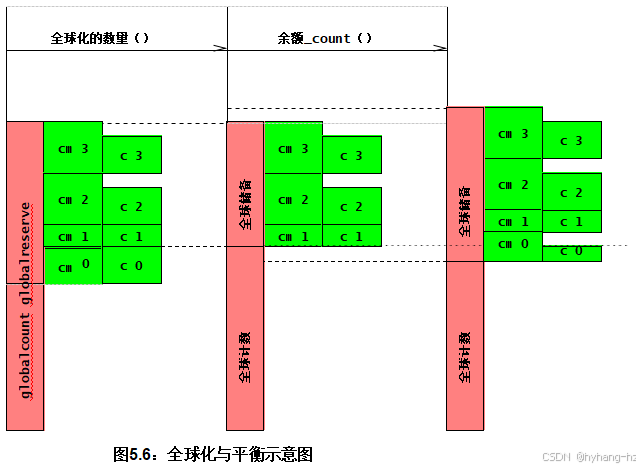
查看图5.6所示的示意图有助于了解counter之间的关系如何随着first globalize_ count()和then balance_ count()的执行而变化。 时间从左向右推进,最左边的配置大致如图5.5所示。 中心配置展示了线程0执行globalize_count()后这些相同计数器之间的关系。从图中可以看出,线程0的计数器(图中的“c 0”)被加到全局计数上,而全局保留量则相应减少。线程0的计数器及其最大值(图中的“cm 0”)都被减少到零。其他三个线程的计数器保持不变。请注意,这一变化并未影响计数器的整体值,这由连接最左侧和中心配置的最下方虚线表示。换句话说,在两种配置中,全局计数与四个线程计数变量之和是相同的。同样,这一变化也未影响全局计数与全局保留量之和,这由上方的虚线表示。
最右侧的配置展示了在线程0执行balance_ count()后,这些计数器之间的关系。剩余计数的四分之一,由从所有三个配置向上延伸的垂直线表示,被加到线程0的countermax中,再将其中的一半加到线程0的counter中。加到线程0的
为了防止改变计数器的总体值(它仍然是全局计数器和三个线程的总和,因此也会从全局计数器中减去计数器
| 清单5.10:近似限位计变量 |
| 1个未签名的长线程计数器=0; |
| 2个未签名的长线程计数器max=0; |
| 3个未签名的长全局计数器max=10000; |
| 4个未签名的长全局计数=0; |
| 5个未签名的长全局保留=0; |
| 6个未签名的长* counterp[ NR_线程]={NULL}; |
| 7DEFINE_SPINLOCK(gblcnt_mutex); |
| 8#defineMAX_COUNTERMAX 100 |
计数变量),再次由连接中心和最右侧配置的两条虚线中的下一条表示。全局保留变量也进行了调整,使其等于四个线程的计数最大值之和。由于线程0的计数小于其计数最大值,线程0可以再次局部增加计数。
 第21行 – 28 显示count_ register_ thread(),它为新创建的线程设置状态。此函数只是将指向新创建线程计数器变量的指针安装到counterp[]数组中相应条目的ofgblcnt_mutex保护下。
第21行 – 28 显示count_ register_ thread(),它为新创建的线程设置状态。此函数只是将指向新创建线程计数器变量的指针安装到counterp[]数组中相应条目的ofgblcnt_mutex保护下。
最后,第30行 – 38 显示count_ unregister_ thread(),它会为即将退出的线程删除状态。第34行 收购gblcnt_mutex和37号线 释放它。第35行 调用globalize_ count()清除此线程的计数状态,以及第36行 清除计数器counterp[]中此线程的条目。
这种计数器在聚合值接近零时非常快,但由于加法计数器和减法计数器的快速路径中存在比较和分支操作,会产生一些开销。然而,使用每个线程的计数器最大预留量意味着即使聚合值远未达到全局最大值,加法计数器也可能失败。同样地,即使聚合值远未接近零,减法计数器也可能失败。
在许多情况下,这是不可接受的。即使全局计数最大值旨在作为近似限制,通常也有一个具体的近似程度上限。一种限制近似程度的方法是为每个线程的计数最大值实例设置上限。这项任务将在下一节中进行。
因为这个实现(count_lim_app.c)与上一节的实现(清单5.6非常相似, 5.7 ,和5.9 ),这里只显示了更改。列表5.10 与清单5.6相同, 加上ofMAX_COUNTERMAX,它设置每个线程计数器变量max的最大允许值。
同样,列表5.11 与清单5.9中的balance_ count()函数相同, 加上第6行 和7, 这些变量对每个线程的计数器变量执行theMAX_COUNT ERMAX限制。
| 清单5.11:近似限位器平衡 | |
| 1静态2{ 3 4 5 6 7 8 9 10 11 12 13} | voidbalance_count(空) countermax=globalcountmax - globalcount-globalreserve;countermax/=num_online_threads(); countermax =MAX_COUNTERMAX; globalreserve+= countermax; counter= countermax / 2;如果(counter> globalcount) counter=globalcount; globalcount-=counter; |
| 这些改进大大减少了前一版本中出现的极限不准确性,但带来了另一个问题:任何给定的MAX_COUNTERMAX值都会导致依赖于工作负载的访问比例从快速路径中脱落。随着线程数量的增加,非快速路径执行将成为性能和可扩展性的问题。然而,我们将推迟解决这个问题,转而使用具有精确限制的计数器。 | |
5.4 精确限位计数器
精确性可能代价高昂。明智地花钱。
未知的
为了解决在快速测试5.4中提到的确切结构-分配限制问题, 我们需要一个能够准确判断其限制是否被超过的限制计数器。实现这种限制计数器的一种方法是让那些预留了计数的线程释放这些计数。一种实现方式是使用原子指令。当然,原子指令会减慢快速路径的速度,但另一方面,不尝试一下也是愚蠢的。
不幸的是,如果一个线程要安全地从另一个线程中移除计数,两个线程都需要原子操作对方线程的计数和最大计数变量。通常的做法是将这两个变量合并为一个变量,例如,给定一个32位变量,使用高16位表示计数,低16位表示最大计数。

简单原子限制计数器的变量和访问函数如清单5.12所示 (count_lim_at omic.c)。早期算法中的counter和countermax变量被合并到单个变量counterandmax中,如第1行所示, upper半部分为counter,lower半部分为countermax。此变量的类型为atomic_t,其底层表示为int。
第2行 – 6 显示globalcountmax、globalcount、globalreserve、counterp、andgblcnt_mu tex的定义,它们都扮演着rolemi-
| 清单5.12:原子限制计数器变量和访问函数 |
| 1atomic_t __thread counterandmax = ATOMIC_INIT(0); 2无符号长全局计数最大值=1 << 25; 3个未签名的长全局计数=0; 4个未签名的长全局保留=0; 5 atomic_t * counterp[ NR_ THREADS] = { NULL }; 6DEFINE_SPINLOCK(gblcnt_mutex); 7 #define CM_BITS(sizeof(atomic_t)* 4) 8#defineMAX_COUNTERMAX((1 <<CM_BITS)- 1) 9 10个静态__内联__空 11 split_counterandmax_int(内凸轮,内*c,内*cm)12{ 13 *c =(cami>>CM_BITS)& MAX_COUNTERMAX;14 *cm= cami &MAX_COUNTERMAX; 15} 16 17静态__内联__空 18 split_counterandmax(atomic_t *cam,int *old,int*c,int*cm)19{ 20 unsigned int cami = atomic_read(cam);21 22*老=卡米; 23split_counterandmax_int(厘米,c,cm);24} 25 26静态__inline__ intmerge_counterandmax(int c,int cm)27{ 28 unsigned int cami;29 30个cami=(c<< CM_BITS)|cm; |
与Li sting 5.10中的对应项比较。 第7行 definesCM_BITS,它给出了计数器和max的每个半部分的位数,以及第8行 定义MAX_COUNTERMA X,它给出计数器和max的任一半中可能持有的最大值。
![]()
第10行 – 15显示split_ counterandmax_ int()函数,当给定来自theatomic_t counter和max变量的基本int时,它将其拆分为counter (c)和countermax(cm)组件。第13行 隔离该int中最重要的半部分,将结果置于参数c指定的位置,并在第14行 隔离该整数的最不显著半部分,并将结果置于由参数cm指定的位置。
第17行 – 24 显示split_counter和max()函数,它们从第20行指定的变量中提取底层的int ,按照第22行的旧参数指定的方式存储它, 然后invokessplit_counterandmax_in t()在第23行将其拆分。

第26行 – 32 显示merge_counter和max()函数,可以将其视为逆ofsplit_counterandmax()。第30行 将通过c和cm分别传递的计数器和countermax值合并,并返回结果。

清单5.13 显示add_ count()和sub_ count()函数。
| 1 intadd_count(未签名的长delta) | ||
| 2{ | ||
| 3 intc; | ||
| 4 intcm; | ||
| 5 intold; | ||
| 6 intnew; | ||
| 7 | ||
| 9split_counterandmax(&counterandmax,&old, 10如果(delta>MAX_COUNTERMAX || c+ delta> 11转到慢路径; | ||
| 12新的= merge_counterandmax(c + delta,cm);13 }而(atomic_cmpxchg(&counterandmax, | ||
| 14个旧的,新的)!=旧的); 16slowpath: | ||
| 17spin_lock(&gblcnt_mutex); 18globalize_count(); | ||
| 19if (globalcountmax -globalcount - 21flush_local_count(); | ||
| 22如果(globalcountmax -globalcount - | ||
| 24spin_unlock(&gblcnt_mutex); 25 return0; 26} 27} | ||
| 29balance_count(); | ||
| 31返回1;32} | ||
| 33 | ||
| 36 intc; 37int cm; 38 intold; 39 intnew; | ||
| 40 | ||
| 42split_counterandmax(&counterandmax,&old, 43如果(delta> c) | &c, | & cm); |
| 44转到慢路径; | ||
| 45个新=merge_counterandmax(c-delta,cm); 46 }而(atomic_cmpxchg(counterandmax, | ||
| 47岁,新)!=老); 49slowpath: | ||
| 50spin_lock(&gblcnt_mutex); 51globalize_count(); | ||
| 52如果(globalcount< delta){ 53flush_local_count(); | ||
| 54如果(globalcount< delta){ | ||
| 55spin_unlock(&gblcnt_mutex); 56返回0;57} 58} | ||
| 59 globalcount-=delta; 60balance_count(); | ||
| 61spin_unlock(&gblcnt_mutex); | ||
| 列表5.14:原子Limi t计数器读数 |
| 1未签名的long read_count(void)2{ 3 intc; 4 intcm; 5 intold; 6 intt; 7个未签名的长字节;8 9spin_lock(&gblcnt_mutex); 11for_each_thread(t){ 12if(counter[t]!=NULL){ 13split_counterandmax(反[t,&old,&c,&cm); 16} 18返回总和;19} |
第1行 – 32显示add_count(),其快速路径跨越第8行– 15 ,其余的函数是慢路径。第8行 – 14快速路径形成比较和交换(CAS)循环,在第13行使用了atomic_ cmpxchg()原语 – 14 执行实际的CAS。第9行 将当前线程的counter和max变量拆分为它的counter
(在c)和countermax(在cm)组件中,同时将底层插入旧的。第10行 检查是否可以本地容纳量delta(注意避免整数溢出),如果不是,行11 转至slowpa th。否则,第12行 将更新后的计数器值与原始计数器最大值结合成新的值。atomic_cmpxchg()原语在第13行 – 14然后原子地将此线程的计数器和最大变量与old进行比较,如果比较成功,则将其值更新为new。如果比较成功,第15行 返回成功,否则,执行继续在第8行的循环中。

第16行 – 31见清单5.13 显示add_count()的慢路径,该路径由gblcnt_mutex保护,在线17获取 并在第24行发布 和30。 第18行 调用globalize_ count(),将此线程的状态移动到全局计数器中。第19行 – 20 检查delta值是否可以被当前的全局状态所容纳,如果不能,则行21 调用flush_ local_ count()将所有线程的本地状态刷新到全局计数器,然后行22 – 23重新检查是否可以容纳delta。如果在所有这些之后,仍然不能容纳delta的添加,则行24 发布gblcnt_mutex(如前面所述),然后行25返回s失败。
否则,第28行 将delta添加到全局计数器中,第29行 如果合适,sp读取计数到本地状态,第30行 释放gblcnt_互斥锁(如前面所述),最后,第31行 返回成功。
第34行 – 63 见清单5.13 显示子计数(),其结构与add_count()类似,在第41行有一个快速路径 – 48 在第49行加一个慢音 – 62 .对这个函数的逐行分析留给读者作为练习。
清单5.14 显示read_ count()。第9行 获取gblcnt_互斥锁和第17行 释放它。第10行 将局部变量sum初始化为globalcount的值,并且
| 1静态2{ 3 4 5 6 7 8 9 10 11 12} 13 14静态 15{ 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 | voidglobalize_count(空) intc; intcm; intold; split_counterandmax(&counterandmax,&old,&c,&cm);全球计数+=c; globalreserve-=cm; old=merge_counterandmax(0,0);atomic_set(&counterandmax,old); intc; intcm; intold; intt; intzero; 如果(globalreserve== 0) 返回 零=merge_counterandmax(0,0);对于每个线程(t) old=atomic_xchg(反[t],零);split_counterandmax_int(老,&c,&cm);globalcount+=c; |
跨越线路11的环 – 16 将每个线程计数器添加到此总和中,使用split_ counterandmax在第13行隔离每个线程计数器。 最后,第18行 返回总和。
清单5.15 和5.16 显示实用程序functionsglobalize_count(),flush_local_count(),balance_count(),count_register_thread(),andcount_unregister_thread()。globalize_count()的代码显示在第1行 – 12 见清单5.15 ,与之前的算法类似,增加了第7行, 现在需要将counter和countermax从counterandmax中分离出来。
flush_ local_ count()代码将所有线程的本地计数器状态移动到全局计数器,代码显示在第14行 – 32 .第22行 检查s,以查看globalreserve的值是否允许任何线程计数,如果不是,则请参阅第23行 返回。否则,第24行 将局部变量ze ro初始化为组合零计数器和countermax。循环跨越行25 – 31 通过每个线程的序列。第26行 检查ks,以查看当前线程是否具有计数状态,如果是,则行27 – 30将该状态移动到全局计数器。第27行 原子地获取当前线程的状态,同时将其替换为零。第28行 将此状态分为其计数器(在局部变量c中)和计数器最大值(在局部变量cm中)组件。第29行 将此线程的计数器添加到全局计数器,而行30 从globalreserve中减去此线程的countermax。
第1行 – 22 见清单5.16 显示balance_ count()的代码,该函数会重新填充调用线程的本地计数器和最大变量。此函数与前面的算法非常相似,但需要对合并后的计数器和最大变量进行处理。代码的详细分析留作读者练习,正如从第24行开始的count_register_thread()函数一样。 并且count_unregister_thread()函数从第33行开始。

下一节对这一设计进行了定性评价。
这是首次实现让计数器运行至任一极限的情况,但这样做是以在快速路径中添加原子操作为代价的,这在某些系统上会显著减慢快速路径的速度。尽管某些工作负载可能能够容忍这种减速,但寻找写侧性能更好的算法仍然是值得的。其中一种算法使用信号处理程序来窃取计数。
来自其他线程。由于信号处理程序在被信号化的线程的上下文中运行,因此不需要原子操作,如下一节所示。

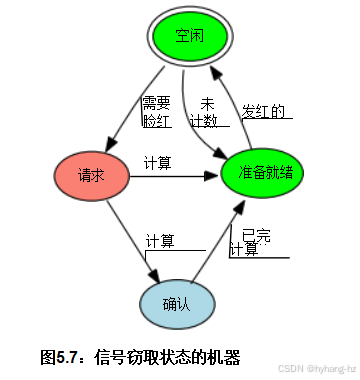
尽管现在每个线程的状态只由相应的线程来操纵,但仍需要与信号处理程序进行同步。这种同步是由图5.7所示的状态机提供的。
状态机初始处于空闲状态,whenadd_count()orsub_ count()发现本地线程的计数与全局计数的组合无法满足请求,相应的慢路径会将每个线程的偷盗状态设置为REQ(除非该线程没有计数,在这种情况下,它会直接进入就绪)。只有持有gblcnt_互斥锁的慢路径才被允许从空闲状态转换,这由绿色表示。4 慢路径随后向每个线程发送信号,相应的信号处理程序检查相应线程的偷窃和计数变量。如果偷窃状态不是REQ,则信号处理程序不允许改变状态,因此直接返回。否则,如果计数变量被设置,表明当前线程的快路径正在进行,信号处理程序将偷窃状态设置为AC K,否则设置为就绪。
如果偷窃状态为ACK,只有快速路径才被允许改变偷窃状态,如蓝色颜色所示。当快速路径完成时,它将偷窃状态设置为READY。
一旦慢路径看到线程的偷窃状态已准备就绪,慢路径就可以偷窃该线程的计数。然后,慢路径将该线程的偷窃状态设置为IDLE。
1#定义THEFT_ IDLE 0 2 #defineTHEFT_REQ 1 3#定义THEFT_ACK 2 4 #defineTHEFT_READY 3 5
8个未签名的长__线程计数器=0;
9个未签名的长__threadcountermax = 0;
10个未签名的长全局计数器max=10000;
11个未签名的长全局计数=0;
12个未签名的长全局保留字=0;
13个未签名的长* counterp[ NR_ THREADS] = { NULL};
14个未签名的长* countermaxp[ NR_ THREADS] = { NULL};
15 int * theftp[ NR_ THREADS] = { NULL };16 DEFINE_ SPINLOCK(gblcnt_ mutex);
17#defineMAX_COUNTERMAX 100

清单5.17 (count_ lim_ sig .c)显示了基于信号窃听的计数器实现所使用的数据结构。第1行 – 7定义前一节中描述的每个线程窃取状态机的状态和值。第8行 – 17 与早期实现类似,增加了行s 14 和15 允许远程访问线程的countermax和theft变量。
清单5.18 显示负责在每个线程变量和全局变量之间迁移计数的函数。第1行 – 7 显示globalize_ count(),与早期实现相同。第9行 – 16 show flush_local_count_sig(),这是在盗窃过程中使用的信号处理程序。行11 和12 检查是否为“REQ”状态,如果不是,则返回,不作任何更改。第13行 将盗窃状态设置为ACK,如果第14行 看到此线程的快速路径未运行,第15行 usessmp_store_release()将盗窃状态设置为“就绪”,进一步确保快速路径中的任何计数器更改都发生在此“盗窃”状态变为“就绪”之前。

第18行 – 47 显示flush_ local_ count(),该函数从slowpath调用以清空所有线程的本地计数。循环跨越第2和3行 – 32 为每个具有本地计数的线程推进偷窃状态,并向该线程发送信号。第24行 跳过任何不存在的线程。否则,第25行 检查当前线程是否持有任何本地计数,如果没有,则行26 将线程的偷盗状态设置为READY,行27 跳到下一个线程。否则,第29行 将线程的偷窃状态设置为REQ和行30 向线程发送信号。

| 1静态2{ 3 4 5 6 7} 8 9静态 10{ 11 12 13 14 15 18静态19{ 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 49静态50{ 51 52 53 54 55 56 57 58 59 60 61} | voidglobalize_count(空) globalcount+=counter; counter=0; globalreserve-=countermax; countermax = 0; voidflush_local_count_sig(未使用) 如果(READ_ONCE(theft)!=THEFT_REQ) 返回 一次写入(盗窃,THEFT_ ACK);如果(不计数) smp_store_release(和盗窃,THEFT_READY); voidflush_local_count(空) intt; thread_id_ttid; 如果(*countermaxp[t]==0){ WRITE_ ONCE(* theftp[t],THEFT_ready);继续; } WRITE_ONCE(*theftp[t],THEFT_REQ);pthread_kill(tid,SIGUSR1); }} 如果(ftpt[t]==NULL) 持续 而(smp_load_acquire(theftp[t])!= THEFT_READY){ poll(NULL,0,1); 如果(READ_ ONCE(* theftp[t])== THEFT_ REQ)pthread_kill(tid,SIGUSR1); } globalcount+=*counterp[t];*counterp[t]=0; globalreserve-=*countermaxp[t];*countermaxp[t]=0; smp_store_release(ftp[t],THEFT_IDLE} voidbalance_count(空) countermax= globalcountmax- globalcount- globalreserve; countermax/=num_online_threads();如果(countermax>MAX_COUNTERMAX) countermax =MAX_COUNTERMAX; globalreserve+= countermax; counter= countermax / 2;如果(counter> globalcount) |
1 intadd_count(未签名的长delta) 2{
3 int fastpath=0; 4
6barrier();
7如果( smp_ load_ acquire(& theft)<= THEFT_ REQ &&
8 countermax- counter>= delta){
14barrier();
15如果(READ_ ONCE(theft)== THEFT_ ACK)
16smp_store_release(和盗窃,THEFT_READY);
19spin_lock(&gblcnt_mutex);
20globalize_count();
21if (globalcountmax - globalc ount-
22 globalreserve< delta){
23flush_local_count();
24如果(globalcountmax -globalcount -
25 globalreserve< delta){
26spin_unlock(&gblcnt_mutex);
27 return0; 28}
29}
30 globalcount+=delta;
31balance_count();
33返回1;
34}

跨越线路33的环 – 46等待每个线程达到就绪状态,然后窃取该线程的计数。第34行 – 35 跳过任何不存在的线程,以及跨越第36行的循环 – 40 等待当前线程的偷窃状态准备好。第37行 为避免优先级反转问题,将阻塞1毫秒,如果第38行 确定线程的信号尚未到达,第39行 重新设置信号。执行到达第41行 当线程的偷窃状态变为就绪时,所以行4 1 – 44行窃。第45行 然后将线程的偷窃状态重新设置为IDLE。
![]()
第49行 – 61 显示balance_count(),它与前面示例中的类似。
清单5.19 显示了add_count()函数。快速路径跨越第5行 – 18 ,以及慢速路径线路19 – 33 .第5行 将每个线程计数变量设置为1,这样任何后续中断此线程的信号处理程序都将把偷窃状态设置为ACK而不是READY,从而允许此快速路径正确完成。第6行 防止编译器重新排序任何快速路径体,使其在计数设置之前出现。第7行 和8 检查每个线程的数据是否可以容纳add_count(),如果没有正在进行的盗窃行为,则行9 快速路径添加和行10 注意到已经采取了快速途径。
| 清单5.20:信号窃取限制计数器减法函数 | |
| 1 int 2{ 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32} | sub_count(无符号长delta) int fastpath=0; WRITE_ONCE(计数,1);barrier(); 如果(smp_ load_ acquire(& theft)<= THEFT_ REQ && counter>= delta){ WRITE_ONCE(计数器,计数器-差值); fastpath= 1;} 屏障 WRITE_ONCE(计数器,0);barrier(); 如果(READ_ ONCE(theft)== THEFT_ ACK) smp_store_release(和盗窃,THEFT_READY);如果(快速路径) return1; spin_lock(&gblcnt_mutex);globalize_count(); 如果(globalcount< delta){flush_local_count(); 如果(globalcount< delta){ spin_unlock(&gblcnt_mutex);返回0; }} globalcount-=delta;balance_count(); spin_unlock(&gblcnt_mutex);返回1; |
| 1未签名的长读取计数(void)2{ 3 intt; 4个无符号长整型;5 6spin_lock(&gblcnt_mutex); 7 sum=globalcount; 8for_each_thread(t){ 9if(counter[t]!=NULL) 10 sum += READ_ ONCE(* counterp[t]);11} 12spin_unlock(&gblcnt_mutex); 13返回总和;14} |
在任何情况下,第12行 防止编译器重新排序快速路径主体以遵循第13行 ,允许后续的信号处理程序进行窃取。第14行 再次禁用编译器重排序,然后是第15行 检查信号处理程序是否将偷窃状态更改为“就绪”,如果是,则行16 使用smp_ store_ release()将偷盗状态设置为READY,进一步确保任何看到READY状态的CPU也看到第9行的效果。 如果在第9行进行快速路径添加 执行,然后第18行 返回成功。
否则,我们将进入从第19行开始的慢路径。 慢路径的结构与前面的例子类似,因此分析这部分内容留给读者练习。同样,子计数()在清单5.20中的结构 与add_count()相同,因此对sub_count()的分析也留给读者作为练习,对read_count()的分析也如清单5.21所示。
| 1空2{ 3 4 5 6 7 8 9 10 11 14空15{ 16 17 18 19 20 21 22 23} 24 25空26{ 27 28 29 30 31 32 33 34 35} | count_init(空) 结构信号a; sa.sa_handler=flush_local_count_sig;sigemptyset(&sa.sa_mask); sa.sa_flags=0; 如果(sigaction(SIGUSR1,&sa,NULL)!=0){perror(“sigaction”); 退出(EXIT_FAILURE); } count_register_thread(void)int idx=smp_thread_id(); spin_lock(&gblcnt_mutex); counterp[idx]=&counter; countermaxp[idx]=&countermax; theftp[idx]=&theft; spin_unlock(&gblcnt_mutex); count_unregister_thread(int nthreadsexpected)int idx=smp_thread_id(); spin_lock(&gblcnt_mutex);globalize_count(); counterp[idx]=NULL; countermaxp[idx]=NULL;theftp[idx]=NULL; spin_unlock(&gblcnt_mutex); |
第1行– 12 见清单5.22 showcount_init()将upflush_local_count_sig()设为SIGUSR 1的信号处理程序,从而允许pthread_kill()调用inflush_local_count()到invokeflush_local_count_sig()。线程注册和注销的代码与前面的例子类似,因此其分析留作读者练习。
信号窃取实现的速度比我六核x86笔记本电脑上的原子实现快八倍以上。它总是更可取吗?
信号窃取实现方式在奔腾4系统上更为理想,因为它们的原子指令较慢,但基于旧80386的顺序对称系统由于原子实现的较短路径长度表现更好。然而,这种更新侧性能的提升是以更高的读侧开销为代价的:这些POSIX信号并非免费。如果最终性能至关重要,你需要在应用程序将要部署的系统上同时测量两者。

这是高质量API如此重要的一个原因:它们允许根据不断变化的硬件性能特性进行更改。

尽管本节中提出的精确计数器实现非常有用,但如果计数器的值始终接近零,这并不会有多大帮助,例如在计算对I/O设备的未完成访问次数时。这种接近零的计数方式带来的高开销尤其令人头疼,因为我们通常并不关心有多少次引用。正如快速测验5.5提出的可移动I/O设备访问计数问题所指出的那样。 ,访问次数是无关紧要的,除非有人真的想删除设备。
解决这个问题的一个简单方法是在计数器中添加一个较大的“偏置”(例如十亿),以确保数值远离零,从而使计数器能够高效运行。当有人想要移除设备时,这个偏置会被从计数值中减去。最后几次访问的计数会相当低效,但关键在于之前的多次访问已经以全速被记录下来了。
尽管带有偏置的计数器可能非常有用,但它只是第77页所提到的可移除I/O设备访问计数问题的部分解决方案。 在尝试移除设备时,我们不仅需要知道当前I/O访问的确切次数,还需要防止任何未来的访问开始。一种实现方法是在更新计数器时读取并获取一个读写锁,在检查计数器时写入并获取同一个读写锁。执行I/O操作的代码可能如下:
| read_lock(&mylock); read_unlock(&mylock);cancel_io(); } else{ add_count(1); |
第1行 读取-获取锁,然后执行第3行 或7 释放它。行2 检查设备是否正在被移除,如果是,则行3 释放锁和行4 取消I/O,或者采取适当的措施,以确保设备被移除。否则,第6行 增加访问计数,第7行 释放锁,第8行 执行I/O,以及第9行 减少访问计数。

| write_lock(&mylock); removing=1; 子计数(mybias); |
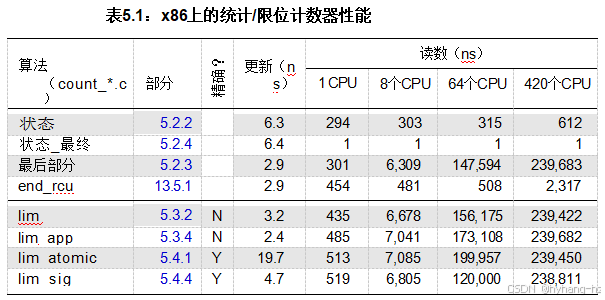
第1行 write-获取锁和行4 释放它。行2 指出设备正在被移除,循环跨越行5 – 6等待任何I/O操作完成。最后,行7 是否需要额外处理以准备器械取出。
![]()
5.5 并行计数讨论
这种认为具体事物具有普遍性的观点具有深远的意义。
道格拉斯·R·霍夫施塔特
本章介绍了传统计数原语的可靠性、性能和可扩展性问题。C语言++操作符在多线程代码中无法保证可靠运行,而对单个变量的原子操作既不高效也不适合大规模处理。因此,本章提出了一系列在特定情况下表现和扩展性极佳的计数算法。
对这些计数算法的教训进行回顾是很有价值的。为此,第5.5.1节 概述要求进行现场确认,第5.5.2节 总结性能和可扩展性,第5.5.3节 讨论了专业化的需求,最后,第5.5.4节 列举了所学到的教训,并提醒读者注意后面章节将对这些教训进行扩展。
本节中的许多算法相当简单,以至于人们很容易认为它们是构造正确或通过检查就能确定正确的。不幸的是,执行构造或检查的人很容易变得过于自信、疲惫、困惑,或者干脆粗心大意,所有这些都可能导致错误。事实上,早期实现的限幅计数器确实存在错误,在某些情况下
由于在32位系统中维护64位计数的复杂性,因此即使对于本章介绍的简单算法,验证也不是可选的。
统计计数器被测试是否像计数器一样工作(counttorture.h),即计数器中的总和会随着各个更新侧线程添加的量之和而变化。
还对限位计数器进行了测试,以确定其是否具有计数器的功能(“limtorture.h”),并检查了它们是否能够满足指定的限值。
这两个测试套件均生成性能数据,这些数据将在第5.5.2节中使用。
尽管这种验证水平对于这些教科书级别的实现已经足够好,但在将类似的算法投入生产之前,进行额外的验证是明智之举。第十一章描述了其他测试方法,鉴于大多数计数算法的简单性,第十二章中介绍的许多技术也非常有帮助。
表5.1的上半部分 展示了四种并行统计计数算法的性能。所有四种算法在更新时都提供了接近完美的近似可扩展性。线程变量实现(count_end.c)在更新时比基于数组的实现(count_stat.c)快得多,但在大量核心读取时较慢,并且当有许多并行读取者时会遭受严重的锁竞争。这种竞争可以通过第9章介绍的延迟处理技术来解决,如表5.1的count_end_rcu .c ro w所示。 Deferred processing还对count_stat_eventual .c行进行了优化,这得益于最终一致性。

表5.1下半部分 展示了并行限制计数算法的性能。严格执行这些限制会导致显著的更新侧性能损失,尽管在这种x86系统中,通过用信号替代原子操作可以减少这种损失。所有这些实现都面临着并发读取时的读侧锁竞争问题。

简而言之,本章展示了一系列计数算法,在多种特殊情况下表现和扩展都非常出色。但我们的并行计数是否必须局限于这些特殊情况?难道不是应该有一个通用算法,在所有情况下都能高效运行吗?下一节将探讨这些问题。
这些算法只在各自特殊情况下才能很好地工作,这可能被认为是并行编程的一个主要问题。毕竟,C语言中的++运算符在单线程代码中也能很好地工作,而且不仅限于特殊情况,而是普遍适用,对吧?
这种观点确实包含了一丝真理,但本质上是错误的。问题不在于并行性本身,而在于可扩展性。要理解这一点,首先考虑C语言中的++运算符。事实上,它通常并不适用,仅限于特定范围内的数字。如果你需要处理1000位的十进制数,C语言中的++运算符将无法满足你的需求。

这个问题不仅限于算术。假设你需要存储和查询数据。你应该使用ASCII文件吗?XML?关系数据库?链表?密集数组?AB树?基数树?还是其他众多允许数据存储和查询的数据结构和环境之一?这取决于你需要做什么,需要多快完成,以及你的数据集有多大——即使是在顺序系统上也是如此。
同样,如果需要计数,你的解决方案将取决于需要处理的数字大小,需要同时操作给定数字的cpu数量,数字将如何使用,以及你需要的性能和可扩展性水平。
这个问题并不仅限于软件。一座供人们步行过小溪的桥设计可能简单到只有一块木板。但你大概不会用一块木板来跨越哥伦比亚河宽达数千米的河口,这样的设计也不适合承载混凝土卡车的桥梁。简而言之,正如桥梁设计必须随着跨度和负载的增加而变化一样,软件设计也必须随着CPU数量的增加而改变。话虽如此,最好能自动化这一过程,使软件能够适应硬件配置和工作负载的变化。事实上,已经有一些研究探讨了这种自动化[AHS+03,SAH+03],Linux内核在启动时会进行一些重新配置,包括有限的二进制重写。随着主流系统中CPU数量的不断增加,这种适应性将变得越来越重要。
简而言之,正如第三章所述,物理定律对并行软件的限制与对桥梁等机械制品的限制一样严格。这些限制迫使软件实现专业化,尽管在软件领域,可能可以自动化选择适合特定硬件和工作负载的专业化方案。
当然,即使是概括性的计数也是相当专业的。我们需要用计算机做许多其他的事情。下一节将把我们从计数器中学到的知识与本书后面讨论的主题联系起来。
本章的开头段落承诺,我们对计数的研究将为并行编程提供一个极好的介绍。本节明确地建立了本章的教训与后续章节中所介绍的内容之间的联系。
中的例子表明,分区是可扩展性和性能的一个重要工具。计数器可以完全分区,如第5.2节中讨论的统计计数器 ,或者部分分区,如第5.3节中讨论的限位计数器 和5.4。 分区将在第6章中进行更深入的讨论,部分并行化则在第6.4节中进行讨论,其中称为并行快速路径。

部分分区计数算法使用锁定来保护全局数据,而锁定是第七章的主题。相比之下,分区数据通常完全受相应线程的控制,因此无需任何同步操作。这种数据所有权将在第六章第三节中介绍,并在第八章中详细讨论。
由于整数加法和减法相比典型的同步操作成本极低,要实现合理的可扩展性就需要谨慎使用同步操作。一种方法是批量处理加法和减法操作,使得大量这些低成本的操作由一次同步操作来完成。表5.1中列出的每种计数算法都采用了某种形式的批量优化。
最后,讨论了第5.2.4节中提到的最终一致统计计数器 展示了如何通过延迟活动(在这种情况下,更新全局计数器)来提供显著的性能和可扩展性优势。这种方法使得常见代码能够使用比其他方式更便宜的同步操作。第9章将探讨延迟可以如何进一步提高性能、可扩展性和实时响应。
总结摘要:
1.分区可提高性能和可扩展性。
2.部分分区,即只应用于公共代码路径的分区,几乎同样有效。
3.部分分区可以应用于代码(如第5.2节所述 的统计计数器的分区更新和非分区读取),但也可以跨时间(如第5.3节所述和第5.4节 当远离极限时,其极限计数器运行速度较快,而接近极限时运行速度较慢)。
4.跨时间分区通常会将更新本地批处理,以减少昂贵的全局操作数量,从而减少同步过载,进而提高性能和可扩展性。表5.1中列出的所有算法均如此。大量使用分批。
5.只读代码路径应保持只读:如表5.1的count_end .c行所示,对共享内存进行虚假同步写入会破坏性能和可扩展性。
6.谨慎使用延迟可提高性能和可扩展性,如第5.2.4节所示。
7.并行性能和可扩展性通常是一种平衡:超过某个点后,优化某些代码路径会降低其他路径的性能。表5.1中的count_stat .c和count_ end_ rcu. c行说明这一点。
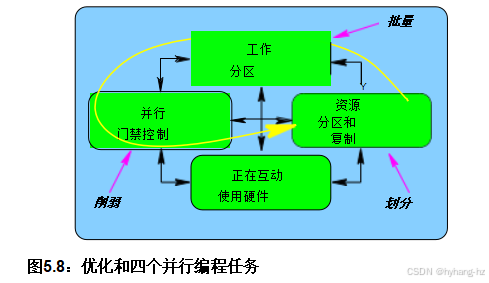
8.不同级别的性能和可扩展性将影响算法和数据结构设计,还有许多其他因素。图5.1 说明这一点:原子增量对于一个两CPU系统可能是完全可接受的,但对于一个八CPU系统来说却完全不够用。
进一步总结,我们有三种提高性能和可扩展性的“大三”方法,即(1)在CPU或线程上进行分区,(2)批量处理以使每次昂贵的同步操作能够完成更多工作,以及(3)在可行的情况下弱化同步操作。作为一个大致的经验法则,你应该按此顺序应用这些方法,正如前面讨论图2.6时所指出的那样。分区优化适用于“资源分区和复制”气泡,批量处理优化适用于“工作分区”气泡,而弱化优化则适用于“并行访问控制”气泡,如所示。见图5.8。 当然,如果你使用的是专用硬件,如数字信号处理器(DSP)、现场可编程门阵列(FPGA)或通用图形处理单元(GPU),你可能需要在整个设计过程中密切关注“与硬件交互”这一环节。例如,GPGPU的硬件线程结构和内存连接可能会极大地受益于非常细致的分区和批量设计决策。
简而言之,正如本章开头所述,计数的简单性使我们能够探索许多基本的并发问题,而无需被复杂的同步原语或复杂的数据结构所干扰。这些同步原语和数据结构将在后续章节中介绍。